Post Syndicated from DAMODAR SHENVI WAGLE original https://aws.amazon.com/blogs/devops/implementing-long-running-deployments-with-aws-cloudformation-custom-resources-using-aws-step-functions/
AWS CloudFormation custom resource provides mechanisms to provision AWS resources that don’t have built-in support from CloudFormation. It lets us write custom provisioning logic for resources that aren’t supported as resource types under CloudFormation. This post focusses on the use cases where CloudFormation custom resource is used to implement a long running task/job. With custom resources, you can manage these custom tasks (which are one-off in nature) as deployment stack resources.
The routine pattern used for implementing custom resources is via AWS Lambda function. However, when using the Lambda function as the custom resource provider, you must consider its trade-offs, such as its 15 minute timeout. Tasks involved in the provisioning of certain AWS resources can be long running and could span beyond the Lambda timeout. In these scenarios, you must look beyond the conventional Lambda function-based approach for custom resources.
In this post, I’ll demonstrate how to use AWS Step Functions to implement custom resources using AWS Cloud Development Kit (AWS CDK). Step Functions allow complex deployment tasks to be orchestrated as a step-by-step workflow. It also offers direct integration with any AWS service via AWS SDK integrations. By default the CloudFormation stack waits for 1 hour before timing out. The timeout can be increased to maximum 12 hours using wait conditions. In this post, you’ll also see how to use wait conditions with custom resource to run long running deployment tasks as part of a CloudFormation stack.
Prerequisites
Before proceeding any further, you must identify and designate an AWS account required for the solution to work. You must also create an AWS account profile in ~/.aws/credentials for the designated AWS account, if you don’t already have one. The profile must have sufficient permissions to run an AWS CDK stack. It should be your private profile and only be used during the course of this post. Therefore, it should be fine if you want to use admin privileges. Don’t share the profile details, especially if it has admin privileges. I recommend removing the profile when you’re finished with this walkthrough. For more information about creating an AWS account profile, see Configuring the AWS CLI.
Services and frameworks used in the post include CloudFormation, Step Functions, Lambda, DynamoDB, Amazon S3, and AWS CDK.
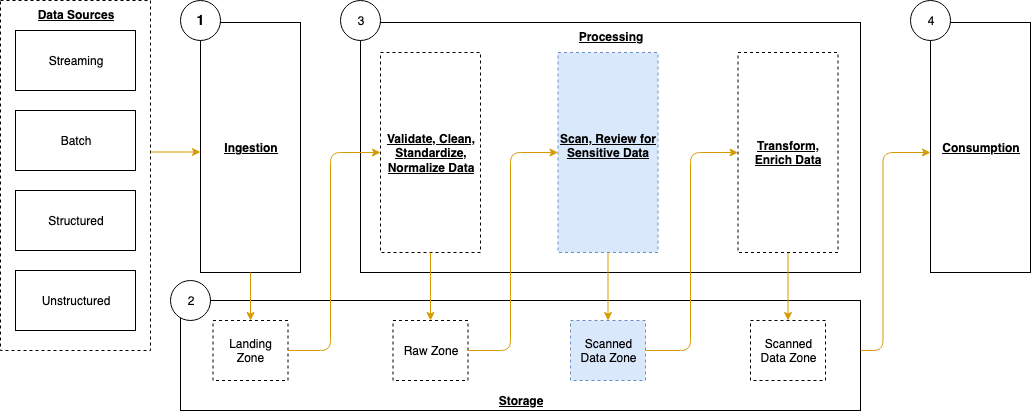
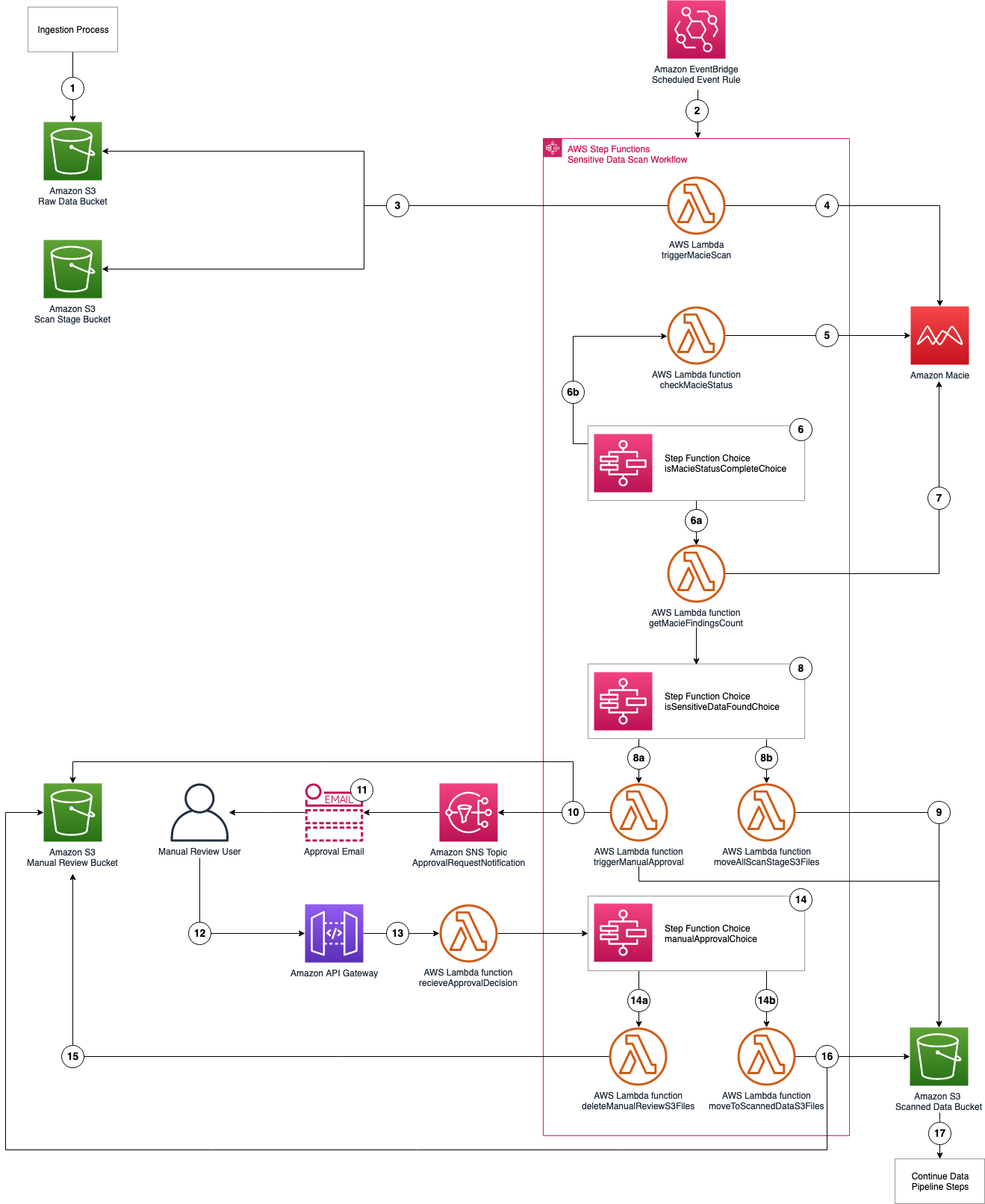
Solution overview
The following architecture diagram shows the application of Step Functions to implement custom resources.

Figure 1. Architecture diagram
- The user deploys a CloudFormation stack that includes a custom resource implementation.
- The CloudFormation custom resource triggers a Lambda function with the appropriate event which can be CREATE/UPDATE/DELETE.
- The custom resource Lambda function invokes Step Functions workflow and offloads the event handling responsibility. The CloudFormation event and context are wrapped inside the Step Function input at the time of invocation.
- The custom resource Lambda function returns SUCCESS back to CloudFormation stack indicating that the custom resource provisioning has begun. CloudFormation stack then goes into waiting mode where it waits for a SUCCESS or FAILURE signal to continue.
- In the interim, Step Functions workflow handles the custom resource event through one or more steps.
- Step Functions workflow prepares the response to be sent back to CloudFormation stack.
- Send Response Lambda function sends a success/failure response back to CloudFormation stack. This propels CloudFormation stack out of the waiting mode and into completion.
Solution deep dive
In this section I will get into the details of several key aspects of the solution
Custom Resource Definition
Following code snippet shows the custom resource definition which can be found here. Please note that we also define AWS::CloudFormation::WaitCondition and AWS::CloudFormation::WaitConditionHandle alongside the custom resource. AWS::CloudFormation::WaitConditionHandle resource sets up a pre-signed URL which is passed into the CallbackUrl property of the Custom Resource.
The final completion signal for the custom resource i.e. SUCCESS/FAILURE is received over this CallbackUrl. To learn more about wait conditions please refer to its user guide here. Note that, when updating the custom resource, you cannot use the existing WaitCondition-WaitConditionHandle resource pair. You need to create a new pair for tracking each update/delete operation on the custom resource.
/************************** Custom Resource Definition *****************************/
// When you intend to update CustomResource make sure that a new WaitCondition and
// a new WaitConditionHandle resource is created to track CustomResource update.
// The strategy we are using here is to create a hash of Custom Resource properties.
// The resource names for WaitCondition and WaitConditionHandle carry this hash.
// Anytime there is an update to the custom resource properties, a new hash is generated,
// which automatically leads to new WaitCondition and WaitConditionHandle resources.
const resourceName: string = getNormalizedResourceName('DemoCustomResource');
const demoData = {
pk: 'demo-sfn',
sk: resourceName,
ts: Date.now().toString()
};
const dataHash = hash(demoData);
const wcHandle = new CfnWaitConditionHandle(
this,
'WCHandle'.concat(dataHash)
)
const customResource = new CustomResource(this, resourceName, {
serviceToken: customResourceLambda.functionArn,
properties: {
DDBTable: String(demoTable.tableName),
Data: JSON.stringify(demoData),
CallbackUrl: wcHandle.ref
}
});
// Note: AWS::CloudFormation::WaitCondition resource type does not support updates.
new CfnWaitCondition(
this,
'WC'.concat(dataHash),
{
count: 1,
timeout: '300',
handle: wcHandle.ref
}
).node.addDependency(customResource)
/**************************************************************************************/
Custom Resource Lambda
Following code snippet shows how the custom resource lambda function passes the CloudFormation event as an input into the StepFunction at the time of invocation. CloudFormation event contains the CallbackUrl resource property I discussed in the previous section.
private async startExecution() { const input = { cfnEvent: this.event, cfnContext: this.context }; const params: StartExecutionInput = { stateMachineArn: String(process.env.SFN_ARN), input: JSON.stringify(input) }; let attempt = 0; let retry = false; do { try { const response = await this.sfnClient.startExecution(params).promise(); console.debug('Response: ' + JSON.stringify(response)); retry = false;
Custom Resource StepFunction
The StepFunction handles the CloudFormation event based on the event type. The CloudFormation event containing CallbackUrl is passed down the stages of StepFunction all the way to the final step. The last step of the StepFunction sends back the response over CallbackUrl via send-cfn-response lambda function as shown in the following code snippet.
/**
* Send response back to cloudformation
* @param event
* @param context
* @param response
*/
export async function sendResponse(event: any, context: any, response: any) {
const responseBody = JSON.stringify({
Status: response.Status,
Reason: "Success",
UniqueId: response.PhysicalResourceId,
Data: JSON.stringify(response.Data)
});
console.debug("Response body:\n", responseBody);
const parsedUrl = url.parse(event.ResourceProperties.CallbackUrl);
const options = {
hostname: parsedUrl.hostname,
port: 443,
path: parsedUrl.path,
method: "PUT",
headers: {
"content-type": "",
"content-length": responseBody.length
}
};
await new Promise(() => {
const request = https.request(options, function(response: any) {
console.debug("Status code: " + response.statusCode);
console.debug("Status message: " + response.statusMessage);
context.done();
})
request.on("error", function(error) {
console.debug("send(..) failed executing https.request(..): " + error);
context.done();
});
request.write(responseBody);
request.end();
});
return;
}Demo
Clone the GitHub repo cfn-custom-resource-using-step-functions and navigate to the folder cfn-custom-resource-using-step-functions. Now, execute the script script-deploy.sh by passing the name of the AWS profile that you created in the prerequisites section above. This should deploy the solution. The commands are shown as follows for your reference. Note that if you don’t pass the AWS profile name ‘default’ the profile will be used for deployment.
git clone
cd cfn-custom-resource-using-step-functions
./script-deploy.sh "<AWS- ACCOUNT-PROFILE-NAME>"
The deployed solution consists of 2 stacks as shown in the following screenshot
cfn-custom-resource-common-lib: Deploys common components- DynamoDB table that custom resources write to during their lifecycle events
- Lambda layer used across the rest of the stacks
cfn-custom-resource-sfn: Deploys Step Functions backed custom resource implementation

Figure 2. CloudFormation stacks deployed
For demo purposes, I implemented a custom resource that inserts data into the DynamoDB table. When you deploy the solution for the first time, like you just did in the previous step, it initiates a CREATE event resulting in the creation of a new custom resource using Step Functions. You should see a new record with unix epoch timestamp in the DynamoDB table, indicating that the resource was created as shown in the following screenshot. You can find the DynamoDB table name/arn from the SSM Parameter Store /CUSTOM_RESOURCE_PATTERNS/DYNAMODB/ARN

Figure 3. DynamoDB record indicating custom resource creation
Now, execute the script script-deploy.sh again. This should initiate an UPDATE event, resulting in the update of custom resources. The code also automatically creates new WaitConditionHandle and WaitCondition resources required to wait for the update event to finish. Now you should see that the records in the DynamoDb table have been updated with new values for lastOperation and ts attributes as follows.

Figure 4. DynamoDB record indicating custom resource update
Cleaning up
To remove all of the stacks, run the script script-undeploy.sh as follows.
./script-undeploy.sh "<AWS- ACCOUNT-PROFILE-NAME>"Conclusion
In this post I showed how to look beyond the conventional approach of building CloudFormation custom resources using a Lambda function. I discussed implementing custom resources using Step Functions and CloudFormation wait conditions. Try this solution in scenarios where you must execute a long running deployment task/job as part of your CloudFormation stack deployment.