Post Syndicated from Grab Tech original https://engineering.grab.com/reducing-your-go-binary-size
Grab’s engineering teams currently own and manage more than 250+ microservices. Depending on the business problems that each team tackles, our development ecosystem ranges from Golang, Java, and everything in between.
Although there are centralised systems that help automate most of the build and deployment tasks, there are still some teams working on different technologies that manage their own build, test and deployment systems at different maturity levels. Managing a varied build and deploy ecosystems brings their own challenges.
Build challenges
- Broken external dependencies.
- Non-reproducible builds due to changes in AMI, configuration keys and other build parameters.
- Missing security permissions between different repositories.
Deployment challenges
- Varied deployment environments necessitating a bigger learning curve.
- Managing the underlying infrastructure as code.
- Higher downtime when bringing the systems up after a scale down event.
Grab’s appetite for customer obsession and quality drives the engineering teams to innovate and deliver value rapidly. The time that the team spends in fixing build issues or deployment-related tasks has a direct impact on the time they spend on delivering business value.
Introduction to containerisation
Using the Container architecture helps the team deploy and run multiple applications, isolated from each other, on the same virtual machine or server and with much less overhead.
At Grab, both the platform and the core engineering teams wanted to move to the containerisation architecture to achieve the following goals:
- Support to build and push container images during the CI process.
- Create a standard virtual machine image capable of running container workloads. The AMI is maintained by a central team and comes with Grab infrastructure components such as (DataDog, Filebeat, Vault, etc.).
- A deployment experience which allows existing services to migrate to container workload safely by initially running both types of workloads concurrently.
The core engineering teams wanted to adopt container workloads to achieve the following benefits:
- Provide a containerised version of the service that can be run locally and on different cloud providers without any dependency on Grab’s internal (runtime) tooling.
- Allow reuse of common Grab tools in different projects by running the zero dependency version of the tools on demand whenever needed.
- Allow a more flexible staging/dev/shadow deployment of new features.
Adoption of containerisation
Engineering teams at Grab use the containerisation model to build and deploy services at scale. Our containerisation effort helps the development teams move faster by:
- Providing a consistent environment across development, testing and production
- Deploying software efficiently
- Reducing infrastructure cost
- Abstracting OS dependency
- Increasing scalability between cloud vendors
When we started using containers we realised that building smaller containers had some benefits over bigger containers. For example, smaller containers:
- Include only the needed libraries and therefore are more secure.
- Build and deploy faster as they can be pulled to the running container cluster quickly.
- Utilise disk space and memory efficiently.
During the course of containerising our applications, we noted that some service binaries appeared to be bigger (~110 MB) than they should be. For a statically-linked Golang binary, that’s pretty big! So how do we figure out what’s bloating the size of our binary?
Go binary size visualisation tool
In the course of poking around for tools that would help us analyse the symbols in a Golang binary, we found go-binsize-viz based on this article. We particularly liked this tool, because it utilises the existing Golang toolchain (specifically, Go tool nm) to analyse imports, and provides a straightforward mechanism for traversing through the symbols present via treemap. We will briefly outline the steps that we did to analyse a Golang binary here.
-
First, build your service using the following command (important for consistency between builds):
$ go build -a -o service_name ./path/to/main.go - Next, copy the binary over to the cloned directory of
go-binsize-vizrepository. -
Run the following script that covers the steps in the go-binsize-viz README.
#!/usr/bin/env bash # # This script needs more input parsing, but it serves the needs for now. # mkdir dist # step 1 go tool nm -size $1 | c++filt > dist/$1.symtab # step 2 python3 tab2pydic.py dist/$1.symtab > dist/$1-map.py # step 3 # must be data.js python3 simplify.py dist/$1-map.py > dist/$1-data.js rm data.js ln -s dist/$1-data.js data.jsRunning this script creates a dist folder where each intermediate step is deposited, and a
data.jssymlink in the top-level directory which points to the consumable.jsfile by treemap.html.# top-level directory $ ll -rw-r--r-- 1 stan.halka staff 1.1K Aug 20 09:57 README.md -rw-r--r-- 1 stan.halka staff 6.7K Aug 20 09:57 app3.js -rw-r--r-- 1 stan.halka staff 1.6K Aug 20 09:57 cockroach_sizes.html lrwxr-xr-x 1 stan.halka staff 65B Aug 25 16:49 data.js -> dist/v2.0.709356.segments-paxgroups-macos-master-go1.13-data.js drwxr-xr-x 8 stan.halka staff 256B Aug 25 16:49 dist ... # dist folder $ ll dist total 71728 drwxr-xr-x 8 stan.halka staff 256B Aug 25 16:49 . drwxr-xr-x 21 stan.halka staff 672B Aug 25 16:49 .. -rw-r--r-- 1 stan.halka staff 4.2M Aug 25 16:37 v2.0.709356.segments-paxgroups-macos-master-go1.13-data.js -rw-r--r-- 1 stan.halka staff 3.4M Aug 25 16:37 v2.0.709356.segments-paxgroups-macos-master-go1.13-map.py -rw-r--r-- 1 stan.halka staff 11M Aug 25 16:37 v2.0.709356.segments-paxgroups-macos-master-go1.13.symtabAs you can probably tell from the file names, these steps were explored on the segments-paxgroups service, which is a microservice used for segment information at Grab. You can ignore the versioning metadata, branch name, and Golang information embedded in the name.
-
Finally, run a local python3 server to visualise the binary components.
$ python3 -m http.server Serving HTTP on 0.0.0.0 port 8000 (http://0.0.0.0:8000/) ...So now that we have a methodology to consistently generate a service binary, and a way to explore the symbols present, let’s dive in!
-
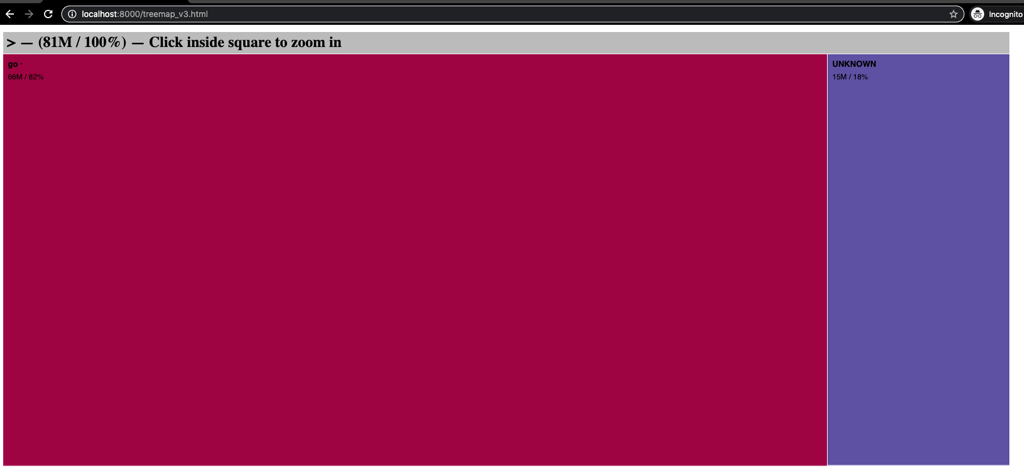
Open your browser and visit http://localhost:8000/treemap_v3.html:
Of the 103MB binary produced, 81MB are recognisable, with 66MB recognised as Golang (UNKNOWN is present, and also during parsing there were a fair number of warnings. Note that we haven’t spent enough time with the tool to understand why we aren’t able to recognise and index all the symbols present).

The next step is to figure out where the symbols are coming from. There’s a bunch of Grab-internal stuff that for the sake of this blog isn’t necessary to go into, and it was reasonably easy to come to the right answer based on the intuitiveness of the
go-binsize-viztool.This visualisation shows us the source of how 11 MB of symbols are sneaking into the segments-paxgroups binary.
Every message format for any service that reads from, or writes to, streams at Grab is included in every service binary! Not cloud native!
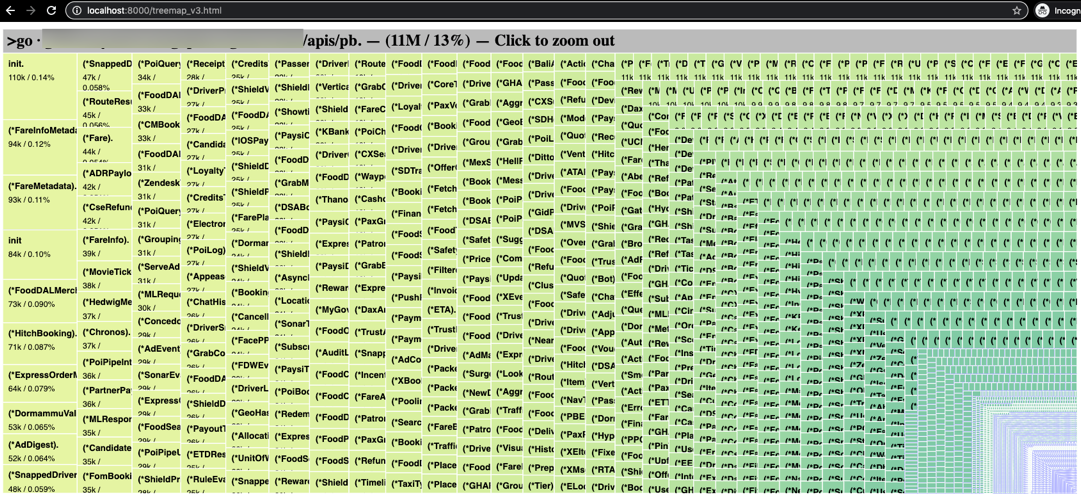
How did this happen?
The short answer is that Golang doesn’t import only the symbols that it requires, but rather all the symbols defined within an imported directory and transitive symbols as well. So, when we think we’re importing just one directory, if our code structure doesn’t follow principles of encapsulation or isolation, we end up importing 11 MB of symbols that we don’t need! In our case, this occurred because a generic Message interface was included in the same directory with all the auto-generated code you see in the pretty picture above.
The Streams team did an awesome job of restructuring the code, which when built again, led to this outcome:
$$ ll | grep paxgroups
-rwxr-xr-x 1 stan.halka staff 110M Aug 21 14:53 v2.0.709356.segments-paxgroups-macos-master-go1.12
-rwxr-xr-x 1 stan.halka staff 103M Aug 25 16:34 v2.0.709356.segments-paxgroups-macos-master-go1.13
-rwxr-xr-x 1 stan.halka staff 80M Aug 21 14:53 v2.0.709356.segments-paxgroups-macos-tinkered-go1.12
-rwxr-xr-x 1 stan.halka staff 78M Aug 25 16:34 v2.0.709356.segments-paxgroups-macos-tinkered-go1.13
Not a bad reduction in service binary size!
Lessons learnt
The go-binsize-viz utility offers a treemap representation for imported symbols, and is very useful in determining what symbols are contributing to the overall size.
Code architecture matters: Keep binaries as small as possible!
To reduce your binary size, follow these best practices:
- Structure your code so that the interfaces and common classes/utilities are imported from different locations than auto-generated classes.
- Avoid huge, flat directory structures.
- If it’s a platform offering and has too many interwoven dependencies, try to decouple the actual platform offering from the company specific instantiations. This fosters creating isolated, minimalistic code.
Join us
Grab is more than just the leading ride-hailing and mobile payments platform in Southeast Asia. We use data and technology to improve everything from transportation to payments and financial services across a region of more than 620 million people. We aspire to unlock the true potential of Southeast Asia and look for like-minded individuals to join us on this ride.
If you share our vision of driving South East Asia forward, apply to join our team today.