Post Syndicated from Grab Tech original https://engineering.grab.com/enabling-near-realtime-data-analytics
Introduction
In the domain of data processing, data analysts run their ad hoc queries on the data lake. The lake serves as an interface between our analytics and production environment, preventing downstream queries from impacting upstream data ingestion pipelines. To ensure efficient data processing in the data lake, choosing appropriate storage formats is crucial.
The vanilla data lake solution is built on top of cloud object storage with Hive metastore, where data files are written in Parquet format. Although this setup is optimised for scalable analytics query patterns, it struggles to handle frequent updates to the data due to two reasons:
- The Hive table format requires us to rewrite the Parquet files with the latest data. For instance, to update one record in a Hive unpartitioned table, we would need to read all the data, update the record, and write back the entire data set.
- Writing Parquet files is expensive due to the overhead of organising the data to a compressed columnar format, which is more complex than a row format.
The issue is further exacerbated by the scheduled downstream transformations. These necessary steps, which clean and process the data for use, increase the latency because the total delay now includes the combined scheduled intervals of these processing jobs.
Fortunately, the introduction of the Hudi format, which supports fast writes by allowing Avro and Parquet files to co-exist on a Merge On Read (MOR) table, opens up the possibility of having a data lake with minimal data latency. The concept of a commit timeline further allows data to be served with Atomicity, Consistency, Isolation, and Durability (ACID) guarantees.
We employ different sets of configurations for the different characteristics of our input sources:
- High or low throughput. A high-throughput source refers to one that has a high level of activity. One example of this can be our stream of booking events generated from each customer transaction. On the other hand, a low-throughput source would be one that has a relative low level of activity. An example of this can be transaction events generated from reconciliation happening on a nightly basis.
- Kafka (unbounded) or Relational Database Sources (bounded). Our sinks have sources that can be broadly categorised into unbounded and bounded sources. Unbounded sources are usually related to transaction events materialised as Kafka topics, representing user-generated events as they interact with the Grab superapp. Bounded sources usually refer to Relational Database (RDS) sources, whose size is bound to storage provisioned.
The following sections will delve into the differences between each source and our corresponding configurations optimised for them.
High throughput source
For our data sources with high throughput, we have chosen to write the files in MOR format since the writing of files in Avro format allows for fast writes to meet our latency requirements.
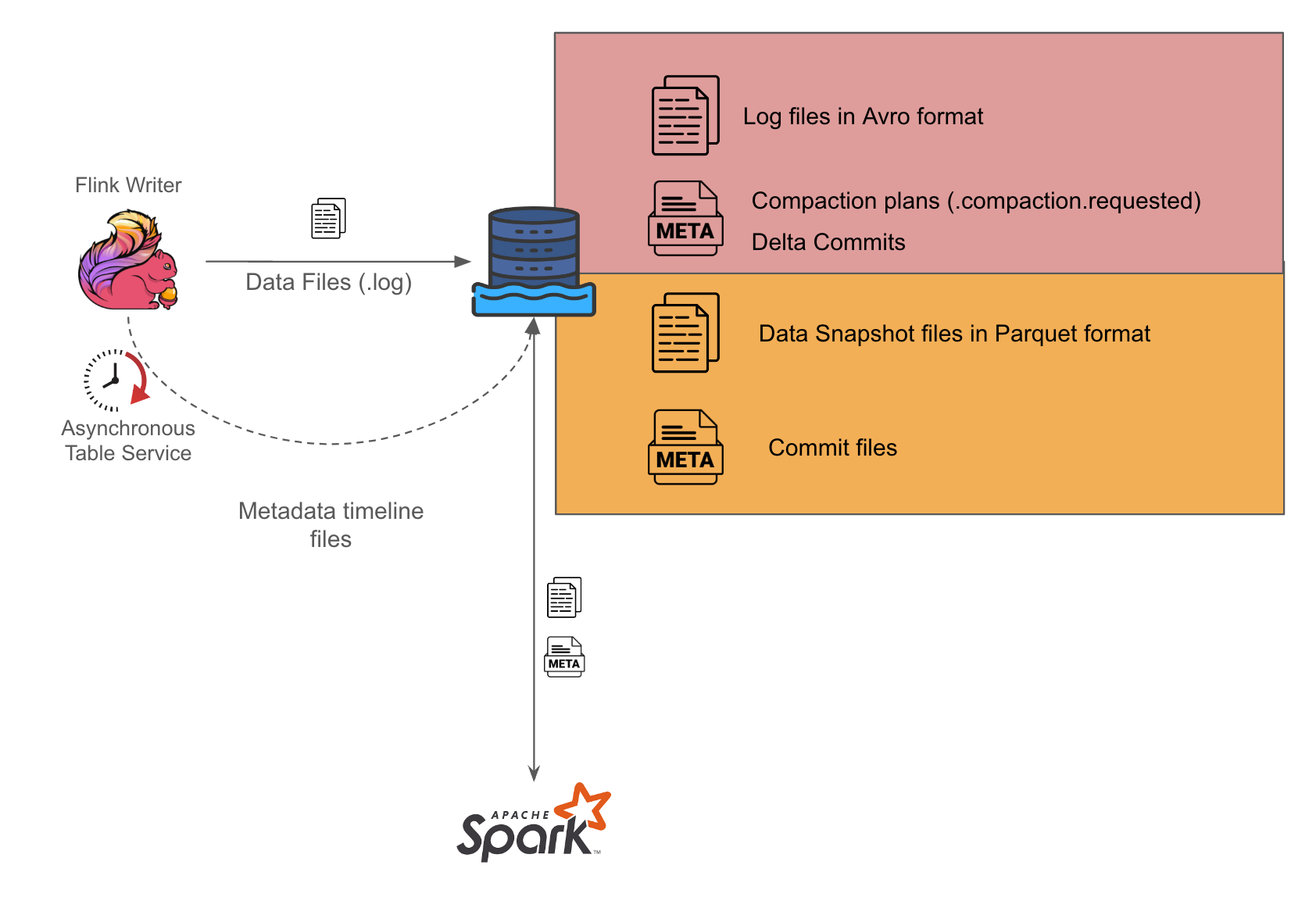
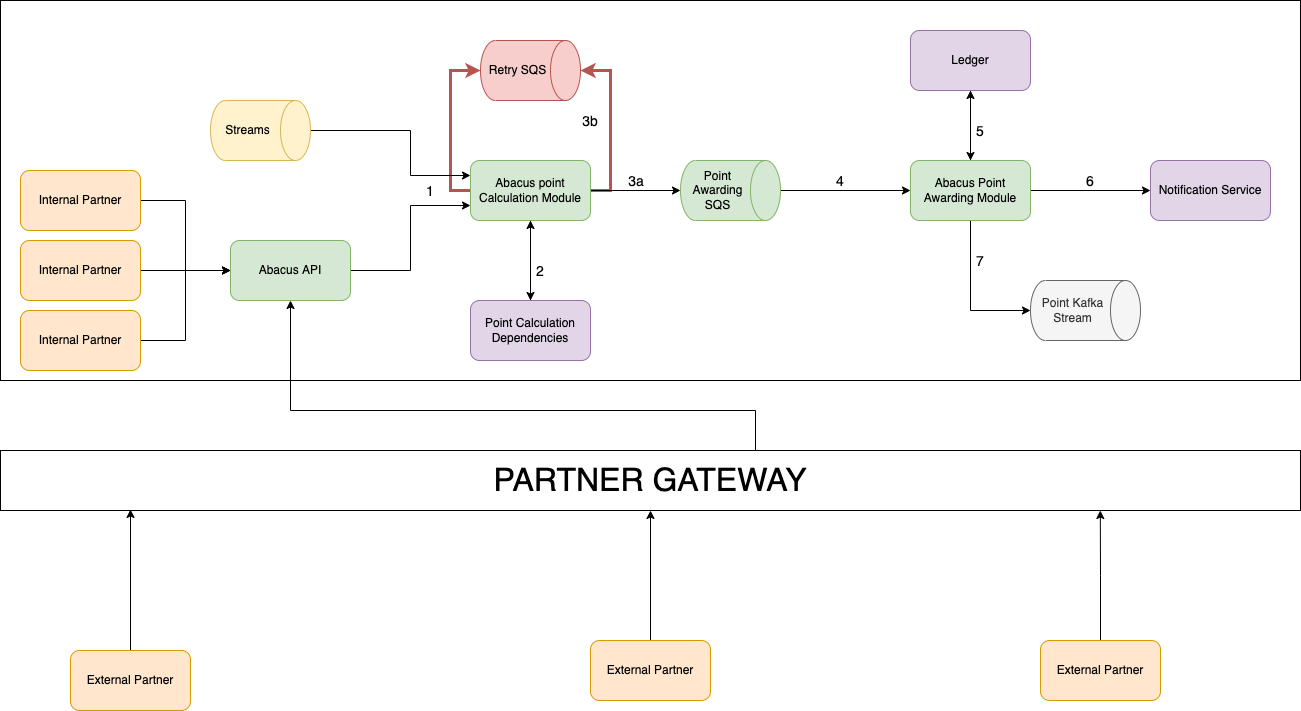
As seen in Figure 1, we use Flink to perform the stream processing and write out log files in Avro format in our setup. We then set up a separate Spark writer which periodically converts the Avro files into Parquet format in the Hudi compaction process.
We have further simplified the coordination between the Flink and Spark writers by enabling asynchronous services on the Flink writer so it can generate the compaction plans for Spark writers to act on. During the Spark job runs, it checks for available compaction plans and acts on them, placing the burden of orchestrating the writes solely on the Flink writer. This approach could help minimise potential concurrency problems that might otherwise arise, as there would be a single actor
orchestrating the associated Hudi table services.
Low throughput source
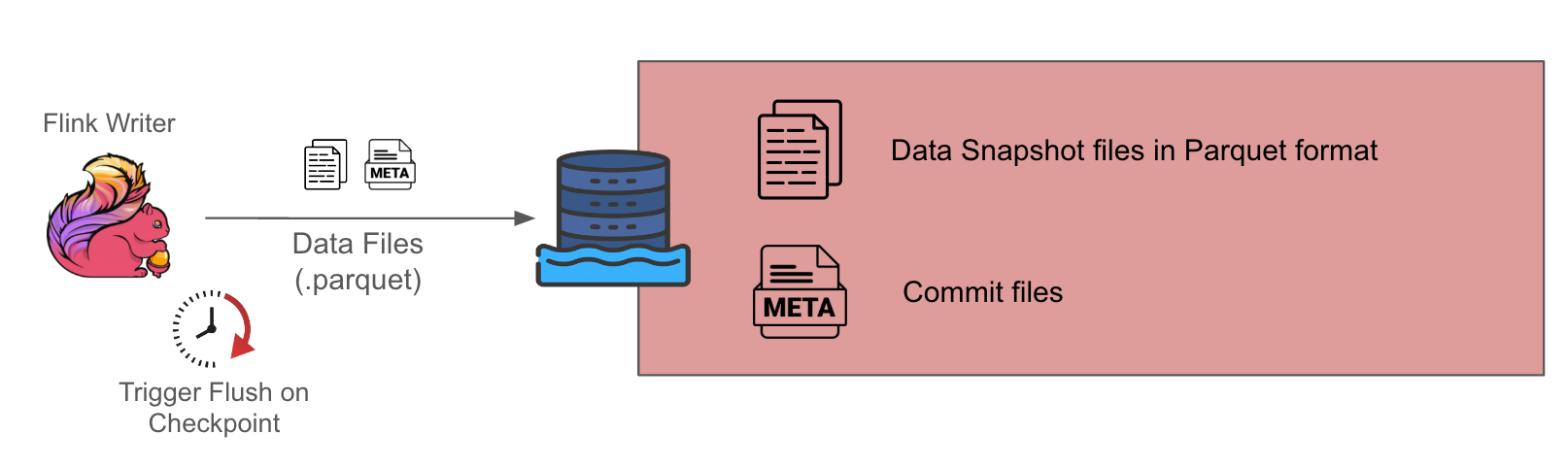
For low throughput sources, we gravitate towards the choice of Copy On Write (COW) tables given the simplicity of its design, since it only involves one component, which is the Flink writer. The downside is that it has higher data latency because this setup only generates Parquet format data snapshots at each checkpoint interval, which is typically about 10-15 minutes.
Connecting to our Kafka (unbounded) data source
Grab uses Protobuf as our central data format in Kafka, ensuring schema evolution compatibility. However, the derivation of the schema of these topics still requires some transformation to make it compatible with Hudi’s accepted schema. Some of these transformations include ensuring that Avro record fields do not contain just a single array field, and handling logical decimal schemas to transform them to fixed byte schema for Spark compatibility.
Given the unbounded nature of the source, we decided to partition it by Kafka event time up to the hour level. This ensured that our Hudi operations would be faster. Parquet file writes would be faster since they would only affect files within the same partition, and each Parquet file within the same event time partition would have a bounded size given the monotonically increasing nature of Kafka event time.
By partitioning tables by Kafka event time, we can further optimise compaction planning operations, since the amount of file lookups required is now reduced with the use of BoundedPartitionAwareCompactionStrategy. Only log files in recent partitions would be selected for compaction and the job manager need not list every partition to figure out which log files to select for compaction during the planning phase anymore.
Connecting to our RDS (bounded) data source
For our RDS, we decided to use the Flink Change Data Capture (CDC) connectors by Veverica to obtain the binlog streams. The RDS would then treat the Flink writer as a replication server and start streaming its binlog data to it for each MySQL change. The Flink CDC connector presents the data as a Kafka Connect (KC) Source record, since it uses the Debezium connector under the hood. It is then a straightforward task to deserialise these records and transform them into Hudi records, since
the Avro schema and associated data changes are already captured within the KC source record.
The obtained binlog timestamp is also emitted as a metric during consumption for us to monitor the observed data latency at the point of ingestion.
Optimising for these sources involves two phases:
- First, assigning more resources for the cold start incremental snapshot process where Flink takes a snapshot of the current data state in the RDS and loads the Hudi table with that snapshot. This phase is usually resource-heavy as there are a lot of file writes and data ingested during this process.
- Once the snapshotting is completed, Flink would then start to process the binlog stream and the observed throughput would drop to a level similar to the DB write throughput. The resources required by the Flink writer at this stage would be much lower than in the snapshot phase.
Indexing for Hudi tables
Indexing is important for upserting Hudi tables when the writing engine performs updates, allowing it to efficiently locate the file groups of the data to be updated.
As of version 0.14, the Flink engine only supports Bucket Index or Flink State Index. Bucket Index performs indexing of the file record by hashing the record key and matching it to a specific bucket of files indicated by the naming convention of the written data files. Flink State Index on the other hand stores the index map of record keys to files in memory.
Given that our tables include unbounded Kafka sources, there is a possibility for our state indexes to grow indefinitely. Furthermore, the requirement of state preservation for Flink State Index across version deployments and configuration updates adds complexity to the overall solution.
Thus, we opted for the simple Bucket Index for its simplicity and the fact that our Hudi table size per partition does not change drastically across the week. However, this comes with a limitation whereby the number of buckets cannot be updated easily and imposes a parallelism limit at which our Flink pipelines can scale. Thus, as traffic grows organically, we would find ourselves in a situation whereby our configuration grows obsolete and cannot handle the increased load.
To resolve this going forward, using consistent hashing for the Bucket Index would be something to explore to optimise our Parquet file sizes and allow the number of buckets to grow seamlessly as traffic grows.
Impact
Fresh business metrics
Post creation of our Hudi Data Ingestion solution, we have enabled various users such as our data analysts to perform ad hoc queries much more easily on data that has lower latency. Furthermore, Hudi tables can be seamlessly joined with Hive tables in Trino for additional context. This enabled the construction of operational dashboards reflecting fresh business metrics to our various operators, empowering them with the necessary information to quickly respond to any abnormalities (such as high-demand events like F1 or seasonal holidays).
Quicker fraud detection
Another significant user of our solution is our fraud detection analysts. This enabled them to rapidly access fresh transaction events and analyse them for fraudulent patterns, particularly during the emergence of a new attack pattern that hadn’t been detected by their rules engine. Our solution also allowed them to perform multiple ad hoc queries that involve lookbacks of various days’ worth of data without impacting our production RDS and Kafka clusters by using the data lake as the data interface, reducing the data latency to the minute level and, in turn, empowering them to respond more quickly to attacks.
What’s next?
As the landscape of data storage solutions evolves rapidly, we are eager to test and integrate new features like Record Level Indexing and the creation of Pre Join tables. This evolution extends beyond the Hudi community to other table formats such as IceBerg and DeltaLake. We remain ready to adapt ourselves to these changes and incorporate the advantages of each format into our data lake within Grab.
References
- Hudi: https://hudi.apache.org/docs/next/overview/
- Ververica Flink CDC: https://github.com/ververica/flink-cdc-connectors
- Debezium: https://debezium.io/documentation/reference/stable/connectors/mysql.html
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!