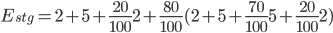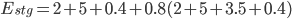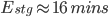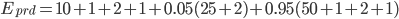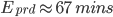This article illustrates how the Cauldron Machine Learning (ML) Platform team uses GitLab parent-child pipelines to dynamically generate GitLab CI files to solve several limitations of GitLab for large repositories, namely:
Limitations to the number of includes (100 by default).
Simplifying the GitLab CI file from 1800 lines to 50 lines.
Reducing the need for nested gitlab-ci yml files.
Introduction
Cauldron is the Machine Learning (ML) Platform team at Grab. The Cauldron team provides tools for ML practitioners to manage the end to end lifecycle of ML models, from training to deployment. GitLab and its tooling are an integral part of our stack, for continuous delivery of machine learning.
One of our core products is MerLin Pipelines. Each team has a dedicated repo to maintain the code for their ML pipelines. Each pipeline has its own subfolder. We rely heavily on GitLab rules to detect specific changes to trigger deployments for the different stages of different pipelines (for example, model serving with Catwalk, and so on).
Background
Approach 1: Nested child files
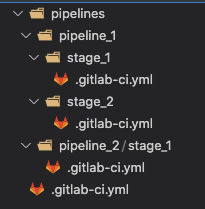
Our initial approach was to rely heavily on static code generation to generate the child gitlab-ci.yml files in individual stages. See Figure 1 for an example directory structure. These nested yml files are pre-generated by our cli and committed to the repository.
Figure 1: Example directory structure with nested gitlab-ci.yml files.
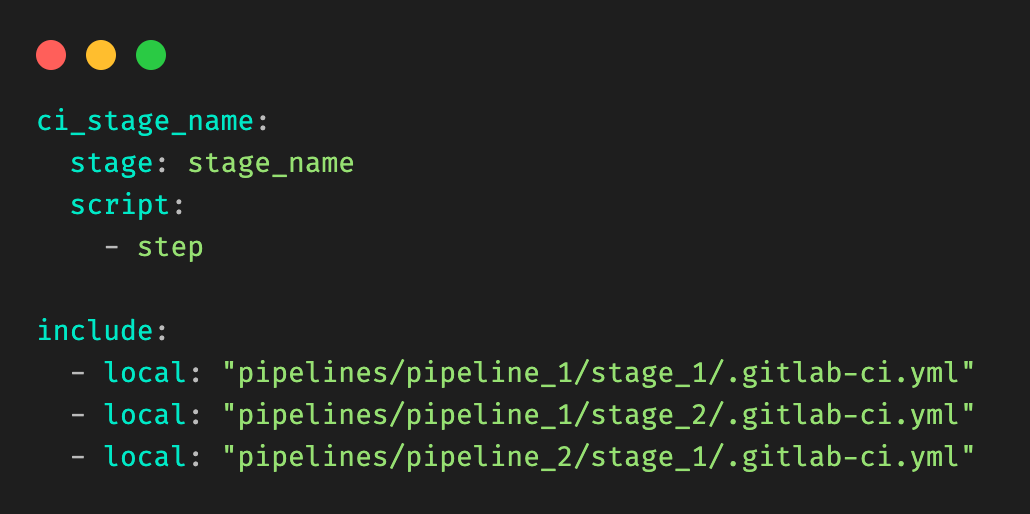
Child gitlab-ci.yml files are added by using the include keyword.
Figure 2: Example root .gitlab-ci.yml file, and include clauses.
Figure 3: Example child `.gitlab-ci.yml` file for a given stage (Deploy Model) in a pipeline (pipeline 1).
As teams add more pipelines and stages, we soon hit a limitation in this approach:
There was a soft limit in the number of includes that could be in the base .gitlab-ci.yml file.
It became evident that this approach would not scale to our use-cases.
Approach 2: Dynamically generating a big CI file
Our next attempt to solve this problem was to try to inject and inline the nested child gitlab-ci.yml contents into the root gitlab-ci.yml file, so that we no longer needed to rely on the in-built GitLab “include” clause.
To achieve it, we wrote a utility that parsed a raw gitlab-ci file, walked the tree to retrieve all “included” child gitlab-ci files, and to replace the includes to generate a final big gitlab-ci.yml file.
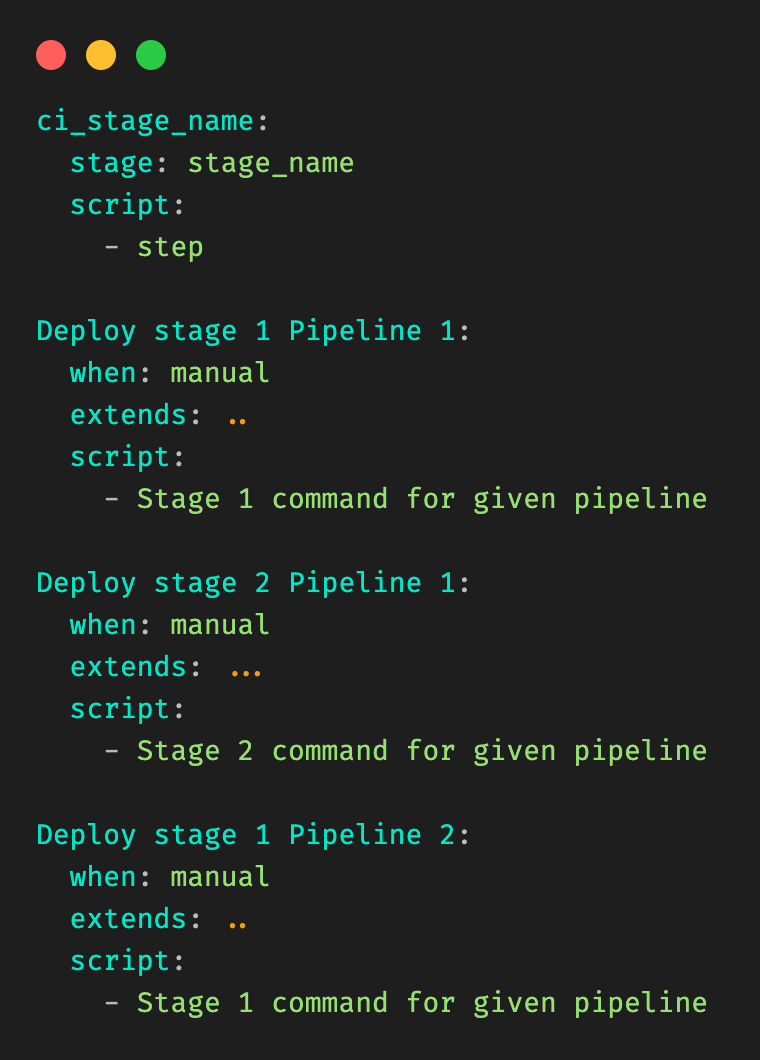
Figure 4 illustrates the resulting file is generated from Figure 3.
Figure 4: “Fat” YAML file generated through this approach, assumes the original raw file of Figure 3.
This approach solved our issues temporarily. Unfortunately, we ended up with GitLab files that were up to 1800 lines long. There is also a soft limit to the size of gitlab-ci.yml files. It became evident that we would eventually hit the limits of this approach.
Solution
Our initial attempt at using static code generation put us partially there. We were able to pre-generate and infer the stage and pipeline names from the information available to us. Code generation was definitely needed, but upfront generation of code had some key limitations, as shown above. We needed a way to improve on this, to somehow generate GitLab stages on the fly. After some research, we stumbled upon Dynamic Child Pipelines.
Quoting the official website:
Instead of running a child pipeline from a static YAML file, you can define a job that runs your own script to generate a YAML file, which is then used to trigger a child pipeline.
This technique can be very powerful in generating pipelines targeting content that changed or to build a matrix of targets and architectures.
We were already on the right track. We just needed to combine code generation with child pipelines, to dynamically generate the necessary stages on the fly.
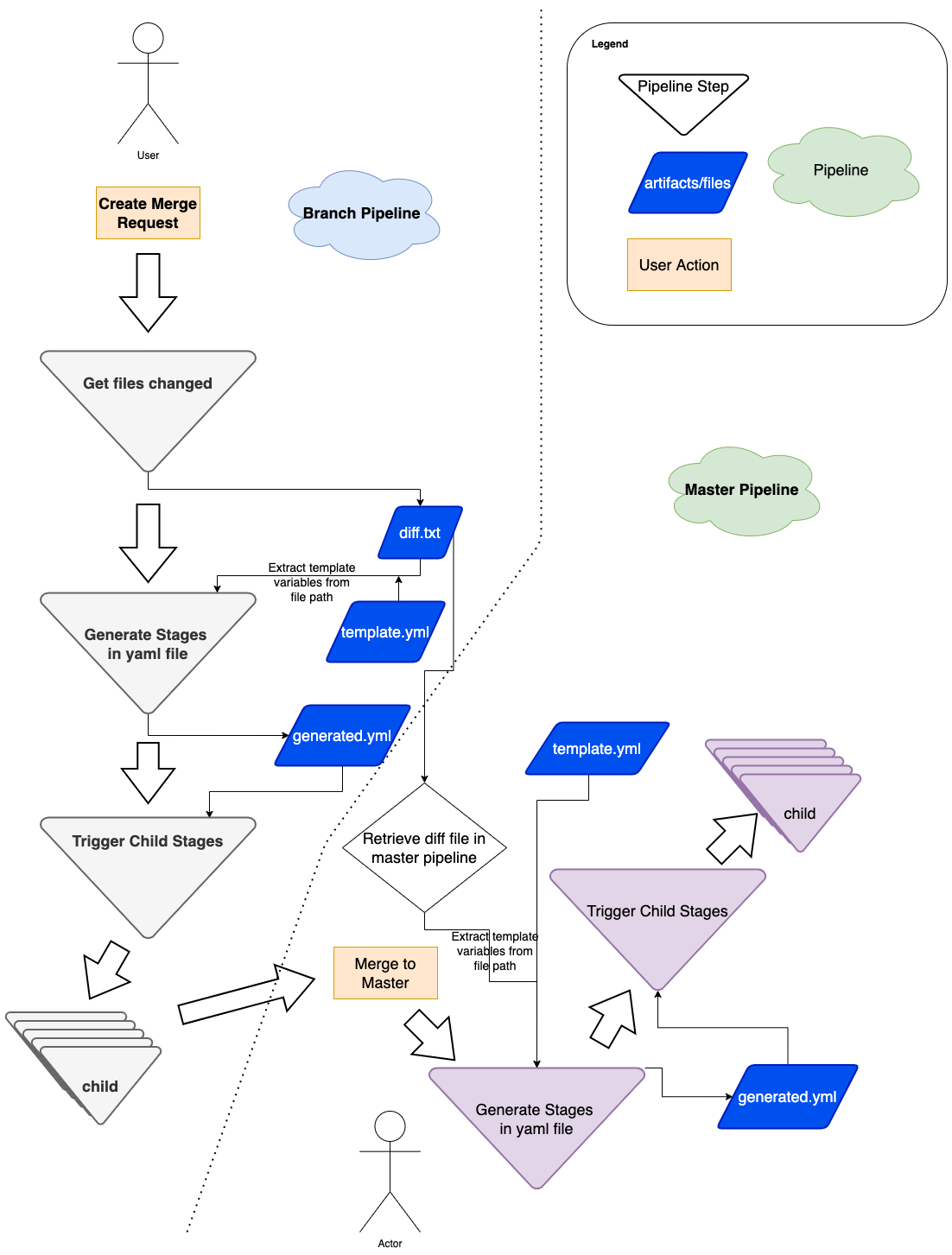
Architecture details
Figure 5: Flow diagram of how we use dynamic yaml generation. The user raises a merge request in a branch, and subsequently merges the branch to master.
Implementation
The user Git flow can be seen in Figure 5, where the user modifies or adds some files in their respective Git team repo. As a refresher, a typical repo structure consists of pipelines and stages (see Figure 1). We would need to extract the information necessary from the branch environment in Figure 5, and have a stage to programmatically generate the proper stages (for example, Figure 3).
In short, our requirements can be summarized as:
Detecting the files being changed in the Git branch.
Extracting the information needed from the files that have changed.
Passing this to be templated into the necessary stages.
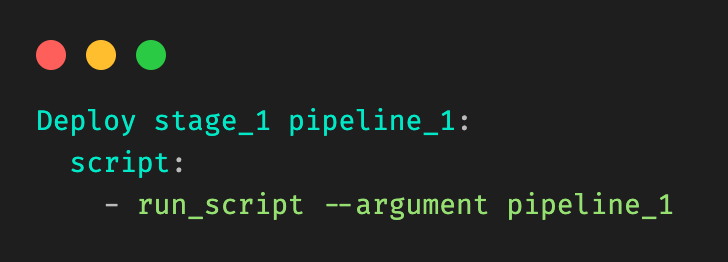
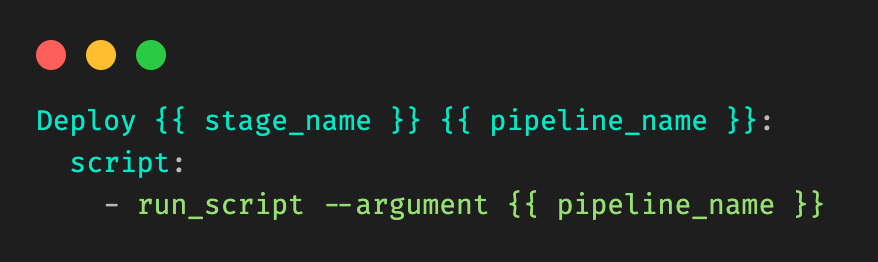
Let’s take a very simple example, where a user is modifying a file in stage_1 in pipeline_1 in Figure 1. Our desired output would be:
Figure 6: Desired output that should be dynamically generated.
Our template would be in the form of:
Figure 7: Example template, and information needed. Let’s call it template_file.yml.
First, we need to detect the files being modified in the branch. We achieve this with native git diff commands, checking against the base of the branch to track what files are being modified in the merge request. The output (let’s call it diff.txt) would be in the form of:
M pipelines/pipeline_1/stage_1/modelserving.yaml
Figure 8: Example diff.txt generated from git diff.
We must extract the yellow and green information from the line, corresponding to pipeline_name and stage_name.
Figure 9: Information that needs to be extracted from the file.
We take a very simple approach here, by introducing a concept called stop patterns.
Stop patterns are defined as a comma separated list of variable names, and the words to stop at. The colon (:) denotes how many levels before the stop word to stop.
For example, the stop pattern:
pipeline_name:pipelines
tells the parser to look for the folder pipelines and stop before that, extracting pipeline_1 from the example above tagged to the variable name pipeline_name.
The stop pattern with two colons (::):
stage_name::pipelines
tells the parser to stop two levels before the folder pipelines, and extract stage_1 as stage_name.
Our cli tool allows the stop patterns to be comma separated, so the final command would be:
We elected to write the util in Rust due to its high performance, and its rich templating libraries (for example, Tera) and decent cli libraries (clap).
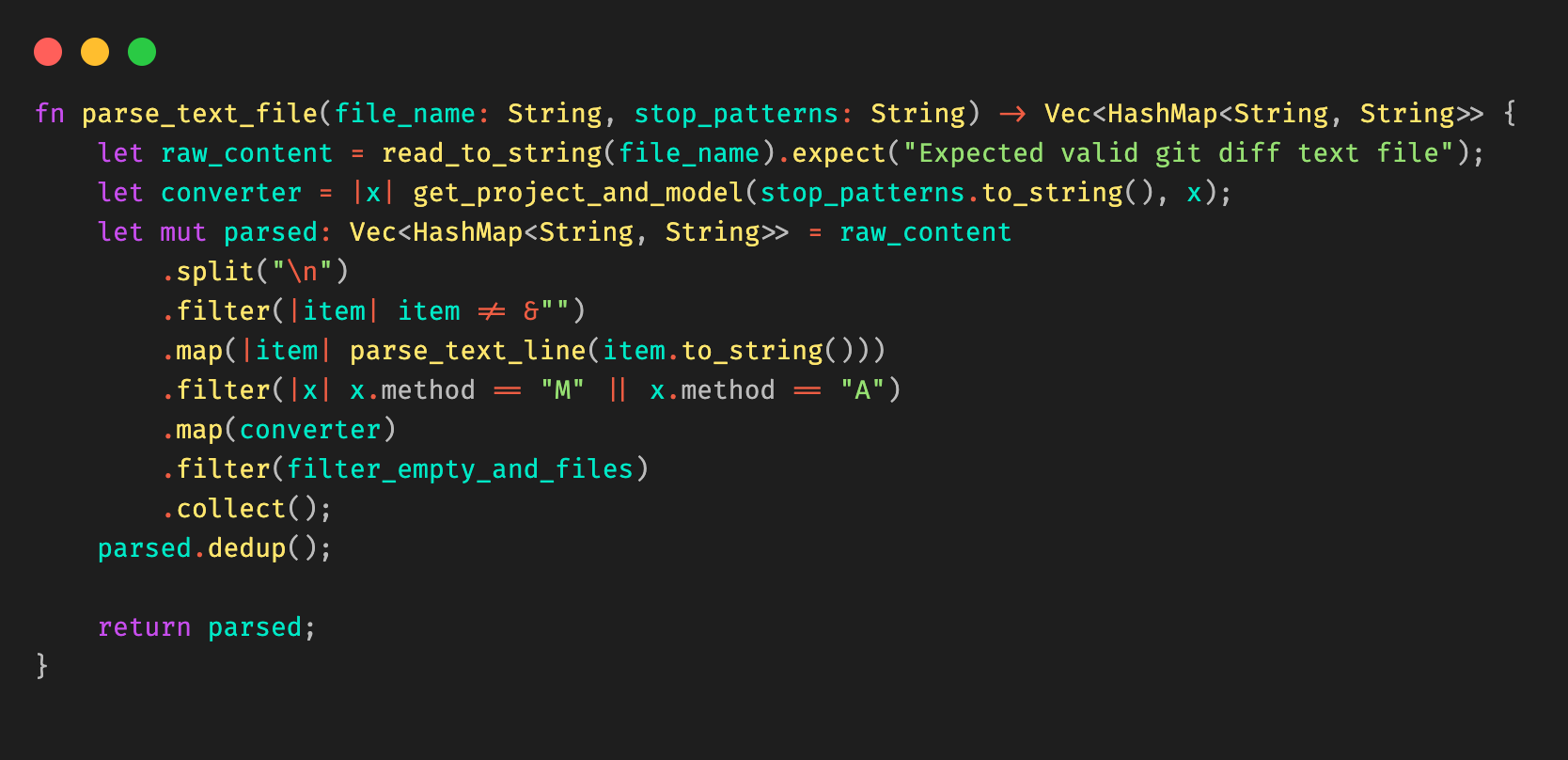
Combining all these together, we are able to extract the information needed from git diff, and use stop patterns to extract the necessary information to be passed into the template. Stop patterns are flexible enough to support different types of folder structures.
Figure 10: Example Rust code snippet for parsing the Git diff file.
When triggering pipelines in the master branch (see right side of Figure 5), the flow is the same, with a small caveat that we must retrieve the same diff.txt file from the source branch. We achieve this by using the rich GitLab API, retrieving the pipeline artifacts and using the same util above to generate the necessary GitLab steps dynamically.
Impact
After implementing this change, our biggest success was reducing one of the biggest ML pipeline Git repositories from 1800 lines to 50 lines. This approach keeps the size of the .gitlab-ci.yaml file constant at 50 lines, and ensures that it scales with however many pipelines are added.
Our users, the machine learning practitioners, also find it more productive as they no longer need to worry about GitLab yaml files.
Learnings and conclusion
With some creativity, and the flexibility of GitLab Child Pipelines, we were able to invest some engineering effort into making the configuration re-usable, adhering to DRY principles.
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
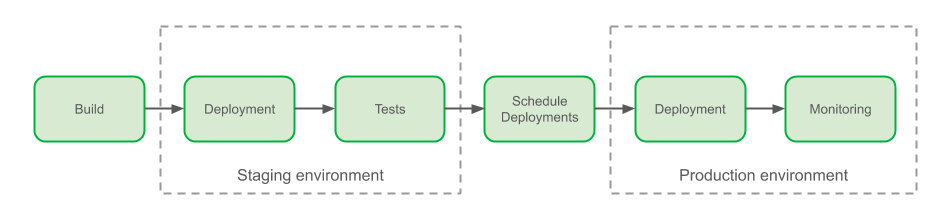
In the first part of this blog post, you’ve read about the improvements made to our build and staging deployment process, and how plenty of manual tasks routinely taken by engineers have been automated with Conveyor: an in-house continuous delivery solution.
This new post begins with the introduction of the hermeticity principle for our deployments, and how it improves the confidence with promoting changes to production. Changes sent to production via Conveyor’s deployment pipelines are then described in detail.
Overview of Grab delivery process
Finally, looking back at the engineering efficiency improvements around velocity and reliability over the last 2 years, we answer the big question – was the investment on a custom continuous delivery solution like Conveyor the right decision for Grab?
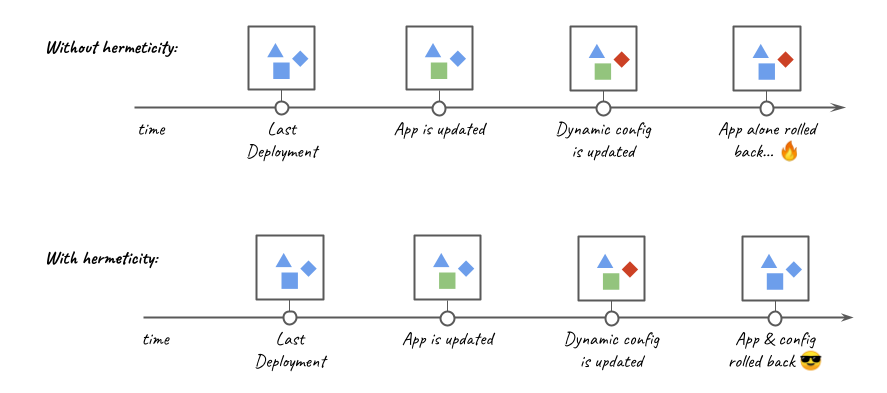
Improving Confidence in our Production Deployments with Hermeticity
The term deployment hermeticity is borrowed from build systems. A build system is called hermetic if builds always produce the same artefacts regardless of changes in the environment they run on. Similarly, we call our deployments hermetic if they always result in the same deployed artefacts regardless of the environment’s change or the number of times they are executed.
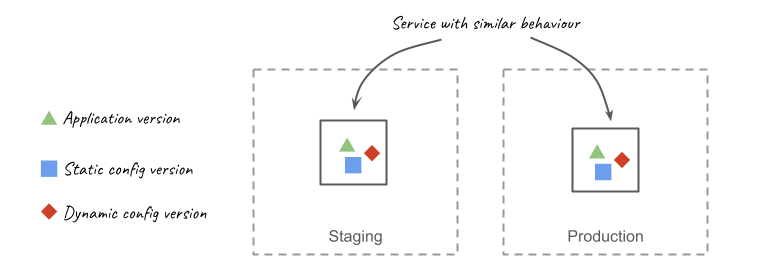
The behaviour of a service is rarely controlled by a single variable. The application that makes up your service is an important driver of its behaviour, but its configuration is an important contributor, for example. The behaviour for traditional microservices at Grab is dictated mainly by 3 versioned artefacts: application code, static and dynamic configuration.
Conveyor has been integrated with the systems that operate changes in each of these parameters. By tracking all 3 parameters at every deployment, Conveyor can reproducibly deploy microservices with similar behaviour: its deployments are hermetic.
Building upon this property, Conveyor can ensure that all deployments made to production have been tested before with the same combination of parameters. This is valuable to us:
An outcome of staging deployments for a specific set of parameters is a good predictor of outcomes in production deployments for the same set of parameters and thus it makes testing in staging more relevant.
Rollbacks are hermetic; we never rollback to a combination of parameters that has not been used previously.
In the past, incidents had resulted from an application rollback not compatible with the current dynamic configuration version; this was aggravating since rollbacks are expected to be a safe recovery mechanism. The introduction of hermetic deployments has largely eliminated this category of problems.
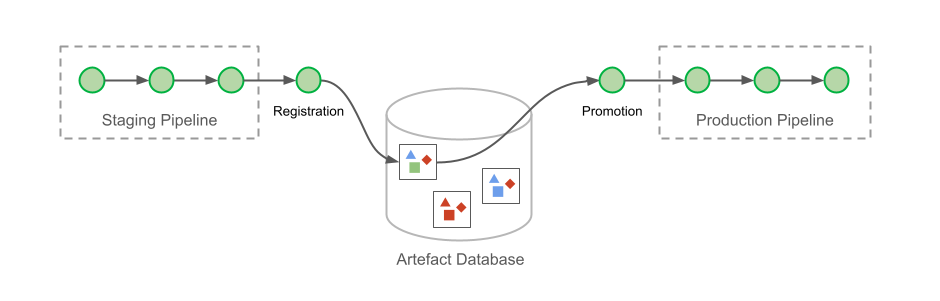
Hermeticity is maintained by registering the deployment parameters as artefacts after each successfully completed pipeline. Users must then select one of the registered deployment metadata to promote to production.
At this point, you might be wondering: why not use a single pipeline that includes both staging and production deployments? This was indeed how it started, with a single pipeline spanning multiple environments. However, engineers soon complained about it.
The most obvious reason for the complaint was that less than 20% of changes deployed in staging will make their way to production. This meant that engineers would have toil associated with each completed staging deployment since the pipeline must be manually cancelled rather than continued to production.
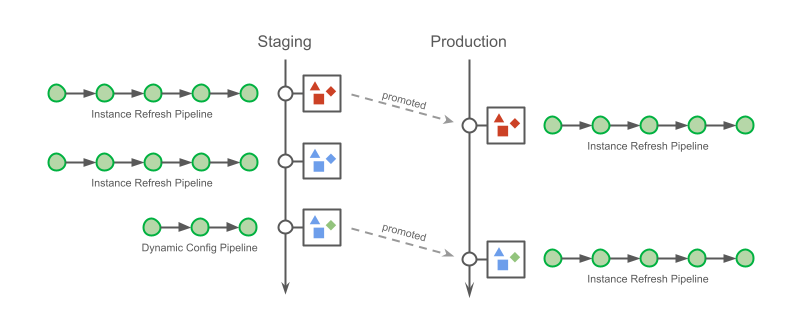
The other reason is that this multi-environment pipeline approach reduced flexibility when promoting changes to production. There are different ways to apply changes to a cluster. For example, lengthy pipelines that refresh instances can be used to deploy any combination of changes, while there are quicker pipelines restricted to dynamic configuration changes (such as feature flags rollouts). Regardless of the order in which the changes are made and how they are applied, Conveyor tracks the change.
Eventually, engineers promote a deployment artefact to production. However they do not need to apply changes in the same sequence with which were applied to staging. Furthermore, to prevent erroneous actions, Conveyor presents only changes that can be applied with the requested pipeline (and sometimes, no changes are available). Not being forced into a specific method of deploying changes is one of added benefits of hermetic deployments.
Returning to Our Journey Towards Engineering Efficiency
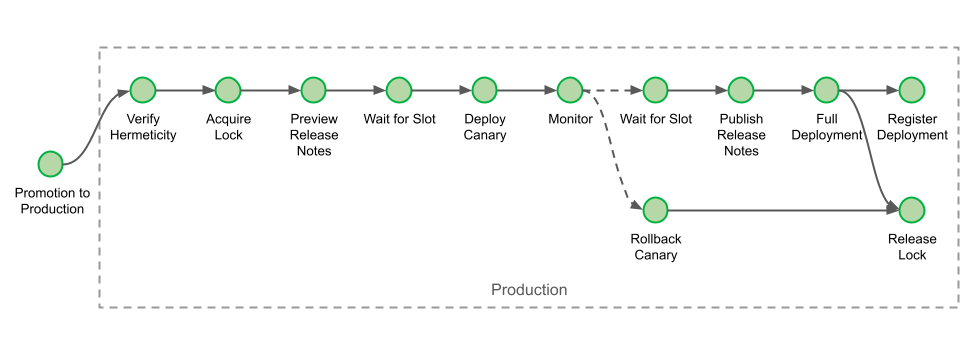
If you can recall, the first part of this blog post series ended with a description of staging deployment. Our deployment to production starts with a verification that we uphold our hermeticity principle, as explained above.
Our production deployment pipelines can run for several hours for large clusters with rolling releases (few run for days), so we start by acquiring locks to ensure there are no concurrent deployments for any given cluster.
Before making any changes to the environment, we automatically generate release notes, giving engineers a chance to abort if the wrong set of changes are sent to production.
The pipeline next waits for a deployment slot. Early on, engineers adopted deployment windows that coincide with office hours, such that if anything goes wrong, there is always someone on hand to help. Prior to the introduction of Conveyor, however, engineers would manually ask a Slack bot for approval. This interaction is now automated, and the only remaining action left is for the engineer to approve that the deployment can proceed via a single click, in line with our hands-off deployment principle.
When the canary is in production, Conveyor automates monitoring it. This process is similar to the one already discussed in the first part of this blog post: Engineers can configure a set of alerts that Conveyor will keep track of. As soon as any one of the alerts is triggered, Conveyor automatically rolls back the service.
If no alert is raised for the duration of the monitoring period, Conveyor waits again for a deployment slot. It then publishes the release notes for that deployment and completes the deployments for the cluster. After the lock is released and the deployment registered, the pipeline finally comes to its successful completion.
Benefits of Our Journey Towards Engineering Efficiency
All these improvements made over the last 2 years have reduced the effort spent by engineers on deployment while also reducing the failure rate of our deployments.
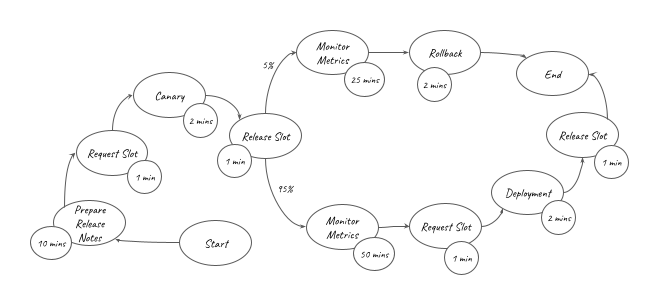
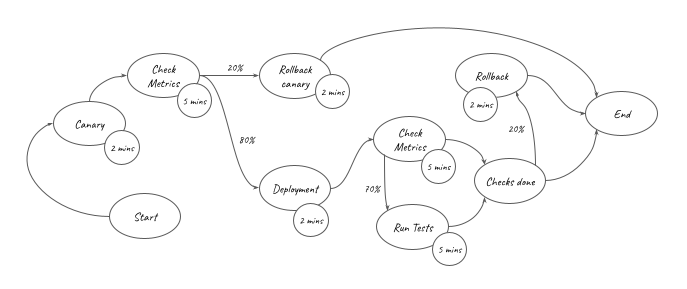
If you are an engineer working on DevOps in your organisation, you know how hard it can be to measure the impact you made on your organisation. To estimate the time saved by our pipelines, we can model the activities that were previously done manually with a rudimentary weighted graph. In this graph, each edge carries a probability of the activity being performed (100% when unspecified), while each vertex carries the time taken for that activity.
Focusing on our regular staging deployments only, such a graph would look like this:
The overall amount of effort automated by the staging pipelines () is represented in the graph above. It can be converted into the equation below:
This equation shows that for each staging deployment, around 16 minutes of work have been saved. Similarly, for regular production deployments, we find that 67 minutes of work were saved for each deployment:
Moreover, efficiency was not the only benefit brought by the use of deployment pipelines for our traditional microservices. Surprisingly perhaps, the rate of failures related to production changes is progressively reducing while the amount of production changes that were made with Conveyor increased across the organisation (starting at 1.5% of failures per deployments, and finishing at 0.3% on average over the last 3 months for the period of data collected):
Keep Calm and Automate
Since the first draft for this post was written, we’ve made many more improvements to our pipelines. We’ve begun automating Database Migrations; we’ve extended our set of hermetic variables to Amazon Machine Image (AMI) updates; and we’re working towards supporting container deployments.
Through automation, all of Conveyor’s deployment pipelines have contributed to save more than 5,000 man-days of efforts in 2020 alone, across all supported teams. That’s around 20 man-years worth of effort, which is around 3 times the capacity of the team working on the project! Investments in our automation pipelines have more than paid for themselves, and the gains go up every year as more workflows are automated and more teams are onboarded.
If Conveyor has saved efforts for engineering teams, has it then helped to improve velocity? I had opened the first part of this blog post with figures on the deployment funnel for microservice teams at Grab, towards the end of 2018. So where do the figures stand today for these teams?
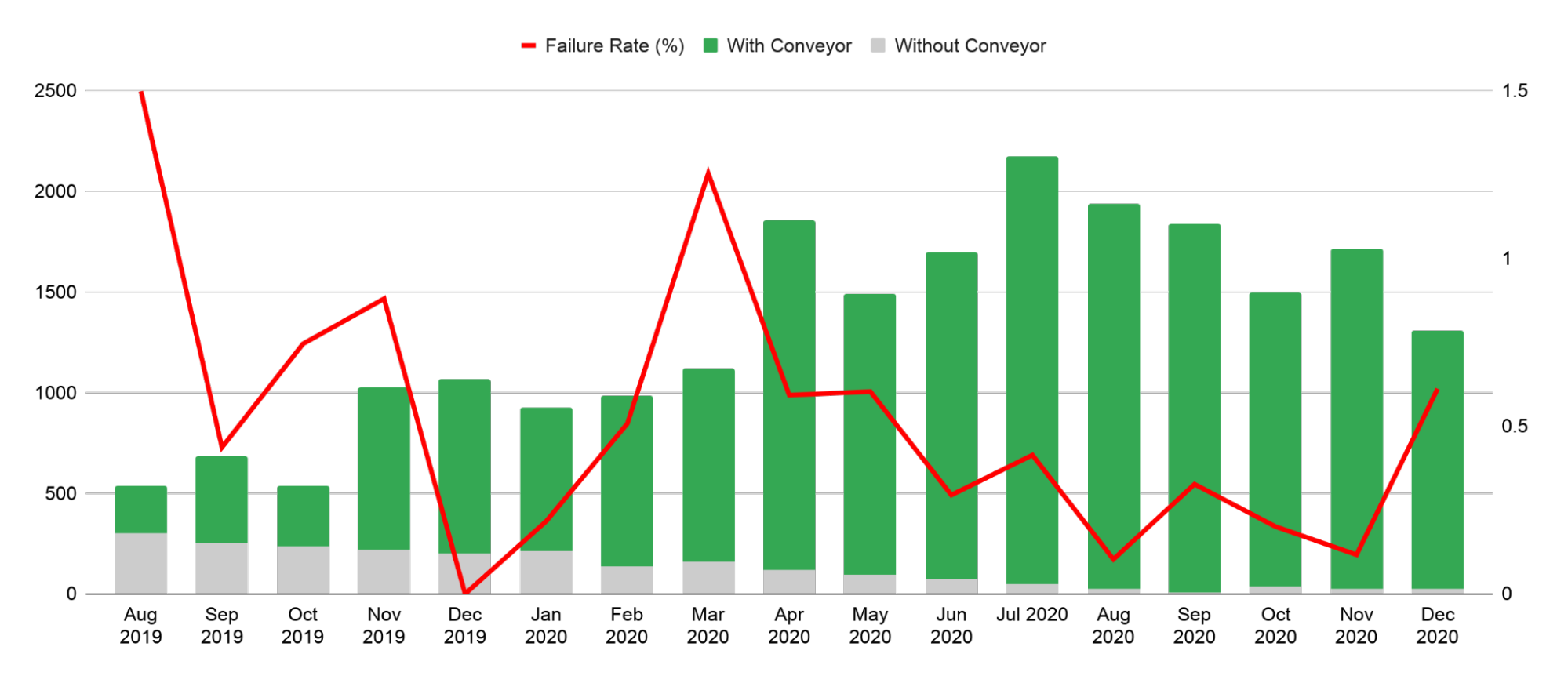
In the span of 2 years, the average number of build and staging deployment performed each day has not varied much. However, in the last 3 months of 2020, engineers have sent twice more changes to production than they did for the same period in 2018.
Perhaps the biggest recognition received by the team working on the project, was from Grab’s engineers themselves. In the 2020 internal NPS survey for engineering experience at Grab, Conveyor received the highest score of any tools (built in-house or not).
All these improvements in efficiency for our engineers would never have been possible without the hard work of all team members involved in the project, past and present: Tanun Chalermsinsuwan, Aufar Gilbran, Deepak Ramakrishnaiah, Repon Kumar Roy (Kowshik), Su Han, Voislav Dimitrijevikj, Stanley Goh, Htet Aung Shine, Evan Sebastian, Qijia Wang, Oscar Ng, Jacob Sunny, Subhodip Mandal and many others who have contributed and collaborated with them.
Join Us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
This blog post is a two-part presentation of the effort that went into improving the continuous delivery processes for backend services at Grab in the past two years. In the first part, we take stock of where we started two years ago and describe the software and tools we created while introducing some of the integrations we’ve done to automate our software delivery in our staging environment.
Continuous Delivery is the principle of delivering software often, every day.
As a backend engineer at Grab, nothing matters more than the ability to innovate quickly and safely. Around the end of 2018, Grab’s transportation and deliveries backend architecture consisted of roughly 270 services (the majority being microservices). The deployment process was lengthy, required careful inputs and clear communication. The care needed to push changes in production and the risk associated with manual operations led to the introduction of a Slack bot to coordinate deployments. The bot ensures that deployments occur only during off-peak and within work hours:
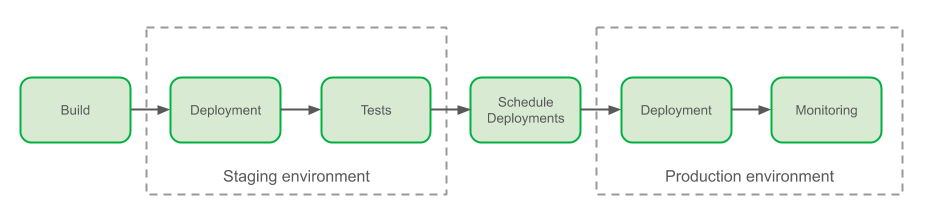
Overview of the Grab Delivery Process
Once the build was completed, engineers who desired to deploy their software to the Staging environment would copy release versions from the build logs, and paste them in a Jenkins job’s parameter. Tests needed to be manually triggered from another dedicated Jenkins job.
Prior to production deployments, engineers would generate their release notes via a script and update them manually in a wiki document. Deployments would be scheduled through interactions with a Slack bot that controls release notes and deployment windows. Production deployments were made once again by pasting the correct parameters into two dedicated Jenkins jobs, one for the canary (a.k.a. one-box) deployment and the other for the full deployment, spread one hour apart. During the monitoring phase, engineers would continuously observe metrics reported on our dashboards.
In spite of the fragmented process and risky manual operations impacting our velocity and stability, around 614 builds were running each business day and changes were deployed on our staging environment at an average rate of 300 new code releases per business day, while production changes averaged a rate of 28 new code releases per business day.
Our Deployment Funnel, Towards the End of 2018
These figures meant that, on average, it took 10 business days between each service update in production, and only 10% of the staging deployments were eventually promoted to production.
Automating Continuous Deployments at Grab
With an increased focus on Engineering efficiency, in 2018 we started an internal initiative to address frictions in deployments that became known as Conveyor. To build Conveyor with a small team of engineers, we had to rely on an already mature platform which exhibited properties that are desirable to us to achieve our mission.
Hands-off deployments
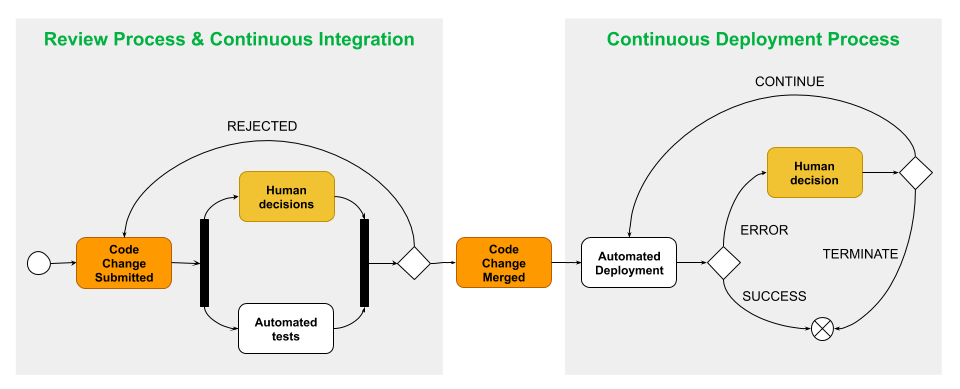
Deployments should be an afterthought. Engineers should be as removed from the process as possible, and whenever possible, decisions should be taken early, during the code review process. The machine will do the heavy lifting, and only when it can’t decide for itself, should the engineer be involved. Notifications can be leveraged to ensure that engineers are only informed when something goes wrong and a human decision is required.
Hands-off Deployment Principle
Confidence in Deployments
Grab’s focus on gathering internal Engineering NPS feedback helped us collect valuable metrics. One of the metrics we cared about was our engineers’ confidence in their production deployments. A team’s entire deployment process to production could last for more than a day and may extend up to a week for teams with large infrastructures running critical services. The possibility of losing progress in deployments when individual steps may last for hours is detrimental to the improvement of Engineering efficiency in the organisation. The deployment automation platform is the bedrock of that confidence. If the platform itself fails regularly or does provide a path of upgrade that is transparent to end-users, any features built on top of it would suffer from these downtimes and ultimately erode confidence in deployments.
Tailored To Most But Extensible For The Few
Our backend engineering teams are working on diverse stacks, and so are their deployment processes. Right from the start, we wanted our product to benefit the largest population of engineers that had adopted the same process, so as to maximize returns on our investments. To ease adoption, we decided to tailor a deployment pipeline such that:
It would model the exact sequence of manual processes followed by this population of engineers.
Switching to use that pipeline should require as little work as possible by service teams.
However, in cases where this model would not fit a team’s specific process, our deployment platform should be open and extensible and support new customizations even when they are not originally supported by the product’s ecosystem.
Cloud-Agnosticity
While we were going to target a specific process and team, to ensure that our solution would stand the test of time, we needed to ensure that our solution would support the variety of environments currently used in production. This variety was also likely to increase, and we wanted a platform that would mature together with the rest of our ecosystem.
Overview Of Conveyor
Setting Sail With Spinnaker
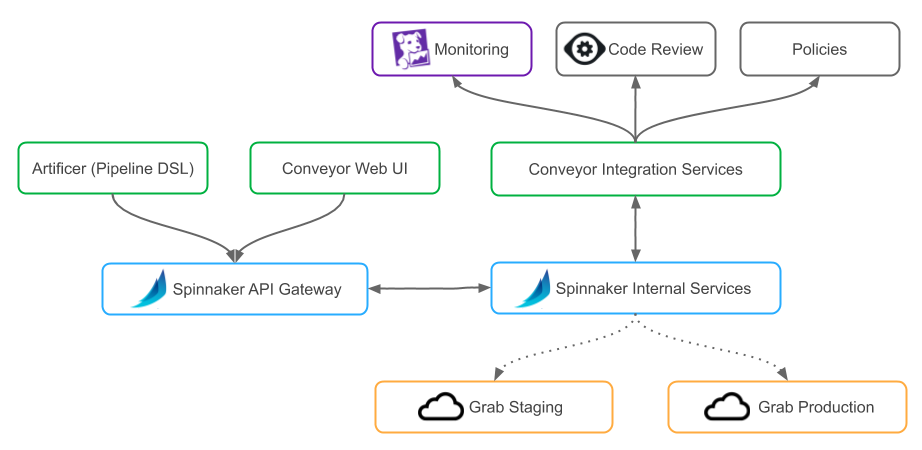
Conveyor is based on Spinnaker, an open-source, multi-cloud continuous delivery platform. We’ve chosen Spinnaker over other platforms because it is a mature deployment platform with no single point of failure, supports complex workflows (referred to as pipelines in Spinnaker), and already supports a large array of cloud providers. Since Spinnaker is open-source and extensible, it allowed us to add the features we needed for the specificity of our ecosystem.
To further ease adoption within our organization, we built a tailored user interface and created our own domain-specific language (DSL) to manage its pipelines as code.
Outline of Conveyor’s Architecture
Onboarding To A Simpler Interface
Spinnaker comes with its own interface, it has all the features an engineer would want from an advanced continuous delivery system. However, Spinnaker interface is vastly different from Jenkins and makes for a steep learning curve.
To reduce our barrier to adoption, we decided early on to create a simple interface for our users. In this interface, deployment pipelines take the center stage of our application. Pipelines are objects managed by Spinnaker, they model the different steps in the workflow of each deployment. Each pipeline is made up of stages that can be assembled like lego-bricks to form the final pipeline. An instance of a pipeline is called an execution.
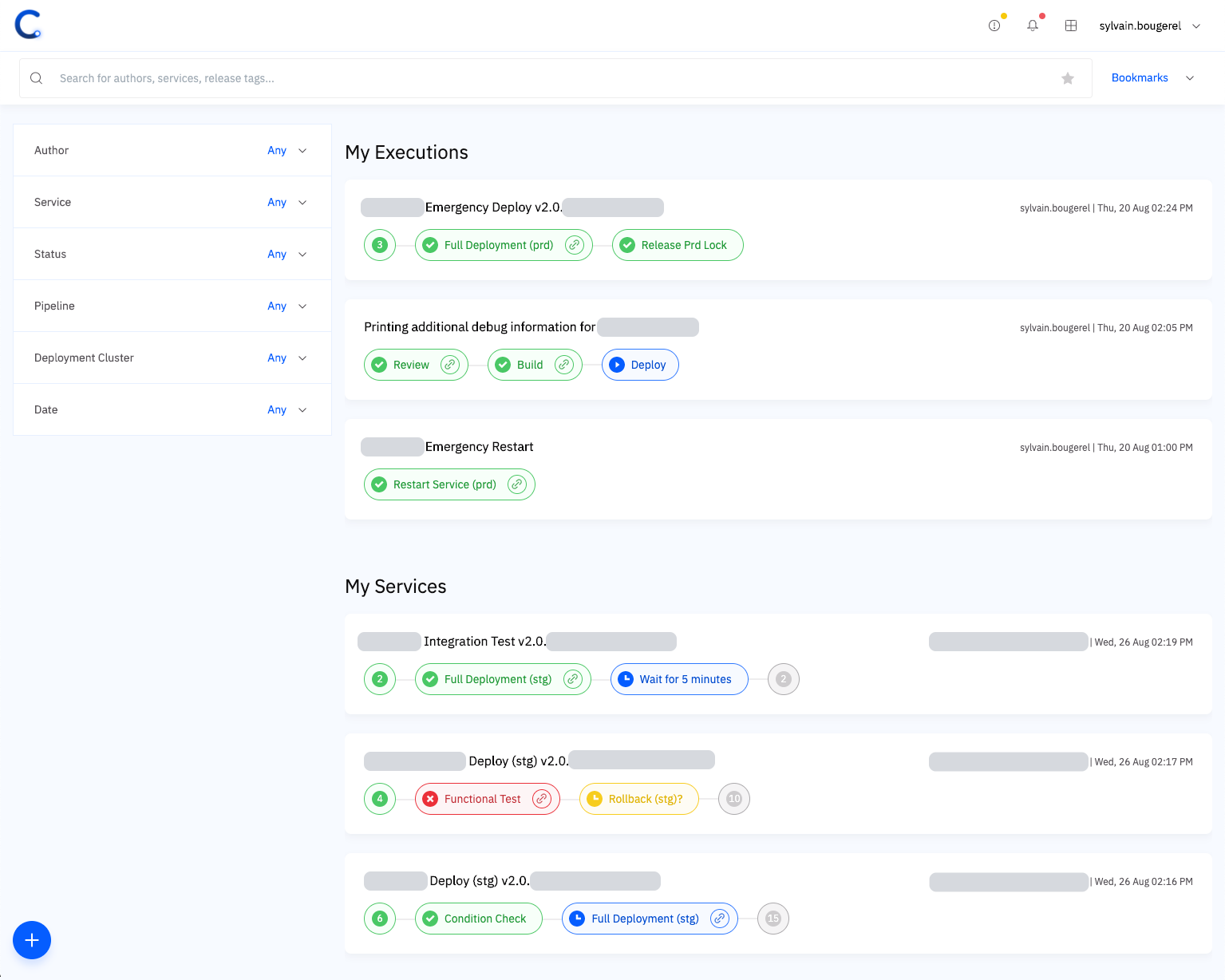
Conveyor Dashboard
With this interface, each engineer can focus on what matters to them immediately: the pipeline they have started, or those started by other teammates working on the same services as they are. Conveyor also provides a search bar (on the top) and filters (on the left) that work in concert to explore all pipelines executed at Grab.
We adopted a consistent set of colours to model all information in our interface:
blue: represent stages that are currently running;
red: stages that have failed or important information;
yellow: stages that require human interaction;
and finally, in green: stages that were successfully completed.
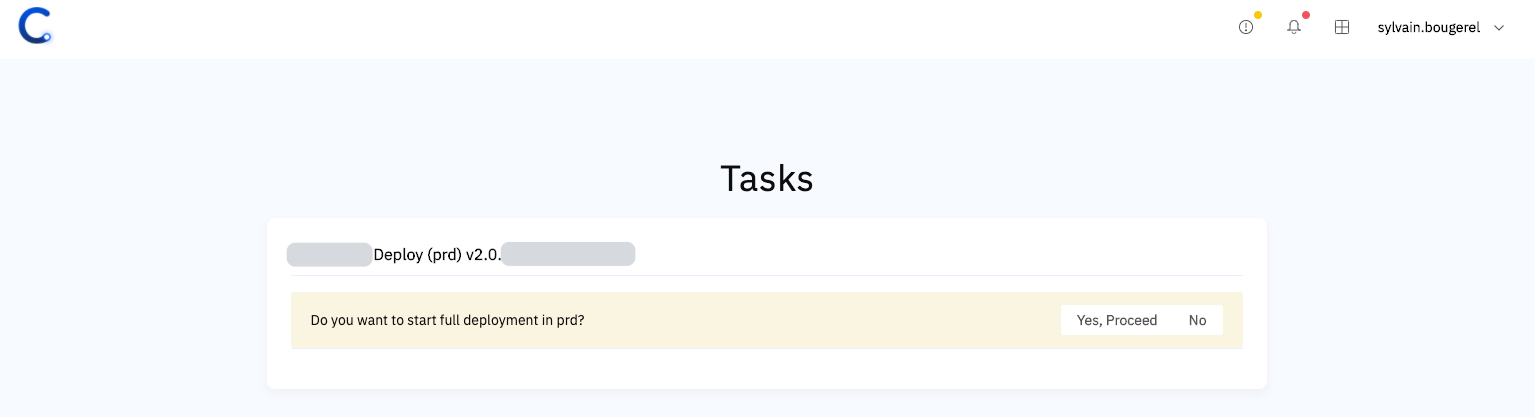
Conveyor also provides a task and notifications area, where all stages requiring human intervention are listed in one location. Manual interactions are often no more than just YES or NO questions:
Conveyor Tasks
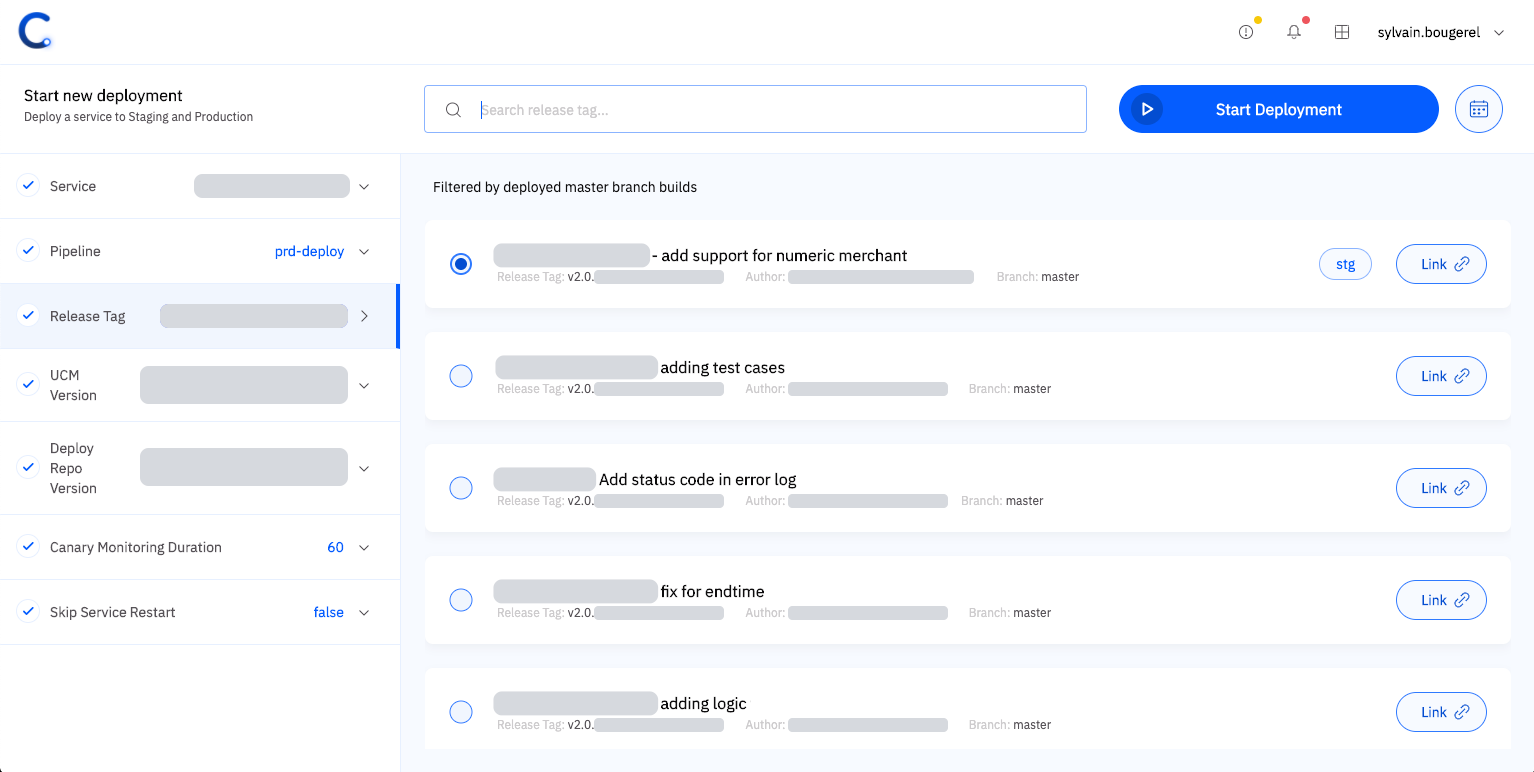
Finally, in addition to supporting automated deployments, we greatly simplified the start of manual deployments. Instead of being required to copy/paste information, each parameter can be selected on the interface from a set of predefined items, sorted chronologically, and presented with contextual information to help engineers in their decision.
Several parameters are required for our deployments and their values are selected from the UI to ensure correctness.
Simplified Manual Deployments
Ease Of Adoption With Our Pipeline-As-Code DSL
Ease of adoption for the team is not simply about the learning curve of the new tools. We needed to make it easy for teams to configure their services to deploy with Conveyor. Since we focused on automating tasks that were already performed manually, we needed only to configure the layer that would enable the integration.
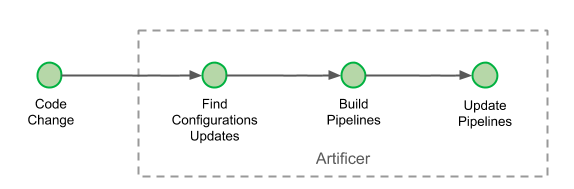
We set on creating a pipeline-as-code implementation when none were widely being developed in the Spinnaker community. It’s interesting to see that two years on, this idea has grown in parallel in the community, with the birth of other pipeline-as-code implementations. Our pipeline-as-code is referred to as the Pipeline DSL, and its configuration is located inside each team’s repository. Artificer is the name of our Pipeline DSL interpreter and it runs with every change inside our monorepository:
Artificer: Our Pipeline DSL
Pipelines are being updated at every commit if necessary.
Creating a conveyor.jsonnet file inside with the service’s directory of our monorepository with the few lines below is all that’s required for Artificer to do its work and get the benefits of automation provided by Conveyor’s pipeline:
Sample minimal conveyor.jsonnet configuration to onboard services.
In this file, engineers simply specify the name of their service and the group that a user should belong to, to have deployment rights for the service.
Once the build is completed, teams can log in to Conveyor and start manual deployments of their services with our pipelines. Three pipelines are provided by default: the integration pipeline used for tests and developments, the staging pipeline used for pre-production tests, and the production pipeline for production deployment.
Thanks to the simplicity of this minimal configuration file, we were able to generate these configuration files for all existing services of our monorepository. This resulted in the automatic onboarding of a large number of teams and was a major contributing factor to the adoption of Conveyor throughout our organisation.
Our Journey To Engineering Efficiency (for backend services)
The sections below relate some of the improvements in engineering efficiency we’ve delivered since Conveyor’s inception. They were not made precisely in this order but for readability, they have been mapped to each step of the software development lifecycle.
Automate Deployments at Build Time
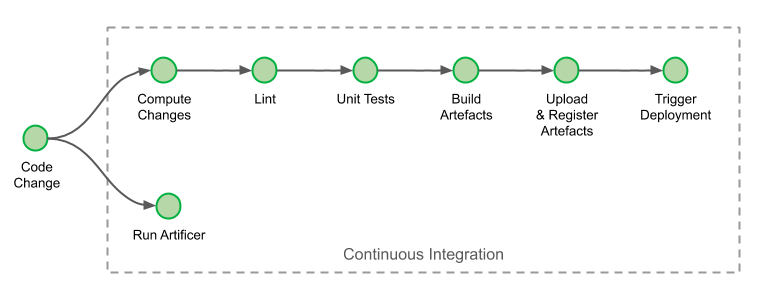
Continuous Integration Job
Continuous delivery begins with a pushed code commit in our trunk-based development flow. Whenever a developer pushes changes onto their development branch or onto the trunk, a continuous integration job is triggered on Jenkins. The products of this job (binaries, docker images, etc) are all uploaded into our artefact repositories. We’ve made two additions to our continuous integration process.
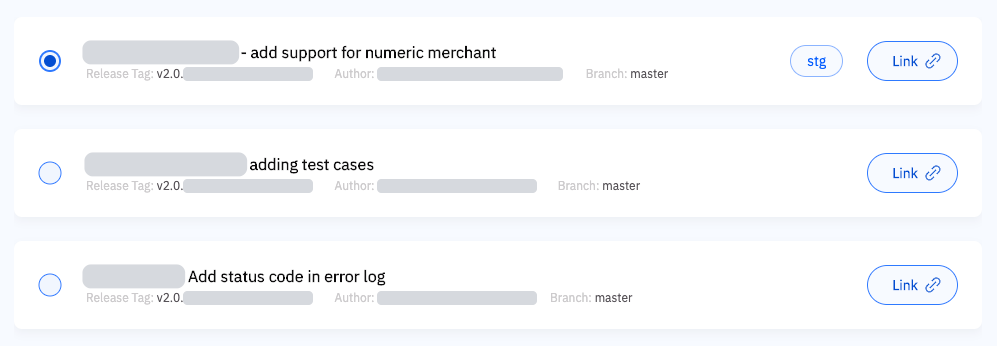
The first modification happens at the step “Upload & Register artefacts”. At this step, each artefact created is now registered in Conveyor with its associated metadata. When and if an engineer needs to trigger a deployment manually, Conveyor can display the list of versions to choose from, eliminating the need for error-prone manual inputs:
Staging
Each selectable version shows contextual information: title, author, version and link to the code change where it originated. During registration, the commit time is also recorded and used to order entries chronologically in the interface. To ensure this integration is not a single point of failure for deployments, manual input is still available optionally.
The second modification implements one of the essential feature continuous delivery: your deployments should happen often, automatically. Engineers are now given the possibility to start automatic deployments once continuous integration has successfully completed, by simply modifying their project’s continuous integration settings:
Sample settings needed to trigger auto-deployments. ‘Diff’ refers to code review submissions, and ‘Land’ refers to merged code changes.
Staging Pipeline
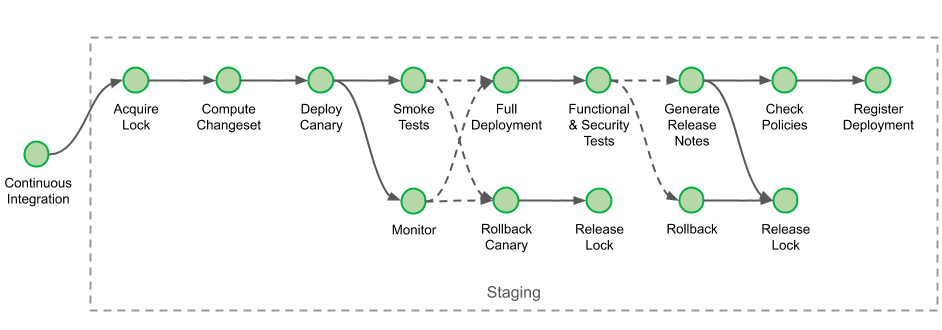
Before deploying a new artefact to a service in production, changes are validated on the staging environment. During the staging deployment, we verify that canary (one-box) deployments and full deployments with automated smoke and functional tests suites.
Staging Pipeline
We start by acquiring a deployment lock for this service and this environment. This prevents another deployment of the same service on the same environment to happen concurrently, other deployments will be waiting in a FIFO queue until the lock is released.
The stage “Compute Changeset” ensures that the deployment is not a rollback. It verifies that the new version deployed does not correspond to a rollback by comparing the ancestry of the commits provided during the artefact registration at build time: since we automate deployments after the build process has completed, cases of rollback may occur when two changes are created in quick succession and the latest build completes earlier than the older one.
After the stage “Deploy Canary” has completed, smoke test run. There are three kinds of tests executed at different stages of the pipeline: smoke, functional and security tests. Smoke tests directly reach the canary instance’s endpoint, by-passing load-balancers. If the smoke tests fail, the canary is immediately rolled back and this deployment is terminated.
All tests are generated from the same builds as the artefact being tested and their versions must match during testing. To ensure that the right version of the test run and distinguish between the different kind of tests to perform, we provide additional metadata that will be passed by Conveyor to the tests system, known internally as Gandalf:
Sample conveyor.jsonnet configuration with integration tests added.
Additionally, in parallel to the execution of the smoke tests, the canary is also being monitored from the moment its deployment has completed and for a predetermined duration. We leverage our integration with Datadog to allow engineers to select the alerts to monitor. If an alert is triggered during the monitoring period, and while the tests are executed, the canary is again rolled back, and the pipeline is terminated. Engineers can specify the alerts by adding them to the conveyor.jsonnet configuration file together with the monitoring duration:
Sample conveyor.jsonnet configuration with alerts in staging added.
When the smoke tests and monitor pass and the deployment of new artefacts is completed, the pipeline execution triggers functional and security tests. Unlike smoke tests, functional & security tests run only after that step, as they communicate with the cluster through load-balancers, impersonating other services.
Before releasing the lock, release notes are generated to inform engineers of the delta of changes between the version they just released and the one currently running in production. Once the lock is released, the stage “Check Policies” verifies that the parameters and variable of the deployment obeys a specific set of criteria, for example: if its service metadata is up-to-date in our service inventory, or if the base image used during deployment is sufficiently recent.
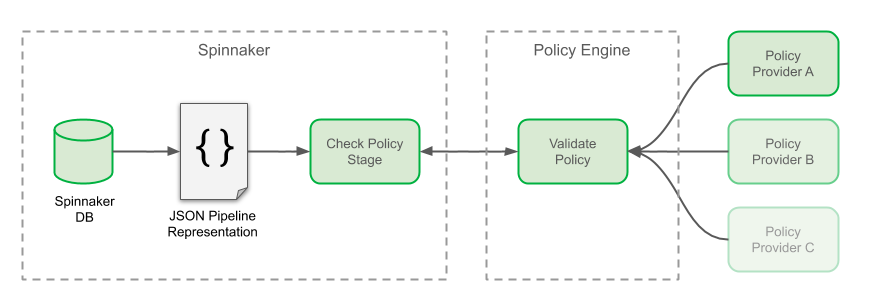
Here’s how the policy stage, the engine, and the providers interact with each other:
Check Policy Stage
In Spinnaker, each event of a pipeline’s execution updates the pipeline’s state in the database. The current state of the pipeline can be fetched by its API as a single JSON document, describing all information related to its execution: including its parameters, the contextual information related to each stage or even the response from the various interfacing components. The role of our “Policy Check” stage is to query this JSON representation of the pipeline, to extract and transform the variables which are forwarded to our policy engine for validation. Our policy engine gathers judgements passed by different policy providers. If the validation by the policy engine fails, the deployment is not rolled back this time; however, promotion to production is not possible and the pipeline is immediately terminated.
The journey through staging deployment finally ends with the stage “Register Deployment”. This stage registers that a successful deployment was made in our staging environment as an artefact. Similarly to the policy check above, certain parameters of the deployment are picked up and consolidated into this document. We use this kind of artefact as proof for upcoming production deployment.
Continuing Our Journey to Engineering Efficiency
With the advancements made in continuous integration and deployment to staging, Conveyor has reduced the efforts needed by our engineers to just three clicks in its interface, when automated deployment is used. Even when the deployment is triggered manually, Conveyor gives the assurance that the parameters selected are valid and it does away with copy/pasting and human interactions across heterogeneous tools.
In the sequel to this blog post, we’ll dive into the improvements that we’ve made to our production deployments and introduce a crucial concept that led to the creation of our proof for successful staging deployment. Finally, we’ll cover the impact that Conveyor had on the continuous delivery of our backend services, by comparing our deployment velocity when we started two years ago versus where we are today.
All these improvements in efficiency for our engineers would never have been possible without the hard work of all team members involved in the project, past and present: Evan Sebastian, Tanun Chalermsinsuwan, Aufar Gilbran, Deepak Ramakrishnaiah, Repon Kumar Roy (Kowshik), Su Han, Voislav Dimitrijevikj, Qijia Wang, Oscar Ng, Jacob Sunny, Subhodip Mandal, and many others who have contributed and collaborated with them.
Join us
Grab is more than just the leading ride-hailing and mobile payments platform in Southeast Asia. We use data and technology to improve everything from transportation to payments and financial services across a region of more than 620 million people. We aspire to unlock the true potential of Southeast Asia and look for like-minded individuals to join us on this ride.
If you share our vision of driving South East Asia forward, apply to join our team today.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.


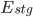 ) is represented in the graph above. It can be converted into the equation below:
) is represented in the graph above. It can be converted into the equation below: