Post Syndicated from Dawn Parzych original https://blog.cloudflare.com/icymi-developer-week-2022-announcements/


Developer Week 2022 has come to a close. Over the last week we’ve shared with you 31 posts on what you can build on Cloudflare and our vision and roadmap on where we’re headed. We shared product announcements, customer and partner stories, and provided technical deep dives. In case you missed any of the posts here’s a handy recap.
Product and feature announcements
| Announcement | Summary |
|---|---|
| Welcome to the Supercloud (and Developer Week 2022) | Our vision of the cloud — a model of cloud computing that promises to make developers highly productive at scaling from one to Internet-scale in the most flexible, efficient, and economical way. |
| Build applications of any size on Cloudflare with the Queues open beta | Build performant and resilient distributed applications with Queues. Available to all developers with a paid Workers plan. |
| Migrate from S3 easily with the R2 Super Slurper | A tool to easily and efficiently move objects from your existing storage provider to R2. |
| Get started with Cloudflare Workers with ready-made templates | See what’s possible with Workers and get building faster with these starter templates. |
| Reduce origin load, save on cloud egress fees, and maximize cache hits with Cache Reserve | Cache Reserve is graduating to open beta – users can now test and integrate it into their content delivery strategy without any additional waiting. |
| Store and process your Cloudflare Logs… with Cloudflare | Query Cloudflare logs stored on R2. |
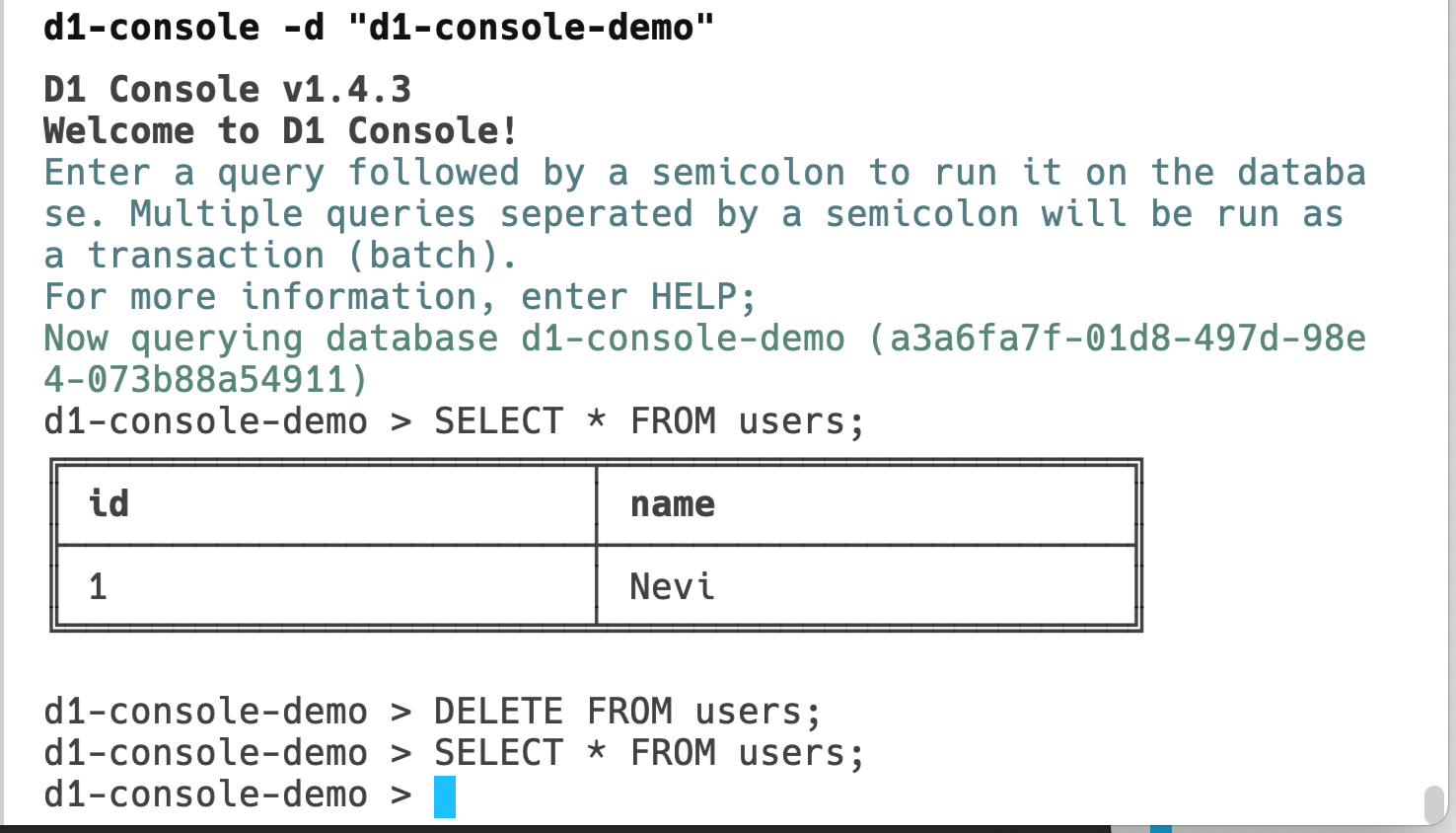
| UPDATE Supercloud SET status = ‘open alpha’ WHERE product = ‘D1’ | D1, our first global relational database, is in open alpha. Start building and share your feedback with us. |
| Automate an isolated browser instance with just a few lines of code | The Browser Rendering API is an out of the box solution to run browser automation tasks with Puppeteer in Workers. |
| Bringing authentication and identification to Workers through Mutual TLS | Send outbound requests with Workers through a mutually authenticated channel. |
| Spice up your sites on Cloudflare Pages with Pages Functions General Availability | Easily add dynamic content to your Pages projects with Functions. |
| Announcing the first Workers Launchpad cohort and growth of the program to $2 billion | We were blown away by the interest in the Workers Launchpad Funding Program and are proud to introduce the first cohort. |
| The most programmable Supercloud with Cloudflare Snippets | Modify traffic routed through the Cloudflare CDN without having to write a Worker. |
| Keep track of Workers’ code and configuration changes with Deployments | Track your changes to a Worker configuration, binding, and code. |
| Send Cloudflare Workers logs to a destination of your choice with Workers Trace Events Logpush | Gain visibility into your Workers when logs are sent to your analytics platform or object storage. Available to all users on a Workers paid plan. |
| Improved Workers TypeScript support | Based on feedback from users we’ve improved our types and are open-sourcing the automatic generation scripts. |
Technical deep dives
| Announcement | Summary |
|---|---|
| The road to a more standards-compliant Workers API | An update on the work the WinterCG is doing on the creation of common API standards in JavaScript runtimes and how Workers is implementing them. |
| Indexing millions of HTTP requests using Durable Objects |
Indexing and querying millions of logs stored in R2 using Workers, Durable Objects, and the Streams API. |
| Iteration isn’t just for code: here are our latest API docs | We’ve revamped our API reference documentation to standardize our API content and improve the overall developer experience when using the Cloudflare APIs. |
| Making static sites dynamic with D1 | A template to build a D1-based comments APi. |
| The Cloudflare API now uses OpenAPI schemas | OpenAPI schemas are now available for the Cloudflare API. |
| Server-side render full stack applications with Pages Functions | Run server-side rendering in a Function using a variety of frameworks including Qwik, Astro, and SolidStart. |
| Incremental adoption of micro-frontends with Cloudflare Workers | How to replace selected elements of a legacy client-side rendered application with server-side rendered fragments using Workers. |
| How we built it: the technology behind Cloudflare Radar 2.0 | Details on how we rebuilt Radar using Pages, Remix, Workers, and R2. |
| How Cloudflare uses Terraform to manage Cloudflare | How we made it easier for our developers to make changes with the Cloudflare Terraform provider. |
| Network performance Update: Developer Week 2022 | See how fast Cloudflare Workers are compared to other solutions. |
| How Cloudflare instruments services using Workers Analytics Engine | Instrumentation with Analytics Engine provides data to find bugs and helps us prioritize new features. |
| Doubling down on local development with Workers:Miniflare meets workerd | Improving local development using Miniflare3, now powered by workerd. |
Customer and partner stories
| Announcement | Summary |
|---|---|
| Cloudflare Workers scale too well and broke our infrastructure, so we are rebuilding it on Workers | How DevCycle re-architected their feature management tool using Workers. |
| Easy Postgres integration with Workers and Neon.tech | Neon.tech solves the challenges of connecting to Postgres from Workers |
| Xata Workers: client-side database access without client-side secrets | Xata uses Workers for Platform to reduce security risks of running untrusted code. |
| Twilio Segment Edge SDK powered by Cloudflare Workers | The Segment Edge SDK, built on Workers, helps applications collect and track events from the client, and get access to realtime user state to personalize experiences. |
Next
And that’s it for Developer Week 2022. But you can keep the conversation going by joining our Discord Community.