Post Syndicated from Sarah Khalife original https://github.blog/2020-10-09-devops-cloud-testing/
See this post in action during GitHub Demo Days on October 16.
What makes a project successful? For developers building cloud-native applications, successful projects thrive on transparent, consistent, and rigorous collaboration. That collaboration is one of the reasons that many open source projects, like Docker containers and Kubernetes, grow to become standards for how we build, deliver, and operate software. Our Open Source Guides and Introduction to innersourcing are great first steps to setting up and encouraging these best practices in your own projects.
However, a common challenge that application developers face is manually testing against inconsistent environments. Accurately testing Kubernetes applications can differ from one developer’s environment to another, and implementing a rigorous and consistent environment for end-to-end testing isn’t easy. It can also be very time consuming to spin up and down Kubernetes clusters. The inconsistencies between environments and the time required to spin up new Kubernetes clusters can negatively impact the speed and quality of cloud-native applications.
Building a transparent CI process
On GitHub, integration and testing becomes a little easier by combining GitHub Actions with open source tools. You can treat Actions as the native continuous integration and continuous delivery (CI/CD) tool for your project, and customize your Actions workflow to include automation and validation as next steps.
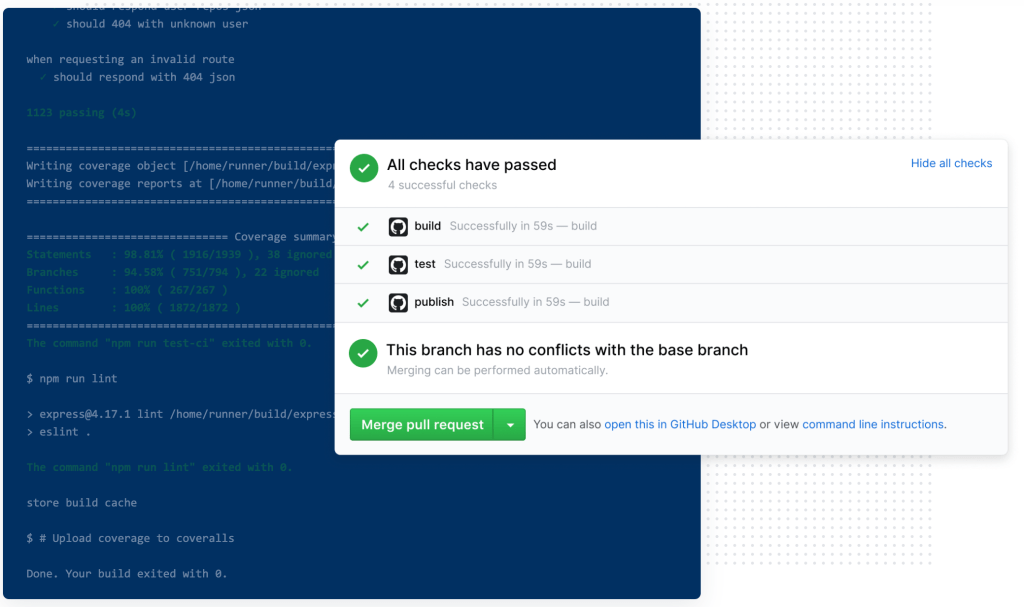
Since Actions can be triggered based on nearly any GitHub event, it’s also possible to build in accountability for updating tests and fixing bugs. For example, when a developer creates a pull request, Actions status checks can automatically block the merge if the test fails.
Here are a few more examples:

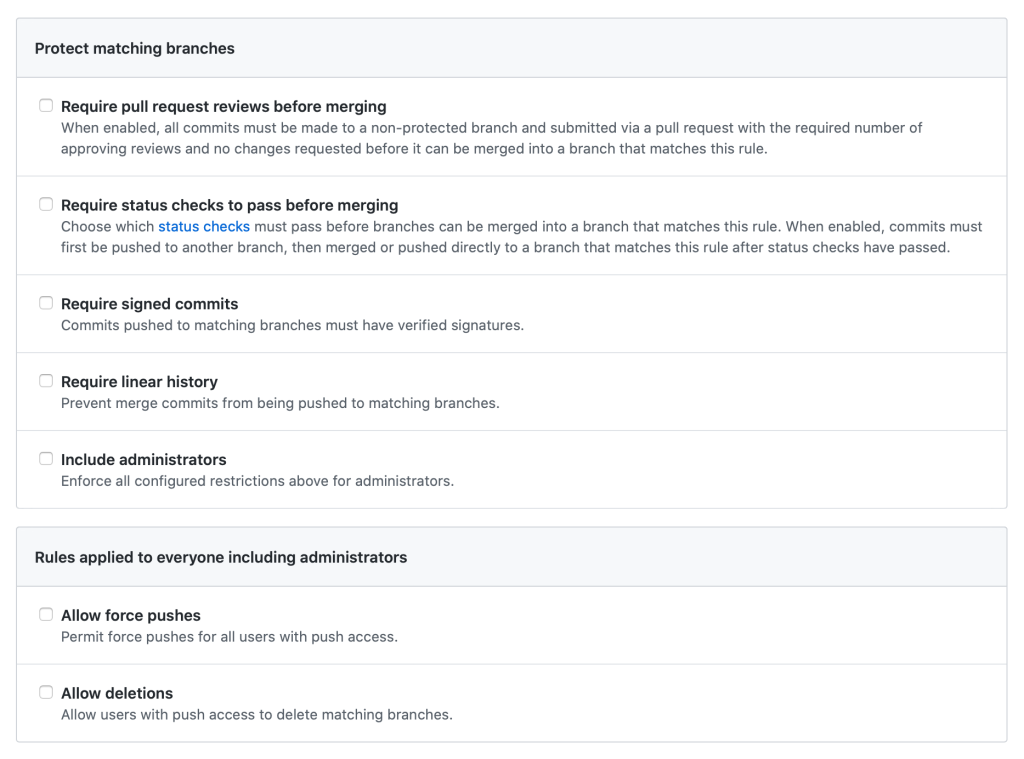
Branch protection rules in the repository help enforce certain workflows, such as requiring more than one pull request review or requiring certain status checks to pass before allowing a pull request to merge.

GitHub Actions are natively configured to act as status checks when they’re set up to trigger `on: [pull_request]`.
Continuous integration (CI) is extremely valuable as it allows you to run tests before each pull request is merged into production code. In turn, this will reduce the number of bugs that are pushed into production and increases confidence that newly introduced changes will not break existing functionality.
But transparency remains key: Requiring CI status checks on protected branches provides a clearly-defined, transparent way to let code reviewers know if the commits meet the conditions set for the repository—right in the pull request view.
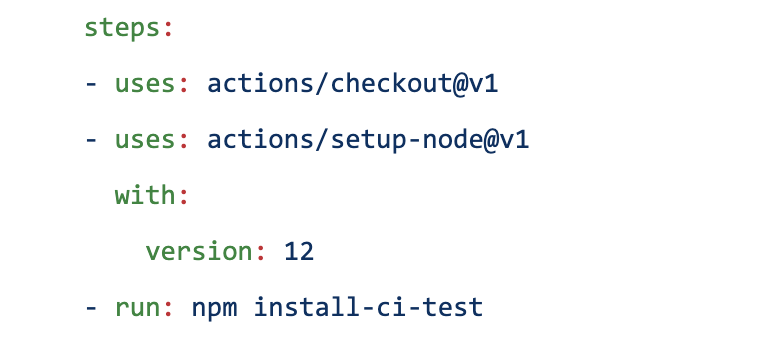
Now that we’ve thought through the simple CI policies, automated workflows are next. Think of an Actions workflow as a set of “plug and play” open sourced, automated steps contributed by the community. You can use them as they are, or customize and make them your own. Once you’ve found the right one, open sourced Actions can be plugged into your workflow with the`- uses: repo/action-name` field.

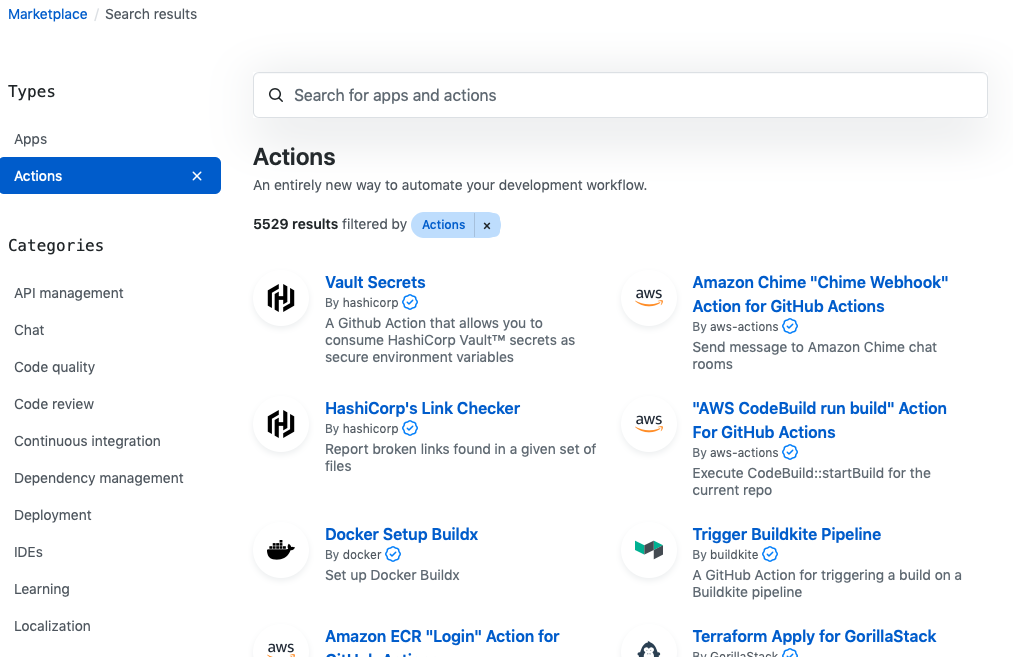
You might ask, “So how do I find available Actions that suit my needs?”
The GitHub Marketplace!

As you’re building automation and CI pipelines, take advantage of Marketplace to find pre-built Actions provided by the community. Examples of pre-built Actions span from a Docker publish and the kubectl CLI installation to container scans and cloud deployments. When it comes to cloud-native Actions, the list keeps growing as container-based development continues to expand.
Testing with kind
Testing is a critical part of any CI/CD pipeline, but running tests in Kubernetes can absorb the extra time that automation saves. Enter kind. kind stands for “Kubernetes in Docker.” It’s an open source project from the Kubernetes special interest group (SIGs) community, and a tool for running local Kubernetes clusters using Docker container “nodes.” Creating a kind cluster is a simple way to run Kubernetes cluster and application testing—without having to spin up a complete Kubernetes environment.

As the number of Kubernetes users pushing critical applications to production grows, so does the need for a repeatable, reliable, and rigorous testing process. This can be accomplished by combining the creation of a homogenous Kubernetes testing environment with kind, the community-powered Marketplace, and the native and transparent Actions CI process.
Bringing it all together with kind and Actions
Come see kind and Actions at work during our next GitHub Demo Day live stream on October 16, 2020 at 11am PT. I’ll walk you through how to easily set up automated and consistent tests per pull request, including how to use kind with Actions to automatically run end-to-end tests across a common Kubernetes environment.