Post Syndicated from Esra Kayabali original https://aws.amazon.com/blogs/aws/introducing-amazon-route-53-global-resolver-for-secure-anycast-dns-resolution-preview/
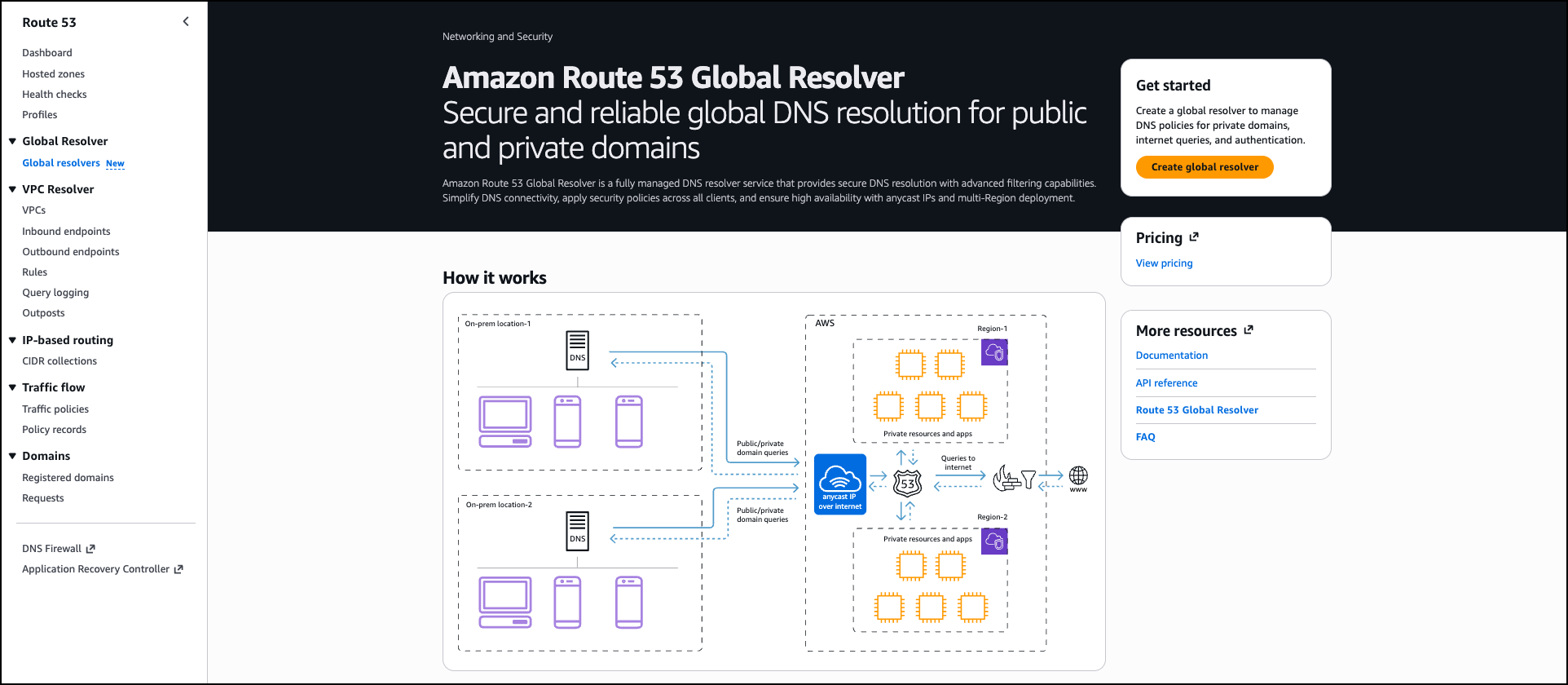
Today, we’re announcing Amazon Route 53 Global Resolver, a new Amazon Route 53 service that provides secure and reliable DNS resolution globally for queries from anywhere (preview). You can use Global Resolver to resolve DNS queries to public domains on the internet and private domains associated with Route 53 private hosted zones. Route 53 Global Resolver offers network administrators a unified solution to resolve queries from authenticated clients and sources in on-premises data centers, branch offices, and remote locations through globally distributed anycast IP addresses. This service includes built-in security controls including DNS traffic filtering, support for encrypted queries, and centralized logging to help organizations reduce operational overhead while maintaining compliance with security requirements.
Organizations with hybrid deployments face operational complexity when managing DNS resolution across distributed environments. Resolving public internet domains and private application domains often requires maintaining split DNS infrastructure, which increases cost and administrative burden especially when replicating to multiple locations. Network administrators must configure custom forwarding solutions, deploy Route 53 Resolver endpoints for private domain resolution, and implement separate security controls across different locations. Additionally, they must configure and maintain multi-Region failover strategies for Route 53 Resolver endpoints and provide consistent security policy enforcement across all Regions while testing failover scenarios.
Route 53 Global Resolver has key capabilities that address these challenges. The service resolves both public internet domains and Route 53 private hosted zones, eliminating the need for separate split-DNS forwarding. It provides DNS resolution through multiple protocols, including DNS over UDP (Do53), DNS-over-HTTPS (DoH), and DNS-over-TLS (DoT). Each deployment provides a single set of common IPv4 and IPv6 anycast IP addresses that route queries to the nearest AWS Region, reducing latency for distributed client populations.
Route 53 Global Resolver provides integrated security features equivalent to Route 53 Resolver DNS Firewall. Administrators can configure filtering rules using AWS Managed Domain Lists that provide flexible controls with lists classified by DNS threats (malware, spam, phishing) or web content (adult sites, gambling, social networking) that might not be safe for work or create custom domain lists by importing domains from a file. Advanced threat protection detects and blocks domain generation algorithm (DGA) patterns and DNS tunneling attempts. For encrypted DNS traffic, Route 53 Global Resolver supports DoH and DoT protocols to protect queries from unauthorized access during transit.
Route 53 Global Resolver only accepts traffic from known clients that need to authenticate with the Resolver. For Do53, DoT, and DoH connections, administrators can configure IP and CIDR allowlists. For DoH and DoT connections, token-based authentication provides granular access control with customizable expiration periods and revocation capabilities. Administrators can assign tokens to specific client groups or individual devices based on organizational requirements.
Route 53 Global Resolver supports DNSSEC validation to verify the authenticity and integrity of DNS responses from public nameservers. It also includes EDNS Client Subnet support, which forwards client subnet information to enable more accurate geographic-based DNS responses from content delivery networks.
Getting started with Route 53 Global Resolver
This walkthrough shows how to configure Route 53 Global Resolver for an organization with offices on the US East and West coasts that needs to resolve both public domains and private applications hosted in Route 53 private hosted zones. To configure Route 53 Global Resolver, go to the AWS Management Console, choose Global resolvers from the navigation pane, and choose Create global resolver.
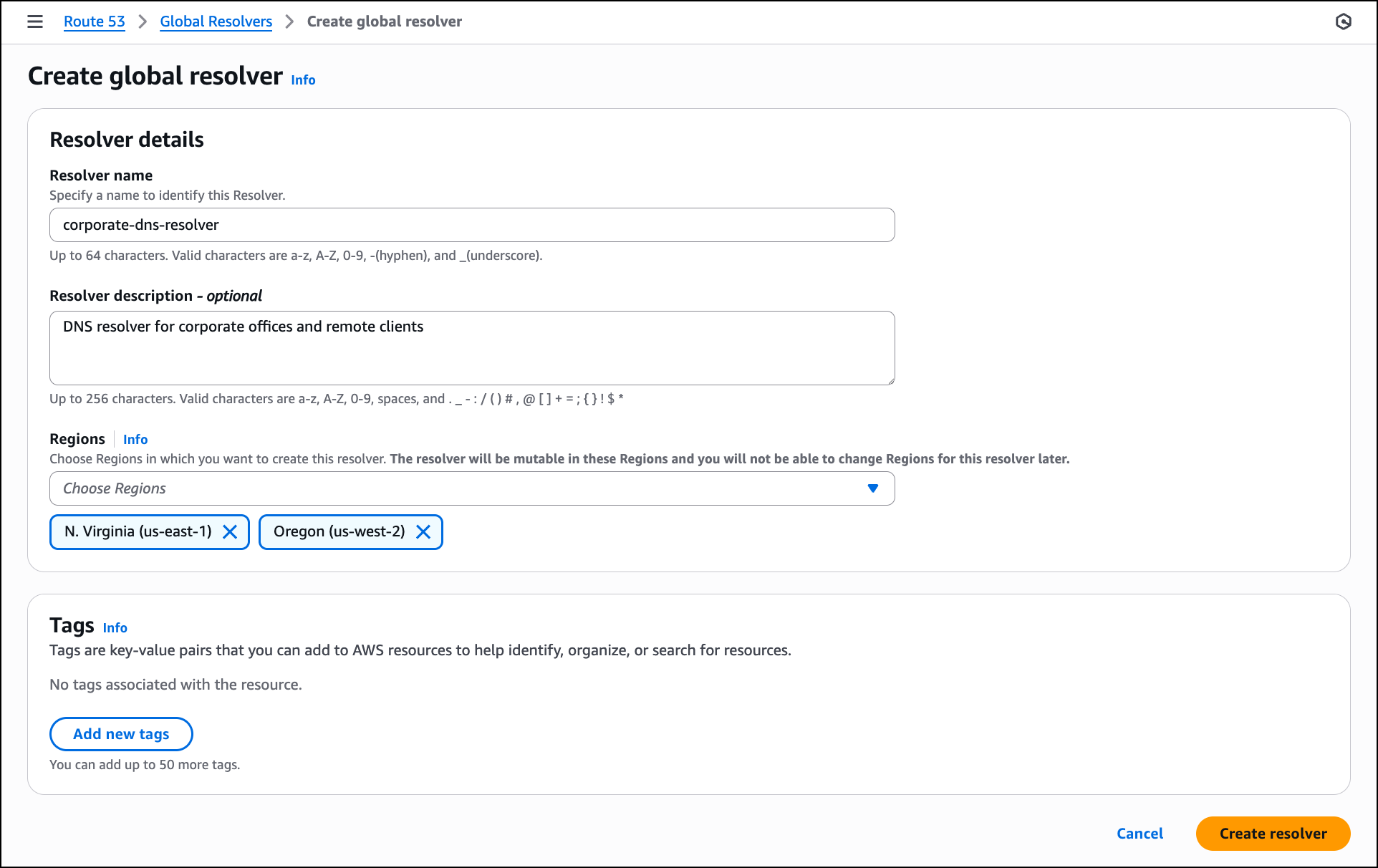
In the Resolver details section, enter a Resolver name such as corporate-dns-resolver. Add an optional description like DNS resolver for corporate offices and remote clients. In the Regions section, choose the AWS Regions where you want the resolver to operate, such as US East (N. Virginia) and US West (Oregon). The anycast architecture routes DNS queries from your clients to the nearest selected Region.
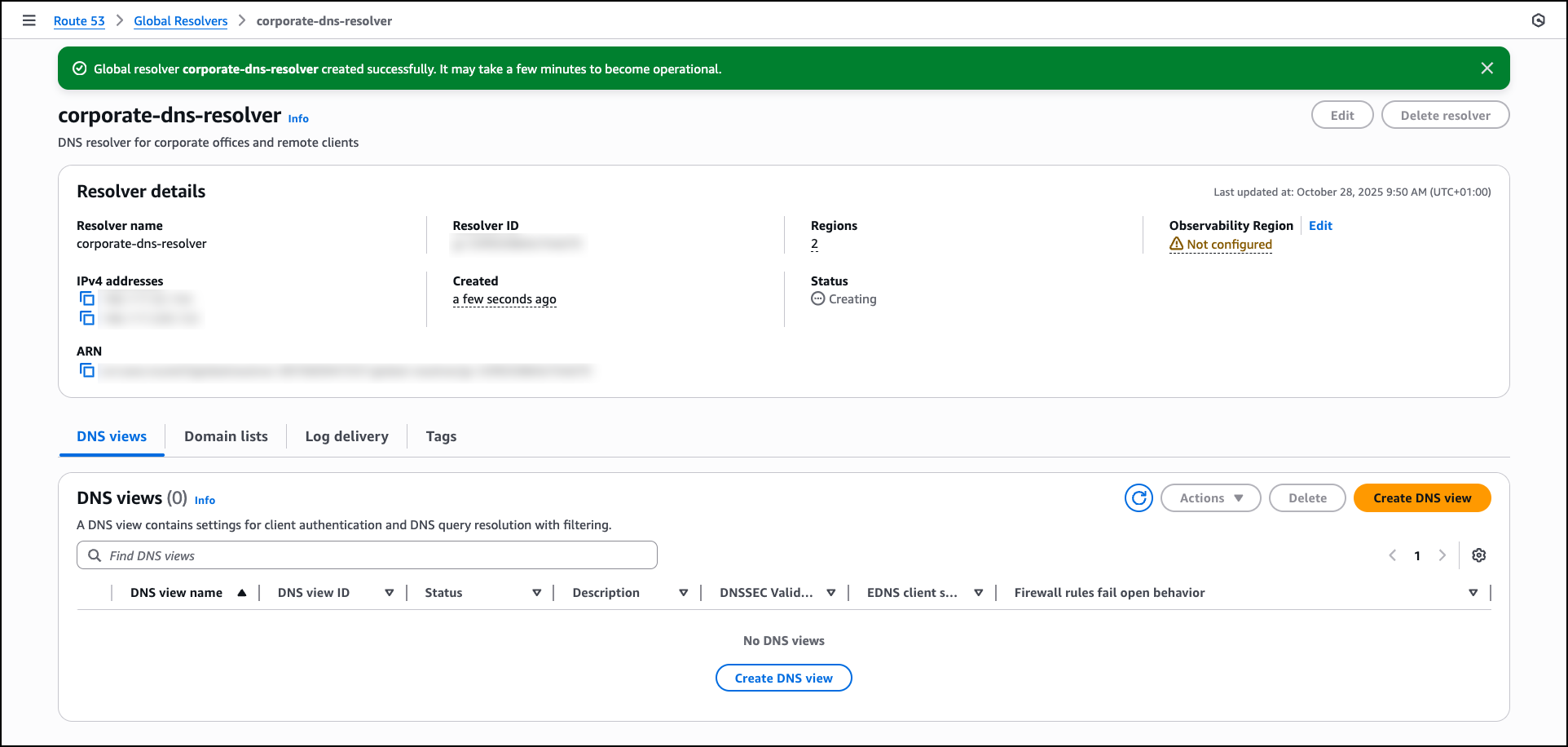
After the resolver is created, the console displays the resolver details, including the anycast IPv4 and IPv6 addresses that you will use for DNS queries. You can proceed to create a DNS view by choosing Create DNS view to configure client authentication and DNS query resolution settings.
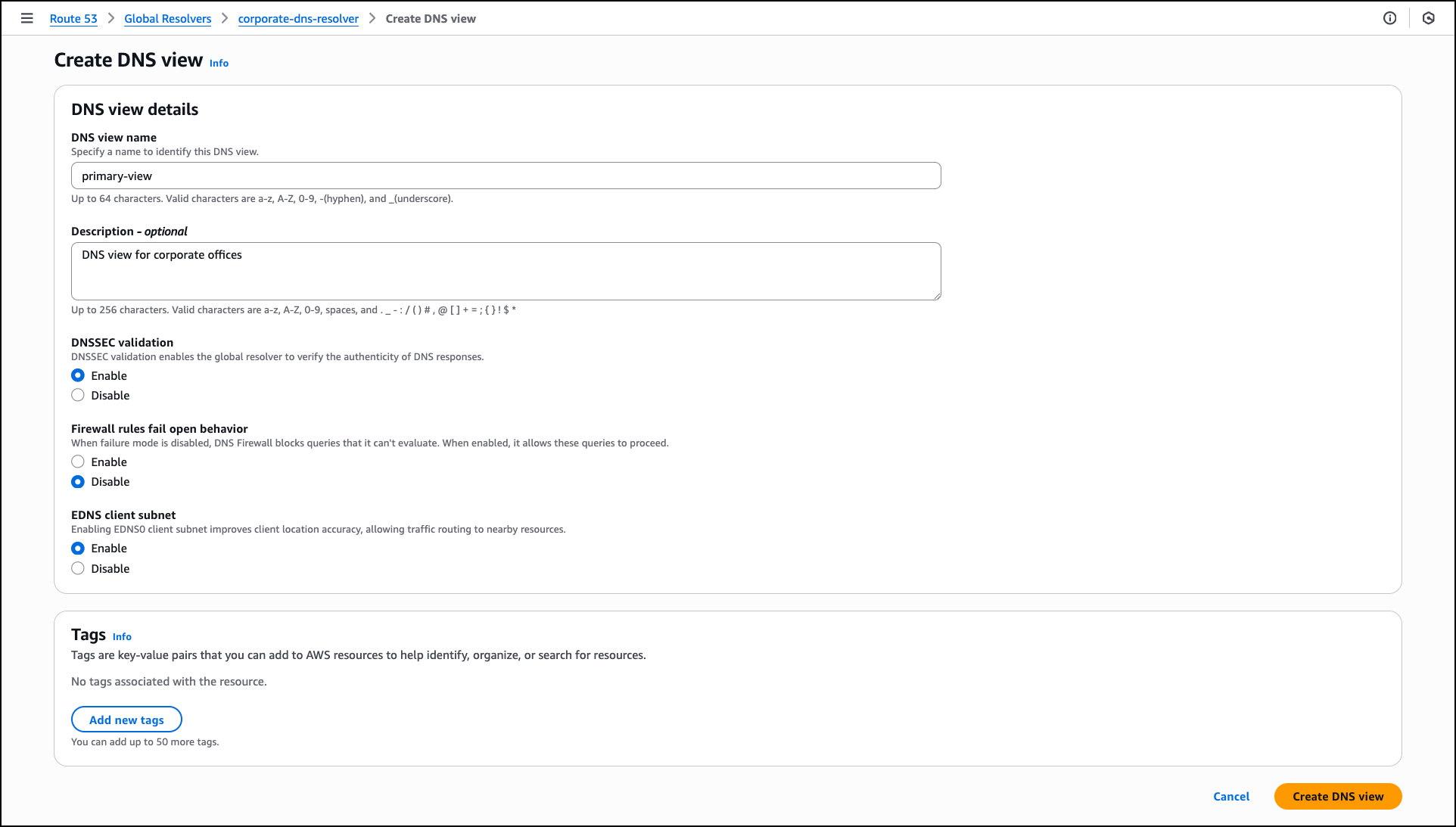
In the Create DNS view section, enter a DNS view name such as primary-view and optionally add a Description like DNS view for corporate offices. A DNS view helps you create different logical groupings for your clients and sources, and determine the DNS resolution for those groups. This helps you maintain different DNS filtering rules and private hosted zone resolution policies for different clients in your organization.
For DNSSEC validation, choose Enable to verify the authenticity of DNS responses from public DNS servers. For Firewall rules fail open behavior, choose Disable to block DNS queries when firewall rules can’t be evaluated, which provides additional security. For EDNS client subnet, keep Enable selected to forward client location information to DNS servers, which allows content delivery networks to provide more accurate geographic responses. DNS view creation might take a few minutes to become operational.
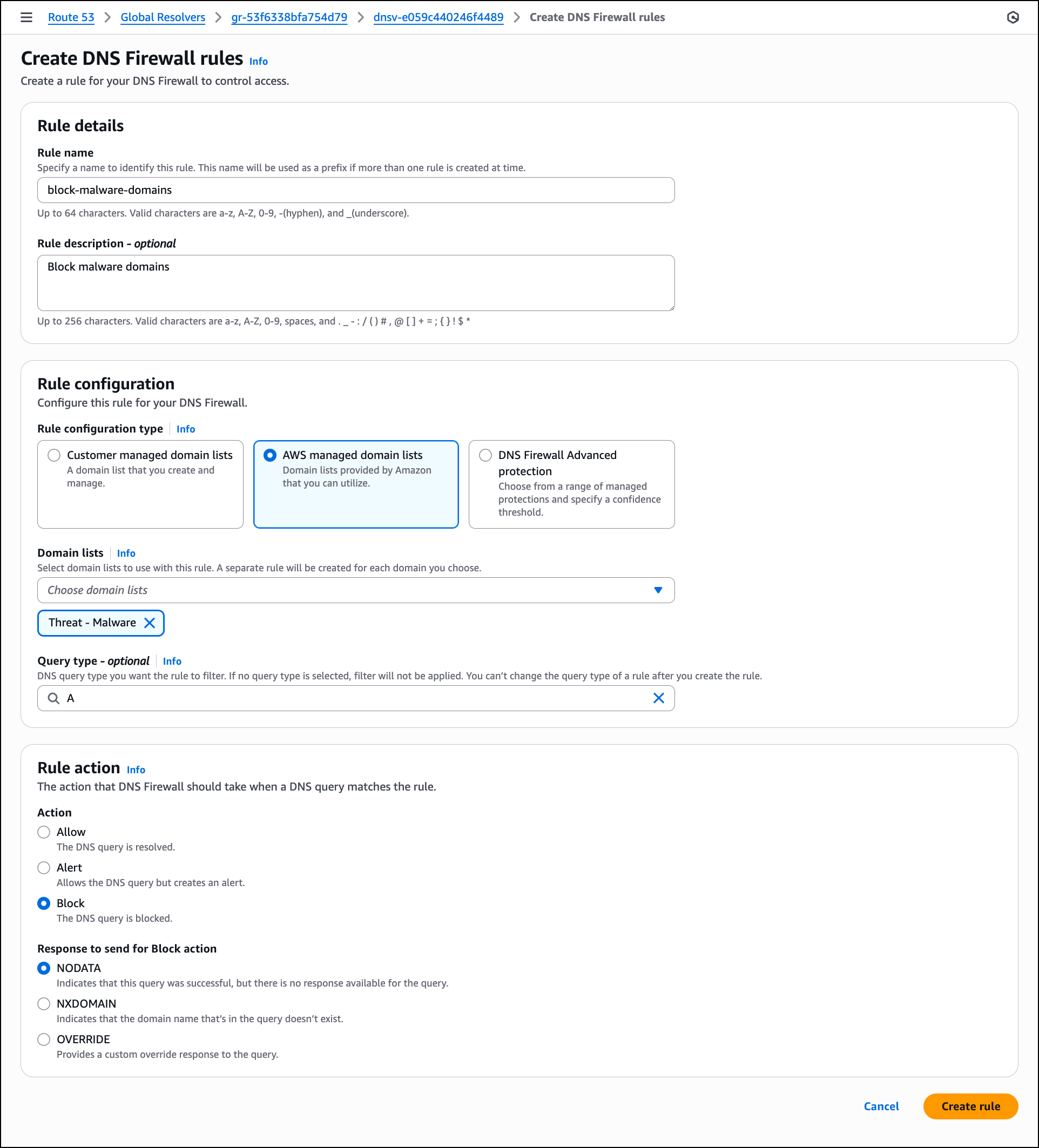
After the DNS view is created and operational, configure DNS Firewall rules to filter network traffic by choosing Create rule. In the Create DNS Firewall rules section, enter a Rule name such as block-malware-domains and optionally add a description. For Rule configuration type, you can choose Customer managed domain lists, AWS managed domain lists provided by AWS or DNS Firewall Advanced protection.
For this walkthrough, choose AWS managed domain lists. In the Domain lists dropdown, choose one or more AWS managed lists such as Threat – Malware to block known malicious domains. You can leave Query type empty to apply the rule to all DNS query types. In this example, choose A to apply this rule only to IPv4 address queries. In the Rule action section, select Block to prevent DNS resolution for domains that match the selected lists. For Response to send for Block action, keep NODATA selected to indicate that the query was successful but no response is available, then choose Create rules.
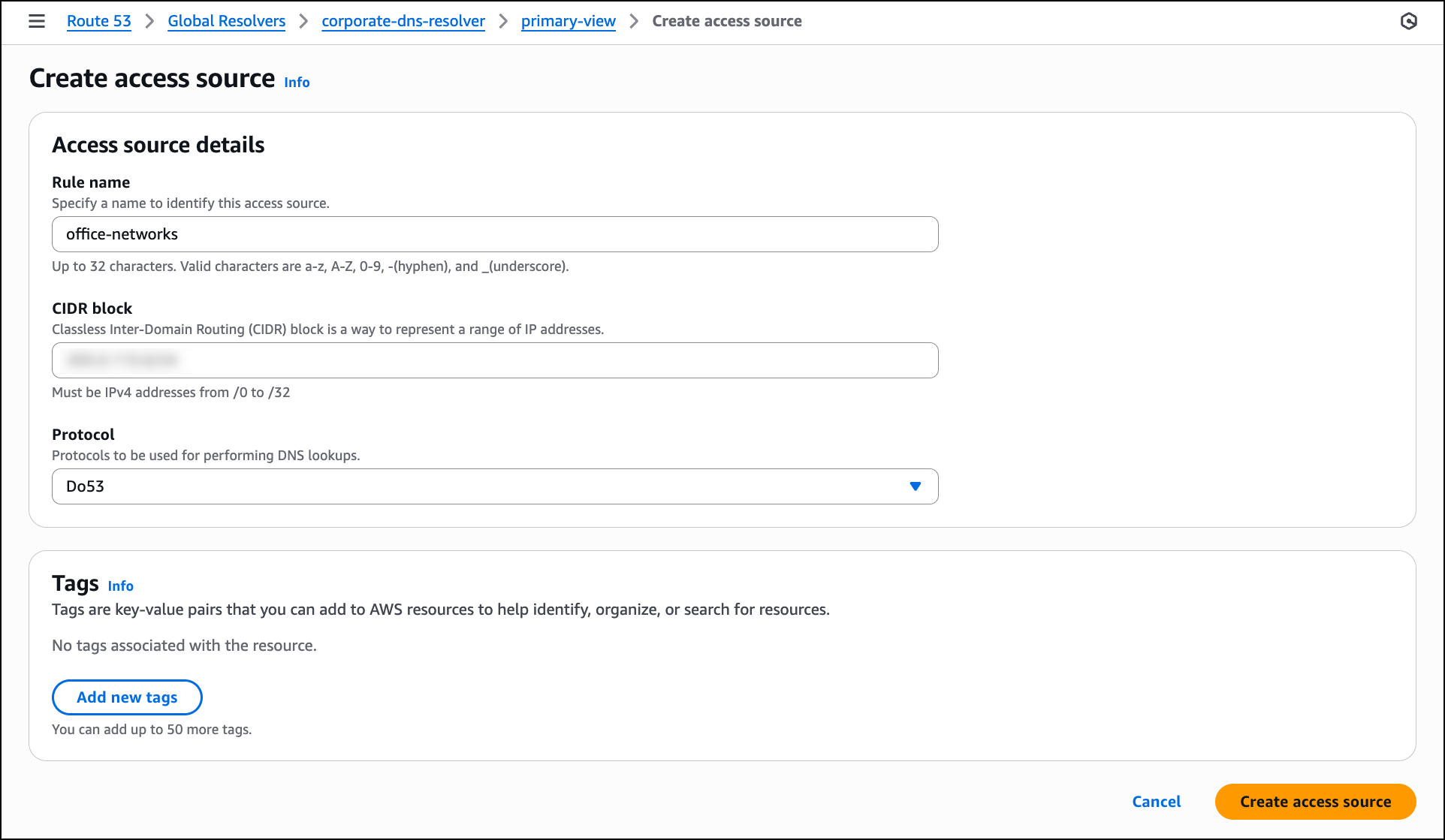
The next step is to configure access sources to specify which IP addresses or CIDR blocks are allowed to send DNS queries to the resolver. Navigate to the Access sources tab in the DNS view and then choose Create access source.
In the Access source details section, enter a Rule name such as office-networks to identify the access source. In the CIDR block field, enter the IP address range for your offices to allow queries from that network. For Protocol, select Do53 for standard DNS queries over UDP or choose DoH or DoT if you want to require encrypted DNS connections from clients. After configuring these settings, choose Create access source to allow the specified network to send DNS queries to the resolver.
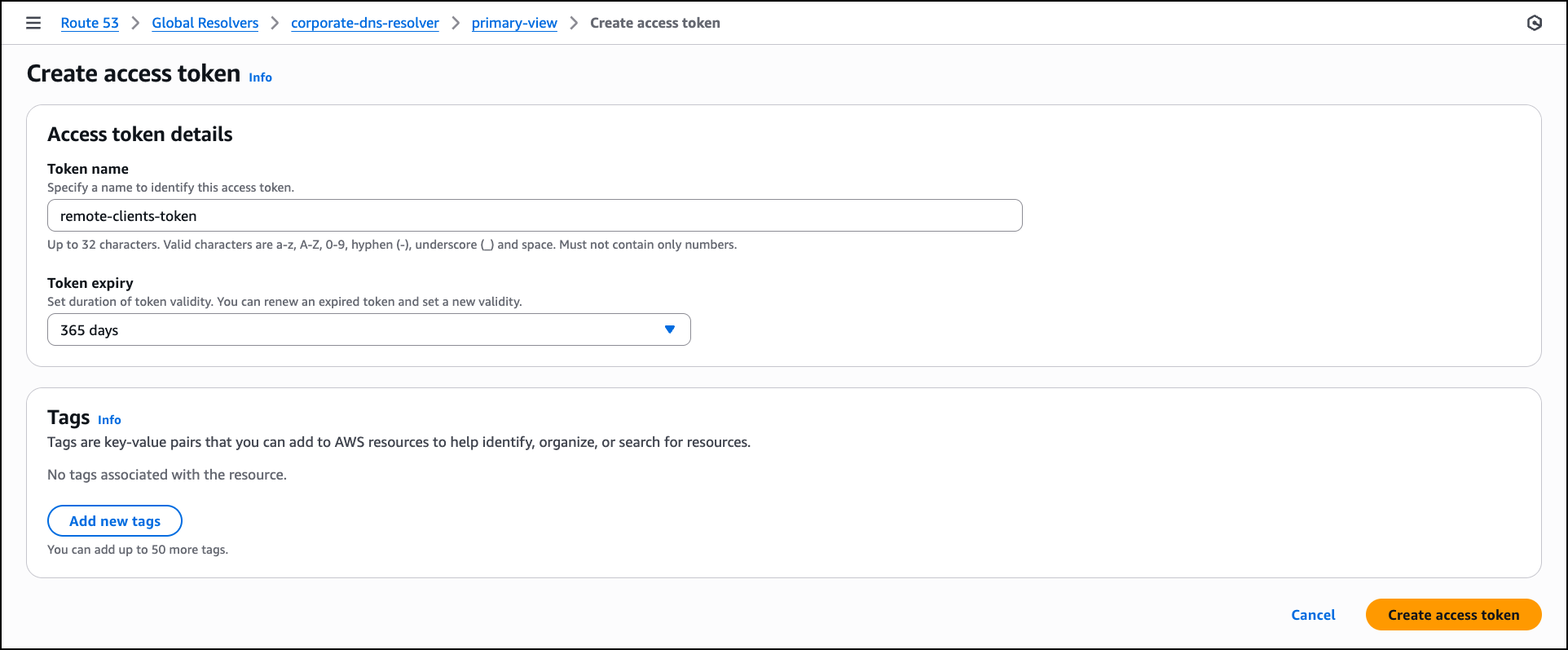
Next, navigate to the Access tokens tab in the DNS view to create token-based authentication for clients and choose Create access token. In the Access token details section, enter a Token name such as remote-clients-token. For Token expiry, select an expiration period from the dropdown based on your security requirements, such as 365 days for long-term client access, or choose a shorter duration like 30 days or 90 days for tighter access control. After configuring these settings, choose Create access token to generate the token, which clients can use to authenticate DoH and DoT connections to the resolver.
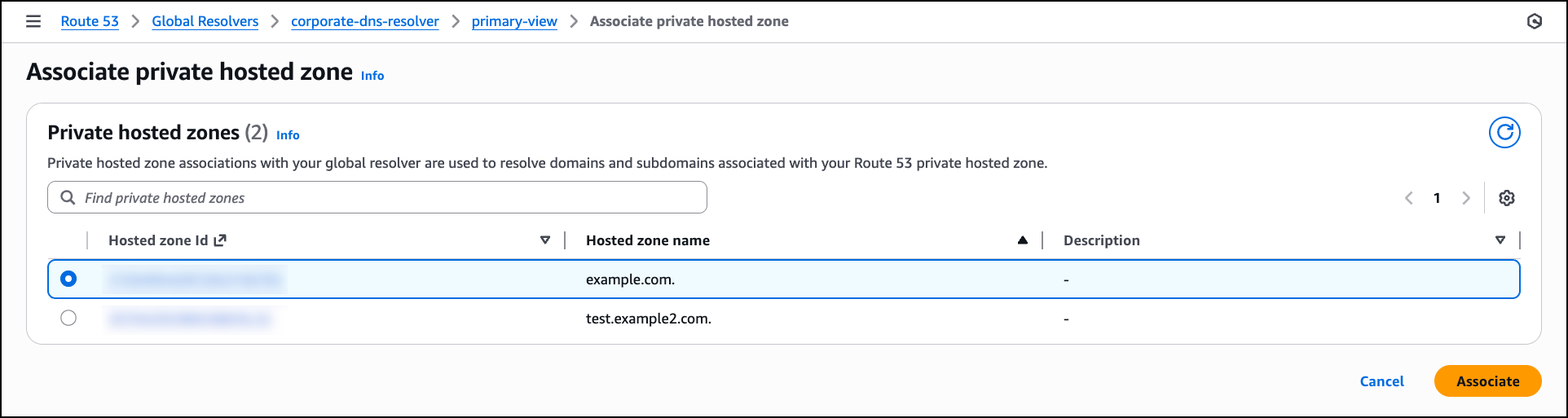
After the access token is created, navigate to the Private hosted zones tab in the DNS view to associate Route 53 private hosted zones with the DNS view so that the resolver can resolve queries for your private application domains. Choose Associate private hosted zone and in the Private hosted zones section, select a private hosted zone from the list that you want the resolver to handle. After selecting the zone, choose Associate to enable the resolver to respond to DNS queries for these private domains from your configured access sources.
With the DNS view configured, firewall rules created, access sources and tokens defined, and private hosted zones associated, the Route 53 Global Resolver setup is complete and ready to handle DNS queries from your configured clients.
After creating your Route 53 Global Resolver, you need to configure your DNS clients to send queries to the resolver’s anycast IP addresses. The configuration method depends on the access control you configured in your DNS view:
- For IP-based access sources (CIDR blocks) – Configure your source clients to point DNS traffic to the Route 53 Global Resolver anycast IP addresses provided in the resolver details. Global Resolver will only allow access from allowlisted IPs that you have specified in your access sources. You can also associate the access sources to different DNS views to provide more granular DNS resolution views for different sets of IPs.
- For access token–based authentication – Deploy the tokens on your clients to authenticate DoH and DoT connections with Route 53 Global Resolver. You must also configure your clients to point the DNS traffic to the Route 53 Global Resolver anycast IP addresses provided in the resolver details.
For detailed configuration instructions for your specific operating system and protocol, refer to the technical documentation.
Additional things to know
We’re renaming the existing Route 53 Resolver to Route 53 VPC Resolver. This naming change clarifies the architectural distinction between the two services. VPC Resolver operates Regionally within your VPCs to provide DNS resolution for resources in your Amazon VPC environment. VPC Resolver continues to support inbound and outbound resolver endpoints for hybrid DNS architectures within specific AWS Regions.
Route 53 Global Resolver complements Route 53 VPC Resolver by providing internet-reachable, global and private DNS resolution for on-premises and remote clients without requiring VPC deployment or private connections.
Existing VPC Resolver configurations remain unchanged and continue to function as configured. The renaming affects the service name in the AWS Management Console and documentation, but API operation names remain unchanged. If your architecture requires DNS resolution for resources within your VPCs, continue using VPC Resolver.
Join the preview
Route 53 Global Resolver reduces operational overhead by providing unified DNS resolution for public and private domains through a single managed service. The global anycast architecture improves reliability and reduces latency for distributed clients. Integrated security controls and centralized logging help organizations maintain consistent security policies across all locations while meeting compliance requirements.
To learn more about Amazon Route 53 Global Resolver, visit the Amazon Route 53 documentation.
You can start using Route 53 Global Resolver through the AWS Management Console in US East (N. Virginia), US East (Ohio), US West (N. California), US West (Oregon), Europe (Frankfurt), Europe (Ireland), Europe (London), Asia Pacific (Mumbai), Asia Pacific (Singapore), Asia Pacific (Tokyo), and Asia Pacific (Sydney) Regions.









 Ankush Goyal is a Enterprise Support Lead in AWS Enterprise Support who helps customers streamline their cloud operations on AWS. He is a results-driven IT professional with over 20 years of experience.
Ankush Goyal is a Enterprise Support Lead in AWS Enterprise Support who helps customers streamline their cloud operations on AWS. He is a results-driven IT professional with over 20 years of experience. Anvesh Koganti is a Solutions Architect at AWS specializing in Networking. He focuses on helping customers build networking architectures for highly scalable and resilient AWS environments. Outside of work, Anvesh is passionate about consumer technology and enjoys listening to podcasts on tech and business. When disconnecting from the digital world, Anvesh spends time outdoors hiking and biking.
Anvesh Koganti is a Solutions Architect at AWS specializing in Networking. He focuses on helping customers build networking architectures for highly scalable and resilient AWS environments. Outside of work, Anvesh is passionate about consumer technology and enjoys listening to podcasts on tech and business. When disconnecting from the digital world, Anvesh spends time outdoors hiking and biking. Salman Ahmed is a Senior Technical Account Manager in AWS Enterprise Support. He specializes in guiding customers through the design, implementation, and support of AWS solutions. Combining his networking expertise with a drive to explore new technologies, he helps organizations successfully navigate their cloud journey. Outside of work, he enjoys photography, traveling, and watching his favorite sports teams.
Salman Ahmed is a Senior Technical Account Manager in AWS Enterprise Support. He specializes in guiding customers through the design, implementation, and support of AWS solutions. Combining his networking expertise with a drive to explore new technologies, he helps organizations successfully navigate their cloud journey. Outside of work, he enjoys photography, traveling, and watching his favorite sports teams.












































 .
.


















 Happy New Year! Cloud technologies, machine learning, and generative AI have become more accessible, impacting nearly every aspect of our lives. Amazon CTO Dr. Werner Vogels offers four tech predictions for 2024 and beyond:
Happy New Year! Cloud technologies, machine learning, and generative AI have become more accessible, impacting nearly every aspect of our lives. Amazon CTO Dr. Werner Vogels offers four tech predictions for 2024 and beyond:










