Post Syndicated from Micah Walter original https://aws.amazon.com/blogs/aws/introducing-aws-lambda-managed-instances-serverless-simplicity-with-ec2-flexibility/
Today, we’re announcing AWS Lambda Managed Instances, a new capability you can use to run AWS Lambda functions on your Amazon Elastic Compute Cloud (Amazon EC2) compute while maintaining serverless operational simplicity. This enhancement addresses a key customer need: accessing specialized compute options and optimizing costs for steady-state workloads without sacrificing the serverless development experience you know and love.
Although Lambda eliminates infrastructure management, some workloads require specialized hardware, such as specific CPU architectures, or cost optimizations from Amazon EC2 purchasing commitments. This tension forces many teams to manage infrastructure themselves, sacrificing the serverless benefits of Lambda only to access the compute options or pricing models they need. This often leads to a significant architectural shift and greater operational responsibility.
Lambda Managed Instances
You can use Lambda Managed Instances to define how your Lambda functions run on EC2 instances. Amazon Web Services (AWS) handles setting up and managing these instances in your account. You get access to the latest generation of Amazon EC2 instances, and AWS handles all the operational complexity—instance lifecycle management, OS patching, load balancing, and auto scaling. This means you can select compute profiles optimized for your specific workload requirements, like high-bandwidth networking for data-intensive applications, without taking on the operational burden of managing Amazon EC2 infrastructure.
Each execution environment can process multiple requests rather than handling just one request at a time. This can significantly reduce compute consumption, because your code can efficiently share resources across concurrent requests instead of spinning up separate execution environments for each invocation. Lambda Managed Instances provides access to Amazon EC2 commitment-based pricing models such as Compute Savings Plans and Reserved Instances, which can provide up to a 72% discount over Amazon EC2 On-Demand pricing. This offers significant cost savings for steady-state workloads while maintaining the familiar Lambda programming model.
Let’s try it out
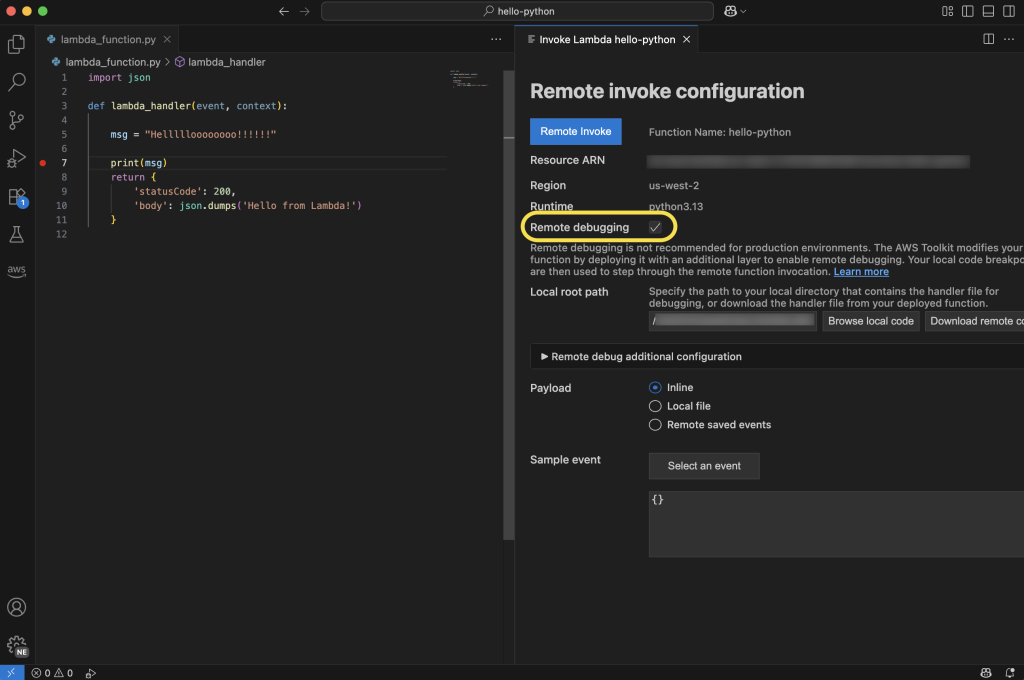
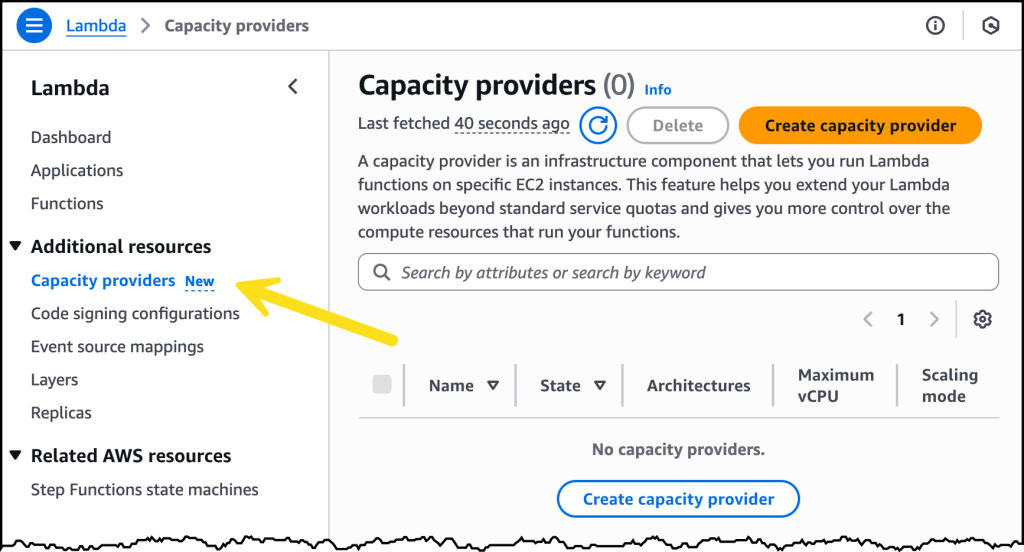
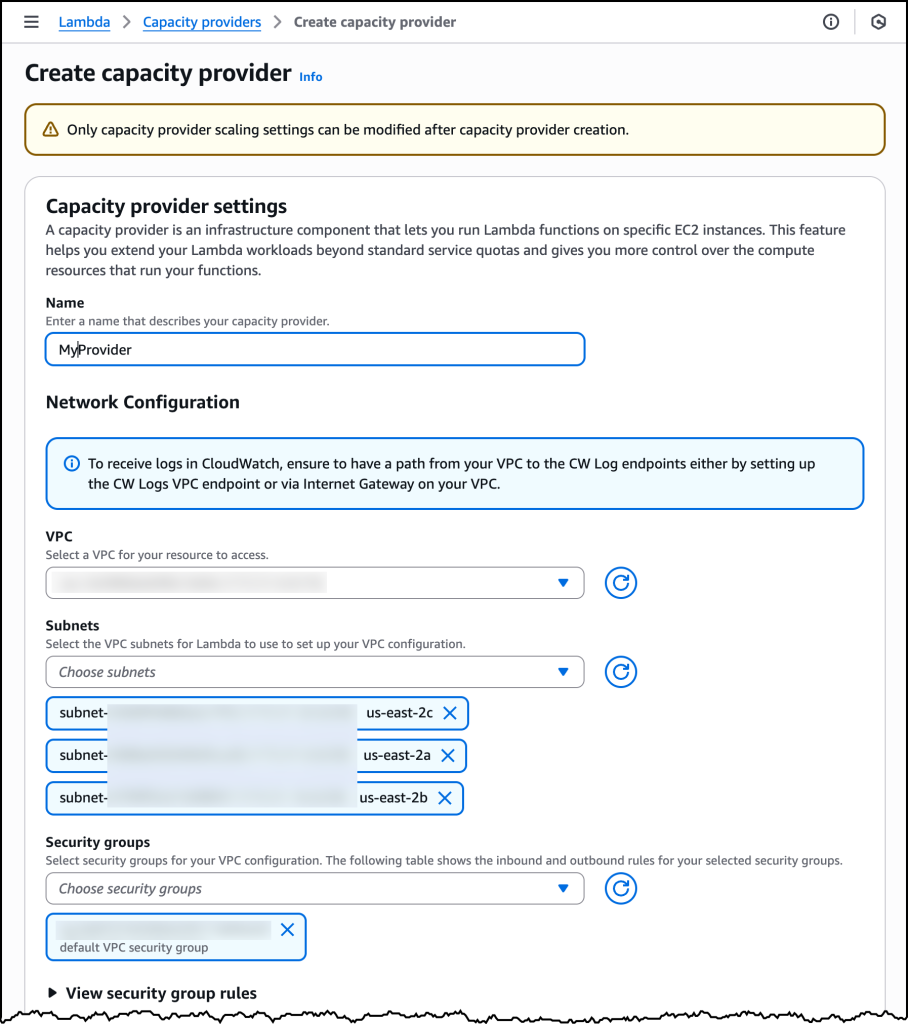
To take Lambda Managed Instances for a spin, I first need to create a Capacity provider. As shown in the following image, there is a new tab for creating these in the navigation pane under Additional resources.

Creating a Capacity provider is where I specify the virtual private cloud (VPC), subnet configuration and security groups. With a capacity provider configuration, I can also tell Lambda where to provision and manage the instances.

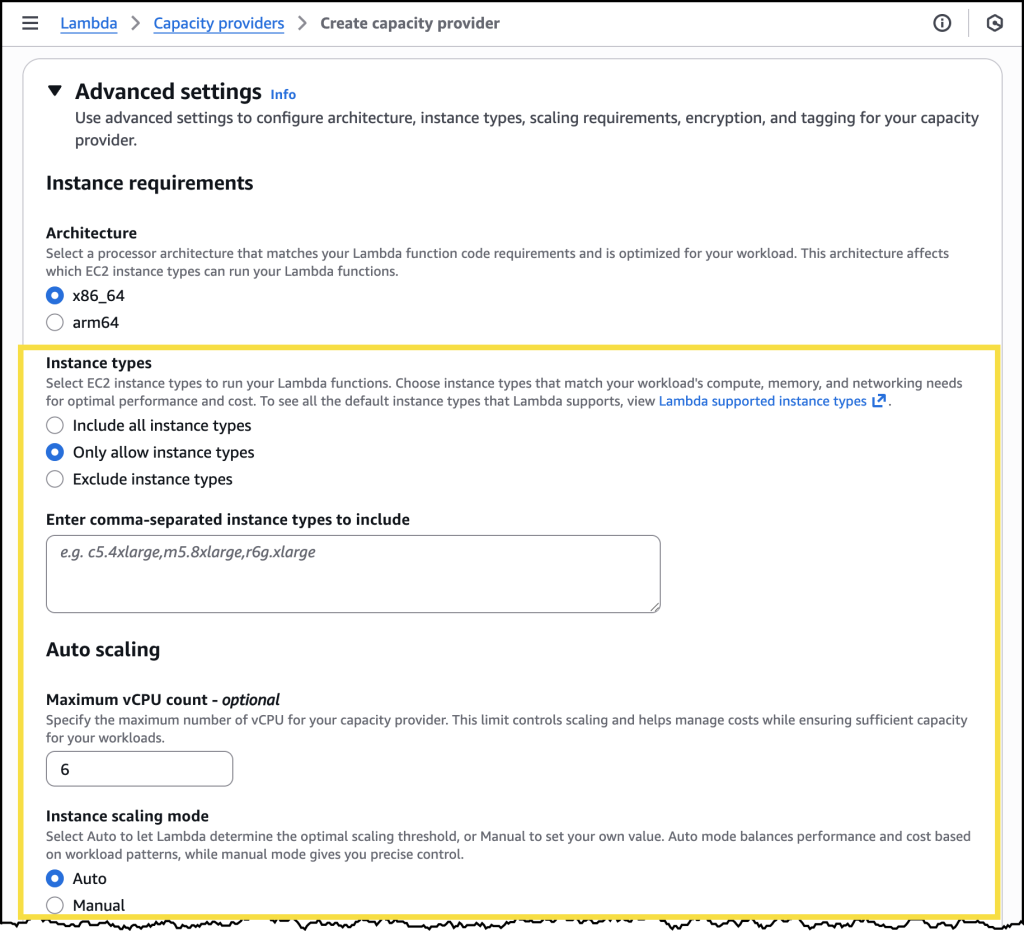
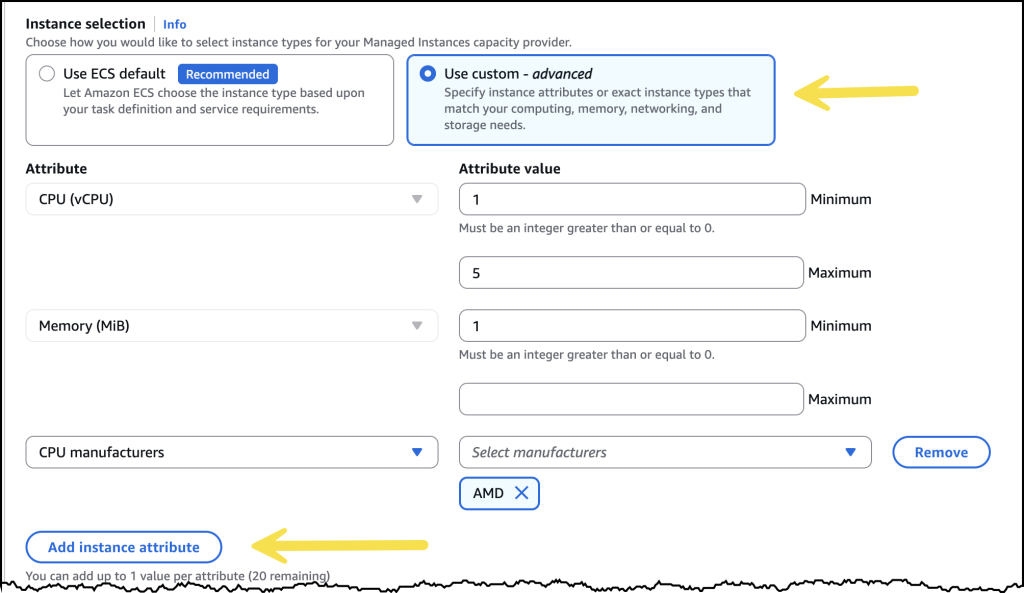
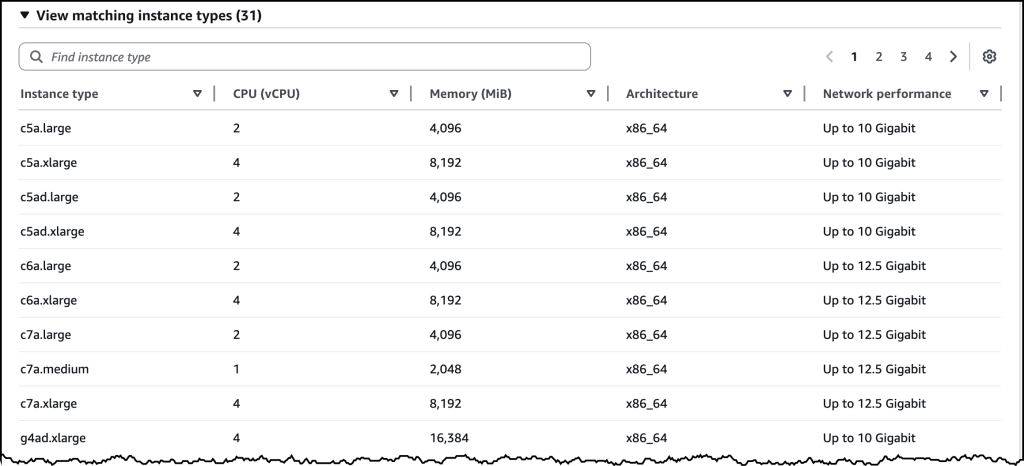
I can also specify the EC2 instance types I’d like to include or exclude, or I can choose to include all instance types for high diversity. Additionally, I can specify a few controls related to auto scaling, including the Maximum vCPU count, and if I want to use Auto scaling or use a CPU policy.

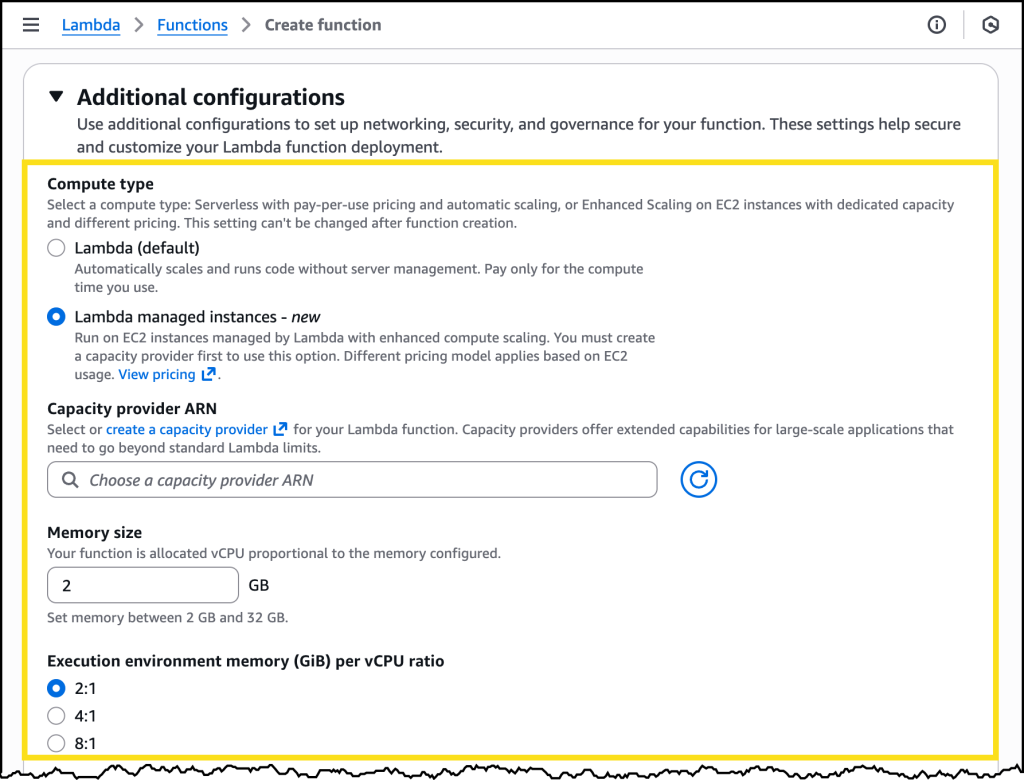
After I have my capacity provider configured, I can choose it through its Amazon Resource Name (ARN) when I go to create a new Lambda function. Here I can also select the memory allocation I want along with a memory-to-vCPU ratio.

Working with Lambda Managed Instances
Now that we’ve seen the basic setup, let’s explore how Lambda Managed Instances works in more detail. The feature organizes EC2 instances into capacity providers that you configure through the Lambda console, AWS Command Line Interface (AWS CLI), or infrastructure as code (IaC) tools such as AWS CloudFormation, AWS Serverless Application Model (AWS SAM), AWS Cloud Development Kit (AWS CDK) and Terraform. Each capacity provider defines the compute characteristics you need, including instance type, networking configuration, and scaling parameters.
When creating a capacity provider, you can choose from the latest generation of EC2 instances to match your workload requirements. For cost-optimized general-purpose compute, you could choose AWS Graviton4 based instances that deliver excellent price performance. If you’re not sure which instance type to select, AWS Lambda provides optimized defaults that balance performance and cost based on your function configuration.
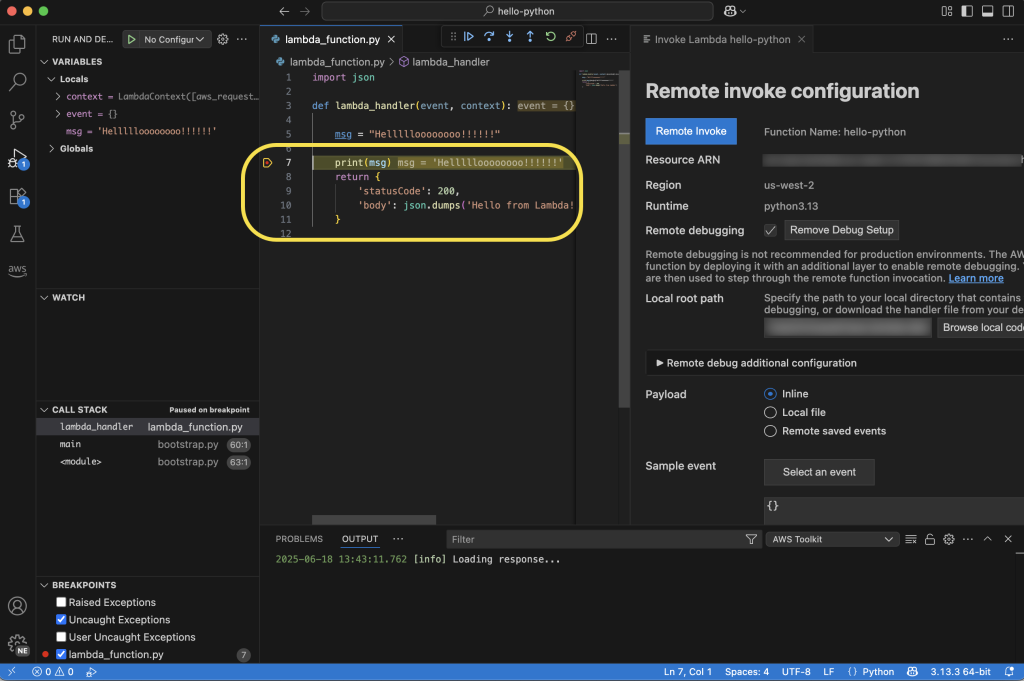
After creating a capacity provider, you attach your Lambda functions to it through a straightforward configuration change. Before attaching a function, you should review your code for programming patterns that can cause issues in multiconcurrency environments, such as writing to or reading from file paths that aren’t unique per request or using shared memory spaces and variables across invocations.
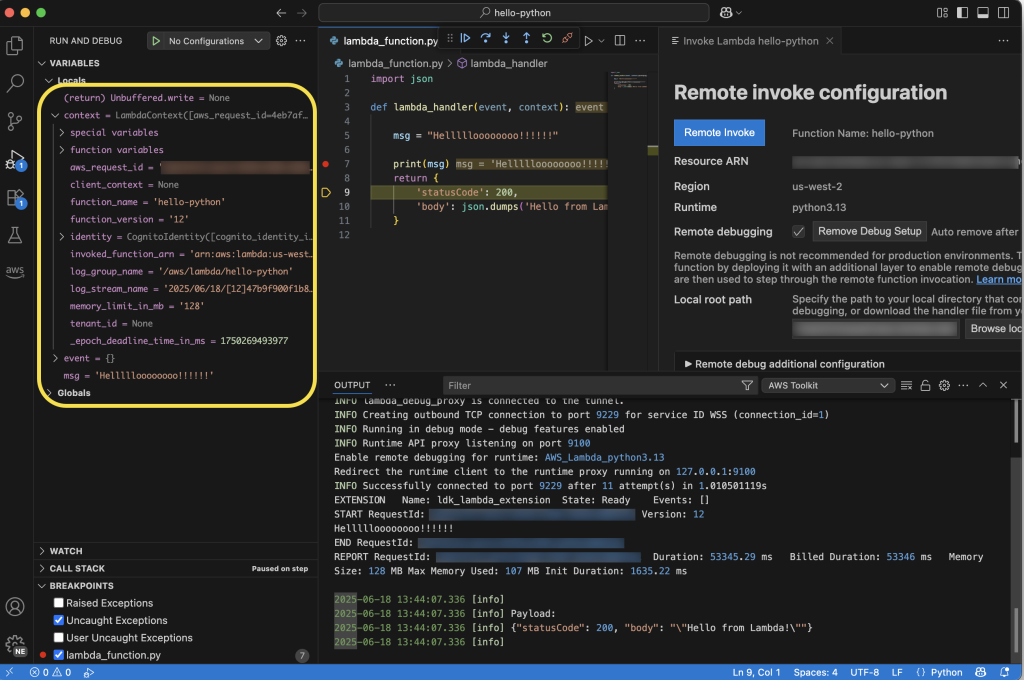
Lambda automatically routes requests to preprovisioned execution environments on the instances, eliminating cold starts that can affect first-request latency. Each execution environment can handle multiple concurrent requests through the multiconcurrency feature, maximizing resource utilization across your functions. When additional capacity is needed during traffic increases, AWS automatically launches new instances within tens of seconds and adds them to your capacity provider. The capacity provider can absorb traffic spikes of up to 50% without needing to scale by default, but built-in circuit breakers protect your compute resources during extreme traffic surges by temporarily throttling requests with 429 status codes if the capacity provider reaches maximum provisioned capacity and additional capacity is still being spun up.
The operational and architectural model remains serverless throughout this process. AWS handles instance provisioning, OS patching, security updates, load balancing across instances, and automatic scaling based on demand. AWS automatically applies security patches and bug fixes to operating system and runtime components, often without disrupting running applications. Additionally, instances have a maximum 14-day lifetime to align with industry security and compliance standards. You don’t need to write automatic scaling policies, configure load balancers, or manage instance lifecycle yourself, and your function code, event source integrations, AWS Identity and Access Management (AWS IAM) permissions, and Amazon CloudWatch monitoring remain unchanged.
Now available
You can start using Lambda Managed Instances today through the Lambda console, AWS CLI, or AWS SDKs. The feature is available in US East (N. Virginia), US East (Ohio), US West (Oregon), Asia Pacific (Tokyo), and Europe (Ireland) Regions. For Regional availability and future roadmap, visit the AWS Capabilities by Region. Learn more about it in the AWS Lambda documentation.
Pricing for Lambda Managed Instances has three components. First, you pay standard Lambda request charges of $0.20 per million invocations. Second, you pay standard Amazon EC2 instance charges for the compute capacity provisioned. Your existing Amazon EC2 pricing agreements, including Compute Savings Plans and Reserved Instances, can be applied to these instance charges to reduce costs for steady-state workloads. Third, you pay a compute management fee of 15% calculated on the EC2 on-demand instance price to cover AWS’s operational management of your instances. Note that unlike traditional Lambda functions, you are not charged separately for execution duration per request. The multiconcurrency feature helps further optimize costs by reducing the total compute time required to process your requests.
The initial release supports the latest versions of Node.js, Java, .NET and Python runtimes, with support for other languages coming soon. The feature integrates with existing Lambda workflows including function versioning, aliases, AWS CloudWatch Lambda Insights, AWS AppConfig extensions, and deployment tools like AWS SAM and AWS CDK. You can migrate existing Lambda functions to Lambda Managed Instances without changing your function code (as long as it has been validated to be thread safe for multiconcurrency) making it easy to adopt this capability for workloads that would benefit from specialized compute or cost optimization.
Lambda Managed Instances represents a significant expansion of Lambda’s capabilities, which means you can run a broader range of workloads while preserving the serverless operational model. Whether you’re optimizing costs for high-traffic applications, or accessing the latest processor architectures like Graviton4, this new capability provides the flexibility you need without operational complexity. We’re excited to see what you build with Lambda Managed Instances.




 This announcement builds upon two significant storage integration milestones we achieved in the past year. In December 2024, we introduced
This announcement builds upon two significant storage integration milestones we achieved in the past year. In December 2024, we introduced