Post Syndicated from Art Baudo original https://aws.amazon.com/blogs/compute/migrating-your-on-premises-workloads-to-aws-outposts-rack-2/
This post is written by Craig Warburton, Senior Solutions Architect, Hybrid; Sedji Gaouaou, Senior Solutions Architect, Hybrid; and Brian Daugherty, Principal Solutions Architect, Hybrid.
Migrating workloads to AWS Outposts Rack offers you the opportunity to gain the benefits of cloud computing while keeping your data and applications on premises.
For organizations with strict data residency requirements, by deploying AWS infrastructure and services on premises, you can keep sensitive data and mission-critical applications within your own data centers or facilities, helping ensure compliance with data sovereignty laws and regulatory frameworks.
On the other hand, if your organization does not have stringent data residency requirements, you may opt for a hybrid approach, using both Outposts Rack and the AWS Regions. With this flexibility, you can process and store data in the most appropriate location based on factors such as latency, cost optimization, and application requirements.
In this post, we cover options to migrate your workloads to an Outposts Rack, taking into account your specific data residency requirements. We explore strategies, tools, and best practices to enable a successful migration tailored to your organization’s needs.
Overview
AWS has several services to help you migrate and rehost workloads, including AWS Migration Hub, AWS Application Migration Service, AWS Elastic Disaster Recovery. Alternatively, you can use backup and recovery solutions provided by AWS partners.
At AWS, we use the 7 Rs framework to help organizations evaluate and choose the appropriate migration strategy for moving applications and workloads to the AWS Cloud. The 7 Rs represent:
- Rehosting (rehost or lift and shift)
- Replatforming (lift, tinker, and shift)
- Repurchasing (republish or re-vendor)
- Refactoring (re-architecting)
- Retiring
- Retaining (revisit)
- Relocating (remigrate).
This post focuses on rehosting and the services available to help rehost on-premises applications to Outposts Rack.
Before getting started with any migration, AWS recommends a three-phase approach to migrating workloads to the cloud (AWS Region or Outposts Rack). The three phases are assess, mobilize, and migrate and modernize.

Figure 1: Diagram showing the three migration phases of assess, mobilize, and migrate and modernize
This post describes the steps that you can take in the migrate and modernize phase. However, the assess and mobilize phases are also critical to allow you to understand what applications are migrated, the dependencies between them, and the planning associated with how and when migration occurs.
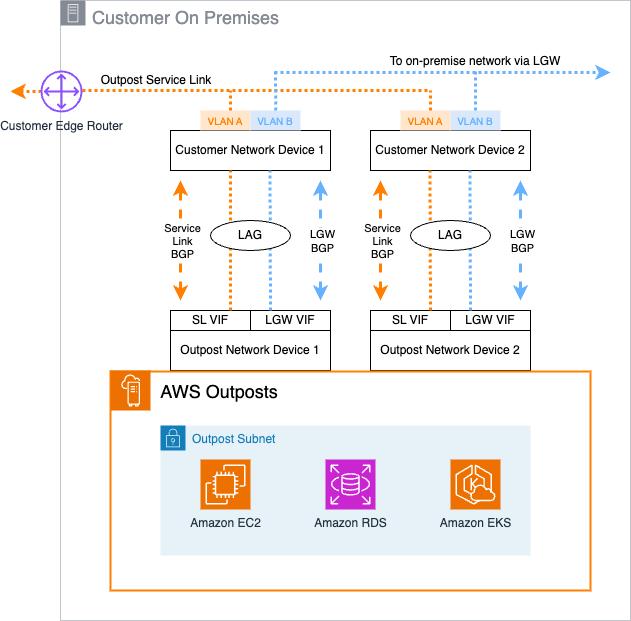
Workload migration to Outposts Rack: With staging environment in a Region
After deploying an Outposts Rack to your desired on-premises location, you can perform migrations of on-premises systems and virtual machines using either Application Migration Service and AMI creation or third-party backup and recovery services. Both scenarios are described in the following sections.
Scenario 1: Using Application Migration Service with AMI creation
Application Migration Service is able to lift and shift a large number of physical or virtual servers without compatibility issues, performance disruption, or long cutover windows.
In this scenario, at least one Outposts Rack is deployed on premises with the following prerequisites:
- An AWS Replication Agent installed on each source server
- At least one Outposts Rack installed and activated
- VPC in an AWS Region
- Staging subnet for staging migrated instances
- Cutover subnet to validating migrated instances
- Extended VPC spanning Region to the Outposts Rack
- Migrated resources subnet where instances will be deployed from AMIs
The following diagram shows the solution architecture including the prerequisites and the on-premises servers that will be migrated to the Outposts Rack.

Figure 2: Architecture diagram showing migration with Application Migration Service
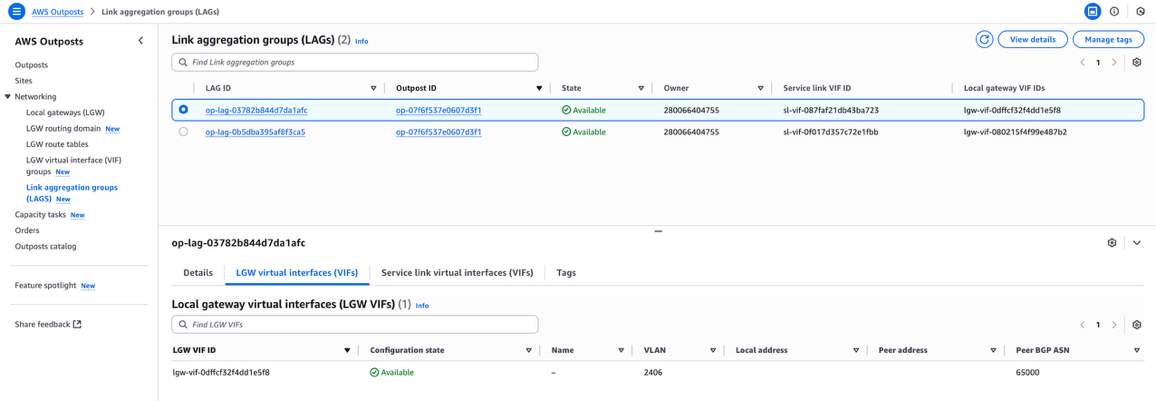
Step 1: Outposts Rack configuration
You can work with AWS specialists to size your Outposts for your workload and application requirements. In this scenario, you don’t need additional Outposts Rack capacity for migration because the staging area will be deployed in the Region (see 1 in Figure 2).
Step 2: Prepare Application Migration service
Set up Application Migration Service from the console in the Region to which your Outposts Rack is anchored. If this is your first setup, then choose Get started on the Application Migration Service console. When creating the replication settings template, ensure that your staging area is using subnets in the anchor Region (see 2 in Figure 2).
Step 3: Install the AWS Replication Agent to the source servers or machines
For large migrations, source servers may have a wide variety of operating system versions and may be distributed across multiple data centers. Application Migration Service offers the MGN connector, a feature that allows you to automate running commands on your source environment. Finally, ensure that communication is possible between the agent and Application Migration Service (see 3 in Figure 2).
In the following image, there is an example of deploying the AWS Replication Agent providing the necessary parameters (AWS Region, AWS access key and AWS secret access key).

When the AWS Replication Agent is installed, the server is added to the Application Migration Service console. Next, it undergoes the initial syncronization process, which is completed when showing the Ready for testing lifecycle state in the Application Migration Service console.
Step 4: Configure launch settings
Prior to testing or cutting over an instance, you must configure the launch settings by creating Amazon Elastic Compute Cloud (Amazon EC2) launch templates, ensuring that your cutover subnet is selected and that you choose an available instance type (see 4 in Figure 2). The instance type right-sizing feature allows AWS Application Migration Service to launch a test or cutover instance type that best matches the hardware configuration of the source server, by selecting the Basic option, AWS Application Migration Service will launch a test or cutover AWS instance type that best matches the OS, CPU, and RAM of your source server.
Step 5: Install AWS Systems Manager Agent on your cutover instances. When the launch settings are defined, you must activate the post-launch actions for either a specific server or all the servers. You must leave the Install the Systems Manager agent and allow executing actions on launched servers option toggled on in order for post-launch actions to work. Untoggling the option would disallow Application Migration Service to install the AWS Systems Manager Agent on your servers, and post-launch actions would no longer be executed (see 5 in Figure 2).

Figure 3: Post-launch actions on the Application Migration Service console
Step 6: Testing and cutover in Region
When you have configured the launch settings for each source server, you are ready to launch the servers as test instances. Best practice is to test instances before cutover.

Figure 4: Application Migration Service console ready to launch test instances
Finally, after completing the testing of all the source servers, you are ready for cutover (see 6 on Figure 2). Prior to launching cutover instances, check that the source servers are listed as Ready for cutover under Migration lifecycle and Healthy under Data replication status.

Figure 5: Application Migration Console ready for cutover
To launch the cutover instances, choose the instances you want to cutover and then choose Launch cutover instances under Cutover (see Figure 5). The Application Migration Service console indicates Cutover finalized when the cutover has completed successfully the chosen source servers’ Migration lifecycle column shows the Cutover complete status, the Data replication status column shows Disconnected, and the Next step column shows Mark as archived. The source servers have now been successfully migrated into AWS. You can now archive your source servers that have launched cutover instances.
Step 7: Create a Migration AMI
After migrating all your workloads in the region where the Outposts is anchored to, create Amazon Machine Images (AMI). When you create an AMI from an instance, Amazon EC2 powers down the instance before creating the AMI to make sure that everything on the instance is stopped and in a consistent state during the creation process. If you are confident that your instance is in a consistent state appropriate for AMI creation, you can tell Amazon EC2 not to power down and reboot the instance.
This step can be automated using an existing Post Launch Action.
Step 8: Launch instances on AWS Outposts
The final part is to launch your created AMIs to your Outposts. To identify the EC2 instances configured on your Outpost you can use the following AWS Command Line Interface (AWS CLI):
Outposts get-outpost-instance-types \
–outpost-id op-abcdefgh123456789
The output of this command lists the instance types and sizes configured on your Outpost:
InstanceTypes:
– InstanceType: c5.xlarge
– InstanceType: c5.4xlarge
– InstanceType: r5.2xlarge
– InstanceType: r5.4xlarge
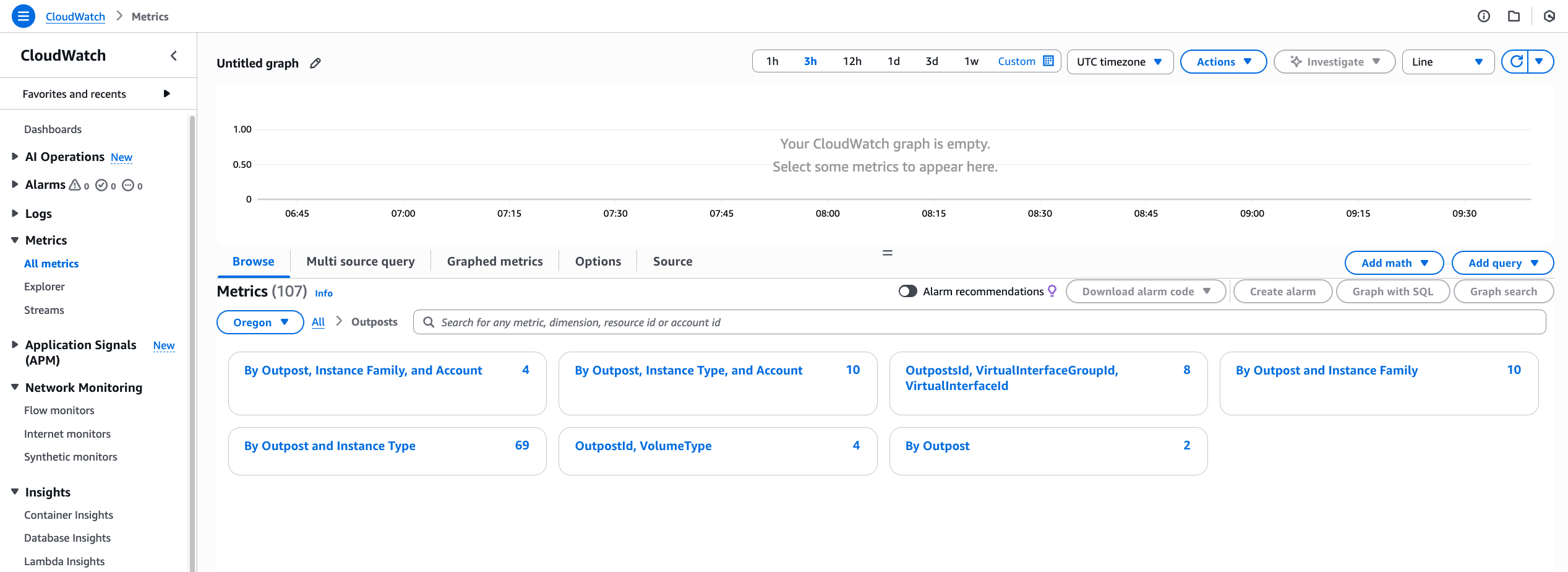
With knowledge of the instance types configured, you can now determine how many of each are available. For example, the following AWS CLI command, which is run on the account that owns the Outpost, lists the number of c5.xlarge instances available for use:
aws cloudwatch get-metric-statistics \
–namespace AWS/Outposts \
–metric-name AvailableInstanceType_Count \
–statistics Average –period 3600 \
–start-time $(date -u -Iminutes -d ‘-1hour’) \
–end-time $(date -u -Iminutes) \
–dimensions \
Name=OutpostId,Value=op-abcdefgh123456789 \
Name=InstanceType,Value=c5.xlarge
This command returns:
Datapoints:
– Average: 10.0
Timestamp: ‘2024-04-10T10:39:00+00:00’
Unit: Count
Label: AvailableInstanceType_Count
The output indicates that there were (on average) 10 c5.xlarge instances available in the specified time period (one hour). Using the same command for the other instance types, you discover that there are also 20 c5.4xlarge, 10 r5.2xlarge, and 6 r5.4xlarge available for use in completing the necessary EC2 launch templates.
Scenario 2: Using partner backup and replication solutions
You may already be using a third-party or AWS Partner solution to create on-premises backups of bare-metal or virtualized systems. These solutions often use local disk-arrays or object stores to create tiered backups of systems covering restore-points going back years, days, or just a few hours or minutes.
These solutions may also have inherent capabilities to restore from these backups directly to the AWS. This enables migration of on-premises systems to EC2 instances deployed to Outposts Rack.
In the scenario illustrated in Figure 6, the partner backup and replication service (BR) creates backups (see 1 in Figure 6) of virtual machines to on-premises disk or object storage repositories. Using the service’s AWS integration, virtual machines can be restored (see 2 in Figure 6) to an EC2 instance deployed on Outposts Rack, which is also on-premises. The restoration may follow a process that uses helper instances and volumes (see 3 in Figure 6) during intermediate steps to create Amazon Elastic Block Store (Amazon EBS) snapshots (see 4 in Figure 6) and then AMIs of the systems being migrated (see 5 in Figure 6), which are ultimately deployed (see 6 in Figure 6) to Outposts Rack.

Figure 6: Architecture diagram of the partner backup and replication scenario
When deploying an AMI created from a restored instance you must specify the target VPC and subnet. These should be the VPC being extended to the Outpost and a subnet that has been created in that VPC on the Outpost. You also need to specify an EC2 instance type that is available on the Outpost, which can be discovered using the process described in the previous section.
Workload migration to Outposts Rack using AWS Elastic Disaster Recovery (DRS)
Data residency can be a critical consideration for organizations that collect and store sensitive information, such as personally identifiable information (PII), financial data, or medical records. AWS Elastic Disaster Recovery, supported on Outposts Rack, helps enable seamless replication of on-premises data to Outposts Rack and addresses data residency concerns by keeping data within your on-premises environment, using Amazon EBS and Amazon S3 on Outposts.
In this scenario, an Outpost Rack is deployed on-premises with the following prerequisites:
- At least one Outposts Rack installed and activated
- The Outposts Rack must be in Direct VPC Routing (DVR) mode
- VPC extended to the Outposts Rack containing subnets for staging and target resources
- Amazon S3 on Outposts (necessary for all Elastic Disaster Recovery replication destinations)
- An AWS Replication Agent installed on each source server
The following diagram shows the solution architecture and includes the on-premises servers that are migrated from the local network to the Outposts Rack. It also includes the staging VPC used to deploy the replication servers on Outposts Rack, Amazon S3 on Outposts to store the local Amazon EBS snapshots, and the target VPC extended to Outposts Rack.

Figure 7: Architecture diagram for workflow migration to Outposts Rack
Step 1: Outposts Rack configuration
To use Elastic Disaster Recovery on Outposts Rack, you need to configure both Amazon EBS and Amazon S3 on Outposts to support continuous replication and point-in-time recovery for your workload needs (see 1 in Figure 7). Specifically, you need to size the Amazon EBS and Amazon S3 on Outposts capacity according to your workload capacity requirements and application interdependencies. To do this, you can define dependency groups: each dependency group is a collection of applications and their underlying infrastructure with technical or non-technical dependencies. A 2:1 ratio is recommended for the EBS volumes to be used for near-continuous replication, and a 1:1 ratio is recommended for the Amazon S3 on Outposts ratio for EBS snapshots. For example, to migrate 40 TB of workloads, you need to plan for 80 TB of EBS volumes and 40 TB of Amazon S3 on Outposts capacity.
Step 2: Extend VPC to your Outposts Rack
When your Outpost has been provisioned and is available, extend the necessary Amazon Virtual Private Cloud (Amazon VPC) connection to the Outpost from the Region by creating the desired staging and target subnets (see 2 in Figure 7).
Step 3: Prepare Elastic Disaster Recovery service
Prepare the Elastic Disaster Recovery service from the Console to set the default replication and launch settings. When defining these settings, make sure that the Outposts resources available are chosen for staging and target subnets and instance and storage type (see 3 in Figure 7).
Step 4: Install the AWS Replication Agent to the source servers or machines
The next phase is to install the AWS Replication Agent to the source servers and to make sure that communication is possible between the AWS Replication Agent and your Outposts replication subnet through the Outposts local gateway, which makes sure that replication traffic uses the local network (see 4 in Figure 7).
Step 5: Continuous block-level replication
Staging area resources are automatically created and managed by Elastic Disaster Recovery. When the AWS Replication Agent has been deployed, continuous block-level replication (compressed and encrypted in transit) occurs (see 5 in Figure 7) over the local network.
Step 6: Launch Outposts Rack resources
Finally, migrated instances can now be launched using Outposts Rack resources based on the launch settings defined previously (see 6 in Figure 7).
Conclusion
In this post, you have learned how to migrate your workloads from your on-premises environment to AWS Outposts Rack based on your specific data residency requirements. When you have the flexibility of using AWS Regional services, AWS migration services or partner solutions can be used with infrastructure already in place. If your data must stay on-premises, then using AWS Elastic Disaster Recovery allows you to migrate your data without using Regional services, allowing you to migrate to Outposts Rack without your data leaving the boundary of a certain geographic location.
To learn more about an end-to-end migration and modernization journey, visit the AWS Migration Hub.
 This announcement builds upon two significant storage integration milestones we achieved in the past year. In December 2024, we introduced the ability to attach block data volumes from third-party storage arrays to Amazon EC2 instances on Outposts directly through the AWS Management Console. Then in July 2025, we enabled booting Amazon EC2 instances directly from these external storage arrays. Now, with the addition of Dell and HPE, customers have even more choice in how they integrate their on-premises storage investments with AWS Outposts.
This announcement builds upon two significant storage integration milestones we achieved in the past year. In December 2024, we introduced the ability to attach block data volumes from third-party storage arrays to Amazon EC2 instances on Outposts directly through the AWS Management Console. Then in July 2025, we enabled booting Amazon EC2 instances directly from these external storage arrays. Now, with the addition of Dell and HPE, customers have even more choice in how they integrate their on-premises storage investments with AWS Outposts.












































 directly from the
directly from the 

























