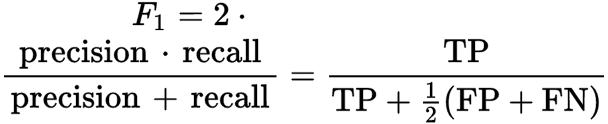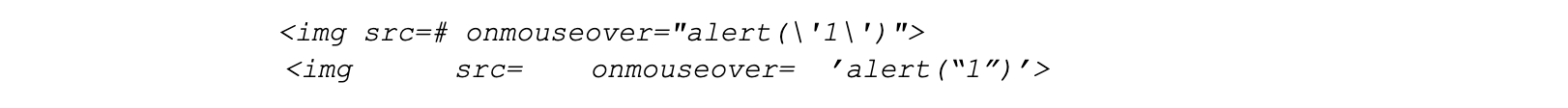The kernel is, in many ways, a marvel of scalability, but there is a
longstanding pain point in the memory-management subsystem that has
resisted all attempts at elimination: the mmap_lock. This lock
was inevitably a topic at the 2022 Linux
Storage, Filesystem, Memory-Management and BPF Summit (LSFMM), where the idea of
using per-VMA locks was raised. Suren Baghdasaryan has posted
an implementation of that idea — but with an interesting twist on how
those locks are implemented.
Monday’s crop of stable kernels consists of 5.19.7, 5.15.65, 5.10.141, 5.4.212, 4.19.257, 4.14.292, and 4.9.327. They are relatively small updates,
but still contain important fixes in various parts of the kernel tree;
users of those series should upgrade.
Developers use AWS Step Functions, a low-code visual workflow service to build distributed applications, automate IT and business processes, and orchestrate AWS services with minimal code. Step Functions Amazon States Language (ASL) provides a set of functions known as intrinsics that perform basic data transformations.
Customers have asked for additional intrinsics to perform more data transformation tasks, such as formatting JSON strings, creating arrays, generating UUIDs, and encoding data. We have added 14 new intrinsic functions to Step Functions. This blog post examines how to use intrinsic functions to optimize and simplify your workflows.
Why use intrinsic functions?
Intrinsic functions can allow you to reduce the use of other services, such as AWS Lambda or AWS Fargate to perform basic data manipulation. This helps to reduce the amount of code and maintenance in your application.
Intrinsics can also help reduce the cost of running your workflows by decreasing the number of states, number of transitions, and total workflow duration. This allows you to focus on delivering business value, using the time spent on writing custom code for more complex processing operations rather than basic transformations.
Using intrinsic functions
Amazon States Language is a JSON-based, structured language used to define Step Functions workflows. Each state within a workflow receives a JSON input and passes a JSON output to the next state.
ASL enables developers to filter and manipulate data at various stages of a workflow state’s execution using paths. A path is a string beginning with $ that lets you identify and filter subsets of JSON text. Learn how to apply these filters to build efficient workflows with minimal state transitions.
Apply intrinsics using ASL in task states within the ResultSelector field, or in a Pass state in either the Parameters or Result field. All intrinsic functions have the prefix “States.” followed by function, as shown in the following example, which uses the new UUID intrinsic for a generating Unique Universal ID:
Reducing execution duration with intrinsic functions to lower cost
The following example shows the cost and simplicity benefits of intrinsic functions. The same payload is input to both examples. One uses intrinsic functions, the other uses a Lambda function with custom code. This is an extract from a workflow that is used in production for Serverlesspresso, a serverless ordering system for a pop-up coffee bar. It sanitizes new customer orders against menu options stored in an Amazon DynamoDB table.
This example uses a Lambda function to unmartial data from a DynamoDB table and iterates through each item, checking if the order is present and therefore valid. This Lambda function has 18 lines of code with dependencies on an SDK library for DynamoDB operations.
The improved workflow uses a Map state to iterate through, and unmarshal DynamoDB data, and then an intrinsic function within a pass state to sanitize new customer orders against the menu options. Here, the intrinsic used is the new States. ArrayContains(). It searches an array for a value.
I run both workflows 1000 times. The following image from an Amazon CloudWatch dashboard shows their average execution time and billed execution time.
The billed execution time for the workflow using intrinsics is half that of the workflow using a Lambda function (100ms vs. 200ms).
These are Express Workflows, so the total workflow cost is calculated as execution cost + duration cost x number of requests. This means the workflow that uses intrinsics costs approximately half that of the one using Lambda. This doesn’t consider the additional cost associated with running Lambda functions. Read more about building cost efficient workflows from this blog post.
Cost saving: Reducing state transitions with intrinsic functions
The previous example shows how a single intrinsic function can have a large impact on workflow duration, which directly affects the cost of running an Express Workflow. Intrinsics can also help to reduce the number of states in a workflow. This directly affects the cost of running a Standard Workflow, which is billed on the number of state transitions.
The following example runs a sentiment analysis on a text input. If it detects negative sentiment, it invokes a Lambda function to generate a UUID; it saves the information to a DynamoDB table and notifies an administrator. The workflow then pauses using the .waitFortaskToken pattern. The workflow resumes when an administrator takes action, to either allow or deny a refund. The most common path through this workflow comprises 9 state transitions.
In the following example, I remove the Lambda function, which generates a UUID. It contained the following code:
var AWS = require ('aws-sdk');
exports. handler = async (event, context) => {
let r = Math.random().toString(36).substring(7);
return r;
};
Instead, I use the new States.UUID() intrinsic in the ResultPath of the DetectSentimentState.
This has reduced code, resources, and states. The reduction in states from 9 to 8 means that there is one less state transition in the workflow. This has a positive effect on the cost of my Standard Workflow, which is billed by the number of state transitions. It also means that there are no longer any costs incurred for running a Lambda function.
The new intrinsic functions
Standard Workflows, Express Workflows, and synchronous Express Workflows all support the new intrinsic functions. The new intrinsics can be grouped into six categories:
With the new intrinsic functions, you can do more with workflows. The following example shows how I apply the States.ArrayLength intrinsic function in the Serverlesspresso workflow to check how many instances of the workflow are currently running, and branch accordingly.
The Step Functions List executions SDK task is first used to retrieve a list of executions for the given state machine. I use the States.ArrayLength in the ResultsSelector path to retrieve the length of the response array (total number of executions). It passes the result to a choice state as a numerical constant, allowing the workflow to branch accordingly. Serverlesspresso uses this as a graceful denial of service mechanism, preventing a new customer order when there are too many orders currently in flight.
Conclusion
AWS has added an additional 14 intrinsic functions to Step Functions. These allow you to reduce the use of other services to perform basic data manipulations. This can help reduce workflow duration, state transitions, code, and additional resource management and configuration.
Apply intrinsics using ASL in Task states within the ResultSelector field, or in a Pass state in either the Parameters or Result field. Check the AWS intrinsic functions documentation for the complete list of intrinsics.
Visit the Serverless Workflows Collection to browse the many deployable workflows to help build your serverless applications.
At Cloudflare, we are always looking for ways to make our customers’ faster and more secure. A key part of that commitment is our ongoing investment in research and development of new technologies, such as the work on our machine learning based Web Application Firewall (WAF) solution we announced during security week.
In this blog, we’ll be discussing some of the data challenges we encountered during the machine learning development process, and how we addressed them with a combination of data augmentation and generation techniques.
Let’s jump right in!
Introduction
The purpose of a WAF is to analyze the characteristics of a HTTP request and determine whether the request contains any data which may cause damage to destination server systems, or was generated by an entity with malicious intent. A WAF typically protects applications from common attack vectors such as cross-site-scripting (XSS), file inclusion and SQL injection, to name a few. These attacks can result in the loss of sensitive user data and damage to critical software infrastructure, leading to monetary loss and reputation risk, along with direct harm to customers.
How do we use machine learning for the WAF?
The Cloudflare ML solution, at a high level, trains a classifier to distinguish between various traffic types and attack vectors, such as SQLi, XSS, Command Injection, etc. based on structural or statistical properties of the content. This is achieved by performing the following operations:
We inspect the raw HTTP input and perform some number of transformations on it such as normalization, content substitutions, or de-duplication.
Decompose or partition it via some process of tokenization, generate statistical information about the content, or extract structural data.
Compute optimal internal numerical representations of the inputs via the process of training the model. The nature of these internal representations depends on the class of model and architecture.
Learn to map internal content representations against classes (XSS, SQLi or others), scores or some other target of interest.
At run-time, use previously learned representations and mappings to analyze a new input and provide the most likely label or score for it. The score ranges from 1 to 99, with 1 indicating that the request is almost certainly malicious and 99 indicating that the request is probably clean.
This reasonable starting point stumbles immediately upon a critical challenge right from the start: we need high quality labeled data, and lots of it as that has the biggest impact on model performance. Contrary to well-researched fields like image recognition, text sentiment analysis, or classification, large datasets of HTTP requests with malicious payloads embedded are difficult to get.
To make matters even harder, strict implementation requirements for a production-quality WAF restrict the complexity of our potential ML models or architectures to ones that are relatively simple and light-weight, implying that we cannot simply pave over shortcomings of the data.
Data and challenges
The selection of a dataset is likely the most difficult of all the aspects that contribute to the final set of attributes of a machine learning model. In most cases, the model is tasked with learning the distribution of the data in some statistical sense, thus choosing and curating the dataset to ensure that the desired properties of the final solution are even possible to learn is incredibly crucial! ML models are only as reliable as the data used to train them. If we train an ML model on an incomplete dataset, or on data that doesn’t accurately represent the population, predictions might be inaccurate as they will be a direct reflection of the data.
To build a strong ML WAF, a good dataset must have large volumes of heterogeneous data covering malicious samples for all attack categories, a diverse set of negative/benign samples, and samples representing a broad spectrum of obfuscation techniques.
Due to those constraints, creating a solid dataset has a number of challenges:
Privacy
Privacy requirements limit data availability and how it can be used. Cloudflare has strict privacy guidelines and does not keep all request data – it simply isn’t available, and what is available must be carefully selected, anonymised, and stripped of sensitive information.
Heterogeneity of samples
Due to the wide assortment of potential request content types and forms, finding enough benign samples is difficult. Furthermore, it is challenging to collect data that represents requests with various charsets and content-encodings. Covering all attack configurations is also important because some attacks can be inserted into essentially any kind of request (e.g. five bytes in a huge “regular” request)
Sample difficulty
We want a dataset with a good mix of attack techniques and isn’t dominated by the ones that are easily generated by tools which simply swap out constants, transform expressions through invariants, and so on (sqli-fuzzer). Additionally, the vast majority of freely available samples in the wild are fairly trivial auto-generated payloads as part of indiscriminate scanning and discovery tools. They have very similar structural and statistical characteristics. Some of them are fairly old as well and do not reflect the current software landscape. How to “grade” the sample difficulty is not immediately obvious! What’s easy to a human may not be easy for a particular preprocessor/model, and vice-versa.
Noisy labels
Label noise affects results a lot, especially when it comes to esoteric, specific, or unusual attacks which are likely to be classified as benign by rules WAF.
What’s the strategy to overcome this?
Data augmentation
In simple terms, Data Augmentation is a process of generating artificial (but realistic) data to increase the diversity of our data by studying statistical distribution of existing real-world data.
This is crucial for us because one of the biggest concerns with rules-based WAFs is false positives. False positives are a serious challenge for WAFs because the risk of accidentally filtering legitimate traffic deters users from employing very strict rulesets. Data augmentation is used to build a solution that does not rely on observing specific high-risk keywords or character sequences, but instead uses a more holistic analysis of content and context, making it considerably less likely to block legitimate requests.
There are many sequences of characters which appear almost exclusively in payloads, but are themselves not dangerous. In order to reduce false positives and improve overall performance, we focussed on generating a lot of heterogeneous negative samples to force the model to consider the structural, semantic, and statistical properties of the content when making a classification decision.
In the context of our data and use cases, data augmentation means that we mutate benign content in a variety of ways as the content will remain benign (this isn’t going to accidentally turn it into a valid payload, with probability 1). For instance, we can add random character noise, permute keywords, merge benign content together from multiple sources, and so on. Alternatively, we can seed benign content with ‘dangerous’ keywords or ngrams frequently occuring in payloads – this results in a benign sample, but ideally will teach the model not to be too sensitive to the presence of malicious tokens lacking the proper semantics and structure.
Benign content
First and foremost, generating benign content is way easier. Mutating a malicious block of content into different malicious blocks is difficult because malicious payloads have a stricter grammar and syntax than general HTTP content due to the fact that it has code, therefore they must be manipulated in a specific manner.
However, there are a few options if we want to do this in the future. Tools like sqli-fuzzer, automates the process of fuzzing a given payload by applying transformations which preserve the underlying semantics while changing the representation or adding obfuscation. Outside existing third-party tools, it’s possible to generate our own malicious payloads using various “append malicious content to non-malicious content” techniques, with the trade off that this doesn’t actually generate *new* malicious content, just puts it into a different context.
Pseudo-random noise samples
A useful approach we identified for bolstering the number of negative training samples was to generate large quantities of pseudo-random strings of increasing complexity.
The probability of any pseudo-random string (drawn from essentially any token distribution) being a valid payload or malicious attack is essentially zero, but we can build a series of token sampling distributions that make it increasingly difficult for the model to distinguish them from a real payload, and we discovered that this resulted in dramatically better performance in terms of false positive rate, robustness, and overall model properties.
This approach works by taking a collection of tokens and a probability distribution over these tokens, and independently sampling a stream of tokens from it to create our ‘sample’. Each sample length is selected from a separate discrete sample length distribution.
For an extremely simple example, we could take a token collection consisting of ASCII characters and a uniform sampling distribution:
We wouldn’t expect even a very simple model to struggle to learn that these samples are benign, but as we increase the complexity of the token collections, we can move towards much more ‘difficult’ noise examples, including elements such as: fragments of valid URIs, user agents, XML/XSLT content or even restricted language identifiers, or keywords.
Here are some examples of more complex token collections and the kinds of random strings they produce as our negative samples:
alphanumerics, plus special characters, plus a variant of full javascript or sql keywords and (multi-character) sub-token fragments
It’s fairly straightforward to construct a suite of these noise generators of varying complexity, and targeting different types of content: JSON, XML, URIs with SQL-esque ‘noise’, and so on. As the strings get sufficiently long, the probability that they will contain at least some dangerous looking subsequences grows, so it’s also an excellent test of model robustness.
We make extensive use of noise strings to enhance the core dataset used for training and testing the model by directly training the model on increasingly difficult noise before fine-tuning on exclusively real data, appending noise of varying complexity to malicious(real) samples or benign samples to both induce and test for model robustness for padding attacks, and estimating false positive rate for certain classes of benign content.
Beyond independent sampling of random strings?
A natural extension to the above method for generating pseudo-random strings is to drop the ‘independence’ assumption for sampling tokens. This means that we’re starting to emulate the process by which real data is generated, to some extent, yielding samples with increasingly realistic local (and eventually global) structure. Some approaches for this might include a simple Markov chain, and extend all the way to state-of-the-art Large Language Models.
We experimented with using contemporary autoregressive language models trained on our corpus of real malicious payloads and found it extremely effective at generating novel payloads, as well as transforming payloads into sophisticated obfuscated representations. As the language models approached convergence on the data the likelihood of each sample being a valid payload approached 100%, allowing us to use early samples as ‘extremely strong negatives’ and the later samples as positive samples. The success of this work has suggested that deeper investigation into the use of language models for security analysis may be fruitful, not only for training classifiers, but also for creating powerful adversarial pen-testing agents.
Results summary
Let’s see a comparative summary of results and improvements, before and after the augmentation:
Model performance on evaluation metrics
The effectiveness of machine learning models for classification problems can be evaluated using a wide range of metrics, including accuracy, precision, recall, F1 Score, and others. It is important to note that in addition to using quantitative metrics, we also consider the model’s general properties and behavioral constraints. This criteria and metrics-based approach is especially important in our domain where data is inherently noisy, labels are not trustworthy, the domain of the inputs is extremely large, and hard to cover with samples.
For this post, we will concentrate on key quantitative metrics like F1 score even though we examine a variety of metrics to assess the model performance. F1 score is the weighted average (harmonic mean) of precision and recall. We can represent the F1 score with the formula:
Where,
True Positives (TP): malicious content classified correctly by the model
False Positives (FP): benign content that the model classified as malicious
True Negatives (TN): benign content classified correctly by the model
False Negatives (FN): malicious content that the model classified as benign
Since this formula takes false positives and false negatives into consideration, this score is more reliable than other metrics. There are a few methods to calculate this for multi-class problems, like Macro F1 Score, Micro F1 Score and Weighted F1 Score. Although each method has advantages and disadvantages, we obtained nearly identical results with all three methods. Below are the numbers:
Without Augmentation
With Augmentation
Class
Precision
Recall
F1 Score
Precision
Recall
F1 Score
Benign
0.69
0.17
0.27
0.98
1.00
0.99
SQLi
0.77
0.96
0.85
1.00
1.00
1.00
XSS
0.56
0.94
0.70
1.00
0.98
0.99
Total(Micro Average)
0.67
0.99
Total(Macro Average)
0.67
0.69
0.61
0.99
0.99
0.99
Total(Weighted Average)
0.68
0.67
0.60
0.99
0.99
0.99
The important takeaway is that the range of this F1 score is best at 1 and worst at 0.
The model after augmentation appears to have similar precision and recall with good overall performance, as indicated by a value of 0.99 after augmentation, compared to 0.61 for Macro F1.
So far in the results summary, we’ve only discussed F1 Score; however, there are other improvements in characteristics that we’ve observed in the model that are listed below:
False positive characteristics
Estimated false positive rate reduced by approximately 80% on test data sets. There are significantly fewer false positives involving PromQL and other SQL-structured analogues. PromQL examples result in high scores and are classified correctly:
Today, the only major category of false positives are literal SQL or JavaScript files.
General false positive rate on noise from JSON-esque, XML/SOAP-esque, and SQL-esque content-generators reduced to about a 1/100,000 rate from about 1/50 to 1/1.
True positive characteristics
True positive rate for highly fuzzed content is vastly improved. Models trained solely on real data were easily bypassed by advanced fuzzing tools, whereas models trained on real plus augmented data are extremely resistant, with many payloads receiving higher risk scores as fuzzing increases. Examples:
These yield approximately same scores as they are a result of only a few byte alterations
Proportion of client-provided test sets that primarily contain payloads not blocked by rules-waf for XSS/SQLi successfully classified is about 97.5% (with the remaining 2.5% being arguable) up from about 91%.
Padding a payload with almost any amount of ASCII, JSON-esque, special-characters, or other content will not reduce the risk score substantially. Due to the addition of hard noise long length augmented training samples, even a six byte payload in a 100 kilobyte string will be caught. Examples:
They both generate similar scores even though the latter has junk padding around the payload.
Execution performance
Runtime characteristics are unchanged for inference.
On top of that, we validated the model against the Cloudflare’s highly mature signature-based WAF and confirmed that machine learning WAF performs comparable to signature WAF, with the ML WAF demonstrating its strength particularly in cases of correctly handling highly obfuscated or irregularly fuzzed content (as well as avoiding some rules-based engine false positives). Finally, we were able to conclude that augmentation helps in improving the model performance and induce the right set of properties.
Conclusion
We built a machine learning powered WAF, with the substantial challenge to gather a diversified training set, given constraints to avoid sensitive real customer data for privacy and regulatory considerations. To create a broader and diversified dataset without requiring vast amounts of sensitive data, we used techniques such as fuzzing, data augmentation, and synthetic data generation. This allowed us to improve the solution’s false positive robustness and overall model performance.
Furthermore, these techniques reduced the time complexity required to retrieve/clean real data, and helped induce the correct model behavior. In the future, we intend to investigate autoregressive language models to generate synthetic pseudo-valid payloads.
The 6.0-rc4 kernel prepatch is out for
testing. “We’re up to rc4, and things mostly still look fairly
normal“.
Beyond the usual fixes, 6.0-rc4 includes one feature change: a hook to allow
security modules to control access to the io_uring command pass-through
mechanism. See this article for the
background behind this late-arriving change.
Peter Eckersley, one of the original founders of the Let’s Encrypt non-profit TLS certificate authority, has died suddenly, as reported by Seth Schoen:
Peter was the leader of EFF’s contributions to Let’s Encrypt and ACME over the course of several years during which these technologies turned from a wild idea into an important part of Internet infrastructure. He also took a lot of initiative in coalescing the EFF, Mozilla, and University of Michigan teams into a single team and a single project. He later served on the initial board of directors of the Internet Security Research Group.
[…]
Toward the end of his life, Peter focused his career on ethics and safety of artificial intelligence, and he founded the AI Objectives Institute to examine the concrete parallels he saw between surprising and undesirable outcomes that can emerge within economies and those that can emerge in machine learning systems.
We have blocked Kiwifarms. Visitors to any of the Kiwifarms sites that use any of Cloudflare’s services will see a Cloudflare block page and a link to this post. Kiwifarms may move their sites to other providers and, in doing so, come back online, but we have taken steps to block their content from being accessed through our infrastructure.
This is an extraordinary decision for us to make and, given Cloudflare’s role as an Internet infrastructure provider, a dangerous one that we are not comfortable with. However, the rhetoric on the Kiwifarms site and specific, targeted threats have escalated over the last 48 hours to the point that we believe there is an unprecedented emergency and immediate threat to human life unlike we have previously seen from Kiwifarms or any other customer before.
Escalating threats
Kiwifarms has frequently been host to revolting content. Revolting content alone does not create an emergency situation that necessitates the action we are taking today. Beginning approximately two weeks ago, a pressure campaign started with the goal to deplatform Kiwifarms. That pressure campaign targeted Cloudflare as well as other providers utilized by the site.
Cloudflare provides security services to Kiwifarms, protecting them from DDoS and other cyberattacks. We have never been their hosting provider. As we outlined last Wednesday, we do not believe that terminating security services is appropriate, even to revolting content. In a law-respecting world, the answer to even illegal content is not to use other illegal means like DDoS attacks to silence it.
We are also not taking this action directly because of the pressure campaign. While we have empathy for its organizers, we are committed as a security provider to protecting our customers even when they run deeply afoul of popular opinion or even our own morals. The policy we articulated last Wednesday remains our policy. We continue to believe that the best way to relegate cyberattacks to the dustbin of history is to give everyone the tools to prevent them.
However, as the pressure campaign escalated, so did the rhetoric on the Kiwifarms site. Feeling attacked, users of the site became even more aggressive. Over the last two weeks, we have proactively reached out to law enforcement in multiple jurisdictions highlighting what we believe are potential criminal acts and imminent threats to human life that were posted to the site.
Legal process
While law enforcement in these areas are working to investigate what we and others reported, unfortunately the process is moving more slowly than the escalating risk. While we believe that in every other situation we have faced — including the Daily Stormer and 8chan — it would have been appropriate as an infrastructure provider for us to wait for legal process, in this case the imminent and emergency threat to human life which continues to escalate causes us to take this action.
Hard cases make bad law. This is a hard case and we would caution anyone from seeing it as setting precedent. The policies we articulated last Wednesday remain our policies. For an infrastructure provider like Cloudflare, legal process is still the correct way to deal with revolting and potentially illegal content online.
But we need a mechanism when there is an emergency threat to human life for infrastructure providers to work expediently with legal authorities in order to ensure the decisions we make are grounded in due process. Unfortunately, that mechanism does not exist and so we are making this uncomfortable emergency decision alone.
Not the end
Finally, we are aware and concerned that our action may only fan the flames of this emergency. Kiwifarms itself will most likely find other infrastructure that allows them to come back online, as the Daily Stormer and 8chan did themselves after we terminated them. And, even if they don’t, the individuals that used the site to increasingly terrorize will feel even more isolated and attacked and may lash out further. There is real risk that by taking this action today we may have further heightened the emergency.
We will continue to work proactively with law enforcement to help with their investigations into the site and the individuals who have posted what may be illegal content to it. And we recognize that while our blocking Kiwifarms temporarily addresses the situation, it by no means solves the underlying problem. That solution will require much more work across society. We are hopeful that our action today will help provoke conversations toward addressing the larger problem. And we stand ready to participate in that conversation.
Arti is a reimplementation of the Tor server in Rust; version 1.0.0 has
just been released and proclaimed ready for production use.
When we defined our set of milestones, we defined Arti 1.0.0 as
“ready for production use”: You should be able to use it in the
real world, to get a similar degree of privacy, usability, and
stability to what you would with a C client Tor. The APIs should be
(more or less) stable for embedders.
We believe we have achieved this. You can now use arti
proxy to
connect to the Tor network to anonymize your network connections.
This week Metasploit has a new ICPR Certificate Management module from Oliver Lyak and our very own Spencer McIntyre, which can be utilized for issuing certificates via Active Directory Certificate Services. It has the capability to issue certificates which is useful in a few contexts including persistence, ESC1 and as a primitive necessary for exploiting CVE-2022-26923. Resulting in the PFX certificate file being stored to loot and is encrypted using a blank password.
ManageEngine ADAudit Plus and DataSecurity Plus Xnode enum
Another addition thanks to Erik Wynter and Sahil Dhar, that brings two new auxiliary/gather modules and docs that take advantage of default Xnode credentials (CVE-2020–11532) in order to enumerate active directory information and other sensitive data via the DataEngine Xnode server (Xnode). Because both modules rely on the same code to interact with Xnode, this change also adds a mixin at lib/msf/core/auxiliary/manageengine_xnode that is leveraged by both modules (plus by a third module that will be part of a separate PR). Both modules also come with configuration files to determine what data will be enumerated from Xnode. The PR contains even more information on the vulnerable systems and extensive notes!
New module content (5)
ICPR Certificate Management by Oliver Lyak and Spencer McIntyre – This adds a module for issuing certificates via Active Directory Certificate Services, which is useful in a few contexts including persistence and for some specific exploits. The resulting PFX certificate file is stored to the loot and is encrypted using a blank password.
ManageEngine ADAudit Plus Xnode Enumeration by Erik Wynter and Sahil Dhar, which exploits CVE-2020-11532 – Two new auxiliary/gather modules have been added that take advantage of default Xnode credentials, aka CVE-2020–11532, in order to enumerate Active Directory information and other sensitive data via the DataEngine Xnode server. Additionally, a new library has been added to provide reusable functionality for interacting with Xnode servers.
ManageEngine DataSecurity Plus Xnode Enumeration by Erik Wynter and Sahil Dhar, which exploits CVE-2020-11532 – Two new auxiliary/gather modules have been added that take advantage of default Xnode credentials, a.k.a CVE-2020–11532, in order to enumerate Active Directory information and other sensitive data via the DataEngine Xnode server. Additionally, a new library has been added to provide reusable functionality for interacting with Xnode servers.
Zyxel Firewall SUID Binary Privilege Escalation by jbaines-r7, which exploits CVE-2022-30526 – This adds an LPE exploit for Zyxel Firewalls that can allow a user to escalate themselves to root. The vulnerability is identified as CVE-2022-30526 and is due to a suid binary that allows any user to copy files with root permissions.
CVE-2022-30190 AKA Follina by bwatters-r7 – This updates the exploit for CVE-2022-30190 (A.K.A Follina) to support generating RTF exploit documents. RTF documents are helpful for not only being another exploit vector, but they will trigger the payload execution when viewed by Explorer’s preview tab without needing user interaction to enable editing functionality.
Enhancements and features (4)
#16746 from adfoster-r7 – This updates the MSSQL login scanner to catch exceptions and continue running.
#16900 from bcoles – This adds a new #kill_process method that supports shell, PowerShell, and Meterpreter sessions on different platforms.
#16903 from bcoles – This cleans up the enum_shares post modules and adds support for shell sessions.
#16959 from adfoster-r7 – The time command has been updated with the --cpu and --memory profiler options to allow users to get memory and CPU usage profiles when running a command inside msfconsole.
Bugs fixed (5)
#16750 from bojanisc – This updates the exploit/multi/http/jenkins_script_console module to use the decoder from the java.util.Base64 class in place of the now-deprecated decoder from the sun.misc.BASE64Decoder class, enabling exploitation of newer Jenkins versions.
#16869 from bcoles – This fixes an issue in the file_remote_digestmd5() and file_remote_digestsha1() methods where read_file() would return an error message instead of the remote file contents. Additionally, the file_remote_digest* methods now support more session types, and they have a new util option that allows the user to perform the hashing on the remote host instead of downloading the remote file and performing the hashing locally.
#16918 from rbowes-r7 – A bug has been fixed in the module for CVE-2022-30333 whereby if the server responded with a 200 OK response, the module would keep trying to trigger the payload. This would lead to multiple sessions being returned when only one was desired.
#16920 from zeroSteiner – A typo has been fixed in _msfvenom that prevented ZSH autocompletion from working when using the --arch argument with msfvenom.
#16955 from gwillcox-r7 – This fixes an issue in the LDAP query module that would cause issues if the user queried for a field that was populated with binary data.
Get it
As always, you can update to the latest Metasploit Framework with msfupdate
and you can get more details on the changes since the last blog post from
GitHub:
[Pull Requests 6.2.14…6.2.15][prs-landed]
[Full diff 6.2.14…6.2.15][diff]
If you are a git user, you can clone the [Metasploit Framework repo][repo] (master branch) for the latest.
To install fresh without using git, you can use the open-source-only [Nightly Installers][nightly] or the
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.