Post Syndicated from Amrit Singh original https://www.backblaze.com/blog/the-free-credit-trap-building-saas-infrastructure-for-long-term-sustainability/
In today’s economic climate, cost cutting is on everyone’s mind, and businesses are doing everything they can to save money. But, it’s equally important that they can’t afford to compromise the integrity of their infrastructure or the quality of the customer experience. As a startup, taking advantage of free cloud credits from cloud providers like Amazon AWS, especially at a time like this, seems enticing.
Using those credits can make sense, but it takes more planning than you might think to use them in a way that allows you to continue managing cloud costs once the credits run out.
In this blog post, I’ll walk through common use cases for credit programs, the risks of using credits, and alternatives that help you balance growth and cloud costs.
The True Cost of “Free”
This post is part of a series exploring free cloud credits and the hidden complexities and limitations that come with these offers. Check out our previous installments:
The Shift to Cloud 3.0
As we see it, there have been three stages of “The Cloud” in its history:
Phase 1: What is the Cloud?
Starting around when Backblaze was founded in 2007, the public cloud was in its infancy. Most people weren’t clear on what cloud computing was or if it was going to take root. Businesses were asking themselves, “What is the cloud and how will it work with my business?”
Phase 2: Cloud = Amazon Web Services
Fast forward to 10 years later, and AWS and “The Cloud” started to become synonymous. Amazon had nearly 50% of market share of public cloud services, more than Microsoft, Google, and IBM combined. “The Cloud” was well-established, and for most folks, the cloud was AWS.
Phase 3: Multi-Cloud
Today, we’re in Phase 3 of the cloud. “The Cloud” of today is defined by the open, multi-cloud internet. Traditional cloud vendors are expensive, complicated, and seek to lock customers into their walled gardens. Customers have come to realize that (see below) and to value the benefits they can get from moving away from a model that demands exclusivity in cloud infrastructure.
In Cloud Phase 3.0, companies are looking to reign in spending, and are increasingly seeking specialized cloud providers offering affordable, best-of-breed services without sacrificing speed and performance. How do you balance that with the draw of free credits? I’ll get into that next, and the two are far from mutually exclusive.
Getting Hooked on Credits: Common Use Cases
So, you have $100k in free cloud credits from AWS. What do you do with them? Well, in our experience, there are a wide range of use cases for credits, including:
- App development and testing: Teams may leverage credits to run an app development proof of concept (PoC) utilizing Amazon EC2, RDS, and S3 for compute, database, and storage needs, for example, but without understanding how these will scale in the longer term, there may be risks involved. Spinning up EC2 instances can quickly lead to burning through your credits and getting hit with an unexpected bill.
- Machine learning (ML): Machine learning models require huge amounts of computing power and storage. Free cloud credits might be a good way to start, but you can expect them to quickly run out if you’re using them for this use case.
- Data analytics: While free cloud credits may cover storage and computing resources, data transfer costs might still apply. Analyzing large volumes of data or frequently transferring data in and out of the cloud can lead to unexpected expenses.
- Website hosting: Hosting your website with free cloud credits can eliminate the up front infrastructure spend and provide an entry point into the cloud, but remember that when the credits expire, traffic spikes you should be celebrating can crater your bottom line.
- Backup and disaster recovery: Free cloud credits may have restrictions on data retention, limiting the duration for which backups can be stored. This can pose challenges for organizations requiring long-term data retention for compliance or disaster recovery purposes.
All of this is to say: Proper configuration, long-term management and upkeep, and cost optimization all play a role on how you scale on monolith platforms. It is important to note that the risks and benefits mentioned above are general considerations, and specific terms and conditions may vary depending on the cloud service provider and the details of their free credit offerings. It’s crucial to thoroughly review the terms and plan accordingly to maximize the benefits and mitigate the risks associated with free cloud credits for each specific use case. (And, given the complicated pricing structures we mentioned before, that might take some effort.)
Monument Uses Free Credits Wisely
Monument, a photo management service with a strong focus on security and privacy, utilized free startup credits from AWS. But, they knew free credits wouldn’t last forever. Monument’s co-founder, Ercan Erciyes, realized they’d ultimately lose money if they built the infrastructure for Monument Cloud on AWS.
He also didn’t want to accumulate tech debt and become locked in to AWS. Rather than using the credits to build a minimum viable product as fast as humanly possible, he used the credits to develop the AI model, but not to build their infrastructure. Read more about how they put AWS credits to use while building infrastructure that could scale as they grew.

The Risks of AWS Credits: Lessons from Founders
If you’re handed $100,000 in credits, it’s crucial to be aware of the risks and implications that come along with it. While it may seem like an exciting opportunity to explore the capabilities of the cloud without immediate financial constraints, there are several factors to consider:
- The temptation to overspend: With a credit balance at your disposal just waiting to be spent, there is a possibility of underestimating the actual costs of your cloud usage. This can lead to a scenario where you inadvertently exhaust the credits sooner than anticipated, leaving you with unexpected expenses that may strain your budget.
- The shock of high bills once credits expire: Without proper planning and monitoring of your cloud usage, the transition from “free” to paying for services can result in high bills that catch you off guard. It is essential to closely track your cloud usage throughout the credit period and have a clear understanding of the costs associated with the services you’re utilizing. Or better yet, use those credits for a discrete project to test your PoC or develop your minimum viable product, and plan to build your long-term infrastructure elsewhere.
- The risk of vendor lock-in: As you build and deploy your infrastructure within a specific cloud provider’s ecosystem, the process of migrating to an alternative provider can seem complex and can definitely be costly (shameless plug: at Backblaze, we’ll cover your migration over 50TB). Vendor lock-in can limit your flexibility, making it challenging to adapt to changing business needs or take advantage of cost-saving opportunities in the future.
The problems are nothing new for founders, as the online conversation bears out.
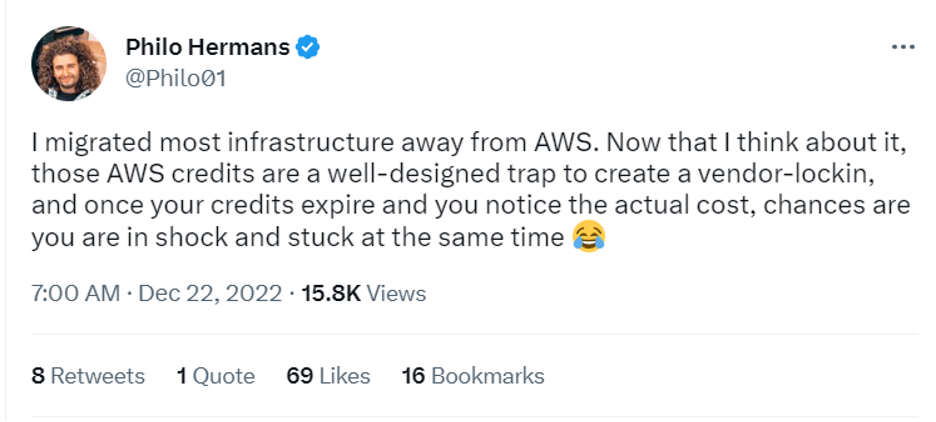
First, there’s the old surprise bill:
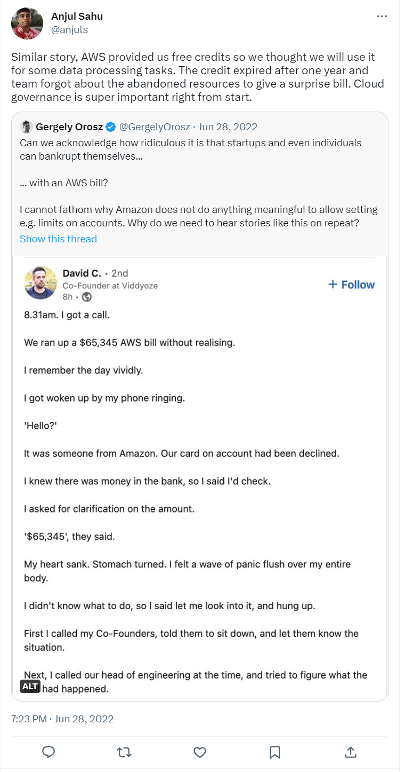
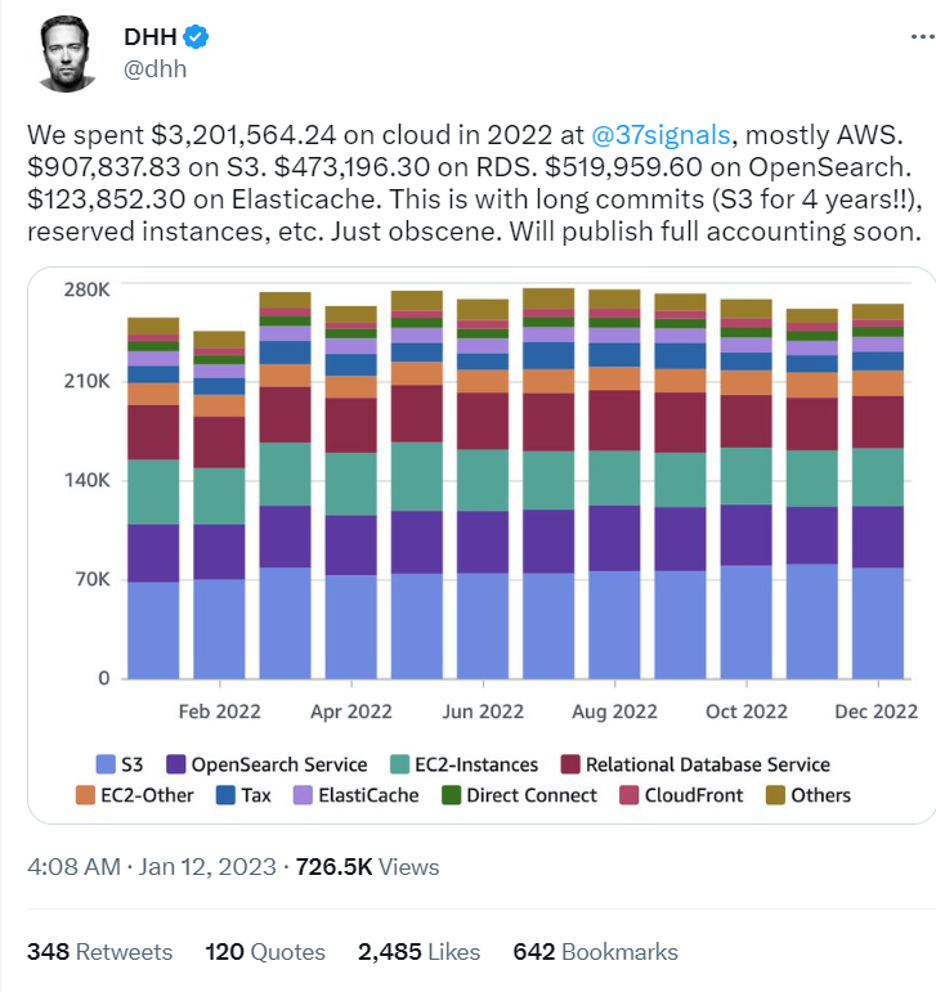
Even with some optimization, AWS cloud spend can still be pretty “obscene” as this user vividly shows:
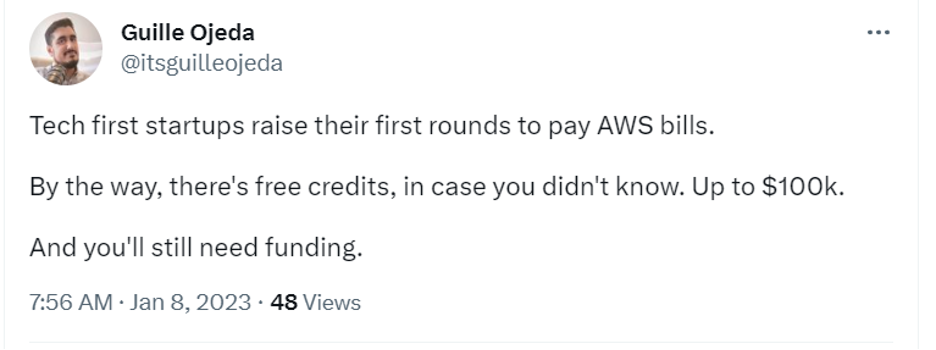
There’s the founder raising rounds just to pay AWS bills:
Some use the surprise bill as motivation to get paying customers.
![A tweet from user Leo Guinan @leo_guinan that says (I also got my AWS bill for last month and it was about 4x what I was expecting after my credits ran out, so a little more push to get paid users [laughing emoji])](https://www.backblaze.com/blog/wp-content/uploads/2023/05/5_Cloud-Credits-Tweet.png)
Lastly, there’s the comic relief:
Strategies for Balancing Growth and Cloud Costs
Where does that leave you today? Here are some best practices startups and early founders can implement to balance growth and cloud costs:
- Establishing a cloud cost management plan early on.
- Monitoring and optimizing cloud usage to avoid wasted resources.
- Leveraging multiple cloud providers.
- Moving to a new cloud provider altogether.
- Setting aside some of your credits for the migration.
1. Establishing a Cloud Cost Management Plan
Put some time into creating a well-thought-out cloud cost management strategy from the beginning. This includes closely monitoring your usage, optimizing resource allocation, and planning for the expiration of credits to ensure a smooth transition. By understanding the risks involved and proactively managing your cloud usage, you can maximize the benefits of the credits while minimizing potential financial setbacks and vendor lock-in concerns.
2. Monitoring and Optimizing Cloud Usage
Monitoring and optimizing cloud usage plays a vital role in avoiding wasted resources and controlling costs. By regularly analyzing usage patterns, organizations can identify opportunities to right-size resources, adopt automation to reduce idle time, and leverage cost-effective pricing options. Effective monitoring and optimization ensure that businesses are only paying for the resources they truly need, maximizing cost efficiency while maintaining the necessary levels of performance and scalability.
3. Leveraging Multiple Cloud Providers
By adopting a multi-cloud strategy, businesses can diversify their cloud infrastructure and services across different providers. This allows them to benefit from each provider’s unique offerings, such as specialized services, geographical coverage, or pricing models. Additionally, it provides a layer of protection against potential service disruptions or price increases from a single provider. Adopting a multi-cloud approach requires careful planning and management to ensure compatibility, data integration, and consistent security measures across multiple platforms. However, it offers the flexibility to choose the best-fit cloud services from different providers, reducing dependency on a single vendor and enabling businesses to optimize costs while harnessing the capabilities of various cloud platforms.
4. Moving to a New Cloud Provider Altogether
If you’re already deeply invested in a major cloud platform, shifting away can seem cumbersome, but there may be long-term benefits that outweigh the short term “pains” (this leads into the shift to Cloud 3.0). The process could involve re-architecting applications, migrating data, and retraining personnel on the new platform. However, factors such as pricing models, performance, scalability, or access to specialized services may win out in the end. It’s worth noting that many specialized providers have taken measures to “ease the pain” and make the transition away from AWS more seamless without overhauling code. For example, at Backblaze, we developed an S3 compatible API so switching providers is as simple as dropping in a new storage target.
5. Setting Aside Credits for the Migration
By setting aside credits for future migration, businesses can ensure they have the necessary resources to transition to a different provider without incurring significant up front expenses like egress fees to transfer large data sets. This strategic allocation of credits allows organizations to explore alternative cloud platforms, evaluate their pricing models, and assess the cost-effectiveness of migrating their infrastructure and services without worrying about being able to afford the migration.
Welcome to Cloud 3.0: Alternatives to AWS
In 2022, David Heinemeier Hansson, the creator of Basecamp and Hey, announced that he was moving Hey’s infrastructure from AWS to on-premises. Hansson cited the high cost of AWS as one of the reasons for the move. His estimate? “We stand to save $7m over five years from our cloud exit,” he said.
Going back to on-premises solutions is certainly one answer to the problem of AWS bills. In fact, when we started designing Backblaze’s Personal Backup solution, we were faced with the same problem. Hosting data storage for our computer backup product on AWS was a non-starter—it was going to be too expensive, and our business wouldn’t be able to deliver a reasonable consumer price point and be solvent. So, we didn’t just invest in on-premises resources: We built our own Storage Pods, the first evolution of the Backblaze Storage Cloud.
But, moving back to on-premises solutions isn’t the only answer—it’s just the only answer if it’s 2007 and your two options are AWS and on-premises solutions. The cloud environment as it exists today has better choices. We’ve now grown that collection of Storage Pods into the Backblaze B2 Storage Cloud, which delivers performant, interoperable storage at one-fifth the cost of AWS. And, we offer free egress to our content delivery network (CDN) and compute partners. Backblaze may provide an even more cost-effective solution for mid-sized SaaS startups looking to save on cloud costs while maintaining speed and performance.
As we transition to Cloud 3.0 in 2023 and beyond, companies are expected to undergo a shift, reevaluating their cloud spending to ensure long-term sustainability and directing saved funds into other critical areas of their businesses. The age of limited choices is over. The age of customizable cloud integration is here.
So, shout out to David Heinemeier Hansson: We’d love to chat about your storage bills some time.
Want to Test It Yourself?
Take a proactive approach to cloud cost management: If you’ve got more than 50TB of data storage or want to check out our capacity-based pricing model, B2 Reserve, contact our Sales Team to test a PoC for free with Backblaze B2.
And, for the streamlined, self–serve option, all you need is an email to get started today.
FAQs About Cloud Spend
If you’re thinking about moving to Backblaze B2 after taking AWS credits, but you’re not sure if it’s right for you, we’ve put together some frequently asked questions that folks have shared with us before their migrations:
My cloud credits are running out. What should I do?
Backblaze’s Universal Data Migration service can help you off-load some of your data to Backblaze B2 for free. Speak with a migration expert today.
AWS has all of the services I need, and Backblaze only offers storage. What about the other services I need?
Shifting away from AWS doesn’t mean ditching the workflows you have already set up. You can migrate some of your data storage while keeping some on AWS or continuing to use other AWS services. Moreover, AWS may be overkill for small to midsize SaaS businesses with limited resources.
How should I approach a migration?
Identify the specific services and functionalities that your applications and systems require, such as CDN for content delivery or compute resources for processing tasks. Check out our partner ecosystem to identify other independent cloud providers that offer the services you need at a lower cost than AWS.
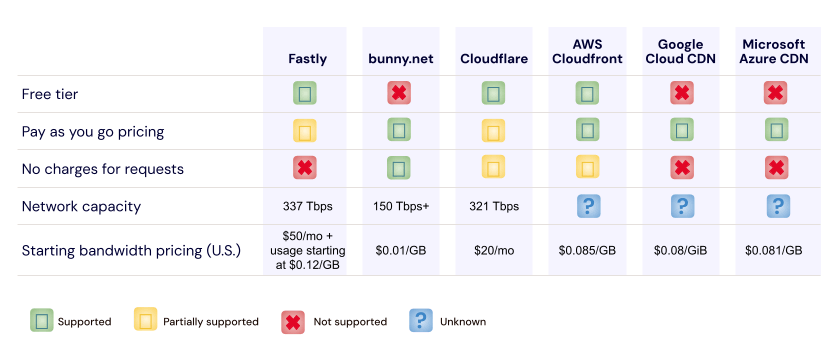
What CDN partners does Backblaze have?
With the ease of use, predictable pricing, zero egress, our joint solutions are perfect for businesses looking to reduce their IT costs, improve their operational efficiency, and increase their competitive advantage in the market. Our CDN partners include Fastly, bunny.net, and Cloudflare. And, we extend free egress to joint customers.
What compute partners does Backblaze have?
Our compute partners include Vultr and Equinix Metal. You can connect Backblaze B2 Cloud Storage with Vultr’s global compute network to access, store, and scale application data on-demand, at a fraction of the cost of the hyperscalers.
The post The Free Credit Trap: Building SaaS Infrastructure for Long-Term Sustainability appeared first on Backblaze Blog | Cloud Storage & Cloud Backup.