Post Syndicated from Kinnar Kumar Sen original https://aws.amazon.com/blogs/big-data/introducing-amazon-emr-on-eks-with-apache-flink-a-scalable-reliable-and-efficient-data-processing-platform/
AWS recently announced that Apache Flink is generally available for Amazon EMR on Amazon Elastic Kubernetes Service (EKS). Apache Flink is a scalable, reliable, and efficient data processing framework that handles real-time streaming and batch workloads (but is most commonly used for real-time streaming). Amazon EMR on EKS is a deployment option for Amazon EMR that allows you to run open source big data frameworks such as Apache Spark and Flink on Amazon Elastic Kubernetes Service (Amazon EKS) clusters with the EMR runtime. With the addition of Flink support in EMR on EKS, you can now run your Flink applications on Amazon EKS using the EMR runtime and benefit from both services to deploy, scale, and operate Flink applications more efficiently and securely.
In this post, we introduce the features of EMR on EKS with Apache Flink, discuss their benefits, and highlight how to get started.
EMR on EKS for data workloads
AWS customers deploying large-scale data workloads are adopting the EMR runtime with Amazon EKS as the underlying orchestrator to benefit from complimenting features. This also enables multi-tenancy and allows data engineers and data scientists to focus on building the data applications, and the platform engineering and the site reliability engineering (SRE) team can manage the infrastructure. Some key benefits of Amazon EKS for these customers are:
- The AWS-managed control plane, which improves resiliency and removes undifferentiated heavy lifting
- Features like multi-tenancy and resource-based access policies (RBAC), which allow you to build cost-efficient platforms and enforce organization-wide governance policies
- The extensibility of Kubernetes, which allows you to install open source add-ons (observability, security, notebooks) to meet your specific needs
The EMR runtime offers the following benefits:
- Takes care of the undifferentiated heavy lifting of managing installations, configuration, patching, and backups
- Simplifies scaling
- Optimizes performance and cost
- Implements security and compliance by integrating with other AWS services and tools
Benefits of EMR on EKS with Apache Flink
The flexibility to choose instance types, price, and AWS Region and Availability Zone according to the workload specification is often the main driver of reliability, availability, and cost-optimization. Amazon EMR on EKS natively integrates tools and functionalities to enable these—and more.
Integration with existing tools and processes, such as continuous integration and continuous development (CI/CD), observability, and governance policies, helps unify the tools used and decreases the time to launch new services. Many customers already have these tools and processes for their Amazon EKS infrastructure, which you can now easily extend to your Flink applications running on EMR on EKS. If you’re interested in building your Kubernetes and Amazon EKS capabilities, we recommend using EKS Blueprints, which provides a starting place to compose complete EKS clusters that are bootstrapped with the operational software that is needed to deploy and operate workloads.
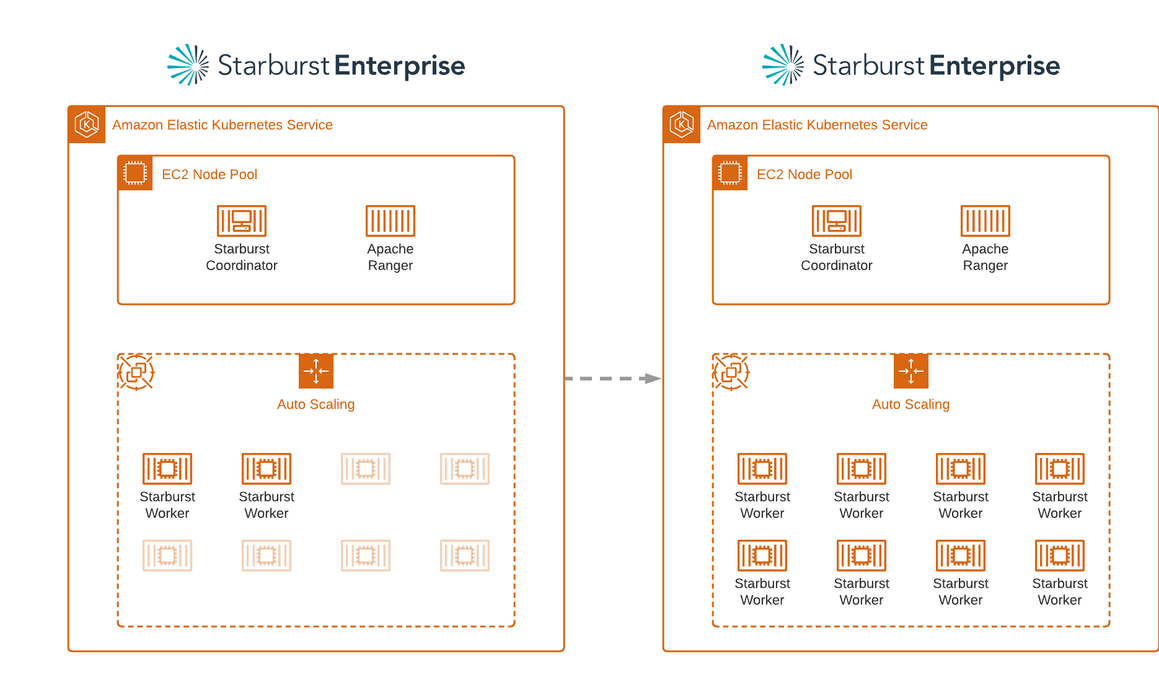
Another benefit of running Flink applications with Amazon EMR on EKS is improving your applications’ scalability. The volume and complexity of data processed by Flink apps can vary significantly based on factors like the time of the day, day of the week, seasonality, or being tied to a specific marketing campaign or other activity. This volatility makes customers trade off between over-provisioning, which leads to inefficient resource usage and higher costs, or under-provisioning, where you risk missing latency and throughput SLAs or even service outages. When running Flink applications with Amazon EMR on EKS, the Flink auto scaler will increase the applications’ parallelism based on the data being ingested, and Amazon EKS auto scaling with Karpenter or Cluster Autoscaler will scale the underlying capacity required to meet those demands. In addition to scaling up, Amazon EKS can also scale your applications down when the resources aren’t needed so your Flink apps are more cost-efficient.
Running EMR on EKS with Flink allows you to run multiple versions of Flink on the same cluster. With traditional Amazon Elastic Compute Cloud (Amazon EC2) instances, each version of Flink needs to run on its own virtual machine to avoid challenges with resource management or conflicting dependencies and environment variables. However, containerizing Flink applications allows you to isolate versions and avoid conflicting dependencies, and running them on Amazon EKS allows you to use Kubernetes as the unified resource manager. This means that you have the flexibility to choose which version of Flink is best suited for each job, and also improves your agility to upgrade a single job to the next version of Flink rather than having to upgrade an entire cluster, or spin up a dedicated EC2 instance for a different Flink version, which would increase your costs.
Key EMR on EKS differentiations
In this section, we discuss the key EMR on EKS differentiations.
Faster restart of the Flink job during scaling or failure recovery
This is enabled by task local recovery via Amazon Elastic Block Store (Amazon EBS) volumes and fine-grained recovery support in Adaptive Scheduler.
Task local recovery via EBS volumes for TaskManager pods is available with Amazon EMR 6.15.0 and higher. The default overlay mount comes with 10 GB, which is sufficient for jobs with a lower state. Jobs with large states can enable the automatic EBS volume mount option. The TaskManager pods are automatically created and mounted during pod creation and removed during pod deletion.
Fine-grained recovery support in the adaptive scheduler is available with Amazon EMR 6.15.0 and higher. When a task fails during its run, fine-grained recovery restarts only the pipeline-connected component of the failed task, instead of resetting the entire graph, and triggers a complete rerun from the last completed checkpoint, which is more expensive than just rerunning the failed tasks. To enable fine-grained recovery, set the following configurations in your Flink configuration:
Logging and monitoring support with customer managed keys
Monitoring and observability are key constructs of the AWS Well-Architected framework because they help you learn, measure, and adapt to operational changes. You can enable monitoring of launched Flink jobs while using EMR on EKS with Apache Flink. Amazon Managed Service for Prometheus is deployed automatically, if enabled while installing the Flink operator, and it helps analyze Prometheus metrics emitted for the Flink operator, job, and TaskManager.
You can use the Flink UI to monitor health and performance of Flink jobs through a browser using port-forwarding. We have also enabled collection and archival of operator and application logs to Amazon Simple Storage Service (Amazon S3) or Amazon CloudWatch using a FluentD sidecar. This can be enabled through a monitoringConfiguration block in the deployment customer resource definition (CRD):
Cost-optimization using Amazon EC2 Spot Instances
Amazon EC2 Spot Instances are an Amazon EC2 pricing option that provides steep discounts of up to 90% over On-Demand prices. It’s the preferred choice to run big data workloads because it helps improve throughput and optimize Amazon EC2 spend. Spot Instances are spare EC2 capacity and can be interrupted with notification if Amazon EC2 needs the capacity for On-Demand requests. Flink streaming jobs running on EMR on EKS can now respond to Spot Instance interruption, perform a just-in-time (JIT) checkpoint of the running jobs, and prevent scheduling further tasks on these Spot Instances. When restarting the job, not only will the job restart from the checkpoint, but a combined restart mechanism will provide a best-effort service to restart the job either after reaching target resource parallelism or the end of the current configured window. This can also prevent consecutive job restarts caused by Spot Instances stopping in a short interval and help reduce cost and improve performance.
To minimize the impact of Spot Instance interruptions, you should adopt Spot Instance best practices. The combined restart mechanism and JIT checkpoint is offered only in Adaptive Scheduler.
Integration with the AWS Glue Data Catalog as a metadata store for Flink applications
The AWS Glue Data Catalog is a centralized metadata repository for data assets across various data sources, and provides a unified interface to store and query information about data formats, schemas, and sources. Amazon EMR on EKS with Apache Flink releases 6.15.0 and higher support using the Data Catalog as a metadata store for streaming and batch SQL workflows. This further enables data understanding and makes sure that it is transformed correctly.
Integration with Amazon S3, enabling resiliency and operational efficiency
Amazon S3 is the preferred cloud object store for AWS customers to store not only data but also application JARs and scripts. EMR on EKS with Apache Flink can fetch application JARs and scripts (PyFlink) through deployment specification, which eliminates the need to build custom images in Flink’s Application Mode. When checkpointing on Amazon S3 is enabled, a managed state is persisted to provide consistent recovery in case of failures. Retrieval and storage of files using Amazon S3 is enabled by two different Flink connectors. We recommend using Presto S3 (s3p) for checkpointing and s3 or s3a for reading and writing files including JARs and scripts. See the following code:
Role-based access control using IRSA
IAM Roles for Service Accounts (IRSA) is the recommended way to implement role-based access control (RBAC) for deploying and running applications on Amazon EKS. EMR on EKS with Apache Flink creates two roles (IRSA) by default for Flink operator and Flink jobs. The operator role is used for JobManager and Flink services, and the job role is used for TaskManagers and ConfigMaps. This helps limit the scope of AWS Identity and Access Management (IAM) permission to a service account, helps with credential isolation, and improves auditability.
Get started with EMR on EKS with Apache Flink
If you want to run a Flink application on recently launched EMR on EKS with Apache Flink, refer to Running Flink jobs with Amazon EMR on EKS, which provides step-by-step guidance to deploy, run, and monitor Flink jobs.
We have also created an IaC (Infrastructure as Code) template for EMR on EKS with Flink Streaming as part of Data on EKS (DoEKS), an open-source project aimed at streamlining and accelerating the process of building, deploying, and scaling data and ML workloads on Amazon Elastic Kubernetes Service (Amazon EKS). This template will help you to provision a EMR on EKS with Flink cluster and evaluate the features as mentioned in this blog. This template comes with the best practices built in, so you can use this IaC template as a foundation for deploying EMR on EKS with Flink in your own environment if you decide to use it as part of your application.
Conclusion
In this post, we explored the features of recently launched EMR on EKS with Flink to help you understand how you might run Flink workloads on a managed, scalable, resilient, and cost-optimized EMR on EKS cluster. If you are planning to run/explore Flink workloads on Kubernetes consider running them on EMR on EKS with Apache Flink. Please do contact your AWS Solution Architects, who can be of assistance alongside your innovation journey.
About the Authors
 Kinnar Kumar Sen is a Sr. Solutions Architect at Amazon Web Services (AWS) focusing on Flexible Compute. As a part of the EC2 Flexible Compute team, he works with customers to guide them to the most elastic and efficient compute options that are suitable for their workload running on AWS. Kinnar has more than 15 years of industry experience working in research, consultancy, engineering, and architecture.
Kinnar Kumar Sen is a Sr. Solutions Architect at Amazon Web Services (AWS) focusing on Flexible Compute. As a part of the EC2 Flexible Compute team, he works with customers to guide them to the most elastic and efficient compute options that are suitable for their workload running on AWS. Kinnar has more than 15 years of industry experience working in research, consultancy, engineering, and architecture.
 Alex Lines is a Principal Containers Specialist at AWS helping customers modernize their Data and ML applications on Amazon EKS.
Alex Lines is a Principal Containers Specialist at AWS helping customers modernize their Data and ML applications on Amazon EKS.
 Mengfei Wang is a Software Development Engineer specializing in building large-scale, robust software infrastructure to support big data demands on containers and Kubernetes within the EMR on EKS team. Beyond work, Mengfei is an enthusiastic snowboarder and a passionate home cook.
Mengfei Wang is a Software Development Engineer specializing in building large-scale, robust software infrastructure to support big data demands on containers and Kubernetes within the EMR on EKS team. Beyond work, Mengfei is an enthusiastic snowboarder and a passionate home cook.
 Jerry Zhang is a Software Development Manager in AWS EMR on EKS. His team focuses on helping AWS customers to solve their business problems using cutting-edge data analytics technology on AWS infrastructure.
Jerry Zhang is a Software Development Manager in AWS EMR on EKS. His team focuses on helping AWS customers to solve their business problems using cutting-edge data analytics technology on AWS infrastructure.



 Kinnar Kumar Sen is a Sr. Solutions Architect at Amazon Web Services (AWS) focusing on Flexible Compute. As a part of the EC2 Flexible Compute team, he works with customers to guide them to the most elastic and efficient compute options that are suitable for their workload running on AWS. Kinnar has more than 15 years of industry experience working in research, consultancy, engineering, and architecture.
Kinnar Kumar Sen is a Sr. Solutions Architect at Amazon Web Services (AWS) focusing on Flexible Compute. As a part of the EC2 Flexible Compute team, he works with customers to guide them to the most elastic and efficient compute options that are suitable for their workload running on AWS. Kinnar has more than 15 years of industry experience working in research, consultancy, engineering, and architecture.