Post Syndicated from Charles Burnett original http://blog.cloudflare.com/faster-workers-kv-architecture/


We’re excited to announce a significant performance improvement coming to Workers KV, focused on dramatically improving cold read performance and reducing latency, even for long tail access patterns.
Developers using KV have seen great performance on hot reads, but ask why their 95th percentile latency — often on a key (or set of keys) that hadn’t been accessed recently or in that region — was higher than expected. We took this feedback to heart: we’ve been working feverishly on a new caching layer for KV behind the scenes, which enables customers to achieve much more frequent hot reads, reduced worst case latency times, better flexibility and control over cache TTLs, and much faster consistency over our previous iterations, and it’s now live for all KV users.
The best part? Developers using KV don’t need to change anything to benefit from this increased performance.
What is Workers KV?
Workers KV is a key value store designed for read heavy use-cases and applications powered by Cloudflare’s network. KV’s focus on read-heavy use-cases allows it to serve hot (cached) reads in milliseconds, which makes it ideal for storing per-application or customer configuration data, routing configuration, multivariate (A/B testing) configurations, and even small asset data that you need to serve quickly. Anything that you can serialize and need quickly you can store in KV, all the way up to 25 MiB worth of data per each individual key, with no cap on total data stored.
The problem
KV might be optimized for read-heavy workloads, but it’s critical that writes are globally available quickly enough that they’re useful for your application. Under typical conditions, the convergence delay for an eventually consistent system like KV is approximately one minute, globally: a write from one location should be able to be observed by all readers. Typical conditions are great, but typical unfortunately didn’t mean “always”. It could take significant time to restore global consistency where regions like North America and Europe are reading the same value. We needed to improve not just the average convergence, but the worst case as well.
Speaking of consistency, setting a long cache Time to Live (cacheTTL) for reads would result in a situation where you won’t notice a write for the entire cacheTTL duration, as the existing cached data had not timed out yet. This means you have to trade off read latency for infrequently accessed keys against noticing writes. Developers using KV have been consistent in their feedback: a higher cache TTL should improve performance, but not multiply the time it takes for KV to converge on a write to that key.
Lastly, our cold read times also left room for improvement. While cache hits are fast in KV, a cache miss would result in a request being routed all the way to our storage backends. While this is slow for everyone, it was particularly slow for folks in regions not immediately in the US or EU.This is poor performance that doesn’t represent what we can achieve with our global presence.
Our solution
A new horizontally scaled tiered cache
We’ve revamped Workers KV to be powered by a new tiered cache implementation. This implementation is written as a Worker service. We reuse the Dynamic Dispatch infrastructure developed for Workers for Platforms which lets us jump from our old KV worker into our new caching service within hundreds of microseconds. Importantly, this means we don’t impact cache hit performance to implement this new transparent caching layer. We leverage the same infrastructure powering Smart Placement to implement the tiering.
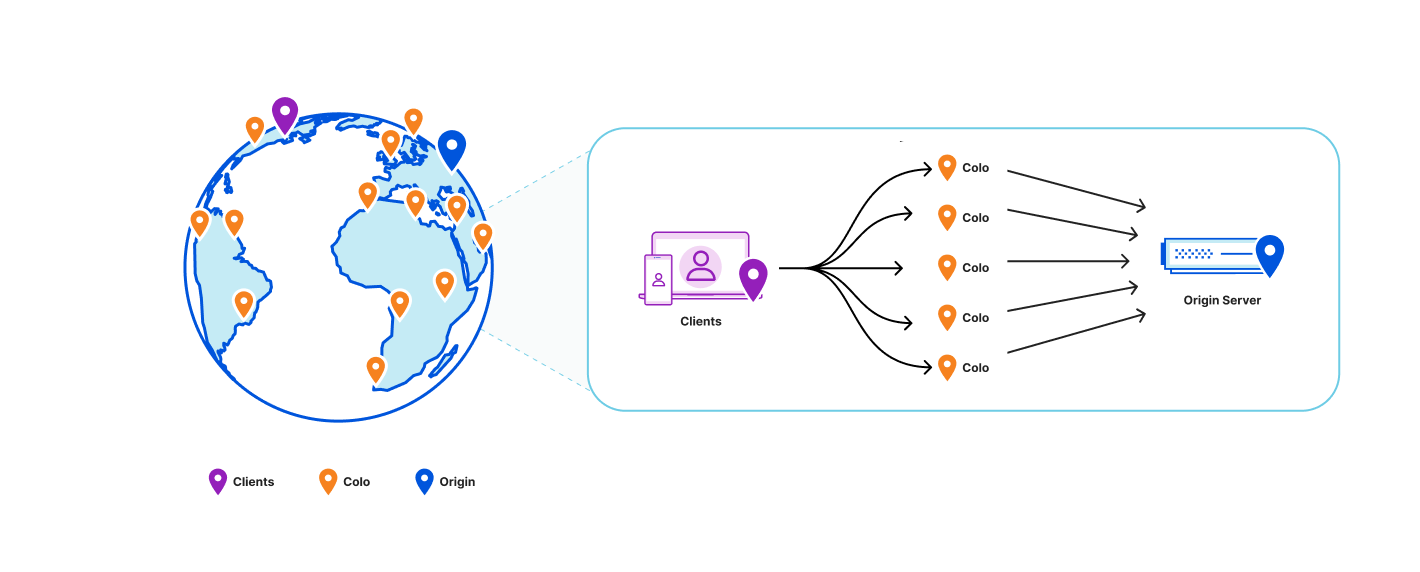
Before we re-designed KV, our topology looked like this:
Cache TTL and efficiency
Our design goal was clear and ambitious: “can we relax honoring the cacheTTL constraint without violating it”? While this seems contradictory, the motivation is clear: we want to minimize the need to communicate with our storage backends while honoring the user-facing semantics of the cacheTTL setting, as it can have security implications if violated (e.g. if you use it to store and validate security tokens). Answering this design question also manages to simultaneously solve many of the problems outlined earlier.
Comparing existing solutions
First, let’s look at the design constraints for two eventually consistent storage systems at Cloudflare: Quicksilver and Tiered CDN.
Quicksilver gives us global consistency within seconds using a push architecture to replicate the data across all machines at Cloudflare. That architecture however doesn’t scale for Workers KV’s needs, which can have terabytes of data just within one namespace. This would be too much to replicate to every single data center.
By comparison, the tiered CDN cache is a pull mechanism where each hop pulls a more recent version of the asset into the local cache on access. That scales better because we only use storage for assets that are accessed, which works well with most use-cases where the vast majority of data is never retrieved. However, a pull based architecture is insufficient because it can only let us aggregate traffic across broader regions but we still can’t decouple how long we serve from the cache from the cacheTTL.
Push based architectures let us know when an asset is updated and enable scalable storage. By blending the properties of both systems, we can decouple how long we store the assets in cache from the cacheTTL. And that’s exactly what we did: KV now uses a hybrid push/pull caching layer where data centers closest to customers will pull from the regional data centers that are a little bit farther away. Writes will broadcast to all regional data centers that a key has been updated, so that the regional data center will remove that key from the local cache.
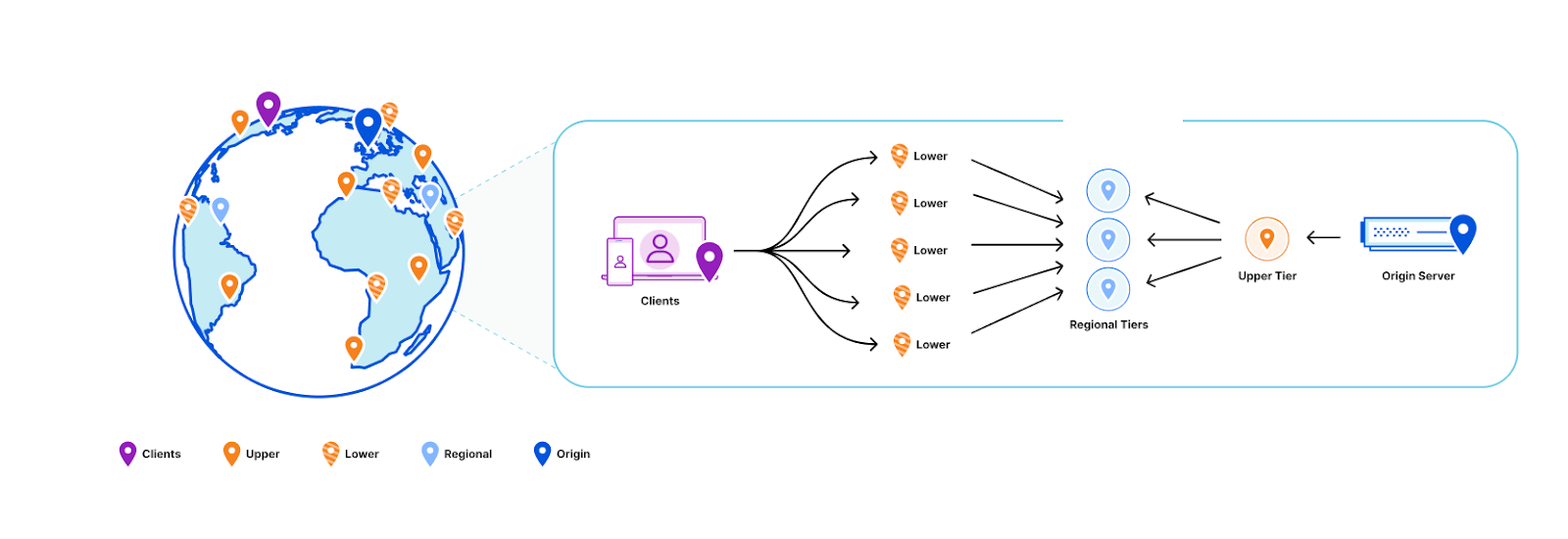
We can solve this problem by taking advantage of the fact that we semantically understand the write operations that are happening within Workers KV:
- Workers KV doesn’t have one data center per region as might be typical for your zone in a Cloudflare CDN regional tiered cache topology. Instead, each key in a KV namespace is deterministically assigned a data center by performing a weighted rendezvous hash. The rendezvous hash ensures that load is distributed equally across the region and outages result in optimal shifts of traffic.
- When the data center closest to a customer has a miss, it computes the regional data center affinity and provides that information to our Smart Placement infrastructure. When a regional tier misses, we repeat this process except using data centers in the KV origin region.
- Finally, a miss at the upper tier exits to our storage nodes located in that origin region.
When we do a write, we only purge (invalidate) the key from the regional and upper tier data centers. This is a fixed number of data centers in our network regardless of how many data centers we add, which ensures that we aren’t reducing cache hit rates as our network continues to grow Compared with a global purge that delivers the event to every data center in our network, because we only need to deliver this purge to a random fixed set of data centers in our network, our aggregate write capacity for Workers KV automatically scales horizontally as we add more data centers.
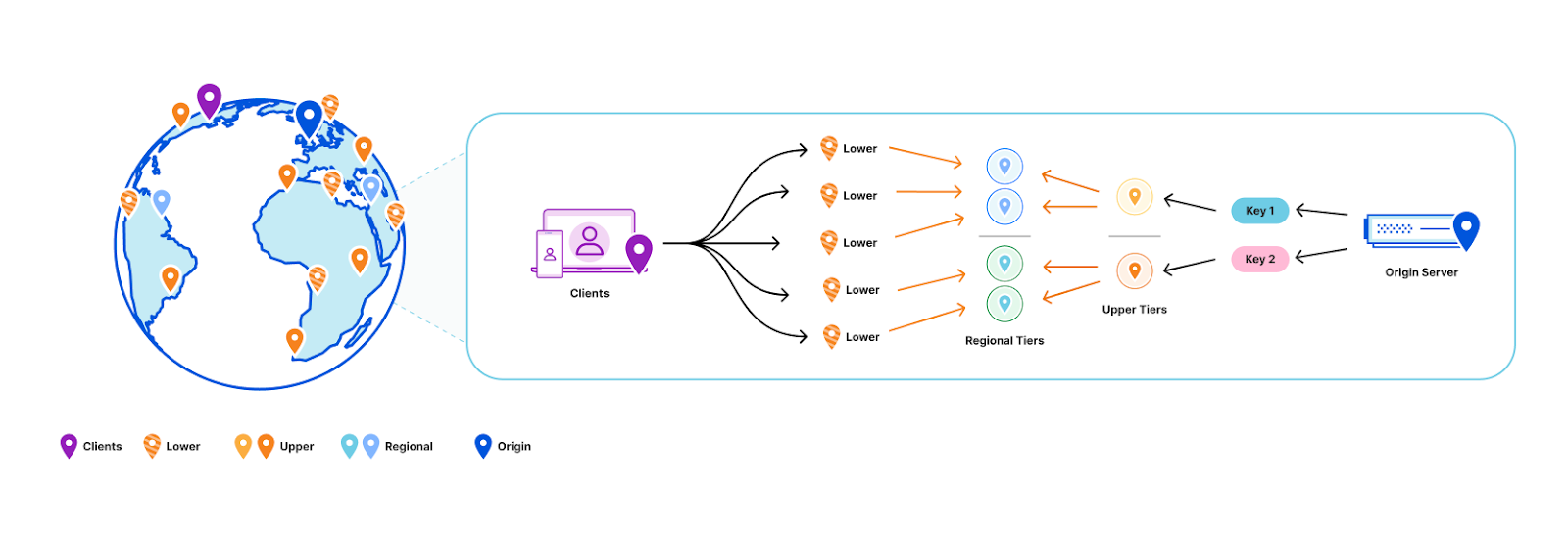
Why do we call this a hybrid topology? The data centers closest to customers pull from the regional data centers as normal, but we automatically push invalidation events to the regional tier data centers on every write. That way, those customer data center pulls know to get an updated value when there is one. This means that while the cacheTTL parameter controls the caching behavior closest to the customer, it’s treated as a suggestion at best at the regional and upper tiers.
This way we’ve combined the push design principles behind Quicksilver, which delivers global consistency within seconds, with the pull-based design of our CDN tiered caching which can scale to handle “infinite” size workloads and prioritizes the assets that are most frequently accessed.
Visualizing it
It can be a bit hard to follow what’s happening in the new caching layer since there’s so many moving parts.
Here’s a video of a simplified version of how it works:
Small yellow balls represent KV read requests, larger green balls represent read responses. A larger purple ball represents a KV write request, while a read response ball represents a KV write response. Teal balls represent purge requests being broadcast. The “E” is a data center that doesn’t participate as a regional tier. The R represents the regional tier for key N while O is the upper tier for key N.
Decoupled cache TTL and consistency parameters
As a refresher, the objects written to KV can specify a cacheTTL: by default this is set to 1 minute, which is also the minimum acceptable value. This means that if an asset has been in the cache for longer than a minute, we bypass the cache and read instead from our durable storage nodes. In order to prevent eyeballs noticing origin fetches every minute, we implement stale while revalidate logic in our caching layer that automatically refreshes from the storage nodes in the background as requests come in.
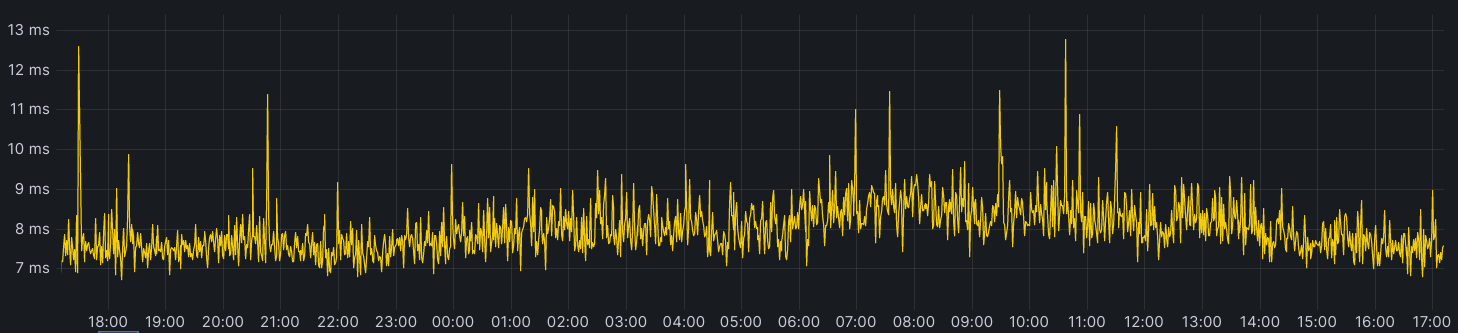
Notice the absence of any spikes indicating a cache miss? You’d expect to see them regularly every minute or so in the tens or even hundreds of milliseconds when the cacheTTL should expire. The reason this doesn’t happen is because as the expiry time is approaching, a background request to the storage nodes occurs and the cache is updated with an expiry time one more minute into the future; thus the asset in cache is never too stale and eyeball requests are always served from cache. Let’s take a look at requests to our storage layer before and after adding tiering:

The above chart is for a system with conservative parameters set. The upper tier doesn’t store the data for much longer than the cacheTTL currently and the upper tier will itself still do a background refresh probabilistically even though it doesn’t actually need to since we see all writes.
The new caching layer we’ve built inherits the old background refresh mechanism and expands on it. The first thing we did is decouple the background refresh period from the cacheTTL as a separate parameter (also defaulting to 1 minute). This means that even if you set a cacheTTL for 1 hour, KV will still check every minute from the regional tier to see if the value has been updated. If the data you’re storing within KV doesn’t have strict requirements on stale reads (think a key that’s accessed once every 10 minutes but needs to honor a write within 1 minute like security tokens), then you can increase the cacheTTL so that infrequently accessed keys stick around in the cache without changing the observed consistency.
Consistency improvements
Speaking of consistency, we’ve improved the worst case performance of that as well. Historically, we’ve had a background system that crawls all data in the storage nodes to figure out which region has the most up to date value and update accordingly. This gives us complete consistency coverage, but could take a significant amount of time to confirm. We would also periodically check both backends to see if network conditions had changed to pick the primary storage region to use for a given customer-close data center. Of course inconsistencies would be resolved then, but in practice this happens randomly, and at a low probability that won’t typically catch any meaningful values served inconsistently.
With the new caching layer all this changes. Since we’re now only reading keys on first access or after a write, we have enough storage capacity that we can check both backends on every read. When a customer requests data, we make a call to each origin data center, with the fastest response being returned immediately to reduce read latency. If the other data center has a newer value than what was returned first, we synchronize both data centers and notify our caching layer to purge that key from all regional data centers. If the other data center instead has an older value, we just synchronize the data centers without purging since we served the latest value. This means that even if our data centers are inconsistent, readers will notice new values much more quickly.
Latency improvements
Here’s the latency improvement at 10% rollout on a logarithmic x-axis:

Architecture that just gets better
This is just the start of what we can do. We now have a solid foundation for making further improvements, including making our best case reads even faster. We’ll be working on cutting out parts of our traditional stack that add unnecessary latency, and adding new high performance features that were too difficult to integrate otherwise. We can also explore features like setting the consistency TTL parameter for sub one minute consistency for additional cost. Similarly, we could create a best effort global purge feature if you want to choose to signal writes that way. Finally, we’re looking at exposing this new caching layer as a general Worker binding anyone can use within a Worker in front of their own service or to put in front of their Worker. If these sound like the killer features you need, please reach out to us if you’re interested in trying them out.
What next?
Developers don’t have to do anything to benefit from KV’s new performance improvements. We are currently in the process of rolling out our new architecture, and you don’t have to redeploy your Worker or change the way you use KV to benefit.
Workers KV is a natural fit for any application built on top of our Workers platform. We provide a native API that enables any Worker script to read, write, list, and manageyour Workers KV storage. You can also interact with Workers KV directly via our REST API from any client that can make a HTTP request, and the Cloudflare Dashboard provides an easy way to create, list, and delete keys to be used with the rest of your Workers setup.
Regardless of how you use Workers KV, it will be faster than ever before. We’re excited to see what you build with us, and you can dive into our documentation to start building with it.