Post Syndicated from Donnie Prakoso original https://aws.amazon.com/blogs/aws/aws-week-in-review-generative-ai-with-llm-hands-on-course-amazon-sagemaker-data-wrangler-updates-and-more-july-3-2023/
In last week’s AWS Week in Review post, Danilo mentioned that it’s summer in London. Well, I’m based in Singapore, and it’s mostly summer here. But, June is a special month here as it marks the start of durian season.
Starting next week, I’ll be travelling to Thailand, Malaysia, and the Philippines. But before I go, I want to share some interesting updates from last week for you.
Let’s get started.
Last Week’s Launches
Here are some launches that caught my attention:
New Hands-on Course: Generative AI with Large Language Models – Generative AI has been a technology highlight for the past few months. If you are on your journey to learn large language models (LLM), then you can try the new hands-on course Generative AI with LLMs at Coursera. Antje wrote a post to announce this collaboration course between DeepLearning.AI and AWS. This course is designed to prepare data scientists and engineers to become experts in selecting, training, fine-tuning, and deploying LLMs for real-world applications.

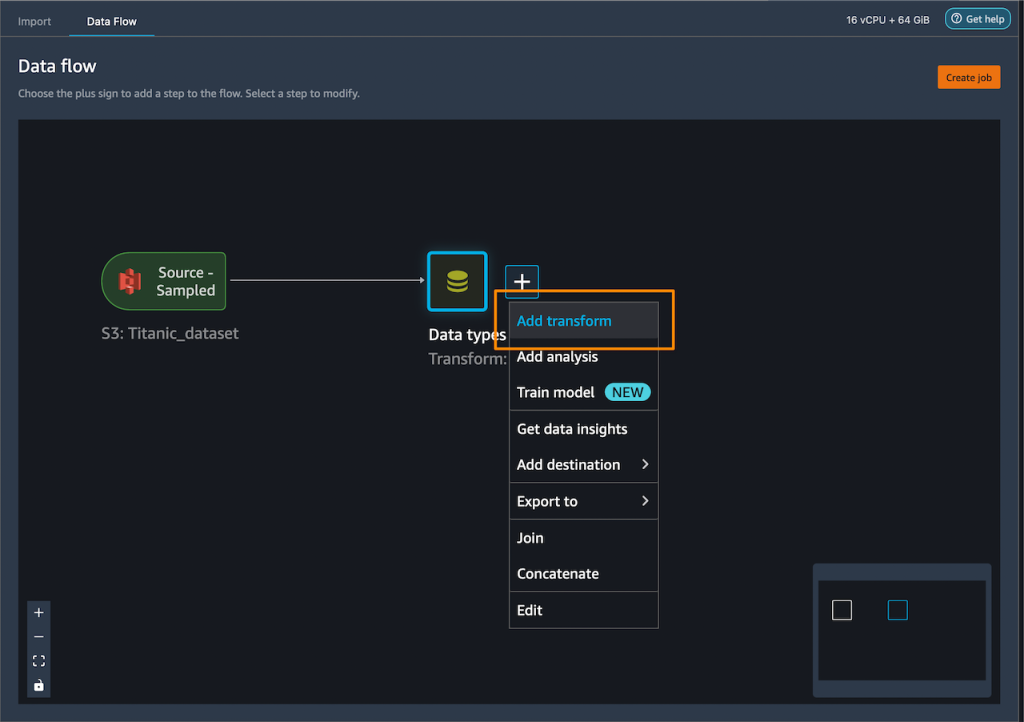
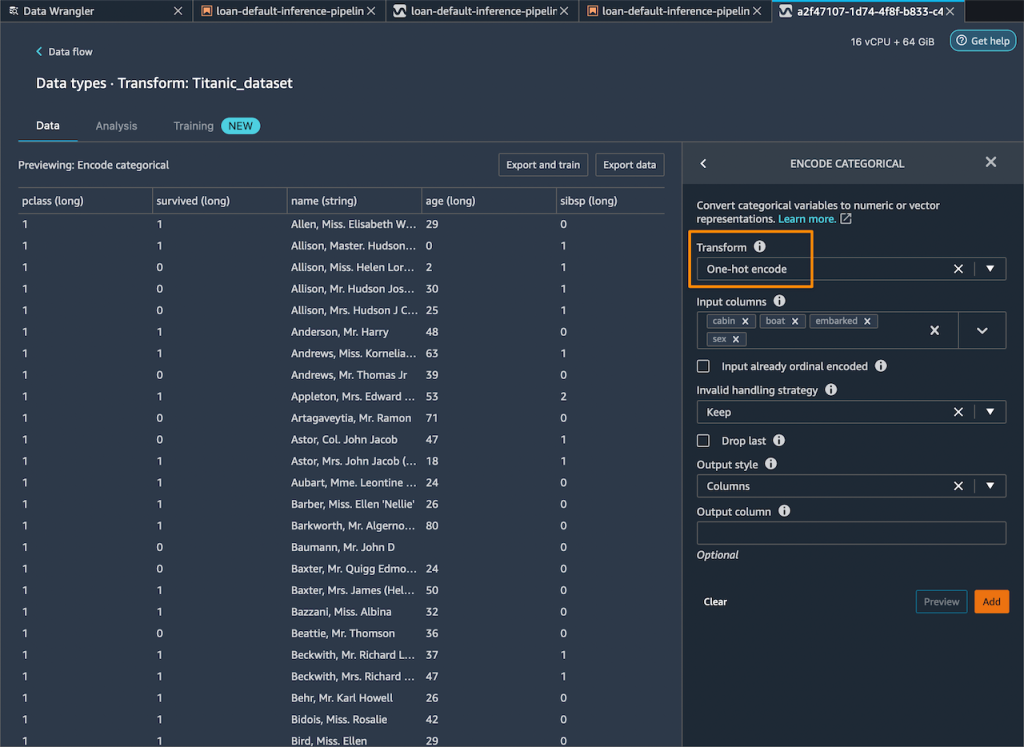
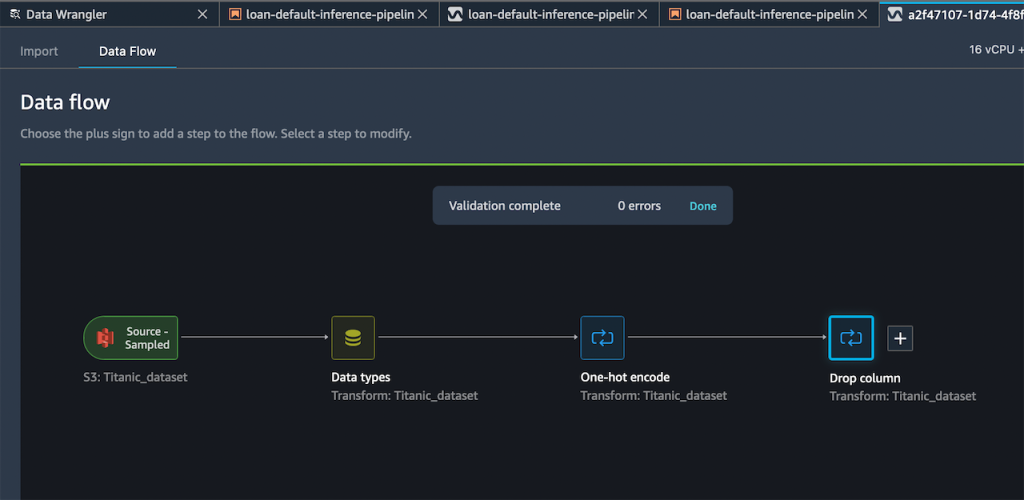
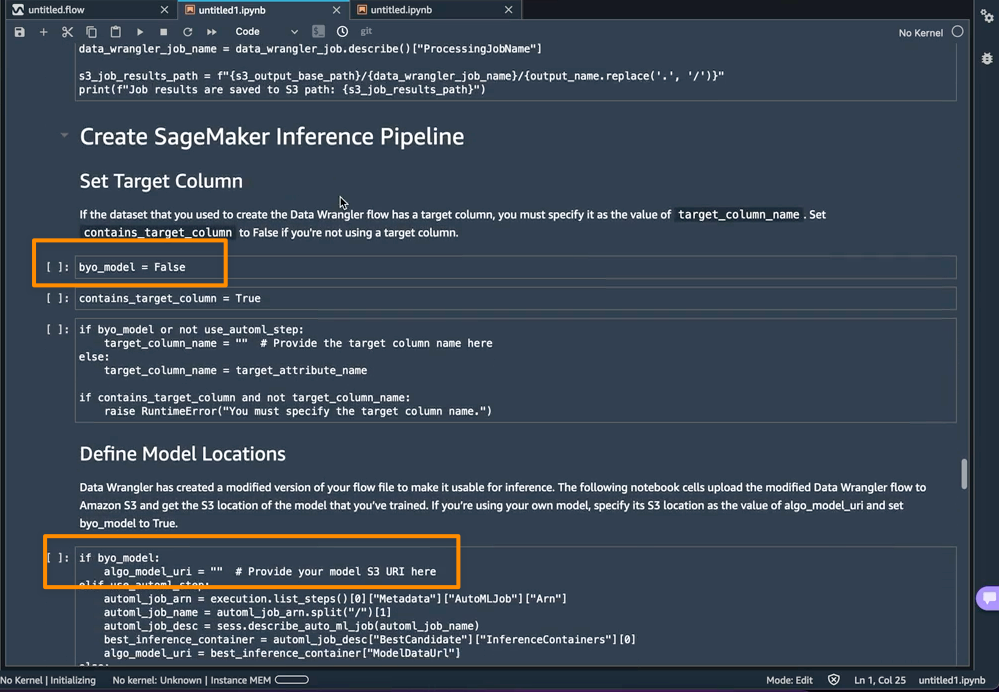
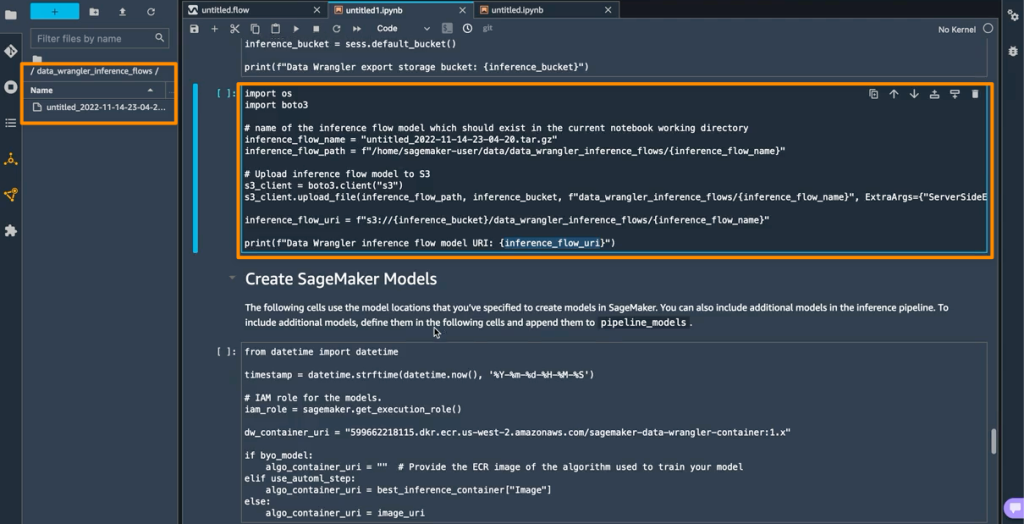
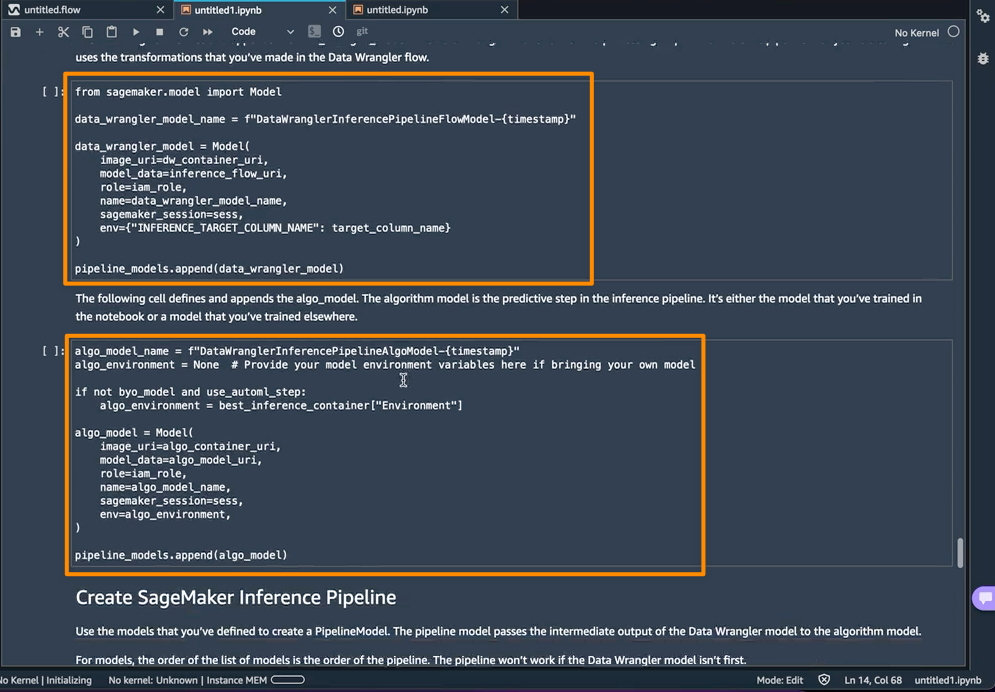
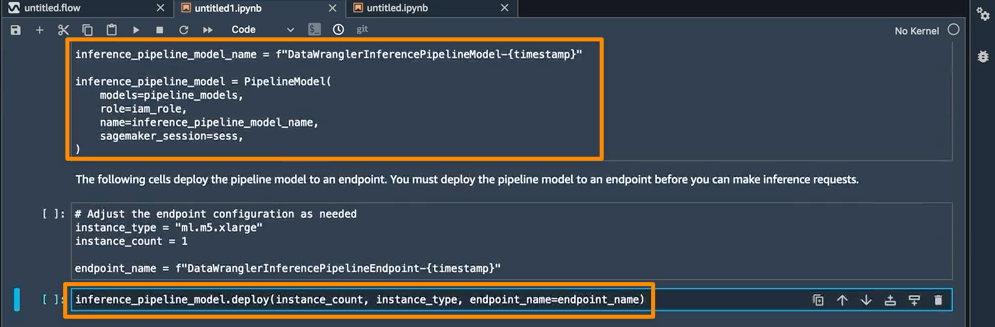
Amazon SageMaker Data Wrangler direct connection to Snowflake – With this announcement, you can now browse databases, tables, schemas, and query data from Snowflake in SageMaker Data Wrangler. This unlocks the possibility for you to join your data with other popular data sources, such as S3, Amazon Athena, Amazon Redshift, Amazon EMR and over 50 SaaS applications to create the right data set for machine learning.
Amazon SageMaker Role Manager now provides CDK library to create fine-grained permissions — The CDK support for Amazon SageMaker Role Manager lets you define permissions with fine-grained access for SageMaker users, jobs, and SageMaker pipelines programmatically. This will reduce manual efforts and consistent permissions management. For example, the following code grants permissions with a set of related machine learning activities specific to a persona.
export class myCDKStack extends cdk.Stack {
constructor(scope: cdk.App, id: string, props?: cdk.StackProps) {
super(scope, id, props);
const persona = new Persona(this, 'example-persona-id', {
activities: [
Activity.runStudioAppsV2(this, 'example-id1', {}),
Activity.accessS3Buckets(this, 'example-id2', {s3buckets: [s3.S3Bucket.fromBucketName('DOC-EXAMPLE-BUCKET')]})
Activity.accessAwsServices(this, 'example-id3', {})
]
});
const role = persona.createRole(this, 'example-IAM-role-id', 'example-IAM-role-name');
}
}
AWS SDK for SAP ABAP – Great news for SAP ABAP developers! We just recently announced the general availability of the AWS SDK for SAP ABAP. With this, ABAP developers can use simple, secure and configurable connections between ABAP environments and 200+ supported AWS services in all AWS Regions, including AWS GovCloud (US) Regions. This AWS SDK helps ABAP developers to modernize their business processes with AWS services.
Amazon OpenSearch Ingestion now supports ingesting events from Amazon Security Lake – Amazon OpenSearch Ingestion now lets you bring data in the Apache Parquet format. As Amazon Security Lake also uses Open Cybersecurity Schema Framework (OCSF) in Apache Parquet format, it means you can easily ingest data from Amazon Security Lake.
For a full list of AWS announcements, be sure to keep an eye on the What’s New at AWS page.
AWS Open-Source Updates
As always, my colleague Ricardo has curated the latest updates for open-source news at AWS. Here are some of the highlights.
lightsail-miab-installer – This handy command-line tool developed by my colleague Rio Astamal was designed to simplify the process of setting up Mail-in-a-Box on Amazon Lightsail. With lightsail-miab-installer, you can effortlessly streamline the installation and configuration of Mail-in-a-Box, making it even more accessible and user-friendly.
rdsconn – This amazing tool, created by AWS Hero Aidan Steele, simplifies the process of connecting to an AWS RDS instance within a VPC directly from your laptop. Using the recently launched EC2 Instance Connect, rdsconn eliminates the need for cumbersome SSH tunnels.
cdk-appflow – If you’re using AWS CDK to build your applications and Amazon AppFlow to create bidirectional data transfer integrations between various SaaS applications and AWS, then you’re going to love cdk-appflow, a new AWS CDK construct for Amazon AppFlow. It’s currently in technical preview, but you’re more than welcome to try it and provide us with your feedback.
Upcoming AWS Events
There are also upcoming events that you can join to learn. Let’s start with AWS Summit events:
- AWS Summit Hong Kong, July 20
- AWS Summit New York, July 26
- AWS Summit Taiwan, August 2-3
- AWS Summit São Paulo, August 3
And, let’s learn from our fellow builders and join AWS Community Days:
- AWS Community Day Malaysia, July 22
- AWS Community Day Philippines, July 29-30
Open for Registration for AWS re:Invent
Before I end this post, AWS re:Invent registration is now open!

This learning conference hosted by AWS for the global cloud computing community will be held from Nov 27 to Dec 1, 2023 in Las Vegas.
Pro-tip: You can use information on the Justify Your Trip page to prove the value of your trip to AWS re:Invent.
That’s all for this week. Check back next Monday for another Week in Review.
Happy building.
— Donnie