Post Syndicated from Achraf Moussadek-Kabdani original https://aws.amazon.com/blogs/security/establishing-a-data-perimeter-on-aws-analyze-your-account-activity-to-evaluate-impact-and-refine-controls/
A data perimeter on Amazon Web Services (AWS) is a set of preventive controls you can use to help establish a boundary around your data in AWS Organizations. This boundary helps ensure that your data can be accessed only by trusted identities from within networks you expect and that the data cannot be transferred outside of your organization to untrusted resources. Review the previous posts in the Establishing a data perimeter on AWS series for information about the security objectives and foundational elements needed to define and enforce each perimeter type.
In this blog post, we discuss how to use AWS logging and analytics capabilities to help accelerate the implementation and effectively operate data perimeter controls at scale.
You start your data perimeter journey by identifying access patterns that you want to prevent and defining what trusted identities, trusted resources, and expected networks mean to your organization. After you define your trust boundaries based on your business and security requirements, you can use policy examples provided in the data perimeter GitHub repository to design the authorization controls for enforcing these boundaries. Before you enforce the controls in your organization, we recommend that you assess the potential impacts on your existing workloads. Performing the assessment helps you to identify unknown data access patterns missed during the initial design phase, investigate, and refine your controls to help ensure business continuity as you deploy them.
Finally, you should continuously monitor your controls to verify that they operate as expected and consistently align with your requirements as your business grows and relationships with your trusted partners change.
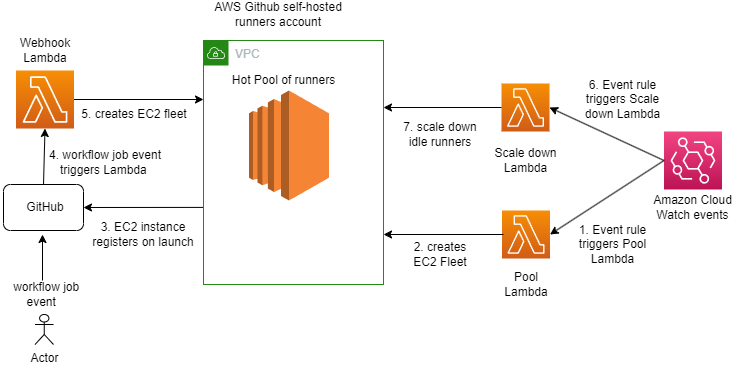
Figure 1 illustrates common phases of a data perimeter journey.

Figure 1: Data perimeter implementation journey
The usual phases of the data perimeter journey are:
- Examine your security objectives
- Set your boundaries
- Design data perimeter controls
- Anticipate potential impacts
- Implement data perimeter controls
- Monitor data perimeter controls
- Continuous improvement
In this post, we focus on phase 4: Anticipate potential impacts. We demonstrate how to analyze activity observed in your AWS environment to evaluate impact and refine your data perimeter controls. We also demonstrate how you can automate the analysis by using the data perimeter helper open source tool.
You can use the same techniques to support phase 6: Monitor data perimeter controls, where you will continuously monitor data access patterns in your organization and potentially troubleshoot permissions issues caused by overly restrictive or overly permissive policies as new data access paths are introduced.
Setting prerequisites for impact analysis
In this section, we describe AWS logging and analytics capabilities that you can use to analyze impact of data perimeter controls on your environment. We also provide instructions for configuring them.
While you might have some capabilities covered by other AWS tools (for example, AWS Security Lake) or external tools, the proposed approach remains applicable. For instance, if your logs are stored in an external security data lake or your configuration state recording is performed by an external cloud security posture management (CSPM) tool, you can extract and adapt the logic from this post to suit your context. The flexibility of this approach allows you to use the existing tools and processes in your environment while benefiting from the insights provided.
Pricing
Some of the required capabilities can generate additional costs in your environment.
AWS CloudTrail charges based on the number of events delivered to Amazon Simple Storage Service (Amazon S3). Note that the first copy of management events is free. To help control costs, you can use advanced event selectors to select only events that matter to your context. For more details, see CloudTrail pricing.
AWS Config charges based on the number of configuration items delivered, the AWS Config aggregator and advanced queries are included in AWS Config pricing. To help control costs, you can select which resource types AWS Config records or change the recording frequency. For more details, see AWS Config pricing.
Amazon Athena charges based on the number of terabytes of data scanned in Amazon S3. To help control costs, use the proposed optimized tables with partitioning and reduce the time frame of your queries. For more details, see Athena pricing.
AWS Identity and Access Management Access Analyzer doesn’t charge additional costs for external access findings. For more details, see IAM Access Analyzer pricing.
Create a CloudTrail trail to record access activity
The primary capability that you will use is a CloudTrail trail. CloudTrail records AWS API calls and events from your AWS accounts that contain the following information relevant to data perimeter objectives:
- API calls performed by your identities or on your resources (record fields:
eventSource, eventName)
- Identity that performed API calls (record field:
userIdentity)
- Network origin of API calls (record fields:
sourceIPAddress, vpcEndpointId)
- Resources API calls are performed on (record fields:
resources, requestParameters)
See the CloudTrail record contents page for the description of all available fields.
Data perimeter controls are meant to be applied across a broad set of accounts and resources, therefore, we recommend using a CloudTrail organization trail that collects logs across the AWS accounts in your organization. If you don’t have an organization trail configured, follow these steps or use one of the data perimeter helper templates for deploying prerequisites. If you use AWS services that support CloudTrail data events and want to analyze the associated API calls, enable the relevant data events.
Though CloudTrail provides you information about parameters of an API request, it doesn’t reflect values of AWS Identity and Access Management (IAM) condition keys present in the request. Thus, you still need to analyze the logs to help refine your data perimeter controls.
Create an Athena table to analyze CloudTrail logs
To ease and accelerate logs analysis, use Athena to query and extract relevant data from the log files stored by CloudTrail in an S3 bucket.
To create an Athena table
- Open the Athena console. If this is your first time visiting the Athena console in your current AWS Region, choose Edit settings to set up a query result location in Amazon S3.
- Next, navigate to the Query editor and create a SQL table by entering the following DDL statement into the Athena console query editor. Make sure to replace
s3://<BUCKET_NAME_WITH_PREFIX>/AWSLogs/<ORGANIZATION_ID>/ to point to the S3 bucket location that contains your CloudTrail log data and <REGIONS> with the list of AWS regions where you want to analyze API calls. For example, to analyze API calls made in the AWS Regions Paris (eu-west-3) and North Virginia (us-east-1), use eu-west-3,us-east-1. We recommend that you include us-east-1 to retrieve API calls performed on global resources such as IAM roles.
CREATE EXTERNAL TABLE IF NOT EXISTS cloudtrail_logs (
eventVersion STRING,
userIdentity STRUCT<
type: STRING,
principalId: STRING,
arn: STRING,
accountId: STRING,
invokedBy: STRING,
accessKeyId: STRING,
userName: STRING,
sessionContext: STRUCT<
attributes: STRUCT<
mfaAuthenticated: STRING,
creationDate: STRING>,
sessionIssuer: STRUCT<
type: STRING,
principalId: STRING,
arn: STRING,
accountId: STRING,
userName: STRING>,
ec2RoleDelivery: STRING,
webIdFederationData: MAP<STRING,STRING>>>,
eventTime STRING,
eventSource STRING,
eventName STRING,
awsRegion STRING,
sourceIpAddress STRING,
userAgent STRING,
errorCode STRING,
errorMessage STRING,
requestParameters STRING,
responseElements STRING,
additionalEventData STRING,
requestId STRING,
eventId STRING,
readOnly STRING,
resources ARRAY<STRUCT<
arn: STRING,
accountId: STRING,
type: STRING>>,
eventType STRING,
apiVersion STRING,
recipientAccountId STRING,
serviceEventDetails STRING,
sharedEventID STRING,
vpcEndpointId STRING,
tlsDetails STRUCT<
tlsVersion:string,
cipherSuite:string,
clientProvidedHostHeader:string
>
)
PARTITIONED BY (
`p_account` string,
`p_region` string,
`p_date` string
)
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://<BUCKET_NAME_WITH_PREFIX>/AWSLogs/<ORGANIZATION_ID>/'
TBLPROPERTIES (
'projection.enabled'='true',
'projection.p_date.type'='date',
'projection.p_date.format'='yyyy/MM/dd',
'projection.p_date.interval'='1',
'projection.p_date.interval.unit'='DAYS',
'projection.p_date.range'='2022/01/01,NOW',
'projection.p_region.type'='enum',
'projection.p_region.values'='<REGIONS>',
'projection.p_account.type'='injected',
'storage.location.template'='s3://<BUCKET_NAME_WITH_PREFIX>/AWSLogs/<ORGANIZATION_ID>/${p_account}/CloudTrail/${p_region}/${p_date}'
)
- Finally, run the Athena query and confirm that the
cloudtrail_logs table is created and appears under the list of Tables.
Create an AWS Config aggregator to enrich query results
To further reduce manual steps for retrieval of relevant data about your environment, use the AWS Config aggregator and advanced queries to enrich CloudTrail logs with the configuration state of your resources.
To have a view into the resource configurations across the accounts in your organization, we recommend using the AWS Config organization aggregator. You can use an existing aggregator or create a new one. You can also use one of the data perimeter helper templates for deploying prerequisites.
Create an IAM Access Analyzer external access analyzer
To identify resources in your organization that are shared with an external entity, use the IAM Access Analyzer external access analyzer with your organization as the zone of trust.
You can use an existing external access analyzer or create a new one.
Install the data perimeter helper tool
Finally, you will use the data perimeter helper, an open-source tool with a set of purpose-built data perimeter queries, to automate the logs analysis process.
Clone the data perimeter helper repository and follow instructions in the Getting Started section.
Analyze account activity and refine your data perimeter controls
In this section, we provide step-by-step instructions for using the AWS services and tools you configured to effectively implement common data perimeter controls. We first demonstrate how to use the configured CloudTrail trail, Athena table, and AWS Config aggregator directly. We then show you how to accelerate the analysis with the data perimeter helper.
Example 1: Review API calls to untrusted S3 buckets and refine your resource perimeter policy
One of the security objectives targeted by companies is ensuring that their identities can only put or get data to and from S3 buckets belonging to their organization to manage the risk of unintended data disclosure or access to unapproved data. You can help achieve this security objective by implementing a resource perimeter on your identities using a service control policy (SCP). Start crafting your policy by referring to the resource_perimeter_policy template provided in the data perimeter policy examples repository:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "EnforceResourcePerimeterAWSResourcesS3",
"Effect": "Deny",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:PutObjectAcl"
],
"Resource": "*",
"Condition": {
"StringNotEqualsIfExists": {
"aws:ResourceOrgID": "<my-org-id>",
"aws:PrincipalTag/resource-perimeter-exception": "true"
},
"ForAllValues:StringNotEquals": {
"aws:CalledVia": [
"dataexchange.amazonaws.com",
"servicecatalog.amazonaws.com"
]
}
}
}
]
}
Replace the value of the aws:ResourceOrgID condition key with your organization identifier. See the GitHub repository README file for information on other elements of the policy.
As a security engineer, you can anticipate potential impacts by reviewing account activity and CloudTrail logs. You can perform this analysis manually or use the data perimeter helper tool to streamline the process.
First, let’s explore the manual approach to understand each step in detail.
Perform impact analysis without tooling
To assess the effects of the preceding policy before deployment, review your CloudTrail logs to understand on which S3 buckets API calls are performed. The targeted Amazon S3 API calls are recorded as CloudTrail data events, so make sure you enable the S3 data event for this example. CloudTrail logs provide request parameters from which you can extract the bucket names.
Below is an example Athena query to list the targeted S3 API calls made by principals in the selected account within the last 7 days. The 7-day timeframe is set to verify that the query runs quickly, but you can adjust the timeframe later to suit your specific requirements and obtain more realistic results. Replace <ACCOUNT_ID> with the AWS account ID you want to analyze the activity of.
SELECT
useridentity.sessioncontext.sessionissuer.arn AS principal_arn,
useridentity.type AS principal_type,
eventname,
JSON_EXTRACT_SCALAR(requestparameters, '$.bucketName') AS bucketname,
resources,
COUNT(*) AS nb_reqs
FROM "cloudtrail_logs"
WHERE
p_account = '<ACCOUNT_ID>'
AND p_date BETWEEN DATE_FORMAT(CURRENT_DATE - INTERVAL '7' day, '%Y/%m/%d') AND DATE_FORMAT(CURRENT_DATE, '%Y/%m/%d')
AND eventsource = 's3.amazonaws.com'
-- Get only requests performed by principals in the selected account
AND useridentity.accountid = '<ACCOUNT_ID>'
-- Keep only the targeted API calls
AND eventname IN ('GetObject', 'PutObject', 'PutObjectAcl')
-- Remove API calls made by AWS service principals - `useridentity.principalid` field in CloudTrail log equals `AWSService`.
AND useridentity.principalid != 'AWSService'
-- Remove API calls made by service-linked roles in the selected account
AND COALESCE(NOT regexp_like(useridentity.sessioncontext.sessionissuer.arn, '(:role/aws-service-role/)'), True)
-- Remove calls with errors
AND errorcode IS NULL
GROUP BY
useridentity.sessioncontext.sessionissuer.arn,
useridentity.type,
eventname,
JSON_EXTRACT_SCALAR(requestparameters, '$.bucketName'),
resources
As shown in Figure 2, this query provides you with a list of the S3 bucket names that are being accessed by principals in the selected account, while removing calls made by service-linked roles (SLRs) because they aren’t governed by SCPs. In this example, the IAM roles AppMigrator and PartnerSync performed API calls on S3 buckets named app-logs-111111111111, raw-data-111111111111, expected-partner-999999999999, and app-migration-888888888888.
Figure 2: Sample of the Athena query results
The CloudTrail record field resources provides information on the list of resources accessed in an event. The field is optional and can notably contain the resource Amazon Resource Names (ARNs) and the account ID of the resource owner. You can use this record field to detect resources owned by accounts not in your organization. However, because this record field is optional, to scale your approach you can also use the AWS Config aggregator data to list resources currently deployed in your organization.
To know if the S3 buckets belong to your organization or not, you can run the following AWS Config advanced query. This query lists the S3 buckets inventoried in your AWS Config organization aggregator.
SELECT
accountId,
awsRegion,
resourceId
WHERE
resourceType = 'AWS::S3::Bucket'
As shown in Figure 3, buckets expected-partner-999999999999 and app-migration-888888888888 aren’t inventoried and therefore don’t belong to this organization.
Figure 3: Sample of the AWS Config advanced query results
By combining the results of the Athena query and the AWS Config advanced query, you can now pinpoint S3 API calls made by principals in the selected account on S3 buckets that are not part of your AWS organization.
If you do nothing, your starting resource perimeter policy would block access to these buckets. Therefore, you should investigate with your development teams why your principals performed those API calls and refine your policy if there is a legitimate reason, such as integration with a trusted third party. If you determine, for example, that your principals have a legitimate reason to access the bucket expected-partner-999999999999, you can discover the account ID (<third-party-account-a>) that owns the bucket by reviewing the record field resources in your CloudTrail logs or investigating with your developers and edit the policy as follows:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "EnforceResourcePerimeterAWSResourcesS3",
"Effect": "Deny",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:PutObjectAcl"
],
"Resource": "*",
"Condition": {
"StringNotEqualsIfExists": {
"aws:ResourceOrgID": "<my-org-id>",
"aws:ResourceAccount": "<third-party-account-a>",
"aws:PrincipalTag/resource-perimeter-exception": "true"
},
"ForAllValues:StringNotEquals": {
"aws:CalledVia": [
"dataexchange.amazonaws.com",
"servicecatalog.amazonaws.com"
]
}
}
}
]
}
Now your resource perimeter policy helps ensure that access to resources that belong to your trusted third-party partner aren’t blocked by default.
Automate impact analysis with the data perimeter helper
Data perimeter helper provides queries that perform and combine the results of Athena and AWS Config aggregator queries on your behalf to accelerate policy impact analysis.
For this example, we use the s3_scp_resource_perimeter query to analyze S3 API calls made by principals in a selected account on S3 buckets not owned by your organization or inventoried in your AWS Config aggregator.
You can first add the bucket names of your trusted third-party partners that are already known in the data perimeter helper configuration file (resource_perimeter_trusted_bucket parameter). You then run the data perimeter helper query using the following command. Replace <ACCOUNT_ID> with the AWS account ID you want to analyze the activity of.
data_perimeter_helper --list-account <ACCOUNT_ID> --list-query s3_scp_resource_perimeter
Data perimeter helper performs these actions:
- Runs an Athena query to list S3 API calls made by principals in the selected account, filtering out:
- S3 API calls made at the account level (for example, s3:ListAllMyBuckets)
- S3 API calls made on buckets that your organization owns
- S3 API calls made on buckets listed as trusted in the data perimeter helper configuration file (
resource_perimeter_trusted_bucket parameter)
- API calls made by service principals and SLRs because SCPs don’t apply to them
- API calls with errors
- Gets the list of S3 buckets in your organization using an AWS Config advanced query.
- Removes from the Athena query’s results API calls performed on S3 buckets inventoried in your AWS Config aggregator. This is done as a second clean-up layer in case the optional CloudTrail record field
resources isn’t populated.
Data perimeter helper exports the results in the selected format (HTML, Excel, or JSON) so that you can investigate API calls that don’t align with your initial resource perimeter policy. Figure 4 shows a sample of results in HTML:
Figure 4: Sample of the s3_scp_resource_perimeter query results
The preceding data perimeter helper query results indicate that the IAM role PartnerSync performed API calls on S3 buckets that aren’t part of the organization, giving you a head start in your investigation efforts. Following the investigation, you can document a trusted partner bucket in the data perimeter helper configuration file to filter out the associated API calls from subsequent queries:
111111111111:
network_perimeter_expected_public_cidr: [
]
network_perimeter_trusted_principal: [
]
network_perimeter_expected_vpc: [
]
network_perimeter_expected_vpc_endpoint: [
]
identity_perimeter_trusted_account: [
]
identity_perimeter_trusted_principal: [
]
resource_perimeter_trusted_bucket: [
expected-partner-999999999999
]
With a single command line, you have identified for your selected account the S3 API calls crossing your resource perimeter boundaries. You can now refine and implement your controls while lowering the risk of potential impacts. If you want to scale your approach to other accounts, you just need to run the same query against them.
Example 2: Review granted access and API calls by untrusted identities on your S3 buckets and refine your identity perimeter policy
Another security objective pursued by companies is ensuring that their S3 buckets can be accessed only by principals belonging to their organization to manage the risk of unintended access to company data. You can help achieve this security objective by implementing an identity perimeter on your buckets. You can start by crafting your identity perimeter policy using policy samples provided in the data perimeter policy examples repository.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "EnforceIdentityPerimeter",
"Effect": "Deny",
"Principal": "*",
"Action": "s3:*",
"Resource": [
"arn:aws:s3:::<my-data-bucket>",
"arn:aws:s3:::<my-data-bucket>/*"
],
"Condition": {
"StringNotEqualsIfExists": {
"aws:PrincipalOrgID": "<my-org-id>",
"aws:PrincipalAccount": [
"<load-balancing-account-id>",
"<third-party-account-a>",
"<third-party-account-b>"
]
},
"BoolIfExists": {
"aws:PrincipalIsAWSService": "false"
}
}
}
]
}
Replace values of the aws:PrincipalOrgID and aws:PrincipalAccount condition keys based on what trusted identities mean for your organization and on your knowledge of the intended access patterns you need to support. See the GitHub repository README file for information on elements of the policy.
To assess the effects of the preceding policy before deployment, review your IAM Access Analyzer external access findings to discover the external entities that are allowed in your S3 bucket policies. Then to accelerate your analysis, review your CloudTrail logs to learn who is performing API calls on your S3 buckets. This can help you accelerate the removal of granted but unused external accesses.
Data perimeter helper provides queries that streamline these processes for you:
Run these queries by using the following command, replacing <ACCOUNT_ID> with the AWS account ID of the buckets you want to analyze the access activity of:
data_perimeter_helper --list-account <ACCOUNT_ID> --list-query s3_external_access_org_boundary s3_bucket_policy_identity_perimeter_org_boundary
The query s3_external_access_org_boundary performs this action:
- Extracts IAM Access Analyzer external access findings from either:
- IAM Access Analyzer if the variable external_access_findings in the data perimeter variable file is set to IAM_ACCESS_ANALYZER
- AWS Security Hub if the same variable is set to SECURITY_HUB. Security Hub provides cross-Region aggregation, enabling you to retrieve external access findings across your organization
The query s3_external_access_org_boundary performs this action:
- Runs an Athena query to list S3 API calls made on S3 buckets in the selected account, filtering out:
- API calls made by principals in the same organization
- API calls made by principals belonging to trusted accounts listed in the data perimeter configuration file (
identity_perimeter_trusted_account parameter)
- API calls made by trusted identities listed in the data perimeter configuration file (
identity_perimeter_trusted_principal parameter)
Figure 5 shows a sample of results for this query in HTML:
Figure 5: Sample of the s3_bucket_policy_identity_perimeter_org_boundary and s3_external_access_org_boundary queries results
The result shows that only the bucket my-bucket-open-to-partner grants access (PutObject) to principals not in your organization. Plus, in the configured time frame, your CloudTrail trail hasn’t recorded S3 API calls made by principals not in your organization on buckets that the account 111111111111 owns.
This means that your proposed identity perimeter policy accounts for the access patterns observed in your environment. After reviewing with your developers, if the granted action on the bucket my-bucket-open-to-partner is not needed, you could deploy it on the analyzed account with a reduced risk of impacting business applications.
Example 3: Investigate resource configurations to support network perimeter controls implementation
The blog post Require services to be created only within expected networks provides an example of an SCP you can use to make sure that AWS Lambda functions can only be created or updated if associated with an Amazon Virtual Private Cloud (Amazon VPC).
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "EnforceVPCFunction",
"Action": [
"lambda:CreateFunction",
"lambda:UpdateFunctionConfiguration"
],
"Effect": "Deny",
"Resource": "*",
"Condition": {
"Null": {
"lambda:VpcIds": "true"
}
}
}
]
}
Before implementing the preceding policy or to continuously review the configuration of your Lambda functions, you can use your AWS Config aggregator to understand whether there are functions in your environment that aren’t attached to a VPC.
Data perimeter helper provides the referential_lambda_function query that helps you automate the analysis. Run the query by using the following command:
data_perimeter_helper --list-query referential_lambda_function
Figure 6 shows a sample of results for this query in HTML:
Figure 6: Sample of the referential_lambda_function query results
By reviewing the inVpc column, you can quickly identify functions that aren’t currently associated with a VPC and investigate with your development teams before enforcing your network perimeter controls.
Example 4: Investigate access denied errors to help troubleshoot your controls
While you refine your data perimeter controls or after deploying them, you might encounter API calls that fail with an access denied error message. You can use CloudTrail logs to review those API calls and use the record to investigate the root-cause.
Data perimeter helper provides the common_only_denied query, which lists the API calls with access denied errors in the configured time frame. Run the query by using the following command, replacing <ACCOUNT_ID> with your account ID:
data_perimeter_helper --list-account <ACCOUNT_ID> --list-query common_only_denied
Figure 7 shows a sample of results for this query in HTML:
Figure 7: Sample of the common_only_denied query results
Let’s say you want to review S3 API calls with access denied error messages for one of your developers who uses a role called DevOps. You can update, in the HTML report, the input fields below the principal_arn and eventsource columns to match your lookup.
Then by reviewing the columns principal_arn, eventname, isAssumableBy, and nb_reqs, you learn that the role DevOps is assumable through a SAML provider and performed two GetObject API calls that failed with an access denied error message. By reviewing the sourceipaddress field you discover that the request has been performed from an IP address outside of your network perimeter boundary, you can then advise your developer to perform the API calls again from an expected network.
Data perimeter helper provides several ready-to-use queries and a framework to add new queries based on your data perimeter objectives and needs. See Guidelines to build a new query for detailed instructions.
Clean up
If you followed the configuration steps in this blog only to test the solution, you can clean up your account to avoid recurring charges.
If you used the data perimeter helper deployment templates, use the respective infrastructure as code commands to delete the provisioned resources (for example, for Terraform, terraform destroy).
To delete configured resources manually, follow these steps:
- If you created a CloudTrail organization trail:
- Navigate to the CloudTrail console, select the trail your created, and choose Delete.
- Navigate to the Amazon S3 console and delete the S3 bucket you created to store CloudTrail logs from all accounts.
- If you created an Athena table:
- Navigate to the Athena console and select Query editor in the left navigation panel.
- Run the following SQL query by replacing <TABLE_NAME> with the name of the created table:
- If you created an AWS Config aggregator:
- Navigate to the AWS Config console and select Aggregators in the left navigation panel.
- Select the created aggregator and select Delete from the Actions drop-down list.
- If you installed data perimeter helper:
- Follow the uninstallation steps in the data perimeter helper README file.
Conclusion
In this blog post, we reviewed how you can analyze access activity in your organization by using the CloudTrail logs to evaluate impact of your data perimeter controls and perform troubleshooting. We discussed how the log events data can be enriched using resource configuration information from AWS Config to streamline your analysis. Finally, we introduced the open source tool, data perimeter helper, that provides a set of data perimeter tailored queries to speed up your review process and a framework to create new queries.
For additional learning opportunities, see the Data perimeters on AWS page, which provides additional material such as a data perimeter workshop, blog posts, whitepapers, and webinar sessions.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, start a new thread on the AWS Security, Identity, and Compliance re:Post or contact AWS Support.
Want more AWS Security news? Follow us on X.