Post Syndicated from Julian Wood original https://aws.amazon.com/blogs/compute/serverless-icymi-q1-2023/
Welcome to the 21st edition of the AWS Serverless ICYMI (in case you missed it) quarterly recap. Every quarter, we share all the most recent product launches, feature enhancements, blog posts, webinars, live streams, and other interesting things that you might have missed!

In case you missed our last ICYMI, check out what happened last quarter here.
Artificial intelligence (AI) technologies, ChatGPT, and DALL-E are creating significant interest in the industry at the moment. Find out how to integrate serverless services with ChatGPT and DALL-E to generate unique bedtime stories for children.

Example notification of a story hosted with Next.js and App Runner
Serverless Land is a website maintained by the Serverless Developer Advocate team to help you build serverless applications and includes workshops, code examples, blogs, and videos. There is now enhanced search functionality so you can search across resources, patterns, and video content.

ServerlessLand search
AWS Lambda
AWS Lambda has improved how concurrency works with Amazon SQS. You can now control the maximum number of concurrent Lambda functions invoked.
The launch blog post explains the scaling behavior of Lambda using this architectural pattern, challenges this feature helps address, and a demo of maximum concurrency in action.

Maximum concurrency is set to 10 for the SQS queue.
AWS Lambda Powertools is an open-source library to help you discover and incorporate serverless best practices more easily. Lambda Powertools for .NET is now generally available and currently focused on three observability features: distributed tracing (Tracer), structured logging (Logger), and asynchronous business and application metrics (Metrics). Powertools is also available for Python, Java, and Typescript/Node.js programming languages.
To learn more:
Lambda announced a new feature, runtime management controls, which provide more visibility and control over when Lambda applies runtime updates to your functions. The runtime controls are optional capabilities for advanced customers that require more control over their runtime changes. You can now specify a runtime management configuration for each function with three settings, Automatic (default), Function update, or manual.
There are three new Amazon CloudWatch metrics for asynchronous Lambda function invocations: AsyncEventsReceived, AsyncEventAge, and AsyncEventsDropped. You can track the asynchronous invocation requests sent to Lambda functions to monitor any delays in processing and take corrective actions if required. The launch blog post explains the new metrics and how to use them to troubleshoot issues.
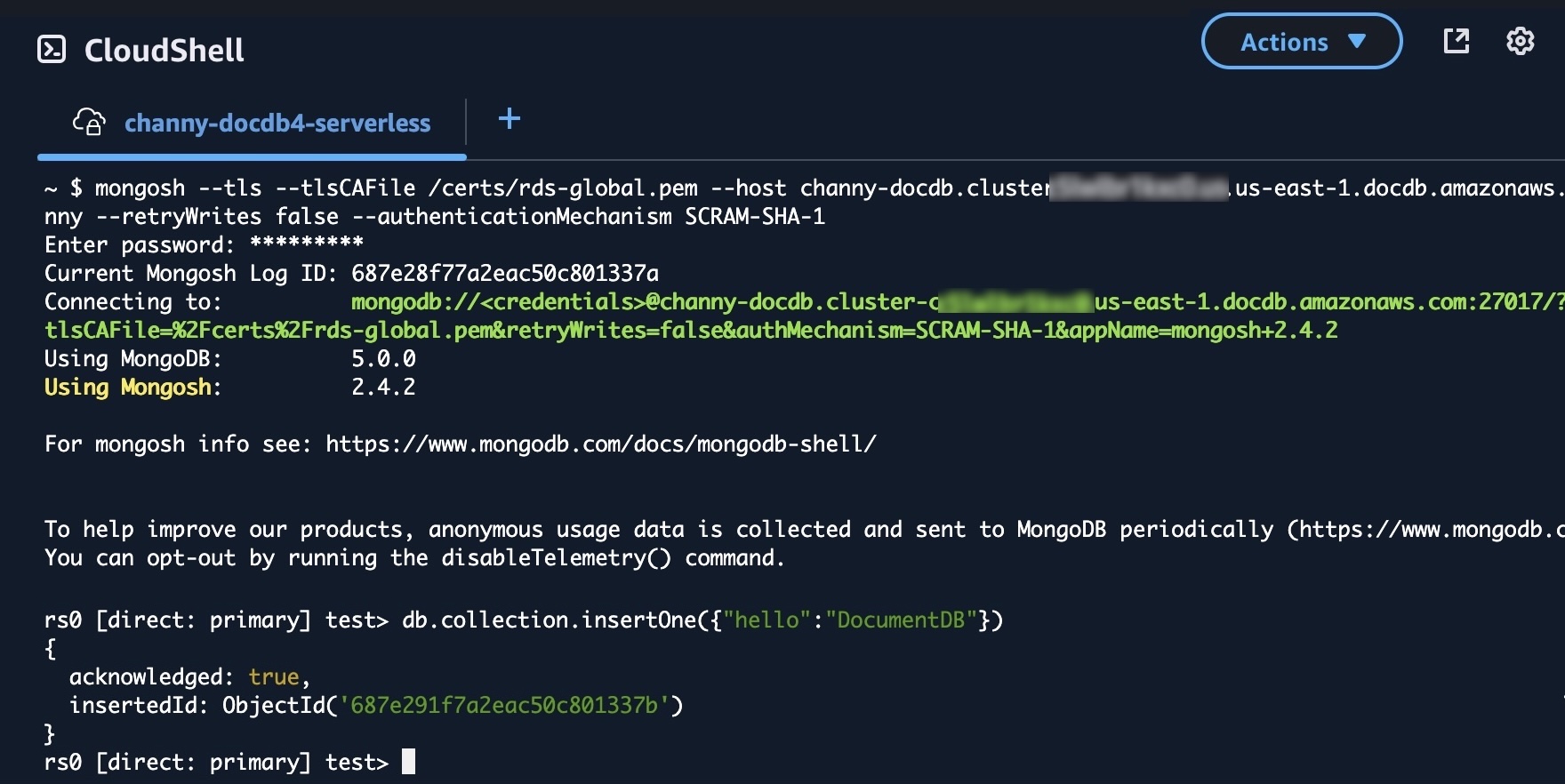
Lambda now supports Amazon DocumentDB change streams as an event source. You can use Lambda functions to process new documents, track updates to existing documents, or log deleted documents. You can use any programming language that is supported by Lambda to write your functions.
There is a helpful blog post suggesting best practices for developing portable Lambda functions that allow you to port your code to containers if you later choose to.
AWS Step Functions
AWS Step Functions has expanded its AWS SDK integrations with support for 35 additional AWS services including Amazon EMR Serverless, AWS Clean Rooms, AWS IoT FleetWise, AWS IoT RoboRunner and 31 other AWS services. In addition, Step Functions also added support for 1000+ new API actions from new and existing AWS services such as Amazon DynamoDB and Amazon Athena. For the full list of added services, visit AWS SDK service integrations.
Amazon EventBridge
Amazon EventBridge has launched the AWS Controllers for Kubernetes (ACK) for EventBridge and Pipes . This allows you to manage EventBridge resources, such as event buses, rules, and pipes, using the Kubernetes API and resource model (custom resource definitions).
EventBridge event buses now also support enhanced integration with Service Quotas. Your quota increase requests for limits such as PutEvents transactions-per-second, number of rules, and invocations per second among others will be processed within one business day or faster, enabling you to respond quickly to changes in usage.
AWS SAM
The AWS Serverless Application Model (SAM) Command Line Interface (CLI) has added the sam list command. You can now show resources defined in your application, including the endpoints, methods, and stack outputs required to test your deployed application.
AWS SAM has a preview of sam build support for building and packaging serverless applications developed in Rust. You can use cargo-lambda in the AWS SAM CLI build workflow and AWS SAM Accelerate to iterate on your code changes rapidly in the cloud.
You can now use AWS SAM connectors as a source resource parameter. Previously, you could only define AWS SAM connectors as a AWS::Serverless::Connector resource. Now you can add the resource attribute on a connector’s source resource, which makes templates more readable and easier to update over time.
AWS SAM connectors now also support multiple destinations to simplify your permissions. You can now use a single connector between a single source resource and multiple destination resources.
In October 2022, AWS released OpenID Connect (OIDC) support for AWS SAM Pipelines. This improves your security posture by creating integrations that use short-lived credentials from your CI/CD provider. There is a new blog post on how to implement it.
Find out how best to build serverless Java applications with the AWS SAM CLI.
AWS App Runner
AWS App Runner now supports retrieving secrets and configuration data stored in AWS Secrets Manager and AWS Systems Manager (SSM) Parameter Store in an App Runner service as runtime environment variables.
AppRunner also now supports incoming requests based on HTTP 1.0 protocol, and has added service level concurrency, CPU and Memory utilization metrics.
Amazon S3
Amazon S3 now automatically applies default encryption to all new objects added to S3, at no additional cost and with no impact on performance.
You can now use an S3 Object Lambda Access Point alias as an origin for your Amazon CloudFront distribution to tailor or customize data to end users. For example, you can resize an image depending on the device that an end user is visiting from.
S3 has introduced Mountpoint for S3, a high performance open source file client that translates local file system API calls to S3 object API calls like GET and LIST.
S3 Multi-Region Access Points now support datasets that are replicated across multiple AWS accounts. They provide a single global endpoint for your multi-region applications, and dynamically route S3 requests based on policies that you define. This helps you to more easily implement multi-Region resilience, latency-based routing, and active-passive failover, even when data is stored in multiple accounts.
Amazon Kinesis
Amazon Kinesis Data Firehose now supports streaming data delivery to Elastic. This is an easier way to ingest streaming data to Elastic and consume the Elastic Stack (ELK Stack) solutions for enterprise search, observability, and security without having to manage applications or write code.
Amazon DynamoDB
Amazon DynamoDB now supports table deletion protection to protect your tables from accidental deletion when performing regular table management operations. You can set the deletion protection property for each table, which is set to disabled by default.
Amazon SNS
Amazon SNS now supports AWS X-Ray active tracing to visualize, analyze, and debug application performance. You can now view traces that flow through Amazon SNS topics to destination services, such as Amazon Simple Queue Service, Lambda, and Kinesis Data Firehose, in addition to traversing the application topology in Amazon CloudWatch ServiceLens.
SNS also now supports setting content-type request headers for HTTPS notifications so applications can receive their notifications in a more predictable format. Topic subscribers can create a DeliveryPolicy that specifies the content-type value that SNS assigns to their HTTPS notifications, such as application/json, application/xml, or text/plain.
EDA Visuals collection added to Serverless Land
The Serverless Developer Advocate team has extended Serverless Land and introduced EDA visuals. These are small bite sized visuals to help you understand concept and patterns about event-driven architectures. Find out about batch processing vs. event streaming, commands vs. events, message queues vs. event brokers, and point-to-point messaging. Discover bounded contexts, migrations, idempotency, claims, enrichment and more!

EDA Visuals
To learn more:
Serverless Repos Collection on Serverless Land
There is also a new section on Serverless Land containing helpful code repositories. You can search for code repos to use for examples, learning or building serverless applications. You can also filter by use-case, runtime, and level.

Serverless Repos Collection
Serverless Blog Posts
January
Jan 12 – Introducing maximum concurrency of AWS Lambda functions when using Amazon SQS as an event source
Jan 20 – Processing geospatial IoT data with AWS IoT Core and the Amazon Location Service
Jan 23 – AWS Lambda: Resilience under-the-hood
Jan 24 – Introducing AWS Lambda runtime management controls
Jan 24 – Best practices for working with the Apache Velocity Template Language in Amazon API Gateway
February
Feb 6 – Previewing environments using containerized AWS Lambda functions
Feb 7 – Building ad-hoc consumers for event-driven architectures
Feb 9 – Implementing architectural patterns with Amazon EventBridge Pipes
Feb 9 – Securing CI/CD pipelines with AWS SAM Pipelines and OIDC
Feb 9 – Introducing new asynchronous invocation metrics for AWS Lambda
Feb 14 – Migrating to token-based authentication for iOS applications with Amazon SNS
Feb 15 – Implementing reactive progress tracking for AWS Step Functions
Feb 23 – Developing portable AWS Lambda functions
Feb 23 – Uploading large objects to Amazon S3 using multipart upload and transfer acceleration
Feb 28 – Introducing AWS Lambda Powertools for .NET
March
Mar 9 – Server-side rendering micro-frontends – UI composer and service discovery
Mar 9 – Building serverless Java applications with the AWS SAM CLI
Mar 10 – Managing sessions of anonymous users in WebSocket API-based applications
Mar 14 –
Implementing an event-driven serverless story generation application with ChatGPT and DALL-E
Videos

Serverless Office Hours – Tues 10AM PT
Weekly office hours live stream. In each session we talk about a specific topic or technology related to serverless and open it up to helping you with your real serverless challenges and issues. Ask us anything you want about serverless technologies and applications.
January
Jan 10 – Building .NET 7 high performance Lambda functions
Jan 17 – Amazon Managed Workflows for Apache Airflow at Scale
Jan 24 – Using Terraform with AWS SAM
Jan 31 – Preparing your serverless architectures for the big day
February
Feb 07- Visually design and build serverless applications
Feb 14 – Multi-tenant serverless SaaS
Feb 21 – Refactoring to Serverless
Feb 28 – EDA visually explained
March
Mar 07 – Lambda cookbook with Python
Mar 14 – Succeeding with serverless
Mar 21 – Lambda Powertools .NET
Mar 28 – Server-side rendering micro-frontends
FooBar Serverless YouTube channel
Marcia Villalba frequently publishes new videos on her popular serverless YouTube channel. You can view all of Marcia’s videos at https://www.youtube.com/c/FooBar_codes.

January
Jan 12 – Serverless Badge – A new certification to validate your Serverless Knowledge
Jan 19 – Step functions Distributed map – Run 10k parallel serverless executions!
Jan 26 – Step Functions Intrinsic Functions – Do simple data processing directly from the state machines!
February
Feb 02 – Unlock the Power of EventBridge Pipes: Integrate Across Platforms with Ease!
Feb 09 – Amazon EventBridge Pipes: Enrichment and filter of events Demo with AWS SAM
Feb 16 – AWS App Runner – Deploy your apps from GitHub to Cloud in Record Time
Feb 23 – AWS App Runner – Demo hosting a Node.js app in the cloud directly from GitHub (AWS CDK)
March
Mar 02 – What is Amazon DynamoDB? What are the most important concepts? What are the indexes?
Mar 09 – Choreography vs Orchestration: Which is Best for Your Distributed Application?
Mar 16 – DynamoDB Single Table Design: Simplify Your Code and Boost Performance with Table Design Strategies
Mar 23 – 8 Reasons You Should Choose DynamoDB for Your Next Project and How to Get Started
Sessions with SAM & Friends

AWS SAM & Friends
Eric Johnson is exploring how developers are building serverless applications. We spend time talking about AWS SAM as well as others like AWS CDK, Terraform, Wing, and AMPT.
Feb 16 – What’s new with AWS SAM
Feb 23 – AWS SAM with AWS CDK
Mar 02 – AWS SAM and Terraform
Mar 10 – Live from ServerlessDays ANZ
Mar 16 – All about AMPT
Mar 23 – All about Wing
Mar 30 – SAM Accelerate deep dive
Still looking for more?
The Serverless landing page has more information. The Lambda resources page contains case studies, webinars, whitepapers, customer stories, reference architectures, and even more Getting Started tutorials.
You can also follow the Serverless Developer Advocacy team on Twitter to see the latest news, follow conversations, and interact with the team.










 Kaarthiik Thota is a Senior Amazon DocumentDB Specialist Solutions Architect at AWS based out of London. He is passionate about database technologies and enjoys helping customers solve problems and modernize applications using NoSQL databases. Before joining AWS, he worked extensively with relational databases, NoSQL databases, and business intelligence technologies for over 15 years.
Kaarthiik Thota is a Senior Amazon DocumentDB Specialist Solutions Architect at AWS based out of London. He is passionate about database technologies and enjoys helping customers solve problems and modernize applications using NoSQL databases. Before joining AWS, he worked extensively with relational databases, NoSQL databases, and business intelligence technologies for over 15 years. Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics o f networking and security, and is based out of Austin, Texas.
Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics o f networking and security, and is based out of Austin, Texas.








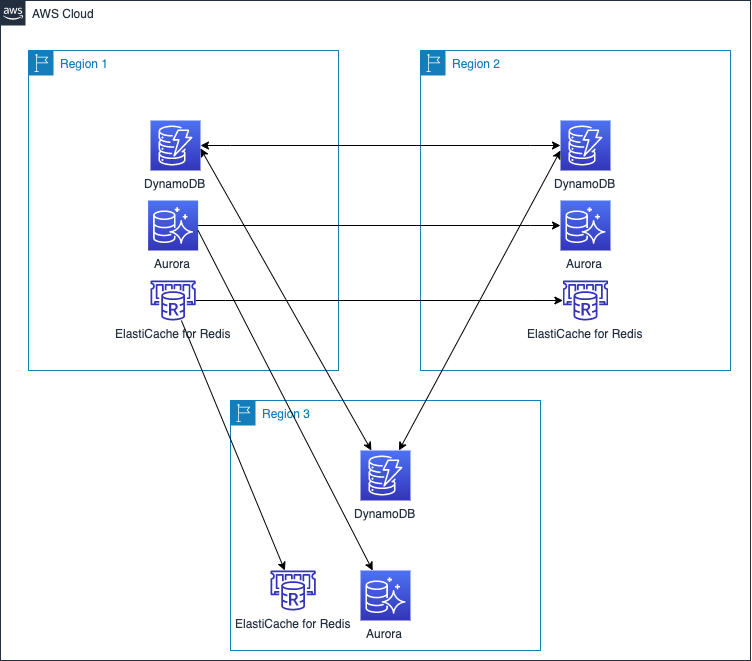






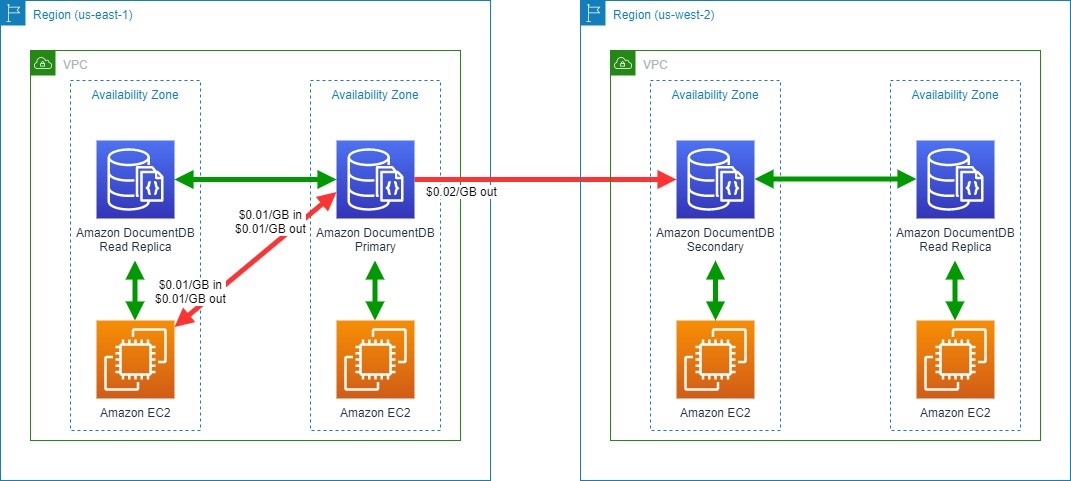











 Naresh Gautam is a Sr. Analytics Specialist Solutions Architect at AWS. His role is helping customers architect highly available, high-performance, and cost-effective data analytics solutions to empower customers with data-driven decision-making. In his free time, he enjoys meditation and cooking.
Naresh Gautam is a Sr. Analytics Specialist Solutions Architect at AWS. His role is helping customers architect highly available, high-performance, and cost-effective data analytics solutions to empower customers with data-driven decision-making. In his free time, he enjoys meditation and cooking. Srikanth Sopirala is a Sr. Analytics Specialist Solutions Architect at AWS. He is a seasoned leader with over 20 years of experience, who is passionate about helping customers build scalable data and analytics solutions to gain timely insights and make critical business decisions. In his spare time, he enjoys reading, spending time with his family and road biking.
Srikanth Sopirala is a Sr. Analytics Specialist Solutions Architect at AWS. He is a seasoned leader with over 20 years of experience, who is passionate about helping customers build scalable data and analytics solutions to gain timely insights and make critical business decisions. In his spare time, he enjoys reading, spending time with his family and road biking.

