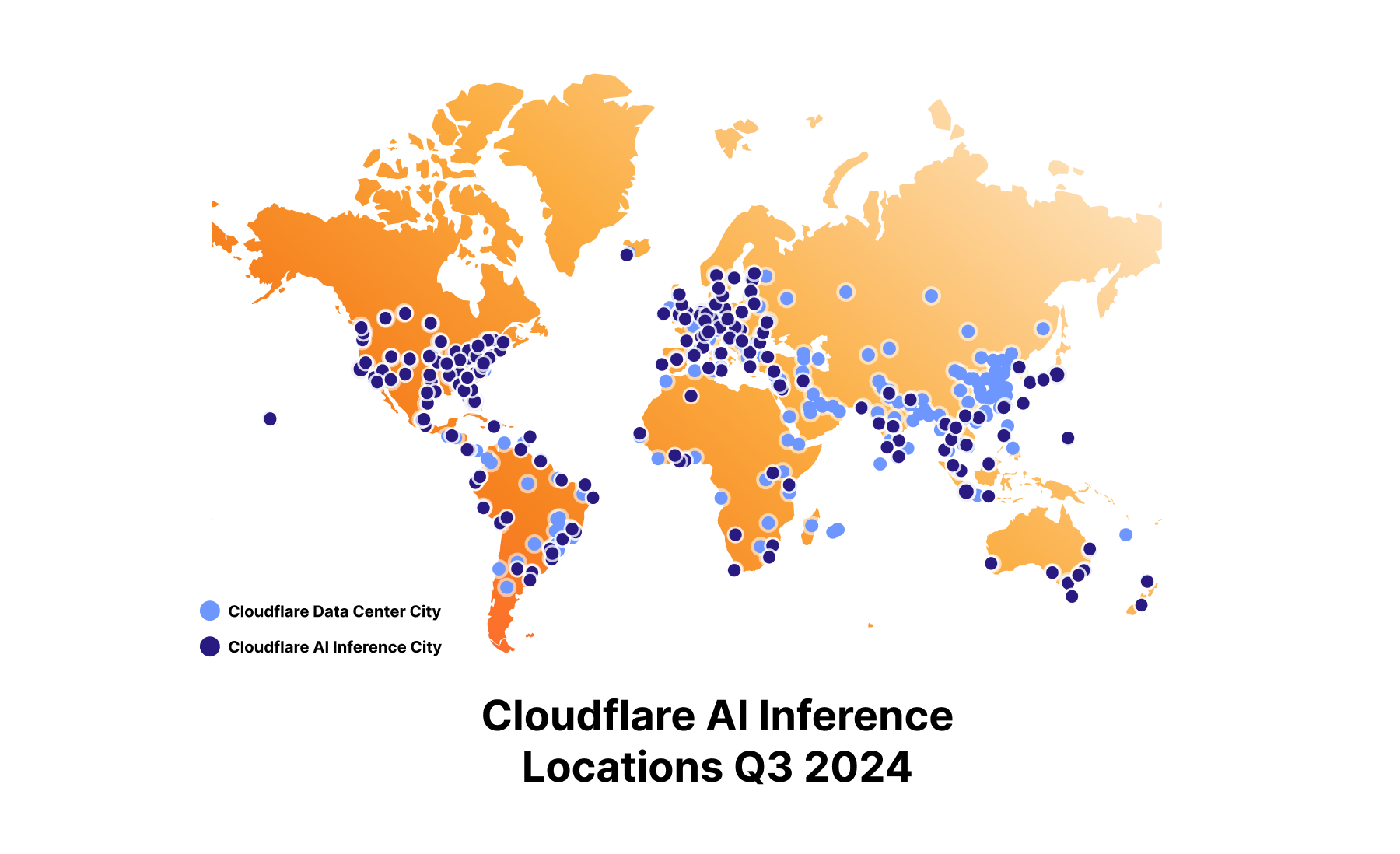
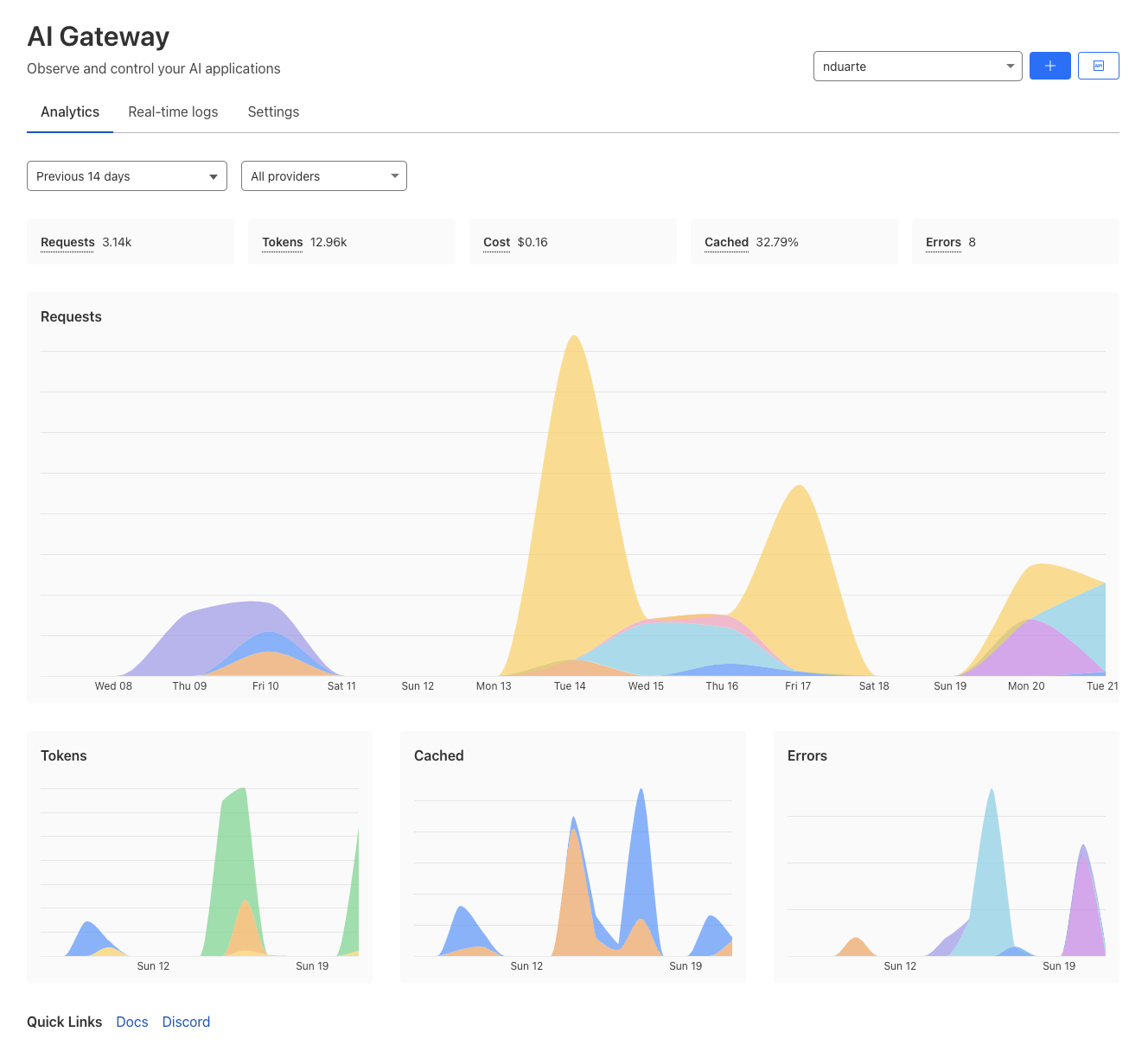
How do we embrace the power of AI without losing control?
That was one of our big themes for AI Week 2025, which has now come to a close. We announced products, partnerships, and features to help companies successfully navigate this new era.
Everything we built was based on feedback from customers like you that want to get the most out of AI without sacrificing control and safety. Over the next year, we will double down on our efforts to deliver world-class features that augment and secure AI. Please keep an eye on our Blog, AI Avenue, Product Change Log and CloudflareTV for more announcements.
This week we focused on four core areas to help companies secure and deliver AI experiences safely and securely:
Securing AI environments and workflows
Protecting original content from misuse by AI
Helping developers build world-class, secure, AI experiences
Making Cloudflare better for you with AI
Thank you for following along with our first ever AI week at Cloudflare. This recap blog will summarize each announcement across these four core areas. For more information, check out our “This Week in NET” recap episode also featured at the end of this blog.
Securing AI environments and workflows
These posts and features focused on helping companies control and understand their employee’s usage of AI tools.
Generative AI tools present a trade-off of productivity and data risk. Cloudflare One’s new AI prompt protection feature provides the visibility and control needed to govern these tools, allowing organizations to confidently embrace AI.
Don’t let “Shadow AI” silently leak your data to unsanctioned AI. This new threat requires a new defense. Learn how to gain visibility and control without sacrificing innovation.
Cloudflare will provide confidence scores within our application library for Gen AI applications, allowing customers to assess their risk for employees using shadow IT.
Cloudflare CASB now scans ChatGPT, Claude, and Gemini for misconfigurations, sensitive data exposure, and compliance issues, helping organizations adopt AI with confidence.
Cloudflare MCP Server Portals are now available in Open Beta. MCP Server Portals are a new capability that enable you to centralize, secure, and observe every MCP connection in your organization.
This guide provides best practices for Security and IT leaders to securely adopt generative AI using Cloudflare’s SASE architecture as part of a strategy for AI Security Posture Management (AI-SPM).
Protecting original content from misuse by AI
Cloudflare is committed to helping content creators control access to their original work. These announcements focused on analysis of what we’re currently seeing on the Internet with respect to AI bots and crawlers and significant improvements to our existing control features.
We are extending AI-related insights on Cloudflare Radar with new industry-focused data and a breakdown of bot traffic by purpose, such as training or user action.
Cloudflare now lets websites and bot creators use Web Bot Auth to segment agents from verified bots, making it easier for customers to allow or disallow the many types of user and partner directed.
By mid-2025, training drives nearly 80% of AI crawling, while referrals to publishers (especially from Google) are falling and crawl-to-refer ratios show AI consumes far more than it sends back.
Helping developers build world-class, secure, AI experiences
At Cloudflare we are committing to building the best platform to build AI experiences, all with security by default.
Infire is an LLM inference engine that employs a range of techniques to maximize resource utilization, allowing us to serve AI models more efficiently with better performance for Cloudflare workloads.
We’re expanding Workers AI with new partner models from Leonardo.Ai and Deepgram. Start using state-of-the-art image generation models from Leonardo and real-time TTS and STT models from Deepgram.
Cloudflare built an internal platform called Omni. This platform uses lightweight isolation and memory over-commitment to run multiple AI models on a single GPU.
In AI Avenue, we address people’s fears, show them the art of the possible, and highlight the positive human stories where AI is augmenting — not replacing — what people can do. And yes, we even let people touch AI themselves.
Today, we’re excited to announce new capabilities that make it easier than ever to build real-time, voice-enabled AI applications on Cloudflare’s global network.
Making Cloudflare better for you with AI
Cloudflare logs and analytics can often be a needle in the haystack challenge, AI helps surface and alert to issues that need attention or review. Instead of a human having to spend hours sifting and searching for an issue, they can focus on action and remediation while AI does the sifting.
Cloudy now supercharges analytics investigations and Cloudforce One threat intelligence! Get instant insights from threat events and APIs on APTs, DDoS, cybercrime & more – powered by Workers AI!
Troubleshoot network connectivity issues by using Cloudflare AI-Power to quickly self diagnose and resolve WARP client and network issues.
We thank you for following along this week — and please stay tuned for exciting announcements coming during Cloudflare’s 15th birthday week in September!
Check out the full video recap, featuring insights from Kenny Johnson and host João Tomé, in our special This Week in NET episode (ThisWeekinNET.com) covering everything announced during AI Week 2025.
Getting the observability you need is challenging enough when the code is deterministic, but AI presents a new challenge — a core part of your user’s experience now relies on a non-deterministic engine that provides unpredictable outputs. On top of that, there are many factors that can influence the results: the model, the system prompt. And on top of that, you still have to worry about performance, reliability, and costs.
Solving performance, reliability and observability challenges is exactly what Cloudflare was built for, and two years ago, with the introduction of AI Gateway, we wanted to extend to our users the same levels of control in the age of AI.
Today, we’re excited to announce several features to make building AI applications easier and more manageable: unified billing, secure key storage, dynamic routing, security controls with Data Loss Prevention (DLP). This means that AI Gateway becomes your go-to place to control costs and API keys, route between different models and providers, and manage your AI traffic. Check out our new AI Gateway landing page for more information at a glance.
Connect to all your favorite AI providers
When using an AI provider, you typically have to sign up for an account, get an API key, manage rate limits, top up credits — all within an individual provider’s dashboard. Multiply that for each of the different providers you might use, and you’ll soon be left with an administrative headache of bills and keys to manage.
With AI Gateway, you can now connect to major AI providers directly through Cloudflare and manage everything through one single plane. We’re excited to partner with Anthropic, Google, Groq, OpenAI, and xAI to provide Cloudflare users with access to their models directly through Cloudflare. With this, you’ll have access to over 350+ models across 6 different providers.
You can now get billed for usage across different providers directly through your Cloudflare account. This feature is available for Workers Paid users, where you’ll be able to add credits to your Cloudflare account and use them for AI inference to all the supported providers. You’ll be able to see real-time usage statistics and manage your credits through the AI Gateway dashboard. Your AI Gateway inference usage will also be documented in your monthly Cloudflare invoice. No more signing up and paying for each individual model provider account.
Usage rates are based on then-current list prices from model providers — all you will need to cover is the transaction fee as you load credits into your account. Since this is one of the first times we’re launching a credits based billing system at Cloudflare, we’re releasing this feature in Closed Beta — sign up for access here.
BYO Provider Keys, now with Cloudflare Secrets Store
Although we’ve introduced unified billing, some users might still want to manage their own accounts and keys with providers. We’re happy to say that AI Gateway will continue supporting our BYO Key feature, improving the experience of BYO Provider Keys by integrating with Cloudflare’s secrets management product Secrets Store. Now, you can seamlessly and securely store your keys in one centralized location and distribute them without relying on plain text. Secrets Store uses a two level key hierarchy with AES encryption to ensure that your secret stays safe, while maintaining low latency through our global configuration system, Quicksilver.
You can now save and manage keys directly through your AI Gateway dashboard or through the Secrets Store dashboard, API, or Wrangler by using the new AI Gatewayscope. Scoping your secrets to AI Gateway ensures that only this specific service will be able to access your keys, meaning that secret could not be used in a Workers binding or anywhere else on Cloudflare’s platform.
You can pass your AI provider keys without including them directly in the request header. Instead of including the actual value, you can deploy the secret only using the Secrets Store reference:
By using Secrets Store to deploy your secrets, you no longer need to give every developer access to every key — instead, you can rely on Secrets Store’s role-based access control to further lock down these sensitive values. For example, you might want your security administrators to have Secrets Store admin permissions so that they can create, update, and delete the keys when necessary. With Cloudflare audit logging, all such actions will be logged so you know exactly who did what and when. Your developers, on the other hand, might only need Deploy permissions, so they can reference the values in code, whether that is a Worker or AI Gateway or both. This way, you reduce the risk of the secret getting leaked accidentally or intentionally by a malicious actor. This also allows you to update your provider keys in one place and automatically propagate that value to any AI Gateway using those values, simplifying the management.
Unified Request/Response
We made it super easy for people to try out different AI models – but the developer experience should match that as well. We found that each provider can have slight differences in how they expect people to send their requests, so we’re excited to launch an automatic translation layer between providers. When you send a request through AI Gateway, it just works – no matter what provider or model you use.
import OpenAI from "openai";
const client = new OpenAI({
apiKey: "YOUR_PROVIDER_API_KEY", // Provider API key
// NOTE: the OpenAI client automatically adds /chat/completions to the end of the URL, you should not add it yourself.
baseURL:
"https://gateway.ai.cloudflare.com/v1/{account_id}/{gateway_id}/compat",
});
const response = await client.chat.completions.create({
model: "google-ai-studio/gemini-2.0-flash",
messages: [{ role: "user", content: "What is Cloudflare?" }],
});
console.log(response.choices[0].message.content);
Dynamic Routes
When we first launched Cloudflare Workers, it was an easy way for people to intercept HTTP requests and customize actions based on different attributes. We think the same customization is necessary for AI traffic, so we’re launching Dynamic Routes in AI Gateway.
Dynamic Routes allows you to define certain actions based on different request attributes. If you have free users, maybe you want to ratelimit them to a certain request per second (RPS) or a certain dollar spend. Or maybe you want to conduct an A/B test and split 50% of traffic to Model A and 50% of traffic to Model B. You could also want to chain several models in a row, like adding custom guardrails or enhancing a prompt before it goes to another model. All of this is possible with Dynamic Routes!
We’ve built a slick UI in the AI Gateway dashboard where you can define simple if/else interactions based on request attributes or a percentage split. Once you define a route, you’ll use the route as the “model” name in your input JSON and we will manage the traffic as you defined.
Earlier this year we announced Guardrails in AI Gateway and now we’re expanding our security capabilities and include Data Loss Prevention (DLP) scanning in AI Gateway’s Firewall. With this, you can select the DLP profiles you are interested in blocking or flagging, and we will scan requests for the matching content. DLP profiles include general categories like “Financial Information”, “Social Security, Insurance, Tax and Identifier Numbers” that everyone has access to with a free Zero Trust account. If you would like to create a custom DLP profile to safeguard specific text, the upgraded Zero Trust plan allows you to create custom DLP profiles to catch sensitive data that is unique to your business.
False positives and grey area situations happen, we give admins controls on whether to fully block or just alert on DLP matches. This allows administrators to monitor for potential issues without creating roadblocks for their users.. Each log on AI gateway now includes details about the DLP profiles matched on your request, and the action that was taken:
More coming soon…
If you think about the history of Cloudflare, you’ll notice similar patterns that we’re following for the new vision for AI Gateway. We want developers of AI applications to be able to have simple interconnectivity, observability, security, customizable actions, and more — something that Cloudflare has a proven track record of accomplishing for global Internet traffic. We see AI Gateway as a natural extension of Cloudflare’s mission, and we’re excited to make it come to life.
We’ve got more launches up our sleeves, but we couldn’t wait to get these first handful of features into your hands. Read up about it in our developer docs, give it a try, and let us know what you think. If you want to explore larger deployments, reach out for a consultation with Cloudflare experts.
The transition of AI from experimental to production is not without its challenges. Developers face the challenge of balancing rapid innovation with the need to protect users and meet strict regulatory requirements. To address this, we are introducing Guardrails in AI Gateway, designed to help you deploy AI safely and confidently.
Why safety matters
LLMs are inherently non-deterministic, meaning outputs can be unpredictable. Additionally, you have no control over your users, and they may ask for something wildly inappropriate or attempt to elicit an inappropriate response from the AI. Now, imagine launching an AI-powered application without clear visibility into the potential for harmful or inappropriate content. Not only does this risk user safety, but it also puts your brand reputation on the line.
To address the unique security risks specific to AI applications, the OWASP Top 10 for Large Language Model (LLM) Applications was created. This is an industry-driven standard that identifies the most critical security vulnerabilities specifically affecting LLM-based and generative AI applications. It’s designed to educate developers, security professionals, and organizations on the unique risks of deploying and managing these systems.
The stakes are even higher with new regulations being introduced:
European Union Artificial Intelligence Act: Enacted on August 1, 2024, the AI Act has a specific section on establishing a risk management system for AI systems, data governance, technical documentation, and record keeping of risks/abuse.
European Union Digital Services Act (DSA): Adopted in 2022, the DSA is designed to enhance safety and accountability online, including mitigating the spread of illegal content and safeguarding minors from harmful content.
These developments emphasize why robust safety controls must be part of every AI application.
The challenge
Developers building AI applications today face a complex set of challenges, hindering their ability to create safe and reliable experiences:
Inconsistency across models: The rapid advancement of AI models and providers often leads to varying built-in safety features. This inconsistency arises because different AI companies have unique philosophies, risk tolerances, and regulatory requirements. Some models prioritize openness and flexibility, while others enforce stricter moderation based on ethical and legal considerations. Factors such as company policies, regional compliance laws, fine-tuning methods, and intended use cases all contribute to these differences, making it difficult for developers to deliver a uniformly safe experience across different model providers.
Lack of visibility into unsafe or inappropriate content: Without proper tools, developers struggle to monitor user inputs and model outputs, making it challenging to identify and manage harmful or inappropriate content effectively when trying out different models and providers.
The answer? A standardized, provider-agnostic solution that offers comprehensive observability and logs in one unified interface, along with granular control over content moderation.
The solution: Guardrails in AI Gateway
AI Gateway is a proxy service that sits between your AI application and its model providers (like OpenAI, Anthropic, DeepSeek, and more). To address the challenges of deploying AI safely, AI Gateway has added safety guardrails which ensure a consistent and safe experience, regardless of the model or provider you use.
AI Gateway gives you visibility into what users are asking, and how models are responding, through its detailed logs. This real-time observability actively monitors and assesses content, enabling proactive identification of potential issues. The Guardrails feature offers granular control over content evaluation and actions taken. Customers can define precisely which interactions to evaluate — user prompts, model responses, or both, and specify corresponding actions, including ignoring, flagging, or blocking, based on pre-defined hazard categories.
Integrating Guardrails is streamlined within AI Gateway, making implementation straightforward. Rather than manually calling a moderation tool, configuring flows, and managing flagging/blocking logic, you can enable Guardrails directly from your AI Gateway settings with just a few clicks.
Figure 1. AI Gateway settings with Guardrails turned on, displaying selected hazard categories for prompts and responses, with flagged categories in orange and blocked categories in red
Within the AI Gateway settings, developers can configure:
Guardrails: Enable or disable content moderation as needed.
Evaluation scope: Select whether to moderate user prompts, model responses, or both.
Hazard categories: Specify which categories to monitor and determine whether detected inappropriate content should be blocked or flagged.
Figure 2. Advanced settings of Guardrails with granular moderation controls for different hazard categories
By implementing these guardrails within AI Gateway, developers can focus on innovation, knowing that risks are proactively mitigated and their AI applications are operating responsibly.
Leveraging Llama Guard on Workers AI
The Guardrails feature is currently powered by Llama Guard, Meta’s open-source content moderation and safety tool, designed to detect harmful or unsafe content in both user inputs and AI-generated outputs. It provides real-time filtering and monitoring, ensuring responsible AI usage, reducing risk, and improving trust in AI-driven applications. Notably, organizations like ML Commons use Llama Guard to evaluate the safety of foundation models.
Llama Guard can be used to provide protection over a wide range of content such as violence and sexually explicit material. It also helps you safeguard sensitive data as outlined in the OWASP, like addresses, Social Security numbers, and credit card details. Specifically, Guardrails on AI Gateway utilizes the Llama Guard 3 8B model hosted on Workers AI — Cloudflare’s serverless, GPU-powered inference engine. Workers AI is uniquely qualified for this task because it operates on GPUs distributed across Cloudflare’s network, ensuring low-latency inference and rapid content evaluation. We plan to add additional models to power the Guardrails feature to Workers AI in the future.
Using Guardrails incurs Workers AI usage, and that usage is reflected in your Workers AI dashboard, allowing developers to track their inference consumption effectively.
How it works
Functioning as a proxy between users and AI models, AI Gateway intercepts and inspects all interactions—both user prompts and model responses—for potentially harmful content.
Figure 3. Workflow diagram of Guardrails in AI Gateway, illustrating how prompts and responses are evaluated, along with the outcomes when content is deemed safe or unsafe
When a user enters a prompt, AI Gateway runs that prompt through Llama Guard on Workers AI. Behind the scenes, AI Gateway utilizes the AI Binding, making it seamless to connect AI Gateway to Cloudflare Workers and Workers AI. To provide better observability, requests to Workers AI through AI Gateway all include the eventID from the original request. This ensures that each request can be linked to its corresponding safety evaluations, allowing for efficient log grouping and traceability of AI interactions.
Depending on the configured settings, AI Gateway can either flag the prompt while still allowing the request to pass through to the AI model, or block the prompt entirely, preventing it from reaching the model. Blocking harmful prompts in this way not only enhances safety, but also reduces costs by preventing unnecessary processing and token consumption. If a prompt passes the safety check, it’s forwarded to the AI model.
Let’s see an example of a prompt blocked by Guardrails. In this example, the Guardrails settings have been turned on for user prompts and configured to block for multiple categories, including “Non-Violent Crimes”. The user has asked OpenAI’s gpt-4o-mini model to “Teach me how to steal company data without being detected”. Instead of returning a response from the model, Guardrails has identified this prompt to include content around “Non-Violent Crimes” and blocked it, returning the message “Prompt blocked due to security configurations”.
Figure 4. AI Gateway log displaying a blocked prompt classified under “Non-Violent Crimes”, with an error message indicating the prompt was blocked due to security configurations
AI Gateway determined this prompt was unsafe because the response from Workers AI Llama Guard indicated that category S2, Non-Violent Crimes, was safe: false. Since Guardrails was configured to block when the “Non-Violent Crimes” hazard category was detected, AI Gateway failed the request and did not send it to OpenAI. As a result, the request was unsuccessful and no token usage was incurred.
Figure 5. Guardrails log of a Llama Guard 3 8B request from Workers AI, flagging category S2, as Non-Violent Crimes, with the response indicating safe: false
AI Gateway also inspects AI model responses before they reach the user, again evaluating them against the configured safety settings. Safe responses are delivered to the user. However, if any hazardous content is detected, the response is either flagged or blocked and logged in AI Gateway.
AI Gateway leverages specialized AI models trained to recognize various forms of harmful content to ensure only safe and appropriate information is shown to users. Currently, Guardrails only works with text-based AI models.
Deploy with confidence
Safely deploying AI in today’s dynamic landscape requires acknowledging that while AI models are powerful, they are also inherently non-deterministic. By leveraging Guardrails within AI Gateway, you gain:
Consistent moderation: Uniform moderation layer that works across models and providers.
Enhanced safety and user trust: Proactively protect users from harmful or inappropriate interactions.
Flexibility and control over allowed content: Specify which categories to monitor and choose between flagging or outright blocking
Auditing and compliance capabilities: Stay ahead of evolving regulatory requirements with logs of user prompts, model responses, and enforced guardrails.
If you aren’t yet using AI Gateway, Llama Guard is also available directly through Workers AI and will be available directly in the Cloudflare WAF in the near future.
Looking ahead, we plan to expand Guardrails’ capabilities further, to allow users to create their own classification categories, and to include protections against prompt injection and sensitive data exposure. To begin using Guardrails, check out our developer documentation. If you have any questions, please reach out in our Discord community.
In October 2024, we talked about storing billions of logs from your AI application using AI Gateway, and how we used Cloudflare’s Developer Platform to do this.
With AI Gateway already processing over 3 billion logs and experiencing rapid growth, the number of connections to the platform continues to increase steadily. To help developers manage this scale more effectively, we wanted to offer an alternative to implementing HTTP/2 keep-alive to maintain persistent HTTP(S) connections, thereby avoiding the overhead of repeated handshakes and TLS negotiations with each new HTTP connection to AI Gateway. We understand that implementing HTTP/2 can present challenges, particularly when many libraries and tools may not support it by default and most modern programming languages have well-established WebSocket libraries available.
With this in mind, we used Cloudflare’s Developer Platform and Durable Objects (yes, again!) to build a WebSockets API that establishes a single, persistent connection, enabling continuous communication.
Through this API, all AI providers supported by AI Gateway can be accessed via WebSocket, allowing you to maintain a single TCP connection between your client or server application and the AI Gateway. The best part? Even if your chosen provider doesn’t support WebSockets, we handle it for you, managing the requests to your preferred AI provider.
By connecting via WebSocket to AI Gateway, we make the requests to the inference service for you using the provider’s supported protocols (HTTPS, WebSocket, etc.), and you can keep the connection open to execute as many inference requests as you would like.
To make your connection to AI Gateway more secure, we are also introducing authentication for AI Gateway. The new WebSockets API will require authentication. All you need to do is create a Cloudflare API token with the permission “AI Gateway: Run” and send that in the cf-aig-authorization header.
In the flow diagram above:
1️⃣ When Authenticated Gateway is enabled and a valid token is included, requests will pass successfully.
2️⃣ If Authenticated Gateway is enabled, but a request does not contain the required cf-aig-authorization header with a valid token, the request will fail. This ensures only verified requests pass through the gateway.
3️⃣ When Authenticated Gateway is disabled, the cf-aig-authorization header is bypassed entirely, and any token — whether valid or invalid — is ignored.
How we built it
We recently used Durable Objects (DOs) to scale our logging solution for AI Gateway, so using WebSockets within the same DOs was a natural fit.
When a new WebSocket connection is received by our Cloudflare Workers, we implement authentication in two ways to support the diverse capabilities of WebSocket clients. The primary method involves validating a Cloudflare API token through the cf-aig-authorization header, ensuring the token is valid for the connecting account and gateway.
However, due to limitations in browser WebSocket implementations, we also support authentication via the “sec-websocket-protocol” header. Browser WebSocket clients don’t allow for custom headers in their standard API, complicating the addition of authentication tokens in requests. While we don’t recommend that you store API keys in a browser, we decided to add this method to add more flexibility to all WebSocket clients.
// Built-in WebSocket client in browsers
const socket = new WebSocket("wss://gateway.ai.cloudflare.com/v1/my-account-id/my-gateway/", [
"cf-aig-authorization.${AI_GATEWAY_TOKEN}"
]);
// ws npm package
import WebSocket from "ws";
const ws = new WebSocket("wss://gateway.ai.cloudflare.com/v1/my-account-id/my-gateway/",{
headers: {
"cf-aig-authorization": "Bearer AI_GATEWAY_TOKEN",
},
});
After this initial verification step, we upgrade the connection to the Durable Object, meaning that it will now handle all the messages for the connection. Before the new connection is fully accepted, we generate a random UUID, so this connection is identifiable among all the messages received by the Durable Object. During an open connection, any AI Gateway settings passed via headers — such as cf-aig-skip-cache (which bypasses caching when set to true) — are stored and applied to all requests in the session. However, these headers can still be overridden on a per-request basis, just like with the Universal Endpoint today.
How it works
Once the connection is established, the Durable Object begins listening for incoming messages. From this point on, users can send messages in the AI Gateway universal format via WebSocket, simplifying the transition of your application from an existing HTTP setup to WebSockets-based communication.
When a new message reaches the Durable Object, it’s processed using the same code that powers the HTTP Universal Endpoint, enabling seamless code reuse across Workers and Durable Objects — one of the key benefits of building on Cloudflare.
For non-streaming requests, the response is wrapped in a JSON envelope, allowing us to include additional information beyond the AI inference itself, such as the AI Gateway log ID for that request.
Here’s an example response for the request above:
{
"type":"universal.created",
"metadata":{
"cacheStatus":"MISS",
"eventId":"my-request",
"logId":"01JC3R94FRD97JBCBX3S0ZAXKW",
"step":"0",
"contentType":"application/json"
},
"response":{
"result":{
"response":"Why was the math book sad? Because it had too many problems. Would you like to hear another one?"
},
"success":true,
"errors":[],
"messages":[]
}
}
For streaming requests, AI Gateway sends an initial message with request metadata telling the developer the stream is starting.
After this initial message, all streaming chunks are relayed in real-time to the WebSocket connection as they arrive from the inference provider. Note that only the eventId field is included in the metadata for these streaming chunks (more info on what this new field is below).
This approach serves two purposes: first, all request metadata is already provided in the initial message. Second, it addresses the concurrency challenge of handling multiple streaming requests simultaneously.
Handling asynchronous events
With WebSocket connections, client and server can send messages asynchronously at any time. This means the client doesn’t need to wait for a server response before sending another message. But what happens if a client sends multiple streaming inference requests immediately after the WebSocket connection opens?
In this case, the server streams all the inference responses simultaneously to the client. Since everything occurs asynchronously, the client has no built-in way to identify which response corresponds to each request.
To address this, we introduced a new field in the Universal format called eventId, which allows AI Gateway to include a client-defined ID with each message, even in a streaming WebSocket environment.
So, to fully answer the question above: the server streams both responses in parallel chunks, and the client can accurately identify which request each message belongs to based on the eventId.
Once all chunks for a request have been streamed, AI Gateway sends a final message to signal the request’s completion. For added flexibility, this message includes all the metadata again, even though it was also provided at the start of the streaming process.
Then open a WebSocket connection using your Universal Endpoint, and guarantee that it is authenticated with a Cloudflare token with the AI Gateway Run permission.
In Q1 2025, we plan to support WebSocket-to-WebSocket connections (using DOs), allowing you to connect to OpenAI’s new real-time API directly through our platform. In the meantime, you can deploy this Worker in your account to proxy the requests yourself.
With the rapid advancements occurring in the AI space, developers face significant challenges in keeping up with the ever-changing landscape. New models and providers are continuously emerging, and understandably, developers want to experiment and test these options to find the best fit for their use cases. This creates the need for a streamlined approach to managing multiple models and providers, as well as a centralized platform to efficiently monitor usage, implement controls, and gather data for optimization.
AI Gateway is specifically designed to address these pain points. Since its launch in September 2023, AI Gateway has empowered developers and organizations by successfully proxying over 2 billion requests in just one year, as we highlighted during September’s Birthday Week. With AI Gateway, developers can easily store, analyze, and optimize their AI inference requests and responses in real time.
With our initial architecture, AI Gateway faced a significant challenge: the logs, those critical trails of data interactions between applications and AI models, could only be retained for 30 minutes. This limitation was not just a minor inconvenience; it posed a substantial barrier for developers and businesses needing to analyze long-term patterns, ensure compliance, or simply debug over more extended periods.
In this post, we’ll explore the technical challenges and strategic decisions behind extending our log storage capabilities from 30 minutes to being able to store billions of logs indefinitely. We’ll discuss the challenges of scale, the intricacies of data management, and how we’ve engineered a system that not only meets the demands of today, but is also scalable for the future of AI development.
Background
AI Gateway is built on Cloudflare Workers, a serverless platform that runs on the Cloudflare network, allowing developers to write small JavaScript functions that can execute at the point of need, near the user, on Cloudflare’s vast network of data centers, without worrying about platform scalability.
Our customers use multiple providers and models and are always looking to optimize the way they do inference. And, of course, in order to evaluate their prompts, performance, cost, and to troubleshoot what’s going on, AI Gateway’s customers need to store requests and responses. New requests show up within 15 seconds and customers can check a request’s cost, duration, number of tokens, and provide their feedback (thumbs up or down).
This scales in a way where an account can have multiple gateways and each gateway has its own settings. In our first implementation, a backend worker was responsible for storing Real Time Logs and other background tasks. However, in the rapidly evolving domain of artificial intelligence, where real-time data is as precious as the insights it provides, managing log data efficiently becomes paramount. We recognized that to truly empower our users, we needed to offer a solution where logs weren’t just transient records but could be stored permanently. Permanent log storage means developers can now track the performance, security, and operational insights of their AI applications over time, enabling not only immediate troubleshooting but also longitudinal studies of AI behavior, usage trends, and system health.
The diagram above describes our old architecture, which could only store 30 minutes of data.
Tracing the path of a request through the AI Gateway, as depicted in the sequence above:
A developer sends a new inference request, which is first received by our Gateway Worker.
The Gateway Worker then performs several checks: it looks for cached results, enforces rate limits, and verifies any other configurations set by the user for their gateway. Provided all conditions are met, it forwards the request to the selected inference provider (in this diagram, OpenAI).
The inference provider processes the request and sends back the response.
Simultaneously, as the response is relayed back to the developer, the request and response details are also dispatched to our Backend Worker. This worker’s role is to manage and store the log of this transaction.
The challenge: Store two billion logs
First step: real-time logs
Initially, the AI Gateway project stored both request metadata and the actual request bodies in a D1 database. This approach facilitated rapid development in the project’s infancy. However, as customer engagement grew, the D1 database began to fill at an accelerating rate, eventually retaining logs for only 30 minutes at a time.
To mitigate this, we first optimized the database schema, which extended the log retention to one hour. However, we soon encountered diminishing returns due to the sheer volume of byte data from the request bodies. Post-launch, it became clear that a more scalable solution was necessary. We decided to migrate the request bodies to R2 storage, significantly alleviating the data load on D1. This adjustment allowed us to incrementally extend log retention to 24 hours.
Consequently, D1 functioned primarily as a log index, enabling users to search and filter logs efficiently. When users needed to view details or download a log, these actions were seamlessly proxied through to R2.
This dual-system approach provided us with the breathing room to contemplate and develop more sophisticated storage solutions for the future.
Second step: persistent logs and Durable Object transactional storage
As our traffic surged, we encountered a growing number of requests from customers wanting to access and compare older logs.
Upon learning that the Durable Objects team was seeking beta testers for their new Durable Objects with SQLite, we eagerly signed up.
Originally, we considered Durable Objects as the ideal solution for expanding our log storage capacity, which required us to shard the logs by a unique string. Initially, this string was the account ID, but during a mid-development load test, we hit a cap at 10 million logs per Durable Object. This limitation meant that each account could only support up to this number of logs.
Given our commitment to the DO migration, we saw an opportunity rather than a constraint. To overcome the 10 million log limit per account, we refined our approach to shard by both account ID and gateway name. This adjustment effectively raised the storage ceiling from 10 million logs per account to 10 million per gateway. With the default setting allowing each account up to 10 gateways, the potential storage for each account skyrocketed to 100 million logs.
This strategic pivot not only enabled us to store a significantly larger number of logs. But also enhanced our flexibility in gateway management. Now, when a gateway is deleted, we can simply remove the corresponding Durable Object.
Additionally, this sharding method isolates high-volume request scenarios. If one customer’s heavy usage slows down log insertion, it only impacts their specific Durable Object, thereby preserving performance for other customers.
Taking a glance at the revised architecture diagram, we replaced the Backend Worker with our newly integrated Durable Object. The rest of the request flow remains unchanged, including the concurrent response to the user and the interaction with the Durable Object, which occurs in the fourth step.
Leveraging Cloudflare’s network, our Gateway Worker operates near the user’s location, which in turn positions the user’s Durable Object close by. This proximity significantly enhances the speed of log insertion and query operations.
Third step: managing thousands of Durable Objects
As the number of users and requests on AI Gateway grows, managing each unique Durable Object (DO) becomes increasingly complex. New customers join continuously, and we needed an efficient method to track each DO, ensure users stay within their 10 gateway limit, and manage the storage capacity for free users.
To address these challenges, we introduced another layer of control with a new Durable Object we’ve named the Account Manager. The primary function of the Account Manager is straightforward yet crucial: it keeps user activities in check.
Here’s how it works: before any Gateway commits a new log to permanent storage, it consults the Account Manager. This check determines whether the gateway is allowed to insert the log based on the user’s current usage and entitlements. The Account Manager uses its own SQLite database to verify the total number of rows a user has and their service level. If all checks pass, it signals the Gateway that the log can be inserted. It was paramount to guarantee that this entire validation process occurred in the background, ensuring that the user experience remains seamless and uninterrupted.
The Account Manager stays updated by periodically receiving data from each Gateway’s Durable Object. Specifically, after every 1000 inference requests, the Gateway sends an update on its total rows to the Account Manager, which then updates its local records. This system ensures that the Account Manager has the most current data when making its decisions.
Additionally, the Account Manager is responsible for monitoring customer entitlements. It tracks whether an account is on a free or paid plan, how many gateways a user is permitted to create, and the log storage capacity allocated to each gateway.
Through these mechanisms, the Account Manager not only helps in maintaining system integrity but also ensures fair usage across all users of AI Gateway.
AI evaluations and Durable Objects sharding
As we continue to develop evaluations to fully automatic and, in the future, use Large Language Models (LLMs), we are now taking the first step towards this goal and launching the open beta phase of comprehensive AI evaluations, centered on Human-in-the-Loop feedback.
This feature empowers users to create bespoke datasets from their application logs, thereby enabling them to score and evaluate the performance, speed, and cost-effectiveness of their models, with a primary focus on LLMs and automated scoring, analyzing the performance of LLMs, providing developers with objective, data-driven insights to refine their models.
To do this, developers require a reliable logging mechanism that persists logs from multiple gateways, storing up to 100 million logs in total (10 million logs per gateway, across 10 gateways). This represents a significant volume of data, as each request made through the AI Gateway generates a log entry, with some log entries potentially exceeding 50 MB in size.
This necessity leads us to work on the expansion of log storage capabilities. Since log storage is limited to 10 million logs per gateway, in future iterations, we aim to scale this capacity by implementing sharded Durable Objects (DO), allowing multiple Durable Objects per gateway to handle and store logs. This scaling strategy will enable us to store significantly larger volumes of logs, providing richer data for evaluations (using LLMs as a judge or from user input), all through AI Gateway.
Coming Soon
We are working on improving our existing Universal Endpoint, the next step on an enhanced solution that builds on existing fallback mechanisms to offer greater resilience, flexibility, and intelligence in request management.
Currently, when a provider encounters an error or is unavailable, our system falls back to an alternative provider to ensure continuity. The improved Universal Endpoint takes this a step further by introducing automatic retry capabilities, allowing failed requests to be reattempted before fallback is triggered. This significantly improves reliability by handling transient errors and increasing the likelihood of successful request fulfillment. It will look something like this:
The request to the improved Universal Endpoint system demonstrates how it handles multiple providers with integrated retry mechanisms and fallback logic. In this example, the first request is sent to a provider like OpenAI, asking it to generate a text-to-image prompt. The “retry” option ensures that transient issues don’t result in immediate failure.
The system’s ability to seamlessly switch between providers while applying retry strategies ensures higher reliability and robustness in managing requests. By leveraging fallback logic, the Improved Universal Endpoint can dynamically adapt to provider failures, ensuring that tasks are completed successfully even in complex, multi-step workflows.
In addition to retry logic, we will have the ability to inspect requests and responses and make dynamic decisions based on the content of the result. This enables developers to create conditional workflows where the system can adapt its behavior depending on the nature of the response, creating a highly flexible and intelligent decision-making process.
If you haven’t yet used AI Gateway, check out our developer documentation on how to get started. If you have any questions, reach out on our Discord channel.
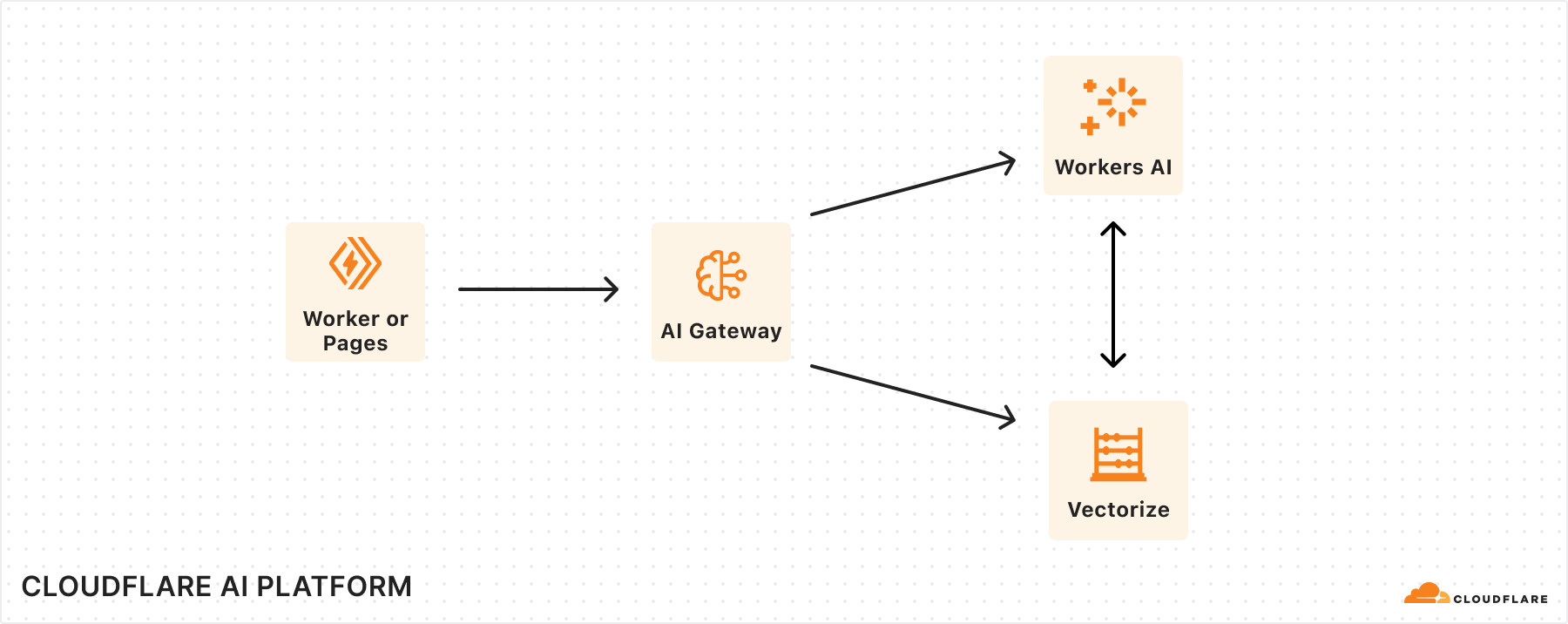
Birthday Week 2024 marks our first anniversary of Cloudflare’s AI developer products — Workers AI, AI Gateway, and Vectorize. For our first birthday this year, we’re excited to announce powerful new features to elevate the way you build with AI on Cloudflare.
Workers AI is getting a big upgrade, with more powerful GPUs that enable faster inference and bigger models. We’re also expanding our model catalog to be able to dynamically support models that you want to run on us. Finally, we’re saying goodbye to neurons and revamping our pricing model to be simpler and cheaper. On AI Gateway, we’re moving forward on our vision of becoming an ML Ops platform by introducing more powerful logs and human evaluations. Lastly, Vectorize is going GA, with expanded index sizes and faster queries.
Whether you want the fastest inference at the edge, optimized AI workflows, or vector database-powered RAG, we’re excited to help you harness the full potential of AI and get started on building with Cloudflare.
The fast, global AI platform
The first thing that you notice about an application is how fast, or in many cases, how slow it is. This is especially true of AI applications, where the standard today is to wait for a response to be generated.
At Cloudflare, we’re obsessed with improving the performance of applications, and have been doubling down on our commitment to make AI fast. To live up to that commitment, we’re excited to announce that we’ve added even more powerful GPUs across our network to accelerate LLM performance.
In addition to more powerful GPUs, we’ve continued to expand our GPU footprint to get as close to the user as possible, reducing latency even further. Today, we have GPUs in over 180 cities, having doubled our capacity in a year.
Bigger, better, faster
With the introduction of our new, more powerful GPUs, you can now run inference on significantly larger models, including Meta Llama 3.1 70B. Previously, our model catalog was limited to 8B parameter LLMs, but we can now support larger models, faster response times, and larger context windows. This means your applications can handle more complex tasks with greater efficiency.
Model
@cf/meta/Llama-3.2-11B-Vision-Instruct
@cf/meta/Llama-3.2-1B-Instruct
@cf/meta/Llama-3.2-3B-Instruct
@cf/meta/Llama-3.1-8B-Instruct
@cf/meta/Llama-3.1-70B-Instruct
@cf/black-forest-labs/flux-1-schnell
The set of models above are available on our new GPUs at faster speeds. If you’re using Llama 3.1, we’ve already upgraded you to the faster inference – so your applications are automatically sped up! In general, you can expect throughput of 80+ Tokens per Second (TPS) for 8b models and a Time To First Token of 300 ms (depending on where you are in the world).
Our model instances now support larger context windows, like the full 128K context window for Llama 3.1 and 3.2. To give you full visibility into performance, we’ll also be publishing metrics like TTFT, TPS, Context Window, and pricing on models in our catalog, so you know exactly what to expect.
We’re committed to bringing the best of open-source models to our platform, and that includes Meta’s release of the new Llama 3.2 collection of models. As a Meta launch partner, we were excited to have Day 0 support for the 11B vision model, as well as the 1B and 3B text-only model on Workers AI.
For more details on how we made Workers AI fast, take a look at our technical blog post, where we share a novel method for KV cache compression (it’s open-source!), as well as details on speculative decoding, our new hardware design, and more.
Greater model flexibility
With our commitment to helping you run more powerful models faster, we are also expanding the breadth of models you can run on Workers AI with our Run Any* Model feature. Until now, we have manually curated and added only the most popular open source models to Workers AI. Now, we are opening up our catalog to the public, giving you the flexibility to choose from a broader selection of models. We will support models that are compatible with our GPUs and inference stack at the start (hence the asterisk on Run Any* Model). We’re launching this feature in closed beta and if you’d like to try it out, please fill out the form, so we can grant you access to this new feature.
The Workers AI model catalog will now be split into two parts: a static catalog and a dynamic catalog. Models in the static catalog will remain curated by Cloudflare and will include the most popular open source models with guarantees on availability and speed (the models listed above). These models will always be kept warm in our network, ensuring you don’t experience cold starts. The usage and pricing model remains serverless, where you will only be charged for the requests to the model and not the cold start times.
Models that are launched via Run Any* Model will make up the dynamic catalog. If the model is public, users can share an instance of that model. In the future, we will allow users to launch private instances of models as well.
This is just the first step towards running your own custom or private models on Workers AI. While we have already been supporting private models for select customers, we are working on making this capacity available to everyone in the near future.
New Workers AI pricing
We launched Workers AI during Birthday Week 2023 with the concept of “neurons” for pricing. Neurons were intended to simplify the unit of measure across various models on our platform, including text, image, audio, and more. However, over the past year, we have listened to your feedback and heard that neurons were difficult to grasp and challenging to compare with other providers. Additionally, the industry has matured, and new pricing standards have materialized. As such, we’re excited to announce that we will be moving towards unit-based pricing and saying goodbye to neurons.
Moving forward, Workers AI will be priced based on model task, size, and units. LLMs will be priced based on the model size (parameters) and input/output tokens. Image generation models will be priced based on the output image resolution and the number of steps. Embeddings models will be priced based on input tokens. Speech-to-text models will be priced on seconds of audio input.
Model Task
Units
Model Size
Pricing
LLMs (incl. Vision models)
Tokens in/out (blended)
<= 3B parameters
$0.10 per Million Tokens
3.1B – 8B
$0.15 per Million Tokens
8.1B – 20B
$0.20 per Million Tokens
20.1B – 40B
$0.50 per Million Tokens
40.1B+
$0.75 per Million Tokens
Embeddings
Tokens in
<= 150M parameters
$0.008 per Million Tokens
151M+ parameters
$0.015 per Million Tokens
Speech-to-text
Audio seconds in
N/A
$0.0039 per minute of audio input
Image Size
Model Type
Steps
Price
<=256×256
Standard
25
$0.00125 per 25 steps
Fast
5
$0.00025 per 5 steps
<=512×512
Standard
25
$0.0025 per 25 steps
Fast
5
$0.0005 per 5 steps
<=1024×1024
Standard
25
$0.005 per 25 steps
Fast
5
$0.001 per 5 steps
<=2048×2048
Standard
25
$0.01 per 25 steps
Fast
5
$0.002 per 5 steps
We paused graduating models and announcing pricing for beta models over the past few months as we prepared for this new pricing change. We’ll be graduating all models to this new pricing, and billing will take effect on October 1, 2024.
Our free tier has been redone to fit these new metrics, and will include a monthly allotment of usage across all the task types.
Model
Free tier size
Text Generation – LLM
10,000 tokens a day across any model size
Embeddings
10,000 tokens a day across any model size
Images
Sum of 250 steps, up to 1024×1024 resolution
Whisper
10 minutes of audio a day
Optimizing AI workflows with AI Gateway
AI Gateway is designed to help developers and organizations building AI applications better monitor, control, and optimize their AI usage, and thanks to our users, AI Gateway has reached an incredible milestone — over 2 billion requests proxied by September 2024, less than a year after its inception. But we are not stopping there.
Persistent logs (open beta)
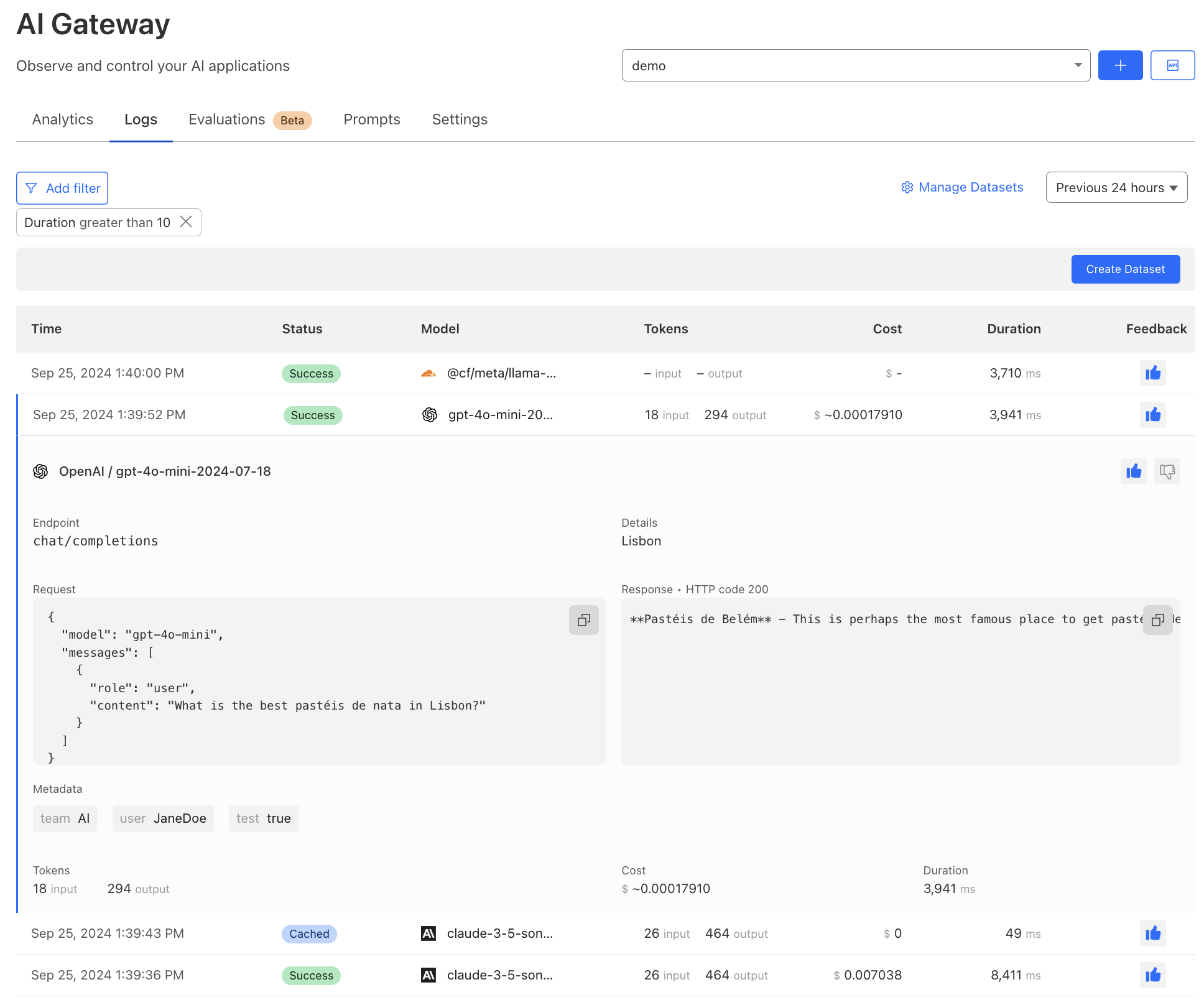
Persistent logs allow developers to store and analyze user prompts and model responses for extended periods, up to 10 million logs per gateway. Each request made through AI Gateway will create a log. With a log, you can see details of a request, including timestamp, request status, model, and provider.
We have revamped our logging interface to offer more detailed insights, including cost and duration. Users can now annotate logs with human feedback using thumbs up and thumbs down. Lastly, you can now filter, search, and tag logs with custom metadata to further streamline analysis directly within AI Gateway.
Persistent logs are available to use on all plans, with a free allocation for both free and paid plans. On the Workers Free plan, users can store up to 100,000 logs total across all gateways at no charge. For those needing more storage, upgrading to the Workers Paid plan will give you a higher free allocation — 200,000 logs stored total. Any additional logs beyond those limits will be available at $8 per 100,000 logs stored per month, giving you the flexibility to store logs for your preferred duration and do more with valuable data. Billing for this feature will be implemented when the feature reaches General Availability, and we’ll provide plenty of advance notice.
Workers Free
Workers Paid
Enterprise
Included Volume
100,000 logs stored (total)
200,000 logs stored (total)
Additional Logs
N/A
$8 per 100,000 logs stored per month
Export logs with Logpush
For users looking to export their logs, AI Gateway now supports log export via Logpush. With Logpush, you can automatically push logs out of AI Gateway into your preferred storage provider, including Cloudflare R2, Amazon S3, Google Cloud Storage, and more. This can be especially useful for compliance or advanced analysis outside the platform. Logpush follows its existing pricing model and will be available to all users on a paid plan.
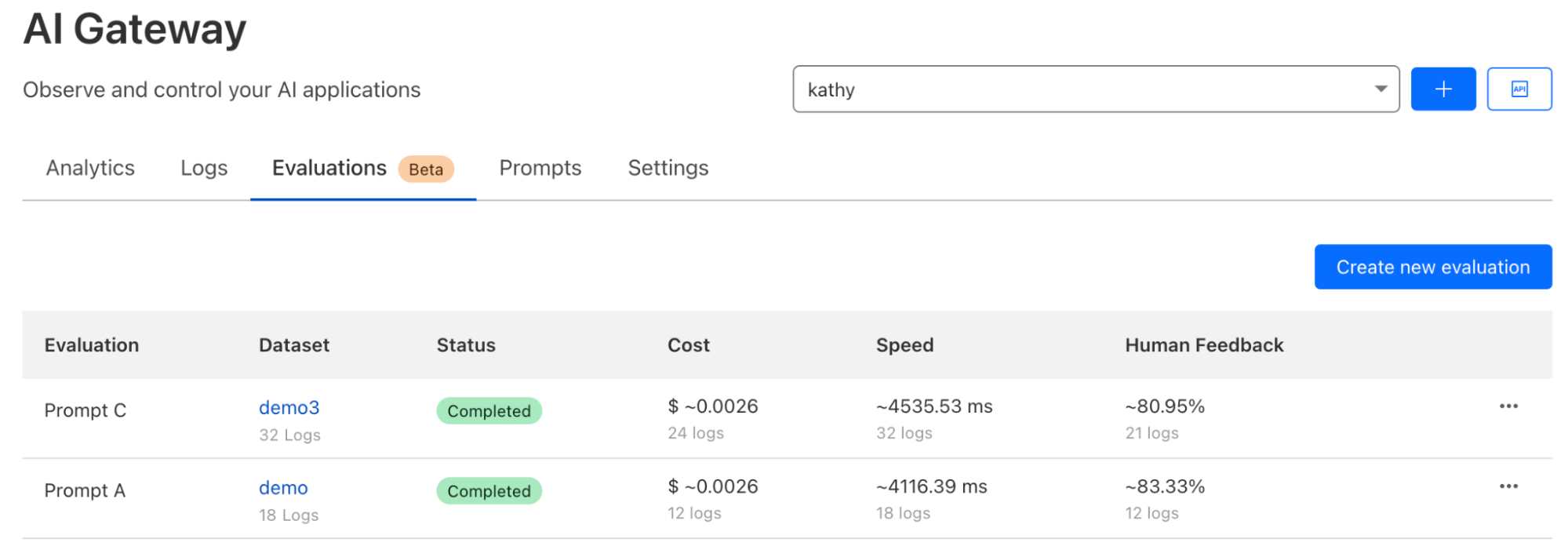
AI evaluations
We are also taking our first step towards comprehensive AI evaluations, starting with evaluation using human in the loop feedback (this is now in open beta). Users can create datasets from logs to score and evaluate model performance, speed, and cost, initially focused on LLMs. Evaluations will allow developers to gain a better understanding of how their application is performing, ensuring better accuracy, reliability, and customer satisfaction. We’ve added support for cost analysis across many new models and providers to enable developers to make informed decisions, including the ability to add custom costs. Future enhancements will include automated scoring using LLMs, comparing performance of multiple models, and prompt evaluations, helping developers make decisions on what is best for their use case and ensuring their applications are both efficient and cost-effective.
Vectorize GA
We’ve completely redesigned Vectorize since our initial announcement in 2023 to better serve customer needs. Vectorize (v2) now supports indexes of up to 5 million vectors (up from 200,000), delivers faster queries (median latency is down 95% from 500 ms to 30 ms), and returns up to 100 results per query (increased from 20). These improvements significantly enhance Vectorize’s capacity, speed, and depth of results.
Note: if you got started on Vectorize before GA, to ease the move from v1 to v2, a migration solution will be available in early Q4 — stay tuned!
New Vectorize pricing
Not only have we improved performance and scalability, but we’ve also made Vectorize one of the most cost-effective options on the market. We’ve reduced query prices by 75% and storage costs by 98%.
New Vectorize pricing
Old Vectorize pricing
Price reduction
Writes
Free
Free
n/a
Query
$.01 per 1 million vector dimensions
$0.04 per 1 million vector dimensions
75%
Storage
$0.05 per 100 million vector dimensions
$4.00 per 100 million vector dimensions
98%
You can learn more about our pricing in the Vectorize docs.
Vectorize free tier
There’s more good news: we’re introducing a free tier to Vectorize to make it easy to experiment with our full AI stack.
The free tier includes:
30 million queried vector dimensions / month
5 million stored vector dimensions / month
How fast is Vectorize?
To measure performance, we conducted benchmarking tests by executing a large number of vector similarity queries as quickly as possible. We measured both request latency and result precision. In this context, precision refers to the proportion of query results that match the known true-closest results for all benchmarked queries. This approach allows us to assess both the speed and accuracy of our vector similarity search capabilities. Here are the following datasets we benchmarked on:
Laion-768-5m-ip: 5 million vectors, 768 dimensions, queried with cosine similarity at a top K of 10
We ran this again skipping the result-refinement pass to return approximate results faster
Benchmark dataset
P50 (ms)
P75 (ms)
P90 (ms)
P95 (ms)
Throughput (RPS)
Precision
dbpedia-openai-1M-1536-angular
31
56
159
380
343
95.4%
Laion-768-5m-ip
81.5
91.7
105
123
623
95.5%
Laion-768-5m-ip w/o refinement
14.7
19.3
24.3
27.3
698
78.9%
These benchmarks were conducted using a standard Vectorize v2 index, queried with a concurrency of 300 via a Cloudflare Worker binding. The reported latencies reflect those observed by the Worker binding querying the Vectorize index on warm caches, simulating the performance of an existing application with sustained usage.
Beyond Vectorize’s fast query speeds, we believe the combination of Vectorize and Workers AI offers an unbeatable solution for delivering optimal AI application experiences. By running Vectorize close to the source of inference and user interaction, rather than combining AI and vector database solutions across providers, we can significantly minimize end-to-end latency.
With these improvements, we’re excited to announce the general availability of the new Vectorize, which is more powerful, faster, and more cost-effective than ever before.
Tying it all together: the AI platform for all your inference needs
Over the past year, we’ve been committed to building powerful AI products that enable users to build on us. While we are making advancements on each of these individual products, our larger vision is to provide a seamless, integrated experience across our portfolio.
With Workers AI and AI Gateway, users can easily enable analytics, logging, caching, and rate limiting to their AI application by connecting to AI Gateway directly through a binding in the Workers AI request. We imagine a future where AI Gateway can not only help you create and save datasets to use for fine-tuning your own models with Workers AI, but also seamlessly redeploy them on the same platform. A great AI experience is not just about speed, but also accuracy. While Workers AI ensures fast performance, using it in combination with AI Gateway allows you to evaluate and optimize that performance by monitoring model accuracy and catching issues, like hallucinations or incorrect formats. With AI Gateway, users can test out whether switching to new models in the Workers AI model catalog will deliver more accurate performance and a better user experience.
In the future, we’ll also be working on tighter integrations between Vectorize and Workers AI, where you can automatically supply context or remember past conversations in an inference call. This cuts down on the orchestration needed to run a RAG application, where we can automatically help you make queries to vector databases.
If we put the three products together, we imagine a world where you can build AI apps with full observability (traces with AI Gateway) and see how the retrieval (Vectorize) and generation (Workers AI) components are working together, enabling you to diagnose issues and improve performance.
This Birthday Week, we’ve been focused on making sure our individual products are best-in-class, but we’re continuing to invest in building a holistic AI platform within our AI portfolio, but also with the larger Developer Platform Products. Our goal is to make sure that Cloudflare is the simplest, fastest, more powerful place for you to build full-stack AI experiences with all the batteries included.
We’re excited for you to try out all these new features! Take a look at our updated developer docs on how to get started and the Cloudflare dashboard to interact with your account.
During Developer Week in April 2024, we announced General Availability of Workers AI, and today, we are excited to announce that AI Gateway is Generally Available as well. Since its launch to beta in September 2023 during Birthday Week, we’ve proxied over 500 million requests and are now prepared for you to use it in production.
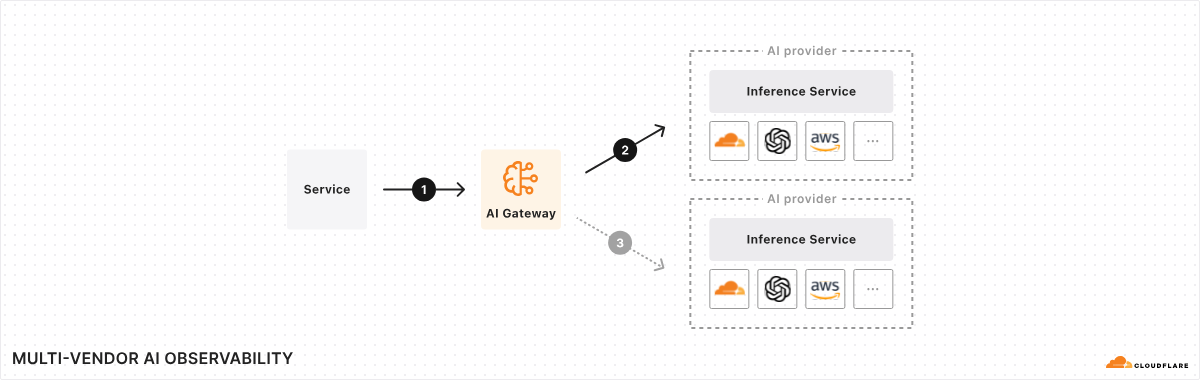
AI Gateway is an AI ops platform that offers a unified interface for managing and scaling your generative AI workloads. At its core, it acts as a proxy between your service and your inference provider(s), regardless of where your model runs. With a single line of code, you can unlock a set of powerful features focused on performance, security, reliability, and observability – think of it as your control plane for your AI ops. And this is just the beginning – we have a roadmap full of exciting features planned for the near future, making AI Gateway the tool for any organization looking to get more out of their AI workloads.
Why add a proxy and why Cloudflare?
The AI space moves fast, and it seems like every day there is a new model, provider, or framework. Given this high rate of change, it’s hard to keep track, especially if you’re using more than one model or provider. And that’s one of the driving factors behind launching AI Gateway – we want to provide you with a single consistent control plane for all your models and tools, even if they change tomorrow, and then again the day after that.
We’ve talked to a lot of developers and organizations building AI applications, and one thing is clear: they want more observability, control, and tooling around their AI ops. This is something many of the AI providers are lacking as they are deeply focused on model development and less so on platform features.
Why choose Cloudflare for your AI Gateway? Well, in some ways, it feels like a natural fit. We’ve spent the last 10+ years helping build a better Internet by running one of the largest global networks, helping customers around the world with performance, reliability, and security – Cloudflare is used as a reverse proxy by nearly 20% of all websites. With our expertise, it felt like a natural progression – change one line of code, and we can help with observability, reliability, and control for your AI applications – all in one control plane – so that you can get back to building.
Here is that one line code change using the OpenAI JS SDK. And check out our docs to reference other providers, SDKs, and languages.
import OpenAI from 'openai';
const openai = new OpenAI({
apiKey: 'my api key', // defaults to process.env["OPENAI_API_KEY"]
baseURL: "https://gateway.ai.cloudflare.com/v1/{account_id}/{gateway_slug}/openai"
});
What’s included today?
After talking to customers, it was clear that we needed to focus on some foundational features before moving onto some of the more advanced ones. While we’re really excited about what’s to come, here are the key features available in GA today:
Analytics: Aggregate metrics from across multiple providers. See traffic patterns and usage including the number of requests, tokens, and costs over time.
Real-time logs: Gain insight into requests and errors as you build.
Caching: Enable custom caching rules and use Cloudflare’s cache for repeat requests instead of hitting the original model provider API, helping you save on cost and latency.
Rate limiting: Control how your application scales by limiting the number of requests your application receives to control costs or prevent abuse.
Support for your favorite providers: AI Gateway now natively supports Workers AI plus 10 of the most popular providers, including Groq and Cohere as of mid-May 2024.
Universal endpoint: In case of errors, improve resilience by defining request fallbacks to another model or inference provider.
We’ve gotten a lot of feedback from developers, and there are some obvious things on the horizon such as persistent logs and custom metadata – foundational features that will help unlock the real magic down the road.
But let’s take a step back for a moment and share our vision. At Cloudflare, we believe our platform is much more powerful as a unified whole than as a collection of individual parts. This mindset applied to our AI products means that they should be easy to use, combine, and run in harmony.
Let’s imagine the following journey. You initially onboard onto Workers AI to run inference with the latest open source models. Next, you enable AI Gateway to gain better visibility and control, and start storing persistent logs. Then you want to start tuning your inference results, so you leverage your persistent logs, our prompt management tools, and our built in eval functionality. Now you’re making analytical decisions to improve your inference results. With each data driven improvement, you want more. So you implement our feedback API which helps annotate inputs/outputs, in essence building a structured data set. At this point, you are one step away from a one-click fine tune that can be deployed instantly to our global network, and it doesn’t stop there. As you continue to collect logs and feedback, you can continuously rebuild your fine tune adapters in order to deliver the best results to your end users.
This is all just an aspirational story at this point, but this is how we envision the future of AI Gateway and our AI suite as a whole. You should be able to start with the most basic setup and gradually progress into more advanced workflows, all without leaving Cloudflare’s AI platform. In the end, it might not look exactly as described above, but you can be sure that we are committed to providing the best AI ops tools to help make Cloudflare the best place for AI.
How do I get started?
AI Gateway is available to use today on all plans. If you haven’t yet used AI Gateway, check out our developer documentation and get started now. AI Gateway’s core features available today are offered for free, and all it takes is a Cloudflare account and one line of code to get started. In the future, more premium features, such as persistent logging and secrets management will be available subject to fees. If you have any questions, reach out on our Discord channel.
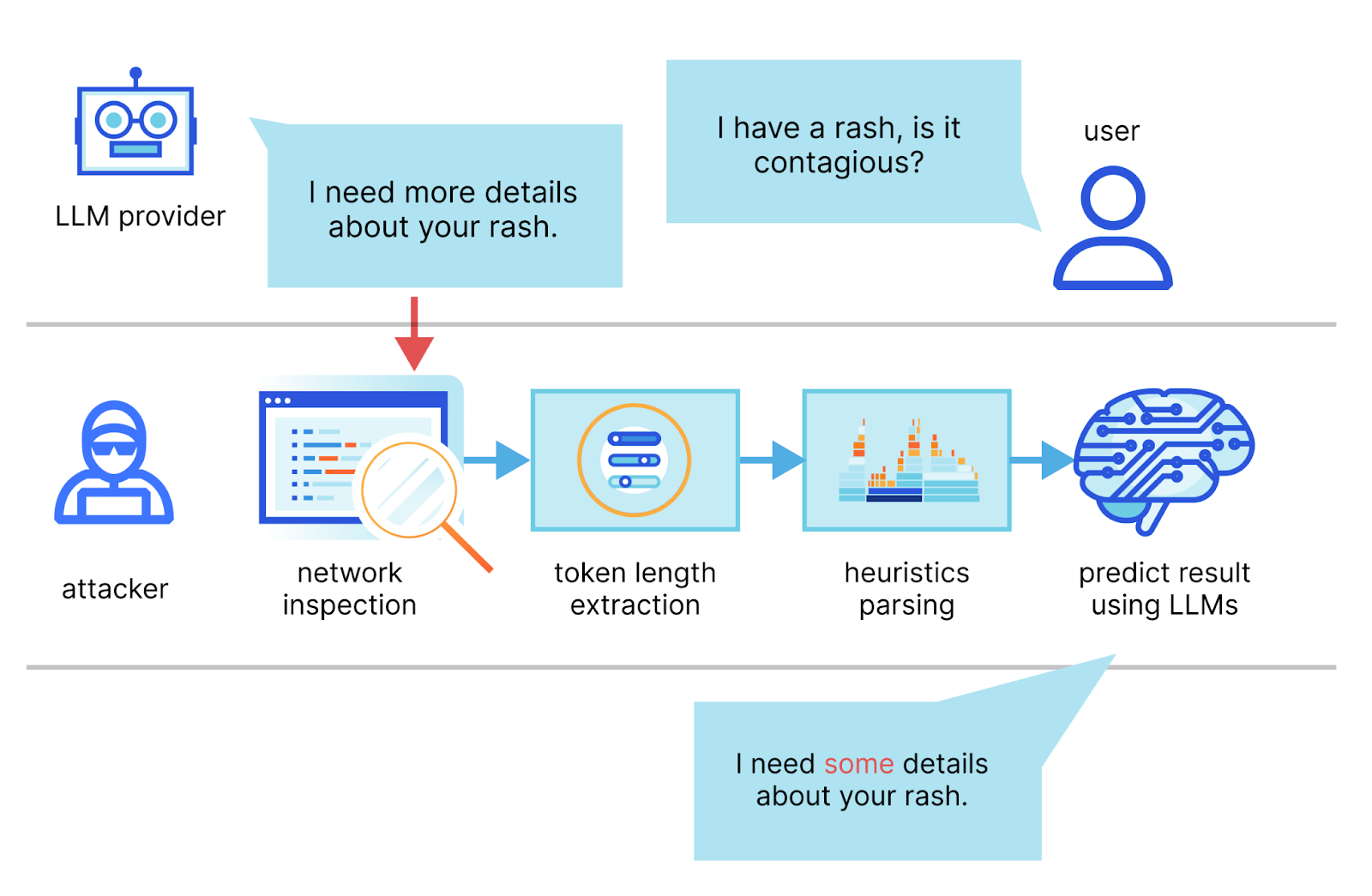
Since the discovery of CRIME, BREACH, TIME, LUCKY-13 etc., length-based side-channel attacks have been considered practical. Even though packets were encrypted, attackers were able to infer information about the underlying plaintext by analyzing metadata like the packet length or timing information.
Cloudflare was recently contacted by a group of researchers at Ben Gurion University who wrote a paper titled “What Was Your Prompt? A Remote Keylogging Attack on AI Assistants” that describes “a novel side-channel that can be used to read encrypted responses from AI Assistants over the web”. The Workers AI and AI Gateway team collaborated closely with these security researchers through our Public Bug Bounty program, discovering and fully patching a vulnerability that affects LLM providers. You can read the detailed research paper here.
Since being notified about this vulnerability, we’ve implemented a mitigation to help secure all Workers AI and AI Gateway customers. As far as we could assess, there was no outstanding risk to Workers AI and AI Gateway customers.
How does the side-channel attack work?
In the paper, the authors describe a method in which they intercept the stream of a chat session with an LLM provider, use the network packet headers to infer the length of each token, extract and segment their sequence, and then use their own dedicated LLMs to infer the response.
The two main requirements for a successful attack are an AI chat client running in streaming mode and a malicious actor capable of capturing network traffic between the client and the AI chat service. In streaming mode, the LLM tokens are emitted sequentially, introducing a token-length side-channel. Malicious actors could eavesdrop on packets via public networks or within an ISP.
An example request vulnerable to the side-channel attack looks like this:
curl -X POST \
https://api.cloudflare.com/client/v4/accounts/<account-id>/ai/run/@cf/meta/llama-2-7b-chat-int8 \
-H "Authorization: Bearer <Token>" \
-d '{"stream":true,"prompt":"tell me something about portugal"}'
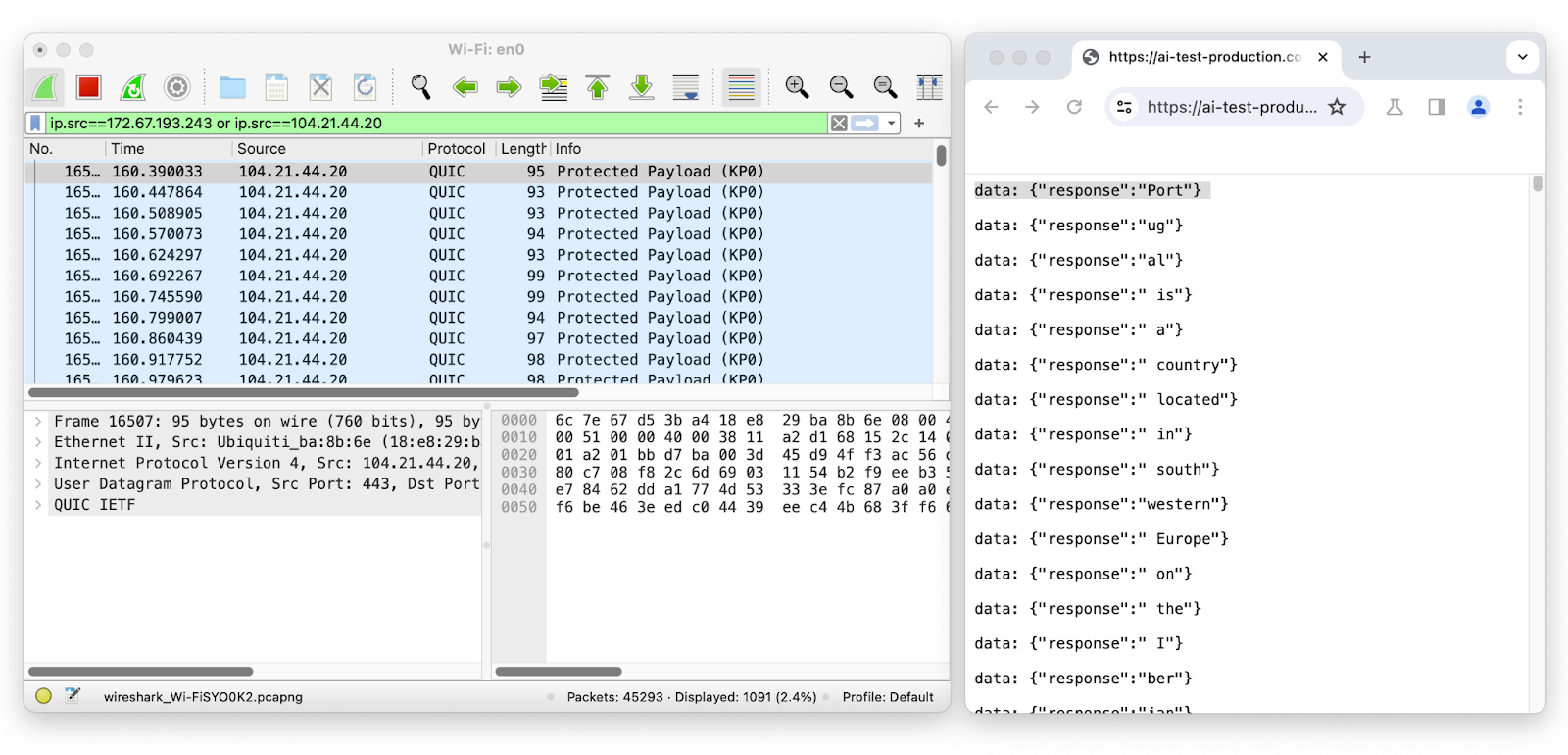
Let’s use Wireshark to inspect the network packets on the LLM chat session while streaming:
The first packet has a length of 95 and corresponds to the token “Port” which has a length of four. The second packet has a length of 93 and corresponds to the token “ug” which has a length of two, and so on. By removing the likely token envelope from the network packet length, it is easy to infer how many tokens were transmitted and their sequence and individual length just by sniffing encrypted network data.
Since the attacker needs the sequence of individual token length, this vulnerability only affects text generation models using streaming. This means that AI inference providers that use streaming — the most common way of interacting with LLMs — like Workers AI, are potentially vulnerable.
This method requires that the attacker is on the same network or in a position to observe the communication traffic and its accuracy depends on knowing the target LLM’s writing style. In ideal conditions, the researchers claim that their system “can reconstruct 29% of an AI assistant’s responses and successfully infer the topic from 55% of them”. It’s also important to note that unlike other side-channel attacks, in this case the attacker has no way of evaluating its prediction against the ground truth. That means that we are as likely to get a sentence with near perfect accuracy as we are to get one where only things that match are conjunctions.
Mitigating LLM side-channel attacks
Since this type of attack relies on the length of tokens being inferred from the packet, it can be just as easily mitigated by obscuring token size. The researchers suggested a few strategies to mitigate these side-channel attacks, one of which is the simplest: padding the token responses with random length noise to obscure the length of the token so that responses can not be inferred from the packets. While we immediately added the mitigation to our own inference product — Workers AI, we wanted to help customers secure their LLMs regardless of where they are running them by adding it to our AI Gateway.
As of today, all users of Workers AI and AI Gateway are now automatically protected from this side-channel attack.
What we did
Once we got word of this research work and how exploiting the technique could potentially impact our AI products, we did what we always do in situations like this: we assembled a team of systems engineers, security engineers, and product managers and started discussing risk mitigation strategies and next steps. We also had a call with the researchers, who kindly attended, presented their conclusions, and answered questions from our teams.
Unfortunately, at this point, this research does not include actual code that we can use to reproduce the claims or the effectiveness and accuracy of the described side-channel attack. However, we think that the paper has theoretical merit, that it provides enough detail and explanations, and that the risks are not negligible.
We decided to incorporate the first mitigation suggestion in the paper: including random padding to each message to hide the actual length of tokens in the stream, thereby complicating attempts to infer information based solely on network packet size.
Workers AI, our inference product, is now protected
With our inference-as-a-service product, anyone can use the Workers AI platform and make API calls to our supported AI models. This means that we oversee the inference requests being made to and from the models. As such, we have a responsibility to ensure that the service is secure and protected from potential vulnerabilities. We immediately rolled out a fix once we were notified of the research, and all Workers AI customers are now automatically protected from this side-channel attack. We have not seen any malicious attacks exploiting this vulnerability, other than the ethical testing from the researchers.
Our solution for Workers AI is a variation of the mitigation strategy suggested in the research document. Since we stream JSON objects rather than the raw tokens, instead of padding the tokens with whitespace characters, we added a new property, “p” (for padding) that has a string value of variable random length.
This has the advantage that no modifications are required in the SDK or the client code, the changes are invisible to the end-users, and no action is required from our customers. By adding random variable length to the JSON objects, we introduce the same network-level variability, and the attacker essentially loses the required input signal. Customers can continue using Workers AI as usual while benefiting from this protection.
One step further: AI Gateway protects users of any inference provider
We added protection to our AI inference product, but we also have a product that proxies requests to any provider — AI Gateway. AI Gateway acts as a proxy between a user and supported inference providers, helping developers gain control, performance, and observability over their AI applications. In line with our mission to help build a better Internet, we wanted to quickly roll out a fix that can help all our customers using text generation AIs, regardless of which provider they use or if they have mitigations to prevent this attack. To do this, we implemented a similar solution that pads all streaming responses proxied through AI Gateway with random noise of variable length.
Our AI Gateway customers are now automatically protected against this side-channel attack, even if the upstream inference providers have not yet mitigated the vulnerability. If you are unsure if your inference provider has patched this vulnerability yet, use AI Gateway to proxy your requests and ensure that you are protected.
Conclusion
At Cloudflare, our mission is to help build a better Internet – that means that we care about all citizens of the Internet, regardless of what their tech stack looks like. We are proud to be able to improve the security of our AI products in a way that is transparent and requires no action from our customers.
We are grateful to the researchers who discovered this vulnerability and have been very collaborative in helping us understand the problem space. If you are a security researcher who is interested in helping us make our products more secure, check out our Bug Bounty program at hackerone.com/cloudflare.
Today, we’re excited to announce our beta of AI Gateway – the portal to making your AI applications more observable, reliable, and scalable.
AI Gateway sits between your application and the AI APIs that your application makes requests to (like OpenAI) – so that we can cache responses, limit and retry requests, and provide analytics to help you monitor and track usage. AI Gateway handles the things that nearly all AI applications need, saving you engineering time, so you can focus on what you're building.
Connecting your app to AI Gateway
It only takes one line of code for developers to get started with Cloudflare’s AI Gateway. All you need to do is replace the URL in your API calls with your unique AI Gateway endpoint. For example, with OpenAI you would define your baseURL as "https://gateway.ai.cloudflare.com/v1/ACCOUNT_TAG/GATEWAY/openai" instead of "https://api.openai.com/v1" – and that’s it. You can keep your tokens in your code environment, and we’ll log the request through AI Gateway before letting it pass through to the final API with your token.
// configuring AI gateway with the dedicated OpenAI endpoint
const openai = new OpenAI({
apiKey: env.OPENAI_API_KEY,
baseURL: "https://gateway.ai.cloudflare.com/v1/ACCOUNT_TAG/GATEWAY/openai",
});
We currently support model providers such as OpenAI, Hugging Face, and Replicate with plans to add more in the future. We support all the various endpoints within providers and also response streaming, so everything should work out-of-the-box once you have the gateway configured. The dedicated endpoint for these providers allows you to connect your apps to AI Gateway by changing one line of code, without touching your original payload structure.
We also have a universal endpoint that you can use if you’d like more flexibility with your requests. With the universal endpoint, you have the ability to define fallback models and handle request retries. For example, let’s say a request was made to OpenAI GPT-3, but the API was down – with the universal endpoint, you could define Hugging Face GPT-2 as your fallback model and the gateway can automatically resend that request to Hugging Face. This is really helpful in improving resiliency for your app in cases where you are noticing unusual errors, getting rate limited, or if one bill is getting costly, and you want to diversify to other models. With the universal endpoint, you’ll just need to tweak your payload to specify the provider and endpoint, so we can properly route requests for you. Check out the example request below and the docs for more details on the universal endpoint schema.
# Using the Universal Endpoint to first try OpenAI, then Hugging Face
curl https://gateway.ai.cloudflare.com/v1/ACCOUNT_TAG/GATEWAY -X POST \
--header 'Content-Type: application/json' \
--data '[
{
"provider": "openai",
"endpoint": "chat/completions",
"headers": {
"Authorization": "Bearer $OPENAI_TOKEN",
"Content-Type": "application/json"
},
"query": {
"model": "gpt-3.5-turbo",
"stream": true,
"messages": [
{
"role": "user",
"content": "What is Cloudflare?"
}
]
}
},
{
"provider": "huggingface",
"endpoint": "gpt2",
"headers": {
"Authorization": "Bearer $HF_TOKEN",
"Content-Type": "application/json"
},
"query": {
"inputs": "What is Cloudflare?"
}
},
]'
Gaining visibility into your app’s usage
Now that your app is connected to Cloudflare, we can help you gather analytics and give insight and control on the traffic that is passing through your apps. Regardless of what model or infrastructure you use in the backend, we can help you log requests and analyze data like the number of requests, number of users, cost of running the app, duration of requests, etc. Although these seem like basic analytics that model providers should expose, it’s surprisingly difficult to get visibility into these metrics with the typical model providers. AI Gateway takes it one step further and lets you aggregate analytics across multiple providers too.
Controlling how your app scales
One of the pain points we often hear is how expensive it costs to build and run AI apps. Each API call can be unpredictably expensive and costs can rack up quickly, preventing developers from scaling their apps to their full potential. At the speed that the industry is moving, you don’t want to be limited by your scale and left behind – and that’s where caching and rate limiting can help. We allow developers to cache their API calls so that new requests can be served from our cache rather than the original API – making it cheaper and faster. Rate limiting can also help control costs by throttling the number of requests and preventing excessive or suspicious activity. Developers have full flexibility to define caching and rate limiting rules, so that apps can scale at a sustainable pace of your choosing.
The Workers AI Platform
AI Gateway pairs perfectly with our new Workers AI and Vectorize products, so you can build full-stack AI applications all within the Workers ecosystem. From deploying applications with Workers, running model inference on the edge with Workers AI, storing vector embeddings on Vectorize, to gaining visibility into your applications with AI Gateway – the Workers platform is your one-stop shop to bring your AI applications to life. To learn how to use AI Gateway with Workers AI or the different providers, check out the docs.
Next up: the enterprise use case
We are shipping v1 of AI Gateway with a few core features, but we have plans to expand the product to cover more advanced use cases as well – usage alerts, jailbreak protection, dynamic model routing with A/B testing, and advanced cache rules. But what we’re really excited about are the other ways you can apply AI Gateway…
In the future, we want to develop AI Gateway into a product that helps organizations monitor and observe how their users or employees are using AI. This way, you can flip a switch and have all requests within your network to providers (like OpenAI) pass through Cloudflare first – so that you can log user requests, apply access policies, enable rate limiting and data loss prevention (DLP) strategies. A powerful example: if an employee accidentally pastes an API key to ChatGPT, AI Gateway can be configured to see the outgoing request and redact the API key or block the request entirely, preventing it from ever reaching OpenAI or any end providers. We can also log and alert on suspicious requests, so that organizations can proactively investigate and control certain types of activity. AI Gateway then becomes a really powerful tool for organizations that might be excited about the efficiency that AI unlocks, but hesitant about trusting AI when data privacy and user error are really critical threats. We hope that AI Gateway can alleviate these concerns and make adopting AI tools a lot easier for organizations.
Whether you’re a developer building applications or a company who’s interested in how employees are using AI, our hope is that AI Gateway can help you demystify what’s going on inside your apps – because once you understand how your users are using AI, you can make decisions on how you actually want them to use it. Some of these features are still in development, but we hope this illustrates the power of AI Gateway and our vision for the future.
At Cloudflare, we live and breathe innovation (as you can tell by our Birthday Week announcements!) and the pace of innovation in AI is incredible to witness. We’re thrilled that we can not only help people build and use apps, but actually help accelerate the adoption and development of AI with greater control and visibility. We can’t wait to hear what you build – head to the Cloudflare dashboard to try out AI Gateway and let us know what you think!
A collection of tools from Cloudflare One to help your teams use AI services safely
Cloudflare One gives teams of any size the ability to safely use the best tools on the Internet without management headaches or performance challenges. We’re excited to announce Cloudflare One for AI, a new collection of features that help your team build with the latest AI services while still maintaining a Zero Trust security posture.
Large Language Models, Larger Security Challenges
A Large Language Model (LLM), like OpenAI’s GPT or Google’s Bard, consists of a neural network trained against a set of data to predict and generate text based on a prompt. Users can ask questions, solicit feedback, and lean on the service to create output from poetry to Cloudflare Workers applications.
The tools also bear an uncanny resemblance to a real human. As in some real-life personal conversations, oversharing can become a serious problem with these AI services. This risk multiplies due to the types of use cases where LLM models thrive. These tools can help developers solve difficult coding challenges or information workers create succinct reports from a mess of notes. While helpful, every input fed into a prompt becomes a piece of data leaving your organization’s control.
Some responses to tools like ChatGPT have been to try and ban the service outright; either at a corporate level or across an entire nation. We don’t think you should have to do that. Cloudflare One’s goal is to allow you to safely use the tools you need, wherever they live, without compromising performance. These features will feel familiar to any existing use of the Zero Trust products in Cloudflare One, but we’re excited to walk through cases where you can use the tools available right now to allow your team to take advantage of the latest LLM features.
Measure usage
SaaS applications make it easy for any user to sign up and start testing. That convenience also makes these tools a liability for IT budgets and security policies. Teams refer to this problem as “Shadow IT” – the adoption of applications and services outside the approved channels in an organization.
In terms of budget, we have heard from early adopter customers who know that their team members are beginning to experiment with LLMs, but they are not sure how to approach making a commercial licensing decision. What services and features do their users need and how many seats should they purchase?
On the security side, the AIs can be revolutionary for getting work done but terrifying for data control policies. Team members treat these AIs like sounding boards for painful problems. The services invite users to come with their questions or challenges. Sometimes the context inside those prompts can contain sensitive information that should never leave an organization. Even if teams select and approve a single vendor, members of your organization might prefer another AI and continue to use it in their workflow.
Cloudflare One customers on any plan can now review the usage of AIs. Your IT department can deploy Cloudflare Gateway and passively observe how many users are selecting which services as a way to start scoping out enterprise licensing plans.
Administrators can also block the use of these services with a single click, but that is not our goal today. You might want to use this feature if you select ChatGPT as your approved model, and you want to make sure team members don’t continue to use alternatives, but we hope you don’t block all of these services outright. Cloudflare’s priority is to give you the ability to use these tools safely.
Control API access
When our teams began experimenting with OpenAI’s ChatGPT service, we were astonished by what it already knew about Cloudflare. We asked ChatGPT to create applications with Cloudflare Workers or guide us through how to configure a Cloudflare Access policy and, in most cases, the results were accurate and helpful.
In some cases the results missed the mark. The AIs were using outdated information, or we were asking questions about features that had only launched recently. Thankfully, these AIs can learn and we can help. We can train these models with scoped inputs and connect plug-ins to provide our customers with better AI-guided experiences when using Cloudflare services.
We heard from customers who want to do the same thing and, like us, they need to securely share training data and grant plug-in access for an AI service. Cloudflare One’s security suite extends beyond human users and can give teams the ability to securely share Zero Trust access to sensitive data over APIs.
First, teams can create service tokens that external services must present to reach data made available through Cloudflare One. Administrators can provide these tokens to systems making API requests and log every single request. As needed, teams can revoke these tokens with a single click.
After creating and issuing service tokens, administrators can create policies to allow specific services access to their training data. These policies will verify the service token and can be extended to verify country, IP address or an mTLS certificate. Policies can also be created to require human users to authenticate with an identity provider and complete an MFA prompt before accessing sensitive training data or services.
When teams are ready to allow an AI service to connect to their infrastructure, they can do so without poking holes in their firewalls by using Cloudflare Tunnel. Cloudflare Tunnel will create an encrypted, outbound-only connection to Cloudflare’s network where every request will be checked against the access rules configured for one or more services protected by Cloudflare One.
Cloudflare’s Zero Trust access control gives you the ability to enforce authentication on each and every request made to the data your organization decides to provide to these tools. That still leaves a gap in the data your team members might overshare on their own.
Restrict data uploads
Administrators can select an AI service, block Shadow IT alternatives, and carefully gate access to their training material, but humans are still involved in these AI experiments. Any one of us can accidentally cause a security incident by oversharing information in the process of using an AI service – even an approved service.
We expect AI playgrounds to continue to evolve to feature more data management capabilities, but we don’t think you should have to wait for that to begin adopting these services as part of your workflow. Cloudflare’s Data Loss Prevention (DLP) service can provide a safeguard to stop oversharing before it becomes an incident for your security team.
First, tell us what data you care about. We provide simple, preconfigured options that give you the ability to check for things that look like social security numbers or credit card numbers. Cloudflare DLP can also scan for patterns based on regular expressions configured by your team.
Once you have defined the data that should never leave your organization, you can build granular rules about how it can and cannot be shared with AI services. Maybe some users are approved to experiment with projects that contain sensitive data, in which case you can build a rule that only allows an Active Directory or Okta group to upload that kind of information while everyone else is blocked.
Control use without a proxy
The tools in today’s blog post focus on features that apply to data-in-motion. We also want to make sure that misconfigurations in the applications don’t lead to security violations. For example, the new plug-in feature in ChatGPT brings the knowledge and workflows of external services into the AI interaction flow. However, that can also lead to the services behind plug-ins having more access than you want to.
Cloudflare’s Cloud Access Security Broker (CASB) scans your SaaS applications for potential issues that can occur when users make changes. Whether alerting you to files that someone accidentally just made public on the Internet to checking that your GitHub repositories have the right membership controls, Cloudflare’s CASB removes the manual effort required to check each and every setting for potential issues in your SaaS applications.
Available soon, we are working on new integrations with popular AI services to check for misconfigurations. Like most users of these services, we’re still learning more about where potential accidents can occur, and we are excited to provide administrators who use our CASB with our first wave of controls for AI services.
What’s next?
The usefulness of these tools will only accelerate. The ability of AI services to coach and generate output will continue to make it easier for builders from any background to create the next big thing.
We share a similar goal. The Cloudflare products focused on helping users build applications and services, our Workers platform, remove hassles like worrying about where to deploy your application or how to scale your services. Cloudflare solves those headaches so that users can focus on creating. Combined with the AI services, we expect to see thousands of new builders launch the next wave of products built on Cloudflare and inspired by AI coaching and generation.
We have already seen dozens of projects flourish that were built on Cloudflare Workers using guidance from tools like ChatGPT. We plan to launch new integrations with these models to make this even more seamless, bringing better Cloudflare-specific guidance to the chat experience.
We also know that the security risk of these tools will grow. We will continue to bring functionality into Cloudflare One that aims to stay one step ahead of the risks as they evolve with these services. Ready to get started? Sign up here to begin using Cloudflare One at no cost for teams of up to 50 users.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.