Streamline your AWS infrastructure development with AI-powered documentation search, validation, and troubleshooting
Introduction
Today, we’re excited to introduce the AWS Infrastructure-as-Code (IaC) MCP Server, a new tool that bridges the gap between AI assistants and your AWS infrastructure development workflow. Built on the Model Context Protocol (MCP), this server enables AI assistants like Kiro CLI, Claude or Cursor to help you search AWS CloudFormation and Cloud Development Kit (CDK) documentation, validate templates, troubleshoot deployments, and follow best practices – all while maintaining the security of local execution.
Whether you’re writing AWS CloudFormation templates or AWS Cloud Development Kit (CDK) code, the IaC MCP Server acts as an intelligent companion that understands your infrastructure needs and provides contextual assistance throughout your development lifecycle.
The Model Context Protocol (MCP) is an open standard that enables AI assistants to securely connect to external data sources and tools. Think of it as a universal adapter that lets AI models interact with your development tools while keeping sensitive operations local and under your control.
The IaC MCP Server provides nine specialized tools organized into two categories:
Remote Documentation Search Tools
These tools connect to the AWS Knowledge MCP backend to retrieve relevant, up-to-date information:
search_cdk_documentation Search the AWS CDK knowledge base for APIs, concepts, and implementation guidance.
search_cdk_samples_and_constructs Discover pre-built AWS CDK constructs and patterns from the AWS Construct Library.
search_cloudformation_documentation Query CloudFormation documentation for resource types, properties, and intrinsic functions.
read_cdk_documentation_page Retrieve and read full documentation pages returned from searches or provided URLs.
Local Validation and Troubleshooting Tools
These tools run entirely on your machine
cdk_best_practices Access a curated collection of AWS CDK best practices and design principles.
validate_cloudformation_template Perform syntax and schema validation using cfn-lint to catch errors before deployment.
check_cloudformation_template_compliance Run security and compliance checks against your templates using AWS Guard rules and cfn-guard.
troubleshoot_cloudformation_deployment Analyze CloudFormation stack deployment failures with integrated CloudTrail event analysis. This tool will use your AWS credentials to analyze your stack status.
get_cloudformation_pre_deploy_validation_instructions Returns instructions for CloudFormation’s pre-deployment validation feature, which validates templates during change set creation.
Key Use Cases
Intelligent Documentation Assistant
Instead of manually searching through documentation, ask your AI assistant natural language questions:
“How do I create an S3 bucket with encryption enabled in CDK?”
The server searches CDK best practic and samples, returning relevant code examples and explanations.
2. Proactive Template Validation
Before deploying infrastructure changes:
User: “Validate my CloudFormation template and check for security issues”
AI Agent: [Uses validate_cloudformation_template and check_cloudformation_template_compliance]
“Found 2 issues: Missing encryption on EBS volumes,
and S3 bucket lacks public access block configuration”
3. Rapid Deployment Troubleshooting
When a stack deployment fails:
User: “My stack ‘stack_03’ in us-east-1 failed to deploy. What happened?”
AI Agent: [Uses troubleshoot_stack_deployment with CloudTrail integration]
“The deployment failed due to insufficient IAM permissions.
CloudTrail shows AccessDenied for ec2:CreateVpc.
You need to add VPC permissions to your deployment role.”
4. Learning and Exploration
New to AWS CDK? The server helps you discover constructs and patterns:
User: “Show me how to build a serverless API”
AI Agent: [Searches CDK constructs and samples]
“Here are three approaches using API Gateway + Lambda…”
Architecture and Security
Security Design
Local Execution: The MCP server runs entirely on your local machine using uv (the fast Python package manager). No code or templates are sent to external services except for documentation searches.
AWS Credentials: The server uses your existing AWS credentials (from ~/.aws/credentials, environment variables, or IAM roles) to access CloudFormation and CloudTrail APIs. This follows the same security model as the AWS CLI.
stdio Communication: The server communicates with AI assistants over standard input/output (stdio), with no network ports opened.
Minimal Permissions: For full functionality, the server requires read-only access to CloudFormation stacks and CloudTrail events—no write permissions needed for validation and troubleshooting workflows.
Getting Started
Prerequisites
Python 3.10 or later uv package manager AWS credentials configured locally MCP-compatible AI client (e.g., Kiro CLI, Claude Desktop)
Configuration
Configure the MCP server in your MCP client configuration. For this blog we will focus on Kiro CLI. Edit .kiro/settings/mcp.json):
Privacy Notice: This MCP server executes AWS API calls using your credentials and shares the response data with your third-party AI model provider (e.g., Amazon Q, Claude Desktop, Cursor, VS Code). Users are responsible for understanding your AI provider’s data handling practices and ensuring compliance with your organization’s security and privacy requirements when using this tool with AWS resources.
IAM Permissions
The MCP server requires the following AWS permissions:
For Template Validation and Compliance:
No AWS permissions required (local validation only)
For Deployment Troubleshooting:
cloudformation:DescribeStacks
cloudformation:DescribeStackEvents
cloudformation:DescribeStackResources
cloudtrail:LookupEvents (for CloudTrail deep links)
IMPORTANT: Ensure you have satisfied all prerequisites before attempting these commands.
1. With the mcp.json file correctly set, try to run a sample prompt. In your terminal, run kiro-cli chat to start using Kiro-cli in the CLI.
Figure 1: Kiro-CLI with AWS IaC MCP server
Scenarios:
“What are the CDK best practices for Lambda functions?”
Figure 2: Search the CDK best practices for Lambda functions
“Search for CDK samples that use DynamoDB with Lambda”
Figure 3: Search for CDK samples that use DynamoDB with Lambda
“Validate my CloudFormation template at ./template.yaml”
Figure 4: Validate my CloudFormation template with AWS IaC MCP Server
“Check if my template complies with security best practices”
Figure 5: Check if my template complies with security best practices with AWS IaC MCP Server
Best Practices
Start with Documentation Search: Before writing code, search for existing constructs and patterns
Validate Early and Often: Run validation tools before attempting deployment
Check Compliance: Use check_template_compliance to catch security issues during development
Leverage CloudTrail: When troubleshooting, the CloudTrail integration provides detailed failure context
Follow CDK Best Practices: Use the cdk_best_practices tool to align with AWS recommendations
What’s Next?
The IAC MCP Server represents a new paradigm in the AI agentic workflow infrastructure development – one where AI assistants understand your tools, help you navigate complex documentation, and provide intelligent assistance throughout the development lifecycle.
Feedback: We welcome issues and pull requests! Or respond to our IaC survey here.
Ready to supercharge your infrastructure as code development? Install the IaC MCP Server today and experience AI-powered assistance for your AWS CDK and CloudFormation workflows.
Have questions or feedback? Reach out to the blog authors on the AWS Developer Forums.
Next week, don’t miss AWS re:Invent, Dec. 1-5, 2025, for the latest AWS news, expert insights, and global cloud community connections! Our News Blog team is finalizing posts to introduce the most exciting launches from our service teams. If you’re joining us in person in Las Vegas, review the agenda, session catalog, and attendee guides before arriving. Can’t attend in person? Watch our Keynotes and Innovation Talks via livestream.
AWS CloudFormation StackSets offers deployment ordering for auto-deployment mode. You can define the sequence in which your stack instances automatically deploy across accounts and Regions.
AWS NAT Gateway supports Regional availability to create a single NAT Gateway that automatically expands and contracts across availability zones (AZs).
AWS CloudFormation models and provisions cloud infrastructure as code, letting you manage entire lifecycle operations through declarative templates. Stack Refactoring console experience, announced today, extends the AWS CLI experience launched earlier. Now, you move resources between stacks, rename logical IDs, and decompose monolithic templates into focused components without touching the underlying infrastructure using the CloudFormation console. Your resources maintain stability and operational state throughout the reorganization. Whether you’re modernizing legacy stacks, aligning infrastructure with evolving architectural patterns, or improving long-term maintainability, Stack Refactoring adapts your CloudFormation stacks organization to changing requirements without forcing disruptive workarounds.
Stack Refactoring enables you to move resources between stacks, rename logical resource IDs, and split monolithic stacks into smaller, more manageable components—all while maintaining resource stability and preserving your infrastructure’s operational state. If you’re modernizing legacy infrastructure, aligning stack organization with evolving architectural patterns, or improving maintainability across your cloud resources, Stack Refactoring provides the flexibility you need to adapt your CloudFormation organization to changing
How It Works
Stack Refactoring operates through a controlled, multi-phase process designed around resource safety. When you initiate a refactor operation, CloudFormation analyzes both source and destination templates, constructs a detailed execution plan, then orchestrates resource movement without disrupting running infrastructure. Resource mappings define how assets transfer between stacks and how logical IDs should change. CloudFormation handles the orchestration complexity automatically – moving resources from source stacks, updating or creating destination stacks, and preserving all dependency relationships through exports and imports.
Each refactor operation receives a unique Stack Refactor ID for tracking progress, reviewing planned actions before execution, and monitoring the operation from initiation through completion. This preview-then-execute model gives you confidence in complex refactoring scenarios where dependencies span multiple stacks or templates.
Compared to the CLI, the console experience provides an easier way to view refactor actions, get automatic resource mapping, and easily rename logical IDs.
Example Scenario
Scenario 1: Splitting a Monolithic Stack
In this scenario, you have an Amazon Simple Notification Service (SNS) and AWS Lambda Function subscribed to it. As usage patterns evolve, you want to separate the subscriptions into a different stack for better organizational boundaries. You can also rename a resource’s logical ID to improve template clarity or align with naming conventions. Stack Refactoring handles this without recreating the underlying resource.
Create a new template MySNS.yaml using the following :
Create a new template called afterSns.yaml with the content below. This template has your SNS topic in it and has a new export in it that will export the SNS topic ARN. This export will be used by your other templates to get the required SNS topic ARN.
Create a new template afterLambda.yaml with the following content. This template includes all the resources to create a Lambda subscription to your SNS topic. This template switched the !Ref Topic to use the exported valued by using !ImportValue TopicArn. We are also updating the Logical Resource Id of Lambda function from MyFunction to Function
Go to stack refactor home page, click on ‘create stack refactor’
Provide a description to help you identify your stack refactor.
For this scenario, we are splitting a monolithic stack so select ‘Update the template for an existing stack’ and ‘Choose a stack’ options.
Search and choose the stack MySns that was created in Step 1.
Upload the afterSns.yaml file
You want to create a new stack to manage the Lambda function and SNS subscription resources. Choose ‘Create a new stack’ and name it ‘LambdaSubscription’.
Upload afterLambda.yaml template file In some scenarios, CloudFormation console can automatically detect logical resource ID renames and pre-fill the mapping for you. The resource mapping is required when there are logical resource ID changes between the original stack and refactored template. Ensure that the mappings are correct before proceeding to the next step.
The stack refactor preview will start generating. Wait for the preview to complete. You can verify actions under Stack 1 and Stack 2. It will show you the action for each resource.
You can also preview the new Stack refactored templates
Once you verify the details, go ahead and Execute Refactor. You should be redirected to the stack refactor details.
Once the Stack refactor execution is complete you can view the actions and templates for each of the stacks in your stack refactor.
Scenario 2: Move resources across multiple stacks.
This scenario demonstrates how to refactor resources across three stacks using the AWS CLI, then review and execute the operation in the CloudFormation console.
Create a new template many-stacks-original.yaml and create a new stack named ‘RefactorManyStacks’ using AWS CLI. This template contains SNS topic (IngestTopic),Lambda function(IngestFunction) and SNS subscription.
Create another template many-stacks-original-1.yaml and run the AWS CLI command to create a new stack ‘RefactorManyStacks1’. This template creates another SNS topic (UserTopic), Lambda function (UserFunction) and SNS subscription.
Create a new template many-stacks-original-2.yaml and run the AWS CLI command to create the stack RefactorManyStacks2. This template will also create SNS topic (ConsumerTopic), Lambda function (ConsumerFunction) and SNS subscription to lambda function.
Once all 3 stacks have been created successfully. Create refactored templates.
Create new template many-stacks-refactored.yaml This refactored template only contains SNS topic named IngestTopic and has a new export in it that will export the SNS topic ARN. This export will be used by your other templates to get the required SNS topic ARN.
Create another template many-stacks-refactored-1.yaml. This template **** has the SNS topic UserTopic and contains the IngestFunction and IngestSubscription and required IAM resources from ‘RefactorManyStacks’. This template switched the !Ref IngestTopic to use the exported valued by using !ImportValue IngestTopicArn. This refactored template also a new export in it that will export the UserTopic ARN.
Create another template many-stacks-refactored-2.yaml. This template has the Consumer* resources along with Lambda function (UserFunction) and SNS subscription (UserSubscription). The template is using exported value from many-stacks-refactored-1.yaml by using !ImportValue UserTopicArn
Go to stack CloudFormation console and go to ‘Stack refactor’ homepage, click on the stack refactor you just created.
Review actions for each resource and each stack. You can choose individual stacks from drop down.
Once you’re ready to execute the stack refactor, click on ‘Execute stack refactor’ and input the confirmation text.
Wait for stack refactor execution to finish.
Click on the stack in the details to navigate to the stack details. You can verify the refactor changes here.
Scenario 3: Move stacks between 2 nested child stacks stacks
This scenario demonstrates how to move resources between child stacks in a nested stack architecture. Upload child stack templates toAmazon Simple Storage Service (Amazon S3), create a parent stack that references them, then use Stack Refactoring to move resources (like a security group) from one child stack to another. The key is to work directly with the child stack names (which CloudFormation auto-generates based on parent stack name and logical IDs) rather than the parent stack itself. After refactoring, update the parent stack to reference the new child template versions in S3.
This approach lets you reorganize nested stack architectures while maintaining the parent-child relationship structure.
Create first child stack template vpc.yaml. This template creates a new Virtual Private Cloud(VPC). Upload this new template file to S3 bucket
Create second child stack template resource.yaml . This template will create S3 bucket and EC2 Security Group. Once you create this template file, upload it to an S3 bucket
Create ResourceStackAfter.yaml The resource stack will only contain s3 bucket resource. Upload this template to S3 bucket
AWSTemplateFormatVersion: '2010-09-09'
Description: 'Resource Stack AFTER - Contains only S3 bucket'
Resources:
MyS3Bucket:
Type: AWS::S3::Bucket
Outputs:
S3BucketName:
Value: !Ref MyS3Bucket
Navigate to CloudFormation Console and select Start stack refactor
Add a description for Stack refactor:
Choose “Update the template for an existing stack” and select child stack “ParentStack-VPCStack-12345”. Make sure to choose the child stack and not the Root/Parent stack.
Upload the new template VPCStackAfter.yaml
For Stack2, again select ‘Update the template for an existing stack’ and select to 2nd child stack “ParentStack-ResourceStack-12345”
Upload the template ResourceStackAfter.yaml
Review the Stack refactor. Once you have verified all the actions and details choose ‘Execute Refactor’
You can verify the refactor templates.
Lastly, update your ParentStack.yaml to reference the new child template versions in S3 bucket.
Stack Refactoring offers powerful flexibility, but a few strategic considerations will help ensure smooth operations. Test your refactoring plans in non-production environments first, particularly when working with complex dependency chains or resources that have strict ordering requirements. The preview phase becomes your primary safety mechanism—treat it as a thorough code review, examining each planned action before execution. When moving resources between stacks, pay close attention to cross-stack references. Converting direct references to export/import patterns maintains loose coupling and prevents circular dependencies. CloudFormation will automatically manage these conversions during refactoring, but understanding the resulting architecture helps you avoid introducing fragility into your infrastructure.
For scenarios where you’re emptying a source stack entirely, remember that CloudFormation requires at least one resource per stack. This makes placeholder resources like AWS::CloudFormation::WaitConditionHandle a useful temporary measure—they consume no actual AWS resources and can be safely deleted along with the stack once the refactoring completes.
Document your refactoring decisions alongside the templates themselves. Future maintainers (including yourself in six months) will appreciate understanding why resources were organized in particular ways. Include comments in your templates explaining the reasoning behind stack boundaries and resource groupings.
Consider the operational impact of your refactoring. While resources themselves remain stable, monitoring dashboards, automation scripts, or other tooling that references stack names or logical IDs may need updates. Plan these ancillary changes as part of your refactoring workflow rather than discovering them afterward.
Finally, leverage refactoring as an opportunity to improve template quality more broadly. If you’re already reorganizing resources, consider also updating documentation, standardizing naming conventions, or adding tags for better resource management.
Conclusion
CloudFormation Stack Refactoring transforms how you organize and maintain infrastructure as code, enabling stack architecture to evolve alongside applications and organizational needs. This capability provides the flexibility to restructure without the risk and complexity of traditional resource recreation approaches. Whether you’re breaking apart monolithic stacks, consolidating fragmented infrastructure, or simply renaming resources to match current conventions, Stack Refactoring lets you adapt CloudFormation organization to changing requirements without operational disruption.
To get started, visit the CloudFormation console or explore the AWS CloudFormation API reference for programmatic access patterns. Stack Refactoring is available today in all commercial AWS regions.
AWS CloudFormation StackSets enable you to deploy CloudFormation stacks across multiple AWS accounts and regions with a single operation, providing centralized management of infrastructure at scale through AWS Organizations integration. In enterprise environments, multiple StackSet often need to deploy in a specific order. For example, networking infrastructure must be ready before applications can deploy successfully.
Figure 1: Example of a multi-region AWS CloudFormation StackSet architecture with an administrative account and target accounts
Previously, when multiple StackSets had auto-deployment enabled, they operated independently without coordination. This could cause deployment failures when dependent infrastructure wasn’t ready, forcing customers to implement complex workarounds or disable auto-deployment entirely.
We are announcing StackSets dependencies, a new feature that gives you fine-grained control over the deployment order of your auto-deployed StackSets, elegantly solving these orchestration challenges.
Feature Overview
This new feature introduces the ability to define dependencies between StackSets using the new DependsOn parameter in the AutoDeployment configuration. When accounts move between Organizational Units or are added to your organization, StackSets automatically orchestrates deployments according to your defined sequence, ensuring foundational infrastructure deploys before dependent applications.
Key capabilities include:
Dependency Management: Define up to 10 dependencies per StackSet, with up to 100 dependencies per account. For example, if you have 5 StackSets with 5 dependencies each, you have 25 dependencies counting towards the 100 dependency limit. You can request a limit increase through the service quota console.
Cycle Detection: Built-in validation prevents circular dependencies with error messages.
Cross-Region Support: Dependencies work across regions.
Automatic Cleanup: Dependencies are removed when StackSets are deleted or Organizations are deactivated.
How it works
Let’s walk through this feature with a practical example. Consider an infrastructure setup where you have: A central Infrastructure StackSet that creates IAM roles and networking components and multiple Application StackSets that depend on these foundational resources.
With StackSets dependencies, you can make sure the Infrastructure StackSet completes deployment before any Application StackSets begin, preventing deployment failures due to missing dependencies.
Implementation Scenarios
Let’s explore three common scenarios where StackSets Dependencies provides value:
Scenario 1: Foundation-First Deployment
Use Case: You have a foundational Infrastructure StackSet that creates IAM roles and networking components, and multiple Application StackSets that depend on these resources.
Setup:
Infrastructure StackSet ARNs (creates IAM roles, VPCs, security groups)
App1 StackSet (web application requiring IAM roles)
App2 StackSet (API service requiring networking components)
No additional permissions are required to use this feature.
Console Experience
The CloudFormation console provides an intuitive interface for managing StackSet dependencies. Log into the AWS console with your credentials, with an IAM user or administrative user, according to your access. Navigate to the Cloudformation service and create a new Stack or add a YAML/JSON template, where you will be configuring dependencies. In the Step 4 of the Create StackSet wizard, you’ll find a new “StackSet dependencies” form field in the Auto-deployment options section. You can use the attribute editor to add StackSet ARNs for dependencies. The console includes input validation for ARN format and helpful alerts about dependency behavior.
As a result, Networking and Security StackSets deploy in parallel, and Application waits for both to complete before starting.
Scenario 3: Resolving Dependency Conflicts
Use Case: You need to update existing StackSets to fix incorrect dependency relationships.
Problem: You have App1 and App2 StackSets. There is an existing dependency that App2 has on App1, but you realize App1 should depend on App2, not the other way around.
Implementation:
First, try to set App1 to depend on App2 (this will fail due to cycle):
This action will result in error: “Detected cycle(s) between auto-deployment dependencies”. If dependency validation cannot be completed, you’ll receive appropriate error messages to help troubleshoot configuration issues.
Now let’s remove the existing dependency from App2:
This scenario demonstrates cycle detection and how to resolve dependency conflicts.
Getting Started
StackSet dependencies is available now in all AWS Regions where CloudFormation StackSets are supported. To get started:
Identify Dependencies: Determine which StackSets should deploy first in your infrastructure.
Configure Relationships: Use the CloudFormation console or AWS CLI to set up dependencies using StackSet ARNs.
Test Your Sequence: Validate your dependency configuration in a test environment.
Monitor Deployments: Use CloudFormation events to track sequenced deployments.
Log into your account in the console and visit the AWS CloudFormation StackSets console or use the AWS CLI/SDK with AWS credentials configured to start controlling StackSet dependencies today.
Authors
Tanvi Ravindra Malali
Tanvi Ravindra Malali is an Associate Delivery Consultant in the AWS A2C team in ProServe. She is based in New York City. She handles customer projects and codebases, specializing in AI/ML, Data Engineering and Infrastructure as Code. Outside of work, she loves to paint landscapes, DJing her favorite songs, and dances Tango.
Idriss Laouali Abdou
Idriss Laouali Abdou is a Sr. Product Manager Technical on the AWS Infrastructure-as-Code team based in Seattle. He focuses on improving developer productivity through CloudFormation and StackSets Infrastructure provisioning experiences. Outside of work, you can find him creating educational content for thousands of students, cooking, or dancing.
If you’ve developed AWS CloudFormation templates, you know the drill; write YAML(YAML Ain’t Markup Language) in your IDE(Integrated Development Environment), switch to the AWS Management Console to validate, jump to documentation to verify property names. Then run CFN Lint(Cloudformation Linter) in your terminal, deploy and wait, then troubleshoot failures back in the console. This constant context switching between your IDE, AWS Console, documentation pages, and validation tools fragments your workflow and kills productivity. What should take 30 minutes often stretches into hours of iteration cycles.
Today, we’re excited to introduce the CloudFormation IDE Experience, a comprehensive solution that brings the entire CloudFormation development lifecycle into your IDE. No more context switching. No more fragmented workflows. Just one unified, intelligent development experience from authoring to deployment.
In this post, you’ll learn how the Cloudformation IDE Experience transforms your workflow with intelligent authoring, real-time validation, AWS integration, and more.
What is the CloudFormation IDE Experience?
The CloudFormation IDE Experience reimagines how you build infrastructure as code by creating an end-to-end development loop entirely within your IDE. Unlike generic YAML or JSON editors, this is a CloudFormation-first solution built specifically for infrastructure developers.
This solution covers the complete lifecycle; from intelligent authoring with smart code completion and navigation that understands CloudFormation semantics, to real-time multi-layer validation that catches issues before deployment. It provides direct AWS integration for seamless resource imports and stack visibility, monitors configuration drift between your templates and deployed resources, and includes server-side pre-deployment checks that prevent common deployment failures. The result? A development environment that understands your infrastructure code as deeply as your IDE understands your application code.
Core Features
Quick Project Setup with CFN Init
CFN Init streamlines project setup by creating a structured CloudFormation project with environment configurations in seconds. Run “CFN Init: Initialize Project” from the Command Palette, configure your environments (dev, staging, production), and associate each with an AWS profile.
The CloudFormation Explorer displays your environments, letting you switch between them with a single click. Each environment maintains its own deployment settings and parameter values, eliminating manual configuration and ensuring consistent deployments across your infrastructure lifecycle.
Intelligent Authoring with Intelligent Code Completion
The IDE understands CloudFormation semantics and provides context-aware suggestions as you type. Only required properties appear automatically, while optional properties surface on hover, so when you add a Properties section to an EC2 VPC resource, nothing appears because it has no required properties. Create a subnet, however, and VpcId appears immediately because it’s required.
When you use !GetAtt or !Ref, the IDE knows exactly which attributes and resources are available. Navigation features like go-to-definition for logical IDs and hover tooltips let you explore complex templates without losing context. The IDE also provides full support for CloudFormation intrinsic functions and pseudo parameters.
Multi-Layer Validation System
The IDE provides comprehensive validation at multiple levels:
Static Validation (Real-time)
CloudFormation Guard Integration: Security and compliance checks using AWS Security pillar rules. For example, it automatically flags insecure configurations like MapPublicIpOnLaunch: true on subnets
CFN Lint Integration: Advanced syntax and logic validation, including overlapping CIDR block detection, resource dependency validation, and property checks beyond basic schema validation
Interactive Error Resolution When errors occur, the IDE doesn’t just highlight them, it helps you fix them. Contextual error messages explain what’s wrong and why it matters, while one-click quick fixes automatically correct common issues like missing required properties or invalid reference formats. If you reference a non-existent resource, the IDE suggests valid alternatives from your template. Reference an invalid attribute with !GetAtt, the IDE immediately shows which attributes are actually available for that resource type.
AWS Resource Integration (CCAPI)
Import existing AWS resources directly into your templates using the Cloud Control API (CCAPI). Browse live resources and view all CloudFormation stacks in your AWS account from within the IDE. Pull resource configurations directly into your template with one click, complete with accurate property values. This transforms existing infrastructure into Infrastructure-as-Code without manual reconstruction or switching to the console to look up property values.
Server-Side Validation
Before you deploy, the IDE performs comprehensive server-side validation through AWS’s intelligent validation service that analyzes your CloudFormation templates against real-world deployment patterns and catches issues static analysis can’t detect.
The AWS’s intelligent validation service uses AWS-managed hooks to analyze your change sets before execution across three categories. Enhanced template validation covers CFN Lint blind spots like transforms and parameter values. Primary identifier conflict detection finds existing resources with the same identifiers before you attempt deployment. Resource state validation checks resource readiness ensuring, for example, that Amazon Simple Storage Service(S3) buckets are empty before deletion attempts.
This validation is based on analysis of the top CloudFormation failure patterns, helping you catch issues before they cause rollbacks or failed states.
Getting Started
Getting started with the CloudFormation IDE Experience is straightforward:
Prerequisite:
Install an IDE that supports the CloudFormation extension, such as Visual Studio Code, Kiro
Download the CloudFormation extension for your platform (available through the AWS Toolkit)
No complex dependency management or schema updates required—all configuration and updates are handled automatically.
Let’s See How It Works
Let’s walk through a practical example that demonstrates the IDE experience in action. We’ll build a simple Amazon Virtual Private Cloud (Amazon VPC) infrastructure with subnets and an S3 bucket.
Setting Up Your Project
Start by initializing a new CloudFormation project. Open the Command Palette, run “CFN Init: Initialize Project”, choose your project location, and set up environments. For this example, create a “beta” environment and associate it with your AWS development profile. The IDE creates your project structure with configuration files ready to use. You can now select your “beta” environment from the CloudFormation Explorer to ensure all deployments use the correct settings.
Figure 1: Initializing a CloudFormation project with environment configuration
Starting with Intelligent Authoring
Create a new CloudFormation template and start typing AWS::EC2::VPC. The IDE provides intelligent completions as you type.
Figure 2.0: Resource type auto-completion with CloudFormation-aware IntelliSense
When you add the Properties section, notice something interesting: nothing appears automatically. That’s because Amazon Elastic Compute Cloud (Amazon EC2) VPC has no required properties.
Figure 2.1: No automatic suggestions for VPC properties since none are required
Hover over Properties to see all available options with their types and documentation links.
Figure 2.2: Hover information displaying optional properties and their documentation
Add a CIDR block, then create a subnet. This time, when you type Properties, VpcId appears immediately because it’s required.
Figure 2.3: Required properties VpcID automatically suggested for EC2 Subnet
The IDE provides the resource names in your template, and when you use !GetAtt or !Ref, it knows which attributes are available for each resource type.
Figure 2.4: Type-aware completions for intrinsic functions like !GetAtt & !Ref
Real-Time Validation in Action
As you continue building, add MapPublicIpOnLaunch: true to make a public subnet. Immediately, a blue squiggly line appears.
Figure 3: CloudFormation Guard warning highlighted in real-time
Hovering reveals a CloudFormation Guard warning from the AWS Security pillar rules: this configuration isn’t recommended for security compliance.
Figure 3.1: Security compliance warning with detailed explanation
Create a second subnet by copying the first, but now red squiggly lines appear. CFN Lint has detected overlapping CIDR blocks between your two subnets – an issue that would fail during deployment. You can fix it immediately with the contextual information provided.
Figure 3.2: CFN Lint error detection for overlapping CIDR blocks providing detailed error information helping you resolve the issue quickly
Importing Existing Resources
Now you need an S3 bucket. Instead of writing it from scratch, open the Resource Explorer panel on the left. Using CCAPI integration, you can see all your existing AWS resources. Select an S3 bucket and click “Import resource state”. The IDE pulls in the complete resource configuration with all properties already set. You can now iterate on this resource without needing to remember or look up all the configuration details.
Figure 4: Automatically imported resource configuration from live AWS resources
Developer Experience Benefits
The CloudFormation IDE Experience delivers measurable improvements across productivity and quality:
Productivity Gains:
Reduced context switching: Keep your entire workflow in one place
Faster iteration cycles: Catch and fix issues in seconds, not minutes or hours
Shift-left validation: Identify problems before deployment, not after
Intelligent assistance: Spend less time in documentation, more time building
Quality Improvements:
Proactive error prevention: Multi-layer validation catches issues early
Security by default: Built-in compliance checks from CloudFormation Guard
Best practice enforcement: Automated guidance aligned with AWS recommendations
JetBrains IDEs: Complete integration across the IntelliJ family (Fast Follow)
Operating Systems: macOS (ARM), Linux (x64) and Windows(…)
Conclusion
The CloudFormation IDE Experience eliminates the context switching that fragments your workflow. Write, validate, and deploy all from one environment. What used to take hours of iteration now takes minutes.
Ready to get started? Install the CloudFormation extension from the AWS Toolkit for VS Code and experience the difference. For detailed setup instructions and feature documentation, see the CloudFormation IDE Experience guide.
Is configuration drift preventing you from accessing the speed, safety, and governance benefits of AWS CloudFormation for infrastructure management? Configuration drift occurs when cloud resources are modified outside of CloudFormation, leading to a mismatch in the actual state and template definition of resources. Drift tends to accumulate from infrastructure changes that engineers make via the AWS Management Console to resolve production incidents or troubleshoot malfunctioning applications. Drift can cause unexpected changes during subsequent IaC deployments or leave resources in a non-compliant state. Unresolved drift can lead to cost increases when resources are over-provisioned outside of template definitions, or compliance violations that may result in audit penalties. Additionally, drift makes it hard to reproduce applications for testing or disaster recovery.
CloudFormation now offers drift-aware change sets that allow you to safely handle configuration drift and keep your infrastructure in sync with your templates. In this post, we will explore the process of leveraging drift-aware change sets to resolve common scenarios in which drift impacts the availability or security of your application.
Solution Overview
Drift-aware change sets are a type of CloudFormation change sets that can bring drifted resources in line with template definitions and preview the required changes to actual infrastructure states before deployment. Drift-aware change sets surface a three-way comparison of your new template, actual resource states, and previous template before deployment, allowing you to prevent unexpected overwrites of drift. Additionally, drift-aware change sets offer you a systematic mechanism to restore drifted resources to approved template definitions, strengthening the reproducibility and compliance posture of applications. You can create drift-aware change sets either from the CloudFormation Management Console or from the AWS CLI or SDK by passing the --deployment-mode REVERT_DRIFT parameter to the CreateChangeSet API.
Prerequisites
• AWS CLI latest version with CloudFormation permissions configured.
Important Note: These sample templates are provided for educational purposes only and should not be used in production environments without proper security review and testing. You are responsible for testing, securing, and optimizing these templates based on your specific quality control practices and standards. Deploying these templates may incur AWS charges for creating or using AWS resources. Work with your security and legal teams to meet your organizational security, regulatory, and compliance requirements before any production deployment.
Scenario 1: Prevent Dangerous Overwrites
This scenario demonstrates how drift-aware change sets prevent dangerous overwrites when Lambda function memory is increased outside of CloudFormation during an outage, and a subsequent template update could accidentally reduce memory, causing performance issues.
Story: Your team deploys a Lambda function with 128 MB memory via CloudFormation. During a production outage, an engineer increases the memory to 512 MB through the Lambda Console to resolve performance issues. Later, another developer updates the template to 256 MB for a code change, unaware of the console modification. Without drift-aware change sets, CloudFormation would unexpectedly reduce memory from 512 MB to 256 MB—potentially causing the outage to recur.
User journey: Create stack with 128MB => Increase memory to 512MB via console during outage => Create drift-aware change set with 256MB template => Review three-way comparison showing dangerous memory reduction => Cancel change set to prevent outage => Update template to match production state (512MB) => Create and execute drift-aware change set with updated template (512MB) to resolve drift
Scenario Flow
1. Create Stack
Deploy CloudFormation stack with Lambda function (128 MB memory).
CloudFormation stack “lambda-memory-drift-test” successfully deployed with CREATE_COMPLETE status
2. Emergency Memory Increase (Console)
Manually increase Lambda memory to 512 MB through AWS Console (simulating emergency performance fix during outage).
Initial Lambda function showing 128 MB memory as configured in template
Lambda memory increased to 512 MB through console during outage, creating drift from template
3. Create Drift-Aware Change Set
Create change set with 256 MB template using drift-aware mode to reveal the dangerous memory reduction.
CloudFormation console showing the new “Drift aware change set” option selected. This compares the new template with the live state of your stack and shows changes to drifted resources before deployment, unlike standard change sets that only compare templates.
4. Review Change Set – The Critical Three-Way Comparison
Examine the drift-aware change set to see the dangerous memory reduction that would occur.
Critical insight revealed: The change set shows Live resource state (512 MB) vs Proposed resource state (256 MB), revealing a dangerous memory reduction that would impact performance.
Drift analysis: Clicking “View drift” reveals the complete picture – Previous template (128 MB) vs Live resource state (512 MB). This shows the live state has 4x more memory than the original template, indicating emergency changes were made during the outage that must be preserved.
Key Insight: The drift-aware change set reveals that:
Previous template: 128 MB (original deployment)
Live resource state: 512 MB (emergency change during outage)
Proposed template: 256 MB (new deployment)
This would cause a dangerous reduction from 512 MB to 256 MB, potentially recreating the original performance issue. Without drift-aware change sets, this critical information would be hidden.
5. Recreate Drift-aware Change Set with Updated Template (512MB) to Resolve Drift
Update the template to match the live production state (512 MB) and create a new drift-aware change set to safely resolve the drift.
Resolution confirmed: The drift-aware change set shows both Live resource state and Proposed resource state at 512 MB, with change set action ” Sync with live”. This verifies that the updated template now matches production, preventing the dangerous memory reduction and safely resolving the drift without impacting performance.
This scenario demonstrates how drift-aware change sets systematically remediate unauthorized changes when a developer adds temporary debugging rules to a security group but forgets to remove them, creating a compliance violation.
Story: Your team deploys a security group with only HTTP access via CloudFormation for compliance. During debugging, a developer adds SSH access (port 22) through the AWS Console for their IP address to troubleshoot an application issue. They forget to remove this rule after debugging. Later, security compliance requires reverting to the original template state. A standard change set shows no changes since the template is unchanged, but a drift-aware change set can detect and systematically remove the unauthorized SSH rule.
User journey: Create stack with HTTP-only access => Add SSH rule via console for debugging => Forget to remove SSH rule => Create drift-aware change set with REVERT_DRIFT mode => Review change set showing SSH rule removal => Execute change set to restore compliance
Scenario Flow
1. Create Stack
Deploy CloudFormation stack with security group allowing only HTTP traffic.
CloudFormation stack “sg-revert-drift-test” successfully deployed with DriftTestSecurityGroup resource
2. Make Unauthorized Changes (Console)
Manually add SSH ingress rule through AWS Console (simulating developer debugging access that wasn’t removed).
Initial security group showing only HTTP (port 80) access as configured in template – compliant state
Security group now shows 2 permission entries: SSH (port 22) for specific IP and HTTP (port 80) for all traffic. The SSH rule creates drift and a compliance violation that needs systematic removal.
3. Create Drift-Aware Change Set
Create change set using REVERT_DRIFT mode to systematically remove the unauthorized SSH rule.
Creating drift-aware change set for security group compliance restoration. Note the “Drift aware change set” option is selected to compare with live state and detect unauthorized changes.
4. Review Change Set – Systematic Compliance Restoration
Examine the drift-aware change set to see systematic removal of unauthorized SSH rule.
Compliance violation detected: The drift -aware change set shows that the SSH rule in the live resource state (rule 232 for IP 15.248.7.53/32 on port 22) is not present in the proposed resource state derived from the template. This unauthorized SSH rule violates security policy and will be systematically removed
Key Insight: The drift-aware change set enables systematic compliance restoration by:
Previous template: Only HTTP (port 80) access – compliant state
Live resource state: HTTP + SSH (port 22) for 15.248.7.53/32 – compliance violation
Action: Remove unauthorized SSH rule to restore compliance
This provides a systematic, auditable way to remove unauthorized changes rather than manual cleanup.
Stack events showing successful execution of the drift-aware change set – SSH rule removed
CloudFormation Templates
security-group-drift-scenario.yaml:
Resources:
DriftTestSecurityGroup:
Type: AWS::EC2::SecurityGroup
Properties:
GroupDescription: "Security group for drift testing"
SecurityGroupIngress:
- IpProtocol: tcp
FromPort: 80
ToPort: 80
CidrIp: 0.0.0.0/0
Description: "Allow HTTP traffic for demo purposes"
SecurityGroupEgress:
- IpProtocol: -1
CidrIp: 0.0.0.0/0
Description: "Allow all outbound traffic"
This scenario demonstrates drift detection when a dependent resource (logs bucket) is accidentally deleted outside of CloudFormation during troubleshooting. The main application bucket depends on this logs bucket for access logging. You need to recreate the deleted resource while maintaining the existing infrastructure dependencies.
Story: Your team deploys a main S3 bucket with a dependent logs bucket for access logging via CloudFormation. During troubleshooting, an operator accidentally deletes the logs bucket through the AWS Console. The main bucket still exists but its logging configuration now references a non-existent bucket. You need to recreate the deleted logs bucket while maintaining the dependency relationship.
User journey: Create stack with main and logs buckets => Accidentally delete logs bucket => Create drift-aware change set with REVERT_DRIFT mode => Review change set showing LogBucket will be recreated => Execute change set to restore deleted resource
Scenario Flow
1. Create Stack
Deploy CloudFormation stack with main S3 bucket and dependent logs bucket.
CloudFormation stack “s3-deletion-drift-test” successfully deployed with both LogBucket and MainBucket resources in CREATE_COMPLETE status
2. Accidental Deletion (Console)
Manually delete the logs bucket through AWS Console (simulating accidental deletion during troubleshooting).
LogBucket accidentally deleted outside of CloudFormation during troubleshooting, creating drift – the MainBucket still exists but its logging configuration now references a non-existent bucket
3. Create Drift-Aware Change Set
Create change set using REVERT_DRIFT mode to recreate the deleted LogBucket.
Creating drift-aware change set with “Drift aware change set” option selected to detect and recreate the deleted resource by comparing template with live state
When working with drift-aware change sets, consider these best practices:
• Always review three-way comparisons before executing change sets to understand the full impact
• Use REVERT_DRIFT deployment mode when you want to bring resources back to template compliance
• Document emergency changes made outside of CloudFormation to inform future template updates
• Implement change management processes to minimize unauthorized drift
• Regular drift detection helps identify configuration changes before they become problematic
• Test drift-aware change sets in non-production environments first
Cleanup
Important: Execute these cleanup commands promptly after completing the scenarios to avoid incurring unnecessary AWS charges. Resources such as Lambda functions, S3 buckets (even if empty), and security groups may incur costs if left running. Ensure all stacks are successfully deleted by verifying the DELETE_COMPLETE status.
Note: CloudFormation will automatically clean up all resources created by the stacks, including Lambda functions, security groups, and S3 buckets.
Conclusion
Drift-aware change sets enable you to mitigate the operational and security risks of configuration drift, allowing you to confidently automate and govern your infrastructure updates with CloudFormation. Through the scenarios described in this post, you have seen how you can leverage drift-aware change sets to prevent outages in production environments, maintain the integrity of your test environments, and manage the compliance posture of all environments. Remember to thoroughly review the infrastructure changes previewed by drift-aware change sets before executing deployments.
Available Now
Drift-aware change sets are available in AWS Regions where CloudFormation is available. Please refer to the AWS Region table to learn more.
AWS CloudFormation makes it easy to model and provision your cloud application infrastructure as code. CloudFormation templates can be written directly in JSON or YAML, or they can be generated by tools like the AWS Cloud Development Kit (CDK). Resources are created and managed by CloudFormation as units called Stacks. Additionally, change set enable you to preview the stack changes before deployment.
CloudFormation now offers powerful new features that transform how you develop and troubleshoot infrastructure as code, pre-deployment validation that catches errors in seconds, enhanced operation tracking, and simplified failure debugging. These capabilities shift-left infrastructure code validation, helping you prevent infrastructure deployment failures that impacts development velocity.
In this blog post, we’ll explore how these new features accelerate development cycles by catching common errors during change set creation and providing precise troubleshooting through operation tracking and failure filtering. Whether you’re a platform engineer managing complex multi-service deployments or a developer iterating on infrastructure templates, we’ll show you how to:
Validate resource properties and detect naming conflicts before deployment
Prevent deployment failures by checking S3 bucket emptiness before deletion operations
Track operations with unique IDs for focused troubleshooting
Quickly identify root causes using the new describe-events API
This comprehensive guide will walk through real-world scenarios demonstrating how these capabilities can reduce infrastructure deployment failures from hours of debugging to seconds of validation, helping you deliver cloud infrastructure faster and more reliably.
Key Capabilities
Pre-deployment Validation: Catch template errors instantly instead of discovering them after resource provisioning attempts. These include pre-deployment validation for resource property syntax errors, resource naming conflicts for existing resources in your account, and S3 bucket emptiness constraint violations on delete operations.
Operation Tracking: Say goodbye to long debugging sessions. Each stack action now comes with a unique Operation ID, transforming the “needle in haystack” troubleshooting experience into precise, targeted problem-solving.
Streamlined Events API for simplified Debugging: Use the new describe-events API and FailedEvents=true filter to instantly pinpoint issues. One command tells you exactly what went wrong, eliminating the need to scroll through endless logs.
Immediate Feedback: Transform your CI/CD pipeline from a potential bottleneck into a rapid iteration engine. Get immediate feedback on common deployment issues, allowing your team to fix and deploy faster than ever before.
How It works
Pre-deployment Validation
The following scenarios show how you can leverage CloudFormation pre-deployment validation to detect property syntax errors, resource naming conflicts, and constraint violations during change set creation.
Understanding Validation Modes CloudFormation pre-deployment validation operates in two modes that determine how validation failures are handled.
FAIL mode prevents change set execution when validation detects errors, ensuring problematic templates cannot proceed to deployment. This applies to property syntax errors and resource naming conflicts.
WARN mode allows change set creation to succeed despite validation failures, providing warnings that developers can review and address before execution. This applies to constraint violations like S3 bucket emptiness that may be resolvable through manual intervention.
Understanding these modes helps you anticipate whether validation issues will block your deployment workflow or simply require attention before execution.
Let’s walk you through practical scenarios:
Scenario 1: Validate Resource Property Syntax
CloudFormation evaluates each resource property definition or value before provisioning begins. The following example illustrates several common resource property errors:
The “AWS::Lambda::Function” Role property requires an ARN pattern.
The “AWS::Lambda::Function” Timeout property expects an integer instead of a string.
The “AWS::Lambda::Function” TracingConfig.Mode nested property ENUM value is invalid.
The “AWS::Lambda::Alias” Name property is required but not defined.
The “AWS::Lambda::Alias” the extra property Description in a nested path RoutingConfig.AdditionalVersionWeights.0 is not supported.
Prior to this launch, these resource configuration errors would be detected at the resource provisioning time only. However, with the pre-deployment validations feature, these errors can be identified ahead of the deployment phase, streamlining the development-test lifecycle efficiency and minimizing rollbacks during deployments.
You can see the status of the change set is failed with a detailed status reason. You can now proceed to review the change set validation results.
Step 3: Review validation results
Console
With the console, you can review multiple validation errors in a single interface. When you click on a validation, CloudFormation pinpoints the location of the invalid property error in your template.
Figure 3: Pre-deployment validations view
Use Case: Invalid ENUM value for nested property Catching invalid configuration values before deployment. This demonstrates validation of nested properties like TracingConfig.Mode. The tool helpfully shows the supported values “Active” & “Pass through” as well as the provided invalid value “DISABLED”.
Figure 4: Validation of Invalid ENUM value for nested property
Use Case: Lambda Function Timeout property type mismatch Preventing type-related deployment failures. Shows how validation catches string values (“30s”) where integers are required, saving developers from runtime errors.
Figure 5: Validation of Lambda Function Timeout property type mismatch
Use Case: Lambda Function Role property pattern mismatch Validating ARN format requirements. Demonstrates pattern validation ensuring Role properties match required ARN format.
Figure 6: Lambda Function Role property pattern mismatch
Use Case: Undefined required Lambda Alias Name property Catching missing required properties. Shows validation detecting absent mandatory fields, preventing incomplete resource definitions from reaching deployment.
Figure 7: Validation of undefined required Lambda Alias Name property
Notice how the validation Path field (e.g., “/Resources/MyLambdaFunction/Properties/TracingConfig/Mode”) pinpoints the exact template location of each error. This eliminates manual searching through hundreds of lines of infrastructure code – a common time sink that can take minutes in complex templates.
Use case: Unsupported property Shows how CloudFormation validation catches unsupported properties. In this example, the AWS::Lambda::Alias resource had an unsupported extra property Description in a nested path RoutingConfig.AdditionalVersionWeights.0.
Figure 8: CloudFormation validation of unsupported resource property
CLI command You can also use the new describe-events API to review the validation responses.
Scenario 2: Resource Name Conflict Validation Resource name conflict validation makes sure that new resources added to a template are not already present in your AWS account or globally (e.g: Amazon S3, Amazon Route 53 DNS), preventing deployment errors caused due to resource name conflicts
After reviewing the property validation exceptions, let’s assume that you resolved all the issues and successfully deployed the stack. Next, the you have decided to include a S3 bucket resource in the template. You name the bucket “dev-thumbnails” but didn’t verify if the bucket with this name already exists. If a bucket with this name already exists, the CreateChangeSet operation will fail, reporting to the developer that the bucket already exists.
Step 2: Review Deployment Validations Use CloudFormation change set console to review validations response or use the new DescribeEvents API in the CLi.
Scenario 3: S3 bucket not empty Since AWS S3 service does not allow customers to delete S3 Buckets when there are objects in them, the new pre-deployment validations will warn you if you try to delete a bucket that is not empty.
Resuming our journey, let’s assume that you fix the name conflict issue by renaming the bucket to “dev-test-tumbnails”, and then updates the stack. After testing the lambda function’s integration with S3, the dev-cycle generated a few thumbnail objects in the S3 bucket.
Later, you decide to fix the bucket name because you notice a typo: “dev-test-tumbnails” should be “dev-test-thumbnails” (missing “h”). When you update the template to use the corrected name, CloudFormation will need to create the new bucket then delete the old one during the clean-up phase.
{
"OperationEvents": [
{
"EventId": "24920e0f-1941-45a5-9177-786bc805b724",
"StackId": "arn:aws:cloudformation:us-west-2:123456789012:stack/dev-lambda-stack/2d2c3240-bb59-11f0-b080-0613dc96740d",
"OperationId": "8fef2b60-b411-4d0e-920e-7ec7c7aa39f2",
"OperationType": "CREATE_CHANGESET",
"OperationStatus": "SUCCEEDED",
"EventType": "STACK_EVENT",
"Timestamp": "2025-11-06T22:52:26.355000+00:00",
"StartTime": "2025-11-06T22:52:21.071000+00:00",
"EndTime": "2025-11-06T22:52:26.355000+00:00"
},
{
"EventId": "c117e02d-a652-4755-9586-6d4ccb0f6504",
"StackId": "arn:aws:cloudformation:us-west-2:123456789012:stack/dev-lambda-stack/2d2c3240-bb59-11f0-b080-0613dc96740d",
"OperationId": "8fef2b60-b411-4d0e-920e-7ec7c7aa39f2",
"OperationType": "CREATE_CHANGESET",
"EventType": "VALIDATION_ERROR",
"LogicalResourceId": "MyDevThumbnailsBucket",
"PhysicalResourceId": "",
"ResourceType": "AWS::S3::Bucket",
"Timestamp": "2025-11-06T22:52:25.960000+00:00",
"ValidationFailureMode": "WARN", "ValidationName": "BUCKET_EMPTINESS_VALIDATION", "ValidationStatus": "FAILED", "ValidationStatusReason": "The bucket 'dev-tumbnails' is not empty. You must either delete all objects and versions or use the deletion policy to retain it, otherwise the delete operation will fail.", "ValidationPath": "/Resources/MyDevThumbnailsBucket"
},
{
"EventId": "6c66ff53-6751-4b4c-96b8-d1a33fc43b4f",
"StackId": "arn:aws:cloudformation:us-west-2:123456789012:stack/dev-lambda-stack/2d2c3240-bb59-11f0-b080-0613dc96740d",
"OperationId": "8fef2b60-b411-4d0e-920e-7ec7c7aa39f2",
"OperationType": "CREATE_CHANGESET",
"OperationStatus": "IN_PROGRESS",
"EventType": "STACK_EVENT",
"Timestamp": "2025-11-06T22:52:21.071000+00:00",
"StartTime": "2025-11-06T22:52:21.071000+00:00"
}
]
}
Bucket emptiness validation uses WARN mode, which allows change set creation to succeed even when the validation check fails. This gives you time to review and empty the bucket before execution. However, if you execute the change set without emptying the bucket, the delete operation will fail.
Notice in the output above:
ValidationStatus: "FAILED" – The emptiness check detected objects in the bucket
ValidationFailureMode: "WARN" – This is a warning, not a blocking error
OperationStatus: "SUCCEEDED" – Change set creation completed successfully despite the warning
This design allows you to review the warning, take corrective action (such as emptying the bucket), and then proceed with execution.
Beyond catching errors early, these capabilities also transform how you troubleshoot failed deployments with enhanced operation tracking and filtering.
New DescribeEvents API with Operation IDs and root cause filtering
The new DescribeEvents API retrieves CloudFormation events based on flexible query criteria. It groups stack operations by operation ID, enabling you to focus specifically on individual stack operations involved during your stack deployment.
Operation: An operation is any action performed on a stack, including stack lifecycle actions (Create, Update, Delete, Rollback), change set creation, nested stack creation, and automatic rollbacks triggered by failures. Each operation has a unique identifier and represents a discrete change attempt on the stack.
Figure 11: Stack Events grouped by Operation Id
Scenario When an update operation on an existing stack fails and results in a rollback, and you want to understand the reason behind the update stack failure. Using the operation ID obtained from the update stack response or from the describe stacks response, you can call describe events to get details on the failure.
The stack description available via describe-stacks API now includes LastOperations information showing recent operation IDs and their types. This enables you to quickly identify which operations occurred and their current status without parsing through event logs.
Figure 11: CloudFormation Stack Info page showing new operation IDs
Step 3: Review operation status with describe events API and operation id Using the operation ID from the previous step, you can now query specific operation events to understand exactly what happened during that operation. This targeted approach eliminates the need to search through all stack events to find relevant information.
Figure 12: New CloudFormation stack operation page
Step 4: Identify failure root cause(s) with FailedEvents filter The new failure root cause filter instantly surfaces only the events that caused the operation to fail. This eliminates the need to manually scan through progress events to identify the root cause of deployment failures.
The FailedEvents=true filter transforms troubleshooting from parsing dozens of progress events to instantly seeing only what matters. This can make diagnosis of issues during an incident much easier..
Real-World Impact These features improve your Infrastructure development experience with CloudFormation:
Template syntax errors: Previously discovered after minutes of provisioning, now caught in seconds
Resource conflicts: No more failed deployments due to existing resources
Debugging complexity: Transform troubleshooting sessions into faster targeted fixes
CI/CD reliability: Reduce pipeline failures and improve deployment confidence
Getting Started
These capabilities are available today in all AWS Regions where CloudFormation is supported. Pre-deployment validation is automatically enabled for all change set operations, no configuration required.
Try it now:
Create any change set from the CloudFormation console or via SDK or CLI with aws cloudformation create-change-set
Use `aws cloudformation describe-events –change-set-name <your-changeset-arn>` to see validation results
Filter failure root causes instantly: via console or CLI with aws cloudformation describe-events –operation-id <id> –filter FailedEvents=true
Best Practices
Always use change sets: Even for simple updates, change sets now provide validation feedback
Leverage Operation IDs: Use the unique identifiers for focused troubleshooting
Filter events strategically: Use –filters FailedEvents=true to focus on problems
Automate validation: Integrate the describe-events API into your CI/CD pipelines
Use Console: CloudFormation console provides a visual experience with error source mapping to the specific line on your template.
Conclusion
Start using these features today in your development workflow. Whether you’re building new infrastructure or maintaining existing stacks, early validation and enhanced troubleshooting will accelerate your deployment cycles and make it easier to manage infrastructure.
Ready to experience faster CloudFormation development? Create your first change set and see validation in action.
Organizations operating at scale on AWS often need to manage resources across multiple accounts and regions. Whether it’s deploying security controls, compliance configurations, or shared services, maintaining consistency can be challenging.
AWS CloudFormation StackSets (StackSets) has been helping organizations deploy resources across multiple accounts and regions since its launch. While the service is powerful on its own, combining it with Infrastructure as Code (IaC) tools and implementing automated deployments can significantly enhance its capabilities.
In this post, we’ll show you how to leverage AWS CloudFormation StackSets at scale using AWS CDK and implement a robust CI/CD pipeline for automated deployments with AWS CodePipeline.
StackSets key concepts
AWS CloudFormation StackSets allows you to create, update, or delete CloudFormation stacks across multiple AWS accounts and regions with a single operation. It’s essentially a way to manage infrastructure at scale across your AWS organization. Using an administrator account, you define and manage a CloudFormation template, and use the template as the basis for provisioning stacks into selected target accounts across specified AWS Regions:
Figure 1. StackSets overview.
The Administrator Account is the AWS account where you create and manage StackSets and the Target Accounts are the AWS accounts where the stack instances are deployed.
The Stack Instances are individual stacks created from the StackSet template deployed to specific account-region combinations.
You can make the following operations using StackSets: Create, update, and delete actions performed on stack instances. These operations can be applied in concurrent or sequential way.
Sequential Deployment:
Account-by-account deployment
Region-by-region within accounts
Configurable failure thresholds
Parallel Deployment:
Concurrent account deployments
Maximum concurrent account setting
Region priority configuration
Hybrid Deployment:
Combine sequential and parallel
Account group-based deployment
Regional deployment strategies
The power of StackSets
The use of StackSets allows us to extend AWS CloudFormation’s capabilities in several important ways:
Governance
It provides you with Centralized Management as a single point of control while including consistent deployment patterns and automated stack instance management across AWS accounts and regions.
With Drift Detection feature, you can identify if any of the stack instances of your StackSet have configuration differences according to its expected configuration. You detect changes made outside CloudFormation and changes made to an instance stack through CloudFormation directly without using the StackSet.
Flexible Deployment
You also have flexible deployment options with controlled rollout. For example, with Concurrent Deployments you can deploy to multiple accounts within each region simultaneously while controlling deployment order. It also includes failure tolerance with automated retry failed operations.
Operational Efficiency
It reduces manual effort in managing multi-account and multi-region environments while minimizes human error in deployments.
Cost Management
It delivers comprehensive resource organization and streamlined tracking of resources across accounts and regions containing instance stacks. Using centralized management, simplifies the resource tracking and organization enabling you you to have:
unified visibility: view all related stacks from a single StackSet console (with their deployment status)
consistent tagging: apply standardized tags across all stack instances for cost allocation and resource grouping
drift detection: run drift detection across all stack instances simultaneously
operations tracking: track all operations (create, update and delete) across account/regions from one place
Built-in Safety
You can establish maximum concurrent operation limits, failure tolerance thresholds and automatic retry mechanisms. You also have recovery capabilities through update operations. All these features make a built-in safety mechanisms that prevent widespread failures.
Let’s say you have 100 target accounts, with the maximum concurrent limits, you can for example deploy a change to only 10 accounts. Also, with a failure threshold you can set how many failures do you allow before automatically stopping the process (e.g., stop if more than 5 accounts fail). This way you can gradually deploy and test your templates with a little group, establishing failure thresholds, instead of affecting the stacks preventing mass failures.
When an operation fails, AWS CloudFormation performs a rollback in the stack instances deploying the previous working template. You will still need to correct the template and apply it again in all the stack instances. With StackSets, you can fix the issues in the template and run again an update across all the stacks including the concurrent limit and failure threshold mentioned before to safety test the fix.
Security and Compliance management
This security-focused approach with StackSets helps organizations maintain a strong security posture across their AWS environment while reducing the operational overhead of managing security at scale.
You can use StackSets to deploy standardized security policies across accounts, enforce security baselines automatically and implement security guardrails organization-wide. For example, you can deploy detective control resource and its configuration in all your accounts like Amazon GuardDuty or Amazon Macie. You can also deploy preventive controls like SCPs, AWS Firewall Manager or AWS Shield Advanced. For example you can deploy through StackSets the following CloudFormation template en each target account to block certain actions in a region:
<code>AWSTemplateFormatVersion: '2010-09-09'</code><br /><code>Description: 'Service Control Policy to block access to specific AWS regions'</code><br /><br /><code>Parameters:</code><br /><code> PolicyName:</code><br /><code> Type: String</code><br /><code> Default: 'RegionDenyPolicy'</code><br /><code> Description: 'Name for the Service Control Policy'</code><br /><code> </code><br /><code> PolicyDescription:</code><br /><code> Type: String</code><br /><code> Default: 'Blocks access to Singapore region (ap-southeast-1) while allowing global services'</code><br /><code> Description: 'Description for the Service Control Policy'</code><br /><code> </code><br /><code> BlockedRegion:</code><br /><code> Type: String</code><br /><code> Default: 'ap-southeast-1'</code><br /><code> Description: 'AWS Region to block access to'</code><br /><code> AllowedValues:</code><br /><code> - 'ap-southeast-1'</code><br /><code> - 'ap-southeast-2'</code><br /><code> - 'eu-west-3'</code><br /><code> - 'us-west-1'</code><br /><code> - 'ca-central-1'</code><br /><code> </code><br /><code> TargetOUId:</code><br /><code> Type: String</code><br /><code> Description: 'Organizational Unit ID to attach the policy to (e.g., ou-root-xxxxxxxxxx)'</code><br /><code> </code><br /><code>Resources:</code><br /><code> RegionDenySCP:</code><br /><code> Type: AWS::Organizations::Policy</code><br /><code> Properties:</code><br /><code> Name: !Ref PolicyName</code><br /><code> Description: !Ref PolicyDescription</code><br /><code> Type: SERVICE_CONTROL_POLICY</code><br /><code> Content:</code><br /><code> Version: '2012-10-17'</code><br /><code> Statement:</code><br /><code> - Sid: DenyAccessToSpecificRegion</code><br /><code> Effect: Deny</code><br /><code> NotAction:</code><br /><code> - 'route53:*'</code><br /><code> - 'cloudfront:*'</code><br /><code> - 'sts:*'</code><br /><code> Resource: '*'</code><br /><code> Condition:</code><br /><code> StringEquals:</code><br /><code> 'aws:RequestedRegion':</code><br /><code> - !Ref BlockedRegion</code><br /><code> TargetIds:</code><br /><code> - !Ref TargetOUId</code><br /><code> Tags:</code><br /><code> - Key: Purpose</code><br /><code> Value: RegionCompliance</code><br /><code> - Key: ManagedBy</code><br /><code> Value: CloudFormation</code><br /><br /><code>Outputs:</code><br /><code> PolicyId:</code><br /><code> Description: 'ID of the created Service Control Policy'</code><br /><code> Value: !Ref RegionDenySCP</code><br /><code> Export:</code><br /><code> Name: !Sub '${AWS::StackName}-PolicyId'</code><br /><code> </code><br /><code> PolicyArn:</code><br /><code> Description: 'ARN of the created Service Control Policy'</code><br /><code> Value: !GetAtt RegionDenySCP.Arn</code><br /><code> Export:</code><br /><code> Name: !Sub '${AWS::StackName}-PolicyArn'</code>
Other capabilities include compliance-related resources consistently, maintain audit trails of security configurations and ensure regulatory requirements are met across all accounts. For example, you can enable CouldTrail and deploy AWS Config rules across all the instance stacks managed by the StackSet.
For both Security and Compliance incidents you can use StackSets to deploy automated response workflows, configure event notifications and implement remediation actions across your accounts and regions.
Import existing stacks into StackSets
A stack import operation can import existing stacks into new or existing StackSets, so that you can migrate existing stacks to a StackSet in one operation.
Solution Overview
This solution includes an AWS CodePipeline stack that creates a CI/CD pipeline to deploy our StackSet. This pipeline deploys an application stack containing the AWS CloudFormation StackSet with a monitoring dashboard in AWS CloudWatch.
Figure 2. Solution overview
The following Amazon CloudWatch dashboard is an example of what you will in the target accounts after the StackSet is deployed:
Figure 3. Dashboard example
In the CI/CD pipeline, before running the deployment commands, it applies python security and quality code checks to ensure code quality and security and cdk-nag to ensure AWS Well Architected best practices. You can find more details about these checks in the solution repository in README.md file.
The solution includes 2 AWS CloudFormation stacks defined by in the AWS CDK application and a template for the StackSet that will be deployed in the target accounts and regions. This stack contains the monitoring dashboard that will be deployed en the target regions of each target account as a single unit.
The idea of using AWS CodePipeline with IaC is that development teams can define and share “pipelines-as-code” patterns for deploying their applications making it easy to add stages. This way, security and quality code testing can run any time you change the source code.
Figure 4. Pipeline overview
The best practice is to ensure shift-left: adding this checks to the earlier stages of the SDLC. You can accomplish this complementing your CI/CD pipeline with githooks or IDE Plugins. For example with Amazon Q Developer IDE extension you can use the review function to analyze the security of your code locally.
To use the CI/CD pipeline just create a repository using any of the AWS CodeConnection git supported providers and add the contents of the folder. All details are included in the README.md so you can always get the latest version of the code and how it works.
Conclusion
In this post, we showed how to use AWS CDK to deploy AWS CloudFormation StackSets to reduce operational overhead and ensure consistency, compliance and security across multiple regions and accounts. We also learned how to create a CI/CD pipeline to guarantee a robust DevSecOps cycle for our Infrastructure as Code.
Now that we’ve explored the main concepts together, you can clone the example repository from the walkthrough section, follow the setup instructions, and customize the implementation to enhance AWS resources management across accounts and regions. Whether you’re managing a single account or multiple organizations, these practices can be adapted to your specific needs. Now that you learned the main concepts, go ahead and clone the example repository from walkthrough section, follow the setup instructions and customize the implementation to improve the AWS resources management across your accounts and regions.
As organizations adopt multi-account strategies for improved security features and governance, AWS CloudFormation StackSets enables organizations to deploy infrastructure across multiple accounts and regions. However, monitoring and tracking these distributed deployments across multiple accounts presents operational challenges. When a critical security baseline deployed across 50 accounts suddenly starts failing, teams face the daunting task of logging into each account individually to understand what went wrong and which accounts were affected.
This operational overhead scales exponentially with organization growth, requiring platform teams to spend countless hours switching between accounts and manually correlating deployment events. The lack of centralized visibility slows incident response and makes it difficult to identify patterns or implement proactive monitoring. In this blog post, we’ll explore a solution that centralizes AWS CloudFormation logs from multiple accounts into a single management account, making it easier to monitor and troubleshoot StackSets deployments.
Solution Architecture
Our solution creates a centralized logging system that collects AWS CloudFormation events from all target accounts and forwards them to a central management account. This approach provides a single pane of glass for monitoring and troubleshooting AWS CloudFormation deployments across your entire organization.
Figure 1. Architecture diagram showing event flow from member accounts to management account through EventBridge and CloudWatch Logs.
The architecture consists of four main components:
Management Account Setup: Creates a central event bus, log group, and necessary permissions in the organization’s management account.
Target Account Configuration: Deployed via StackSets to configure event rules that forward AWS CloudFormation events to the management account.
Resource Deployment: Uses StackSets to deploy common resources across target accounts, generating the events we want to monitor.
Monitoring and Visualization: Provides dashboards and queries for operational insights.
Event Capture:Amazon EventBridge rules in each target account capture these AWS CloudFormation events based on defined patterns.
Cross-Account Forwarding: Events are forwarded to a custom event bus in the management account using cross-account permissions.
Centralized Logging: The central event bus routes all events to a Amazon CloudWatch Log Group with structured logging.
Monitoring and Alerting: Administrators can view consolidated logs, create custom queries, and set up alerts from a single location.
Prerequisites
Before implementing this solution, ensure you have the following prerequisites in place:
AWS account: Ensure you have valid AWS account.
AWS Organizations: You must have an AWS Organization structure set up with a primary management account and several member accounts under the management account.
Appropriate Permissions: You must have access to the management account or be configured as a delegated administrator to create and manage StackSets. For detailed information about permissions and security considerations when using StackSets with AWS Organizations, please review the Prerequisites in the AWS CloudFormation StackSets documentation.
Implementation Deep Dive
The solution is implemented using two AWS CloudFormation templates that work together to create a comprehensive monitoring system:
This template establishes the central logging infrastructure in the management account by creating a custom Amazon EventBridge event bus with cross-account access policies and an encrypted Amazon CloudWatch Log Group using a customer-managed AWS Key Management Service (AWS KMS) key. A key feature is the included stack set resource that automatically deploys the target account configuration to all member accounts, eliminating manual setup and ensuring consistent configuration across the entire organization.
This template creates a service-managed stack set that deploys common resources to all accounts in specified organizational units. The StackSet is configured with auto-deployment enabled to automatically provision new accounts added to the organization and includes operation preferences for parallel regional deployment with fault tolerance settings.
On the Stacks page, choose Create stack at top right, and then choose With new resources (standard).
On the Create stack page, Upload a template file, choose Choose File to choose a template file from your local computer.
Choose Next to continue and to validate the template.
On the Specify stack details page, type a stack name in the Stack name box.
In the Parameters section, specify values for the parameters that were defined in the template.
Choose Next to continue creating the stack.
Acknowledge capabilities and transforms.
Choose Next to continue.
Choose Submit to launch your stack.
This creates a stack set that deploys Amazon Simple Storage Service (Amazon S3) infrastructure to all target accounts, generating AWS CloudFormation events that will be captured by your centralized logging system.
Figure 3: Screenshot showing successful deployment of common-resources-stackset.yaml template for target accounts
Step 4: Validation and Testing
Confirm event flow and monitoring functionality by viewing the log streams in the ‘central-cloudformation-logs’ log group.
Monitoring and Visualization
The centralized logging solution provides advanced monitoring capabilities through Amazon CloudWatch Logs Insights and custom dashboards.
You can customize your queries to get:
Recent AWS CloudFormation events across all accounts.
Failed stack operations for quick troubleshooting.
Successful deployments for verification.
Event distribution by account and region.
Status breakdown of all AWS CloudFormation operations.
The following query helps you analyze CloudFormation events across your organization by showing:
You can customize your queries to filter for specific conditions such as failed deployment status, particular resource types, or specific accounts to quickly identify and troubleshoot issues across your organization’s AWS CloudFormation deployments.
Cost Implications
When implementing this centralized monitoring solution, you should consider the following cost components:
Amazon EventBridge pricing – Costs associated with events being published across accounts to the central event bus
Amazon CloudWatch pricing – Storage costs for the centralized log group storing CloudFormation events from all accounts. Query costs when analyzing the centralized logs
To clean up the resources created in this solution, follow these steps:
First, delete the common resources stack set (common-resources-stackset) from the AWS CloudFormation console in your management account. This will remove all the resources deployed across your member accounts.
After the stack set operations are complete, delete the management account logging setup stack (log-setup-management) to remove the centralized logging infrastructure, including the event bus, log groups, and associated IAM roles.
Note: Make sure all stack set operations are complete before deleting the management account logging setup to ensure proper cleanup of all resources.
Conclusion
Managing infrastructure across multiple AWS accounts doesn’t have to be complex. By centralizing AWS CloudFormation logs, you can gain visibility into your multi-account deployments, troubleshoot issues more efficiently, and help achieve consistent resource deployment across your organization.
This solution demonstrates how AWS services like AWS CloudFormation StackSets, Amazon EventBridge, and Amazon CloudWatch Logs can be combined to create a powerful monitoring system for your infrastructure as code deployments.
Get started today by implementing this solution in your AWS Organization to gain immediate visibility into your multi-account deployments. Download the templates from our GitHub repository and follow the step-by-step guide to enhance your cloud operations.
This post is cowritten by Danilo Tommasina and Lalit Kumar B from Thomson Reuters.
Large organizations often struggle with infrastructure management challenges including compliance issues, development bottlenecks and errors from inconsistent AWS resource creation across teams. Without standardized naming, tagging and policy enforcement, teams face repeated boilerplate code and difficulty accessing centrally-managed resources.
In this post, we will show you how Thomson Reuters developed an extension of the AWS Cloud Development Kit (CDK) to automate compliance, standardization and policy enforcement in Infrastructure as Code (IaC) scripts. We will explore the strategic reasoning behind this initiative, outline foundational design principles, and provide technical details on TR’s journey from concept to implementation. The solution accelerates and standardizes cloud infrastructure deployment and management through seamless integration between TR’s custom library and AWS CDK.
Thomson Reuters (TR) is one of the world’s leading information organizations for businesses and professionals. TR provides companies with the intelligence, technology, and human expertise they need to find trusted answers, enabling them to make better decisions more quickly. TR’s customers span the financial, risk, legal, tax, accounting, and media industries.
Overview
In a large organization that offers a variety of customer products, it is essential to manage numerous cloud resources effectively. This involves overseeing multiple AWS accounts, implementing access control or addressing financial tracking challenges. These tasks require the application of centrally defined standards and conventions, with additional requirements tailored to specific sub-organizations.
Infrastructure as Code (IaC) is an effective method for managing cloud resources. However, utilizing vanilla AWS CloudFormation for extensive and intricate infrastructure can pose challenges. It requires careful attention to naming conventions, tagging standards, security, and best practices for infrastructure deployments. Additionally, repeating infrastructure patterns across various services and products often leads to excessive use of copy-paste and dealing with boilerplate code. When projects require configurable and dynamic components – including conditionals, loops, repeatable patterns, and distribution to a large user base – delivering CloudFormation scripts can become quite cumbersome and prone to errors.
AWS CDK addresses these challenges by enabling IaC development in high-level programming languages like TypeScript, JavaScript, Python, Java. AWS CDK Level 2 and 3 constructs simplify and reduce the amount of code to be written to manage complex infrastructure. It allows TR to create custom libraries that extend the vanilla AWS CDK with additional patterns and utilities. The extension libraries can also be distributed for multiple programming languages and package managers thanks to JSII. JSII enables TypeScript libraries to be automatically compiled and packaged for native consumption in each target language, allowing CDK libraries to be written once but used in many different programming environments.
Solution to optimize the process
In a medium to large company, different teams provide the fundamental infrastructure services (e.g. authentication and authorization, networking, security, financial tracking and optimization, base infrastructure provisioning, etc.) to enable use of the cloud for a large community of developers.
Figure 1 illustrates the conventional method involving teams producing documentation that outlines the usage of pre-deployed infrastructure. This includes naming and tagging standards, required security boundaries, default settings and other relevant guidelines. Subsequently, the implementation team reviews these documents and integrates the established rules into their tool chain consistently, often working in isolation. This results in inefficiencies, misinterpretation risks and maintenance challenges when specifications change.
Figure 1: The traditional approach
TR’s optimized approach replaces documentation with working code as shown in Figure 2.
Figure 2: The optimized approach
Infrastructure teams contribute their specifications into an extension library for AWS CDK, while the implementation teams can also contribute common patterns back into the central extension. The central extension library is released as polyglot packages allowing the implementation teams to pick the programming language that fits best to their knowledge.
With this approach, TR introduce a “shift-left” in the development and delivery lifecycle. Standards and best practices are introduced early, things are done right by default, and TR minimizes the risks of getting inappropriately configured resources to be deployed, which leads to a reduction in the number of governance and security incidents. Implementation delivery teams can share well architected patterns for re-use by other teams to improve overall effectiveness.
Implementation
Design principles
Key factors for the adoption of a framework are:
Simplicity, ease-of-use, self-service, and fast onboarding
Low maintenance effort and cost
Controlled roll-out, ability to quickly roll-back
With the above in mind, TR delivered a minimally invasive framework that can be enabled with a tiny set of custom code on top of vanilla AWS CDK code.
Using the TR-AWS CDK core library is straightforward – users simply import the package and adapt their entry point. From there, they can leverage standard AWS CDK code and documentation for most development tasks. There’s no need to learn custom construct classes or follow extensive specialized tutorials – vanilla AWS CDK knowledge is sufficient for most requirements. Additionally, developers can quickly incorporate open-source construct libraries through standard package managers. These third-party libraries integrate seamlessly with the TR implementation, automatically conforming to company standards without requiring additional configuration.
By managing distribution of the library following standard software packaging and release procedures TR enable consumers to adopt new capabilities in a controlled way, with the ability to roll-back to previous versions if something goes wrong during an update.
All this together allows TR to tick off the key factors listed above.
The monorepo approach
TR created a monorepo (monolithic repository) which is a version control strategy where multiple projects or packages are stored in a single repository. This approach offers several advantages over maintaining separate repositories for each package: unified versioning, simplified dependency management, consistent tooling, atomic changes across packages and improved collaboration.
This setup mirrors the configuration used by AWS CDK itself.
TR organized their monorepo following this structure:
repo/package.json: Defines dev dependencies and global scripts used by all packages
repo/packages: contains the different modules
repo/packages/core/package.json: deps of core module and scripts for core module
repo/packages/core/lib/*: typescript code that composes the core module
repo/packages/core/lib/augmentation/*: module augmentations for AWS CDK core components
repo/packages/constructs-pattern-X: define multiple reusable and independent level 3 constructs
repo/packages/tr-cdk-lib/package.json: assembly module that defines scripts to assemble the final mono package that will be shared via a npm repository
Figure 3: Repo structure
This structure enables TR to maintain a collection of related, but distinct CDK constructs while making sure they work together seamlessly.
The modules are assembled and released into one single versioned package which simplifies the end-user’s consumption.
The core module: Foundation of TR AWS CDK library
The core module is the foundation of TR’s CDK extension library, it consists of several key components that work together to “TR-ify” AWS resources and offer simplified access to centrally managed infrastructure resources that are provided by TR’s AWS landing zone teams.
TR refers to “TR-ification”, as the process of dynamically adapting AWS CDK constructs to meet their standards and best practices. From a user perspective, the process happens in a minimally invasive way, for most of the time the user is coding with vanilla AWS CDK components, while having access to short-cuts to a variety of TR specific resources.
The core module serves several critical purposes:
Standardization: makes sure the AWS resources follow TR naming conventions and tagging standards
Simplification: abstracts away complex configurations required for TR compliance
Integration: provides seamless access to TR-managed resources like VPCs, security groups, and Route53 hosted zones
Policy Enforcement: automatically applies custom security and financial optimization policies
The “TR-ification” process happens on every construct following a consistent order, for each construct it will:
If applicable, set a name following a consistent pattern
Apply custom initialization logic (e.g. set IAM permission boundary)
Apply security and financial optimization defaults (if not set)
Perform custom validations
Verify security and financial optimization policies
Tag resources
TR uses a single root-level Aspect instead of multiple Aspects to avoid complex resource type checking and improve maintainability:
// This is the entrypoint that triggers the trification process on all CDK constructs
// we apply all TR specific transformations at this point
Aspects.of(this).add({
visit: (node: IConstruct) => {
node.getTRifier().trify();
},
});
The careful readers at this point will scream: Wait a moment! node.getTRifier().trify() won’t compile!
Which is absolutely correct… unless you know a topic in TypeScript called module augmentation, in TR’s case, they augment the IConstruct interface and Construct class as follows:
/** Defines the set of functionality needed when trifying resources */
export interface ITRifier {
trify(): void;
readonly name: string | undefined;
readonly nameFromTree: string;
}
declare module 'constructs/lib/construct' {
interface IConstruct {
/** Obtain the ITRifier responsible to add TR specific features to this CDK IConstruct */
getTRifier(): ITRifier;
trContext(): AppContext | StageContext | StackContext;
}
interface Construct extends IConstruct {
/** Build the ITRifier responsible to add TR specific features to this CDK IConstruct */
buildTRifier(): ITRifier;
}
}
Then provide default implementations for the generic Construct:
Construct.prototype.getTRifier = function () {
// Lazy getter, build the TRifier only when needed and cache it
return ObjectUtils.lazyGetFrom(this, 'trifier', () => this.buildTRifier());
};
Construct.prototype.buildTRifier = function () {
return new ConstructTRifier(this); // Default dummy implementation
};
Construct.prototype.trContext = function (): StackContext {
return Stack.of(this).trContext() as StackContext;
};
Since AWS CDK constructs implement the IConstruct interface, respectively extend the Construct class automatically, the “TR-ification” process becomes available for many types of constructs. All you need to do now is inject your custom logic for all resources you need customization and make sure the module is loaded, e.g. in case of a Lambda function, it uses:
lambda.CfnFunction.prototype.buildTRifier = function () {
return new CfnResourceTRifierLambda.CfnFunction(
this,
() => { // Accessor for retrieving the lambda function name
return this.functionName;
},
(name: string) => { // Accessor for setting the lambda function name
this.functionName = name;
},
() => {
// Our own stuff to set defaults for financial optimizations
const policyChecker = FinOps.Lambda.Defaults.apply(this);
this.node.addValidation({
validate: () => {
// Inject a custom validation logic to check compliance with financial policies
return policyChecker.addErrorIfNotCompliant(this);
}
});
}
);
};
TR targets L1 (Cfn) constructs like CfnFunction because the higher-level L2 and L3 constructs internally create L1 constructs during synthesis. This architectural decision makes sure TR-ification is applied universally, whether users write new lambda.Function() or new lambda.CfnFunction(), both will be TR-ified. This approach provides complete coverage with a single implementation point while remaining completely transparent to library users who can continue using their preferred abstraction level without awareness of this internal mechanism.
Naming standardization
TR uses standardized naming to support IAM policy filtering and consistent resource management. In order to support a broad range of use-cases, TR defined the resource name pattern as follows: <segregationPrefix>[-appPrefix]-<resourceName>[-region]-<envSuffix> where the elements mean:
segregationPrefix: A prefix used for grouping resources for a specific asset, it implies that a segregated administrative group is responsible for this resource, where applicable it is used for ARN based IAM resource filtering.
appPrefix: Optional, a prefix used to map a resource to a specific application or service, this is shared across stacks within a CDK app.
resourceName: The name of a resource indicating its purpose.
region: Optional, applied only to resources that are global but are part of a CDK stack that is bound to a specific region.
envSuffix: A suffix used to segregate different deployment environments, e.g. development, continuous integration, quality assurance, production.
Traditional approaches require developers to manually construct these names, propagating prefixes and suffixes throughout their code:
new lambda.Function(stack, 'foo', {
runtime: lambda.Runtime.NODEJS_LATEST,
handler: 'index.handler',
code: new lambda.InlineCode('bar'),
functionName: `\${segregationPrefix}-\${appPrefix}-compute-stats-\${envSuffix}`,
});
With TR AWS CDK extension, the code is simplified to:
new lambda.Function(stack, 'MyFunction', {
runtime: lambda.Runtime.NODEJS_LATEST,
handler: 'index.handler',
code: new lambda.InlineCode('foo'),
functionName: 'compute-stats',
});
The functionName describes what the function does without “noise”, TR AWS CDK will transparently generate and inject the name into the synthetized CloudFormation script, matching the specification. Note that functionName is optional and TR-CDK will either TR-ify a provided name or automatically generate a valid one if the user omits it, making sure CloudFormation receives a properly formatted name.
Access to “Landing Zone” resources
TR’s central AWS Landing Zone team is responsible of inflating a set of standard resources (e.g. VPC, subnets, security groups, Route 53 zones, golden AMIs, etc.) into AWS accounts that are made available to application development teams.
Through module augmentation (shown earlier), the TR-ifier defines the function trContext() which provides access to a context-aware utility. When calling this function on a resource that resides within a Stack, it will return an object that implements StackContext interface.
export interface StackContext extends StageContext {
/** Get access to the TR IVpc */
readonly vpc: IVpc;
/** Provides access to standard security groups that are available in all TR accounts */
readonly securityGroups: trparams.ISecurityGroupsResolver;
/** Provides access to private and public hosted zones (with numeric digits) that are available in all TR accounts */
readonly route53: trparams.IRoute53Resolver;
/** Provides access to TR golden AMIs that are available in all TR accounts */
readonly goldenAMI: TRGoldenAMI;
}
The readonly attributes are accessors for the AWS Landing Zones resources listed above. With calls like the following examples, you have a simple way to obtain access to the standard VPC, subnets selections, route 53 private hosted zone, …
// Get the IVpc:
const trVpc: IVpc = stack.trContext().vpc;
// Get the private subnets as array
const privateSubnets: ISubnet[] = trVpc.privateSubnets;
// Get the private subnets as SubnetSelection
const privateSubSel: SubnetSelection = trVpc.selectSubnets({
subnetType: SubnetType.PRIVATE_WITH_EGRESS,
});
// Get the private Route53 hosted zone
const privateHZ = stack.trContext().route53.privateHostedZone;
You might now wonder how TR resolves the resources and obtain objects implementing IVpc, ISubnet, ISecurityGroup, …
Instead of using hard-coded resource attributes (e.g. Id, ARN, …) or complex lookups, TR uses CloudFormation’s ability to resolve Systems Manager parameters at execution time, as part of the AWS account initial inflation along with the resources, Systems Manager parameters are registered as well. The parameter names are the same across TR’s AWS accounts, the value contains e.g. the id of the matching AWS Landing Zone standard resource, e.g. /landing-zone/vpc/vpc-id, /landing-zone/vpc/subnets/private-1-id, /landing-zone/vpc/subnets/private-2-id, …
TR then defined custom IVpc, ISubnet, IHostedZone… implementations and for each function they implemented dynamic resolution of resource attributes via Systems Manager parameters. With this approach, TR obtains portable code that runs on AWS accounts initialized via TR inflation process. There are no hard-coded resource identifiers, and there is no need for lookups via AWS SDK during synthesis.
As a user of the TR AWS CDK library, TR developers interact with an object implementing the IVpc interface and do not have to care about how to obtain e.g. the VPC-id and subnet ids. The same principle applies to Route53 hosted zones, Golden AMI ids, etc.
Application initialization
As mentioned previously, one key design principle is to minimize the custom code that a user of TR AWS CDK is required to use compared to using vanilla AWS CDK. This approach leverages existing AWS CDK and reduces the learning curve for developers.
This is how TR developers initialize an App with vanilla CDK, compared to how they initialize it with TR AWS CDK.
From this point on, the developers can continue using vanilla AWS CDK code, the value returned by TRCdk.newApp(…) is an instance of an extension of CDK’s App class and is fully compatible with it. It, however, injects the TR-ification aspect, manages the tagging process, and initializes contextual information.
Here and there, e.g. when they need to pass the VPC into a construct, they will need to call TR AWS CDK code via the trContext() entry point that is exposed on CDK constructs through TypeScript’s module augmentation feature, but that’s it! 99% of the code is vanilla AWS CDK code.
The segregationId, namingProps, and deploymentEnv attributes are used for multiple purposes like formatting resource names and tagging resources.
Standardized Tagging
TR defines tagging standards, there are mandatory tags (e.g. for attribution to a specific product asset and for tracking resource ownership), and there are optional tags (e.g. for specifying resources that belong to different services within the same product asset).
The segregationId, the resourceOwner, and deploymentEnv attributes are used to set mandatory tags using CDK’s built-in functionality for tagging. TR also defines a standardized set of optional tags that can be passed into the application context or set ad-hoc on individual constructs.
This approach maintains consistency in the use of tag names and setting the values, it happens automatically behind the scenes and will be applied to the taggable constructs. No copy-pasting of tag definitions like in AWS CloudFormation, no issues dealing with CloudFormation’s inconsistent syntax for tag declarations, no forgetting of tagging resources.
Conclusion
In this post, we discussed how the monorepo approach to AWS CDK development, centered around the core module, has significantly improved the infrastructure management at Thomson Reuters. By providing well-architected L3 constructs, standardizing and simplifying AWS resource creation, they’ve reduced errors, enhanced governance, and accelerated development.
The core module’s ability to enforce policies, standardize naming and tagging, and provide access to TR-managed resources makes it an invaluable tool for teams working with AWS infrastructure at Thomson Reuters.
To get started with AWS CDK and build your CDK solutions, check out the AWS CDK Developer Guide.
AWS CloudFormation StackSets enables organizations to deploy infrastructure consistently across multiple AWS accounts and regions. However, success depends on choosing the right deployment strategy that balances three critical factors: deployment speed, operational safety, and organizational scale. This guide explores proven StackSets deployment strategies specifically designed for multi-account infrastructure management.
Understanding StackSets Deployment Fundamentals
What are StackSets Actually Used For?
Unlike single-account AWS CloudFormation templates, StackSets are specifically designed for multi-account infrastructure governance. Common use cases include Security baselines (deploying IAM policies, security groups, and access controls across all accounts), Compliance controls (rolling out AWS Config rules, AWS CloudTrail configurations, and audit requirements), Organizational standards (establishing consistent VPC configurations, tagging policies, and naming conventions), Shared services (deploying monitoring solutions, logging infrastructure, and backup policies) or Cost management (implementing budget controls, cost allocation tags, and resource optimization policies)
The Multi-Account Challenge
Managing infrastructure across dozens or hundreds of AWS accounts presents unique challenges:
Single Account (CFN Template) Multi-Account (StackSets) App A Org Unit A (50 accounts) | | [Deploy Once] [Deploy consistently across all] | | Success/Fail Complex success/failure matrix
Multi account and multi region Cloudformation deployment complexity
The Speed-Safety-Scale Triangle
Every StackSets deployment strategy involves trade-offs: Speed (how quickly changes propagate across your organization), Safety (risk mitigation and failure containment) and Scale (ability to manage hundreds of accounts efficiently)
Prerequisites
Before implementing any of the deployment strategies described in this guide, ensure you have:
“For a more conservative deployment, set Maximum Concurrent Accounts to 1, and Failure Tolerance to 0. Set your lowest-impact region to be first in the Region Order Start with one region.”
“For a faster deployment, increase the values of Maximum Concurrent Accounts and Failure Tolerance as needed. ”
Based on the above, we are proposing below several deployment strategies, depending on the speed, safety and scale you want to achieve.
1. Sequential Deployment: Maximum Safety
Use Case : Critical security updates, compliance requirements, first-time organizational rollouts
Below are listed some possible use cases:
Security baseline updates: New IAM policies affecting root access
Compliance rollouts: SOX, HIPAA, or PCI-DSS control implementations
Critical infrastructure changes: VPC security group modifications
Organizational policy changes: New AWS Config rules for audit compliance
Implementation Example:
For this example, we will download the following template ConfigRuleCloudtrailEnabled.yml from the Cloudformation sample library in the AWS documentation to configure an AWS Config rule to determine if AWS CloudTrail is enabled and follow the next steps:
The expected response should be similar to the following :
{"StacksetId": "security-baseline: ...."}
Step 2: Create Stack Instances
Before you launch the below command, you need to adjust the values of the following parameters:
OrganizationalUnitIds: you must change the value “ou-test” in the below command line to the name of the target OU you want to deploy to. I recommend creating a new test OU in the console or via the CLI for the purpose of this test.
regions: if needed, change the “us-east-1 eu-west-1” value, here you need to list all the regions you want to deploy to. AWS Config must be active in the accounts/regions that you choose, otherwise you’ll get an error when deploying the Stack.
# Deploy security baseline to production accounts # StackSet operation managed from us-east-1 # Deployed to regions us-east-1 and eu-west-1 # SEQUENTIAL = One region at a time, sequentially # MaxConcurrentPercentage = Deploy to 5% of accounts at once # FailureTolerancePercentage = Stop on first failure aws cloudformation create-stack-instances \ --stack-set-name security-baseline \ --deployment-targets OrganizationalUnitIds=ou-test\ --regions us-east-1 eu-west-1 \ --region us-east-1 \ --operation-preferences RegionConcurrencyType=SEQUENTIAL,MaxConcurrentPercentage=5,FailureTolerancePercentage=0
AWS CLI to create security-baseline Stack Instances sequentially for maximum safety
The CLI output should look like the following:
{"OperationId": ....}
Or create the StackSet and add the Stacks with the AWS Console:
In the CloudFormation Console, click “Create StackSet”
AWS CloudFormation Console: create a security-baseline Stackset
Upload your template from S3 or from your computer and click Next:
AWS CloudFormation Console: specify a template
Specify the StackSet name and parameters and click Next:
AWS CloudFormation Console: specify the StackSet name and parameters
Configure StackSet options and click Next:
AWS CloudFormation Console: configure the StackSet options
Set deployment options and click Next:
AWS CloudFormation Console: set deployment options
AWS CloudFormation Console: set more deployment options
Then Review and Submit.
Not to overweight this blog, we’ll provide only this example of CLI output and Console screenshot, but the “Parallel Deployment” and “Balanced Approach” will be similar to this example. You just need to update the parameters for the different StackSet Operations options.
A real-world example would be a financial services company deploying new MFA requirements across 200 production accounts. They could use sequential deployment with 5 concurrency to ensure each batch was validated before proceeding.
2. Parallel Deployment: Maximum Speed
The Parallel Deployment is best for non-critical updates, development environments, routine maintenance
Here are some possible use cases:
Development account standardization: Rolling out new development tools
Monitoring infrastructure: Deploying Amazon CloudWatch dashboards and alarms
Non-production updates: Updating development and staging environments
Implementation Example:
For this example, we will copy paste the .yml template from this Re:Post article about monitoring IAM events in a file called “monitoring-baseline.yml”, and use it in the following command lines.
Just like in the previous example, before you launch the below command, you need to adjust the values of the OrganizationalUnitIds and regions parameters.
# Deploy monitoring baseline to dev and sandbox accounts # StackSet operation managed from us-east-1 # Deployed to regions us-east-1 and eu-west-1 # PARALLEL = Deployment in parallel # MaxConcurrentPercentage = Deploy to 80% of accounts at once # FailureTolerancePercentage = Tolerate failures in 20% of accounts aws cloudformation create-stack-instances \ --stack-set-name monitoring-baseline \ --deployment-targets OrganizationalUnitIds=ou-development,ou-sandbox \ --regions us-east-1 eu-west-1 \ --region us-east-1 \ --operation-preferences RegionConcurrencyType=PARALLEL,MaxConcurrentPercentage=80,FailureTolerancePercentage=20
AWS CLI to create monitoring-baseline Stack Instances in parallel with high value for max concurrent percentage for maximum speed
3. Progressive Deployment: Balanced Approach or Multi Phase Approach (Recommended)
For most production scenarios with moderate risk tolerance, it is recommended to use a Balanced Approach, or Multi-Phase Implementation.
Balanced Approach
For this example, to make it easier, you can create a copy of “monitoring-baseline.yml” created previously, and name it “balanced-template.yml”.
cp monitoring-baseline.yml balanced-template.yml
bash command to copy the monitoring-baseline.yml file to balanced-template.yml
Then you can use it in the following command lines.
You need to adjust the values of the OrganizationalUnitIds and regions parameters.
# Deploy monitoring baseline to production accounts # StackSet operation managed from us-east-1 # Deployed to regions us-east-1 # SEQUENTIAL = Deployment in sequence # MaxConcurrentPercentage = 100% Deploy full speed for small pilot # FailureTolerancePercentage = Zero tolerance in pilot aws cloudformation create-stack-instances \ --stack-set-name balanced-deployment \ --deployment-targets Accounts=pilot-account-1,pilot-account-2 \ --regions us-east-1 \ --region us-east-1 \ --operation-preferences RegionConcurrencyType=SEQUENTIAL,MaxConcurrentPercentage=100,FailureTolerancePercentage=0
AWS CLI to create balanced-deployment Stack Instances sequentially for maximum safety in Pilot accounts
Wait for Pilot validation before proceeding to Phase 2
Phase 2: Early Adopter OUs (30% of target)
Phase 2: Create Early Adopter Stack Instances
You need to adjust the values of the OrganizationalUnitIds and regions parameters.
# Deploy monitoring baseline to production accounts # StackSet operation managed from us-east-1 # Deployed to regions us-east-1, eu-west-1 # PARALLEL = Deployment in parallel # MaxConcurrentPercentage = Deploy to 25% of accounts at once # FailureTolerancePercentage = Tolerate failures in 5% of accounts aws cloudformation create-stack-instances \ --stack-set-name balanced-deployment \ --deployment-targets OrganizationalUnitIds=ou-early-adopter \ --regions us-east-1 \ --region us-east-1 eu-west-1 \ --operation-preferences RegionConcurrencyType=PARALLEL,MaxConcurrentPercentage=25,FailureTolerancePercentage=5
AWS CLI to create balanced-deployment Stack Instances in parallel with low max concurrent percentage for a balanced deployment in Early Adopter OU
Wait for Early Adopter validation before proceeding to Phase 3
Phase 3: Full Deployment (Remaining 60%)
Phase 3: Full Deployment
You need to adjust the values of the OrganizationalUnitIds and regions parameters.
# Deploy monitoring baseline to production accounts # StackSet operation managed from us-east-1 # Deployed to regions us-east-1, eu-west-1 and ap-southeast-1 # PARALLEL = Deployment in parallel # MaxConcurrentPercentage = Deploy to 40% of accounts at once for higher speed after validation # FailureTolerancePercentage = Tolerate failures in 10% of accounts for moderate tolerance aws cloudformation create-stack-instances \ --stack-set-name balanced-deployment \ --deployment-targets OrganizationalUnitIds=ou-standard-prod,ou-legacy-prod \ --regions us-east-1 \ --region us-east-1 eu-west-1 ap-southeast-1 \ --operation-preferences RegionConcurrencyType=PARALLEL,MaxConcurrentPercentage=25,FailureTolerancePercentage=5
AWS CLI to create balanced-deployment Stack Instances in parallel with low max concurrent percentage for a balanced deployment in the remaining OUs
Using Step Functions for Orchestration
AWS Step Functions provides a serverless workflow service that can orchestrate StackSets deployments with advanced control flow, error handling, and state management capabilities. This approach enhances your multi-account deployments with features not available through standard StackSets operations alone.
Some of the Key Benefits include:
Advanced Deployment Orchestration: Coordinate multi-phase rollouts with validation gates
Human Approval Workflows: Implement manual approval steps for critical changes
Enhanced Error Handling: Define sophisticated retry policies and fallback mechanisms
Visual Monitoring: Track deployment progress through the Step Functions visual console
Real-World Use Case: Compliance Control Rollout
In regulated industries, AWS Step Functions enables a phased approach that combines automation with necessary governance. For instance, you can:
Deploy compliance controls to test accounts
Run automated validation and generate compliance reports
Obtain manual approval from compliance team
Deploy to production accounts with comprehensive monitoring
This approach ensures consistent governance while maintaining the complete audit trail required for regulatory compliance.
Monitoring and Optimization
AWS CloudFormation StackSets do not have extensive built-in Amazon CloudWatch metrics specifically designed for monitoring StackSet operations and health. This is actually why the monitoring implementation in our blog post is valuable.
Here’s what AWS does and doesn’t provide out of the box:
What AWS provides natively:
Basic AWS API call metrics via AWS CloudTrail (which show that operations happened but don’t track success rates or performance)
General service quotas and throttling metrics for CloudFormation as a whole
CloudFormation provides some metrics for individual stacks, but not consolidated StackSet-specific metrics
What requires custom implementation (as in our blog post):
Success rate metrics for StackSet operations across accounts
Deployment completion time tracking
Configuration drift detection and monitoring
Account-specific failure analysis
Comprehensive dashboards that show StackSet health across your organization
The code in our blog post demonstrates how to implement the success rate custom metrics by:
Gathering data from the CloudFormation API about StackSet operations
Calculating the success rate metrics for StackSet deployments
Creating custom Amazon CloudWatch metrics in a custom namespace (like “StackSetMonitoring”)
Setting up alerts for issues
This explains why organizations need to implement custom monitoring solutions like the one shown in our blog post rather than relying solely on built-in metrics.
Automated Monitoring Implementation: example of a custom metric to monitor the StackSet operations success rate
The following AWS Cloudformation template provides real-time monitoring and alerting for AWS CloudFormation StackSet operations through automated infrastructure deployment. This solution creates a complete monitoring system using a AWS Lambda function, Amazon EventBridge rules, Amazon SNS notifications, and Amazon CloudWatch dashboards to track StackSet success and failure rates. The core Lambda function named StackSetMonitor continuously monitors all active StackSets in your account, calculating success rates and publishing custom metrics to Amazon CloudWatch under the StackSetMonitoring namespace.
Below you’ll find a few example of possible custom metrics that could be implemented based on this AWS Cloudformation template:
Count of all operations (CREATE, UPDATE, DELETE) per StackSet over time periods
Number of stack instances with configuration drift (requires additional API calls)
Average time taken for StackSet operations to complete
Rate of StackSet operations to identify peak usage times
Number of individual stack instances that failed during operations
Number of retried operations (indicates infrastructure issues)
…
Here’s the StackSetMonitor.yml CloudFormation Template:
# StackSetMonitor.yml
# CFN template for monitoring AWS CloudFormation StackSet operations with real-time alerts, metrics, and dashboards.
AWSTemplateFormatVersion: '2010-09-09'
Description: 'CloudFormation template for StackSet operation monitoring using CloudWatch and SNS'
Parameters:
StackSetName:
Type: String
Description: 'Name of the StackSet to monitor'
Default: 'security-baseline'
MinLength: 1
MaxLength: 128
AllowedPattern: '[a-zA-Z][-a-zA-Z0-9]*'
ConstraintDescription: 'Must be a valid StackSet name (1-128 characters, alphanumeric and hyphens, must start with a letter)'
VpcId:
Type: String
Description: 'VPC ID where the Lambda function will be deployed (leave empty to create new VPC)'
Default: ''
SubnetIds:
Type: CommaDelimitedList
Description: 'List of subnet IDs for the Lambda function (leave empty to create new subnets)'
Default: ''
SecurityGroupIds:
Type: CommaDelimitedList
Description: 'List of security group IDs for the Lambda function (leave empty to create new security group)'
Default: ''
Conditions:
CreateVPC: !Equals [!Ref VpcId, '']
CreateVPCAndSubnets: !And [!Equals [!Ref VpcId, ''], !Equals [!Join [',', !Ref SubnetIds], '']]
HasCustomSecurityGroups: !Not [!Equals [!Join [',', !Ref SecurityGroupIds], '']]
Resources:
# KMS Key for CloudWatch Logs encryption
LogsKMSKey:
Type: AWS::KMS::Key
DeletionPolicy: Delete
UpdateReplacePolicy: Delete
Properties:
Description: 'KMS Key for StackSet Monitor CloudWatch Logs and Lambda environment variable encryption'
EnableKeyRotation: true
KeyPolicy:
Version: '2012-10-17'
Statement:
- Sid: Enable IAM User Permissions
Effect: Allow
Principal:
AWS: !Sub 'arn:${AWS::Partition}:iam::${AWS::AccountId}:root'
Action: 'kms:*'
Resource: '*'
- Sid: Allow CloudWatch Logs
Effect: Allow
Principal:
Service: !Sub 'logs.${AWS::Region}.amazonaws.com'
Action:
- 'kms:Encrypt'
- 'kms:Decrypt'
- 'kms:ReEncrypt*'
- 'kms:GenerateDataKey*'
- 'kms:DescribeKey'
Resource: '*'
Condition:
ArnEquals:
'kms:EncryptionContext:aws:logs:arn':
- !Sub 'arn:${AWS::Partition}:logs:${AWS::Region}:${AWS::AccountId}:log-group:/aws/lambda/StackSetMonitor'
- !Sub 'arn:${AWS::Partition}:logs:${AWS::Region}:${AWS::AccountId}:log-group:/aws/cloudformation/stacksets'
- Sid: Allow Lambda Service
Effect: Allow
Principal:
Service: lambda.amazonaws.com
Action:
- 'kms:Encrypt'
- 'kms:Decrypt'
- 'kms:ReEncrypt*'
- 'kms:GenerateDataKey*'
- 'kms:DescribeKey'
Resource: '*'
LogsKMSKeyAlias:
Type: AWS::KMS::Alias
Properties:
AliasName: alias/stackset-monitor-logs
TargetKeyId: !Ref LogsKMSKey
# VPC Resources (created when no existing VPC is provided)
StackSetMonitorVPC:
Type: AWS::EC2::VPC
Condition: CreateVPC
Properties:
CidrBlock: 10.0.0.0/16
EnableDnsHostnames: true
EnableDnsSupport: true
Tags:
- Key: Name
Value: StackSetMonitor-VPC
- Key: Purpose
Value: VPC for StackSet Monitor Lambda function
PrivateSubnet1:
Type: AWS::EC2::Subnet
Condition: CreateVPC
Properties:
VpcId: !Ref StackSetMonitorVPC
CidrBlock: 10.0.1.0/24
AvailabilityZone: !Select [0, !GetAZs '']
Tags:
- Key: Name
Value: StackSetMonitor-Private-Subnet-1
- Key: Purpose
Value: Private subnet for StackSet Monitor Lambda
PrivateSubnet2:
Type: AWS::EC2::Subnet
Condition: CreateVPC
Properties:
VpcId: !Ref StackSetMonitorVPC
CidrBlock: 10.0.2.0/24
AvailabilityZone: !Select [1, !GetAZs '']
Tags:
- Key: Name
Value: StackSetMonitor-Private-Subnet-2
- Key: Purpose
Value: Private subnet for StackSet Monitor Lambda
PrivateRouteTable1:
Type: AWS::EC2::RouteTable
Condition: CreateVPC
Properties:
VpcId: !Ref StackSetMonitorVPC
Tags:
- Key: Name
Value: StackSetMonitor-Private-RT-1
PrivateRouteTable2:
Type: AWS::EC2::RouteTable
Condition: CreateVPC
Properties:
VpcId: !Ref StackSetMonitorVPC
Tags:
- Key: Name
Value: StackSetMonitor-Private-RT-2
PrivateSubnet1RouteTableAssociation:
Type: AWS::EC2::SubnetRouteTableAssociation
Condition: CreateVPC
Properties:
RouteTableId: !Ref PrivateRouteTable1
SubnetId: !Ref PrivateSubnet1
PrivateSubnet2RouteTableAssociation:
Type: AWS::EC2::SubnetRouteTableAssociation
Condition: CreateVPC
Properties:
RouteTableId: !Ref PrivateRouteTable2
SubnetId: !Ref PrivateSubnet2
# VPC Endpoints for AWS Services (no internet access needed)
CloudFormationVPCEndpoint:
Type: AWS::EC2::VPCEndpoint
Condition: CreateVPC
Properties:
VpcId: !Ref StackSetMonitorVPC
ServiceName: !Sub com.amazonaws.${AWS::Region}.cloudformation
VpcEndpointType: Interface
SubnetIds:
- !Ref PrivateSubnet1
- !Ref PrivateSubnet2
SecurityGroupIds:
- !Ref VPCEndpointSecurityGroup
PrivateDnsEnabled: true
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Principal: '*'
Action:
- cloudformation:ListStackSets
- cloudformation:ListStackSetOperations
- cloudformation:ListStackInstances
- cloudformation:DescribeStackInstance
- cloudformation:DescribeStacks
- cloudformation:GetTemplate
Resource: '*'
CloudWatchVPCEndpoint:
Type: AWS::EC2::VPCEndpoint
Condition: CreateVPC
Properties:
VpcId: !Ref StackSetMonitorVPC
ServiceName: !Sub com.amazonaws.${AWS::Region}.monitoring
VpcEndpointType: Interface
SubnetIds:
- !Ref PrivateSubnet1
- !Ref PrivateSubnet2
SecurityGroupIds:
- !Ref VPCEndpointSecurityGroup
PrivateDnsEnabled: true
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Principal: '*'
Action:
- cloudwatch:PutMetricData
Resource: '*'
SNSVPCEndpoint:
Type: AWS::EC2::VPCEndpoint
Condition: CreateVPC
Properties:
VpcId: !Ref StackSetMonitorVPC
ServiceName: !Sub com.amazonaws.${AWS::Region}.sns
VpcEndpointType: Interface
SubnetIds:
- !Ref PrivateSubnet1
- !Ref PrivateSubnet2
SecurityGroupIds:
- !Ref VPCEndpointSecurityGroup
PrivateDnsEnabled: true
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Principal: '*'
Action:
- sns:Publish
Resource: '*'
EventsVPCEndpoint:
Type: AWS::EC2::VPCEndpoint
Condition: CreateVPC
Properties:
VpcId: !Ref StackSetMonitorVPC
ServiceName: !Sub com.amazonaws.${AWS::Region}.events
VpcEndpointType: Interface
SubnetIds:
- !Ref PrivateSubnet1
- !Ref PrivateSubnet2
SecurityGroupIds:
- !Ref VPCEndpointSecurityGroup
PrivateDnsEnabled: true
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Principal: '*'
Action:
- events:PutEvents
Resource: '*'
LogsVPCEndpoint:
Type: AWS::EC2::VPCEndpoint
Condition: CreateVPC
Properties:
VpcId: !Ref StackSetMonitorVPC
ServiceName: !Sub com.amazonaws.${AWS::Region}.logs
VpcEndpointType: Interface
SubnetIds:
- !Ref PrivateSubnet1
- !Ref PrivateSubnet2
SecurityGroupIds:
- !Ref VPCEndpointSecurityGroup
PrivateDnsEnabled: true
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Principal: '*'
Action:
- logs:CreateLogGroup
- logs:CreateLogStream
- logs:PutLogEvents
Resource: '*'
SQSVPCEndpoint:
Type: AWS::EC2::VPCEndpoint
Condition: CreateVPC
Properties:
VpcId: !Ref StackSetMonitorVPC
ServiceName: !Sub com.amazonaws.${AWS::Region}.sqs
VpcEndpointType: Interface
SubnetIds:
- !Ref PrivateSubnet1
- !Ref PrivateSubnet2
SecurityGroupIds:
- !Ref VPCEndpointSecurityGroup
PrivateDnsEnabled: true
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Principal: '*'
Action:
- sqs:SendMessage
Resource: '*'
STSVPCEndpoint:
Type: AWS::EC2::VPCEndpoint
Condition: CreateVPC
Properties:
VpcId: !Ref StackSetMonitorVPC
ServiceName: !Sub com.amazonaws.${AWS::Region}.sts
VpcEndpointType: Interface
SubnetIds:
- !Ref PrivateSubnet1
- !Ref PrivateSubnet2
SecurityGroupIds:
- !Ref VPCEndpointSecurityGroup
PrivateDnsEnabled: true
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Principal: '*'
Action:
- sts:AssumeRole
- sts:GetCallerIdentity
- sts:AssumeRoleWithWebIdentity
Resource: '*'
# Security Group for Lambda function
LambdaSecurityGroup:
Type: AWS::EC2::SecurityGroup
Properties:
GroupDescription: Security group for StackSet Monitor Lambda function
VpcId: !If
- CreateVPC
- !Ref StackSetMonitorVPC
- !Ref VpcId
SecurityGroupEgress:
- IpProtocol: tcp
FromPort: 443
ToPort: 443
CidrIp: 10.0.0.0/16
Description: HTTPS to VPC Endpoints
- IpProtocol: tcp
FromPort: 53
ToPort: 53
CidrIp: 10.0.0.0/16
Description: DNS TCP to VPC for name resolution
- IpProtocol: udp
FromPort: 53
ToPort: 53
CidrIp: 10.0.0.0/16
Description: DNS UDP to VPC for name resolution
Tags:
- Key: Name
Value: StackSetMonitor-Lambda-SG
- Key: Purpose
Value: Security group for StackSet Monitor Lambda
VPCEndpointSecurityGroup:
Type: AWS::EC2::SecurityGroup
Condition: CreateVPC
Properties:
GroupDescription: Security group for VPC Endpoints
VpcId: !Ref StackSetMonitorVPC
SecurityGroupIngress:
- IpProtocol: tcp
FromPort: 443
ToPort: 443
SourceSecurityGroupId: !Ref LambdaSecurityGroup
Description: HTTPS from Lambda security group
- IpProtocol: tcp
FromPort: 53
ToPort: 53
SourceSecurityGroupId: !Ref LambdaSecurityGroup
Description: DNS TCP from Lambda security group
- IpProtocol: udp
FromPort: 53
ToPort: 53
SourceSecurityGroupId: !Ref LambdaSecurityGroup
Description: DNS UDP from Lambda security group
SecurityGroupEgress:
- IpProtocol: tcp
FromPort: 443
ToPort: 443
CidrIp: 10.0.0.0/16
Description: HTTPS outbound within VPC
- IpProtocol: tcp
FromPort: 53
ToPort: 53
CidrIp: 10.0.0.0/16
Description: DNS TCP outbound within VPC
- IpProtocol: udp
FromPort: 53
ToPort: 53
CidrIp: 10.0.0.0/16
Description: DNS UDP outbound within VPC
Tags:
- Key: Name
Value: StackSetMonitor-VPCEndpoint-SG
- Key: Purpose
Value: Security group for VPC Endpoints
# Dead Letter Queue for Lambda function
StackSetMonitorDLQ:
Type: AWS::SQS::Queue
DeletionPolicy: Delete
UpdateReplacePolicy: Delete
Properties:
QueueName: StackSetMonitor-DLQ
MessageRetentionPeriod: 1209600 # 14 days
KmsMasterKeyId: alias/aws/sqs
Tags:
- Key: Purpose
Value: Dead Letter Queue for StackSet Monitor Lambda
StackSetAlertsTopic:
Type: AWS::SNS::Topic
Properties:
TopicName: StackSetAlerts
DisplayName: StackSet Monitoring Alerts
KmsMasterKeyId: alias/aws/sns
StackSetLogGroup:
Type: AWS::Logs::LogGroup
DeletionPolicy: Delete
UpdateReplacePolicy: Delete
Properties:
LogGroupName: /aws/cloudformation/stacksets
RetentionInDays: 30
KmsKeyId: !GetAtt LogsKMSKey.Arn
LambdaLogGroup:
Type: AWS::Logs::LogGroup
DeletionPolicy: Delete
UpdateReplacePolicy: Delete
Properties:
LogGroupName: /aws/lambda/StackSetMonitor
RetentionInDays: 30
KmsKeyId: !GetAtt LogsKMSKey.Arn
StackSetMonitoringDashboard:
Type: AWS::CloudWatch::Dashboard
Properties:
DashboardName: StackSetMonitoring
DashboardBody: !Sub |
{
"widgets": [
{
"type": "metric",
"width": 24,
"height": 8,
"properties": {
"metrics": [
[ "StackSetMonitoring", "SuccessRate", "StackSetName", "${StackSetName}" ]
],
"region": "${AWS::Region}",
"title": "StackSet Operations",
"period": 300,
"stat": "Average"
}
},
{
"type": "log",
"width": 24,
"height": 6,
"properties": {
"query": "SOURCE '/aws/lambda/StackSetMonitor' | fields @timestamp, @message\n| sort @timestamp desc\n| limit 20",
"region": "${AWS::Region}",
"title": "Latest StackSet Monitor Logs",
"view": "table"
}
}
]
}
# Consolidated rule to catch ALL StackSet events for comprehensive monitoring
AllStackSetOperationsRule:
Type: AWS::Events::Rule
Properties:
Name: AllStackSetOperationsRule
Description: "Rule for monitoring all CloudFormation StackSet operations with failure notifications"
EventPattern: {source: ["aws.cloudformation"], detail-type: ["CloudFormation StackSet Operation Status Change"]}
State: ENABLED
Targets:
- Id: ProcessAllEvents
Arn: !GetAtt StackSetMonitorLambda.Arn
- Id: NotifyFailure
Arn: !Ref StackSetAlertsTopic
InputTransformer:
InputPathsMap:
"stackSetId": "$.detail.stack-set-id"
"operationId": "$.detail.operation-id"
"status": "$.detail.status"
"time": "$.time"
InputTemplate: '"StackSet Event: ID: <stackSetId>, Op: <operationId>, Status: <status>, Time: <time>"'
StackSetMonitorLambda:
Type: AWS::Lambda::Function
DependsOn: LambdaLogGroup
Properties:
FunctionName: StackSetMonitor
Handler: index.lambda_handler
Role: !GetAtt StackSetMonitorRole.Arn
Runtime: python3.12
Timeout: 300
MemorySize: 512
ReservedConcurrentExecutions: 1
DeadLetterConfig:
TargetArn: !GetAtt StackSetMonitorDLQ.Arn
VpcConfig:
SecurityGroupIds: !If
- HasCustomSecurityGroups
- !Ref SecurityGroupIds
- - !Ref LambdaSecurityGroup
SubnetIds: !If
- CreateVPCAndSubnets
- - !Ref PrivateSubnet1
- !Ref PrivateSubnet2
- !Ref SubnetIds
KmsKeyArn: !GetAtt LogsKMSKey.Arn
Code:
ZipFile: |
import boto3
import json
import os
import logging
import time
import datetime
from typing import Dict, Any, Optional
# Custom JSON encoder to handle datetime objects
class DateTimeEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, datetime.datetime):
return obj.isoformat()
return super().default(obj)
# Set up logging with more details
logger = logging.getLogger()
logger.setLevel(logging.INFO)
# Log initialization to verify Lambda is loading correctly
print("StackSetMonitor Lambda initializing...")
def validate_event(event: Dict[str, Any]) -> bool:
"""Validate the incoming event structure"""
if not isinstance(event, dict):
logger.error("Event must be a dictionary")
return False
# If it's an EventBridge event, validate required fields
if 'detail' in event:
detail = event.get('detail', {})
if not isinstance(detail, dict):
logger.error("Event detail must be a dictionary")
return False
# Validate StackSet event structure
if 'stack-set-id' in detail:
stack_set_id = detail.get('stack-set-id')
if not isinstance(stack_set_id, str) or not stack_set_id.strip():
logger.error("stack-set-id must be a non-empty string")
return False
# Validate operation-id if present
operation_id = detail.get('operation-id')
if operation_id is not None and not isinstance(operation_id, str):
logger.error("operation-id must be a string if provided")
return False
# Validate status if present
status = detail.get('status')
if status is not None and not isinstance(status, str):
logger.error("status must be a string if provided")
return False
return True
def validate_context(context: Any) -> bool:
"""Validate the Lambda context object"""
if context is None:
logger.error("Context cannot be None")
return False
# Check for required context attributes
required_attrs = ['function_name', 'function_version', 'invoked_function_arn', 'memory_limit_in_mb']
for attr in required_attrs:
if not hasattr(context, attr):
logger.error(f"Context missing required attribute: {attr}")
return False
return True
def sanitize_string(value: str, max_length: int = 255) -> str:
"""Sanitize and truncate string inputs"""
if not isinstance(value, str):
return str(value)[:max_length]
return value.strip()[:max_length]
def lambda_handler(event: Dict[str, Any], context: Any) -> Dict[str, Any]:
"""Main Lambda handler function for StackSet monitoring with input validation"""
# Input validation
if not validate_event(event):
return {
"statusCode": 400,
"body": json.dumps({
"status": "error",
"message": "Invalid event structure"
}, cls=DateTimeEncoder)
}
if not validate_context(context):
return {
"statusCode": 400,
"body": json.dumps({
"status": "error",
"message": "Invalid context object"
}, cls=DateTimeEncoder)
}
# Log the validated event for debugging
logger.info(f"Event received: {json.dumps(event, cls=DateTimeEncoder)}")
logger.info(f"Function: {context.function_name}, Version: {context.function_version}")
try:
cf = boto3.client('cloudformation')
cw = boto3.client('cloudwatch')
# Log that we're starting processing
logger.info(f"Starting StackSet monitoring at {time.time()}")
# Check if this is an event from EventBridge
if 'detail' in event and 'stack-set-id' in event.get('detail', {}):
detail = event['detail']
stack_set_id = sanitize_string(detail['stack-set-id'])
operation_id = sanitize_string(detail.get('operation-id', 'N/A'))
status = sanitize_string(detail.get('status', 'N/A'))
# Validate stack_set_id format
if not stack_set_id or len(stack_set_id) > 128:
logger.error(f"Invalid stack_set_id: {stack_set_id}")
return {
"statusCode": 400,
"body": json.dumps({
"status": "error",
"message": "Invalid stack_set_id format"
}, cls=DateTimeEncoder)
}
# Log the StackSet operation with additional context
logger.info(f"Processing StackSet event - ID: {stack_set_id}, Op: {operation_id}, Status: {status}")
# Extract stack set name from the ID
stack_set_name = stack_set_id.split('/')[-1] if '/' in stack_set_id else stack_set_id
stack_set_name = sanitize_string(stack_set_name, 128)
logger.info(f"Extracted StackSet name: {stack_set_name}")
# Always gather metrics regardless of event type
# Get all active StackSets
stack_sets_response = cf.list_stack_sets(Status='ACTIVE')
stack_sets = stack_sets_response.get('Summaries', [])
if not isinstance(stack_sets, list):
logger.error("Invalid response from list_stack_sets")
return {
"statusCode": 500,
"body": json.dumps({
"status": "error",
"message": "Invalid CloudFormation API response"
}, cls=DateTimeEncoder)
}
logger.info(f"Found {len(stack_sets)} active StackSets")
for stack_set in stack_sets:
if not isinstance(stack_set, dict) or 'StackSetName' not in stack_set:
logger.warning(f"Skipping invalid stack_set entry: {stack_set}")
continue
stack_set_name = sanitize_string(stack_set['StackSetName'], 128)
logger.info(f"Processing StackSet: {stack_set_name}")
try:
operations = cf.list_stack_set_operations(StackSetName=stack_set_name, MaxResults=5)
# Validate operations response
if not isinstance(operations, dict):
logger.error(f"Invalid operations response for {stack_set_name}")
continue
# Calculate success rate
successes = 0
operations_list = operations.get('Summaries', [])
if not isinstance(operations_list, list):
logger.error(f"Invalid operations list for {stack_set_name}")
continue
total_ops = len(operations_list)
logger.info(f"Found {total_ops} recent operations for {stack_set_name}")
for op in operations_list:
if isinstance(op, dict) and op.get('Status') == 'SUCCEEDED':
successes += 1
success_rate = (successes / total_ops * 100) if total_ops > 0 else 100
# Validate success_rate is within expected bounds
if not (0 <= success_rate <= 100):
logger.error(f"Invalid success_rate calculated: {success_rate}")
continue
# Publish metrics to CloudWatch
cw.put_metric_data(
Namespace='StackSetMonitoring',
MetricData=[
{'MetricName': 'SuccessRate', 'Value': success_rate,
'Dimensions': [{'Name': 'StackSetName', 'Value': stack_set_name}]}
]
)
logger.info(f"Published metrics for {stack_set_name}: Success Rate = {success_rate}%")
except Exception as e:
logger.error(f"Error processing StackSet {stack_set_name}: {str(e)}")
return {
"statusCode": 200,
"body": json.dumps({
"status": "completed",
"message": f"Processed {len(stack_sets)} StackSets"
}, cls=DateTimeEncoder)
}
except Exception as e:
logger.error(f"Error in Lambda function: {str(e)}")
# Return a proper response even on error
return {
"statusCode": 500,
"body": json.dumps({
"status": "error",
"message": str(e)
}, cls=DateTimeEncoder)
}
# Managed IAM Policies
CloudFormationAccessPolicy:
Type: AWS::IAM::ManagedPolicy
Properties:
Description: 'Policy for CloudFormation and CloudWatch access for StackSet Monitor'
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- cloudformation:ListStackSets
- cloudformation:ListStackSetOperations
- cloudformation:ListStackInstances
- cloudformation:DescribeStackInstance
Resource:
- !Sub "arn:${AWS::Partition}:cloudformation:${AWS::Region}:${AWS::AccountId}:stackset/*"
- !Sub "arn:${AWS::Partition}:cloudformation:${AWS::Region}:${AWS::AccountId}:stackset-target/*"
- Effect: Allow
Action:
- cloudwatch:PutMetricData
Resource: "*"
Condition:
StringEquals:
"cloudwatch:namespace": "StackSetMonitoring"
- Effect: Allow
Action:
- sns:Publish
Resource: !Ref StackSetAlertsTopic
EventsAccessPolicy:
Type: AWS::IAM::ManagedPolicy
Properties:
Description: 'Policy for EventBridge access for StackSet Monitor'
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- events:PutEvents
Resource: !Sub "arn:${AWS::Partition}:events:${AWS::Region}:${AWS::AccountId}:event-bus/default"
LogsAccessPolicy:
Type: AWS::IAM::ManagedPolicy
Properties:
Description: 'Policy for CloudWatch Logs access for StackSet Monitor'
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- logs:CreateLogGroup
- logs:CreateLogStream
- logs:PutLogEvents
Resource:
- !Sub "arn:${AWS::Partition}:logs:${AWS::Region}:${AWS::AccountId}:log-group:/aws/lambda/StackSetMonitor"
- !Sub "arn:${AWS::Partition}:logs:${AWS::Region}:${AWS::AccountId}:log-group:/aws/lambda/StackSetMonitor:*"
- !Sub "arn:${AWS::Partition}:logs:${AWS::Region}:${AWS::AccountId}:log-group:/aws/cloudformation/stacksets"
- !Sub "arn:${AWS::Partition}:logs:${AWS::Region}:${AWS::AccountId}:log-group:/aws/cloudformation/stacksets:*"
DLQAccessPolicy:
Type: AWS::IAM::ManagedPolicy
Properties:
Description: 'Policy for Dead Letter Queue access for StackSet Monitor'
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- sqs:SendMessage
Resource: !GetAtt StackSetMonitorDLQ.Arn
StackSetMonitorRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Principal:
Service: lambda.amazonaws.com
Action: sts:AssumeRole
ManagedPolicyArns:
- arn:aws:iam::aws:policy/service-role/AWSLambdaVPCAccessExecutionRole
- !Ref CloudFormationAccessPolicy
- !Ref EventsAccessPolicy
- !Ref LogsAccessPolicy
- !Ref DLQAccessPolicy
# Permissions for event rules to invoke Lambda
AllOperationsRuleLambdaPermission:
Type: AWS::Lambda::Permission
Properties:
FunctionName: !Ref StackSetMonitorLambda
Action: lambda:InvokeFunction
Principal: events.amazonaws.com
SourceArn: !GetAtt AllStackSetOperationsRule.Arn
# Using a one minute schedule for testing, but you can change this value
StackSetMonitorSchedule:
Type: AWS::Events::Rule
Properties:
Name: RegularStackSetMonitoring
Description: "Triggers Lambda function every 1 minute to check StackSet operations"
ScheduleExpression: "rate(1 minute)"
State: ENABLED
Targets:
- Id: RunMonitor
Arn: !GetAtt StackSetMonitorLambda.Arn
ScheduleLambdaInvokePermission:
Type: AWS::Lambda::Permission
Properties:
FunctionName: !Ref StackSetMonitorLambda
Action: lambda:InvokeFunction
Principal: events.amazonaws.com
SourceArn: !GetAtt StackSetMonitorSchedule.Arn
StackSetSuccessRateAlarm:
Type: AWS::CloudWatch::Alarm
Properties:
AlarmDescription: "Alarm when StackSet operation success rate is low"
MetricName: SuccessRate
Namespace: "StackSetMonitoring"
Statistic: Average
Period: 300
EvaluationPeriods: 3
DatapointsToAlarm: 2
Threshold: 80
ComparisonOperator: LessThanThreshold
AlarmActions: [!Ref StackSetAlertsTopic]
Dimensions: [{Name: StackSetName, Value: !Ref StackSetName}]
Outputs:
SNSTopicArn:
Description: The ARN of the SNS topic for alerts
Value: !Ref StackSetAlertsTopic
DashboardURL:
Description: URL to the CloudWatch Dashboard
Value: !Sub https://console.aws.amazon.com/cloudwatch/home?region=${AWS::Region}#dashboards:name=StackSetMonitoring
LambdaLogGroupName:
Description: Name of the CloudWatch Log Group for Lambda logs
Value: !Ref LambdaLogGroup
DeadLetterQueueArn:
Description: ARN of the Dead Letter Queue for Lambda function failures
Value: !GetAtt StackSetMonitorDLQ.Arn
DeadLetterQueueURL:
Description: URL of the Dead Letter Queue for monitoring failed Lambda executions
Value: !Ref StackSetMonitorDLQ
TestLambdaCommand:
Description: Command to manually test the Lambda function
Value: !Sub "aws lambda invoke --function-name ${StackSetMonitorLambda} --payload '{}' response.json && cat response.json"
LambdaFunctionArn:
Description: ARN of the Lambda function configured with VPC
Value: !GetAtt StackSetMonitorLambda.Arn
LambdaSecurityGroupId:
Description: Security Group ID created for the Lambda function
Value: !Ref LambdaSecurityGroup
VpcConfiguration:
Description: VPC configuration summary for the Lambda function
Value: !Sub
- "VPC: ${VpcId}, Subnets: ${SubnetList}, Security Groups: ${LambdaSecurityGroup}"
- SubnetList: !Join [',', !Ref SubnetIds]
You need to run the following CLI command to deploy the CloudFormation stacks. You can change the ParameterValue of StackSetName“your-stackset-name” by the name of the StackSet you want to monitor. The default value is “security-baseline”. Your CLI profile should use region=“us-east-1“.
AWS CLI to deploy the StackSetMonitor.yml CloudFormation template
The CLI output should look like the following:
{"StackId": "arn:aws:cloudformation:...."}
Here’s the expected output for the CloudFormation template:
StackSetMonitor Console output
And an example of Amazon CloudWatch Dashboard and Alarm screen:
Amazon CloudWatch Dashboard screenshot for StackSetMonitor stack to track StackSet operations success rate
Amazon CloudWatch Alarm screenshot for StackSetMonitor stack to track StackSet operations success rate
SNS subscription setup involves retrieving the topic ARN from stack outputs and configuring notifications for email or SMS endpoints (below example CLI for email subscription):
AWS CLI to subscribe to the topic providing the user email
Cost:
The estimated monthly expenses ranges between 5 and 15 USD depending on StackSet activity levels, with approximately 2,880 Lambda executions per day (each minute) under the default monitoring schedule.
The solution supports customization of monitoring frequency by modifying the ScheduleExpression from the default one-minute interval. The cost will decrease if the monitoring is less frequent.
Cleanup:
For cleanup, you can run the following command lines:
To cleanup the Stack Instances and StackSets created in the Core Deployment Strategies section:
You need to change the parameter OrganizationalUnitIds value with the name of the OU, the parameter regions with the list of regions where you want to delete your stack instances, and the value of the stack-set-name parameter (security-baseline, monitoring-baseline, balanced-deployment…).
You can also remove any IAM roles/policies that you specifically created for this blog that you might not need anymore
Conclusion
Throughout this guide, we’ve explored the nuanced approaches to AWS CloudFormation StackSets deployments across large-scale environments. The key takeaways include:
Balance is Critical: Every deployment strategy requires careful consideration of the trade-offs between speed, safety, and scale based on your organizational needs.
Progressive Adoption Works: For most organizations, a progressive deployment approach with validation gates provides the optimal balance of safety and efficiency.
Organizational Context Matters: Enterprise, startup, and regulated industry patterns demonstrate that deployment strategies should be tailored to your specific business requirements and risk tolerance.
Monitoring is Essential: As organizations scale to hundreds of accounts, comprehensive monitoring becomes critical for maintaining visibility and ensuring compliance.
These different approaches will help you adopt the right strategy for your AWS CloudFormation Stacksets deployments in your AWS Organization.
You can now test these different approaches on your sandbox environment, before adapting them for your specific needs, in order to balance Speed, Safety and Scale to optimize your deployments.
This post is co-written with Rayco Martínez Hernández, Head of Cloud Governance at Moeve.
Moeve, formerly known as Cepsa, is a global integrated energy company with over 90 years of experience and more than 11,000 employees. Moeve is committed to driving Europe’s energy transition and accelerating decarbonization efforts. The company has embraced digital transformation to enhance energy efficiency, safety, and sustainability, focusing on investments in green hydrogen, second-generation biofuels, and ultra-fast electric vehicle charging infrastructure.
At Moeve, we decided to make AWS Control Tower our central governance tool and the foundation of our landing zone at the end of 2022. However, as an organization that wants to ensure that all deployed resources comply with the established requirements, it was challenging for us to remediate errors or vulnerabilities that arise when resources were deployed without compliance with our security definitions. The foundation of controls should be proactive. This is where AWS CloudFormationHooks, along with other AWS measures like Service Control Policies (SCPs), play a differential role.
We have become familiar with CloudFormation Hooks thanks to the Guard Rules that we deploy as part of our proactive deployment policy on AWS. There are times when you want to block the deployment of Amazon API Gateway without security, Amazon VPC security groups with source 0.0.0.0/0, or with an ALL port range open. In these and other cases, we want to take a step further and create our own controls that are more in line with our own policies, and now we can do so in a simple and agile way, using the managed hooks launched in November 2024.
To be able to use these tools, it is essential, among other things, to ensure that resource deployments are only done through Infrastructure as Code (IaC) tools.
Would you like to know how we achieved it? Let’s get to it!
Background
At Moeve, we ensure that all our deployments within our organization are done through IaC. We enforce this by requiring all deployments to go through CloudFormation, which also allows us to enforce organizational policies using CloudFormation Guard Hooks.
However, for teams with more advanced technical expertise, we allow the use of the AWS Cloud Development Kit (CDK). The AWS CDK enables developers to define infrastructure using general-purpose programming languages, which facilitates code reuse, modular design, and better integration with existing development workflows. It provides high-level abstractions that accelerate the definition of common AWS patterns, while also allowing low-level control when needed. Even though it introduces an abstraction layer, the CDK synthesizes into standard CloudFormation templates, maintaining full compatibility with our governance and compliance mechanisms based on CloudFormation Guard Hooks.
We have several ways to perform deployments: directly launching actions against CloudFormation from the AWS Command Line Interface (CLI), through pipelines, or even by executing actions from code. However, the common basis for these deployments is that they cannot be done with Permission Sets associated with individuals. Users do not have access to deploy resources directly; they have read access and can assume a role that can deploy resources.
To make this more user-friendly, we have a small tool that assumes the role with enough permissions and deploys the template code we specify, with just a call like this:
cloudformation-deployer test.yml
It is crucial to make these controls easy for developers if you want them to comply with the established security measures.
Solution
At Moeve, as a best practice, we have delegated the management of Cloudformation StackSets to an AWS account different from the management account. In this account, we deploy an Amazon S3 bucket where we will store all the files for the CloudFormation Guard hooks or the AWS Lambda functions if they are Lambda type. In Figure 1, you can see a simplified version of our multi-account architecture when deploying resources using StackSets.
Figure 1. AWS CloudFormation StackSets configuration in a multi-Account environment
An example of a stack that manages the buckets can be seen below:
AWSTemplateFormatVersion: "2010-09-09"
Description: |
This template creates an Amazon S3 bucket that you can use to deploy an AWS CloudFormation hook.
Parameters:
GuardHooksBucketName:
Type: String
Description: Name for S3 bucket storing the CloudFormation Guard hooks
OrgId:
Description: Organization Id which is in the format o-xyzabcdefg
Type: String
AllowedPattern: ^o-[a-z0-9]{10,32}$
Resources:
S3Bucket:
Type: AWS::S3::Bucket
Properties:
BucketName: !Sub ${GuardHooksBucketName}-${AWS::Region}-${AWS::AccountId}
BucketEncryption:
ServerSideEncryptionConfiguration:
- ServerSideEncryptionByDefault:
SSEAlgorithm: AES256
PublicAccessBlockConfiguration:
BlockPublicAcls: true
BlockPublicPolicy: true
IgnorePublicAcls: true
RestrictPublicBuckets: true
LifecycleConfiguration:
Rules:
- Id: MultipartClean
Status: Enabled
AbortIncompleteMultipartUpload:
DaysAfterInitiation: 5
Tags:
- Key: project
Value: shared
VersioningConfiguration:
Status: Enabled
S3BucketPolicy:
Type: AWS::S3::BucketPolicy
Properties:
Bucket: !Ref S3Bucket
PolicyDocument:
Version: 2012-10-17
Statement:
- Sid: AllowSSLRequestsOnly
Effect: Deny
Action: s3:*
Resource:
- !Sub ${S3Bucket.Arn}/* # "arn:aws:s3:::arn:aws:s3:::<bucket-name>/<path>/*"
- !Sub ${S3Bucket.Arn} # "arn:aws:s3:::arn:aws:s3:::<bucket-name>/<path>/"
Principal: '*'
Condition:
Bool:
aws:SecureTransport: 'false'
- Sid: AllowOrgAccountsDeployAccess
Effect: Allow
Principal:
AWS: "*"
Action: "s3:GetObject"
Resource: !Join
- ""
- - "arn:aws:s3:::"
- !Ref S3Bucket
- /*
Condition:
ForAnyValue:StringLike:
"aws:PrincipalOrgPaths": !Sub "${OrgId}/*"
With this, we achieve having a centralized S3 bucket with an access policy according to which anyone within our organization can access and retrieve the objects. Versioning is configured to keep previous versions of the hooks we deploy. Then, in the bucket, we will store the files of our hooks, differentiating them by folders.
Child Accounts
For the child accounts, we will deploy a StackSet in the central account over the Organizational Units (OUs) that are defined. Auto-deployment will be configured so that all new Accounts added to the OU acquire these same hooks.
Check the example below where an S3 bucket will be deployed to store the logs of the hooks with the IAM role that the hooks will use, and two hooks: to evaluate the creation and update of API Gateway.
AWSTemplateFormatVersion: "2010-09-09"
Description: |
Registers the hook in the AWS CloudFormation Private Registry and bucket to logs.
Parameters:
CustomHooksLogBucketName:
Type: String
Description: Name for S3 bucket storing the CloudFormation Guard hook logs
GuardHooksBucketName:
Type: String
Description: Name for S3 bucket storing the CloudFormation Guard hooks
Resources:
# S3 bucket used to store logs generated by CloudFormation Guard hooks
LogBucket:
Type: AWS::S3::Bucket
Properties:
# Bucket name is built dynamically with account ID and region
BucketName: !Sub ${CustomHooksLogBucketName}-${AWS::AccountId}-${AWS::Region}
BucketEncryption:
ServerSideEncryptionConfiguration:
- ServerSideEncryptionByDefault:
SSEAlgorithm: AES256 # Enforce AES256 encryption
PublicAccessBlockConfiguration:
BlockPublicAcls: true
BlockPublicPolicy: true
IgnorePublicAcls: true
RestrictPublicBuckets: true
LifecycleConfiguration: # Manage bucket lifecycle
Rules:
- Id: MultipartClean
Status: Enabled
AbortIncompleteMultipartUpload:
DaysAfterInitiation: 5 # Abort incomplete uploads after 5 days
- Id: ExpireAfterOneWeek
Status: Enabled
Prefix: ""
ExpirationInDays: 7 # Expire objects after 7 days
Tags:
- Key: project
Value: shared
# Bucket policy that enforces SSL-only access to the log bucket
S3BucketPolicy:
Type: AWS::S3::BucketPolicy
Properties:
Bucket: !Ref LogBucket
PolicyDocument:
Version: 2012-10-17
Statement:
- Sid: AllowSSLRequestsOnly
Effect: Deny
Action: s3:*
Resource:
- !Sub ${LogBucket.Arn}/* # "arn:aws:s3:::arn:aws:s3:::<bucket-name>/<path>/*" # Apply to all objects in the bucket
- !Sub ${LogBucket.Arn} # "arn:aws:s3:::arn:aws:s3:::<bucket-name>/<path>/" # Apply to the bucket itself
Principal: '*'
Condition:
Bool:
aws:SecureTransport: 'false' # Deny if not using HTTPS
# IAM Role that CloudFormation Guard hooks assume to interact with S3
GuardHookRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument: # Trust policy for CloudFormation hooks
Statement:
- Action: sts:AssumeRole
Condition:
StringEquals:
aws:SourceAccount: !Ref 'AWS::AccountId'
StringLike:
'aws:SourceArn': !Sub arn:${AWS::Partition}:cloudformation:${AWS::Region}:${AWS::AccountId}:type/hook/Moeve-*/*
Effect: Allow
Principal:
Service:
- hooks.cloudformation.amazonaws.com
- resources.cloudformation.amazonaws.com
Version: "2012-10-17"
MaxSessionDuration: 8400
Path: /
Policies:
- PolicyName: HookS3Policy # Policy granting permissions to write/read from the log bucket
PolicyDocument:
Statement:
- Action:
- 's3:GetEncryptionConfiguration'
- 's3:ListAllMyBuckets'
- 's3:ListBucket'
- 's3:GetObject'
- 's3:PutObject'
Effect: Allow
Resource:
- !Sub arn:${AWS::Partition}:s3:::${LogBucket}
- !Sub arn:${AWS::Partition}:s3:::${LogBucket}/*
Version: "2012-10-17"
- PolicyName: HookGeneralS3Policy # Policy granting read access to the bucket containing Guard rules
PolicyDocument:
Statement:
- Action:
- 's3:GetEncryptionConfiguration'
- 's3:ListBucket'
- 's3:GetObject'
Effect: Allow
Resource:
- !Sub arn:${AWS::Partition}:s3:::${GuardHooksBucketName}
- !Sub arn:${AWS::Partition}:s3:::${GuardHooksBucketName}/*
Version: "2012-10-17"
Tags:
- Key: project
Value: shared
# Guard hook that validates API Gateway methods before provisioning
GuardHookApiGateway:
Type: AWS::CloudFormation::GuardHook
Properties:
ExecutionRole: !GetAtt GuardHookRole.Arn
LogBucket: !Ref LogBucket
Alias: Moeve::ApiGatewayAuthorization::Coe
FailureMode: FAIL # Fail the operation if validation fails
HookStatus: ENABLED
TargetOperations:
- RESOURCE # Applies at the resource level
TargetFilters:
Actions:
- CREATE # Triggered on CREATE operations
TargetNames:
- AWS::ApiGateway::Method
InvocationPoints:
- PRE_PROVISION # Runs before resource provisioning
RuleLocation:
Uri: !Sub
- s3://${GuardS3Bucket}/${GuardS3File} # Location of Guard rules in S3
- GuardS3Bucket: !Ref GuardHooksBucketName
GuardS3File: APIGATEWAY/ApiGatewaySecureMethod.guard
StackFilters:
FilteringCriteria: ALL
StackNames:
Exclude:
- !Ref AWS::StackName # Exclude the current stack from evaluation
# Guard hook that validates API Gateway at stack UPDATE level
GuardHookApiGatewaySR:
Type: AWS::CloudFormation::GuardHook
Properties:
ExecutionRole: !GetAtt GuardHookRole.Arn
LogBucket: !Ref LogBucket
Alias: Moeve::ApiGatewayAuthorizationwithSR::Coe
FailureMode: FAIL
HookStatus: ENABLED
TargetOperations:
- STACK # Applies at the stack level
TargetFilters:
Actions:
- UPDATE # Triggered on UPDATE operations
RuleLocation:
Uri: !Sub
- s3://${GuardS3Bucket}/${GuardS3File}
- GuardS3Bucket: !Ref GuardHooksBucketName
GuardS3File: APIGATEWAY/ApiGatewaySecureMethodwithSR.guard
StackFilters:
FilteringCriteria: ALL
StackNames:
Exclude:
- !Ref AWS::StackName
It is very important to configure backdoors to avoid blocking our own deployments when working with hooks deployed with CloudFormation StackSets across our organization or in OUs with multiple accounts. For this, we will configure a filter in the hook so that it does not activate on the stack that manages them. If this filter is not applied, it may happen that due to a misconfiguration, the stack cannot be updated and has to be deleted entirely.
Examples
In the following examples, we are going to ensure that no one can deploy an unsecured API Gateway, but at the same time, we do not want to break the current deployments. For this, we have defined two hooks.
When the custom hooks are triggered during deployment, they analyze the CloudFormation template and targets resources of type AWS::ApiGateway::Method, excluding methods that use the OPTIONS HTTP verb. The hooks apply two sequential validation rules to ensure that all API operations are properly secured.
The first rule checks whether each method defines either the ApiKeyRequired or the AuthorizationType property. If neither is present, the hook fails with a clear message: “Fallo en el paso 1 porque no existe ApiKeyRequired o AuthorizationType” (“Step 1 failed because there is no ApiKeyRequired or AuthorizationType”). If the first condition is satisfied, the second rule verifies whether the values themselves enforce security. Specifically, it checks that ApiKeyRequired is set to true, or that AuthorizationType is defined and not set to NONE. If not, the deployment is blocked again with the message: “Fallo en el paso 2, porque existe AuthorizationType o ApiKeyRequired, pero no son valores válidos.” (“Step 2 failed, because AuthorizationType or ApiKeyRequired exists, but they are not valid values.”).
If any of these rules fail, CloudFormation immediately stops the deployment before any resources are created. This avoids partial or insecure configurations and ensures consistency with organizational security standards. The error appears directly in the CloudFormation console or in CI/CD logs and includes the custom message defined in the hook, helping developers quickly identify the issue.
The development team receives immediate feedback during deployment, whether through their CI/CD pipeline (like CodePipeline or GitHub Actions) or the AWS console. The hook’s clear, custom messages make it easy to pinpoint and fix issues. In more mature environments, these failures can also trigger alerts, update dashboards, or create automated tickets, ensuring security enforcement without slowing down delivery.
The responsibility to fix the issue usually lies with the same team that wrote the template, since the error occurs before any infrastructure is provisioned. This approach allows teams to move quickly while still respecting the compliance and security controls in place. In cases where the issue is tied to a broader policy update, the resolution might involve collaboration with the platform or security team
Hook 1: Activates when an API Gateway is created. This hook checks at the resource level for Resources.Type == 'AWS::ApiGateway::Method', and if it does not meet the requirements, this resource cannot be deployed.
let api_gateway_method = Resources.*[ Type == 'AWS::ApiGateway::Method'
Properties.HttpMethod != /(?i)options/
]
#
# Primary Rules
#
rule api_gw_authorization_method_check when %api_gateway_method !empty {
%api_gateway_method{
Properties.ApiKeyRequired exists or
Properties.AuthorizationType exists
<<Fallo en el paso 1 Porque no existe ApiKeyRequired o AuthorizationType>>
}
}
rule api_gw_authorization_method_check_2 when api_gw_authorization_method_check {
%api_gateway_method{
Properties.ApiKeyRequired == true or
Properties.AuthorizationType != /(?i)none/
<<Fallo en el paso 2, porque existe AuthorizationType o ApiKeyRequired, pero no son valores validos. >>
}
}
Hook 2: Activates when an API Gateway is updated. This hook checks at the resource level for Resources.Type == 'AWS::ApiGateway::Method', and if it does not meet the requirements, this resource cannot be deployed.
let api_gateway_method = Resources.*[ Type == 'AWS::ApiGateway::Method'
Properties.HttpMethod != /(?i)options/
Metadata.guard.SuppressedRules not exists or
Metadata.guard.SuppressedRules.* != "API_GW_METHOD_AUTHORIZATION_TYPE_RULE"
]
#
# Primary Rules
#
rule api_gw_authorization_method_check when %api_gateway_method !empty {
%api_gateway_method{
Properties.ApiKeyRequired exists or
Properties.AuthorizationType exists
<<Fallo en el paso 1 Porque no existe ApiKeyRequired o AuthorizationType>>
}
}
rule api_gw_authorization_method_check_2 when api_gw_authorization_method_check {
%api_gateway_method{
Properties.ApiKeyRequired == true or
Properties.AuthorizationType != /(?i)none/
<<Fallo en el paso 2, porque existe AuthorizationType o ApiKeyRequired, pero no son valores validos. >>
}
}
To avoid breaking existing deployments, a backdoor is configured so that if specific metadata is applied, the hook will not activate, and deployments can continue without modifying the code beyond the metadata.
AWSTemplateFormatVersion: '2010-09-09'
Description: |
This template creates an Amazon API Gateway REST API. It shows an example on how to suppress specific checks from CloudFormation Guard.
Resources:
Api:
Type: AWS::ApiGateway::RestApi
Properties:
Name: myAPI
MyApiGatewayMethod:
Type: AWS::ApiGateway::Method
Metadata:
guard:
SuppressedRules:
- API_GW_METHOD_AUTHORIZATION_TYPE_RULE
Properties:
RestApiId: !Ref Api
ResourceId: !GetAtt Api.RootResourceId
HttpMethod: GET
AuthorizationType: 'NONE'
ApiKeyRequired: false
Integration:
IntegrationHttpMethod: 'POST'
Type: 'MOCK'
OptionsMethod:
Type: 'AWS::ApiGateway::Method'
Properties:
AuthorizationType: 'NONE'
HttpMethod: 'OPTIONS'
RestApiId: !Ref Api
ResourceId: !GetAtt Api.RootResourceId
Integration:
IntegrationHttpMethod: 'POST'
Type: 'MOCK'
Conclusion
The implementation of our own hook controls in CloudFormation has significantly improved infrastructure management and deployment within Moeve. This capability has allowed us to achieve a balance between flexibility, autonomy, and governance at scale. One of the key benefits is the automation of validations and specific controls, which helps us reduce manual errors and ensure greater consistency in deployments. This also enhances traceability and simplifies infrastructure maintenance, ensuring that our configurations adhere to established best practices.
From a security perspective, having custom rules allows us to strengthen regulatory compliance and minimize risks. We can ensure that only secure configurations aligned with our operational needs are implemented, reducing vulnerabilities and improving our cloud security posture. Preventing incorrect configurations from the start of the resource lifecycle also contributes to greater system stability and resilience. By avoiding infrastructure failures, we create more reliable environments that are prepared for growth.
Additionally, by ensuring optimal configurations during resource deployment, we optimize resource usage and avoid bottlenecks, resulting in better performance. This, in turn, helps us manage costs more effectively by preventing the use of unnecessary or oversized resources. Also, automating controls reduces manual intervention and minimizes waste, making our operations more efficient and sustainable over time.
In summary, the creation and management of our own hooks in CloudFormation provide us with full control over our infrastructure, ensuring an optimal balance between security, scalability, and operational efficiency. This strengthens our ability to innovate without compromising governance, enabling us to operate more agilely and securely in the cloud.
Security and governance teams across all environments face a common challenge: translating abstract security and governance requirements into a concrete, integrated control framework. AWS services provide capabilities that organizations can use to implement controls across multiple layers of their architecture—from infrastructure provisioning to runtime monitoring. Many organizations deploy multi-account environments with AWS Control Tower, or Landing Zone Accelerator to implement a foundational baseline of controls and security architecture. Once their environment is provisioned, organizations typically look to add additional detective controls from services such as AWS Security Hub and AWS Config based on security, compliance, and operational requirements. While this sequence is a great start, there are more opportunities during this time to implement layered defense-in-depth coverage to enhance your security posture.
Highly regulated industries such as fintech and financial services are often viewed as the gold standard for governance and security controls. While these sectors have established robust frameworks, there’s consistently room for improvement and valuable lessons for other industries looking to enhance their control environments. However, many organizations struggle to move beyond a basic compliance-focused approach. In our experience working with customers across various sectors, this limited perspective often stems from multiple factors, including:
Immediate compliance pressures
Resource constraints
Limited understanding of control maturity pathways
Focus on detection rather than prevention
A tendency to prioritize technology-agnostic controls over bult-in AWS capabilities, leading to unnecessarily complex implementations
The good news? A more comprehensive approach that uses AWS preventative, proactive, detective, and responsive controls can significantly reduce risk while decreasing operational overhead through automation.
In this post, we outline a practical framework that you can adopt to evolve your security and governance controls strategy. We explore how your organization can mature from a detection-focused security posture to a multi-layered control framework, using real-world examples across the resource lifecycle, including infrastructure-as-code testing and preventative controls such as service control policies (SCPs), resource control policies (RCPs), and declarative policies (DPs).
Drawing from best practices in highly regulated industries while incorporating modern cloud capabilities through services such as AWS Organizations and AWS Control Tower, we provide a structured framework that you can use to elevate your organization’s control environment beyond basic compliance requirements.
Customer challenges in implementing controls
Organizations face several significant challenges when attempting to implement a comprehensive control framework in AWS. Let’s explore the main obstacles:
Resource constraints and expertise gaps
Security teams often find themselves caught between limited resources and expanding responsibilities in the cloud. With constrained budgets and personnel, teams typically gravitate toward quick wins through detective controls, which appear straightforward to implement initially. While this provides immediate visibility, it can leave critical gaps in security posture. Many teams lack comprehensive expertise across all control types, particularly in implementing preventative, proactive, and responsive controls effectively. The pressure to demonstrate immediate security improvements, combined with day-to-day operational demands, frequently results in tactical solutions rather than strategic, layered security approaches.
Analysis paralysis
Deciding which tools to prioritize can be a challenge; the breadth of options and extensive capabilities available across AWS security services and third-party tools can feel overwhelming at times. Security teams struggle to determine the optimal mix of controls for their environment and where to begin implementation. This challenge is compounded by the complexity of mapping technical compliance requirements to cloud-focused capabilities and maintaining visibility into emerging threats as the security landscape evolves. The layers of abstraction created by proliferating security controls can further obscure clear decision-making, leading teams to delay critical security improvements while seeking perfect solutions.
Misunderstanding of defense in depth
Defense in depth as a concept is good, but it can be misunderstood and difficult to achieve, leading to vulnerabilities in the security architecture. A common misconception is that a single strong control, separation of duties in AWS Identity and Access Management (IAM) roles, least permission in IAM policies, and so on, provide sufficient protection. This overlooks the crucial value of implementing controls at multiple points and how different control types can be combined to create a robust security posture. Teams often miss how organizational controls like SCPs can work in harmony with workload-specific controls to achieve greater protection. The role of preventative controls in guiding technical implementations is frequently under appreciated.
Maturity journey challenges
The path to security maturity presents numerous obstacles. Many organizations remain stuck in the early stages, implementing detective controls but never progressing to preventative measures. Security controls are often implemented in isolation, without consideration for the broader security landscape. Organizations struggle to create and follow a clear roadmap for evolving their security posture, and measuring improvement over time proves challenging.
Scale and consistency issues
As AWS environments grow, maintaining consistent governance and security becomes increasingly complex. Organizations face mounting challenges in managing exceptions and special cases across their expanding infrastructure. These interrelated challenges often result in controls implementations that fail to achieve their intended risk reduction goals. You need a structured approach to overcome these obstacles and implement comprehensive security controls, which we explore in the following sections.
Strategic investment in security
While implementing comprehensive controls requires an initial investment in time and resources, the long-term benefits fundamentally transform how organizations operate.
The foundation for this transformation begins with establishing baseline controls through proven starting points such as AWS Control Tower and its customization options. AWS Control Tower provides building blocks for secure multi-account architectures with hundreds of security capabilities and proactive controls already built in. Rather than trying to create baselines from scratch by wrangling vast amounts of account-level or resource-specific controls, you can use these accelerators to rapidly establish a strong security foundation. With these baseline controls in place, this transformation extends beyond security teams to enable the entire organization to operate more efficiently. Development and operations teams can deploy faster with confidence when security guardrails are in place. Security becomes an enabler rather than a bottleneck, so that teams across the organization can innovate while maintaining a strong security posture.
As you mature your organization’s control framework through automation and layered defenses, a security transformation occurs. Security teams shift from constant firefighting to proactive risk management. Automated policy enforcement replaces manual reviews, and the time previously spent on routine tasks can be redirected to strategic initiatives.
Preventative controls establish the foundation of a secure environment by defining the policies, standards, and requirements that guide security implementations. At their core, these controls encompass corporate security policies that outline acceptable resource configurations across the organization. They work in conjunction with compliance requirements and frameworks to help maintain regulatory alignment, while architectural standards and guidelines provide technical direction for implementations. Data classification policies play a crucial role by determining specific security requirements based on data sensitivity.
To illustrate how preventative controls work in practice, consider a common S3 bucket security requirement. A typical preventative control might establish a corporate policy stating All S3 buckets must be private by default, with public access granted only through an approved exception process. This simple but effective policy sets clear expectations and requirements before a technical implementation begins.
Organization level: SCPs blocking public S3 bucket creation.
Resource level:
RCPs enforcing network access controls, such as requiring authenticated access or limiting requests to your organization’s network range.
SCPs to stop malicious overwrites of S3 objects using SSE-C encryption by blocking s3:PutObject requests with customer-provided keys unless explicitly allowed, paired with AWS IAM Roles Anywhere for short-term credential enforcement.
Proactive controls act as an early warning system, identifying and addressing potential security issues before they manifest in your environment. These controls work by validating configurations and changes against established security requirements during the development and deployment phases. Through automated validation and policy enforcement at build and deploy time, proactive controls help prevent misconfigurations from reaching production environments, reducing the operational overhead of fixing security issues after the fact. Think of proactive controls as your first line of defense in maintaining a secure cloud environment. In AWS, these can be implemented at multiple levels:
Amazon S3 Block Public Access settings at the account level.
Policy-as-code checks in continuous integration and delivery (CI/CD) pipelines (such as CFN-Nag, or AWS Config proactive rules).
AWS CloudFormation hooks for pre-deployment validation and policy enforcement.
AWS Config rules in proactive mode to evaluate resources before creation.
At the resource level, you can use:
IAM policies restricting bucket policy modifications
CloudFormation Guard rules
#####################################
## Gherkin ##
#####################################
# Rule Identifier:
# S3_BUCKET_SERVER_SIDE_ENCRYPTION_ENABLED
# Description:
# Checks if your Amazon S3 bucket either has the Amazon S3 default encryption enabled or that the Amazon S3 bucket policy
# explicitly denies put-object requests without server side encryption that uses AES-256 or AWS Key Management Service.
# Reports on:
# AWS::S3::Bucket
# Evaluates:
# AWS CloudFormation
# Rule Parameters:
# NA
# Scenarios:
# a) SKIP: when there are no S3 resource present
# b) PASS: when all S3 resources Bucket Encryption ServerSideEncryptionByDefault is set to either "aws:kms" or "AES256"
# c) FAIL: when all S3 resources have Bucket Encryption ServerSideEncryptionByDefault is not set or does not have "aws:kms" or "AES256" configurations
# d) SKIP: when metadata includes the suppression for rule S3_BUCKET_SERVER_SIDE_ENCRYPTION_ENABLED
#
# Select all S3 resources from incoming template (payload)
#
let s3_buckets_server_side_encryption = Resources.*[ Type == 'AWS::S3::Bucket'
Metadata.cfn_nag.rules_to_suppress not exists or
Metadata.cfn_nag.rules_to_suppress.*.id != "W41"
Metadata.guard.SuppressedRules not exists or
Metadata.guard.SuppressedRules.* != "S3_BUCKET_SERVER_SIDE_ENCRYPTION_ENABLED"
]
rule S3_BUCKET_SERVER_SIDE_ENCRYPTION_ENABLED when %s3_buckets_server_side_encryption !empty {
%s3_buckets_server_side_encryption.Properties.BucketEncryption exists
%s3_buckets_server_side_encryption.Properties.BucketEncryption.ServerSideEncryptionConfiguration[*].ServerSideEncryptionByDefault.SSEAlgorithm in ["aws:kms","AES256"]
<<
Violation: S3 Bucket must enable server-side encryption.
Fix: Set the S3 Bucket property BucketEncryption.ServerSideEncryptionConfiguration.ServerSideEncryptionByDefault.SSEAlgorithm to either "aws:kms" or "AES256"
>>
}
Detective controls provide continuous visibility into your security posture by monitoring for and identifying potential security violations or unauthorized changes within your environment. While preventative controls aim to stop issues before they occur, detective controls help you maintain awareness of your security state and can identify when preventative controls have been bypassed or failed. These controls form a critical layer of defense by enabling rapid identification of security issues and providing the visibility needed for effective incident response and compliance reporting. While many organizations start and stop here, detective controls are only part of the solution:
AWS Config rules monitoring for public buckets
Security Hub findings to flag non-compliant resources
Responsive controls complete the security lifecycle by providing automated and manual mechanisms to address security issues after they’re detected. These controls define and implement the actions taken when security violations are identified, ranging from automated remediation of common misconfigurations to coordinated incident response procedures for complex security events. By establishing clear response patterns and using automation where appropriate, responsive controls help facilitate consistent and timely handling of security issues while reducing the mean time to remediation. Responsive controls address violations when they occur:
The power comes not from implementing these controls in isolation, but from using them together in a coordinated way. This layered approach begins with preventative controls to establish the requirements, followed by proactive controls to block most potential violations at the source. Issues that manage to slip through are caught by detective controls, while responsive controls automatically remediate identified problems. Throughout this process, comprehensive documentation tracks issues, remediation plans, and progress, such as through a plan of action and milestones (POAM), helping to make sure that compliance requirements are met and improvements can be measured over time.
Implementation lifecycles: Ideal compared to reality
You can follow one of two paths when implementing security controls: starting fresh with a comprehensive approach or evolving from an existing detective-focused implementation. Let’s examine both scenarios.
Starting fresh: The ideal approach
When starting from scratch, you have a unique opportunity to build your security and governance following an ideal approach. Your team can take advantage of this clean slate to architect controls and processes methodically, free from legacy constraints. The following steps offer guidance though establishing a strong foundation while maintaining the flexibility you need as your business grows.
Rationalize controls against requirements and risk profile:
Choose appropriate security frameworks (for example, CIS and NIST).
Map compliance, regulatory, legal, and contractual requirements to your base framework.
Define clear security objectives and success criteria for your security and compliance program.
Design a comprehensive control strategy:
Document control requirements across all four types (preventive, proactive, detective, and responsive controls). You can use the framework to decide which controls are best for each type of requirement.
Plan implementation phases and priorities.
Define metrics for measuring effectiveness.
Implement controls in layers:
Start with AWS Control Tower, which gives you foundational controls to mature from. You can add customizations if required.
Think about additional preventative controls that can help establish a stronger security and compliance posture.
Deploy proactive controls to stop violations.
Add detective controls as safeguards.
Implement responsive controls for automated or manual remediation.
Monitor and assess effectiveness
Evaluate control performance against defined metrics.
Identify gaps and areas for improvement.
Adjust controls based on emerging threats and changing requirements.
Implement continuous improvement feedback loop.
Evolution from detective controls: The common path
Most organizations find themselves starting with detective controls and face challenges in maturing from there:
Initial state:
Baseline detective controls through Security Hub and AWS Config
Manual remediation processes
Limited visibility into security posture
Maturation steps:
Analyze findings to identify patterns
Implement automated remediation for common issues
Add preventative and proactive controls based on recurring events
Periodically refine and update policies
Optimization:
Review control effectiveness
Identify gaps in coverage
Implement additional preventative, proactive, detective, and responsive measures
Automate processes where possible
The goal: Comprehensive and layered security controls
The goal of implementing security controls across multiple layers isn’t just about compliance or following best practices—it’s about creating a robust, resilient security posture that can effectively help prevent, detect, and respond to security issues. Let’s explore why this approach is crucial:
Why multiple control layers matter
Security controls shouldn’t exist in isolation. When implementing a security requirement, you should consider:
How can we prevent this issue from occurring?
How will we detect if our preventative controls fail?
What should happen when we detect a violation?
What policies and standards guide these decisions?
Moving beyond detection
While detective controls are important, they signal that a security violation has already occurred. A mature security posture requires:
Strong preventative controls to stop violations before they happen
Detective controls as a safety net if there is drift or a violation
Automated remediation where possible, to reduce exposure time
Clear policies to guide implementation and decisions
Measuring success
You should measure the effectiveness of your control framework through several key performance indicators. Success can be seen in the steady reduction of security findings over time, coupled with decreasing time-to-remediation metrics. The maturity of the framework becomes evident through an increasing percentage of automated remediation activities and a declining number of recurring issues. These improvements manifest in better audit outcomes, providing tangible evidence that the control framework is delivering its intended results.
Practical implementation: From theory to practice
Let’s examine how to implement a comprehensive control framework using a common security requirement: preventing exposure of sensitive data through public S3 buckets. This example demonstrates how different control types work together to create defense in depth. While not every control might be necessary for every situation, each should be carefully considered and evaluated based on various factors including system criticality, data sensitivity, operational overhead, and organizational risk tolerance. The decision to implement or omit specific controls should be deliberate and documented, rather than occurring by default.
The architecture will have layers and components like the following.
Preventative layer:
Service control policies (SCPs) or resource control policies (RCPs)
An effective security and compliance strategy includes all four types of security controls. While preventative controls are a first line of defense to help prevent unauthorized access or unwanted changes to your network, it’s important to make sure that you establish detective and responsive controls so that you know when an event occurs and can take immediate and appropriate action to remediate it. Using proactive controls adds another layer of security because it complements preventative controls, which are generally stricter in nature.
Begin by defining your security objectives, then establish clear policies to meet those objectives:
Define organizational and business objectives:
Identify data protection goals
Determine acceptable risk levels
Align with compliance requirements
Establish clear policies:
For example, document business requirements for external data sharing and access controls in security policies. These requirements will drive technical decisions around AWS storage configurations such as S3 bucket policies and public access settings.
Define permitted use cases for public access.
Establish exception processes.
Set clear ownership and responsibilities.
Deploy preventative guardrails:
Organization level:
SCPs to block public bucket creation at the organization level
Account-level S3 Block Public Access settings to enforce account-level restrictions
Resource level:
IAM policies restricting bucket policy modifications
S3 bucket policy templates with controlled deployment
RCPs to enforce rules on specific resource types across your organization
Deploy proactive guardrails:
Infrastructure as code:
Implement policy-as-code checks in CI/CD pipelines using:
Enable relevant optional AWS Control Tower guardrails
Add detective controls by creating a monitoring framework:
AWS CloudTrail for comprehensive API activity logging and auditing to enable investigation of unauthorized access attempts and configuration changes.
AWS Config rules for bucket configuration. AWS Config rules or AWS Config conformance packs deployed for the entire organization can monitor S3 bucket configurations for compliance.
Security Hub findings for continuous assessment by aggregating findings and flagging non-compliant resources.
Amazon EventBridge rules for policy changes to detect and route S3 bucket policy modifications.
IAM Access Analyzer for external access review.
Regular compliance reporting, which can be automated through AWS Audit Manager.
Implement responsive controls by automating remediation where possible:
Security Hub and Systems Manager integration to automate incident response workflows.
Custom Lambda functions for specific use cases.
Integration with ITSM for human review when needed.
The following table describes control types, what a basic implementation includes, and the services and methods used for advanced implementation.
Control type
Basic implementation
Advanced implementation
Preventative
Documentation, peer reviews
SCPs, RCPs, DPs, IAM policies, and S3 Block Public Access
Detective
Security Hub, AWS Config rules
Security Hub, AWS Config, and CloudWatch alerts
Responsive
Manual remediation
Auto-remediation through AWS Config, Systems Manager, EventBridge, and Lambda
Compliance
One-time checks
CIS/NIST mapping with Security Hub and automation of evidence collection and reporting using AWS Audit Manager
Automation
Limited
Full CI/CD Integration (for example, using CloudFormation or Terraform)
Cost optimization effort
High (manual effort)
Low (automation reduces overhead)
Scaling and management considerations
As your security and governance program matures, scaling these controls across a growing organization requires thoughtful management and automation. This section explores key considerations for effectively managing your security posture at scale, optimizing costs, and maintaining consistency across your AWS environment. Whether you’re expanding across multiple accounts, business units, or AWS Regions, these practices help you balance security requirements with operational efficiency and cost management.
Use AWS services effectively:
Consider deploying AWS Control Tower for consistent account setup and centrally deploying and managing controls at scale across multiple use cases and organizational units.
AWS Organizations can aid hierarchical policy management and the implementation of:
IAM policies for identity-based guardrails and permissions
SCPs for access guardrails
RCPs define permissions based on resource attributes
DPs to help facilitate consistent resource configurations across your organization
Tag policies for consistent resource categorization
Backup policies for data protection standards
AI service opt-out policies for data privacy requirements
Cost allocation tag policies to standardize cost attribution
Data residency policies to enforce regional restrictions
Implement resource governance through policy integration
For example, use Organizations tag policies to enforce a Confidential tag on S3 buckets storing personally identifiable information (PII). Combine this with SCPs that mandate AES-256 encryption for tagged buckets, overriding developer attempts to disable it.
Using backup policies to enforce retention rules (for example, Retention=7 years).
Use DPs to help maintain consistent security configurations across resources, such as enforcing encryption settings on Amazon Elastic Block Store (Amazon EBS) volumes or requiring specific security group rules.
Centralize logging and monitoring
Manage compliance exceptions:
Implement clear exception processes
Document and track approved exceptions
Establish regular periodic reviews of exceptions
Use time-bound approvals with automated expiration
Optimize costs:
Use periodic instead of continuous checking where appropriate
Implement targeted monitoring based on resource criticality
Implementing a comprehensive control framework is a journey, not a destination. Start from your organization’s current position, whether that’s with basic detective controls or a fresh implementation, and focus on progressive improvement rather than attempting to implement everything at once. Success comes from carefully documenting decisions about control implementation, regularly reviewing them, and using automation to reduce operational overhead while improving consistency. Progress can be measured through concrete metrics: reduced findings, faster remediation times, and increased automation.
Remember that the goal extends beyond better security—it’s about transforming security and governance from a reactive operation to a strategic enabler that provides real business value. This transformation manifests through reduced risk from systematic controls, improved operational efficiency through automation, and enhanced visibility and governance. Perhaps most importantly, it frees security teams to focus on strategic initiatives rather than routine operational tasks.
By following this approach, you can build a robust security and governance posture that not only protects your organization’s AWS environment but also supports business innovation and growth. The result is a security program that evolves alongside the business, enabling rather than hindering progress, while maintaining a strong approach that can scale with your organization’s needs.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Many AWS Organizations customers begin by creating and manually applying service control policies (SCPs) and resource control policies (RCPs) through the AWS Management Console or AWS Command Line Interface (AWS CLI) when they first set up their environments. However, as the organization grows and the number of policies increases, this manual approach can become cumbersome. It can result in limited visibility into all implemented SCPs and RCPs, the targets they’re attached to (such as accounts, organizational units (OUs), or nested OUs), and the ability to manage updates effectively. Without clear visibility and proper access controls, it becomes challenging to track who’s making changes and how they are being made.
Importing existing SCPs and RCPs into AWS CloudFormation can help streamline the management of your policies by enabling history tracking, policy validation through CloudFormation Hooks, and rollback capabilities. You can also sync stacks with source code stored in a Git repository with Git sync. With Git sync, you can use pull requests and version tracking to configure, deploy, and update your CloudFormation stacks from a centralized location. When you commit changes to the template or the deployment file, CloudFormation automatically updates the stack.
Important: Only existing policies are brought into CloudFormation; policies are not recreated.
Solution overview
The solution in this post includes a command line tool for discovering SCPs and RCPs in your organization and automating policy import into CloudFormation templates. The following figure shows the end-to-end flow:
Figure 1: Solution overview
The end-to-end flow shown in the preceding figure includes:
Run the tool: The tool automates the following steps and can be run in the management account or delegated administrator account.
Identify SCPs and RCPs in the organization: The tool begins by making API calls to the Organizations service to retrieve the policies in your environment. It then provides a count of the total number of SCPs and RCPs present.
Identify AWS Control Tower SCPs and RCPs and policies without targets:
SCPs are identified by the aws-guardrails- prefix in their policy names.
RCPs are identified by the AWSControlTower-Controls- prefix in their policy names.
Policies with no targets: The tool also identifies SCPs and RCPs that aren’t attached to an organizational unit (OU), account, or root and lists them. These policies might be redundant or need reassignment.
CloudFormation IaC generator scan: At this stage, you will be prompted to confirm whether you want to import the policies to the CloudFormation templates using CloudFormation resource scan. If you select yes, the tool will initiate a CloudFormation resource scan using IaC generator to get details about the policies including policy name, targets, policy tags, and so on.
Create template from scanned policy resources: The tool generates CloudFormation template with the policy resources. The template will include the policies without targets (if any).
Review process: After the template is generated, it’s recommended that you preview the template using IaC generator from the CloudFormation console. We recommend viewing the template resource section to verify and adjust the generated templates as needed (step 11 of the solution deployment).
Create CloudFormation stacks with the generated templates: After reviewing the templates, import them into CloudFormation stacks for deployment. It’s important to note that only existing policies are brought into CloudFormation—policies aren’t recreated. The templates reflect the current policies and policy attributes.
Consideration before implementing the solution
There are some considerations that you need to keep in mind before implementing the solution.
If you have enabled the AWS Organizations policy management delegation, you should run this solution from the delegated administrator account. Otherwise, you can run the solution using the management account.
AWS Control Tower SCPs and RCPs (with or without targets) won’t be imported to the CloudFormation templates because they should be managed using AWS Control Tower. Changes made to AWS Control Tower resources outside of AWS Control Tower can cause drift and affect AWS Control Tower functionality in unpredictable ways.
You might see multiple CloudFormation templates created if you exceed the CloudFormation template size quotas. To help ensure smooth creation, the tool is designed to automatically split the content into multiple templates if necessary, allowing you to stay within the quotas while still accommodating the imported content.
Note that the generated templates have the following attributes set by default.
Deletion policy: Set to Retain. This enables persisting the policies even when their related stack is deleted.
Update Replace policy: Set to Delete. This enables deletion of the physical ID associated with the policy when the policy is updated.
Solution deployment
Now that you understand the solution and know the considerations to keep in mind, you’re ready to deploy the solution.
You can run the tool specifying a profile name as a command line argument. Use the following command, replacing <profile_name> with the name of the profile you created in step 4. If you do not specify a profile, the default profile from the file ~./aws/config will be used.
policy-importer --profile <profile_name>
After the preceding command is executed, you will see an output displaying the total number of SCPs and RCPs found in the organization. The output will also list AWS Control Tower managed policies as INFO, in addition to policies without targets as a WARNING. At this point, you can enter Yes to proceed with scanning to import the policies, or enter No if you want to exit.
Note: If policies without targets are detected, we recommend stopping at this point. Either delete the policies without targets or assign appropriate targets to them. You can then rerun the tool from step 5. If you proceed without addressing the policies without targets, be aware that these policies will also be included in the CloudFormation template.
Figure 2: Terminal view with policies identified in the organization
If you enter Yes, the CloudFormation IaC resource scan will begin immediately. You will see the resource scan ID Amazon Resource Name (ARN) displayed.
Note: A scan can take up to 10 minutes for every 1,000 resources.
Figure 3: Terminal view with AWS CloudFormation resource scan details
You can also review the scan progress from the IaC generator page of the CloudFormation console as shown in the following figure. To get to the IaC generator page, go to the CloudFormation console and choose IaC generator from the navigation pane.
Figure 4: View the scan summary in the CloudFormation console to track progress
Upon completion of the scan, the template generation process will be initiated.
Figure 5: Terminal view showing CloudFormation template being created
After the template creation is finished, sign in to the AWS CloudFormation IaC console. Choose the Templates tab to review the generated templates and verify that they align with your requirements.
Figure 6: View CloudFormation templates in the console
You can review the policies added to a template by selecting a template name.
Figure 7: Review policies included in the template
When satisfied, you can proceed to import the templates into CloudFormation stacks for deployment by selecting Import to stack.
Figure 8: Import a template into the CloudFormation stack
Follow the prompts to create a stack.
Figure 9: AWS CloudFormation stack example
The tool automatically creates a folder named Policies in your current directory and downloads the generated templates.
As shown in the following figure, there are two recommended next steps.
Figure 10: Solution overview including recommended next steps
After the existing policies are imported into a CloudFormation stack, we recommend storing your CloudFormation templates in a private Git repository. You can use the Policies folder that was automatically created by the tool in the current local directory with the generated templates downloaded and set up a continuous integration and delivery (CI/CD) pipeline to efficiently manage the imported policies.
By using a Git repository, you can use version control features like pull requests, branch management, and history tracking. This approach allows your team to efficiently review, update, and deploy policies with better collaboration and control. You can also create a CI/CD pipeline to automate the deployment of changes to your CloudFormation stacks, helping to ensure that updates are consistent and reliable.
We also recommend incorporating CloudFormation Hooks in your environment. CloudFormation Hooks can help validate policies (and other resources) against best practices, to help ensure that they adhere to the correct syntax, follow security best practices, and minimize potential vulnerabilities.
Importing existing AWS Organizations service control policies (SCPs) and resource control policies (RCPs) into CloudFormation provides an efficient and scalable approach to managing and automating your AWS governance. After they’ve been imported, you can manage and update policies directly in CloudFormation, to help ensure consistency and version control across your organization. The tool also creates a Policies folder in your current directory, storing downloaded templates for use as a central repository and integration with a CI/CD pipeline.
By using CloudFormation Hooks, you can further improve your policy management by validating SCPs and RCPs against best practices and policy grammar. This approach centralizes your policy updates, making governance more automated and efficient while reducing the risk of misconfiguration.
UNiDAYS is a fast, free digital platform that provides exclusive student offers and benefits to over 29 million verified members worldwide. With a rapidly growing user base and an increasing number of global partnerships, UNiDAYS recognized the need to enhance its platform’s performance to deliver a seamless consumer experience in geographic regions far from its original base of operations.
In this post, we share how UNiDAYS achieved AWS Region expansion in just 3 weeks using AWS services.
Business challenges
In response to growth opportunities, UNiDAYS faced a pressing business requirement: deliver low-latency responses and provide high availability for users across diverse geographic regions. At the same time, the platform needed to guarantee global data consistency while adhering to tight deadlines—all within just a few weeks. However, the existing monolithic application, although built on Amazon Web Services (AWS), wasn’t optimized for active-active multi-Region deployments.
The challenge was further complicated by the need to extend functionality from this legacy system, which used the AWS global network for improved user experience but fell short of meeting new business requirements. Re-architecting the entire platform to support multi-Region deployments within the given timeframe wasn’t feasible.
Solution overview
UNiDAYS opted to create complementary services tailored to these new requirements, using AWS services for a multi-Region, active-active architecture. The key services used included:
Amazon EventBridge – To enable asynchronous integration with existing systems through event-driven patterns
This approach allowed UNiDAYS to meet its latency, availability, and consistency goals while seamlessly integrating with existing infrastructure. The following diagram is the architecture for the solution.
Global delivery and resiliency
To provide the lowest latency and multi-Region resiliency, CloudFront was used with latency-based routing configured in Route 53. This routing directs requests to the Regional Application Load Balancers with the lowest latency, automatically providing resiliency in the event of Regional issues. Security was a key consideration. AWS WAF integration with CloudFront provided application-layer protection at the edge. Additional security measures included:
Custom HTTP headers on origin requests, enforced using Application Load Balancer listener rule conditions
Prefix lists to restrict access to Application Load Balancers, making sure that traffic originated from the intended CloudFront distributions
Rapid Regional deployment
The core infrastructure is deployed through Terraform, and applications are deployed using custom tooling that wraps AWS CloudFormation. This hybrid approach enabled rapid delivery by using existing patterns without disrupting established workflows. Resources were organized into tiers: platform, global, and Regional. Platform and global resources were deployed one time, and Regional resources were rolled out to each activated Region, streamlining expansion efforts.
One technical challenge involved CloudFormation exports, which are Regional by design. To address this, we implemented a custom CloudFormation macro to enable cross-Region access to exported values, providing consistency across deployments.
Amazon ECS enabled progressive application deployments within each Region, allowing teams to focus on scaling applications rather than managing infrastructure. For cost-efficiency, we used Spot Instances. During testing, container start-up latency was observed due to cross-Region image downloads from Amazon Elastic Container Registry (Amazon ECR). This issue was resolved by enabling private image replication in Amazon ECR so that container images were available locally in each Region. This solution significantly reduced start-up times, improving application responsiveness during deployments and scaling events.
Data consistency and performance
DynamoDB global tables were instrumental in providing eventual data consistency and Regional replication. With DynamoDB handling these aspects, we could focus on application logic.
The result was a substantial reduction in latency at key locations. For example, client-experienced latency in one Region dropped from approximately 200 milliseconds to 50 milliseconds upon deployment, as shown in the following screenshot.
Key technical hurdles
We addressed the following technical obstacles while developing the solution:
Cross-Region CloudFormation exports – CloudFormation exports are Regional by design. We addressed this by creating a custom CloudFormation macro to read exports across Regions.
Container start-up latency – Latency caused by cross-Region image downloads was mitigated by implementing Amazon ECR private image replication. This meant that container images were readily available in each Region, reducing deployment times and improving overall performance.
Security assurance – By using CloudFront, AWS WAF, and Application Load Balancer security features, we made sure that traffic and data remained secure.
Why AWS?
UNiDAYS chose AWS due to its comprehensive global infrastructure and robust service offerings, which allowed the platform to:
Seamlessly expand compute operations to Regions closer to its user base
Take advantage of a full stack of services for reliable, secure, and low-latency content delivery
Meet tight delivery deadlines without compromising on performance or security
Maintain flexibility where required, with the ability to use more managed services, which allowed a focus on our applications
Conclusion
By adopting a multi-Region, active-active architecture on AWS, UNiDAYS successfully met its business goals within only 3 weeks, rapidly expanding to new Regions while promoting platform resiliency. The solution improved latency by 75% in new Regions (from 200 milliseconds to 50 milliseconds), provided Regional data availability through DynamoDB global tables, and maintained 100% service uptime during resiliency tests, even in cases of Regional connectivity loss. Additionally, deployment velocity increased by over 40%, allowing faster feature releases and improved agility. This architecture not only provides a scalable and resilient platform for current operations but also establishes a strong foundation for future global expansion.
Learn more
Is your organization looking to expand into new Regions while maintaining performance and reliability?
Contact AWS experts to explore tailored solutions for your multi-Region strategy.
This post demonstrates how to leverage AWS CloudFormation Lambda Hooks to enforce compliance rules at provisioning time, enabling you to evaluate and validate Lambda function configurations against custom policies before deployment. Often these policies impact the way a software should be built, restricting language versions and runtimes. A great example is applying those policies on AWS Lambda, a serverless compute service for running code without having to provision or manage servers. While AWS Lambda already manages the deprecation of runtimes, preventing you from deploying unsupported runtimes, organizations may need to provide and enforce their specific compliance rules not directly linked to the deprecation of a specific language version.
Introducing Lambda Hooks
AWS CloudFormation Lambda Hooks are a powerful feature that allows developers to evaluate CloudFormation and AWS Cloud Control API operations against custom code implemented as Lambda functions. This capability enables proactive inspection of resource configurations before provisioning, enhancing security, compliance, and operational efficiency.
Lambda Hooks provide a mechanism to intercept and evaluate various CloudFormation operations, including resource operations, stack operations, and change set operations (they can also be used with Cloud Control API, but in this post we’re focusing on CloudFormation). By activating a Lambda Hook, CloudFormation creates an entry in your account’s registry as a private Hook, allowing you to configure it for specific AWS accounts and regions. When configuring Lambda Hooks, you can specify one or more Lambda functions to be invoked during the evaluation process. These functions can be in the same AWS account and Region as the Hook, or in another Account you own, provided proper permissions are set up. The evaluation process occurs at specific points in the CloudFormation Stack lifecycle. For instance, during stack creation, update, or deletion, the configured Lambda functions are invoked to assess the proposed changes against your defined compliance rules. Based on the evaluation results, the hook can either block the operation or issue a warning, allowing the operation to proceed.
Lambda Hooks evaluate resources before they are provisioned through CloudFormation, providing a pre-emptive layer of governance. This means that non-compliant resources are caught and prevented from being deployed, rather than requiring retroactive fixes. By leveraging Lambda Hooks, organizations can automate and standardize their compliance checks across all AWS accounts and regions. This centralized approach to policy enforcement ensures consistency and reduces the overhead of managing compliance manually.
Solution Overview
The following sections demonstrate a practical use case for AWS CloudFormation Lambda Hooks, focusing on enforcing compliance rules on AWS Lambda runtimes.
Meet AnyCompany, a forward-thinking enterprise with a robust set of compliance rules governing their software development practices. Among these rules is a strict policy on the use of specific AWS Lambda runtimes.
As they continue to embrace serverless architecture, AnyCompany faces a challenge: how to prevent the deployment of Lambda functions that use non-compliant runtimes. Given their commitment to AWS CloudFormation for deploying Lambda functions, AnyCompany is keen to leverage the power of AWS CloudFormation Lambda Hooks.
We’ll explore the setup process, demonstrate the hook in action, and discuss the broader implications for maintaining compliance in a dynamic cloud environment.
Architecture
The following architecture highlights the implementation of the Lambda Hook. In this implementation, we are using AWS CloudFormation Lambda Hooks to intercept the deployment of Lambda Functions and perform the compliance checks on these resources. The Lambda Hook will interact with an AWS Lambda Function, which will perform the compliance checks. Finally, we’re using AWS Systems Manager Parameter Store to store the Configuration Parameter which contains the list of permitted Lambda Runtimes.
Figure 1: Architecture of the Solution
A Developer (or a CI/CD pipeline) deploys a CloudFormation stack containing Lambda functions.
CloudFormation invokes the respective Lambda Hook, which is configured to intercept operations on AWS Lambda Resources. We are setting this hook to “FAIL” deployment in case checks are not successful.
hook-lambda: directory containing all the code related to the CloudFormation Lambda Hook (Validation Lambda Function, and the CloudFormation template for the Solution)
sample: directory containing the code of the sample used to test the CloudFormation Lambda Hook
deploy.sh: utility script to deploy the Solution via AWS CLI
cleanup.sh: utility script to clean up the AWS CloudFormation Hook infrastructure via the AWS CLI
template.yml: AWS CloudFormation Template containing all the AWS Resources involved in the Solution
Prerequisites
You must have the following prerequisites for this solution:
An AWS account or sign up to create and activate one.
The following software installed on your development machine:
Install the AWS Command Line Interface (AWS CLI) and configure it to point to your AWS account.
Install Node.js and use a package manager such as npm.
Appropriate AWS credentials for interacting with resources in your AWS account.
Walkthrough
Creating the AWS Lambda Validation Function – Lambda Code
The CloudFormation Lambda Hook interacts with a specific Lambda (referred to as Validation Lambda throughout the rest of this post), which gets invoked during CloudFormation CREATE and UPDATE STACK operations involving Lambda Functions. The goal is to check if these Lambda functions have runtimes that comply with AnyCompany’s rules.
Below is the detailed description of the steps that the Validation Lambda function handler follows (the code is written in Typescript).
First, the Validation Lambda retrieves an environment variable containing the SSM Parameter Store parameter name which contains the compliant runtimes list. Additionally, safety checks ensure that only Lambda Resources are considered and that their Runtime property is defined.
Note that both safety checks could be skipped, since the Hook should already be configured to interact only with Lambda Resources and the Lambda’s Runtime property is always required. However, they remain in place to demonstrate how to retrieve this information from the Lambda Hook event in your handler.
const parameterName = process.env.PERMITTED_RUNTIMES_PARAM;
if (!parameterName) {
throw new Error('Permitted Runtimes Parameter is not set');
}
const resourceProperties = event.requestData.targetModel.resourceProperties;
// Check if this is a Lambda function resource
if (event.requestData.targetType !== 'AWS::Lambda::Function') {
console.log("Resource is not a Lambda function, skipping");
return {
hookStatus: 'SUCCESS',
message: 'Not a Lambda function resource, skipping validation',
clientRequestToken: event.clientRequestToken
}
}
// Check runtime version compliance
const runtime = resourceProperties.Runtime;
if (!runtime) {
console.log("Runtime not defined, failing");
return {
hookStatus: 'FAILURE',
errorCode: 'NonCompliant',
message: 'Runtime is required for Lambda functions',
clientRequestToken: event.clientRequestToken
}
}
Then the Validation Lambda retrieves the value of the Configuration Parameter from SSM Parameter Store through a utility class called ParameterStoreService. For this post, consider that the value inside that Configuration Parameter is a list of strings, where each string contains one of the possible Lambda runtime values that you can find here (e.g. nodejs22.x,nodejs20.x,python3.11,python3.10,java17,java11,dotnet6). After retrieving the value, the Validation Lambda checks if the runtime of the Lambda Resource complies with the configured admitted runtimes. If the runtime is not compliant, you’ll receive a properly formatted response with FAILURE as hookStatus, otherwise the response will contain a SUCCESS hookStatus.
// Retrieve configuration from Parameter Store
const compliantRuntimes = await parameterStoreService.getParameterFromStore(parameterName);
// Check if Lambda runtime is permitted or not
if (!compliantRuntimes.includes(runtime)) {
console.log("Runtime " + runtime + " not compliant ");
return {
hookStatus: 'FAILURE',
errorCode: 'NonCompliant',
message: `Runtime ${runtime} is not compliant. Please use one of: ${compliantRuntimes.join(', ')}`,
clientRequestToken: event.clientRequestToken
}
}
return {
hookStatus: 'SUCCESS',
message: 'Runtime version compliance check passed',
clientRequestToken: event.clientRequestToken
}
For more information about the possible response values of CloudFormation Lambda Hooks Lambda, have a look at this link.
Creating the validation Lambda – Lambda CloudFormation definition
The Validation Lambda function will be deployed via CloudFormation, in the same Stack with the CloudFormation Lambda Hook definition and the AWS Systems Manager Parameter Store Parameter. Here’s the fragment of the CloudFormation Template containing its definition:
Please note that the above template contains a reference to an IAM Role because the Hook requires proper permissions to call the target (Lambda Function). Here’s the IAM Role definition:
Configuring the compliant runtimes – Using Systems Manager Parameter Store
AWS Systems Manager Parameter Store is a secure, hierarchical storage service for configuration data management and secrets management, allowing users to store and retrieve data such as configurations, database strings etc. as parameter values.
In this specific example, we’ll leverage Parameter Store to store our permitted Lambda runtimes configuration. This configuration value is a StringList parameter, containing a comma-separated list of permitted runtimes. Here’s the fragment of the CloudFormation template that defines the Parameter:
Please note the usage of CloudFormation parameters for the ‘Name’ and ‘Value’ properties, allowing for dynamic input when deploying the CloudFormation template.
Deploying the Solution
To deploy the solution you can leverage the script deploy.sh in the root folder of the repository. This script will perform the following actions:
Compile and build the Validation Lambda Function
Create an Amazon S3 Bucket to store the CloudFormation Template
Upload the CloudFormation template and Lambda code to the S3 Bucket
Deploy the CloudFormation template
Testing the Lambda Hook
To test the CloudFormation Lambda Hook, deploy a simple testing CloudFormation template containing a Hello World Lambda function. First, test the Lambda configured with a permitted Lambda runtime, then modify the template to configure the Lambda with a non-compliant runtime.
Here’s the initial definition of the testing CloudFormation Template:
Please note that the Runtime value is nodejs22.x, which is currently in the list of permitted runtimes. The expectation is that the deployment of this function will succeed.
As expected, the deployment was successful. You can also see that the CloudFormation Lambda Hook has been invoked by taking a look at the CloudWatch Logs:
Figure 3: Validation Lambda Function Logs with successful validation
Now modify the original sample Template in order to set a Lambda Runtime which is not inside the list of permitted runtimes:
Deploy this template via AWS CLI with the same command used before and check the CloudFormation Console:
Figure 4: CloudFormation Console showing failed Stack deployment due to Hook intervention
As expected, the deployment was not successful. The CloudFormation Lambda Hook has been invoked, and since the Lambda Runtime was not present in the permitted runtimes list, the deployment failed.
You can also see that the hook failed In the CloudWatch Logs:
Figure 5: Validation Lambda Function Logs with validation error
Cleaning up
To clean up the resources related to the sample, you can run the script cleanup_sample.sh inside the sample folder. This script will delete the sample’s CloudFormation Template through the AWS CLI.
To cleanup the resources related to the solution described above and based on AWS CloudFormation Lambda Hook, you can leverage the script cleanup.sh in the root folder of the repository. This script will perform the following actions:
Delete the CloudFormation Stack
Empty the S3 Bucket used for the deployment of the Stack
Delete the S3 Bucket
Conclusion
In this post, you explored the implementation of CloudFormation Hooks to enforce runtime compliance in Lambda functions across your AWS infrastructure. By leveraging the Lambda hook’s capabilities, you learned how to create a preventative control that validates Lambda runtime configurations before deployment.
By activating the Lambda hook and implementing a custom Lambda function validator, you established an automated mechanism to ensure that only compliant runtimes are used within your organization’s Lambda functions during CloudFormation stack creation and updates. The solution’s integration with common development tools like AWS CLI, AWS SAM, CI/CD pipelines, and AWS CDK makes it straightforward to implement these controls within existing workflows, eliminating the need for manual runtime checks or post-deployment remediation.
The validation approach demonstrated in this post extends beyond Lambda runtimes and can be adapted to different AWS Resources supported by CloudFormation, allowing you to enforce policies on different infrastructure components offered by AWS.
Landing Zone Accelerator on AWS (LZA) enables customers to deploy a flexible, configuration-driven solution to establish a landing zone while also leveraging AWS Control Tower. At AWS Professional Services, we’ve helped customers deploy and configure LZA hundreds of times. A common request we encounter is integrating LZA configuration into customers’ existing GitOps workflows. GitOps has emerged as a leading model for Infrastructure as Code (IaC), helping organizations automate and manage their cloud infrastructure. The model uses Git repositories as the single source of truth for infrastructure configuration, enabling teams to maintain consistent, version-controlled environments.
In this blog, we will focus on common LZA implementation steps based on our experience, helping customers jump-start their LZA environment and implement GitOps for their AWS infrastructure management. First, we will demonstrate how to leverage LZA while complying with your organization’s policies such as private package repositories. Next, we will guide you through a new installation of LZA that takes advantage of an auto-generated starter set of configuration files. Finally, we will direct you to another blog post that will enable you to leverage GitOps for ongoing management of your LZA configuration.
Architecture overview
The LZA solution leverages two distinct repositories; one for the LZA source code, and another for your organization’s specific configuration files. LZA creates two separate AWS CodePipelines , which are used to install the LZA solution and apply your organization’s specific configuration. Figure 1 illustrates the association between repositories and pipelines. By default, when installing LZA, the solution uses GitHub as the source and pulls the installation files published by AWS from the official LZA GitHub repository.
Figure 1. Landing Zone Accelerator solution components
Deploy LZA as a new install
Step 1: Preparing your enterprise private GitHub to host LZA source code. Customers may choose to deploy LZA from the official AWS GitHub repository for LZA, but we often we find customers have policies in place that require these types of packages to be deployed from a private repository managed by the organization. For customers using GitHub privately in their enterprise, this can be as easy as cloning the LZA source code repository into your own private GitHub repository, enabling you to take advantage of policies and controls within your organization. Before moving to the next step, take a moment and clone the repository into your own private repository. A GitHub personal access token stored in AWS Secrets Manager is required to enable the stack to access your private repository. Before deploying LZA, follow these instructions to enable stack access to your repository.
Step 2: In the organization management account, install LZA as a CloudFormation Stack.
To get started, we will be going through a new installation of the LZA solution. The following steps provide specific parameter options to the CloudFormation template to support a new installation of LZA.
Specify the following parameters for Source Code Repository Configuration, see Figure 2.
For Stack name, specify a name you like.
For Source Location, choose github.
For Repository Owner, specify your GitHub account owner ID.
For Repository Name, specify your cloned LZA source code repository
For Branch Name, specify the branch name of your LZA source code repository.
We intentionally want to use S3 for the configuration repository because as the LZA solution is installed, it will auto-generate a set of starter configuration YAML files and deploy them for us in S3. This makes it very easy to get started with an initial set of customized YAML files for your environment. We choose “No” in the Use Existing Config Repository field, to have LZA to perform a new LZA installation.
Choose Next, and complete the remainder of the stack settings.
Finally, choose Create stack to launch the CloudFormation stack.
The installer stack typically takes minutes to complete (See Figure 4).
Figure 4. LZA installer stack completion
Step 3: Validate two LZA pipelines are created and successfully completed in AWS CodePipeline console.
After the CloudFormation stack completes, open the AWS CodePipeline console. You’ll see a new pipeline named “AWSAccelerator-Installer” running (See Figure 5). This is the LZA Installer pipeline, and it’s connected to the GitHub source repository you specified in Step 2 above with parameters from 2 to 5. This Installer pipeline automatically generates a set of LZA configuration files stored as a compressed ZIP archive in Amazon S3. It will be designated as configuration repository of the LZA solution.
When the AWSAccelerator-Installer pipeline completes, the solution automatically creates and runs a second pipeline named “AWSAccelerator-Pipeline” as shown in Figure 6. This pipeline connects to both the GitHub source repository, and the newly created configuration repository in Amazon S3. The AWSAccelerator-Pipeline is the pipeline that manages your landing zone deployment and customization.
Figure 6. AWSAccelerator-Pipeline created from the AWSAccelerator-Installer pipeline
After the AWSAccelerator-Pipeline completes, your LZA solution is ready for customization.
Step 4: Migrate the LZA configuration repository from S3 to GitHub
With the AWSAccelerator-Pipeline completed, your initial landing zone is now deployed, leveraging the configuration stored in your S3 bucket. For some customers, they may need to ensure that changes to the landing zone configuration are controlled through their existing GitOps processes and tooling. See Figure 7 as an example where the S3 configuration files have been copied to a customer owned GitHub repository. This transition step can be performed in future LZA upgrade window when there is a new release of LZA source code, or right after the initial LZA installation completes in Step 3. For more information on migrating from S3 to GitHub, follow this guide to configure your AWSAccelerator-Pipelines with AWS CodeConnection.
Figure 7. CodeConnection based LZA Configuration Repository
Conclusion
In this post, we explored key steps to streamline your LZA implementation journey. By demonstrating how to work with your private package repositories, providing guidance on leveraging auto-generated configuration files, and introducing GitOps-based management, we’ve outlined a practical path to establish and maintain a robust AWS infrastructure foundation. These approaches can significantly reduce the time and complexity typically associated with LZA deployments while ensuring compliance with organizational policies. We encourage you to try these implementation steps and explore the referenced resources to enhance your AWS cloud operations. For more information about Landing Zone Accelerator, visit the AWS Landing Zone Accelerator on GitHub.
AWS CloudFormation enables you to model and provision your cloud application infrastructure as code-base templates. Whether you prefer writing templates directly in JSON or YAML, or using programming languages like Python, Java, and TypeScript with the AWS Cloud Development Kit (CDK), CloudFormation and CDK provide the flexibility you need. For organizations adopting multi-account strategies, CloudFormation StackSets offers a powerful capability to deploy resources across multiple regions and accounts in parallel.
Last year, we delivered broad set of enhancements that accelerated the development cycle, simplified troubleshooting, and introduced new deployment safety and configuration governance capabilities. Let’s dive into the key launches that shaped CloudFormation in 2024.
Development cycle improvements
Deploy stacks up to 40% faster with optimistic stabilization and configuration complete
In March, we introduced optimistic stabilization with the new CONFIGURATION_COMPLETE event, delivering up to 40% faster stack creation times. This new event signals that CloudFormation has created the resource and applied the configuration as defined in the stack template, allowing us to begin parallel creation of dependent resources. For example, if your stack contains resource B that depends on resource A, CloudFormation will now start provisioning resource B when resource A reaches the CONFIGURATION_COMPLETE state, rather than waiting for full stabilization. Read How we sped up AWS CloudFormation deployments with optimistic stabilization to learn more.
Figure 1: CloudFormation’s old and new deployment strategy
Catch template errors before deployment with early validation
In March, we launched early resource properties validation checks. This feature validates your stack operation upfront for invalid resource property errors, helping you fail fast and minimize the steps required for a successful deployment. Previously, you had to wait until CloudFormation attempted to provision a resource before discovering property-related errors. Now, we validate your template before deploying the first resource and provide clear error messages upfront.
Figure 2: CloudFormation’s early template properties validation feature
Safely clean up failed stacks with enhanced deletion controls
In May, we enhanced the DeleteStack API with a new DeletionMode parameter, allowing you to safely delete stacks that are in DELETE_FAILED state. By passing the FORCE_DELETE_STACK value to this parameter, you can now resolve stuck stacks more efficiently during your development and testing cycles.
Accelerate feedback loops with CloudFormation custom resource timeout controls
In June, we introduced the ServiceTimeout property for custom resources. This new capability allows you to set custom timeout values for your custom resource logic execution. Previously, custom resources had a fixed one-hour timeout, which could lead to long wait times when debugging custom resource logic. Now, you can set appropriate timeout values to accelerate your development feedback loops. Refer to the custom resourcesdocumentation to learn more about the ServiceTimeout property.
Figure 3: CloudFormation’s ServiceTimeout property for Custom resource
Streamlined Troubleshooting Experience
Resolve deployment issues faster with one-click CloudTrail access
In May, we launched integration with AWS CloudTrail in the Events tab of the CloudFormation console. Troubleshooting some failed stack operations can be time-consuming, so we have streamlined this process by providing direct links from stack operation events to relevant CloudTrail events. When you click ‘Detect Root Cause’ in the CloudFormation Console, you’ll now see a pre-configured CloudTrail deep-link to the API events generated by your stack operation, eliminating multiple manual steps from the troubleshooting process.
Figure 4: CloudFormation troubleshooting with CloudTrail integration
Visualize your entire deployment process with timeline view
In November, we launched deployment timeline view. It gives you unprecedented visibility into your stack operations. This visual tool shows the sequence of actions CloudFormation takes during a deployment, helping you understand resource dependencies and provisioning duration. You can see which resources are being created in parallel, track their status through color-coding, and quickly identify bottlenecks in your deployments.
Get instant troubleshooting help with Amazon Q Developer
We integrated Amazon Q Developer to provide AI-powered assistance for troubleshooting. When you encounter a failed stack operation, you can now click “Diagnose with Q” to receive a clear, human-readable analysis of the error. Need more help? The “Help me resolve” button provides actionable steps tailored to your specific scenario.
Figure 6: CloudFormation troubleshooting with Q feature
We’ve also improved how change sets handle references. When referenced values are available before deployment, Change sets can now resolve them to their expected values, giving you a more accurate preview of your planned changes.
Figure 7: CloudFormation’s change sets feature
Easy onboarding to Infrastructure-as-Code (IaC)
Eliminate weeks of manual effort with IaC Generator
In February, we launched the CloudFormation IaC Generator, a capability addressing one of our customers’ biggest challenges: onboarding existing cloud resources to CloudFormation. This feature makes it easier to generate CloudFormation templates for existing AWS resources. You can now onboard workloads to IaC in minutes instead of spending weeks writing templates manually.
The IaC generator supports over 600 AWS resource types and provides recommendations for related resources. For instance, when you select an S3 bucket, it automatically suggests including associated bucket policies. You can use the generated templates to import resources into CloudFormation, download them for deployment.
Figure 8: CloudFormation’s IaC Generator
In August, we enhanced the IaC Generator with two improvements. First, we added a graphical summary view that helps you quickly find resources after the account scan completes. Second, we integrated with AWS Infrastructure Composer to visualize your application architecture, making it easier to understand resource relationships and configurations.
Figure 9: IaC generator resource scan
Proactive Control Improvements
In November, we launched major enhancements to CloudFormation Hooks, giving you easier ways to author proactive configuration controls and more points to enforce them with your cloud infrastructure provisioning.
CloudFormation Hooks for stack and change set target invocation points
First, we introduced stack and change set target invocation points for CloudFormation Hooks. This extends Hooks beyond individual resource validation, allowing you to run validation checks against entire templates and examine resource relationships. For example, you can now create hooks that validate architectural patterns across multiple resources or enforce team-specific deployment standards. With the change set invocation point, you can automate your change set reviews and reduce the time needed to resolve compliance issues. Refer to the Hooks developer guide to learn more.
Figure 10: CloudFormation’s Hooks for stack and change set target invocation points
Managed hooks for the CloudFormation Guard domain specific language
We introduced the managed hooks to author configuration controls using CloudFormation Guard domain-specific language. This simplifies the hook creation process—you can now write hooks by providing your Guard rule set stored as an S3 object. This is particularly valuable if you’re already using Guard for static template validation, as you can extend these rules to dynamic checks before deployments. To learn more about the Guard hook, check out the AWS DevOps Blog or refer to the Guard Hook User Guide.
Figure 11: CloudFormation Hooks’ Guard language feature
Figure 12: CloudFormation Hooks’ Lambda function feature
CloudFormation Hooks for AWS Cloud Control API target invocation points
Lastly, we extended Hooks to support AWS Cloud Control API (CCAPI) resource configurations. This means your existing resource Hooks can now evaluate configurations from CCAPI create and update operations, allowing you to standardize your proactive control evaluation regardless your IaC tool. If you’re already using pre-built Lambda or Guard hooks, you simply need to specify “Cloud_Control” as a target in your hooks’ configuration to extend their coverage. Learn the detail of this feature from this AWS DevOps Blog. Figure 13: CloudFormation Hooks for AWS Cloud Control API target invocation point
Additional Platform Improvements
StackSets ListStackSetAutoDeploymentTargets API
In March, we enhanced StackSets with the ListStackSetAutoDeploymentTargets API. This new capability gives you better visibility into your auto-deployment configurations by allowing you to list existing target Organizational Units (OUs) and AWS Regions for a given stack set. Instead of logging into individual accounts to understand your deployment scope, you can now get this information in a single API call.
CloudFormation Git sync with request review support
In September, we improved CloudFormation Git sync with pull request workflow support. When you create or update a pull request in a linked repository, CloudFormation automatically posts change set information as PR comments. This integration provides a clear overview of proposed changes within your familiar Git workflow, allowing team members to review infrastructure changes alongside code changes. Visit our user guide and launch blog to learn more.
Figure 14: CloudFormation Git sync with request review support feature
Early 2025 improvements
Reshape your AWS CloudFormation stacks seamlessly with stack refactoring
In February 2025, CloudFormation introduced a new capability called stack refactoring that makes it easy to reorganize cloud resources across your CloudFormation stacks. Stack refactoring enables you to move resources from one stack to another, split monolithic stacks into smaller components, and rename the logical name of resources within a stack. This enables you to adapt your stacks to meet architectural patterns, operational needs, or business requirements. To explore an example scenario, read Introducing AWS CloudFormation Stack Refactoring.
Learn more
Here are some resources to help you get started learning and using CloudFormation to manage your cloud infrastructure:
As we are starting 2025, our focus remains on making infrastructure deployment faster, safer, and more manageable. These enhancements reflect our commitment to solving real customer challenges and improving the CloudFormation experience. We are excited about the roadmap ahead and look forward to bringing you more innovations in 2025.
We encourage you to try these new features and share your feedback. For more detailed information about any of these launches, visit our documentation or check out the AWS DevOps Blog.
We are well settled into 2025 by now, but many people are still catching up with all the exciting new releases and announcements that came out of re:Invent last year. There have been hundreds of re:Invent recap events around the world since the beginning of the year, including in-person all-day official AWS events with multiple tracks to help you discover and dive deeper into the releases you care about, as well as community and virtual events.
Last month, I was lucky to be a co-host for AWS EMEA re:Invent re:Cap which was a nearly 4-hour livestream with experts featuring demos, whiteboard sessions, and a live Q&A. The good news is that you can now watch it on-demand! We had a great team and thousands of people enjoyed learning through the virtual experience. I recommend you check it out or share it with colleagues who have not been able to attend any re:Invent re:Cap events.
The Korean team also did an amazing job hosting their own virtual re:Invent re:Cap event, and it’s also now available on-demand. So if you speak Korean I do recommend you check it out.
If you’re more of a reader, then we have a treat for you. You can download the full official re:Invent re:Cap deck with all the slides covering releases across all areas by visiting community.aws! While there, you can also check all the upcoming in-person re:Invent re:Cap community events remaining across the globe for a chance to still attend one of those in a city near you.
But as we know, new releases, announcements, and updates don’t stop at re:Invent. Every week there are even more, and this is why we have this Weekly Roundup series that you can read every Monday to get the AWS news highlights from the week before.
So here’s what caught my attention last week.
Last week’s AWS Launches If you use AWS Step Functions you may be interested in these:
New data source and output options for Distributed Maps – Distributed Maps area a great fit for large-scale parallel document processing. Now, in addition to the already existing support for JSON and CSV files, it can process JSONL, as well as semicolon or tab-delimited files. You can also use new output transformations such as FLATTEN to combine result sets without any additional code.
Here are some other releases that caught my attention this week from a variety of other AWS services:
AWS CloudFormation introduces stack refactoring – You can now split your CloudFormation stacks, move resources from one stack to another, and change the logical name of resources within the same stack. This adds a lot of flexibility enabling you to keep up with changes within your organization and architectures, such as streamlining resource lifecycle management for existing stacks, keeping up with naming convention changes, and other cases. You can refactor your stacks by using the AWS command line interface (CLI) or AWS SDK.
AWS Config now supports 4 new release types – AWS Config is great for monitoring resources across your AWS environment and help you towards ensuring alignment with your company and security policies as well as compliance requirements. It now has four new types of resources enabling you to monitor Amazon VPC block public access settings, any exceptions made within those settings, as well as monitor S3 Express One Zone bucket policies and directory bucket settings.
Automated recovery of Microsoft SQL Server on EC2 instan ces with VSS – You can now use a new feature called Volume Shadow Copy Services (VSS) to backup Microsoft SQL Server databases to Amazon Elastic Block Store (EBS) snapshots while the database is running. You can then use AWS Systems Manager Automation Runbook to set a recovery point of time of your preference and it will restore the database automatically from your VSS-based EBS snapshot without incurring any downtime.
Other updates Upcoming changes to the AWS Security Token Service (AWS STS) global endpoint – To help improve the resiliency and performance of your applications, we are making changes to the AWS STS global endpoint (https://sts.amazonaws.com), with no action required from customers. Starting in early 2025, requests to the STS global endpoint will be automatically served in the same Region as your AWS deployed workloads. For example, if your application calls sts.amazonaws.com from the US West (Oregon) Region, your calls will be served locally in the US West (Oregon) Region instead of being served by the US East (N. Virginia) Region. These changes will be released in the coming weeks and we will gradually roll it out to AWS Regions that are enabled by default by mid-2025.
Upcoming AWS and community events
AWS Public Sector Day London, February 27 — Join public sector leaders and innovators to explore how AWS is enabling digital transformation in government, education, and healthcare.
AWS Innovate GenAI + Data Edition — A free online conference focusing on generative AI and data innovations. Available in multiple Regions: APJC and EMEA (March 6), North America (March 13), Greater China Region (March 14), and Latin America (April 8).
Looking for some reading recommendations? At the beginning of every year Dr. Werner Vogles, VP and CTO of Amazon, publishes a list of recommended books that he believes should have your attention. This year’s list is looking particularly good in my opinion!
That’s it for this week! For a full list of AWS announcements, be sure to keep an eye on the What’s New with AWS page.
As your cloud infrastructure grows and evolves, you may find the need to reorganize your AWS CloudFormation stacks for better management, for improved modularity, or to align with changing business requirements. CloudFormation now offers a powerful feature that allows you to move resources between stacks. In this post, we’ll explore the process of stack refactoring and how it can help you maintain a well-organized and efficient cloud infrastructure.
Understanding Stack Refactoring
Stack refactoring is the process of restructuring your CloudFormation stacks by moving resources from one stack to another or renaming a resource with a new logical ID within the same stack. This capability is particularly useful when you want to:
Split a large, monolithic stack into smaller, more manageable stacks
Reorganize resources to better align with your application architecture or organizational structure
Rename the logical IDs of resources to make templates more readable
Example Scenario
To demonstrate this capability, you are going to create a stack and then move some of its resources into a new stack. You will evaluate the new CLI commands that you need to leverage to make this possible. For this example, you are going to have an SNS topic with a lambda function subscribed to your SNS topic. As your usage of the SNS topic expands, you want to break apart the subscriptions into a different stack.
Create a new template called before.yaml with your starting template:
Create a new template called afterSns.yaml with the content below. This template has your SNS topic in it and has a new export in it that will export the SNS topic ARN. This export will be used by your other templates to get the required SNS topic ARN.
Create a new template called afterLambda.yaml with the content below. This template includes all the resources to create a Lambda subscription to your SNS topic. This template switched the !Ref Topic to use the exported valued by using !ImportValue TopicArn.
Create a resource mappings file called refactor.json to rename the logical ID of a resource. This file defines the source and destination stack names and logical IDs for resources being refactored. If the logical IDs don’t change, this file doesn’t need to be specified.
Create a stack refactor task. You are using enable-stack-creation to tell the refactoring capability to create the destination stack for us. If the destination stack already exists you don’t have to provide this option.
Stack refactoring in AWS CloudFormation represents a significant advancement in infrastructure management, offering a safer and more efficient way to reorganize your cloud resources without disruption. This feature eliminates the traditional need to remove the resource, with a retain policy, and then import the resource when restructuring stacks, helping you reduce misconfiguration risk and save time. Through the example demonstrated in this post, you’ve seen how to split a monolithic stack into smaller, focused stacks while using exports and imports to maintain dependencies between stacks. You’ve also explored the new CloudFormation CLI commands that make stack refactoring possible while maintaining resource stability during reorganization.
As your infrastructure evolves, stack refactoring provides the flexibility needed to adapt your CloudFormation stack organization to changing requirements while maintaining the integrity of your cloud resources. This capability is particularly valuable for teams looking to improve their infrastructure maintainability and align their resource organization with evolving architectural patterns. Remember to thoroughly test your refactoring plans in a non-production environment first, and always ensure your new stack structure maintains the necessary security and access controls.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.
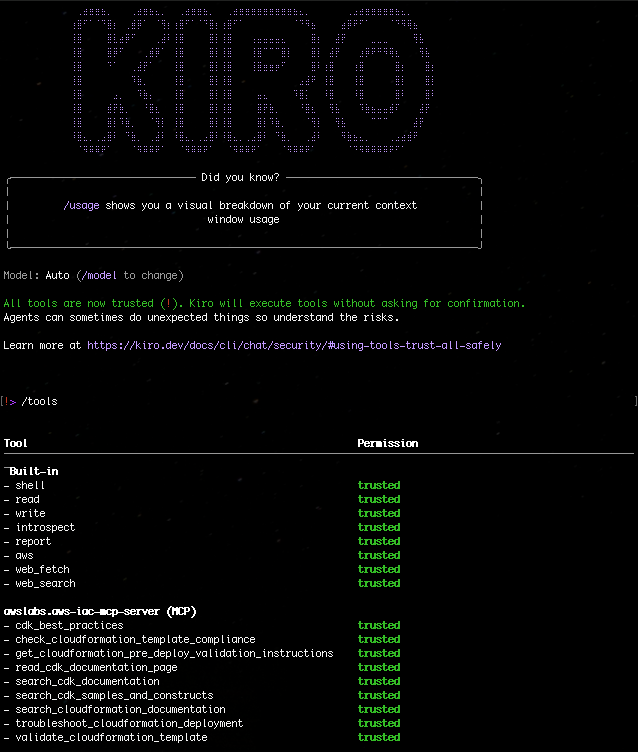
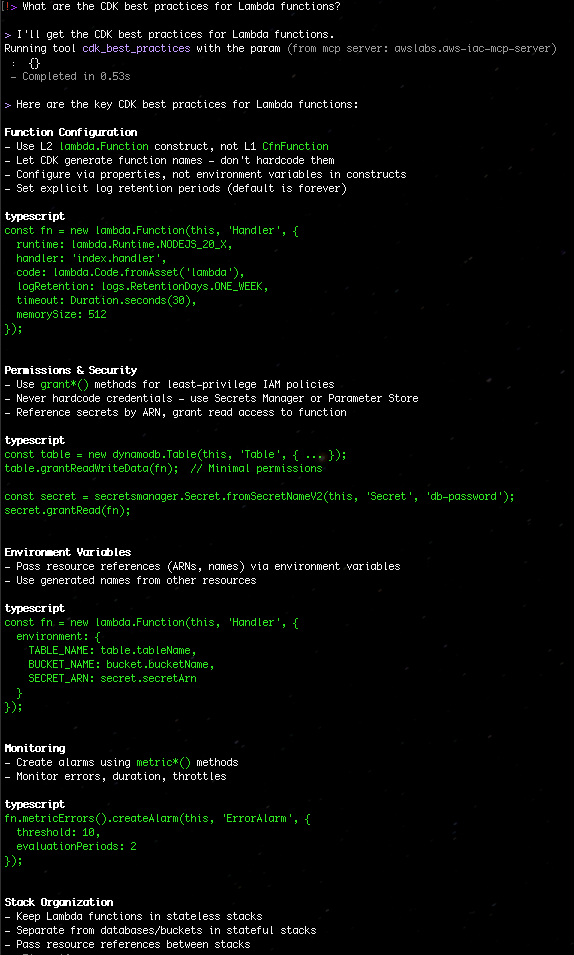
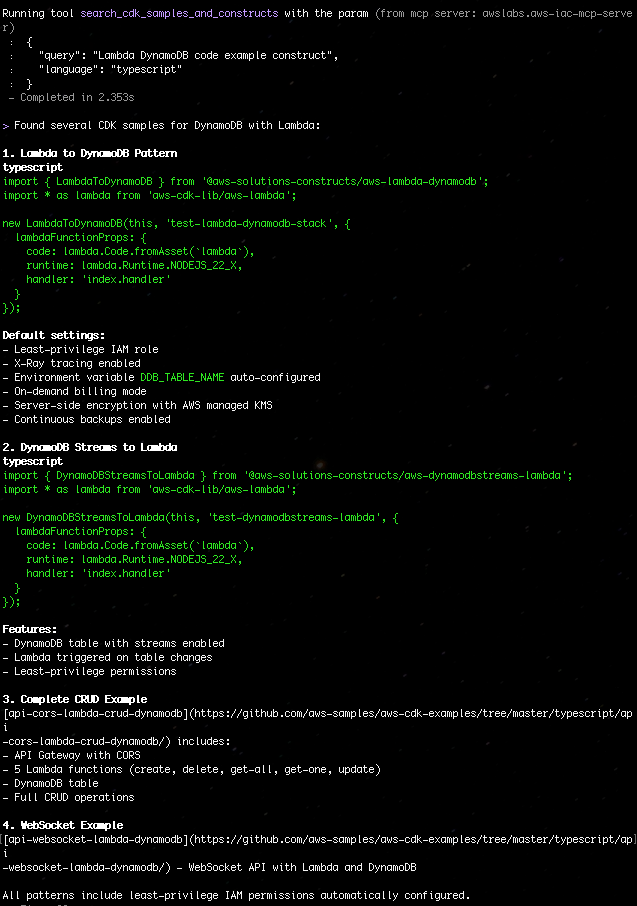
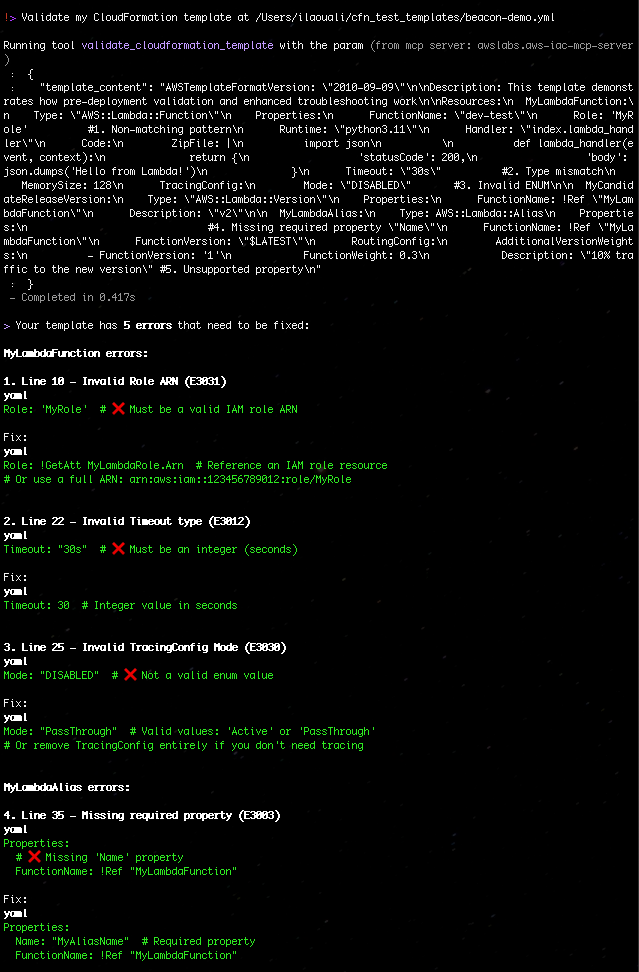
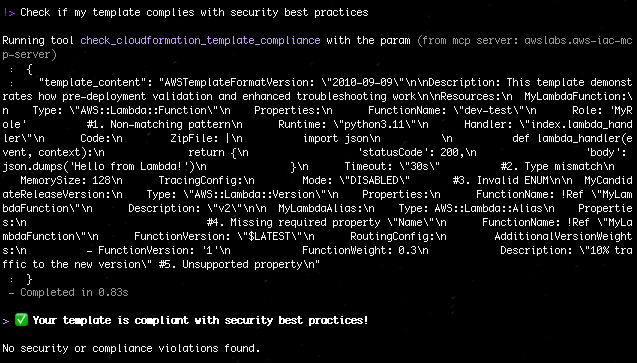
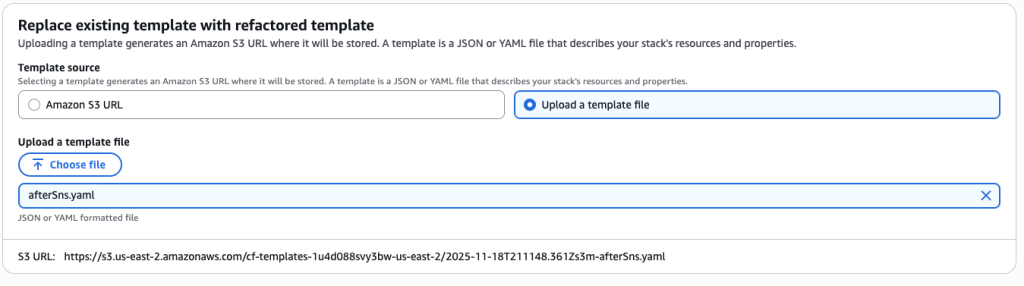
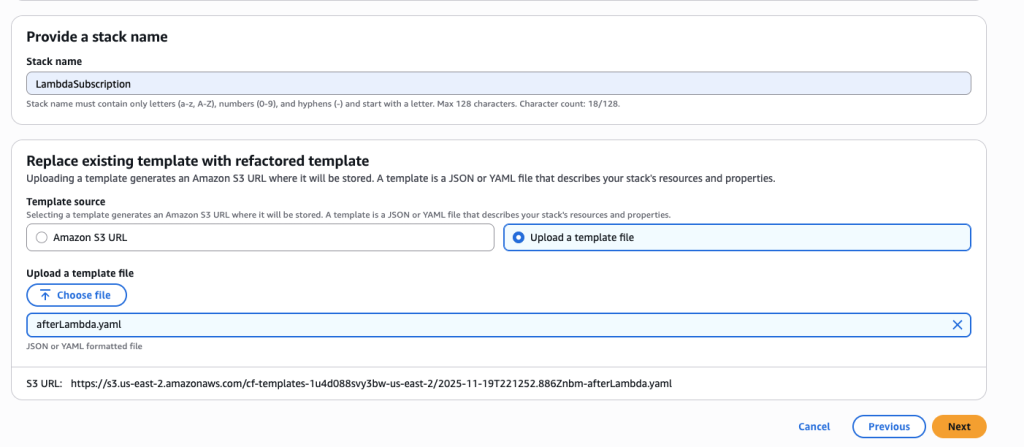 In some scenarios, CloudFormation console can automatically detect logical resource ID renames and pre-fill the mapping for you. The resource mapping is required when there are logical resource ID changes between the original stack and refactored template. Ensure that the mappings are correct before proceeding to the next step.
In some scenarios, CloudFormation console can automatically detect logical resource ID renames and pre-fill the mapping for you. The resource mapping is required when there are logical resource ID changes between the original stack and refactored template. Ensure that the mappings are correct before proceeding to the next step.
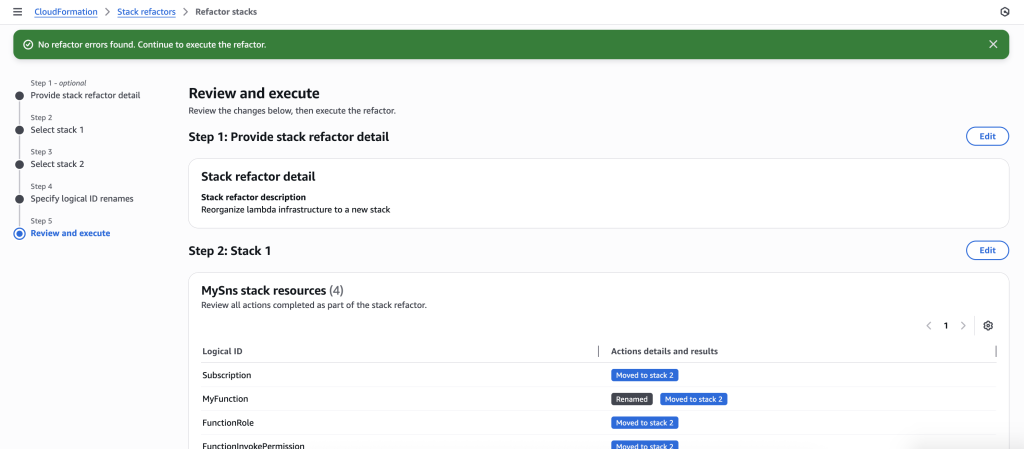
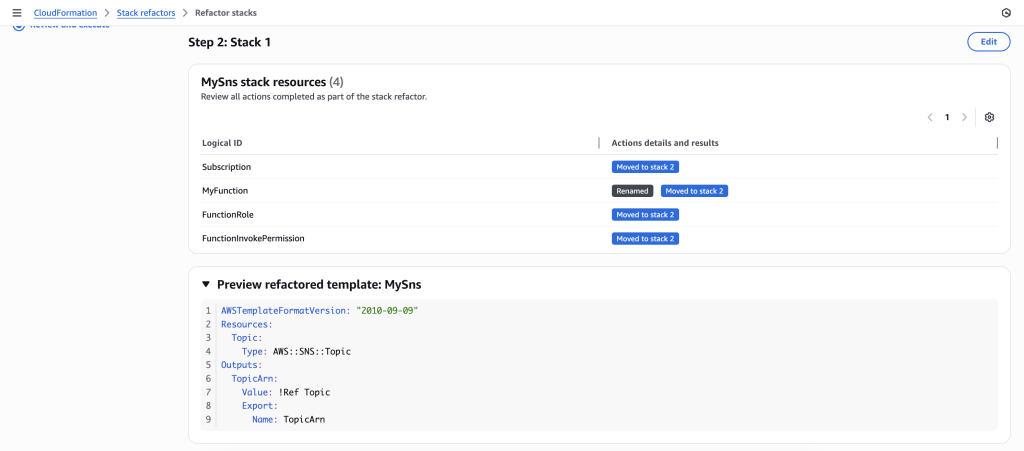

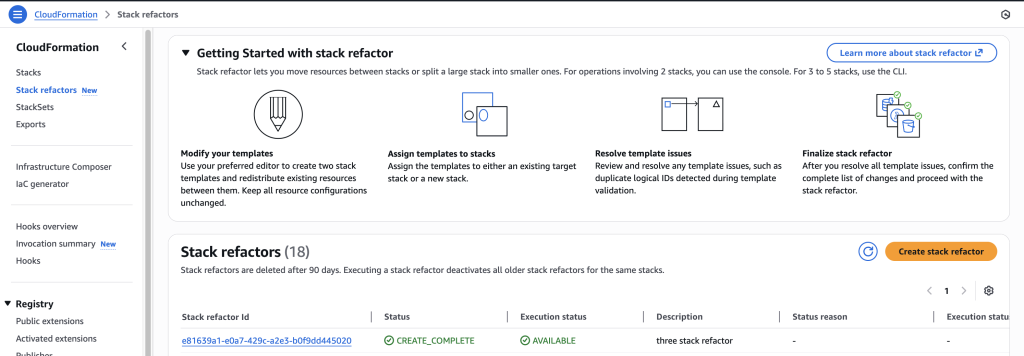
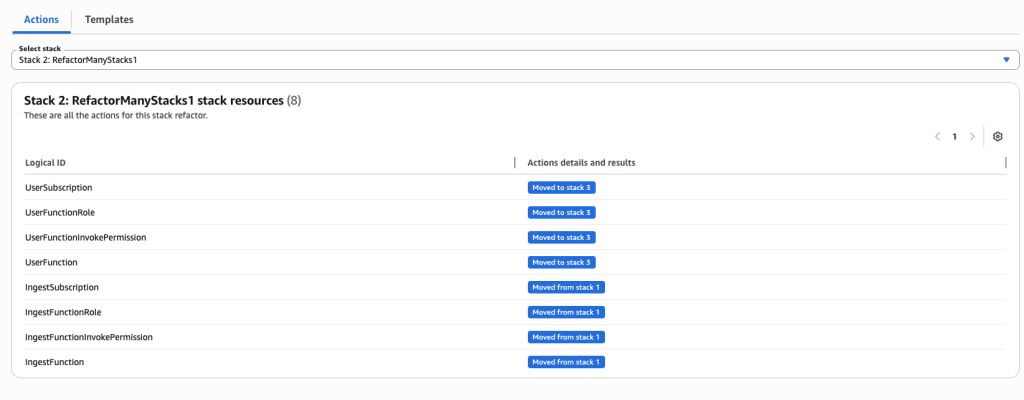
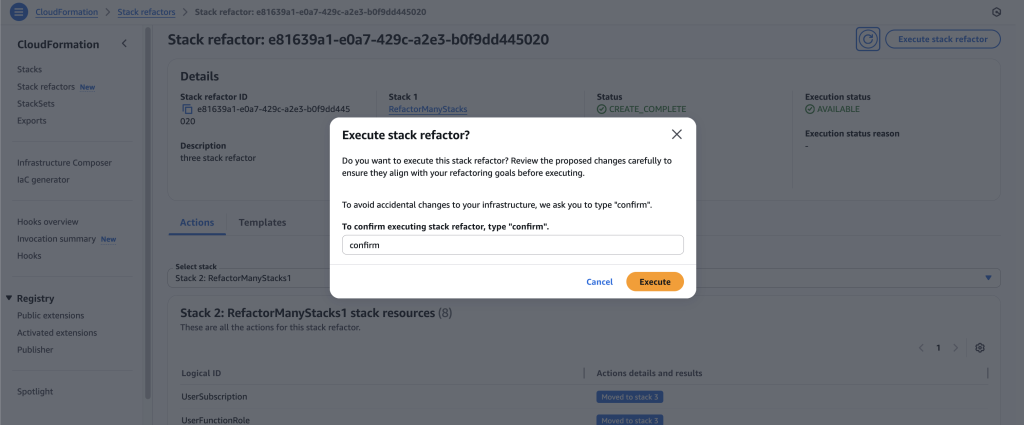
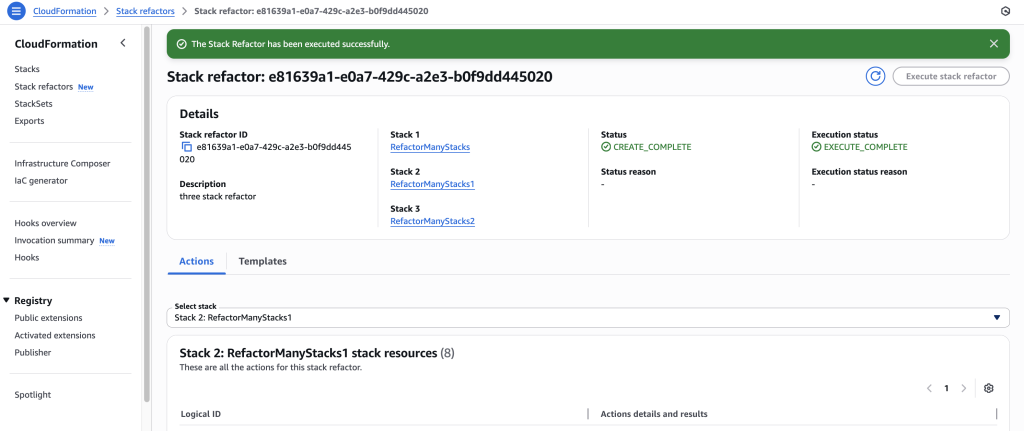
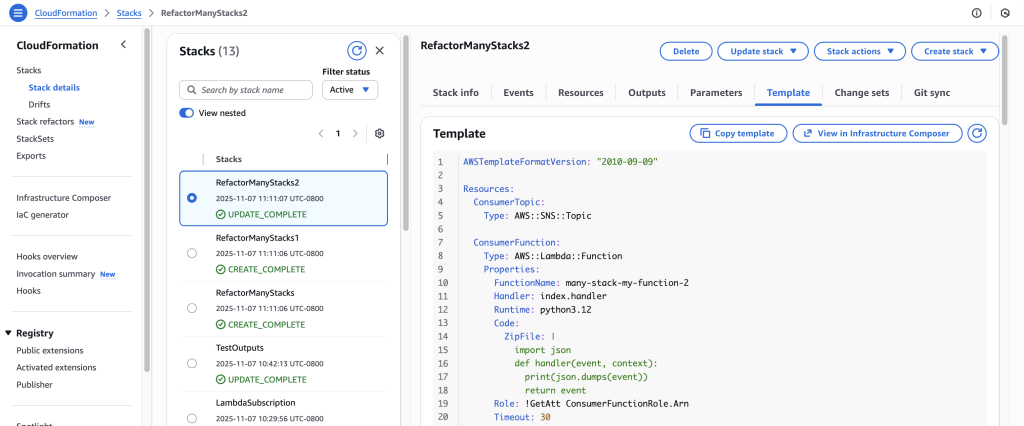

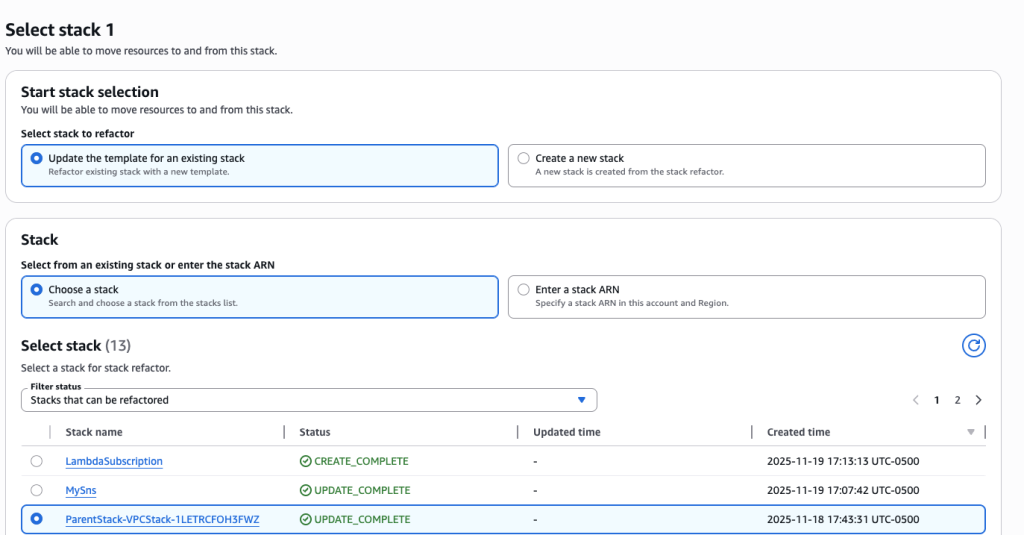
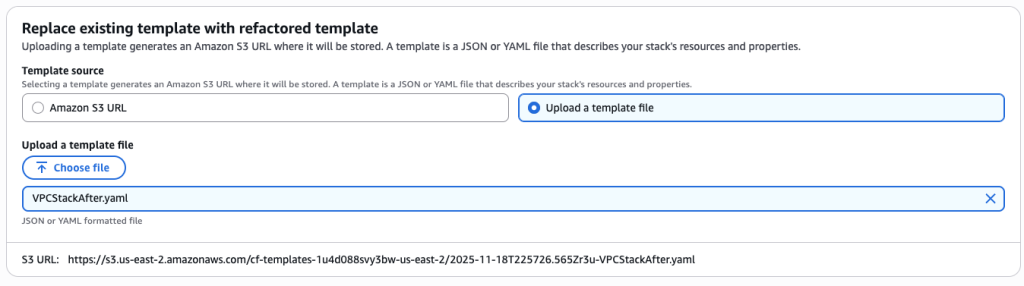
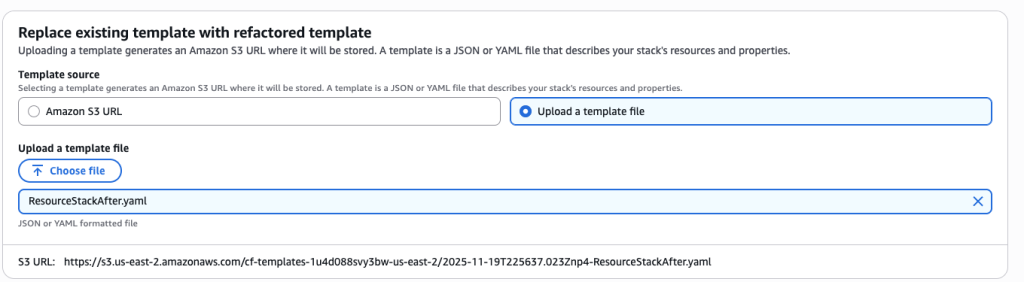
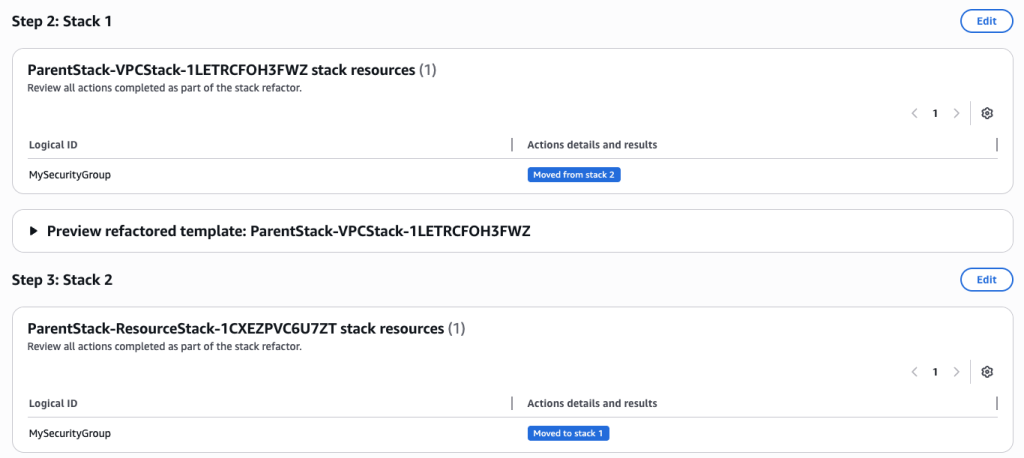
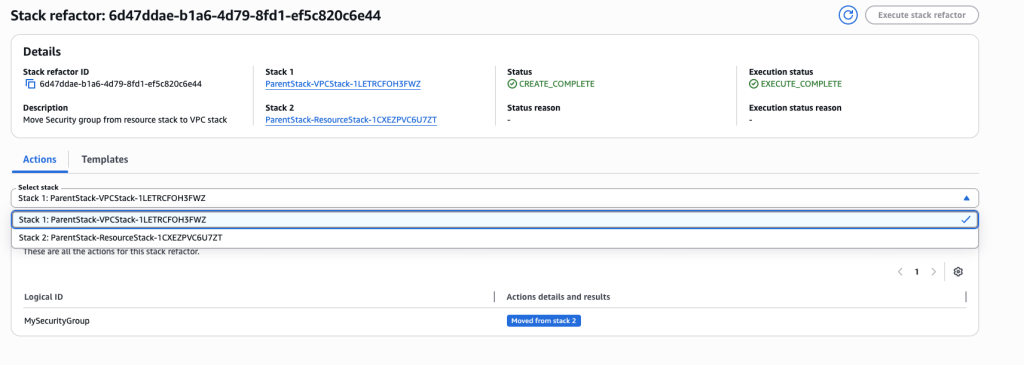
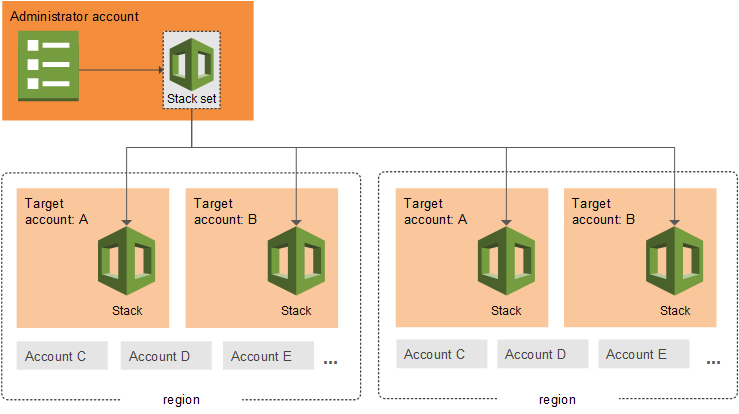
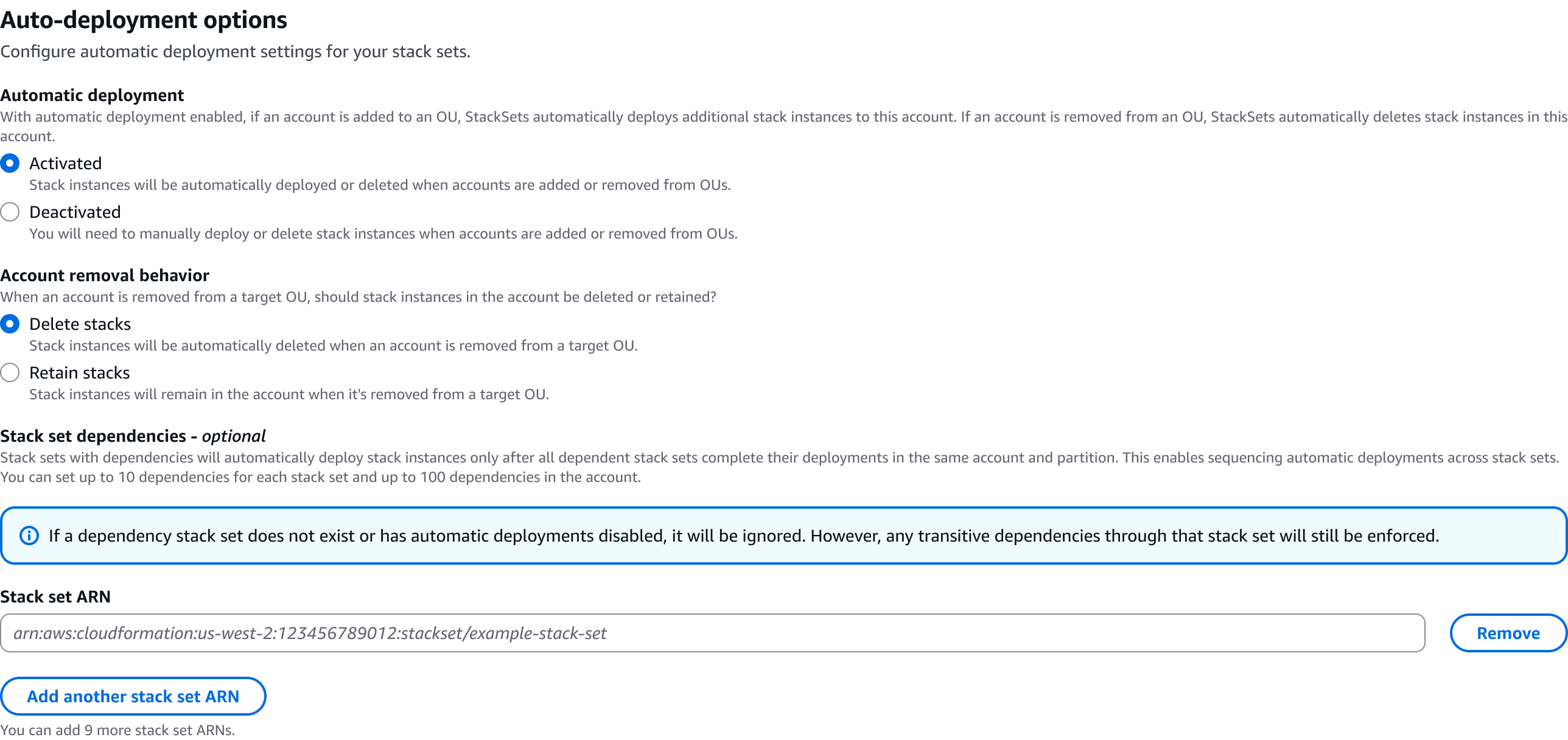



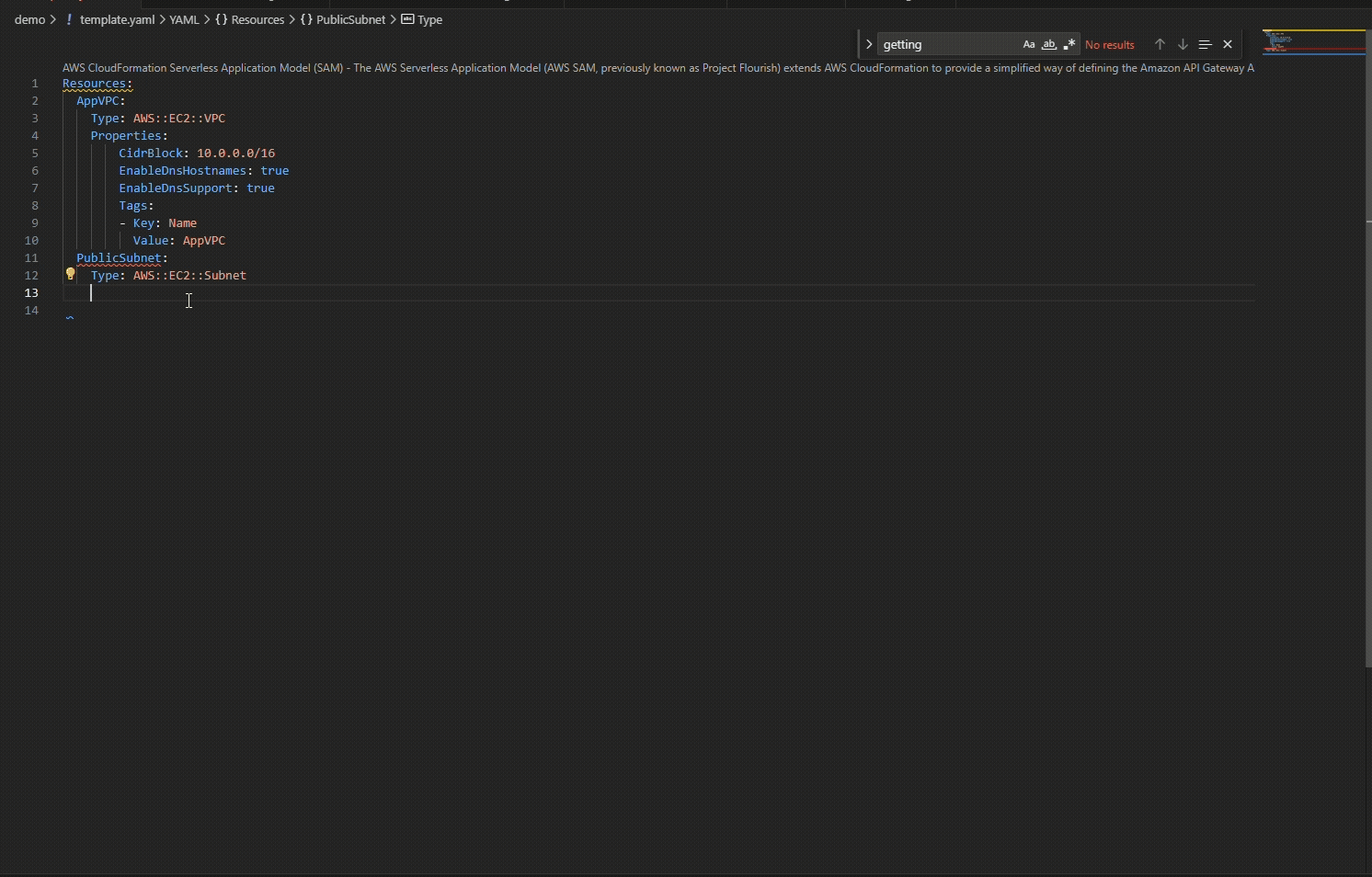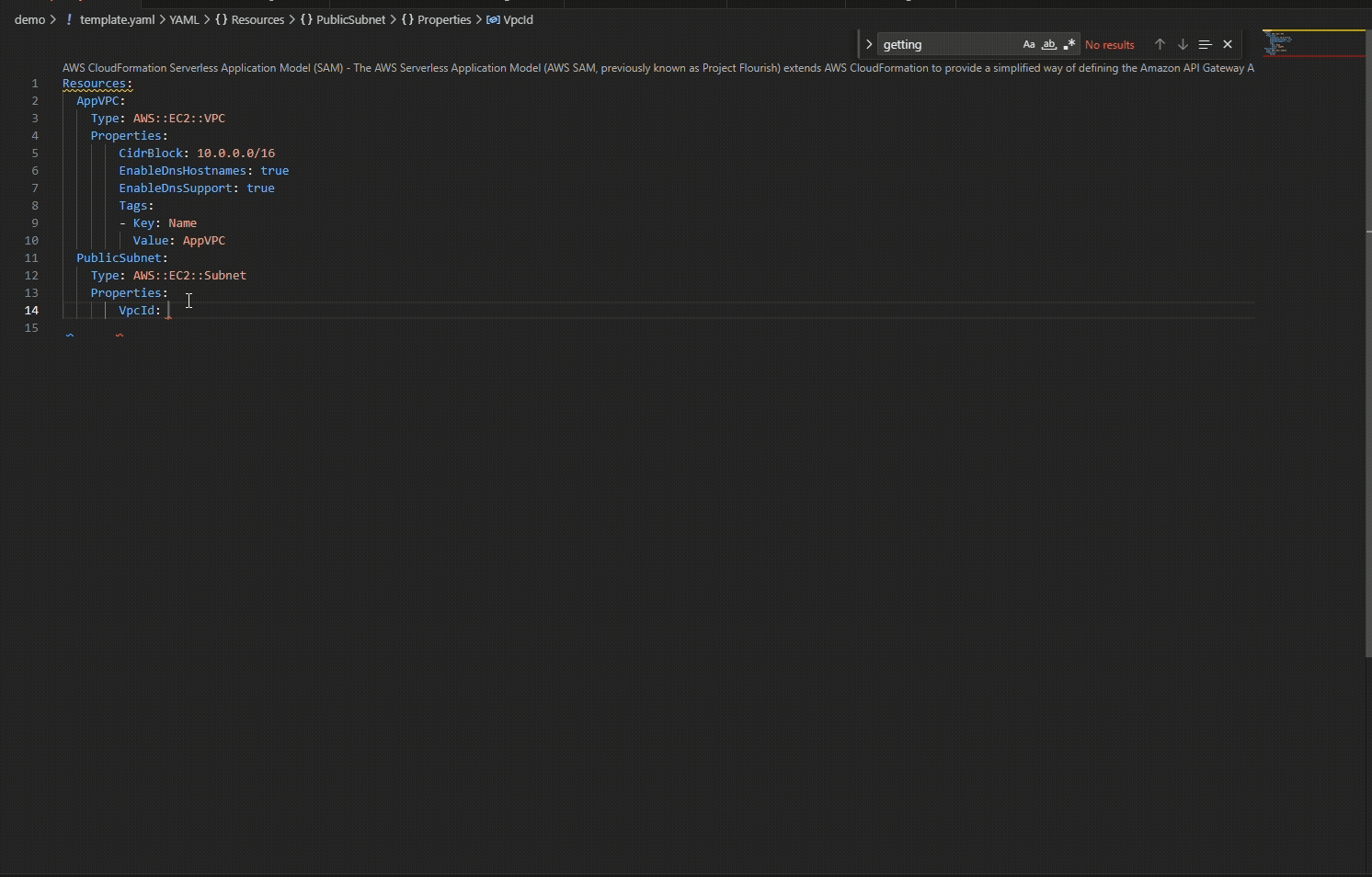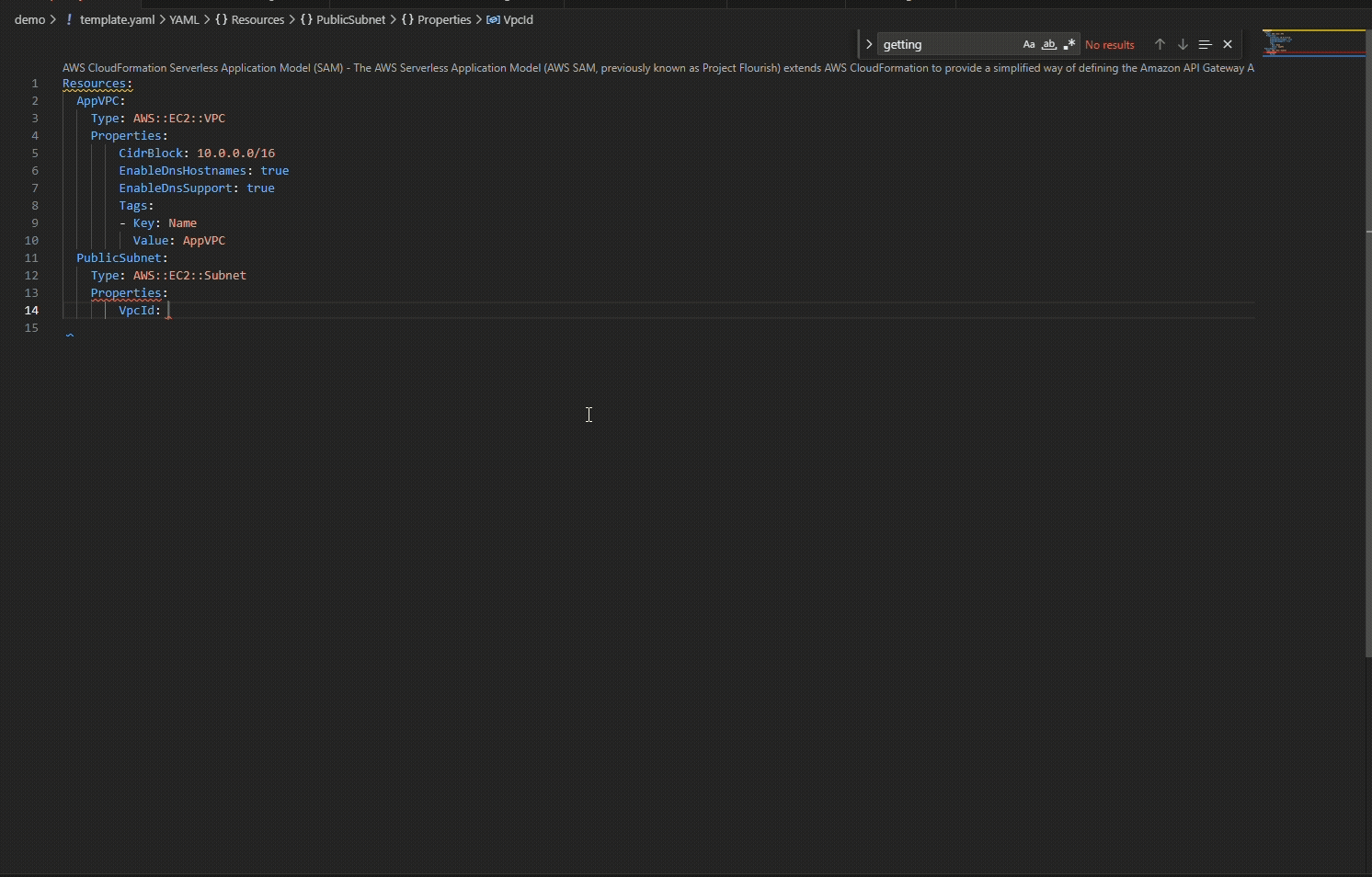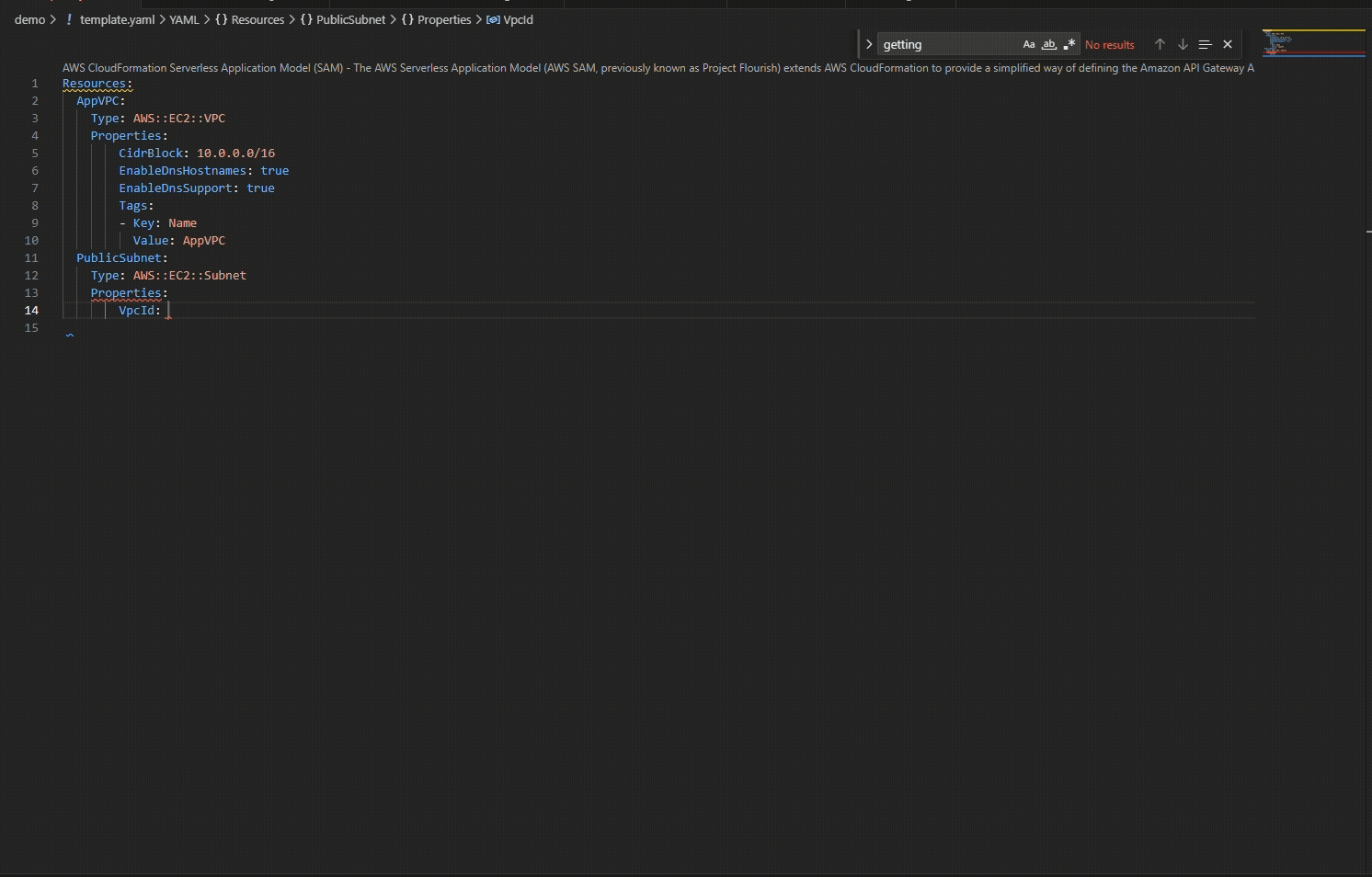
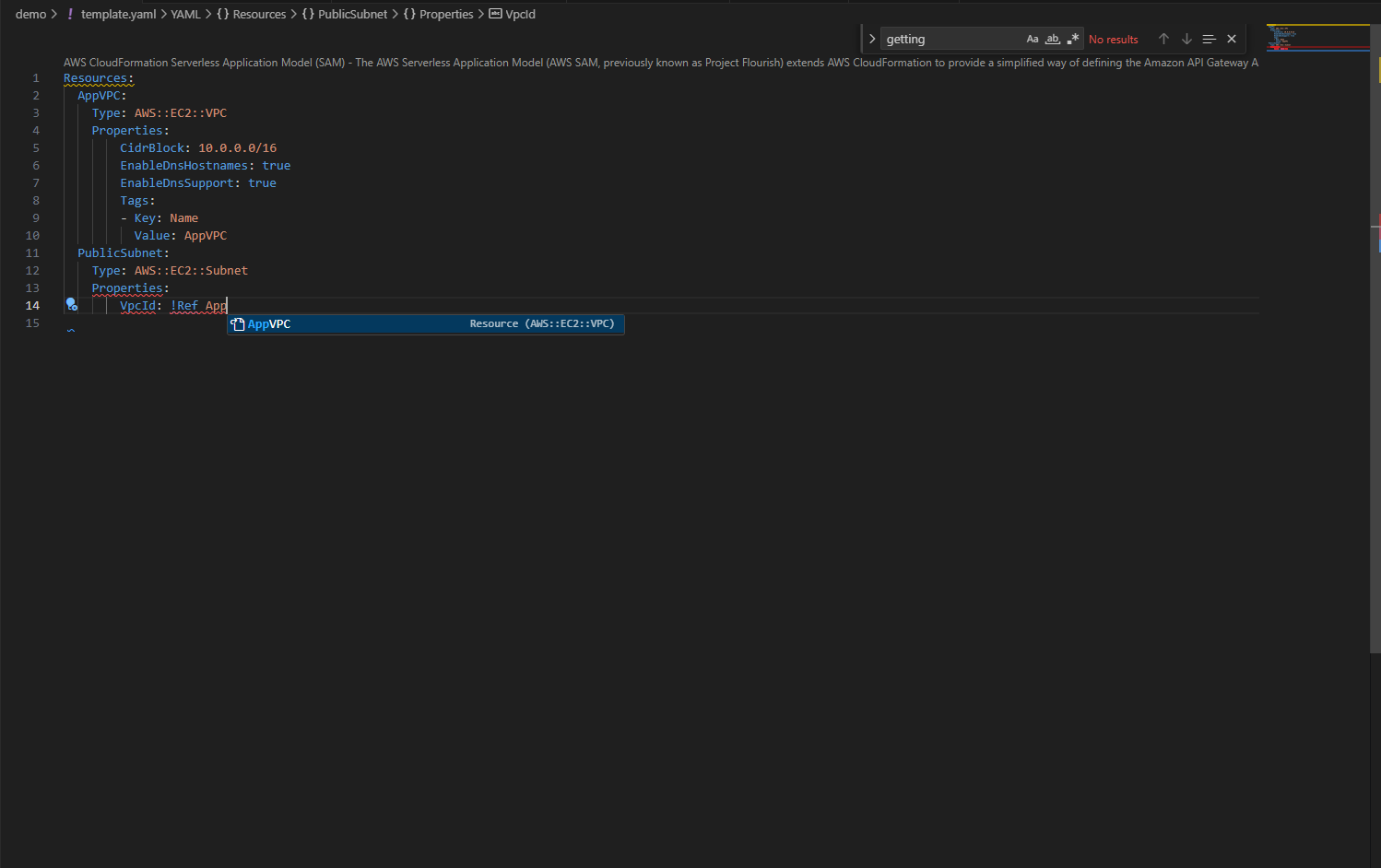
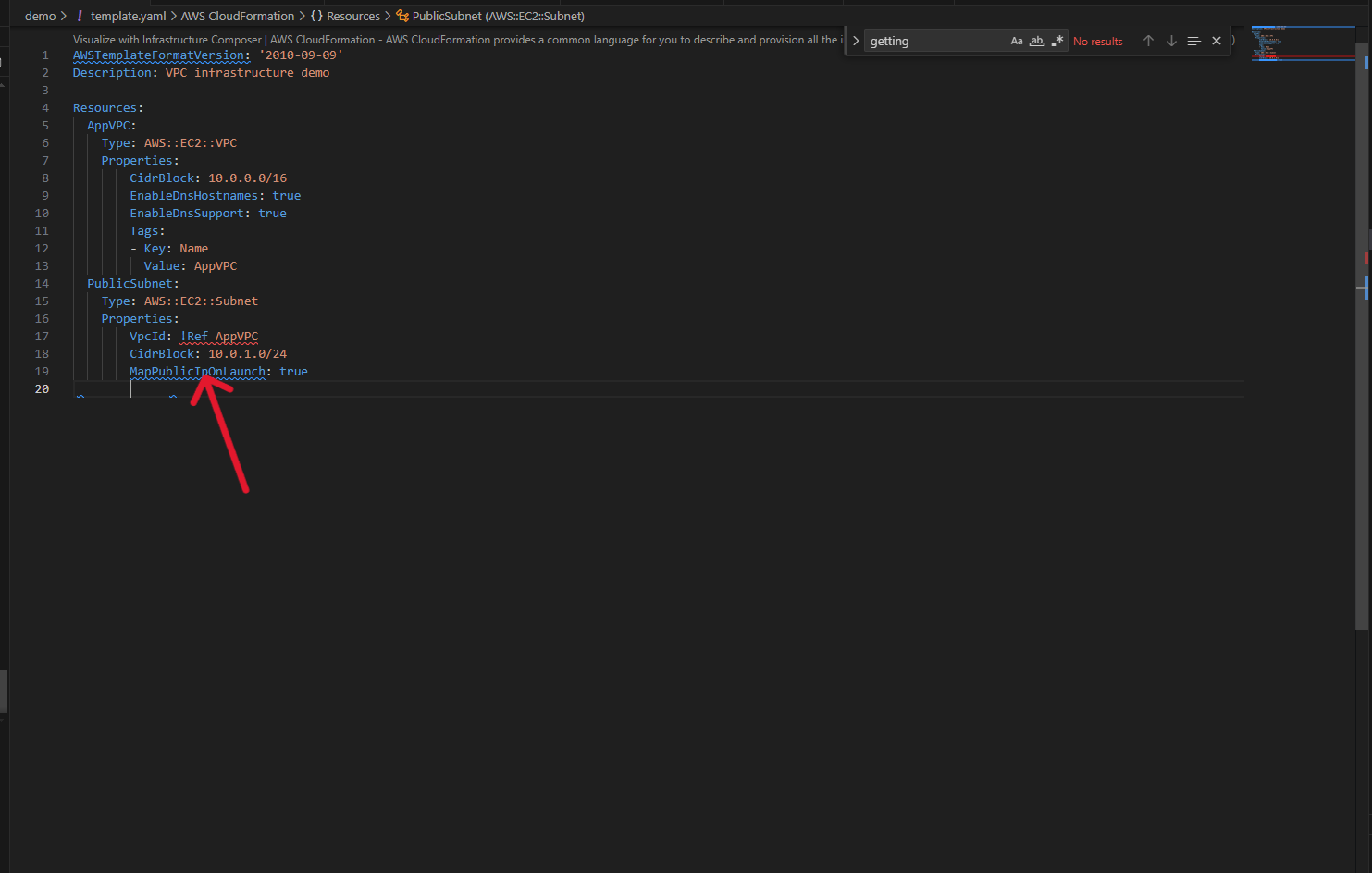
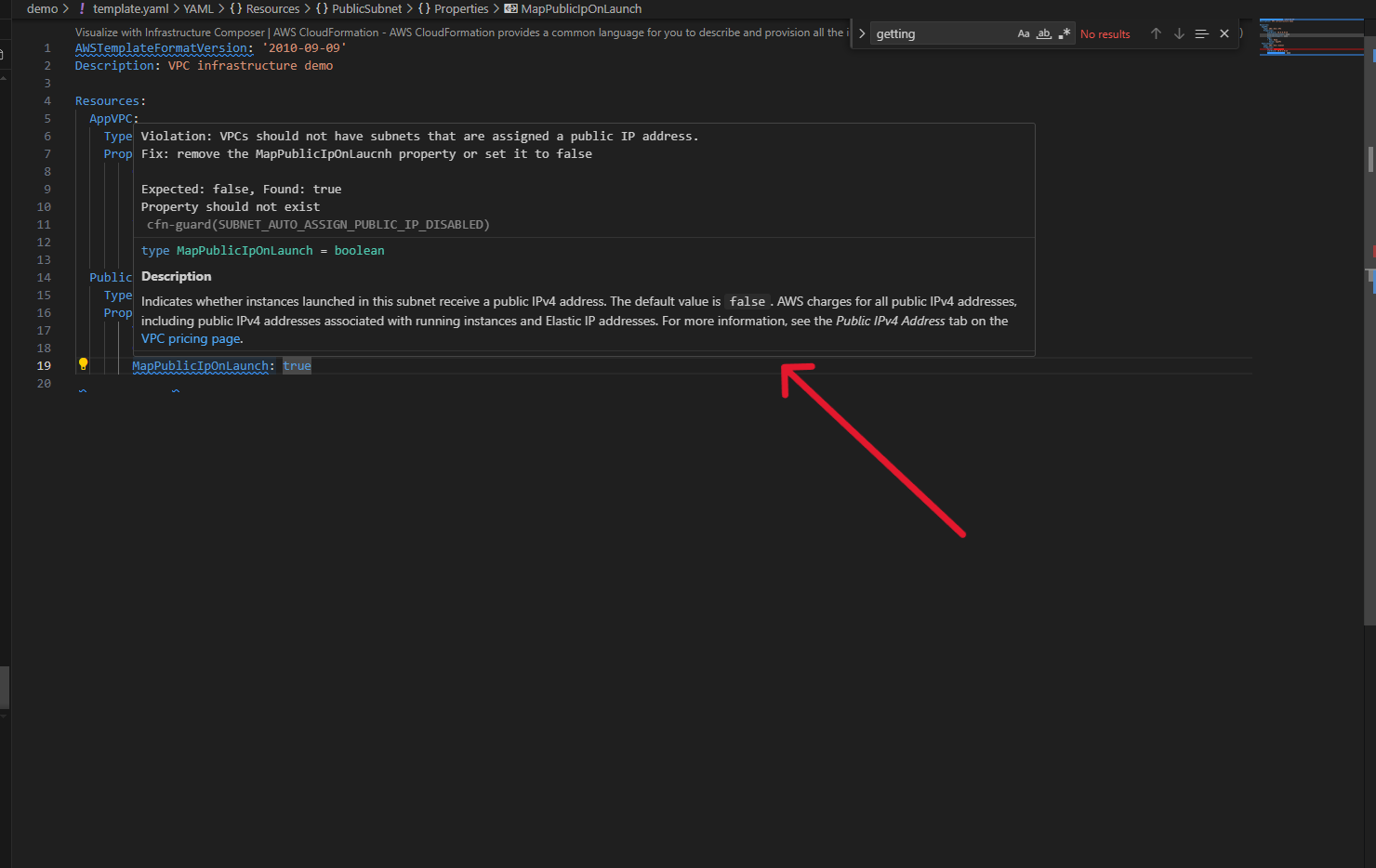

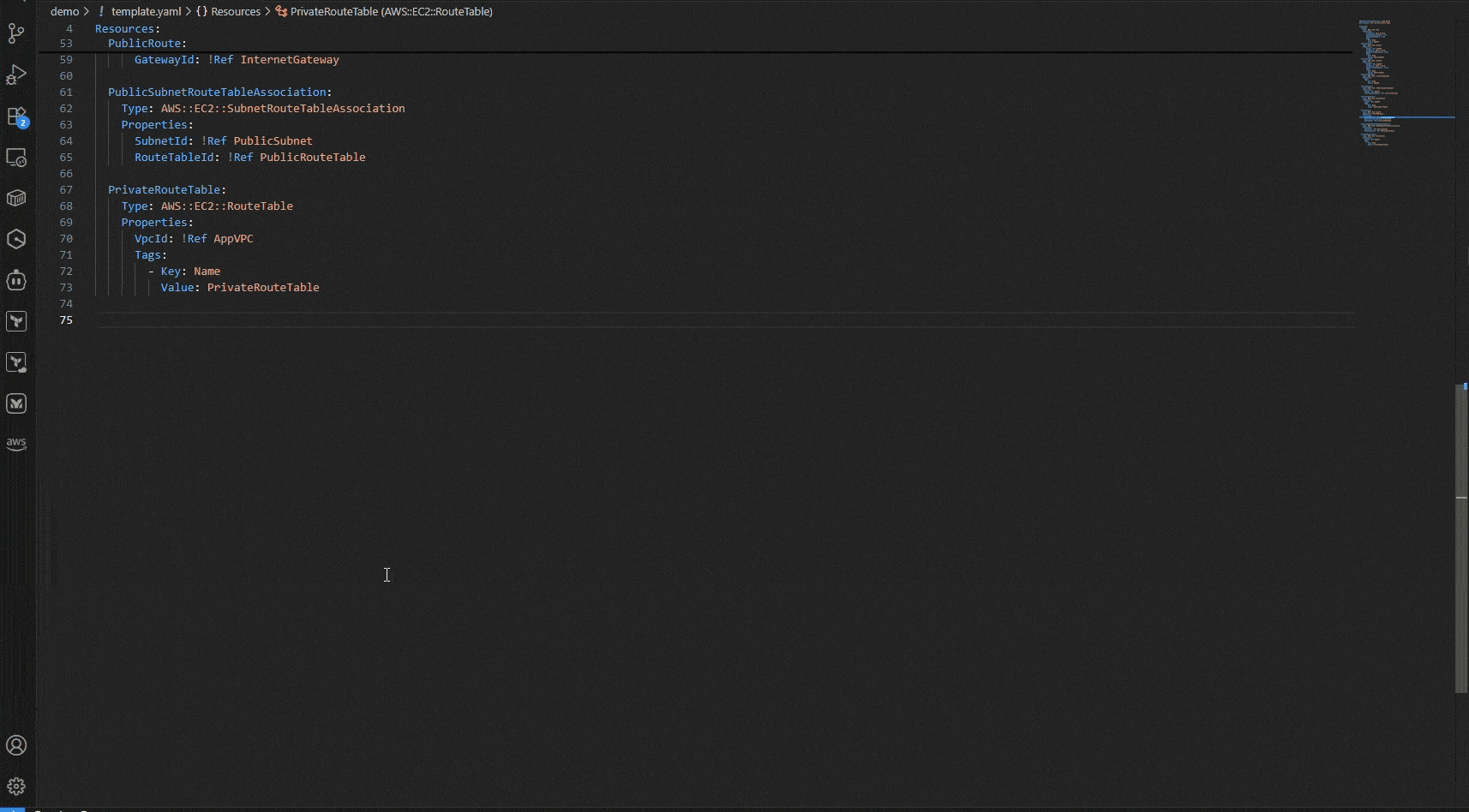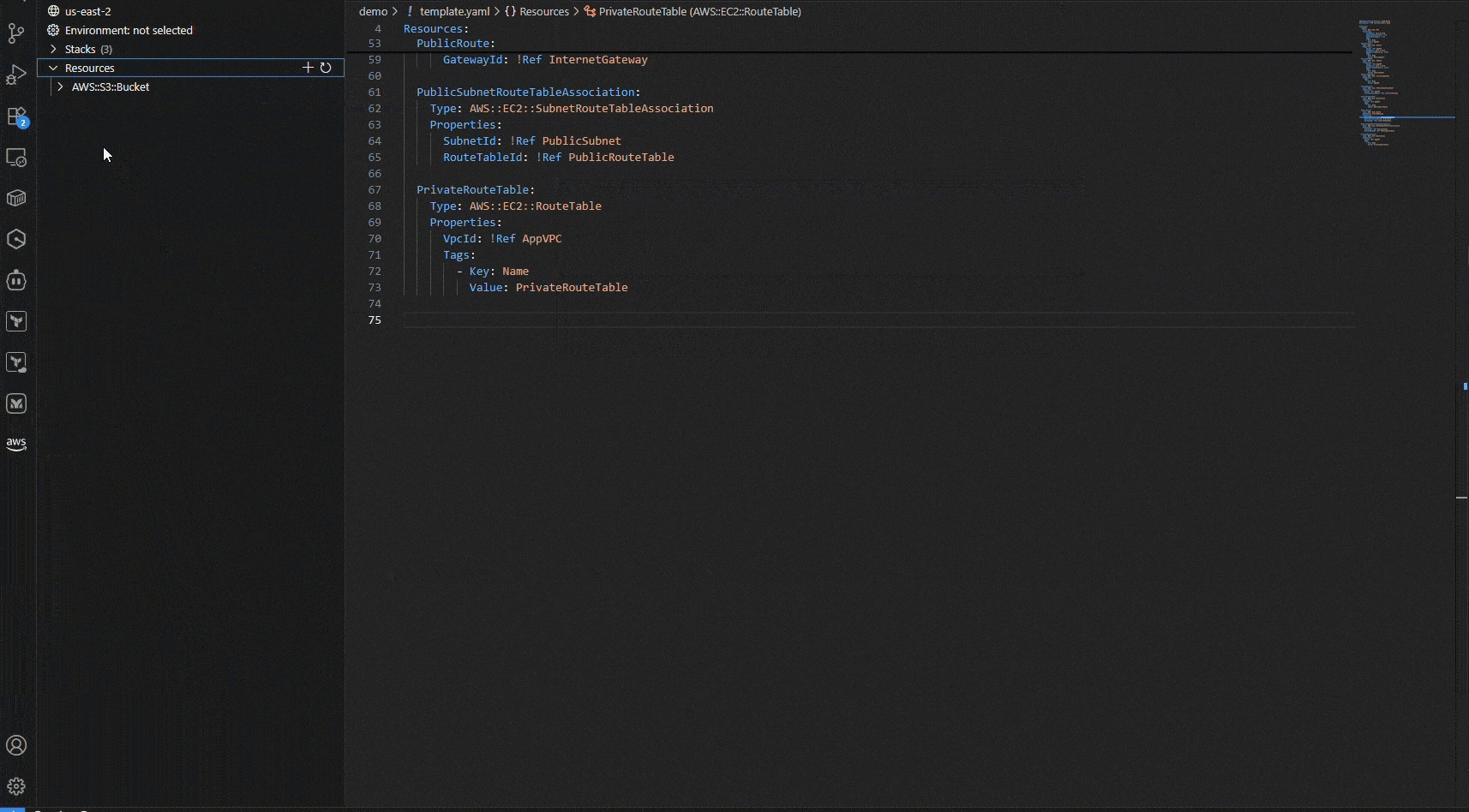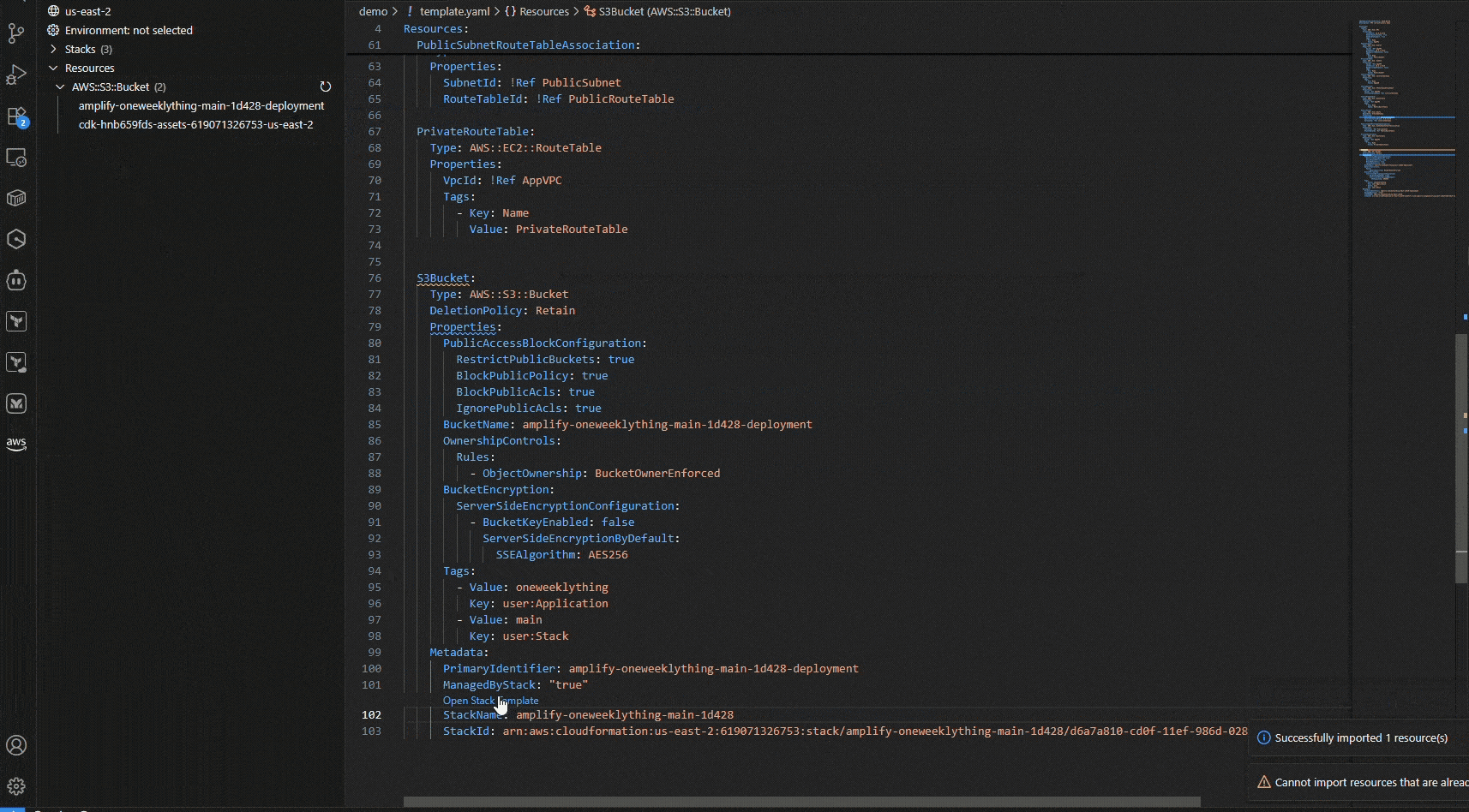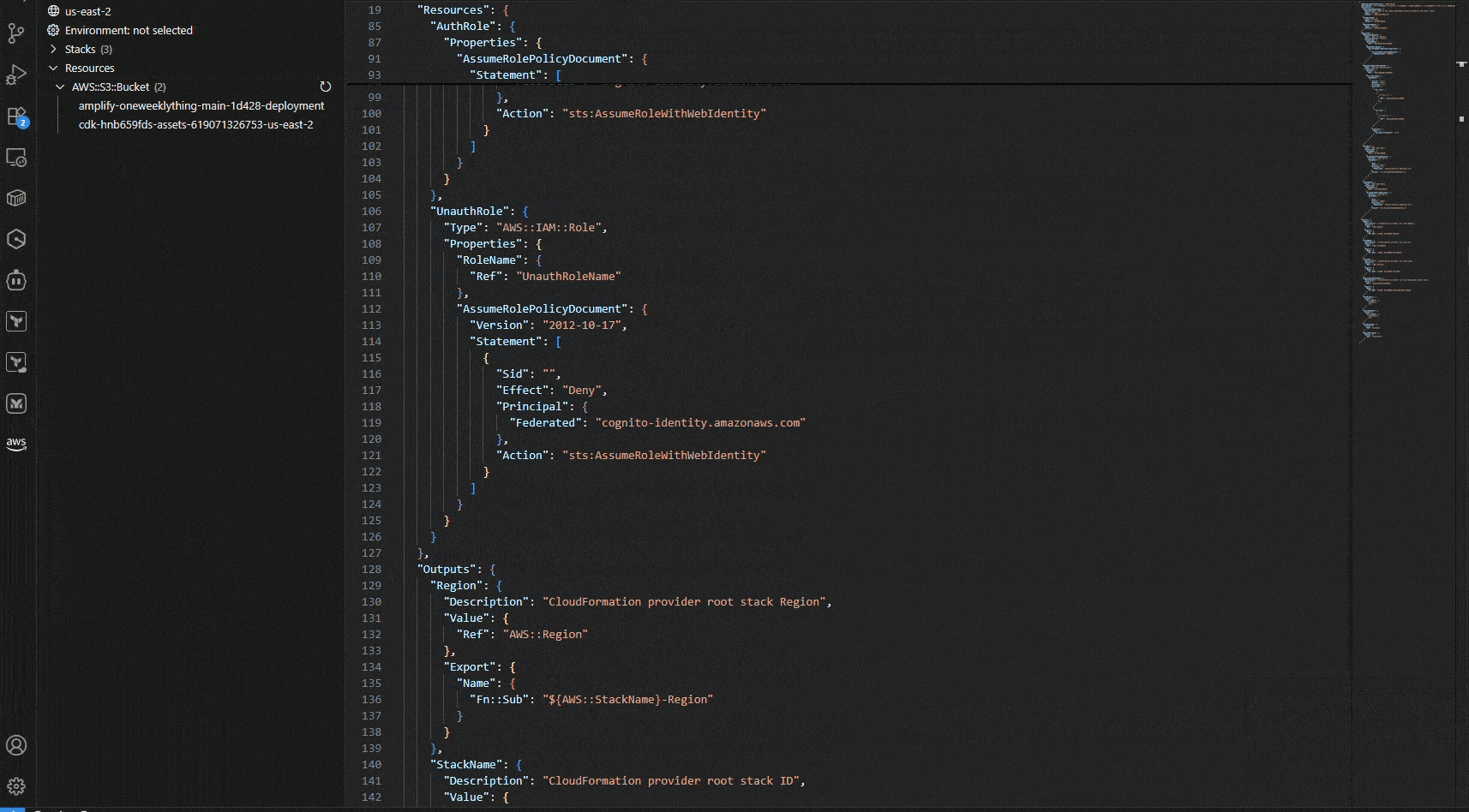



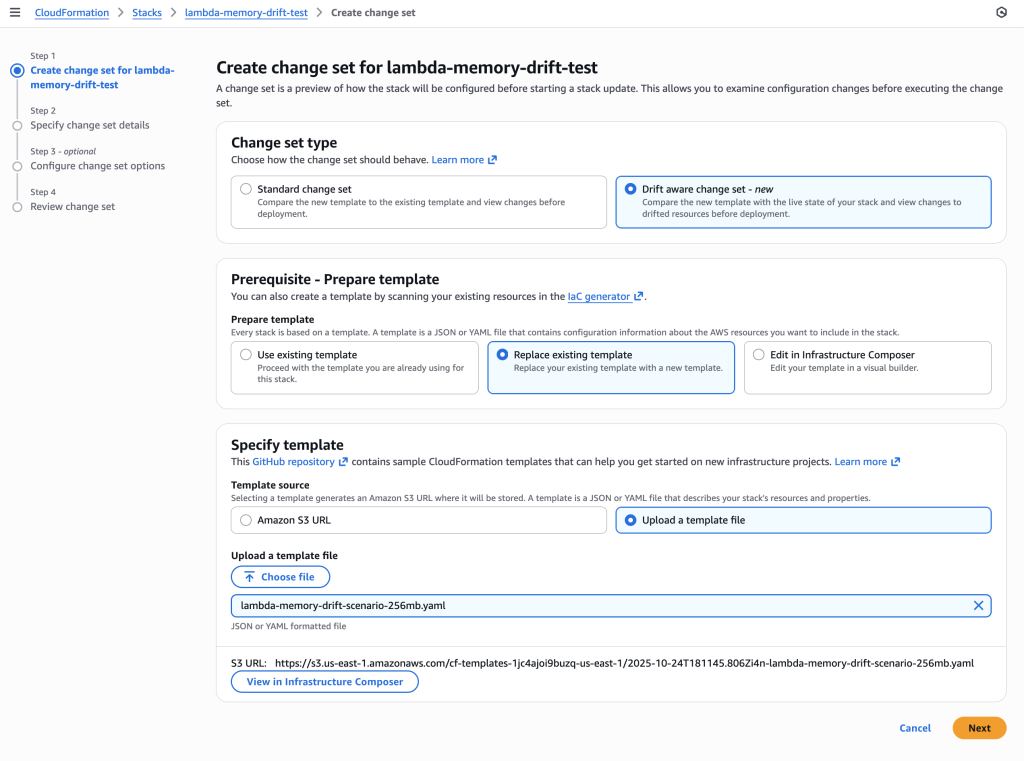
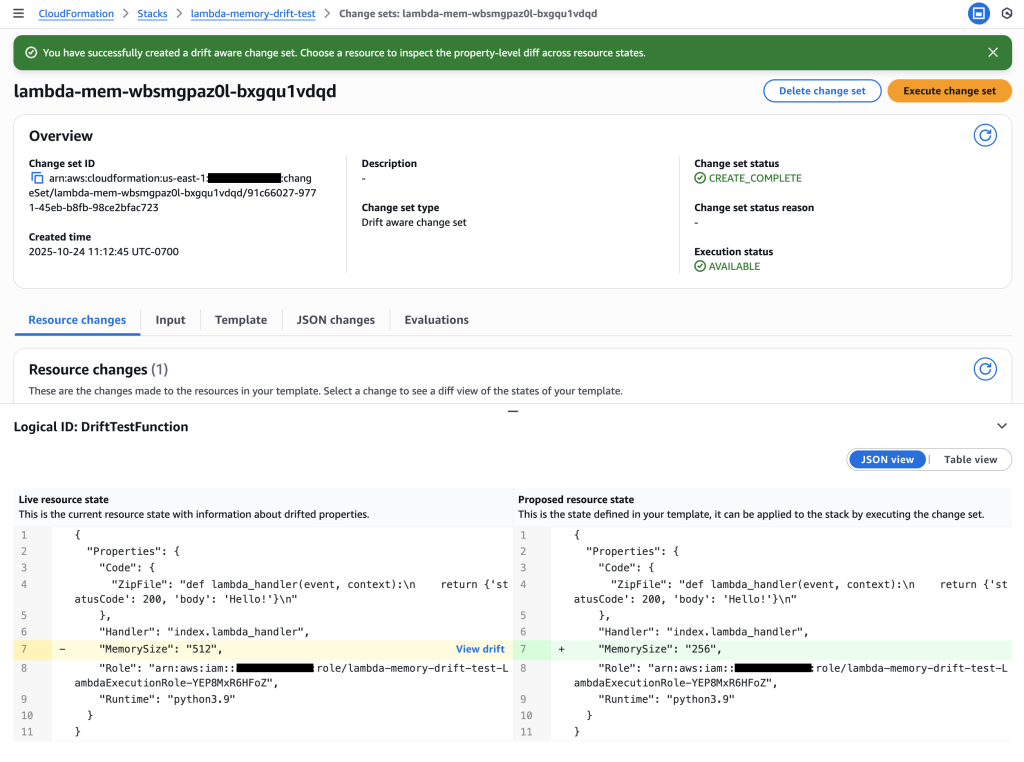
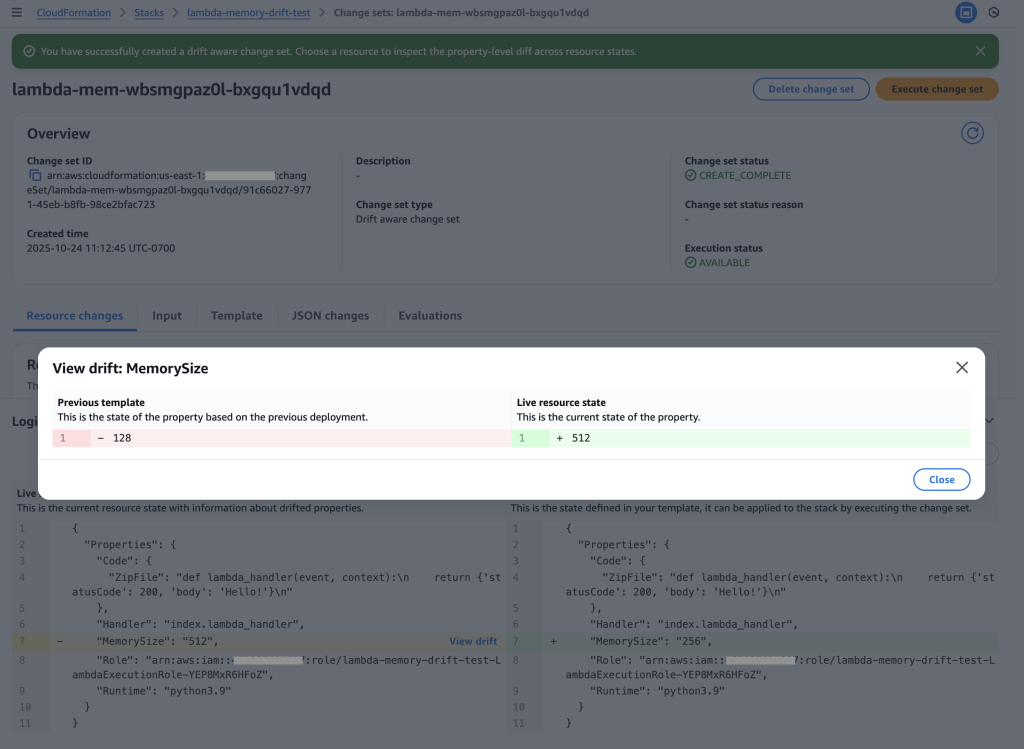
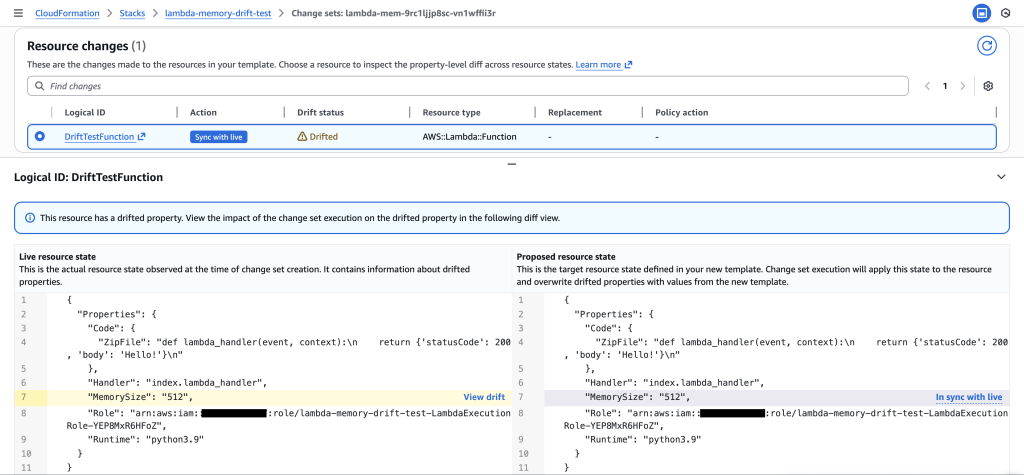
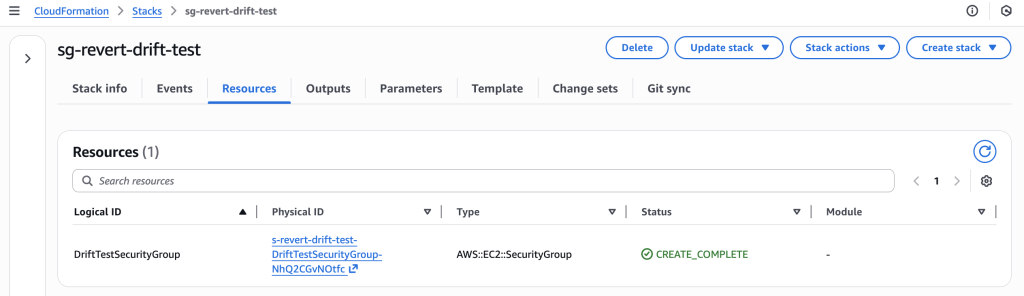
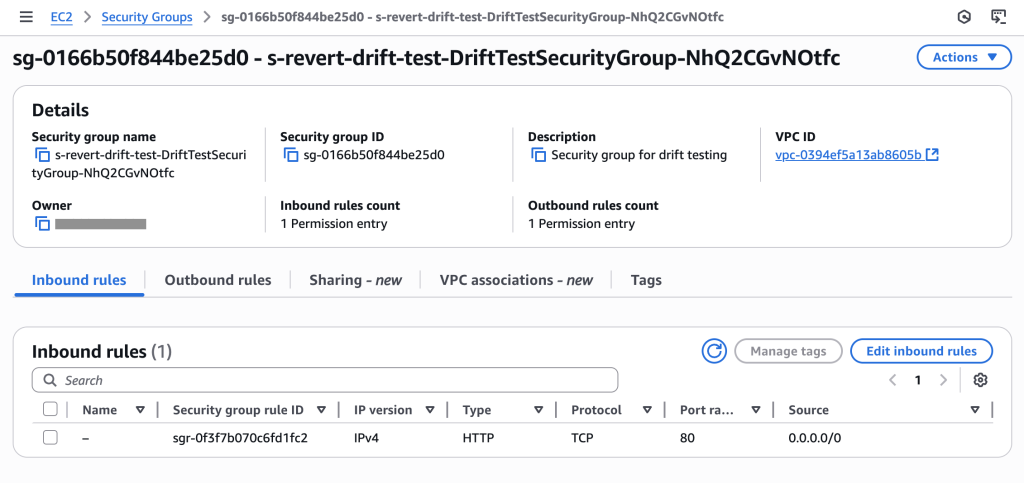
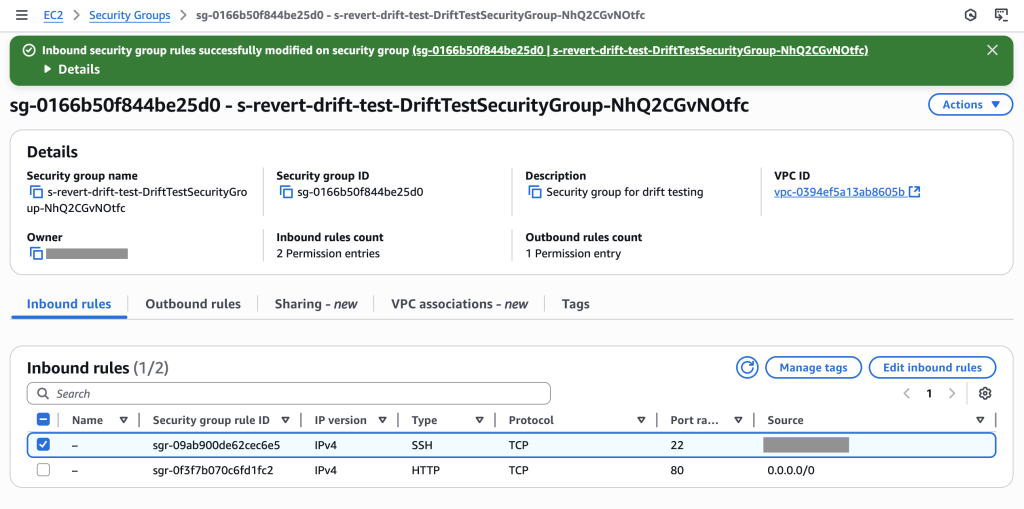
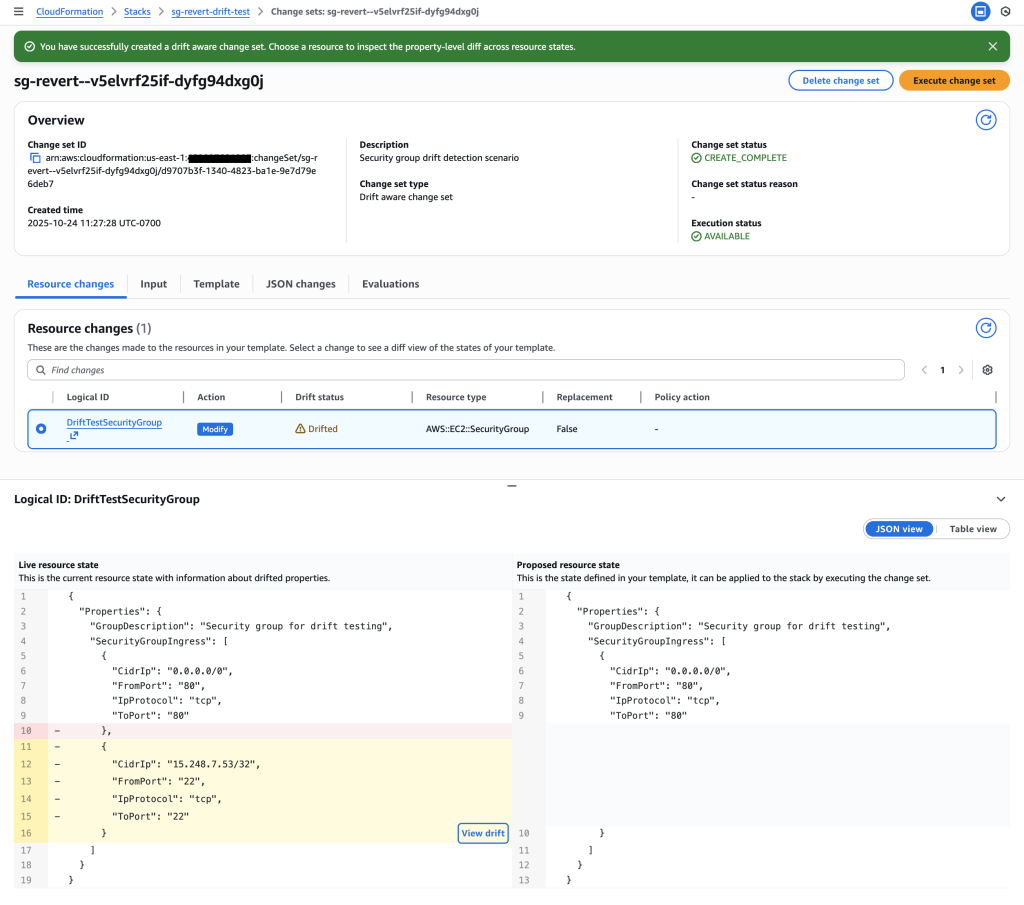
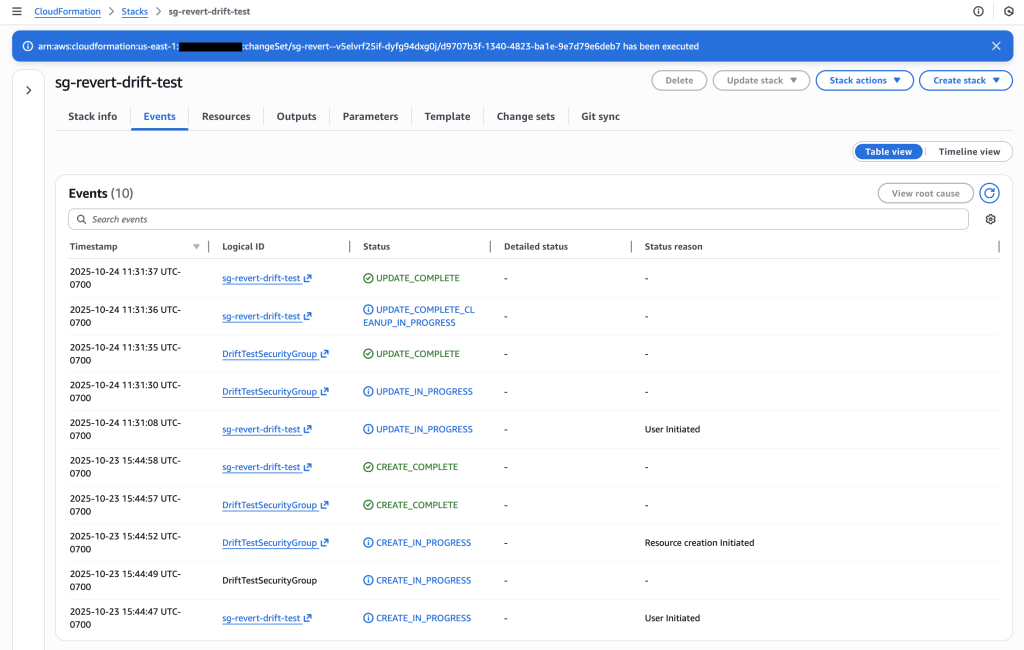
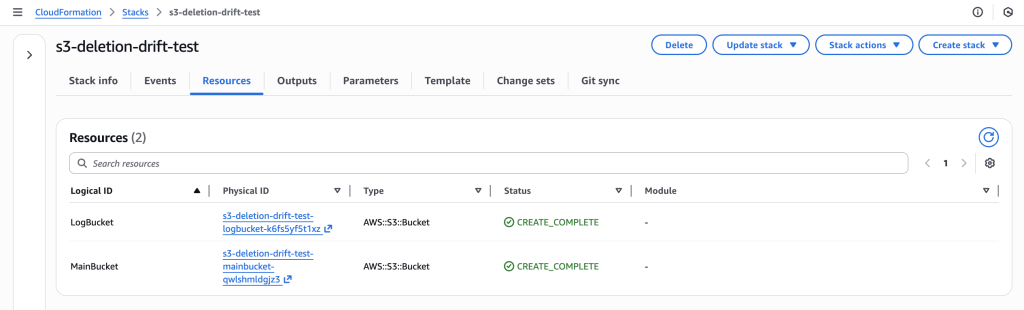
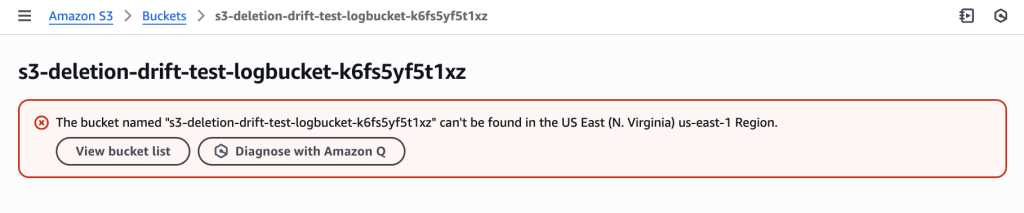
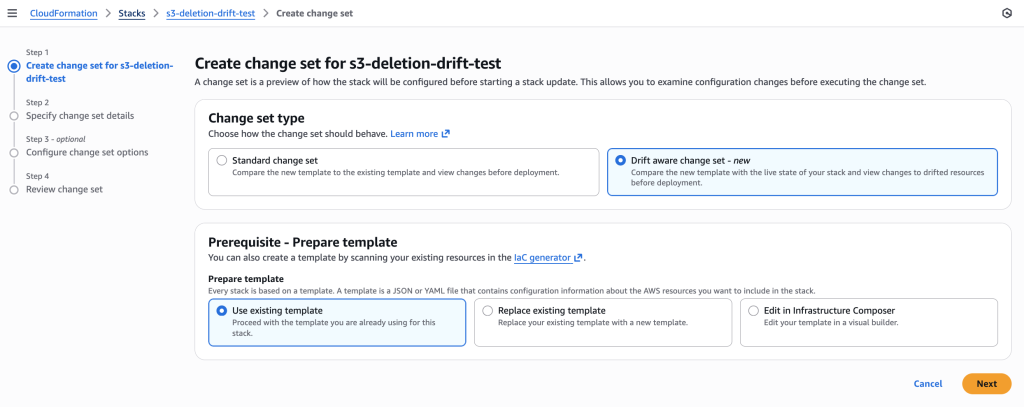
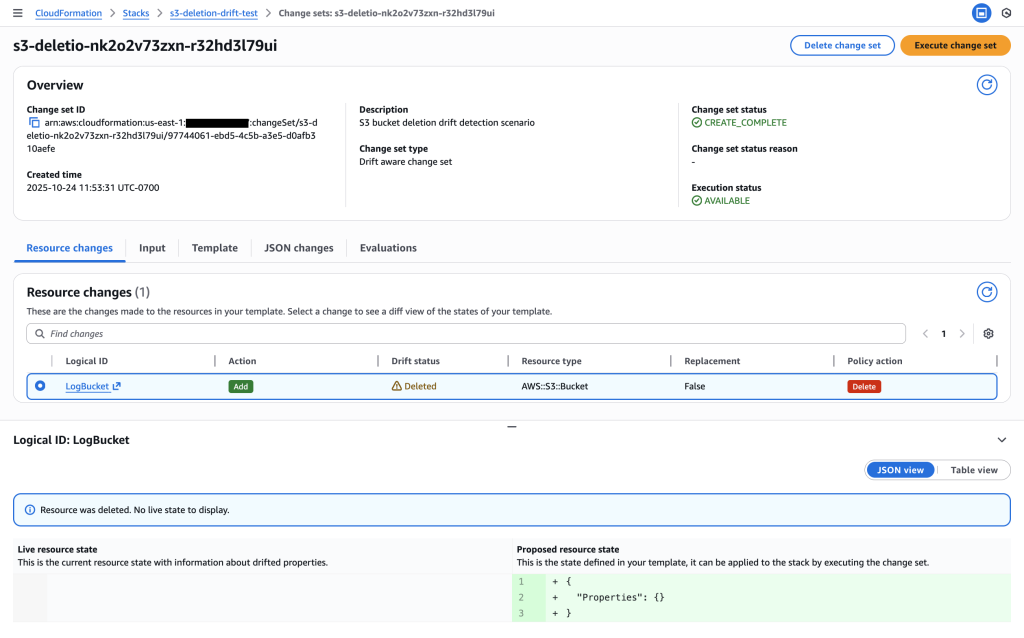
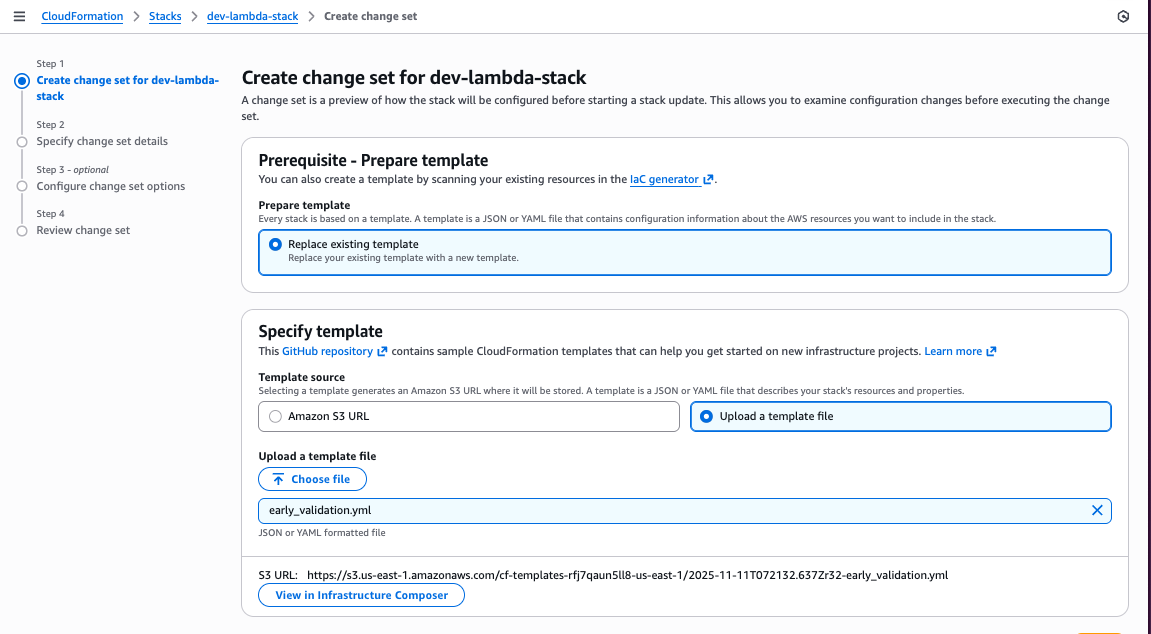
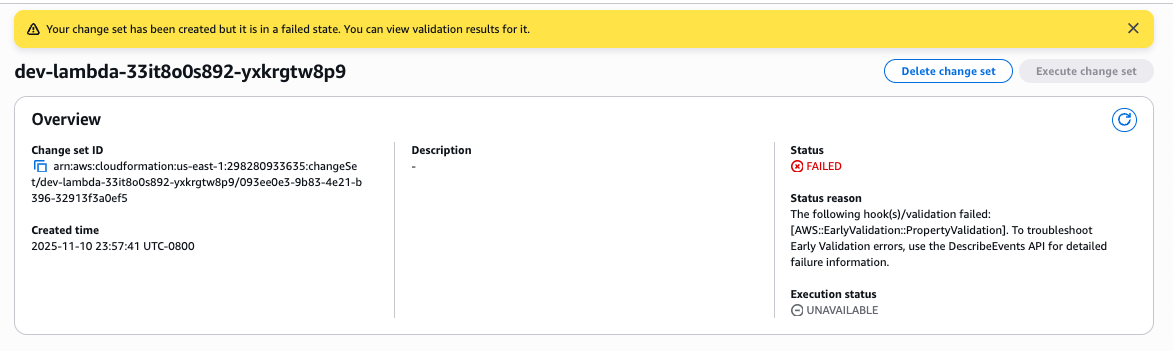
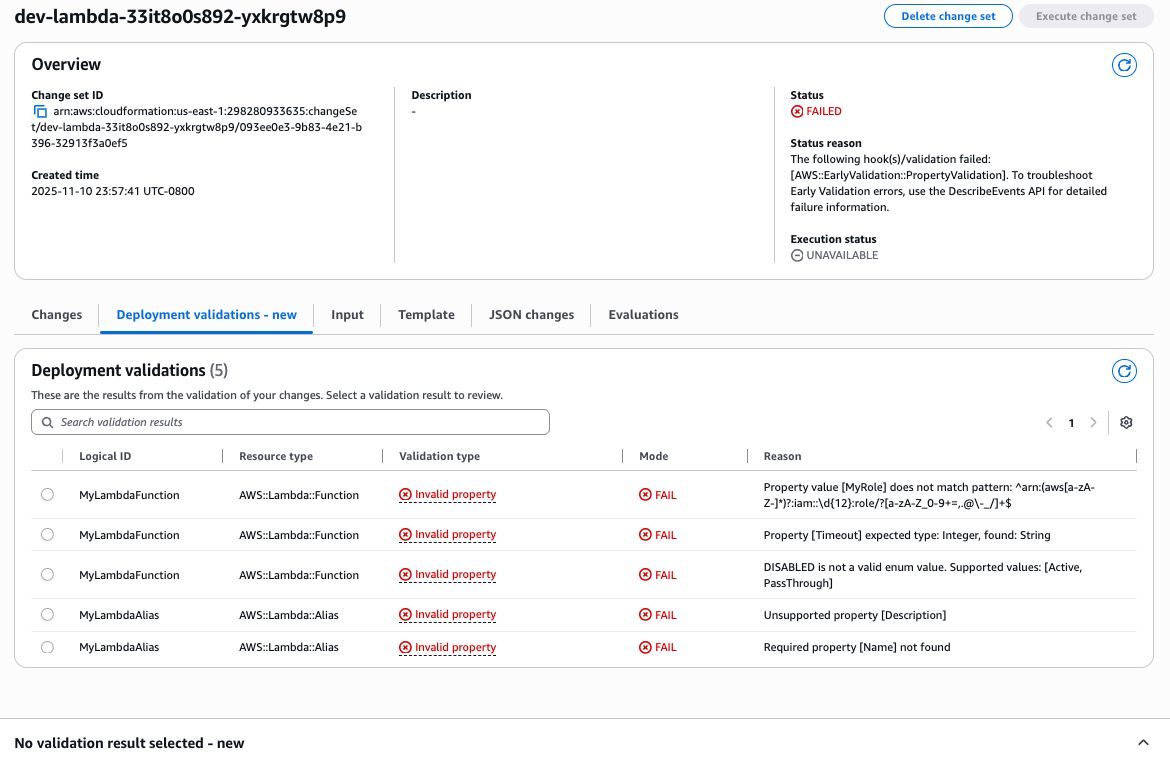
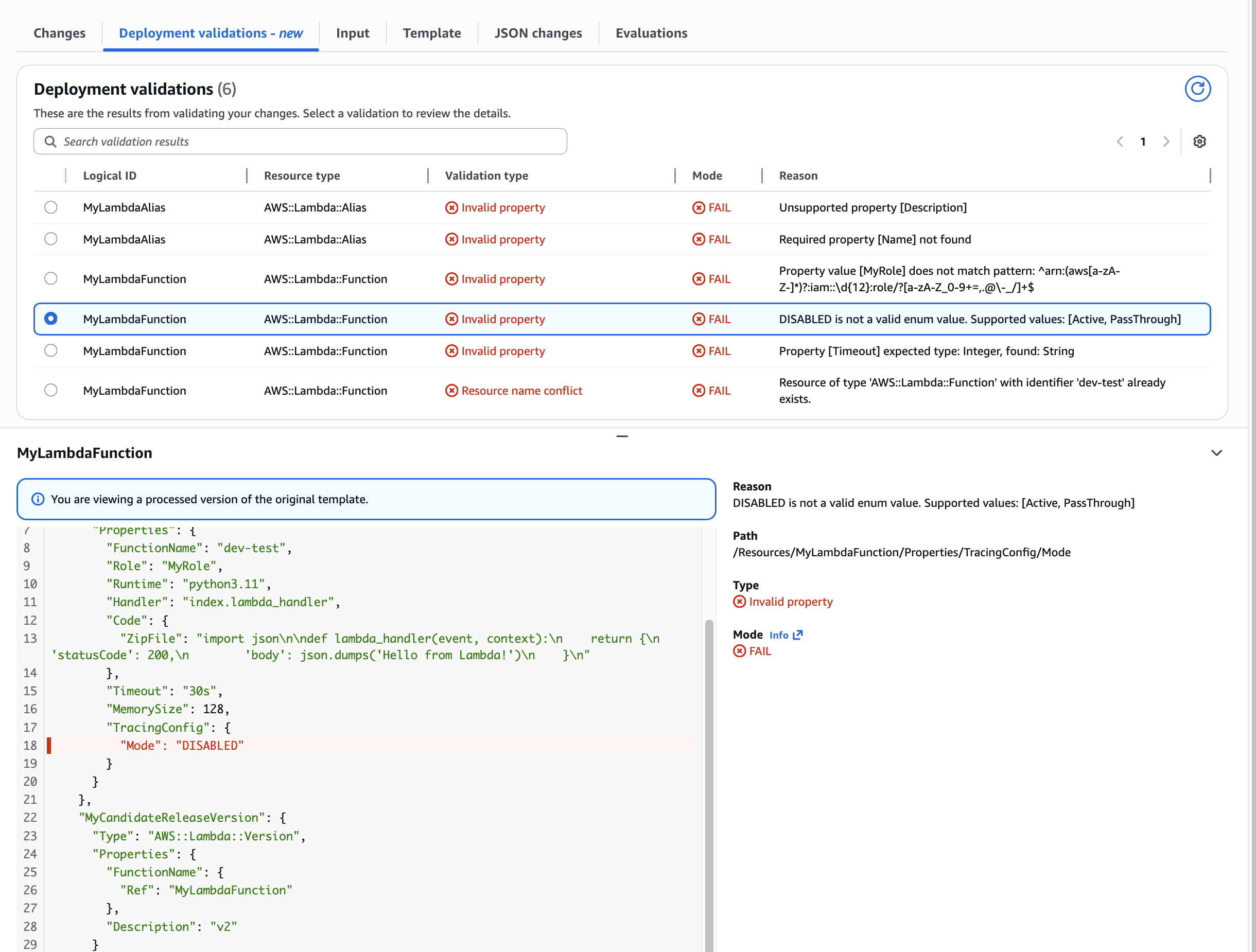
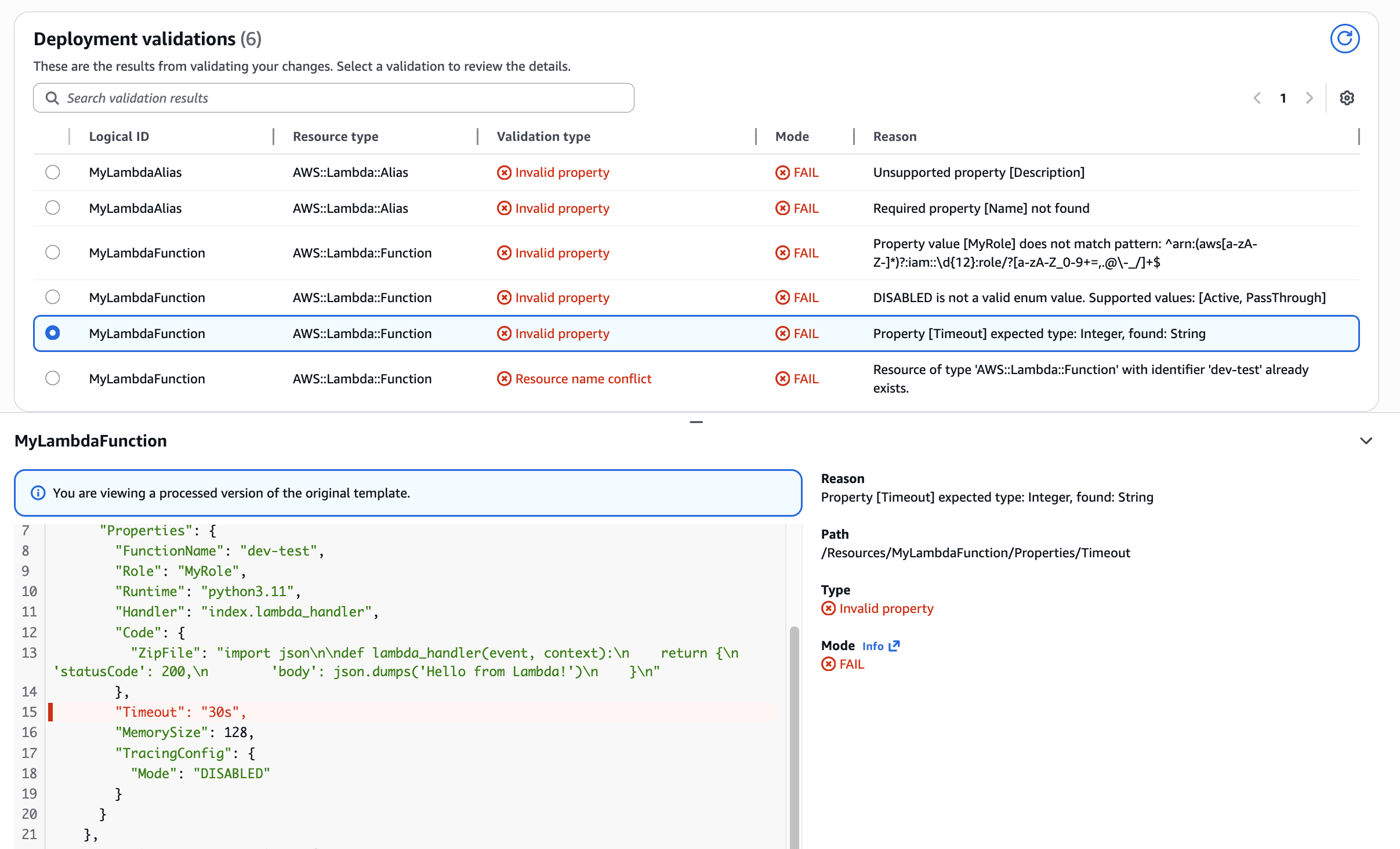
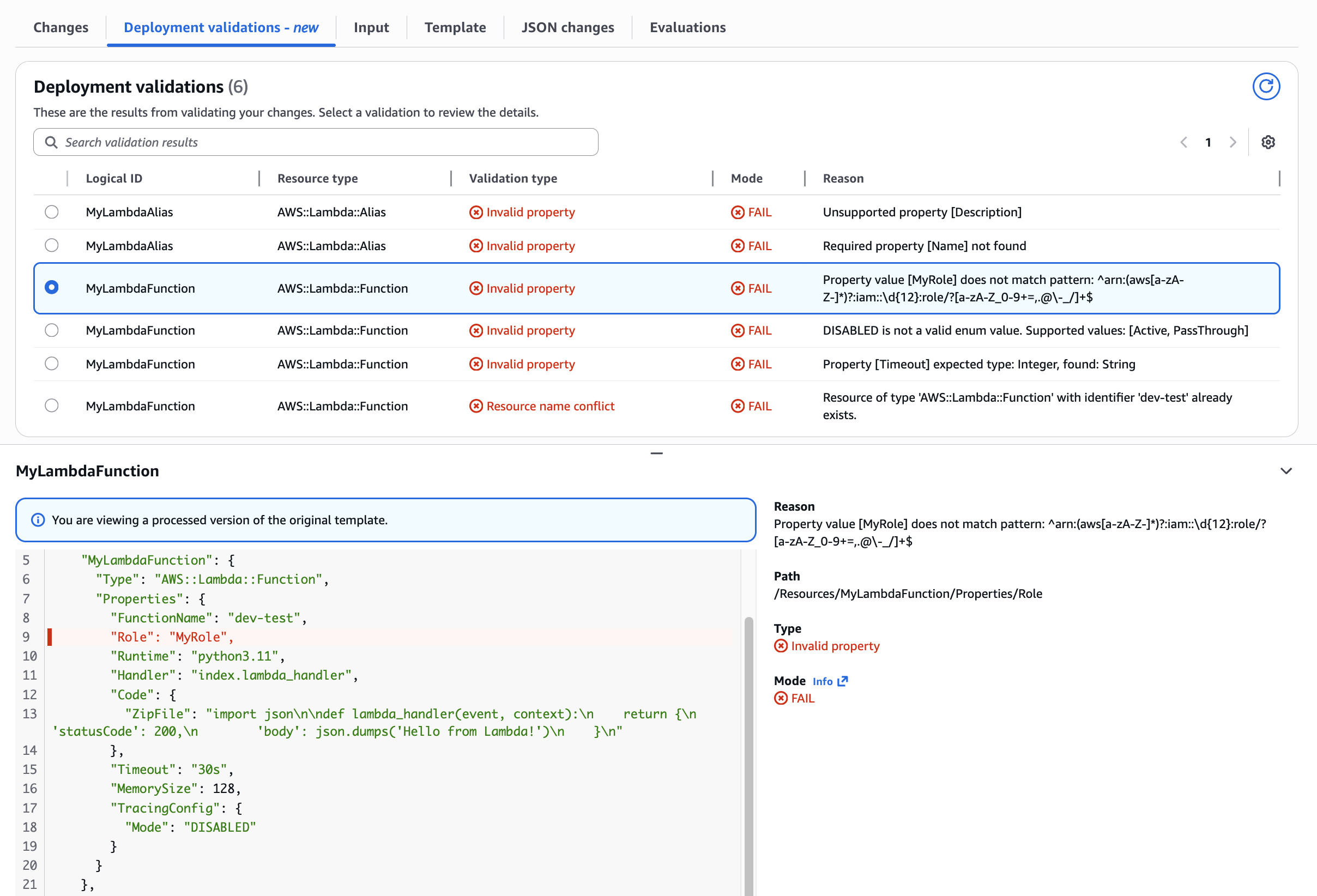
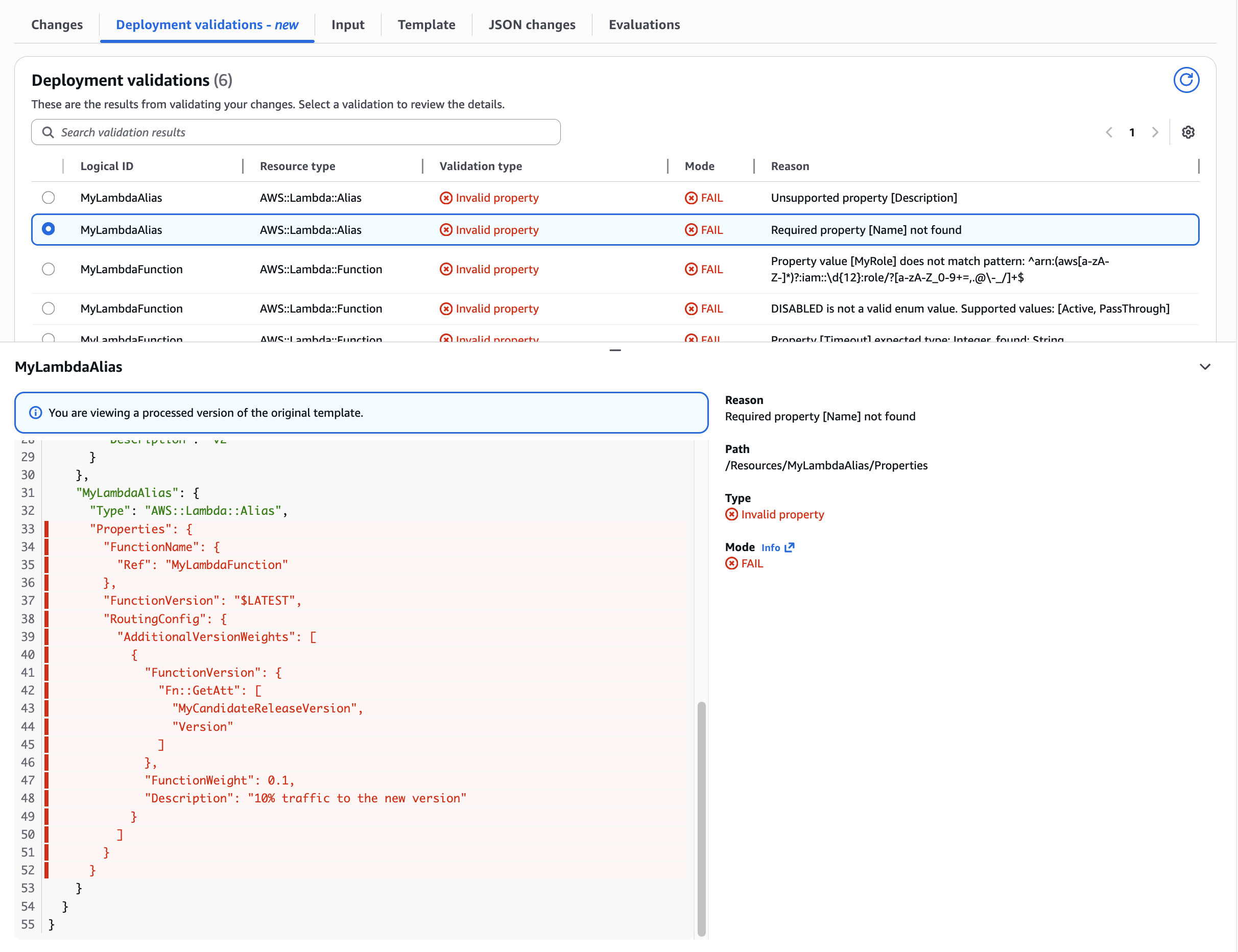
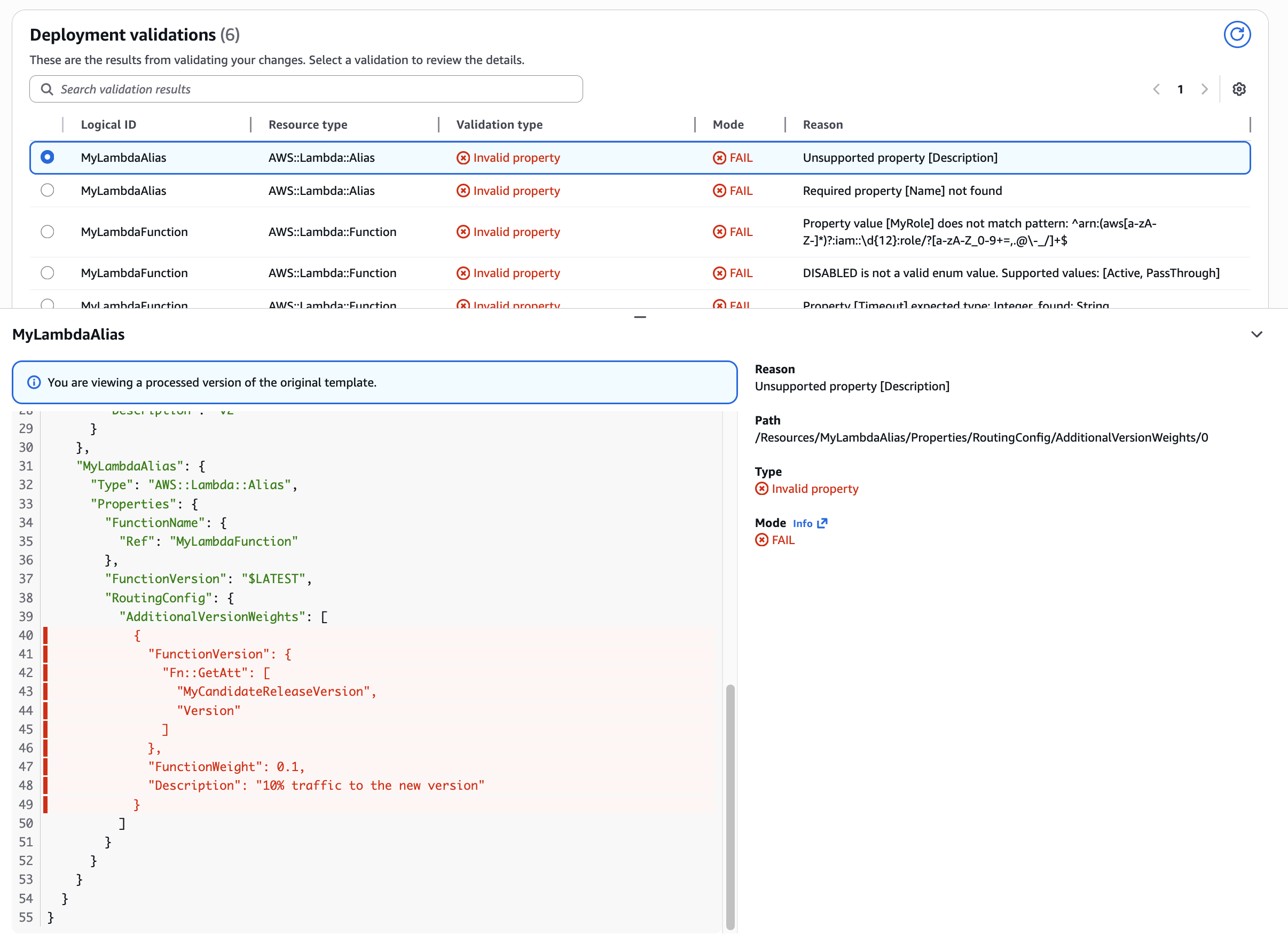
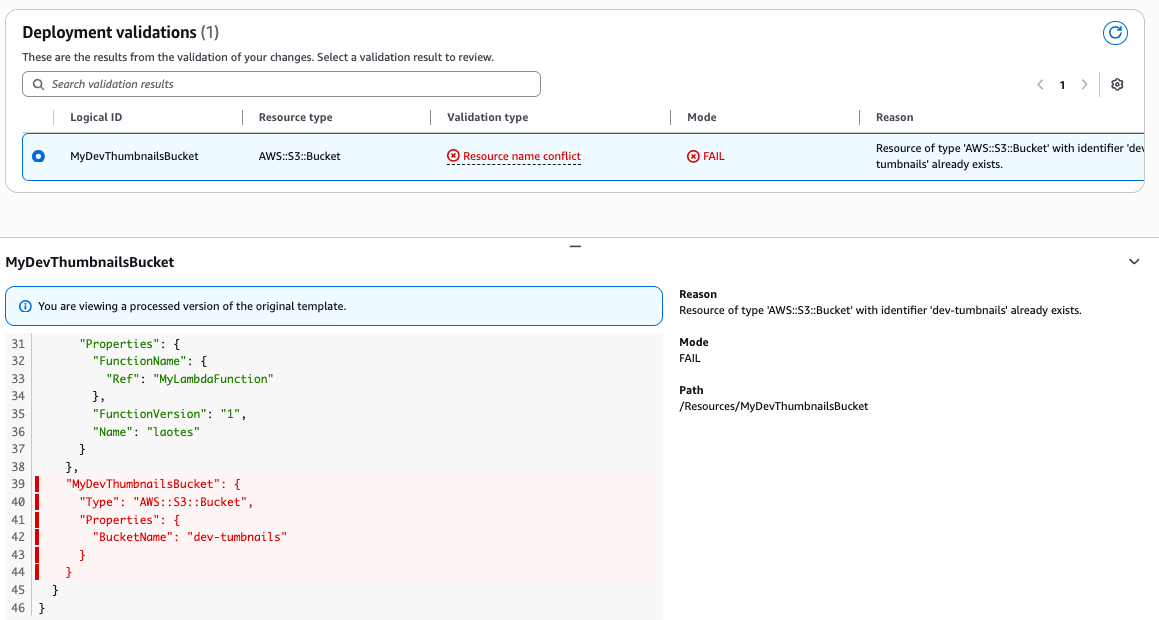
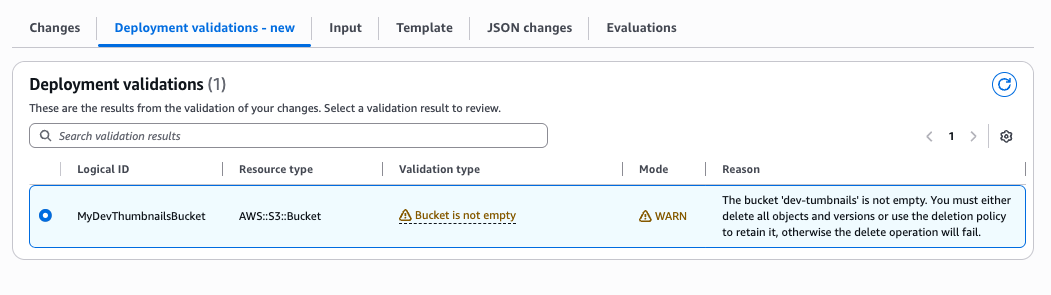
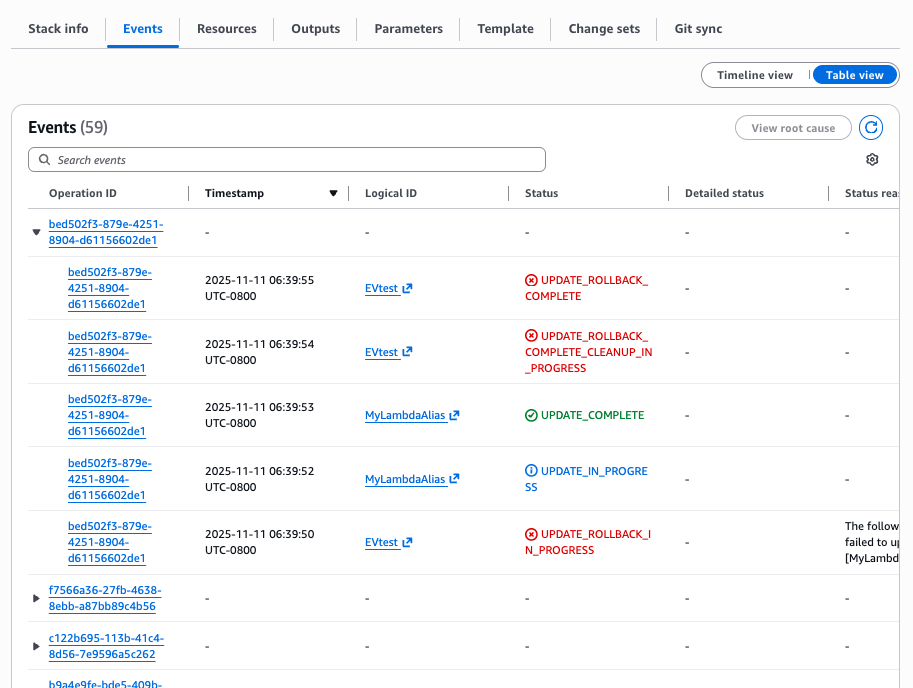
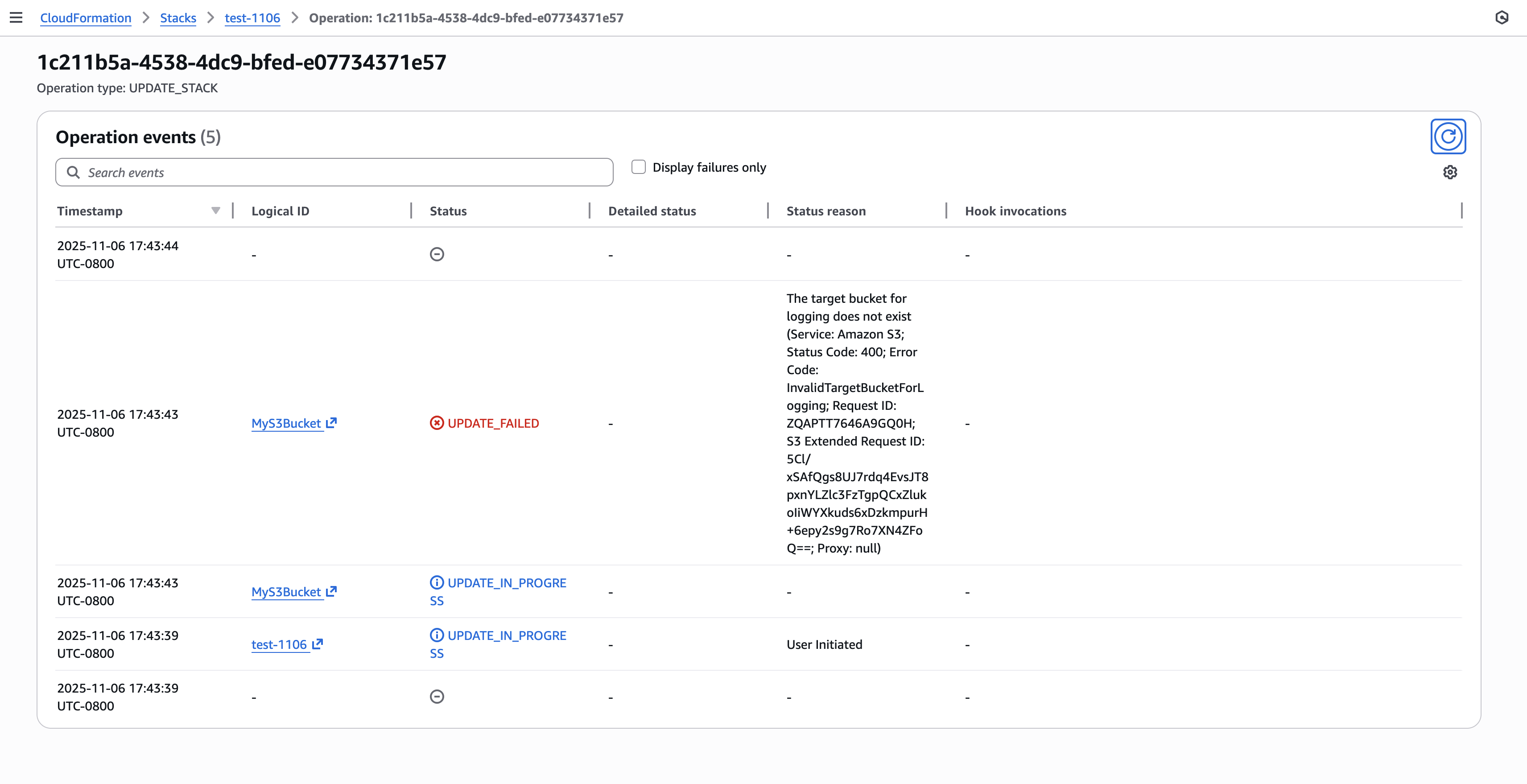 Figure 12: New CloudFormation stack operation page
Figure 12: New CloudFormation stack operation page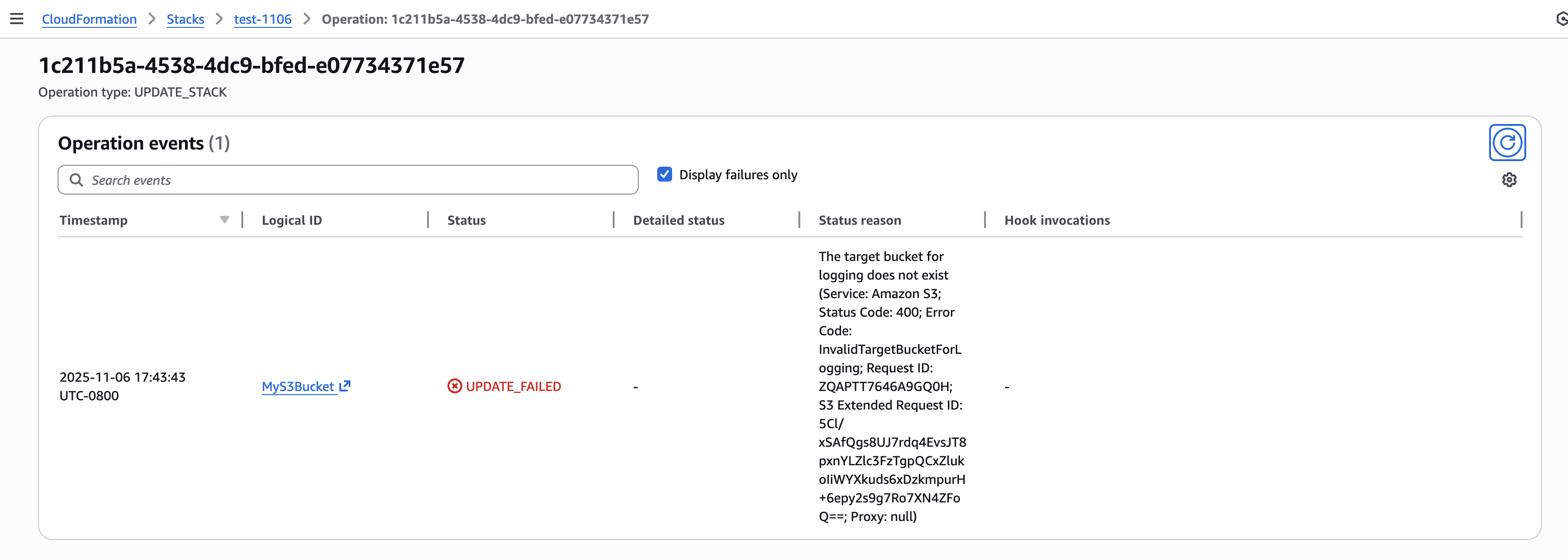
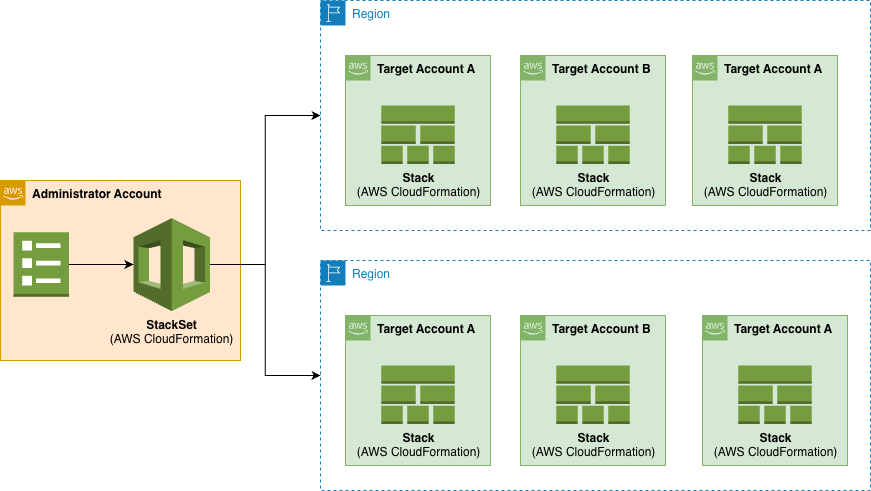
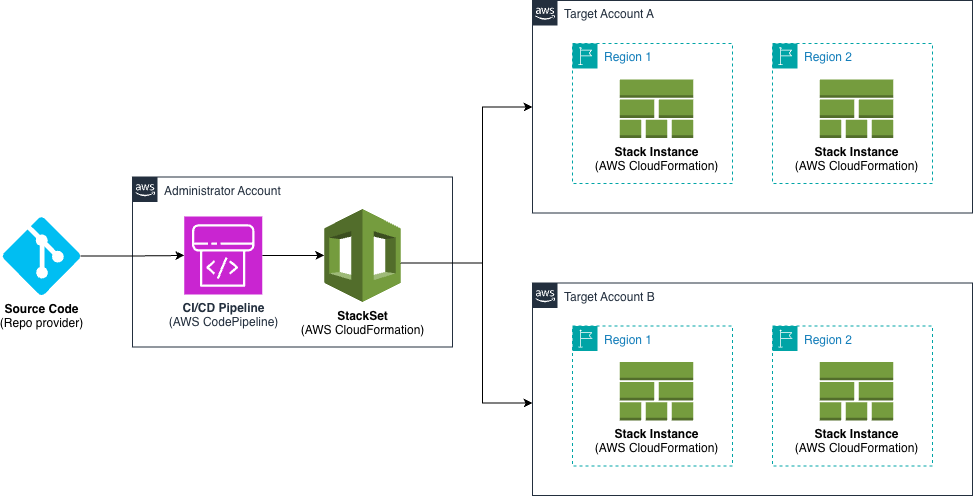
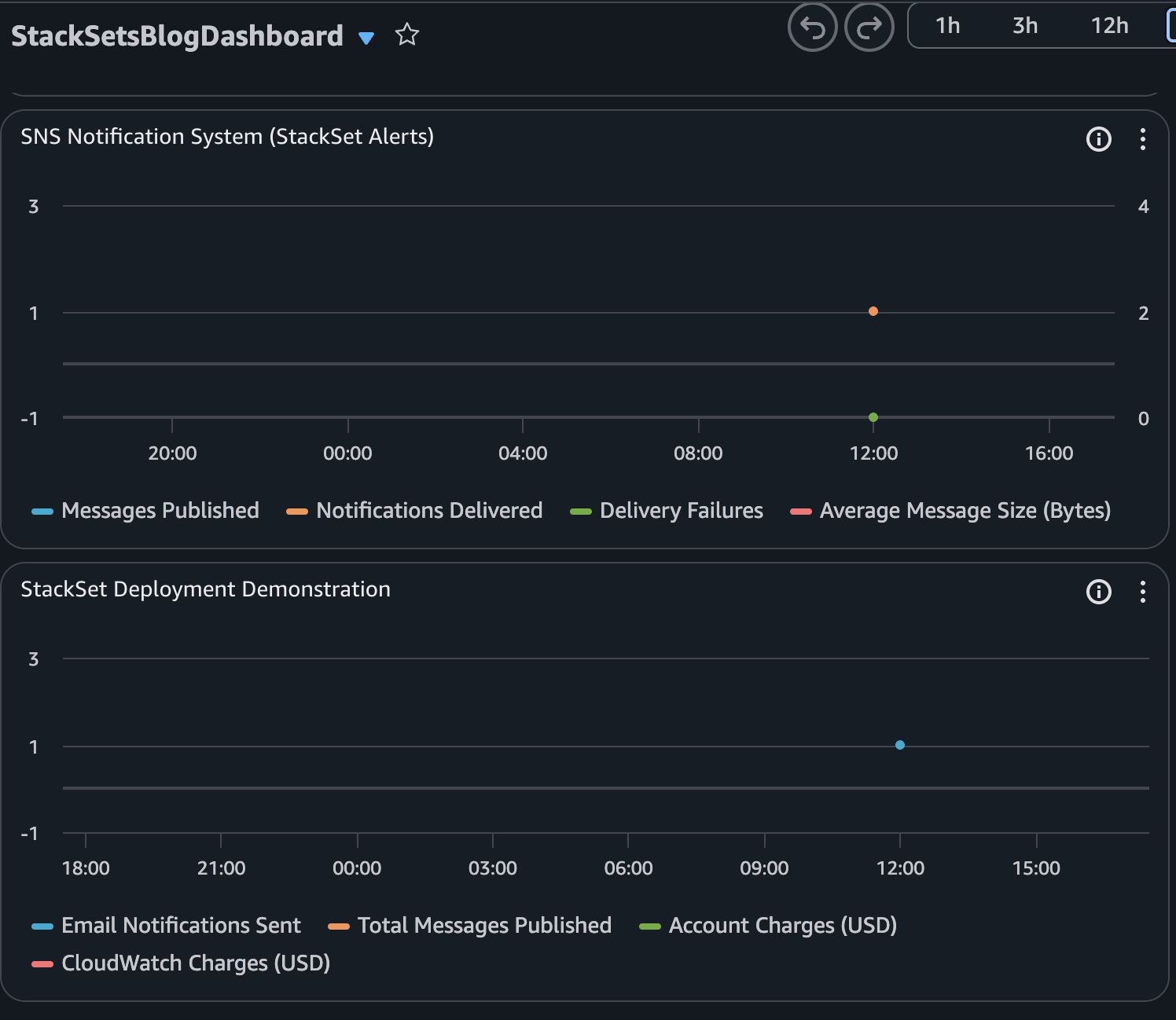
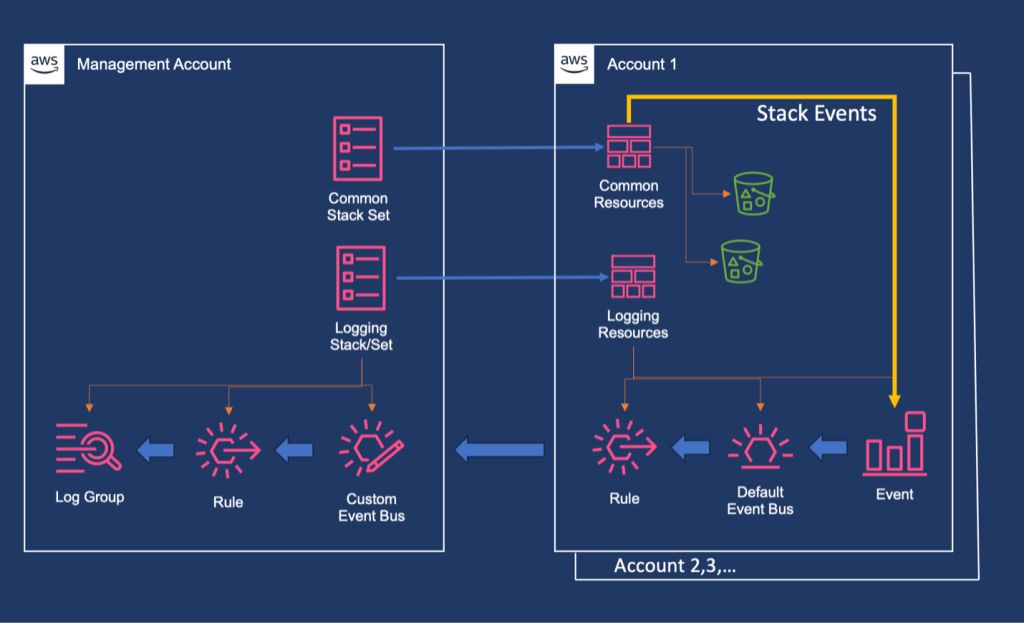
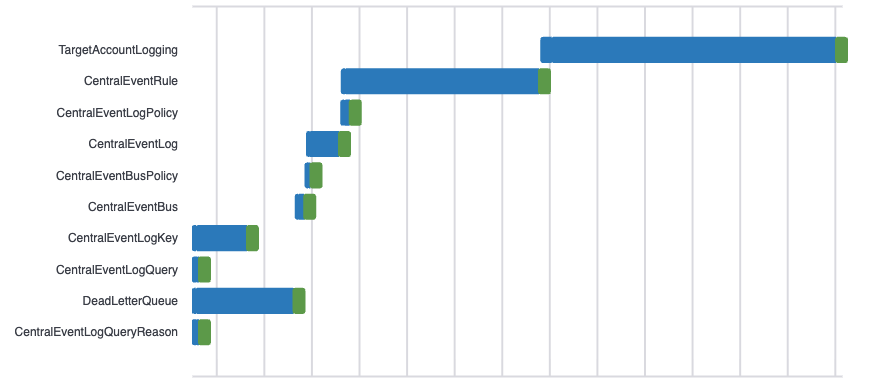
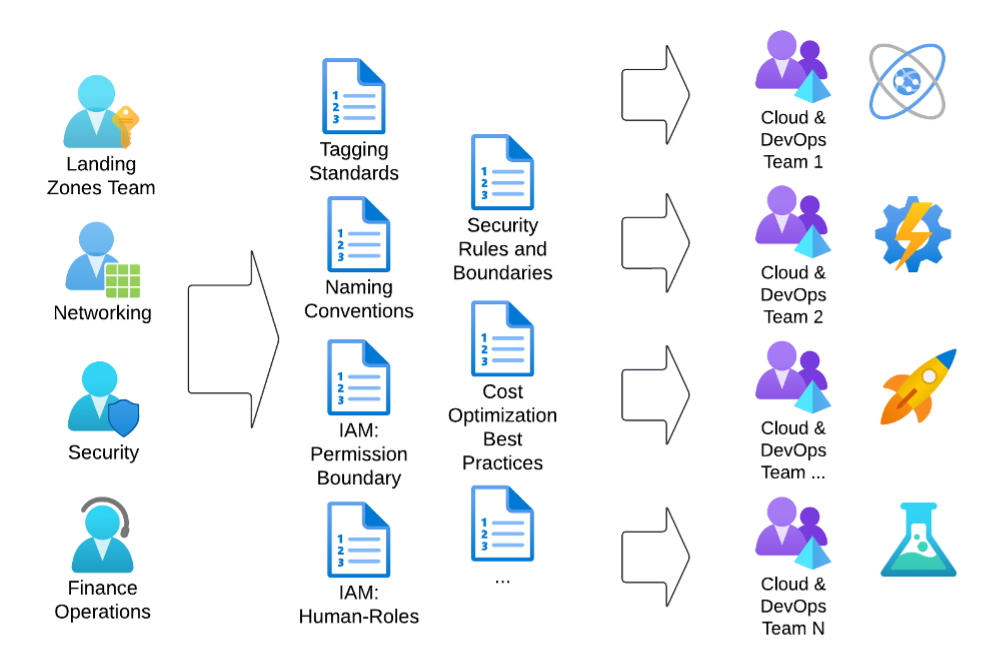
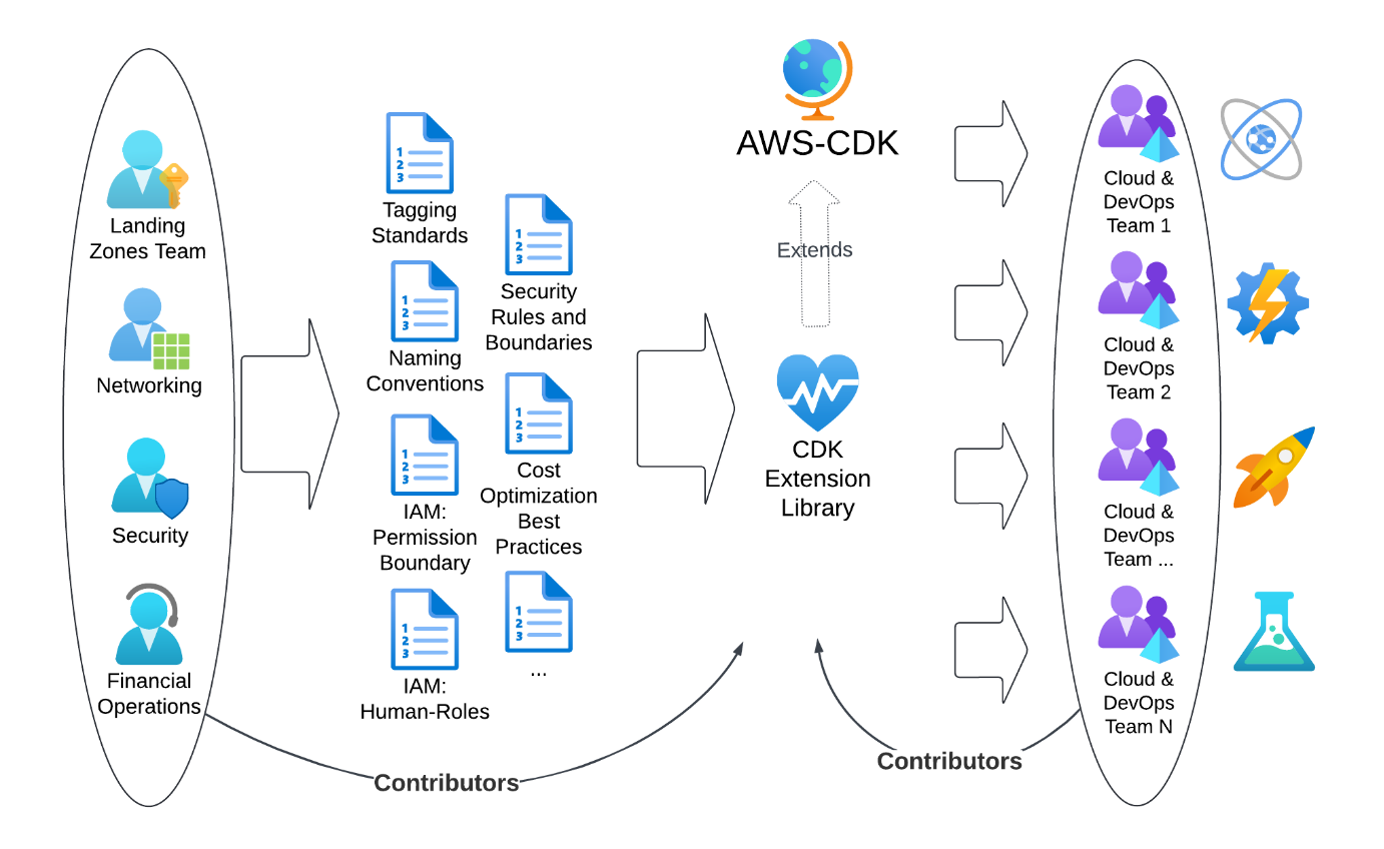

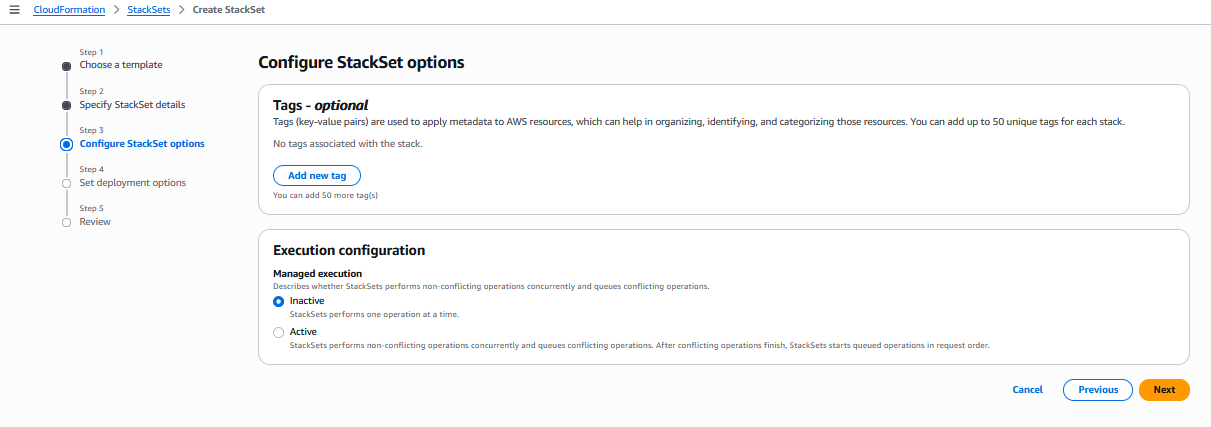
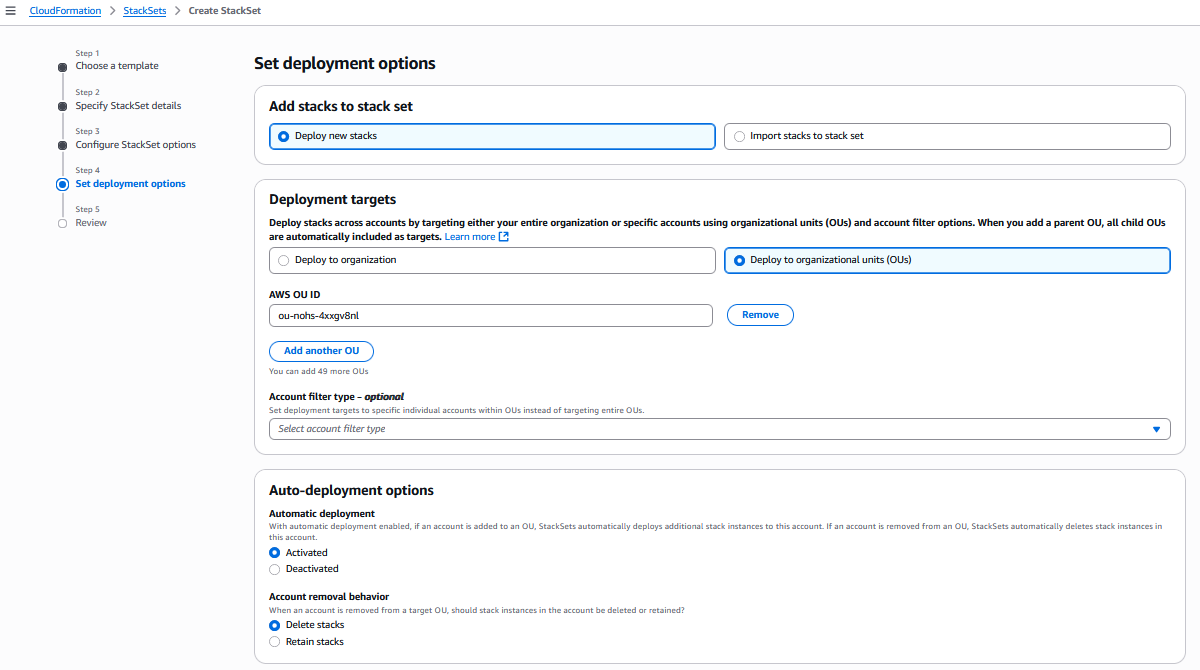
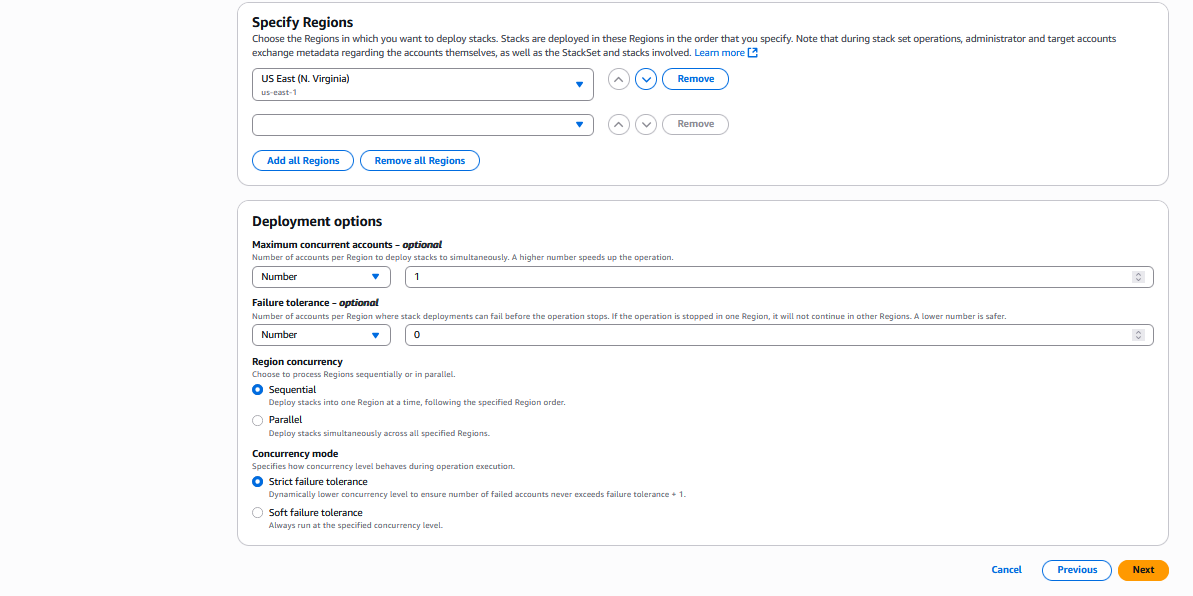
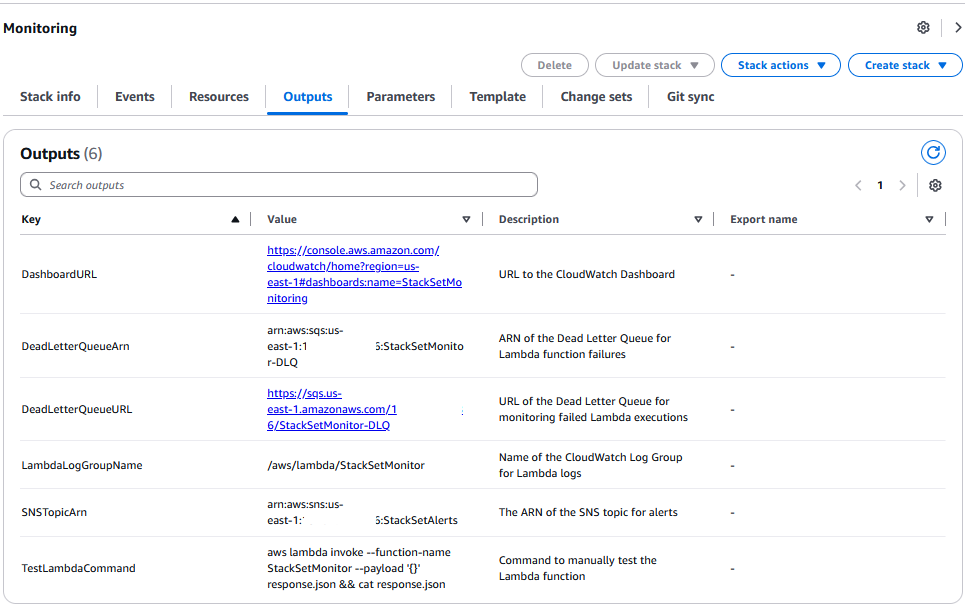
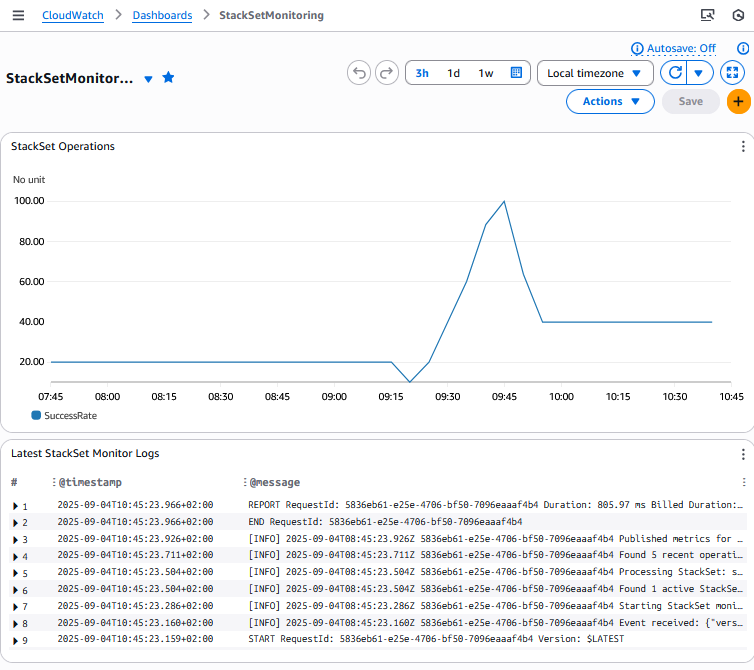

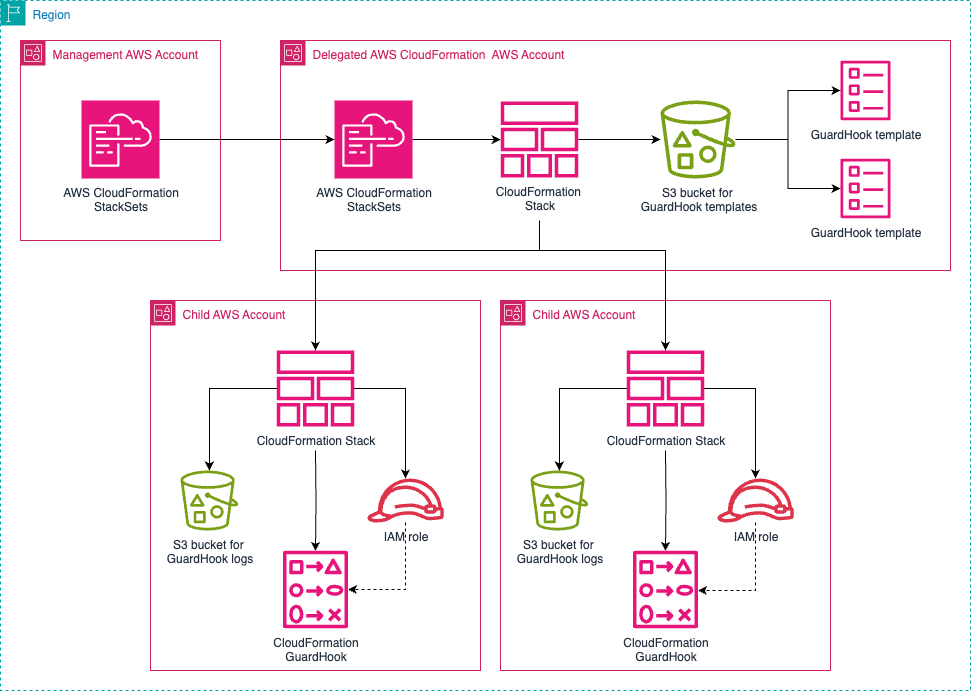












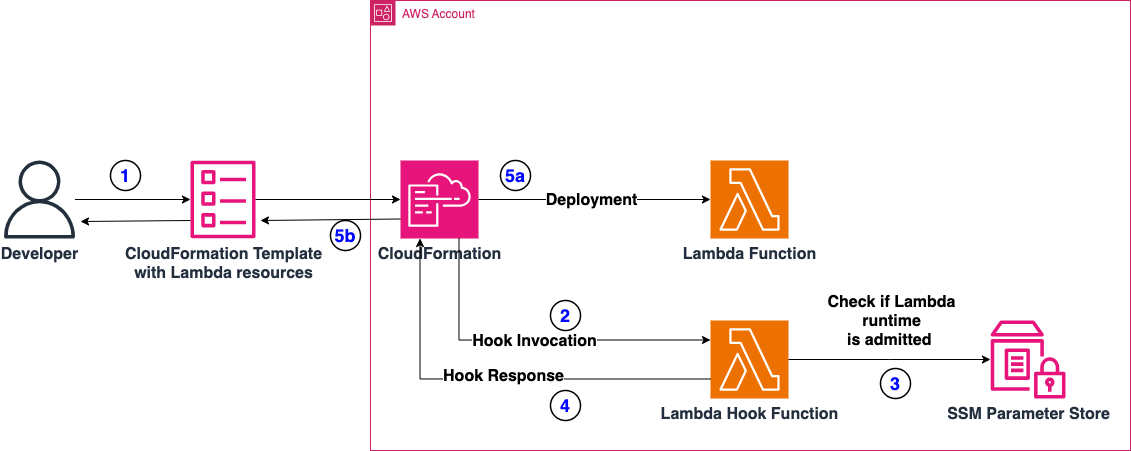
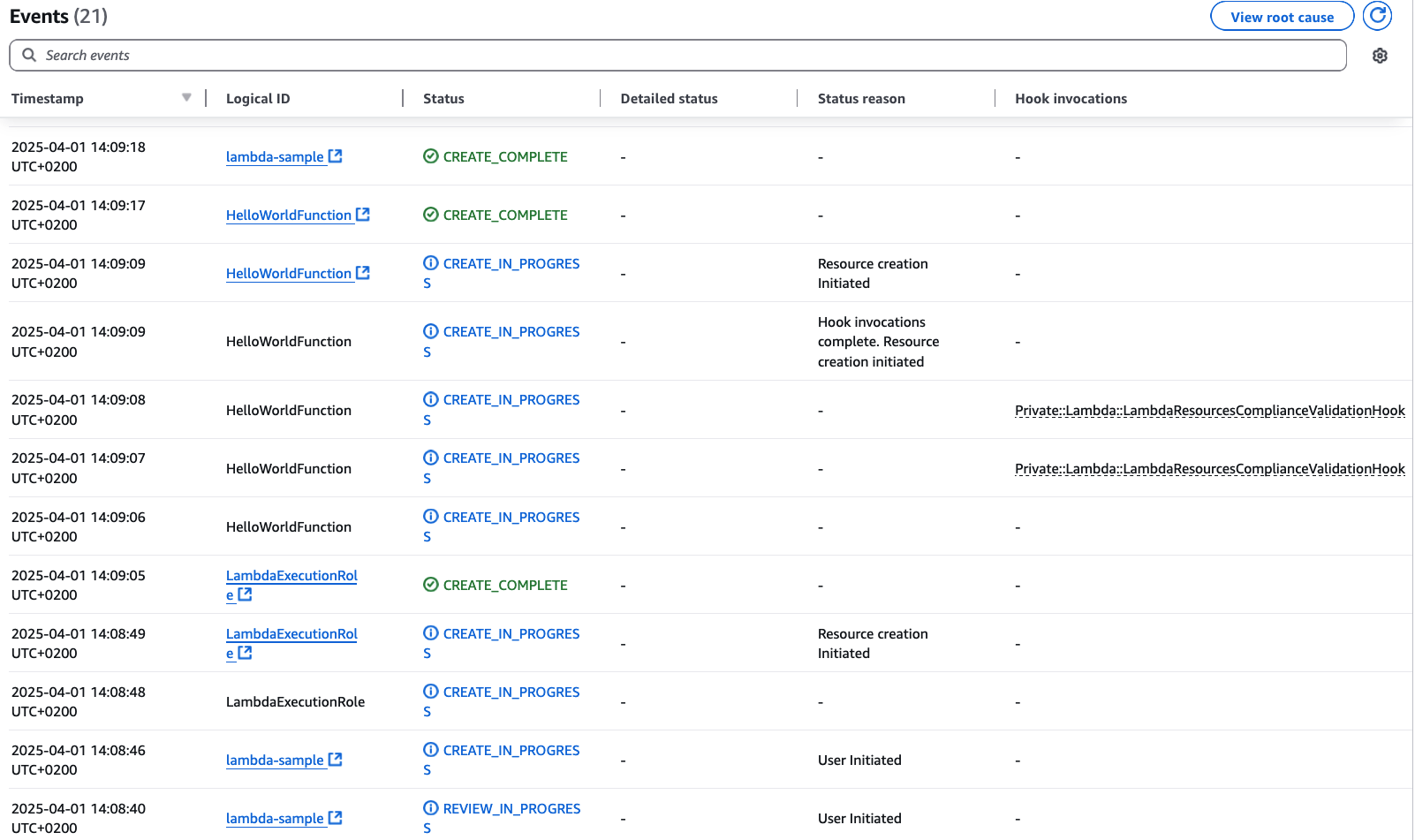
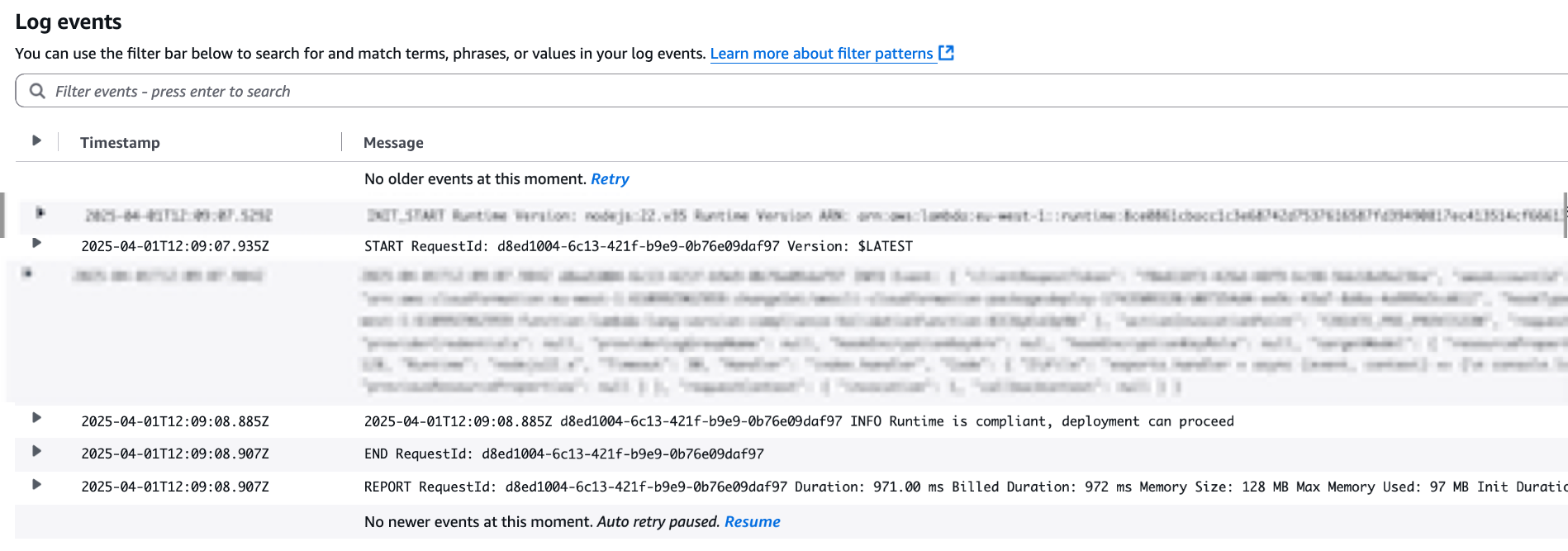
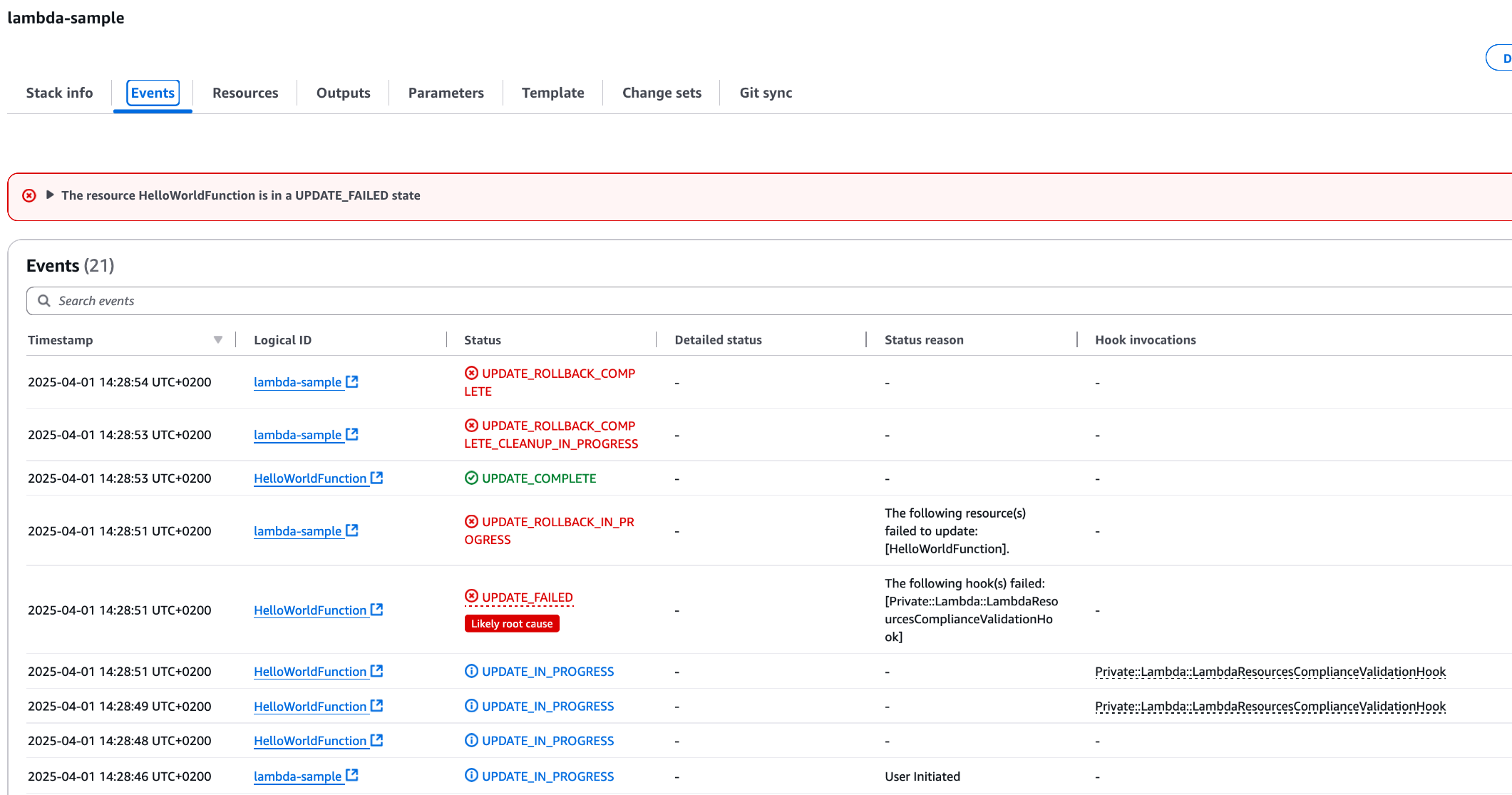
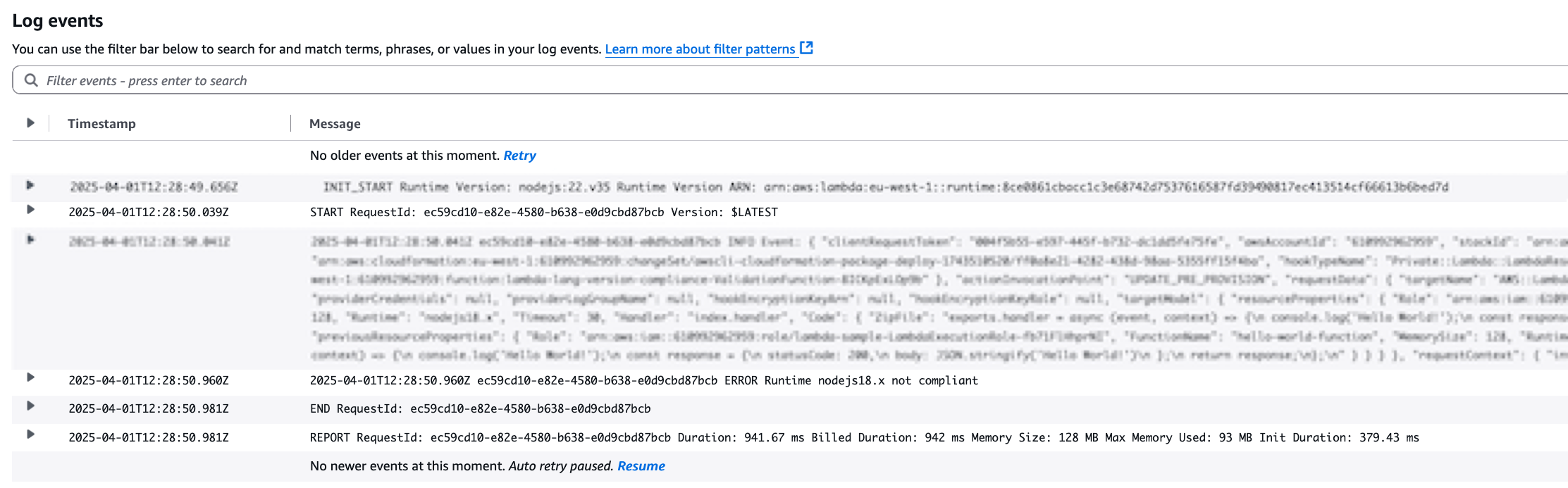










 Figure 4: CloudFormation troubleshooting with CloudTrail integration
Figure 4: CloudFormation troubleshooting with CloudTrail integration
 Figure 6: CloudFormation troubleshooting with Q feature
Figure 6: CloudFormation troubleshooting with Q feature

 Figure 9: IaC generator resource scan
Figure 9: IaC generator resource scan

 Figure 12: CloudFormation Hooks’ Lambda function feature
Figure 12: CloudFormation Hooks’ Lambda function feature
 Figure 14: CloudFormation Git sync with request review support feature
Figure 14: CloudFormation Git sync with request review support feature