Post Syndicated from Julian Wood original https://aws.amazon.com/blogs/compute/building-extensions-for-aws-lambda-in-preview/
AWS Lambda is announcing a preview of Lambda Extensions, a new way to easily integrate Lambda with your favorite monitoring, observability, security, and governance tools. Extensions enable tools to integrate deeply into the Lambda execution environment to control and participate in Lambda’s lifecycle. This simplified experience makes it easier for you to use your preferred tools across your application portfolio today.
In this post I explain how Lambda extensions work, the changes to the Lambda lifecycle, and how to build an extension. To learn how to use extensions with your functions, see the companion blog post “Introducing AWS Lambda extensions”.
Extensions are built using the new Lambda Extensions API, which provides a way for tools to get greater control during function initialization, invocation, and shut down. This API builds on the existing Lambda Runtime API, which enables you to bring custom runtimes to Lambda.
You can use extensions from AWS, AWS Lambda Ready Partners, and open source projects for use-cases such as application performance monitoring, secrets management, configuration management, and vulnerability detection. You can also build your own extensions to integrate your own tooling using the Extensions API.
There are extensions available today for AppDynamics, Check Point, Datadog, Dynatrace, Epsagon, HashiCorp, Lumigo, New Relic, Thundra, Splunk, AWS AppConfig, and Amazon CloudWatch Lambda Insights. For more details on these, see “Introducing AWS Lambda extensions”.
The Lambda execution environment
Lambda functions run in a sandboxed environment called an execution environment. This isolates them from other functions and provides the resources, such as memory, specified in the function configuration.
Lambda automatically manages the lifecycle of compute resources so that you pay for value. Between function invocations, the Lambda service freezes the execution environment. It is thawed if the Lambda service needs the execution environment for subsequent invocations.
Previously, only the runtime process could influence the lifecycle of the execution environment. It would communicate with the Runtime API, which provides an HTTP API endpoint within the execution environment to communicate with the Lambda service.

Lambda and Runtime API
The runtime uses the API to request invocation events from Lambda and deliver them to the function code. It then informs the Lambda service when it has completed processing an event. The Lambda service then freezes the execution environment.
The runtime process previously exposed two distinct phases in the lifecycle of the Lambda execution environment: Init and Invoke.
1. Init: During the Init phase, the Lambda service initializes the runtime, and then runs the function initialization code (the code outside the main handler). The Init phase happens either during the first invocation, or in advance if Provisioned Concurrency is enabled.
2. Invoke: During the invoke phase, the runtime requests an invocation event from the Lambda service via the Runtime API, and invokes the function handler. It then returns the function response to the Runtime API.
After the function runs, the Lambda service freezes the execution environment and maintains it for some time in anticipation of another function invocation.
If the Lambda function does not receive any invokes for a period of time, the Lambda service shuts down and removes the environment.

Previous Lambda lifecycle
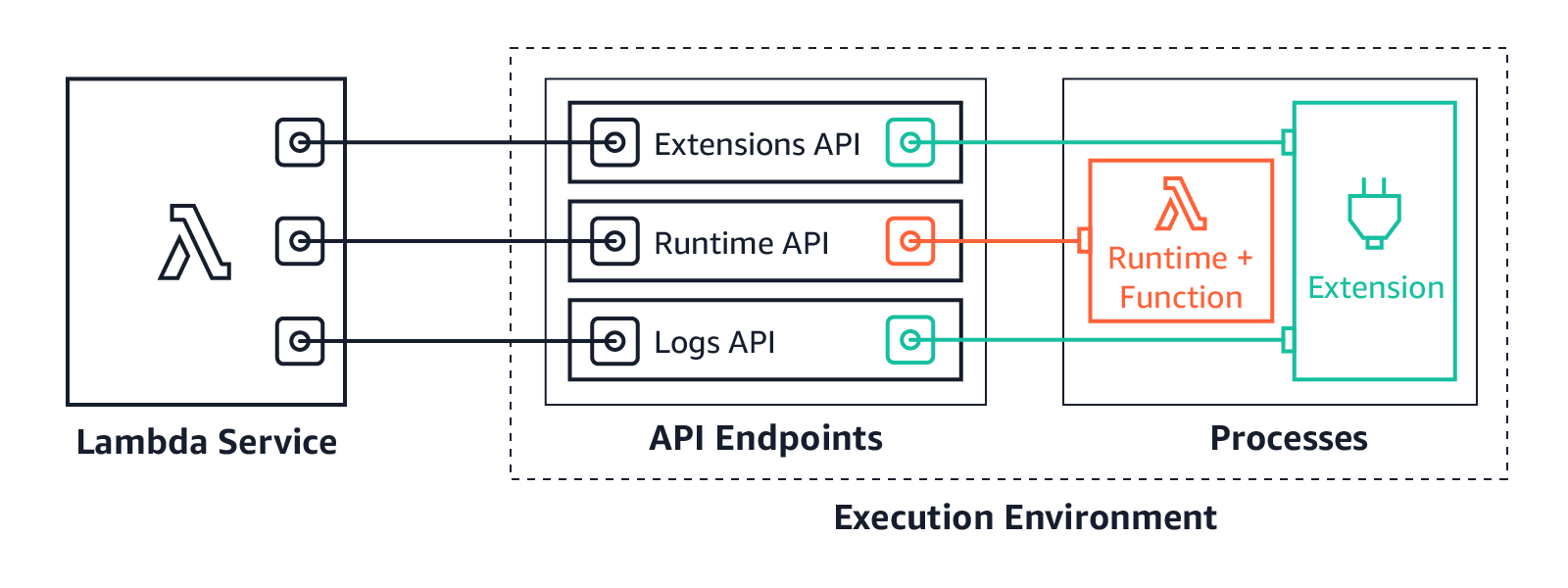
With the addition of the Extensions API, extensions can now influence, control, and participate in the lifecycle of the execution environment. They can use the Extensions API to influence when the Lambda service freezes the execution environment.
AWS Lambda execution environment with the Extensions API
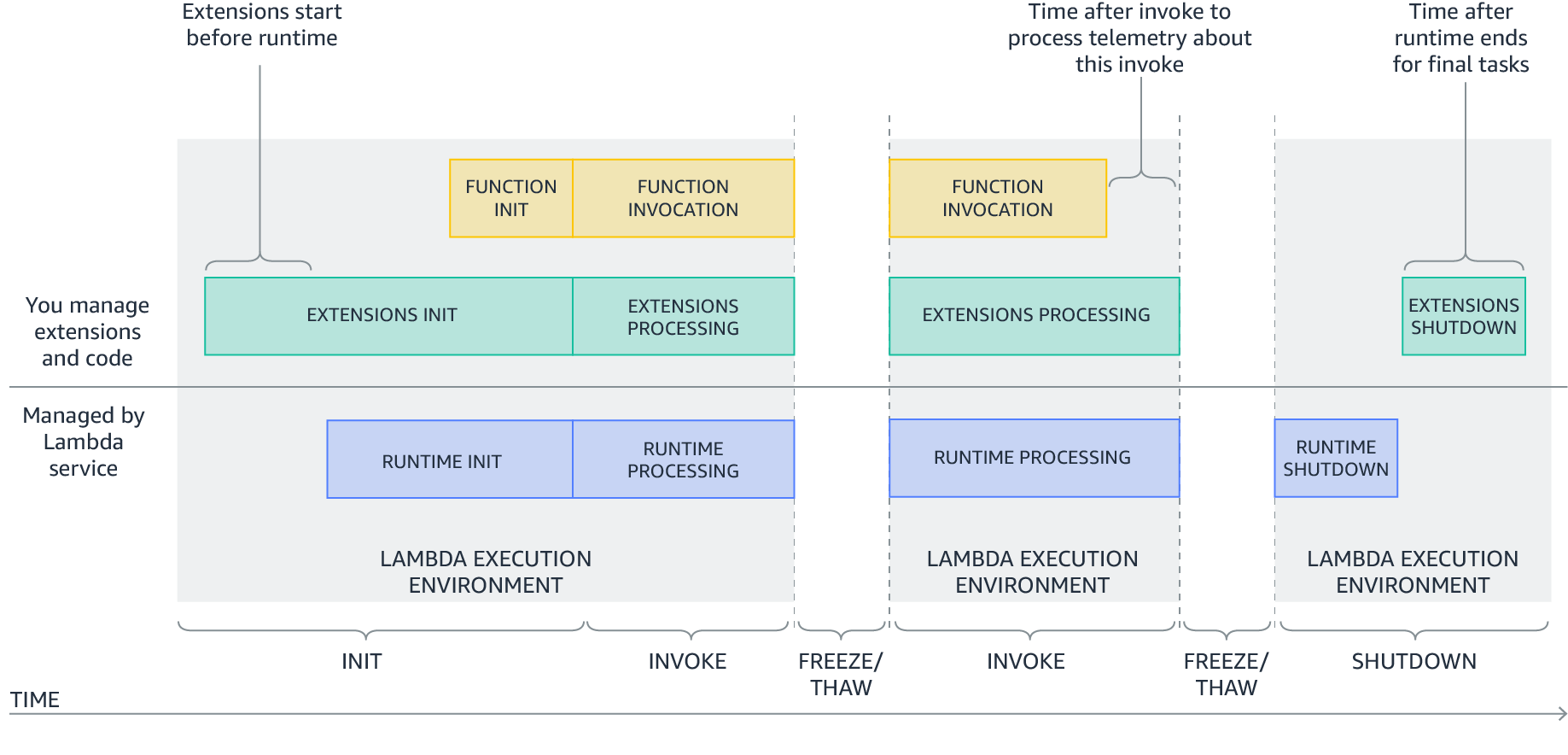
Extensions are initialized before the runtime and the function. They then continue to run in parallel with the function, get greater control during function invocation, and can run logic during shut down.
Extensions allow integrations with the Lambda service by introducing the following changes to the Lambda lifecycle:
- An updated Init phase. There are now three discrete Init tasks: extensions Init, runtime Init, and function Init. This creates an order where extensions and the runtime can perform setup tasks before the function code runs.
- Greater control during invocation. During the invoke phase, as before, the runtime requests the invocation event and invokes the function handler. In addition, extensions can now request lifecycle events from the Lambda service. They can run logic in response to these lifecycle events, and respond to the Lambda service when they are done. The Lambda service freezes the execution environment when it hears back from the runtime and all extensions. In this way, extensions can influence the freeze/thaw behavior.
- Shutdown phase: we are now exposing the shutdown phase to let extensions stop cleanly when the execution environment shuts down. The Lambda service sends a shut down event, which tells the runtime and extensions that the environment is about to be shut down.

New Lambda lifecycle with extensions
Each Lambda lifecycle phase starts with an event from the Lambda service to the runtime and all registered extensions. The runtime and extensions signal that they have completed by requesting the Next invocation event from the Runtime and Extensions APIs. Lambda freezes the execution environment and all extensions when there are no pending events.

Lambda lifecycle for execution environment, runtime, extensions, and function.png
For more information on the lifecycle phases and the Extensions API, see the documentation.
How are extensions delivered and run?
You deploy extensions as Lambda layers, which are ZIP archives containing shared libraries or other dependencies.
To add a layer, use the AWS Management Console, AWS Command Line Interface (AWS CLI), or infrastructure as code tools such as AWS CloudFormation, the AWS Serverless Application Model (AWS SAM), and Terraform.
When the Lambda service starts the function execution environment, it extracts the extension files from the Lambda layer into the /opt directory. Lambda then looks for any extensions in the /opt/extensions directory and starts initializing them. Extensions need to be executable as binaries or scripts. As the function code directory is read-only, extensions cannot modify function code.
Extensions can run in either of two modes, internal and external.
- Internal extensions run as part of the runtime process, in-process with your code. They are not separate processes. Internal extensions allow you to modify the startup of the runtime process using language-specific environment variables and wrapper scripts. You can use language-specific environment variables to add options and tools to the runtime for Java Correto 8 and 11, Node.js 10 and 12, and .NET Core 3.1. Wrapper scripts allow you to delegate the runtime startup to your script to customize the runtime startup behavior. You can use wrapper scripts with Node.js 10 and 12, Python 3.8, Ruby 2.7, Java 8 and 11, and .NET Core 3.1. For more information, see “Modifying-the-runtime-environment”.
- External extensions allow you to run separate processes from the runtime but still within the same execution environment as the Lambda function. External extensions can start before the runtime process, and can continue after the runtime shuts down. External extensions work with Node.js 10 and 12, Python 3.7 and 3.8, Ruby 2.5 and 2.7, Java Corretto 8 and 11, .NET Core 3.1, and custom runtimes.
External extensions can be written in a different language to the function. We recommend implementing external extensions using a compiled language as a self-contained binary. This makes the extension compatible with all of the supported runtimes. If you use a non-compiled language, ensure that you include a compatible runtime in the extension.
Extensions run in the same execution environment as the function, so share resources such as CPU, memory, and disk storage with the function. They also share environment variables, in addition to permissions, using the same AWS Identity and Access Management (IAM) role as the function.
For more details on resources, security, and performance with extensions, see the companion blog post “Introducing AWS Lambda extensions”.
For example extensions and wrapper scripts to help you build your own extensions, see the GitHub repository.
Showing extensions in action
The demo shows how external extensions integrate deeply with functions and the Lambda runtime. The demo creates an example Lambda function with a single extension using either the AWS CLI, or AWS SAM.
The example shows how an external extension can start before the runtime, run during the Lambda function invocation, and shut down after the runtime shuts down.
To set up the example, visit the GitHub repo, and follow the instructions in the README.md file.
The example Lambda function uses the custom provided.al2 runtime based on Amazon Linux 2. Using the custom runtime helps illustrate in more detail how the Lambda service, Runtime API, and the function communicate. The extension is delivered using a Lambda layer.
The runtime, function, and extension, log their status events to Amazon CloudWatch Logs. The extension initializes as a separate process and waits to receive the function invocation event from the Extensions API. It then sleeps for 5 seconds before calling the API again to register to receive the next event. The extension sleep simulates the processing of a parallel process. This could, for example, collect telemetry data to send to an external observability service.
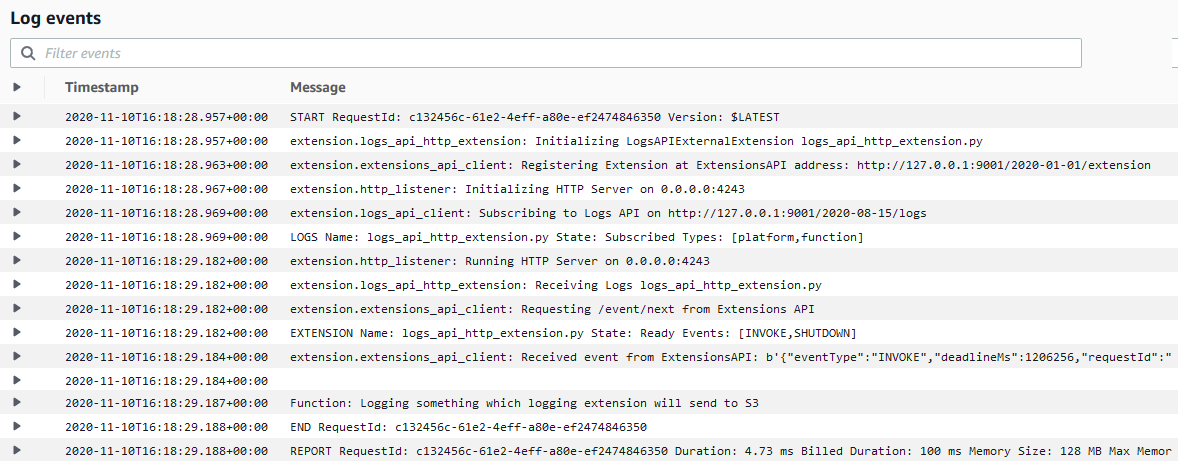
When the Lambda function is invoked, the extension, runtime and function perform the following steps. I walk through the steps using the log output.
1. The Lambda service adds the configured extension Lambda layer. It then searches the /opt/extensions folder, and finds an extension called extension1.sh. The extension executable launches before the runtime initializes. It registers with the Extensions API to receive INVOKE and SHUTDOWN events using the following API call.
curl -sS -LD "$HEADERS" -XPOST "http://${AWS_LAMBDA_RUNTIME_API}/2020-01-01/extension/register" --header "Lambda-Extension-Name: ${LAMBDA_EXTENSION_NAME}" -d "{ \"events\": [\"INVOKE\", \"SHUTDOWN\"]}" > $TMPFILE

Extension discovery, registration, and start
2. The Lambda custom provided.al2 runtime initializes from the bootstrap file.

Runtime initialization
3. The runtime calls the Runtime API to get the next event using the following API call. The HTTP request is blocked until the event is received.
curl -sS -LD "$HEADERS" -X GET "http://${AWS_LAMBDA_RUNTIME_API}/2018-06-01/runtime/invocation/next" > $TMPFILE &
The extension calls the Extensions API and waits for the next event. The HTTP request is again blocked until one is received.
curl -sS -L -XGET "http://${AWS_LAMBDA_RUNTIME_API}/2020-01-01/extension/event/next" --header "Lambda-Extension-Identifier: ${EXTENSION_ID}" > $TMPFILE &

Runtime and extension call APIs to get the next event
4. The Lambda service receives an invocation event. It sends the event payload to the runtime using the Runtime API. It sends an event to the extension informing it about the invocation, using the Extensions API.

Runtime and extension receive event
5. The runtime invokes the function handler. The function receives the event payload.
Runtime invokes handler
6. The function runs the handler code. The Lambda runtime receives back the function response and sends it back to the Runtime API with the following API call.
curl -sS -X POST "http://${AWS_LAMBDA_RUNTIME_API}/2018-06-01/runtime/invocation/$REQUEST_ID/response" -d "$RESPONSE" > $TMPFILE

Runtime receives function response and sends to Runtime API
7. The Lambda runtime then waits for the next invocation event (warm start).

Runtime waits for next event
8. The extension continues processing for 5 seconds, simulating the processing of a companion process. The extension finishes, and uses the Extensions API to register again to wait for the next event.

Extension processing
9. The function invocation report is logged.

Function invocation report
10. When Lambda is about to shut down the execution environment, it sends the Runtime API a shut down event.
Lambda runtime shut down event
11. Lambda then sends a shut down event to the extensions. The extension finishes processing and then shuts down after the runtime.

Lambda extension shut down event
The demo shows the steps the runtime, function, and extensions take during the Lambda lifecycle.
An external extension registers and starts before the runtime. When Lambda receives an invocation event, it sends it to the runtime. It then sends an event to the extension informing it about the invocation. The runtime invokes the function handler, and the extension does its own processing of the event. The extension continues processing after the function invocation completes. When Lambda is about to shut down the execution environment, it sends a shut down event to the runtime. It then sends one to the extension, so it can finish processing.
To see a sequence diagram of this flow, see the Extensions API documentation.
Pricing
Extensions share the same billing model as Lambda functions. When using Lambda functions with extensions, you pay for requests served and the combined compute time used to run your code and all extensions, in 100 ms increments. To learn more about the billing for extensions, visit the Lambda FAQs page.
Conclusion
Lambda extensions enable you to extend Lambda’s execution environment to more easily integrate with your favorite tools for monitoring, observability, security, and governance.
Extensions can run additional code; before, during, and after a function invocation. There are extensions available today from AWS Lambda Ready Partners. These cover use-cases such as application performance monitoring, secrets management, configuration management, and vulnerability detection. Extensions make it easier to use your existing tools with your serverless applications. For more information on the available extensions, see the companion post “Introducing Lambda Extensions – In preview“.
You can also build your own extensions to integrate your own tooling using the new Extensions API. For example extensions and wrapper scripts, see the GitHub repository.
Extensions are now available in preview in the following Regions: us-east-1, us-east-2, us-west-1, us-west-2, ca-central-1, eu-west-1, eu-west-2, eu-west-3, eu-central-1, eu-north-1, eu-south-1, sa-east-1, me-south-1, ap-northeast-1, ap-northeast-2, ap-northeast-3, ap-southeast-1, ap-southeast-2, ap-south-1, and ap-east-1.
For more serverless learning resources, visit https://serverlessland.com.