If you’re a marketer, advertiser, or a business owner that runs your own website, there’s a good chance you’ve used Google tags in order to collect analytics or measure conversions. A Google tag is a single piece of code you can use across your entire website to send events to multiple destinations like Google Analytics and Google Ads.
Historically, the common way to deploy a Google tag meant serving the JavaScript payload directly from Google’s domain. This can work quite well, but can sometimes impact performance and accurate data measurement. That’s why Google developed a way to deploy a Google tag using your own first-party infrastructure using server-side tagging. However, this server-side tagging required deploying and maintaining a separate server, which comes with a cost and requires maintenance.
That’s why we’re excited to be Google’s launch partner and announce our direct integration of Google tag gateway for advertisers, providing many of the same performance and accuracy benefits of server-side tagging without the overhead of maintaining a separate server.
Any domain proxied through Cloudflare can now serve your Google tags directly from that domain. This allows you to get better measurement signals for your website and can enhance your campaign performance, with early testers seeing on average an 11% uplift in data signals. The setup only requires a few clicks — if you already have a Google tag snippet on the page, no changes to that tag are required.
Oh, did we mention it’s free? We’ve heard great feedback from customers who participated in a closed beta, and we are excited to open it up to all customers on any Cloudflare plan today.
Combining Cloudflare’s security and performance infrastructure with Google tag’s ease of use
Google Tag Manager is the most used tag management solution: it makes a complex tagging ecosystem easy to use and requires less effort from web developers. That’s why we’re collaborating with the Ads measurement and analytics teams at Google to make the integration with Google tag gateway for advertisers as seamless and accessible as possible.
Site owners will have two options of where to enable this feature: in the Google tag console, or via the Cloudflare dashboard. When logging into the Google tag console, you’ll see an option to enable Google tag gateway for advertisers in the Admin settings tab.
Alternatively, if you already know your tag ID and have admin access to your site’s Cloudflare account, you can enable the feature, edit the measurement ID and path directly from the Cloudflare dashboard:
Improved performance and measurement accuracy
Before, if site owners wanted to serve first-party tags from their own domain, they had to set up a complex configuration: create a CNAME entry for a new subdomain, create an Origin Rule to forward requests, and a Transform Rule to include geolocation information.
This new integration dramatically simplifies the setup and makes it a one-click integration by leveraging Cloudflare’s position as a reverse proxy for your domain.
In Google Tag Manager’s Admin settings, you can now connect your Cloudflare account and configure your measurement ID directly in Google, and it will push your config to Cloudflare.
When you enable the Google tag gateway for advertisers, specific calls to Google’s measurement servers from your website are intercepted and re-routed through your domain. The result: instead of the browser directly requesting the tag script from a Google domain (e.g. www.googletagmanager.com), the request is routed seamlessly through your own domain (e.g. www.example.com/metrics).
Cloudflare acts as an intermediary for these requests. It first securely fetches the necessary Google tag JavaScript files from Google’s servers in the background, then serves these scripts back to the end user’s browser from your domain. This makes the request appear as a first-party request.
A bit more on how this works: When a browser requests https://example.com/gtag/js?id=G-XXXX, Cloudflare intercepts and rewrites the path into the original Google endpoint, preserving all query-string parameters and normalizing the Origin and Referer headers to match Google’s expectations. It then fetches the script on your behalf, and routes all subsequent measurement payloads through the same first-party proxy to the appropriate Google collection endpoints.
This setup also impacts how cookies are stored from your domain. A cookie is a small text file that a website asks your browser to store on your computer. When you visit other pages on that same website, or return later, your browser sends that cookie back to the website’s server. This allows the site to remember information about you or your preferences, like whether a user is logged in, items in a shopping cart, or, in the case of analytics and advertising, an identifier to recognize your browser across visits.
Traditionally, when your website loaded a script directly from a third-party domain like www.googletagmanager.com, any cookies set by that script were associated with the googletagmanager.com domain. From your website’s perspective, these are “third-party cookies.”
With Cloudflare’s integration with Google tag gateway for advertisers, the tag script itself is delivered from your own domain. When this script instructs the browser to set a cookie, the cookie is created and stored under your website’s domain.
How can I get started?
Detailed instructions to get started can be found here. You can also log in to your Cloudflare Dashboard, navigate to the Engagement Tab, and select Google tag gateway in the navigation to set it up directly in the Cloudflare dashboard.
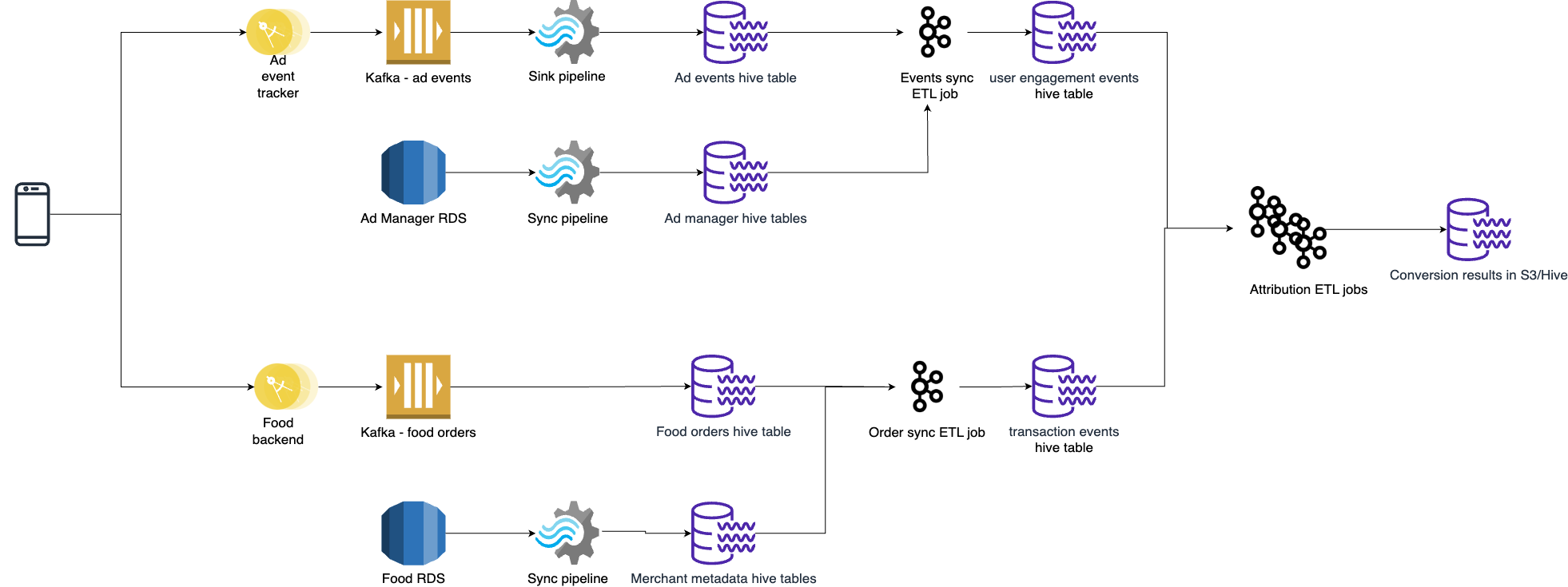
The Grab superapp offers a comprehensive array of services from ride-hailing and food delivery to financial services. This creates multifaceted user journeys, traversing homepages, product pages, checkouts, and interactions with diverse content, including advertisements and promo codes.
Background: Why ads and attribution matter in our superapp
Ads are crucial for Grab in driving user engagement and supporting our ecosystem by seamlessly connecting users with our services. In the ever-evolving world of advertising, the ability to gauge the impact of marketing investments takes on pivotal significance. Advertisers dedicate substantial resources to promote their businesses, necessitating a clear understanding of the return on AdSpend (ROAS) for each campaign. In this context, attribution plays a central role, serving as the guiding compass for advertisers and marketers, elucidating the effectiveness of touchpoints within campaigns.
For instance, a merchant-partner seeks to enhance its reach by advertising on the Grab food delivery homepage. With the assistance of our attribution system, the merchant-partner can now precisely gauge the impact of their homepage ads on Grab. This involves tracking user engagement and monitoring the resulting orders that stem from these interactions. This level of granularity not only highlights the value of attribution but also demonstrates its capability in providing detailed insights into the effectiveness of advertising campaigns and enabling merchant-partners to optimise their campaigns with more precision.
In this blog, we delve into the technical intricacies, software architecture, challenges, and solutions involved in crafting a state-of-the-art engineering solution for the attribution platform.
Genesis: Pre-project landscape
When our journey began in 2020, Grab’s marketing efforts had limited attribution capabilities and data analytics was predominantly reliant on ad hoc queries conducted by business and data analysts. Before the introduction of a standardised approach, we had to manage discrepant results and a time-consuming manual process of data preparation, cleansing, and storage across teams. When issues arose in the analytical pipeline, resolution efforts took relatively longer and were reoccurring. We needed a comprehensive engineering solution that would address the identified gaps, and significantly enhance metrics related to ROI, attribution accuracy, and data-handling efficiency.
Inception: The pure ads attribution engine (Kappa architecture)
We chose Kappa architecture due to its imperative role in achieving near real-time attribution, especially in support of our new pricing model, cost per order (CPO). With this solution, we aimed to drastically reduce data latency from 2-3 days to just a few minutes. Traditional ETL (Extract, Transform, and Load) based batch processing methods were evaluated but quickly found to be inadequate for our purposes, mainly due to their speed.
In the advertising industry, rapid decision-making is critical. Traditional batch processing solutions would introduce significant latency, hampering our ability to make real-time, data-driven decisions. With its architecture’s inherent capability for real-time stream processing, Kappa emerged as the logical choice. Additionally, Kappa offers the agility required to empower our ad-serving team for real-time decision support, and better ad ranking and selection, enabling dynamic and effective targeting decisions without delay.
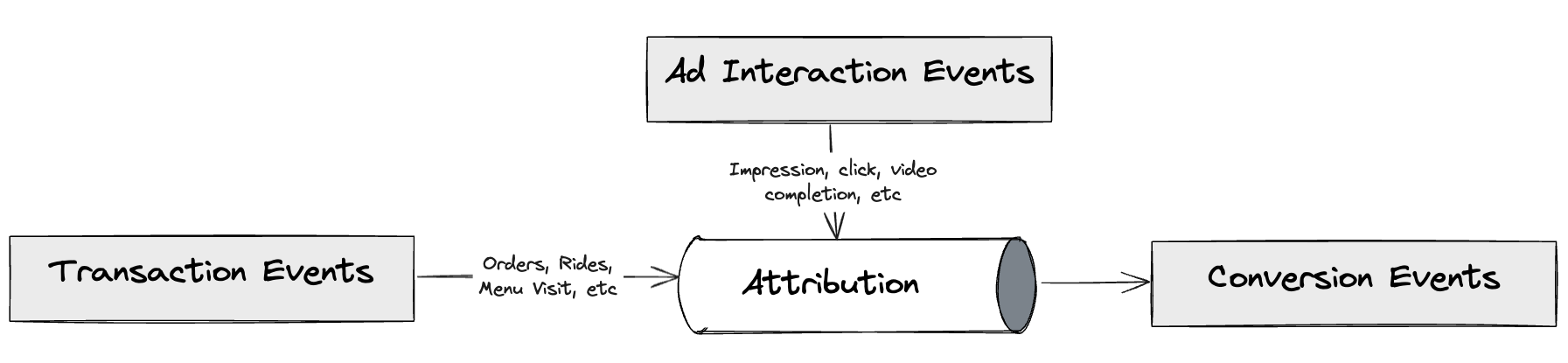
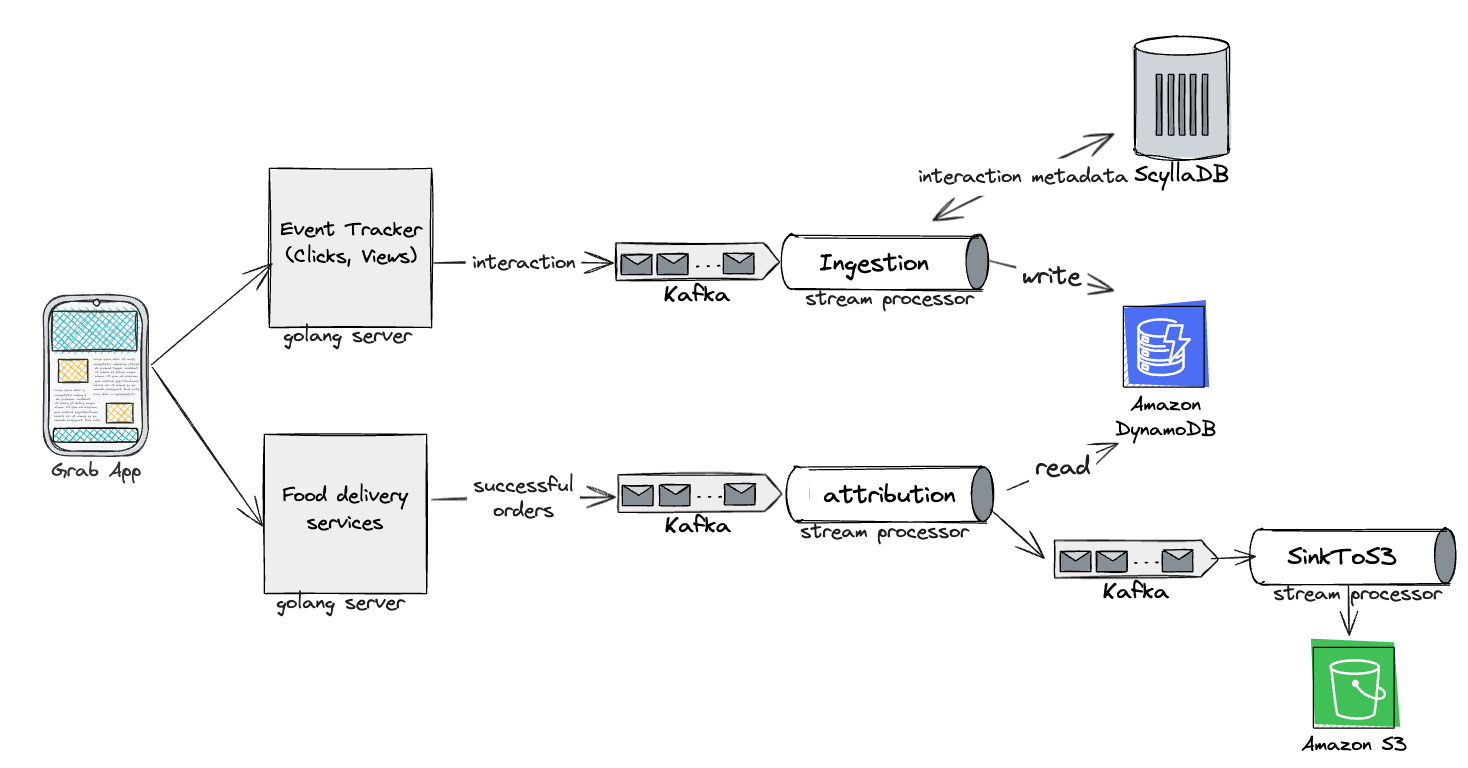
The first step on this journey was to create a pure and near real-time stream processing Ads Attribution Engine. This engine was based on the Kappa architecture to provide advertisers with quick insights into their ROAS offering real-time attribution, enabling advertisers to optimise their campaigns efficiently.
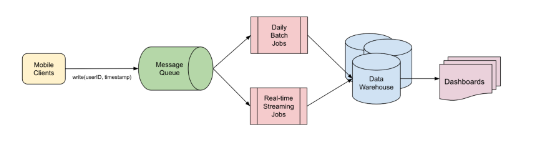
High-level workflow of the Ads Attribution Engine
In this solution, we used the following tools in our tech stack:
Kafka for event streams
DDB for events storage
Amazon S3 as the data lake
An in-house stream processing framework similar to Keystone
Redis for caching events
ScyllaDB for storing ad metadata
Amazon relational database service (RDS) for analytics
Architecture of the near real-time stream processing Ads Attribution Engine
Evolution: Merging marketing levers – Ads and promos
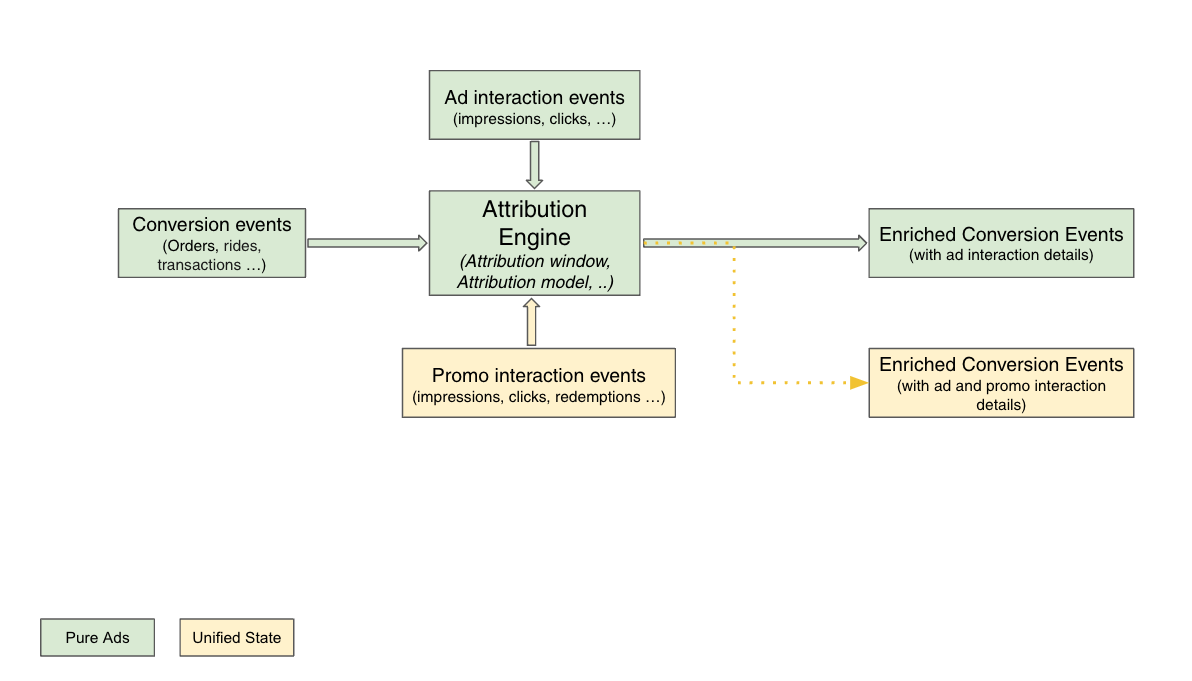
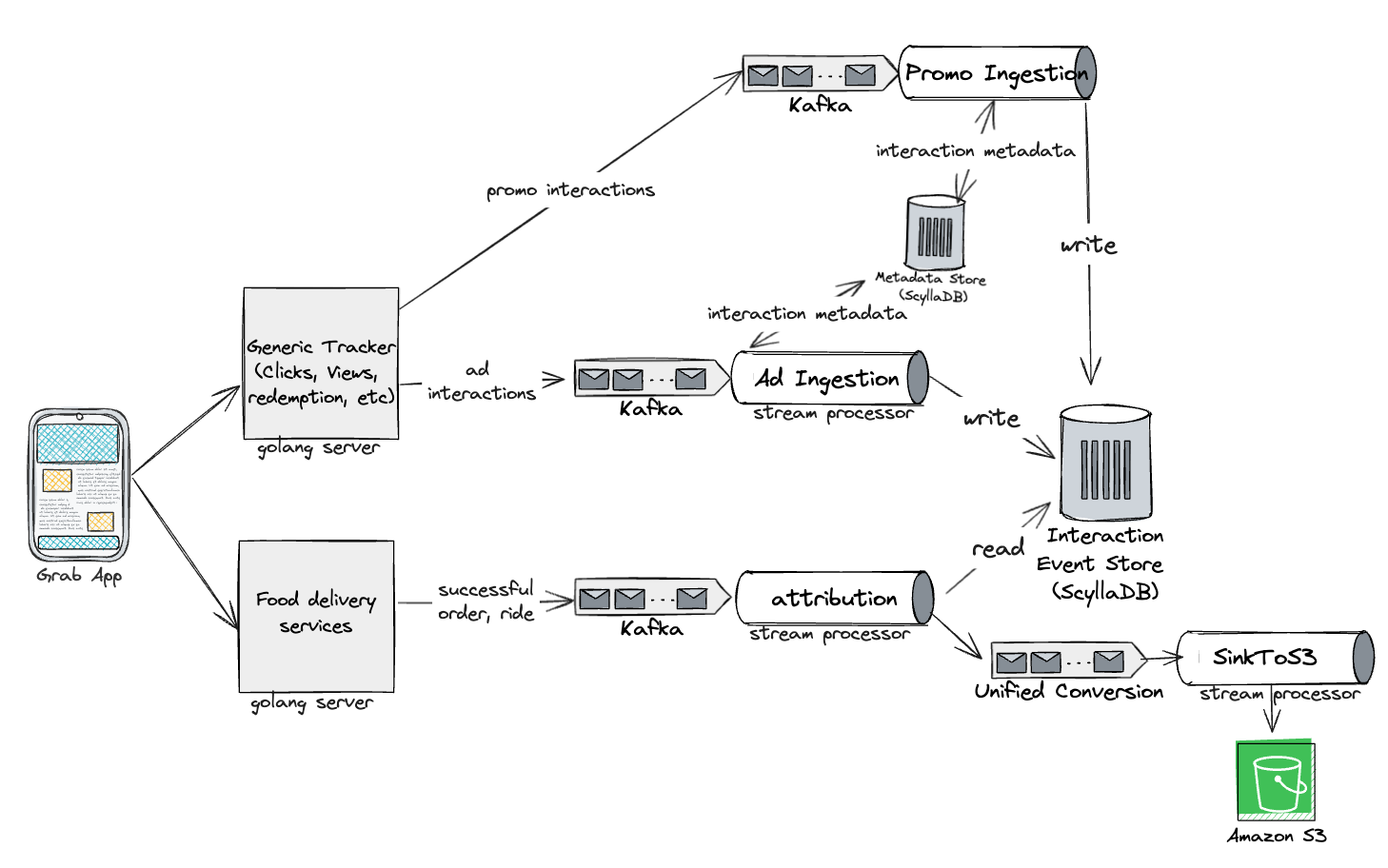
We began to envision a world where we could merge various marketing levers into a unified Attribution Engine, starting with ads and promos. This evolved vision also aimed to prevent order double counting (when a user interacts with both ads and promos in the same checkout), which would provide a more holistic attribution solution.
With the unified Attribution Engine, we would also enable more sophisticated personalisation through machine learning models and drive higher conversions.
The unified Attribution Engine workflow, which included Promo touch points
The unified attribution engine used mostly the same tech stack, except for analytics where Druid was used instead of RDS.
Architecture of the unified Attribution Engine
Introspection: Identifying shortcomings and the path to improvement
While the unified attribution engine was a step in the right direction, it wasn’t without its challenges. There were challenges related to real-time data processing costs, scalability for longer attribution windows, latency and lag issues, out-of-order events leading to misattribution, and the complexity of implementing multi-touch attribution models. To truly empower advertisers and enhance the attribution process, we knew we needed to evolve further.
Rebirth: The birth of a full-fledged attribution platform (Lambda architecture)
This journey eventually led us to build a full-fledged attribution platform using Lambda architecture, which blended both batch and real-time stream processing methods. With this change, our platform could rapidly and accurately process data and attribute the impact of ads and promos on user behaviour.
Why Lambda architecture?
This choice was a strategic one – real-time processing is vital for tracking events as they occur, but it offers only a current snapshot of user behaviour. This means we would not be able to analyse historical data, which is a crucial aspect of accurate attribution and exploring multiple attribution models. Historical data allows us to identify trends, patterns, and correlations not evident in real-time data alone.
High level workflow for the full-fledged attribution platform with Lambda architecture
In this system’s tech stack, the key components are:
Coban, an in-house stream processing framework used for real-time data processing
Spark-based ETL jobs for batch processing
Amazon S3 as the data warehouse
An offline layer that is capable of providing historical context, handling large data volumes, performing complex analytics, and so on.
Key benefits of the offline layer
Provides historical context: The offline layer enriches the attribution process by providing a historical perspective on user interactions, essential for precise attribution analysis spanning extended time periods.
Handles enormous data volumes: This layer efficiently manages and processes extensive data generated by advertising campaigns, ensuring that attribution seamlessly accommodates large-scale data sets.
Performs complex analytics: Enables more intricate computations and data analysis than real-time processing alone, the offline layer is instrumental in fine-tuning attribution models and enhancing their accuracy.
Ensures reliability in the face of challenges: By providing fault tolerance and resilience against system failures, the offline layer ensures the continuous and dependable operation of the attribution system, even during unexpected events.
Optimises data storage and serving: Relying on Amazon S3, the storage layer for raw data optimises storage by building interactive reporting APIs.
Architecture of our comprehensive offline attribution platform
Challenges with Lambda and mitigation
Lambda architecture allows us to have the accuracy and robustness of batch processing along with real-time stream processing. However, we noticed some drawbacks that may lead to complexity due to maintaining both batch and stream processing:
Operating two parallel systems for batch and stream processing can lead to increased complexity in production environments.
Lambda architecture requires two sets of business logic – one for the batch layer and another for the stream layer.
Synchronisation across both layers can make system alterations more challenging.
This dual implementation could also allude to inconsistencies and introduce potential bugs into the system.
To mitigate these complications, we’re establishing an optimisation strategy for our current system. By distinctly separating the responsibilities of our real-time pipelines from those of our offline jobs, we intend to harness the full potential of each approach, while simultaneously curbing the added complexity.
Hence, redefining the way we utilise Lambda architecture, striking an efficient balance between real-time responsiveness and sturdy accuracy with the below proposal.
Vanguard: Enhancements in the future
In the coming months, we will be implementing the optimisation strategy and improving our attribution platform solution. This strategy can be broken down into the following sections.
Real-time pipeline handling time-sensitive data: Real-time pipelines can process and deliver time-sensitive metrics like CPO-related data in near real-time, allowing for budget capping and immediate adjustments to marketing spend. This can provide us with actionable insights that can help with areas like real-time bidding, real-time marketing, or dynamic pricing. By limiting the volume of data through the real-time path, we can ensure it’s more manageable and focused on immediate actionable data.
Batch jobs handling all other reporting data: Batch processing is best suited for computations that are not time-bound and where completeness is more important. By dedicating more time to the processing phase, batch processing can handle larger volumes and more complex computations, providing more comprehensive and accurate reporting.
This approach will simplify our Lambda architecture, as the batch and real-time pipelines will have clear separation of duties. It may also reduce the chance of discrepancies between the real-time and batch-processing datasets and lower the operational load of our real-time system.
Conclusion: A holistic attribution picture
Through our journey of building a comprehensive attribution platform, we can now deliver a holistic and dependable view of user behaviour and empower merchant-partners to use insights from advertisements and promotions. This journey has been a long one, but we were able to improve our attribution solution in several ways:
Attribution latency: Successfully reduced attribution latency from 2-3 days to just a few minutes, ensuring that advertisers can access real-time insights and feedback.
Data accuracy: Through improved data collection and processing, we achieved data discrepancies of less than 1%, enhancing the accuracy and reliability of attribution data.
Conversion rate: Advertisers witnessed a significant increase in conversion rates, a direct result of our real-time attribution capabilities.
Cost efficiency: Embracing the Lambda architecture led to a ~25% reduction in real-time data processing costs, allowing for more efficient campaign optimisations.
Operational resilience: Building an offline layer provided fault tolerance and resilience against system failures, ensuring that our attribution system continued to operate seamlessly, even during unexpected events.
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
After winning Super Bowl LVII in 2023, the Kansas City Chiefs entered Super Bowl LVIII with an opportunity to pull off back-to-back wins, a feat last achieved by the New England Patriots two decades earlier, in 2003 and 2004. They faced the San Francisco 49ers, five-time Super Bowl champions, although their last win was nearly three decades ago, in 1995. The game started slowly, remaining scoreless until the start of the second quarter, after which both teams traded the lead until a tie score at the end of the game made it only the second Super Bowl to go into overtime. And if you weren’t watching it for the football, the advertisements certainly didn’t disappoint. And if you weren’t watching it for the football or the advertisements, but instead were waiting to see how many times CBS cut away to a shot of Taylor Swift during the game, the answer is… 16. (By my count, at least.)
In this blog post, we will explore which Super Bowl advertisements drove the largest spikes in traffic, as well as examine how traffic to food delivery services, social media, sports betting, and video platform websites and applications changed during the game. In addition, we look at local traffic trends seen during the game, as well as email threat volume across related categories in the weeks ahead of the game.
Cloudflare Radar uses a variety of sources to provide aggregate information about Internet traffic and attack trends. In this blog post, as we did last year and the year before, we use DNS name resolution data from our 1.1.1.1 resolver to estimate traffic to websites. We can’t see who visited the websites mentioned, or what anyone did on the websites, but DNS can give us an estimate of the interest generated by the ads or across a set of sites in the categories listed above.
Ads: URLs are no longer cool
In last year’s blog post, we asked “Are URLs no longer cool?”, noting that many of the advertisements shown during Super Bowl LVII didn’t include a URL. The trend continued into 2024, as over 100 ads were shown throughout Super Bowl LVIII, but only about one-third of them contained URLs — some were displayed prominently, some were in very small type. A few of the advertisements contained QR codes, and a few suggested downloading an app from Apple or Google’s app stores, but neither approach appears to be a definitive replacement for including a link to a website in the ad. And although Artificial Intelligence (AI) has all but replaced cryptocurrency as the thing that everyone is talking about, the lone AI ad during this year’s game was for Microsoft Copilot, which the company is positioning as an “everyday AI companion”.
As we did last year, we again tracked DNS request traffic to our 1.1.1.1 resolver in United States data centers for domains associated with the advertised products or brands. Traffic growth is plotted against a baseline calculated as the mean request volume for the associated domains between 12:00-15:00 EST on Sunday, February 11 (Super Bowl Sunday). The brands highlighted below were chosen because their advertisements drove some of the largest percentage traffic spikes observed during the game.
TurboTax
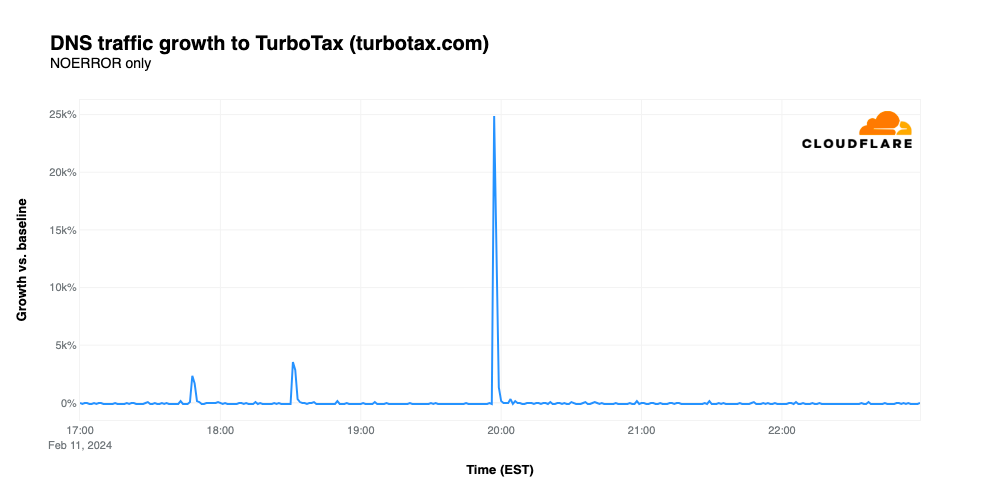
Although most Americans dislike having to pay taxes, they apparently feel that winning a million dollars would make doing so a little less painful. The Intuit TurboTax Super Bowl File ad, starring Emmy Award winner Quinta Brunson, included a URL pointing visitors to turbotax.com, where they could register to win one million dollars. The promotion aired a couple of times before the game began, visible as small spikes in the graph below, but it paid off for Intuit when it was shown at 19:56, driving traffic 24,875% above baseline and placing it as the ad that drove the largest increase in traffic.
DoorDash
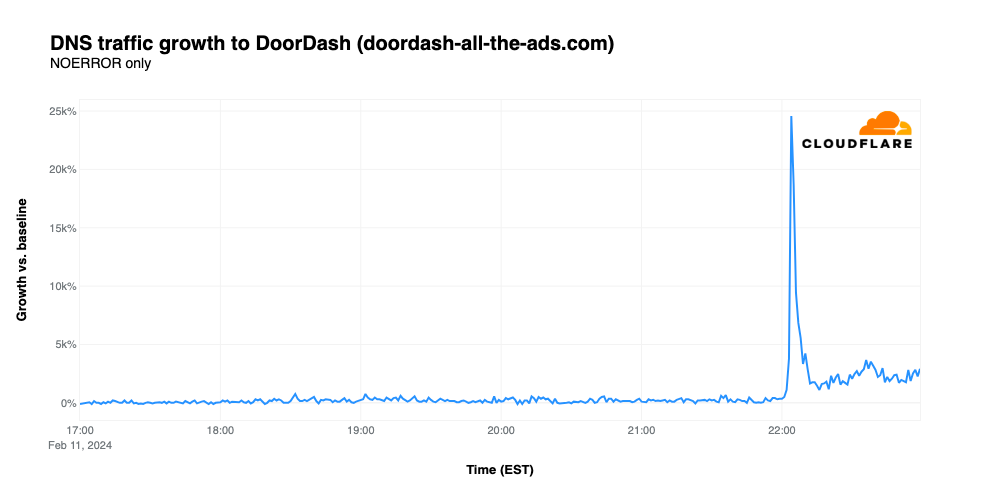
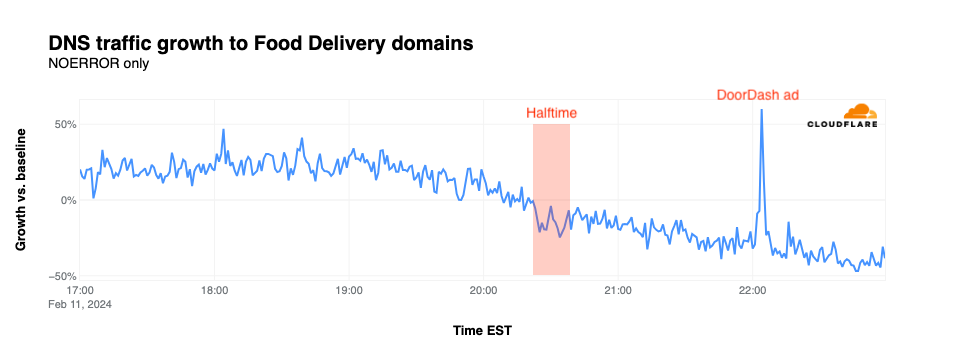
Most DoorDash deliveries are fairly nominal, and should be able to easily fit in the Dasher’s car. However, in a twist, the delivery for the “DoorDash all the ads” promotion includes several cars, as well as candy, cosmetics, trips, mayonnaise, and a myriad of other items, all of which appeared in Super Bowl advertisements, as a way for the company to demonstrate that they deliver more than. The ad, which prominently featured a URL for the contest site, aired at 22:03 EST and drove traffic 24,574% above baseline. The graph below shows that prominent spike, but it also shows traffic remaining 1700-2500% above baseline after the ad aired. This elevated traffic is likely due to efforts to transcribe the full promo code needed to enter the contest. The promo code, as crowdsourced in a Reddit thread, clocks in at a whopping 1,813 characters.
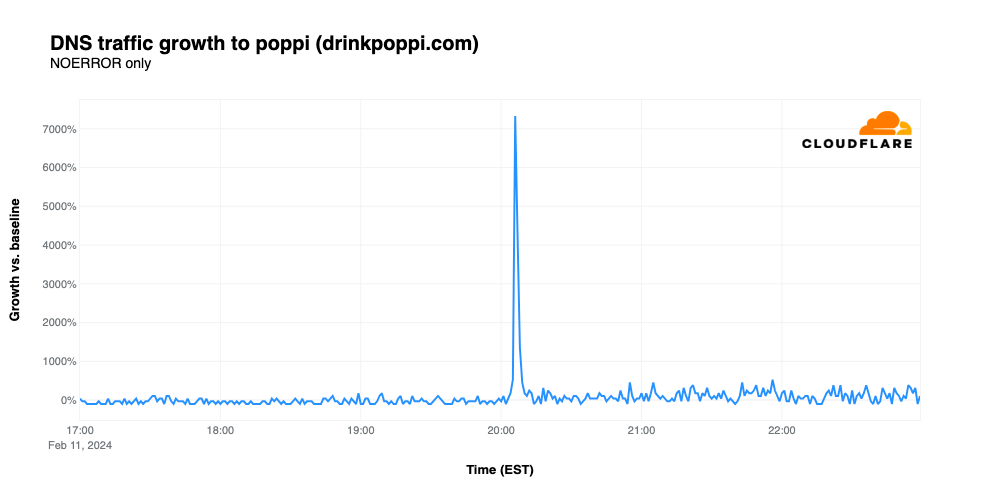
Poppi
Super Bowl ads for “new” drink brands have frequently driven significant amounts of traffic, such as the growth seen by Cutwater Spirits in 2022. Relative newcomer Poppi, a brand of soda that contains prebiotics, continued the trend, with traffic spiking 7,329% above baseline after its ad appeared at 20:04 EST, despite no URL appearing in the advertisement. However, it appears that not everyone was a fan of the ad, as critics complained that it “food shamed” those who choose to drink traditional sodas.
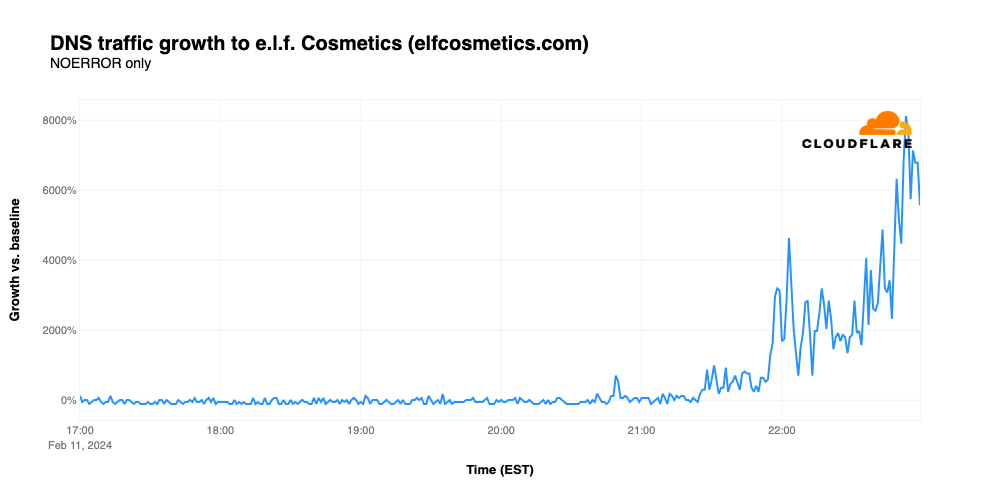
e.l.f. Cosmetics
The cosmetic brand’s second Super Bowl advertisement featured Judge Judy presiding over a courtroom scene featuring musician Meghan Trainor and the cast of the USA Network legal drama Suits. While the ad drove traffic for elfcosmetics.com to 8,118% over baseline despite lacking a URL, the timing of the growth is unusual as it doesn’t align with the time the ad aired (20:22 EST). The traffic starts to tick up around 21:24 EST, just after a Chiefs touchdown put them in the lead, peaking at 22:53, several minutes after the Chiefs won the game. It isn’t clear why e.l.f. appears to buck the trend seen for most Super Bowl ads, showing a gradual ramp in traffic before peaking, as opposed to a large spike aligned with the time that the ad was broadcast.
In addition to the advertisements discussed above, a number of others also experienced traffic spikes greater than 1,000% above baseline, including ads for the NFL, Hallow, He Gets Us, homes.com, Kawasaki, Robert F. Kennedy, Jr. 2024, Snapchat, Skechers, and Volkswagen.
App traffic sees mixed impacts
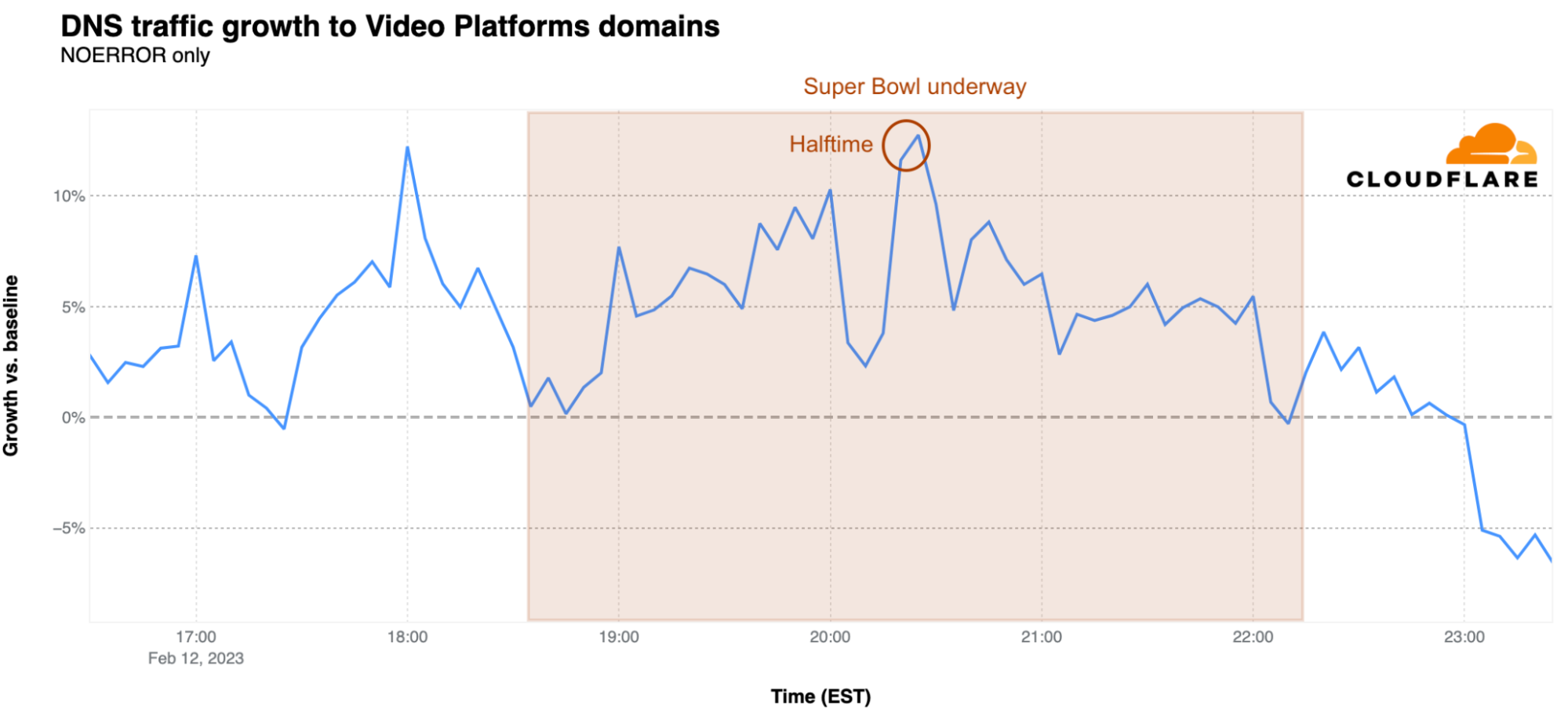
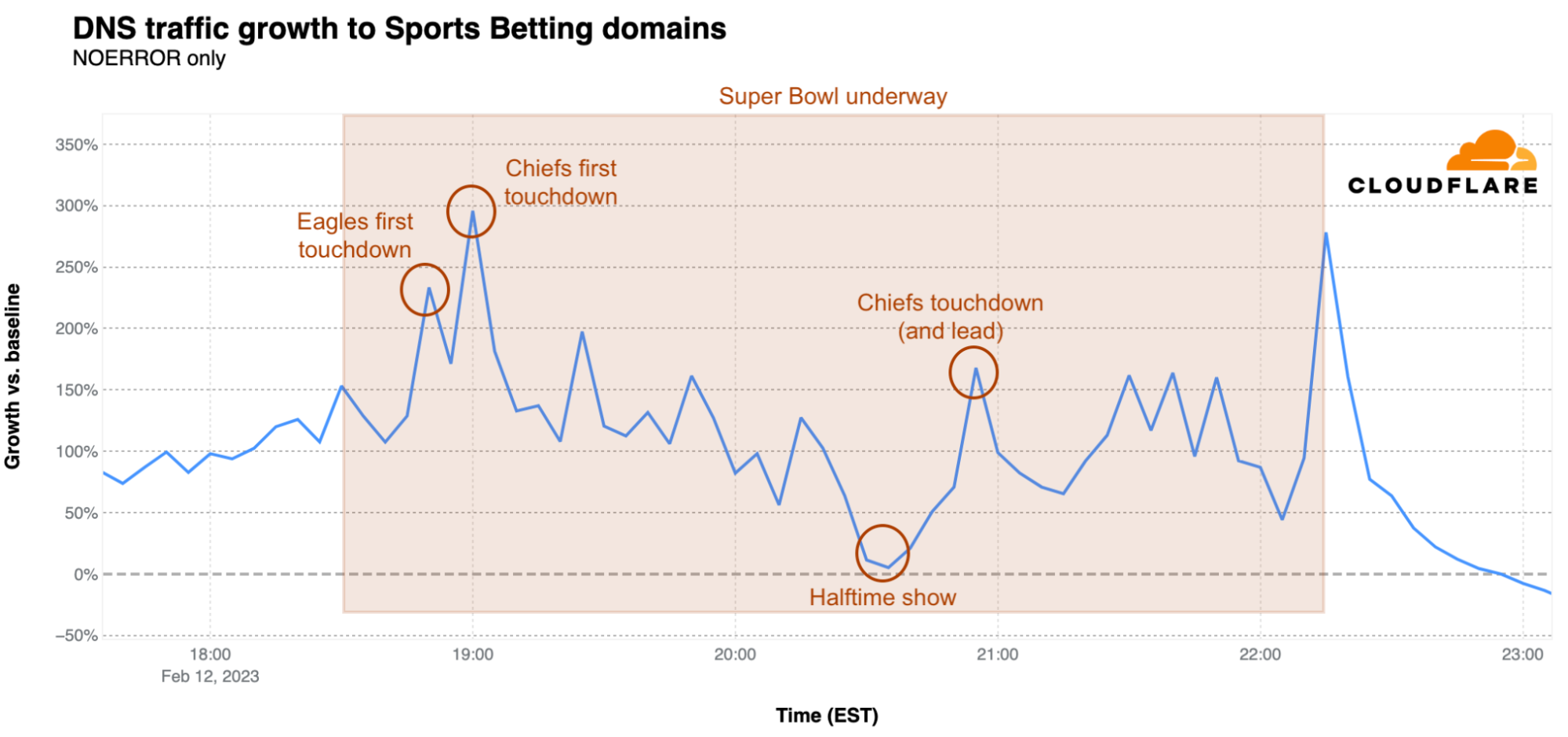
Using the same baseline calculations described above, we also looked at traffic for domains associated with several groups of sites, including food delivery, messaging, social media, and sports betting to see how events that occurred during the game impacted traffic. Traffic shifts among most of these groups remained fairly nominal during the game, with sports betting seeing the largest movement. Halftime is clearly visible within the graphs, as viewers apparently focused on the musical performance, which featured R&B singer Usher, joined by guests Alicia Keys, H.E.R., will.i.am, Ludacris, and Lil Jon.
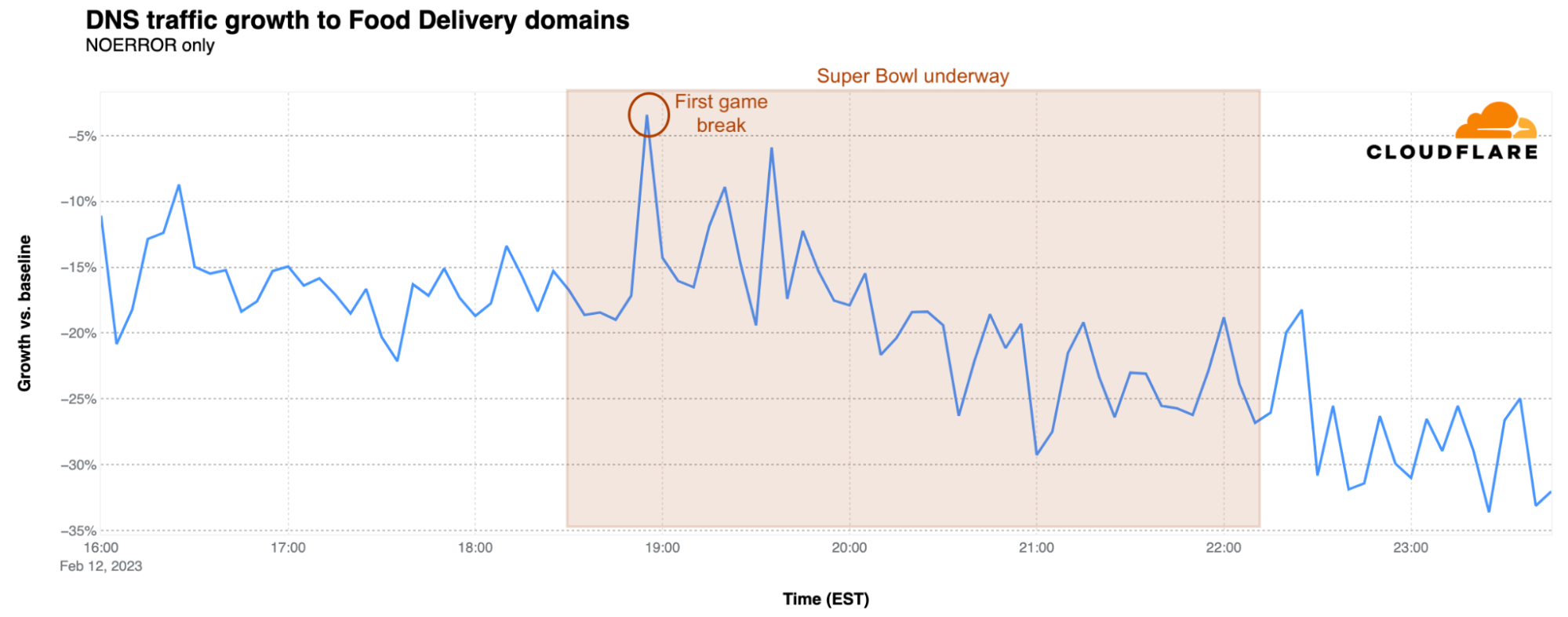
Food delivery
Traffic for food delivery sites remained relatively constant, on average, through the first quarter of the game, and started to decline as the second quarter started. A more significant dip is visible during halftime, with the drop continuing through the end of overtime. The outlier, of course, is the spike that occurred when the DoorDash advertisement aired, even though it featured a domain other than doordash.com, which is a member of this group.
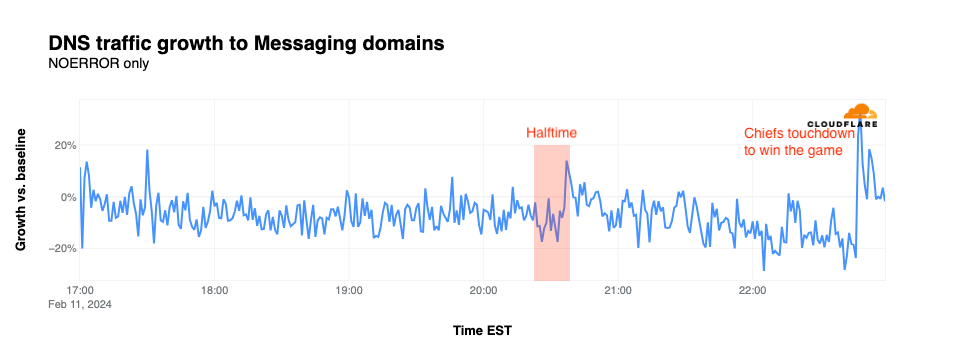
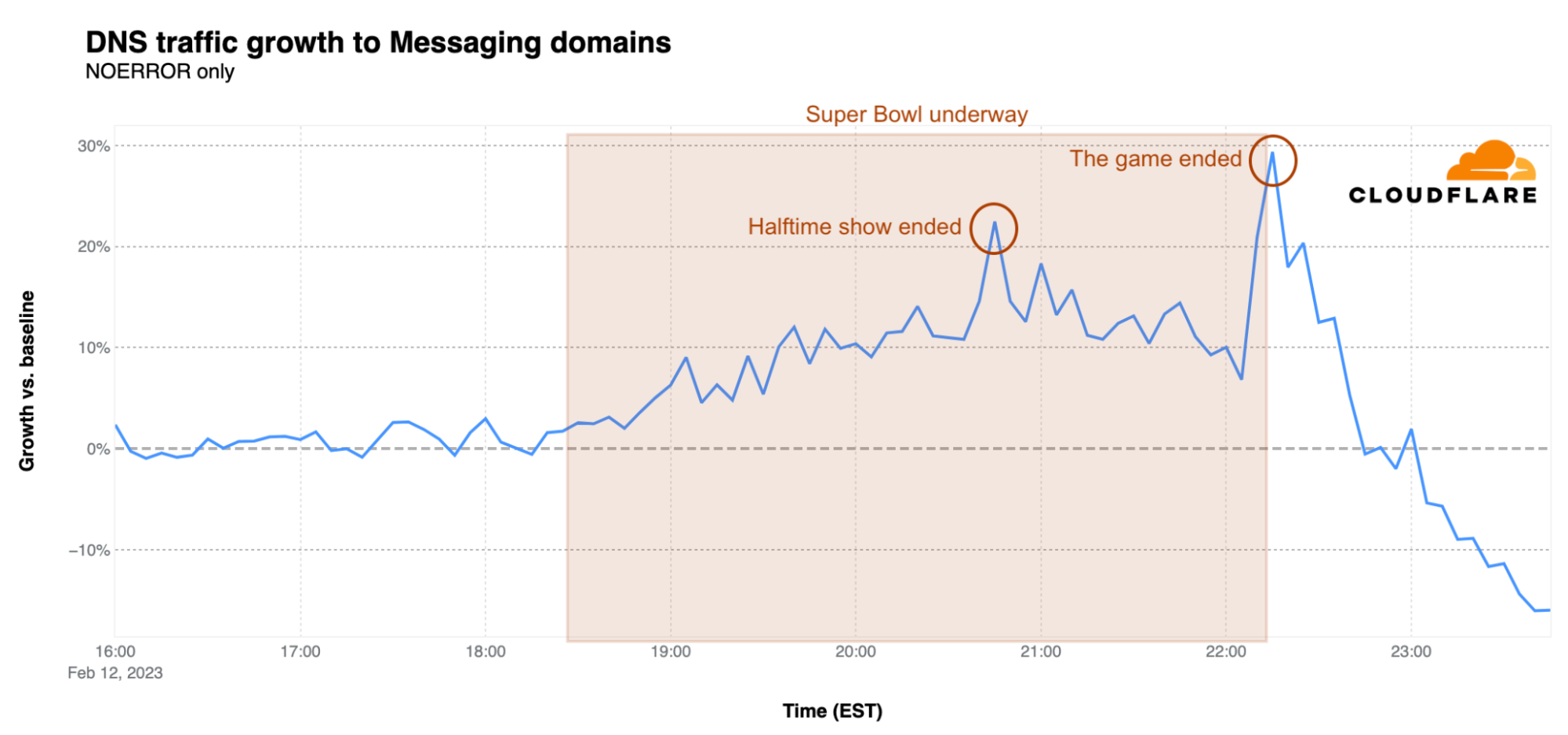
Messaging
Traffic to domains associated with messaging applications generally remained just below baseline throughout the first half of the game. The spikes above baseline during the first half were nominal, and don’t appear to be associated with any notable in-game events. Traffic picked back up briefly as the halftime show ended, jumping to 14% above baseline. After that, traffic continued to drop until 22:46 EST, when the Chiefs sealed their victory with an overtime touchdown, causing traffic for messaging sites to spike to 34% above baseline.
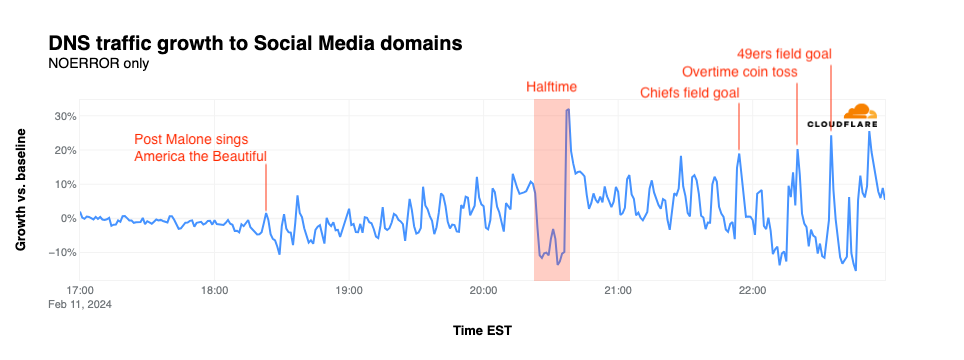
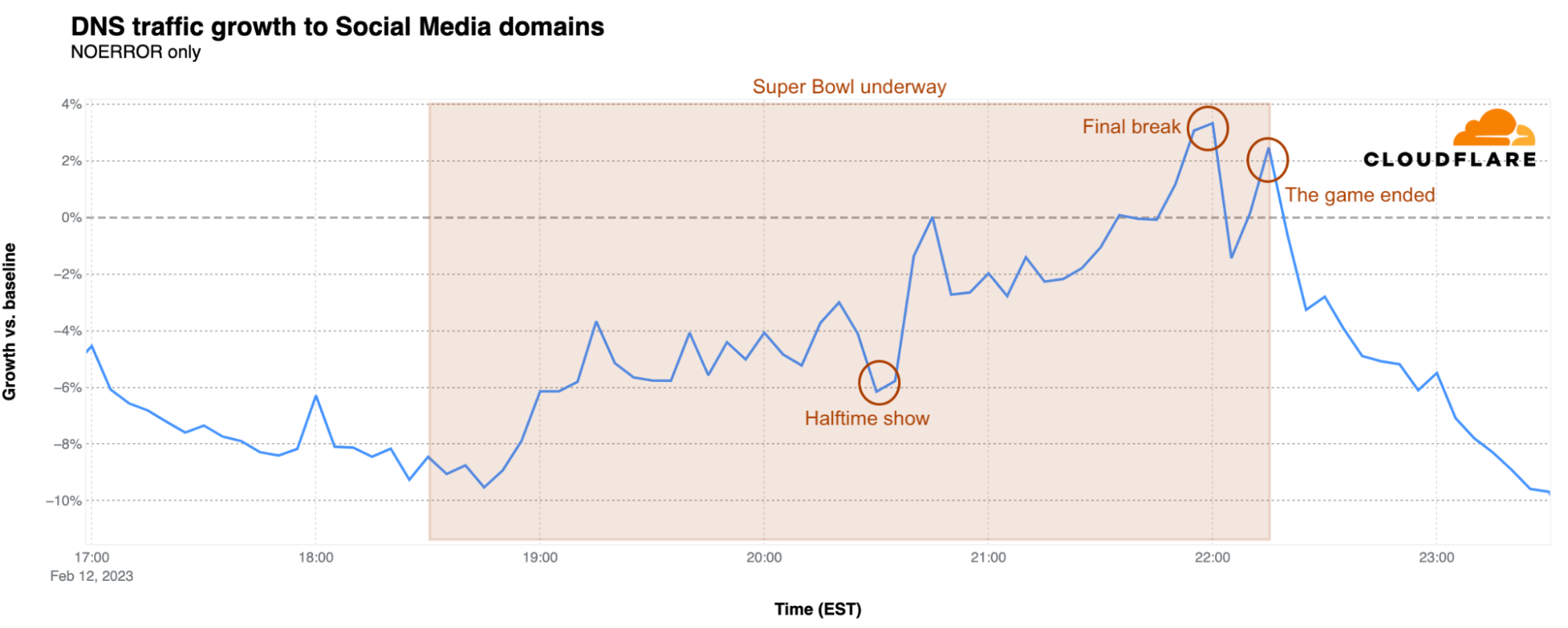
Social media
Traffic for social media sites often spikes in conjunction with major plays, such as fumbles or touchdowns, as fans take to their favorite sites and apps to share photos or videos, or to celebrate or vent, depending on the team they support. Although social media traffic was fairly flat ahead of the start of the game, it began to see some spikiness as Post Malone sang America the Beautiful. This nominal spikiness continued through halftime, although none of the peaks were clearly correlated with major plays during the first half. Similar to messaging, a notable drop in traffic occurred during halftime followed by a spike as Usher’s halftime show ended. In the second half, traffic spiked as the Chiefs tied the game with a field goal, for the overtime coin toss, and as the 49ers took the lead with an overtime field goal. Interestingly, that final spike visible in the graph occurs approximately six minutes after the Chiefs’ game-winning touchdown during an ad break ahead of the post-game show.
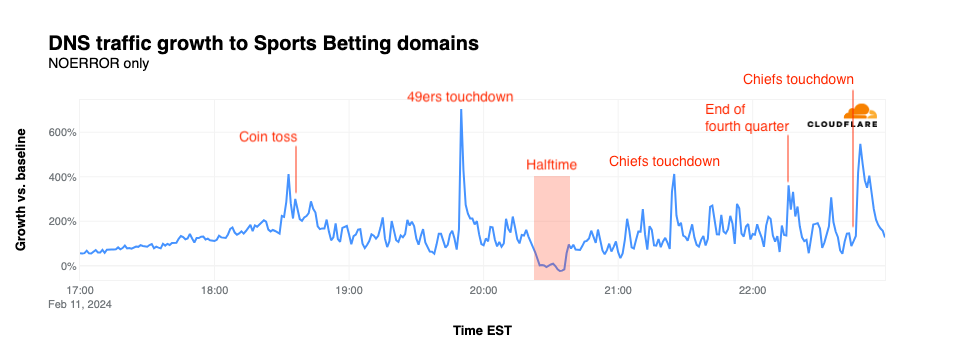
Sports betting
Compared to the relatively anemic traffic growth (when it was actually above baseline) seen for the categories above, traffic for domains associated with sports betting sites and apps remained significantly above baseline throughout the game with the exception of the dip during halftime, similar to what was also seen in the categories above. The first spike occurred just minutes before the coin toss, jumping to 412% above baseline. The game’s first touchdown, scored by the 49ers, caused traffic to spike 705% above baseline. A 413% spike occurred when the Chiefs took the lead late in the third quarter, with a slightly smaller one occurring at the end of regulation play as the game entered overtime. The final spike occurred just a couple of minutes after the Chiefs scored the game-winning touchdown, reaching 548% above baseline.
Zooming in to Kansas City and San Francisco
Using the same baseline calculations highlighted in the previous two sections, we also looked at changes in DNS traffic for the domains associated with the Kansas City Chiefs (chiefs.com) and the San Francisco 49ers (49ers.com). In addition, we looked at HTTP traffic from these two cities, using traffic levels from one week prior as a baseline.
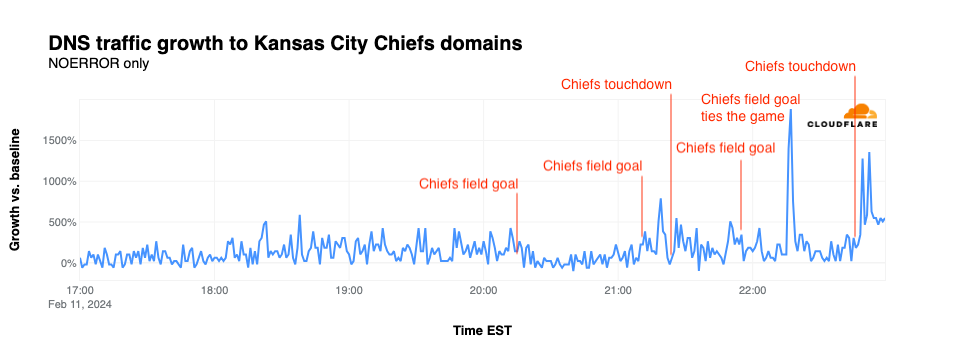
By and large, DNS traffic for chiefs.com did not appear to be significantly impacted by most of the team’s field goals or touchdowns during the game, as seen in the graph below. The exception is the traffic spike seen as the team tied the game towards the end of the fourth quarter, forcing the game into overtime. That play resulted in a spike of traffic for the team’s website that reached 1,887% above baseline. Traffic spiked again after the Chiefs won the game, spiking to 1,360% above baseline.
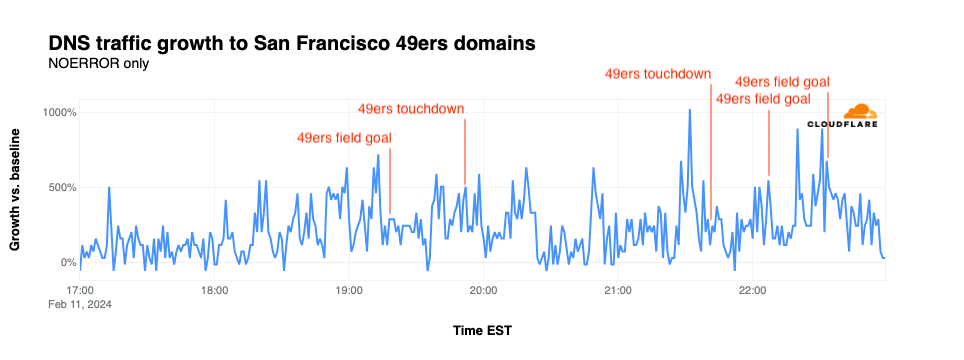
DNS traffic for 49ers.com did not exhibit significant shifts correlated with field goals or touchdowns. The most significant spike reached 1,023% over baseline at the end of the third quarter, minutes after the team called for a timeout.
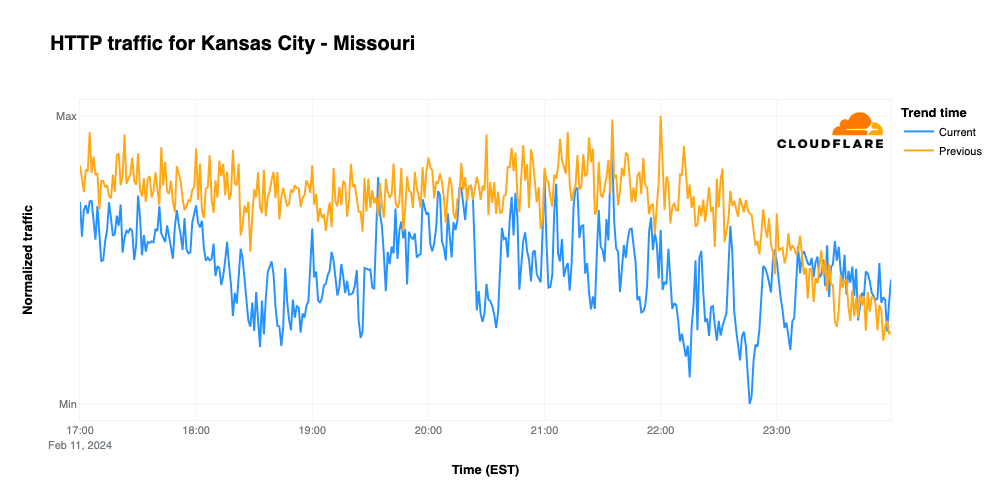
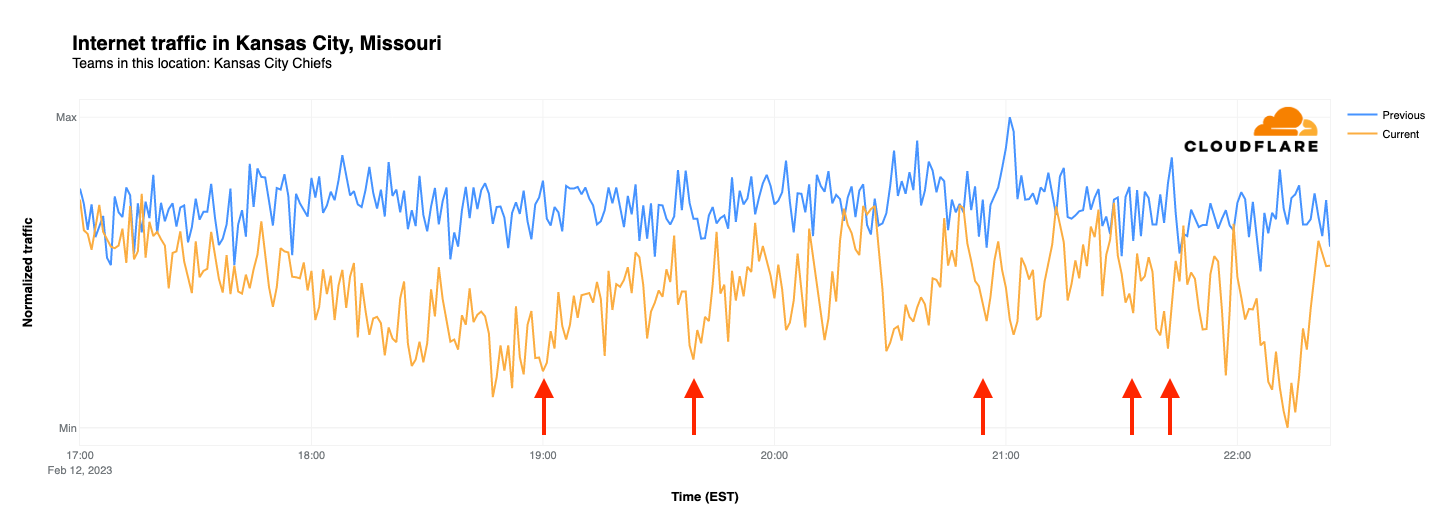
When comparing traffic trends for Kansas City and San Francisco, they could hardly be more different. Looking at request traffic from Kansas City, we find that it remains below traffic seen during the same time frame on February 4, with notable drops at the start of the game, during halftime, and when the Chiefs tied the game with a field goal late in the fourth quarter. Traffic hit its lowest point when the Chiefs won the game, but then recovered to meet/exceed the prior week’s traffic levels once the broadcast had concluded.
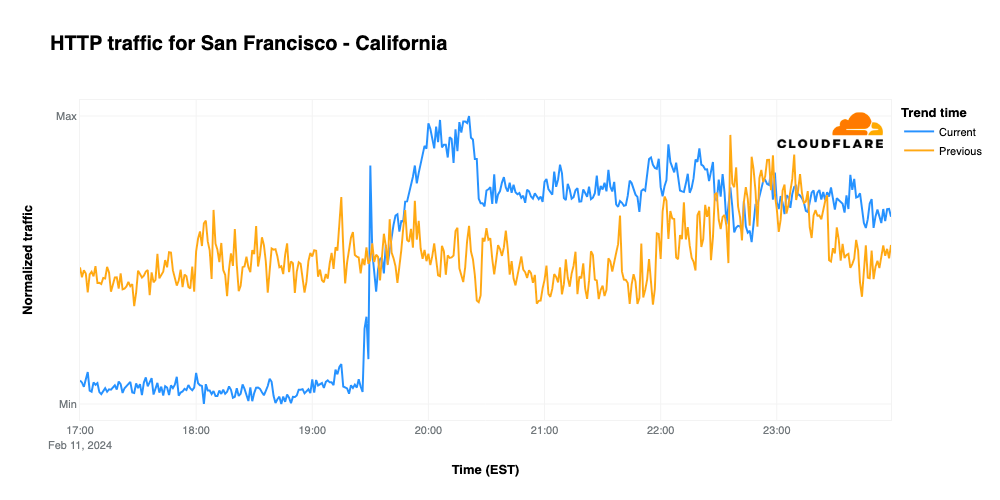
In contrast, traffic from San Francisco remained well below traffic levels seen the previous Sunday before unexpectedly spiking around 19:30 EST. Request traffic then remained well above the previous week’s levels until San Francisco kicked a field goal to take the initial lead during overtime play. Traffic remained roughly in line with the previous week until the broadcast ended, and then remained slightly higher.
Email threats and “The Big Game”
As we noted in last year’s blog post, spammers and scammers will frequently try to take advantage of the popularity of major events when running their campaigns, hoping the tie-in will entice the user to open the message and click on a malicious link, or visit a malicious website where they give up a password or credit card number. The Cloudflare Area 1 Email Security team once again analyzed the subject lines of email messages processed by the service in the weeks leading up to the Super Bowl to identify malicious, suspicious, and spam messages across four topic areas: Super Bowl/football, sports media/websites, sports gambling, and food delivery.
Super Bowl/Football
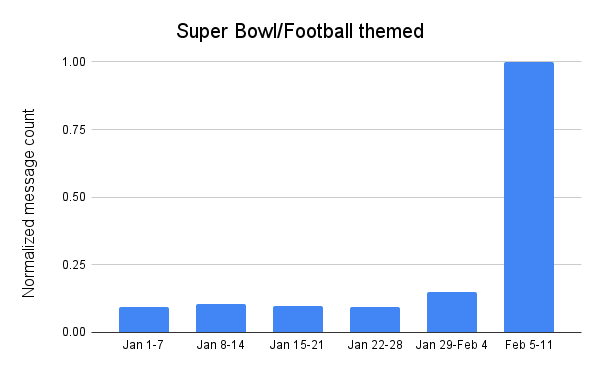
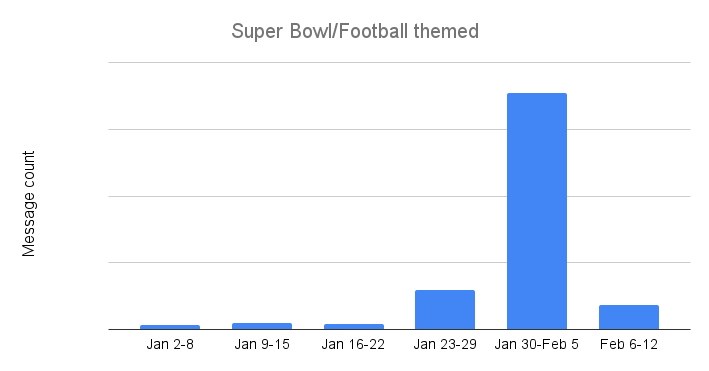
Spammers and scammers apparently didn’t feel that the “Super Wild Card Weekend” nor the divisional playoffs were sufficiently interesting to use as bait for their campaigns, as the volume of Super Bowl and football themed unwanted and potentially malicious email messages throughout January remained relatively low and fairly consistent. However, they apparently knew that the big game itself would draw interest, as the volume of such messages increased more than 6x over the prior week in the days ahead of the game.
Sports media/websites
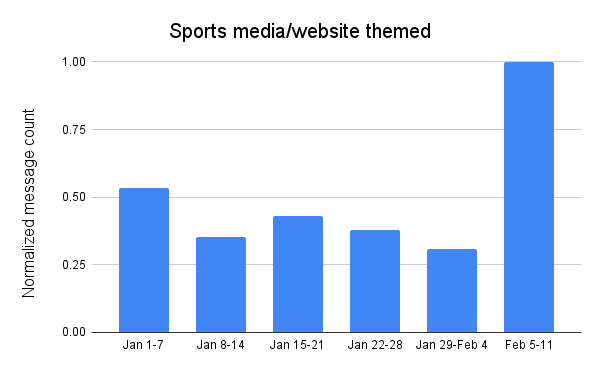
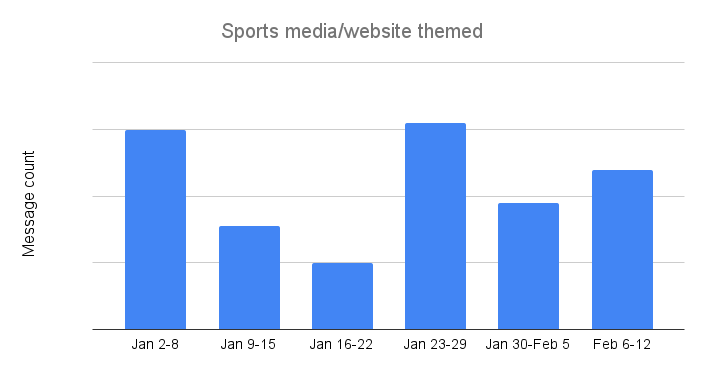
Attackers appeared to lose interest in using messages with subject lines related to sports media and websites as January progressed, with the volume of related messages peaking the first week of the month. However, similar to Super Bowl and football themed messages, this theme took on renewed interest in the week leading up to the Super Bowl, with message volume reaching over 3x the previous week, and 1.8x the peak seen durinthe first week of the year.
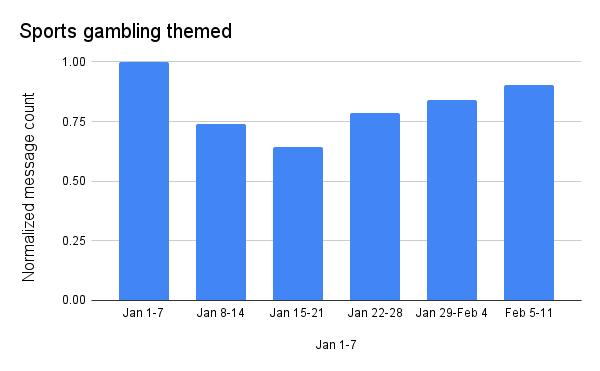
Sports gambling
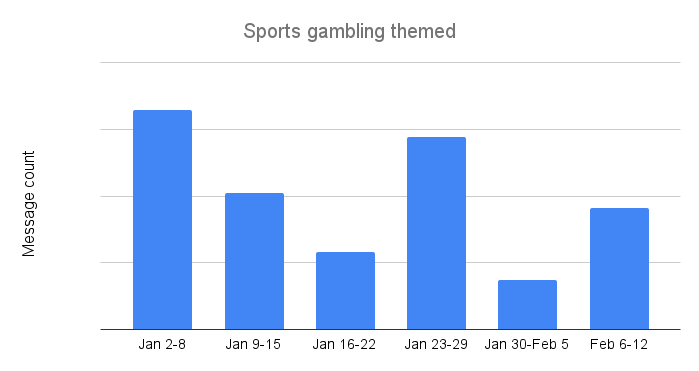
The final weekend of regular season games (on January 6 & 7) again drove the highest volume of sports gambling themed messages, similar to the pattern seen in 2023. Message volume dropped by about a third over the next two weeks, but picked back up around the divisional and conference playoff games and into the Super Bowl. Even with the growth into the Super Bowl, gambling-themed spam and malicious message volume remained 10% lower than the peak seen a month earlier.
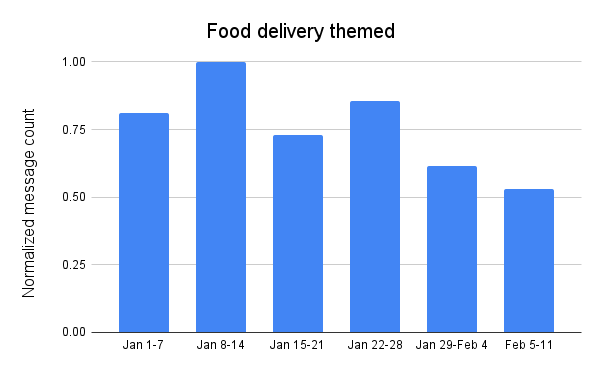
Food delivery
Peak volume of food delivery themed messages was an order of magnitude (10x) higher than the Super Bowl and football themed peak, which was the next largest. Due to the popularity of such services, it appears that it is a regular theme for spam and potentially malicious messages, as volume remained extremely high throughout January. After peaking the week of January 8-14, message volume was lower each of the following weeks, reaching its nadir in the week leading up to the Super Bowl, 47% lower than the peak volume.
Conclusion
Likely peaking during the so-called “dot.com” Super Bowls nearly a quarter-century ago, most Super Bowl ads no longer drive traffic to associated websites by including a URL in their ad. However, as our DNS traffic analysis found, it appears that viewers don’t seem to have much trouble finding these sites. We also found that in-game events had a mixed impact on traffic across domains associated with multiple types of apps, as well as traffic for the websites associated with the teams playing in the Super Bowl.
A promotional campaign is a marketing effort that aims to increase sales, customer engagement, or brand awareness for a product, service, or company. The target is to have more orders and sales by assigning promos to consumers within a given budget during the campaign period.
Figure 1 – Merchant feedback on marketing
From our research, we found that merchants have specific goals for the promos they are willing to offer. They want a simple and cost-effective way to achieve their specific business goals by providing well-designed offers to target the correct customers. From Grab’s perspective, we want to help merchants set up and run campaigns efficiently, and help them achieve their specific business goals.
Problem statement
One of Grab’s platform offerings for merchants is the ability to create promotional campaigns. With the emergence of AI technologies, we found that there are opportunities for us to further optimise the platform. The following are the gaps and opportunities we identified:
Globally assigned promos without smart targeting: The earlier method targeted every customer, so everyone could redeem until the promo reached the redemption limits. However, this method did not accurately meet business goals or optimise promo spending. The promotional campaign should intelligently target the best promo for each customer to increase sales and better utilise promo spending.
No customised promos for every merchant: To better optimise sales for each merchant, merchants should offer customised promos based on their historical consumer trends, not just a general offer set. For example, for a specific merchant, a 27% discount may be the appropriate offer to uplift revenue and sales based on user bookings. However, merchants do not always have the expertise to decide which offer to select to increase profit.
No AI-driven optimisation: Without AI models, it was harder for merchants to assign the right promos at scale to each consumer and optimise their business goals.
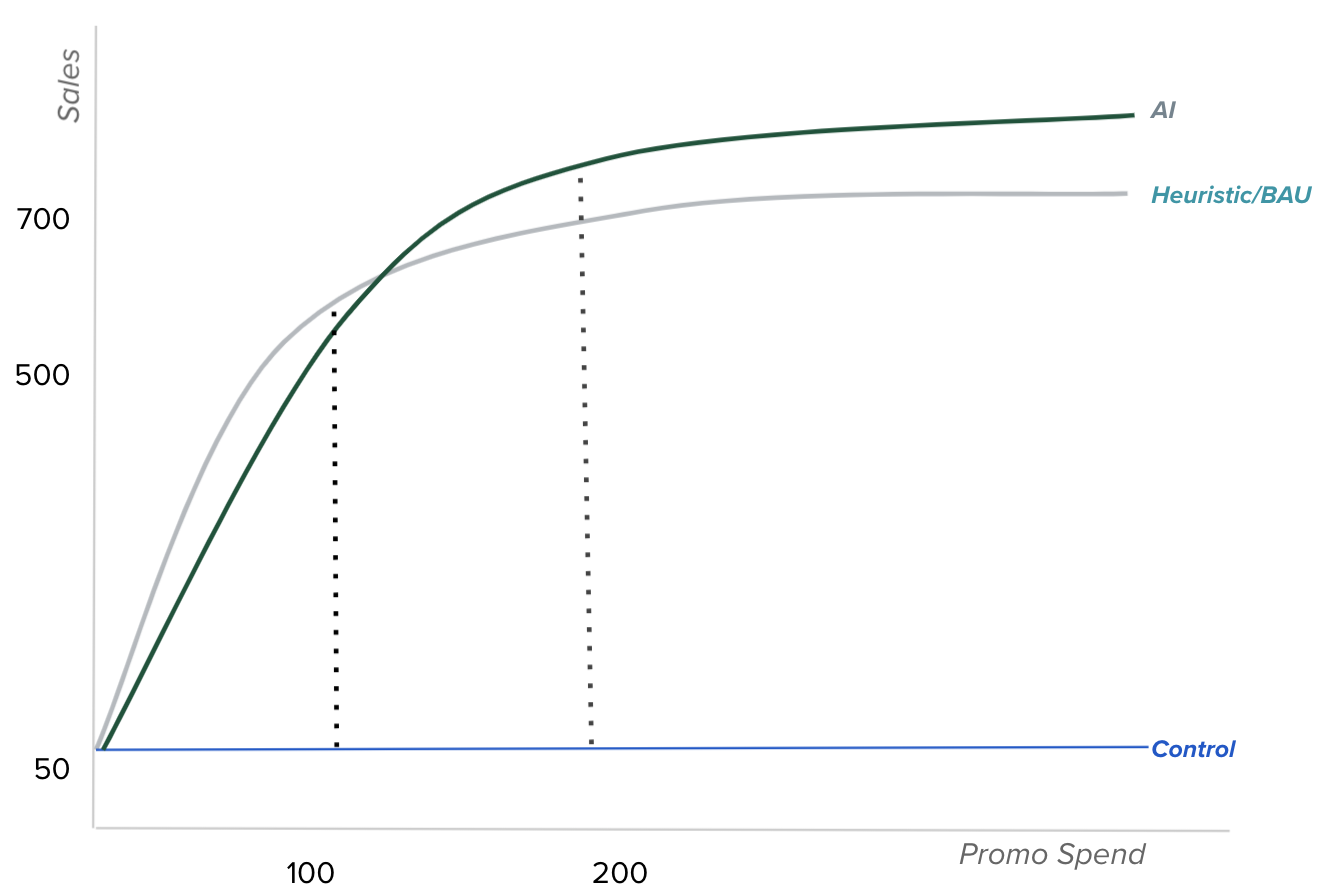
As shown in the following figure, AI-driven promotional campaigns are expected to bring higher sales with more promo spend than heuristic ones. Hence, at Grab we looked to introduce an automated, AI-driven tool that helps merchants intelligently target consumers with appropriate promos, while optimising sales and promo spending. That’s where Bullseye comes in.
Figure 2 – Graph showing the sales expectations for AI-driven pomotional campaigns
Solution
Bullseye is an automated, AI-driven promo assignment system that leverages the following capabilities:
Automated user segmentation: Enables merchants to target new, churned, and active users or all users.
Automatic promo design: Enables a merchant-level promo design framework to customise promos for each merchant or merchant group according to their business goals.
Assign each user the optimal promo: Users will receive promos selected from an array of available promos based on the merchant’s business objective.
Achieve different Grab and merchant objectives: Examples of objectives are to increase merchant sales and decrease Grab promo spend.
Flexibility to optimise for an individual merchant brand or group of merchant brands: For promotional campaigns, targeting and optimisation can be performed for a single or group of merchants (e.g. enabling GrabFood to run cuisine-oriented promo campaigns).
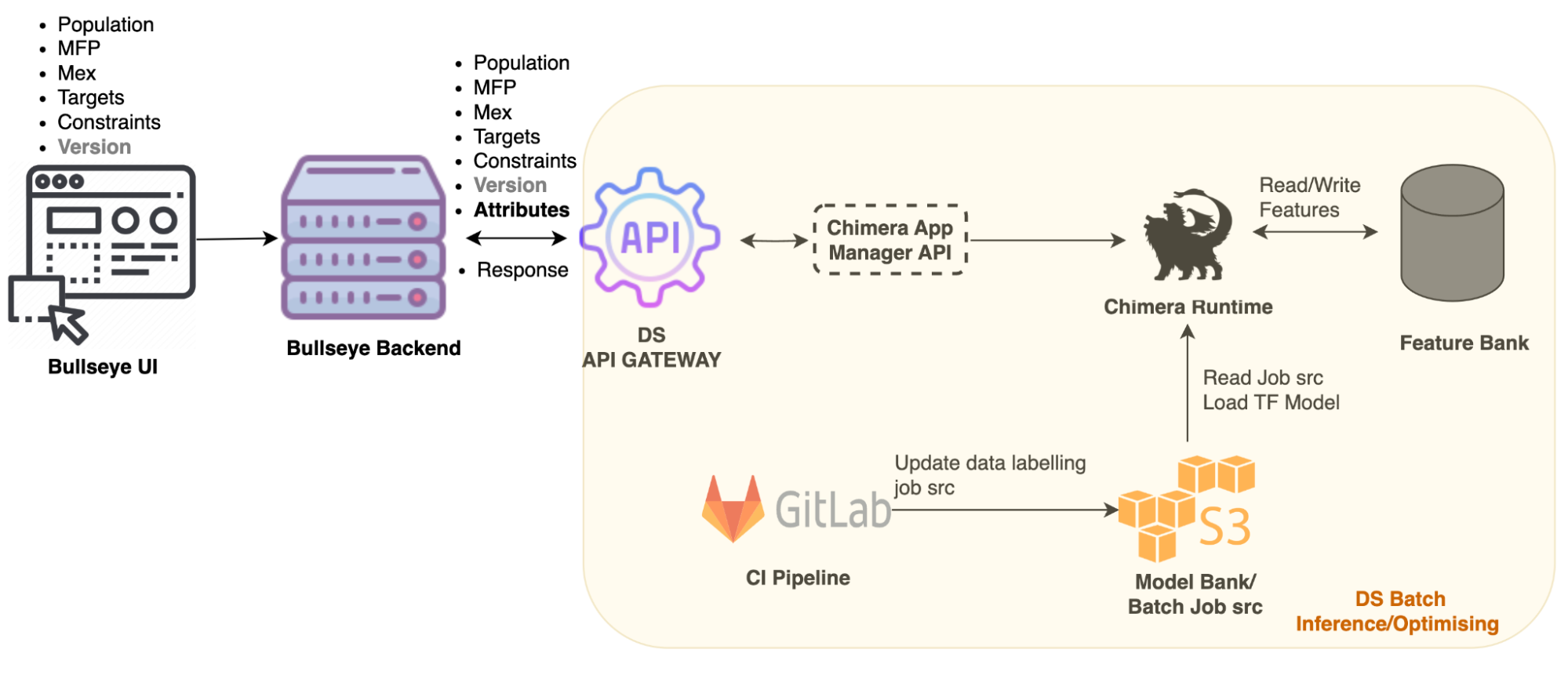
Architecture
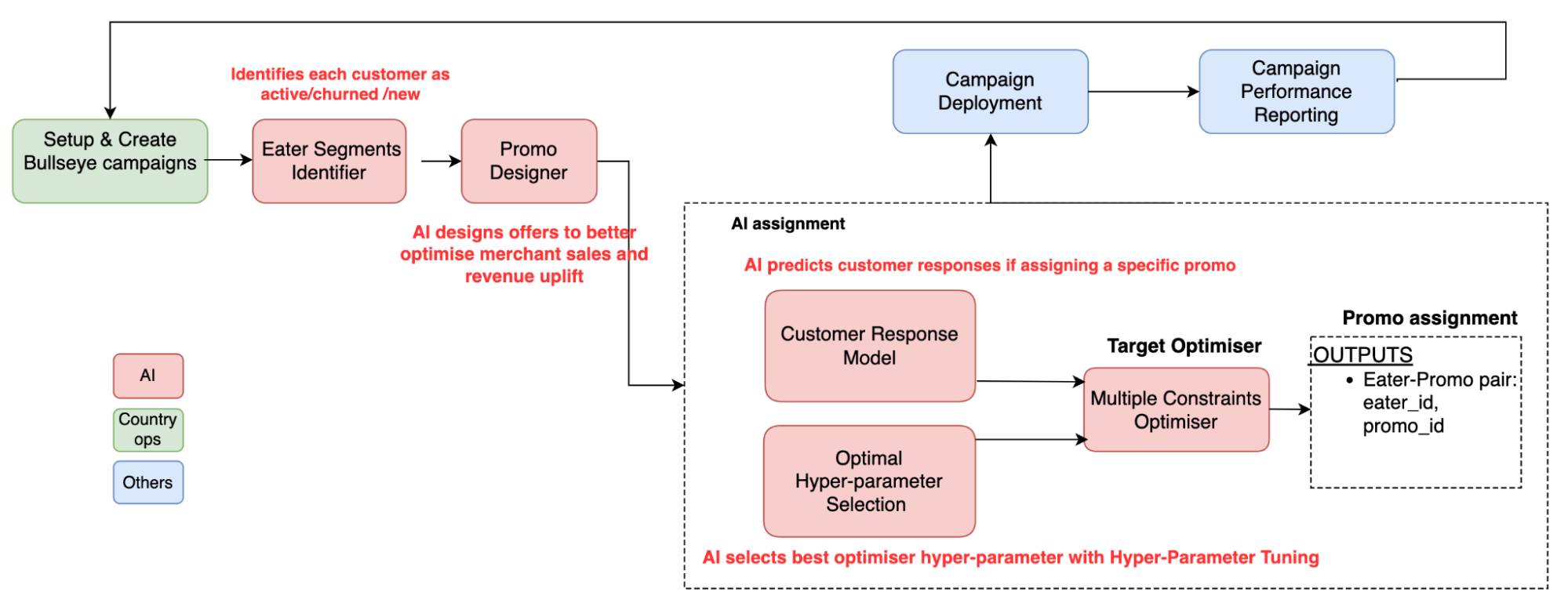
Figure 3 – Bullseye architecture
The Bullseye architecture consists of a user interface (UI) and a backend service to handle requests. To use Bullseye, our operations team inputs merchant information into the Bullseye UI. The backend service will then interact with APIs to process the information using the AI model. As we work with a large customer population, data is stored in S3 and the API service triggering Chimera Spark job is used to run the prediction model and generate promo assignments. During the assignment, the Spark job parses the input parameters, pre-validates the input, makes some predictions, and then returns the promo assignment results to the backend service.
Implementation
The key components in Bullseye are shown in the following figure:
Figure 4 – Key components of Bullseye
Eater Segments Identifier: Identifies each user as active, churned, or new based on their historical orders from target merchants.
Promo Designer: We constructed a promo variation design framework to adaptively design promo variations for each campaign request as shown in the diagram below.
Offer Content Candidate Generation: Generates variant settings of promos based on the promo usage history.
Campaign Impact Simulator: Predicts business metrics such as revenue, sales, and cost based on the user and merchant profiles and offer features.
Optimal Promo Selection: Selects the optimal offer based on the predicted impact and the given campaign objective. The optimal would be based on how you define optimal. For example, if the goal is to maximise merchant sales, the model selects the top candidate which can bring the highest revenue. Finally, with the promo selection, the service returns the promo set to be used in the target campaign.
Figure 5 – Optimal Promo Selection
Customer Response Model: Predicts customer responses such as order value, redemption, and take-up rate if assigning a specific promo. Bullseye captures various user attributes and compares it with an offer’s attributes. Examples of attributes are cuisine type, food spiciness, and discount amount. When there is a high similarity in the attributes, there is a higher probability that the user will take up the offer.
Figure 6 – Customer Response Model
Hyper-parameter Selection: Optimises toward multiple business goals. Tuning of hyper-parameters allows the AI assignment model to learn how to meet success criteria such as cost per merchant sales (cpSales) uplift and sales uplift. The success criteria is the achieving of business goals. For example, the merchant wants the sales uplift after assigning promo, but cpSales uplift cannot be higher than 10%. With tuning, the optimiser can find optimal points to meet business goals and use AI models to search for better settings with high efficiency compared to manual specification. We need to constantly tune and iterate models and hyper-parameters to adapt to ever-evolving business goals and the local landscape.
As shown in the image below, AI assignments without hyper-parameter tuning (HPT) leads to a high cpSales uplift but low sales uplift (red dot). So the hyper-parameters would help to fine-tune the assignment result to be in the optimal space such as the blue dot, which may have lower sales than the red dot but meet the success criteria.
Figure 7 – Graph showing the impact of using AI assignments with HPT
Impact
We started using Bullseye in 2021. From its use we found that:
Hyper-parameters tuning and auto promo design can increase sales and reduce promo spend for food campaigns.
Promo Designer optimises budget utilisation and increases the number of promo redemptions for food campaigns.
The Customer Response Model reduced promo spending for Mart promotional campaigns.
Conclusion
We have seen positive results with the implementation of Bullseye such as reduced promo spending and maximised budget spending returns. In our efforts to serve our merchants better and help them achieve their business goals, we will continue to improve Bullseye. In the next phase, we plan to implement a more intelligent service, enabling reinforcement learning, and online assignment. We also aim to scale AI adoption by onboarding regional promotional campaigns as much as possible.
Special thanks to William Wu, Rui Tan, Rahadyan Pramudita, Krishna Murthy, and Jiesin Chia for making this project a success.
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
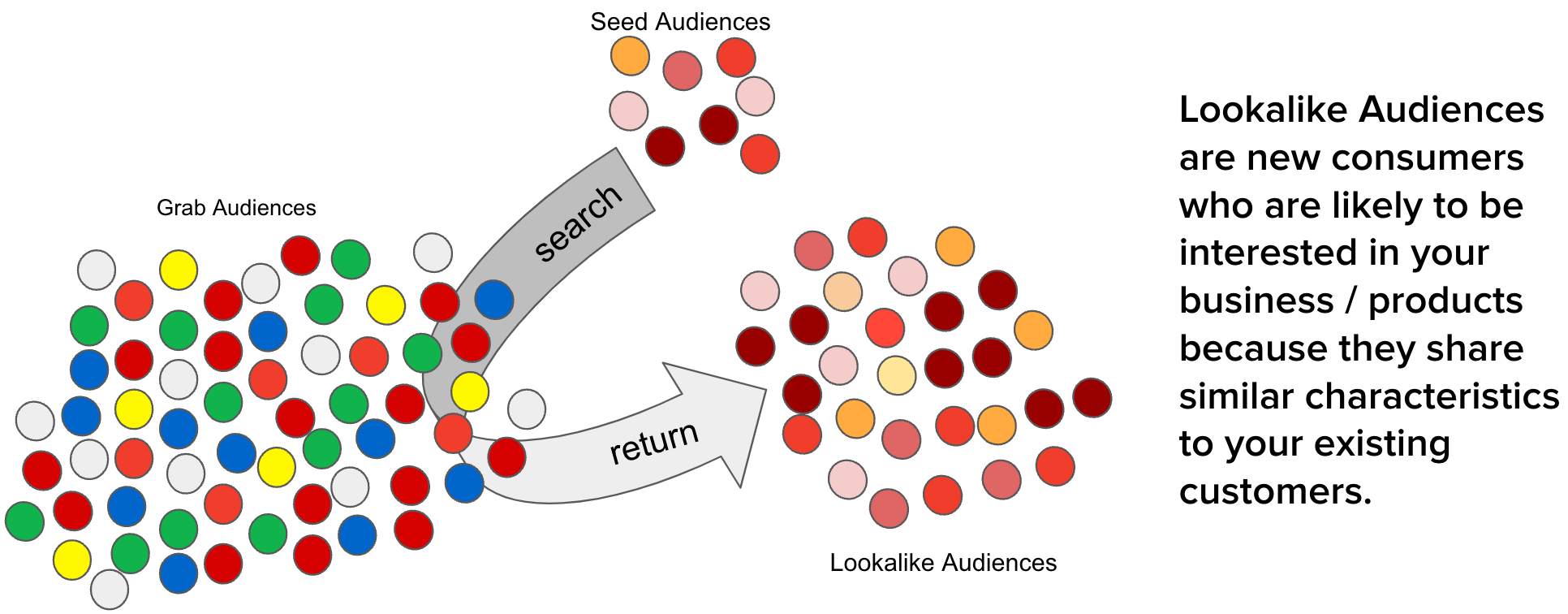
The advertising industry is constantly evolving, driven by advancements in technology and changes in consumer behaviour. One of the key challenges in this industry is reaching the right audience, reaching people who are most likely to be interested in your product or service. This is where the concept of a lookalike audience comes into play. By identifying and targeting individuals who share similar characteristics with an existing customer base, businesses can significantly improve the effectiveness of their advertising campaigns.
However, as the scale of Grab advertisements grows, there are several optimisations needed to maintain the efficacy of creating lookalike audiences such as high service level agreement (SLA), high cost of audience creation, and unstable data ingestion.
The need for an even more efficient and scalable solution for creating lookalike audiences was the motivation behind the development of the scalable lookalike audience platform. By developing a high-performance in-memory lookalike audience retrieval service and embedding-based lookalike audience creation and updating pipelines, this improved platform builds on the existing system and provides an even more effective tool for advertisers to reach their target audience.
Constant optimisation for greater precision
In the dynamic world of digital advertising, the ability to quickly and efficiently reach the right audience is paramount and a key strategy is targeted advertising. As such, we have to constantly find ways to improve our current approach to creating lookalike audiences that impacts both advertisers and users. Some of the gaps we identified included:
Long SLA for audience creation. Earlier, the platform stored results on Segmentation Platform (SegP) and it took two working days to generate a lookalike audience list. This is because inserting a single audience into SegP took three times longer than generating the audience. Extended creation times impacted the effectiveness of advertising campaigns, as it limited the ability of advertisers to respond quickly to changing market dynamics.
Low scalability. As the number of onboarded merchant-partners increased, the time and cost of generating lookalike audiences also increased proportionally. This limited the availability of lookalike audience generation for all advertisers, particularly those with large customer bases or rapidly changing audience profiles.
Low updating frequency of lookalike audiences. With automated updates only occurring on a weekly basis, this increased the likelihood that audiences may become outdated and ineffective. This meant there was scope to further improve to help advertisers more effectively reach their campaign goals, by targeting individuals who fit the desired audience profile.
High cost of creation. The cost of producing one segment can add up quickly for advertisers who need to generate multiple audiences. This could impact scalability for advertisers as they could hesitate to effectively use multiple lookalike audiences in their campaigns.
Solution
To efficiently identify the top N lookalike audiences for each Grab user from our pool of millions of users, we developed a solution that leverages user and audience representations in the form of embeddings. Embeddings are vector representations of data that utilise linear distances to capture structure from the original datasets. With embeddings, large sets of data are compressed and easily processed without affecting data integrity. This approach ensures high accuracy, low latency, and low cost in retrieving the most relevant audiences.
Our solution takes into account the fact that representation drift varies among entities as data is added. For instance, merchant-partner embeddings are more stable than passenger embeddings. By acknowledging this reality, we optimised our process to minimise cost while maintaining a desirable level of accuracy. Furthermore, we believe that having a strong representation learning strategy in the early stages reduced the need for complex models in the following stages.
Our solution comprises two main components:
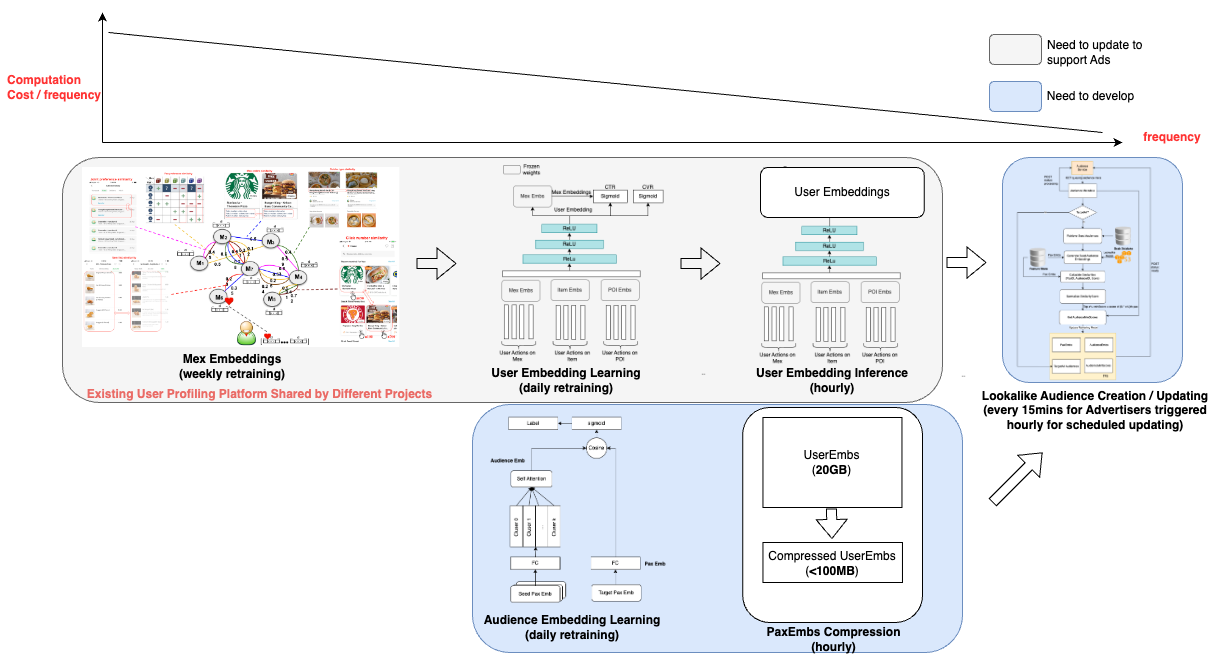
Real-time lookalike audience retrieving: We developed an in-memory high-performance retrieving service that stores passenger embeddings, audience embeddings, and audience score thresholds. To further reduce cost, we designed a passenger embedding compression algorithm that reduces the memory needs of passenger embeddings by around 90%.
Embedding-based audience creation and updating: The output of this part of the project is an online retrieving model that includes passenger embeddings, audience embeddings, and thresholds. To minimise costs, we leverage the passenger embeddings that are also utilised by other projects within Grab, beyond advertising, thus sharing the cost. The audience embeddings and thresholds are produced with a low-cost small neural network.
In summary, our approach to creating scalable lookalike audiences is designed to be cost-effective, accurate, and efficient, leveraging the power of embeddings and smart computational strategies to deliver the best possible audiences for our advertisers.
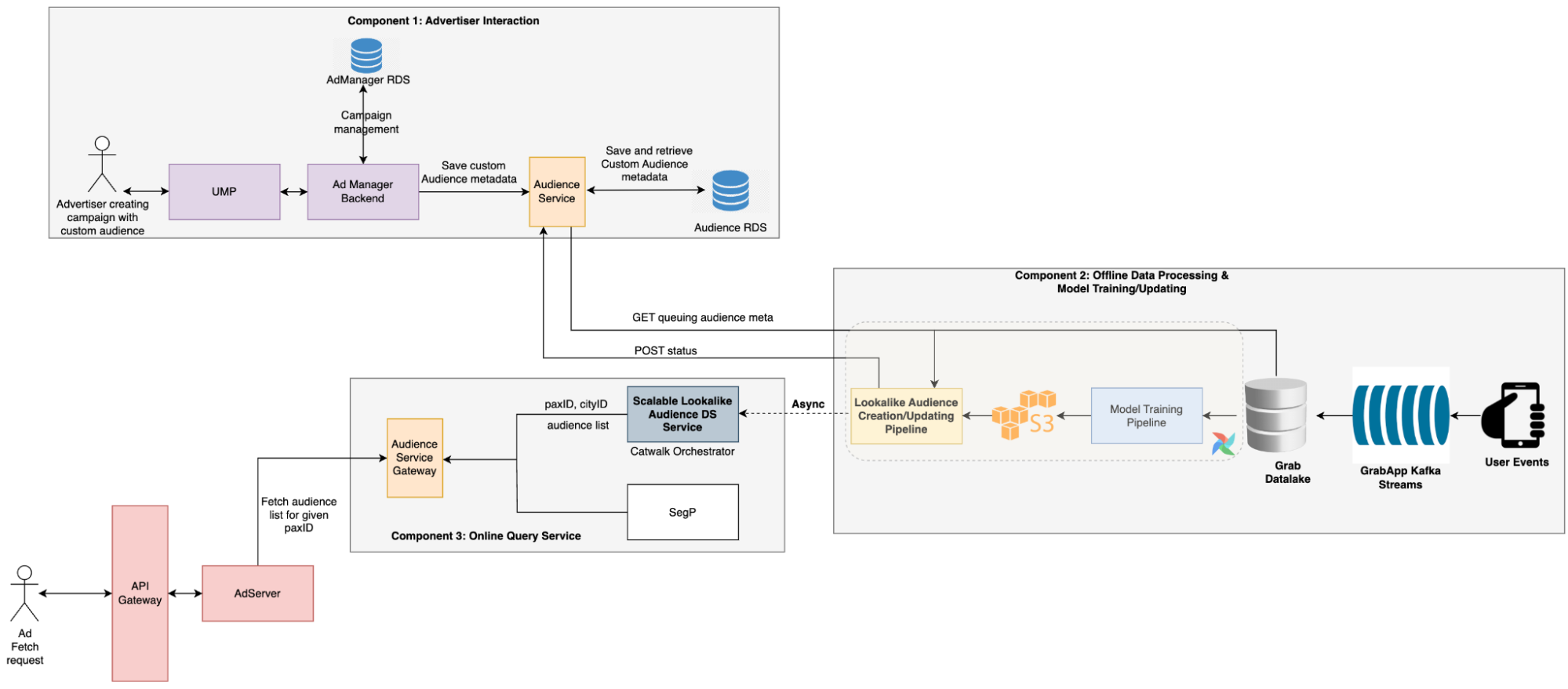
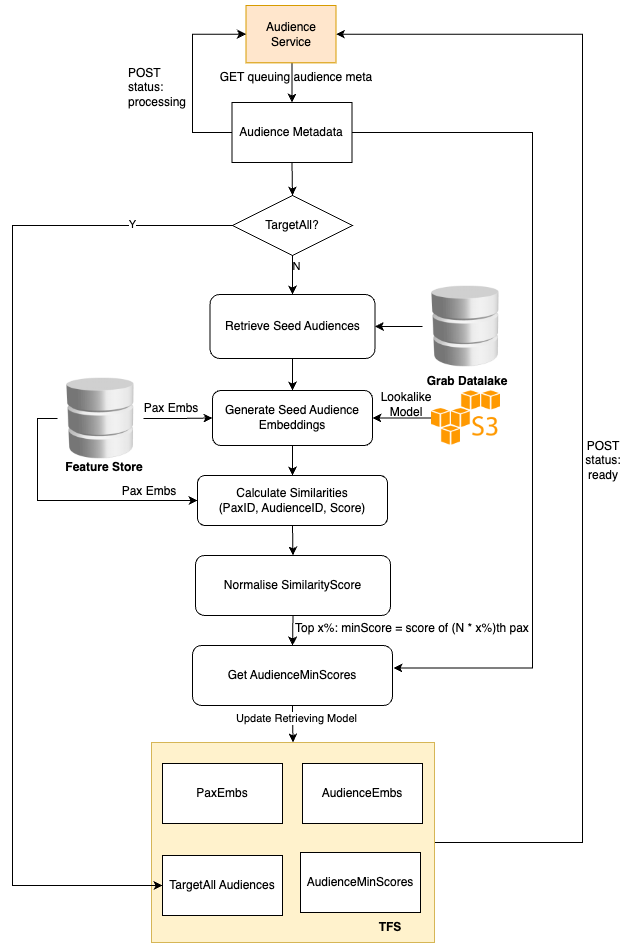
Solution architecture
The advertiser creates a campaign with a custom audience, which triggers the audience creation process. During this process, the audience service stores the audience metadata provided by advertisers in a message queue.
A scheduled Data Science (DS) job then retrieves the pending audience metadata, creates the audience, and updates the TensorFlow Serving (TFS) model.
During the serving period, the Backend (BE) service calls the DS service to retrieve all audiences that include the target user. Ads that are targeting these audiences are then selected by the Click-Through Rate (CTR) model to be displayed to the user.
Implementation
To ensure the efficiency of the lookalike audience retrieval model and minimise the costs associated with audience creation and serving, we’ve trained the user embedding model using billions of user actions. This extensive training allows us to employ straightforward methods for audience creation and serving, while still maintaining high levels of accuracy.
Creating lookalike audiences
The Audience Creation Job retrieves the audience metadata from the online audience service, pulls the passenger embeddings, and then averages these embeddings to generate the audience embedding.
We use the cosine score of a user and the audience embedding to identify the audiences the user belongs to. Hence, it’s sufficient to store only the audience embedding and score threshold. Additionally, a global target-all-pax Audience list is stored to return these audiences for each online request.
Serving lookalike audiences
The online audience service is also tasked with returning all the audiences to which the current user belongs. This is achieved by utilising the cosine score of the user embedding and audience embeddings, and filtering out all audiences that surpass the audience thresholds.
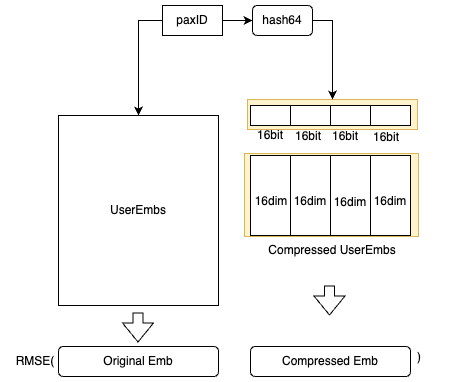
To adhere to latency requirements, we avoid querying any external feature stores like Redis and instead, store all the embeddings in memory. However, the embeddings of all users are approximately 20 GB, which could affect model loading. Therefore, we devised an embedding compression method based on hash tricks inspired by Bloom Filter.
We utilise hash functions to obtain the hash64 value of the paxID, which is then segmented into four 16-bit values. Each 16-bit value corresponds to a 16-dimensional embedding block, and the compressed embedding is the concatenation of these four 16-dimensional embeddings.
For each paxID, we have both the original user embedding and the compressed user embedding. The compressed user embeddings are learned by minimising the Mean Square Error loss.
We can balance the storage cost and the accuracy by altering the number of hash functions used.
Impact
Users can see advertisements targeting a new audience within 15 mins after the advertiser creates a campaign.
This new system doubled the impressions and clicks, while also improving the CTR, conversion rate, and return on investment.
Costs for generating lookalike audiences decreased by 98%.
Learnings/Conclusion
To evaluate the effectiveness of our new scalable system besides addressing these issues, we conducted an A/B test to compare it with the earlier system. The results revealed that this new system effectively doubled the number of impressions and clicks while also enhancing the CTR, conversion rate, and return on investment.
Over the years, we have amassed over billions of user actions, which have been instrumental in training the model and creating a comprehensive representation of user interests in the form of embeddings.
What’s next?
While this scalable system has proved its effectiveness and demonstrated impressive results in CTR, conversion rate, and return on investment, there is always room for improvement.
In the next phase, we plan to explore more advanced algorithms, refine our feature engineering process, and conduct more extensive hyperparameter tuning. Additionally, we will continue to monitor the system’s performance and make necessary adjustments to ensure it remains robust and effective in serving our advertisers’ needs.
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
The Super Bowl has been happening since the end of the 1966 season, the same year that the ARPANET project, which gave birth to the Internet, was initiated. Around 20 years ago, 50% of the US population were Internet users, and that number is now around 92%. So, it’s no surprise that interest in an event like Super Bowl LVII resulted in a noticeable dip in Internet traffic in the United States at the time of the game’s kickoff, dropping to around 5% lower than the previous Sunday. During the game, Rihanna’s halftime show also caused a significant drop in Internet traffic across most states, with Pennsylvania and New York feeling the biggest impact, but messaging and video platforms saw a surge of traffic right after her show ended.
In this blog post, we will dive into who the biggest winners were among Super Bowl advertisers, as well as examine how traffic to food delivery services, social media and sports and betting websites changed during the game. In addition, we look at traffic trends seen at city and state levels during the game, as well as email threat volume across related categories in the weeks ahead of the game.
Cloudflare Radar uses a variety of sources to provide aggregate information about Internet traffic and attack trends. In this blog post, as we did last year and the year before, we use DNS name resolution data from our 1.1.1.1 resolver to estimate traffic to websites. We can’t see who visited the websites mentioned, or what anyone did on the websites, but DNS can give us an estimate of the interest generated by the ads or across a set of sites in the categories listed above.
Ads: are URLs no longer cool?
In contrast to Super Bowl commercials of the past 25 years, many of this year’s advertisements didn’t include a URL, possibly suggesting strong confidence by brands in their search engine results placement, or an assumption that the viewer would engage with the brand through an app on their phone, rather than a website. To that end, several ads did include an app store-related call to action, encouraging the viewer to download the associated mobile app. And possibly in an effort to capitalize on the success of Coinbase’s QR code commercial during Super Bowl LVI, a number of brands, including Toyota, Michelob Ultra, and Mr. Peanut included QR codes as a way for viewers to get additional information or see more.
As we did last year, we again tracked DNS request traffic to our 1.1.1.1 resolver in United States data centers for domains associated with the advertised products or brands. Traffic growth is plotted against a baseline calculated as the mean request volume for the associated domains between 1200-1500 EST on Sunday, February 12 (Super Bowl Sunday.) Although over 50 brands advertised during the game, the brands highlighted below were chosen because their advertisements drove some of the largest percentage traffic spikes, as well as one interesting tale.
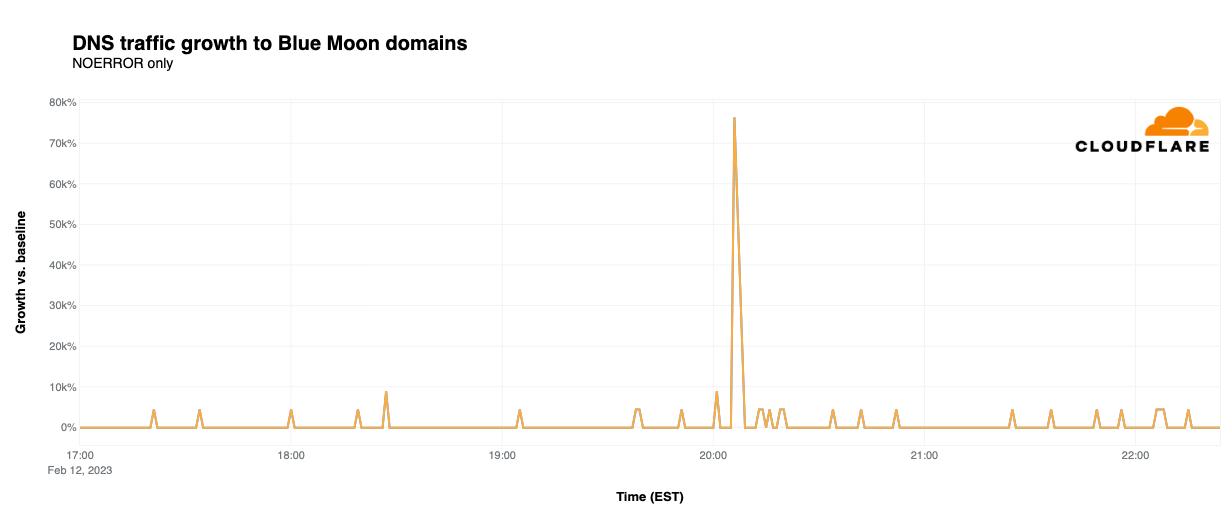
BlueMoon
Although the commercial initially seemed to be for sibling beer brands Coors Light and Miller Lite, there was a twist at the end, This twist was only fitting, as the ad was actually for Blue Moon, which is often served with a twist of orange on the rim of the glass. Although beer ads don’t usually drive significant traffic spikes, this one did, reaching 76,400% above baseline for Blue Moon’s site. Coors Light saw a 275% bump in DNS traffic coincident with the ad, while Miller Lite grew 120%. However, traffic for Coors and Miller was fairly volatile at other times during the game.
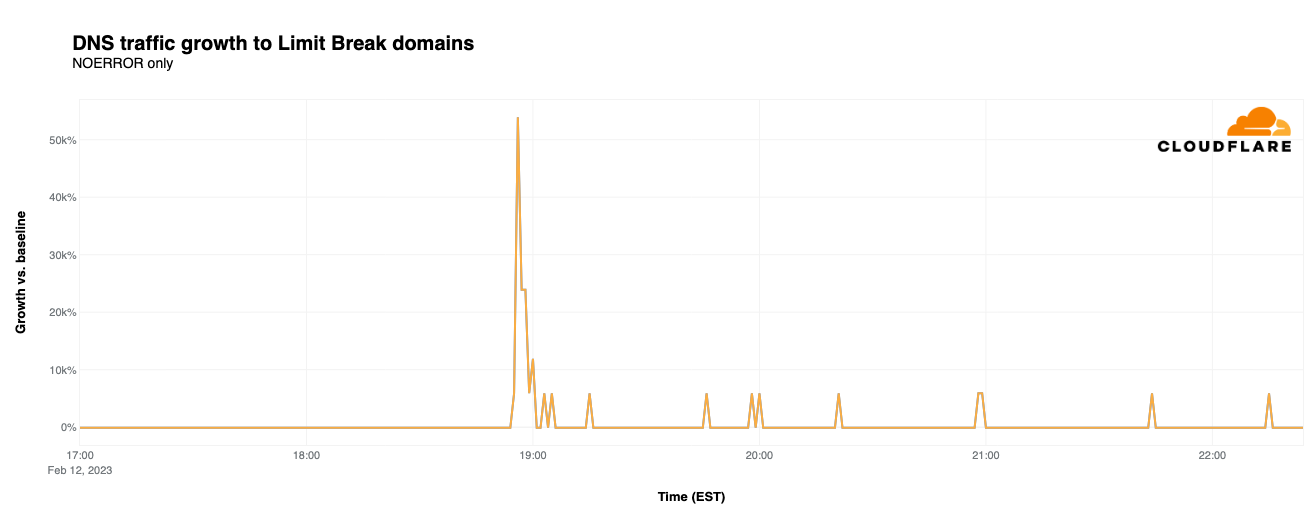
LimitBreak
Although last year’s advertisements included a number of cryptocurrency-related brands, they were all but absent from this year’s slate of ads. The closest we got during this year’s game was a commercial from LimitBreak, which describes itself as “bringing the free-to-play gaming experience to Web3 and beyond”, in which it promoted a giveaway of thousands of its Dragon series NFTs. This ad featured a QR code and a URL, and given the nearly 54,000% increase in DNS traffic observed, both were effective means of driving traffic to the LimitBreak website.
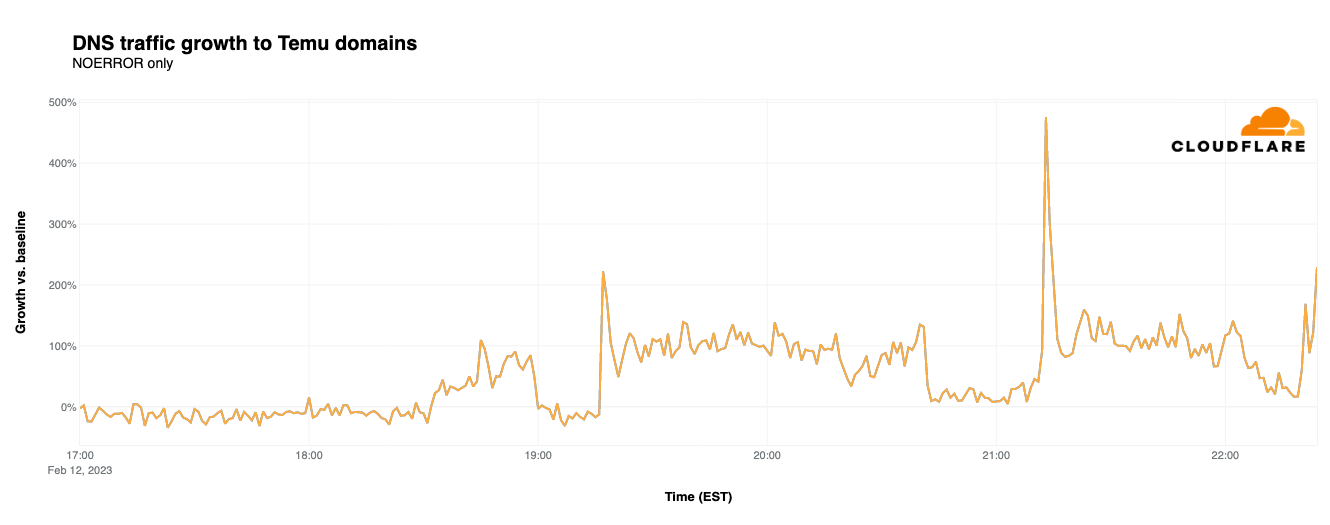
Temu
Upstart mobile shopping app Temu purchased multiple Super Bowl ad slots to promote its “shop like a billionaire” campaign, urging viewers to download its mobile app. As seen in the graph below, these advertisements drove spikes in traffic, and continued engagement, each time they ran. The first airing at 19:16 EST drove a 222% spike over baseline in DNS traffic. However, the second airing at 21:12 EST apparently resulted in significantly more interest, driving a 475% traffic increase. A third airing at 22:20 EST reached 169% over baseline, with another one just after that reaching over 200%.
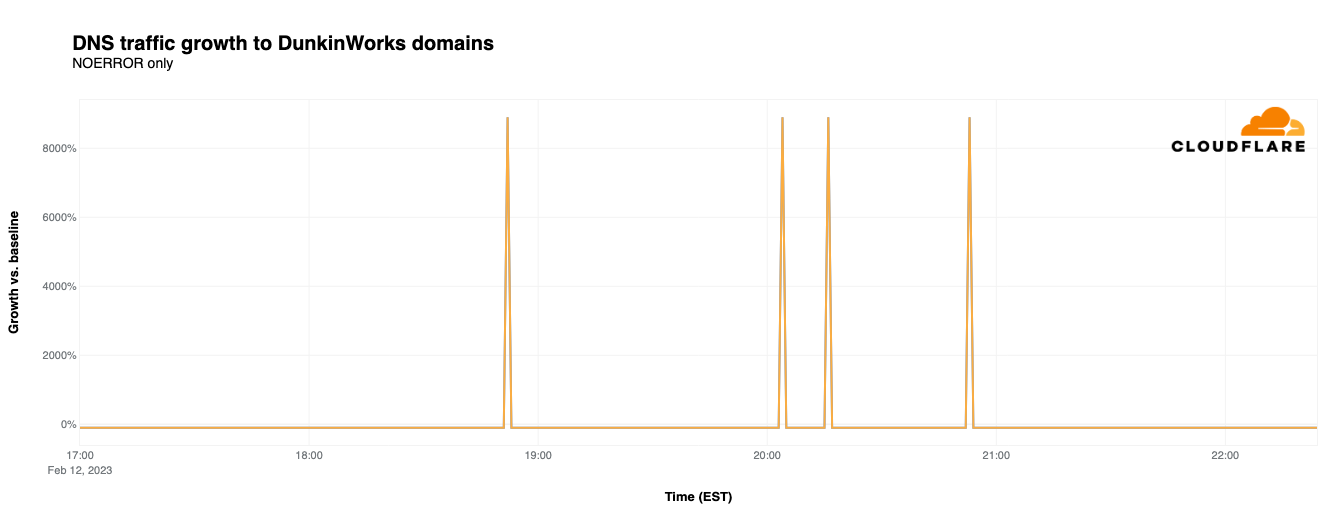
Dunkin’
In early January, Boston-area media blew up with the news that local celebrity Ben Affleck was spotted working the drive-through window at one of the coffee chain’s Medford locations, raising some speculation that he was filming a Super Bowl commercial. That speculation turned out to be true, as the commercial aired at 18:53 EST. But the commercial had a side effect: DNS traffic for dunkin.com, associated with DunkinWorks (a small personal coaching and training business), spiked 8,000% when the commercial aired, as shown in the graph below. (It isn’t clear what drove the later three spikes for dunkin.com, as the advertisement didn’t air again nationally during the remainder of the game.) We can only hope that the dunkin.com system administrators were fueled with plenty of coffee and donuts as they dealt with the rapid growth in traffic.
Site categories: touchdowns bring attention
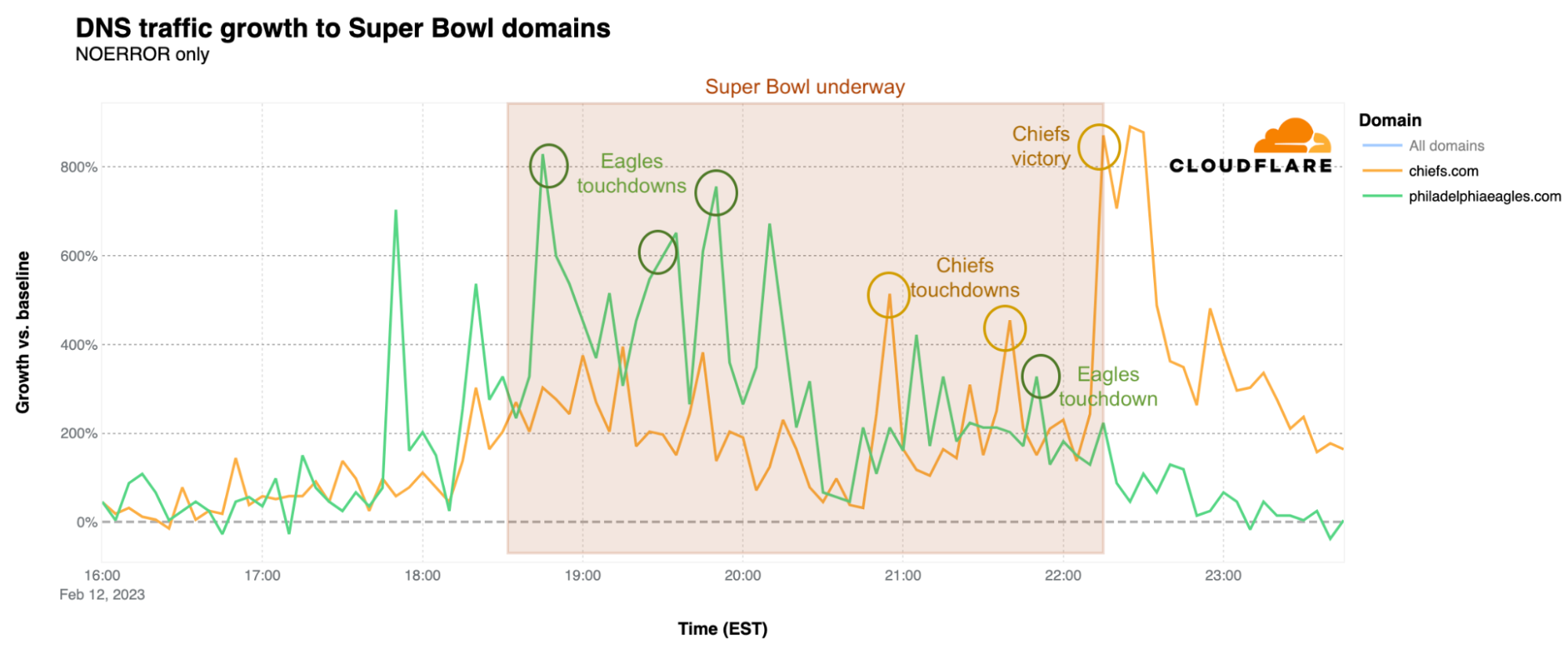
As we saw last year, there are two factors that bring a surge of traffic to the websites of Super Bowl participants: touchdowns and winning. However, nothing is more impactful than the sweet taste of victory. Both the Kansas City Chiefs’ and Philadelphia Eagles’ websites experienced a surge in DNS traffic just before the game started, as compared to a baseline calculated as the mean request volume for the associated domains between 12:00-15:00 EST on Sunday, February 12 (Super Bowl Sunday.). The Eagles website had its peak just around the time of the kickoff, with 828% growth over baseline, and continued to grow more rapidly than traffic to the Chiefs’ website until 20:55 EST, when traffic to chiefs.com began to pull ahead.
What happened at that time? That was the moment of the Chiefs’ third touchdown of the game, when DNS traffic to the team’s website had its first peak of the evening, at 514% above baseline. There was a clear spike during another Chiefs touchdown at 21:42 EST, at 454% above baseline, but that was nothing compared to the end of the game, when the Kansas City Chiefs were once again, after their 2019 victory, the winners. At 22:15 EST, when the game ended, DNS traffic to the Chiefs’ website was 871% higher, and peaked 10 minutes later at 890%, as compared to the baseline. At this same time, DNS traffic for the Eagles’ website dropped significantly. As we saw last year as well, winning the Super Bowl clearly drives increased traffic to the victor’s website.
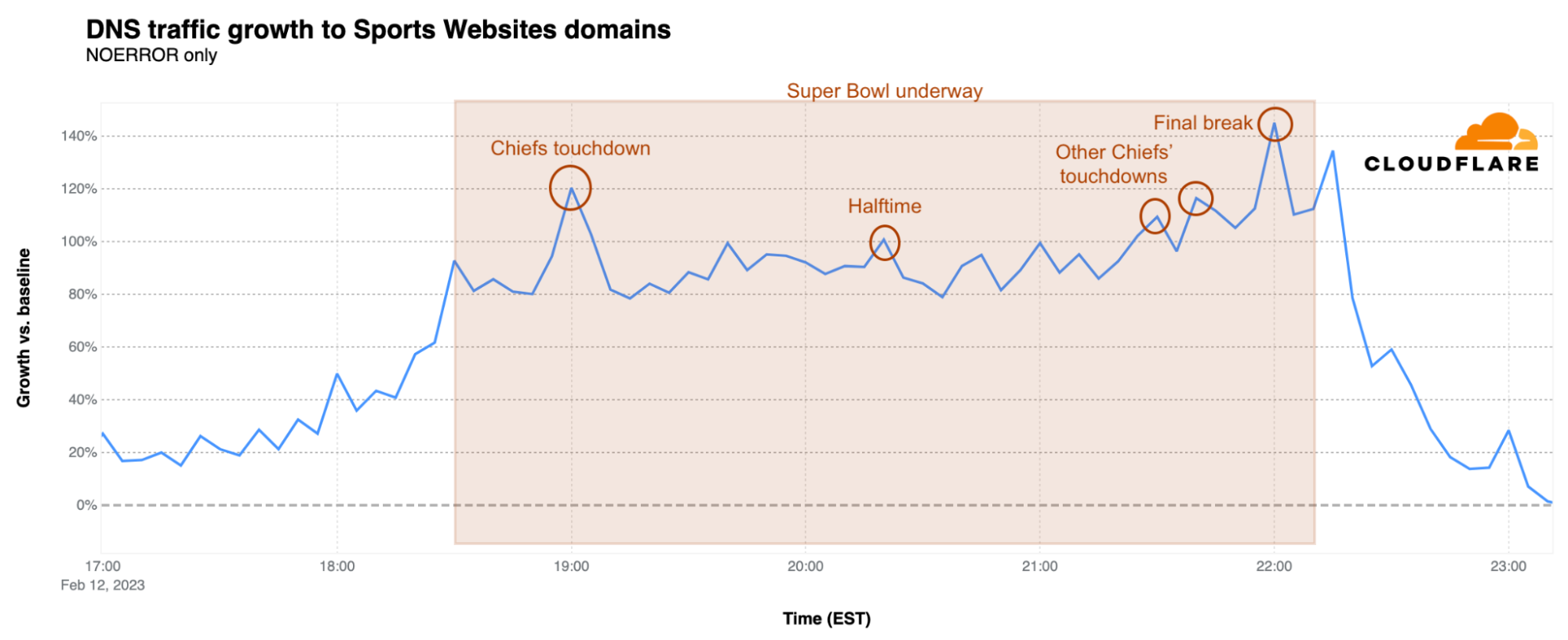
Sports websites trends also followed the in-game events. There was a clear spike to approximately 90% above baseline when the game started at 18:30 EST, with further growth to 120% over baseline at 19:00 EST during the Kansas City Chiefs’ first touchdown. There were also clear spikes at 21:30 and 21:40 EST coinciding with the two more Chiefs touchdowns. The Super Bowl peak for these websites was reached during the final break at 22:00 EST, reaching 145% above baseline, just before the Chiefs’ game-winning field goal. After a brief drop as the game ended, there was an additional spike to 134%.
Rihanna’s impact on messaging and social media sites
What happened following Rihanna’s performance during the Super Bowl halftime show? As the game resumed, we saw a clear increase in traffic for messaging websites, with a first peak right after the end of the show at around 20:45 EST, 22% over baseline. The biggest peak, however, was when the game ended. At 22:15 EST, DNS traffic for messaging sites was 30% higher than the earlier baseline.
Rihanna’s announcement of her second pregnancy, which made news after her performance, also impacted traffic to social media platforms. After a small increase when halftime started, there was a clear drop during Rihanna’s show, followed by a jump from 6% below baseline back to 0% right after the show. An additional 3% of traffic growth was reached during the final break at 22:00 EST, just before the Kansas City Chiefs’ winning field goal. After a brief drop, traffic reached 2% above baseline as the game ended.
Is halftime also a time for rewatching ads?
The arrival of halftime at 20:21 EST also brought a surge in DNS traffic for video platforms. The first peak was reached at 18:00 EST, before the game started, at 12% above baseline. The peak during halftime was reached at 20:25 EST with 13% growth above baseline, suggesting that viewers may have been looking at that time to Super Bowl related videos or just using the time to browse those platforms.
Food delivery websites saw flat to lower DNS traffic just before the game as compared to the earlier baseline, suggesting that food orders were placed/scheduled earlier in the afternoon, hours before the game. At kickoff, traffic was 19% below baseline, but there was a clear spike at the time of the first break and right after the first Kansas City touchdown at 18:55 EST. After falling again during the game, there was a small increase in traffic observed just after the game ended.
What about betting sites? They expected a big day during the Super Bowl, given that more states have recently legalized gambling on sports. The peak was reached at 19:00 EST, as DNS traffic reached 295% over baseline, when the Chiefs had their first touchdown, The first Eagles touchdown, minutes before, resulted in a 233% spike. The lowest traffic for betting sites during the Super Bowl was during the halftime show. In the second half of the game, two other clear spikes in traffic are visible. The first was at 20:55 EST at 167% above baseline when the Chiefs pulled ahead with a touchdown, and then a jump to 278% over baseline when the game ended.
Rihanna runs this town city
While the so-called NFL cities across the country are loyal to their local teams, looking at traffic trends across cities from both conferences makes it clear that fans everywhere find joy, not division, in the unknown pleasures of a good halftime show. The drop visible in both graphs below between 20:30-20:50 EST coincides with Rihanna’s return to live performance, as she last performed live in January 2018. Based on the observed drop in traffic, viewers apparently turned away from their computers and devices, giving their attention to Rihanna, or at least stopped their general Internet surfing during the halftime show. As the graphs show, traffic recovered as soon as halftime was over.
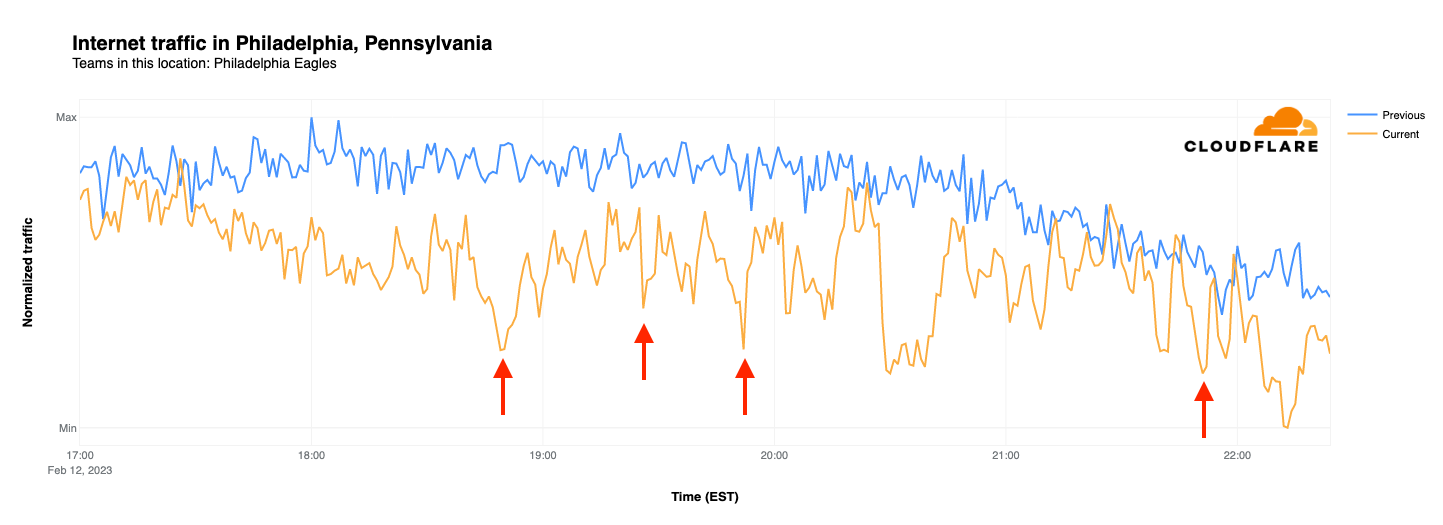
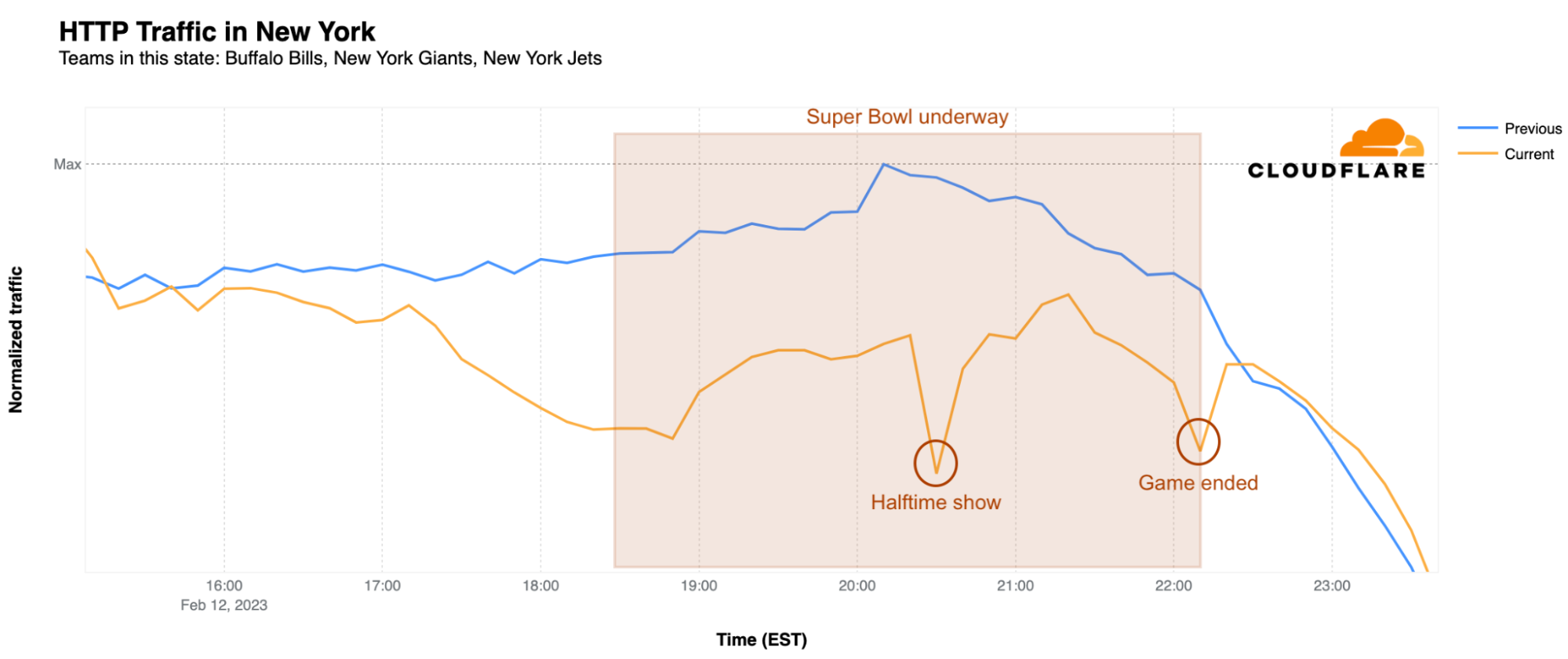
Zooming in to individual cities, we examined the traffic patterns observed in both Philadelphia and Kansas City. While both teams have fans across the country, we can use their home cities as a proxy. In this case, we compared normalized Internet traffic levels between 17:00-22:30 EST on Super Bowl Sunday (February 12) with the same time frame on the prior Sunday (February 5).
In Kansas City last Sunday, traffic volumes remained fairly consistent across the surveyed time period. However, on Super Bowl Sunday, traffic levels were initially similar, but by the start of the game were 84% lower than the same time the previous week. Slight drops in traffic are visible coincident with Chiefs touchdowns, but don’t stand out from the overall noisiness of the graph. The graph reached its nadir at 22:13 EST when the Chiefs broke the tie and kicked the game-winning field goal, with the significant drop in traffic likely due to an increased shift in focus towards the outcome of the game, even by those that hadn’t previously been paying close attention.
As the graph below shows, last Sunday saw Internet traffic in Philadelphia gradually decline as the evening wore on. On Super Bowl Sunday, traffic started out slightly lower than the week prior, and also diverged as game time approached, reaching nearly 50% lower at kickoff. As the Eagles took an early lead, their first touchdown resulted in a noticeable drop in traffic from Philadelphia, seen at 18:52 EST, less than 10 minutes after the start of the game. Visible drops in traffic are also coincident with the Eagles’ other three touchdowns, although they don’t stand out against the volatility of the graph. Traffic began to drop towards the end of the game, as the tie score added tension, and reached its lowest point when it became clear that the Eagles were not going to emerge victorious in Super Bowl LVII.
State-level traffic trends: the winning impact
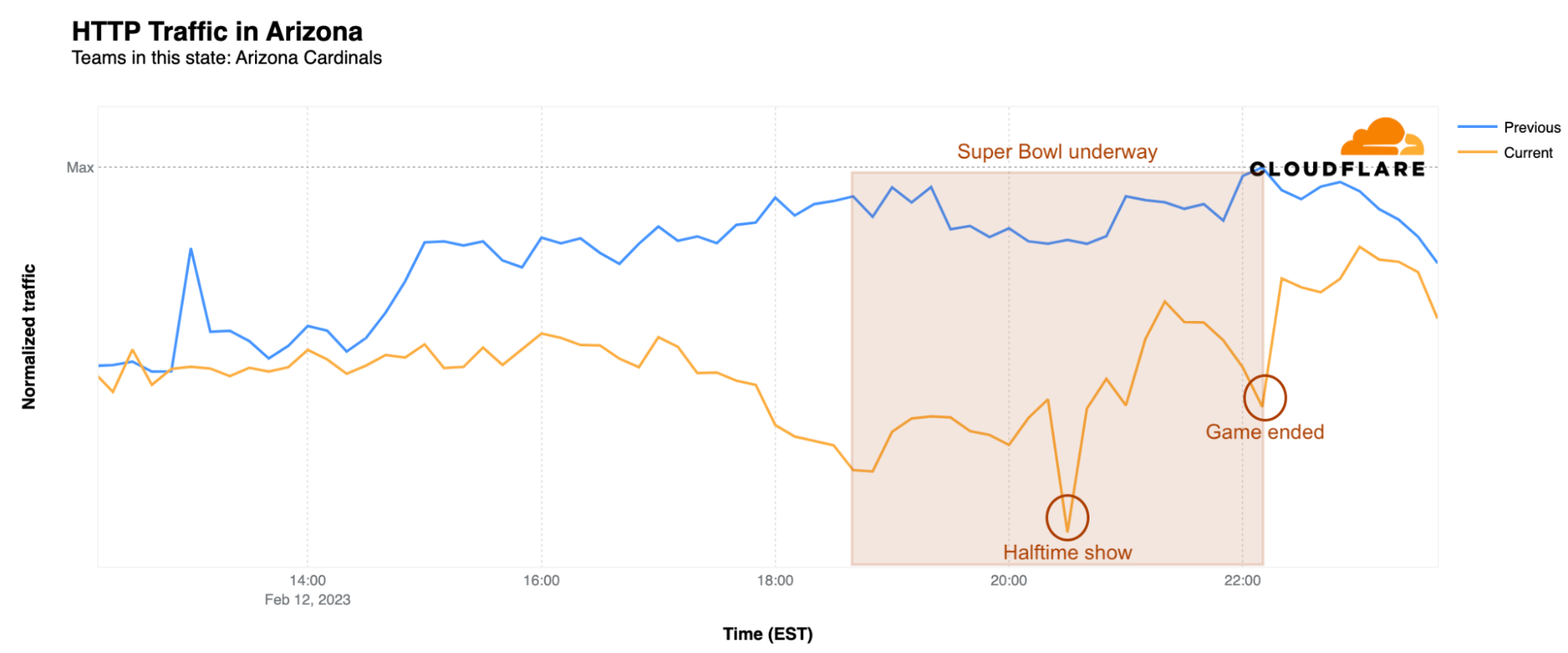
In addition to looking at traffic impacts at a city level, we can also zoom out to examine Internet traffic trends in the Super Bowl states. Arizona, which hosted the big game at State Farm Stadium in Glendale, saw a drop in state-level traffic starting around 13:00 EST. At the time of the kickoff, traffic was 25% lower than the previous Sunday, but the biggest impact was during the wildly popular halftime show by Rihanna. At 20:30 EST, traffic was 29% lower than the same time on the previous Sunday. After the game ended, traffic levels returned to normal around 23:30 EST.
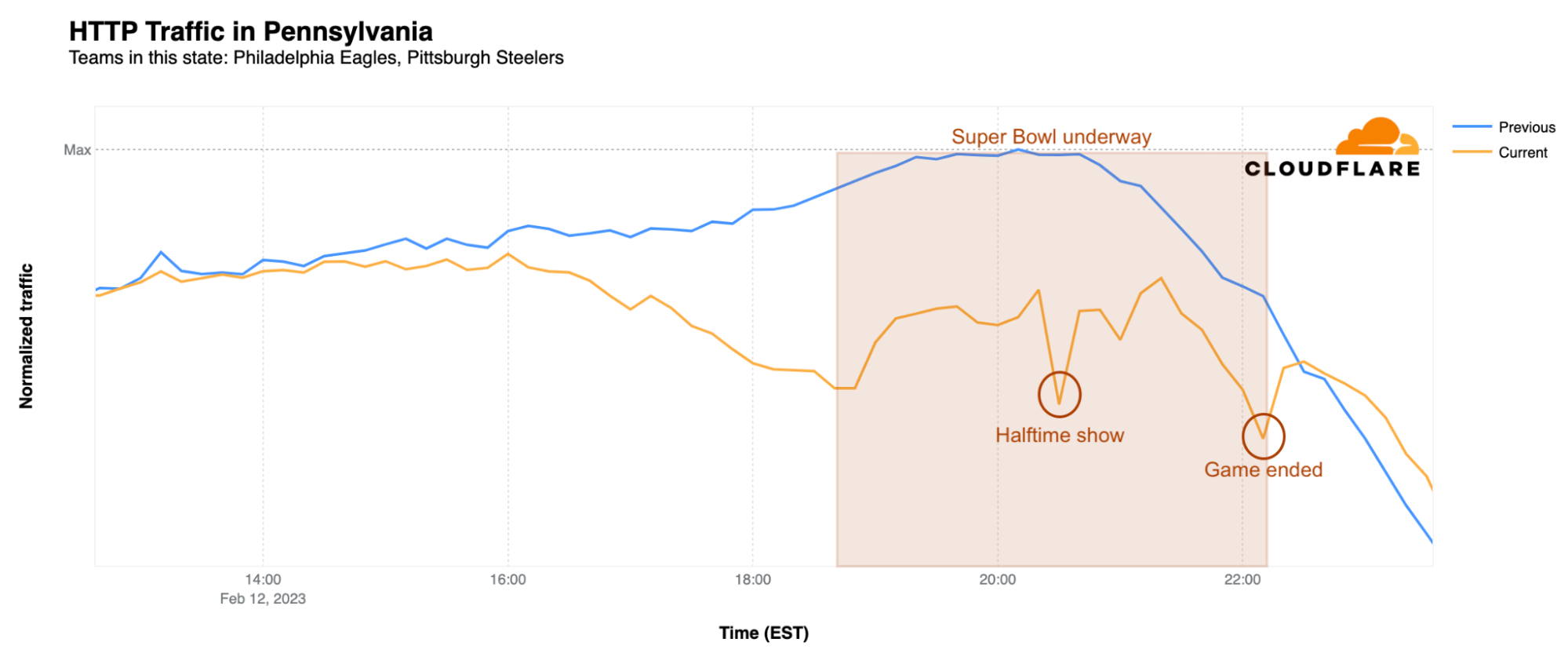
In Pennsylvania, home of the Philadelphia Eagles, traffic began to dip after 15:00 EST and reached its first low point around kickoff, when it was 28% lower than the previous Sunday. Just like in Arizona, the biggest difference was during Rihanna’s halftime show, when it was a whopping 33% lower than usual. However, just a few minutes after the game ended at 22:30 EST, traffic returned to normal.
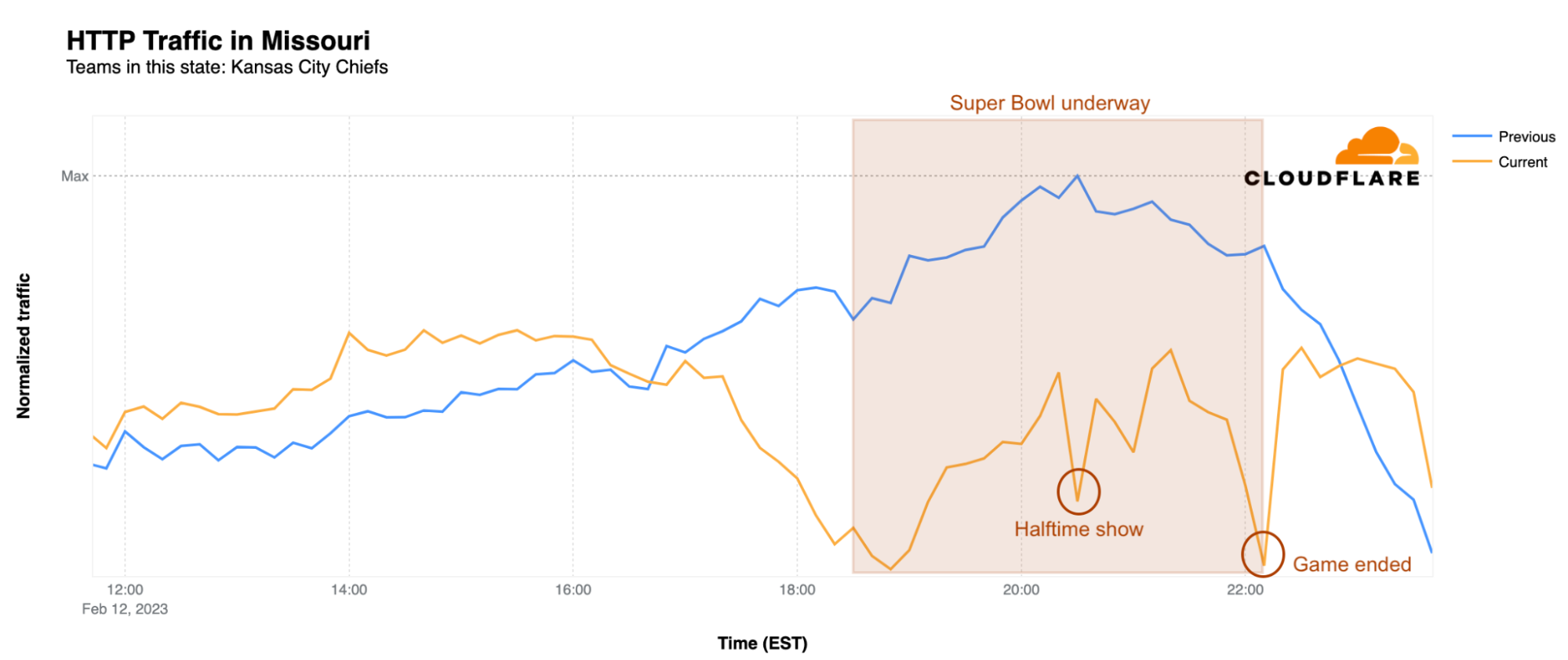
What about the winning team’s state of Missouri? There, traffic started to decrease only after 17:00 EST and was actually higher than the previous Sunday before that point. With the kickoff came a clear drop, resulting in 28% less traffic than the previous Sunday at the same time. Traffic increased a bit heading towards halftime, but dropped again during Rihanna’s show, when it was 30% lower than usual. The biggest drop in traffic, not surprisingly, was during the exciting moment of the Kansas City Chiefs’ winning field goal. At 22:15 EST, traffic was 33% lower than the previous Sunday. However, after 22:50 EST, Internet traffic in Missouri was back on the fast track, with traffic increasing to levels higher than the previous Sunday.
Rihanna’s halftime performance had a clear impact on Internet traffic at a state level, which dropped across all states with NFL teams at the time of her show. Below we take a closer look at the most populous states, among which Pennsylvania, New York and Arizona were winners, with the largest traffic declines. The impacts in Pennsylvania and Arizona are shown above, and the graph below shows the traffic trends seen in New York.
California, Texas, Florida, and New York all had their fair share of Internet traffic dropping before and throughout the game, but it was during the halftime show when things really got interesting. At the time of Rihanna’s performance, Internet traffic in California was 24% lower than the previous Sunday, while in Texas it was 21% below a week earlier, and Florida also saw a 21% drop. Meanwhile, New York had a clear 30% decrease in traffic during the show and, as shown above, Pennsylvania took the cake with a 33% drop. Illinois, Ohio, Georgia, North Carolina, and Michigan were close behind with 23%, 27%, 22%, 25%, and 22% drops respectively.
This seems to be a clear indication that the Super Bowl in general, but also the much-anticipated halftime shows, and the winning celebrations, all have a massive impact on the Internet, causing a noticeable dip in Internet traffic, especially in the state of the winning team.
Do email spammers and scammers take advantage of “The Big Game”?
Spammers and scammers will frequently try to take advantage of the popularity of major events when running their campaigns, hoping the tie-in will entice the user to open the message and click on a malicious link, or visit a malicious website where they give up a password or credit card number. Cloudflare Area 1 Email Security analyzed the subject lines of email messages processed by the service in the weeks leading up to the Super Bowl to identify malicious, suspicious, and spam messages across four topic areas: Super Bowl/football, sports gambling, sports media/websites, and food delivery.
As the “regular” season NFL games wrapped up, Super Bowl and football themed email threat volume remained relatively low. However, campaigns clearly picked up between January 23-29 as the message count grew sevenfold. However, campaigns kicked into high gear once the Chiefs and Eagles were headed to the Super Bowl, as the number of identified messages between January 30 and February 5 was nearly six times higher than the previous week. These campaigns quickly ended in the week before the big game, though, as Super Bowl and football themed suspicious, malicious, and spam email volume dropped by nearly 90%.
Overall, the number of sports gambling themed subject lines remained fairly low over the survey period. This is somewhat surprising, given that an increasing number of US states have recently legalized betting on sporting events. Interestingly, the trend was highest at the beginning of the year, although that first week was too late to capture potential interest in college football “bowl” games. However, the weeks ahead of the NFL conference championship games (January 23-29) and the Super Bowl (February 6-12) saw message volume increase to levels nearly 2.5x higher than previous weeks.
Sports media and website themed suspicious, malicious, and spam email messages apparently don’t draw the clicks, because the volume of such messages seen by Cloudflare Area 1 has remained extremely low since the start of the year, but peaked during the week of January 23-29. And although lower in volume, the observed trends were similar to those seen for sports gambling, with peaks during the same weeks.
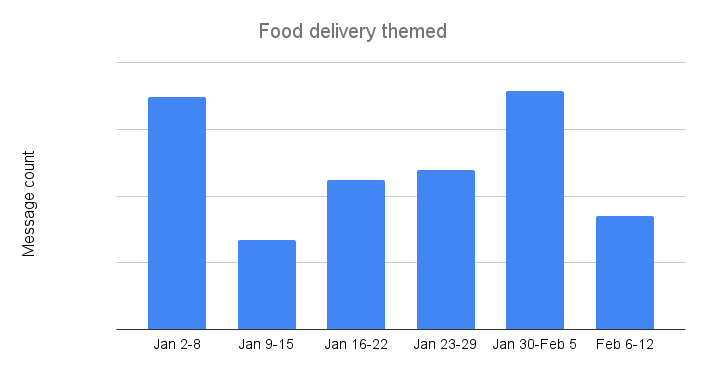
For many people, the Super Bowl is less about the football game than it is about the commercials and the food, and the growth of food delivery services over the last few years have made it easier to ensure that the snacks and libations never run out during the game. Scammers and spammers have apparently learned to take advantage of this hunger, as food delivery themed email messages saw the highest counts across the four categories reviewed here. Peak message counts were seen the weeks of January 2-8 and January 30-February 5. Message volume the weeks following these peaks fell by over 50% in both cases.
Conclusion
As we have seen time and again, advertising during the Super Bowl can drive significant traffic spikes, and apparently this holds true even if a URL isn’t included as a call to action within the commercial. In addition, the trends observed during the game remain a clear reminder that human behavior drives Internet traffic, especially when the halftime show features a popular singer that last performed live five years ago.
Visit Cloudflare Radar for up to date Internet traffic and attack trends, and follow the Cloudflare Radar Twitter and Mastodon accounts for regular insights on Internet events.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.