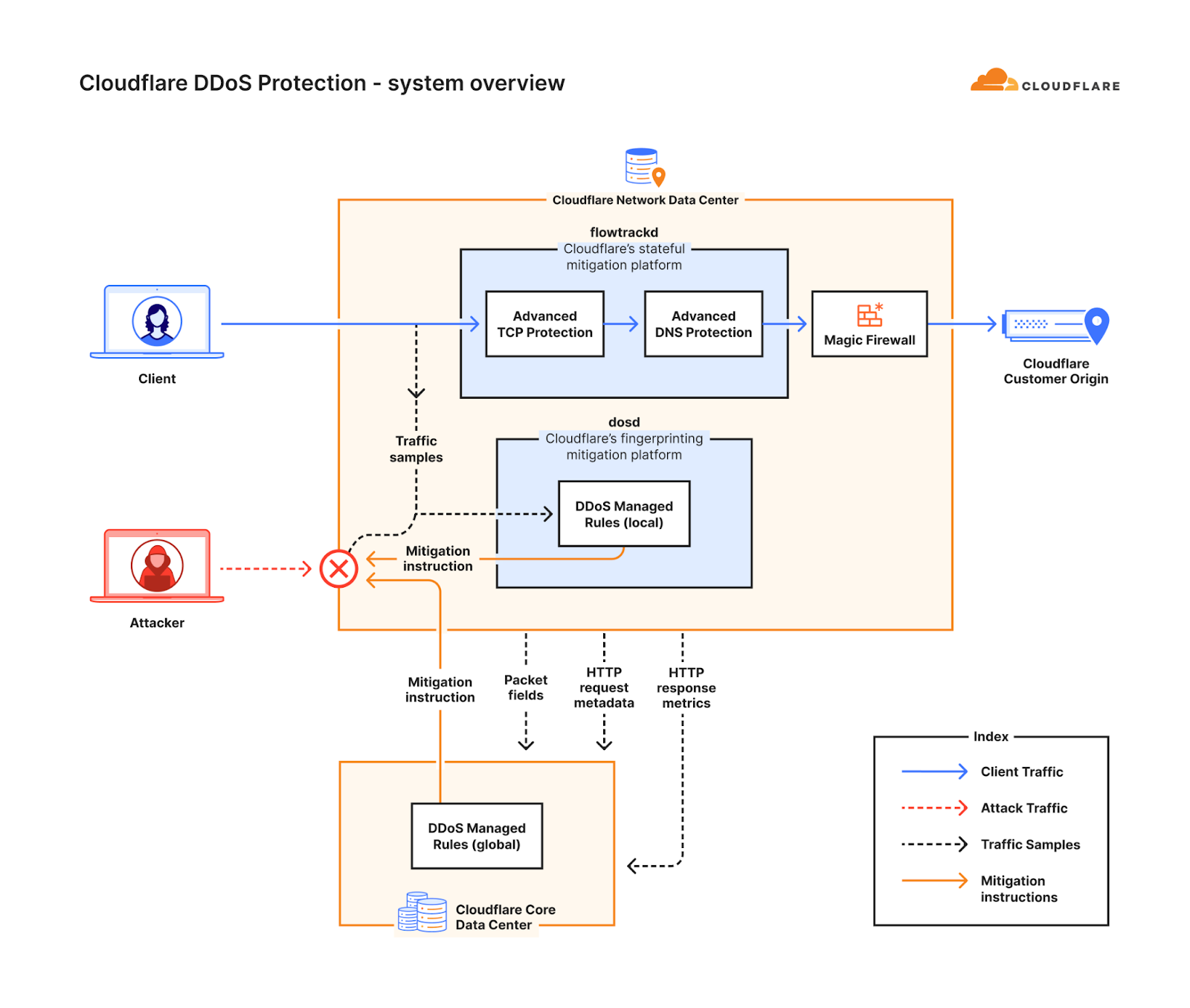
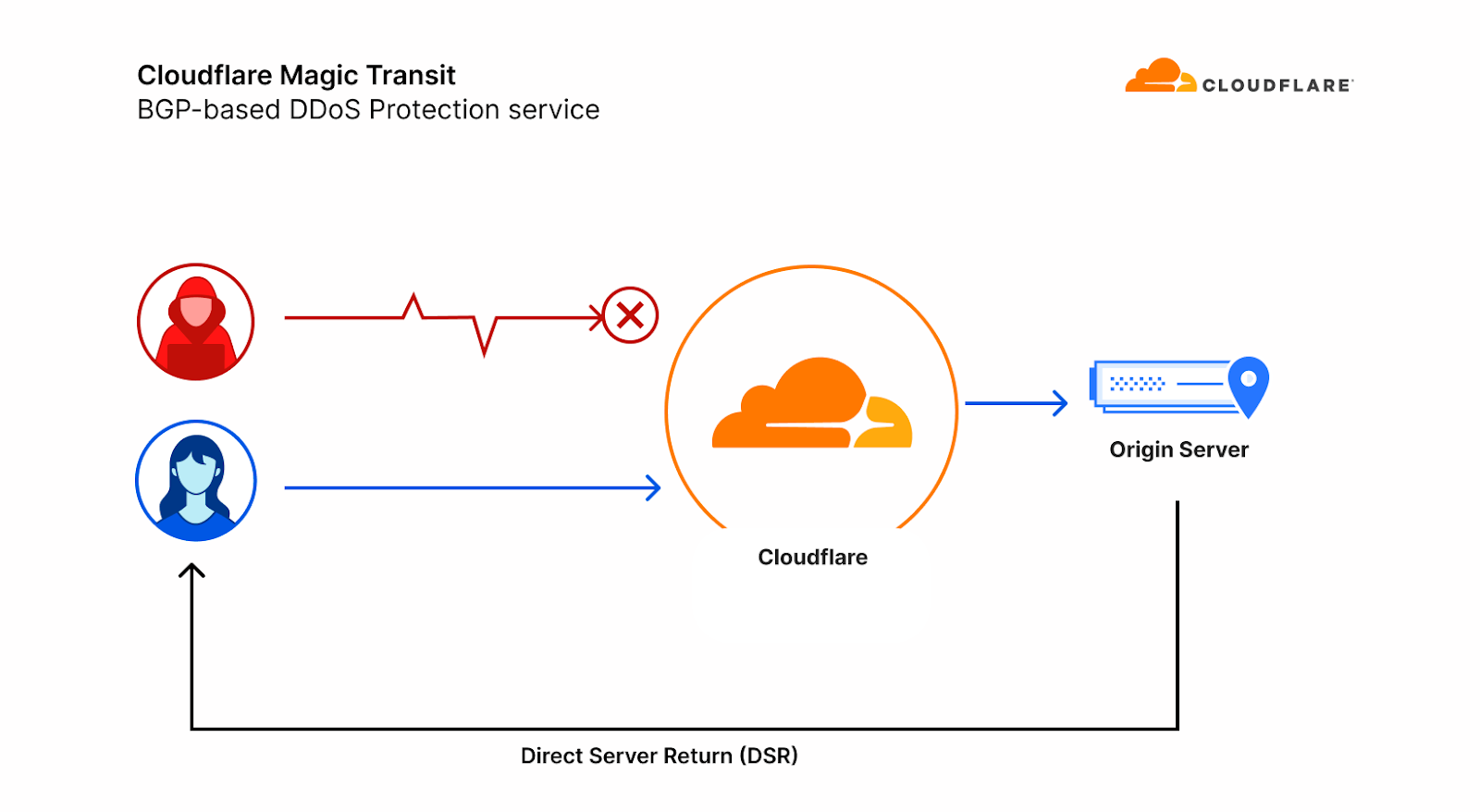
Post Syndicated from Nitin Rao original https://blog.cloudflare.com/cloudflares-commitment-to-free
Cloudflare launched our free tier at the same time our company launched — fourteen years ago, on September 27, 2010. Of course, a bit has changed since then — there are now millions of Internet properties behind Cloudflare. As we’ve grown in size and amassed millions of free customers, one of the questions we often get asked is: how can Cloudflare afford to do this at such scale?
Cloudflare always has, and always will, offer a generous free version for public-facing applications (Application Services), internal private networks and people (Cloudflare One), and developer tools (Developer Platform). Counterintuitively: our free service actually helps us keep our costs lower. Not only is it mission-aligned, our free tier is business-aligned. We want to make abundantly clear: our free plan is here to stay, and we reaffirmed that commitment this week with 15 releases across our product portfolio that make the Free plan even better.
Understanding our Cost of Goods Sold
To understand the economics of Free, you need to understand our Cost of Goods Sold (COGS). Cloudflare hasn’t outsourced its network — we built it ourselves, and it spans more than 330 cities. We design and ship our own hardware across the world, we interconnect with more than 12,500 networks, and we manage over 300 Tbps of network capacity. We even have a dedicated backbone that spans the globe.
There are three major costs of running our network, which together comprise about 80% of our COGS. First and largest is bandwidth: the traffic that traverses our network. Then there is hardware: the servers that process traffic. And third are colocation costs: the power and space at the data centers where we house our servers. There are other parts of COGS, too, like our SRE team that keeps the network running, and our payment processor fees, without which we couldn’t collect revenue.
To get traffic across the Internet for a network of our scale, we need a lot of bandwidth. Typically, a network like ours would pay third-party transit networks and Internet Service Providers (ISPs) to transmit data anywhere on the Internet. But there are thousands of ISPs that we don’t have to pay at all, and hundreds that also offer us space in their data center at no cost. How did we manage that? The surprising answer: Free.
How our Free services keep costs low
Imagine you run an ISP serving your local community. Your job is to connect your customers to the Internet. You notice that your customers are often visiting sites behind Cloudflare, which sits in front of roughly 20% of the web. You need to deliver those webpages and facilitate connections to the applications behind Cloudflare, but right now you have to pay a transit provider to reach them. Instead, you could choose to peer directly with Cloudflare and exchange traffic at no cost.
Cloudflare is one of the most peered networks in the world. We freely exchange traffic with thousands of ISPs, who in turn benefit because they can cut out a third-party transit provider to reach the millions of sites and applications behind Cloudflare.
Continuing with this hypothetical, if as an ISP, your customers pay for Internet connectivity based on data usage (a common model outside of Western Europe and the US), your revenue scales with data consumption. One simple way to increase data consumption? Make the Internet faster! Hosting Cloudflare’s servers in your facility, as close to your users as possible, reduces latency for millions of websites and apps. So it’s in your best interest to host Cloudflare’s servers in your data centers, too.
We have hundreds of ISP partnerships that look just like that. The value ISPs get from Cloudflare stems from the breadth of the web that sits behind Cloudflare, a number driven by our Free customers. This arrangement is a big part of why we have a free service, and is part of what enables us to continue to offer one. PS: If you really are an operator for a local ISP and don’t partner with us yet, please connect with us through our peering portal!
These days, we are at such a scale that the traffic our customers generate requires much more capacity than can fit within our ISP partners. To reliably serve our enterprise customers, we operate in multiple facilities in every major Internet hub city. And yet, the traffic patterns of our enterprise customers are typically very predictable. They usually follow a diurnal cycle, with peaks and troughs throughout a day. Enterprise customer traffic is prioritized and served as close to end users as possible, regardless of the time of day. But our Free customers use off-cycle headroom. That’s why we’re able to continue to offer unmetered bandwidth on the Free plan: we serve the traffic from across our network, wherever there is spare room. It might not have quite the same performance as our enterprise traffic, but it’s still reliable and fast.
There do have to be some rules for this to continue to work, however. Free traffic needs to remain a manageable proportion of our total traffic. To ensure that remains true, and that we can continue to offer unmetered traffic to Free customers at no cost, we have to be opinionated about what kind of traffic we serve for free. Our terms of service specify that large assets (like videos) are not supported on our Free plan. So we require that customers pushing large files and videos move onto one of our paid services, like Images and Stream.
Free customers help us build better products and grow our business
The benefits of our Free plan extend well beyond direct economics.
Our Free plan gives Cloudflare access to unique threat intelligence. A wide surface area exposes our network to diverse traffic and attacks that we wouldn’t otherwise see, often allowing us to identify potential security and reliability issues at the earliest stage. Like an immune system, we learn from these attacks and adapt to improve our products for all customers. This is a special competitive advantage. Visibility into attacks allows us to build products that no one else could.
Our Free customers help us do quality assurance (QA) quickly. Free customers are often the first to try new products and features. When we launch something new, we get signal immediately and at an incredible scale. We use that signal to swiftly address bugs and iterate on our products.
Offering a Free plan challenges us to build more intuitive products. Free customers represent a broad audience, from tech enthusiasts to those simply looking to secure their website or build an application. Building for a broad spectrum of users forces us to create more user-friendly tools for everyone.
Offering a Free service has other benefits, too. Some of our strongest customer advocates are folks that used our Free plan on their hobby projects before bringing Cloudflare with them to work. Some of them even end up working at Cloudflare!
Our free plan will keep getting better
Our Free offering is a flywheel that helps make Cloudflare’s products, team, and cost structure more efficient. We pay back these efficiencies by continuing to improve our free offerings. Just this week, we’ve announced 15 updates that make our Free plans even better:
-
Free customers can audit and control the AI models accessing their content.
-
Turnstile, our privacy-first CAPTCHA alternative available to everyone, gets more accurate with granular, device-level identification.
-
Free customers now have access to our Cloud Access Security Broker (CASB), Data Loss Prevention (DLP), Digital Experience Monitoring (DEX), and Magic Network Monitoring (MNM) tools, for up to 50 seats.
-
A new version of Leaked Credential Checks (LCC) is available to all customers to help mitigate account takeover (ATO) attacks.
-
All customers can now monitor third-party scripts with Page Shield Script Monitor.
-
Free customers can use API Shield’s Schema Validation to ensure only valid requests to their API make it through to the origin.
-
Free customers get more robust analytics, with versions of Security Analytics and DNS GraphQL for everyone.
-
All customers can now log in to the Cloudflare Dashboard using Sign in with Google.
-
Free customers using our Terraform provider to configure their infrastructure will now benefit from autogenerated API SDKs.
-
Cloudflare Calls managed TURN service is now GA and free up to 1,000 GB per month.
-
All customers will benefit from the introduction of Zstandard compression, which improves web performance by compressing up to 42% faster than Brotli.
-
Free customer traffic is now more private as we roll out Encrypted Client Hello (ECH) which obfuscates the Server Name Identifier (SNI) during a TLS handshake.
-
All customers can store and query 3 days of logs from their Cloudflare Worker.
-
Requests made through Service Bindings and to Tail Workers are now free.
-
Cloudflare Image Optimization is now available for free to all Cloudflare customers.
We offer a Free plan out of more than goodwill — it is a core business differentiator that helps us build better products, drive growth, and keep costs low. And it helps us advance our mission. Building a better Internet is a collective effort. Today, more than 30 million domains, comprising some 20% of the web, sit behind Cloudflare. Our Free plan makes that portion of the web faster, more secure, and more efficient. Free is not just a commitment — it’s a cornerstone of our strategy.
Become part of a better Internet and sign up for Cloudflare’s Free plan.