Post Syndicated from Marten van de Sanden original https://blog.cloudflare.com/quicksilver-v2-evolution-of-a-globally-distributed-key-value-store-part-2-of-2/
Cloudflare has servers in 330 cities spread across 125+ countries. All of these servers run Quicksilver, which is a key-value database that contains important configuration information for many of our services, and is queried for all requests that hit the Cloudflare network.
Because it is used while handling requests, Quicksilver is designed to be very fast; it currently responds to 90% of requests in less than 1 ms and 99.9% of requests in less than 7 ms. Most requests are only for a few keys, but some are for hundreds or even more keys.
Quicksilver currently contains over five billion key-value pairs with a combined size of 1.6 TB, and it serves over three billion keys per second, worldwide. Keeping Quicksilver fast provides some unique challenges, given that our dataset is always growing, and new use cases are added regularly.
Quicksilver used to store all key-values on all servers everywhere, but there is obviously a limit to how much disk space can be used on every single server. For instance, the more disk space used by Quicksilver, the less disk space is left for content caching. Also, with each added server that contains a particular key-value, the cost of storing that key-value increases.
This is why disk space usage has been the main battle that the Quicksilver team has been waging over the past several years. A lot was done over the years, but we now think that we have finally created an architecture that will allow us to get ahead of the disk space limitations and finally make Quicksilver scale better.
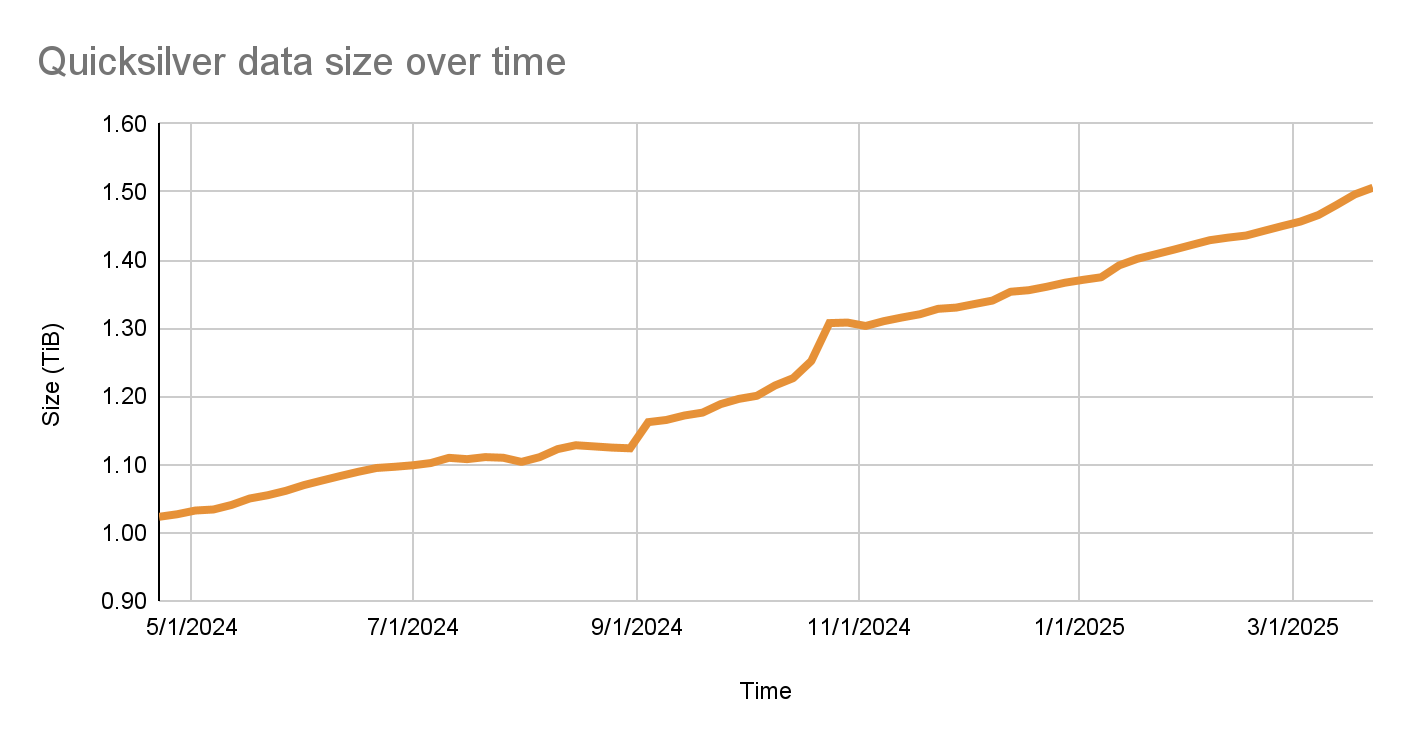
The size of the Quicksilver database has grown by 50% to about 1.6 TB in the past year
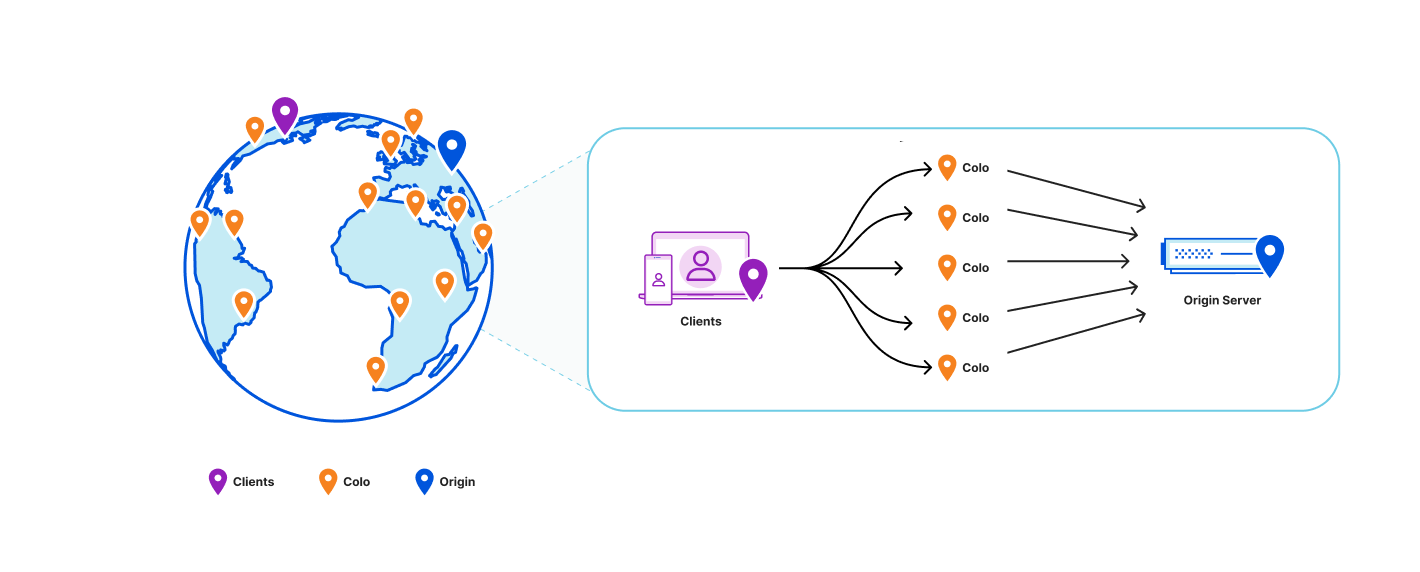
Part one of the story explained how Quicksilver V1 stored all key-value pairs on each server all around the world. It was a very simple and fast design, it worked very well, and it was a great way to get started. But over time, it turned out to not scale well from a disk space perspective.
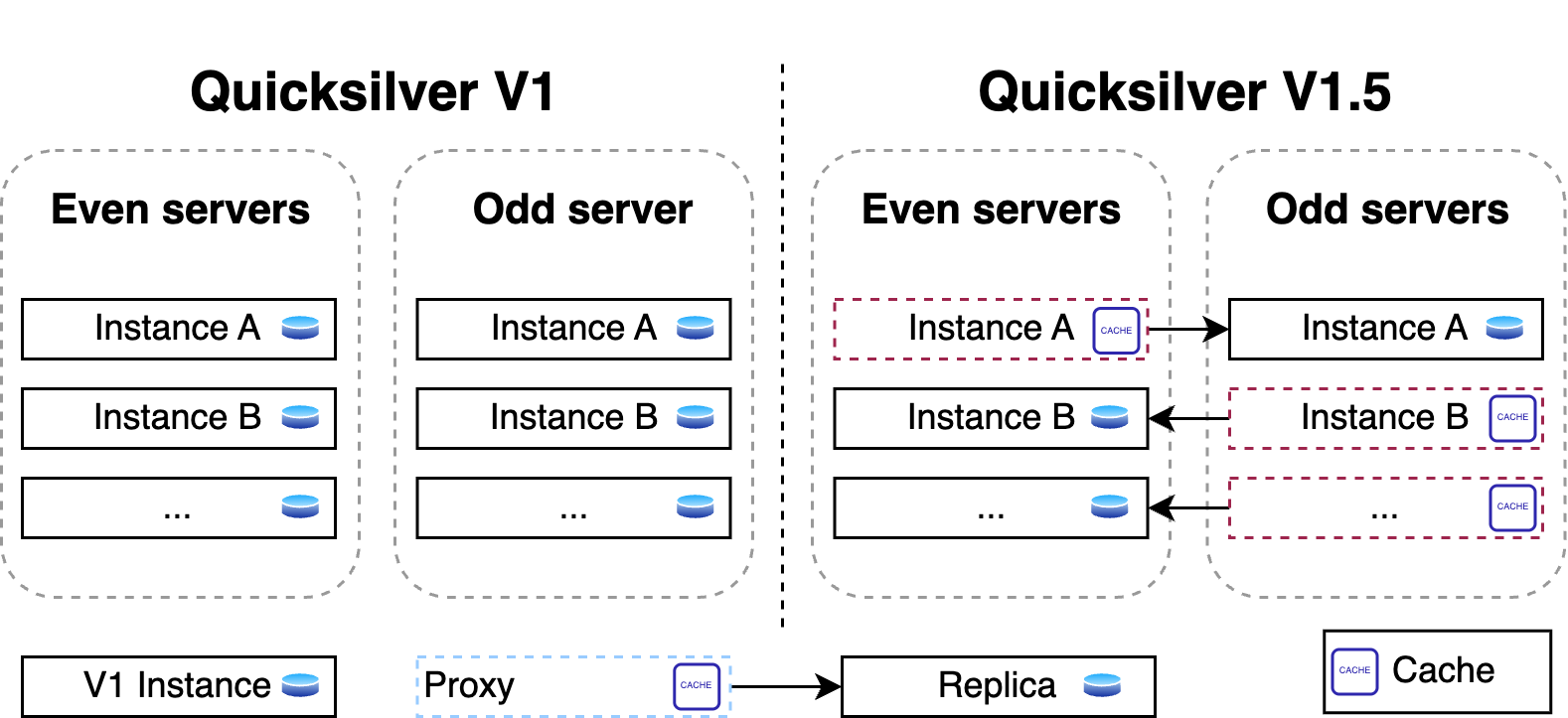
The problem was that disk space was running out so fast that there was not enough time to design and implement a fully scalable version of Quicksilver. Therefore, Quicksilver V1.5 was created first. It halved the disk space used on each server compared to V1.
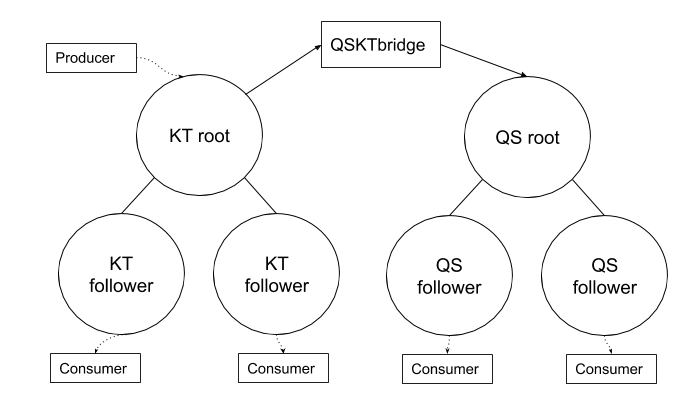
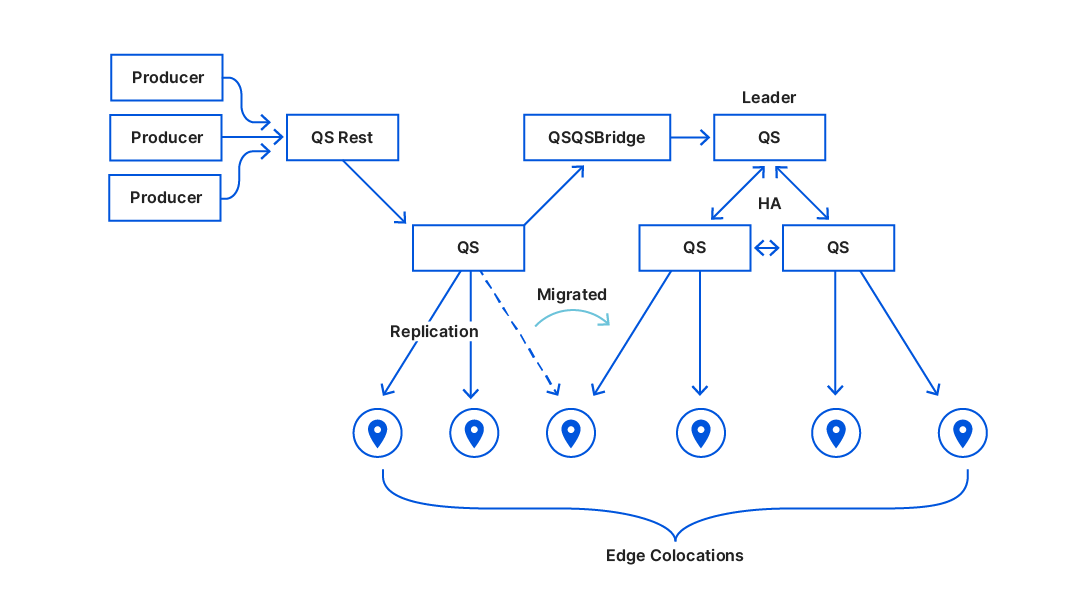
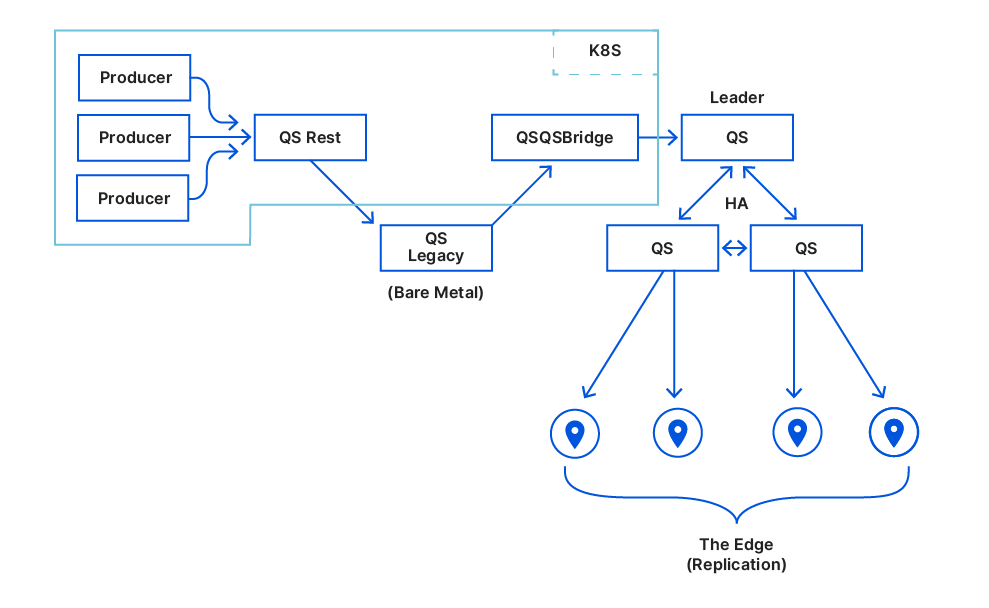
For this, a new proxy mode was introduced for Quicksilver. In this mode, Quicksilver does not contain the full dataset anymore, but only contains a cache. All cache misses are looked up on another server that runs Quicksilver with a full dataset. Each server runs about ten separate instances of Quicksilver, and all have different databases with different sets of key-values. We call Quicksilver instances with the full data set replicas.
For Quicksilver V1.5, half of those instances on a particular server would run Quicksilver in proxy mode, and therefore would not have the full dataset anymore. The other half would run in replica mode. This worked well for a time, but it was not the final solution.
Building this intermediate solution had the added benefit of allowing the team to gain experience running an even more distributed version of Quicksilver.
There were a few reasons why Quicksilver V1.5 was not fully scalable.
First, the size of the separate instances were not very stable. The key-space is owned by the teams that use Quicksilver, not by the Quicksilver team, and the way those teams use Quicksilver changes frequently. Furthermore, while most instances grow in size over time, some instances have actually gotten smaller, such as when the use of Quicksilver is optimised by teams. The result of this is that the split of instances that was well-balanced at the start, quickly became unbalanced.
Second, the analyses that were done to estimate how much of the key space would need to be in cache on each server assumed that taking all keys that were accessed in a three-day period would represent a good enough cache. This assumption turned out to be wildly off. This analysis estimated that we needed about 20% of the key space in cache, which turned out to not be entirely accurate. Whereas most instances did have a good cache hit rate, with 20% or less of the key space in cache, some instances turned out to need a much higher percentage.
The main issue, however, was that reducing the disk space used by Quicksilver on our network by as much as 40% does not actually make it more scalable. The number of key-values that are stored in Quicksilver keeps growing. It only took about two years before disk space was running low again.
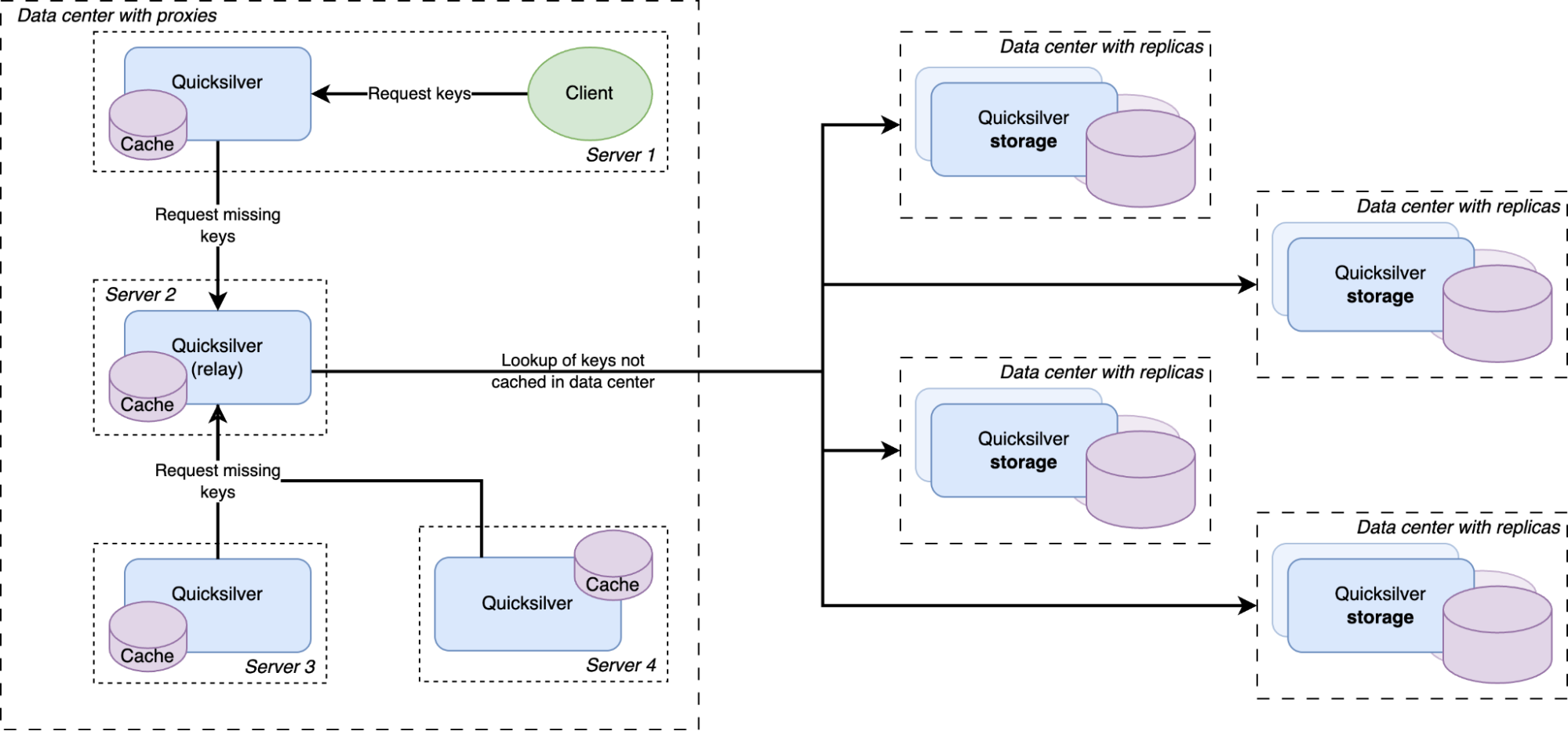
Except for a handful of special storage servers, Quicksilver does not contain the full dataset anymore, but only cache. Any cache misses will be looked up in replicas on our storage servers, which do have the full dataset.
The solution to the scalability problem was brought on by a new insight. As it turns out, numerous key-values were actually almost never used. We call these cold keys. There are different reasons for these cold keys: some of them were old and not well cleaned up, some were used only in certain regions or in certain data centers, and some were not used for a very long time or maybe not at all (a domain name that is never looked up for example or a script that was uploaded but never used).
At first, the team had been considering solving our scalability problem by splitting up the entire dataset into shards and distributing those across the servers in the different data centers. But sharding the full dataset adds a lot of complexity, corner cases, and unknowns. Sharding also does not optimize for data locality. For example, if the key-space is split into 4 shards and each server gets one shard, that server can only serve 25% of the requested keys from its local database. The cold keys would also still be contained in those shards and would take up disk space unnecessarily.
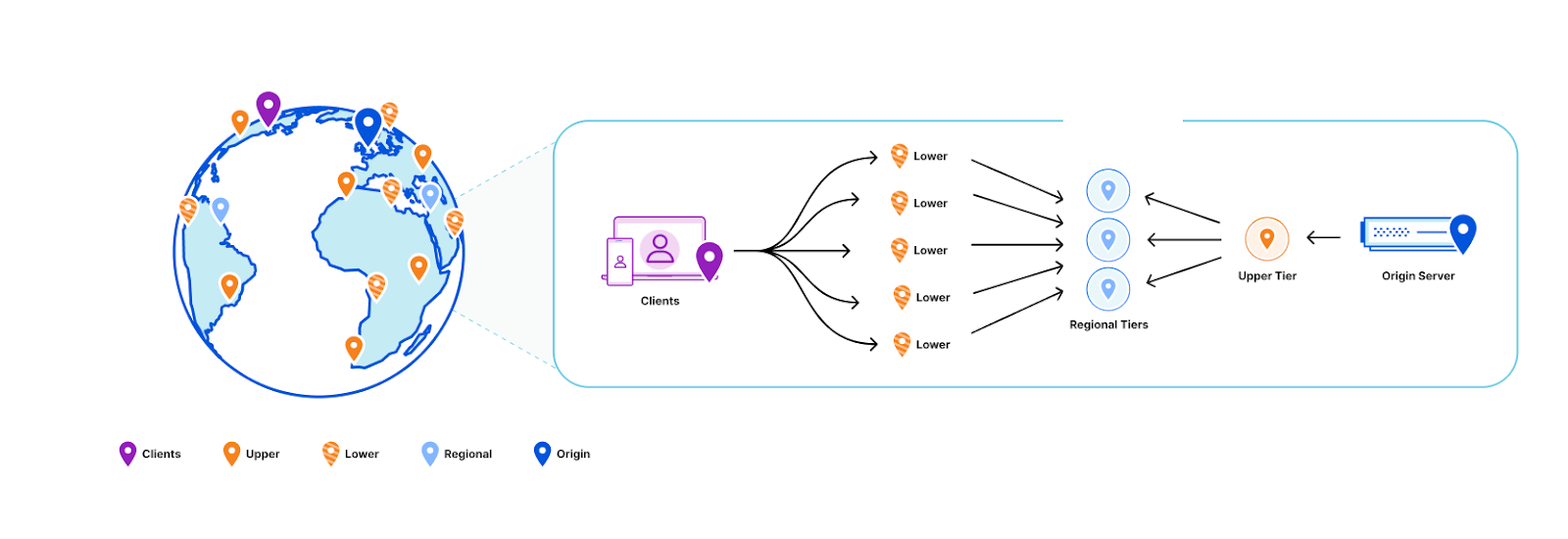
Another data structure that is much better at data locality and explicitly avoids storing keys that are never used is a cache. So it was decided that only a handful of servers with large disks would maintain the full data set, and all other servers would only have a cache. This was an obvious evolution from Quicksilver V1.5. Caching was already being done on a smaller scale, so all the components were already available. The caching proxies and the inter-data center discovery mechanisms were already in place. They had been used since 2021 and were therefore thoroughly battle tested. However, one more component needed to be added.
There was a concern that having all instances on all servers connect to a handful of storage nodes with replicas would overload them with too many connections. So a Quicksilver relay was added. For each instance, a few servers would be elected within each data center on which Quicksilver would run in relay mode. The relays would maintain the connections to the replicas on the storage nodes. All proxies inside a data center would discover those relays and all cache misses would be relayed through them to the replicas.
This new architecture worked very well. The cache hit rates still needed some improvement, however.
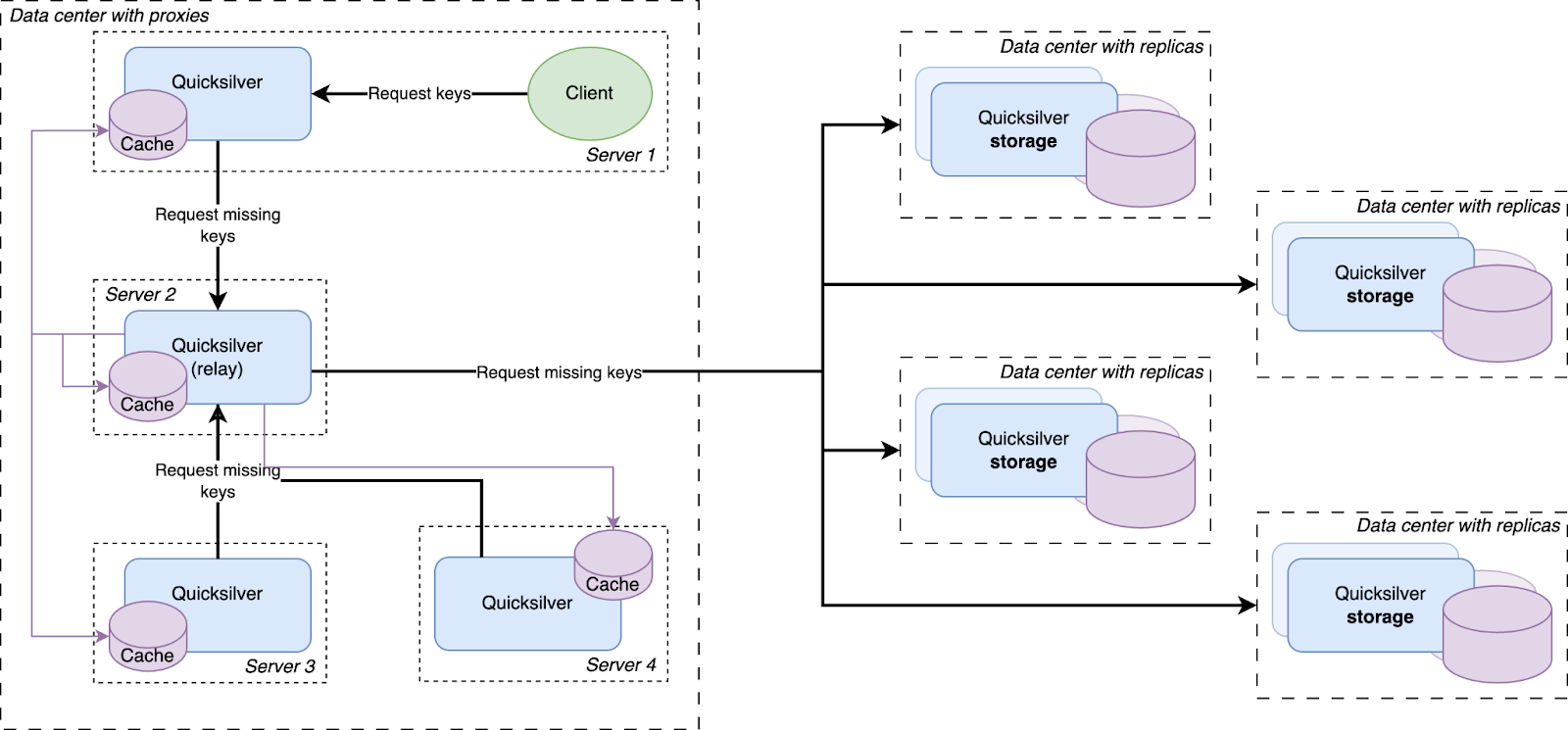
Every resolved cache miss is prefetched by all servers in the data center
We had a hypothesis that prefetching all keys that were cache misses on the other servers inside the same data center would improve the cache hit rate. So an analysis was done, and it indeed showed that every key that was a cache miss on one server in a data center had a very high probability of also being a cache miss on another server in the same data center sometime in the near future. Therefore, a mechanism was built that distributed all resolved cache misses on relays to all other servers.
All cache misses in a data center are resolved by requesting them from a relay, which subsequently forwards the requests to one of the replicas on the storage nodes. Therefore, the prefetching mechanism was implemented by making relays publish a stream of all resolved cache misses, to which all Quicksilver proxies in the same data center subscribe. The resulting key-values were then added to the proxy local caches.
This strategy is called reactive prefetching, because it fills caches only with the key-values that directly resulted from cache misses inside the same data center. Those prefetches are a reaction to the cache misses. Another way of prefetching is called predictive prefetching, in which an algorithm tries to predict which keys that have not yet been requested will be requested in the near future. A few approaches for making these predictions were tried, but they did not result in any improvement, and so this idea was abandoned.
With the prefetching enabled, cache hit rates went up to about 99.9% for the worst performing instance. This was the goal that we were trying to reach. But while rolling this out to more of our network, it turned out that there was one team that needed an even higher cache hit rate, because the tail latencies they were seeing with this new architecture were too high.
This team was using a Quicksilver instance called dnsv2. This is a very latency sensitive instance, because it is the one from which DNS queries are served. Some of the DNS queries under the hood need multiple queries to Quicksilver, so any added latency to Quicksilver multiplies for them. This is why it was decided that one more improvement to the Quicksilver cache was needed.
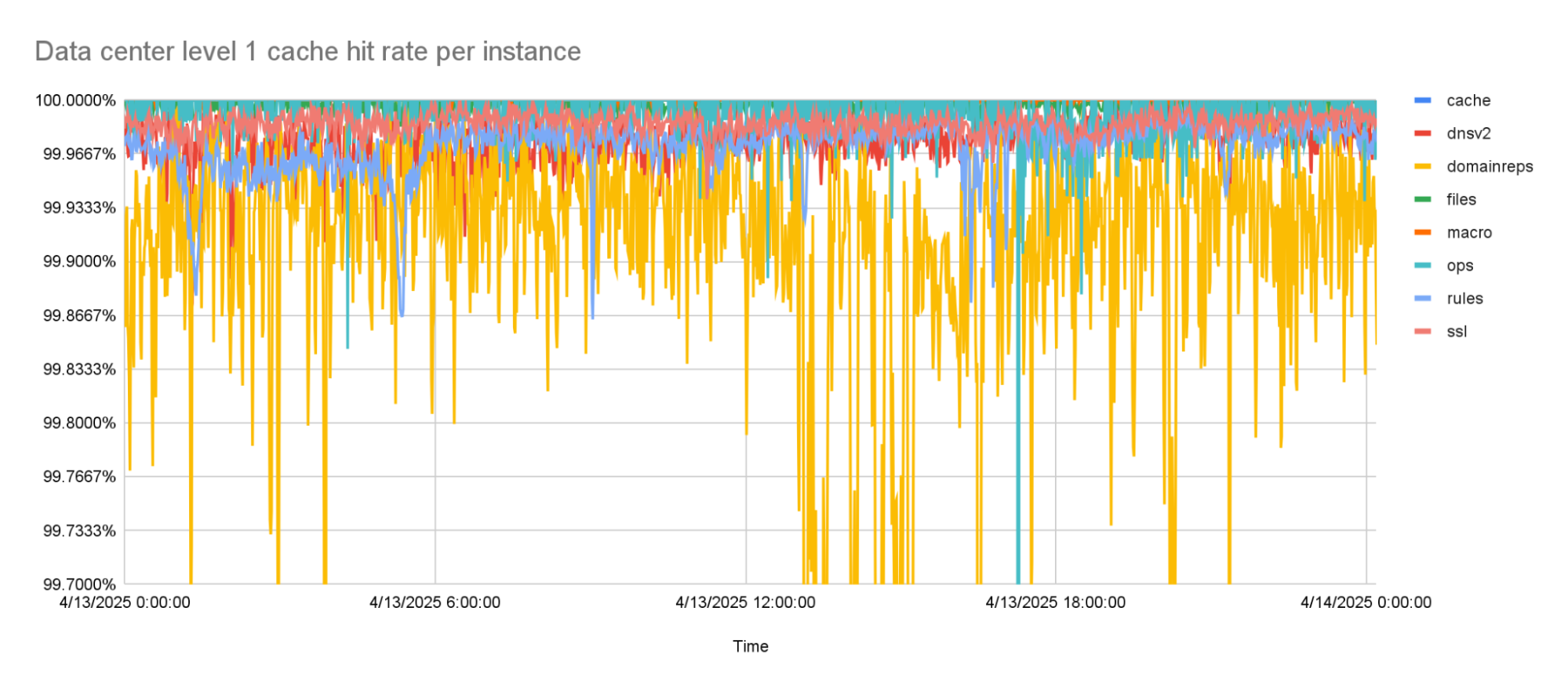
The level 1 cache hit-rate is 99.9% or higher, on average.
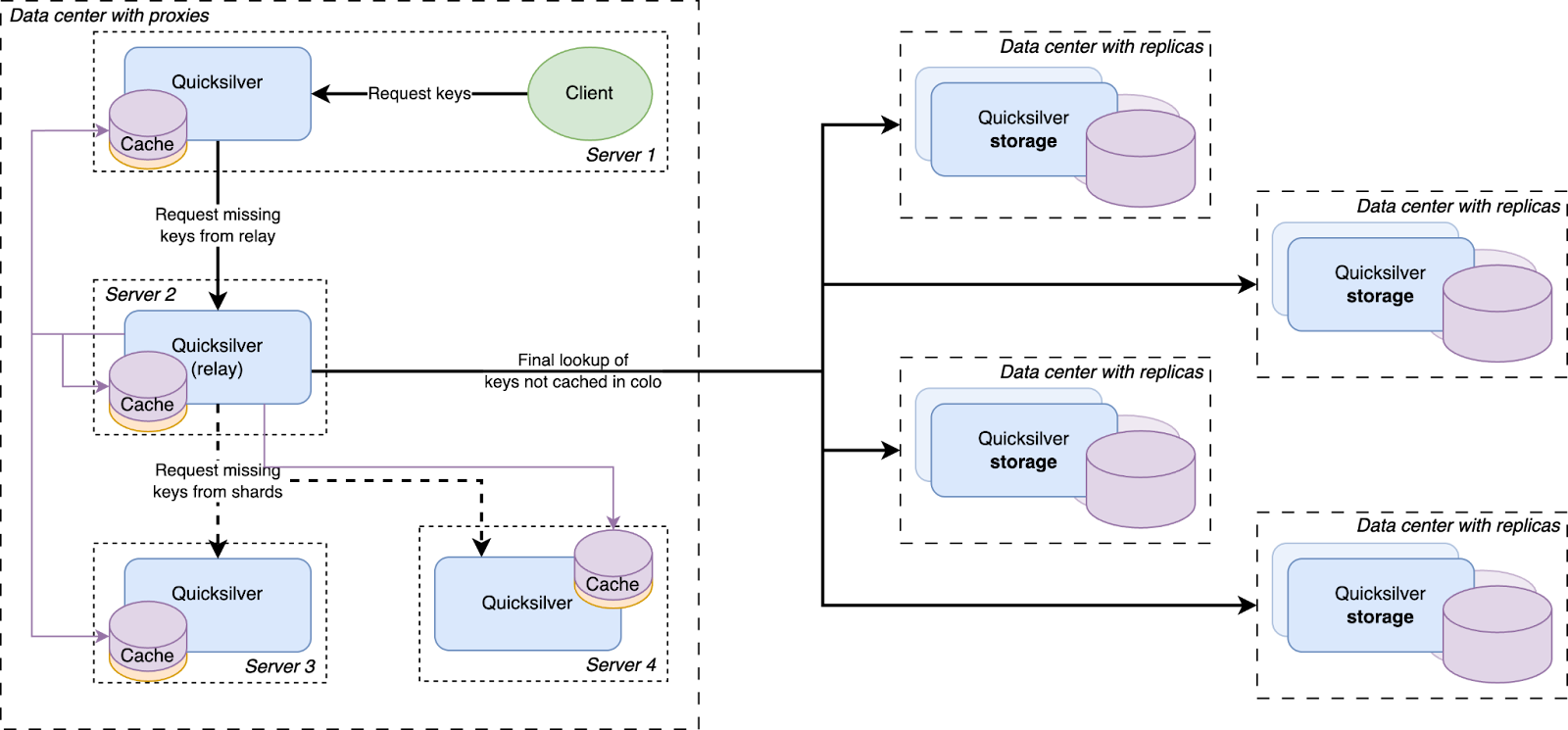
Before going to a replica in another data center, a cache miss is first looked up in a data center-wide sharded cache
The instance on which higher cache hit rates were required was also the instance on which the cache performed the worst. The cache works with a retention time, defined as the number of days a key-value is kept in cache after it was last accessed, after which it is evicted from the cache. An analysis of the cache showed that this instance needed a much longer retention time. But, a higher retention time also causes the cache to take up more disk space — space that was not available.
However, while running Quicksilver V1.5, we had already noticed the pattern that caches generally performed much better in smaller data centers as compared to larger ones. This sparked the hypothesis that led to the final improvement.
It turns out that smaller data centers, with fewer servers, generally needed less disk space for their cache. Vice versa, the more servers there are in a data center, the larger the Quicksilver cache needs to be. This is easily explained by the fact that larger data centers generally serve larger populations, and therefore have a larger diversity of requests. More servers also means more total disk space available inside the data center. To be able to make use of this pattern the concept of sharding was reintroduced.
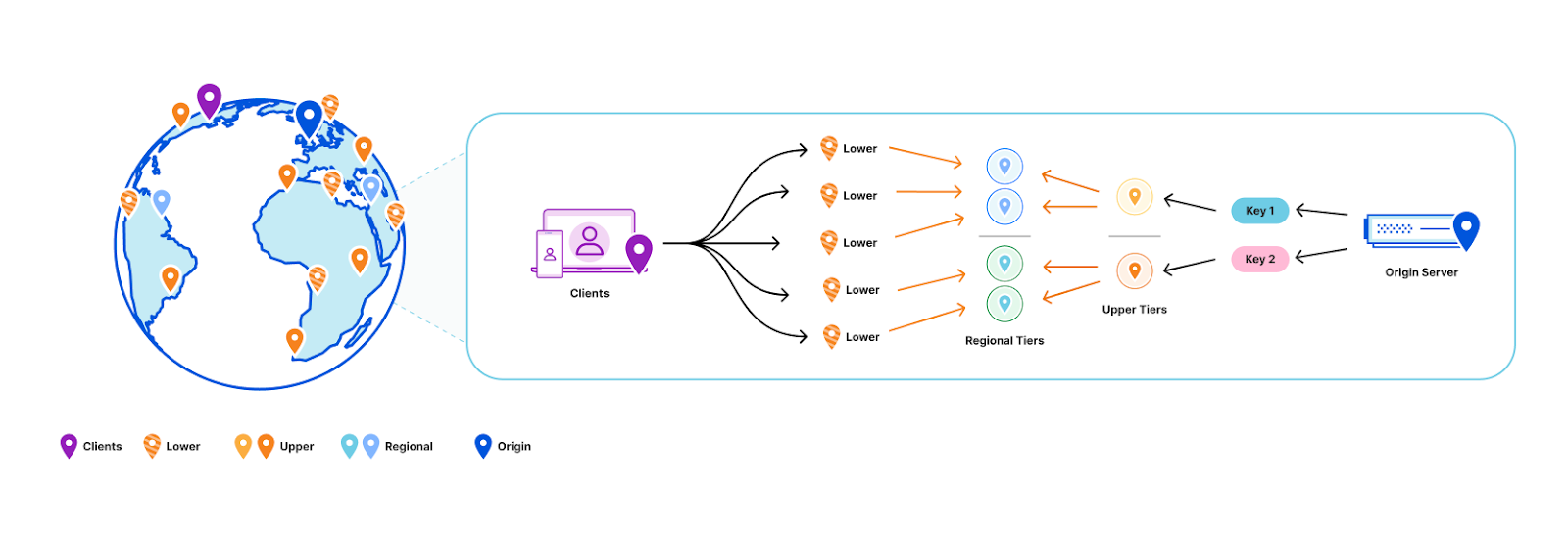
Our key space was split up into multiple shards. Each server in a data center was assigned one of the shards. Instead of those shards containing the full dataset for their part of the key space, they contain a cache for it. Those cache shards are populated by all cache misses inside the data center. This all forms a data center-wide cache that is distributed using sharding.
The data locality issue that sharding the full dataset has, as described above, is solved by keeping the local per-server caches as well. The sharded cache is in addition to the local caches. All servers in a data center contain both their local cache and a cache for one physical shard of the sharded cache. Therefore, each requested key is first looked up in the server’s local cache, after that the data center-wide sharded cache is queried, and finally if both caches miss the requested key, it is looked up on one of the storage nodes.
The key space is split up into separate shards by first dividing hashes of the keys by range into 1024 logical shards. Those logical shards are then divided up into physical shards, again by range. Each server gets one physical shard assigned by repeating the same process on the server hostname.
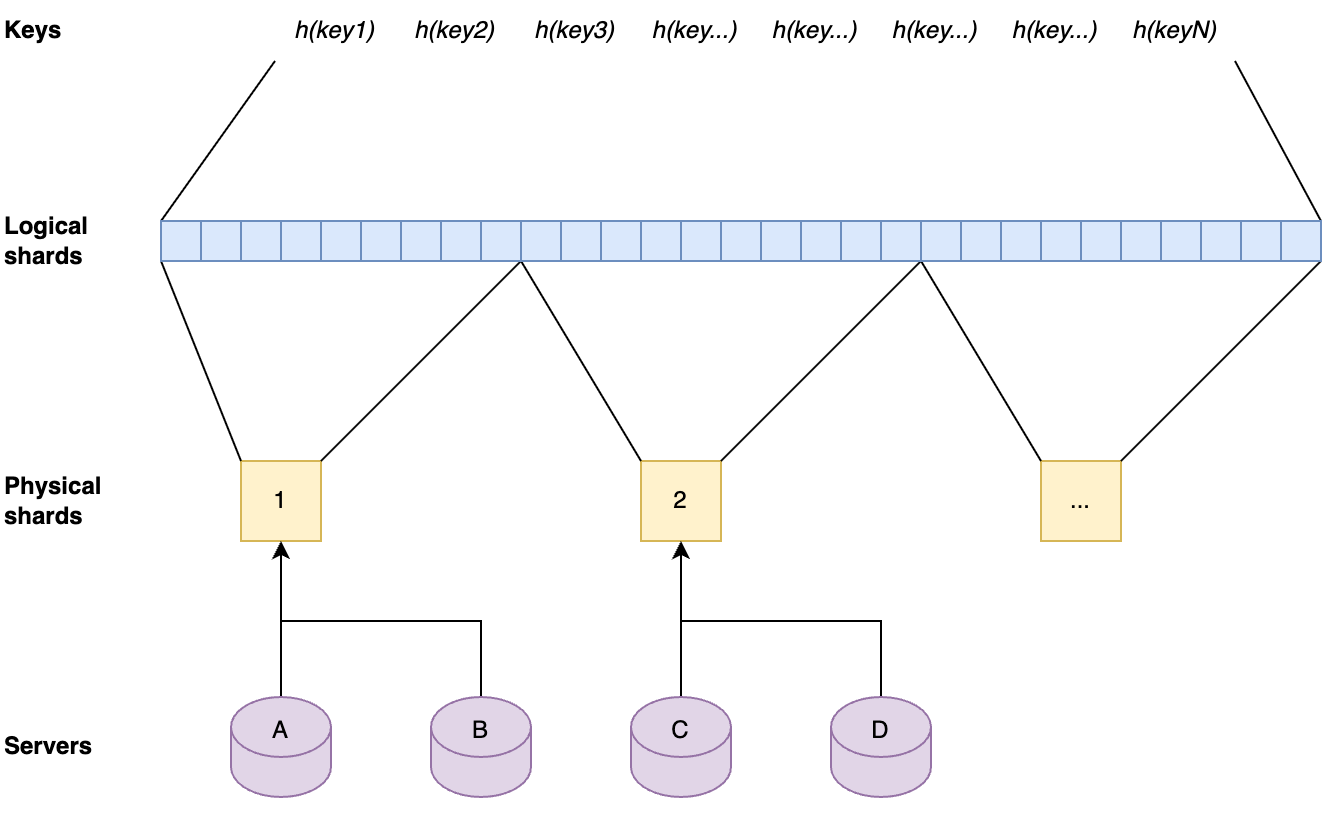
Each server contains one physical shard. A physical shard contains a range of logical shards. A local shard contains a range of the ordered set that result from hashing all keys.
This approach has the advantage that the sharding factor can be scaled up by factors of two without the need for copying caches to other servers. When the sharding factor is increased in this way, the servers will automatically get a new physical shard assigned that contains a subset of the key space that the previous physical shard on that server contained. After this has happened, their cache will contain supersets of the needed cache. The key-values that are not needed anymore will be evicted over time.
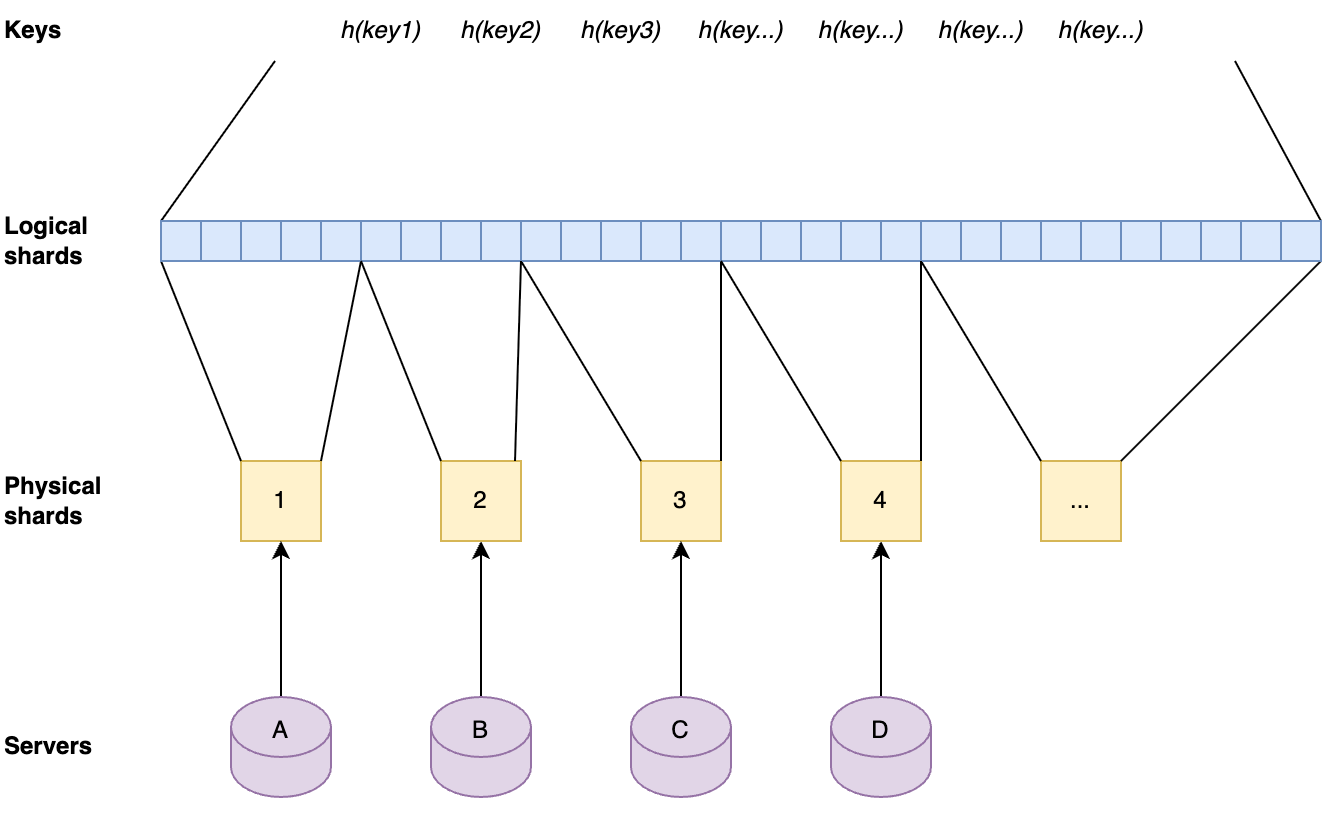
When the number of physical shards are doubled the servers will automatically get new physical shards that are subsets of their previous physical shards, therefore still have the relevant key-values in cache.
This approach means that the sharded caches can easily be scaled up when needed as the number of keys that are in Quicksilver grows, and without any need for relocating data. Also, shards are well-balanced due to the fact that they contain uniform random subsets of a very large key-space.
Adding new key-values to the physical cache shards piggybacks on the prefetching mechanism, which already distributes all resolved cache misses to all servers in a data center. The keys that are part of the key space for a physical shard on a particular server are just kept longer in cache than the keys that are not part of that physical shard.
Another reason why a sharded cache is simpler than sharding the full key-space is that it is possible to cut some corners with a cache. For instance, looking up older versions of key-values (as used for multiversion concurrency control) is not supported on cache shards. As explained in an earlier blog post, this is needed for consistency when looking up key-values on different servers, when that server has a newer version of the database. It is not needed in the cache shards, because lookups can always fall back to the storage nodes when the right version is not available.
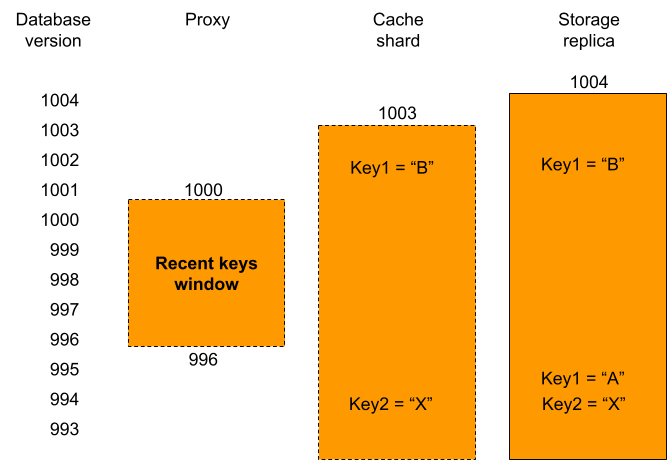
Proxies have a recent keys window that contains all recently written key-values. A cache shard only has its cached key-values. Storage replicas contain all key-values and on top of that they contain multiple versions for recently written key-values. When the proxy, that has database version 1000, has a cache miss for key1 it can be seen that the version of that key on the cache shard was written at database version 1002 and therefore is too new. This means that it is not consistent with the proxy’s database version. This is why the relay will fetch that key from a replica instead, which can return the earlier consistent version. In contrast, key2 on the cache shard can be used, because it was written at index 994, well below the database version of the proxy.
There is only one very specific corner case in which a key-value on a cache shard cannot be used. This happens when the key-value in the cache shard was written at a more recent database version than the version of the proxy database at that time. This would mean that the key-value probably has a different value than it had at the correct version. Because, in general, the cache shard and the proxy database versions are very close to each other, and this only happens for key-values that were written in between those two database versions, this happens very rarely. As such, deferring the lookup to storage nodes has no noticeable effect on the cache hit rate.

To summarize, Quicksilver V2 has three levels of storage.
-
Level 1: The local cache on each server that contains the key-values that have most recently been accessed.
-
Level 2: The data center wide sharded cache that contains key-values that haven’t been accessed in a while, but do have been accessed.
-
Level 3: The replicas on the storage nodes that contain the full dataset, which live on a handful of storage nodes and are only queried for the cold keys.
The percentage of keys that can be resolved within a data center improved significantly by adding the second caching layer. The worst performing instance has a cache hit rate higher than 99.99%. All other instances have a cache hit rate that is higher than 99.999%.
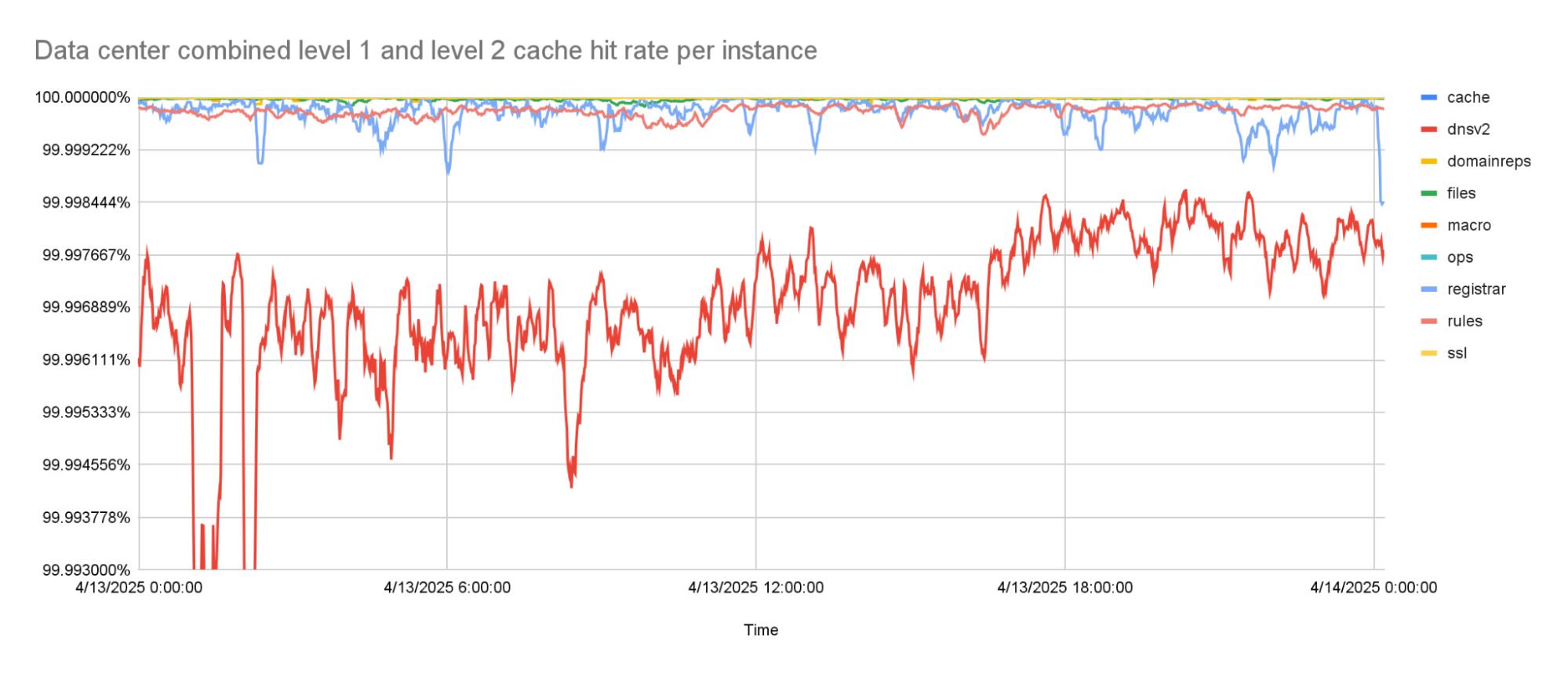
The combined level 1 and level 2 cache hit-rate is 99.99% or higher for the worst caching instance.
It took the team quite a few years to go from the old Quicksilver V1, where all data was stored on each server to the tiered caching Quicksilver V2, where all but a handful of servers only have cache. We faced many challenges, including migrating hundreds of thousands of live databases without interruptions, while serving billions of requests per second. A lot of code changes were rolled out, with the result that Quicksilver now has a significantly different architecture. All of this was done transparently to our customers. It was all done iteratively, always learning from the previous step before taking the next one. And always making sure that, if at all possible, all changes are easy to revert. These are important strategies for migrating complex systems safely.
If you like these kinds of stories, keep an eye out for more development stories on our blog. And if you are enthusiastic about solving these kinds of problems, we are hiring for multiple types of roles across the organization
And finally, a big thanks to the rest of the Quicksilver team, because we all do this together: Aleksandr Matveev, Aleksei Surikov, Alex Dzyoba, Alexandra (Modi) Stana-Palade, Francois Stiennon, Geoffrey Plouviez, Ilya Polyakovskiy, Manzur Mukhitdinov, Volodymyr Dorokhov.