Post Syndicated from Mike English original https://blog.cloudflare.com/moq/
For over two decades, we’ve built real-time communication on the Internet using a patchwork of specialized tools. RTMP gave us ingest. HLS and DASH gave us scale. WebRTC gave us interactivity. Each solved a specific problem for its time, and together they power the global streaming ecosystem we rely on today.
But using them together in 2025 feels like building a modern application with tools from different eras. The seams are starting to show—in complexity, in latency, and in the flexibility needed for the next generation of applications, from sub-second live auctions to massive interactive events. We’re often forced to make painful trade-offs between latency, scale, and operational complexity.
Today Cloudflare is launching the first Media over QUIC (MoQ) relay network, running on every Cloudflare server in datacenters in 330+ cities. MoQ is an open protocol being developed at the IETF by engineers from across the industry—not a proprietary Cloudflare technology. MoQ combines the low-latency interactivity of WebRTC, the scalability of HLS/DASH, and the simplicity of a single architecture, all built on a modern transport layer. We’re joining Meta, Google, Cisco, and others in building implementations that work seamlessly together, creating a shared foundation for the next generation of real-time applications on the Internet.
To understand the promise of MoQ, we first have to appreciate the history that led us here—a journey defined by a series of architectural compromises where solving one problem inevitably created another.
The RTMP era: Conquering latency, compromising on scale
In the early 2000s, RTMP (Real-Time Messaging Protocol) was a breakthrough. It solved the frustrating “download and wait” experience of early video playback on the web by creating a persistent, stateful TCP connection between a Flash client and a server. This enabled low-latency streaming (2-5 seconds), powering the first wave of live platforms like Justin.tv (which later became Twitch).
But its strength was its weakness. That stateful connection, which had to be maintained for every viewer, was architecturally hostile to scale. It required expensive, specialized media servers and couldn’t use the commodity HTTP-based Content Delivery Networks (CDNs) that were beginning to power the rest of the web. Its reliance on TCP also meant that a single lost packet could freeze the entire stream—a phenomenon known as head-of-line blocking—creating jarring latency spikes. The industry retained RTMP for the “first mile” from the camera to servers (ingest), but a new solution was needed for the “last mile” from servers to your screen (delivery).
The HLS & DASH era: Solving for scale, compromising on latency
The catalyst for the next era was the iPhone’s rejection of Flash. In response, Apple created HLS (HTTP Live Streaming). HLS, and its open-standard counterpart MPEG-DASH abandoned stateful connections and treated video as a sequence of small, static files delivered over standard HTTP.
This enabled much greater scalability. By moving to the interoperable open standard of HTTP for the underlying transport, video could now be distributed by any web server and cached by global CDNs, allowing platforms to reach millions of viewers reliably and relatively inexpensively. The compromise? A significant trade-off in latency. To ensure smooth playback, players needed to buffer at least three video segments before starting. With segment durations of 6-10 seconds, this baked 15-30 seconds of latency directly into the architecture.
While extensions like Low-Latency HLS (LL-HLS) have more recently emerged to achieve latencies in the 3-second range, they remain complex patches fighting against the protocol’s fundamental design. These extensions introduce a layer of stateful, real-time communication—using clever workarounds like holding playlist requests open—that ultimately strain the stateless request-response model central to HTTP’s scalability and composability.
The WebRTC Era: Conquering conversational latency, compromising on architecture
In parallel, WebRTC (Web Real-Time Communication) emerged to solve a different problem: plugin-free, two-way conversational video with sub-500ms latency within a browser. It worked by creating direct peer-to-peer (P2P) media paths, removing central servers from the equation.
But this P2P model is fundamentally at odds with broadcast scale. In a mesh network, the number of connections grows quadratically with each new participant (the “N-squared problem”). For more than a handful of users, the model collapses under the weight of its own complexity. To work around this, the industry developed server-based topologies like the Selective Forwarding Unit (SFU) and Multipoint Control Unit (MCU). These are effective but require building what is essentially a private, stateful, real-time CDN—a complex and expensive undertaking that is not standardized across infrastructure providers.
This journey has left us with a fragmented landscape of specialized, non-interoperable silos, forcing developers to stitch together multiple protocols and accept a painful three-way tension between latency, scale, and complexity.
This is the context into which Media over QUIC (MoQ) emerges. It’s not just another protocol; it’s a new design philosophy built from the ground up to resolve this historical trilemma. Born out of an open, community-driven effort at the IETF, MoQ aims to be a foundational Internet technology, not a proprietary product.
Its promise is to unify the disparate worlds of streaming by delivering:
-
Sub-second latency at broadcast scale: Combining the latency of WebRTC with the scale of HLS/DASH and the simplicity of RTMP.
-
Architectural simplicity: Creating a single, flexible protocol for ingest, distribution, and interactive use cases, eliminating the need to transcode between different technologies.
-
Transport efficiency: Building on QUIC, a UDP based protocol to eliminate bottlenecks like TCP head-of-line blocking.
The initial focus was “Media” over QUIC, but the core concepts—named tracks of timed, ordered, but independent data—are so flexible that the working group is now simply calling the protocol “MoQ.” The name reflects the power of the abstraction: it’s a generic transport for any real-time data that needs to be delivered efficiently and at scale.
MoQ is now generic enough that it’s a data fanout or pub/sub system, for everything from audio/video (high bandwidth data) to sports score updates (low bandwidth data).
MoQ’s elegance comes from solving the right problem at the right layer. Let’s build up from the foundation to see how it achieves sub-second latency at scale.
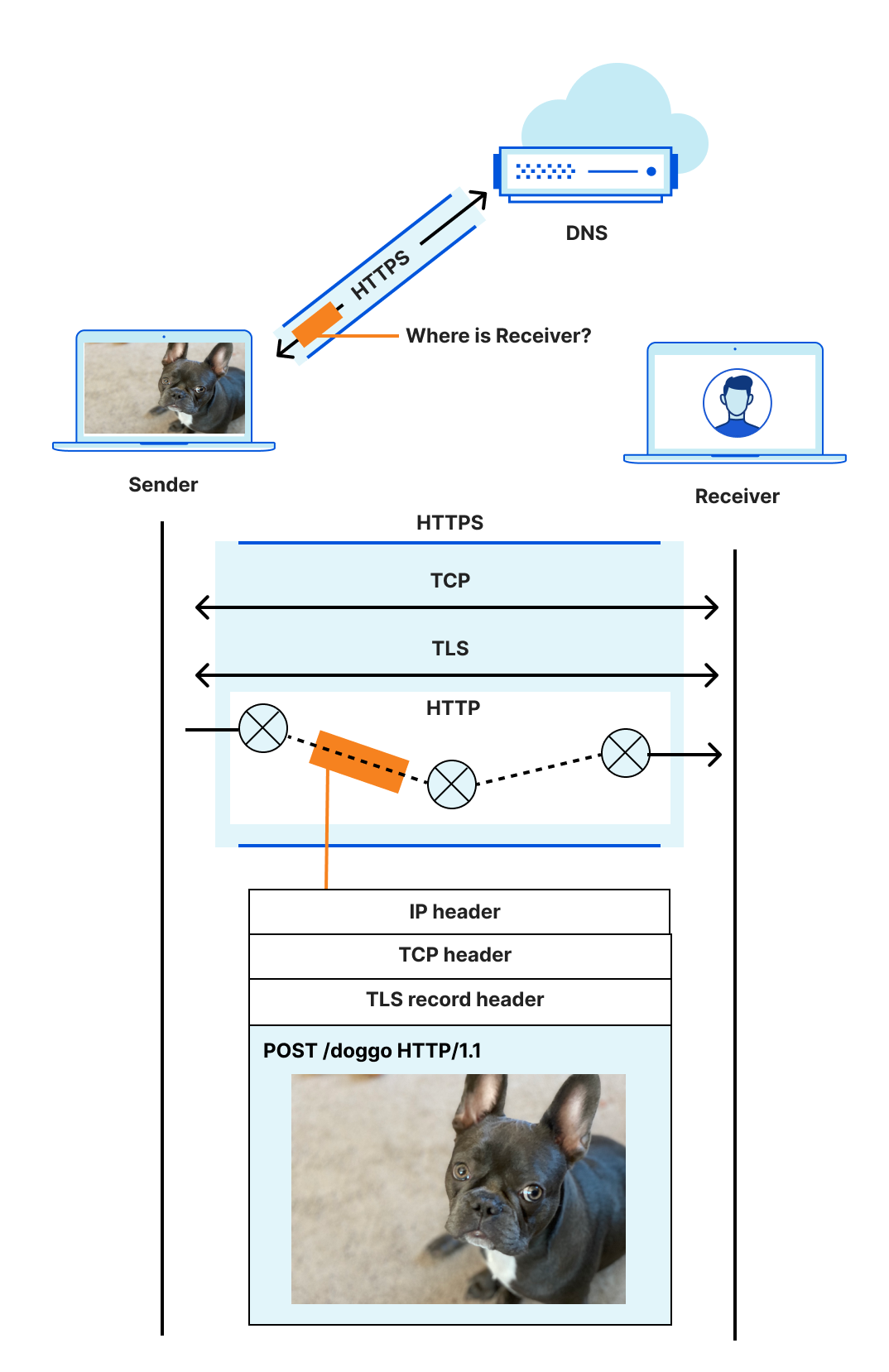
The choice of QUIC as MoQ’s foundation isn’t arbitrary—it addresses issues that have plagued streaming protocols for decades.
By building on QUIC (the transport protocol that also powers HTTP/3), MoQ solves some key streaming problems:
-
No head-of-line blocking: Unlike TCP where one lost packet blocks everything behind it, QUIC streams are independent. A lost packet on one stream (e.g., an audio track) doesn’t block another (e.g., the main video track). This alone eliminates the stuttering that plagued RTMP.
-
Connection migration: When your device switches from Wi-Fi to cellular mid-stream, the connection seamlessly migrates without interruption—no rebuffering, no reconnection.
-
Fast connection establishment: QUIC’s 0-RTT resumption means returning viewers can start playing instantly.
-
Baked-in, mandatory encryption: All QUIC connections are encrypted by default with TLS 1.3.
With QUIC solving transport issues, MoQ introduces its key innovation: treating media as subscribable tracks in a publish/subscribe system. But unlike traditional pub/sub, this is designed specifically for real-time media at CDN scale.
Instead of complex session management (WebRTC) or file-based chunking (HLS), MoQ lets publishers announce named tracks of media that subscribers can request. A relay network handles the distribution without needing to understand the media itself.
Before we see how media flows through the network, let’s understand how MoQ structures it. MoQ organizes data in a hierarchy:
-
Tracks: Named streams of media, like “video-1080p” or “audio-english”. Subscribers request specific tracks by name.
-
Groups: Independently decodable chunks of a track. For video, this typically means a GOP (Group of Pictures) starting with a keyframe. New subscribers can join at any Group boundary.
-
Objects: The actual packets sent on the wire. Each Object belongs to a Track and has a position within a Group.
This simple hierarchy enables two capabilities:
-
Subscribers can start playback at Group boundaries without waiting for the next keyframe
-
Relays can forward Objects without parsing or understanding the media format
MoQ’s network components are also simple:
-
Publishers: Announce track namespaces and send Objects
-
Subscribers: Request specific tracks by name
-
Relays: Connect publishers to subscribers by forwarding immutable Objects without parsing or transcoding the media
A Relay acts as a subscriber to receive tracks from upstream (like the original publisher) and simultaneously acts as a publisher to forward those same tracks downstream. This model is the key to MoQ’s scalability: one upstream subscription can fan out to serve thousands of downstream viewers.

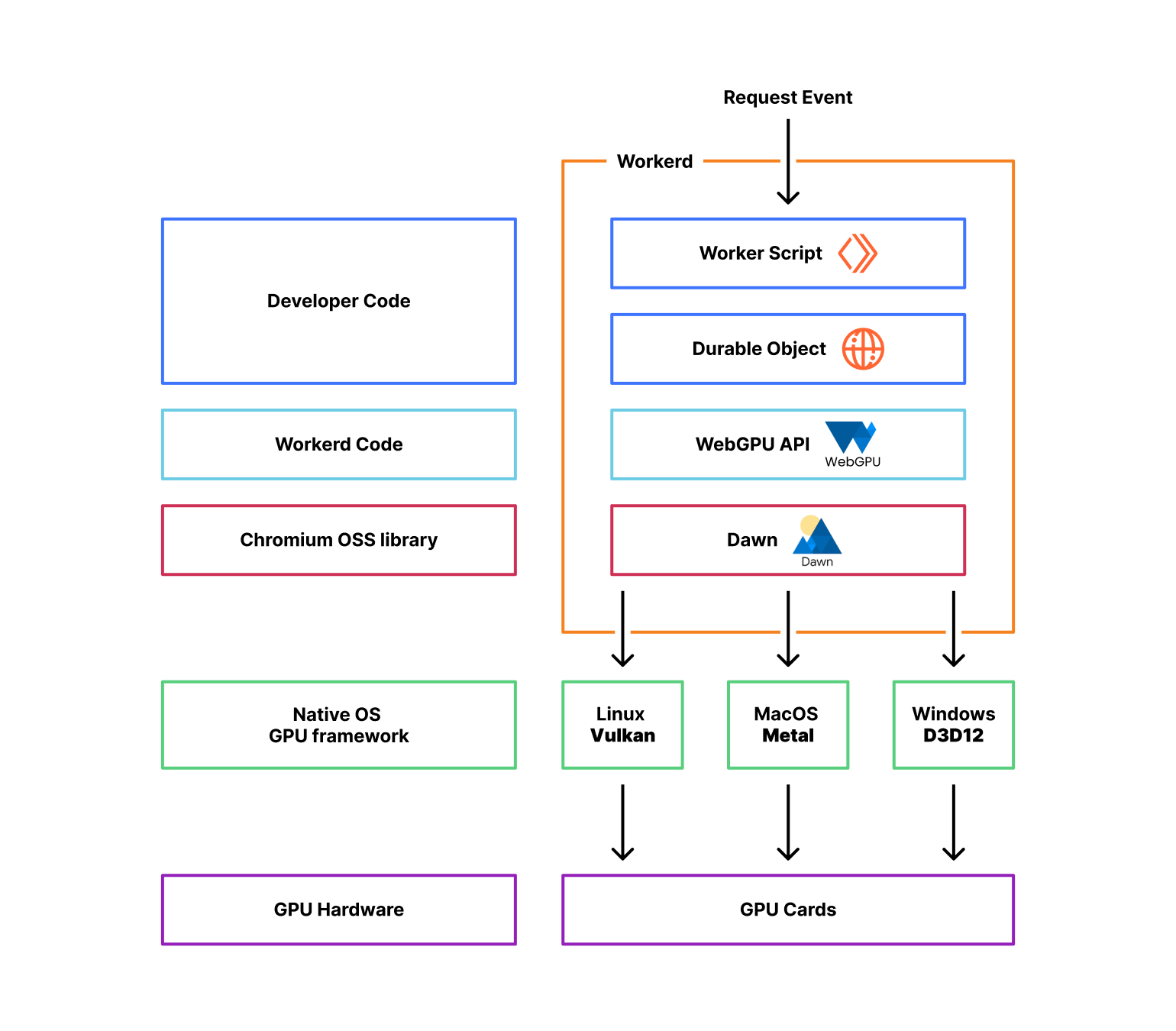
MoQ’s architecture can be understood as three distinct layers, each with a clear job:
-
The Transport Foundation (QUIC or WebTransport): This is the modern foundation upon which everything is built. MoQT can run directly over raw QUIC, which is ideal for native applications, or over WebTransport, which is required for use in a web browser. Crucially, the WebTransport protocol and its corresponding W3C browser API make QUIC’s multiplexed reliable streams and unreliable datagrams directly accessible to browser applications. This is a game-changer. Protocols like SRT may be efficient, but their lack of native browser support relegates them to ingest-only roles. WebTransport gives MoQ first-class citizenship on the web, making it suitable for both ingest and massive-scale distribution directly to clients.
-
The MoQT Layer: Sitting on top of QUIC (or WebTransport), the MoQT layer provides the signaling and structure for a publish-subscribe system. This is the primary focus of the IETF working group. It defines the core control messages—like ANNOUNCE, and SUBSCRIBE—and the basic data model we just covered. MoQT itself is intentionally spartan; it doesn’t know or care if the data it’s moving is H.264 video, Opus audio, or game state updates.
-
The Streaming Format Layer: This is where media-specific logic lives. A streaming format defines things like manifests, codec metadata, and packaging rules.
WARP is one such format being developed alongside MoQT at the IETF, but it isn’t the only one. Another standards body, like DASH-IF, could define a CMAF-based streaming format over MoQT. A company that controls both original publisher and end subscriber can develop its own proprietary streaming format to experiment with new codecs or delivery mechanisms without being constrained by the transport protocol.
This separation of layers is why different organizations can build interoperable implementations while still innovating at the streaming format layer.
Now that we understand the architecture and the data model, let’s walk through how these pieces come together to deliver a stream. The protocol is flexible, but a typical broadcast flow relies on the ANNOUNCE and SUBSCRIBE messages to establish a data path from a publisher to a subscriber through the relay network.

Here is a step-by-step breakdown of what happens in this flow:
-
Initiating Connections: The process begins when the endpoints, acting as clients, connect to the relay network. The Original Publisher initiates a connection with its nearest relay (we’ll call it Relay A). Separately, an End Subscriber initiates a connection with its own local relay (Relay B). These endpoints perform a
SETUPhandshake with their respective relays to establish a MoQ session and declare supported parameters. -
Announcing a Namespace: To make its content discoverable, the Publisher sends an
ANNOUNCEmessage to Relay A. This message declares that the publisher is the authoritative source for a given track namespace. Relay A receives this and registers in a shared control plane (a conceptual database) that it is now a source for this namespace within the network. -
Subscribing to a Track: When the End Subscriber wants to receive media, it sends a
SUBSCRIBEmessage to its relay, Relay B. This message is a request for a specific track name within a specific track namespace. -
Connecting the Relays: Relay B receives the
SUBSCRIBErequest and queries the control plane. It looks up the requested namespace and discovers that Relay A is the source. Relay B then initiates a session with Relay A (if it doesn’t already have one) and forwards theSUBSCRIBErequest upstream. -
Completing the Path and Forwarding Objects: Relay A, having received the subscription request from Relay B, forwards it to the Original Publisher. With the full path now established, the Publisher begins sending the
Objectsfor the requested track. The Objects flow from the Publisher to Relay A, which forwards them to Relay B, which in turn forwards them to the End Subscriber. If another subscriber connects to Relay B and requests the same track, Relay B can immediately start sending them the Objects without needing to create a new upstream subscription.

More recent drafts of the MoQ specification have introduced an alternative, push-based model using a PUBLISH message. In this flow, a publisher can effectively ask for permission to send a track’s objects to a relay without waiting for a SUBSCRIBE request. The publisher sends a PUBLISH message, and the relay’s PUBLISH_OK response indicates whether it will accept the objects. This is particularly useful for ingest scenarios, where a publisher wants to send its stream to an entry point in the network immediately, ensuring the media is available the instant the first subscriber connects.
MoQ’s benefits really shine when networks get congested. MoQ includes mechanisms for handling the reality of network traffic. One such mechanism is Subgroups.
Subgroups are subdivisions within a Group that effectively map directly to the underlying QUIC streams. All Objects within the same Subgroup are generally sent on the same QUIC stream, guaranteeing their delivery order. Subgroup numbering also presents an opportunity to encode prioritization: within a Group, lower-numbered Subgroups are considered higher priority.
This enables intelligent quality degradation, especially with layered codecs (e.g. SVC):
-
Subgroup 0: Base video layer (360p) – must deliver
-
Subgroup 1: Enhancement to 720p – deliver if bandwidth allows
-
Subgroup 2: Enhancement to 1080p – first to drop under congestion
When a relay detects congestion, it can drop Objects from higher-numbered Subgroups, preserving the base layer. Viewers see reduced quality instead of buffering.
The MoQ specification defines a scheduling algorithm that determines the order for all objects that are “ready to send.” When a relay has multiple objects ready, it prioritizes them first by group order (ascending or descending) and then, within a group, by subgroup id. Our implementation supports the group order preference, which can be useful for low-latency broadcasts. If a viewer falls behind and its subscription uses descending group order, the relay prioritizes sending Objects from the newest “live” Group, potentially canceling unsent Objects from older Groups. This can help viewers catch up to the live edge quickly, a highly desirable feature for many interactive streaming use cases. The optimal strategies for using these features to improve QoE for specific use cases are still an open research question. We invite developers and researchers to use our network to experiment and help find the answers.
Theory is one thing; implementation is another. To validate the protocol and understand its real-world challenges, we’ve been building one of the first global MoQ relay networks. Cloudflare’s network, which places compute and logic at the edge, is very well suited for this.
Our architecture connects the abstract concepts of MoQ to the Cloudflare stack. In our deep dive, we mentioned that when a publisher ANNOUNCEs a namespace, relays need to register this availability in a “shared control plane” so that SUBSCRIBE requests can be routed correctly. For this critical piece of state management, we use Durable Objects.
When a publisher announces a new namespace to a relay in, say, London, that relay uses a Durable Object—our strongly consistent, single-threaded storage solution—to record that this namespace is now available at that specific location. When a subscriber in Paris wants a track from that namespace, the network can query this distributed state to find the nearest source and route the SUBSCRIBE request accordingly. This architecture builds upon the technology we developed for Cloudflare’s real-time services and provides a solution to the challenge of state management at a global scale.
Building on a new protocol in the open means implementing against a moving target. To get MoQ into the hands of the community, we made a deliberate trade-off: our current relay implementation is based on a subset of the features defined in draft-ietf-moq-transport-07. This version became a de facto target for interoperability among several open-source projects and pausing there allowed us to put effort towards other aspects of deploying our relay network.
This draft of the protocol makes a distinction between accessing “past” and “future” content. SUBSCRIBE is used to receive future objects for a track as they arrive—like tuning into a live broadcast to get everything from that moment forward. In contrast, FETCH provides a mechanism for accessing past content that a relay may already have in its cache—like asking for a recording of a song that just played.
Both are part of the same specification, but for the most pressing low-latency use cases, a performant implementation of SUBSCRIBE is what matters most. For that reason, we have focused our initial efforts there and have not yet implemented FETCH.
This is where our roadmap is flexible and where the community can have a direct impact. Do you need FETCH to build on-demand or catch-up functionality? Or is more complete support for the prioritization features within SUBSCRIBE more critical for your use case? The feedback we receive from early developers will help us decide what to build next.
As always, we will announce our updates and changes to our implementation as we continue with development on our developer docs pages.
We believe in building in the open and interoperability in the community. MoQ is not a Cloudflare technology but a foundational Internet technology. To that end, the first demo client we’re presenting is an open source, community example.
You can access the demo here: https://moq.dev/publish/
Even though this is a preview release, we are running MoQ relays at Cloudflare’s full scale, like we do every production service. This means every server that is part of the Cloudflare network in more than 330 cities is now a MoQ relay.
We invite you to experience the “wow” moment of near-instant, sub-second streaming latency that MoQ enables. How would you use a protocol that offers the speed of a video call with the scale of a global broadcast?
We’ve been working with others in the IETF WG community and beyond on interoperability of publishers, players and other parts of the MoQ ecosystem. So far, we’ve tested with:
The Internet’s media stack is being refactored. For two decades, we’ve been forced to choose between latency, scale, and complexity. The compromises we made solved some problems, but also led to a fragmented ecosystem.
MoQ represents a promising new foundation—a chance to unify the silos and build the next generation of real-time applications on a scalable protocol. We’re committed to helping build this foundation in the open, and we’re just getting started.
MoQ is a realistic way forward, built on QUIC for future proofing, easier to understand than WebRTC, compatible with browsers unlike RTMP.
The protocol is evolving, the implementations are maturing, and the community is growing. Whether you’re building the next generation of live streaming, exploring real-time collaboration, or pushing the boundaries of interactive media, consider whether MoQ may provide the foundation you need.
We want developers to start building with MoQ today. To make that possible MoQ at Cloudflare is in tech preview – this means it’s available free of charge for testing (at any scale). Visit our developer homepage for updates and potential breaking changes.
Indie developers and large enterprises alike ask about pricing early in their adoption of new technologies. We will be transparent and clear about MoQ pricing. In general availability, self-serve customers should expect to pay 5 cents/GB outbound with no cost for traffic sent towards Cloudflare.
Enterprise customers can expect usual pricing in line with regular media delivery pricing, competitive with incumbent protocols. This means if you’re already using Cloudflare for media delivery, you should not be wary of adopting new technologies because of cost. We will support you.
If you’re interested in partnering with Cloudflare in adopting the protocol early or contributing to its development, please reach out to us at [email protected]! Engineers excited about the future of the Internet are standing by.
-
Try the demo: https://moq.dev/publish/
-
Read the Internet draft: https://datatracker.ietf.org/doc/draft-ietf-moq-transport/
-
Contribute to the protocol’s development: https://datatracker.ietf.org/group/moq/documents/
-
Visit our developer homepage: https://developers.cloudflare.com/moq/


{kind=link}
{kind=link}