In our previous post, we discussed how we utilize FieldMask as a solution when designing our APIs so that consumers can request the data they need when fetched via gRPC. In this blog post we will continue to cover how Netflix Studio Engineering uses FieldMask for mutation operations such as update and remove.
Example: Netflix Studio Production
Money Heist (La casa de papel) / Netflix
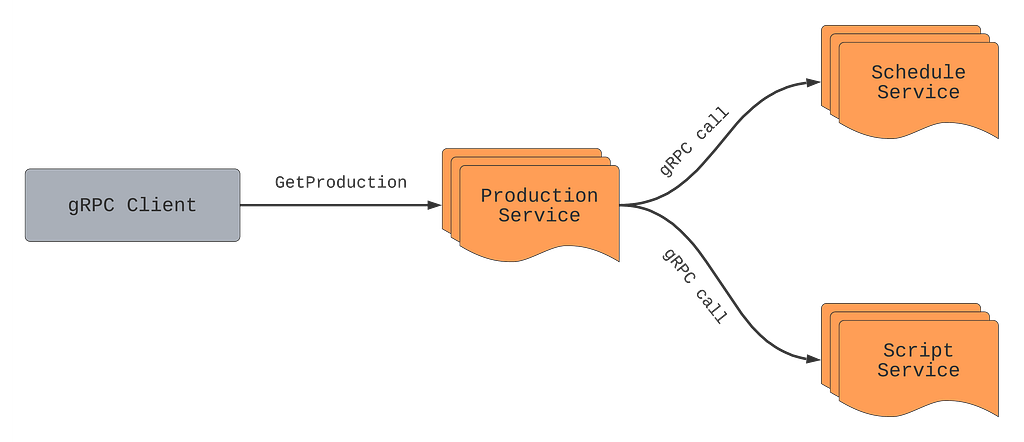
Previously we outlined what a Production is and how the Production Service makes gRPC calls to other microservices such as the Schedule Service and Script Service to retrieve schedules and scripts (aka screenplay) for a particular production such as La Casa De Papel. We can take that model and showcase how we can mutate particular fields on a production.
Mutating Production Details
Let’s say we want to update the format field from LIVE_ACTION to HYBRID as our production has added some animated elements. A naive way for us to solve this is to add an updateProductionFormatRequest method and gRPC endpoint just to update the productionFormat:
This allows us to update the production format for a particular production but what if we then want to update other fields such as titleor even multiple fields such as productionFormat, schedule, etc? Building on top of this we could just implement an update method for every field: one for Production format, another for title and so on:
This can become unmanageable when maintaining our APIs due to the number of fields on the Production. What if we want to update more than one field and do it atomically in a single RPC? Creating additional methods for various combinations of fields will lead to an explosion of mutation APIs. This solution is not scalable.
Instead of trying to create every single combination possible, another solution could be to have an UpdateProduction endpoint that requires all fields from the consumer:
The issue with this solution is two-fold as the consumer must know and provide every single required field in a Production even if they just want to update one field such as the format. The other issue is that since a Production has many fields the request payload can become quite large particularly if the production has schedule or scripts information.
What if, instead of all the fields, we send only the fields we actually want to update, and leave all other fields unset? In our example, we would only set the production format field (and ID to reference the production):
This could work if we never need to remove or blank out any fields. But what if we want to remove the value of the title field? Again, we can introduce one-off methods like RemoveProductionTitle, but as discussed above, this solution does not scale well. What if we want to remove a value of a nested field such as the planned launch date field from the schedule? We would end up adding remove RPCs for every individual nullable sub-field.
Utilizing FieldMask for Mutations
Instead of numerous RPCs or requiring a large payload, we can utilize a FieldMask for all our mutations. The FieldMask will list all of the fields we would like to explicitly update. First, let’s update our proto file to add in the UpdateProductionRequest, which will contain the data we want to update from a production, and a FieldMask of what should be updated:
Now, we can use a FieldMask to make mutations. We can update the format by creating a FieldMask for the format field by using the FieldMaskUtil.fromStringList() utility method which constructs a FieldMask for a list of field paths in a certain type. In this case, we will have one type, but will build upon this example later:
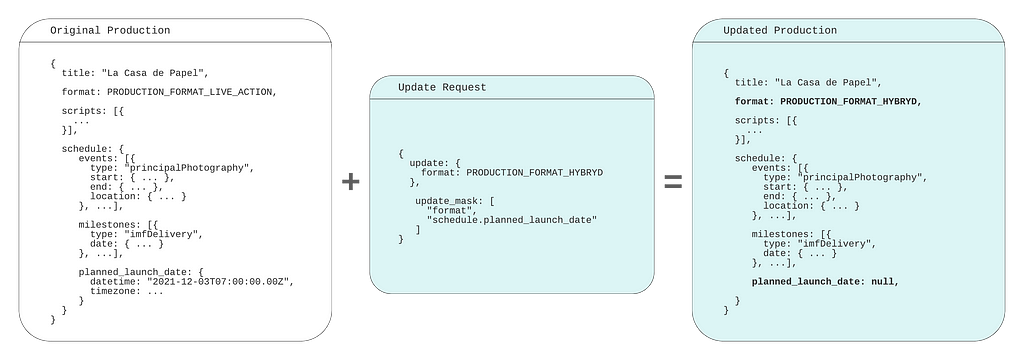
Since our FieldMask only specifies the format field that will be the only field that is updated even if we provide more data in ProductionUpdateOperation. It becomes easier to add or remove more fields to our FieldMask by modifying the paths. Data that is provided in the payload but not added in a path of a FieldMask will not be updated and simply ignored in the operation. But, if we omit a value it will perform a remove mutation on that field. Let’s modify our example above to showcase this and update the format but remove the planned launch date, which is a nested field on the ProductionSchedule as “schedule.planned_launch_date”:
In this example, we are performing both update and remove mutations as we have added “format” and “schedule.planned_launch_date” paths to our FieldMask. When we provide this in our payload these fields will be updated to the new values, but when building our payload we are only providing the format and omitting the schedule.planned_launch_date. Omitting this from the payload but having it defined in our FieldMask will function as a remove mutation:
Empty / Missing Field Mask
When a field mask is unset or has no paths, the update operation applies to all the payload fields. This means the caller must send the whole payload or, as mentioned above, any unset fields will be removed.
This convention has an implication on schema evolution: when a new field is added to the message, all the consumers must start sending its value on the update operation or it will get removed.
Suppose we want to add a new field: production budget. We will extend both the Production message, and ProductionUpdateOperation:
If there is a consumer that doesn’t know about this new field or hasn’t updated client stubs yet, it can accidentally null the budget field out by not sending the FieldMask in the update request.
To avoid this issue, the producer should consider requiring the field mask for all the update operations. Another option would be to implement a versioning protocol: force all callers to send their version numbers and implement custom logic to skip fields not present in the old version.
Bella Ciao
In this blog post series, we have gone over how we use FieldMask at Netflix and how it can be a practical and scalable solution when designing your APIs.
API designers should aim for simplicity, but make their APIs open for extension and evolution. It’s often not easy to keep APIs simple and future-proof. Utilizing FieldMask in APIs helps us achieve both simplicity and flexibility.
At Netflix, we heavily use gRPC for the purpose of backend to backend communication. When we process a request it is often beneficial to know which fields the caller is interested in and which ones they ignore. Some response fields can be expensive to compute, some fields can require remote calls to other services. Remote calls are never free; they impose extra latency, increase probability of an error, and consume network bandwidth. How can we understand which fields the caller doesn’t need to be supplied in the response, so we can avoid making unnecessary computations and remove calls? With GraphQL this comes out of the box through the use of field selectors. In the JSON:API standard a similar technique is known as Sparse Fieldsets. How can we achieve a similar functionality when designing our gRPC APIs? The solution we use within the Netflix Studio Engineering is protobuf FieldMask.
Money Heist (La casa de papel) / Netflix
Protobuf FieldMask
Protocol Buffers, or simply protobuf, is a data serialization mechanism. By default, gRPC uses protobuf as its IDL (interface definition language) and data serialization protocol.
FieldMask is a protobuf message. There are a number of utilities and conventions on how to use this message when it is present in an RPC request. A FieldMask message contains a single field named paths, which is used to specify fields that should be returned by a read operation or modified by an update operation.
Example: Netflix Studio Production
Money Heist (La casa de papel) / Netflix
Let’s assume there is a Production service that manages Studio Content Productions (in the film and TV industry, the term production refers to the process of making a movie, not the environment to run a software).
GetProduction returns a Production message by its unique ID. A production contains multiple fields such as: title, format, schedule dates, scripts aka screenplay, budgets, episodes, etc, but let’s keep this example simple and focus on filtering out schedule dates and scripts when requesting a production.
Reading Production Details
Let’s say we want to get production information for a particular production such as “La Casa De Papel” using the GetProduction API. While a production has many fields, some of these fields are returned from other services such as schedule from the Schedule service, or scripts from the Script service.
The Production service will make RPCs to Schedule and Script services every time GetProduction is called, even if clients ignore the schedule and scripts fields in the response. As mentioned above, remote calls are not free. If the service knows which fields are important for the caller, it can make an informed decision about making expensive calls, starting resource-heavy computations, and/or calling the database. In this example, if the caller only needs production title and production format, the Production service can avoid making remote calls to Schedule and Script services.
Additionally, requesting a large number of fields can make the response payload massive. This can become an issue for some applications, for example, on mobile devices with limited network bandwidth. In these cases it is a good practice for consumers to request only the fields they need.
Money Heist (La casa de papel) / Netflix
A naïve way of solving these problems can be adding additional request parameters, such as includeSchedule and includeScripts:
This approach requires adding a custom includeXXX field for every expensive response field and doesn’t work well for nested fields. It also increases the complexity of the request, ultimately making maintenance and support more challenging.
Add FieldMask to the Request Message
Instead of creating one-off “include” fields, API designers can add field_mask field to the request message:
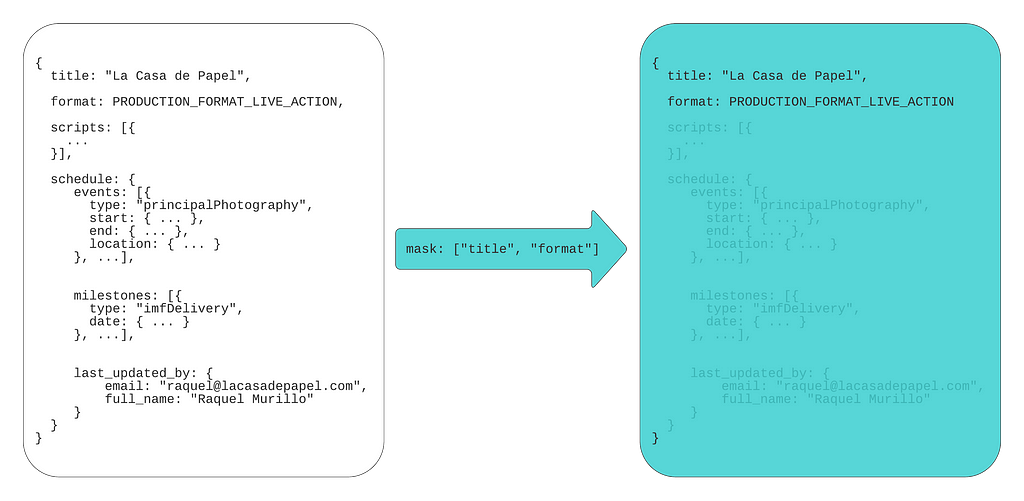
Consumers can set paths for the fields they expect to receive in the response. If a consumer is only interested in production titles and format, they can set a FieldMask with paths “title” and “format”:
Masking fields
Please note, even though code samples in this blog post are written in Java, demonstrated concepts apply to any other language supported by protocol buffers.
If consumers only need a title and an email of the last person who updated the schedule, they can set a different field mask:
By convention, if a FieldMask is not present in the request, all fields should be returned.
Protobuf Field Names vs Field Numbers
You might notice that paths in the FieldMask are specified using field names, whereas on the wire, encoded protocol buffers messages contain only field numbers, not field names. This (alongside some other techniques like ZigZag encoding for signed types) makes protobuf messages space-efficient.
To understand the difference between field numbers and field names, let’s take a detailed look at how protobuf encodes and decodes messages.
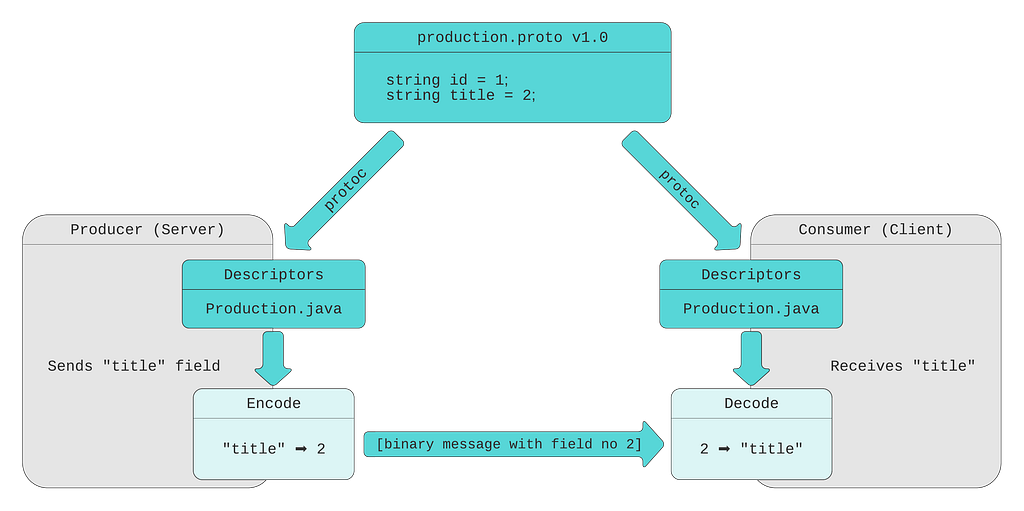
Our protobuf message definition (.proto file) contains Production message with five fields. Every field has a type, name, and number.
When the protobuf compiler (protoc) compiles this message definition, it creates the code in the language of your choice (Java in our example). This generated code contains classes for defined messages, together with message and field descriptors. Descriptors contain all the information needed to encode and decode a message into its binary format. For example, they contain field numbers, names, types. Message producer uses descriptors to convert a message to its wire format. For efficiency, the binary message contains only field number-value pairs. Field names are not included. When a consumer receives the message, it decodes the byte stream into an object (for example, Java object) by referencing the compiled message definitions.
As mentioned above, FieldMask lists field names, not numbers. Here at Netflix we are using field numbers and convert them to field names using FieldMaskUtil.fromFieldNumbers() utility method. This method utilizes the compiled message definitions to convert field numbers to field names and creates a FieldMask.
However, there is an easy-to-overlook limitation: using FieldMask can limit your ability to rename message fields. Renaming a message field is generally considered a safe operation, because, as described above, the field name is not sent on the wire, it is derived using the field number on the consumer side. With FieldMask, field names are sent in the message payload (in the paths field value) and become significant.
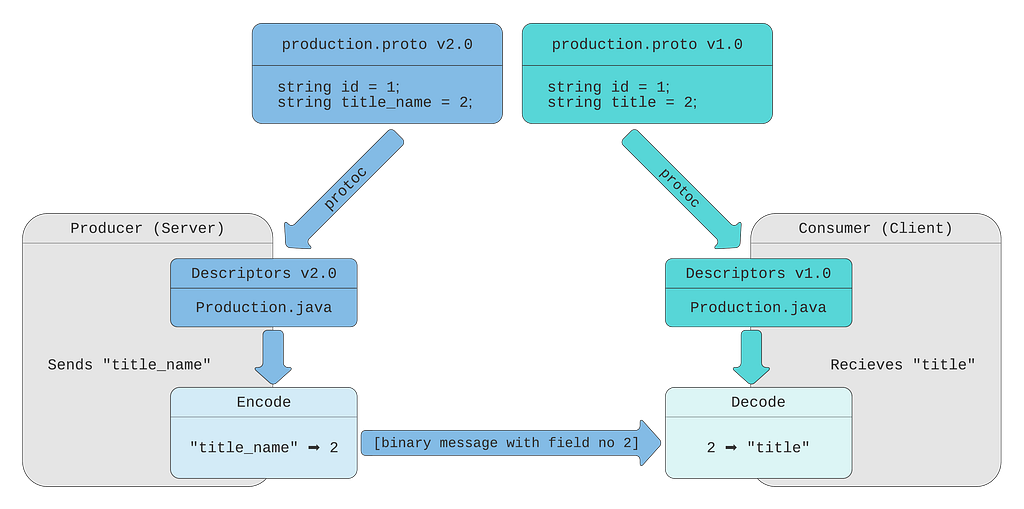
Suppose we want to rename the field title to title_name and publish version 2.0 of our message definition:
In this chart, the producer (server) utilizes new descriptors, with field number 2 named title_name. The binary message sent over the wire contains the field number and its value. The consumer still uses the original descriptors, where the field number 2 is called title. It is still able to decode the message by field number.
This works well if the consumer doesn’t use FieldMask to request the field. If the consumer makes a call with the “title” path in the FieldMask field, the producer will not be able to find this field. The producer doesn’t have a field named title in its descriptors, so it doesn’t know the consumer asked for field number 2.
As we see, if a field is renamed, the backend should be able to support new and old field names until all the callers migrate to the new field name (backward compatibility issue).
There are multiple ways to deal with this limitation:
Never rename fields when FieldMask is used. This is the simplest solution, but it’s not always possible
Require the backend to support all the old field names. This solves the backward compatibility issue but requires extra code on the backend to keep track of all historical field names
Deprecate old and create a new field instead of renaming. In our example, we would create the title_name field number 6. This option has some advantages over the previous one: it allows the producer to keep using generated descriptors instead of custom converters; also, deprecating a field makes it more prominent on the consumer side
Regardless of the solution, it is important to remember that FieldMask makes field names an integral part of your API contract.
Using FieldMask on the Producer (Server) Side
On the producer (server) side, unnecessary fields can be removed from the response payload using the FieldMaskUtil.merge() method (lines ##8 and 9):
If the server code also needs to know which fields are requested in order to avoid making external calls, database queries or expensive computations, this information can be obtained from the FieldMask paths field:
This code calls the makeExpensiveCallToScheduleServicemethod (line #21) only if the schedule field is requested. Let’s explore this code sample in more detail.
(1) The SCHEDULE_FIELD_NAME constant contains the name of the field. This code sample uses message type Descriptor and FieldDescriptor to lookup field name by field number. The difference between protobuf field names and field numbers is described in the Protobuf Field Names vs Field Numbers section above.
(2) FieldMaskUtil.normalize() returns FieldMask with alphabetically sorted and deduplicated field paths (aka canonical form).
(3) Expression (lines ##14 – 17) that yields the scheduleFieldRequestedvalue takes a stream of FieldMask paths, maps it to a stream of top-level fields, and returns true if top-level fields contain the value of the SCHEDULE_FIELD_NAME constant.
(4) ProductionSchedule is retrieved only if scheduleFieldRequested is true.
If you end up using FieldMask for different messages and fields, consider creating reusable utility helper methods. For example, a method that returns all top-level fields based on FieldMask and FieldDescriptor, a method to return if a field is present in a FieldMask, etc.
Ship Pre-built FieldMasks
Some access patterns can be more common than others. If multiple consumers are interested in the same subset of fields, API producers can ship client libraries with FieldMask pre-built for the most frequently used field combinations.
Providing pre-built field masks simplifies API usage for the most common scenarios and leaves consumers the flexibility to build their own field masks for more specific use-cases.
Limitations
Using FieldMask can limit your ability to rename message fields (described in the Protobuf Field Names vs Field Numbers section)
Repeated fields are only allowed in the last position of a path string. This means you cannot select (mask) individual sub-fields in a message inside a list. This can change in the foreseeable future, as a recently approved Google API Improvement Proposal AIP-161 Field masks includes support for wildcards on repeated fields.
Bella Ciao
Protobuf FieldMask is a simple, yet powerful concept. It can help make APIs more robust and service implementations more efficient.
This blog post covered how and why it is used at Netflix Studio Engineering for APIs that read the data. Part 2 will shed light on using FieldMask for update and remove operations.
As most developers can attest, dealing with security protocols and identity tokens, as well as user and device authentication, can be challenging. Imagine having multiple protocols, multiple tokens, 200M+ users, and thousands of device types, and the problem can explode in scope. A few years ago, we decided to address this complexity by spinning up a new initiative, and eventually a new team, to move the complex handling of user and device authentication, and various security protocols and tokens, to the edge of the network, managed by a set of centralized services, and a single team. In the process, we changed end-to-end identity propagation within the network of services to use a cryptographically-verifiable token-agnostic identity object.
Read on to learn more about this journey and how we have been able to:
Reduce complexity for service owners, who no longer need to have knowledge of and responsibility for terminating security protocols and dealing with myriad security tokens,
Improve security by delegating token management to services and teams with expertise in this area, and
Improve audit-ability and forensic analysis.
How We Got Here
Netflix started as a website that allowed members to manage their DVD queue. This website was later enhanced with the capability to stream content. Streaming devices came a bit later, but these initial devices were limited in capability. Over time, devices increased in capability and functions that were once only accessible on the website became accessible through streaming devices. Scale of the Netflix service was growing rapidly, with over 2000 device types supported.
Services supporting these functions now had an increased burden of being able to understand multiple tokens and security protocols in order to identify the user and device and authorize access to those functions. The whole system was quite complex, and starting to become brittle. Plus, the architecture of the Edge tier was evolving to a PaaS (platform as a service) model, and we had some tough decisions to make about how, and where, to handle identity token handling.
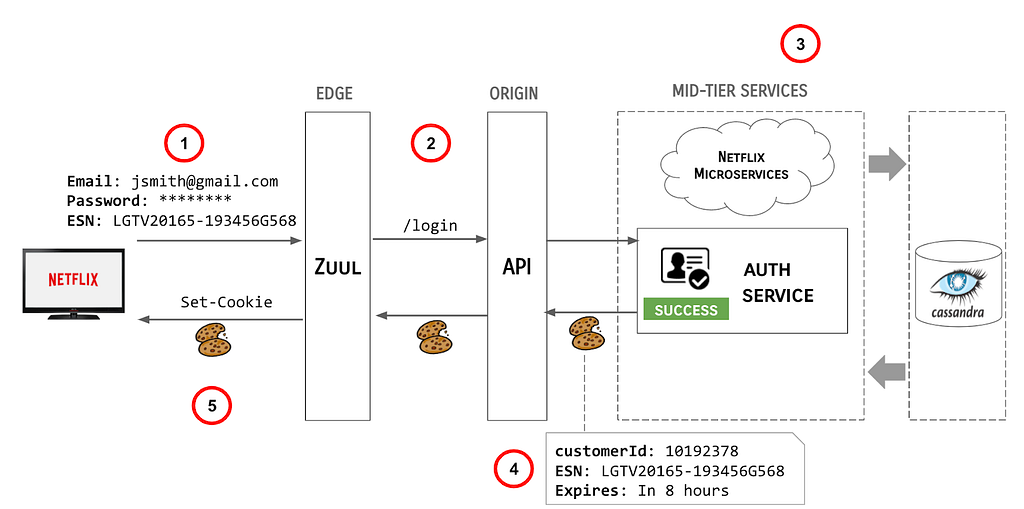
To demonstrate the complexity of the system, following is a description of how the user login flow worked prior to the changes described in this article:
At the highest level, the steps involved in this (greatly simplified) flow are as follows:
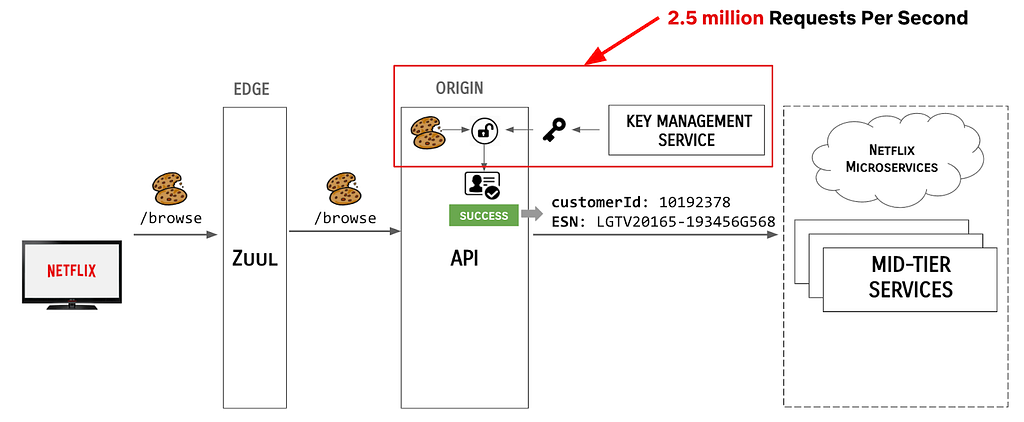
User enters their credentials and the Netflix client transmits the credentials, along with the ESN of the device to the Edge gateway, AKA Zuul.
Zuul redirects the user call to the API /login endpoint.
The API server orchestrates backend systems to authenticate the user.
Upon successful authentication of the claims provided, the API server sends a cookie response back upstream, including the customerId (a Long), the ESN (a String) and an expiration directive.
Zuul sends the Cookies back to the Netflix client.
This model had some problems, e.g.:
Externally valid tokens were being minted deep down in the stack and they needed to be propagated all the way upstream, opening possibilities for them to be logged inappropriately or potentially mismanaged.
Upstream systems had to reopen the tokens to identify the user logging in and potentially manage multiple parallel identity data structures, which could easily get out of sync.
Multiple Protocols & Tokens
The example above shows one flow, dealing with one protocol (HTTP/S) and one type of token (Cookies). There are several protocols and tokens in use across the Netflix streaming product, as summarized below:
These tokens were consumed by, and potentially mutated by, several systems within the Netflix streaming ecosystem, for example:
To complicate things further, there were multiple methods for transmitting these tokens, or the data contained therein, from system to system. In some cases, tokens were cracked open and identity data elements extracted as simple primitives or strings to be used in API calls, or passed from system to system via request context headers, or even as URL parameters. There were no checks in place to ensure the integrity of the tokens or the data contained therein.
At Netflix Scale
Meanwhile, the scale at which Netflix operated grew exponentially. At the time of this article, Netflix has 200M+ subscribers, with over a billion devices. We are serving over 2.5 million requests per second, a large percentage of which require some form of authentication. In the old architecture, each of these requests resulted in an API call to authenticate the claims presented with the request, as shown:
EdgePaas Enters the Picture
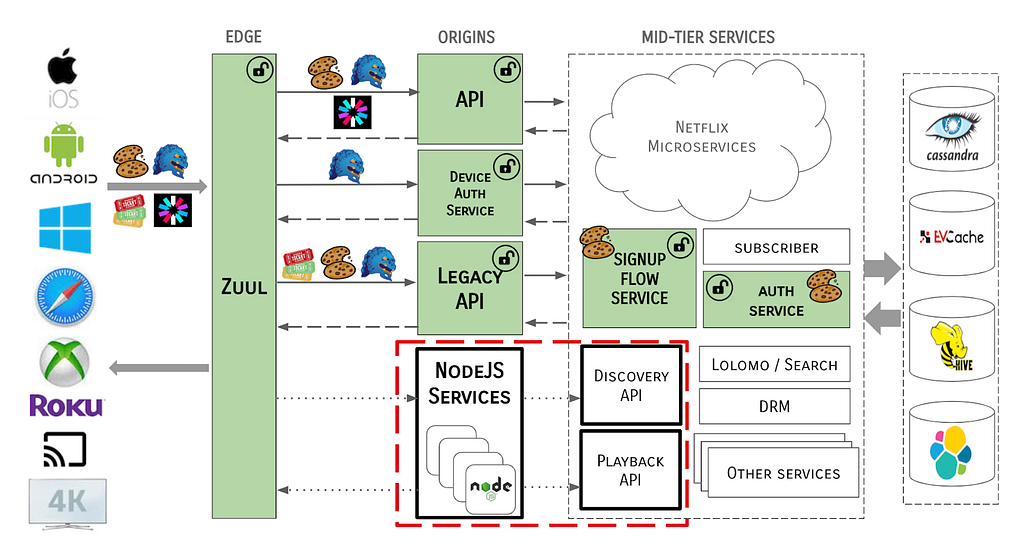
To further complicate the situation, the Edge Engineering team was in the middle of migrating from an old API server architecture to a new PaaS-based approach. As we migrated to EdgePaaS, front-end services were moved from the Java-based API to a BFF (backend for frontend), aka NodeQuark, as shown:
This model enables front-end engineers to own and operate their services outside of the core API framework. However, this introduced another layer of complexity — how would these NodeQuark services deal with identity tokens? NodeQuark services are written in JavaScript and terminating a protocol as complex as MSL would have been difficult and wasteful, as would replicating all of the logic for token management.
So, Where Were We Again?
To summarize, we found ourselves with a complex and inefficient solution for handling authentication and identity tokens at massive scale. We had multiple types and sources of identity tokens, each requiring special handling, the logic for which was replicated in various systems. Critical identity data was being propagated throughout the server ecosystem in an inconsistent fashion.
Edge Authentication to the Rescue
We realized that in order to solve this problem, a unified identity model was needed. We would need to process authentication tokens (and protocols) further upstream. We did this by moving authentication and protocol termination to the edge of the network, and created a new integrity-protected token-agnostic identity object to propagate throughout the server ecosystem.
Moving Authentication to the Edge
Keeping in mind our objectives to improve security and reduce complexity, and ultimately provide a better user experience, we strategized on how to centralize device authentication operations and user identification and authentication token management to the services edge.
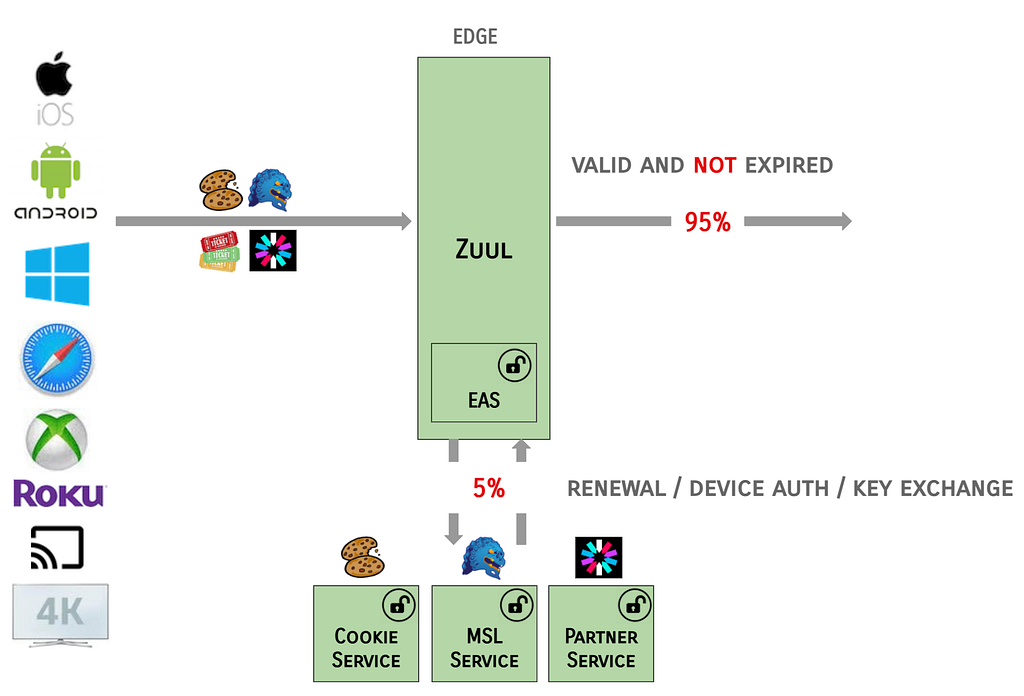
At a high-level, Zuul (cloud gateway) was to become the termination point for token inspection and payload encryption/decryption. In the case that Zuul would be unable to handle these operations (a small percentage), e.g., if tokens were not present, needed to be renewed, or were otherwise invalid, Zuul would delegate those operations to a new set of Edge Authentication Services to handle cryptographic key exchange and token creation or renewal.
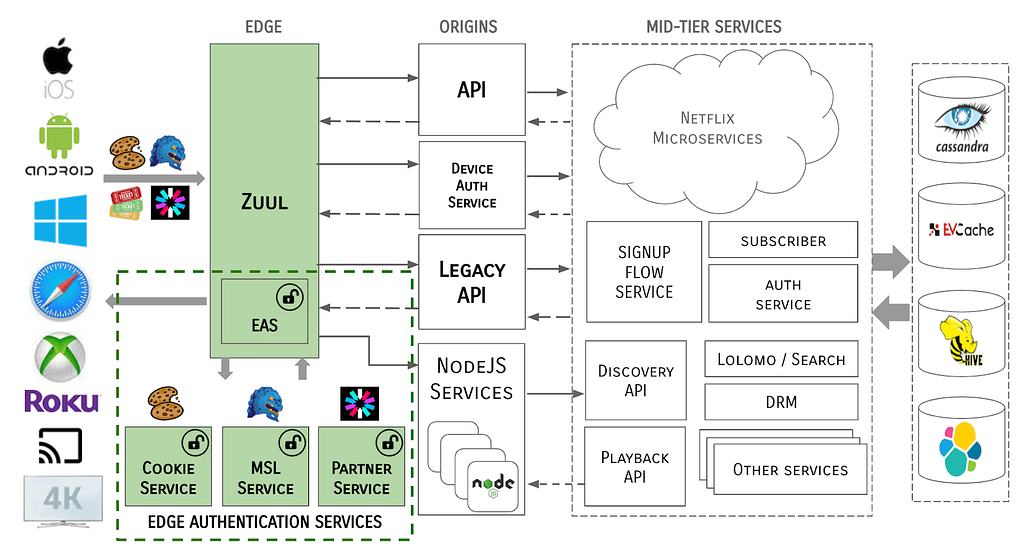
Edge Authentication Services
Edge Authentication Services (EAS) is both an architectural concept of moving authentication and identification of devices and users higher up on the stack to the cloud edge, as well as a suite of services that have been developed to handle each token type.
EAS is functionally a series of filters that run in Zuul, which may call out to external services to support their domain, e.g., to a service to handle MSL tokens or another for Cookies. EAS also covers the read-only processing of tokens to create Passports (more on that later).
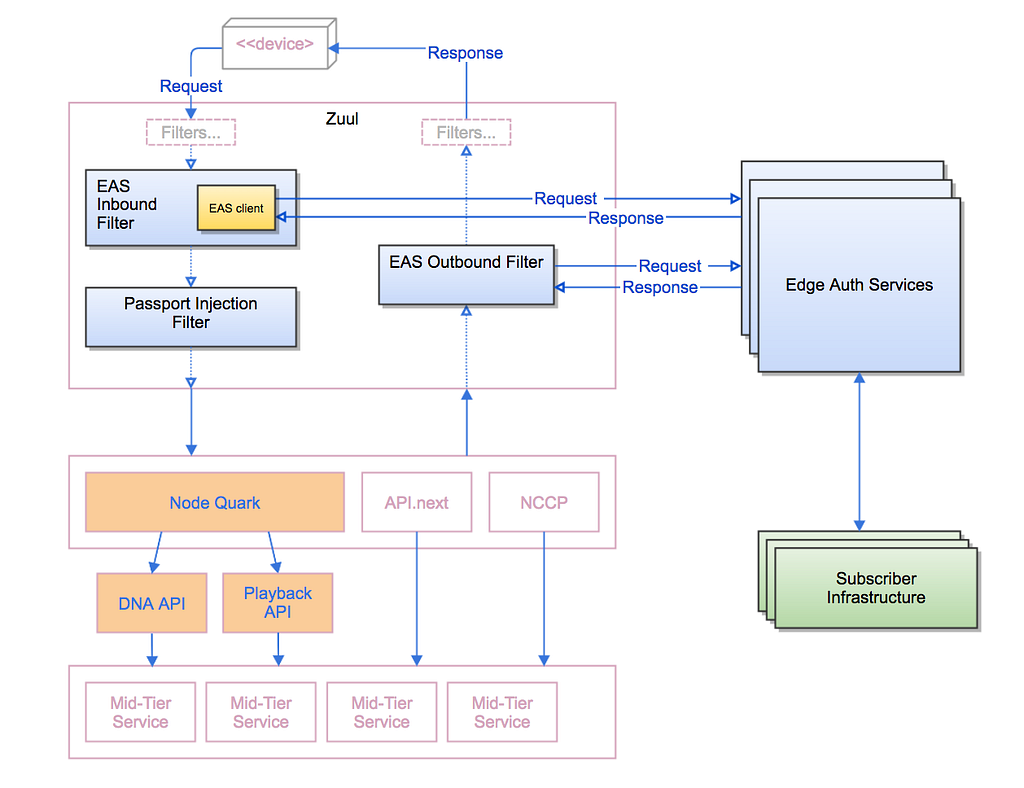
The basic pattern for how EAS handles requests is as follows:
For each request coming into the Netflix service, the EAS Inbound Filter in Zuul inspects the tokens provided by the device client and either passes through the request to the Passport Injection Filter, or delegates to one of the Edge Authentication Services to process. The Passport Injection Filter generates a token-agnostic identity to propagate down through the rest of the server ecosystem. On the response path, the EAS Outbound Filter determines, with help from the Edge Authentication Services as needed, generates the tokens needed to send back to the client device.
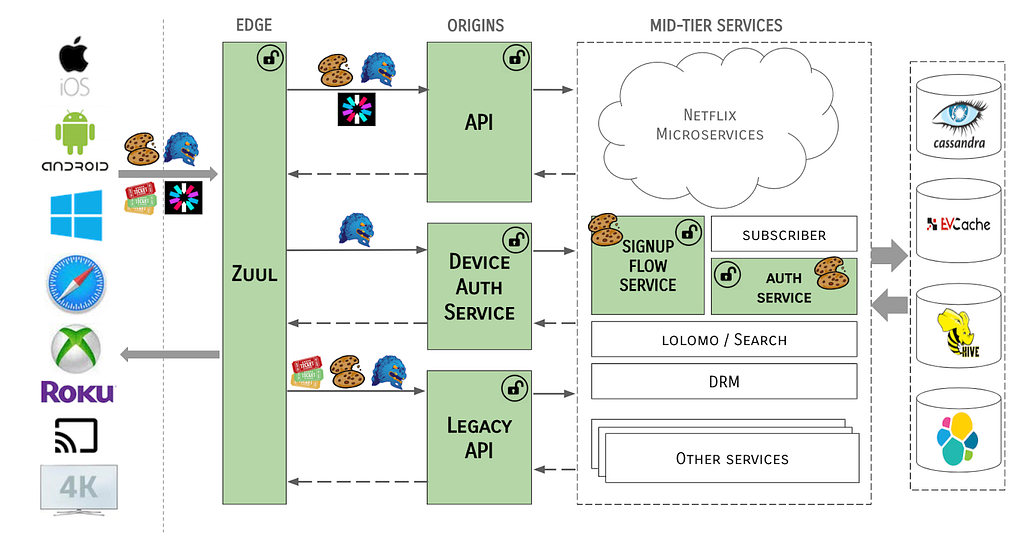
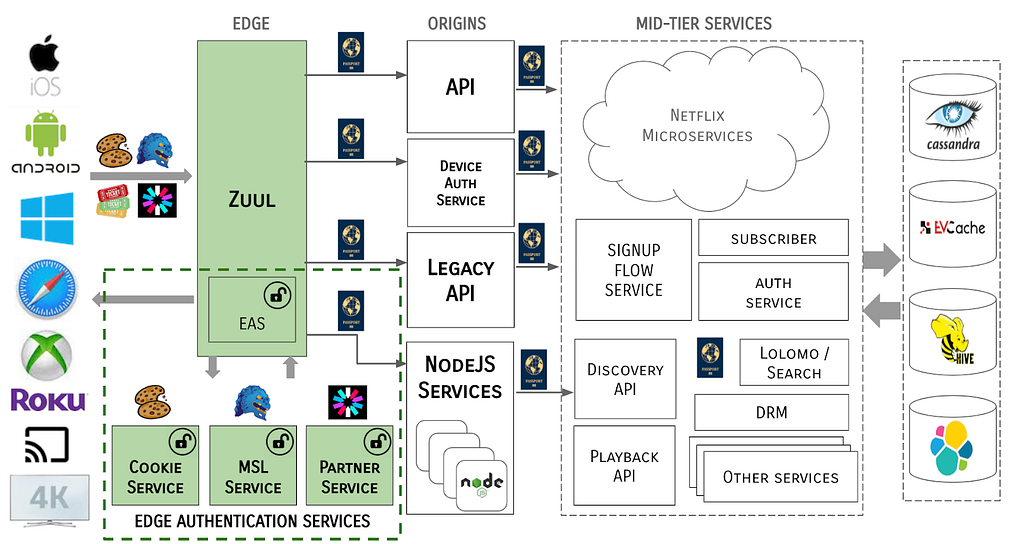
The system architecture now takes the form of:
Notice that tokens never traverse past the Edge gateway / EAS boundary. The MSL security protocol is terminated at the Edge and all tokens are cracked open and identity data is propagated through the server ecosystem in a token-agnostic manner.
A Note on Resilience
On the happy path, Zuul is able to process the large percentage of tokens that are valid and not expired, and the Edge Auth Services handle the remainder of the requests.
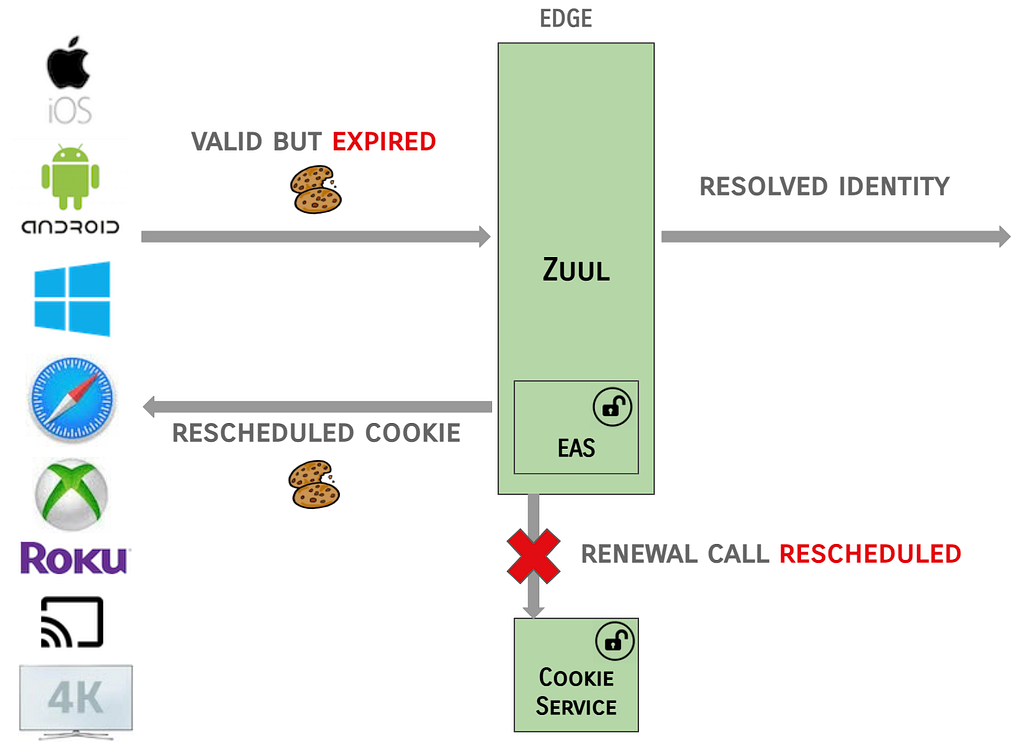
The EAS services are designed to be fault tolerant, e.g., in the case where Zuul identifies that Cookies are valid, but expired, and the renewal call to EAS fails or is latent:
In this failure scenario, the EAS filter in Zuul will be lenient and allow the resolved identity to be propagated and will indicate that the renewal call should be rescheduled on the next request.
Token-Agnostic Identity (Passport)
An easily mutable identity structure would not suffice because that would mean passing less trusted identities from service to service. A token-agnostic identity structure was needed.
We introduced an identity structure called “Passport” which allowed us to propagate the user and device identity information in a uniform way. The Passport is also a kind of token, but there are many benefits to using an internal structure that differs from external tokens. However, downstream systems still need access to the user and device identity.
A Passport is a short-lived identity structure created at the Edge for each request, i.e., it is scoped to the life of the request and it is completely internal to the Netflix ecosystem. These are generated in Zuul via a set of Identity Filters. A Passport contains both user & device identity, is in protobuf format, and is integrity protected by HMAC.
Passport Structure
As noted above, the Passport is modeled as a Protocol Buffer. At the highest level, the definition of the Passport is as follows:
messagePassport {
Header header = 1;
UserInfo user_info = 2;
DeviceInfo device_info = 3;
Integrity user_integrity = 4;
Integrity device_integrity = 5;
}
The Header element communicates the name of the service that created the Passport. What’s more interesting is what is propagated related to the user and device.
User & Device Information
The UserInfo element contains all of the information required to identify the user on whose behalf requests are being made, with the DeviceInfo element containing all of the information required for the device on which the user is visiting Netflix:
Both UserInfo and DeviceInfo carry the Source and PassportAuthenticationLevel for the request. The Source list is a classification of claims, with the protocol being used and the services used to validate the claims. The PassportAuthenticationLevel is the level of trust that we put into the authentication claims.
enum Source {
NONE = 0;
COOKIE = 1;
COOKIE_INSECURE = 2;
MSL = 3;
PARTNER_TOKEN = 4;
…
}
enum PassportAuthenticationLevel {
LOW = 1; // untrusted transport
HIGH = 2; // secure tokens over TLS
HIGHEST = 3; // MSL or user credentials
}
Downstream applications can use these values to make Authorization and/or user experience decisions.
Passport Integrity
The integrity of the Passport is protected via an HMAC (hash-based message authentication code), which is a specific type of MAC involving a crytographic hash function and a secret cryptographic key. It may be used to simultaneously verify both the data integrity and authenticity of a message.
User and device integrity are defined as:
messageIntegrity {
int32 version = 1;
string key_name = 2;
bytes hmac = 3;
}
Version 1 of the Integrity element uses SHA-256 for the HMAC, which is encoded as a ByteArray. Future versions of Integrity may use a different has function or encoding. In version 1, the HMAC field contains the 256 bits from MacSpec.SHA_256.
Integrity protection guarantees that Passport field are not mutated after the Passport is created. Client applications can use the Passport Introspector to check the integrity of the Passport before using any of the values contained therein.
Passport Introspector
The Passport object itself is opaque; clients can use the Passport Introspector to extract the Passport from the headers and retrieve the contents inside it. The Passport Introspector is a wrapper over the Passport binary data. Clients create an Introspector via a factory and then have access to basic accessor methods:
public interface PassportIntrospector {
Long getCustomerId();
Long getAccountOwnerId();
String getEsn();
Integer getDeviceTypeId();
String getPassportAsString();
…
}
Passport Actions
In the Passport protocol buffer definition shown above, there are Passport Actions defined:
messageUserInfo {
repeated UserAction actions = 12;
…
}
messageDeviceInfo {
repeated DeviceAction actions = 7;
…
}
Passport Actions are explicit signals sent by downstream services, when an update to user or device identity has been performed. The signal is used by EAS to either create or update the corresponding type of token.
Login Flow, Revisited
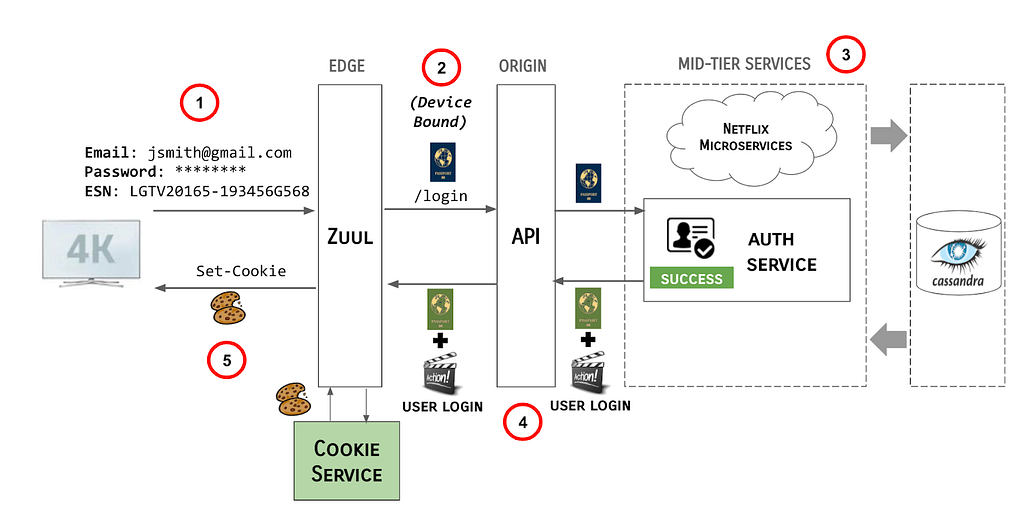
Let’s wrap up with an example of all of these solutions working together.
With the movement of authentication and protocol termination to the Edge, and the introduction of Passports as identity, the Login Flow described earlier has morphed into the following:
User enters their credentials and the Netflix client transmits the credentials, along with the ESN of the device to the Edge gateway, AKA Zuul.
Identity filters running in Zuul generate a device-bound Passport and pass it along to the API /login endpoint.
The API server propagates the Passport to the mid-tier services responsible for authentication the user.
Upon successful authentication of the claims provided, these services create a Passport Action and send it, along with the original Passport, back up stream to API and Zuul.
Zuul makes a call to the Cookie Service to resolve the Passport and Passport Actions and sends the Cookies back to the Netflix client.
Key Benefits and Learnings
Simplified Authorization
One of the reasons there were external tokens flowing into downstream systems was because authorization decisions often depend on authentication claims in tokens and the trust associated with each token type. In our Passport structure, we have assigned levels to this trust, meaning that systems requiring authorization decisions can write sensible rules around the Passport instead of replicating the trust rules in code across many services.
An Explicit and Extensible Identity Model
Having a structure that is the canonical identity is very useful. Alternatives where identity primitives are passed around are brittle and hard to debug. If the customer identity changed from service A to service D in a call chain, who changed it? Once the identity structure is passed through all key systems, it is relatively easy to add new external token types, new trust levels, or new ways to represent identity.
Operational Concerns and Visibility
Having a structure, like Passport, allows you to define the services that can write a Passport and other services can validate it. When the Passport is propagated and when we see it in logs, we can open it up, validate it, and know what the identity is. We also know the provenance of the Passport, and can trace it back to where it entered the system. This makes the debugging of any identity-related anomalies much easier.
Reduced Downstream System Complexity & Load
Passing a uniform structure to downstream systems means that those systems can easily look up the device and user identity, using an introspection library. Instead of having separate handling for each type of external token, they can use the common structure.
By offloading token processing from these systems to the central Edge Authentication Services, downstream systems saw significant gains in CPU, request latency, and garbage collection metrics, all of which help reduce cluster footprint and cloud costs. The following examples of these gains are from the primary API service.
In the prior implementation, it was necessary to incur decryption/termination costs twice per request because we needed the ability to route at the edge but also needed rich termination in the downstream service. Some of the performance improvement is due to consolidation of this — MSL requests now only need to be processed once.
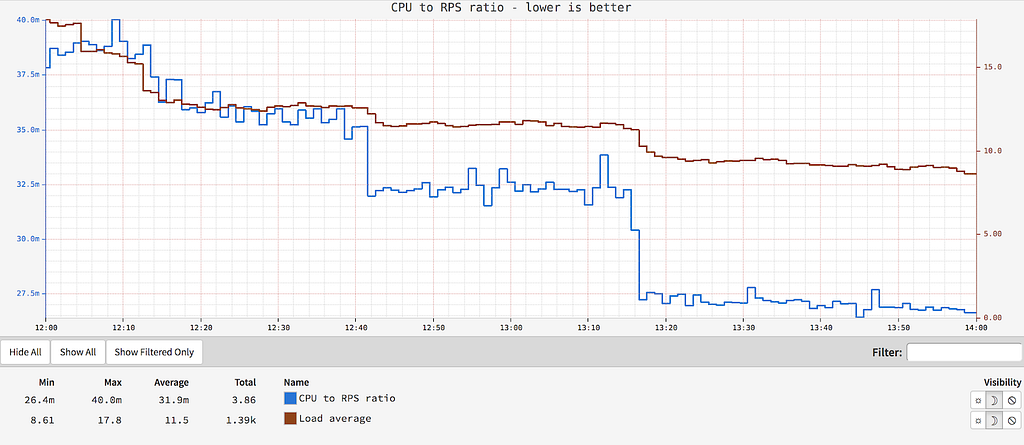
CPU to RPS Ratio
Offloading token processing resulted in a 30% reduction in CPU cost per request and a 40% reduction in load average. The following graph shows the CPU to RPS ratio, where lower is better:
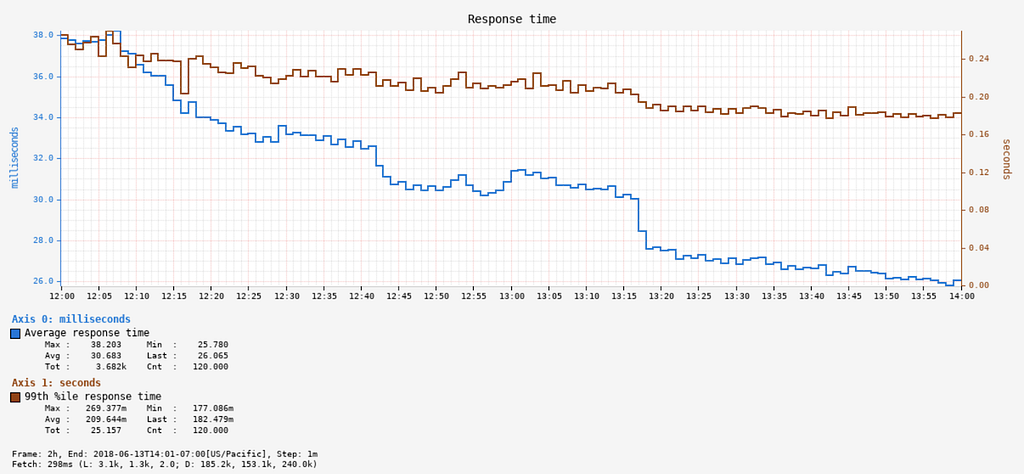
API Response Time
Response times for all calls on the API service showed significant improvement, with a 30% reduction in average latency and a 20% drop in 99th percentile latency:
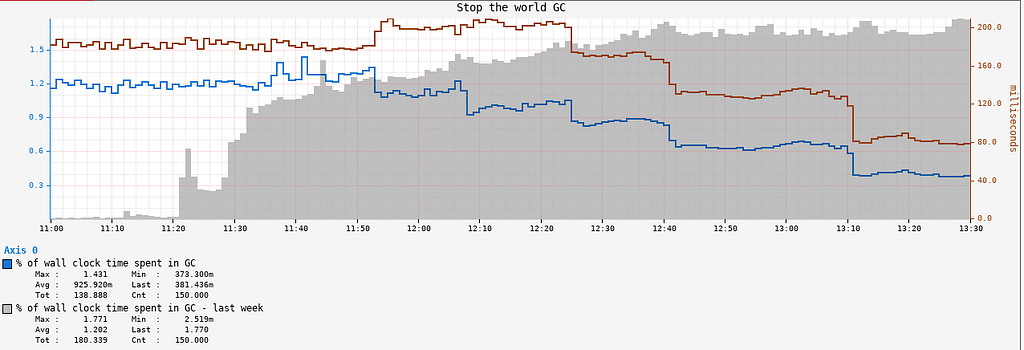
Garbage Collection
The API service also saw a significant reduction in GC pressure and GC pause times, as shown in the Stop The World Garbage Collection metrics:
Developer Velocity
Abstracting these authentication and identity-related concerns away from the developers of microservices means that they can focus on their core domain. Changes in this area are now done once, and in one set of specialized services, versus being distributed across multiple.
What’s Next?
Strong(er) Authentication
We are currently expanding the Edge Authentication Services to support Multi-Factor Authentication via a new service called “Resistor”. We selectively introduce the second factor for connections that are suspicious, based on machine learning models. As we onboard new flows, we are introducing new factors, e.g., one-time passwords (OTP) sent to email or phone, push notifications to mobile devices, and third-party authenticator applications. We may also explore opt-in Multi-Factor Authentication for users who desire the added security on their accounts.
Flexible Authorization
Now that we have a verified identity flowing through the system, we can use that as a strong signal for authorization decisions. Last year, we started to explore a new Product Access Strategy (PACS) and are currently working on moving it into production for several new experiences in the Netflix streaming product. PACS recently powered the experience access control for the Streamfest, a weekend of free Netflix in India.
Want More?
Team members presented this work at QCon San Francisco (and were two of the top three attended talks at the conference!):
Netflix has developed a Domain Graph Service (DGS) framework and it is now open source. The DGS framework simplifies the implementation of GraphQL, both for standalone and federated GraphQL services. Our framework is battle-hardened by our use at scale.
By open-sourcing the project, we hope to contribute to the Java and GraphQL communities and learn from and collaborate with everyone who will be using the framework to make it even better in the future.
The key features of the DGS Framework include:
Annotation-based Spring Boot programming model
Test framework for writing query tests as unit tests
Gradle Code Generation plugin to create Java/Kotlin types from a GraphQL schema
Easy integration with GraphQL Federation
Integration with Spring Security
GraphQL subscriptions (WebSockets and SSE)
File uploads
Error handling
Automatic support for interface/union types
A GraphQL client for Java
Pluggable instrumentation
Why We Needed a DGS Framework
Around Spring 2019, Netflix embarked on a great adventure towards implementing a federated GraphQL architecture. Our colleagues wrote a Netflix Tech Blog post describing the details of this architecture. The transition to the new federated architecture meant that many of our backend teams needed to adopt GraphQL in our Java ecosystem. As you may recall from a previous blog post, Netflix has standardized on Spring Boot for backend development. Therefore, to make this federated architecture a success, we needed to have a great developer experience for GraphQL in Spring Boot.
We created our framework on top of Spring Boot and it leverages the graphql-java library. This framework was initially intended to be internal only, focusing on integration with the Netflix ecosystem for tracing, logging, metrics, etc. However, proper modularization of the framework was always top of mind. It became apparent that much of the framework we had built was not actually Netflix specific. The framework was mostly just an easier way to build GraphQL services, both standalone and federated.
Schema-First Development
A schema represents the GraphQL API. The schema is what makes GraphQL so powerful and different from REST. A GraphQL schema describes the API in terms of Query and Mutation operations along with their related types and fields. The API user can specify precisely which fields to retrieve in a query, making a GraphQL API very flexible.
There are two different approaches to GraphQL development; schema-first and code-first development. With schema-first development, you manually define your API’s schema using the GraphQL Schema Language. The code in your service only implements this schema.
With code-first development, you don’t have a schema file. Instead, the schema gets generated at runtime based on definitions in code.
Both approaches, schema-first and code-first, are supported in our framework. At Netflix we strongly prefer schema-first development because:
The schema design is front and center of the developer experience.
It provides an easy way for tooling to consume the schema.
Backward-incompatible changes are more obvious with schema diffs. Backward compatibility is even more critical when working in a Federated GraphQL architecture.
Although it might be marginally quicker to generate schema from the code, putting the time into designing your schema in a human readable, collaborative way is well worth the effort towards a better API.
The Framework in Action
The framework’s core revolves around the annotation-based programming model familiar to Spring Boot developers. Comprehensive documentation is available on the website but let’s walk through an example to show you how easy it is to use this framework.
Let’s start with a simple schema.
To implement this API, we need to write a data fetcher.
The Show type is a simple POJO that we would typically generate using the DGS Code Generation pluginfor Gradle. A method annotated with @DgsData implements a data fetcher for a field. Note that we don’t need data fetchers for each field, we can return Java objects, and the framework will take care of the rest.The framework also has many conveniences such as the @InputArgument annotation used in this example.
This code is enough to get a GraphQL endpoint running. Just start the Spring Boot application, and the /graphql endpoint will be available, along with the GraphiQL query editor on /graphiql that comes out of the box. Although the code in this example is straightforward, it wouldn’t look much different if we work with Federated types, use @Secured, or add metrics and tracing using an extension point. The framework takes care of all the heavy lifting.
Another key feature is support for lightweight query tests. These tests allow you to execute queries without the need to work with the HTTP endpoint. The tests look and feel like plain JUnit tests.
So how exactly does the DGS framework fit into the existing GraphQL ecosystem? The current ecosystem comprises servers, clients, the federated gateways, and tooling to help with query testing, schema management, code generation, etc. When it comes to building GraphQL servers using JVM, there are both schema-first and code-first libraries available.
A popular code-first library is graphql-kotlin for Kotlin. graphql-java is most popular for implementing schema-first GraphQL APIs in Java, but is designed to be a low level library. The graphql-java-kickstart starter is a set of libraries for implementing GraphQL services, and provides graphql-java-tools and graphql-java-servlet on top of graphql-java.
Regardless of whether you use Java or Kotlin, our framework provides an easy way to build GraphQL services in Spring Boot. It can be used to build a standalone service as well as in the context of Federated GraphQL.
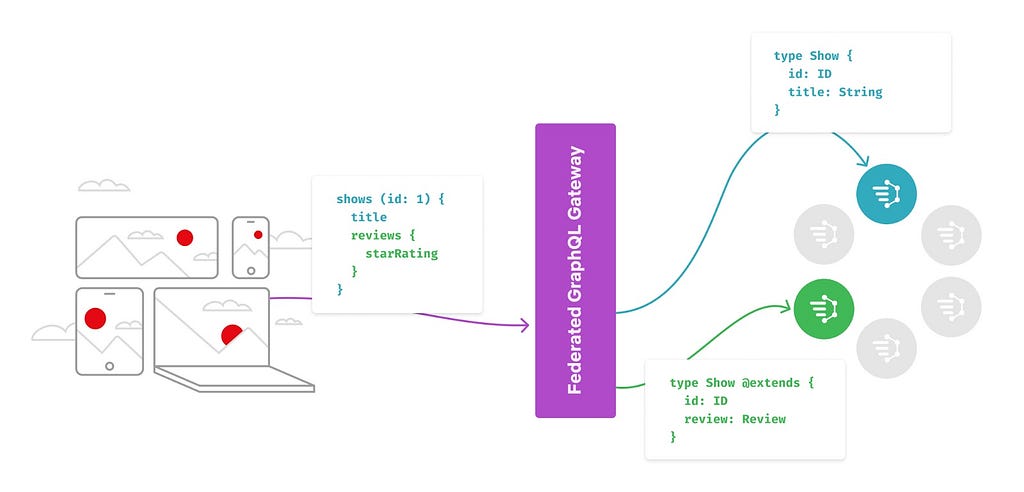
Federation
The DGS Framework provides a convenient way to implement GraphQL services with federation. Federation allows services to share a unified graph exposed by a gateway. Typically, services share and extend types defined in the unified schema using the @extends directive as defined by Apollo’s federation specification. This is an effective way to split the ownership of a large monolithic GraphQL schema across microservices.
For an incoming query, the federated gateway constructs a query plan to call out to the required services to fulfill that query. Each service, in turn, needs to be able to respond to the _entities query in order to partially fulfill the query for the data it owns.
Here is an example of a Reviews service that extends the Show type defined earlier with a reviews field:
Federated GraphQL Architecture with Shows and Reviews DGSs
Given this schema, the Reviews DGS needs to implement a resolver for the federated Show type with the reviews field populated. This can be done easily using the @DgsEntityFetcher annotation as shown here:
The framework also makes it easy to test federated queries using code generation to generate the _entities query for the service based on the schema. The complete code for the given example can be found here.
Framework Architecture
From the early days of development, we focused on good modularization of the code. This was an important design choice that made it possible to open source most of the framework without impacting our internal teams. We couldn’t use the module system introduced in Java 9 yet, because a lot of applications at Netflix are still using Java 8. However, with the help of Gradle api and implementation modules, we were able to create a clean module structure. At Netflix, we have many extensions for Spring Boot to integrate with our infrastructure. We call this Spring Boot Netflix. The DGS framework is built on standard open-source Spring Boot. On top of that, we have some modules that integrate with our specific infrastructure and use only extension points provided by the core framework.
The following is a diagram of how the modules fit together:
DGS Framework with Netflix and OSS modules
Distributed Tracing and Metrics
At Netflix, we have custom infrastructure for features like tracing, metrics, distributed logging, and authentication/authorization. As mentioned earlier, the DGS framework integrates with this infrastructure to provide a seamless experience out of the box. While these features are not open-sourced, they are easy enough to add to the framework.
The framework supports Instrumentation classes as defined in the graphql-java library. By implementing the Instrumentation interface and annotating it @Component, the framework is able to pick it up automatically. You can find some reference examples in our documentation. In the future, we are hopeful and excited to see community contributions around common patterns for distributed tracing and metrics.
Try It Out Today
To get started with the DGS Framework, refer to our documentation and tutorials. To contribute to the DGS framework, please check out the DGS Framework project on GitHub. We also have a Gradle code generation plugin for generating Java and Kotlin types from a GraphQL schema. To contribute to the code generation plugin, please check out the project on GitHub.
A Team Effort
The DGS Framework has been a success at Netflix owing to the efforts of multiple teams coming together. We would like to acknowledge our close collaborators from the BFG team with whom we started on this amazing journey. We would also like to thank our many users for their timely feedback and code contributions.
If you are passionate about GraphQL and building great developer experiences then check out the many job opportunities on our Netflix website.
In our previous post and QConPlus talk, we discussed GraphQL Federation as a solution for distributing our GraphQL schema and implementation. In this post, we shift our attention to what is needed to run a federated GraphQL platform successfully — from our journey implementing it to lessons learned.
Our Journey so Far
Over the past year, we’ve implemented the core infrastructure pieces necessary for a federated GraphQL architecture as described in our previous post:
Studio Edge Architecture
The first Domain Graph Service (DGS) on the platform was the former GraphQL monolith that we discussed in our first post (Studio API). Next, we worked with a few other application teams to make DGSs that would expose their APIs alongside the former monolith. We had our first Studio applications consuming the federated graph, without any performance degradation, by the end of the 2019. Once we knew that the architecture was feasible, we focused on readying it for broader usage. Our goal was to open up the Studio Edge platform for self-service in April 2020.
April 2020 was a turbulent time with the pandemic and overnight transition to working remotely. Nevertheless, teams started to jump into the graph in droves. Soon we had hundreds of engineers contributing directly to the API on a daily basis. And what about that Studio API monolith that used to be a bottleneck? We migrated the fields exposed by Studio API to individually owned DGSs without breaking the API for consumers. The original monolith is slated to be completely deprecated by the end of 2020.
This journey hasn’t been without its challenges. The biggest challenge was aligning on this strategy across the organization. Initially, there was a lot of skepticism and dissent; the concept was fairly new and would require high alignment across the organization to be successful. Our team spent a lot of time addressing dissenting points and making adjustments to the architecture based on feedback from developers. Through our prototype development and proactive partnership with some key critical voices, we were able to instill confidence and close crucial gaps.
Once we achieved broad alignment on the idea, we needed to ensure that adoption was seamless. This required building robust core infrastructure, ensuring a great developer experience, and solving for key cross-cutting concerns.
Core Infrastructure
Our GraphQL Gateway is based on Apollo’s reference implementation and is written in Kotlin. This gives us access to Netflix’s Java ecosystem, while also giving us the robust language features such as coroutines for efficient parallel fetches, and an expressive type system with null safety.
The schema registry is developed in-house, also in Kotlin. For storing schema changes, we use an internal library that implements the event sourcing pattern on top of the Cassandra database. Using event sourcing allows us to implement new developer experience features such as the Schema History view. The schema registry also integrates with our CI/CD systems like Spinnaker to automatically setup cloud networking for DGSs.
Developer Education & Experience
In the previous architecture, only the monolith Studio API team needed to learn GraphQL. In Studio Edge, every DGS team needs to build expertise in GraphQL. GraphQL has its own learning curve and can get especially tricky for complex cases like batching & lookahead. Also, as discussed in the previous post, understanding GraphQL Federation and implementing entity resolvers is not trivial either.
We partnered with Netflix’s Developer Experience (DevEx) team to build out documentation, training materials, and tutorials for developers. For general GraphQL questions, we lean on the open source community plus cultivate an internal GraphQL community to discuss hot topics like pagination, error handling, nullability, and naming conventions.
DGS Framework & Developer Tools
To make it easy for backend engineers to build a GraphQL DGS, the DevEx team built a “DGS Framework” on top of GraphQL Java and Spring Boot. The framework takes care of all the cross-cutting concerns of running a GraphQL service in production while also making it easier for developers to write GraphQL resolvers. In addition, DevEx built robust tooling for pushing schemas to the Schema Registry and a Self Service UI for browsing the various DGS’s schemas. Check out their conference talk and expect a future blog post from our colleagues. The DGS framework is planned to be open-sourced in early 2021.
Schema Governance
Netflix’s studio data is extremely rich and complex. Early on, we anticipated that active schema management would be crucial for schema evolution and overall health. We had a Studio Data Architect already in the org who was focused on data modeling and alignment across Studio. We engaged with them to determine graph schema best practices to best suit the needs of Studio Engineering.
Our goal was to design a GraphQL schema that was reflective of the domain itself, not the database model. UI developers should not have to build Backends For Frontends (BFF) to massage the data for their needs, rather, they should help shape the schema so that it satisfies their needs. Embracing a collaborative schema design approach was essential to achieving this goal.
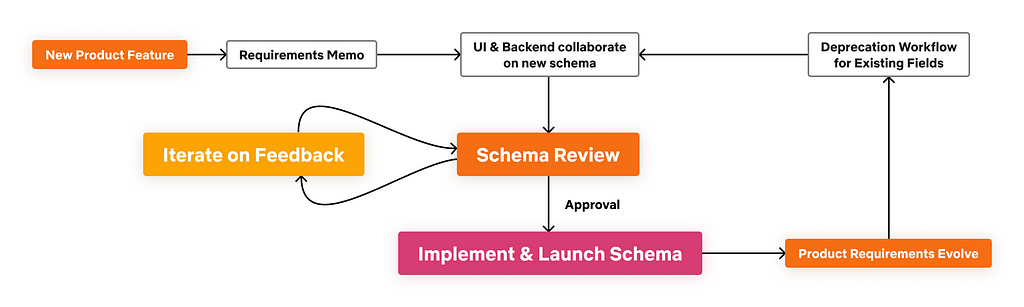
Schema Design Workflow
The collaborative design process involves feedback and reviews across team boundaries. To streamline schema design and review, we formed a schema working group and a managed technical program for on-boarding to the federated architecture. While reviews add overhead to the product development process, we believe that prioritizing the quality of the graph model will reduce the amount of future changes and reworking needed. The level of review varies based on the entities affected; for the core federated types, more rigor is required (though tooling helps streamline that flow).
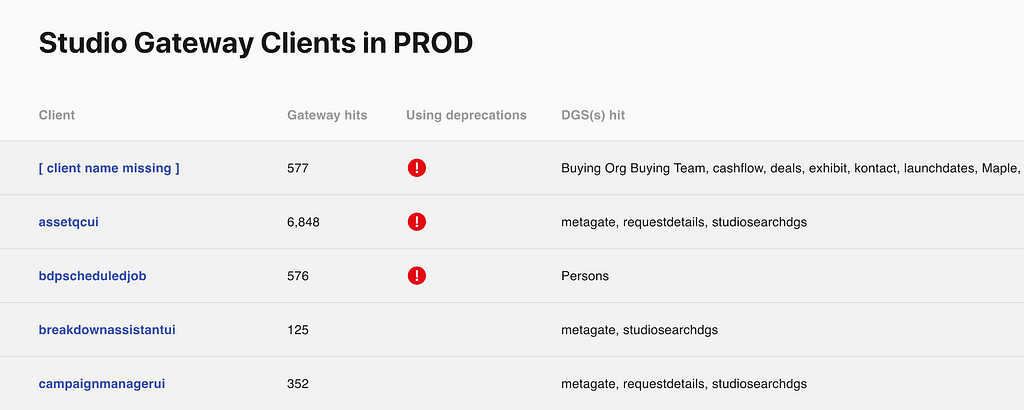
We have a deprecation workflow in place for evolving the schema. We’ve leveraged GraphQL’s deprecation feature and also track usage stats for every field in the schema. Once the stats show that a deprecated field is no longer used, we can make a backward incompatible change to remove the field from the schema.
Clients with Deprecated Field Usage
We embraced a schema-first approach instead of generating our schema from existing models such as the Protobuf objects in our gRPC APIs. While Protobufs and gRPC are excellent solutions for building service APIs, we prefer decoupling our GraphQL schema from those layers to enable cleaner graph design and independent evolvability. In some scenarios, we implement generic mapping code from GraphQL resolvers to gRPC calls, but the extra boilerplate is worth the long-term flexibility of the GraphQL API.
Underlying our approach is a foundation of “context over control”, which is a key tenet of Netflix’s culture. Instead of trying to hold tight control of the entire graph, we give guidance and context to product teams so that they can apply their domain knowledge to make a flexible API for their domain. As this architecture matures, we will continue to monitor schema health and develop new tooling, processes, and best practices where needed.
Observability
In our previous architecture, observability was achieved through manual analysis and routing via the API team, which scaled poorly. For our federated architecture, we prioritized solving observability needs in a more scalable manner. We prioritized three areas:
Alerting — report when something goes awry
Discovery — easily determine what isn’t working
Diagnosis — debug why something isn’t working
Our guiding metrics in this space are mean time to resolution (MTTR) and service level objectives and indicators (SLO/SLI).
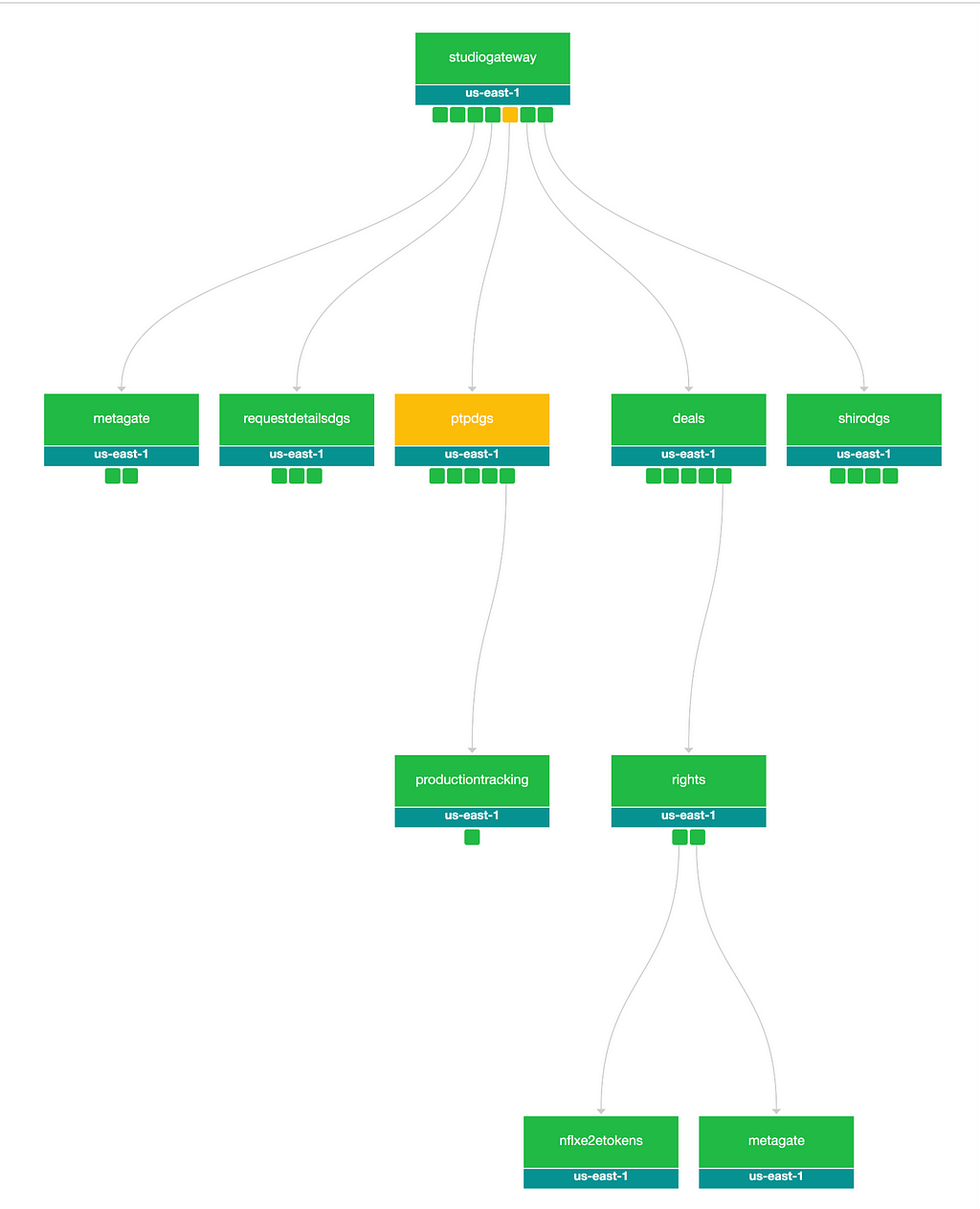
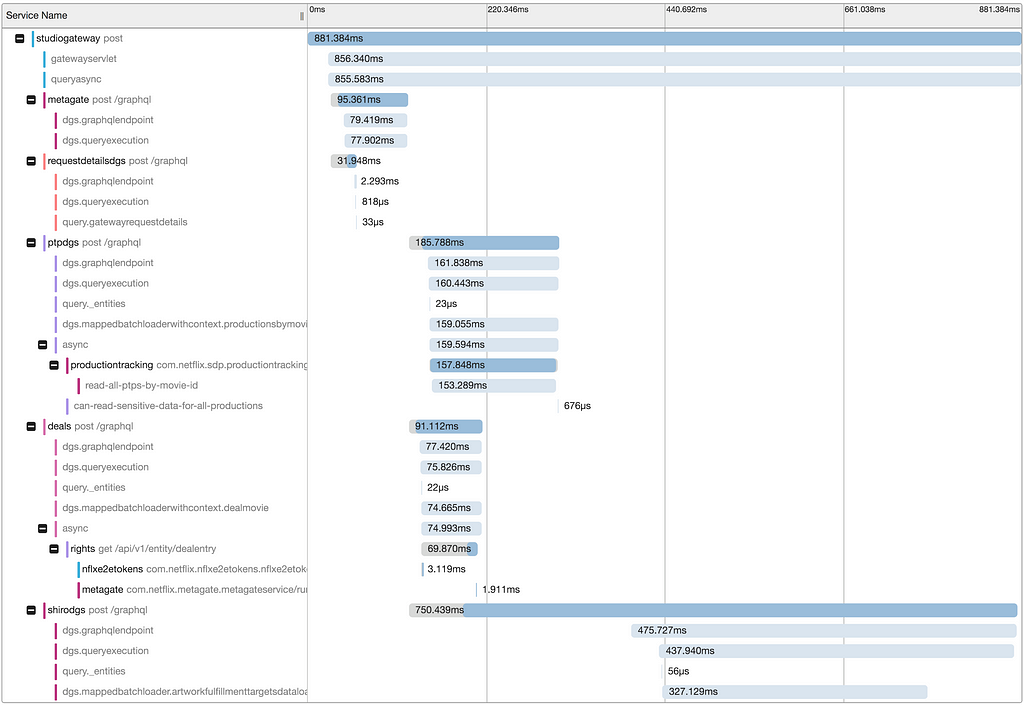
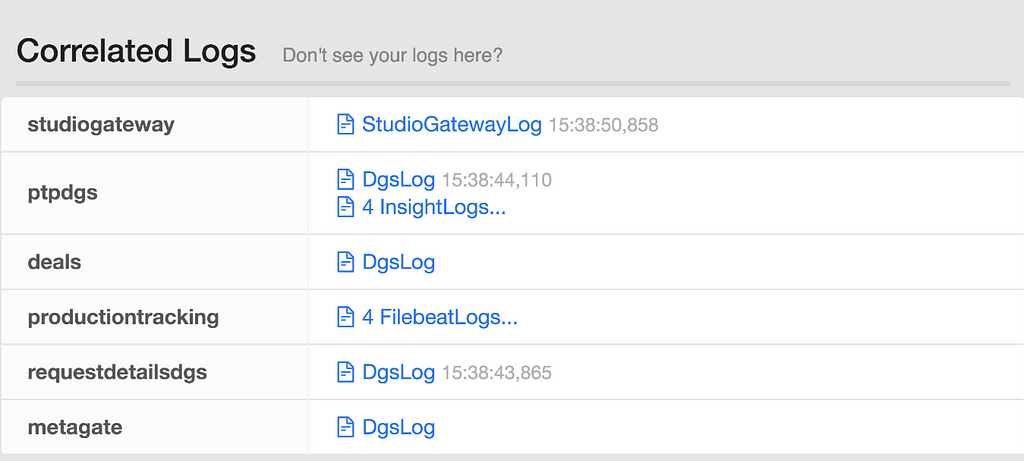
We teamed up with experts from Netflix’s Telemetry team. We integrated the Gateway and DGS architectural components with Zipkin, the internal distributed tracing tool Edgar, and application monitoring tool TellTale. In GraphQL, almost every response is a 200 with custom errors in the error block. We introspect these custom error codes from the response and emit them to our metrics server, Atlas. These integrations created a great foundation of rich visibility and insights for the consumers and developers of the GraphQL API.
Edgar Trace for a Federated Request LifecycleTimeline View for a Federated Request
Distributed Log Correlation helps with debugging more complex server issues. By surfacing the application level logging details for all systems involved in processing a request, we gain deeper insights into what happened across the stack. Developers can easily see what was happening around the same time as a given request, to inspect surrounding factors that might have impacted an interaction.
Logs across multiple services for a Federated Request
To solve the “who do I ask about…” routing problem, we integrated deep linking from GraphQL types and fields to their owning team’s support channels. Finding support is now as simple as clicking a link from a trace, which helps shorten MTTR and reduce the number of times the gateway team needs to get involved.
Securing the Federated Graph
Our goal is to enable robust and consistent security practices across the federated architecture. To achieve this, we partnered with the security experts at Netflix to build security into the graph. Let’s look at two essential parts of our security solution: AuthN and AuthZ.
Authentication
All of our product experiences in the Studio space require an authenticated account, so we restrict the GraphQL Gateway access to only trusted authenticated callers. Additionally, Graph Introspection is restricted to Netflix internal developers.
Authorization
Before Studio Edge, authorization logic was fragmented across teams. Some teams implemented authorization in their BFFs, some in microservices, and others did both for good measure. The result was often a different authorization story for a given piece of data depending on which UI a user was accessing it through. UI teams also found themselves needing to implement (and re-implement) authorization checks with each new frontend.
In Studio Edge, we delegated the authorization responsibility to DGS owners. This resulted in consistent authorization for the same user across different applications. Plus, Product Managers, Engineers and the Security team can easily get a bird’s eye view of who has access to each data type and how.
We have multiple authorization offerings within Netflix: from a simple system that grants access based on user identity to a more granular system that brings in the concept of roles and capabilities. DGS developers can choose a solution based on their needs. Then they simply annotate their resolvers with @Secured annotation and configure that to use one of the available systems. If needed, more complex authorization can be implemented in the resolver or in downstream systems.
Future of Authorization
We are currently prototyping a GraphQL-aware authorization solution. The Schema Registry automatically generates Access Control Groups (ACGs) for each field and its corresponding type when its schema is registered. Product managers & DGS Engineers decide membership and rules for these generated ACGs. Since the ACGs map to a field in GraphQL, the DGS framework then automatically applies the rules associated with the ACG during execution.
Architecting for Failure
The GraphQL Gateway is the single entry point for all requests; a failure on the gateway can cause significant disruptions. Following Netflix engineering best practices, we assume failures will happen and design ways to mitigate the impact of those failures. These are our design principles for ensuring the gateway layer is resilient:
Single purpose
Stateless service
Demand controlled
Multi-region
Sharded by functionality
First, we focus the responsibilities of the gateway layer on a single purpose: parse client queries, then build and execute query plans. By reducing the scope, we limit the range of problems that can occur. We aim to perform any additional resource-intensive operations off-box with the exception of logging and metrics. Taking on additional unrelated logic in the gateway layer could increase surface area for failures in this critical tier.
Second, we run multiple stateless instances of the gateway service. Any gateway instance is able to generate and execute a query plan for any request. When we do code changes to the gateway layer, we rigorously test them before rolling out to production.
Third, we seek to balance the resources each request consumes through applying demand control. We rate-limit callers to avoid overloading the underlying databases that are the source of most of our domain elements. We also run a static query cost calculation on all incoming queries and reject expensive queries to avoid gridlock in gateway and DGS resources. Our partners understand these tradeoffs and work with us to meet these requirements, reworking expensive queries and reducing high volume callers.
Fourth, we deploy our gateway layer to multiple AWS regions around the world. This allows us to limit the blast radius for problems that inevitably arise. When problems happen, we can fail over to another region to ensure our clients are minimally impacted.
Last, we deploy multiple functional shards of our gateway layer. The code is the same in each shard and incoming requests are routed based on category. For example, GraphQL subscriptions generally result in long-lived connections while Queries & Mutations are short-lived. We use a separate fleet of instances for Subscriptions so “running out of connections” does not affect the availability of Queries and Mutations.
There is more we can do to improve resilience. We have plans to do canary deployments and analysis for gateway deployments and, eventually, schema changes. Today, our gateway dynamically updates its schema by polling the schema registry. We are in the process of decoupling these by storing the federation config in a versioned S3 bucket, making the gateway resilient to schema registry failures.
Closing Thoughts
GraphQL and Federation have been a productivity multiplier for Studio applications. Motivated by this, we’ve recently prototyped using GraphQL Federation for the Netflix consumer app search page on iOS & Android. To do this, we created three DGSs to provide the data for a minimal portion of the consumer graph. We are sending a small subset of users to this alternative stack and measuring high-level metrics. We are excited to see the results and explore further applicability in the Netflix consumer space.
Despite our positive experience, GraphQL Federation is early in its maturity lifecycle and may not be the best fit for every team or organization. Learning GraphQL and DGS development, running a federation layer, and doing a migration requires high commitment from partner teams and seamless cross-functional collaboration. If you’re considering going in this direction, we recommend checking out Apollo’s SaaS offering for Federation and the many online resources for learning GraphQL. For ecosystems like ours with a large swath of microservices that need to be aggregated together, the development velocity and improved operability has made the transition worth it.
In closing, we want to hear from you! If you have already implemented federation or tried to solve this problem with another approach, we would love to learn more. Sharing knowledge is one of the ways our industry learns and improves rapidly. Finally, if you’d like to be a part of solving complex and interesting problems like this at Netflix scale, check out our jobs page or reach out to us directly.
Netflix is known for its loosely coupled and highly scalable microservice architecture. Independent services allow for evolving at different paces and scaling independently. Yet they add complexity for use cases that span multiple services. Rather than exposing 100s of microservices to UI developers, Netflix offers a unified API aggregation layer at the edge.
UI developers love the simplicity of working with one conceptual API for a large domain. Back-end developers love the decoupling and resilience offered by the API layer. But as our business has scaled, our ability to innovate rapidly has approached an invisible asymptote. As we’ve grown the number of developers and increased our domain complexity, developing the API aggregation layer has become increasingly harder.
In order to address this rising problem, we’ve developed a federated GraphQL platform to power the API layer. This solves many of the consistency and development velocity challenges with minimal tradeoffs on dimensions like scalability and operability. We’ve successfully deployed this approach for Netflix’s studio ecosystem and are exploring patterns and adaptations that could work in other domains. We’re sharing our story to inspire others and encourage conversations around applicability elsewhere.
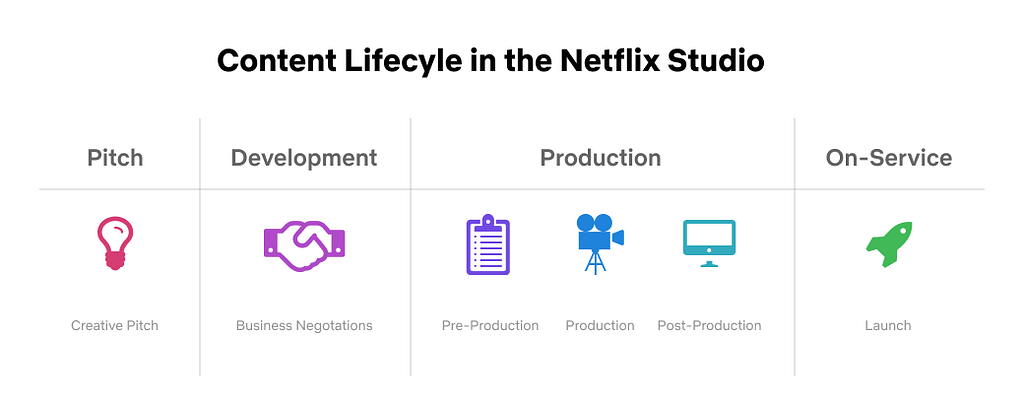
Netflix is producing original content at an accelerated pace. From the time a TV show or a movie is pitched to when it’s available on Netflix, a lot happens behind the scenes. This includes but is not limited to talent scouting and casting, deal and contract negotiations, production and post-production, visual effects and animations, subtitling and dubbing, and much more. Studio Engineering is building hundreds of applications and tools that power these workflows.
Content Lifecycle
Studio API
Looking back to a few years ago, one of the pains in the studio space was the growing complexity of the data and its relationships. The workflows depicted above are inherently connected but the data and its relationships were disparate and existed in myriads of microservices. The product teams solved for this with two architectural patterns.
1) Single-use aggregation layers — Due to the loose coupling, we observed that many teams spent considerable effort building duplicative data-fetching code and aggregation layers to support their product needs. This was either done by UI teams via BFF (Backend For Frontend) or by a backend team in a mid-tier service.
2) Materialized views for data from other teams — some teams used a pattern of building a materialized view of another service’s data for their specific system needs. Materialized views had performance benefits, but data consistency lagged by varying degrees. This was not acceptable for the most important workflows in the Studio. Inconsistent data across different Studio applications was the top support issue in Studio Engineering in 2018.
Graph API: To better address the underlying needs, our team started building a curated graph API called “Studio API”. Its goal was to provide an unified abstraction on top of data and relationships. Studio API used GraphQL as its underlying API technology and created significant leverage for accessing core shared data. Consumers of Studio API were able to explore the graph and build new features more quickly. We also observed fewer instances of data inconsistency across different UI applications, as every field in GraphQL resolves to a single piece of data-fetching code.
Studio API GraphStudio API Architecture
Bottlenecks of Studio API
The One Graph exposed by Studio API was a runaway success; product teams loved the reusability and easy, consistent data access. But new bottlenecks emerged as the number of consumers and amount of data in the graph increased.
First, the Studio API team was disconnected from the domain expertise and the product needs, which negatively impacted the schema’s health. Second, connecting new elements from a back-end into the graph API was manual and ran counter to the rapid evolution promised by a microservice architecture. Finally, it was hard for one small team to handle the increasing operational and support burden for the expanding graph.
We knew that there had to be a better way — unified but decoupled, curated but fast moving.
Returning to Core Principles
To address these bottlenecks, we leaned into our rich history of microservices and breaking monoliths apart. We still wanted to keep the unified GraphQL schema of Studio API but decentralize the implementation of the resolvers to their respective domain teams.
As we were brainstorming the new architecture back in early 2019, Apollo released the GraphQL Federation Specification. This promised the benefits of a unified schema with distributed ownership and implementation. We ran a test implementation of the spec with promising results, and reached out to collaborate with Apollo on the future of GraphQL Federation. Our next generation architecture, “Studio Edge”, emerged with federation as a critical element.
GraphQL Federation Primer
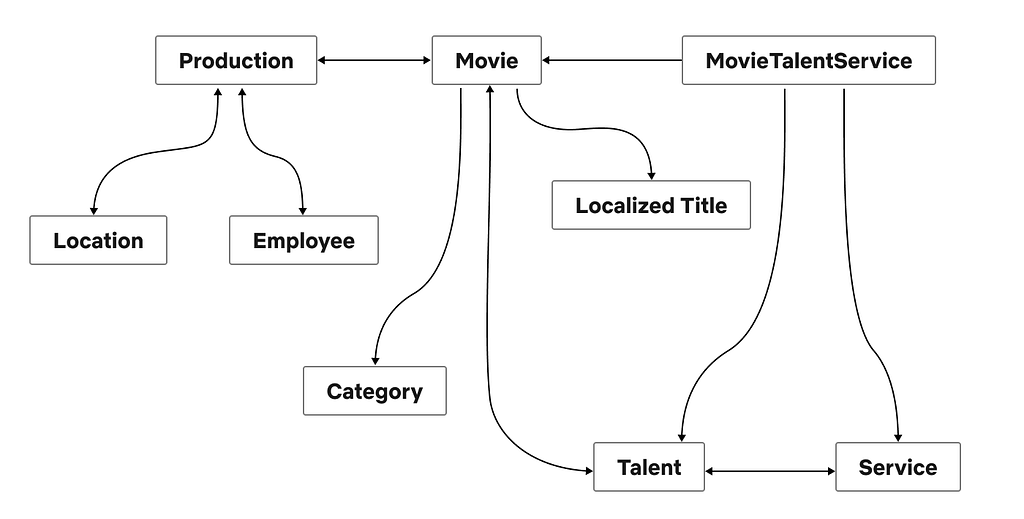
The goal of GraphQL Federation is two-fold: provide a unified API for consumers while also giving backend developers flexibility and service isolation. To achieve this, schemas need to be created and annotated to indicate how ownership is distributed. Let’s look at an example with three core entities:
Movie: At Netflix, we make titles (shows, films, shorts etc.). For simplicity, let’s assume each title is a Movie object.
Production: Each Movie is associated with a Studio Production. A Production object tracks everything needed to make a Movie including shooting location, vendors, and more.
Talent: the people working on a Movie are the Talent, including actors, directors, and so on.
These three domains are owned by three separate engineering teams responsible for their own data sources, business logic, and corresponding microservices. In an unfederated implementation, we would have this simple Schema and Resolvers owned and implemented by the Studio API team. The GraphQL Framework would take in queries from clients and orchestrate the calls to the resolvers in a breadth-first traversal.
Schema & Resolvers for Studio API
To transition to a federated architecture, we need to transfer ownership of these resolvers to their respective domains without sacrificing the unified schema. To achieve this, we need to extend the Movie type across GraphQL service boundaries:
Federating Movie
This ability to extend a Movie type across GraphQL service boundaries makes Movie a Federated Type. Resolving a given field requires delegation by a gateway layer down to the owning domain services.
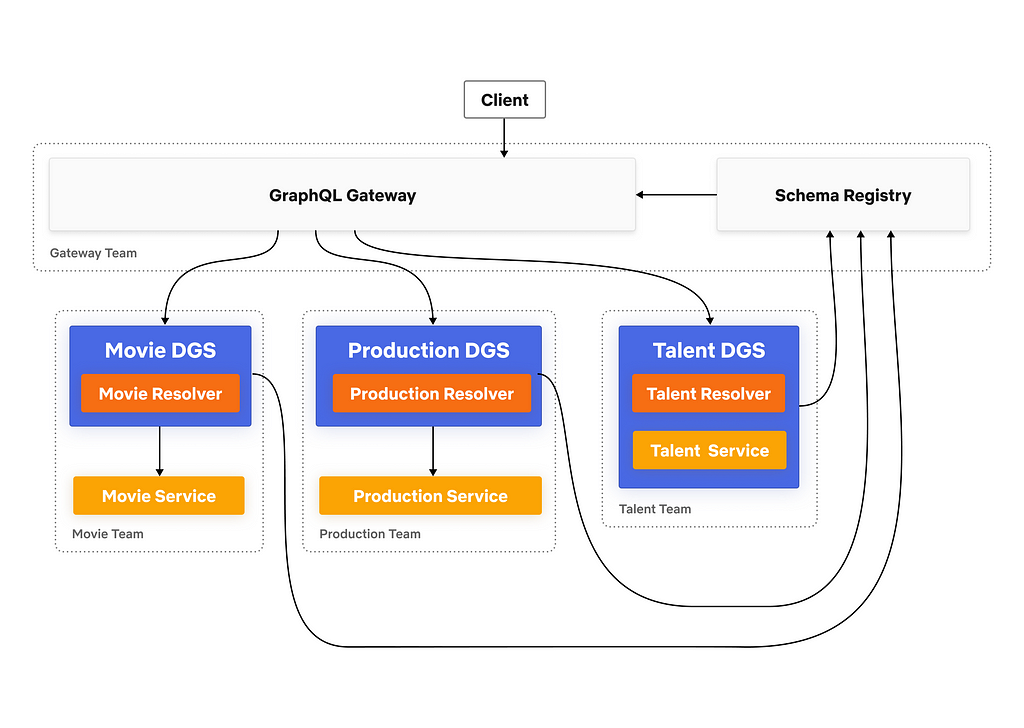
Studio Edge Architecture
Using the ability to federate a type, we envisioned the following architecture:
Studio Edge Architecture
Key Architectural Components
Domain Graph Service (DGS) is a standalone spec-compliant GraphQL service. Developers define their own federated GraphQL schema in a DGS. A DGS is owned and operated by a domain team responsible for that subsection of the API. A DGS developer has the freedom to decide if they want to convert their existing microservice to a DGS or spin up a brand new service.
Schema Registry is a stateful component that stores all the schemas and schema changes for every DGS. It exposes CRUD APIs for schemas, which are used by developer tools and CI/CD pipelines. It is responsible for schema validation, both for the individual DGS schemas and for the combined schema. Last, the registry composes together the unified schema and provides it to the gateway.
GraphQL Gateway isprimarily responsible for serving GraphQL queries to the consumers. It takes a query from a client, breaks it into smaller sub-queries (a query plan), and executes that plan by proxying calls to the appropriate downstream DGSs.
Implementation Details
There are 3 main business logic components that power GraphQL Federation.
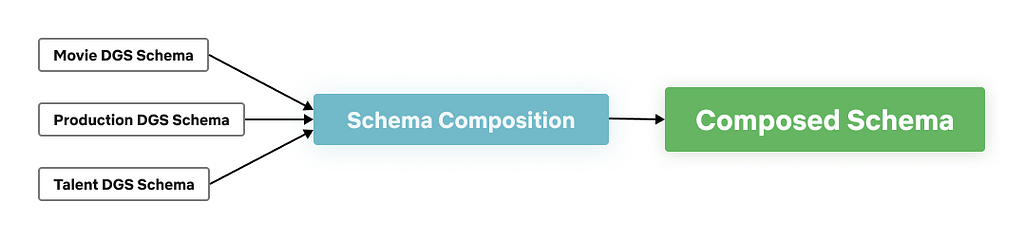
Schema Composition
Composition is the phase that takes all of the federated DGS schemas and aggregates them into a single unified schema. This composed schema is exposed by the Gateway to the consumers of the graph.
Schema Composition Phases
Whenever a new schema is pushed by a DGS, the Schema Registry validates that:
New schema is a valid GraphQL schema
New schema composes seamlessly with the rest of the DGSs schemas to create a valid composed schema
New schema is backwards compatible
If all of the above conditions are met, then the schema is checked into the Schema Registry.
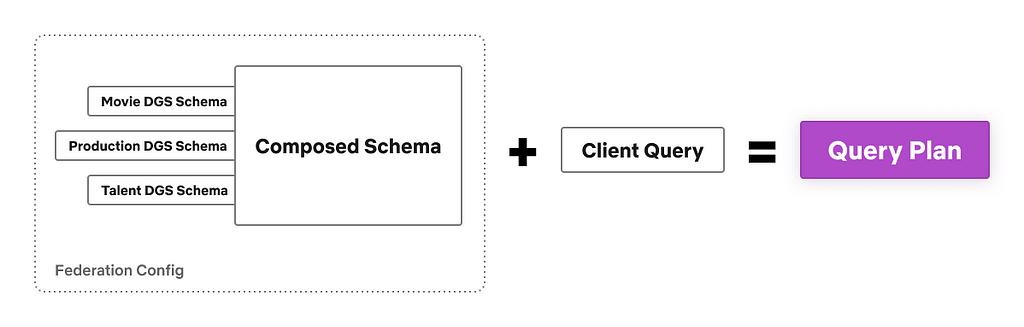
Query Planning and Execution
The federation config consists of all the individual DGS schemas and the composed schema. The Gateway uses the federation config and the client query to generate a query plan. The query plan breaks down the client query into smaller sub-queries that are then sent to the downstream DGSs for execution, along with an execution ordering that includes what needs to be done in sequence versus run in parallel.
Query Plan Inputs
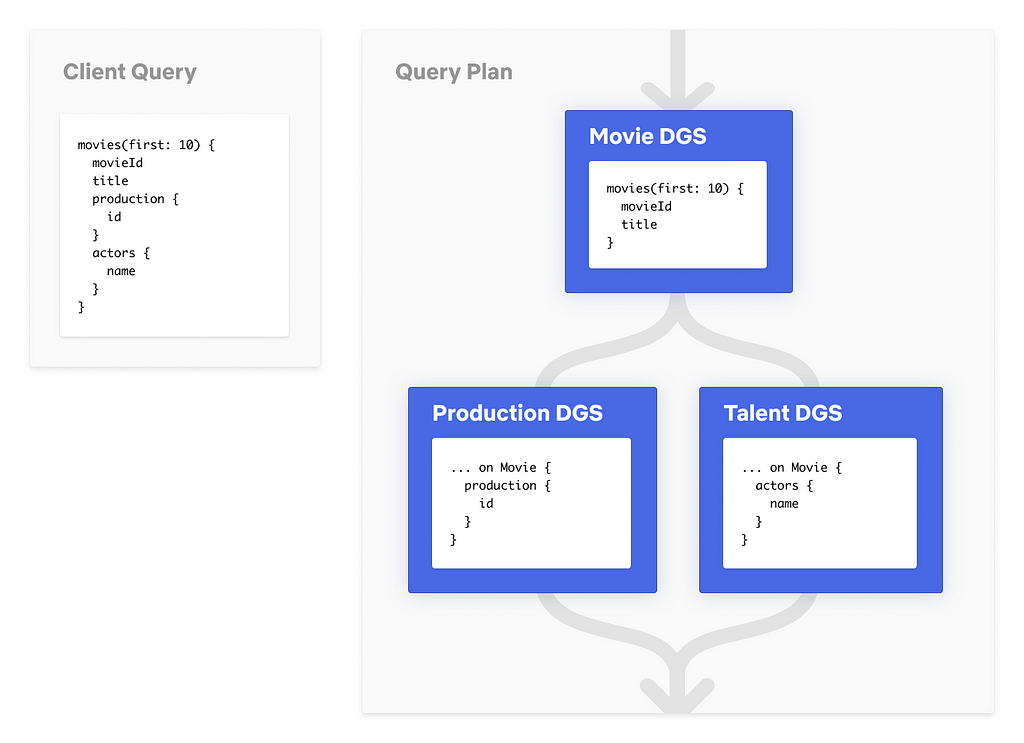
Let’s build a simple query from the schema referenced above and see what the query plan might look like.
Simplified Query Plan
For this query, the gateway knows which fields are owned by which DGS based on the federation config. Using that information, it breaks the client query into three separate queries to three DGSs. The first query is sent to Movie DGS since the root field movies is owned by that DGS. This results in retrieving the movieId and title fields for the first 10 movies in the dataset. Then using the movieIds it got from the previous request, the gateway executes two parallel requests to Production DGS and Talent DGS to fetch the production and actors fields for those 10 movies. Upon completion, the sub-query responses are merged together and the combined data response is returned to the caller.
A note on performance: Query Planning and Execution adds a ~10ms overhead in the worst case. This includes the compute for building the query plan, as well as the deserialization of DGS responses and the serialization of merged gateway response.
Entity Resolver
Now you might be wondering, how do the parallel sub-queries to Production and Talent DGS actually work? That’s not something that the DGS supports. This is the final piece of the puzzle.
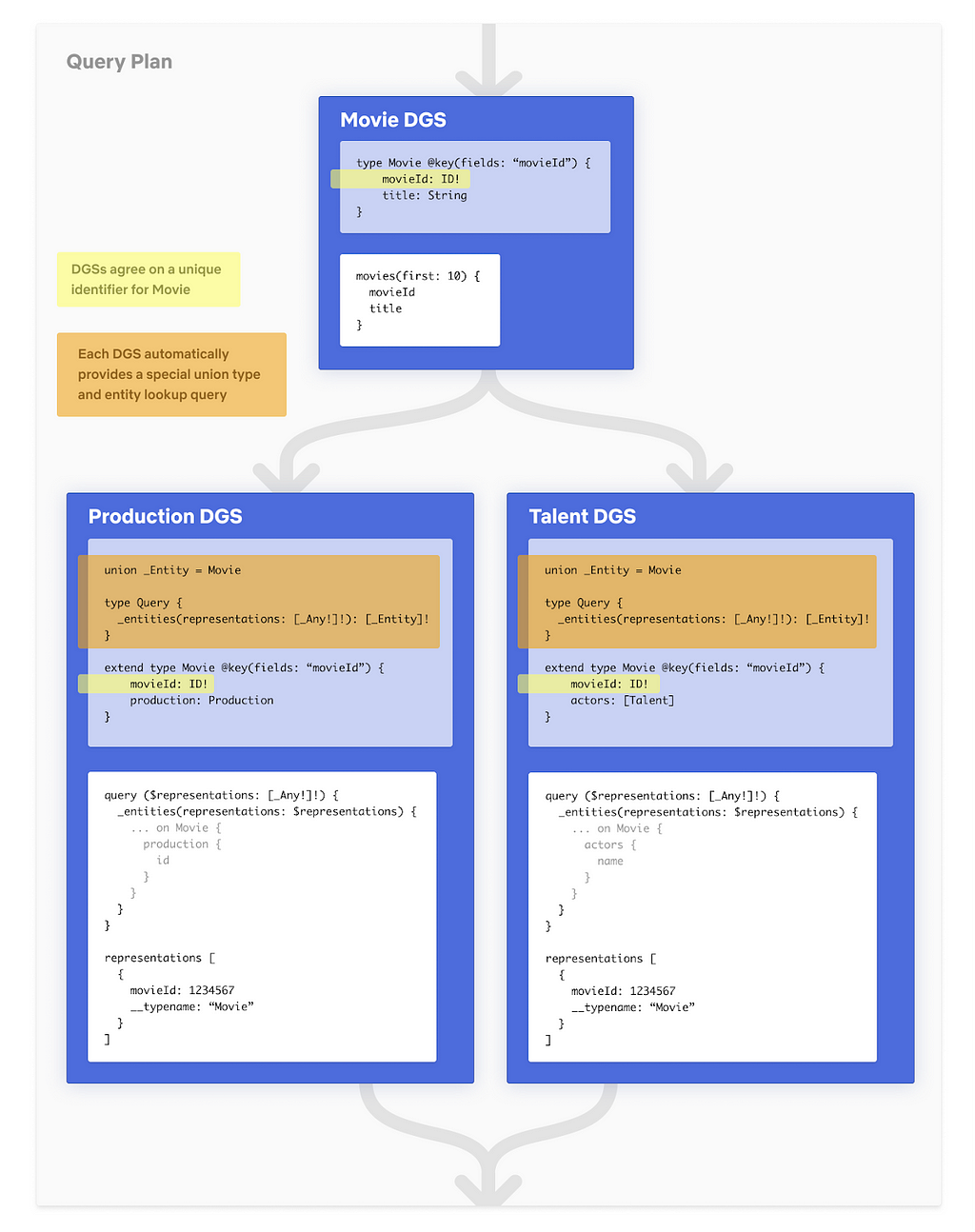
Let’s go back to our federated type Movie. In order for the gateway to join Movie seamlessly across DGSs, all the DGSs that define and extend the Movie need to agree on one or more fields that define the primary key (e.g. movieId). To make this work, Apollo introduced the @key directive in the Federation Spec. Second, DGSs have to implement a resolver for a generic Query field, _entities. The _entities query returns a union type of all the federated types in that DGS. The gateway uses the _entities query to look up Movie by movieId.
Let’s take a look at how the query plan actually looks like
Detailed Federated Query Plan
The representation object consists of the movieId and is generated from the response of the first request to Movie DGS. Since we requested for the first 10 movies, we would have 10 representation objects to send to Production and Talent DGS.
This is similar to Relay’s Object Identification with a few differences. _Entity is a union type, while Relay’s Node is an interface. Also, with @key, there is support for variable key names and types as well as composite keys while in Relay, the id is a single opaque ID field.
Combined together, these are the ingredients that power the core of a federated API architecture.
The Journey, Summarized
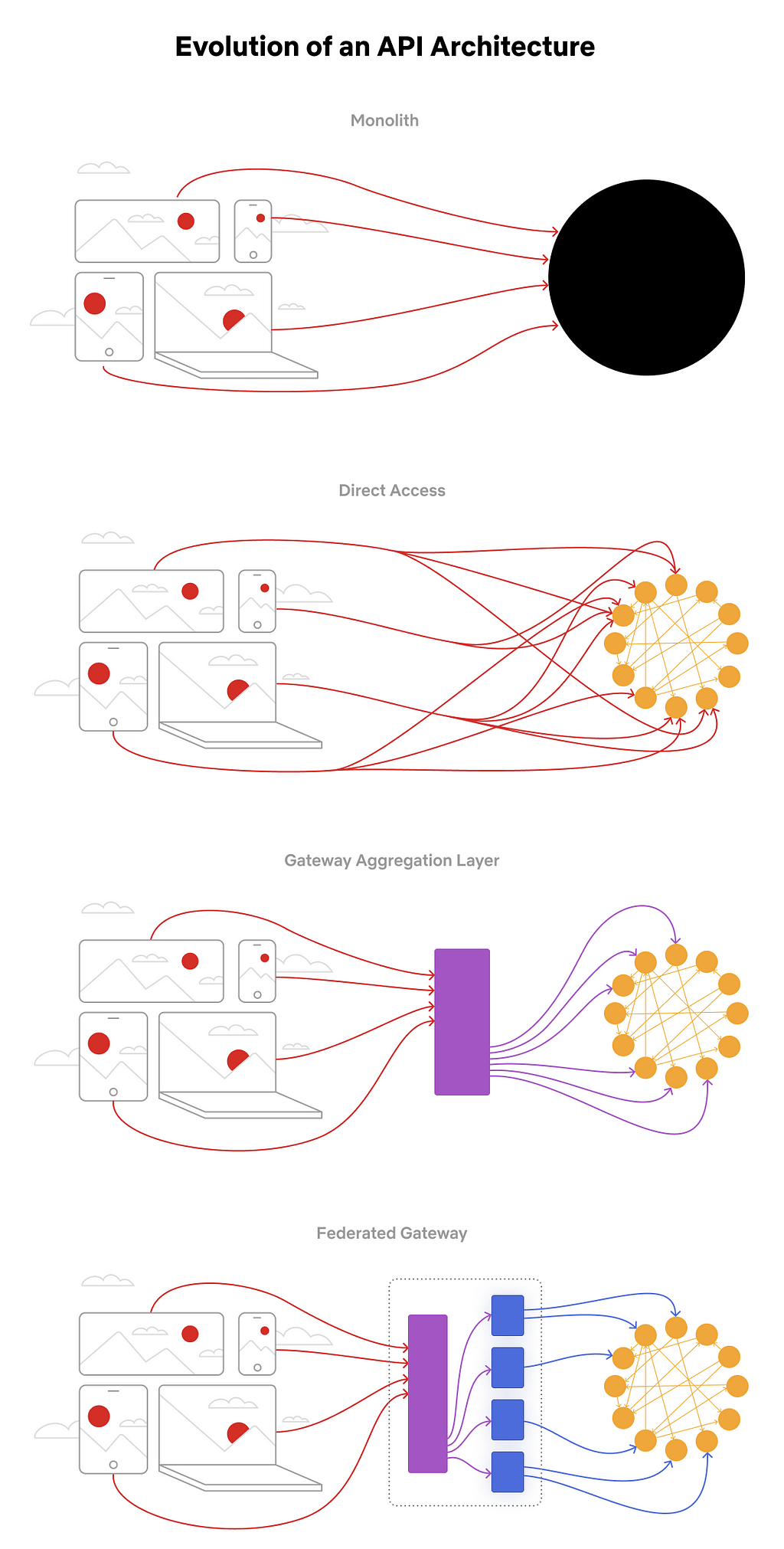
Our Studio Ecosystem architecture has evolved in distinct phases, all motivated by reducing the time between idea and implementation, improving the developer experience, and streamlining operations. The architectural phases look like:
Evolution of an API Architecture
Stay Tuned
Over the past year we’ve implemented the federated API architecture components in our Studio Edge. Getting here required rapid iteration, lots of cross-functional collaborations, a few pivots, and ongoing investment. We’re live with 70 DGSes and hundreds of developers contributing to and using the Studio Edge architecture. In our next Netflix Tech Blog post, we’ll share what we learned along the way, including the cross-cutting concerns necessary to build a holistic solution.
We want to thank the entire GraphQL open-source community for all the generous contributions and paving the path towards the promise of GraphQL. If you’d like to be a part of solving complex and interesting problems like this at Netflix scale, check out our jobs page or reach out to us directly.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.