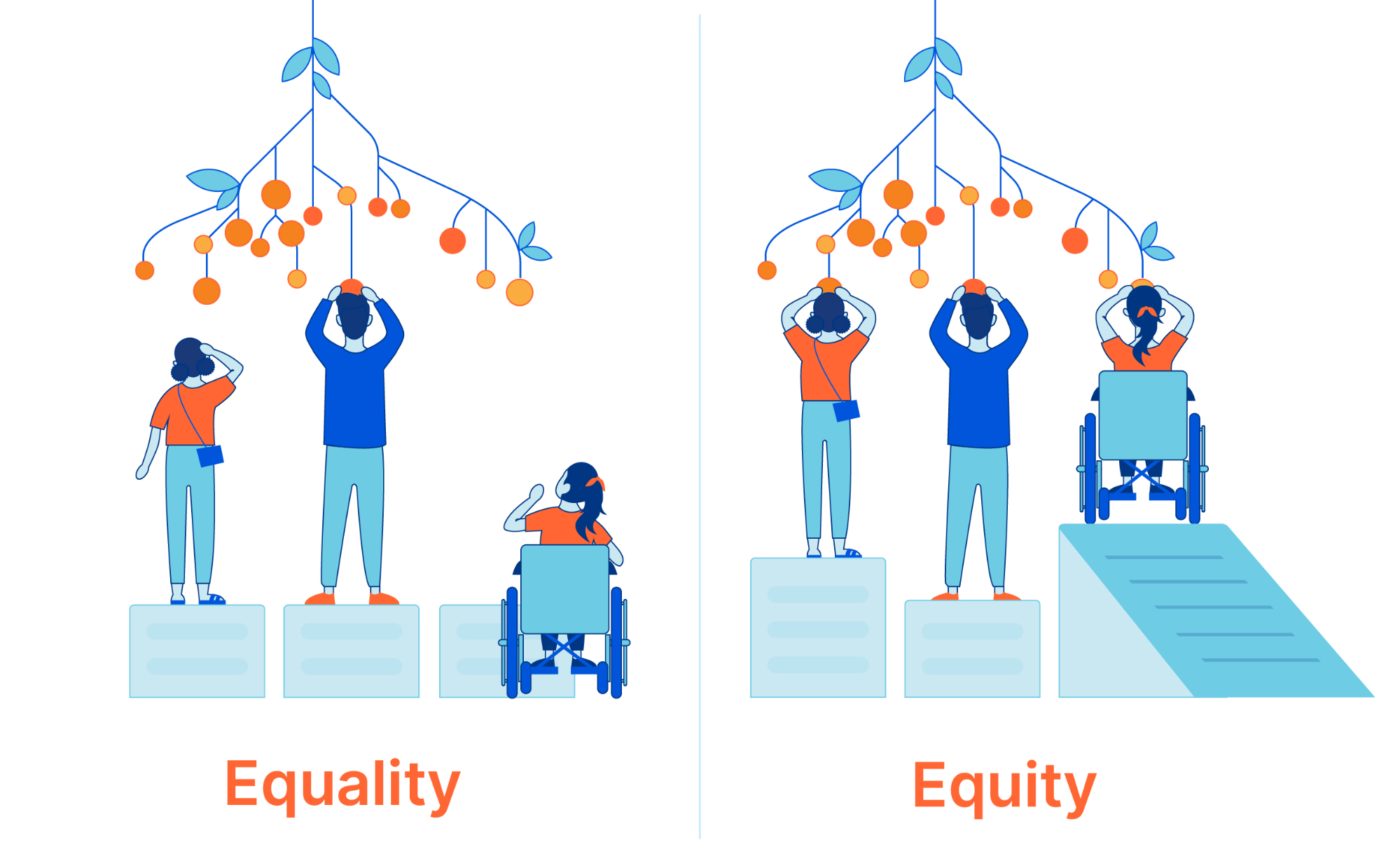
Happy International Women’s Day! The global theme for 2023 is #EmbraceEquity, which is part of an ongoing effort to raise awareness around “Why equal opportunities are no longer enough.” Today is a time to highlight achievements made by women, but also an opportunity to become better informed, and collaborate and brainstorm about the path forward.
“People start from different places, so true inclusion and belonging require equitable action.” — internationalwomensday.com
Help put an end to gender bias and discrimination
Consider taking a few minutes today to learn about pervasive challenges affecting women, including in the workplace. Since unconscious bias is a major driver of hurdles holding women back, it is beneficial for people of all gender identities to educate ourselves about the varied experiences of others.
Here are some resources to get help get you started:
Read highlights from the Women in the Workplace report from McKinsey and LeanIn.Org to examine factors that are holding women back from advancement and in many cases making them decide to leave a company. One notable statistic: “For every 100 men who are promoted from entry-level roles to manager positions, only 87 women are promoted, and only 82 women of color are promoted.”
Watch a five-minute video of the history of the concept of intersectionality, explained by Kimberlé Crenshaw, who coined the term. Intersectionality refers to the “double bind of simultaneous racial and gender prejudice.”
Better understand challenges within the tech sector in the reportWhat (and Who) is Holding Women Back in Tech? One finding from this survey, conducted by Girls Who Code and Logitech, is that 90% of women report experiencing microaggressions at work. The report describes key career drivers and the importance of communities of support.
What is Womenflare and how are we celebrating International Women’s Day?
Womenflare is a Cloudflare employee resource group (ERG) for women and people who advocate for women. We are an employee-led group that is here to empower, represent, and support.
At Cloudflare, we are continuing our tradition of building community and celebrating women’s achievements together throughout March. We are also encouraging discussion on equity vs. equality and how we can champion equity for ourselves and those around us with these internal events in the weeks ahead:
Celebrating with comedy: We are kicking things off with some fun and jokes from Laugh.Events! Offering “Laughter as a Service (LaaS),” they will deliver stand-up comedy, musical comedy, and other comedic activities for a celebratory “Workplace Variety Hour.”
Equity and allyship chats:After our celebrations, we are opening forums to discuss equity and what this means for each of us in our unique intersectionalities. We have invited some of our fellow employee resource group leads from Asianflare, Nativeflare, and Proudflare to share with us and dive into how we can be both supported and supportive.
Equity leadership panel:Our internal leadership panels were always well received in previous years, so we decided not to mess with a good thing. This year, we will be inviting another group of inspirational women leaders in Cloudflare to share their experiences with us and explore the areas where we can promote equity in the workplace.
And more: We have so much more planned for March! From Book Club and meetups to Cloudflare TV episodes and networking events, we are partnering across teams to ensure there are plenty of opportunities to participate and join in on the fun and discussions.
No matter how you plan to celebrate International Women’s Day and Women’s History Month, consider how you can do your part to champion an equitable world. Join the #IWD2023 movement — #EmbraceEquity today (and every day)!
Life at Cloudflare
Learn more about how we are cultivating community, including through employee resource groups like Womenflare, via our careers page—and check out our open positions.
To read about our progress on the UN Ten Principles and the Sustainable Development Goals (SDGs), download our latest Impact Report.
“I would venture to guess that Anon, who wrote so many poems without signing them, was often a woman.” – Virginia Woolf
Welcome to International Women’s Day 2022! Here at Cloudflare, we are happy to celebrate it with you! Our celebration is not only this blog post, but many events prepared for the month of March: our way of honoring Women’s History Month by showcasing women’s empowerment. We want to celebrate the achievements, ideas, passion and work that women bring to the world. We want to advocate for equality and to achieve gender parity. And we want to highlight the brilliant work that our women colleagues do every day. Welcome!
This is a time of celebration but also one to reflect on the current state. The global gender gap is not expected to close for another 136 years. This gap has also worsened due to the COVID-19 pandemic, which has negatively impacted the lives of women and girls by deepening pre-existing inequalities. Improving this state is a collective effort—we all need to get involved!
Who are we? Womenflare!
First, let’s introduce ourselves. We are Womenflare—Cloudflare’s Employee Resource Group (ERG) for all who identify as and advocate for women. We’re an employee-led group that is here to empower, represent, and support.
Our purpose is not only to celebrate women’s achievements but also to shed a light on inequalities. That is why for International Women’s Day 2022, we’re joining in focusing on the theme of #BreakTheBias throughout our month of events and activities:
We can break the bias in our communities.
We can break the bias in our workplaces. We can break the bias in our schools, colleges, and universities. Together, we can all break the bias – on International Women’s Day (IWD) and beyond
What are some of our internal activities for this month?
Celebrating International Women’s Day
Internally, we are kicking off our celebration on March 8. We will be joined by several women from North Coast hip hop improv comedy group. We hope this fun and freestyle event will encourage participants to think about unconscious biases, breaking them down, and how they can get more involved in empowering the women around them.
Intersectionality and Allyship at Cloudflare
Following our kick-off celebrations, we’re hosting open discussions about intersectionality and allyship alongside some of our fellow Employee Resource Groups including Afroflare, Asianflare, Flarability, and Nativeflare. It’s important to us to include other ERGs in these conversations since the goal of empowerment, representation, and support is shared among us and can’t be done alone. And we want to play closer attention to the layers that form a person’s social identity, creating compounding experiences of discrimination. “All inequality is not created equal,” says Kimberlé Crenshaw, the law professor who coined “intersectional feminism” term in 1989. Understanding the way different inequalities play a role in a person’s life means understanding the history, systematic discrimination, and the non-uniformity of it.
Internal Leadership Panel
Last year, we brought together an internal panel of women leaders at Cloudflare to share their journeys and lessons learned. It was extremely well received, so we decided to build upon its success by inviting another group of internal women leaders to discuss their experiences and insights with us. Some important takeaways from these panel discussions have been the realization that most backgrounds and journeys are vastly different, paths to success are often rocky but rewarding, and perseverance, tenacity, and an open mind, often rule the day. What better way to learn from others and encourage more women to lead!
What can we all do?
Allyship is integral to systemic change. An ally is someone who recognizes unearned privileges in their lives and takes responsibility to end patterns of injustice. At Cloudflare, we’re working hard to build more diverse and equitable teams, as well as create and maintain an environment that is inclusive and welcoming. There are many actions you can take as an ally; some include:
Educating yourself: listen to the experiences of your women colleagues and work with them to understand their perspectives.
Amplifying women’s opinions and advocating for them: speak up for others and champion them when they need support and encouragement.
Taking action in the workplace: if you see inequality or discrimination happening, reach out to discuss further and understand what can be done.
Advocating for diversity: talk with your peers and leaders about the ways you can get involved with improving diversity, equity, and inclusion.
Celebrate International Women’s Day and Women’s Empowerment Month in your own creative ways! And all throughout the year, remember to empower women and to recognize them in such a way that their work is no longer anonymous. Join the #IWD2022 movement — #BreakTheBias this month and beyond!
At Cloudflare, we have our eyes set on an ambitious goal: to help build a better Internet. Today the company runs one of the world’s largest networks that powers approximately 25 million Internet properties. This is made possible by our 1,900 team members around the world. We believe the key to achieving our potential is to build diverse teams and create an environment where everyone can do their best work.
That is why we place a lot of value on the importance of diversity, equity and inclusion. Diversity, equity, and inclusion lead to better outcomes through improved decision-making, more innovative teams, stronger financial returns and simply a better place to work for everyone.
To become more diverse, equitable, and inclusive, we believe it’s important to focus on communities within and around our company.
Building internal communities at Cloudflare
At Cloudflare, like most workplaces, there are built-in communities: your direct team, your cross-functional partners and (because we take onboarding very seriously) your new hire class. These communities, especially the first two, are important to help you get your job done. But we want more than that for our team at Cloudflare. We believe that community builds connection and fosters a sense of belonging.
Because of that, we have supported the growth of over 16 Employee Resource Groups (ERG’s). We use the term ERG broadly at Cloudflare. We have many ERG’s focused on traditionally under-represented groups in tech: Afroflare (Black, African diaspora), Latinflare, and Womenflare; groups that have been historically marginalized: Proudflare (LGBTQIA+), Cloudflarents (parents and caregivers); as well as interest and affinity groups like Mindflare and Soberflare. To read more about all of our ERGs, visit our diversity, equity, and inclusion webpage or read about them on our blog. In addition to creating a community of support and belonging, our ERGs also work to enhance career development of their members and contribute to the development of a more inclusive culture at Cloudflare.
Building the skills to build communities
We define an inclusive culture as one where everyone feels safe, welcome and respected with a sense of belonging. We do not leave this to chance. We make investments in training and programs to develop and deepen the skills needed to nurture and preserve inclusive communities at Cloudflare.
One of our earliest offerings was Ally Skills training. The aim of this workshop is to help build awareness of the types of behavior and language which can be harmful to inclusivity at Cloudflare, and teach simple, everyday ways to support people who are targets of systemic oppression. During the workshop, team members share strategies on how to act as allies and how to create a long-lasting, inclusive culture at Cloudflare. As the program was being rolled out, the management team did the workshop together and quickly realized these were not skills reserved for ‘allies’ but it was our expectation that this was how all of our team members treated each other. These were necessary skills to be successful at Cloudflare. As a result, we reworked some pieces of the workshop and renamed it: How We Work Together.
We have also partnered with Paradigm IQ and Included to create a three-part Unconscious Bias Education Program. These workshops are a mix of eLearning and facilitated workshops where we learn about how to help mitigate unconscious bias and make our company a more welcoming and inclusive place for everyone. tEQuitable is an additional comprehensive resource which helps us create a safe, inclusive, and equitable workplace. They provide an independent sounding board where our employees may confidentially raise a concern, access a just-in-time learning platform, and get advice from professional Ombuds. They also help us identify systemic workplace issues and provide us with actionable recommendations for how to improve our workplace culture. What we especially love about tEQuitable is that it’s all about empowering our employees with tools and resources to address issues that may be impacting them, or they may witness impacting others, so we all play an active role in maintaining and nurturing our culture.
One other program worth highlighting is our Week On: Learning and Inclusion. This program came as a response to the murder of George Floyd in the US at the end of May 2020. Our Afroflare global leaders suggested we use Juneteenth as a full-day of deep learning from external experts on topics ranging from the history of race and racism to the psychological impact of racism on people of color. In 2021, we expanded it from a one-day program to a week full of programming with topics ranging from antiracism keynotes, inclusive people management workshops and inclusive recruiting practices.
Holding ourselves accountable to an inclusive culture
Increasing awareness and skill-building is valuable, but it is not enough. We also have to hold ourselves accountable by analyzing data, setting goals and measuring progress objectively. Each year we set company-wide goals around our diversity, and for the last few years we’ve added individual goals for managers — one focused on building a more diverse team, and one focused on building an inclusive team culture.
We also place a high value on behaviors at Cloudflare. This is imperative because we believe that culture is defined by the behaviors we reward. So in order to have a healthy and inclusive culture, we must reward the behaviors that promote and preserve that. We have defined these behaviors as our Cloudflare Capabilities.
We screen for these Capabilities during our interview process, and they are used in performance and promotion conversations. We hold ourselves accountable by using a very simple formula: Performance = results + behaviors. Equally weighted.
Our Recruiting Efforts
Speaking of interviewing, hiring is an important part of our diversity story. We believe that diverse teams win, and we put in a lot of effort to build diverse teams across the company. We have many team members who took unconventional paths into tech, and we believe that makes us stronger as a company. In fact, many of our job descriptions read: We realize people do not fit into neat boxes. We are looking for curious and empathetic individuals who are committed to developing themselves and learning new skills, and we are ready to help you do that. We cannot complete our mission without building a diverse and inclusive team.
In addition to an inclusive and expansive mindset around hiring, we also have interviews dedicated specifically to fit against our Capabilities, as well as leveraging technology and tools to help identify great talent who help to increase the diversity of our teams.
We have also made investments in events and partnerships that help support our diversity recruiting efforts. In August 2016, Cloudflare was one of the first companies to partner with Path Forward when it first launched its program in California. [Fun fact: that’s how I learned about Cloudflare and became interested in working here]. In Singapore, we have a similar partnership with Mums@Work.
We also engage with organizations and participate in events that help us reach talent from underrepresented groups. We have sponsored and spoke on stage at events like Lesbians Who Tech and Grace Hopper, where our co-founder, President and COO, Michelle Zatlyn, delivered the keynote in 2020. We regularly attend events and conferences hosted by AfroTech, Women Who Code, Girls Who Code, TAPIA, NSN, and more.
Engaging with external communities
Our ethos is to support and connect with external communities as well. Prior to the pandemic, when our offices were fully open and social and professional events were a thing, we regularly hosted external organizations to host events in our communal spaces. One example of such an organization is Wu Yee Children’s Services, a San Francisco Chinatown-based nonprofit that connects parents and caregivers to affordable childcare options, offers payment assistance to low-income families, and other family and community services. We were honored to host their orientation session. Another organization we hosted was Women Who Code SF. We regularly hosted their “ algorithm and interview prep” workshops, which helped women coders gain the skills they need to land good jobs in the tech industry. Unlike many of our tech company peers, we did not offer free lunch five days a week. It was important to us that our team members got out of the office and supported local businesses and restaurants. It is important that we do not isolate ourselves, but rather are part of a larger community.
We also believe in giving back to our local communities. Prior to COVID, Cloudflare dedicated one week every year to volunteer efforts. Coordinated across many of our large office locations, we would dedicate each day for a full week volunteering at employee-nominated, local non-profit organizations. Our participation pivoted to virtual during COVID, but we are anxious to return to in-person giving when we can.
While we are proud of these efforts, it is in using Cloudflare products and services for good that is truly special. Cloudflare’s mission to help build a better Internet means we are in a unique position to help vulnerable websites, applications and services be safer, faster and more reliable online.
Organizations working in the arts, human rights, civil society, journalism, or democracy, may apply for Project Galileo to get Cloudflare’s cybersecurity protection, for free. Since 2014, we’ve been leveraging our services to support vulnerable public interest web properties including, but are not limited to: minority rights organizations, human rights organizations, independent media outlets, arts groups, and democracy and voter protection programs.
Our support of one of these organizations has blossomed over the years. We are proud to announce our partnership with The Trevor Project. Founded in 1998 by the creators of the Academy Award®-winning short film TREVOR, The Trevor Project is the leading national organization providing crisis intervention and suicide prevention services to lesbian, gay, bisexual, transgender, queer & questioning (LGBTQ) young people under 25. We support the organization through monetary donations, a partnership with our LGBTQIA+ Employee Resource Group, Proudflare, and free Cloudflare services through our Project Galileo Program.
Since 2017, we have donated about $8 million in cybersecurity tools under Project Galileo.
Cloudflare launched the Athenian Project in 2017 to provide our highest level of cybersecurity services for free to state and local governments in the United States that run elections. The project is designed to protect these websites tied to elections including information related to voting and polling places, voter registration and sites that publish election results. And voter data from cyberattack, and keep them online. During the 2020 U.S. election, we worked closely with civil society and government agencies to share threat information that we saw targeted against these participants and protected more than 292 websites in 30 states, including the Missouri Secretary of State, Solano County in California and The Colorado Department of State.
In recognition that election security is a global issue, we recently announced our partnerships with the International Foundation for Electoral Systems, National Democratic Institute and International Republican Institute to extend our cybersecurity protections to election management bodies around the world, as well as organizations that support free and fair elections. We look forward to continuing our work to protect resources in the voting process and help build trust in democratic institutions around the world.
Around the world, governments, hospitals, and pharmacies are struggling to distribute the COVID-19 vaccine. Technical limitations are causing vaccine registration sites to crash under the load of registrations. At Cloudflare, we want to help. Cloudflare’s Waiting Room feature allows organizations with more demand for a resource — be it concert tickets, new edition sneakers, or vaccines — to allow individuals to queue and then allocate access. Waiting Rooms can be deployed in front of any existing registration website without requiring code changes. As we watched the world struggle to fairly and efficiently distribute the COVID-19 vaccine we wanted to lend our technologies and expertise to help. Under Project Fair Shot, Cloudflare is providing Waiting Room to any government agency, hospital, pharmacy, or other organization facilitating the distribution of the COVID-19 vaccine for free until anyone who wants to be vaccinated can be, until at least 31-December 2021.
At Cloudflare, we believe in being principled, curious and transparent. Publishing our diversity report is aligned with these values.
We are Principled: One of the Cloudflare Capabilities is “Do the Right Thing” — that includes long-term thinking about how we build an innovative and sustainable workforce. We have a fundamental belief that fairness is the right thing. We believe that equity is the right thing.
We are Curious: Creating a more diverse and sustainable workforce is hard work. We want to draw lessons from the things we try, and we want to learn from what others are trying. Sustainable communities is not a zero-sum game, and we believe we can all benefit as an active part of the broader community.
We believe in Transparency: For many years, we have been transparent with our team about our diversity data and our goals, and we have measured our progress regularly. Now we are taking the step to share publicly because we believe in accountability and accept the responsibility to build a diverse and sustainable workforce.
You can check out our Diversity, Equity, and Inclusion webpage with our diversity report here.
While there is always more work to be done, we are grateful for the empathetic and curious team that makes Cloudflare what it is today. Together, we are optimistic we can build a better — and more inclusive — Internet.
In the United States, May is Asian American and Pacific Islander Heritage Month. This year, we wanted to celebrate this occasion in a more inclusive and comprehensive way, which is why we called our celebration APAC Heritage Month. This initiative was a collaboration between Desiflare and Asianflare, Cloudflare’s Employee Resource Groups (ERGs) for employees of Asian descent. We are proud to have run a diverse slate of events and content that we had planned throughout this month of celebration.
Our priority for APAC Heritage Month has been to share the stories and experiences of those in our community: we hosted several different segments to highlight the strong culture and heritage with moderated panels. We also took this opportunity to highlight some of the leaders in the industry of APAC descent around the world, to talk about their journey and struggles, so we can learn from each other and grow to be inspired. Although there has been progress in the past several years regarding representation of APAC stories being told, this small handful of narratives have a hard time representing two thirds of the world. By telling a more diverse set of APAC stories — our own, from immigrants, stories about food, culture and our careers — we hope to bring visibility to our experiences and our existence.
Lending the Microphone to APAC Voices
To keep everyone safe during the pandemic, all of our external events this year have been virtual and televised on Cloudflare TV:
The Asian American Experience: a CFTV series on the collective experience of Asian Americans.
Coming of Age: a guided exploration through large cultural concepts and concerns that folks of Asian heritage stay cognizant of as they go through life.
Founder Focus: a spotlight on the human stories behind startup founders.
Quinn Wang – Quinn Wang is the founder of Quadrant Eye, a convenient way to renew your eye prescription online and get your glasses or contact lens prescription emailed to you.
Angus Luk – Angus Luk is the founder of EventX, Asia’s leading virtual events platform. We’ll be discussing everything from pivoting during the pandemic, to the trade-off of in-person, virtual, or hybrid events in different places around the world.
Beyang Liu – Beyang Liu co-founded Sourcegraph, a web-based code search and navigation tool for dev teams.
Kathy Zhou – Kathy Zhou is founder and CTO of Queenly, the largest marketplace for formalwear, from prom, pageant, to all evening gowns.
Jeremy Lam – Jeremy Lam is founder and CEO of Venu, a YC startup focused on virtual trade shows, expo halls, and hybrid events. We’ll be discussing everything from the economics of trade shows, the impact of the pandemic, and predictions for the future.
Fireside Chats: a chat set to explore the different careers of Asians in influential positions and what their experiences are of getting there.
We Are Cloudflare: Interviews with the people behind the scenes that make Cloudflare what it is. Join Chaat as he interviews people from across all teams and offices. Get to know what they do and the kind of people we are.
Cooking with Cloudflare: a live segment from our kitchens where we learn to make a dish or two from a Cloudflarian somewhere around the world.
A Mile in Your Shoes: A story about their family’s migration, their childhood pets, education and unique experiences, to better understand the lives of our colleagues.
Check out our APAC Heritage month landing page for the recordings of the events that occurred this month. We wanted to celebrate this month and truly embrace the culture and diversity, so please watch the recordings back on Cloudflare TV and beyond. Cloudflare embraces diversity and values diverse teams. We have also taken the recommendations of our teammates and put together a Playlist for you to be inspired by and deep dive into the deep rooted culture and practices we have celebrated this month.
In the spirit of highlighting APAC voices, we also wanted to take this opportunity to share a little about how our Asianflare and Desiflare Employee Resource Groups (ERGs) got started.
How Asianflare started
In March 2020, I (Jade) was having lunch with my colleague Stanley. We were venting to each other about the family of four who had been attacked in a grocery store parking lot in Texas. A few other co-workers joined the conversation, and we got to talk about how it echoed experiences of growing up as a minority in the US with Asian heritage.
That day turned out to be one of the last times we would physically be together in an office.
Stanley and I created Asianflare, the employee resource group for Asian heritage at Cloudflare, when we realized that we needed a space to serve as a support group. Surely, we weren’t the only ones who needed an emotional outlet about current events that impact our demographic. And we had a feeling that things were going to get worse before they got better. In the beginning, we just needed a safe space to just share our experiences with each other. And as lockdowns began across all the offices across the world, the Asianflare community became a real social hub as casual office chatter vanished into the ether.
The community blossomed with every food photo, every music or movie recommendation, every article discussion. We celebrated festivals together, held Zoom Lo Hei (“Prosperity Toss”) in multiple time zones, and held fireside chats on everything from career advice to public policy. Remember when WeChat and TikTok looked like they might be banned in the U.S.? We organized an internal fireside chat with Alissa Starzak, our public policy expert, to answer our questions on what to expect, especially those of us who feared getting cut off from our friends and family. On the average day, though, about 80% of our conversations are about food.
In March 2021, amidst the background radiation of escalating anti-Asian hate, a shooter killed eight people in Atlanta, six of whom were Asian women. What changed this time was the social support structures we had in place. We have a community that can grieve together, just as much as we celebrate together. Our People Team connected us with group therapy sessions offered by one of our benefits providers. At the BEER meeting our CEO, Matthew Prince, not only brought awareness to the issues and what our community was experiencing, but also offered our physical security team’s help. Even when I went outside, the flags were flying at half-mast. Colleagues I hadn’t heard from in ages reached out to make sure we were OK.
I know now that a kid like me growing up today would not see their families’ experiences swept under the rug, because our experiences are a part of the conversation now.
How Desiflare started
At the San Francisco office in 2019, we started to notice a sizable number of both folks of South Asian origin and folks with a deep interest in South Asian culture. So during Diwali (a festival of lights), we decided to have a small lunch get-together. The precursor to Desiflare was thus born in a room with 25 people congregating together for a commemorative vegetarian meal. The success of this small event led to monthly lunch meetings and eventually the formalization of the Desiflare ERG. Given the sizable Desi presence across all of our offices and the expansive interest we’ve seen in Desi culture across Cloudflare, today we see our ERG heavily represented around the world, especially in San Francisco, Austin, NYC, London, and Singapore!
Our Mission is to “Foster a sense of belonging and community amongst Cloudflare employees with an interest in the rich South Asian Culture as a platform to bring people together.”
We welcome everyone who identifies with or is otherwise interested in South Asian culture and look forward to welcoming all into our Desi community! While we are bound by the common fabric of South Asian, we realize that South Asia is vast and varied. Our shared body of culture embraces a breadth of diverse traditions, cuisines, habits, and beliefs, which is only magnified by the variation across the Desi diaspora across the world.
We therefore aspire to embrace and learn about each other to make the Desiflare ERG a place where all feel welcome!
In our brand-new issue of Hello World magazine, Hayley Leonard from our team gives a primer on how computing educators can apply the Universal Design for Learning framework in their lessons.
Universal Design for Learning (UDL) is a framework for considering how tools and resources can be used to reduce barriers and support all learners. Based on findings from neuroscience, it has been developed over the last 30 years by the Center for Applied Special Technology (CAST), a nonprofit education research and development organisation based in the US. UDL is currently used across the globe, with research showing it can be an efficient approach for designing flexible learning environments and accessible content.
Engaging a wider range of learners is an important issue in computer science, which is often not chosen as an optional subject by girls and those from some minority ethnic groups. Researchers at the Creative Technology Research Lab in the US have been investigating how UDL principles can be applied to computer science, to improve learning and engagement for all students. They have adapted the UDL guidelines to a computer science education context and begun to explore how teachers use the framework in their own practice. The hope is that understanding and adapting how the subject is taught could help to increase the representation of all groups in computing.
The UDL guidelines help educators anticipate barriers to learning and plan activities to overcome them.
A scientific approach
The UDL framework is based on neuroscientific evidence which highlights how different areas or networks in the brain work together to process information during learning. Importantly, there is variation across individuals in how each of these networks functions and how they interact with each other. This means that a traditional approach to teaching, in which a main task is differentiated for certain students with special educational needs, may miss out on the variation in learning between all students across different tasks.
The UDL framework is based on neuroscientific evidence
The UDL guidelines highlight different opportunities to take learner differences into account when planning lessons. The framework is structured according to three main principles, which are directly related to three networks in the brain that play a central role in learning. It encourages educators to plan multiple, flexible methods of engagement in learning (affective networks), representation of the teaching materials (recognition networks), and opportunities for action and expression of what has been learnt (strategic networks).
The three principles of UDL are each expanded into guidelines and checkpoints that allow educators to identify the different methods of engagement, representation, and expression to be used in a particular lesson. Each principle is also broken down into activities that allow learners to access the learning goals, remain engaged and build on their learning, and begin to internalise the approaches to learning so that they are empowered for the future.
Examples of UDL guidelines for computer science education from the Creative Technology Research Lab
Multiple means of engagement
Multiple means of representation
Multiple means of action and expression
Provide options for recruiting interests * Give students choice (software, project, topic) * Allow students to make projects relevant to culture and age
Provide options for perception * Model computing through physical representations as well as through interactive whiteboard/videos etc. * Select coding apps and websites that allow adjustment of visual settings (e.g. font size/contrast) and that are compatible with screen readers
Provide options for physical action * Include CS unplugged activities that show physical relationships of abstract computing concepts * Use assistive technology, including a larger or smaller mouse or touchscreen devices
Provide options for sustaining effort and persistence * Utilise pair programming and group work with clearly defined roles * Discuss the integral role of perseverance and problem-solving in computer science
Provide options for language, mathematical expressions, and symbols * Teach and review computing vocabulary (e.g. code, animations, algorithms) * Provide reference sheets with images of blocks, or with common syntax when using text
Provide options for expression and communication * Provide sentence starters or checklists for communicating in order to collaborate, give feedback, and explain work * Provide options that include starter code
Provide options for self-regulation * Break up coding activities with opportunities for reflection, such as ‘turn and talk’ or written questions * Model different strategies for dealing with frustration appropriately
Provide options for comprehension * Encourage students to ask questions as comprehension checkpoints * Use relevant analogies and make cross-curricular connections explicit
Provide options for executive function * Embed prompts to stop and plan, test, or debug throughout a lesson or project * Demonstrate debugging with think-alouds
Each principle of the UDL framework is associated with three areas of activity which may be considered when planning lessons or units of work. It will not be the case that each area of activity should be covered in every lesson, and some may prove more important in particular contexts than others. The full table and explanation can be found on the Creative Technology Research Lab website at ctrl.education.ufl.edu/projects/tactic.
Applying UDL to computer science education
While an advantage of UDL is that the principles can be applied across different subjects, it is important to think carefully about what activities to address these principles could look like in the case of computer science.
Researcher Maya Israel will speak at our April seminar
Researchers at the Creative Technology Research Lab, led by Maya Israel, have identified key activities, some of which are presented in the table on the previous page. These guidelines will help educators anticipate potential barriers to learning and plan activities that can overcome them, or adapt activities from those in existing schemes of work, to help engage the widest possible range of students in the lesson.
UDL in the classroom
As well as suggesting approaches to applying UDL to computer science education, the research team at the Creative Technology Research Lab has also investigated how teachers are using UDL in practice. Israel and colleagues worked with four novice computer science teachers in US elementary schools to train them in the use of UDL and understand how they applied the framework in their teaching.
The research found that the teachers were most likely to include in their teaching multiple means of engagement, followed by multiple methods of representation. For example, they all offered choice in their students’ activities and provided materials in different formats (such as oral and visual presentations and demonstrations). They were less likely to provide multiple means of action and expression, and mainly addressed this principle through supporting students in planning work and checking their progress against their goals.
Although the study included only four teachers, it highlighted the flexibility of the UDL approach in catering for different needs within variable teaching contexts. More research will be needed in future, with larger samples, to understand how successful the approach is in helping a wide range of students to achieve good learning outcomes.
Find out more about using UDL
There are numerous resources designed to help teachers learn more about the UDL framework and how to apply it to teaching computing. The CAST website (helloworld.cc/cast) includes an explainer video and the detailed UDL guidelines. The Creative Technology Research Lab website has computing-specific ideas and lesson plans using UDL (helloworld.cc/udl).
Maya Israel will be presenting her research at our computing education research seminar series, on 20 April 2021. Our seminars are free to attend and open to anyone from anywhere around the world. Find out more about the current seminar series, which focuses on diversity and inclusion, and sign up to attend for free.
Israel, M., Jeong, G., Ray, M., & Lash, T. (2020). Teaching Elementary Computer Science Through Universal Design for Learning. Proceedings of the 51st ACM Technical Symposium on Computer Science Education, pp. 1220-1226. dl.acm.org/doi/abs/10.1145/3328778.3366823
Rose, D. H. & Strangman, N. (2007). Universal design for learning: Meeting the challenge of individual learning differences through a neurocognitive perspective. Universal Access in the Information Society, 5(4), pp. 381-391. dl.acm.org/doi/abs/10.1007/s10209-006-0062-8
Leaders from across the tech industry and beyond recently joined us for Cloudflare’s Birthday Week, helping us celebrate Cloudflare’s 10th birthday. Many of them touched on the importance of diversity and making the Internet accessible to everyone.
Here are some of the highlights.
On the value of soliciting feedback
Selina Tobaccowala Chief Digital Officer at Openfit, Co-Founder of Gixo Former President & CTO of SurveyMonkey
When you think about diversity and inclusion, unfortunately, it’s often only the loudest voice, the squeakiest wheel [who gets heard]. And what a survey allows you to do is let people’s voices be heard who are not always willing to raise their hand or speak the loudest.
So at SurveyMonkey, we always made sure that when we were thinking about user testing and we were thinking about usability testing — that it was that broad swath of the customer because you wanted people across all different segments to submit their opinion.
I think that collecting data in a way that can be anonymized, collecting data in a way that lets people have a thoughtful versus always off the cuff conversation is really important. And what we also provided was a benchmarking product, because if you don’t know how you rank and stack against other people, you don’t know if you’re doing well or not.
Bonita Stewart Vice President, Global Partnerships & Americas Partnerships Solutions of Google
It’s been part of my mission to make sure that technology is introduced particularly into the African-American community, so that people see it as a viable career and not something that’s on a path that requires a different risk profile or certain level of education. It should be accessible. So one of the things that I did — I was doing some research and I found that close to 25% of the STEM grads come from historically Black colleges. And there are many education programs we [Google] work with, but there was never anything for the students to have an immersive experience.
And the thought was, what if we had Howard West at Google? So we had a partnership with Howard University, and worked with Dr. Frederick (President of Howard University) and said: what if your students could actually spend time in the valley so that they could have an immersive experience? So they brought their faculty, along with their students. And there was just an outpouring from Google of volunteers saying, “I’d love to teach the students, is there a role for me that I can play?”
And that was in 2017. Now we have over ten schools — historically Black colleges, as well as historically Hispanic colleges and universities.
On making the Internet accessible to those who can’t afford the expense
Erik Hersman Co-founder and CEO of BRCK
BRCK makes rugged, portable devices that provide free Wi-Fi access to areas throughout Kenya and Rwanda.
We install our devices in buses and public transportation in Kenya and Rwanda. We also put them in fixed locations across the two countries. And we have a platform on it that’s much like what you’d see at an airport, where you get you get a dashboard that pops up, you watch an ad, you do a survey, you do something to earn your time and get online — which in East Africa is really important because people have time, but they don’t have money.
And so if you want to hit this demographic and allow them to have equal access to that kind of global digital ecosystem that’s out there, that we all take part in, you need to find a way that they can do so without going into their wallet. And this is the only way we found that we could do that. And so we have businesses who end up paying us [to serve advertisements, surveys, and microwork tasks] and that’s what subsidizes that cost.
Shellye Archambeau Former CEO of MetricStream Board member for Verizon, Okta, Nordstrom, and Roper Technologies
When I first came to Silicon Valley, I was shocked. I was shocked because I’m thinking, OK, I’m going to Silicon Valley — the place with innovation, new ideas, creativity, et cetera — I just knew it had to be diverse and… [it wasn’t]. And so that part was really a shock. And you know, I’m sure some things were more challenging for me. I wasn’t in anybody else’s shoes, so I don’t know if it was easier for them, but…
I’ve been in tech my entire career so I always approach things the same way. I assume that people are going to think that I’m not quite capable. Not quite competent, not quite… Just that little — I know people are going to think that.
So I try to go in the same way each time. It’s like I have to prove myself both to the people who I’m working for and to the people who are working for me. And I’ve always found that using a servant leader approach is the most effective way. To really go in and focus on the team. If I can help the team be successful, then I will be successful. So that has worked for me over and over again.
Be intentional about expanding your networks. So get out there and meet a Black investor, get out there and meet a Black founder, get out there and meet a female founder, get out there and be intentional. Don’t sit in your chair. They’re not going to come to you. Somebody gave me a beautiful analogy once and said, “It’s like fishing in the forest. There are plenty of fish there over there in the lake.”
So if you’re fishing in the forest and you’re shocked and surprised to find that there’s no fish on your hook, well, get yourself over to the lake. And you’re going to have to get up out of your chair and walk over — especially if your company or your firm doesn’t look diverse, because it’s not welcoming. And so you have to be intentional about expanding your network.
And you’re not going to get there if you just think you’ll do it. You need to treat it like OKRs, you need to make it a strategic imperative. You need to tie executive compensation to it, and do what you need to do in order to keep the focus and make sure it is appropriately resourced.
Over the past 8 months, it’s become more important for us all to stay in contact with peers around the globe. Today, I’m proud to bring you the second episode of our new video series, Verified: Presented by AWS re:Inforce. Even though we couldn’t be together this year at re:Inforce, our annual security conference, we still wanted to share some of the conversations with security leaders that would have taken place at the conference. The series showcases conversations with security leaders around the globe. In episode two, I’m talking to Emma Smith, Vodafone’s Global Cyber Security Director.
Vodafone is a global technology communications company with an optimistic culture. Their focus is connecting people and building the digital future for society. During our conversation, Emma detailed how the core values of the Global Cyber Security team were inspired by the company. “We’ve got a team of people who are ultimately passionate about protecting customers, protecting society, protecting Vodafone, protecting all of our services and our employees.” Emma shared experiences about the evolution of the security organization during her past 5 years with the company.
We were also able to touch on one of Emma’s passions, diversity and inclusion. Emma has worked to implement diversity and drive a policy of inclusion at Vodafone. In June, she was named Diversity Champion in the SC Awards Europe. In her own words: “It makes me realize that my job is to smooth the way for everybody else and to try and remove some of those obstacles or barriers that were put in their way… it means that I’m really passionate about trying to get a very diverse team in security, but also in Vodafone, so that we reflect our customer base, so that we’ve got diversity of thinking, of backgrounds, of experience, and people who genuinely feel comfortable being themselves at work—which is easy to say but really hard to create that culture of safety and belonging.”
Stay tuned for future episodes of Verified: Presented by AWS re:Inforce here on the AWS Security Blog. You can watch episode one, an interview with Jason Chan, Vice President of Information Security at Netflix on YouTube. If you have an idea or a topic you’d like covered in this series, please drop us a comment below.
Want more AWS Security how-to content, news, and feature announcements? Follow us on Twitter.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.