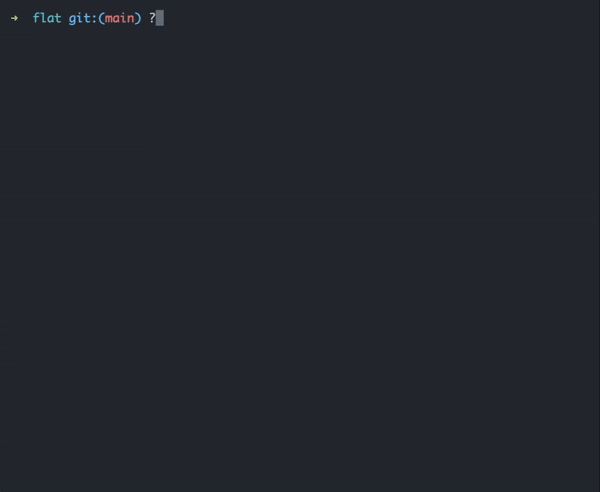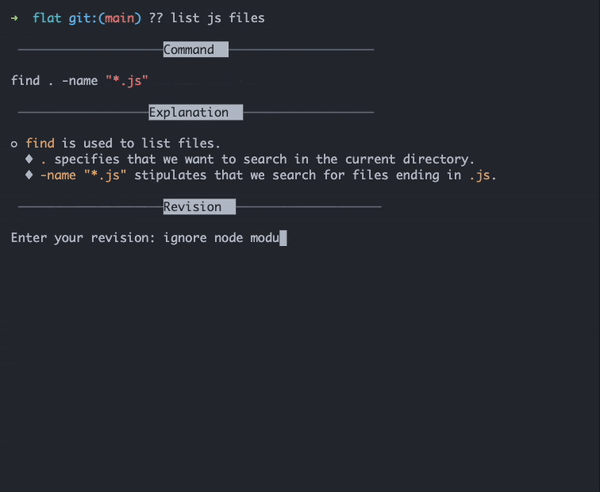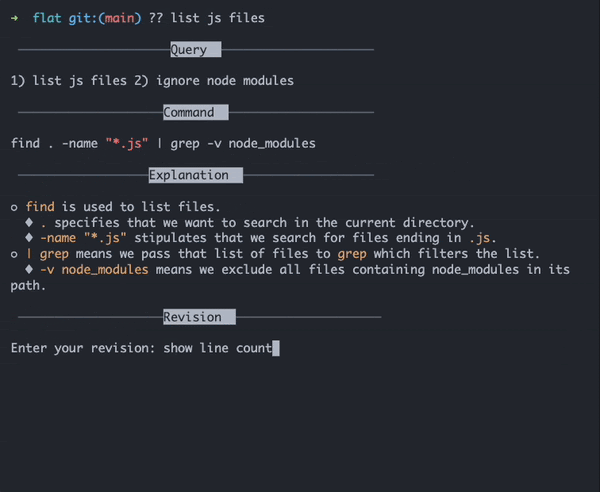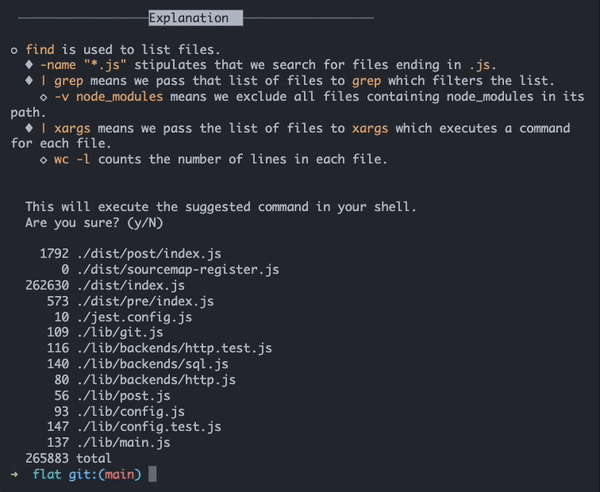
Earlier this year, it seemed like every headline or dinner conversation was earmarked by the buzzwords “generative AI.” And while 2023 has been a benchmark year for the adoption of generative AI, it’s not entirely a new technology. Arguably, AI has been around since the ‘60s, but the AI as we know it today came to be with the invention of machine learning frameworks known as neural networks (you can read more about that here).
For the past few years at GitHub, we’ve been experimenting with generative AI models to create new, meaningful tools for developers—which is how GitHub Copilot was born. And since GitHub Copilot’s initial preview release in 2021, we’ve been thinking a lot about how generative AI can (and should) empower developers to be more productive at every stage of the software development lifecycle. That led us to our vision for the future of AI-powered software development with GitHub Copilot, which we covered in detail this year at GitHub Universe 2023.
In this blog post, we’ll explore some of the experiments we’ve conducted with generative AI models over the past few years, as well as take a behind-the-scenes look at some of our key learnings. We’ll also explore what going from a concept to a product looks like with a radically new technology.
Predictable. We want to create tools that guide developers towards their end goals but don’t suprise or overwhelm them.
Tolerable. As we’ve seen, AI models can be wrong. Users should be able to spot incorrect suggestions easily, and address them at a low cost to focus and productivity.
Steerable. When a response isn’t right or isn’t what a user is looking for, they should be able to steer the AI towards a solution. Otherwise, we’re optimistically banking on the models producing perfect answers.
Verifiable. Solutions must be easy to evaluate. The models are not perfect, but they can be very helpful tools if users verify their outputs.
Last year, researchers from GitHub Next, our R&D department focused on the future of software development, were given advanced access to OpenAI’s large language model (LLM) that would soon be released as GPT-4.
“At the time, no one had seen anything like this,” Idan Gazit, senior director of research for GitHub Next recalls. “It became a race to discover what the new models are capable of doing and what kinds of applications are possible tomorrow that were impossible yesterday.”
So, the GitHub Next team did what they do best: experiment. Over the course of several months, researchers from GitHub Next used the GPT-4 model to develop potential new tools and features that could be used across the GitHub platform. Once the team identified the projects that showed true value, the sprint to build began.
“In classic GitHub Next fashion, we sat down and spiked a bunch of ideas and saw what looked promising or exciting to us,” Gazit explains. “And then we doubled down on the things that we believed would bear fruit.”
In the time between receiving the model and the slated announcement of the model’s release in March 2023, the team had come up with several concepts and technical previews.
At the time, no one had seen anything like this. It became a race to discover what the new models are capable of doing and what kinds of applications are possible tomorrow that were impossible yesterday.
– Idan Gazit, Senior Director of Research // GitHub Next
As these projects came together, senior leadership at GitHub began to think about what these meant for the future of GitHub Copilot. Mario Rodriguez, VP of product management, says, “We knew we wanted to make an announcement of our own around the joint Microsoft and OpenAI announcement of GPT-4. At that time, GitHub Next had a set of investments that they were making that they thought were worthwhile for the announcement. Those investments were not production-ready—they were more future-focused.” He explains, “But that got us thinking, so we put pen to paper and came up with the ambition behind the latest evolution of GitHub Copilot.”
Thinking ahead
As teams at GitHub thought about evolving GitHub Copilot beyond a pair programmer in the IDE, they imagined a future where GitHub Copilot was:
Ubiquitous across every tool that developers use and integrated into every task that developers perform.
Conversational by default, so that natural language can be used to achieve anything.
Personalized to the context and knowledge of the individual, project, team, and community.
This thought exercise, in conjunction with GitHub Next’s work to conceptualize and create new tools that could revolutionize the developer workflow, crystallized what would make up the latest evolution of GitHub Copilot. And on March 22, 2023, the technical preview for what GitHub Copilot would evolve into was released to the world with GitHub Copilot Chat and the following technical previews created by GitHub Next:
So, what happened behind the scenes to come up with these previews? Let’s find out.
Experimenting with AI’s place in the developer experience
If you asked just about any developer what’s something that is specifically unique to GitHub, it would be pretty shocking if they didn’t say “pull requests.” Pull requests play a central role in the GitHub developer experience—they’re not only a point of collaboration, but a gateway for teams to view and approve any changes to code.
“GitHub invented pull requests, so we started thinking, how could we add AI smarts around pull requests?” Rice says. “We tried a bunch of stuff—we prototyped automatic code suggestions for reviews, we had a sort of summarize mode, and a bunch of other things around test generation.” But as the deadline of March 22 approached, a few of these prototyped features weren’t working as desired, so Rice and team began focusing their attention and efforts solely on the summary feature.
With the early version of Copilot for Pull Requests, a developer could submit their pull request and the AI model would generate a description and walkthrough of the code in the first comment to provide important context for the reviewer.
“We did an internal study of the feature with Hubbers and it didn’t go well,” Rice laughs. It wasn’t that the developers didn’t like what the feature was trying to achieve, it was the user experience, Rice believes, they were having challenges with. “The developers were concerned that the AI would be wrong. But there’s two things: you have the content the AI generates and then you have the way that it’s presented to the user and how it interacts with the workflow. At first, we focused a lot on the first bit, the AI-generated content, but it turned out that the second bit was far more crucial in getting this thing to fly,” he explains.
To work around this, Rice and team decided to pivot and use the same AI-generated content but frame it differently. “Instead of a comment, we put it as a suggestion to the developer that let them get a preview of what the description of their pull request could look like that they could then edit,” Rice says. “So, we moved it to a suggestion system, and all of a sudden the feedback changed to ‘wow, these are helpful suggestions.’ The content was exactly the same as before, it was just presented differently.”
Nobody’s perfect—not even AI
For Rice, the key takeaway during this process was the importance of how the AI output is presented to the developer, rather than the total accuracy of the suggestion. That doesn’t mean that it’s acceptable for the AI to be completely wrong, but it does mean that a developer’s demand for the quality of the suggestion sits on a spectrum—developers will view something as it fits within their workflow regardless of what is served to them. When the content was served as a suggestion that the developer had the authority to accept and edit, the typical attitude toward the feature changed.
Eddie Aftandilian, a principal researcher that headed up the development of another GitHub Copilot feature, shared some similar sentiments and takeaways throughout the process of building Copilot for Docs. In late 2022, Aftandilian and Johan Rosenkilde were examining embeddings and retrievals, and they prototyped a vector database for a different GitHub Copilot experiment. “This got us thinking, what if we could use this for retrievals of things other than just code,” Aftandilian remembers. “Once we got access to GPT-4, we realized we could use the retrieval engine to search a large corpus of documentation, and then compose those search results into a prompt that elicits better, more topical answers based on the documentation,” he explains.
“Since GitHub is all about developer tools, we thought, how can we make this into a useful developer tool?” Aftandilian says. Developers spend an enormous amount of time poring over docs to find solutions—and as Aftandilian plainly puts it, “No one really likes reading documentation!” He continues, “It also can be hard to get the right answer out of docs, too. So, it seemed like there was an opportunity here for something that could answer a developer’s question more directly and unblock them. It’s also an area of the development process that we felt was underexplored. We spend a lot of time searching around for answers, which can be a real pain point, and we thought we could do better with these new LLMs.”
Aftandilian, along with Devon Rifkin, Jake Donham, and Amelia Wattenberger, also deployed their early version of Copilot for Docs to Hubbers, extending GitHub Copilot’s reach to GitHub’s internal docs in addition to public documentation. But once the preview reached public testing, he got some interesting feedback about the quality of the AI outputs.
“One challenge we came across during the development process was that the models don’t always give the right answer or the right document,” Aftandilian says. “To address this, we built in the capability for our answers to provide references or links to other documentation. We found that when we deployed it, the feedback we received was that developers didn’t mind if the output wasn’t always perfectly correct if the linked references made it easier to evaluate what the AI produced. They were using Copilot for Docs as a search engine,” he says.
The UX needs to be tolerant of AI’s mistakes—you can’t assume that the AI will always be right.
– Eddie Aftandilian, Principal Researcher // GitHub Next
Another key learning for Aftandilian was that human feedback is the true gold standard for developing AI-based tools. “One of our conclusions was that you should ship something sooner rather than later to get real, human feedback to drive improvements,” he says.
And similar to Rice’s earlier point, user experience is also critical to the success of these AI-powered tools. “The UX needs to be tolerant of AI’s mistakes—you can’t assume that the AI will always be right,” Aftandilian says. “Initially we were focused on getting everything right, but we soon learned that the chat-like modality of Copilot for Docs makes the answers feel less authoritative and folks are more tolerant of the responses when they point the user in the right direction. The AI isn’t always perfect, but it’s a great start.”
Small but mighty
In October 2022, the entire GitHub Next team met up in Oxford, England to get together and discuss all of the projects that they were currently working on, as well as some exciting—and maybe even far-fetched—ideas.
“One of the things that I pitched at this crazy ideas session was a project that would use LLMs to help you figure out CLI commands,” Johan Rosenkilde, a principal researcher for GitHub Next, recalls. “I was thinking about something that could use natural language prompts to describe what you wanted to do in the command line, then some sort of GUI or interface pops up that helps you narrow down what you want to do.”
As Rosenkilde talked through his pitch, one of his colleagues, Matt Rothenberg, began writing an application that did almost exactly that. “By the time my talk ended, he asked if he could show me something, and my mind was just blown,” Rosenkilde laughs. That thirty-minute prototype was the genesis for what would become Copilot for CLI.
“What he had created clearly showed that there was something of value here, but it lacked maturity of course,” Rosenkilde says. “And so what we did was carve out time to refine this rough demo into something that we could deliver to developers,” he says. By the time March 2023 rolled around, they had a preview that brought the power of GitHub Copilot right to the CLI for developers to quickly ask for and receive their desired shell commands, including a breakdown that explains each part of the command—without ever needing to search the web for answers.
When reflecting on the process of taking this app from that original, scrappy version to a technical preview, Rosenkilde echoes Rice and Aftandilian in his appreciation for the subtlety of UX decisions.
“I’m a backend person: I’m heavy on theory and I like really difficult problems that cause me to think for weeks about a solution,” Rosenkilde says. “Matt was the UX guy, and he iterated extremely quickly through a lot of options. So much of the success of this application hinged on the UX, and that’s a lesson that I’ve taken with me. All that we do in GitHub Next, in the end, is think up tools that will add value to the user experience, so it’s crucial that we get the design right and that it fits in with what the AI model can do. As we know, the AI models aren’t perfect, but when they are imperfect, the cost to the user should be as low as possible,” Rosenkilde says.
That simple fact is what informs the explanation field that can be found in Copilot for CLI. “This actually wasn’t part of the original UI. As the product matured, we came up with the explanation field, but we had some difficulty with the LLM producing the structured type of explanations we sought. It’s very unnatural for a language model to produce something that looks like this, I had to hit it with a very large hammer,” he jokes. “We wanted it to be clearly structured, but if you just ask the AI to explain a shell command, it would feed you a long paragraph that is not readily scannable and might not include the details you want.”
Rosenkilde also felt that it was important to add the explanation field to help developers learn about shell scripts and double check that they have received the correct command. “It’s also a security feature because you can read in natural language whether the command will change files you didn’t expect to change,” he explains. This multifaceted explanation field is not only useful, it’s a testament to the UX of the application. “When you have such a small application, you want every feature to have multiple different uses so that you can package up a lot of complexity in something that visually is very simple.”
Where we’re headed
We’re focused on something great here: creating delightful AI experiences for everyone who interacts with the GitHub platform. And while we’re working on it, we invite you to be part of the process. You can get involved by joining the waitlists for our current previews and giving us your honest feedback on what you think and what you want to see going forward.
Today AWS made the much-anticipated announcement of Graviton4 which should be available in 2024. This is AWS’s latest Graviton processor and the fourth generation launched in the last five years. The company also announced its second-generation Tranium2 processor for AI workloads. AWS Graviton4 is an Even Bigger Arm Server Processor AWS is continuing on its […]
We want to empower you to experiment with LLM models, build your own applications, and discover untapped problem spaces. That’s why we sat down with GitHub’s Alireza Goudarzi, a senior machine learning researcher, and Albert Ziegler, a principal machine learning engineer, to discuss the emerging architecture of today’s LLMs.
In this post, we’ll cover five major steps to building your own LLM app, the emerging architecture of today’s LLM apps, and problem areas that you can start exploring today.
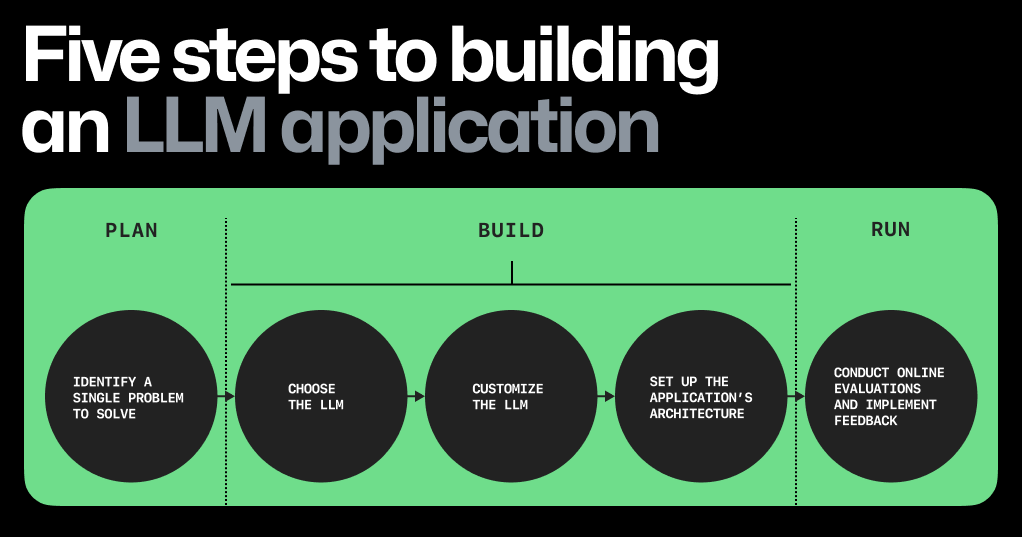
Five steps to building an LLM app
Building software with LLMs, or any machine learning (ML) model, is fundamentally different from building software without them. For one, rather than compiling source code into binary to run a series of commands, developers need to navigate datasets, embeddings, and parameter weights to generate consistent and accurate outputs. After all, LLM outputs are probabilistic and don’t produce the same predictable outcomes.
Click on diagram to enlarge and save.
Let’s break down, at a high level, the steps to build an LLM app today. 👇
1. Focus on a single problem, first. The key? Find a problem that’s the right size: one that’s focused enough so you can quickly iterate and make progress, but also big enough so that the right solution will wow users.
For instance, rather than trying to address all developer problems with AI, the GitHub Copilot team initially focused on one part of the software development lifecycle: coding functions in the IDE.
2. Choose the right LLM. You’re saving costs by building an LLM app with a pre-trained model, but how do you pick the right one? Here are some factors to consider:
Licensing. If you hope to eventually sell your LLM app, you’ll need to use a model that has an API licensed for commercial use. To get you started on your search, here’s a community-sourced list of open LLMs that are licensed for commercial use.
Model size. The size of LLMs can range from 7 to 175 billion parameters—and some, like Ada, are even as small as 350 million parameters. Most LLMs (at the time of writing this post) range in size from 7-13 billion parameters.
Conventional wisdom tells us that if a model has more parameters (variables that can be adjusted to improve a model’s output), the better the model is at learning new information and providing predictions. However, the improved performance of smaller models is challenging that belief. Smaller models are also usually faster and cheaper, so improvements to the quality of their predictions make them a viable contender compared to big-name models that might be out of scope for many apps.
Model performance. Before you customize your LLM using techniques like fine-tuning and in-context learning (which we’ll cover below), evaluate how well and fast—and how consistently—the model generates your desired output. To measure model performance, you can use offline evaluations.
3. Customize the LLM. When you train an LLM, you’re building the scaffolding and neural networks to enable deep learning. When you customize a pre-trained LLM, you’re adapting the LLM to specific tasks, such as generating text around a specific topic or in a particular style. The section below will focus on techniques for the latter. To customize a pre-trained LLM to your specific needs, you can try in-context learning, reinforcement learning from human feedback (RLHF), or fine-tuning.
In-context learning, sometimes referred to as prompt engineering by end users, is when you provide the model with specific instructions or examples at the time of inference—or the time you’re querying the model—and asking it to infer what you need and generate a contextually relevant output.
In-context learning can be done in a variety of ways, like providing examples, rephrasing your queries, and adding a sentence that states your goal at a high-level.
RLHF comprises a reward model for the pre-trained LLM. The reward model is trained to predict if a user will accept or reject the output from the pre-trained LLM. The learnings from the reward model are passed to the pre-trained LLM, which will adjust its outputs based on user acceptance rate.
The benefit to RLHF is that it doesn’t require supervised learning and, consequently, expands the criteria for what’s an acceptable output. With enough human feedback, the LLM can learn that if there’s an 80% probability that a user will accept an output, then it’s fine to generate. Want to try it out? Check out these resources, including codebases, for RLHF.
Fine-tuning is when the model’s generated output is evaluated against an intended or known output. For example, you know that the sentiment behind a statement like this is negative: “The soup is too salty.” To evaluate the LLM, you’d feed this sentence to the model and query it to label the sentiment as positive or negative. If the model labels it as positive, then you’d adjust the model’s parameters and try prompting it again to see if it can classify the sentiment as negative.
Fine-tuning can result in a highly customized LLM that excels at a specific task, but it uses supervised learning, which requires time-intensive labeling. In other words, each input sample requires an output that’s labeled with exactly the correct answer. That way, the actual output can be measured against the labeled one and adjustments can be made to the model’s parameters. The advantage of RLHF, as mentioned above, is that you don’t need an exact label.
4. Set up the app’s architecture. The different components you’ll need to set up your LLM app can be roughly grouped into three categories:
User input which requires a UI, an LLM, and an app hosting platform.
Input enrichment and prompt construction tools. This includes your data source, embedding model, a vector database, prompt construction and optimization tools, and a data filter.
Efficient and responsible AI tooling, which includes an LLM cache, LLM content classifier or filter, and a telemetry service to evaluate the output of your LLM app.
5. Conduct online evaluations of your app. These evaluations are considered “online” because they assess the LLM’s performance during user interaction. For example, online evaluations for GitHub Copilot are measured through acceptance rate (how often a developer accepts a completion shown to them), as well as the retention rate (how often and to what extent a developer edits an accepted completion).
The emerging architecture of LLM apps
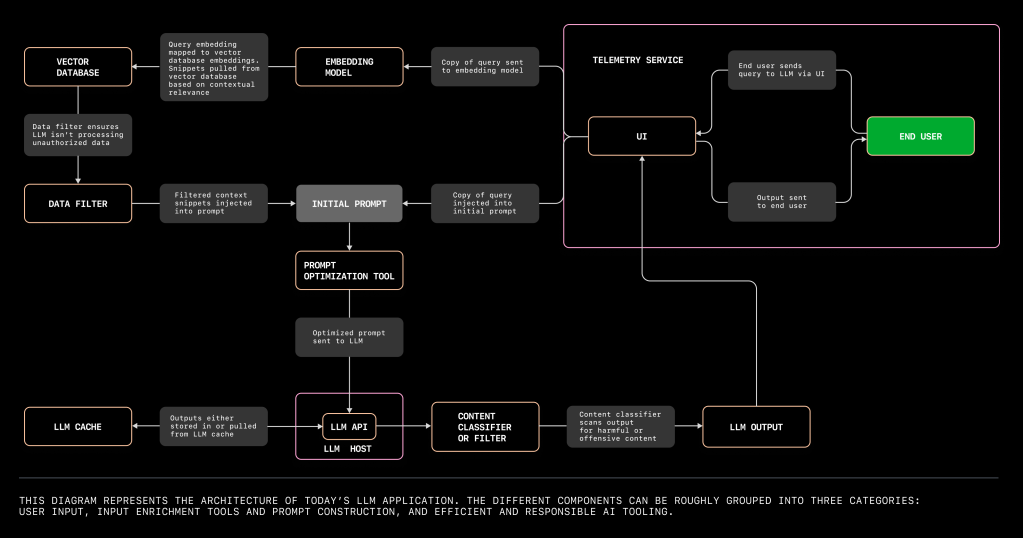
Let’s get started on architecture. We’re going to revisit our friend Dave, whose Wi-Fi went out on the day of his World Cup watch party. Fortunately, Dave was able to get his Wi-Fi running in time for the game, thanks to an LLM-powered assistant.
We’ll use this example and the diagram above to walk through a user flow with an LLM app, and break down the kinds of tools you’d need to build it. 👇
Click diagram to enlarge and save.
User input tools
When Dave’s Wi-Fi crashes, he calls his internet service provider (ISP) and is directed to an LLM-powered assistant. The assistant asks Dave to explain his emergency, and Dave responds, “My TV was connected to my Wi-Fi, but I bumped the counter, and the Wi-Fi box fell off! Now, we can’t watch the game.”
In order for Dave to interact with the LLM, we need four tools:
LLM API and host: Is the LLM app running on a local machine or in the cloud? In an ISP’s case, it’s probably hosted in the cloud to handle the volume of calls like Dave’s. Vercel and early projects like jina-ai/rungpt aim to provide a cloud-native solution to deploy and scale LLM apps.
But if you want to build an LLM app to tinker, hosting the model on your machine might be more cost effective so that you’re not paying to spin up your cloud environment every time you want to experiment. You can find conversations on GitHub Discussions about hardware requirements for models like LLaMA‚ two of which can be found here and here.
The UI: Dave’s keypad is essentially the UI, but in order for Dave to use his keypad to switch from the menu of options to the emergency line, the UI needs to include a router tool.
Speech-to-text translation tool: Dave’s verbal query then needs to be fed through a speech-to-text translation tool that works in the background.
Input enrichment and prompt construction tools
Let’s go back to Dave. The LLM can analyze the sequence of words in Dave’s transcript, classify it as an IT complaint, and provide a contextually relevant response. (The LLM’s able to do this because it’s been trained on the internet’s entire corpus, which includes IT support documentation.)
Input enrichment tools aim to contextualize and package the user’s query in a way that will generate the most useful response from the LLM.
A vector database is where you can store embeddings, or index high-dimensional vectors. It also increases the probability that the LLM’s response is helpful by providing additional information to further contextualize your user’s query.
Let’s say the LLM assistant has access to the company’s complaints search engine, and those complaints and solutions are stored as embeddings in a vector database. Now, the LLM assistant uses information not only from the internet’s IT support documentation, but also from documentation specific to customer problems with the ISP.
But in order to retrieve information from the vector database that’s relevant to a user’s query, we need an embedding model to translate the query into an embedding. Because the embeddings in the vector database, as well as Dave’s query, are translated into high-dimensional vectors, the vectors will capture both the semantics and intention of the natural language, not just its syntax.
Dave’s contextualized query would then read like this:
// pay attention to the the following relevant information.
to the colors and blinking pattern.
// pay attention to the following relevant information.
// The following is an IT complaint from, Dave Anderson, IT support expert.
Answers to Dave's questions should serve as an example of the excellent support
provided by the ISP to its customers.
*Dave: Oh it's awful! This is the big game day. My TV was connected to my
Wi-Fi, but I bumped the counter and the Wi-Fi box fell off and broke! Now we
can't watch the game.
Not only do these series of prompts contextualize Dave’s issue as an IT complaint, they also pull in context from the company’s complaints search engine. That context includes common internet connectivity issues and solutions.
MongoDB released a public preview of Vector Atlas Search, which indexes high-dimensional vectors within MongoDB. Qdrant, Pinecone, and Milvus also provide free or open source vector databases.
A data filter will ensure that the LLM isn’t processing unauthorized data, like personal identifiable information. Preliminary projects like amoffat/HeimdaLLM are working to ensure LLMs access only authorized data.
A prompt optimization tool will then help to package the end user’s query with all this context. In other words, the tool will help to prioritize which context embeddings are most relevant, and in which order those embeddings should be organized in order for the LLM to produce the most contextually relevant response. This step is what ML researchers call prompt engineering, where a series of algorithms create a prompt. (A note that this is different from the prompt engineering that end users do, which is also known as in-context learning).
Prompt optimization tools like langchain-ai/langchain help you to compile prompts for your end users. Otherwise, you’ll need to DIY a series of algorithms that retrieve embeddings from the vector database, grab snippets of the relevant context, and order them. If you go this latter route, you could use GitHub Copilot Chat or ChatGPT to assist you.
Learn how the GitHub Copilot team uses the Jaccard similarity to decide which pieces of context are most relevant to a user’s query >
Efficient and responsible AI tooling
To ensure that Dave doesn’t become even more frustrated by waiting for the LLM assistant to generate a response, the LLM can quickly retrieve an output from a cache. And in the case that Dave does have an outburst, we can use a content classifier to make sure the LLM app doesn’t respond in kind. The telemetry service will also evaluate Dave’s interaction with the UI so that you, the developer, can improve the user experience based on Dave’s behavior.
An LLM cache stores outputs. This means instead of generating new responses to the same query (because Dave isn’t the first person whose internet has gone down), the LLM can retrieve outputs from the cache that have been used for similar queries. Caching outputs can reduce latency, computational costs, and variability in suggestions.
You can experiment with a tool like zilliztech/GPTcache to cache your app’s responses.
A content classifier or filter can prevent your automated assistant from responding with harmful or offensive suggestions (in the case that your end users take their frustration out on your LLM app).
A telemetry service will allow you to evaluate how well your app is working with actual users. A service that responsibly and transparently monitors user activity (like how often they accept or change a suggestion) can share useful data to help improve your app and make it more useful.
OpenTelemetry, for example, is an open source framework that gives developers a standardized way to collect, process, and export telemetry data across development, testing, staging, and production environments.
Woohoo! 🥳 Your LLM assistant has effectively answered Dave’s many queries. His router is up and working, and he’s ready for his World Cup watch party. Mission accomplished!
Real-world impact of LLMs
Looking for inspiration or a problem space to start exploring? Here’s a list of ongoing projects where LLM apps and models are making real-world impact.
NASA and IBM recently open sourced the largest geospatial AI model to increase access to NASA earth science data. The hope is to accelerate discovery and understanding of climate effects.
Read how the Johns Hopkins Applied Physics Laboratory is designing a conversational AI agent that provides, in plain English, medical guidance to untrained soldiers in the field based on established care procedures.
Companies like Duolingo and Mercado Libre are using GitHub Copilot to help more people learn another language (for free) and democratize ecommerce in Latin America, respectively.
Large language models (LLMs) are revolutionizing the way we interact with software by combining deep learning techniques with powerful computational resources.
While this technology is exciting, many are also concerned about how LLMs can generate false, outdated, or problematic information, and how they sometimes even hallucinate (generating information that doesn’t exist) so convincingly. Thankfully, we can immediately put one rumor to rest. According to Alireza Goudarzi, senior researcher of machine learning (ML) for GitHub Copilot: “LLMs are not trained to reason. They’re not trying to understand science, literature, code, or anything else. They’re simply trained to predict the next token in the text.”
Let’s dive into how LLMs come to do the unexpected, and why. This blog post will provide comprehensive insights into LLMs, including their training methods and ethical considerations. Our goal is to help you gain a better understanding of LLM capabilities and how they’ve learned to master language, seemingly, without reasoning.
What are large language models?
LLMs are AI systems that are trained on massive amounts of text data, allowing them to generate human-like responses and understand natural language in a way that traditional ML models can’t.
“These models use advanced techniques from the field of deep learning, which involves training deep neural networks with many layers to learn complex patterns and relationships,” explains John Berryman, a senior researcher of ML on the GitHub Copilot team.
What sets LLMs apart is their proficiency at generalizing and understanding context. They’re not limited to pre-defined rules or patterns, but instead learn from large amounts of data to develop their own understanding of language. This allows them to generate coherent and contextually appropriate responses to a wide range of prompts and queries.
And while LLMs can be incredibly powerful and flexible tools because of this, the ML methods used to train them, and the quality—or limitations—of their training data, can also lead to occasional lapses in generating accurate, useful, and trustworthy information.
Deep learning
The advent of modern ML practices, such as deep learning, has been a game-changer when it comes to unlocking the potential of LLMs. Unlike the earliest language models that relied on predefined rules and patterns, deep learning allows these models to create natural language outputs in a more human-like way.
“The entire discipline of deep learning and neural networks—which underlies all of this—is ‘how simple can we make the rule and get as close to the behavior of a human brain as possible?’” says Goudarzi.
By using neural networks with many layers, deep learning enables LLMs to analyze and learn complex patterns and relationships in language data. This means that these models can generate coherent and contextually appropriate responses, even in the face of complex sentence structures, idiomatic expressions, and subtle nuances in language.
While the initial pre-training equips LLMs with a broad language understanding, fine-tuning is where they become versatile and adaptable. “When developers want these models to perform specific tasks, they provide task descriptions and examples (few-shot learning) or task descriptions alone (zero-shot learning). The model then fine-tunes its pre-trained weights based on this information,” says Goudarzi. This process helps it adapt to the specific task while retaining the knowledge it gained from its extensive pre-training.
But even with deep learning’s multiple layers and attention mechanisms enabling LLMs to generate human-like text, it can also lead to overgeneralization, where the model produces responses that may not be contextually accurate or up to date.
Why LLMs aren’t always right
There are several factors that shed light on why tools built on LLMs may be inaccurate at times, even while sounding quite convincing.
Limited knowledge and outdated information
LLMs often lack an understanding of the external world or real-time context. They rely solely on the text they’ve been trained on, and they don’t possess an inherent awareness of the world’s current state. “Typically this whole training process takes a long time, and it’s not uncommon for the training data to be two years out of date for any given LLM,” says Albert Ziegler, principal researcher and member of the GitHub Next research and development team.
This limitation means they may generate inaccurate information based on outdated assumptions, since they can’t verify facts or events in real-time. If there have been developments or changes in a particular field or topic after they have been trained, LLMs may not be aware of them and may provide outdated information. This is why it’s still important to fact check any responses you receive from an LLM, regardless of how fact-based it may seem.
Lack of context
One of the primary reasons LLMs sometimes provide incorrect information is the lack of context. These models rely heavily on the information given in the input text, and if the input is ambiguous or lacks detail, the model may make assumptions that can lead to inaccurate responses.
Training data biases and limitations
LLMs are exposed to massive unlabelled data sets of text during pre-training that are diverse and representative of the language the model should understand. Common sources of data include books, articles, websites—even social media posts!
Because of this, they may inadvertently produce responses that reflect these biases or incorrect information present in their training data. This is especially concerning when it comes to sensitive or controversial topics.
“Their biases tend to be worse. And that holds true for machine learning in general, not just for LLMs. What machine learning does is identify patterns, and things like stereotypes can turn into extremely convenient shorthands. They might be patterns that really exist, or in the case of LLMs, patterns that are based on human prejudices that are talked about or implicitly used,” says Ziegler.
If a model is trained on a dataset that contains biased or discriminatory language, it may generate responses that are also biased or discriminatory. This can have real-world implications, such as reinforcing harmful stereotypes or discriminatory practices.
Overconfidence
LLMs don’t have the ability to assess the correctness of the information they generate. Given their deep learning, they often provide responses with a high degree of confidence, prioritizing generating text that appears sensible and flows smoothly—even when the information is incorrect!
Hallucinations
LLMs can sometimes “hallucinate” information due to the way they generate text (via patterns and associations). Sometimes, when they’re faced with incomplete or ambiguous queries, they try to complete them by drawing on these patterns, sometimes generating information that isn’t accurate or factual. Ultimately, hallucinations are not supported by evidence or real-world data.
For example, imagine that you ask ChatGPT about a historical issue in the 20th century. Instead, it describes a meeting between two famous historical figures who never actually met!
In the context of GitHub Copilot, Ziegler explains that “the typical hallucinations we encounter are when GitHub Copilot starts talking about code that’s not even there. Our mitigation is to make it give enough context to every piece of code it talks about that we can check and verify that it actually exists.”
But the GitHub Copilot team is already thinking about how to use hallucinations to their advantage in a “top-down” approach to coding. Imagine that you’re tackling a backlog issue, and you’re looking for GitHub Copilot to give you suggestions. As Johan Rosenkilde, principal researcher for GitHub Next, explains, “ideally, you’d want it to come up with a sub-division of your complex problem delegated to nicely delineated helper functions, and come up with good names for those helpers. And after suggesting code that calls the (still non-existent) helpers, you’d want it to suggest the implementation of them too!”
This approach to hallucination would be like getting the blueprint and the building blocks to solve your coding challenges.
Ethical use and responsible advocacy of LLMs
It’s important to be aware of the ethical considerations that come along with using LLMs. That being said, while LLMs have the potential to generate false information, they’re not intentionally fabricating or deceiving. Instead, these arise from the model’s attempts to generate coherent and contextually relevant text based on the patterns and information it has learned from its training data.
The GitHub Copilot team has developed a few tools to help detect harmful content. Goudarzi says “First, we have a duplicate detection filter, which helps us detect matches between generated code and all open source code that we have access to, filtering such suggestions out. Another tool we use is called Responsible AI (RAI), and it’s a classifier that can filter out abusive words. Finally, we also separately filter out known unsafe patterns.”
Understanding the deep learning processes behind LLMs can help users grasp their limitations—as well as their positive impact. To navigate these effectively, it’s crucial to verify information from reliable sources, provide clear and specific input, and exercise critical thinking when interpreting LLM-generated responses.
As Berryman reminds us, “the engines themselves are amoral. Users can do whatever they want with them and that can run the gamut of moral to immoral, for sure. But by being conscious of these issues and actively working towards ethical practices, we can ensure that LLMs are used in a responsible and beneficial manner.”
Developers, researchers, and scientists continuously work to improve the accuracy and reliability of these models, making them increasingly valuable tools for the future. All of us can advocate for the responsible and ethical use of LLMs. That includes promoting transparency and accountability in the development and deployment of these models, as well as taking steps to mitigate biases and stereotypes in our own corners of the internet.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.