Post Syndicated from Ayush Agrawal original https://aws.amazon.com/blogs/big-data/building-a-scalable-streaming-data-platform-that-enables-real-time-and-batch-analytics-of-electric-vehicles-on-aws/
The automobile industry has undergone a remarkable transformation because of the increasing adoption of electric vehicles (EVs). EVs, known for their sustainability and eco-friendliness, are paving the way for a new era in transportation. As environmental concerns and the push for greener technologies have gained momentum, the adoption of EVs has surged, promising to reshape our mobility landscape.
The surge in EVs brings with it a profound need for data acquisition and analysis to optimize their performance, reliability, and efficiency. In the rapidly evolving EV industry, the ability to harness, process, and derive insights from the massive volume of data generated by EVs has become essential for manufacturers, service providers, and researchers alike.
As the EV market is expanding with many new and incumbent players trying to capture the market, the major differentiating factor will be the performance of the vehicles.
Modern EVs are equipped with an array of sensors and systems that continuously monitor various aspects of their operation including parameters such as voltage, temperature, vibration, speed, and so on. From battery management to motor performance, these data-rich machines provide a wealth of information that, when effectively captured and analyzed, can revolutionize vehicle design, enhance safety, and optimize energy consumption. The data can be used to do predictive maintenance, device anomaly detection, real-time customer alerts, remote device management, and monitoring.
However, managing this deluge of data isn’t without its challenges. As the adoption of EVs accelerates, the need for robust data pipelines capable of collecting, storing, and processing data from an exponentially growing number of vehicles becomes more pronounced. Moreover, the granularity of data generated by each vehicle has increased significantly, making it essential to efficiently handle the ever-increasing number of data points. The challenges include not only the technical intricacies of data management but also concerns related to data security, privacy, and compliance with evolving regulations.
In this blog post, we delve into the intricacies of building a reliable data analytics pipeline that can scale to accommodate millions of vehicles, each generating hundreds of metrics every second using Amazon OpenSearch Ingestion. We also provide guidelines and sample configurations to help you implement a solution.
Of the prerequisites that follow, the IOT topic rule and the Amazon Managed Streaming for Apache Kafka (Amazon MSK) cluster can be set up by following How to integrate AWS IoT Core with Amazon MSK. The steps to create an Amazon OpenSearch Service cluster are available in Creating and managing Amazon OpenSearch Service domains.
Prerequisites
Before you begin the implementing the solution, you need the following:
- IOT topic rule
- Amazon MSK Simple Authentication and Security Layer/Salted Challenge Response Mechanism (SASL/SCRAM) cluster
- Amazon OpenSearch Service domain
Solution overview
The following architecture diagram provides a scalable and fully managed modern data streaming platform. The architecture uses Amazon OpenSearch Ingestion to stream data into OpenSearch Service and Amazon Simple Storage Service (Amazon S3) to store the data. The data in OpenSearch powers real-time dashboards. The data can also be used to notify customers of any failures occurring on the vehicle (see Configuring alerts in Amazon OpenSearch Service). The data in Amazon S3 is used for business intelligence and long-term storage.

In the following sections, we focus on the following three critical pieces of the architecture in depth:
1. Amazon MSK to OpenSearch ingestion pipeline
2. Amazon OpenSearch Ingestion pipeline to OpenSearch Service
3. Amazon OpenSearch Ingestion to Amazon S3
Solution Walkthrough
Step 1: MSK to Amazon OpenSearch Ingestion pipeline
Because each electric vehicle streams massive volumes of data to Amazon MSK clusters through AWS IoT Core, making sense of this data avalanche is critical. OpenSearch Ingestion provides a fully managed serverless integration to tap into these data streams.
The Amazon MSK source in OpenSearch Ingestion uses Kafka’s Consumer API to read records from one or more MSK topics. The MSK source in OpenSearch Ingestion seamlessly connects to MSK to ingest the streaming data into OpenSearch Ingestion’s processing pipeline.
The following snippet illustrates the pipeline configuration for an OpenSearch Ingestion pipeline used to ingest data from an MSK cluster.

While creating an OpenSearch Ingestion pipeline, add the following snippet in the Pipeline configuration section.
version: "2"
msk-pipeline:
source:
kafka:
acknowledgments: true
topics:
- name: "ev-device-topic "
group_id: "opensearch-consumer"
serde_format: json
aws:
# Provide the Role ARN with access to MSK. This role should have a trust relationship with osis-pipelines.amazonaws.com
sts_role_arn: "arn:aws:iam:: ::<<account-id>>:role/opensearch-pipeline-Role"
# Provide the region of the domain.
region: "<<region>>"
msk:
# Provide the MSK ARN.
arn: "arn:aws:kafka:<<region>>:<<account-id>>:cluster/<<name>>/<<id>>"
When configuring Amazon MSK and OpenSearch Ingestion, it’s essential to establish an optimal relationship between the number of partitions in your Kafka topics and the number of OpenSearch Compute Units (OCUs) allocated to your ingestion pipelines. This optimal configuration ensures efficient data processing and maximizes throughput. You can read more about it in Configure recommended compute units (OCUs) for the Amazon MSK pipeline.
Step 2: OpenSearch Ingestion pipeline to OpenSearch Service
OpenSearch Ingestion offers a direct method for streaming EV data into OpenSearch. The OpenSearch sink plugin channels data from multiple sources directly into the OpenSearch domain. Instead of manually provisioning the pipeline, you define the capacity for your pipeline using OCUs. Each OCU provides 6 GB of memory and two virtual CPUs. To use OpenSearch Ingestion auto-scaling optimally, it’s essential to configure the maximum number of OCUs for a pipeline based on the number of partitions in the topics being ingested. If a topic has a large number of partitions (for example, more than 96, which is the maximum OCUs per pipeline), it’s recommended to configure the pipeline with a maximum of 1–96 OCUs. This way, the pipeline can automatically scale up or down within this range as needed. However, if a topic has a low number of partitions (for example, fewer than 96), it’s advisable to set the maximum number of OCUs to be equal to the number of partitions. This approach ensures that each partition is processed by a dedicated OCU enabling parallel processing and optimal performance. In scenarios where a pipeline ingests data from multiple topics, the topic with the highest number of partitions should be used as a reference to configure the maximum OCUs. Additionally, if higher throughput is required, you can create another pipeline with a new set of OCUs for the same topic and consumer group, enabling near-linear scalability.
OpenSearch Ingestion provides several pre-defined configuration blueprints that can help you quickly build your ingestion pipeline on AWS
The following snippet illustrates pipeline configuration for an OpenSearch Ingestion pipeline using OpenSearch as a SINK with a dead letter queue (DLQ) to Amazon S3. When a pipeline encounters write errors, it creates DLQ objects in the configured S3 bucket. DLQ objects exist within a JSON file as an array of failed events.
sink:
- opensearch:
# Provide an AWS OpenSearch Service domain endpoint
hosts: [ "https://<<domain-name>>.<<region>>.es.amazonaws.com" ]
aws:
# Provide a Role ARN with access to the domain. This role should have a trust relationship with osis-pipelines.amazonaws.com
sts_role_arn: "arn:aws:iam::<<account-id>>:role/<<role-name>>"
# Provide the region of the domain.
region: "<<region>>"
# Enable the 'serverless' flag if the sink is an Amazon OpenSearch Serverless collection
# serverless: true
# index name can be auto-generated from topic name
index: "index_ev_pipe-%{yyyy.MM.dd}"
# Enable 'distribution_version' setting if the AWS OpenSearch Service domain is of version Elasticsearch 6.x
#distribution_version: "es6"
# Enable the S3 DLQ to capture any failed requests in Ohan S3 bucket
dlq:
s3:
# Provide an S3 bucket
bucket: "<<bucket-name>>"
# Provide a key path prefix for the failed requests
key_path_prefix: "oss-pipeline-errors/dlq"
# Provide the region of the bucket.
region: "<<region>>"
# Provide a Role ARN with access to the bucket. This role should have a trust relationship with osis-pipelines.amazonaws.com
sts_role_arn: "arn:aws:iam:: <<account-id>>:role/<<role-name>>"
Step 3: OpenSearch Ingestion to Amazon S3
OpenSearch Ingestion offers a built-in sink for loading streaming data directly into S3. The service can compress, partition, and optimize the data for cost-effective storage and analytics in Amazon S3. Data loaded into S3 can be partitioned for easier query isolation and lifecycle management. Partitions can be based on vehicle ID, date, geographic region, or other dimensions as needed for your queries.
The following snippet illustrates how we’ve partitioned and stored EV data in Amazon S3.
- s3:
aws:
# Provide a Role ARN with access to the bucket. This role should have a trust relationship with osis-pipelines.amazonaws.com
sts_role_arn: "arn:aws:iam::<<account-id>>:role/<<role-name>>"
# Provide the region of the domain.
region: "<<region>>"
# Replace with the bucket to send the logs to
bucket: "evbucket"
object_key:
# Optional path_prefix for your s3 objects
path_prefix: "index_ev_pipe/year=%{yyyy}/month=%{MM}/day=%{dd}/hour=%{HH}"
threshold:
event_collect_timeout: 60s
codec:
parquet:
auto_schema: true
The pipeline can be created following the steps in Creating Amazon OpenSearch Ingestion pipelines.
The following is the complete pipeline configuration, combining the configuration of all three steps. Update the Amazon Resource Names (ARNs), AWS Region, Open Search Service domain endpoint, and S3 names as needed.
The entire OpenSearch Ingestion pipeline configuration can be directly copied into the ‘Pipeline configuration’ field in the AWS Management Console while creating the OpenSearch Ingestion pipeline
version: "2"
msk-pipeline:
source:
kafka:
acknowledgments: true # Default is false
topics:
- name: "<<msk-topic-name>>"
group_id: "opensearch-consumer"
serde_format: json
aws:
# Provide the Role ARN with access to MSK. This role should have a trust relationship with osis-pipelines.amazonaws.com
sts_role_arn: "arn:aws:iam::<<account-id>>:role/<<role-name>>"
# Provide the region of the domain.
region: "<<region>>"
msk:
# Provide the MSK ARN.
arn: "arn:aws:kafka:us-east-1:<<account-id>>:cluster/<<cluster-name>>/<<cluster-id>>"
processor:
- parse_json:
sink:
- opensearch:
# Provide an AWS OpenSearch Service domain endpoint
hosts: [ "https://<<opensearch-service-domain-endpoint>>.us-east-1.es.amazonaws.com" ]
aws:
# Provide a Role ARN with access to the domain. This role should have a trust relationship with osis-pipelines.amazonaws.com
sts_role_arn: "arn:aws:iam::<<account-id>>:role/<<role-name>>"
# Provide the region of the domain.
region: "<<region>>"
# Enable the 'serverless' flag if the sink is an Amazon OpenSearch Serverless collection
# index name can be auto-generated from topic name
index: "index_ev_pipe-%{yyyy.MM.dd}"
# Enable 'distribution_version' setting if the AWS OpenSearch Service domain is of version Elasticsearch 6.x
#distribution_version: "es6"
# Enable the S3 DLQ to capture any failed requests in Ohan S3 bucket
dlq:
s3:
# Provide an S3 bucket
bucket: "<<bucket-name>>"
# Provide a key path prefix for the failed requests
key_path_prefix: "oss-pipeline-errors/dlq"
# Provide the region of the bucket.
region: "<<region>>"
# Provide a Role ARN with access to the bucket. This role should have a trust relationship with osis-pipelines.amazonaws.com
sts_role_arn: "arn:aws:iam::<<account-id>>:role/<<role-name>>"
- s3:
aws:
# Provide a Role ARN with access to the bucket. This role should have a trust relationship with osis-pipelines.amazonaws.com
sts_role_arn: "arn:aws:iam::<<account-id>>:role/<<role-name>>"
# Provide the region of the domain.
region: "<<region>>"
# Replace with the bucket to send the logs to
bucket: "<<bucket-name>>"
object_key:
# Optional path_prefix for your s3 objects
path_prefix: "index_ev_pipe/year=%{yyyy}/month=%{MM}/day=%{dd}/hour=%{HH}"
threshold:
event_collect_timeout: 60s
codec:
parquet:
auto_schema: true
Real-time analytics
After the data is available in OpenSearch Service, you can build real-time monitoring and notifications. OpenSearch Service has robust support for multiple notification channels, allowing you to receive alerts through services like Slack, Chime, custom webhooks, Microsoft Teams, email, and Amazon Simple Notification Service (Amazon SNS).
The following screenshot illustrates supported notification channels in OpenSearch Service.

The notification feature in OpenSearch Service allows you to create monitors that will watch for certain conditions or changes in your data and launch alerts, such as monitoring vehicle telemetry data and launching alerts for issues like battery degradation or abnormal energy consumption. For example, you can create a monitor that analyzes battery capacity over time and notifies the on-call team using Slack if capacity drops below expected degradation curves in a significant number of vehicles. This could indicate a potential manufacturing defect requiring investigation.
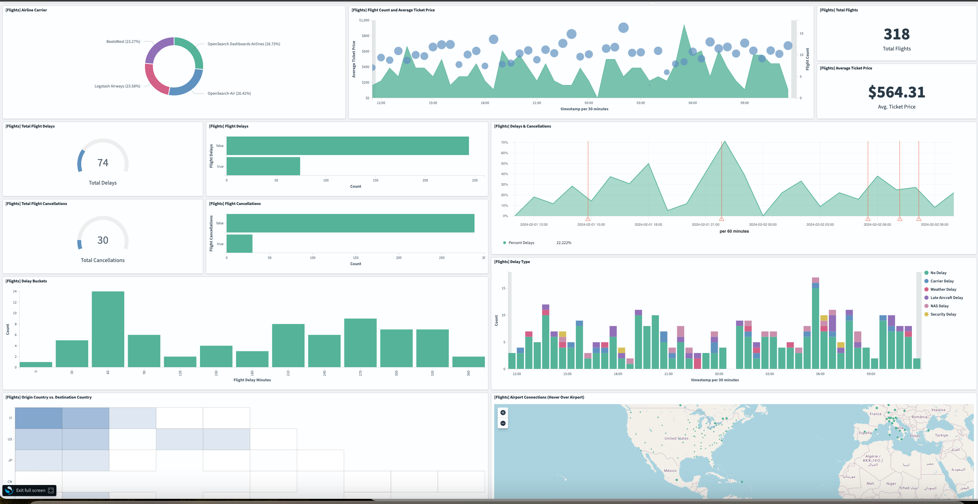
In addition to notifications, OpenSearch Service makes it easy to build real-time dashboards to visually track metrics across your fleet of vehicles. You can ingest vehicle telemetry data like location, speed, fuel consumption, and so on, and visualize it on maps, charts, and gauges. Dashboards can provide real-time visibility into vehicle health and performance.
The following screenshot illustrates creating a sample dashboard on OpenSearch Service

A key benefit of OpenSearch Service is its ability to handle high sustained ingestion and query rates with millisecond latencies. It distributes incoming vehicle data across data nodes in a cluster for parallel processing. This allows OpenSearch to scale out to handle very large fleets while still delivering the real-time performance needed for operational visibility and alerting.
Batch analytics
After the data is available in Amazon S3, you can build a secure data lake to power a variety of analytics use cases deriving powerful insights. As an immutable store, new data is continually stored in S3 while existing data remains unaltered. This serves as a single source of truth for downstream analytics.
For business intelligence and reporting, you can analyze trends, identify insights, and create rich visualizations powered by the data lake. You can use Amazon QuickSight to build and share dashboards without needing to set up servers or infrastructure. Here’s an example of a Quicksight dashboard for IoT device data. For example, you can use a dashboard to gain insights from historical data that can help with better vehicle and battery design.
The Amazon Quicksight public gallery shows examples of dashboards across different domains.
You should consider Amazon OpenSearch dashboards for your operational day-to-day use cases to identify issues and alert in near real time whereas Amazon Quicksight should be used to analyze big data stored in a lake house and generate actionable insights from them.
Clean up
Delete the OpenSearch pipeline and Amazon MSK cluster to stop incurring costs on these services.
Conclusion
In this post, you learned how Amazon MSK, OpenSearch Ingestion, OpenSearch Services, and Amazon S3 can be integrated to ingest, process, store, analyze, and act on endless streams of EV data efficiently.
With OpenSearch Ingestion as the integration layer between streams and storage, the entire pipeline scales up and down automatically based on demand. No more complex cluster management or lost data from bursts in streams.
See Amazon OpenSearch Ingestion to learn more.
About the authors
 Ayush Agrawal is a Startups Solutions Architect from Gurugram, India with 11 years of experience in Cloud Computing. With a keen interest in AI, ML, and Cloud Security, Ayush is dedicated to helping startups navigate and solve complex architectural challenges. His passion for technology drives him to constantly explore new tools and innovations. When he’s not architecting solutions, you’ll find Ayush diving into the latest tech trends, always eager to push the boundaries of what’s possible.
Ayush Agrawal is a Startups Solutions Architect from Gurugram, India with 11 years of experience in Cloud Computing. With a keen interest in AI, ML, and Cloud Security, Ayush is dedicated to helping startups navigate and solve complex architectural challenges. His passion for technology drives him to constantly explore new tools and innovations. When he’s not architecting solutions, you’ll find Ayush diving into the latest tech trends, always eager to push the boundaries of what’s possible.
 Fraser Sequeira is a Solutions Architect with AWS based in Mumbai, India. In his role at AWS, Fraser works closely with startups to design and build cloud-native solutions on AWS, with a focus on analytics and streaming workloads. With over 10 years of experience in cloud computing, Fraser has deep expertise in big data, real-time analytics, and building event-driven architecture on AWS.
Fraser Sequeira is a Solutions Architect with AWS based in Mumbai, India. In his role at AWS, Fraser works closely with startups to design and build cloud-native solutions on AWS, with a focus on analytics and streaming workloads. With over 10 years of experience in cloud computing, Fraser has deep expertise in big data, real-time analytics, and building event-driven architecture on AWS.






 Aswath Srinivasan is a Senior Search Engine Architect at Amazon Web Services currently based in Munich, Germany. With over 17 years of experience in various search technologies, Aswath currently focuses on OpenSearch. He is a search and open-source enthusiast and helps customers and the search community with their search problems.
Aswath Srinivasan is a Senior Search Engine Architect at Amazon Web Services currently based in Munich, Germany. With over 17 years of experience in various search technologies, Aswath currently focuses on OpenSearch. He is a search and open-source enthusiast and helps customers and the search community with their search problems. Jon Handler is a Senior Principal Solutions Architect at Amazon Web Services based in Palo Alto, CA. Jon works closely with OpenSearch and Amazon OpenSearch Service, providing help and guidance to a broad range of customers who have search and log analytics workloads that they want to move to the AWS Cloud. Prior to joining AWS, Jon’s career as a software developer included 4 years of coding a large-scale, ecommerce search engine. Jon holds a Bachelor of the Arts from the University of Pennsylvania, and a Master of Science and a PhD in Computer Science and Artificial Intelligence from Northwestern University.
Jon Handler is a Senior Principal Solutions Architect at Amazon Web Services based in Palo Alto, CA. Jon works closely with OpenSearch and Amazon OpenSearch Service, providing help and guidance to a broad range of customers who have search and log analytics workloads that they want to move to the AWS Cloud. Prior to joining AWS, Jon’s career as a software developer included 4 years of coding a large-scale, ecommerce search engine. Jon holds a Bachelor of the Arts from the University of Pennsylvania, and a Master of Science and a PhD in Computer Science and Artificial Intelligence from Northwestern University.


 Ayush Agrawal is a Startups Solutions Architect from Gurugram, India with 11 years of experience in Cloud Computing. With a keen interest in AI, ML, and Cloud Security, Ayush is dedicated to helping startups navigate and solve complex architectural challenges. His passion for technology drives him to constantly explore new tools and innovations. When he’s not architecting solutions, you’ll find Ayush diving into the latest tech trends, always eager to push the boundaries of what’s possible.
Ayush Agrawal is a Startups Solutions Architect from Gurugram, India with 11 years of experience in Cloud Computing. With a keen interest in AI, ML, and Cloud Security, Ayush is dedicated to helping startups navigate and solve complex architectural challenges. His passion for technology drives him to constantly explore new tools and innovations. When he’s not architecting solutions, you’ll find Ayush diving into the latest tech trends, always eager to push the boundaries of what’s possible. Fraser Sequeira is a Solutions Architect with AWS based in Mumbai, India. In his role at AWS, Fraser works closely with startups to design and build cloud-native solutions on AWS, with a focus on analytics and streaming workloads. With over 10 years of experience in cloud computing, Fraser has deep expertise in big data, real-time analytics, and building event-driven architecture on AWS.
Fraser Sequeira is a Solutions Architect with AWS based in Mumbai, India. In his role at AWS, Fraser works closely with startups to design and build cloud-native solutions on AWS, with a focus on analytics and streaming workloads. With over 10 years of experience in cloud computing, Fraser has deep expertise in big data, real-time analytics, and building event-driven architecture on AWS.
 Clarisa Tavolieri is a Software Engineering graduate with qualifications in Business, Audit, and Strategy Consulting. With an extensive career in the financial and tech industries, she specializes in data management and has been involved in initiatives ranging from reporting to data architecture. She currently serves as the Global Head of Cyber Data Management at Zurich Group. In her role, she leads the data strategy to support the protection of company assets and implements advanced analytics to enhance and monitor cybersecurity tools.
Clarisa Tavolieri is a Software Engineering graduate with qualifications in Business, Audit, and Strategy Consulting. With an extensive career in the financial and tech industries, she specializes in data management and has been involved in initiatives ranging from reporting to data architecture. She currently serves as the Global Head of Cyber Data Management at Zurich Group. In her role, she leads the data strategy to support the protection of company assets and implements advanced analytics to enhance and monitor cybersecurity tools. Austin Rappeport is a Computer Engineer who graduated from the University of Illinois Urbana/Champaign in 2011 with a focus in Computer Security. After graduation, he worked for the Federal Energy Regulatory Commission in the Office of Electric Reliability, working with the North American Electric Reliability Corporation’s Critical Infrastructure Protection Standards on both the audit and enforcement side, as well as standards development. Austin currently works for Zurich Insurance as the Global Head of Detection Engineering and Automation, where he leads the team responsible for using Zurich’s security tools to detect suspicious and malicious activity and improve internal processes through automation.
Austin Rappeport is a Computer Engineer who graduated from the University of Illinois Urbana/Champaign in 2011 with a focus in Computer Security. After graduation, he worked for the Federal Energy Regulatory Commission in the Office of Electric Reliability, working with the North American Electric Reliability Corporation’s Critical Infrastructure Protection Standards on both the audit and enforcement side, as well as standards development. Austin currently works for Zurich Insurance as the Global Head of Detection Engineering and Automation, where he leads the team responsible for using Zurich’s security tools to detect suspicious and malicious activity and improve internal processes through automation. Samantha Gignac is a Global Security Architect at Zurich Insurance. She graduated from Ferris State University in 2014 with a Bachelor’s degree in Computer Systems & Network Engineering. With experience in the insurance, healthcare, and supply chain industries, she has held roles such as Storage Engineer, Risk Management Engineer, Vulnerability Management Engineer, and SOC Engineer. As a Cybersecurity Architect, she designs and implements secure network systems to protect organizational data and infrastructure from cyber threats.
Samantha Gignac is a Global Security Architect at Zurich Insurance. She graduated from Ferris State University in 2014 with a Bachelor’s degree in Computer Systems & Network Engineering. With experience in the insurance, healthcare, and supply chain industries, she has held roles such as Storage Engineer, Risk Management Engineer, Vulnerability Management Engineer, and SOC Engineer. As a Cybersecurity Architect, she designs and implements secure network systems to protect organizational data and infrastructure from cyber threats. Claire Sheridan is a Principal Solutions Architect with Amazon Web Services working with global financial services customers. She holds a PhD in Informatics and has more than 15 years of industry experience in tech. She loves traveling and visiting art galleries.
Claire Sheridan is a Principal Solutions Architect with Amazon Web Services working with global financial services customers. She holds a PhD in Informatics and has more than 15 years of industry experience in tech. She loves traveling and visiting art galleries. Jake Obi is a Principal Security Consultant with Amazon Web Services based in South Carolina, US, with over 20 years’ experience in information technology. He helps financial services customers improve their security posture in the cloud. Prior to joining Amazon, Jake was an Information Assurance Manager for the US Navy, where he worked on a large satellite communications program as well as hosting government websites using the public cloud.
Jake Obi is a Principal Security Consultant with Amazon Web Services based in South Carolina, US, with over 20 years’ experience in information technology. He helps financial services customers improve their security posture in the cloud. Prior to joining Amazon, Jake was an Information Assurance Manager for the US Navy, where he worked on a large satellite communications program as well as hosting government websites using the public cloud. Srikanth Daggumalli is an Analytics Specialist Solutions Architect in AWS. Out of 18 years of experience, he has over a decade of experience in architecting cost-effective, performant, and secure enterprise applications that improve customer reachability and experience, using big data, AI/ML, cloud, and security technologies. He has built high-performing data platforms for major financial institutions, enabling improved customer reach and exceptional experiences. He is specialized in services like cross-border transactions and architecting robust analytics platforms.
Srikanth Daggumalli is an Analytics Specialist Solutions Architect in AWS. Out of 18 years of experience, he has over a decade of experience in architecting cost-effective, performant, and secure enterprise applications that improve customer reachability and experience, using big data, AI/ML, cloud, and security technologies. He has built high-performing data platforms for major financial institutions, enabling improved customer reach and exceptional experiences. He is specialized in services like cross-border transactions and architecting robust analytics platforms. Freddy Kasprzykowski is a Senior Security Consultant with Amazon Web Services based in Florida, US, with over 20 years’ experience in information technology. He helps customers adopt AWS services securely according to industry best practices, standards, and compliance regulations. He is a member of the Customer Incident Response Team (CIRT), helping customers during security events, a seasoned speaker at AWS re:Invent and AWS re:Inforce conferences, and a contributor to open source projects related to AWS security.
Freddy Kasprzykowski is a Senior Security Consultant with Amazon Web Services based in Florida, US, with over 20 years’ experience in information technology. He helps customers adopt AWS services securely according to industry best practices, standards, and compliance regulations. He is a member of the Customer Incident Response Team (CIRT), helping customers during security events, a seasoned speaker at AWS re:Invent and AWS re:Inforce conferences, and a contributor to open source projects related to AWS security.



 Adam McCarthy is the EMEA Tech Leader for Healthcare and Life Sciences Startups at AWS. He has over 15 years’ experience researching and implementing machine learning, HPC, and scientific computing environments, especially in academia, hospitals, and drug discovery.
Adam McCarthy is the EMEA Tech Leader for Healthcare and Life Sciences Startups at AWS. He has over 15 years’ experience researching and implementing machine learning, HPC, and scientific computing environments, especially in academia, hospitals, and drug discovery.
 Jatinder Singh is a Senior Technical Account Manager at AWS and finds satisfaction in aiding customers in their cloud migration and innovation endeavors. Beyond his professional life, he relishes spending moments with his family and indulging in hobbies such as reading, culinary pursuits, and playing chess.
Jatinder Singh is a Senior Technical Account Manager at AWS and finds satisfaction in aiding customers in their cloud migration and innovation endeavors. Beyond his professional life, he relishes spending moments with his family and indulging in hobbies such as reading, culinary pursuits, and playing chess. Hajer Bouafif is an Analytics Specialist Solutions Architect at Amazon Web Services. She focuses on Amazon OpenSearch Service and helps customers design and build well-architected analytics workloads in diverse industries. Hajer enjoys spending time outdoors and discovering new cultures.
Hajer Bouafif is an Analytics Specialist Solutions Architect at Amazon Web Services. She focuses on Amazon OpenSearch Service and helps customers design and build well-architected analytics workloads in diverse industries. Hajer enjoys spending time outdoors and discovering new cultures. Puneetha Kumara is a Senior Technical Account Manager at AWS, with over 15 years of industry experience, including roles in cloud architecture, systems engineering, and container orchestration.
Puneetha Kumara is a Senior Technical Account Manager at AWS, with over 15 years of industry experience, including roles in cloud architecture, systems engineering, and container orchestration. Manpreet Kour is a Senior Technical Account Manager at AWS and is dedicated to ensuring customer satisfaction. Her approach involves a deep understanding of customer objectives, aligning them with software capabilities, and effectively driving customer success. Outside of her professional endeavors, she enjoys traveling and spending quality time with her family.
Manpreet Kour is a Senior Technical Account Manager at AWS and is dedicated to ensuring customer satisfaction. Her approach involves a deep understanding of customer objectives, aligning them with software capabilities, and effectively driving customer success. Outside of her professional endeavors, she enjoys traveling and spending quality time with her family.





 Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics of networking and security, and is based out of Austin, Texas.
Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics of networking and security, and is based out of Austin, Texas. Arjun Nambiar is a Product Manager with Amazon OpenSearch Service. He focuses on ingestion technologies that enable ingesting data from a wide variety of sources into Amazon OpenSearch Service at scale. Arjun is interested in large-scale distributed systems and cloud-centered technologies, and is based out of Seattle, Washington.
Arjun Nambiar is a Product Manager with Amazon OpenSearch Service. He focuses on ingestion technologies that enable ingesting data from a wide variety of sources into Amazon OpenSearch Service at scale. Arjun is interested in large-scale distributed systems and cloud-centered technologies, and is based out of Seattle, Washington.





 Felix John is a Solutions Architect and data streaming expert at AWS, based in Germany. He focuses on supporting small and medium businesses on their cloud journey. Outside of his professional life, Felix enjoys playing Floorball and hiking in the mountains.
Felix John is a Solutions Architect and data streaming expert at AWS, based in Germany. He focuses on supporting small and medium businesses on their cloud journey. Outside of his professional life, Felix enjoys playing Floorball and hiking in the mountains. Michelle Mei-Li Pfister is a Solutions Architect at AWS. She is supporting customers in retail and consumer packaged goods (CPG) industry on their cloud journey. She is passionate about topics around data and machine learning.
Michelle Mei-Li Pfister is a Solutions Architect at AWS. She is supporting customers in retail and consumer packaged goods (CPG) industry on their cloud journey. She is passionate about topics around data and machine learning.


 Utkarsh Agarwal is a Cloud Support Engineer in the Support Engineering team at Amazon Web Services. He specializes in Amazon OpenSearch Service. He provides guidance and technical assistance to customers thus enabling them to build scalable, highly available, and secure solutions in the AWS Cloud. In his free time, he enjoys watching movies, TV series, and of course, cricket. Lately, he has also been attempting to master the art of cooking in his free time – the taste buds are excited, but the kitchen might disagree.
Utkarsh Agarwal is a Cloud Support Engineer in the Support Engineering team at Amazon Web Services. He specializes in Amazon OpenSearch Service. He provides guidance and technical assistance to customers thus enabling them to build scalable, highly available, and secure solutions in the AWS Cloud. In his free time, he enjoys watching movies, TV series, and of course, cricket. Lately, he has also been attempting to master the art of cooking in his free time – the taste buds are excited, but the kitchen might disagree. Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.
Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.









 ML-powered search with OpenSearch
ML-powered search with OpenSearch Praveen Mohan Prasad is an Analytics Specialist Technical Account Manager at Amazon Web Services and helps customers with pro-active operational reviews on analytics workloads. Praveen actively researches on applying machine learning to improve search relevance.
Praveen Mohan Prasad is an Analytics Specialist Technical Account Manager at Amazon Web Services and helps customers with pro-active operational reviews on analytics workloads. Praveen actively researches on applying machine learning to improve search relevance. Aruna Govindaraju is an Amazon OpenSearch Specialist Solutions Architect and has worked with many commercial and open-source search engines. She is passionate about search, relevancy, and user experience. Her expertise with correlating end-user signals with search engine behavior has helped many customers improve their search experience. Her favourite pastime is hiking the New England trails and mountains.
Aruna Govindaraju is an Amazon OpenSearch Specialist Solutions Architect and has worked with many commercial and open-source search engines. She is passionate about search, relevancy, and user experience. Her expertise with correlating end-user signals with search engine behavior has helped many customers improve their search experience. Her favourite pastime is hiking the New England trails and mountains.









 Sharmila Shanmugam is a Solutions Architect at Amazon Web Services. She is passionate about solving the customers’ business challenges with technology and automation and reduce the operational overhead. In her current role, she helps customers across industries in their digital transformation journey and build secure, scalable, performant and optimized workloads on AWS.
Sharmila Shanmugam is a Solutions Architect at Amazon Web Services. She is passionate about solving the customers’ business challenges with technology and automation and reduce the operational overhead. In her current role, she helps customers across industries in their digital transformation journey and build secure, scalable, performant and optimized workloads on AWS. Harsh Bansal is an Analytics Solutions Architect with Amazon Web Services. In his role, he collaborates closely with clients, assisting in their migration to cloud platforms and optimizing cluster setups to enhance performance and reduce costs. Before joining AWS, he supported clients in leveraging OpenSearch and Elasticsearch for diverse search and log analytics requirements.
Harsh Bansal is an Analytics Solutions Architect with Amazon Web Services. In his role, he collaborates closely with clients, assisting in their migration to cloud platforms and optimizing cluster setups to enhance performance and reduce costs. Before joining AWS, he supported clients in leveraging OpenSearch and Elasticsearch for diverse search and log analytics requirements. Rohit Kumar works as a Cloud Support Engineer in the Support Engineering team at Amazon Web Services. He focuses on Amazon OpenSearch Service, offering guidance and technical help to customers, helping them create scalable, highly available, and secure solutions on AWS Cloud. Outside of work, Rohit enjoys watching or playing cricket. He also loves traveling and discovering new places. Essentially, his routine revolves around eating, traveling, cricket, and repeating the cycle.
Rohit Kumar works as a Cloud Support Engineer in the Support Engineering team at Amazon Web Services. He focuses on Amazon OpenSearch Service, offering guidance and technical help to customers, helping them create scalable, highly available, and secure solutions on AWS Cloud. Outside of work, Rohit enjoys watching or playing cricket. He also loves traveling and discovering new places. Essentially, his routine revolves around eating, traveling, cricket, and repeating the cycle.
 Praveen Nischal is a Cloud Software Engineer, and leads the cloud workload performance framework at Intel.
Praveen Nischal is a Cloud Software Engineer, and leads the cloud workload performance framework at Intel. Mulugeta Mammo is a Senior Software Engineer, and currently leads the OpenSearch Optimization team at Intel.
Mulugeta Mammo is a Senior Software Engineer, and currently leads the OpenSearch Optimization team at Intel. Akash Shankaran is a Software Architect and Tech Lead in the Xeon software team at Intel. He works on pathfinding opportunities, and enabling optimizations for data services such as OpenSearch.
Akash Shankaran is a Software Architect and Tech Lead in the Xeon software team at Intel. He works on pathfinding opportunities, and enabling optimizations for data services such as OpenSearch. Sarthak Aggarwal is a Software Engineer at Amazon OpenSearch Service. He has been contributing towards open-source development with indexing and storage performance as a primary area of interest.
Sarthak Aggarwal is a Software Engineer at Amazon OpenSearch Service. He has been contributing towards open-source development with indexing and storage performance as a primary area of interest. Prabhakar Sithanandam is a Principal Engineer with Amazon OpenSearch Service. He primarily works on the scalability and performance aspects of OpenSearch.
Prabhakar Sithanandam is a Principal Engineer with Amazon OpenSearch Service. He primarily works on the scalability and performance aspects of OpenSearch.














 Joshua Bright is a Senior Product Manager at Amazon Web Services. Joshua leads data lake integration initiatives within the OpenSearch Service team. Outside of work, Joshua enjoys listening to birds while walking in nature.
Joshua Bright is a Senior Product Manager at Amazon Web Services. Joshua leads data lake integration initiatives within the OpenSearch Service team. Outside of work, Joshua enjoys listening to birds while walking in nature.

















 Anand Komandooru is a Principal Cloud Architect at AWS. He joined AWS Professional Services organization in 2021 and helps customers build cloud-native applications on AWS cloud. He has over 20 years of experience building software and his favorite Amazon leadership principle is “
Anand Komandooru is a Principal Cloud Architect at AWS. He joined AWS Professional Services organization in 2021 and helps customers build cloud-native applications on AWS cloud. He has over 20 years of experience building software and his favorite Amazon leadership principle is “ Rama Krishna Ramaseshu is a Senior Application Architect at AWS. He joined AWS Professional Services in 2022 and with close to two decades of experience in application development and software architecture, he empowers customers to build well architected solutions within the AWS cloud. His favorite Amazon leadership principle is “
Rama Krishna Ramaseshu is a Senior Application Architect at AWS. He joined AWS Professional Services in 2022 and with close to two decades of experience in application development and software architecture, he empowers customers to build well architected solutions within the AWS cloud. His favorite Amazon leadership principle is “ Sachin Vighe is a Senior DevOps Architect at AWS. He joined AWS Professional Services in 2020, and specializes in designing and architecting solutions within the AWS cloud to guide customers through their DevOps and Cloud transformation journey. His favorite leadership principle is “
Sachin Vighe is a Senior DevOps Architect at AWS. He joined AWS Professional Services in 2020, and specializes in designing and architecting solutions within the AWS cloud to guide customers through their DevOps and Cloud transformation journey. His favorite leadership principle is “ Molly Wu is an Associate Cloud Developer at AWS. She joined AWS Professional Services in 2023 and specializes in assisting customers in building frontend technologies in AWS cloud. Her favorite leadership principle is “
Molly Wu is an Associate Cloud Developer at AWS. She joined AWS Professional Services in 2023 and specializes in assisting customers in building frontend technologies in AWS cloud. Her favorite leadership principle is “ Andrew Yankowsky is a Security Consultant at AWS. He joined AWS Professional Services in 2023, and helps customers build cloud security capabilities and follow security best practices on AWS. His favorite leadership principle is “
Andrew Yankowsky is a Security Consultant at AWS. He joined AWS Professional Services in 2023, and helps customers build cloud security capabilities and follow security best practices on AWS. His favorite leadership principle is “





 Dhaval Shah is a Principal Solutions Architect with Amazon Web Services based out of New York, where he guides global financial services customers to build highly secure, scalable, reliable, and cost-efficient applications on the cloud. He brings over 20 years of technology experience on Software Development and Architecture, Data Engineering, and IT Management.
Dhaval Shah is a Principal Solutions Architect with Amazon Web Services based out of New York, where he guides global financial services customers to build highly secure, scalable, reliable, and cost-efficient applications on the cloud. He brings over 20 years of technology experience on Software Development and Architecture, Data Engineering, and IT Management. Soujanya Konka is a Senior Solutions Architect and Analytics specialist at AWS, focused on helping customers build their ideas on cloud. Expertise in design and implementation of Data platforms. Before joining AWS, Soujanya has had stints with companies such as HSBC & Cognizant
Soujanya Konka is a Senior Solutions Architect and Analytics specialist at AWS, focused on helping customers build their ideas on cloud. Expertise in design and implementation of Data platforms. Before joining AWS, Soujanya has had stints with companies such as HSBC & Cognizant Jon Handler is a Senior Principal Solutions Architect at Amazon Web Services based in Palo Alto, CA. Jon works closely with OpenSearch and Amazon OpenSearch Service, providing help and guidance to a broad range of customers who have search and log analytics workloads that they want to move to the AWS Cloud. Prior to joining AWS, Jon’s career as a software developer included 4 years of coding a large-scale, ecommerce search engine. Jon holds a Bachelor of the Arts from the University of Pennsylvania, and a Master of Science and a PhD in Computer Science and Artificial Intelligence from Northwestern University.
Jon Handler is a Senior Principal Solutions Architect at Amazon Web Services based in Palo Alto, CA. Jon works closely with OpenSearch and Amazon OpenSearch Service, providing help and guidance to a broad range of customers who have search and log analytics workloads that they want to move to the AWS Cloud. Prior to joining AWS, Jon’s career as a software developer included 4 years of coding a large-scale, ecommerce search engine. Jon holds a Bachelor of the Arts from the University of Pennsylvania, and a Master of Science and a PhD in Computer Science and Artificial Intelligence from Northwestern University. Jianwei Li is a Principal Analytics Specialist TAM at Amazon Web Services. Jianwei provides consultant service for customers to help customer design and build modern data platform. Jianwei has been working in big data domain as software developer, consultant and tech leader.
Jianwei Li is a Principal Analytics Specialist TAM at Amazon Web Services. Jianwei provides consultant service for customers to help customer design and build modern data platform. Jianwei has been working in big data domain as software developer, consultant and tech leader. Hrishikesh Karambelkar is a Principal Architect for Data and AIML with AWS Professional Services for Asia Pacific and Japan. He is proactively engaged with customers in APJ region to enable enterprises in their Digital Transformation journey on AWS Cloud in the areas of Generative AI, machine learning and Data, Analytics, Previously, Hrishikesh has authored books on enterprise search, biig data and co-authored research publications in the areas of Enterprise Search and AI-ML.
Hrishikesh Karambelkar is a Principal Architect for Data and AIML with AWS Professional Services for Asia Pacific and Japan. He is proactively engaged with customers in APJ region to enable enterprises in their Digital Transformation journey on AWS Cloud in the areas of Generative AI, machine learning and Data, Analytics, Previously, Hrishikesh has authored books on enterprise search, biig data and co-authored research publications in the areas of Enterprise Search and AI-ML.
 Build On Generative AI — Now streaming every Thursday, 2:00 PM US PT on
Build On Generative AI — Now streaming every Thursday, 2:00 PM US PT on 











