Post Syndicated from Kalaiselvi Kamaraj original https://aws.amazon.com/blogs/big-data/accelerate-amazon-redshift-data-lake-queries-with-column-level-statistics/
Amazon Redshift enables you to efficiently query and retrieve structured and semi-structured data from open format files in Amazon S3 data lake without having to load the data into Amazon Redshift tables. Amazon Redshift extends SQL capabilities to your data lake, enabling you to run analytical queries. Amazon Redshift supports a wide variety of tabular data formats like CSV, JSON, Parquet, ORC and open tabular formats like Apache Hudi, Linux foundation Delta Lake and Apache Iceberg.
You create Redshift external tables by defining the structure for your files, S3 location of the files and registering them as tables in an external data catalog. The external data catalog can be AWS Glue Data Catalog, the data catalog that comes with Amazon Athena, or your own Apache Hive metastore.
Over the last year, Amazon Redshift added several performance optimizations for data lake queries across multiple areas of query engine such as rewrite, planning, scan execution and consuming AWS Glue Data Catalog column statistics. To get the best performance on data lake queries with Redshift, you can use AWS Glue Data Catalog’s column statistics feature to collect statistics on Data Lake tables. For Amazon Redshift Serverless instances, you will see improved scan performance through increased parallel processing of S3 files and this happens automatically based on RPUs used.
In this post, we highlight the performance improvements we observed using industry standard TPC-DS benchmarks. Overall execution time of TPC-DS 3 TB benchmark improved by 3x. Some of the queries in our benchmark experienced up to 12x speed up.
Performance Improvements
Several performance optimizations were done over the last year to improve performance of data lake queries including the following.
- Consume AWS Glue Data Catalog column statistics and tuning of Redshift optimizer to improve quality of query plans
- Utilize bloom filters for partition columns
- Improved scan efficiency for Amazon Redshift Serverless instances through increased parallel processing of files
- Novel query rewrite rules to merge similar scans
- Faster retrieval of metadata from AWS Glue Data Catalog
To understand the performance gains, we tested the performance on the industry-standard TPC-DS benchmark using 3 TB data sets and queries which represents different customer use cases. Performance was tested on a Redshift serverless data warehouse with 128 RPU. In our testing, the dataset was stored in Amazon S3 in Parquet format and AWS Glue Data Catalog was used to manage external databases and tables. Fact tables were partitioned on the date column, and each fact table consisted of approximately 2,000 partitions. All of the tables had their row count table property, numRows, set as per the spectrum query performance guidelines.
We did a baseline run on Redshift patch version (patch 172) from last year. Later, we ran all TPC-DS queries on latest patch version (patch 180) that includes all performance optimizations added over last year. Then we used AWS Glue Data Catalog’s column statistics feature to compute statistics for all the tables and measured improvements with the presence of AWS Glue Data Catalog column statistics.
Our analysis revealed that the TPC-DS 3TB Parquet benchmark saw substantial performance gains with these optimizations. Specifically, partitioned Parquet with our latest optimizations achieved 2x faster runtimes compared to the previous implementation. Enabling AWS Glue Data Catalog column statistics further improved performance by 3x versus last year. The following graph illustrates these runtime improvements for the full benchmark (all TPC-DS queries) over the past year, including the additional boost from using AWS Glue Data Catalog column statistics.

Figure 1: Improvement in total runtime of TPC-DS 3T workload
The following graph presents the top queries from the TPC-DS benchmark with the greatest performance improvement over the last year with and without AWS Glue Data Catalog column statistics. You can see that performance improves a lot when statistics exist on AWS Glue Data Catalog (for details on how to get statistics for your Data Lake tables, please refer to optimizing query performance using AWS Glue Data Catalog column statistics). Specifically, multi-join queries will benefit the most from AWS Glue Data Catalog column statistics because the optimizer uses statistics to choose the right join order and distribution strategy.

Figure 2: Speed-up in TPC-DS queries
Let’s discuss some of the optimizations that contributed to improved query performance.
Optimizing with table-level statistics
Amazon Redshift’s design enables it to handle large-scale data challenges with superior speed and cost-efficiency. Its massively parallel processing (MPP) query engine, AI-powered query optimizer, auto-scaling capabilities, and other advanced features allow Redshift to excel at searching, aggregating, and transforming petabytes of data.
However, even the most powerful systems can experience performance degradation if they encounter anti-patterns like grossly inaccurate table statistics, such as the row count metadata.
Without this crucial metadata, Redshift’s query optimizer may be limited in the number of possible optimizations, especially those related to data distribution during query execution. This can have a significant impact on overall query performance.
To illustrate this, consider the following simple query involving an inner join between a large table with billions of rows and a small table with only a few hundred thousand rows.
If executed as-is, with the large table on the right-hand side of the join, the query will lead to sub-optimal performance. This is because the large table will need to be distributed (broadcast) to all Redshift compute nodes to perform the inner join with the small table, as shown in the following diagram.

Figure 3: Inaccurate table statistics lead to limited optimizations and large amounts of data broadcast among compute nodes for a simple inner join
Now, consider a scenario where the table statistics, such as the row count, are accurate. This allows the Amazon Redshift query optimizer to make more informed decisions, such as determining the optimal join order. In this case, the optimizer would immediately rewrite the query to have the large table on the left-hand side of the inner join, so that it is the small table that is broadcast across the Redshift compute nodes, as illustrated in the following diagram.

Figure 4: Accurate table statistics lead to high degree of optimizations and very little data broadcast among compute nodes for a simple inner join
Fortunately, Amazon Redshift automatically maintains accurate table statistics for local tables by running the ANALYZE command in the background. For external tables (data lake tables), however, AWS Glue Data Catalog column statistics are recommended for use with Amazon Redshift as we will discuss in the next section. For more general information on optimizing queries in Amazon Redshift, please refer to the documentation on factors affecting query performance, data redistribution, and Amazon Redshift best practices for designing queries.
Improvements with AWS Glue Data Catalog column statistics
AWS Glue Data Catalog has a feature to compute column level statistics for Amazon S3 backed external tables. AWS Glue Data Catalog can compute column level statistics such as NDV, Number of Nulls, Min/Max and Avg. column width for the columns without the need for additional data pipelines. Amazon Redshift cost-based optimizer utilizes these statistics to come up with better quality query plans. In addition to consuming statistics, we also made several improvements in cardinality estimations and cost tuning to get high quality query plans thereby improving query performance.
TPC-DS 3TB dataset showed 40% improvement in total query execution time when these AWS Glue Data Catalog column statistics were provided. Individual TPC-DS queries showed up to 5x improvements in query execution time. Some of the queries that had greater impact in execution time are Q85, Q64, Q75, Q78, Q94, Q16, Q04, Q24 and Q11.
We will go through an example where cost-based optimizer generated a better query plan with statistics and how it improved the execution time.
Let’s consider following simpler version of TPC-DS Q64 to showcase the query plan differences with statistics.
|
Without Statistics Following figure represents the logical query plan of Q64. You can observe that cardinality estimation of joins is not accurate. With inaccurate cardinalities, optimizer produces a sub-optimal query plan leading to higher execution time. |
With Statistics Following figure represents the logical query plan after consuming AWS Glue Data Catalog column statistics. Based on the highlighted changes, you can observe that the cardinality estimations of JOIN improved by many magnitudes helping the optimizer to choose a better join order and join strategy (broadcast |

Figure 5: Logical query plan of Q64 without statistics |

Figure 6: Logical query plan of Q64 after consuming AWS Glue Data Catalog column statistics |
This change in query plan improved the query execution time of Q64 from 383s to 81s.
Given the greater benefits with AWS Glue Data Catalog column statistics for the optimizer, you should consider collecting stats for your data lake using AWS Glue. If your workload is a JOIN heavy workload, then collecting stats will show greater improvement on your workload. Refer to generating AWS Glue Data Catalog column statistics for instructions on how to collect statistics in AWS Glue Data Catalog.
Query rewrite optimization
We introduced a new query rewrite rule which combines scalar aggregates over the same common expression using slightly different predicates. This rewrite resulted in performance improvements on TPC-DS queries Q09, Q28, and Q88. Let’s focus on Q09 as a representative of these queries, given by the following fragment:
In total, there are 15 scans of the fact table store_sales, each one returning various aggregates over different subsets of data. The engine first performs subquery removal and transforms the various expressions in the CASE statements into relational subtrees connected via cross products, and then they are fused into one subquery handling all scalar aggregates. The resulting plan for Q09, described below using SQL for clarity, is given by:
In general, this rewrite rule results in the largest improvements both in latency (from 3x to 8x improvements) and bytes read from Amazon S3 (from 6x to 8x reduction in scanned bytes and, consequently, cost).
Bloom filter for partition columns
Amazon Redshift already uses Bloom filters on data columns of external tables in Amazon S3 to enable early and effective data filtering. Last year, we extended this support for partition columns as well. A Bloom filter is a probabilistic, memory-efficient data structure that accelerates join queries at scale by filtering rows that do not match the join relation, significantly reducing the amount of data transferred over the network. Amazon Redshift automatically determines what queries are suitable for leveraging Bloom filters at query runtime.
This optimization resulted in performance improvements on TPC-DS queries Q05, Q17 and Q54. This optimization resulted in large improvements in both latency (from 2x to 3x improvement) and bytes read from S3 (from 9x to 15x reduction in scanned bytes and, consequently cost).
Following is the subquery of Q05 which showcased improvements with runtime filter.
|
Without bloom filter support on partition columns Following figure is the logical query plan for sub-query of Q05. This appends two large fact tables |
With bloom filter support on partition columns With support of bloom filter on partition columns, we now create bloom filter for |

Figure 7: Logical query plan for sub-query of Q05 without bloom filter support on partition columns |

Figure 8: Logical query plan for sub-query of Q05 with bloom filter support on partition columns |
Overall, bloom filter on partition column will reduce the number of partitions processed resulting in reduced S3 listing calls and lesser number of data files to be read (reduction in scanned bytes). You can see that we only scan 89M rows from store_sales and 4M rows from store_returns because of the bloom filter. This reduced number of rows to process at JOIN level and helped in improving the overall query performance by 2x and scanned bytes by 9x.
Conclusion
In this post, we covered new performance optimizations in Amazon Redshift data lake query processing and how AWS Glue Data Catalog statistics helps to enhance quality of query plans for data lake queries in Amazon Redshift. These optimizations together improved TPC-DS 3 TB benchmark by 3x. Some of the queries in our benchmark benefited up to 12x speed up.
In summary, Amazon Redshift now offers enhanced query performance with optimizations such as AWS Glue Data Catalog column statistics, bloom filters on partition columns, new query rewrite rules and faster retrieval of metadata. These optimizations are enabled by default and Amazon Redshift users will benefit with better query response times for their workloads. For more information, please reach out to your AWS technical account manager or AWS account solutions architect. They will be happy to provide additional guidance and support.
About the authors
 Kalaiselvi Kamaraj is a Sr. Software Development Engineer with Amazon. She has worked on several projects within Redshift Query processing team and currently focusing on performance related projects for Redshift Data Lake.
Kalaiselvi Kamaraj is a Sr. Software Development Engineer with Amazon. She has worked on several projects within Redshift Query processing team and currently focusing on performance related projects for Redshift Data Lake.
 Mark Lyons is a Principal Product Manager on the Amazon Redshift team. He works on the intersection of data lakes and data warehouses. Prior to joining AWS, Mark held product leadership roles with Dremio and Vertica. He is passionate about data analytics and empowering customers to change the world with their data.
Mark Lyons is a Principal Product Manager on the Amazon Redshift team. He works on the intersection of data lakes and data warehouses. Prior to joining AWS, Mark held product leadership roles with Dremio and Vertica. He is passionate about data analytics and empowering customers to change the world with their data.
 Asser Moustafa is a Principal Worldwide Specialist Solutions Architect at AWS, based in Dallas, Texas, USA. He partners with customers worldwide, advising them on all aspects of their data architectures, migrations, and strategic data visions to help organizations adopt cloud-based solutions, maximize the value of their data assets, modernize legacy infrastructures, and implement cutting-edge capabilities like machine learning and advanced analytics. Prior to joining AWS, Asser held various data and analytics leadership roles, completing an MBA from New York University and an MS in Computer Science from Columbia University in New York. He is passionate about empowering organizations to become truly data-driven and unlock the transformative potential of their data.
Asser Moustafa is a Principal Worldwide Specialist Solutions Architect at AWS, based in Dallas, Texas, USA. He partners with customers worldwide, advising them on all aspects of their data architectures, migrations, and strategic data visions to help organizations adopt cloud-based solutions, maximize the value of their data assets, modernize legacy infrastructures, and implement cutting-edge capabilities like machine learning and advanced analytics. Prior to joining AWS, Asser held various data and analytics leadership roles, completing an MBA from New York University and an MS in Computer Science from Columbia University in New York. He is passionate about empowering organizations to become truly data-driven and unlock the transformative potential of their data.





 Lakshmi Nair is a Senior Analytics Specialist Solutions Architect at AWS. She specializes in designing advanced analytics systems across industries. She focuses on crafting cloud-based data platforms, enabling real-time streaming, big data processing, and robust data governance.
Lakshmi Nair is a Senior Analytics Specialist Solutions Architect at AWS. She specializes in designing advanced analytics systems across industries. She focuses on crafting cloud-based data platforms, enabling real-time streaming, big data processing, and robust data governance. Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She enjoys building analytics and data mesh solutions on AWS and sharing them with the community.
Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She enjoys building analytics and data mesh solutions on AWS and sharing them with the community.











 Anirban Sinha is a Senior Technical Account Manager at AWS. He is passionate about building scalable data warehouses and big data solutions working closely with customers. He works with large ISVs customers, in helping them build and operate secure, resilient, scalable, and high-performance SaaS applications in the cloud.
Anirban Sinha is a Senior Technical Account Manager at AWS. He is passionate about building scalable data warehouses and big data solutions working closely with customers. He works with large ISVs customers, in helping them build and operate secure, resilient, scalable, and high-performance SaaS applications in the cloud. Phil Bates is a Senior Analytics Specialist Solutions Architect at AWS. He has more than 25 years of experience implementing large-scale data warehouse solutions. He is passionate about helping customers through their cloud journey and using the power of ML within their data warehouse.
Phil Bates is a Senior Analytics Specialist Solutions Architect at AWS. He has more than 25 years of experience implementing large-scale data warehouse solutions. He is passionate about helping customers through their cloud journey and using the power of ML within their data warehouse. Gaurav Singh is a Senior Solutions Architect at AWS, specializing in AI/ML and Generative AI. Based in Pune, India, he focuses on helping customers build, deploy, and migrate ML production workloads to SageMaker at scale. In his spare time, Gaurav loves to explore nature, read, and run.
Gaurav Singh is a Senior Solutions Architect at AWS, specializing in AI/ML and Generative AI. Based in Pune, India, he focuses on helping customers build, deploy, and migrate ML production workloads to SageMaker at scale. In his spare time, Gaurav loves to explore nature, read, and run.






 Nita Shah is an Analytics Specialist Solutions Architect at AWS based out of New York. She has been building data warehouse solutions for over 20 years and specializes in Amazon Redshift. She is focused on helping customers design and build enterprise-scale well-architected analytics and decision support platforms.
Nita Shah is an Analytics Specialist Solutions Architect at AWS based out of New York. She has been building data warehouse solutions for over 20 years and specializes in Amazon Redshift. She is focused on helping customers design and build enterprise-scale well-architected analytics and decision support platforms. Ranjan Burman is an Analytics Specialist Solutions Architect at AWS. He specializes in Amazon Redshift and helps customers build scalable analytical solutions. He has more than 15 years of experience in different database and data warehousing technologies. He is passionate about automating and solving customer problems with the use of cloud solutions.
Ranjan Burman is an Analytics Specialist Solutions Architect at AWS. He specializes in Amazon Redshift and helps customers build scalable analytical solutions. He has more than 15 years of experience in different database and data warehousing technologies. He is passionate about automating and solving customer problems with the use of cloud solutions.












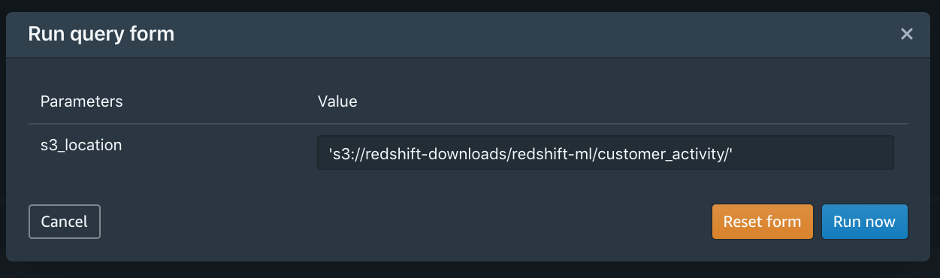
 You would probably like to reuse the load query in the future to load data in from another S3 location. In that case, you can use the parameterized query by replacing the S3 URL of the as shown in the following screenshot:
You would probably like to reuse the load query in the future to load data in from another S3 location. In that case, you can use the parameterized query by replacing the S3 URL of the as shown in the following screenshot:


 Debu Panda is a Principal Product Manager at AWS, is an industry leader in analytics, application platform, and database technologies, and has more than 25 years of experience in the IT world.
Debu Panda is a Principal Product Manager at AWS, is an industry leader in analytics, application platform, and database technologies, and has more than 25 years of experience in the IT world. Cansu Aksu is a Front End Engineer at AWS, has a several years of experience in developing user interfaces. She is detail oriented, eager to learn and passionate about delivering products and features that solve customer needs and problems
Cansu Aksu is a Front End Engineer at AWS, has a several years of experience in developing user interfaces. She is detail oriented, eager to learn and passionate about delivering products and features that solve customer needs and problems Chengyang Wang is a Frontend Engineer in Redshift Console Team. He worked on a number of new features delivered by redshift in the past 2 years. He thrives to deliver high quality products and aim to improve customer experience from UI
Chengyang Wang is a Frontend Engineer in Redshift Console Team. He worked on a number of new features delivered by redshift in the past 2 years. He thrives to deliver high quality products and aim to improve customer experience from UI