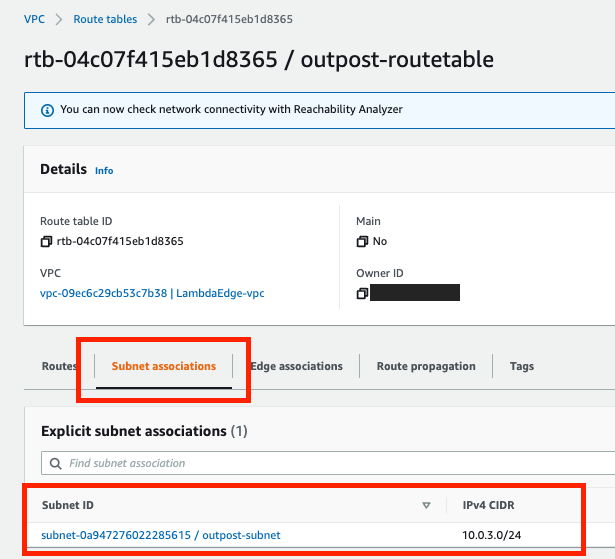
Post Syndicated from Ram Ramani original https://aws.amazon.com/blogs/security/how-to-enforce-multi-party-approval-for-creating-matter-compliant-certificate-authorities/
Customers who build smart home devices using the Matter protocol from the Connectivity Standards Alliance (CSA) need to create and maintain digital certificates, called device attestation certificates (DACs), to allow their devices to interoperate with devices from other vendors. DACs must be issued by a Matter device attestation certificate authority (CA). The CSA mandates multi-party approval for creating Matter compliant CAs. You can use AWS Private CA to create your Matter device attestation CA, which will store two important certificates: the product attestation authority (PAA) and product attestation intermediate (PAI) certificate. The PAA is the root CA that signs the PAI; the PAI is the intermediate CA that issues DACs. In this blog post, we will show how to implement multi-party approval for creation of these two certificates within AWS Private CA.
The CSA allows the use of delegated service providers (DSP) to provide you with public key infrastructure (PKI) services to create your Matter device attestation CA. You can use AWS Private CA as a DSP to create a Matter device attestation CA to issue DACs.
You should carefully plan to implement and demonstrate compliance with the Matter PKI Certificate Policy (CP) requirements when you issue Matter certificates by using the CA infrastructure services provided by AWS Private CA. Matter PKI CP is not just a technical standard; it also covers people, processes, and technology. For information about the requirements to comply with the Matter PKI CP and a reference list of acronyms, see the Matter PKI Compliance Guide. In this blog post, we address one of the Matter requirements for technical security controls for implementing multi-party approval for the creation of PAA and PAI certificates
Note: The solution presented in this post uses AWS Systems Manager Change Manager, a capability of AWS Systems Manager, for demonstrating multi-party approval as required by the Matter CP for the creation of the PAA and PAI. Additionally, the solution also uses AWS Systems Manager documents (SSM documents), which contain the code to automate the creation of PAA and PAI DAC certificates.
Implementing multi-party approval: Personas and IAM roles
For the process of achieving the multi-party approval required for Matter compliance, we will use the following human personas:
- Jane Doe and Paulo Santos as the two approvers responsible for signing off on the creation of PAA and PAI.
- Shirley Rodriguez as the persona responsible for setting up the prerequisite infrastructure and creating the change template that governs the multi-party approval process and specifying the human personas who are authorized to approve change requests.
- Richard Roe as the persona responsible for reviewing and approving change template changes made by Shirley Rodriguez, to verify the separation of duties.
AWS offers support for identity federation to enable federated single sign-on (SSO). This allows users to sign into the AWS Management Console or call AWS API operations by using the credentials of an IAM role. To establish a secure authentication and authorization model, we highly recommend that you map the identities of the human personas to IAM roles.
As a prerequisite, Shirley Rodriguez will create the following AWS Identity and Access Management (IAM) roles that support the multi-party approval operations:
- TmpltReview-Role — Richard Roe will assume this role to review and approve changes to the change template that is used to run the SSM document to create the matter CAs.
- CreatePAA-Role and CreatePAI-Role — Clone the solution GitHub repository and create the roles by using the policies from the repository:
- CreatePAA-Role — This role is assumed by the AWS Systems Manager service to create the PAA.
- CreatePAI-Role — This role is assumed by the AWS Systems Manager service to create the PAI.
- MatterCA-Admin-1 and MatterCA-Admin-2 — Jane Doe will use the MatterCA-Admin-1 role, while Paulo Santos will use the MatterCA-Admin-2 role. These individuals will serve as the two approvers for the multi-party approval process.
Note: It’s important that one person cannot approve an action by themselves. If a person is allowed to assume the MatterCA-Admin-1 role, they must not be allowed to assume the MatterCA-Admin-2 role also. If the same person can assume both roles, then that person can bypass the requirement for two different people to approve.
To create the IAM roles
- Create IAM roles MatterCA-Admin-1 and MatterCA-Admin-2, and attach the following AWS-managed policies:
- You should configure the trust relationship to allow Jane Doe to use the Matter-CA-Admin-1-Role and Paulo Santos to use the Matter-CA-Admin-2-Role for the multi-party approval process. This is intended to restrict Jane Doe and Paulo Santos from assuming each other’s roles. Use the following policy as a guide, and make sure to replace <AccountNumber> and <Role_Name> with your own information, depending on the federated identity models that you have chosen.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "aws:PrincipalARN":"arn:aws:iam::<AccountNumber>:role/<Role-Name>" }, "Action": "sts:AssumeRole" } ] } - Create the IAM role TmpltReview-Role, and attach the following policies.
- AmazonSSMReadOnlyAccess
- Attach the following custom inline policy to enable review and approval of the change template.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "TemplateReviewer", "Effect": "Allow", "Action": "ssm:UpdateDocumentMetadata", "Resource": "*" } ] } - Modify the trust relationship to allow only Richard Roe to use the role, as shown in the following policy. Make sure to replace <AccountNumber> and <Role-Name> with your own information.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS":"aws:PrincipalARN":"arn:aws:iam::<AccountNumber>:role/<Role-Name>" }, "Action": "sts:AssumeRole" } ] } - Create the IAM role CreatePAA-Role, which will be used by the AWS Systems Manager change template to run the SSM document to create PAA.
- Attach the following inline policy to the CreatePAA-Role.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "acm-pca:ImportCertificateAuthorityCertificate", "acm-pca:IssueCertificate", "acm-pca:CreateCertificateAuthority", "acm-pca:GetCertificate", "acm-pca:GetCertificateAuthorityCsr", "acm-pca:DescribeCertificateAuthority" ], "Resource": "*" } ] } - Modify the trust relationship for CreatePAA-Role to allow only the AWS Systems Manager service to assume this role, as shown following.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "ssm.amazonaws.com" }, "Action": "sts:AssumeRole", "Condition": {} } ]
- Attach the following inline policy to the CreatePAA-Role.
- Create the IAM role CreatePAI-Role, which will be used by the change template to run the SSM document to create the PAI certificate.
- Attach the following policy as an inline policy on the CreatePAI-Role.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "acm-pca:ImportCertificateAuthorityCertificate", "acm-pca:CreateCertificateAuthority", "acm-pca:GetCertificateAuthorityCsr", "acm-pca:DescribeCertificateAuthority" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "acm-pca:GetCertificateAuthorityCertificate", "acm-pca:GetCertificate", "acm-pca:IssueCertificate" ], "Resource": “*” } ] }
- Attach the following policy as an inline policy on the CreatePAI-Role.
- Modify the trust relationship for CreatePAI-Role to allow only AWS Systems Manager to assume this role, as shown following.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "ssm.amazonaws.com" }, "Action": "sts:AssumeRole", "Condition": {} } ] }
Preventive security controls recommended for this solution
We recommend that you apply the following security controls for this solution:
- Dedicate an AWS account to this solution – It is important that the only users who can perform actions on the PAA and PAI are the users in this account. By deploying these items in a dedicated AWS account, you limit the number of users who might have elevated privileges, but don’t have cause to use those privileges here.
- SCPs (service control policies) – The IAM policies in this solution do not prevent someone with privileges, such as an administrator, from bypassing your expected controls and approving usage of the CA. SCPs, if they are applied by using AWS Organizations, can restrict the creation of CAs (certificate authorities) exclusively to CreatePAA-Role and CreatePAI-Role.
The following example SCP will enforce this type of restriction. Make sure to replace <AccountNumber> with your own information. With a strong SCP, even the root account will not be able to perform these operations or change these security controls.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "RestrictCACreation", "Effect": "Deny", "Action": ["acm-pca:CreateCertificateAuthority"], "Resource": "*", "Condition": { "StringNotLike": { "aws:PrincipalARN": [ "arn:aws:iam::<AccountNumber>:role/CreatePAA-Role", "arn:aws:iam::<AccountNumber>:role/CreatePAI-Role" ] } } } ] }
AWS Systems Manager configuration
Shirley Rodriguez will download the following sample Systems Manager (SSM) documents from our GitHub repository and perform the listed steps in this section.
The content in these yaml files will be used in the next steps to create SSM documents.
Create the SSM document
The first step is to create the SSM document that automates resource creation of the PAA and PAI in AWS Private CA.
To create the SSM document
- Open the Systems Manager console.
- In the left navigation pane, under Shared Resources, choose Documents.
- Choose the Owned by me tab, choose Create document, and from the dropdown list, choose Automation.

Figure 1: Create the automation document
- Under Create automation, choose the Editor tab, and then choose Edit.
Figure 2: Automation document editor
- Copy the sample automation code from the file CreatePAA.yaml that you downloaded from the GitHub repository, and paste it into the editor.
- For Name, enter CreatePAA, and then choose Create automation.
- To check that the CreatePAA document was created successfully, choose the Owned by me tab. You should see the Systems Manager document, as shown in Figure 3.
Figure 3: Successful creation of the CreatePAA document
- Repeat the preceding steps for creating the PAI. Make sure that you paste the code from the file CreatePAI.yaml into the editor and enter the name CreatePAI to create the PAI CA.
- To check that the CreatePAI document was created successfully, choose the Owned by me tab. You should see the CreatePAI Systems Manager document, as shown in Figure 4.
Figure 4: Successful creation of the PAA and PAI documents




You’ve now completed the creation of an SSM document that contains the automation code to create certificate authorities PAA and PAI. The next step is to create Change Manager templates, which will use the SSM document and apply multi-party approval before the creation of the PAA and PAI.
Create the Change Manager templates
Shirley Rodriguez will next create two change templates that run the SSM documents: one for the PAA and one for the PAI.
To create the change templates
- Open the Systems Manager console.
- In the left navigation pane, under Change Management, choose Change Manager.
- On the Change Manager page, in the top right, choose Create template.
- For Name, enter CreatePAATemplate.
- In the Builder section, add a description (optional), and for Runbook, search and select CreatePAA. Keep the defaults for the other selections.
Figure 5: Select the runbook CreatePAA in the change template
- Scroll down to the Change request approvals section and choose Add approval level. This is where you configure multi-party approval for the change template.
- Because there are two approvers, for Number of approvers required at this level, choose 1 from the dropdown.
- Choose Add approver, choose Template specified approvers, and then select the MatterCA-Admin-1. Then choose Add another approval level for the second approver.
Figure 6: Add first level approver for the template
- Choose Template specified approvers, and then select the MatterCA-Admin-2 role for multi-party approval. These roles can now approve the change request.
Figure 7: Add second level approver for the template.
- Keep the defaults for the rest of the options, and at the bottom of the screen, choose Save and preview.
- On the preview screen, review the configurations, and then on the top right, choose Submit for review. This pushes the template to be reviewed by template reviewer Richard Roe. In the Templates tab, the template status shows as Pending review.
Figure 8: Template with a status of pending review
- Repeat the preceding steps to create the PAI change template. Make sure to name it CreatePAITemplate, and at step 5, for Runbook, select the CreatePAI document.
Figure 9: Both templates ready for review





You’ve successfully created two change templates, CreatePAATemplate and CreatePAITemplate, that generate a change request that contains an SSM document with automation code for building the PAA and PAI. These change requests are configured with multi-party approval before running the SSM document. However, before you can proceed with running the change template, it must undergo review and approval by the template reviewer Richard Roe.
Review and approve the Change Manager templates
First you need to make sure that TmpltReview-Role is added as a reviewer and approver of change templates. Shirley Rodriguez will follow the steps in this section to add TmpltReview-Role as change template reviewer.
To add the change template reviewer
- Follow the instructions in the Systems Manager documentation to configure the IAM role TmpltReview-Role to review and approve the change template. Figure 10 shows how this setup looks in the Systems Manager console.
Figure 10: The template reviewer role in Settings
Now you have TmpltReview-Role added as a reviewer. Change templates that are created or modified will now need to be reviewed and approved by this role. Richard Roe will use the role TmpltReview-Role for governance of change templates, to make sure changes made by Shirley Rodriguez are in alignment with the organization’s compliance needs for Matter.
- Richard Roe will follow the steps in the Systems Manager documentation for reviewing and approving change templates, to approve CreatePAATemplate and CreatePAITemplate. After the change template is approved, its status changes to Approved, and it’s ready to be run.
Figure 11: Change template approval details


You now have the change templates CreatePAATemplate and CreatePAITemplate in approved status.
Create the PAA and PAI with multi-party approval for Matter compliance
Up to this point, these instructions have described one-time configurations of AWS Systems Manager to set up the IAM roles, SSM documents, and change templates that are required to enforce multi-party approval. Now you are ready to use these change templates to create the PAA and PAI and perform multi-party approval.
Shirley Rodriguez will generate change requests that require approval from Jane Doe and Paulo Santos. This manual approval process will then run the SSM documents to create the PAA and PAI.
Create a change request for the PAA
Perform the following steps to create a change request for the PAA.
To create a change request for the PAA
- Open the Systems Manager console.
- In the left navigation pane, choose Change Manager, and then choose Create request.
- Search for and select CreatePAATemplate, and then choose Next.
- For Name, enter the name CreatePAA_ChangeRequest.
- (Optional) For Change request information, provide additional information about the change request.
- For Workflow start time, choose Run the operation as soon as possible after approval to run the change immediately after the request is approved.
- For Change request approvals, validate that the list of First-level approvals includes the change request approvers MatterCA-Admin-1 and MatterCA-Admin-2, which you configured previously in the section Create Change Manager template. Then choose Next.
Figure 12: Change request approvers
- For Automation assume role, select the IAM role CreatePAA_Role for creating the PAA.
Figure 13: Change request role
- For Runbook parameters, enter the PAA certificate details for CommonName, Organization, VendorId, and ValidityInYears, and then choose Next.
- Review the change request content and then, at the bottom of the screen, choose Submit for approval. Optionally, you can set up an SNS topic to notify the approvers.


You have successfully created a change request that is currently awaiting approval from Jane Doe and Paulo Santos. Let’s now move on to the approval steps.
Multi-party approval: Approve the change request for the PAA
Each of the approvers should now follow the steps in this section for approval. Jane Doe will use the IAM role MatterCA-Admin-1, while Paulo Santos will need to use the IAM role MatterCA-Admin-2.
To approve the change request for the PAA
- Open the Systems Manager console and do the following.
- In the navigation pane, choose Change Manager.
- Choose the Approvals tab, select the CreatePAA change request, and then choose Approve.
Figure 14: Change request approval
After Jane Doe and Paulo Santos each follow these steps to approve the change request, the change request will run and will complete with status “Success,” and the PAA will be created in AWS Private CA.
- Check that the status of the change request is Success, as shown in Figure 15.
Figure 15: The change request ran successfully


Validate that the PAA is created in AWS Private CA
Next, you need to validate that the PAA was created successfully and copy its Amazon Resource Name (ARN) to use for PAI creation.
To validate the creation of the PAA and retrieve its ARN
- In the AWS Private CA console, choose the PAA CA that you created in the previous step.
- Copy the ARN of the PAA root CA. You will use PAA CA ARN when you set up the PAI change request.
Figure 16: ARN of the PAA root CA PAA

After successfully completing these steps, you have created the certificate authority PAA by using AWS Private CA with multi-party approval. You can now proceed to the next section, where we will demonstrate how to use this PAA to issue a CA for PAI.
Create a change request for the PAI
Perform the following steps to create a change request for the PAI.
Note: Creation of a valid PAA is a prerequisite for creating the PAI in the following steps.
To create a change request for the PAI
- After the PAA is created successfully, you can complete the creation of the PAI by repeating the same steps that you did in the Create a change request for the PAA section, but with the following changes:
- At step 3, make sure that you search for and select CreatePAITemplate.

Figure 17: CreatePAITemplate template
- At step 4, for Name, enter CreatePAI_ChangeRequest.
- At step 8, for Automation assume role, select the IAM role CreatePAI_Role.
Figure 18: Change request IAM role selection
- At step 9, for Runbook parameters, enter the PAA CA ARN that you made note of earlier, along with the CommonName, Organization, VendorId, ProductId, and ValidityInYears for the PAI, and then choose Next.
Multi-party approval: Approve the change request for the PAI
Each of the approvers should now follow the steps in this section for approval for the PAI. Jane Doe will need to use IAM role MatterCA-Admin-1, and Paulo Santos will need to use IAM role MatterCA-Admin-2.
To approve the change request for the PAI
- Open the Systems Manager console and do the following:
- In the navigation pane, choose Change Manager.
- Choose the Approvals tab, select the CreatePAI change request, and choose Approve.
After both approvers (Jane Doe and Paulo Santos) approve the change request, the change request will run, and the PAA will be created inside AWS Private CA.
- Check that the status of the change request shows Success, as shown in Figure 19.
Figure 19: The change requests for the PAA and PAI have run successfully
- In the AWS Private CA console, verify that the PAA and PAI have been created successfully, as shown in Figure 20.
Figure 20: PAA and PAI in AWS Private CA
After successfully completing these steps, you have created the certificate authority PAI by using AWS Private CA with multi-party approval. You can now issue DAC certificates by using this PAI. Next, we will show how to validate the logs to confirm multi-party approval.
Demonstrate compliance with multi-party approval requirements of the Matter CP by using the change manager timeline
To keep audit records that show that multi-party approval was used to create the PAA and PAI to issue DACs, you can use the Change Manager timeline.
To retrieve the change manager timeline report
- Open the Systems Manager console.
- In the left navigation pane, choose Change Manager.
- Choose Requests, and then select either the CreatePAA_ChangeRequest or the CreatePAI_ChangeRequest change request.
- Select the Timeline tab. Figure 21 shows an example of a timeline with complete runbook steps for PAA creation. It also shows the two approvers, Jane Doe and Paulo Santos, approving the change request. You can use this information to demonstrate multi-party approval.
Figure 21: Audit trail for approval and creation of the PAA
Likewise, Figure 22 shows an example of a timeline with complete runbook steps for creating the PAI by using multi-party approval.
Figure 22: Audit trail for approval and creation of the PAI
Conclusion
In this post, you learned how to use AWS Private CA to facilitate the creation of Matter CAs in compliance with the Matter PKI CP. By using AWS Systems Manager, you can effectively fulfill the technical security control outlined in the Matter PKI CP for implementing multi-party approval for the creation of PAA and PAI certificates.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, start a new thread on the AWS Private Certificate Authority re:Post or contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
- At step 3, make sure that you search for and select CreatePAITemplate.