Post Syndicated from Rob Sutter original https://blog.cloudflare.com/cloudflare-queues-open-beta/


Message queues are a fundamental building block of cloud applications—and today the Cloudflare Queues open beta brings queues to every developer building for Region: Earth. Cloudflare Queues follows Cloudflare Workers and Cloudflare R2 in a long line of innovative services built for the Workers Developer Platform, enabling developers to build more complex applications without configuring networks, choosing regions, or estimating capacity. Best of all, like many other Cloudflare services, there are no egregious egress charges!

If you’ve ever purchased something online and seen a message like “you will receive confirmation of your order shortly,” you’ve interacted with a queue. When you completed your order, your shopping cart and information were stored and the order was placed into a queue. At some later point, the order fulfillment service picks and packs your items and hands it off to the shipping service—again, via a queue. Your order may sit for only a minute, or much longer if an item is out of stock or a warehouse is busy, and queues enable all of this functionality.
Message queues are great at decoupling components of applications, like the checkout and order fulfillment services for an ecommerce site. Decoupled services are easier to reason about, deploy, and implement, allowing you to ship features that delight your customers without worrying about synchronizing complex deployments.
Queues also allow you to batch and buffer calls to downstream services and APIs. This post shows you how to enroll in the open beta, walks you through a practical example of using Queues to build a log sink, and tells you how we built Queues using other Cloudflare services. You’ll also learn a bit about the roadmap for the open beta.
Getting started
Enrolling in the open beta
Open the Cloudflare dashboard and navigate to the Workers section. Select Queues from the Workers navigation menu and choose Enable Queues Beta.
Review your order and choose Proceed to Payment Details.
Note: If you are not already subscribed to a Workers Paid Plan, one will be added to your order automatically.
Enter your payment details and choose Complete Purchase. That’s it – you’re enrolled in the open beta! Choose Return to Queues on the confirmation page to return to the Cloudflare Queues home page.
Creating your first queue
After enabling the open beta, open the Queues home page and choose Create Queue. Name your queue `my-first-queue` and choose Create queue. That’s all there is to it!
The dash displays a confirmation message along with a list of all the queues in your account.
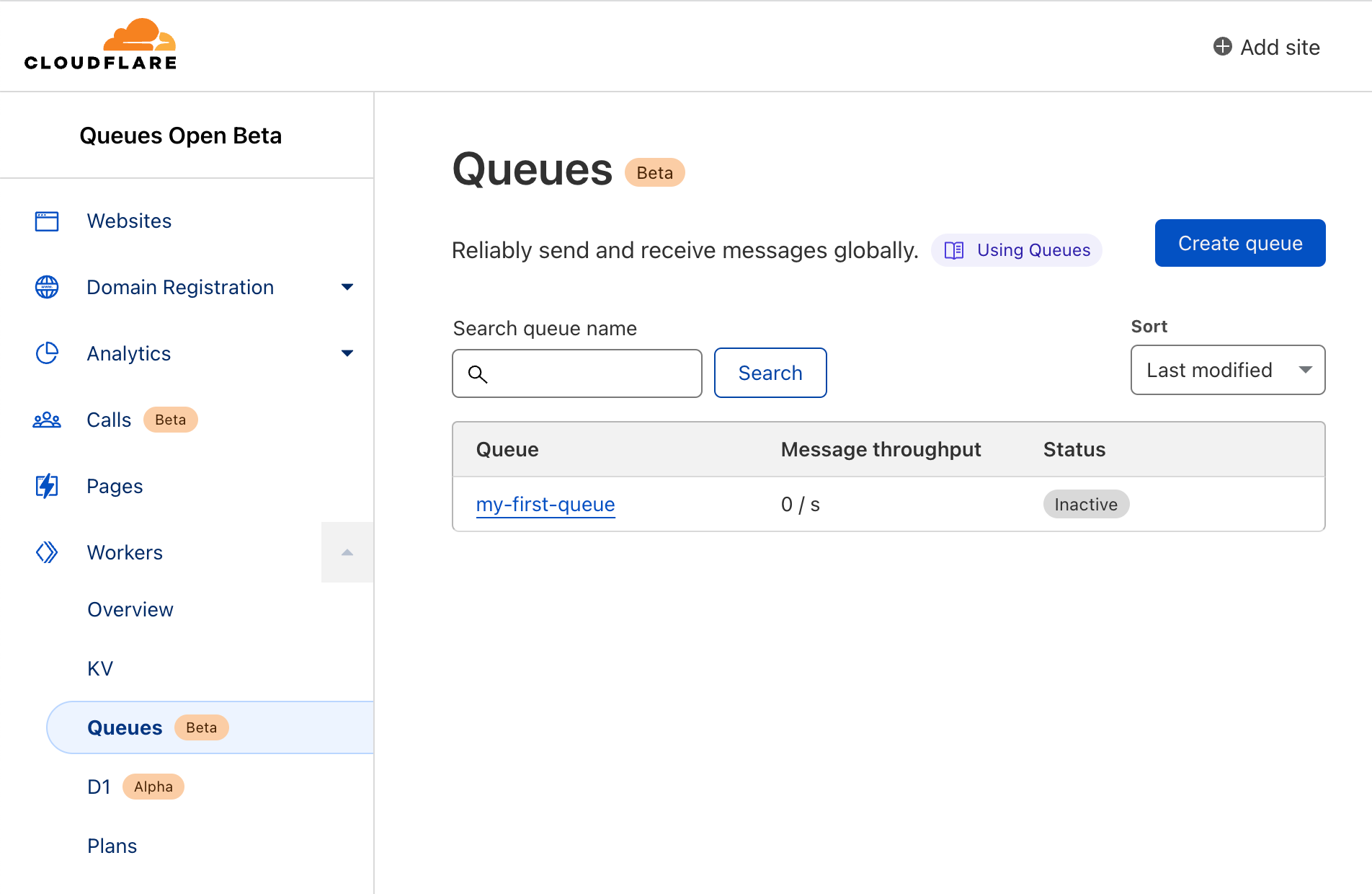
Note: As of the writing of this blog post each account is limited to ten queues. We intend to raise this limit as we build towards general availability.
Managing your queues with Wrangler
You can also manage your queues from the command line using Wrangler, the CLI for Cloudflare Workers. In this section, you build a simple but complete application implementing a log aggregator or sink to learn how to integrate Workers, Queues, and R2.
Setting up resources
To create this application, you need access to a Cloudflare Workers account with a subscription plan, access to the Queues open beta, and an R2 plan.
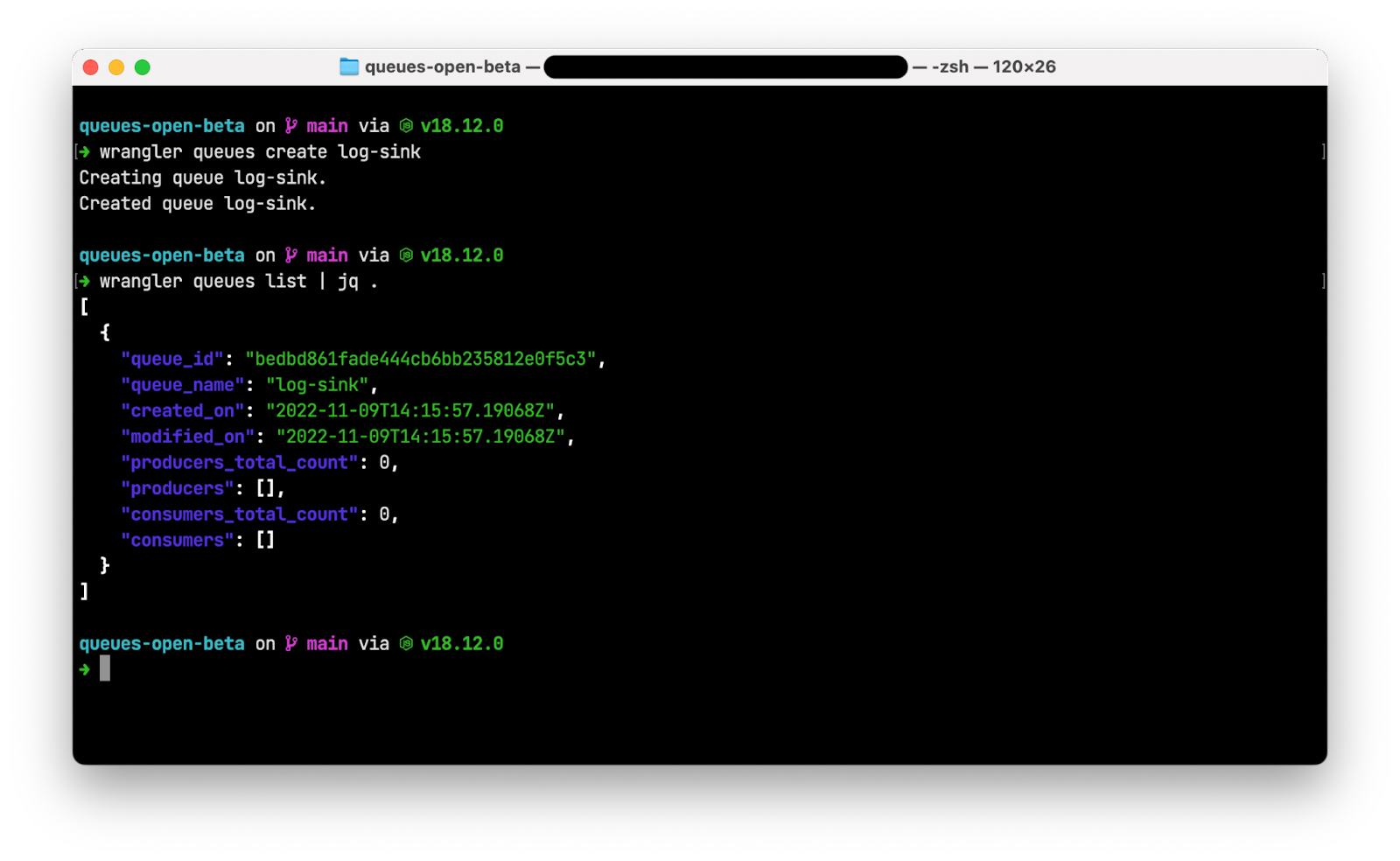
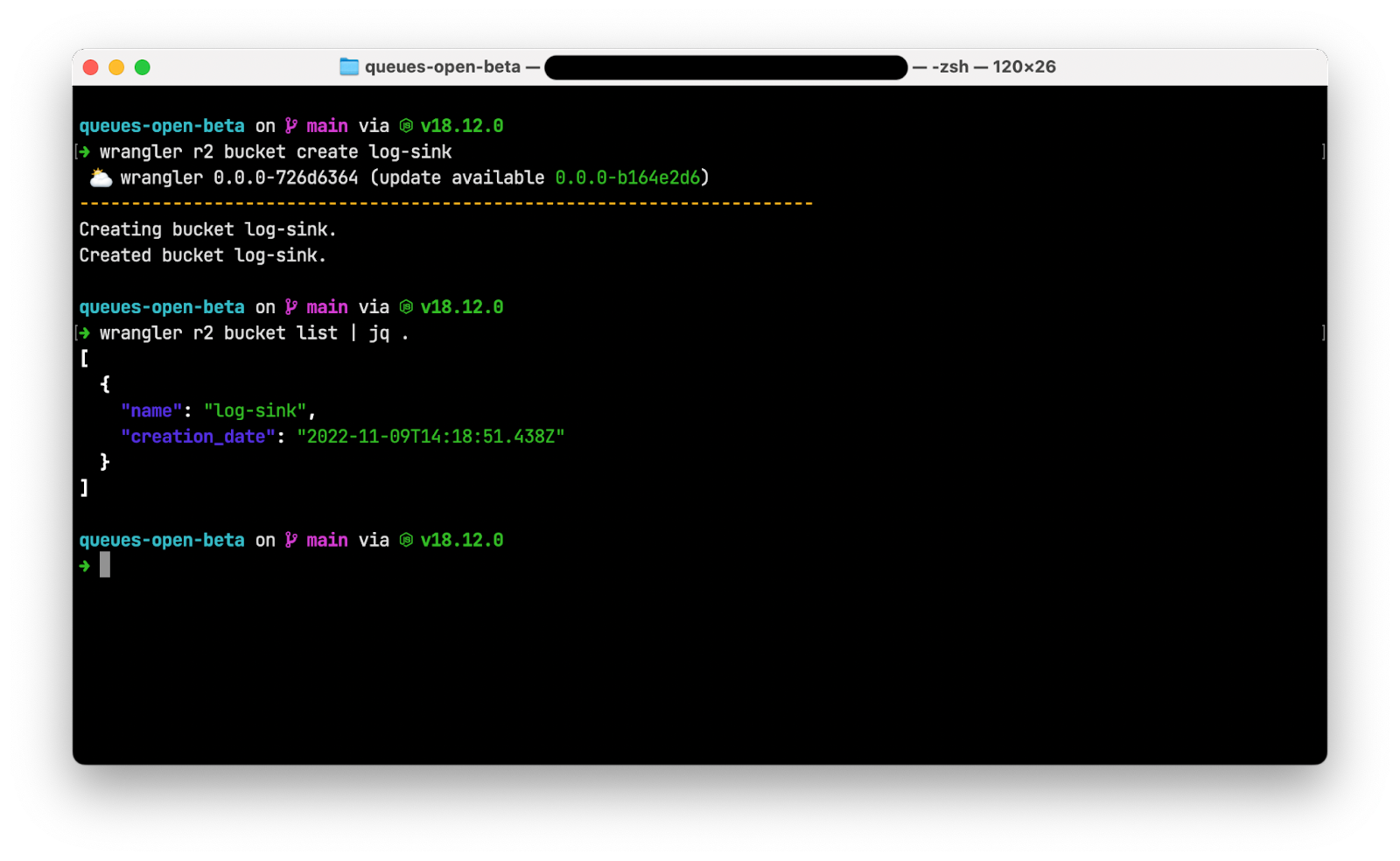
Install and authenticate Wrangler then run wrangler queues create log-sink from the command line to create a queue for your application.
Run wrangler queues list and note that Wrangler displays your new queue.
Note: The following screenshots use the jq utility to format the JSON output of wrangler commands. You do not need to install jq to complete this application.
Finally, run wrangler r2 bucket create log-sink to create an R2 bucket to store your aggregated logs. After the bucket is created, run wrangler r2 bucket list to see your new bucket.
Creating your Worker
Next, create a Workers application with two handlers: a fetch() handler to receive individual incoming log lines and a queue() handler to aggregate a batch of logs and write the batch to R2.
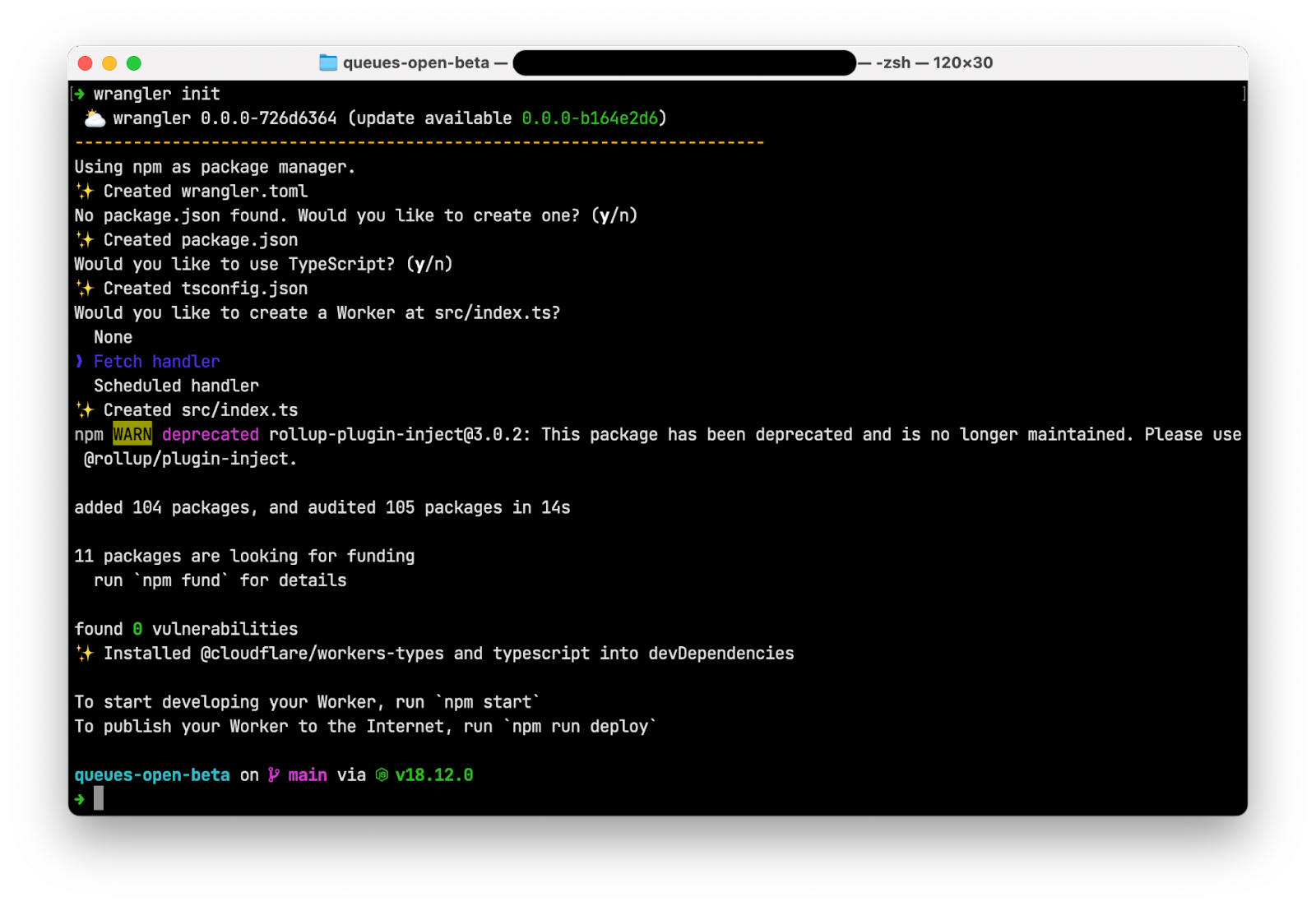
In an empty directory, run wrangler init to create a new Cloudflare Workers application. When prompted:
- Choose “y” to create a new package.json
- Choose “y” to use TypeScript
- Choose “Fetch handler” to create a new Worker at src/index.ts
Open wrangler.toml and replace the contents with the following:
wrangler.toml
name = "queues-open-beta"
main = "src/index.ts"
compatibility_date = "2022-11-03"
[[queues.producers]]
queue = "log-sink"
binding = "BUFFER"
[[queues.consumers]]
queue = "log-sink"
max_batch_size = 100
max_batch_timeout = 30
[[r2_buckets]]
bucket_name = "log-sink"
binding = "LOG_BUCKET"
The [[queues.producers]] section creates a producer binding for the Worker at src/index.ts called BUFFER that refers to the log-sink queue. This Worker can place messages onto the log-sink queue by calling await env.BUFFER.send(log);
The [[queues.consumers]] section creates a consumer binding for the log-sink queue for your Worker. Once the log-sink queue has a batch ready to be processed (or consumed), the Workers runtime will look for the queue() event handler in src/index.ts and invoke it, passing the batch as an argument. The queue() function signature looks as follows:
async queue(batch: MessageBatch<Error>, env: Environment): Promise<void> {
The final binding in your wrangler.toml creates a binding for the log-sink R2 bucket that makes the bucket available to your Worker via env.LOG_BUCKET.
src/index.ts
Open src/index.ts and replace the contents with the following code:
export interface Env {
BUFFER: Queue;
LOG_BUCKET: R2Bucket;
}
export default {
async fetch(request: Request, env: Environment): Promise<Response> {
let log = await request.json();
await env.BUFFER.send(log);
return new Response("Success!");
},
async queue(batch: MessageBatch<Error>, env: Environment): Promise<void> {
const logBatch = await JSON.stringify(batch.messages);
await env.LOG_BUCKET.put(`logs/${Date.now()}.log.json`, logBatch);
},
};
The export interface Env section exposes the two bindings you defined in wrangler.toml: a queue named BUFFER and an R2 bucket named LOG_BUCKET.
The fetch() handler transforms the request body into JSON, adds the body to the BUFFER queue, then returns an HTTP 200 response with the message Success!
The `queue()` handler receives a batch of messages that each contain log entries, iterates through concatenating each log into a string buffer, then writes that buffer to the LOG_BUCKET R2 bucket using the current timestamp as the filename.
Publishing and running your application
To publish your log sink application, run wrangler publish. Wrangler packages your application and its dependencies and deploys it to Cloudflare’s global network.
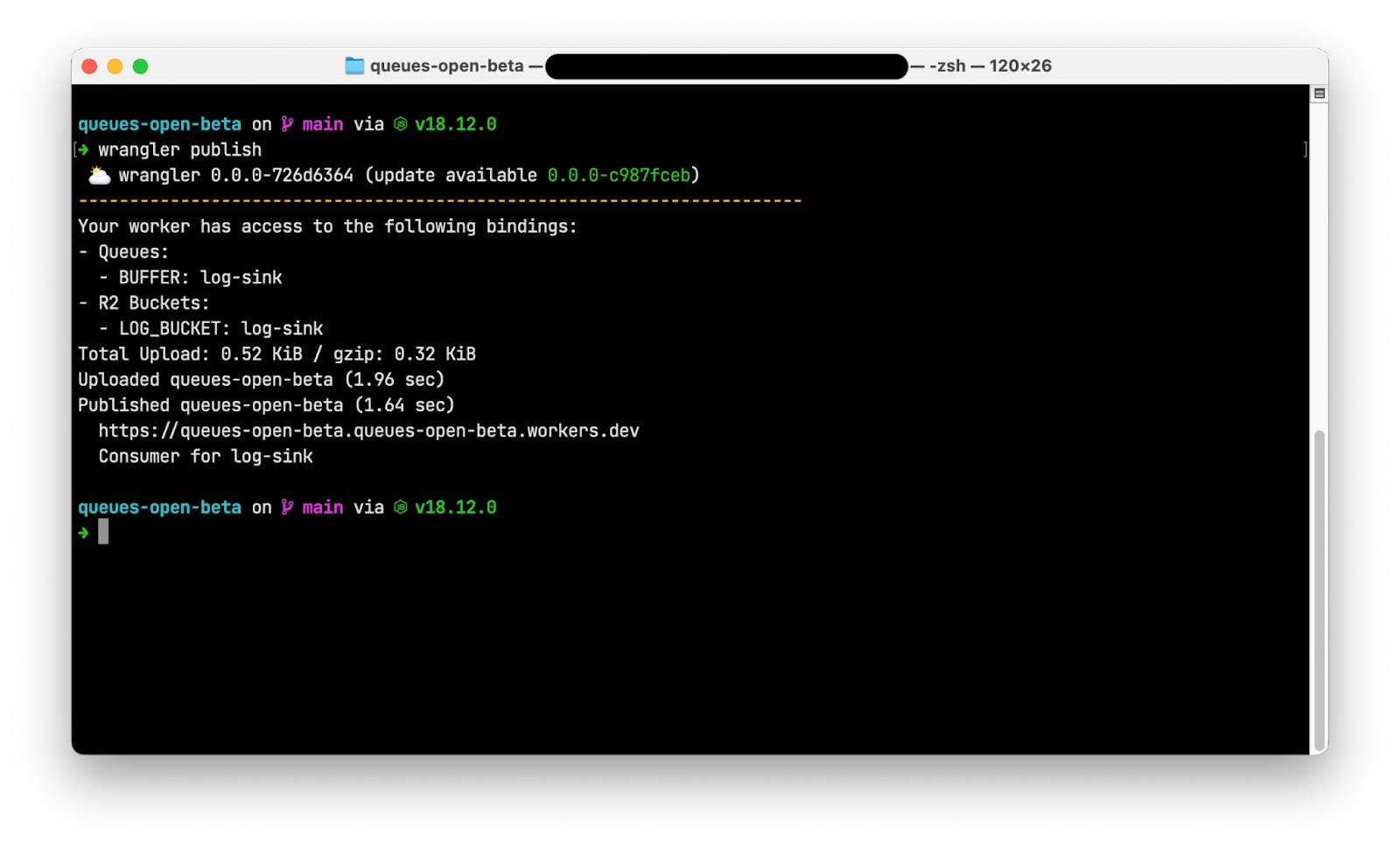
Note that the output of wrangler publish includes the BUFFER queue binding, indicating that this Worker is a producer and can place messages onto the queue. The final line of output also indicates that this Worker is a consumer for the log-sink queue and can read and remove messages from the queue.
Use your favorite API client, like curl, httpie, or Postman, to send JSON log entries to the published URL for your Worker via HTTP POST requests. Navigate to your log-sink R2 bucket in the Cloudflare dashboard and note that the logs prefix is now populated with aggregated logs from your request.
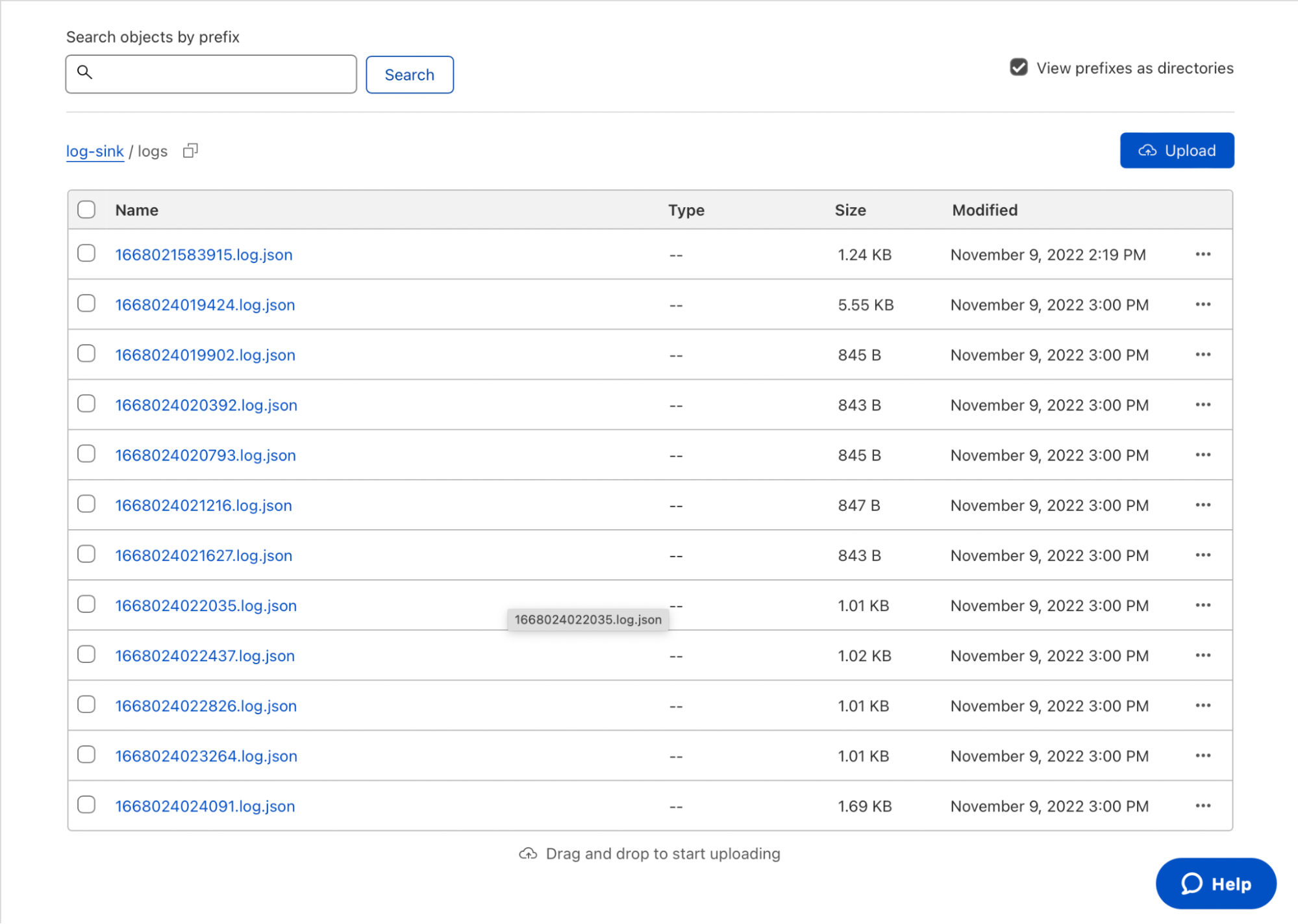
Download and open one of the logfiles to view the JSON array inside. That’s it – with fewer than 45 lines of code and config, you’ve built a log aggregator to ingest and store data in R2!
Buffering R2 writes with Queues in the real world
In the previous example, you create a simple Workers application that buffers data into batches before writing the batches to R2. This reduces the number of calls to the downstream service, reducing load on the service and saving you money.
UUID.rocks, the fastest UUIDv4-as-a-service, wanted to confirm whether their API truly generates unique IDs on every request. With 80,000 requests per day, it wasn’t trivial to find out. They decided to write every generated UUID to R2 to compare IDs across the entire population. However, writing directly to R2 at the rate UUIDs are generated is inefficient and expensive.
To reduce writes and costs, UUID.rocks introduced Cloudflare Queues into their UUID generation workflow. Each time a UUID is requested, a Worker places the value of the UUID into a queue. Once enough messages have been received, the buffered batch of JSON objects is written to R2. This avoids invoking an R2 write on every API call, saving costs and making the data easier to process later.
The uuid-queue application consists of a single Worker with three event handlers:
- A fetch handler that receives a JSON object representing the generated UUID and writes it to a Cloudflare Queue.
- A queue handler that writes batches of JSON objects to R2 in CSV format.
- A scheduled handler that combines batches from the previous hour into a single file for future processing.
To view the source or deploy this application into your own account, visit the repository on GitHub.
How we built Cloudflare Queues
Like many of the Cloudflare services you use and love, we built Queues by composing other Cloudflare services like Workers and Durable Objects. This enabled us to rapidly solve two difficult challenges: securely invoking your Worker from our own service and maintaining a strongly consistent state at scale. Several recent Cloudflare innovations helped us overcome these challenges.
Securely invoking your Worker
In the Before Times (early 2022), invoking one Worker from another Worker meant a fresh HTTP call from inside your script. This was a brittle experience, requiring you to know your downstream endpoint at deployment time. Nested invocations ran as HTTP calls, passing all the way through the Cloudflare network a second time and adding latency to your request. It also meant security was on you – if you wanted to control how that second Worker was invoked, you had to create and implement your own authentication and authorization scheme.
Worker to Worker requests
During Platform Week in May 2022, Service Worker Bindings entered general availability. With Service Worker Bindings, your Worker code has a binding to another Worker in your account that you invoke directly, avoiding the network penalty of a nested HTTP call. This removes the performance and security barriers discussed previously, but it still requires that you hard-code your nested Worker at compile time. You can think of this setup as “static dispatch,” where your Worker has a static reference to another Worker where it can dispatch events.
Dynamic dispatch
As Service Worker Bindings entered general availability, we also launched a closed beta of Workers for Platforms, our tool suite to help make any product programmable. With Workers for Platforms, software as a service (SaaS) and platform providers can allow users to upload their own scripts and run them safely via Cloudflare Workers. User scripts are not known at compile time, but are dynamically dispatched at runtime.
Workers for Platforms entered general availability during GA week in September 2022, and is available for all customers to build with today.
With dynamic dispatch generally available, we now have the ability to discover and invoke Workers at runtime without the performance penalty of HTTP traffic over the network. We use dynamic dispatch to invoke your queue’s consumer Worker whenever a message or batch of messages is ready to be processed.
Consistent stateful data with Durable Objects
Another challenge we faced was storing messages durably without sacrificing performance. We took the design goal of ensuring that all messages were persisted to disk in multiple locations before we confirmed receipt of the message to the user. Again, we turned to an existing Cloudflare product—Durable Objects—which entered general availability nearly one year ago today.
Durable Objects are named instances of JavaScript classes that are guaranteed to be unique across Cloudflare’s entire network. Durable Objects process messages in-order and on a single-thread, allowing for coordination across messages and provide a strongly consistent storage API for key-value pairs. Offloading the hard problem of storing data durably in a distributed environment to Distributed Objects allowed us to reduce the time to build Queues and prepare it for open beta.
Open beta roadmap
Our open beta process empowers you to influence feature prioritization and delivery. We’ve set ambitious goals for ourselves on the path to general availability, most notably supporting unlimited throughput while maintaining 100% durability. We also have many other great features planned, like first-in first-out (FIFO) message processing and API compatibility layers to ease migrations, but we need your feedback to build what you need most, first.
Conclusion
Cloudflare Queues is a global message queue for the Workers developer. Building with Queues makes your applications more performant, resilient, and cost-effective—but we’re not done yet. Join the Open Beta today and share your feedback to help shape the Queues roadmap as we deliver application integration services for the next generation cloud.