Post Syndicated from Marco Masciola original https://aws.amazon.com/blogs/architecture/physics-on-aws-optimizing-wind-turbine-performance-using-openfast-in-a-digital-twin/
Wind energy plays a crucial role in global decarbonization efforts by generating emission-free power from an abundant resource. In 2022, wind energy produced 2100 terawatt-hours (TWh) globally, or over 7% of global electricity, with expectations to reach 7400 TWh by 2030.
Despite its potential, several challenges must be addressed to help meet grid decarbonization targets. As wind energy adoption grows, issues like gearbox fatigue and leading-edge erosion need to be resolved to ensure a predictable supply of energy. For example, in the United States, wind turbines underperform by as much as 10% after 11 years of operation, despite expectations for the machine to operate at full potential for 25 years.
This blog reveals a digital twin architecture using the National Renewable Energy Laboratory’s (NREL) OpenFAST, an open-source multi-physics wind turbine simulation tool, to characterize operational anomalies and continuously improve wind farm performance. This approach can be used to support an overall maintenance strategy to optimize performance and profitability while reducing risk.
While a digital twin can take many forms, this architecture represents it with a physical wind turbine connected to the cloud using IoT devices to monitor performance and augmented knowledge using on-demand simulations. The insight gained from simulations can update the physical asset control system in near real-time to balance operational performance.
Why build this?
This digital twin can catch reliability assessment discrepancies by benchmarking real-world time series with simulations. Aeroelastic simulators like OpenFAST define operational envelopes as part of wind turbine design and certification in accordance with IEC 61400-1 and 61400-3. However, subtle, unanticipated changes in environmental conditions not accounted for in the initial design certification, such as higher turbulence intensity, accelerate degradation.
This architecture can be used to validate if a controller change can limit gradual performance damage before the controller changes are deployed by using the same simulation software for wind turbine design. This example scenario, one that operators currently struggle with, is threaded in the next section.
Digital twin architecture
Figure 1 illustrates the event-driven architecture in which resources launch on-demand simulations as anomalies occur.
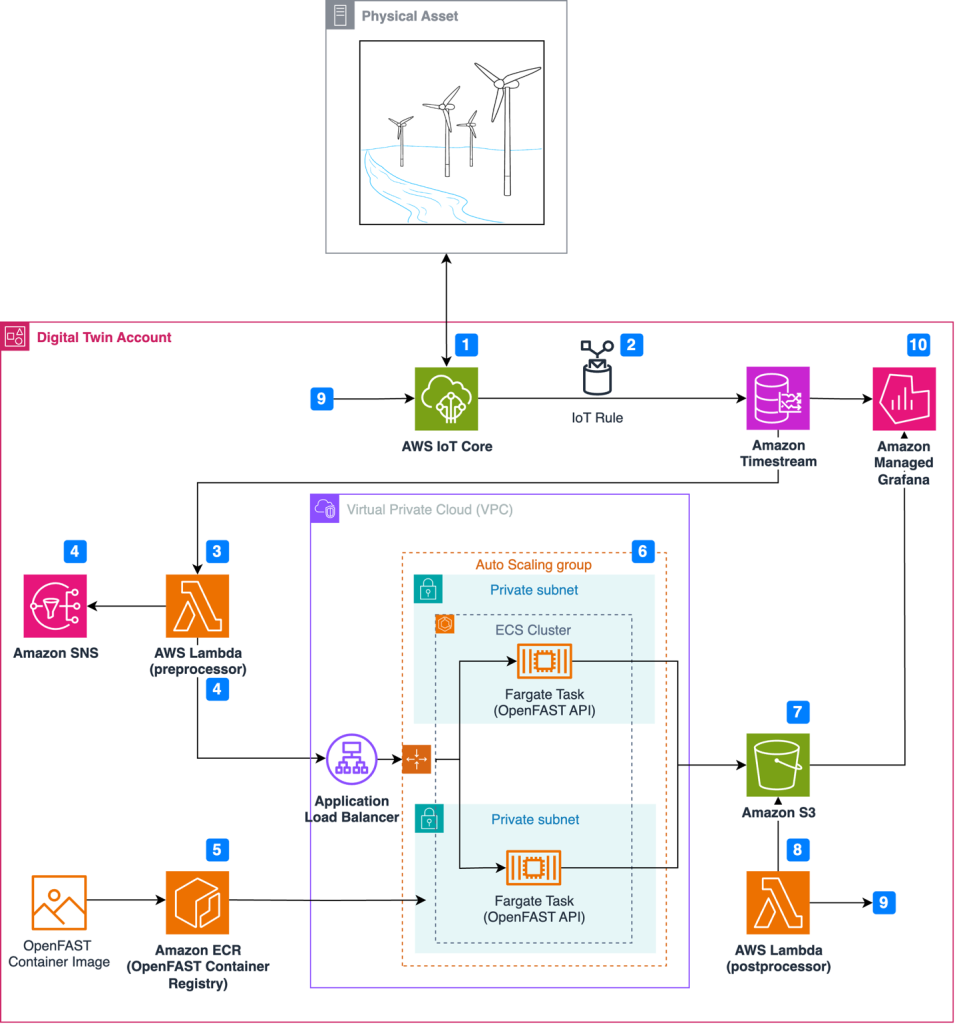
Figure 1. Architecture for wind turbine digital twin solution
Simulation and real-world results can feed into a calculation engine to update the wind turbine controller software and improve operational performance through this workflow:
- Wind turbine sensors are connected to the AWS cloud using AWS IoT Core.
- An IoT rule forwards sensor data to Amazon Timestream, a purpose-built time series database.
- A scheduled AWS Lambda function queries Timestream to detect anomalies in time-series data.
- Upon anomaly detection, Amazon Simple Notification Service (Amazon SNS) publishes notifications and OpenFAST simulation input files are prepared in the Lambda preprocessor.
- Simulations are executed on demand, where the latest OpenFAST simulation is pulled from Amazon Elastic Container Registry (Amazon ECR).
- Simulations are dispatched through RESTful API and run using AWS Fargate.
- Simulation results are uploaded to Amazon Simple Storage Service (Amazon S3).
- Simulation time-series data is processed using AWS Lambda, where a decision is made to update the controller software based on the anomaly.
- The Lambda post-processer initiates a wind turbine controller software update, which is communicated to the wind turbine through AWS IoT Core.
- Results are visualized in Amazon Managed Grafana.
An example of an anomaly in step 3 is a controller overspeed alarm. Simple rule-based anomaly detection can be used to detect exceedance thresholds. You can also incorporate more sophisticated forms of anomaly detection using machine learning through Amazon SageMaker. The workflow above preserves four elements to create a digital twin. We will explore these four elements in the next section:
- Event-driven architecture workflow
- OpenFAST execution through RESTful API and containers
- Executing multiple concurrent OpenFAST simulations using Application Load Balancer (ALB) and Amazon Elastic Compute Cloud (Amazon EC2) Autoscaling
- Visualizing physical assets and simulation results using Amazon Managed Grafana
Event-driven architecture
Event-driven architectures enable decoupled systems and asynchronous communications between services. An event-driven workflow is initiated automatically as events occur. An event might be an active alarm or an OpenFAST output file uploaded to Amazon S3. This means that the number of actively monitored wind turbines can scale from one to 100 (or more) without allocating new resources.
AWS Lambda provides instant scaling to increase the number of OpenFAST simulations available for processing. Additionally, Fargate removes the need to provision or manage the underlying OpenFAST compute instances. Leveraging serverless compute services removes the need to manage underlying infrastructure, provides demand-based scaling, and reduces costs compared to statically provisioned infrastructure.
In practice, event-driven architecture provides teams with flexibility to automatically prepare input files, dispatch simulations, and post-process results without manually provisioning resources.
Containerization
Containerization is a process to deploy an application with libraries needed for execution. Docker creates a container image that bundles the OpenFAST executable. FastAPI is also included in the OpenFAST container so that simulations can be dispatched through a web RESTful API, as demonstrated in Figure 2. Note that OpenFAST and FastAPI are independent projects. The RESTful API for OpenFAST is provisioned with commands to:
- Run the simulation with initial conditions (
PUT: /execute) - Upload simulation results to Amazon S3 (
POST: /upload_to_s3) - Provide simulation status (
GET: /status) - Delete simulation results (
DELETE: /simulation)
This setup enables engineering teams to pull an OpenFAST simulation version aligned with physical wind turbines in operation without manual configuration.
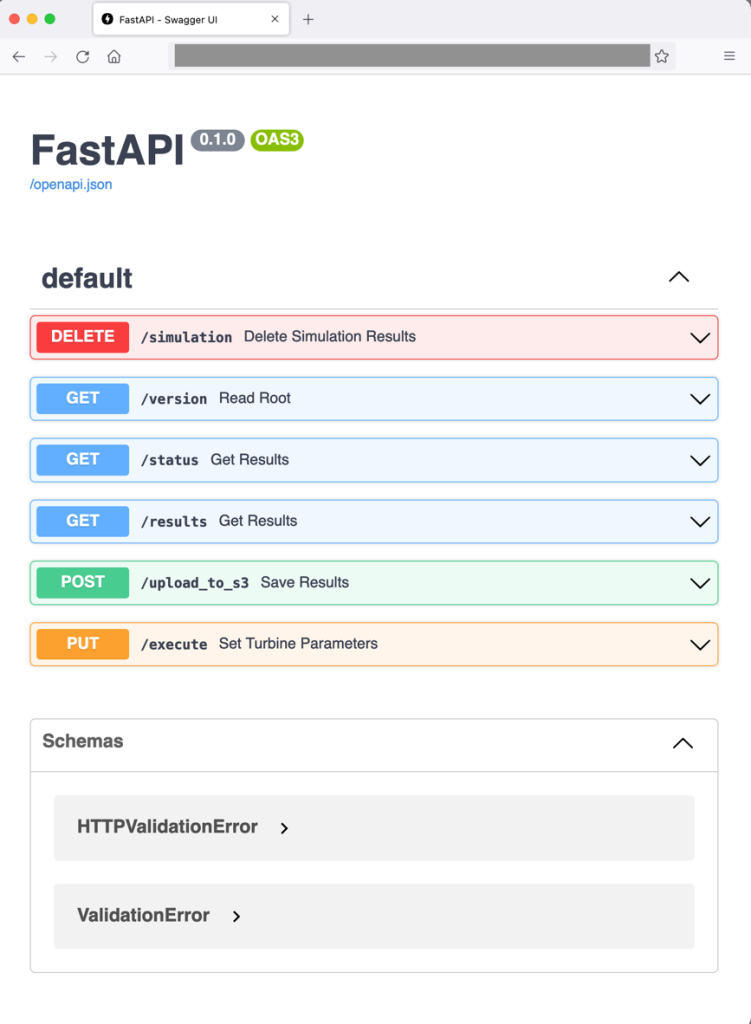
Figure 2. Web frontend showing the RESTfulAPI commands available for dispatching OpenFAST simulations
Load balancing and auto scaling
The architecture uses Amazon EC2 Auto Scaling and an ALB to manage fluctuating processing demands and enable concurrent OpenFAST simulations. EC2 Auto Scaling dynamically scales the number of OpenFAST containers based on the volume of simulation requests and offers cost savings to avoid idle resources. Paired with an ALB, this setup evenly distributes simulation requests across OpenFAST containers, ensuring desired performance levels and high availability.
Data visualization
Amazon Timestream collects and archives real-time metrics from physical wind turbines. Timestream can store any metric from the physical asset collected through IoT Core, including rotor speed, generator power, generator speed, generator torque, or wind turbine control system alarms, as shown in Figure 3. One distinctive Timestream feature is scheduled queries that can regularly perform automated tasks like measuring 10-minute average wind speeds or tracking down units with controller alarms.
This provides operations teams the ability to view granular insights in real time or query historical data using SQL. Amazon Managed Grafana is also connected to OpenFAST results stored in Amazon S3 to compare simulation results with real-world operational data and view the response of simulated components. Engineering teams benefit from Amazon Managed Grafana because it provides a window into how the simulation responds to controller changes. Engineers can then verify whether the physical machine responds in the expected manner.
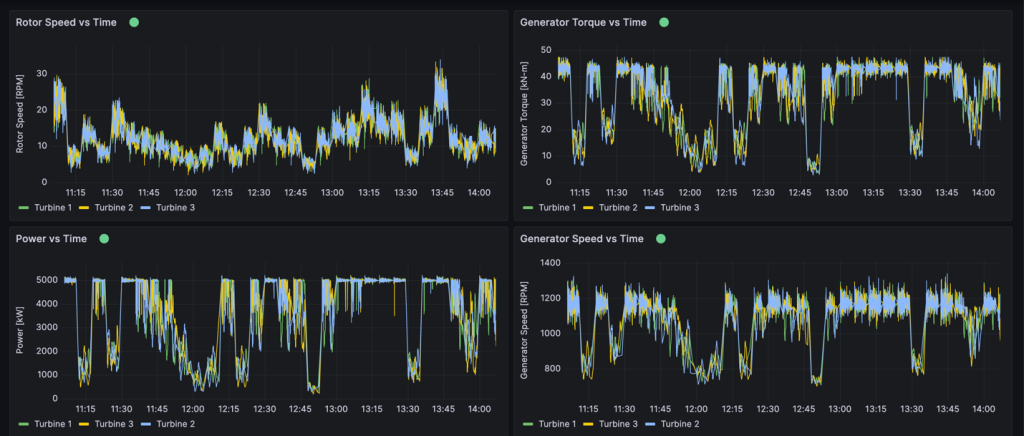
Figure 3. Example Amazon Managed Grafana dashboard
Conclusion
The AWS Cloud offers services and infrastructure to provide organization resources to process data and build digital twins. Organizations can leverage open-source models to improve operational performance and physics-based simulations to improve accuracy. By integrating technology paradigms such as event-drive architectures, wind turbine operators can make data-driven decisions in real time. Organizations can create virtual replicas of physical wind turbines to diagnose the source of alarms and adopt strategies to limit excessive wear before permanent damage occurs.