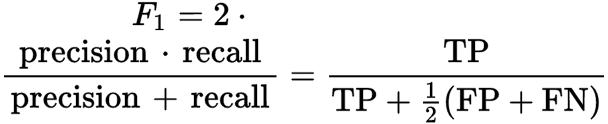By now, you’ve heard of generative artificial intelligence (AI) tools like ChatGPT, DALL-E, and GitHub Copilot, among others. They’re gaining widespread interest thanks to the fact that they allow anyone to create content from email subject lines to code functions to artwork in a matter of moments.
This potential to revolutionize content creation across various industries makes it important to understand what generative AI is, how it’s being used, and who it’s being used by. In this article, we’ll explore what generative AI is, how it works, some real-world applications, and how it’s already changing the way people (and developers) work.
What is generative AI used for?
You may have heard the buzz around new generative AI tools like ChatGPT or the new Bing, but there’s a lot more to generative AI than any one single framework, project, or application.
Traditional AI systems are trained on large amounts of data to identify patterns, and they’re capable of performing specific tasks that can help people and organizations. But generative AI goes one step further by using complex systems and models to generate new, or novel, outputs in the form of an image, text, or audio based on natural language prompts.
Generative AI models and applications can, for example, be used for:
Text generation. Text generation, as a field, with AI tools has been in development since the 1970s—but more recently, AI researchers have been able to train generative adversarial networks (GANs) to produce text that models human-like speech. A prime example is OpenAI’s application ChatGPT, which has been trained on thousands of texts, books, articles, and code repositories, and can respond with full answers to natural language prompts and questions.
An example of text generation in ChatGPT
Image generation. Generative AI models can be used to create new images with natural language prompts, which is one of the most popular techniques with current tools and applications. The goal with text-to-image generation is to create an image that accurately represents the content of a given prompt. For example, when we give the text prompt, “impressionist style oil painting of a Shiba Inu dog giving a tarot card reading,” to the popular AI image generator DALL-E 2 we get something that looks like this (and yes, it’s a gem):
An AI-generated image from DALL-E 2 of a Shiba Inu dog giving a tarot card reading
Video generation. Generative AI models, like Stable Diffusion, are creating new videos from existing videos by applying specified styles through a text prompt or image reference. One project on GitHub, stable-diffusion-videos, offers helpful examples and tips on how to create music videos and videos that can morph between text prompts with Stable Diffusion.
Programming code generation. Rather than scouring the internet or developer community groups for help with code examples, generative AI models can be used to help generate new programming code with natural language prompts, complete partially written code with suggestions, or even translate code from one programming language to another. This is how, at a simple level, GitHub Copilot works: it uses OpenAI’sCodex model to offer code suggestions right from a developer’s editor. However, as you would with any software development tool, we encourage you to review generated code before merging into production.
Data generation. Creating new data—which is called synthetic data—and augmenting existing data sets is another common use case for generative AI. This involves generating new samples from an existing dataset to increase the dataset’s size and improve machine learning models trained on it, all while providing a layer of privacy since real user data is not being utilized to power models. Synthetic data generation provides a way to create useful, meaningful data for more than just ML training though—a number of self-driving car companies like Cruise and Waymoutilize AI-generated synthetic data for training perception systems to prepare vehicles for real-world situations while in operation.
Language translation. Natural-language understanding (NLU) models combined with generative AI have become increasingly popular to provide language translations on-the-fly. These types of tools help companies break language barriers and increase their scope of accessibility for customer bases by being able to provide things like support or documentation in their native language. Through complex, deep learning algorithms, generative AI is able to understand the context of a source text and linguistically construct those sentences in another language. This practice can also apply to coding languages, for example, translating a desired function from Python to Java.
The bottom line: Even though generative AI is a relatively new technology, it’s already being used in consumer and business applications. The use cases, as well as the quantity of applications created with it, will continue evolving to meet more distinct and specific needs.
How does generative AI work?
Generative AI models work by using neural networks to identify patterns from large sets of data, then generate new and original data or content.
But what are neural networks? In simple terms, they use interconnected nodes that are inspired by neurons in the human brain. These networks are the foundation of machine learning and deep learning models, which use a complex structure of algorithms to process large amounts of data such as text, code, or images. Training these neural networks involves adjusting the weights or parameters of the connections between neurons to minimize the difference between predicted and desired outputs, which allows the network to learn from mistakes and make more accurate predictions based on the data.
Algorithms are a key component of machine learning and generative AI models. But beyond helping machines learn from data, algorithms are also used to optimize accuracy of outputs and make decisions, or recommendations, based on input data.
While algorithms help automate these processes, building a generative AI model is incredibly complex due to the massive amounts of data and compute resources they require. People and organizations need large datasets to train these models, and generating high-quality data can be time-consuming and expensive.
To restate the obvious, these models are complicated. Need proof? Here are some common generative AI models and how they work:
Large language models (LLM): LLMs are a type of machine learning model that process and generate natural language text. One of the most significant advancements in the development of large language models has been the availability of vast amounts of text data, such as books, websites, and social media posts. This data can be used to train models that are capable of predicting and generating natural language responses in a variety of contexts. As a result, large language models have multiple practical applications, such as virtual assistants, chatbots, or text generators, like ChatGPT.
Generative adversarial networks (GAN): GANs are one of the most used models for generative AI, and they employ two different neural networks. GANs consist of two different types of neural networks: a generator and a discriminator. The generator network generates new data, such as images or audio, from a random noise signal while the discriminator is trained to distinguish between real data from the training set and the data produced by the generator.
During training, the generator tries to create data that can trick the discriminator network into thinking it’s real. This “adversarial” process will continue until the generator can produce data that is totally indistinguishable from real data in the training set. This process helps both networks improve at their respective tasks, which ultimately results in more realistic and higher-quality generated data.
A diagram illustrating how a generative adversarial network works. Image [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/deed.en) האדם-החושב on wikipedia
Transformer-based models: A transformer-based model’s neural networks operate by learning context and meaning through tracking relationships of sequential data, which means these models are really good at natural language processing tasks like machine translation, language modeling, and answering questions. These models have been used in popular language models, such as GPT-4 (which stands for Generative Pre-trained Transformer 4), and have also been adapted for other such tasks that require the modeling of sequential data such as image recognition.
Variational autoencoder models (VAEs): These models are similar to GANs in that they work with two different neural networks: encoders and decoders. VAEs can take a large amount of data and compress it into a smaller representation, which can be used to create new data that is similar to the original data. VAEs are often used in image, video, and audio generation—and here’s a fun fact: you can train a VAE on datasets like CelebA, which contains over 200,000 images of celebrities, to create completely new portraits of people that don’t exist.
The smile vector, a concept vector discovered by Tom White using VAEs trained on the CelebA dataset.
The real-world applications of generative AI
The impact of generative AI is quickly becoming apparent—but it’s still in its early days. Despite this, we’re already seeing a proliferation of applications, products, and open source projects that are using generative AI models to achieve specific outcomes for people and organizations (and yes, developers, too).
Though generative AI is constantly evolving, it already has some solid real world applications. Here’s just a few of them:
Coding
New and seasoned developers alike can utilize generative AI to improve their coding processes. Generative AI coding tools can help automate some of the more repetitive tasks, like testing, as well as complete code or even generate brand new code. GitHub has its own AI-powered pair programmer, GitHub Copilot, which uses generative AI to provide developers with code suggestions. And GitHub also has announced GitHub Copilot X, which brings generative AI to more of the developer experience across the editor, pull requests, documentation, CLI, and more.
Accessibility
Generative AI has the potential to greatly impact and improve accessibility for folks with disabilities through a variety of modalities, such as speech-to-text transcription, text-to-speech audio generation, or assistive technologies. One of the most exciting facets of our GitHub Copilot tool is its voice-activated capabilities that allow developers with difficulties using a keyboard to code with their voice. By leveraging the power of generative AI, these types of tools are paving the way for a more inclusive and accessible future in technology.
Gaming
Generative AI can take gaming to the next level (get it? ) by generating new characters, storylines, design components, and more. Case in point: The developer behind the game, This Girl Does Not Exist, has said that every component of the game—from the storyline to the art and even the music—was generated entirely by AI. This use of generative AI can enable gaming studios to create new and exciting content for their users, all without increasing the developer workload, which frees them up to work on other aspects of the game, such as story development.
Web design
Designers can utilize generative AI tools to automate the design process and save significant time and resources, which allows for a more streamlined and efficient workflow. Additionally, incorporating these tools into the development process can lead to the creation of highly customized designs and logos, enhancing the overall user experience and engagement with the website or application. Generative AI tools can also be used to do some of the more tedious work, such as creating design layouts that are optimized and adaptable across devices. For example, designers can use tools like designs.ai to quickly generate logos, banners, or mockups for their websites.
Web search
Microsoft and other industry players are increasingly utilizing generative AI models in search to create more personalized experiences. This includes query expansion, which generates relevant keywords to reduce the number of searches. So, rather than the search engine returning a list of links, generative AI can help these new and improved models return search results in the form of natural language responses. Bing now includes AI-powered features in partnership with OpenAI that provide answers to complex questions and allow users to ask follow-up questions in a chatbox for more refined responses.
Healthcare
Interest has emerged around the potential applications of generative AI in the healthcare field to improve disease detection and diagnosis, advance medical research, and accelerate progress in the pharmaceutical space. Potentially, generative AI could be used to analyze large amounts of data to simulate chemical structures and predict new compounds will be the most effective for new drug discoveries. NVIDIA Clara is one example of a generative AI model specifically designed for medical imaging and healthcare research. (Plus, Gartner suggests more than 30 percent of new pharmaceutical drugs and materials will be discovered via generative AI models by 2025.)
In marketing, content is king—and generative AI is making it easier than ever to quickly create large amounts of it. A number of companies, agencies, and creators are already turning to generative AI tools to create images for social posts or write captions, product descriptions, blog posts, email subject lines, and more. Generative AI can also help companies personalize ad experiences by creating custom, engaging content for individuals at speed. Writers, marketers, and creators can leverage tools like Jasper to generate copy, Surfer SEO to optimize organic search, or albert.ai to personalize digital advertising content.
Art and design
As we’ve seen above, the power of AI can be harnessed to create some incredible portraits in a matter of moments (re: the future-telling Shiba ). Artists and designers alike are using these AI tools as a source of inspiration. For example, architects can quickly create 3D models of objects or environments and artists can breathe new life into their portraits by using AI to apply different styles, like adding a Cubist style to their original image. Need proof? Designers are already starting to use AI image generators, such as Midjourney and Microsoft Designer, to create high-quality images by simply typing out Discord commands.
Finance
In a recent discussion about tech trends and how they’ll affect the finance sector, Michael Schrage, a research fellow at the MIT Sloan School Initiative on the Digital Economy, said, “I think, increasingly, we’re going to be seeing generative AI used for financial forecasts and scenario generation.” This is a likely path forward—generative AI can be used to analyze large amounts of data to detect fraud, manage risk, and inform decision making. And that has obvious applications in the financial services industry.
Manufacturing
Manufacturers are starting to turn to generative AI solutions to help with product design, quality control, and predictive maintenance. Generative AI can be used to analyze historical data to improve machine failure predictions and help manufacturers with maintenance planning. According to research conducted by Capgemini, more than half of European manufacturers are implementing some AI solutions (although so far, these aren’t generative AI solutions). This is largely because the sheer amount of manufacturing data is easier for machines to analyze at speed than humans.
AI as a partner: Generative AI models and tools are narrow in focus, and work best at generating content, code, and images. In research at GitHub, we’ve found that GitHub Copilot helps developers code up to 55% faster, underscoring how generative AI models and tools can improve overall productivity and boost efficiency. Metrics like these show how generative AI tools are already changing how people and teams work—but they also underscore how these tools act as complement to human efforts.
Take this with you
Whether it’s creating visual assets for an ad campaign or augmenting medical images to help diagnose diseases, generative AI is helping us solve complex problems at speed. And the emergence of generative AI-based programming tools has revolutionized the way developers approach writing code.
While these models aren’t perfect yet, they’re getting better by the day—and that’s creating an exciting immediate future for developers and generative AI.
In December 2022 we announced the general availability of the WAF Attack Score. The initial release was for our Enterprise customers, but we always had the belief that this product should be enabled for more users. Today we’re announcing “WAF Attack Score Lite” and “Security Analytics” for our Business plan customers.
Looking back on “What is WAF Attack Score and Security Analytics?”
Vulnerabilities on the Internet appear almost on a daily basis. The CVE (common vulnerabilities and exposures) program has a list with over 197,000 records to track disclosed vulnerabilities.
That makes it really hard for web application owners to harden and update their system regularly, especially when we talk about critical libraries and the exploitation damage that can happen in case of information leak. That’s why web application owners tend to use WAFs (Web Application Firewalls) to protect their online presence.
Most WAFs use signature-based detections, which are rules created based on specific attacks that we know about. The signature-based method is very fast, has a low rate of false positives (these are the requests that are categorized as attack when they are actually legitimate), and is very efficient with most of the attack categories we know. However, they sometimes have a blind spot when a new attack happens, often called zero-day attacks. As soon as a new vulnerability is found, our security analysts take fast action to stop it in a matter of hours and update the WAF Managed Rules, yet we want to protect our customers during this time as well.
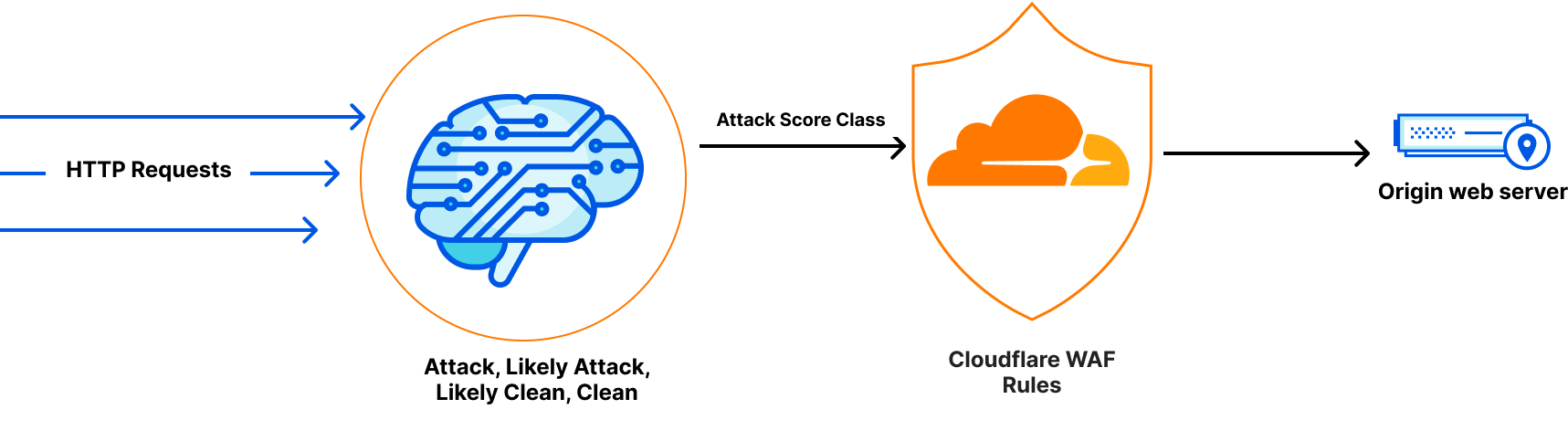
This is the main reason Cloudflare created a complementary feature to the WAF managed rules: a smart machine learning layer to help detect unknown attacks, and protect customers even during the time gap until rules are updated.
Early detection + Powerful mitigation = Safer Internet
The performance of any machine learning drastically depends on the data it was trained on. Our machine learning uses a supervised model that was trained over hundreds of millions of requests generated by WAF Managed Rules, data varies between clean and malicious, some were blended with fuzzy techniques to enable catching similar patterns as covered in our blog “Improving the accuracy of our machine learning WAF”. At the moment, there are three types of attacks our machine learning model is optimized to find: SQL Injection (SQLi), Cross Site Scripting (XSS), and a wide range of Remote Code Execution (RCE) attacks such as shell injection, PHP injection, Apache Struts type compromises, Apache log4j, and similar attacks that result in RCE.
And the reason why we started with them is based on Cloudflare’s Application Security Report. These categories represent more than 24% of the mitigated layer 7 attacks over the last year in our WAF, therefore more prone to exploitations.
In the full Enterprise WAF Attack Score version we offer more granularity on the attack categories and we provide scores for each class where they can be configured freely per domain.
WAF Attack Score Lite Features for Business Plan
WAF Attack Score Lite and the Security Analytics view offer three main functions:
1- Attack detection: This happens through inspecting every incoming HTTP request, bucketing or classifying the requests into 4 types: Attacks, Likely Attacks, Likely Clean and Clean. At the moment there are three types of attacks our machine learning model is optimized to find: SQL Injection (SQLi), Cross Site Scripting (XSS), and a wide range of Remote Code Execution (RCE) attacks.
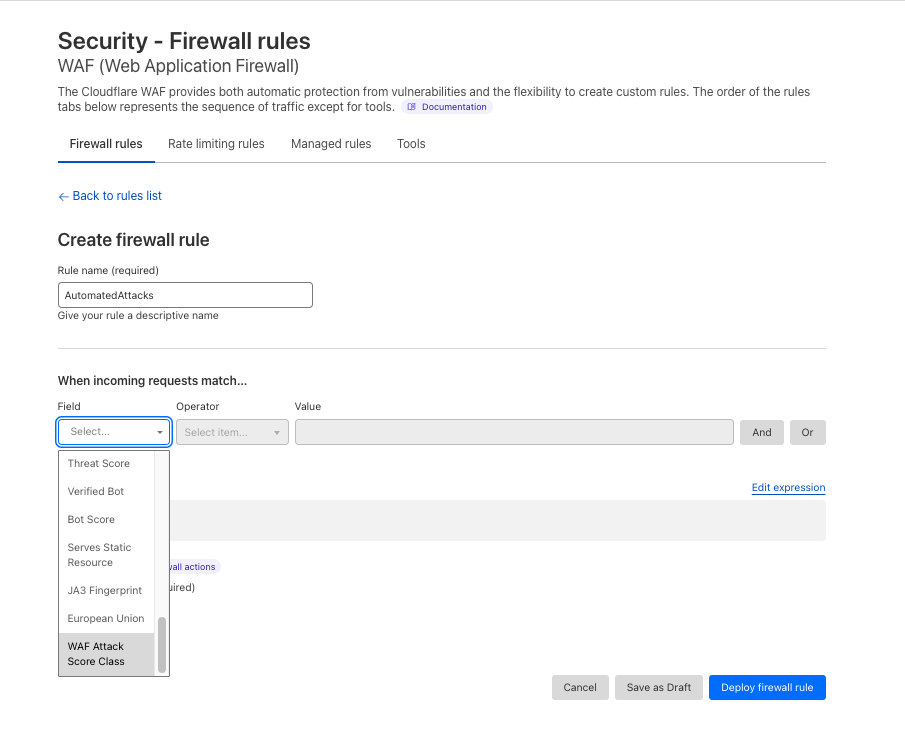
2- Attack mitigation: The ability to create WAF Custom Rules or WAF Rate Limiting Rules to mitigate requests. We’re exposing a new field cf.waf.score.classthat has preset values: attack, likely_attack, likely_clean and clean. customers can use this field in rules expressions and apply needed actions.
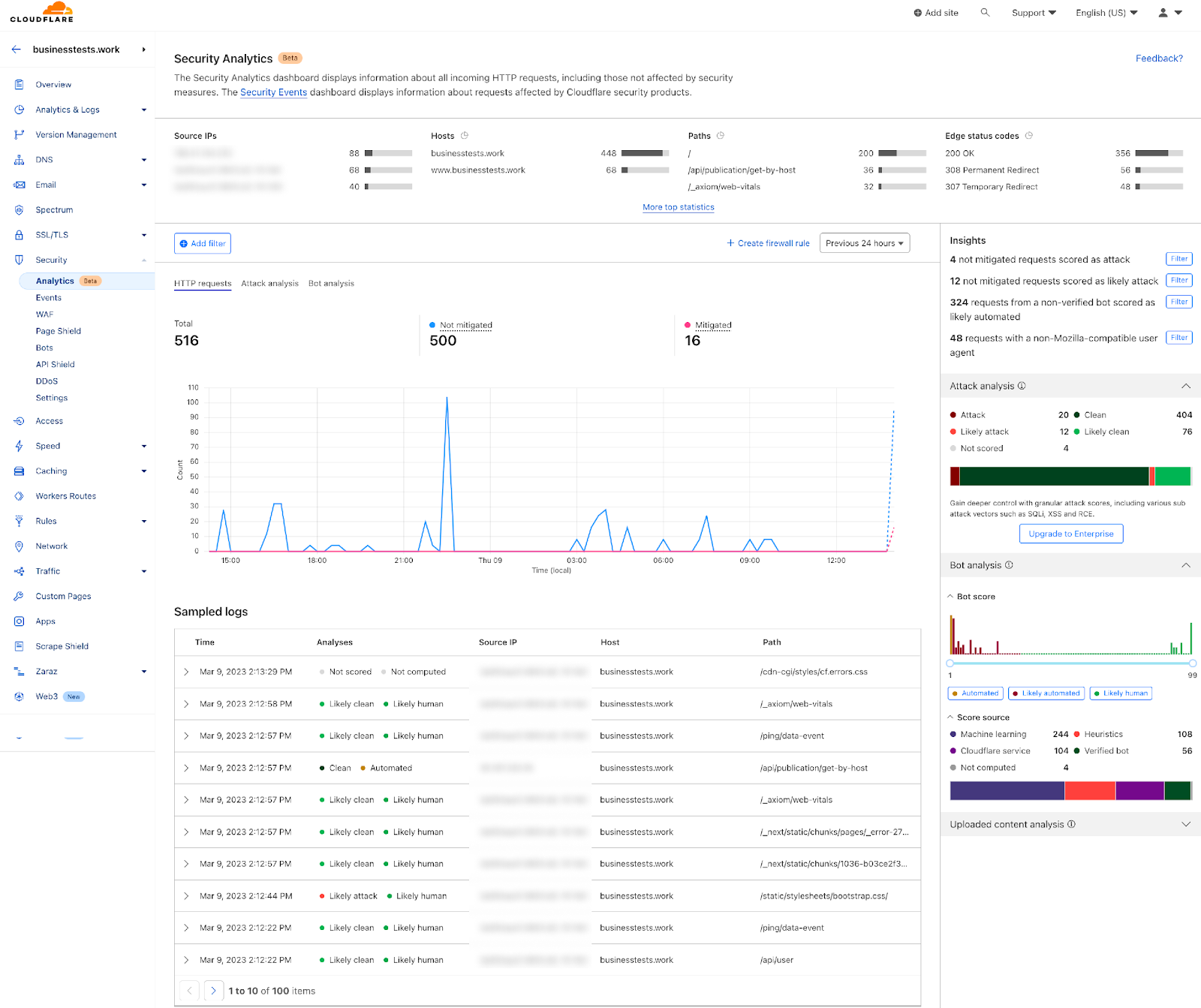
3- Visibility over your entire traffic: Security Analytics is a new dashboard currently in beta. It provides a comprehensive view across all your HTTP traffic, which displays all requests whether they match rules or not. Security Analytics is a great tool for investigating false negatives and hardening your security configurations. Security Events is still available in (Security > Events) and Security Analytics is available in a separate tab (Security > Analytics).
Deployment and configuration
In order to enable WAF Attack Score Lite and Security Analytics, you don’t need to take any action. The HTTP machine learning inspection rollout will start today, and Security Analytics will appear automatically to all Business plan customers by the time the rollout is completed in the upcoming weeks.
It’s worth mentioning that having the detection on and viewing the attack analysis in Security Analytics does not mean you’re blocking traffic. It only offers insights and provides the freedom to create rules and mitigate the desired requests. Creating a rule to block or challenge bad traffic is needed to take effect.
A common use case
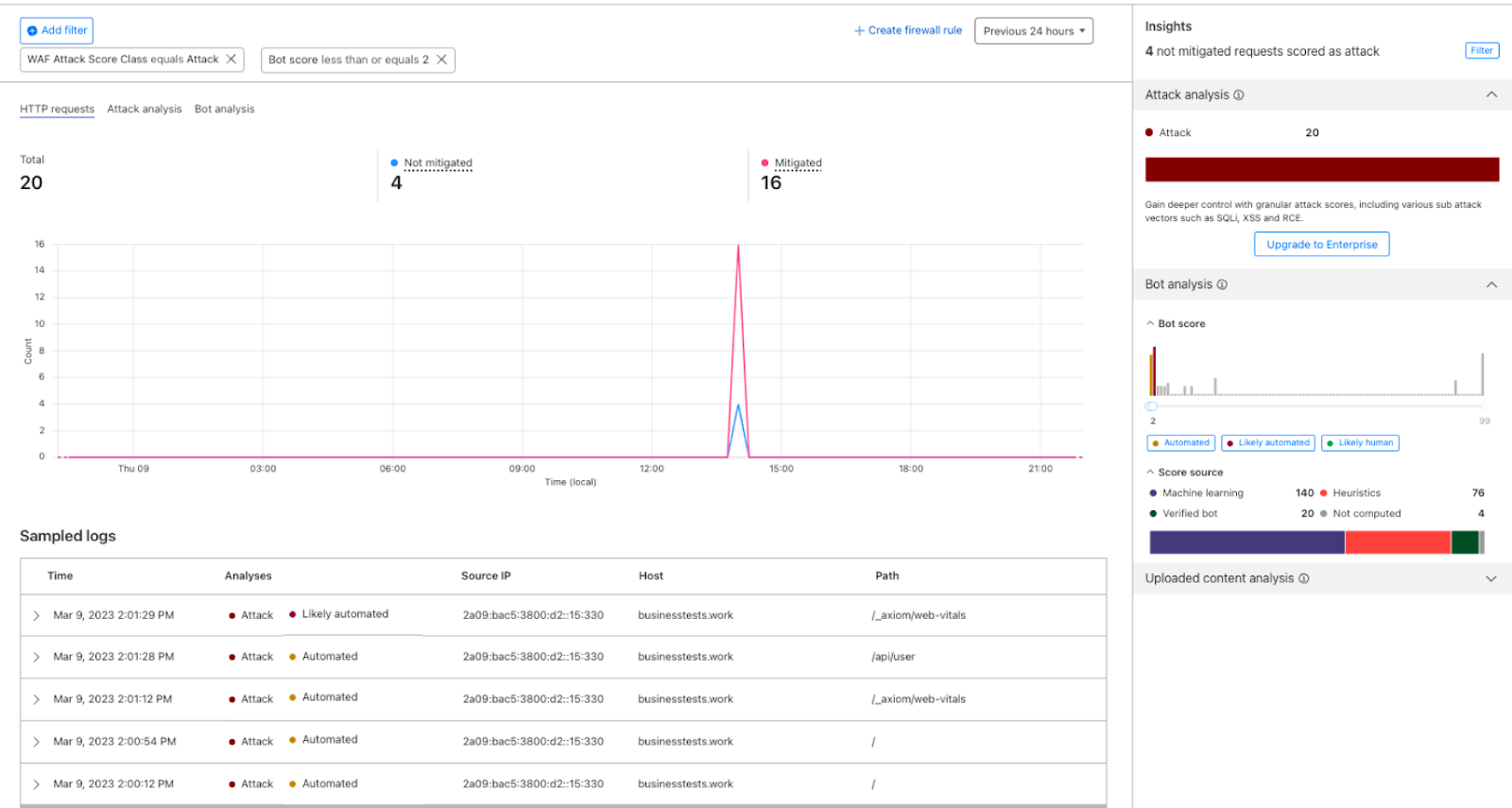
Consider an attacker executing an attack using automated web requests to manipulate or disrupt web applications. One of the best ways to identify this type of traffic and mitigate these requests is by combining bot score with WAF Attack Score.
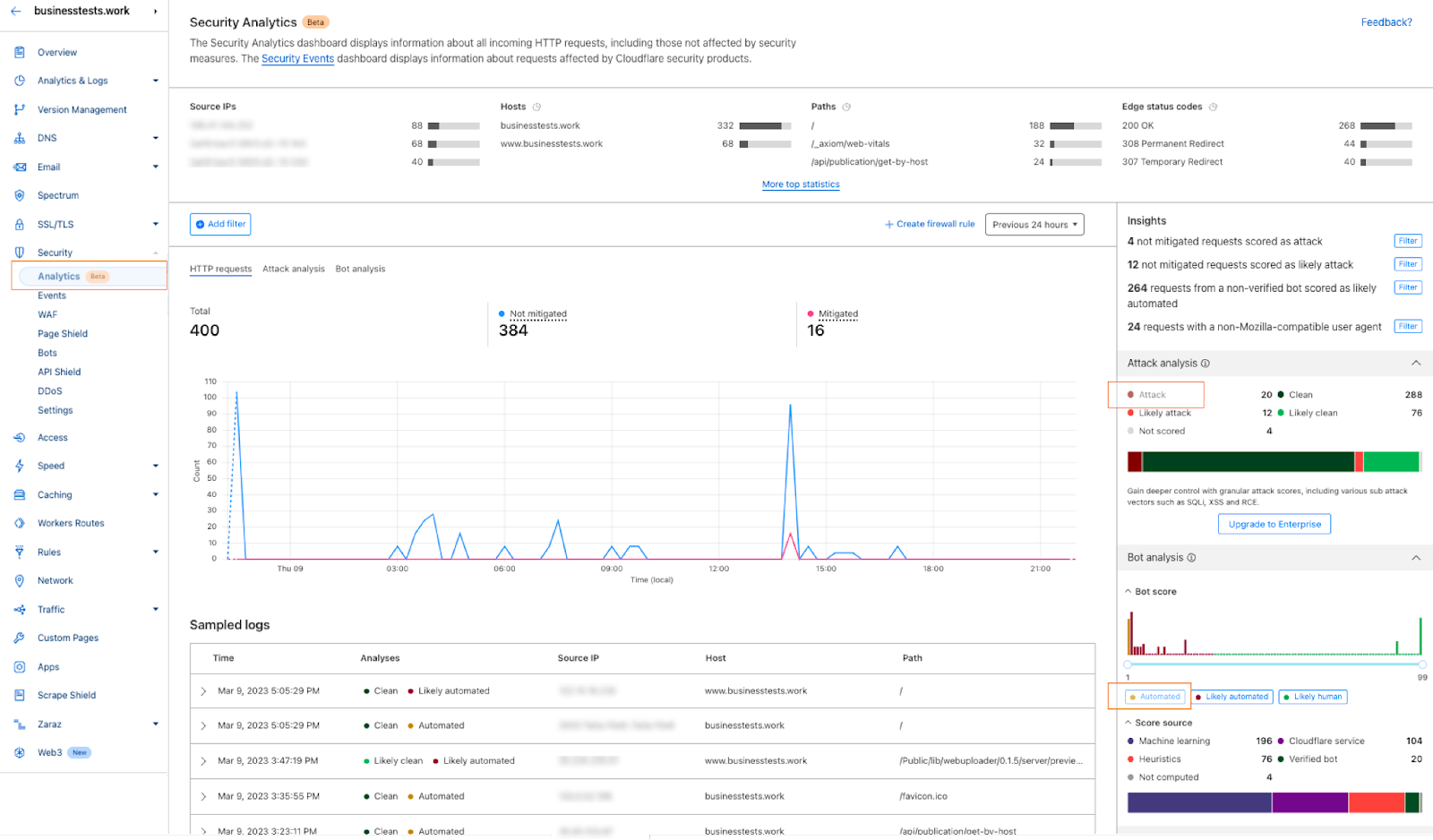
1- Go to the Security Analytics dashboard under Security > Analytics. On the right-hand side the Attack Analysis indicates the attack class. In this case, I can select “Attack” to apply a single filter, or use the quick filters under Insights to propagate multiple filters at once. In addition to the attack class, I can also select the Bot “Automated” filter.
2- After filtering, Security Analytics provides the capability of scrolling down to see the logs and validate the results:
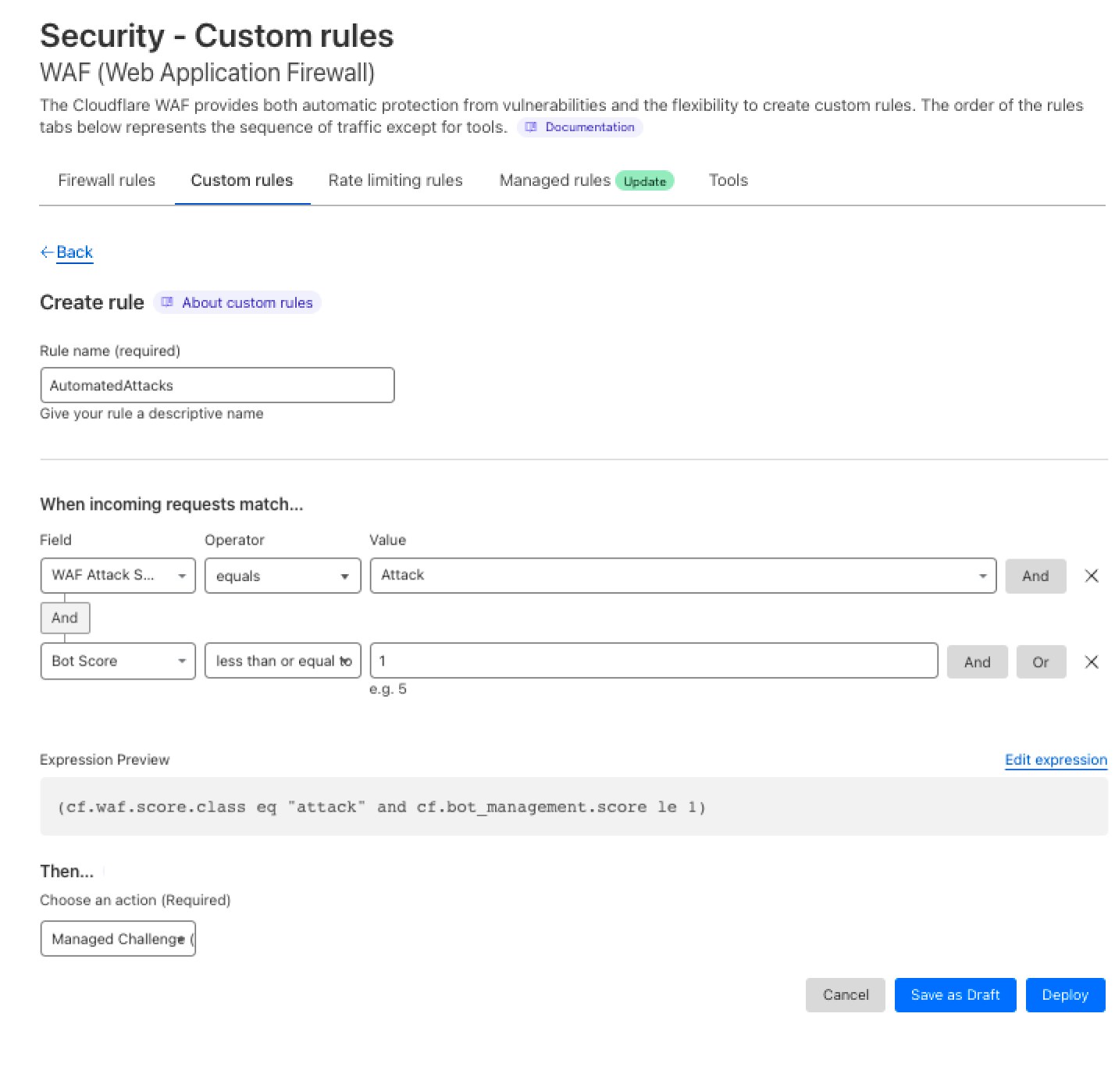
3- Once the selected requests are confirmed, I can select the Create WAF Custom Rules option which will direct me to the Security Events with the pre-assigned filters to deploy a rule. In this case, I want to challenge the requests matched by the rule:
And voila! You have a new rule that challenges traffic matching any automated attack variation.
Next steps
We have been working hard to provide maximum security and visibility for all our customers. This is only one step on this road! We will keep adding more product-focused analytics, and providing additional security against unknown attacks. Try it out, create a rule, and don’t hesitate to contact our sales team if you need the full version of WAF Attack Score.
Every pharmaceutical company manufacturing medicine must provide customers nationwide with a method to report adverse events following medicine usage as well as emergency assistance as needed. To comply with regulatory policy and enable an Adverse Events Reporting System (AERS), pharma companies must provide dedicated, toll-free phone numbers and contact center agents to handle inbound calls.
But they must also be prepared for sudden spikes in call volume, which can increase contact center agents’ workloads and lead to long wait times for customers. With these limitations comes the possibility that customers may not be able to report adverse events.
Further still, as medicine status keeps changing, all agents must be retrained to handle calls and extend support. Pharma companies incur significant costs for training and onboarding additional agents, as well as the physical infrastructure to support their work.
To overcome these challenges, we designed a self-service Interactive Voice Response (IVR) solution with Amazon Connect. The IVR solution handles customer calls without agent involvement. It captures customer information and records data into an enterprise AERS. It also provides an option to receive a link to an Adverse Events (AE) portal using Short Message Service (SMS), or to be routed to a live agent queue.
In this blog post, we introduce a reference architecture for this use case. This framework can help other pharma companies solve similar problems.
Solution overview
Let’s explore how the IVR solution architecture routes customer calls step by step, as shown in Figure 1.
Callers who dial in to report a medicine-related AE are routed to the Amazon Lex chatbot through IVR in Amazon Connect.
Callers can proceed to IVR self-service functions, such as understanding the intent of a customer call and the AE.
AEs are analyzed with Amazon SageMaker for a decision on whether to complete the call on IVR or forward it to an agent.
If the caller remains on the self-service option, the bot captures information from 15 to 20 essential questions.
The bot follows a hybrid workflow that allows for guided responses where appropriate and free-text conversations using AWS Lambda. It confirms captured AE information with the caller before closing the call and submitting information to the AERS system.
The bot provides the option to route the call to a human agent contextually.
The bot provides the option to share an AE reporting link over SMS using Amazon Simple Notification System (SNS), so the caller can access it through a mobile device to continue AE reporting outside of the call.
The bot records customer interactions in AERS using Amazon DynamoDB, leveraging the current validated process used by the AE portal team
The bot makes call recordings available for auditing, monitoring, and training purposes. These recordings are not be provided to live agents.
Standard analytics are available to help the business continuously train the bot and measure its performance.
Leveraging IVR as an extended solution
Recorded customer calls can be used for further analytics with Amazon Transcribe. Actionable insights can be derived from the text using a machine learning (ML) model such as AE detection at scale. A (Named Entity Recognition model (NER) model can also identify medicines and caller types.
Further, all recorded calls may be stored in a secure AWS ecosystem and archived for longer durations for compliance purposes. Storage costs can be optimized by setting up a policy to move old calls to Amazon Simple Storage Service Glacier (Amazon S3 Glacier) storage classes and calls over two years old to the Amazon S3 Deep Glacier storage class. This results in significant cost saving and helps companies archive at scale.
Finally, the Amazon Lex bot can be enhanced and continuously trained with additional intents and utterances to handle complex AE reporting for various drugs. This provides significant cost saving and operational efficiencies as bots can be trained faster than human agents, as well as at scale.
Conclusion: Using IVR to better manage AE reporting
This IVR solution was deployed for a pharma company and helped handle unusually high call volumes for AE reporting with its current agent population. It resulted in cost savings in contact center operations and significantly improved the customer experience by reducing wait times.
The IVR solution can also be used with any existing contact center platform to first forward the calls to Amazon Connect for initial triage, and then handover to existing platforms for agent involvement. This adds intelligence to existing contact centers.
This blog post demonstrates how pharma companies can leverage the self-service option for AERS to handle any AE reporting call. With solution enhancements using Amazon SageMaker models, it can quickly be transformed to handle calls for any medicine. They can also:
Incorporate related information into the model, such as the age, gender, or existing AEs to further improve the ML prediction performance
Leverage audio data augmentation plus handcrafted features to help yield better predictions
Use the audio-based diagnostic prediction in an Amazon Connect contact flow to triage the targeted group of incoming calls and escalate to a doctor for follow up if necessary
Allow call center agents to use the intelligence provided by the acoustic classification in conjunction with Contact Lens for Amazon Connect, which provides a turn-by-turn transcript; real-time alerts; automated call categorization based on keywords and phrases; sentiment analysis, and sensitive data redaction—truly making it a real-time intelligent solution.
The IVR solution can also be used for other industry use cases where a series of data is collected from customers. This solution improves the customer experience and can be implemented without increasing call center agent counts.
At Cloudflare, we are always looking for ways to make our customers’ faster and more secure. A key part of that commitment is our ongoing investment in research and development of new technologies, such as the work on our machine learning based Web Application Firewall (WAF) solution we announced during security week.
In this blog, we’ll be discussing some of the data challenges we encountered during the machine learning development process, and how we addressed them with a combination of data augmentation and generation techniques.
Let’s jump right in!
Introduction
The purpose of a WAF is to analyze the characteristics of a HTTP request and determine whether the request contains any data which may cause damage to destination server systems, or was generated by an entity with malicious intent. A WAF typically protects applications from common attack vectors such as cross-site-scripting (XSS), file inclusion and SQL injection, to name a few. These attacks can result in the loss of sensitive user data and damage to critical software infrastructure, leading to monetary loss and reputation risk, along with direct harm to customers.
How do we use machine learning for the WAF?
The Cloudflare ML solution, at a high level, trains a classifier to distinguish between various traffic types and attack vectors, such as SQLi, XSS, Command Injection, etc. based on structural or statistical properties of the content. This is achieved by performing the following operations:
We inspect the raw HTTP input and perform some number of transformations on it such as normalization, content substitutions, or de-duplication.
Decompose or partition it via some process of tokenization, generate statistical information about the content, or extract structural data.
Compute optimal internal numerical representations of the inputs via the process of training the model. The nature of these internal representations depends on the class of model and architecture.
Learn to map internal content representations against classes (XSS, SQLi or others), scores or some other target of interest.
At run-time, use previously learned representations and mappings to analyze a new input and provide the most likely label or score for it. The score ranges from 1 to 99, with 1 indicating that the request is almost certainly malicious and 99 indicating that the request is probably clean.
This reasonable starting point stumbles immediately upon a critical challenge right from the start: we need high quality labeled data, and lots of it as that has the biggest impact on model performance. Contrary to well-researched fields like image recognition, text sentiment analysis, or classification, large datasets of HTTP requests with malicious payloads embedded are difficult to get.
To make matters even harder, strict implementation requirements for a production-quality WAF restrict the complexity of our potential ML models or architectures to ones that are relatively simple and light-weight, implying that we cannot simply pave over shortcomings of the data.
Data and challenges
The selection of a dataset is likely the most difficult of all the aspects that contribute to the final set of attributes of a machine learning model. In most cases, the model is tasked with learning the distribution of the data in some statistical sense, thus choosing and curating the dataset to ensure that the desired properties of the final solution are even possible to learn is incredibly crucial! ML models are only as reliable as the data used to train them. If we train an ML model on an incomplete dataset, or on data that doesn’t accurately represent the population, predictions might be inaccurate as they will be a direct reflection of the data.
To build a strong ML WAF, a good dataset must have large volumes of heterogeneous data covering malicious samples for all attack categories, a diverse set of negative/benign samples, and samples representing a broad spectrum of obfuscation techniques.
Due to those constraints, creating a solid dataset has a number of challenges:
Privacy
Privacy requirements limit data availability and how it can be used. Cloudflare has strict privacy guidelines and does not keep all request data – it simply isn’t available, and what is available must be carefully selected, anonymised, and stripped of sensitive information.
Heterogeneity of samples
Due to the wide assortment of potential request content types and forms, finding enough benign samples is difficult. Furthermore, it is challenging to collect data that represents requests with various charsets and content-encodings. Covering all attack configurations is also important because some attacks can be inserted into essentially any kind of request (e.g. five bytes in a huge “regular” request)
Sample difficulty
We want a dataset with a good mix of attack techniques and isn’t dominated by the ones that are easily generated by tools which simply swap out constants, transform expressions through invariants, and so on (sqli-fuzzer). Additionally, the vast majority of freely available samples in the wild are fairly trivial auto-generated payloads as part of indiscriminate scanning and discovery tools. They have very similar structural and statistical characteristics. Some of them are fairly old as well and do not reflect the current software landscape. How to “grade” the sample difficulty is not immediately obvious! What’s easy to a human may not be easy for a particular preprocessor/model, and vice-versa.
Noisy labels
Label noise affects results a lot, especially when it comes to esoteric, specific, or unusual attacks which are likely to be classified as benign by rules WAF.
What’s the strategy to overcome this?
Data augmentation
In simple terms, Data Augmentation is a process of generating artificial (but realistic) data to increase the diversity of our data by studying statistical distribution of existing real-world data.
This is crucial for us because one of the biggest concerns with rules-based WAFs is false positives. False positives are a serious challenge for WAFs because the risk of accidentally filtering legitimate traffic deters users from employing very strict rulesets. Data augmentation is used to build a solution that does not rely on observing specific high-risk keywords or character sequences, but instead uses a more holistic analysis of content and context, making it considerably less likely to block legitimate requests.
There are many sequences of characters which appear almost exclusively in payloads, but are themselves not dangerous. In order to reduce false positives and improve overall performance, we focussed on generating a lot of heterogeneous negative samples to force the model to consider the structural, semantic, and statistical properties of the content when making a classification decision.
In the context of our data and use cases, data augmentation means that we mutate benign content in a variety of ways as the content will remain benign (this isn’t going to accidentally turn it into a valid payload, with probability 1). For instance, we can add random character noise, permute keywords, merge benign content together from multiple sources, and so on. Alternatively, we can seed benign content with ‘dangerous’ keywords or ngrams frequently occuring in payloads – this results in a benign sample, but ideally will teach the model not to be too sensitive to the presence of malicious tokens lacking the proper semantics and structure.
Benign content
First and foremost, generating benign content is way easier. Mutating a malicious block of content into different malicious blocks is difficult because malicious payloads have a stricter grammar and syntax than general HTTP content due to the fact that it has code, therefore they must be manipulated in a specific manner.
However, there are a few options if we want to do this in the future. Tools like sqli-fuzzer, automates the process of fuzzing a given payload by applying transformations which preserve the underlying semantics while changing the representation or adding obfuscation. Outside existing third-party tools, it’s possible to generate our own malicious payloads using various “append malicious content to non-malicious content” techniques, with the trade off that this doesn’t actually generate *new* malicious content, just puts it into a different context.
Pseudo-random noise samples
A useful approach we identified for bolstering the number of negative training samples was to generate large quantities of pseudo-random strings of increasing complexity.
The probability of any pseudo-random string (drawn from essentially any token distribution) being a valid payload or malicious attack is essentially zero, but we can build a series of token sampling distributions that make it increasingly difficult for the model to distinguish them from a real payload, and we discovered that this resulted in dramatically better performance in terms of false positive rate, robustness, and overall model properties.
This approach works by taking a collection of tokens and a probability distribution over these tokens, and independently sampling a stream of tokens from it to create our ‘sample’. Each sample length is selected from a separate discrete sample length distribution.
For an extremely simple example, we could take a token collection consisting of ASCII characters and a uniform sampling distribution:
We wouldn’t expect even a very simple model to struggle to learn that these samples are benign, but as we increase the complexity of the token collections, we can move towards much more ‘difficult’ noise examples, including elements such as: fragments of valid URIs, user agents, XML/XSLT content or even restricted language identifiers, or keywords.
Here are some examples of more complex token collections and the kinds of random strings they produce as our negative samples:
alphanumerics, plus special characters, plus a variant of full javascript or sql keywords and (multi-character) sub-token fragments
It’s fairly straightforward to construct a suite of these noise generators of varying complexity, and targeting different types of content: JSON, XML, URIs with SQL-esque ‘noise’, and so on. As the strings get sufficiently long, the probability that they will contain at least some dangerous looking subsequences grows, so it’s also an excellent test of model robustness.
We make extensive use of noise strings to enhance the core dataset used for training and testing the model by directly training the model on increasingly difficult noise before fine-tuning on exclusively real data, appending noise of varying complexity to malicious(real) samples or benign samples to both induce and test for model robustness for padding attacks, and estimating false positive rate for certain classes of benign content.
Beyond independent sampling of random strings?
A natural extension to the above method for generating pseudo-random strings is to drop the ‘independence’ assumption for sampling tokens. This means that we’re starting to emulate the process by which real data is generated, to some extent, yielding samples with increasingly realistic local (and eventually global) structure. Some approaches for this might include a simple Markov chain, and extend all the way to state-of-the-art Large Language Models.
We experimented with using contemporary autoregressive language models trained on our corpus of real malicious payloads and found it extremely effective at generating novel payloads, as well as transforming payloads into sophisticated obfuscated representations. As the language models approached convergence on the data the likelihood of each sample being a valid payload approached 100%, allowing us to use early samples as ‘extremely strong negatives’ and the later samples as positive samples. The success of this work has suggested that deeper investigation into the use of language models for security analysis may be fruitful, not only for training classifiers, but also for creating powerful adversarial pen-testing agents.
Results summary
Let’s see a comparative summary of results and improvements, before and after the augmentation:
Model performance on evaluation metrics
The effectiveness of machine learning models for classification problems can be evaluated using a wide range of metrics, including accuracy, precision, recall, F1 Score, and others. It is important to note that in addition to using quantitative metrics, we also consider the model’s general properties and behavioral constraints. This criteria and metrics-based approach is especially important in our domain where data is inherently noisy, labels are not trustworthy, the domain of the inputs is extremely large, and hard to cover with samples.
For this post, we will concentrate on key quantitative metrics like F1 score even though we examine a variety of metrics to assess the model performance. F1 score is the weighted average (harmonic mean) of precision and recall. We can represent the F1 score with the formula:
Where,
True Positives (TP): malicious content classified correctly by the model
False Positives (FP): benign content that the model classified as malicious
True Negatives (TN): benign content classified correctly by the model
False Negatives (FN): malicious content that the model classified as benign
Since this formula takes false positives and false negatives into consideration, this score is more reliable than other metrics. There are a few methods to calculate this for multi-class problems, like Macro F1 Score, Micro F1 Score and Weighted F1 Score. Although each method has advantages and disadvantages, we obtained nearly identical results with all three methods. Below are the numbers:
Without Augmentation
With Augmentation
Class
Precision
Recall
F1 Score
Precision
Recall
F1 Score
Benign
0.69
0.17
0.27
0.98
1.00
0.99
SQLi
0.77
0.96
0.85
1.00
1.00
1.00
XSS
0.56
0.94
0.70
1.00
0.98
0.99
Total(Micro Average)
0.67
0.99
Total(Macro Average)
0.67
0.69
0.61
0.99
0.99
0.99
Total(Weighted Average)
0.68
0.67
0.60
0.99
0.99
0.99
The important takeaway is that the range of this F1 score is best at 1 and worst at 0.
The model after augmentation appears to have similar precision and recall with good overall performance, as indicated by a value of 0.99 after augmentation, compared to 0.61 for Macro F1.
So far in the results summary, we’ve only discussed F1 Score; however, there are other improvements in characteristics that we’ve observed in the model that are listed below:
False positive characteristics
Estimated false positive rate reduced by approximately 80% on test data sets. There are significantly fewer false positives involving PromQL and other SQL-structured analogues. PromQL examples result in high scores and are classified correctly:
Today, the only major category of false positives are literal SQL or JavaScript files.
General false positive rate on noise from JSON-esque, XML/SOAP-esque, and SQL-esque content-generators reduced to about a 1/100,000 rate from about 1/50 to 1/1.
True positive characteristics
True positive rate for highly fuzzed content is vastly improved. Models trained solely on real data were easily bypassed by advanced fuzzing tools, whereas models trained on real plus augmented data are extremely resistant, with many payloads receiving higher risk scores as fuzzing increases. Examples:
These yield approximately same scores as they are a result of only a few byte alterations
Proportion of client-provided test sets that primarily contain payloads not blocked by rules-waf for XSS/SQLi successfully classified is about 97.5% (with the remaining 2.5% being arguable) up from about 91%.
Padding a payload with almost any amount of ASCII, JSON-esque, special-characters, or other content will not reduce the risk score substantially. Due to the addition of hard noise long length augmented training samples, even a six byte payload in a 100 kilobyte string will be caught. Examples:
They both generate similar scores even though the latter has junk padding around the payload.
Execution performance
Runtime characteristics are unchanged for inference.
On top of that, we validated the model against the Cloudflare’s highly mature signature-based WAF and confirmed that machine learning WAF performs comparable to signature WAF, with the ML WAF demonstrating its strength particularly in cases of correctly handling highly obfuscated or irregularly fuzzed content (as well as avoiding some rules-based engine false positives). Finally, we were able to conclude that augmentation helps in improving the model performance and induce the right set of properties.
Conclusion
We built a machine learning powered WAF, with the substantial challenge to gather a diversified training set, given constraints to avoid sensitive real customer data for privacy and regulatory considerations. To create a broader and diversified dataset without requiring vast amounts of sensitive data, we used techniques such as fuzzing, data augmentation, and synthetic data generation. This allowed us to improve the solution’s false positive robustness and overall model performance.
Furthermore, these techniques reduced the time complexity required to retrieve/clean real data, and helped induce the correct model behavior. In the future, we intend to investigate autoregressive language models to generate synthetic pseudo-valid payloads.
This is a guest post by Videet Parekh, Abelardo Lopez-Lagunas, Sek Chai at Latent AI.
Edge networks present a significant opportunity for Artificial Intelligence (AI) performance and applicability. AI technologies already make it possible to run compelling applications like object and voice recognition, navigation, and recommendations.
AI at the edge presents a host of benefits. One is scalability—it is simply impractical to send all data to a centralized cloud. In fact, one study has predicted a global scope of 90 zettabytes generated by billions of IoT devices by 2025. Another is privacy—many users are reluctant to move their personal data to the cloud, whereas data processed at the edge are more ephemeral.
When AI services are distributed away from centralized data centers and closer to the service edge, it becomes possible to enhance the overall application speed without moving data unnecessarily. However, there are still challenges to make AI from the deep-cloud run efficiently on edge hardware. Here, we use the term deep-cloud to refer to highly centralized, massively-sized data centers. Deploying edge AI services can be hard because AI is both computational and memory bandwidth intensive. We need to tune the AI models so the computational latency and bandwidth can be radically reduced for the edge.
The Case for Distributed AI Services
Edge network infrastructure for distributed AI is already widely available. Edge networks like Cloudflare serve a significant proportion of today’s Internet traffic, and can serve as the bridge between devices and the centralized cloud. Highly-performant AI services are possible because of the distributed processing that has excellent spatial proximity to the edge data.
We at Latent AI are exploring ways to deploy AI at the edge, with technology that transforms and compresses AI models for the edge. The size of our edge AI model is many orders of magnitudes smaller than the sensor data (e.g., kilobytes or megabytes for the edge AI model, compared to petabytes of edge data). We are exploring using WebAssembly (WASM) within the Cloudflare Workers environment. We want to identify possible operating points for the distributed AI services by exploring achievable performance on the available edge infrastructure.
Architectural Approach for Exploration
WebAssembly (WASM) is a new open-standard format for programs that run on the Web. It is a popular way to enable high-performance web-based applications. WASM is closer to machine code, and thus faster than JavaScript (JS) or JIT. Compiler optimizations, already done ahead of time, reduce the overhead in fetching and parsing application code. Today, WASM offers the flexibility and portability of JS at the near-optimum performance of compiled machine code.
AI models have notoriously large memory usage demands because configuring them requires high parameter counts. Cloudflare already extends support for WASM using their Wrangler CLI, and we chose to use it for our exploration. Wrangler is the open-source CLI tool used to manage Workers, and is designed to enable a smooth developer experience.
How Latent AI Accelerates Distributed AI Services
Latent AI’s mission is to enable ambient computing, regardless of any resource constraints. We develop developer tools that greatly reduce the computing resources needed to process AI on the edge while being completely hardware-agnostic.
Latent AI’s tools significantly compress AI models to reduce their memory size. We have shown up to 10x compression for state-of-the-art models. This capability addresses the load time latencies challenging many edge network deployments. We also offer an optimized runtime that executes a neural network natively. Results are a 2-3x speedup on runtime without any hardware-specific accelerators. This dramatic performance boost offers fast and efficient inferences for the edge.
Our compression uses quantization algorithms to convert parameters for the AI model from 32-bit floating-point toward 16-bit or 8-bit models, with minimal loss of accuracy. The key benefit of moving to lower bit-precision is the higher power efficiency with less storage needed. Now AI inference can be processed using more efficient parallel processor hardware on the continuum of platforms at the distributed edge.
Optimized AI services can process data closest to the source and perform inferences at the distributed edge.
Selecting Real-World WASM Neural Network Examples
For our exploration, we use state-of-the-art deep neural networks called MobileNet. MobileNets are designed specifically for embedded platforms such as smartphones, and can achieve high recognition accuracy in visual object detection. We compress MobileNets AI models to be small fast, in order to represent the variety of use cases that can be deployed as distributed AI services. Please see this blog for more details on the AI model architecture.
We use the MobileNetV2 model variant for our exploration. The models are trained with different visual objects that can be detected: (1) a larger sized model with 10 objects derived from ImageNet dataset, and (2) a smaller version with just two classes derived from the COCO dataset. The COCO dataset are public open-source databases of images that are used as benchmarks for AI models. Images are labeled with detected objects such as persons, vehicles, bicycles, traffic lights, etc. Using Latent AI’s compression tool, we were able to compress and compile the MobileNetV2 models into WASM programs. In the WASM form, we can achieve fast and efficient processing of the AI model with a small storage footprint.
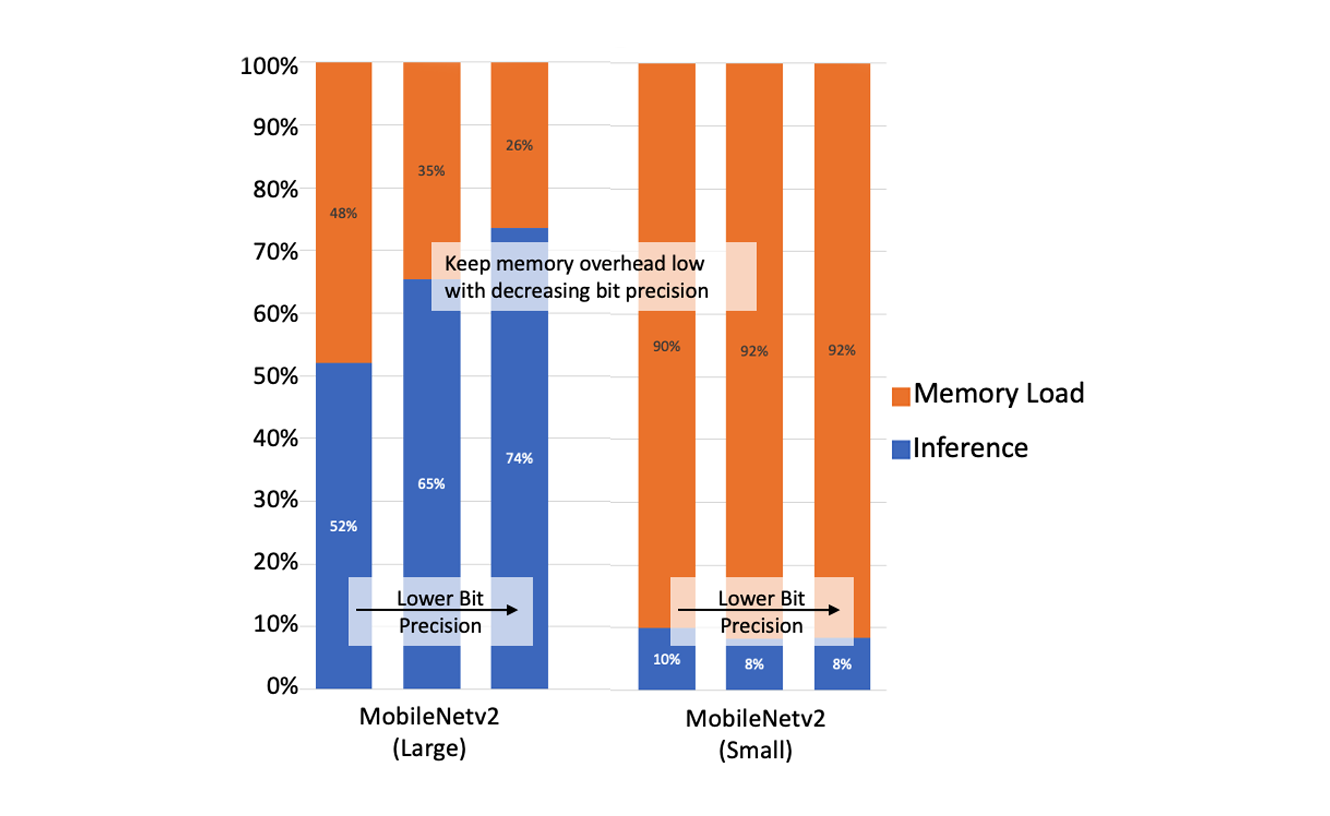
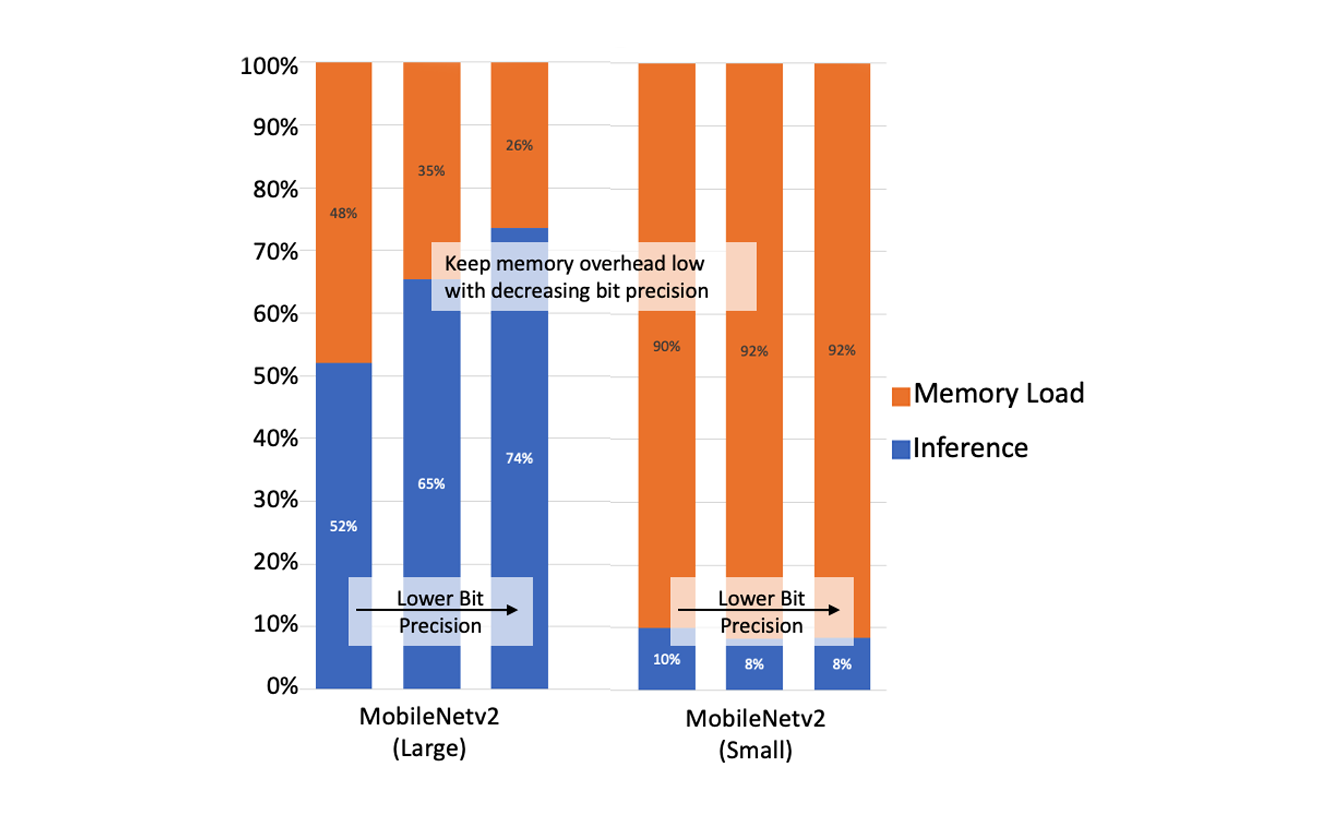
We want WASM neural networks to be as fast and efficient as possible. We spun up a Workers app to accept an image from a client, convert and preprocess the image into a cleaned data array, run it through the model and then return a class for that image. For both the large and small MobileNetv2 models, we create three variants with different bit-precision (32-bit floating point, 16-bit integer, and 8-bit integer). The average memory and inference times for the large AI model are 110ms and 189ms, respectively; And for the smaller AI model, they are 159ms and 15ms, respectively.
Our analysis suggests that overall processing can be improved by reducing the overhead for memory operations. For the large model, lowering bit precision to 8-bits reduces memory operations from 48% to 26%. For the small model, the memory load times dominate over the inference computation with over 90% of the latency in memory operations.
It is important to note that our results are based on our initial exploration, which is focused more on functionality rather than optimization. We make sure the results are consistent by averaging our measurements over 50-100 iterations. We do acknowledge that there are still network and system related latencies that can be further optimized, but we believe that the early results described here show promise with respect to AI model inferences on the distributed edge.
Comparison of memory and inference processing times for large and small DNNs.
Learning from Real-World WASM Neural Network Example
What lessons can we draw from our example use case?
First of all, we recommend a minimal compute and memory footprint for AI models deployed to the network edge. A small footprint allows for better line up of data types for WASM AI models to reduce memory load overhead. WASM practitioners know that WASM speed-ups come from the tighter coupling of the API between JavaScript API and native machine code. Because WASM code does not need to speculate on data types, parallelizing compilation for WASM can achieve better optimization.
Furthermore, we encourage the use of running AI models at 8-bit precision to reduce the overall size. These 8-bit AI models are readily compressed and compiled for the target hardware to greatly reduce the overhead in hosting the models for inference. Furthermore, for video imagery, there is no overhead to convert digitized raw data (e.g. image files digitized and stored as integers) to floating-point values for use with floating point AI models.
Finally, we suggest the use of a smart cache for AI models so that Workers can essentially reduce memory load times and focus solely on neural network inferences at runtime. Again, 8-bit models allow more AI models to be hosted and ready for inference. Referring to our exploratory results, hosted small AI models can be served at approximately 15ms inference time, offering a very compelling user experience with low latency and local processing. The WASM API provides a significant performance increase over pure-JS toolchains like Tensorflow.js. For example, for inference time for the large AI model of 189ms on WASM, we have observed a range of 1500ms on Tensorflow.js workflow, which is approximately an 8X difference in compute latency.
Unlocking the Future of the Distributed Edge
With exceedingly optimized WASM neural networks, distributed edge networks can move the inference closer to users, offering new edge AI services closer to the source of the data. With Latent AI technology to compress and compile WASM neural networks, the distributed edge networks can (1) host more models, (2) offer lower latency responses, and (3) potentially lower power utilization with more efficient computing.
Example person detected using a small AI model, 10x compressed to 150KB.
Imagine for example that the small AI model described earlier can distinguish if a person is in a video feed. Digital systems, e.g. door bell and doorway entry cameras, can hook up to Cloudflare Workers to verify if a person is present in the camera field of view. Similarly, other AI services could conduct sound analyses to check for broken windows and water leaks. With these distributed AI services, applications can run without access to deep cloud services. Furthermore, the sensor platform can be made with ultra low cost, low power hardware, in very compact form factors.
Application developers can now offer AI services with neural networks trained, compressed, and compiled natively as a WASM neural network. Latent AI developer tools can compress WASM neural networks and provide WASM runtimes offering blazingly fast inferences for the device and infrastructure edge. With scale and speed baked in, developers can easily create high-performance experiences for their users, wherever they are, at any scale. More importantly, we can scale enterprise applications on the edge, while offering the desired return on investments using edge networks.
About Latent AI
Latent AI is an early-stage venture spinout of SRI International. Our mission is to enable developers and change the way we think about building AI for the edge. We develop software tools designed to help companies add AI to edge devices and to empower users with new smart IoT applications. For more information about the availability of LEIP SDK, please feel free to contact us at [email protected] or check out our website.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.

.](https://github.blog/wp-content/uploads/2023/04/image3.gif)
 האדם-החושב on wikipedia](https://github.blog/wp-content/uploads/2023/04/image4-1.png?w=1024&fit=1024%2C1024)
 using VAEs trained on the CelebA dataset.](https://github.blog/wp-content/uploads/2023/04/image6.jpg?w=539&fit=1024%2C1024)
 ) by generating new characters, storylines, design components, and more. Case in point: The developer behind the game,
) by generating new characters, storylines, design components, and more. Case in point: The developer behind the game,  ). Artists and designers alike are using these AI tools as a source of inspiration. For example, architects can quickly create 3D models of objects or environments and artists can breathe new life into their portraits by using AI to apply different styles, like adding a Cubist style to their original image. Need proof? Designers are already starting to use AI image generators, such as
). Artists and designers alike are using these AI tools as a source of inspiration. For example, architects can quickly create 3D models of objects or environments and artists can breathe new life into their portraits by using AI to apply different styles, like adding a Cubist style to their original image. Need proof? Designers are already starting to use AI image generators, such as