Post Syndicated from Harry Hough original https://blog.cloudflare.com/building-jetflow-a-framework-for-flexible-performant-data-pipelines-at-cloudflare/
The Cloudflare Business Intelligence team manages a petabyte-scale data lake and ingests thousands of tables every day from many different sources. These include internal databases such as Postgres and ClickHouse, as well as external SaaS applications such as Salesforce. These tasks are often complex and tables may have hundreds of millions or billions of rows of new data each day. They are also business-critical for product decisions, growth plannings, and internal monitoring. In total, about 141 billion rows are ingested every day.
As Cloudflare has grown, the data has become ever larger and more complex. Our existing Extract Load Transform (ELT) solution could no longer meet our technical and business requirements. After evaluating other common ELT solutions, we concluded that their performance generally did not surpass our current system, either.
It became clear that we needed to build our own framework to cope with our unique requirements — and so Jetflow was born.
Over 100x efficiency improvement in GB-s:
-
Our longest running job with 19 billion rows was taking 48 hours using 300 GB of memory, and now completes in 5.5 hours using 4 GB of memory
-
We estimate that ingestion of 50 TB from Postgres via Jetflow could cost under $100 based on rates published by commercial cloud providers
>10x performance improvement:
-
Our largest dataset was ingesting 60-80,000 rows per second, this is now 2-5 million rows per second per database connection.
-
In addition, these numbers scale well with multiple database connections for some databases.
Extensibility:
-
The modular design makes it easy to extend and test. Today Jetflow works with ClickHouse, Postgres, Kafka, many different SaaS APIs, Google BigQuery and many others. It has continued to work well and remain flexible with the addition of new use cases.
The first step to designing our new framework had to be a clear understanding of the problems we were aiming to solve, with clear requirements to stop us creating new ones.
We needed to be able to move more data in less time as some ingestion jobs were taking ~24 hours, and our data will only grow. The data should be ingested in a streaming fashion and use less memory and compute resources than our existing solution.
Given the daily ingestion of thousands of tables, the chosen solution needed to allow for the migration of individual tables as needed. Due to our usage of Spark downstream and Spark’s limitations in merging desperate Parquet schemas, the chosen solution had to offer the flexibility to generate the precise schemas needed for each case to match legacy.
We also required seamless integration with our custom metadata system, used for dependency checks and job status information.
We want a configuration file that can be version-controlled, without introducing bottlenecks on repositories with many concurrent changes.
To increase accessibility for different roles within the team, another requirement was no-code (or configuration as code) in the vast majority of cases. Users should not have to worry about availability or translation of data types between source and target systems, or writing new code for each new ingestion. The configuration needed should also be minimal — for example, data schema should be inferred from the source system and not need to be supplied by the user.
Striking a balance with the no-code requirement above, although we want a low bar of entry we also want to have the option to tune and override options if desired, with a flexible and optional configuration layer. For example, writing Parquet files is often more expensive than reading from the database, so we want to be able to allocate more resources and concurrency as needed.
Additionally, we wanted to allow for control over where the work is executed, with the ability to spin up concurrent workers in different threads, different containers, or on different machines. The execution of workers and communication of data was abstracted away with an interface, and different implementations can be written and injected, controlled via the job configuration.
We wanted a solution capable of running locally in a containerized environment, which would allow us to write tests for every stage of the pipeline. With “black box” solutions, testing often means validating the output after making a change, which is a slow feedback loop, risks not testing all edge cases as there isn’t good visibility of all code paths internally, and makes debugging issues painful.
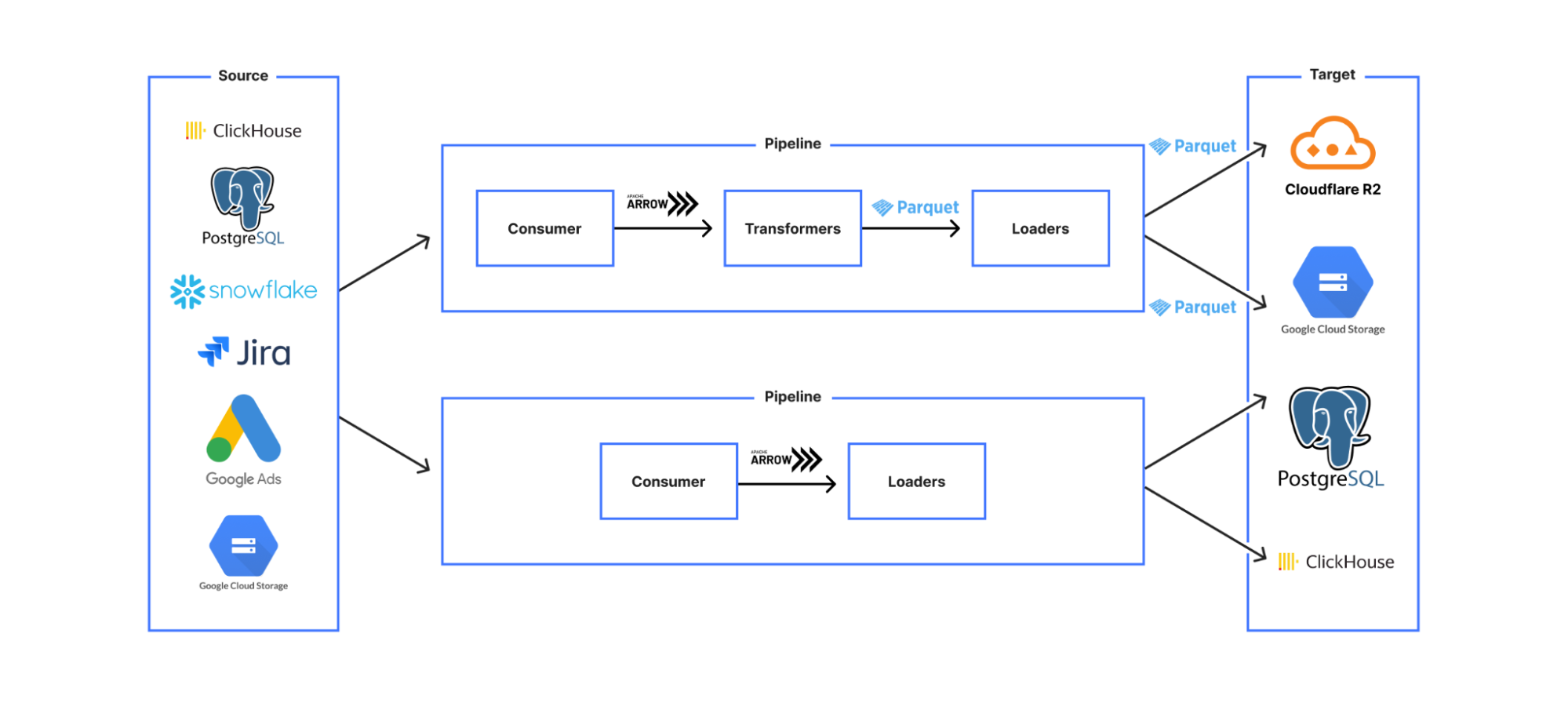
To build a truly flexible framework, we broke the pipeline down into distinct stages, and then create a config layer to define the composition of the pipeline from these stages, and any configuration overrides. Every pipeline configuration that makes sense logically should execute correctly, and users should not be able to create pipeline configs that do not work.
This led us to a design where we created stages which were classified according to the meaningfully different categories of:
-
Consumers
-
Transformers
-
Loaders

The pipeline was constructed via a YAML file that required a consumer, zero or more transformers, and at least one loader. Consumers create a data stream (via reading from the source system), Transformers (e.g. data transformations, validations) take a data stream input and output a data stream conforming to the same API so that they can be chained, and Loaders have the same data streaming interface, but are the stages with persistent effects — i.e. stages where data is saved to an external system.
This modular design means that each stage is independently testable, with shared behaviour (such as error handling and concurrency) inherited from shared base stages, significantly decreasing development time for new use cases and increasing confidence in code correctness.
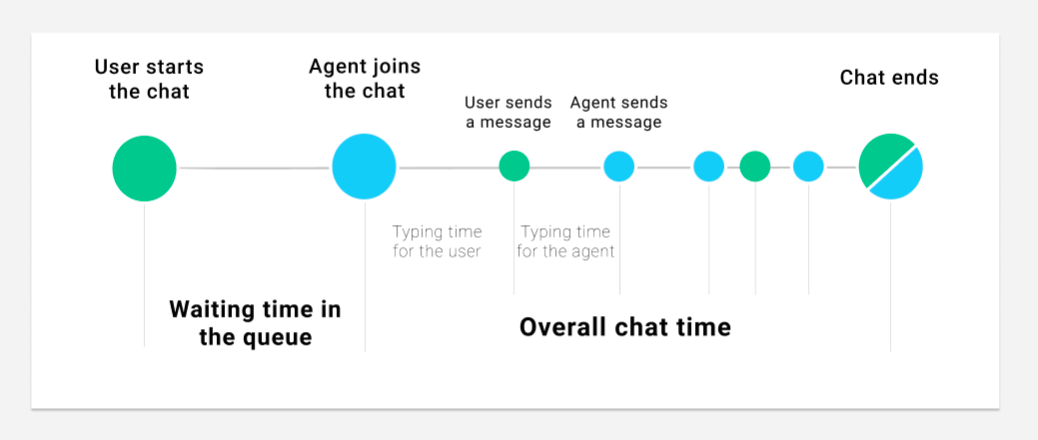
Next, we designed a breakdown for the data that would allow the pipeline to be idempotent both on whole pipeline re-run and also on internal retry of any data partition due to transient error. We decided on a design that let us parallelize processing, while maintaining meaningful data divisions that allowed the pipeline to perform cleanups of data where required for a retry.
-
RunInstance: the least granular division, corresponding to a business unit for a single run of the pipeline (e.g. one month/day/hour of data).
-
Partition: a division of the RunInstance that allows each row to be allocated to a partition in a way that is deterministic and self-evident from the row data without external state, and is therefore idempotent on retry. (e.g. an accountId range, a 10-minute interval)
-
Batch: a division of the partition data that is non-deterministic and used only to break the data down into smaller chunks for streaming/parallel processing for faster processing with fewer resources. (e.g. 10k rows, 50 MB)
The options that the user configures in the consumer stage YAML both construct the query that is used to retrieve the data from the source system, and also encode the semantic meaning of this data division in a system agnostic way, so that later stages understand what this data represents — e.g. this partition contains the data for all accounts IDs 0-500. This means that we can do targeted data cleanup and avoid, for example, duplicate data entries if a single data partition is retried due to error.

Our most common use case is something like read from a database, convert to Parquet format, and then save to object storage, with each of these steps being a separate stage. As more use cases were onboarded to Jetflow, we had to make sure that if someone wrote a new stage it would be compatible with the other stages. We don’t want to create a situation where new code needs to be written for every output format and target system, or you end up with a custom pipeline for every different use case.
The way we have solved this problem is by having our stage extractor class only allow output data in a single format. This means as long as any downstream stages support this format as in the input and output format they would be compatible with the rest of the pipeline. This seems obvious in retrospect, but internally was a painful learning experience, as we originally created a custom type system and struggled with stage interoperability.
For this internal format, we chose to use Arrow, an in-memory columnar data format. The key benefits of this format for us are:
-
Arrow ecosystem: Many data projects now support Arrow as an output format. This means when we write extractor stages for new data sources, it is often trivial to produce Arrow output.
-
No serialisation overhead: This makes it easy to move Arrow data between machines and even programming languages with minimum overhead. Jetflow was designed from the start to have the flexibility to be able to run in a wide range of systems via a job controller interface, so this efficiency in data transmission means there’s minimal compromise on performance when creating distributed implementations.
-
Reserve memory in large fixed-size batches to avoid memory allocations: As Go is a garbage collected (GC) language and GC cycle times are affected mostly by the number of objects rather than the sizes of those objects, fewer heap objects reduces CPU time spent garbage collecting significantly, even if the total size is the same. As the number of objects to scan, and possibly collect, during a GC cycle increases with the number of allocations, if we have 8192 rows with 10 columns each, Arrow would only require us to do 10 allocations versus the 8192 allocations of most drivers that allocate on a row by row basis, meaning fewer objects and lower GC cycle times with Arrow.
Another important performance optimization was reducing the number of conversion steps that happen when reading and processing data. Most data ingestion frameworks internally represent data as rows. In our case, we are mostly writing data in Parquet format, which is column based. When reading data from column-based sources (e.g. ClickHouse, where most drivers receive RowBinary format), converting into row-based memory representations for the specific language implementation is inefficient. This is then converted again from rows to columns to write Parquet files. These conversions result in a significant performance impact.
Jetflow instead reads data from column-based sources in columnar formats (e.g. for ClickHouse-native Block format) and then copies this data into Arrow column format. Parquet files are then written directly from Arrow columns. The simplification of this process improves performance.
When testing an initial version of Jetflow, we discovered that due to the architecture of ClickHouse, using additional connections would not be of any benefit, since ClickHouse was reading faster than we were receiving data. It should then be possible, with a more optimized database driver, to take better advantage of that single connection to read a much larger number of rows per second, without needing additional connections.
Initially, a custom database driver was written for ClickHouse, but we ended up switching to the excellent ch-go low level library, which directly reads Blocks from ClickHouse in a columnar format. This had a dramatic effect on performance in comparison to the standard Go driver. Combined with the framework optimisations above, we now ingest millions of rows per second with a single ClickHouse connection.
A valuable lesson learned is that as with any software, tradeoffs are often made for the sake of convenience or a common use case that may not match your own. Most database drivers tend not to be optimized for reading large batches of rows, and have high per-row overhead.
For Postgres, we use the excellent jackc/pgx driver, but instead of using the database/sql Scan interface, we directly receive the raw bytes for each row and use the jackc/pgx internal scan functions for each Postgres OID (Object Identifier) type.
The database/sql Scan interface in Go uses reflection to understand the type passed to the function and then also uses reflection to set each field with the column value received from Postgres. In typical scenarios, this is fast enough and easy to use, but falls short for our use cases in terms of performance. The jackc/pgx driver reuses the row bytes produced each time the next Postgres row is requested, resulting in zero allocations per row. This allows us to write high-performance, low-allocation code within Jetflow. With this design, we are able to achieve nearly 600,000 rows per second per Postgres connection for most tables, with very low memory usage.
As of early July 2025, the team ingests 77 billion records per day via Jetflow. The remaining jobs are in the process of being migrated to Jetflow, which will bring the total daily ingestion to 141 billion records. The framework has allowed us to ingest tables in cases that would not otherwise have been possible, and provided significant cost savings due to ingestions running for less time and with fewer resources.
In the future, we plan to open source the project, and if you are interested in joining our team to help develop tools like this, then open roles can be found at https://www.cloudflare.com/careers/jobs/.