IPFS, the distributed file system and content addressing protocol, has been around since 2015, and Cloudflare has been a user and operator since 2018, when we began operating a public IPFS gateway. Today, we are announcing our plan to transition this gateway traffic to the Interplanetary Shipyard (“Shipyard”) team and discussing what it means for users and the future of IPFS gateways.
As announced in April 2024, many of the IPFS core developers and maintainers now work within a newly created, independent entity called Interplanetary Shipyard (“Shipyard”). For IPFS to continue exemplifying the open-source ethos, its core developers will work for Shipyard, rather than Protocol Labs, where IPFS was invented and incubated. By operating as a collective, ongoing maintenance and support of important protocols like IPFS are now even more community-owned and managed. We fully support this “exit to community” and are excited to see Shipyard build more great infrastructure for the open web.
On May 14th, 2024, we will begin to transition traffic that comes to Cloudflare’s public IPFS gateway to Shipyard’s IPFS gateway at ipfs.io or dweb.link. Cloudflare’s public IPFS gateway is just one of many – part of a distributed ecosystem that also includes Pinata, eth.limo, and many more. Visit the IPFS Public Gateway Checker to see the other publicly available IPFS gateways.
Cloudflare believes in helping build a better Internet for all and an accessible and private Internet, principles that Protocol Labs, IPFS, and Shipyard all share. We believe the IPFS gateway transition to Shipyard will boost ecosystem collaboration, increase protocol resiliency, and ensure healthy stewardship and governance. Cloudflare is proud to be a partner of Shipyard in this transition and will continue to help sponsor their work as gateway stewards.
What happens next
All traffic using the cloudflare-ipfs.com or cf-ipfs.com hostname(s) will continue to work without interruption and be redirected to ipfs.io or dweb.link until August 14th, 2024, at which time the Cloudflare hostnames will no longer connect to IPFS and all users must switch the hostname they use to ipfs.io or dweb.link to ensure no service interruption takes place. If you are using either of the Cloudflare hostnames, please be sure to switch to one of the new ones as soon as possible ahead of the transition date to avoid any service interruptions!
It is important to both Cloudflare and Shipyard that this transition is completed seamlessly and with as little impact to users as possible. With that in mind, there is no change to the amount or type of end user information that is visible to either Cloudflare or Shipyard before or after the completion of this transition.
We’re excited to see further development and projects from the IPFS community and play our part in helping those applications be secure, performant, and reliable!
—
About Shipyard
Interplanetary Shipyard is an engineering collective that delivers user agency through technical advancements in IPFS and libp2p. As the core maintainers of open source projects in the Interplanetary Stack (including IPFS and libp2p implementations such as Kubo, Rainbow, Boxo, Helia, and go/js-libp2p/js-libp2p), and supporting performance measurement tooling (Probelab), they are committed to open source innovation and building bridges between traditional web frameworks and the decentralized ecosystem. To achieve this, their engineers work alongside technical teams in web2 and web3 to promote adoption and drive practical applications.
In the dynamic world of modern applications, efficient load balancing plays a pivotal role in delivering exceptional user experiences. Customers commonly leverage load balancing, so they can efficiently use their existing infrastructure resources in the best way possible. Though, load balancing is not a ‘one-size-fits-all, out of the box’ solution for everyone. As you go deeper into the details of your traffic shaping requirements and as your architecture becomes more complex, different flavors of load balancing are usually required to achieve these varying goals, such as steering between datacenters for public traffic, creating high availability for critical internal services with private IPs, applying steering between servers in a single datacenter, and more. We are extremely excited to announce a new addition to our Load Balancing solution, Local Traffic Management (LTM) with deep integrations with Zero Trust!
A common problem businesses run into is that almost no providers can satisfy all these requirements, resulting in a growing list of vendors to manage disparate data sources to get a clear view of your traffic pipeline, and investment into incredibly expensive hardware that is complicated to set up and maintain. Not having a single source of truth to dwindle down ‘time to resolution’ and a single partner to work with in times when things are not operating within the ideal path can be the difference between a proactive, healthy growing business versus one that is reactive and constantly having to put out fires. The latter can result in extreme slowdown to developing amazing features/services, reduction in revenue, tarnishing of brand trust, decreases in adoption – the list goes on!
For eight years, we have provided top-tier global traffic load balancing (GTM) capabilities to thousands of customers across the globe. But why should the steering intelligence, failover, and reliability we guarantee stop at the front door of the selected datacenter and only operate with public traffic? We came to the conclusion that we should go even further. Today is the start of a long series of new features that allow traffic steering, failover, session persistence, SSL/TLS offloading and much more to take place between servers after datacenter selection has occurred! Instead of relying only on the relative weight to determine which server traffic should be sent to, you can now bring the same intelligent steering policies, such as least outstanding requests steering or hash steering, to any of your many data centers. This also means you have a single partner for all of your load balancing initiatives and a single pane of glass to inform business decisions! Cloudflare is thrilled to introduce the powerful combination of private IP support for Load Balancing with Cloudflare Tunnels and Local Traffic Management, offering customers a solution that blends unparalleled efficiency, security, flexibility, and privacy.
What is a load balancer?
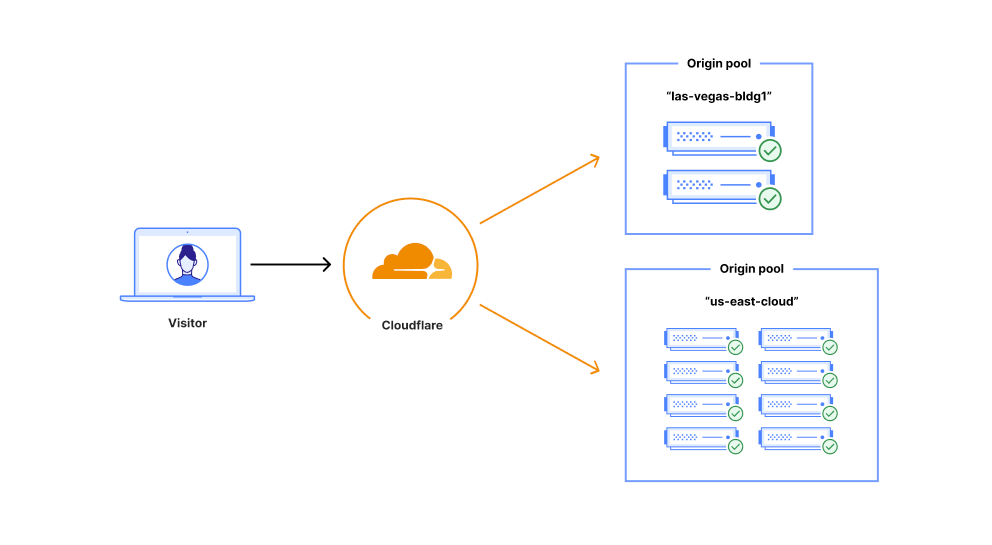
A Cloudflare load balancer directs a request from a user to the appropriate origin pool within a data center
Load balancing — functionality that’s been around for the last 30 years to help businesses leverage their existing infrastructure resources. Load balancing works by proactively steering traffic away from unhealthy origin servers and — for more advanced solutions — intelligently distributing traffic load based on different steering algorithms. This process ensures that errors aren’t served to end users and empowers businesses to tightly couple overall business objectives to their traffic behavior. Cloudflare Load Balancing has made it simpler and easier to securely and reliably manage your traffic across multiple data centers around the world. With Cloudflare Load Balancing, your traffic will be directed reliably regardless of the scale of traffic or where it originates with customizable steering, affinity and failover. This clearly has an advantage over a physical load balancer since it can be configured easily and traffic doesn’t have to reach one of your data centers to be routed to another location, introducing single points of failure and significant latency. When compared with other global traffic management load balancers, Cloudflare’s Load Balancing offering is easier to set up, simpler to understand, and is fully integrated with the Cloudflare platform as one single product for all load balancing needs.
What are Cloudflare Tunnels?
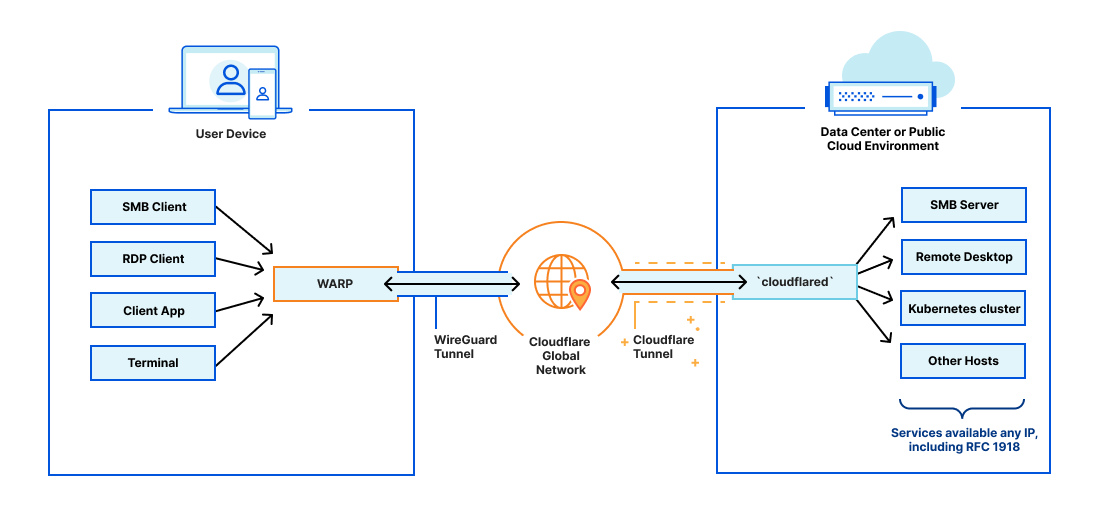
Origins and servers of various types can be connected to Cloudflare using Cloudflare Tunnel. Users can also secure their traffic using WARP, allowing traffic to be secured and managed end to end through Cloudflare.
In 2018, Cloudflare introduced Cloudflare Tunnels, a private, secure connection between your data center and Cloudflare. Traditionally, from the moment an Internet property is deployed, developers spend an exhaustive amount of time and energy locking it down through access control lists, rotating IP addresses, or more complex solutions like GRE tunnels. We built Tunnel to help alleviate that burden. With Tunnels, users can create a private link from their origin server directly to Cloudflare without exposing your services directly to the public internet or allowing incoming connections in your data center’s firewall. Instead, this private connection is established by running a lightweight daemon, cloudflared, in your data center, which creates a secure, outbound-only connection. This means that only traffic that you’ve configured to pass through Cloudflare can reach your private origin.
Unleashing the potential of Cloudflare Load Balancing with Cloudflare Tunnels
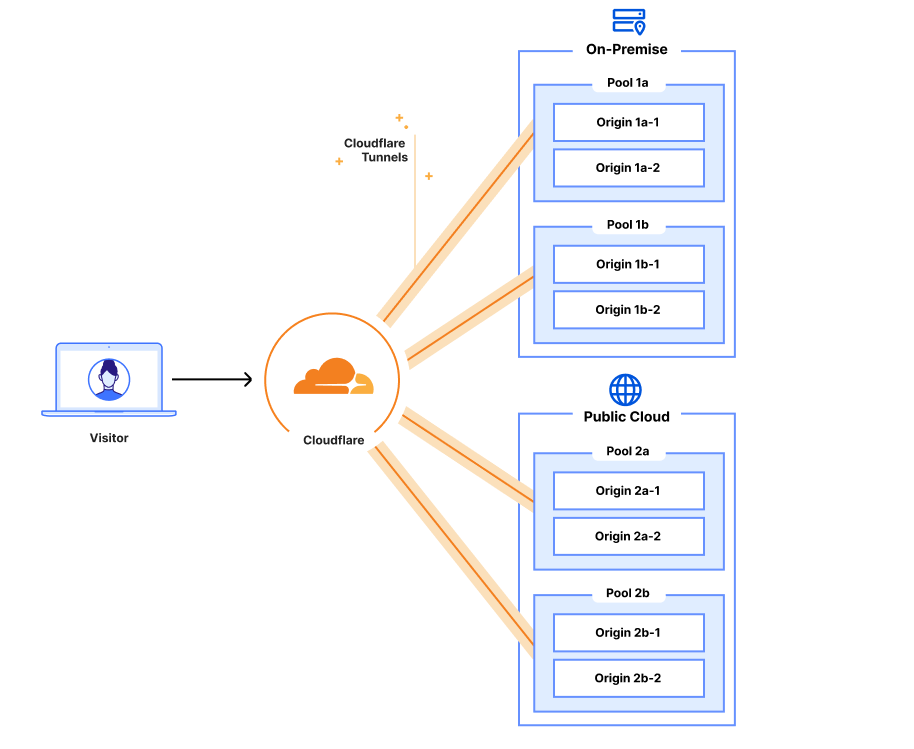
Cloudflare Load Balancing can easily and securely direct a user’s request to a specific origin within your private data center or public cloud using Cloudflare Tunnels
Combining Cloudflare Tunnels with Cloudflare Load Balancing allows you to remove your physical load balancers from your data center and have your Cloudflare load balancer reach out to your servers directly via their private IP addresses with health checks, steering, and all other Load Balancing features currently available. Instead of configuring your on-premise load balancer to expose each service and then updating your Cloudflare load balancer, you can configure it all in one place. This means that from the end-user to the server handling the request, all your configuration can be done in a single place – the Cloudflare dashboard. On top of this, you can say goodbye to the multi hundred thousand dollar price tag to hardware appliances, the incredible management overhead and investing in a solution that has a time limit for its delivered value.
Load Balancing serves as the backbone for online services, ensuring seamless traffic distribution across servers or data centers. Traditional load balancing techniques often require exposing services on a data center’s public IP addresses, forcing organizations to create complex configurations vulnerable to security risks and potential data exposure. By harnessing the power of private IP support for Load Balancing in conjunction with Cloudflare Tunnels, Cloudflare is revolutionizing the way businesses protect and optimize their applications. With clear steps to install the cloudflared agent to connect your private network to Cloudflare’s network via Cloudflare Tunnels, directly and securely routing traffic into your data centers becomes easier than ever before!
Publicly exposing services in private data centers is complicated
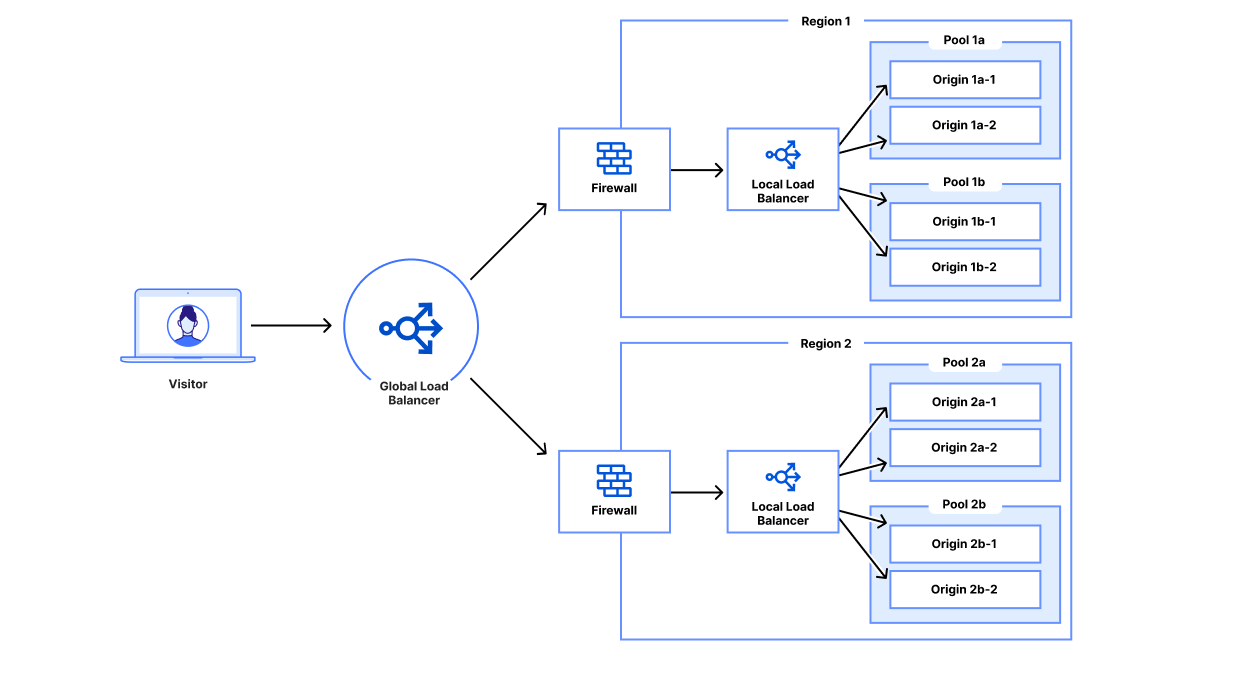
A visitor’s request hits a global traffic management (GTM) load balancer directing the request to a data center, then a firewall, then a local traffic management (LTM) load balancer and then an origin
Load balancing within a private data center can be expensive and difficult to manage. The idea of keeping security first while ensuring ease of use and flexibility for your internal workforce is a tricky balance to strike. It’s not only the ‘how’ of securely exposing internal services, but how to best balance traffic between servers at a single location within your private network!
In a private data center, even a very simple website can be fairly complex in terms of networking and configuration. Let’s walk through a simple example of a customer device connecting to a website. A customer device performs a DNS lookup for the business’s website and receives an IP address corresponding to a customer data center. The customer then makes an HTTPS request to that IP address, passing the original hostname via Server Name Indication (SNI). That load balancer forwards that request to the corresponding origin server and returns the response to the customer device.
This example doesn’t have any advanced functionality and the stack is already difficult to configure:
Expose the service or server on a private IP.
Configure your data center’s networking to expose the LB on a public IP or IP range.
Configure your load balancer to forward requests for that hostname and/or public IP to your server’s private IP.
Configure a DNS record for your domain to point to your load balancer’s public IP.
In large enterprises, each of these configuration changes likely requires approval from several stakeholders and modified through different repositories, websites and/or private web interfaces. Load balancer and networking configurations are often maintained as complex configuration files for Terraform, Chef, Puppet, Ansible or a similar infrastructure-as-code service. These configuration files can be syntax checked or tested but are rarely tested thoroughly prior to deployment. Each deployment environment is often unique enough that thorough testing is often not feasible given the time and hardware requirements needed to do so. This means that changes to these files can negatively affect other services within the data center. In addition, opening up an ingress to your data center widens the attack surface for varying security risks such as DDoS attacks or catastrophic data breaches. To make things worse, each vendor has a different interface or API for configuring their devices or services. For example, some registrars only have XML APIs while others have JSON REST APIs. Each device configuration may have different Terraform providers or Ansible playbooks. This results in complex configurations accumulating over time that are difficult to consolidate or standardize, inevitably resulting in technical debt.
Now let’s add additional origins. For each additional origin for our service, we’ll have to go set up and expose that origin and configure the physical load balancer to use our new origin. Now let’s add another data center. Now we need another solution to distribute across our data centers. This results in a separate global traffic management system and local traffic management system. These solutions have in the past come from different vendors and will have to be configured in different ways even though they should serve the same purpose: load balancing. This makes managing your web traffic unnecessarily difficult. Why should you have to configure your origins in two different load balancers? Why can’t you manage all the traffic for all the origins for a service in the same place?
Simpler and better: Load Balancing with Tunnels
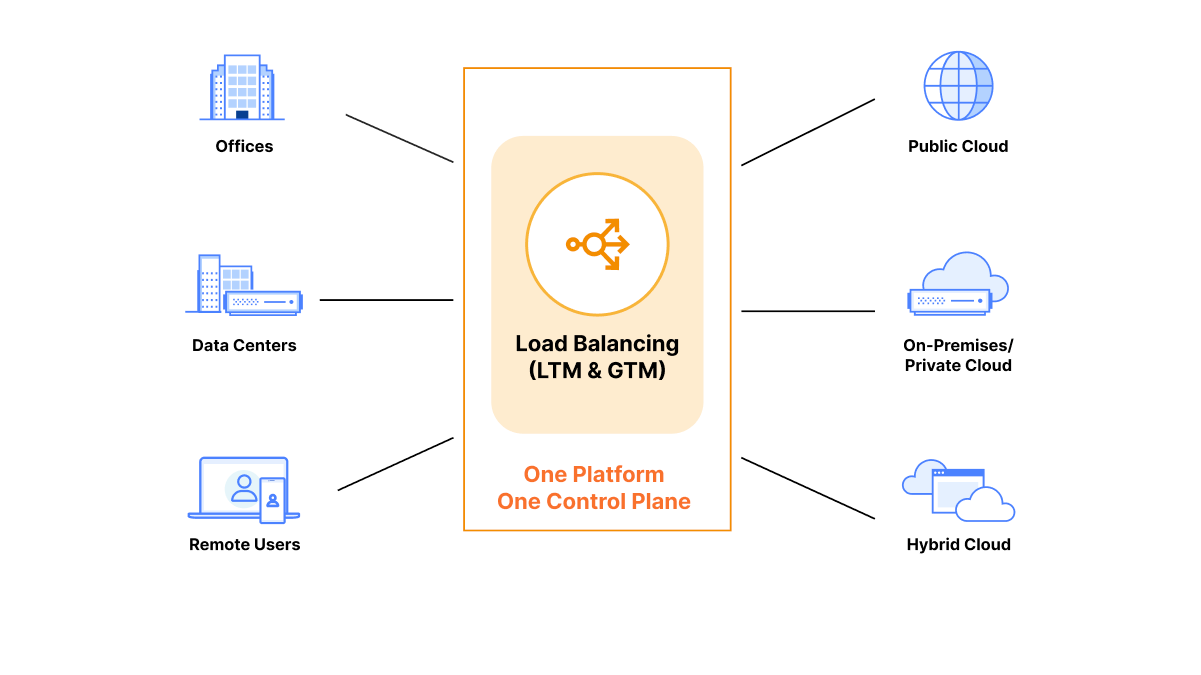
Cloudflare Load Balancing can manage traffic for all your offices, data centers, remote users, public clouds, private clouds and hybrid clouds in one place
With Cloudflare Load Balancing and Cloudflare Tunnel, you can manage all your public and private origins in one place: the Cloudflare dashboard. Cloudflare load balancers can be easily configured using the Cloudflare dashboard or the Cloudflare API. There’s no need to SSH or open a remote desktop to modify load balancer configurations for your public or private servers. All configurations can be done through the dashboard UI or Cloudflare API, with full parity between the two.
With Cloudflare Tunnel set up and running in your data center, everything is ready to connect your origin server to Cloudflare network and load balancers. You do not need to configure any ingress to your data center since Cloudflare Tunnel operates only over outbound connections and can securely reach out to privately addressed services inside your data center. To expose your service to Cloudflare, you just set up your private IP range to be routed over that tunnel. Then, you can create a Cloudflare load balancer and input the corresponding private IP address and virtual network ID into your origin pool. After that, Cloudflare manages the DNS and load balancing across your private servers. Now your origin is receiving traffic exclusively via Cloudflare Tunnel and your physical load balancer is no longer needed!
This groundbreaking integration enables organizations to deploy load balancers while keeping their applications securely shielded from the public Internet. The customer’s traffic passes through Cloudflare’s data centers, allowing customers to continue to take full advantage of Cloudflare’s security and performance services. Also, by leveraging Cloudflare Tunnels, traffic between Cloudflare and customer origins remains isolated within trusted networks, bolstering privacy, security, and peace of mind.
The advantages of Private IP support with Cloudflare Tunnels
Cloudflare Load Balancing works in conjunction with all the security and privacy products that Cloudflare has to offer including DDoS protection, Web Application Firewall and Bot Managment
Combining Global and Local Traffic Management: All the features and ease of use that were part of Cloudflare Load Balancing for Global Traffic Management are also available with Local Traffic Management. You can configure your public and private origins in one dashboard as opposed to several services and vendors. Now, all your private origins can benefit from the features that Cloudflare Load Balancing is known for: instant failover, customizable steering between data centers, ease of use, custom rules and configuration updates in a matter of seconds. They will also benefit from our newer features including least connection steering, least outstanding request steering, and session affinity by header. This is just a small subset of the expansive feature set for Load Balancing. See our dev docs for more features and details on the offering.
Enhanced Security: By combining private IP support with Cloudflare Tunnels, organizations can fortify their security posture and protect sensitive data. With private IP addresses and encrypted connections via Cloudflare Tunnel, the risk of unauthorized access and potential attacks is significantly reduced – traffic remains within trusted networks. You can also configure Cloudflare Access to add single sign-on support for your application and restrict your application to a subset of authorized users. In addition, you still benefit from Firewall rules, Rate Limiting rules, Bot Management, DDoS protection and all the other Cloudflare products available today allowing comprehensive security configurations.
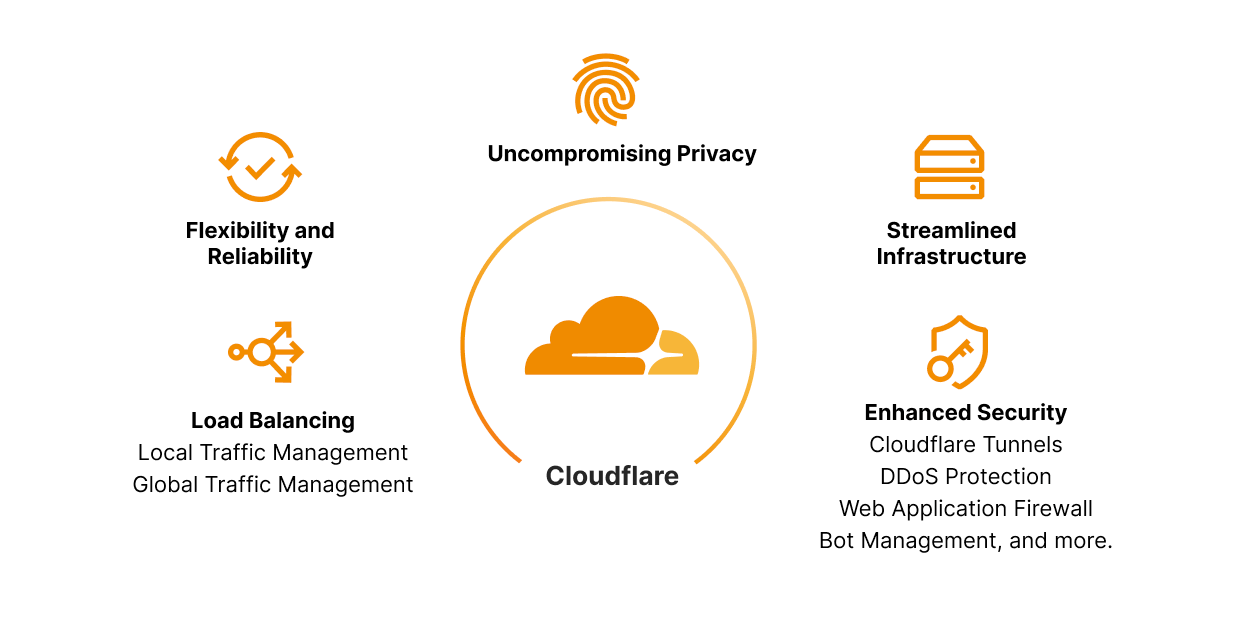
Uncompromising Privacy: As data privacy continues to take center stage, businesses must ensure the confidentiality of user information. Cloudflare's private IP support with Cloudflare Tunnels enables organizations to segregate applications and keep sensitive data within their private network boundaries. Custom rules also allow you to direct traffic for specific devices to specific data centers. For example, you can use custom rules to direct traffic from Eastern and Western Europe to your European data centers, so you can easily keep those users’ data within Europe. This minimizes the exposure of data to external entities, preserving user privacy and complying with strict privacy regulations across different geographies.
Flexibility & Reliability: Scale and adaptability are some of the major foundations of a well-operating business. Implementing solutions that fit your business’ needs today is not enough. Customers must find solutions that meet their needs for the next three or more years. The blend of Load Balancing with Cloudflare Tunnels within our Zero Trust solution lends to the very definition of flexibility and reliability! Changes to load balancer configurations propagate around the world in a matter of seconds, making load balancers an effective way to respond to incidents. Also, instant failover, health monitoring, and steering policies all help to maintain high availability for your applications, so you can deliver the reliability that your users expect. This is all in addition to best in class Zero Trust capabilities that are deeply integrated such as, but not limited to Secure Web Gateway (SWG), remote browser isolation, network logs. Data loss prevention.
Streamlined Infrastructure: Organizations can consolidate their network architecture and establish secure connections across distributed environments. This unification reduces complexity, lowers operational overhead, and facilitates efficient resource allocation. Whether you need to apply a global traffic manager to intelligently direct traffic between datacenters within your private network, or steer between specific servers after datacenter selection has taken place, there is now a clear, single lens to manage your global and local traffic, regardless of whether the source or destination of the traffic is public or private. Complexity can be a large hurdle in achieving and maintaining fast, agile business units. Consolidating into a single provider, like Cloudflare, that provides security, reliability, and observability will not only save significant cost but allows your teams to move faster and focus on growing their business, enhancing critical services, and developing incredible features, rather than taping together infrastructure that may not work in a few years. Leave the heavy lifting to us, and let us empower you and your team to focus on creating amazing experiences for your employees and end-users.
The lack of agility, flexibility, and lean operations of hardware appliances for Local Traffic Management does not justify the hundreds of thousands of dollars spent on them, along with the huge overhead of managing CPU, memory, power, cooling, etc. Instead, we want to help businesses move this logic to the cloud by abstracting away the needless overhead and bringing more focus back to teams to do what they do best, building amazing experiences, and allowing Cloudflare to do what we do best, protecting, accelerating, and building heightened reliability. Stay tuned for more updates on Cloudflare's Local Traffic Manager and how it can reduce architecture complexity while bringing more insight, security, and control to your teams. In the meantime, check out our new whitepaper!
Looking to the future
Cloudflare's impactful solution, private IP support for Load Balancing with Cloudflare Tunnels as part of the Zero Trust solution, reaffirms our commitment to providing cutting-edge tools that prioritize security, privacy, and performance. By leveraging private IP addresses and secure tunnels, Cloudflare empowers businesses to fortify their network infrastructure while ensuring compliance with regulatory requirements. With enhanced security, uncompromising privacy, and streamlined infrastructure, load balancing becomes a powerful driver of efficient and secure public or private services.
As a business grows and its systems scale up, they'll need the features that Cloudflare Load Balancing is known for: health monitoring, steering, and failover. As availability requirements increase due to growing demands and standards from end-users, customers can add health checks, enabling automatic failover to healthy servers when an unhealthy server begins to fail. When the business begins to receive more traffic from around the world, they can create new pools for different regions and use dynamic steering to reduce latency between the user and the server. For intensive or long-running requests, such as complex datastore queries, customers can benefit from leveraging least outstanding requests steering to reduce the number of concurrent requests per server. Before, this could all be done with publicly addressable IPs, but it is now available for pools with public IPs, private servers, or combinations of the two. Private IP Load Balancing along with Local Traffic Management is live and ready to use today! Check out our dev docs for instructions on how to get started.
Stay tuned for our next addition to add new Load Balancing onramp support for Spectrum and WARP with Cloudflare Tunnels with private IPs for your Layer 4 traffic, allowing us to support TCP and UDP applications in your private data centers!
Anyone can take advantage of Cloudflare’s far-reaching network to protect and accelerate their online presence. Our vast number of data centers, and their proximity to Internet users around the world, enables us to secure and accelerate our customers’ Internet applications, APIs and websites. Even a simple service with a single origin server can leverage the massive scale of the Cloudflare network in 270+ cities. Using the Cloudflare cache, you can support more requests and users without purchasing new servers.
Whether it is to guarantee high availability through redundancy, or to support more dynamic content, an increasing number of services require multiple origin servers. The Cloudflare Load Balancer keeps our customer’s services highly available and makes it simple to spread out requests across multiple origin servers. Today, we’re excited to announce a frequently requested feature for our Load Balancer – Weighted Pools!
What’s a Weighted Pool?
Before we can answer that, let’s take a quick look at how our load balancer works and define a few terms:
Origin Servers – Servers which sit behind Cloudflare and are often located in a customer-owned datacenter or at a public cloud provider.
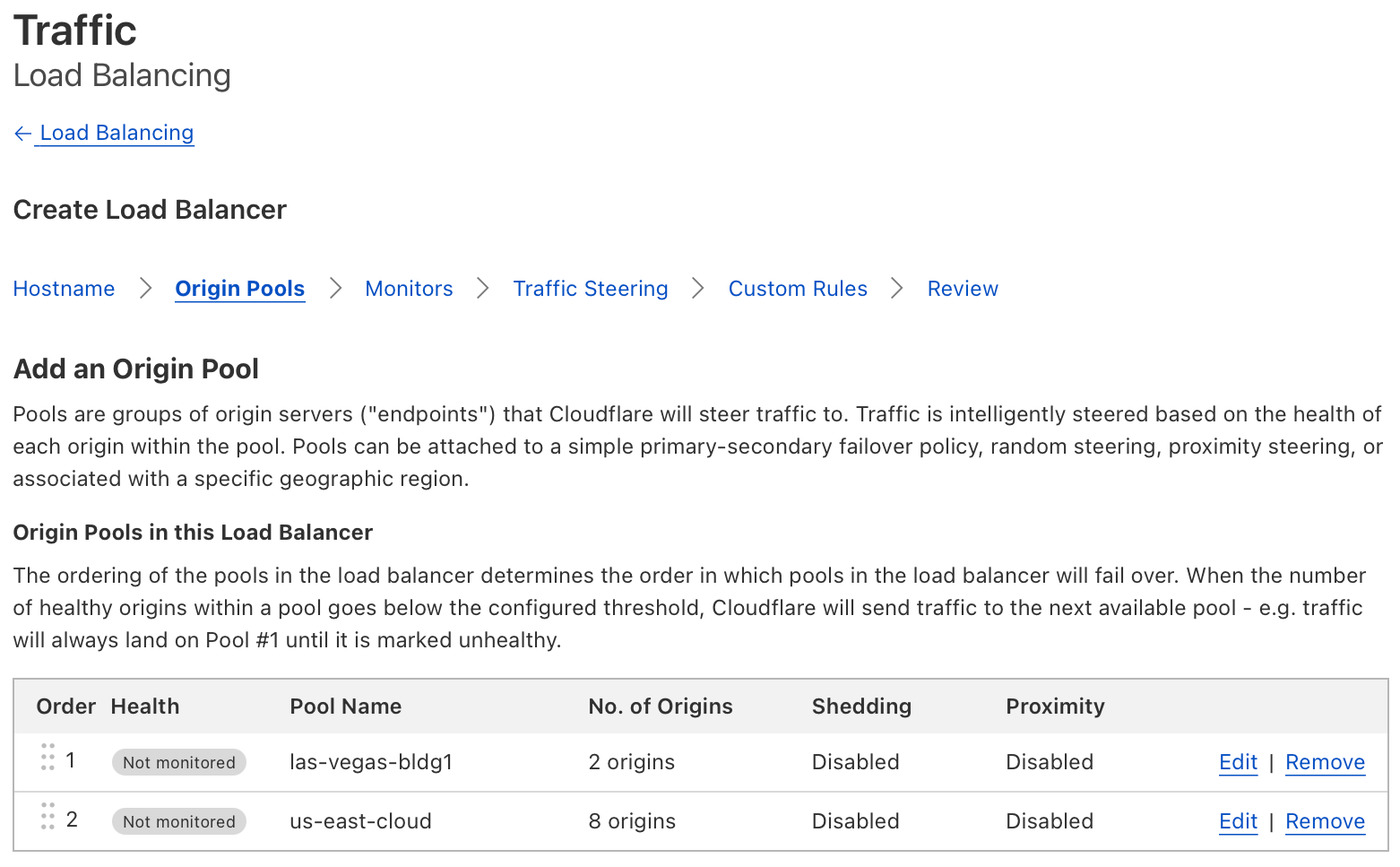
Origin Pool – A logical collection of origin servers. Most pools are named to represent data centers, or cloud providers like “us-east,” “las-vegas-bldg1,” or “phoenix-bldg2”. It is recommended to use pools to represent a collection of servers in the same physical location.
Traffic Steering Policy – A policy specifies how a load balancer should steer requests across origin pools. Depending on the steering policy, requests may be sent to the nearest pool as defined by latitude and longitude, the origin pool with the lowest latency, or based upon the location of the Cloudflare data center.
Pool Weight – A numerical value to describe what percentage of requests should be sent to a pool, relative to other pools.
When a request from a visitor arrives at the Cloudflare network for a hostname with a load balancer attached to it, the load balancer must decide where the request should be forwarded. Customers can configure this behavior with traffic steering policies.
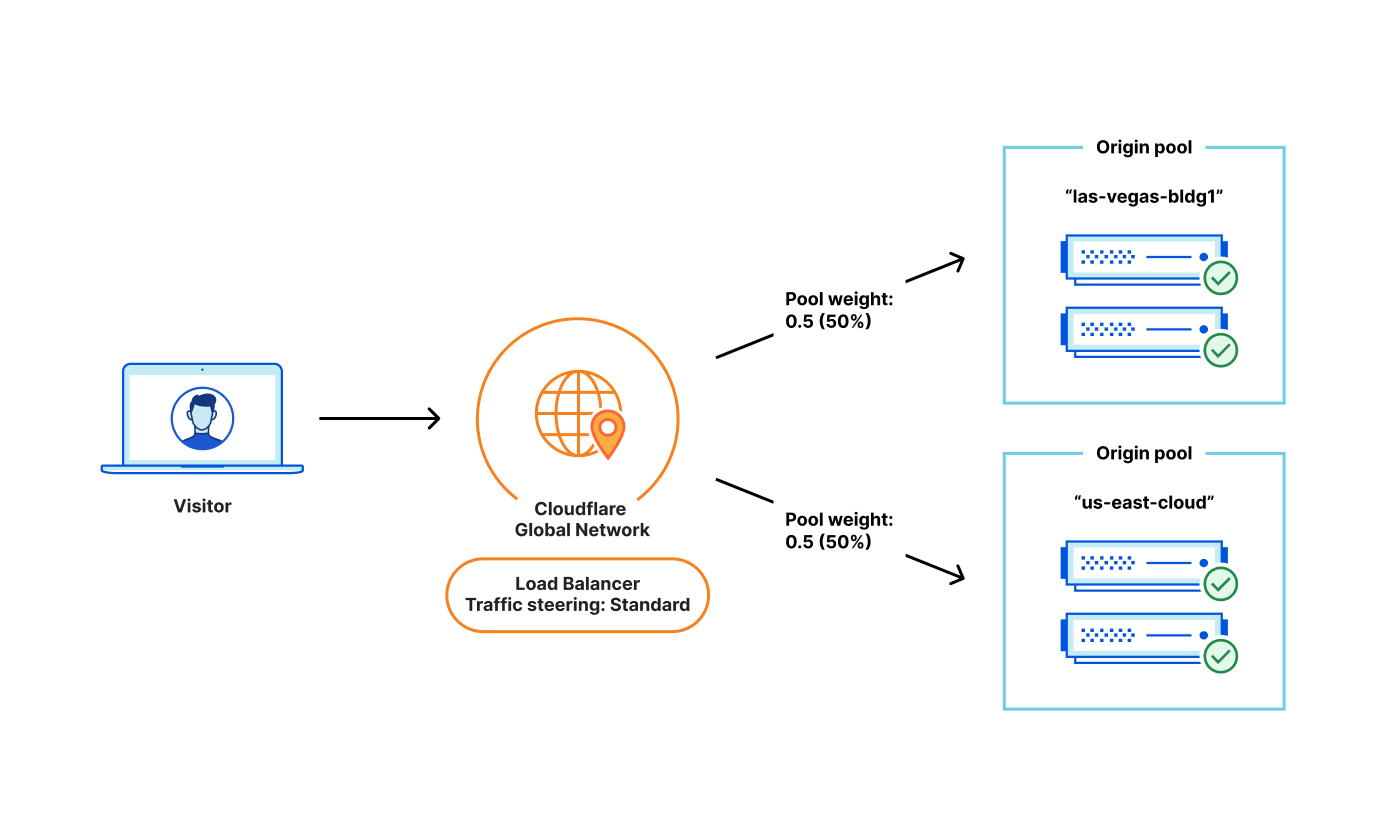
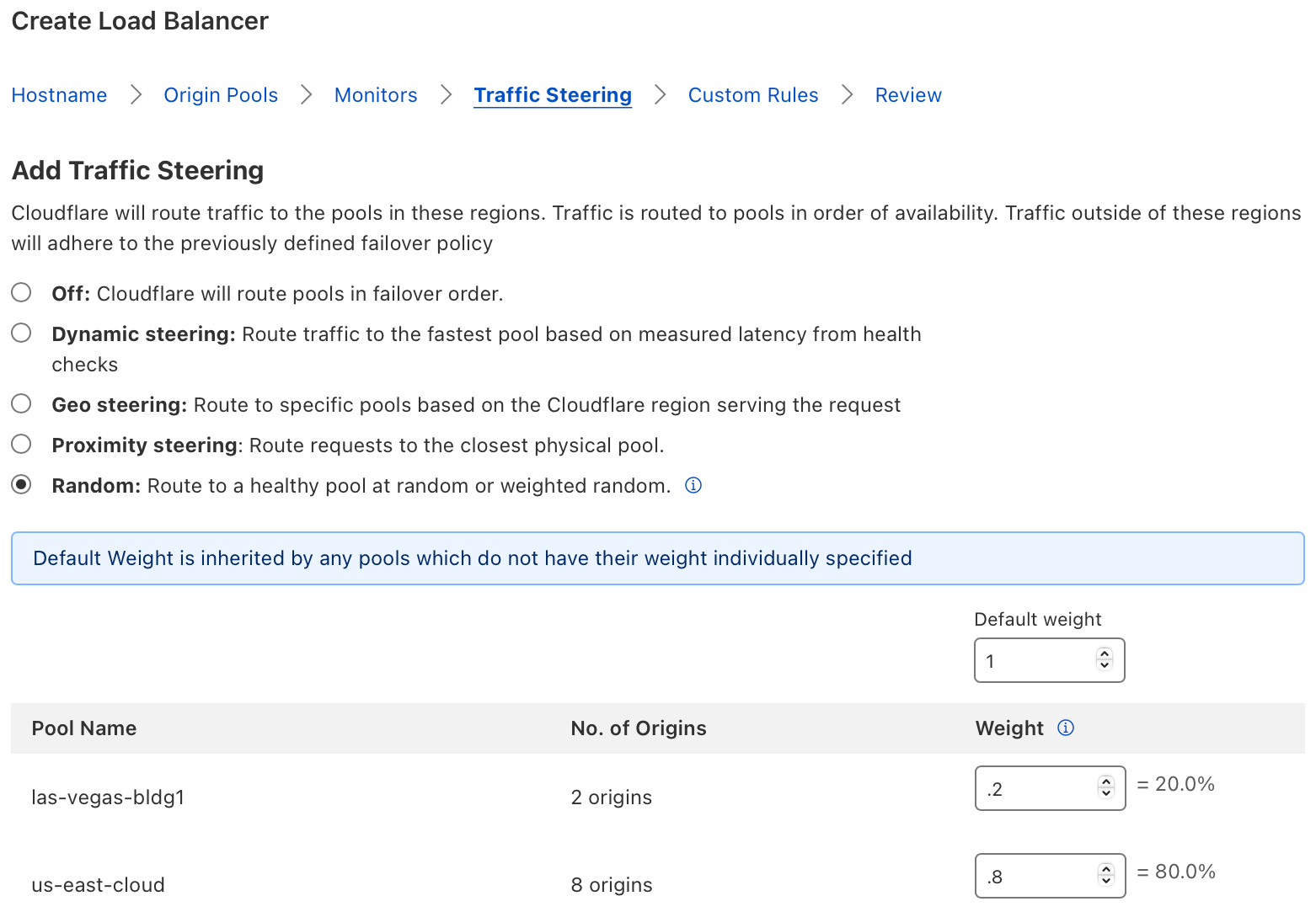
The Cloudflare Load Balancer already supports Standard Steering, Geo Steering, Dynamic Steering, and Proximity Steering. Each of these respective traffic steering policies control how requests are distributed across origin pools. Weighted Pools are an extension of our standard, random steering policy which allows the specification of what relative percentage of requests should be sent to each respective pool.
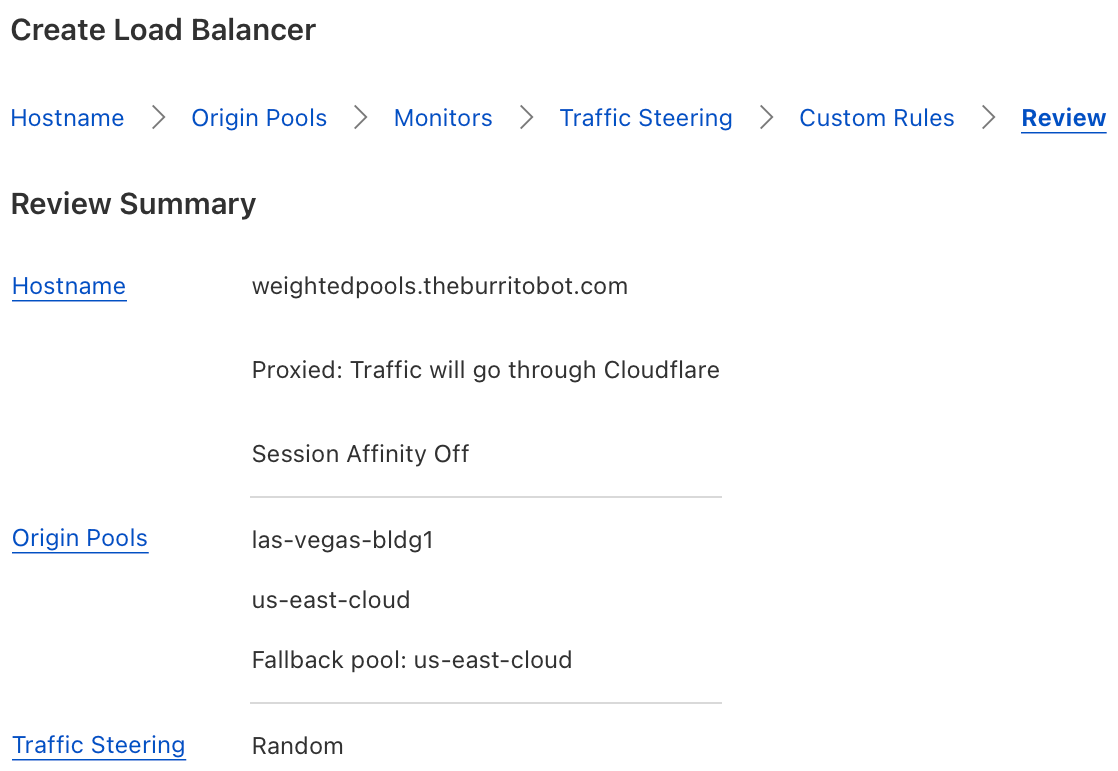
In the example above, our load balancer has two origin pools, “las-vegas-bldg1” (which is a customer operated data center), and “us-east-cloud” (which is a public cloud provider with multiple virtual servers). Each pool has a weight of 0.5, so 50% of requests should be sent to each respective pool.
Why would someone assign weights to origin pools?
Before we built this, Weighted Pools was a frequently requested feature from our customers. Part of the reason we’re so excited about this feature is that it can be used to solve many types of problems.
Unequally Sized Origin Pools
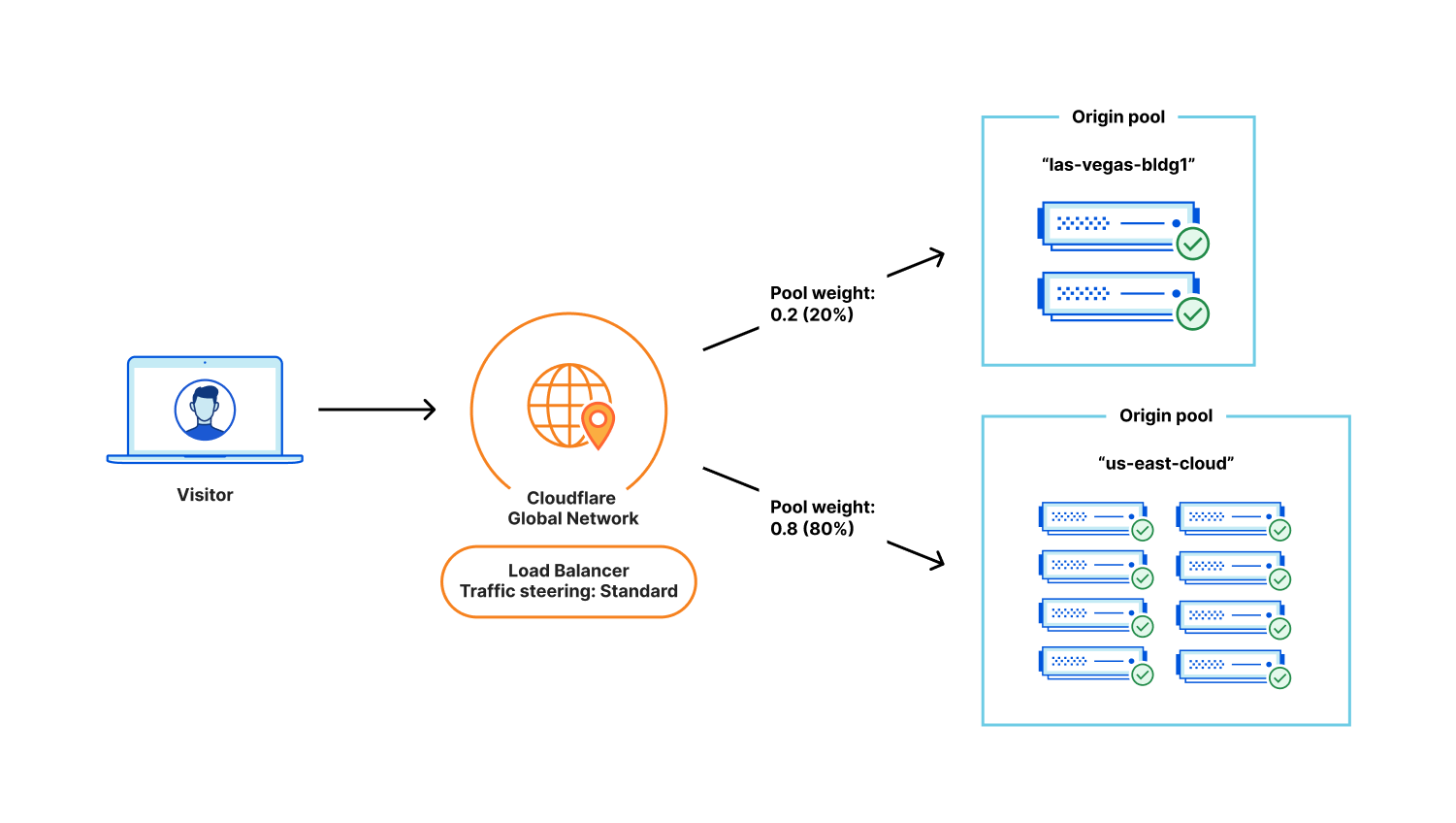
In the example below, the amount of dynamic and uncacheable traffic has significantly increased due to a large sales promotion. Administrators notice that the load on their Las Vegas data center is too high, so they elect to dynamically increase the number of origins within their public cloud provider. Our two pools, “las-vegas-bldg1” and “us-east-cloud” are no longer equally sized. Our pool representing the public cloud provider is now much larger, so administrators change the pool weights so that the cloud pool receives 0.8 (80%) of the traffic, relative to the 0.2 (20%) of the traffic which the Las Vegas pool receives. The administrators were able to use pool weights to very quickly fine-tune the distribution of requests across unequally sized pools.
Data center kill switch
In addition to balancing out unequal sized pools, Weighted Pools may also be used to completely take a data center (an origin pool) out of rotation by setting the pool’s weight to 0. This feature can be particularly useful if a data center needs to be quickly eliminated during troubleshooting or a proactive maintenance where power may be unavailable. Even if a pool is disabled with a weight of 0, Cloudflare will still monitor the pool for health so that the administrators can assess when it is safe to return traffic.
Network A/B testing
One final use case we’re excited about is the ability to use weights to attract a very small amount of requests to pool. Did the team just stand up a brand-new data center, or perhaps upgrade all the servers to a new software version? Using weighted pools, the administrators can use a load balancer to effectively A/B test their network. Only send 0.05 (5%) of requests to a new pool to verify the origins are functioning properly before gradually increasing the load.
How do I get started?
When setting up a load balancer, you need to configure one or more origin pools, and then place origins into your respective pools. Once you have more than one pool, the relative weights of the respective pools will be used to distribute requests.
To set up a weighted pool using the Dashboard, create a load balancer in the Traffic > Load Balancing area.
Once you have set up the load balancer, you’re navigated to the Origin Pools setup page. Under the Traffic Steering Policy, select Random, and then assign relative weights to every pool.
If your weights do not add up to 1.00 (100%), that’s fine! We will do the math behind the scenes to ensure how much traffic the pool should receive relative to other pools.
Weighted Pools may also be configured via the API. We’ve edited an example illustrating the relevant parts of the REST API.
The load balancer should employ a “steering_policy” of random.
Each pool has a UUID, which can then be assigned a “pool_weight.”
We’re excited to launch this simple, yet powerful and capable feature. Weighted pools may be utilized in tons of creative new ways to solve load balancing challenges. It’s available for all customers with load balancers today!
In February 2021, Cloudflare launched Project Fair Shot — a program that gave our Waiting Room product free of charge to any government, municipality, private/public business, or anyone responsible for the scheduling and/or dissemination of the COVID-19 vaccine.
By having our Waiting Room technology in front of the vaccine scheduling application, it ensured that:
Applications would remain available, reliable, and resilient against massive spikes of traffic for users attempting to get their vaccine appointment scheduled.
Visitors could wait for their long-awaited vaccine with confidence, arriving at a branded queuing page that provided accurate, estimated wait times.
Vaccines would get distributed equitably, and not just to folks with faster reflexes or Internet connections.
Since February, we’ve seen a good number of participants in Project Fair Shot. To date, we have helped more than 100 customers across more than 10 countries to schedule approximately 100 million vaccinations. Even better, these vaccinations went smoothly, with customers like the County of San Luis Obispo regularly dealing with more than 20,000 appointments in a day. “The bottom line is Cloudflare saved lives today. Our County will forever be grateful for your participation in getting the vaccine to those that need it most in an elegant, efficient and ethical manner” — Web Services Administrator for the County of San Luis Obispo.
We are happy to have helped not just in the US, but worldwide as well. In Canada, we partnered with a number of organizations and the Canadian government to increase access to the vaccine. One partner stated: “Our relationship with Cloudflare went from ‘Let’s try Waiting Room’ to ‘Unless you have this, we’re not going live with that public-facing site.’” — CEO of Verto Health. In another country in Europe, we saw over three million people go through the Waiting Room in less than 24 hours, leading to a significantly smoother and less stressful experience. Cities in Japan, — working closely with our partner, Classmethod — have been able to vaccinate over 40 million people and are on track to complete their vaccination process across 317 cities. If you want more stories from Project Fair Shot, check out our case studies.
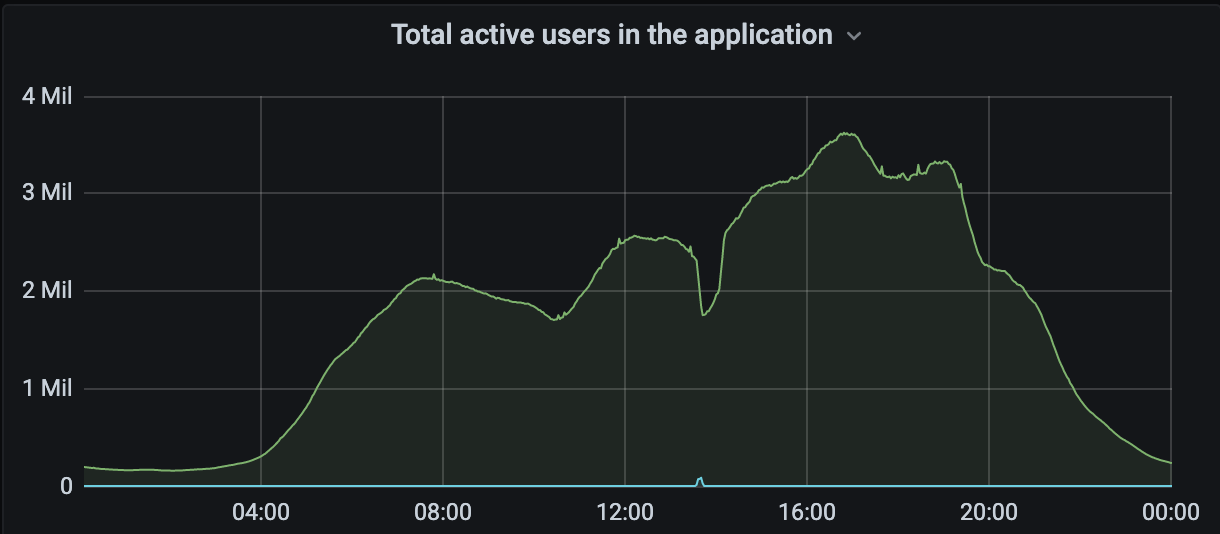
A European customer seeing very high amounts of traffic during a vaccination event
We are continuing to add more customers to Project Fair Shot every day to ensure we are doing all that we can to help distribute more vaccines. With the emergence of the Delta variant and others, vaccine distribution (and soon, booster shots) is still very much a real problem to keep everyone healthy and resilient. Because of these new developments, Cloudflare will be extending Project Fair Shot until at least July 1, 2022. Though we are not excited to see the pandemic continue, we are humbled to be able to provide our services and be a critical part in helping us collectively move towards a better tomorrow.
Load Balancing — functionality that’s been around for the last 30 years to help businesses leverage their existing infrastructure resources. Load balancing works by proactively steering traffic away from unhealthy origin servers and — for more advanced solutions — intelligently distributing traffic load based on different steering algorithms. This process ensures that errors aren’t served to end users and empowers businesses to tightly couple overall business objectives to their traffic behavior.
What’s important for load balancing today?
We are no longer in the age where setting up a fixed amount of servers in a data center is enough to meet the massive growth of users browsing the Internet. This means that we are well past the time when there is a one size fits all solution to suffice the needs of different businesses. Today, customers look for load balancers that are easy to use, propagate changes quickly, and — especially now — provide the most feature flexibility. Feature flexibility has become so important because different businesses have different paths to success and, consequently, different challenges! Let’s go through a few common use cases:
You might have an application split into microservices, where specific origins support segments of your application. You need to route your traffic based on specific paths to ensure no single origin can be overwhelmed and users get sent to the correct server to answer the originating request.
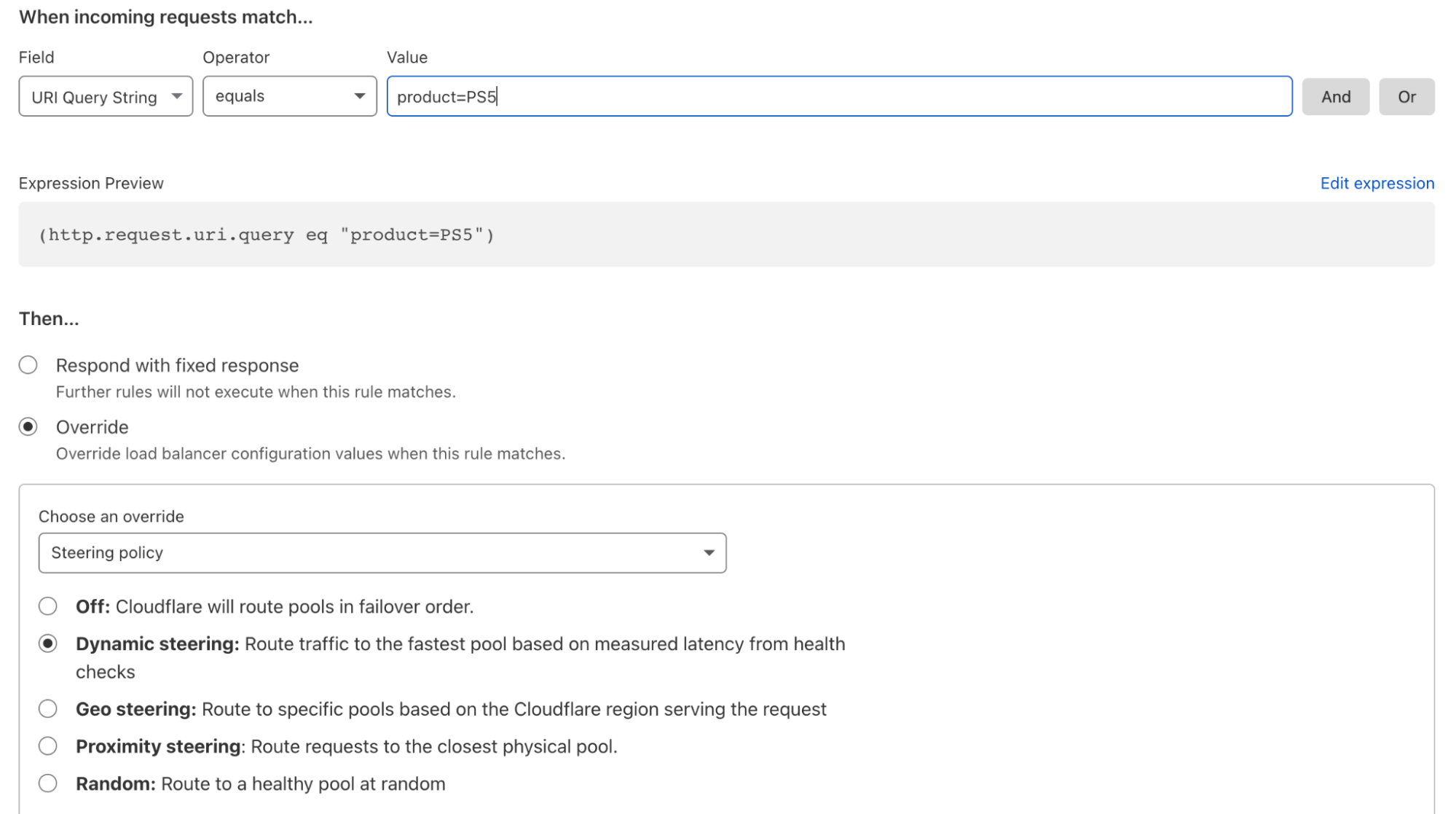
You may want to route traffic based on a specific value within a header request such as “PS5” and send requests to the data center with the matching header.
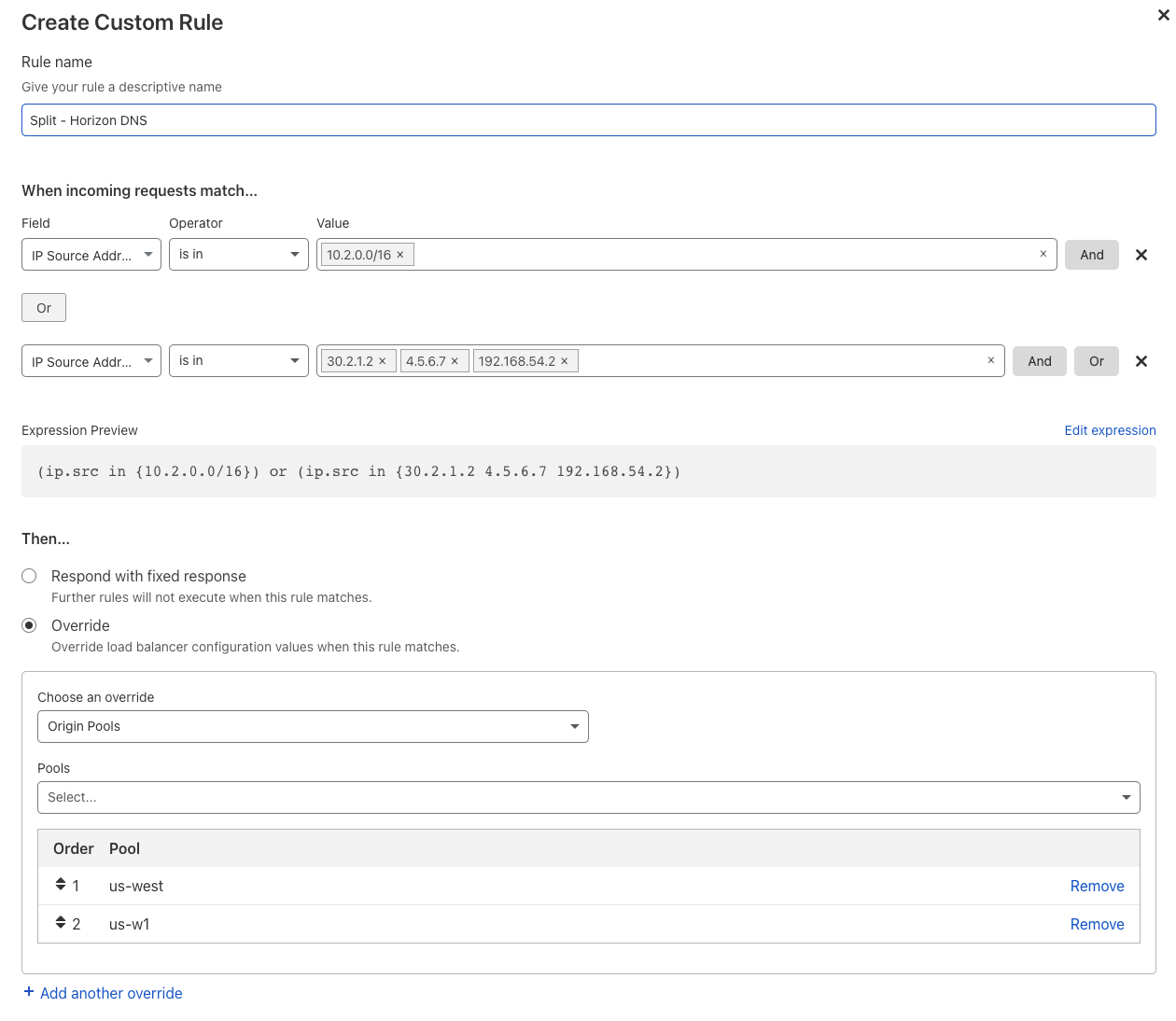
If you heavily prioritize security and privacy, you may adopt a split-horizon DNS setup within your network architecture. You might choose this architecture to separate internal network requests from public requests from the rest of the public Internet. Then, you could route each type of request to pools specifically suited to handle the amount and type of traffic.
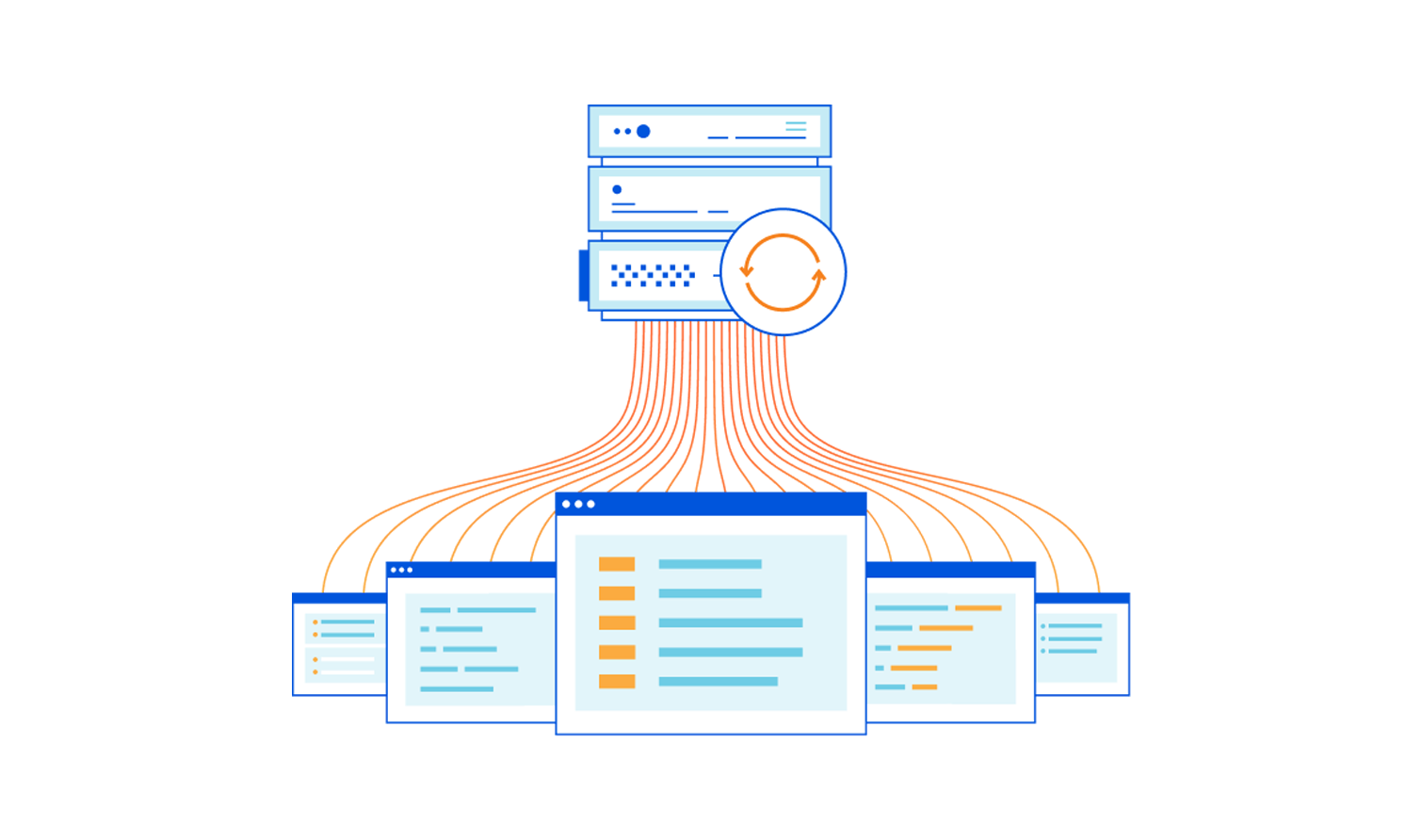
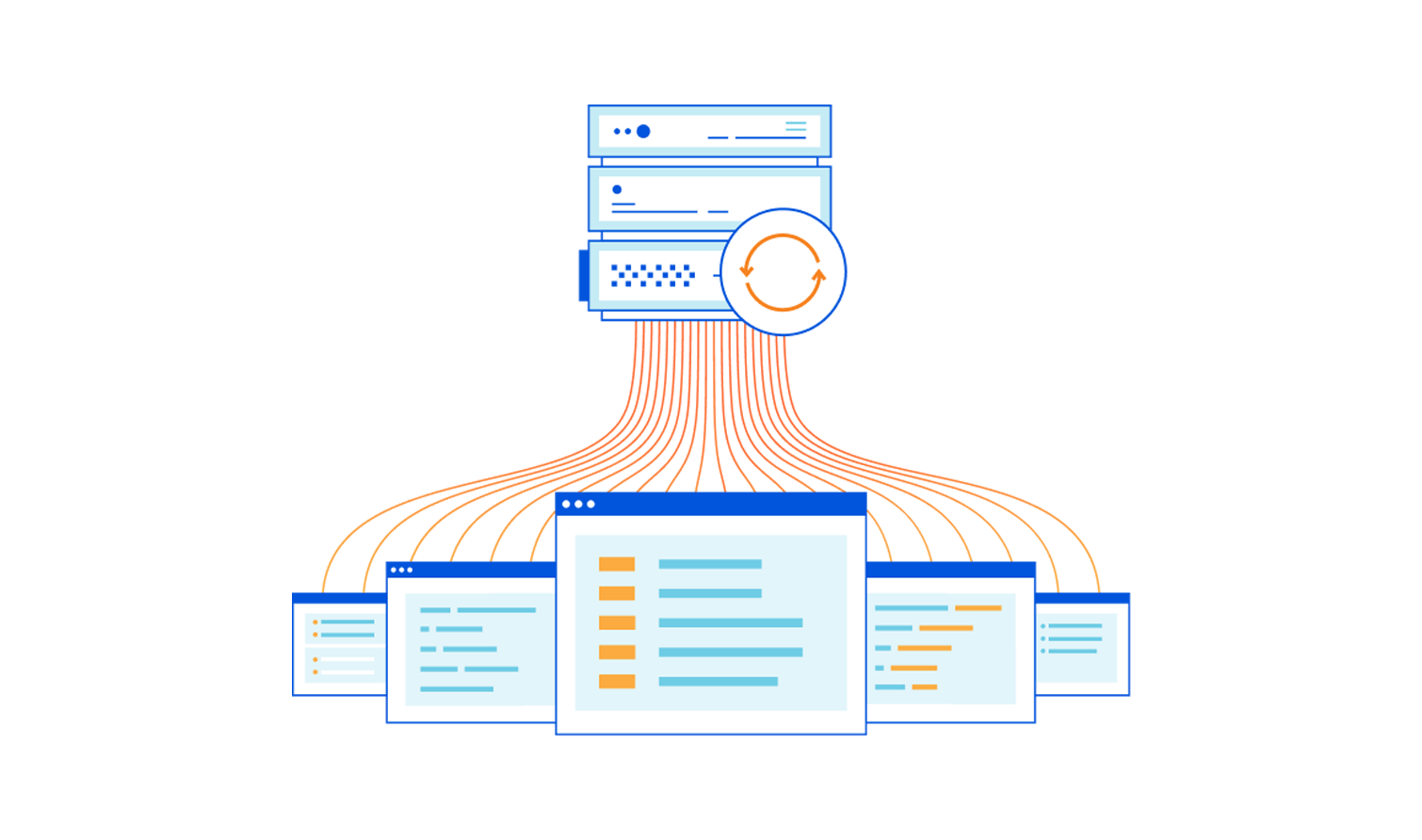
As we continue to build new features and products, we also wanted to build a framework that would allow us to increase our velocity to add new items to our Load Balancing solution while we also take the time to create first class features as well. The result was the creation of our custom rule builder!
Now you can build complex, custom rules to direct traffic using Cloudflare Load Balancing, empowering customers to create their own custom logic around their traffic steering and origin selection decisions. As we mentioned, there is no one size fits all solution in today’s world. We provide the tools to easily and quickly create rules that meet the exact requirements needed for any customer’s unique situation and architecture. On top of that, we also support ‘and’ and ‘or’ statements within a rule, allowing very powerful and complex rules to be created for any situation!
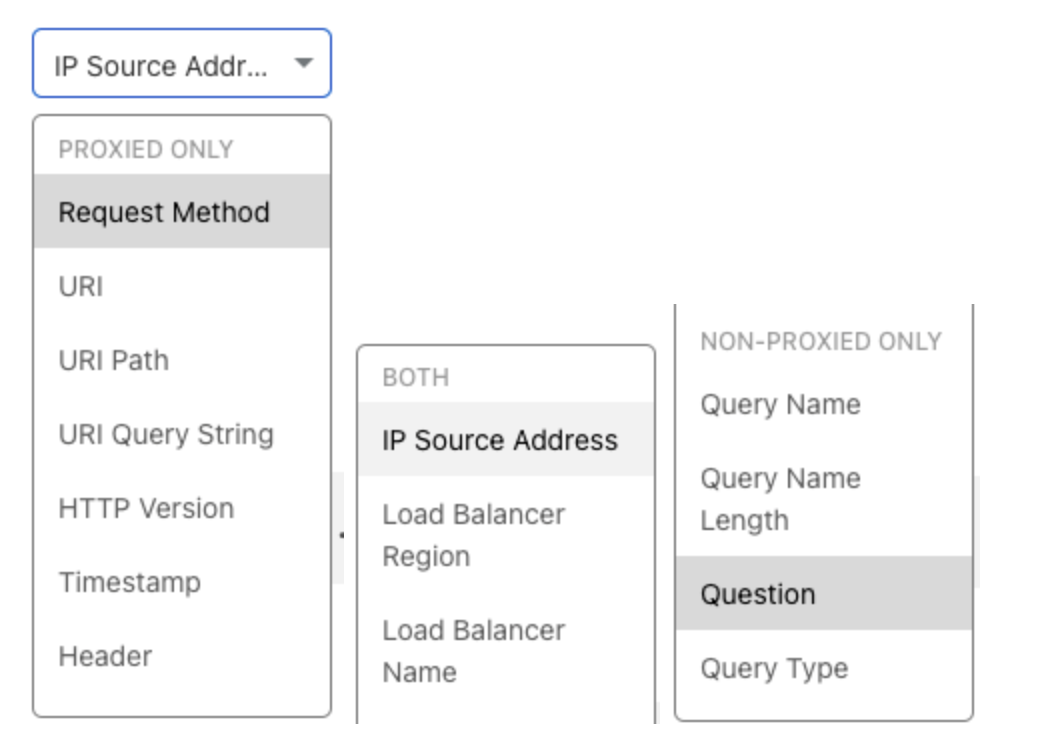
Load Balancing by path becomes easy, requiring just a few minutes to enter the paths and some boolean statements to create complex rules. Steer by a specific header, query string, or cookie. It’s no longer a pain point. Leverage a split horizon DNS design by creating a rule looking at the IP source address and then routing to the appropriate pool based on the value. This is just a small subset of the very robust capabilities that load balancing custom rules makes available to our users and this is just the start! Not only do we have a large amount of functionality right out of the box, but we’re also providing a consistent, intuitive experience by building on our Firewall Rules Engine.
Let’s go through some use cases to explore how custom rules can open new possibilities by giving you more granular control of your traffic.
High-volume transactions for ecommerce
For any high-volume transaction business such as an ecommerce or retail store, ensuring the transactions go through as fast and reliably as possible is a table stakes requirement. As transaction volume increases, no single origin can handle the incoming traffic, and it doesn’t always make sense for it to do so. Why have a transaction request travel around the world to a specifically nominated origin for payment processing? This setup would only add latency, leading to degraded performance, increased errors, and a poor customer experience. But what if you could create custom logic to segment transactions to different origin servers based on a specific value in a query string, such as a PS5 (associated with Sony’s popular PlayStation 5)? What if you could then couple that value with dynamic latency steering to ensure your load balancer always chooses the most performant path to the origin? This would be game changing to not only ensure that table-stakes transactions are reliable and fast but also drastically improve the customer experience. You could do this in minutes with load balancing custom rules:
For any requests where the query string shows ‘PS5’, then route based on which pool is the most performant.
Load balance across multiple DNS vendors to support privacy and security
Some customers may want to use multiple DNS providers to bolster their resiliency along with their security and privacy for the different types of traffic going through their network. By utilizing two DNS providers, customers can not only be sure that they remain highly available in times of outages, but also direct different types of traffic, whether that be internal network traffic across offices or unknown traffic from the public Internet.
Without flexibility, however, it can be difficult to easily and intelligently route traffic to the proper data centers to maintain that security and privacy posture. Not anymore! With load balancing custom rules, supporting a split horizon DNS architecture takes as little as five minutes to set up a rule based on the IP source condition and then overwriting which pools or data centers that traffic should route to.
This can also be extremely helpful if your data centers are spread across multiple areas of the globe that don’t align with the 13 current regions within Cloudflare. By segmenting where traffic goes based on the IP source address, you can create a type of geo-steering setup that is also finely tuned to the requirements of the business!
How did we build it?
We built Load Balancing rules on top of our open-source wirefilter execution engine. People familiar with Firewall Rules and other products will notice similar syntax since both products are built on top of this execution engine.
By reusing the same underlying engine, we can take advantage of a battle-tested production library used by other products that have the performance and stability requirements of their own. For those experienced with our rule-based products, you can reuse your knowledge due to the shared syntax to define conditionals statements. For new users, the Wireshark-like syntax is often familiar and relatively simple.
DNS vs Proxied?
Our Load Balancer supports both DNS and Proxied load balancing. These two protocols operate very differently and as such are handled differently.
For DNS-based load balancing, our load balancer responses to DNS queries sent from recursive resolvers. These resolvers are normally not the end user directly requesting the traffic nor is there a 1-to-1 ratio between DNS query and end-user requests. The DNS makes extensive use of caching at all levels so the result of each query could potentially be used by thousands of users. Combined, this greatly limits the possible feature set for DNS. Since you don’t see the end user directly nor know if your response is going to be used by one or more users, all responses can only be customized to a limited degree.
Our Proxied load balancing, on the other hand, processes rules logic for every request going through the system. Since we act as a proxy for all these requests, we can invoke this logic for all requests and access user-specific data.
These different modes mean the fields available to each end up being quite different. The DNS load balancer gets access to DNS-specific fields such as “dns.qry.name” (the query name) while our Proxied load balancer has access to “http.request.method” (the HTTP method used to access the proxied resource). Some more general fields — like the name of the load balancer being used — are available in both modes.
How does it work under the hood?
When a load balancer rule is configured, that API call will validate that the conditions and actions of the rules are valid. It makes sure the condition only references known fields, isn’t excessively long, and is syntactically valid. The overrides are processed and applied to the load balancers configuration to make sure they won’t cause an invalid configuration. After validation, the new rule is saved to our database.
With the new rule saved, we take the load balancer’s data and all rules used by it and package that data together into one configuration to be shipped out to our edge. This process happens very quickly, so any changes are visible to you in just a few seconds.
While DNS and proxied load balancers have access to different fields and the protocols themselves are quite different, the two code paths overlap quite a bit. When either request type makes it to our load balancer, we first load up the load balancer specific configuration data from our edge datastore. This object contains all the “static” data for a load balancer, such as rules, origins, pools, steering policy, and so forth. We load dynamic data such as origin health and RTT data when evaluating each pool.
At the start of the load balancer processing, we run our rules. This ends up looking very much like a loop where we check each condition and — if the condition is true — we apply the effects specified by the rules. After each condition is processed and the effects are applied we then run our normal load balancing logic as if you have configured the load balancer with the overridden settings. This style of applying each override in turn allows more than one rule to change a given setting multiple times during execution. This lets users avoid extremely long and specific conditionals and instead use shorter conditionals and rule ordering to override specific settings creating a more modular ruleset.
What’s coming next?
For you, the next steps are simple. Start building custom load balancing rules! For more guidance, check out our developer documentation.
For us, we’re looking to expand this functionality. As this new feature develops, we are going to be identifying new fields for conditionals and new options for overrides to allow more specific behavior. As an example, we’ve been looking into exposing a means to creating more time-based conditionals, so users can create rules that only apply during certain times of the day or month. Stay tuned to the blog for more!
Today, we are excited to announce Cloudflare Waiting Room! It will first be available to select customers through a new program called Project Fair Shot which aims to help with the problem of overwhelming demand for COVID-19 vaccinations causing appointment registration websites to fail. General availability in our Business and Enterprise plans will be added in the near future.
Wait, you’re excited about a… Waiting Room?
Most of us are familiar with the concept of a waiting room, and rarely are we excited about the idea of being in one. Usually our first experience of one is at a doctor’s office — yes, you have an appointment, but sometimes the doctor is running late (or one of the patients was). Given the doctor can only see one person at a time… the waiting room was born, as a mechanism to queue up patients.
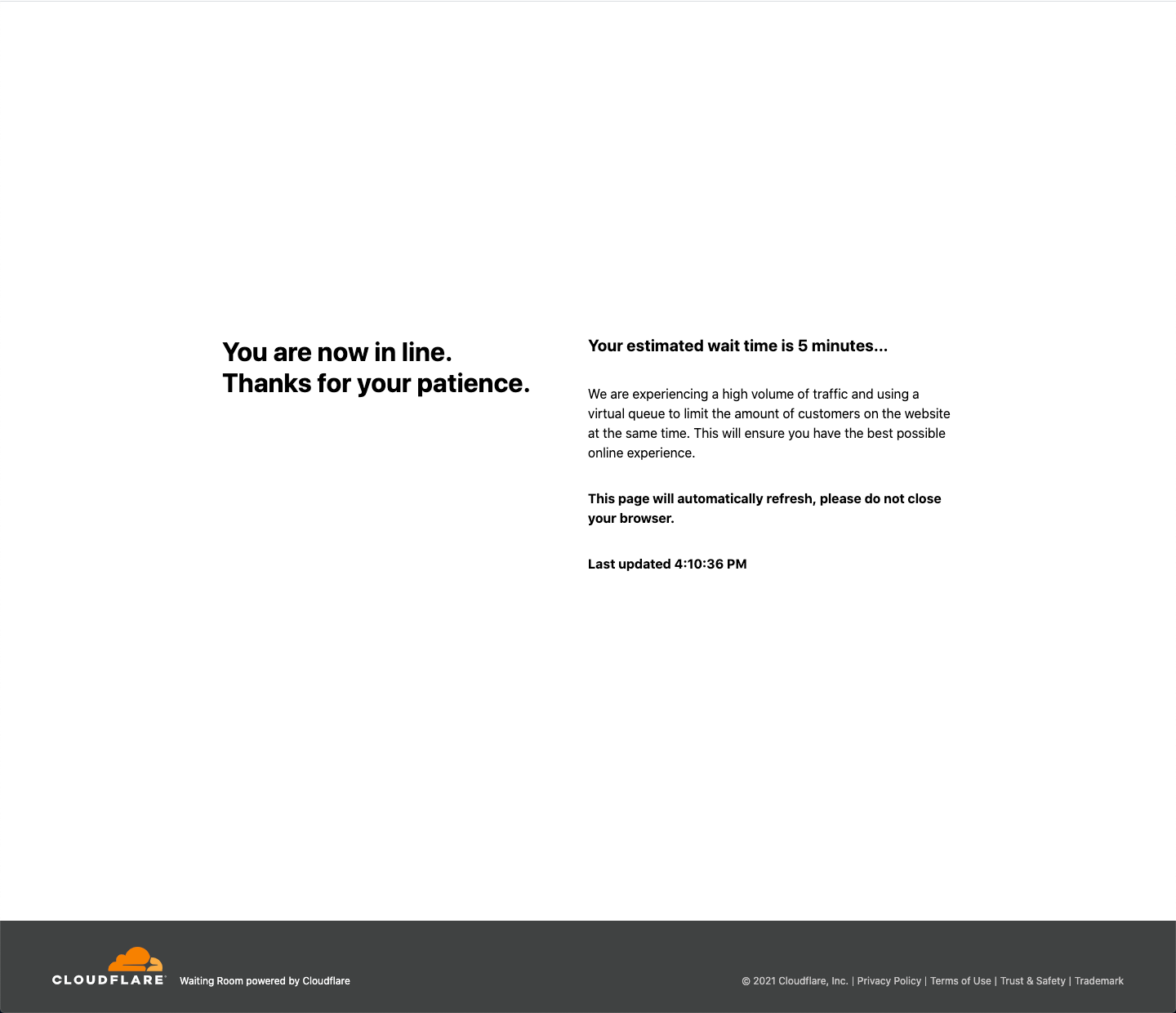
While servers can handle more concurrent requests than a doctor can, they too can be overwhelmed. If, in a pre-COVID world, you’ve ever tried buying tickets to a popular concert or event, you’ve probably encountered a waiting room online. It limits requests inbound to an application, and places these requests into a virtual queue. Once the number of users in the application has reduced, new users are let in within the defined thresholds the application can handle. This protects the origin servers supporting the application from being inundated with too many requests, while also ensuring equity from a user perspective — users who try to access a resource when the system is overloaded are not unfairly dropped and forced to reconnect, hoping to join their chance in the queue.
Why Now?
Given not many of us are going to live concerts any time soon, why is Cloudflare doing this now?
Well, perhaps we aren’t going to concerts, but the second order effects of COVID-19 have created a huge need for waiting rooms. First of all, given social distancing and the closing of many places of business and government, customers and citizens have shifted to online channels, putting substantially more strain on business and government infrastructure.
Second, the pandemic and the flow-on consequences of it have meant many folks around the world have come to rely on resources that they didn’t need twelve months earlier. To be specific, these are often health or government-related resources — for example, unemployment insurance websites. The online infrastructure was set up to handle a peak load that didn’t foresee the impact of COVID-19. We’re seeing a similar pattern emerge with websites that are related to vaccines.
Historically, the number of organizations that needed waiting rooms was quite small. The nature of most businesses online usually involve a more consistent user load, rather than huge crushes of people all at once. Those organizations were able to build custom waiting rooms and were integrated deeply into their application (for example, buying tickets). With Cloudflare’s Waiting Room, no code changes to the application are necessary and a Waiting Room can be set up in a matter of minutes for any website without writing a single line of code.
Whether you are an engineering architect or a business operations analyst, setting up a Waiting Room is simple. We make it quick and easy to ensure your applications are reliable and protected from unexpected spikes in traffic. Other features we felt were important are automatic enablement and dynamic outflow. In other words, a waiting room should turn on automatically when thresholds are exceeded and as users finish their tasks in the application, let out different sized buckets of users and intake new ones already in the queue. It should just work. Lastly, we’ve seen the major impact COVID-19 has made on users and businesses alike, especially, but not limited to, the health and government sectors. We wanted to provide another way to ensure these applications remain available and functional so all users can receive the care that they need and not errors within their browser.
How does Cloudflare’s Waiting Room work?
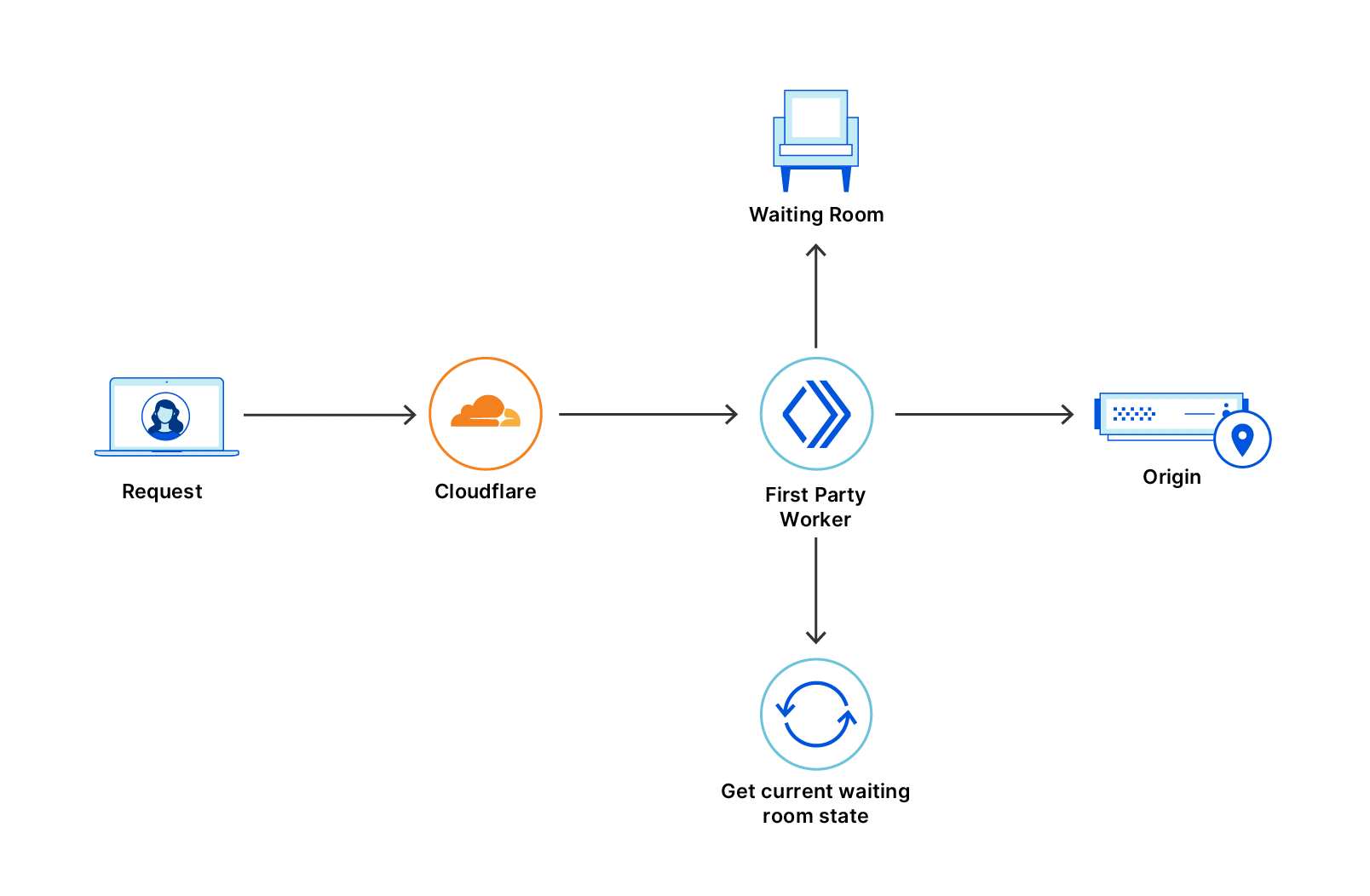
We built Waiting Room on top of our edge network and our Workers product. By leveraging Workers and our new Durable Objects offerings, we were able to remove the need for any customer coding and provide a seamless, out of the box product that will ‘just work’. On top of this, we get the benefits of the scale and performance of our Workers product to ensure we maintain extremely low latency overhead, keep estimated times presented to end users accurate as can be and not keep any user in the queue longer than needed. But building a centralized system in a decentralized network is no easy task. When requests come into an application from around the world, we need to be able to get a broad, accurate view of what that load looks like inbound and outbound to a given application.
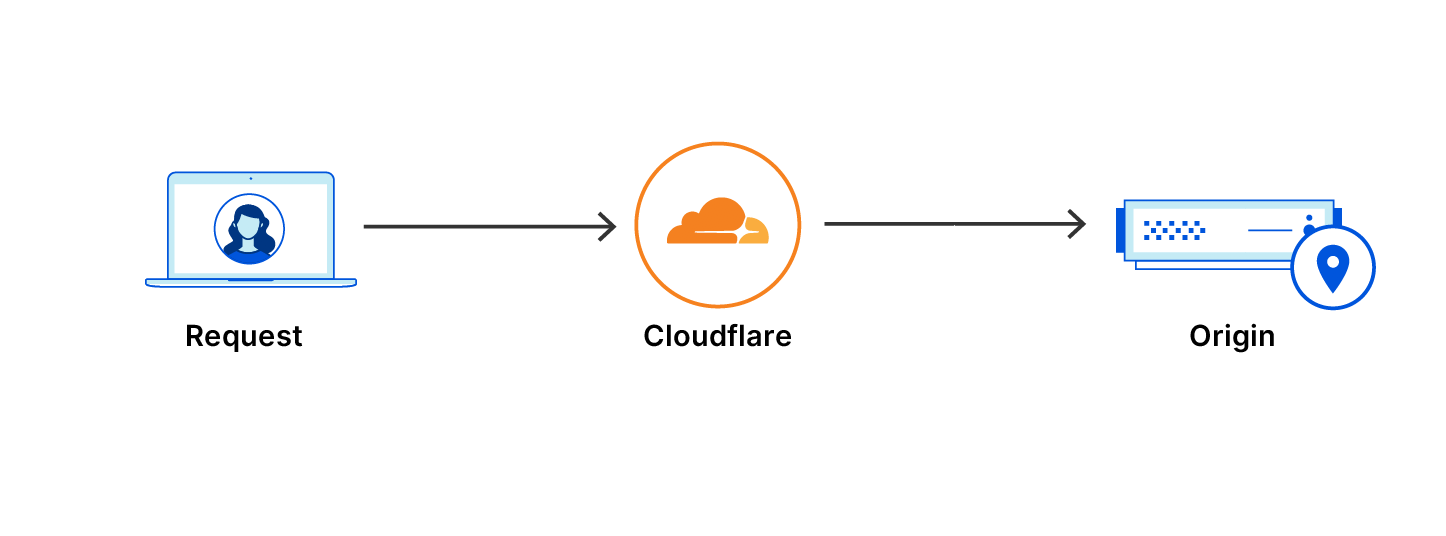
Request going through Cloudflare without a Waiting Room
These requests, as fast as they are, still take time to travel across the planet. And so, a unique edge case was presented. What if a website is getting reasonable traffic from North America and Europe, but then a sudden major spike of traffic takes place from South America – how do we know when to keep letting users into the application and when to kick in the Waiting Room to protect the origin servers from being overloaded?
Thanks to some clever engineering and our Workers product, we were able to create a system that almost immediately keeps itself synced with global demand to an application giving us the necessary insight into when we should and should not be queueing users into the Waiting Room. By leveraging our global Anycast network and over 200+ data centers, we remove any single point of failure to protect our customers’ infrastructure yet also provide a great experience to end-users who have to wait a small amount of time to enter the application under high load.
Request going through Cloudflare with a Waiting Room
How to setup a Waiting Room
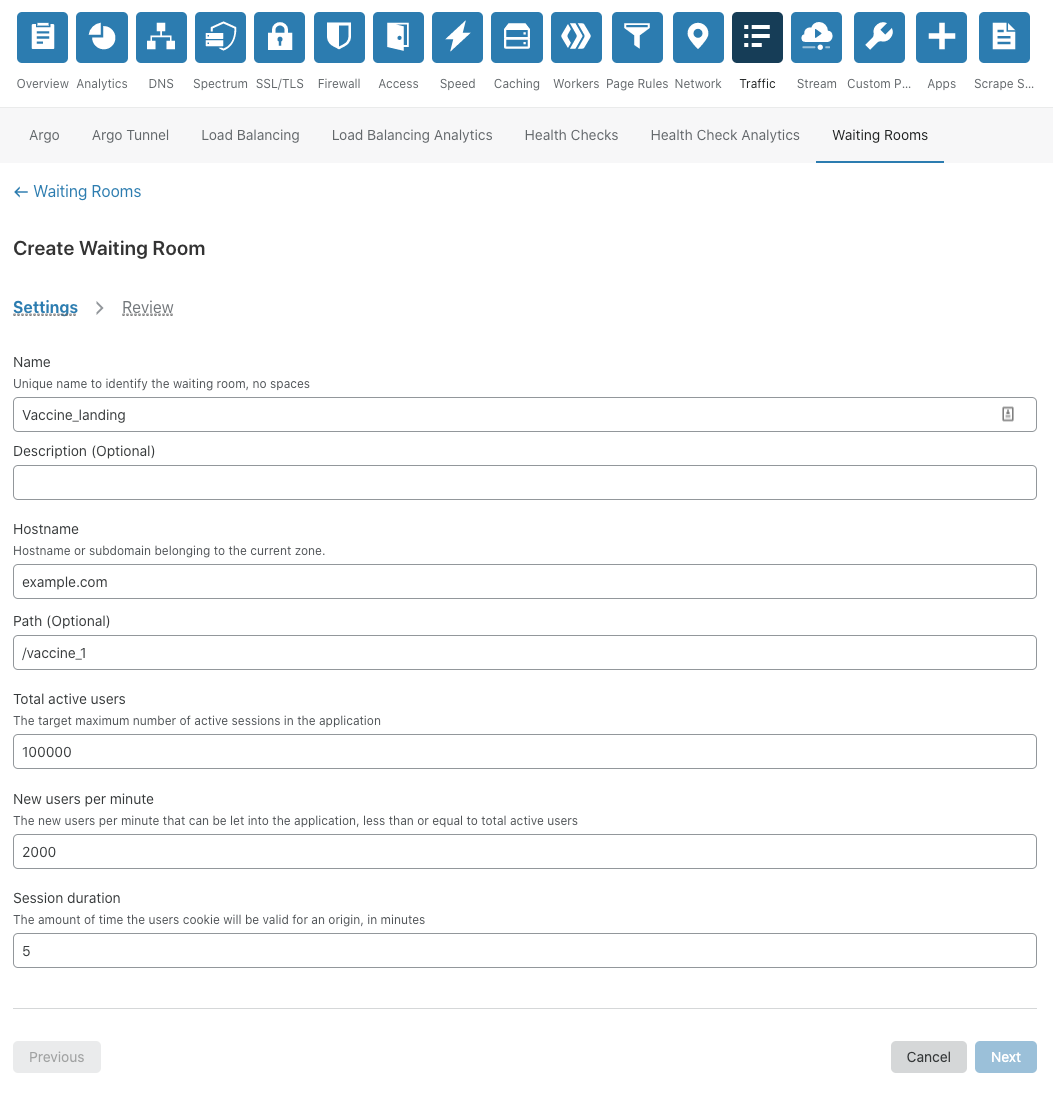
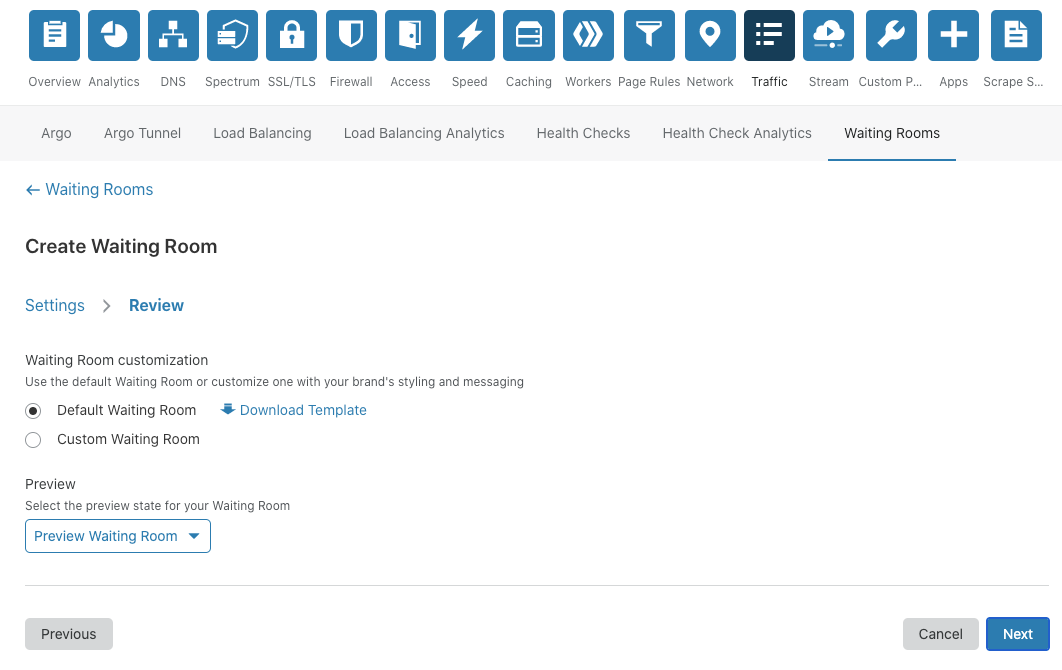
Setting up a Waiting Room is incredibly easy and very fast! At the easiest side of the scale, a user needs to fill out only five fields: 1) the name of the Waiting Room, 2) a hostname (which will already be pre-populated with the zone it’s being configured on), 3) the total active users that can be in the application at any given time, 4) the new users per minute allowed into the application, and 5) the session duration for any given user. No coding or any application changes are necessary.
We provide the option of using our default Waiting Room template for customers who don’t want to add additional branding. This simplifies the process of getting a Waiting Room up and running.
That’s it! Press save and the Waiting Room is ready to go!
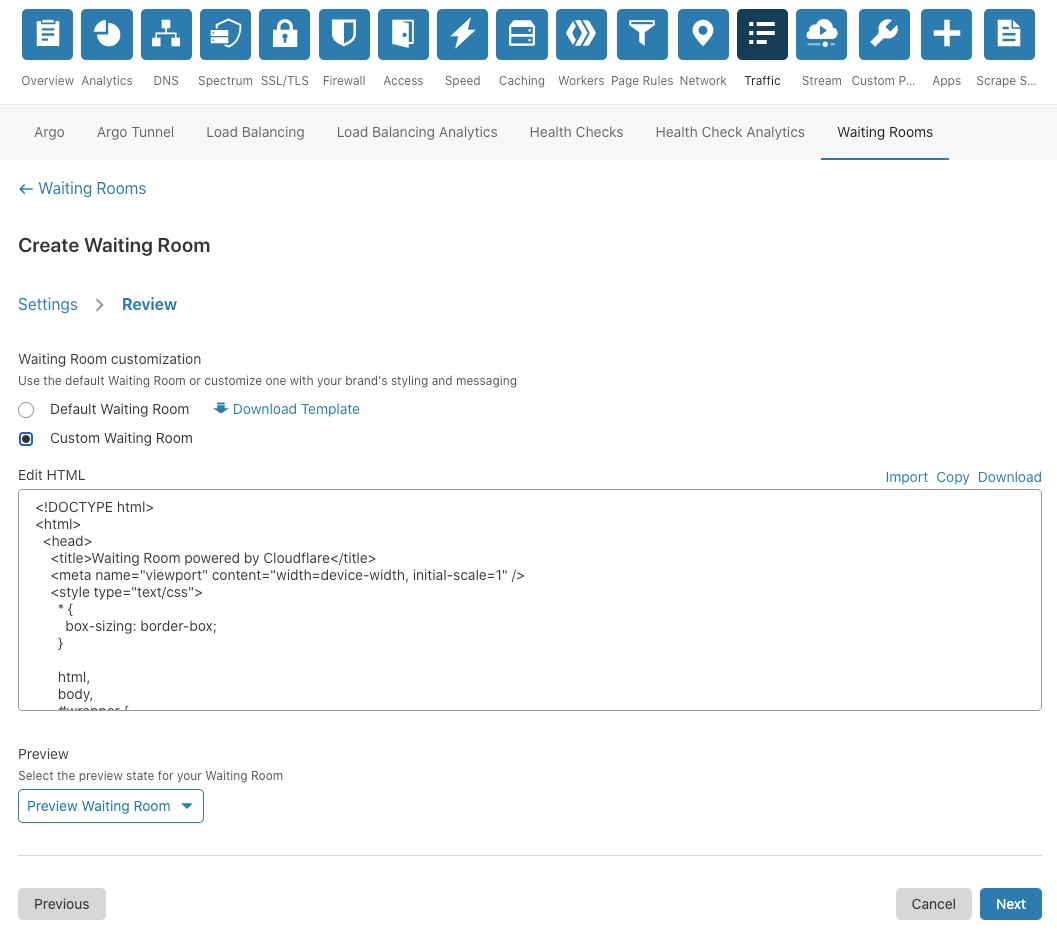
For customers with more time and technical ability, the same process is followed, except we give full customization capabilities to our users so they can brand the Waiting Room, ensuring it matches the look and feel of their overall product.
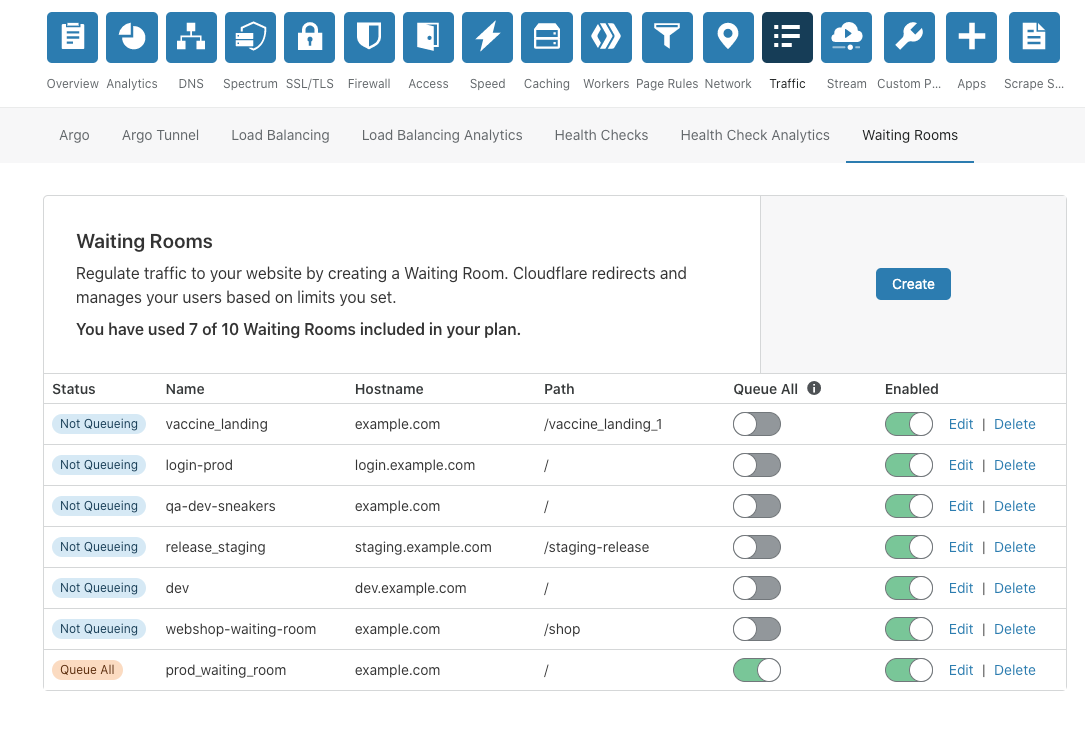
Lastly, managing different Waiting Rooms is incredibly easy. With our Manage Waiting Room table, at a glance you are able to get a full snapshot of which rooms are actively queueing, not queueing, and/or disabled.
We are very excited to put the power of our Waiting Room into the hands of our customers to ensure they continue to focus on their businesses and customers. Keep an eye out for another blog post coming soon with major updates to our Waiting Room product for Enterprise!
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.