Post Syndicated from Ashu Joshi original https://aws.amazon.com/blogs/architecture/building-a-controlled-environment-agriculture-platform/
This post was co-written by Michael Wirig, Software Engineering Manager at Grōv Technologies.
A substantial percentage of the world’s habitable land is used for livestock farming for dairy and meat production. The dairy industry has leveraged technology to gain insights that have led to drastic improvements and are continuing to accelerate. A gallon of milk in 2017 involved 30% less water, 21% less land, a 19% smaller carbon footprint, and 20% less manure than it did in 2007 (US Dairy, 2019). By focusing on smarter water usage and sustainable land usage, livestock farming can grow to provide sustainable and nutrient-dense food for consumers and livestock alike.
Grōv Technologies (Grōv) has pioneered the Olympus Tower Farm, a fully automated Controlled Environment Agriculture (CEA) system. Unique amongst vertical farming startups, Grōv is growing cattle feed to improve that sustainable use of land for livestock farming while increasing the economic margins for dairy and beef producers.
The challenges of CEA
The set of growing conditions for a CEA is called a “recipe,” which is a combination of ingredients like temperature, humidity, light, carbon dioxide levels, and water. The optimal recipe is dynamic and is sensitive to its ingredients. Crops must be monitored in near-real time, and CEAs should be able to self-correct in order to maintain the recipe. To build a system with these capabilities requires answers to the following questions:
- What parameters are needed to measure for indoor cattle feed production?
- What sensors enable the accuracy and price trade-offs at scale?
- Where do you place the sensors to ensure a consistent crop?
- How do you correlate the data from sensors to the nutrient value?
To progress from a passively monitored system to a self-correcting, autonomous one, the CEA platform also needs to address:
- How to maintain optimum crop conditions
- How the system can learn and adapt to new seed varieties
- How to communicate key business drivers such as yield and dry matter percentage
Grōv partnered with AWS Professional Services (AWS ProServe) to build a digital CEA platform addressing the challenges posed above.

Tower automation and edge platform
The Olympus Tower is instrumented for measuring recipe ingredients by combining the mechanical, electrical, and domain expertise of the Grōv team with the IoT edge and sensor expertise of the AWS ProServe team. The teams identified a primary set of features such as height, weight, and evenness of the growth to be measured at multiple stages within the Tower. Sensors were also added to measure secondary features such as water level, water pH, temperature, humidity, and carbon dioxide.
The teams designed and developed a purpose-built modular and industrial sensor station. Each sensor station has sensors for direct measurement of the features identified. The sensor stations are extended to support indirect measurement of features using a combination of Computer Vision and Machine Learning (CV/ML).
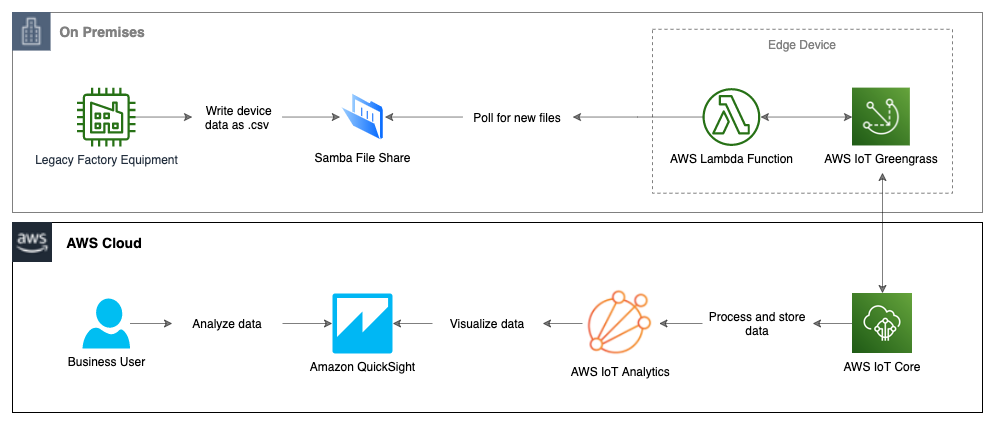
The trays with the growing cattle feed circulate through the Olympus Tower. A growth cycle starts on a tray with seeding, circulates through the tower over the cycle, and returns to the starting position to be harvested. The sensor station at the seeding location on the Olympus Tower tags each new growth cycle in a tray with a unique “Grow ID.” As trays pass by, each sensor station in the Tower collects the feature data. The firmware, jointly developed for the sensor station, uses AWS IoT SDK to stream the sensor data along with the Grow ID and metadata that’s specific to the sensor station. This information is sent every five minutes to an on-site edge gateway powered by AWS IoT Greengrass. Dedicated AWS Lambda functions manage the lifecycle of the Grow IDs and the sensor data processing on the edge.
The Grōv team developed AWS Greengrass Lambda functions running at the edge to ingest critical metrics from the operation automation software running the Olympus Towers. This information provides the ability to not just monitor the operational efficiency, but to provide the hooks to control the feedback loop.
The two sources of data were augmented with site-level data by installing sensor stations at the building level or site level to capture environmental data such as weather and energy consumption of the Towers.
All three sources of data are streamed to AWS IoT Greengrass and are processed by AWS Lambda functions. The edge software also fuses the data and correlates all categories of data together. This enables two major actions for the Grōv team – operational capability in real-time at the edge and enhanced data streamed into the cloud.

Cloud pipeline/platform: analytics and visualization
As the data is streamed to AWS IoT Core via AWS IoT Greengrass. AWS IoT rules are used to route ingested data to store in Amazon Simple Sotrage Service (Amazon S3) and Amazon DynamoDB. The data pipeline also includes Amazon Kinesis Data Streams for batching and additional processing on the incoming data.
A ReactJS-based dashboard application is powered using Amazon API Gateway and AWS Lambda functions to report relevant metrics such as daily yield and machine uptime.
A data pipeline is deployed to analyze data using Amazon QuickSight. AWS Glue is used to create a dataset from the data stored in Amazon S3. Amazon Athena is used to query the dataset to make it available to Amazon QuickSight. This provides the extended Grōv tech team of research scientists the ability to perform a series of what-if analyses on the data coming in from the Tower Systems beyond what is available in the react-based dashboard.

Completing the data-driven loop
Now that the data has been collected from all sources and stored it in a data lake architecture, the Grōv CEA platform established a strong foundation for harnessing the insights and delivering the customer outcomes using machine learning.
The integrated and fused data from the edge (sourced from the Olympus Tower instrumentation, Olympus automation software data, and site-level data) is co-related to the lab analysis performed by Grōv Research Center (GRC). Harvest samples are routinely collected and sent to the lab, which performs wet chemistry and microbiological analysis. Trays sent as samples to the lab are associated with the results of the analysis with the sensor data by corresponding Grow IDs. This serves as a mechanism for labeling and correlating the recipe data with the parameters used by dairy and beef producers – dry matter percentage, micro and macronutrients, and the presence of myco-toxins.
Grōv has chosen Amazon SageMaker to build a machine learning pipeline on its comprehensive data set, which will enable fine tuning the growing protocols in near real-time. Historical data collection unlocks machine learning use cases for future detection of anomalous sensors readings and sensor health monitoring, as well.
Because the solution is flexible, the Grōv team plans to integrate data from animal studies on their health and feed efficiency into the CEA platform. Machine learning on the data from animal studies will enhance the tuning of recipe ingredients that impact the animals’ health. This will give the farmer an unprecedented view of the impact of feed nutrition on the end product and consumer.
Conclusion
Grōv Technologies and AWS ProServe have built a strong foundation for an extensible and scalable architecture for a CEA platform that will nourish animals for better health and yield, produce healthier foods and to enable continued research into dairy production, rumination and animal health to empower sustainable farming practices.