Post Syndicated from Donnie Prakoso original https://aws.amazon.com/blogs/aws/aws-weekly-roundup-kiro-aws-lambda-remote-debugging-amazon-ecs-blue-green-deployments-amazon-bedrock-agentcore-and-more-july-21-2025/
I’m writing this as I depart from Ho Chi Minh City back to Singapore. Just realized what a week it’s been, so let me rewind a bit. This week, I tried my first Corne keyboard, wrapped up rehearsals for AWS Summit Jakarta with speakers who are absolutely raising the bar, and visited Vietnam to participate as a technical keynote speaker in AWS Community Day Vietnam, an energetic gathering of hundreds of cloud practitioners and AWS enthusiasts who shared knowledge through multiple technical tracks and networking sessions.
What I presented was a keynote titled “Reinvent perspective as modern developers”, featuring serverless, containers, and how we can cut the learning curves and be more productive with Amazon Q Developer and Kiro. I got a chance to discuss with a couple of AWS Community Builders and community developers, who shared how Amazon Q Developer actually addressed their challenges on building applications, with several highlighting significant productivity improvements and smoother learning curves in their cloud development journeys.
As I head back to Singapore, I’m carrying with me not just memories of delicious cà phê sữa đá (iced milk coffee), but also fresh perspectives and inspirations from this vibrant community of cloud innovators.
Introducing Kiro
One of the highlights from last week was definitely Kiro, an AI IDE that helps you deliver from concept to production through a simplified developer experience for working with AI agents. Kiro goes beyond “vibe coding” with features like specs and hooks that help get prototypes into production systems with proper planning and clarity.
Join the waitlist to get notified when it becomes available.
Last week’s AWS Launches
In other news, last week we had AWS Summit in New York, where we released several services. Here are some launches that caught my attention:
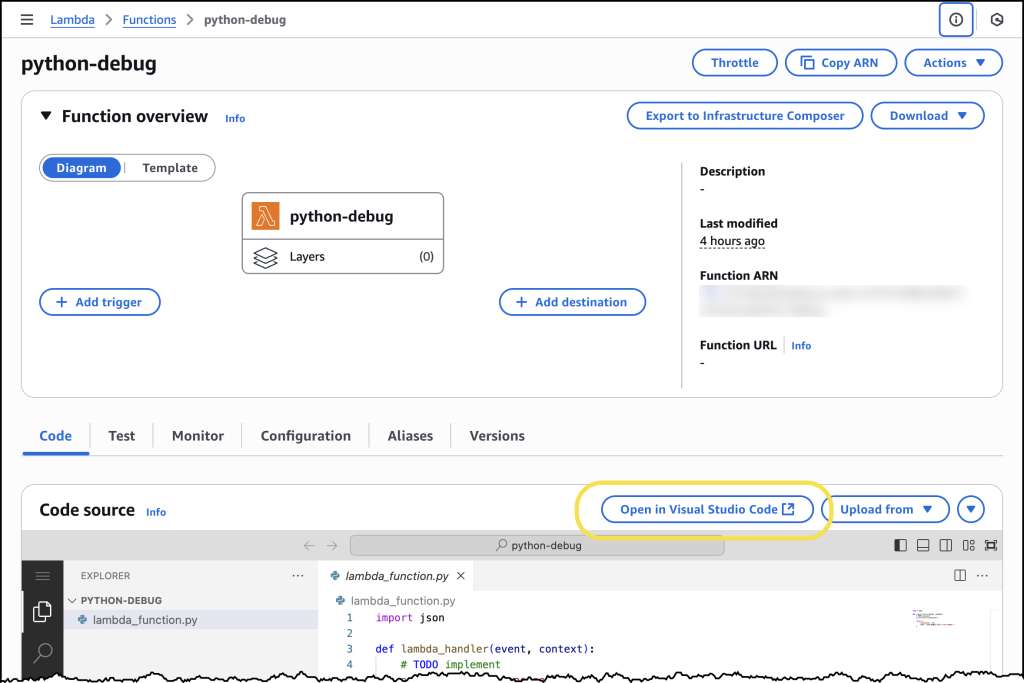
- Simplify serverless development with console to IDE and remote debugging for AWS Lambda — AWS Lambda now offers console to IDE integration and remote debugging capabilities that streamline the developer workflow from browser to Visual Studio Code. These enhancements eliminate time-consuming context switching and enable developers to debug Lambda functions directly in their preferred IDE environment.
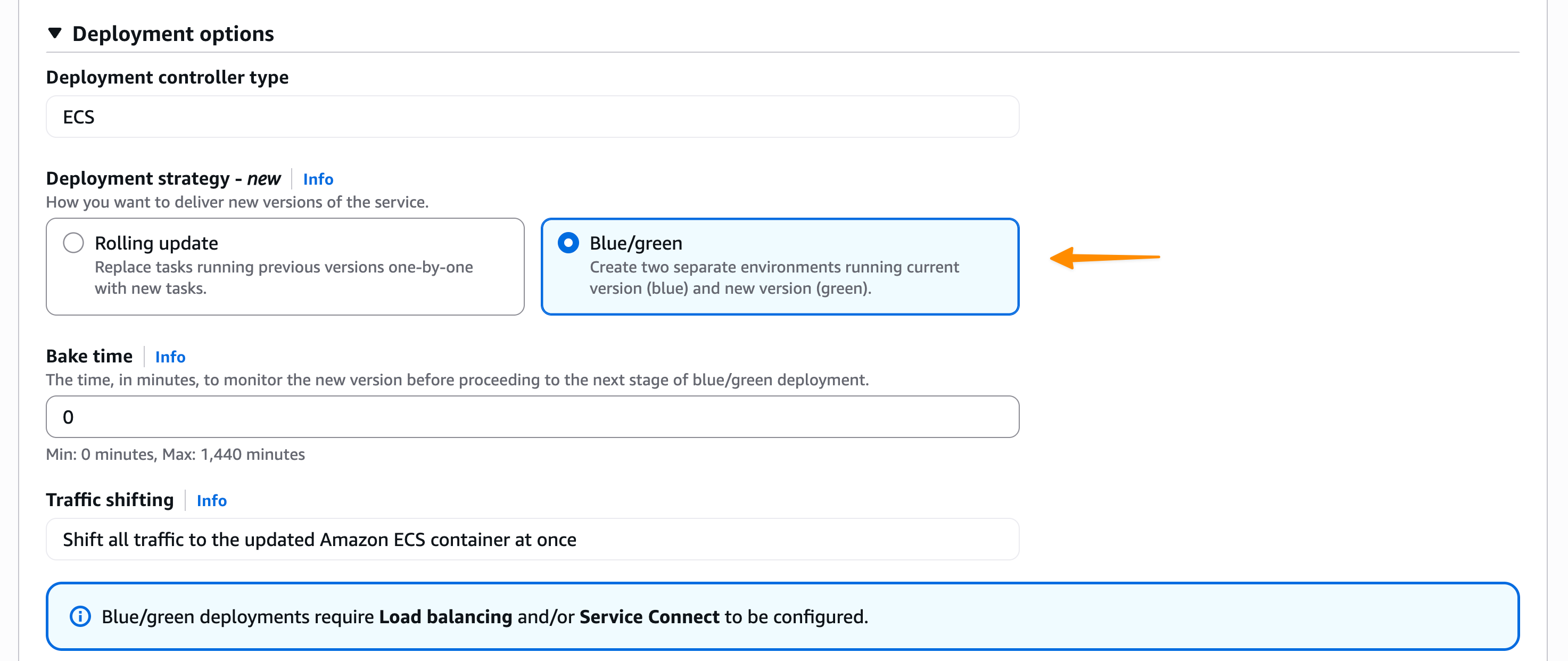
- Accelerate safe software releases with new built-in blue/green deployments in Amazon ECS — Amazon ECS now provides built-in blue-green deployment capability that makes containerized application deployments safer and more consistent. This eliminates the need to build custom deployment tooling while giving you confidence to ship software updates with rollback capability and deployment lifecycle hooks.
- Introducing Amazon Bedrock AgentCore: Securely deploy and operate AI agents at any scale — Amazon Bedrock AgentCore is a comprehensive set of enterprise-grade services that help developers quickly and securely deploy AI agents at scale using any framework and model. It includes AgentCore Runtime, Memory, Observability, Identity, Gateway, Browser, and Code Interpreter services that work together to eliminate infrastructure complexity.
- AWS Free Tier update: New customers can get started and explore AWS with up to $200 in credits — AWS Free Tier now offers enhanced benefits with up to $200 in AWS credits for new customers. You receive $100 upon sign-up and can earn an additional $100 by completing activities with EC2, RDS, Lambda, Bedrock, and AWS Budgets, making it easier to explore AWS services without incurring costs.

- Monitor and debug event-driven applications with new Amazon EventBridge logging — Amazon EventBridge now provides enhanced logging capabilities that offer comprehensive event lifecycle tracking with detailed information about successes, failures, and status codes. This new observability feature addresses microservices and event-driven architecture monitoring challenges by providing visibility into the complete event journey.

- Introducing Amazon S3 Vectors: First cloud storage with native vector support at scale — Amazon S3 Vectors is a purpose-built durable vector storage solution that can reduce the total cost of uploading, storing, and querying vectors by up to 90%. It’s the first cloud object store with native support to store large vector datasets and provide subsecond query performance for AI applications.

- Amazon EKS enables ultra-scale AI/ML workloads with support for 100k nodes per cluster — Amazon EKS now supports up to 100,000 worker nodes in a single cluster, enabling customers to scale up to 1.6 million AWS Trainium accelerators or 800K NVIDIA GPUs. This industry-leading scale empowers customers to train trillion-parameter models and advance AGI development while maintaining Kubernetes conformance and familiar developer experience.
From AWS Builder Center
In case you missed it, we just launched AWS Builder Center and integrated community.aws. Here are my top picks from the posts:
- How I Optimized My AWS Bill by Deleting My Account by Corey Quinn — A humorous yet insightful take on AWS cost optimization strategies and the extreme measures some might consider for bill reduction.
- How to setup MCP with UV in Python the right way by Du’An Lightfoot — A practical guide on setting up Model Context Protocol (MCP) with UV package manager in Python for optimal development workflow.
- Extending My Blog with Translations by Amazon Nova by Jimmy Dahlqvist — Learn how to leverage Amazon Nova’s capabilities to add translation features to your blog and reach a global audience.
- How I used Amazon Q CLI to fix Amazon Q CLI error “Amazon Q is having trouble responding right now” by Matias Kreder — A practical troubleshooting guide that demonstrates using Amazon Q CLI to resolve its own errors, showcasing the power of AI-assisted debugging.
Upcoming AWS events
Check your calendars and sign up for upcoming AWS and AWS Community events:
- AWS re:Invent – Register now to get a head start on choosing your best learning path, booking travel and accommodations, and bringing your team to learn, connect, and have fun. If you’re an early-career professional, you can apply to the All Builders Welcome Grant program, which is designed to remove financial barriers and create diverse pathways into cloud technology.
- AWS Builders Online Series – If you’re based in one of the Asia Pacific time zones, join and learn fundamental AWS concepts, architectural best practices, and hands-on demonstrations to help you build, migrate, and deploy your workloads on AWS.
- AWS Summits — Join free online and in-person events that bring the cloud computing community together to connect, collaborate, and learn about AWS. Register in your nearest city: Taipei (July 29), Mexico City (August 6), and Jakarta (June 26–27).
- AWS Community Days — Join community-led conferences that feature technical discussions, workshops, and hands-on labs led by expert AWS users and industry leaders from around the world: Singapore (August 2), Australia (August 15), Adria (September 5), Baltic (September 10), and Aotearoa (September 18).
You can browse all upcoming AWS led in-person and virtual developer-focused events.
That’s all for this week. Check back next Monday for another Weekly Roundup!
— Donnie
This post is part of our Weekly Roundup series. Check back each week for a quick roundup of interesting news and announcements from AWS!
Join Builder ID: Get started with your AWS Builder journey at builder.aws.com

 Asena Uyar is a Software Engineer at LaunchDarkly, focusing on building impactful experimentation products that empower teams to make better decisions. With a background in mathematics, industrial engineering, and data science, Asena has been working in the tech industry for over a decade. Her experience spans various sectors, including SaaS and logistics, and she has spent a significant portion of her career as a Data Platform Engineer, designing and managing large-scale data systems. Asena is passionate about using technology to simplify and optimize workflows, making a real difference in the way teams operate.
Asena Uyar is a Software Engineer at LaunchDarkly, focusing on building impactful experimentation products that empower teams to make better decisions. With a background in mathematics, industrial engineering, and data science, Asena has been working in the tech industry for over a decade. Her experience spans various sectors, including SaaS and logistics, and she has spent a significant portion of her career as a Data Platform Engineer, designing and managing large-scale data systems. Asena is passionate about using technology to simplify and optimize workflows, making a real difference in the way teams operate. Dean Verhey is a Data Platform Engineer at LaunchDarkly based in Seattle. He’s worked all across data at LaunchDarkly, ranging from internal batch reporting stacks to streaming pipelines powering product features like experimentation and flag usage charts. Prior to LaunchDarkly, he worked in data engineering for a variety of companies, including procurement SaaS, travel startups, and fire/EMS records management. When he’s not working, you can often find him in the mountains skiing.
Dean Verhey is a Data Platform Engineer at LaunchDarkly based in Seattle. He’s worked all across data at LaunchDarkly, ranging from internal batch reporting stacks to streaming pipelines powering product features like experimentation and flag usage charts. Prior to LaunchDarkly, he worked in data engineering for a variety of companies, including procurement SaaS, travel startups, and fire/EMS records management. When he’s not working, you can often find him in the mountains skiing. Daniel Lopes is a Solutions Architect for ISVs at AWS. His focus is on enabling ISVs to design and build their products in alignment with their business goals with all advantages AWS services can provide them. His areas of interest are event-driven architectures, serverless computing, and generative AI. Outside work, Daniel mentors his kids in video games and pop culture.
Daniel Lopes is a Solutions Architect for ISVs at AWS. His focus is on enabling ISVs to design and build their products in alignment with their business goals with all advantages AWS services can provide them. His areas of interest are event-driven architectures, serverless computing, and generative AI. Outside work, Daniel mentors his kids in video games and pop culture.