Cloudflare was recently contacted by a group of anonymous security researchers who discovered a broadcast amplification vulnerability through their QUIC Internet measurement research. Our team collaborated with these researchers through our Public Bug Bounty program, and worked to fully patch a dangerous vulnerability that affected our infrastructure.
Since being notified about the vulnerability, we’ve implemented a mitigation to help secure our infrastructure. According to our analysis, we have fully patched this vulnerability and the amplification vector no longer exists.
Summary of the amplification attack
QUIC is an Internet transport protocol that is encrypted by default. It offers equivalent features to TCP (Transmission Control Protocol) and TLS (Transport Layer Security), while using a shorter handshake sequence that helps reduce connection establishment times. QUIC runs over UDP (User Datagram Protocol).
The researchers found that a single client QUIC Initial packet targeting a broadcast IP destination address could trigger a large response of initial packets. This manifested as both a server CPU amplification attack and a reflection amplification attack.
Transport and security handshakes
When using TCP and TLS there are two handshake interactions. First, is the TCP 3-way transport handshake. A client sends a SYN packet to a server, it responds with a SYN-ACK to the client, and the client responds with an ACK. This process validates the client IP address. Second, is the TLS security handshake. A client sends a ClientHello to a server, it carries out some cryptographic operations and responds with a ServerHello containing a server certificate. The client verifies the certificate, confirms the handshake and sends application traffic such as an HTTP request.
QUIC follows a similar process, however the sequence is shorter because the transport and security handshake is combined. A client sends an Initial packet containing a ClientHello to a server, it carries out some cryptographic operations and responds with an Initial packet containing a ServerHello with a server certificate. The client verifies the certificate and then sends application data.
The QUIC handshake does not require client IP address validation before starting the security handshake. This means there is a risk that an attacker could spoof a client IP and cause a server to do cryptographic work and send data to a target victim IP (aka a reflection attack). RFC 9000 is careful to describe the risks this poses and provides mechanisms to reduce them (for example, see Sections 8 and 9.3.1). Until a client address is verified, a server employs an anti-amplification limit, sending a maximum of 3x as many bytes as it has received. Furthermore, a server can initiate address validation before engaging in the cryptographic handshake by responding with a Retry packet. The retry mechanism, however, adds an additional round-trip to the QUIC handshake sequence, negating some of its benefits compared to TCP. Real-world QUIC deployments use a range of strategies and heuristics to detect traffic loads and enable different mitigations.
In order to understand how the researchers triggered an amplification attack despite these QUIC guardrails, we first need to dive into how IP broadcast works.
Broadcast addresses
In Internet Protocol version 4 (IPv4) addressing, the final address in any given subnet is a special broadcast IP address used to send packets to every node within the IP address range. Every node that is within the same subnet receives any packet that is sent to the broadcast address, enabling one sender to send a message that can be “heard” by potentially hundreds of adjacent nodes. This behavior is enabled by default in most network-connected systems and is critical for discovery of devices within the same IPv4 network.
The broadcast address by nature poses a risk of DDoS amplification; for every one packet sent, hundreds of nodes have to process the traffic.
Dealing with the expected broadcast
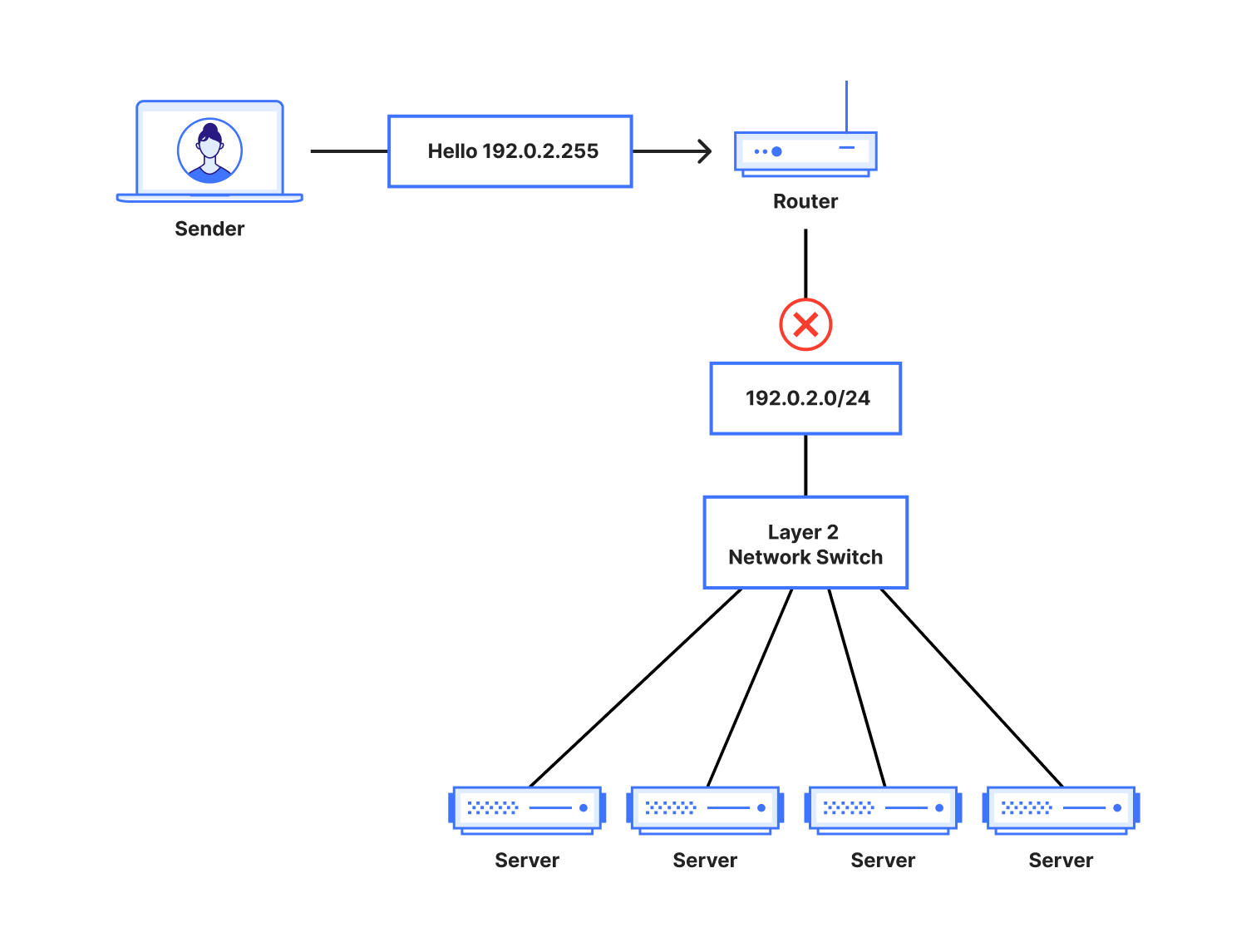
To combat the risk posed by broadcast addresses, by default most routers reject packets originating from outside their IP subnet which are targeted at the broadcast address of networks for which they are locally connected. Broadcast packets are only allowed to be forwarded within the same IP subnet, preventing attacks from the Internet from targeting servers across the world.
The same techniques are not generally applied when a given router is not directly connected to a given subnet. So long as an address is not locally treated as a broadcast address, Border Gateway Protocol (BGP) or other routing protocols will continue to route traffic from external IPs toward the last IPv4 address in a subnet. Essentially, this means a “broadcast address” is only relevant within a local scope of routers and hosts connected together via Ethernet. To routers and hosts across the Internet, a broadcast IP address is routed in the same way as any other IP.
Binding IP address ranges to hosts
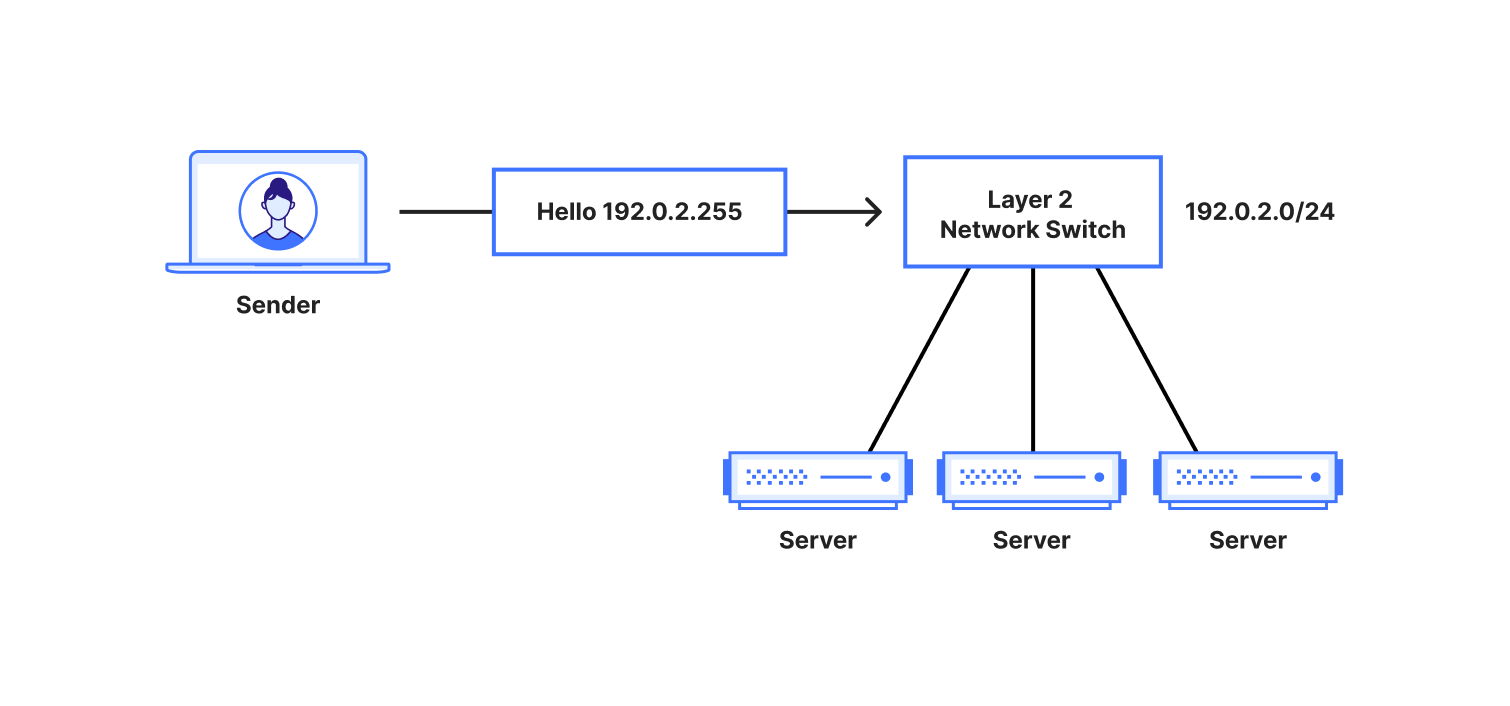
Each Cloudflare server is expected to be capable of serving content from every website on the Cloudflare network. Because our network utilizes Anycast routing, each server necessarily needs to be listening on (and capable of returning traffic from) every Anycast IP address in use on our network.
To do so, we take advantage of the loopback interface on each server. Unlike a physical network interface, all IP addresses within a given IP address range are made available to the host (and will be processed locally by the kernel) when bound to the loopback interface.
The mechanism by which this works is straightforward. In a traditional routing environment, longest prefix matching is employed to select a route. Under longest prefix matching, routes towards more specific blocks of IP addresses (such as 192.0.2.96/29, a range of 8 addresses) will be selected over routes to less specific blocks of IP addresses (such as 192.0.2.0/24, a range of 256 addresses).
While Linux utilizes longest prefix matching, it consults an additional step — the Routing Policy Database (RPDB) — before immediately searching for a match. The RPDB contains a list of routing tables which can contain routing information and their individual priorities. The default RPDB looks like this:
$ ip rule show
0: from all lookup local
32766: from all lookup main
32767: from all lookup default
Linux will consult each routing table in ascending numerical order to try and find a matching route. Once one is found, the search is terminated and the route immediately used.
If you’ve previously worked with routing rules on Linux, you are likely familiar with the contents of the main table. Contrary to the existence of the table named “default”, “main” generally functions as the default lookup table. It is also the one which contains what we traditionally associate with route table information:
$ ip route show table main
default via 192.0.2.1 dev eth0 onlink
192.0.2.0/24 dev eth0 proto kernel scope link src 192.0.2.2
This is, however, not the first routing table that will be consulted for a given lookup. Instead, that task falls to the local table:
$ ip route show table local
local 127.0.0.0/8 dev lo proto kernel scope host src 127.0.0.1
local 127.0.0.1 dev lo proto kernel scope host src 127.0.0.1
broadcast 127.255.255.255 dev lo proto kernel scope link src 127.0.0.1
local 192.0.2.2 dev eth0 proto kernel scope host src 192.0.2.2
broadcast 192.0.2.255 dev eth0 proto kernel scope link src 192.0.2.2
Looking at the table, we see two new types of routes — local and broadcast. As their names would suggest, these routes dictate two distinctly different functions: routes that are handled locally and routes that will result in a packet being broadcast. Local routes provide the desired functionality — any prefix with a local route will have all IP addresses in the range processed by the kernel. Broadcast routes will result in a packet being broadcast to all IP addresses within the given range. Both types of routes are added automatically when an IP address is bound to an interface (and, when a range is bound to the loopback (lo) interface, the range itself will be added as a local route).
Vulnerability discovery
Deployments of QUIC are highly dependent on the load-balancing and packet forwarding infrastructure that they sit on top of. Although QUIC’s RFCs describe risks and mitigations, there can still be attack vectors depending on the nature of server deployments. The reporting researchers studied QUIC deployments across the Internet and discovered that sending a QUIC Initial packet to one of Cloudflare’s broadcast addresses triggered a flood of responses. The aggregate amount of response data exceeded the RFC’s 3x amplification limit.
Taking a look at the local routing table of an example Cloudflare system, we see a potential culprit:
$ ip route show table local
local 127.0.0.0/8 dev lo proto kernel scope host src 127.0.0.1
local 127.0.0.1 dev lo proto kernel scope host src 127.0.0.1
broadcast 127.255.255.255 dev lo proto kernel scope link src 127.0.0.1
local 192.0.2.2 dev eth0 proto kernel scope host src 192.0.2.2
broadcast 192.0.2.255 dev eth0 proto kernel scope link src 192.0.2.2
local 203.0.113.0 dev lo proto kernel scope host src 203.0.113.0
local 203.0.113.0/24 dev lo proto kernel scope host src 203.0.113.0
broadcast 203.0.113.255 dev lo proto kernel scope link src 203.0.113.0
On this example system, the anycast prefix 203.0.113.0/24 has been bound to the loopback interface (lo) through the use of standard tooling. Acting dutifully under the standards of IPv4, the tooling has assigned both special types of routes — a local one for the IP range itself and a broadcast one for the final address in the range — to the interface.
While traffic to the broadcast address of our router’s directly connected subnet is filtered as expected, broadcast traffic targeting our routed anycast prefixes still arrives at our servers themselves. Normally, broadcast traffic arriving at the loopback interface does little to cause problems. Services bound to a specific port across an entire range will receive data sent to the broadcast address and continue as normal. Unfortunately, this relatively simple trait breaks down when normal expectations are broken.
Cloudflare’s frontend consists of several worker processes, each of which independently binds to the entire anycast range on UDP port 443. In order to enable multiple processes to bind to the same port, we use the SO_REUSEPORT socket option. While SO_REUSEPORT has additional benefits, it also causes traffic sent to the broadcast address to be copied to every listener.
Each individual QUIC server worker operates in isolation. Each one reacted to the same client Initial, duplicating the work on the server side and generating response traffic to the client’s IP address. Thus, a single packet could trigger a significant amplification. While specifics will vary by implementation, a typical one-listener-per-core stack (which sends retries in response to presumed timeouts) on a 128-core system could result in 384 replies being generated and sent for each packet sent to the broadcast address.
Although the researchers demonstrated this attack on QUIC, the underlying vulnerability can affect other UDP request/response protocols that use sockets in the same way.
Mitigation
As a communication methodology, broadcast is not generally desirable for anycast prefixes. Thus, the easiest method to mitigate the issue was simply to disable broadcast functionality for the final address in each range.
Ideally, this would be done by modifying our tooling to only add the local routes in the local routing table, skipping the inclusion of the broadcast ones altogether. Unfortunately, the only practical mechanism to do so would involve patching and maintaining our own internal fork of the iproute2 suite, a rather heavy-handed solution for the problem at hand.
Instead, we decided to focus on removing the route itself. Similar to any other route, it can be removed using standard tooling:
$ sudo ip route del 203.0.113.255 table local
To do so at scale, we made a relatively minor change to our deployment system:
{%- for lo_route in lo_routes %}
{%- if lo_route.type == "broadcast" %}
# All broadcast addresses are implicitly ipv4
{%- do remove_route({
"dev": "lo",
"dst": lo_route.dst,
"type": "broadcast",
"src": lo_route.src,
}) %}
{%- endif %}
{%- endfor %}
In doing so, we effectively ensure that all broadcast routes attached to the loopback interface are removed, mitigating the risk by ensuring that the specification-defined broadcast address is treated no differently than any other address in the range.
Next steps
While the vulnerability specifically affected broadcast addresses within our anycast range, it likely expands past our infrastructure. Anyone with infrastructure that meets the relatively narrow criteria (a multi-worker, multi-listener UDP-based service that is bound to all IP addresses on a machine with routable IP prefixes attached in such a way as to expose the broadcast address) will be affected unless mitigations are in place. We encourage network administrators and security professionals to assess their systems for configurations that may present a local amplification attack vector.
Have you ever built a piece of IKEA furniture, or put together a LEGO set, by following the instructions closely and only at the end realized at some point you didn’t quite follow them correctly? The final result might be close to what was intended, but there’s a nagging thought that maybe, just maybe, it’s not as rock steady or functional as it could have been.
Internet protocol specifications are instructions designed for engineers to build things. Protocol designers take great care to ensure the documents they produce are clear. The standardization process gathers consensus and review from experts in the field, to further ensure document quality. Any reasonably skilled engineer should be able to take a specification and produce a performant, reliable, and secure implementation. The Internet is central to everyone’s lives, and we depend on these implementations. Any deviations from the specification can put us at risk. For example, mishandling of malformed requests can allow attacks such as request smuggling.
h3i is a binary command line tool and Rust library designed for low-level testing and debugging of HTTP/3, which runs over QUIC. h3i is free and open source as part of Cloudflare’s quiche project. In this post we’ll explain the motivation behind developing h3i, how we use it to help develop robust and safe standards-compliant software and production systems, and how you can similarly use it to test your own software or services. If you just want to jump into how to use h3i, go to the h3i command line tool section.
A recap of QUIC and HTTP/3
QUIC is a secure-by-default transport protocol that provides performance advantages compared to TCP and TLS via a more efficient handshake, along with stream multiplexing that provides head-of-line blocking avoidance. HTTP/3 is an application protocol that maps HTTP semantics to QUIC, such as defining how HTTP requests and responses are assigned to individual QUIC streams.
Cloudflare has supported QUIC on our global network in some shape or form since 2018. We started while the Internet Engineering Task Force (IETF) was earnestly standardizing the protocol, working through early iterations and using interoperability testing and experience to help provide feedback for the standards process. We launched support for QUIC version 1 and HTTP/3 as soon as RFC 9000 (and its accompanying specifications) were published in 2021.
We work on the Protocols team, who own the ingress proxy into the Cloudflare network. This is essentially Cloudflare’s “front door” — HTTP requests that come to Cloudflare from the Internet pass through us first. The majority of requests are passed onwards to things like rulesets, workers, caches, or a customer origin. However, you might be surprised that many requests don’t ever make it that far because they are, in some way, invalid or malformed. Servers listening on the Internet have to be robust to traffic that is not RFC compliant, whether caused by accident or malicious intent.
The Protocols team actively participates in IETF standardization work and has also helped build and maintain other Cloudflare services that leverage quiche for QUIC and HTTP/3, from the proxies that help iCloud Private Relay via MASQUE proxying, to replacing WARP’s use of Wireguard with MASQUE, and beyond.
Throughout all of these different use cases, it is important for us to extensively test all aspects of the protocols. A deep dive into protocol details is a blog post (or three) in its own right. So let’s take a thin slice across HTTP to help illustrate the concepts.
HTTP Semantics are common to all versions of HTTP — the overall architecture, terminology, and protocol aspects such as request and response messages, methods, status codes, header and trailer fields, message content, and much more. Each individual HTTP version defines how semantics are transformed into a “wire format” for exchange over the Internet. You can read more about HTTP/1.1 and HTTP/2 in some of our previous blogposts.
With HTTP/3, HTTP request and response messages are split into a series of binary frames. HEADERS frames carry a representation of HTTP metadata (method, path, status code, field lines). The payload of the frame is the encoded QPACK compression output. DATA frames carry HTTP content (aka “message body”). In order to exchange these frames, HTTP/3 relies on QUIC streams. These provide an ordered and reliable byte stream and each have an identifier (ID) that is unique within the scope of a connection. There are four different stream types, denominated by the two least significant bits of the ID.
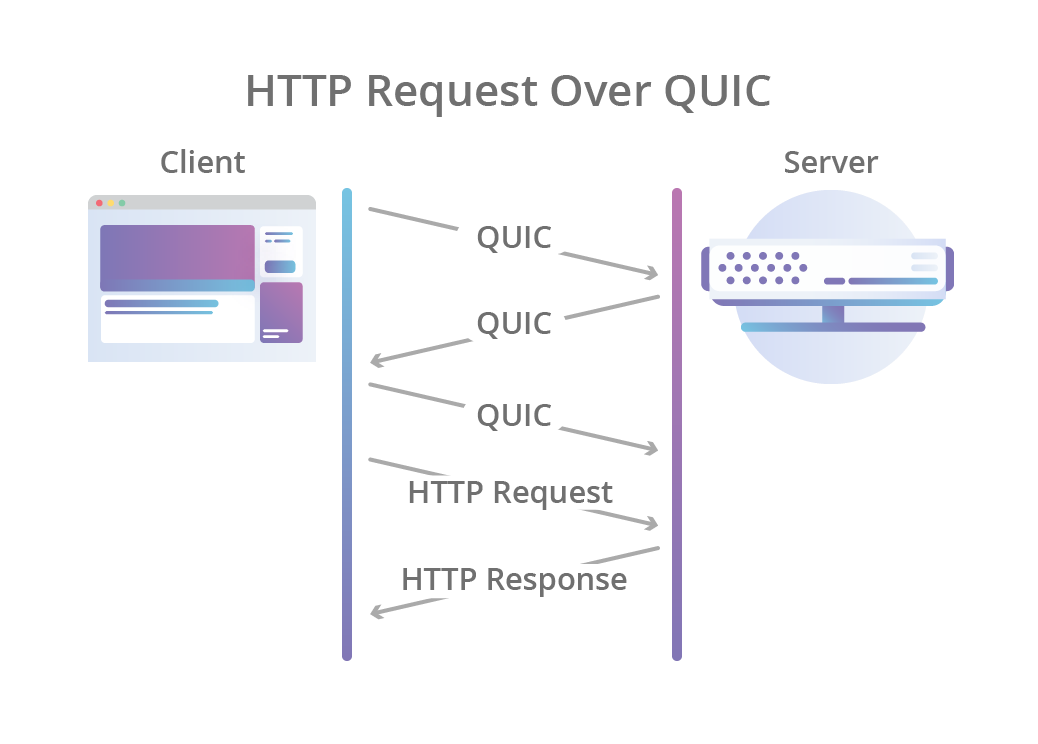
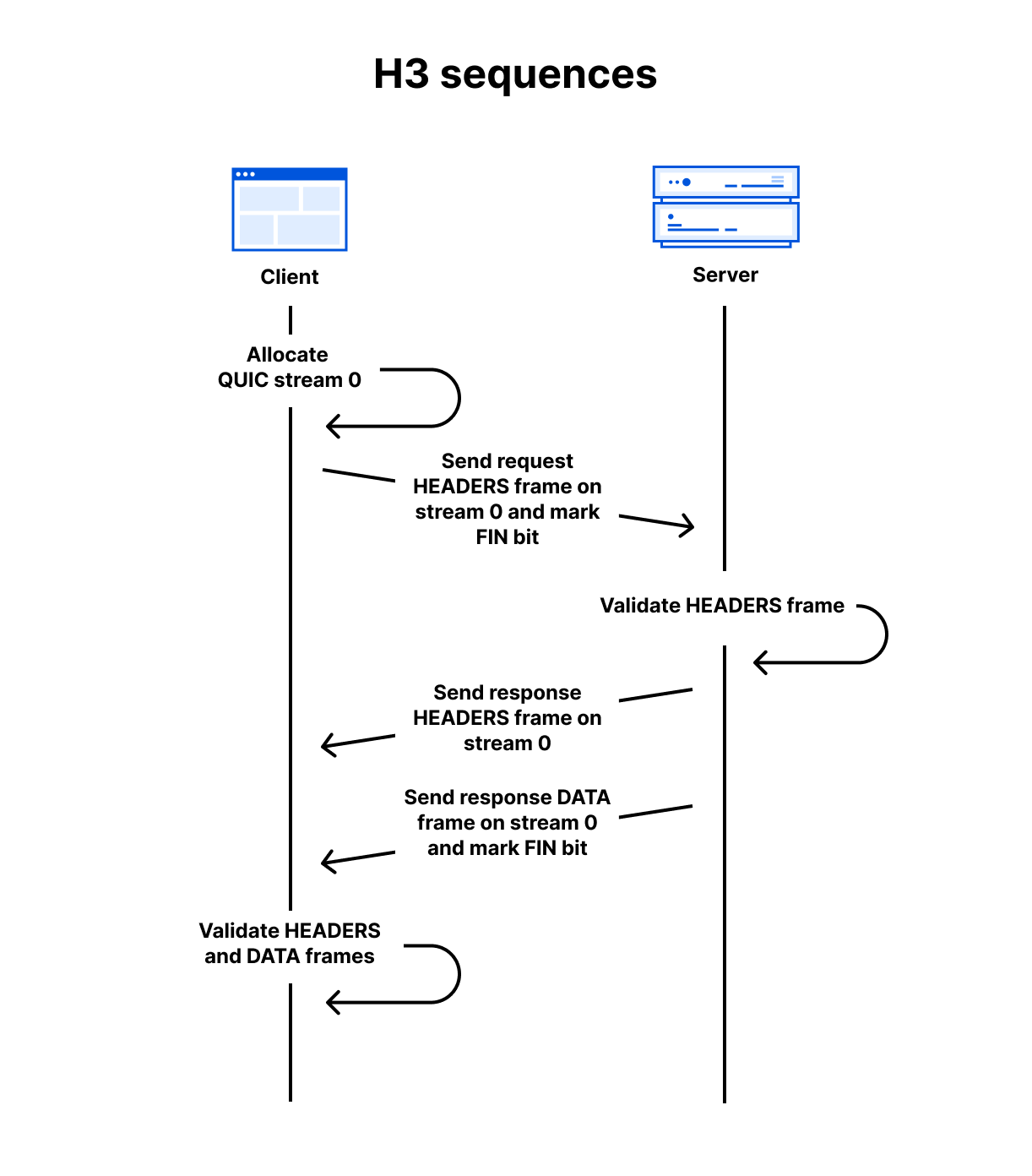
As a simple example, assuming a QUIC connection has already been established, a client can make a GET request and receive a 200 OK response with an HTML body using the follow sequence:
Client allocates the first available client-initiated bidirectional QUIC stream. (The IDs start at 0, then 4, 8, 12 and so on)
Client sends the request HEADERS frame on the stream and sets the stream’s FIN bit to mark the end of stream.
Server receives the request HEADERS frame and validates it against RFC 9114 rules. If accepted, it processes the request and prepares the response.
Server sends the response HEADERS frame on the same stream.
Server sends the response DATA frame on the same stream and sets the FIN bit.
Client receives the response frames and validates them. If accepted, the content is presented to the user.
At the QUIC layer, stream data is split into STREAM frames, which are sent in QUIC packets over UDP. QUIC deals with any loss detection and recovery, helping to ensure stream data is reliable. The layer cake diagram below provides a handy comparison of how HTTP/1.1, HTTP/2 and HTTP/3 use TCP, UDP and IP.
Background on testing QUIC and HTTP/3 at Cloudflare
The Protocols team has a diverse set of automated test tools that exercise our ingress proxy software in order to ensure it can stand up to the deluge that the Internet can throw at it. Just like a bouncer at a nightclub front door, we need to prevent as much bad traffic as possible before it gets inside and potentially causes damage.
HTTP/2 and HTTP/3 share several concepts. When we started developing early HTTP/3 support, we’d already learned a lot from production experience with HTTP/2. While HTTP/2 addressed many issues with HTTP/1.1 (especially problems like request smuggling, caused by its ASCII-based message delineation), HTTP/2 also added complexity and new avenues for attack. Security is an ongoing process, and the Protocols team continually hardens our software and systems to threats. For example, mitigating the range of denial-of-service attacks identified by Netflix in 2019, or the HTTP/2 Rapid Reset attacks of 2023.
For testing HTTP/2, we rely on the Python Requests library for testing conventional HTTP exchanges. However, that mostly only exercises HEADERS and DATA frames. There are eight other frame types and a plethora of ways that they can interact (hence the new attack vectors mentioned above). In order to get full testing coverage, we have to break down into the lower layer h2 library, which allows exact frame-by-frame control. However, even that is not always enough. Libraries tend to want to follow the RFC rules and prevent their users from doing “the wrong thing”. This is entirely logical for most purposes. For our needs though, we need to take off the safety guards just like any potential attackers might do. We have a few cases where the best way to exercise certain traffic patterns is to handcraft HTTP/2 frames in a hex editor, store that as binary, and replay it with a tool such as OpenSSL s_client.
We knew we’d need similar testing approaches for HTTP/3. However, when we started in 2018, there weren’t many other suitable client implementations. The rate of iteration on the specifications also meant it was hard to always keep in sync. So we built tests on quiche, using a mix of our quiche-client and http3_test. Over time, the python library aioquic has matured, and we have used it to add a range of lower-layer tests that break or bend HTTP/3 rules, in order to prove our proxies are robust.
Finally, we would be remiss not to mention that all the tests in our ingress proxy are in addition to the suite of over 500 integration tests that run on the quiche project itself.
Making HTTP/3 testing more accessible and maintainable with h3i
While we are happy with the coverage of our current tests, the smorgasbord of test tools makes it hard to know what to reach for when adding new tests. For example, we’ve had cases where aioquic’s safety guards prevent us from doing something, and it has needed a patch or workaround. This sort of thing requires a time investment just to debug/develop the tests.
We believe it shouldn’t take a protocol or code expert to develop what are often very simple to describe tests. While it is important to provide guide rails for the majority of conventional use cases, it is also important to provide accessible methods for taking them off.
Let’s consider a simple example. In HTTP/3 there is something called the control stream. It’s used to exchange frames such as SETTINGS, which affect the HTTP/3 connection. RFC 9114 Section 6.2.1 states:
Each side MUST initiate a single control stream at the beginning of the connection and send its SETTINGS frame as the first frame on this stream. If the first frame of the control stream is any other frame type, this MUST be treated as a connection error of type H3_MISSING_SETTINGS. Only one control stream per peer is permitted; receipt of a second stream claiming to be a control stream MUST be treated as a connection error of type H3_STREAM_CREATION_ERROR. The sender MUST NOT close the control stream, and the receiver MUST NOT request that the sender close the control stream. If either control stream is closed at any point, this MUST be treated as a connection error of type H3_CLOSED_CRITICAL_STREAM. Connection errors are described in Section 8.
There are many tests we can conjure up just from that paragraph:
Send a non-SETTINGS frame as the first frame on the control stream.
Open two control streams.
Open a control stream and then close it with a FIN bit.
Open a control stream and then reset it with a RESET_STREAM QUIC frame.
Wait for the peer to open a control stream and then ask for it to be reset with a STOP_SENDING QUIC frame.
All of the above actions should cause a remote peer that has implemented the RFC properly to close the connection. Therefore, it is not in the interest of the local client or server applications to ever do these actions.
Many QUIC and HTTP/3 implementations are developed as libraries that are integrated into client or server applications. There may be an extensive set of unit or integration tests of the library checking RFC rules. However, it is also important to run the same tests on the integrated assembly of library and application, since it’s all too common that an unhandled/mishandled library error can cascade to cause issues in upper layers. For instance, the HTTP/2 Rapid Reset attacks affected Cloudflare due to their impact on how one service spoke to another.
We’ve developed h3i, a command line tool and library, to make testing more accessible and maintainable for all. We started with a client that can exercise servers, since that’s what our focus has been. Future developments could support the opposite, a server that behaves in unusual ways in order to exercise clients.
Note: h3i is not intended to be a production client! Its flexibility may cause issues that are not observed in other production-oriented clients. It is also not intended to be used for any type of performance testing and measurement.
The h3i command line tool
The primary purpose of the h3i command line tool is quick low-level debugging and exploratory testing. Rather than worrying about writing code or a test script, users can quickly run an ad-hoc client test against a target, guided by interactive prompts.
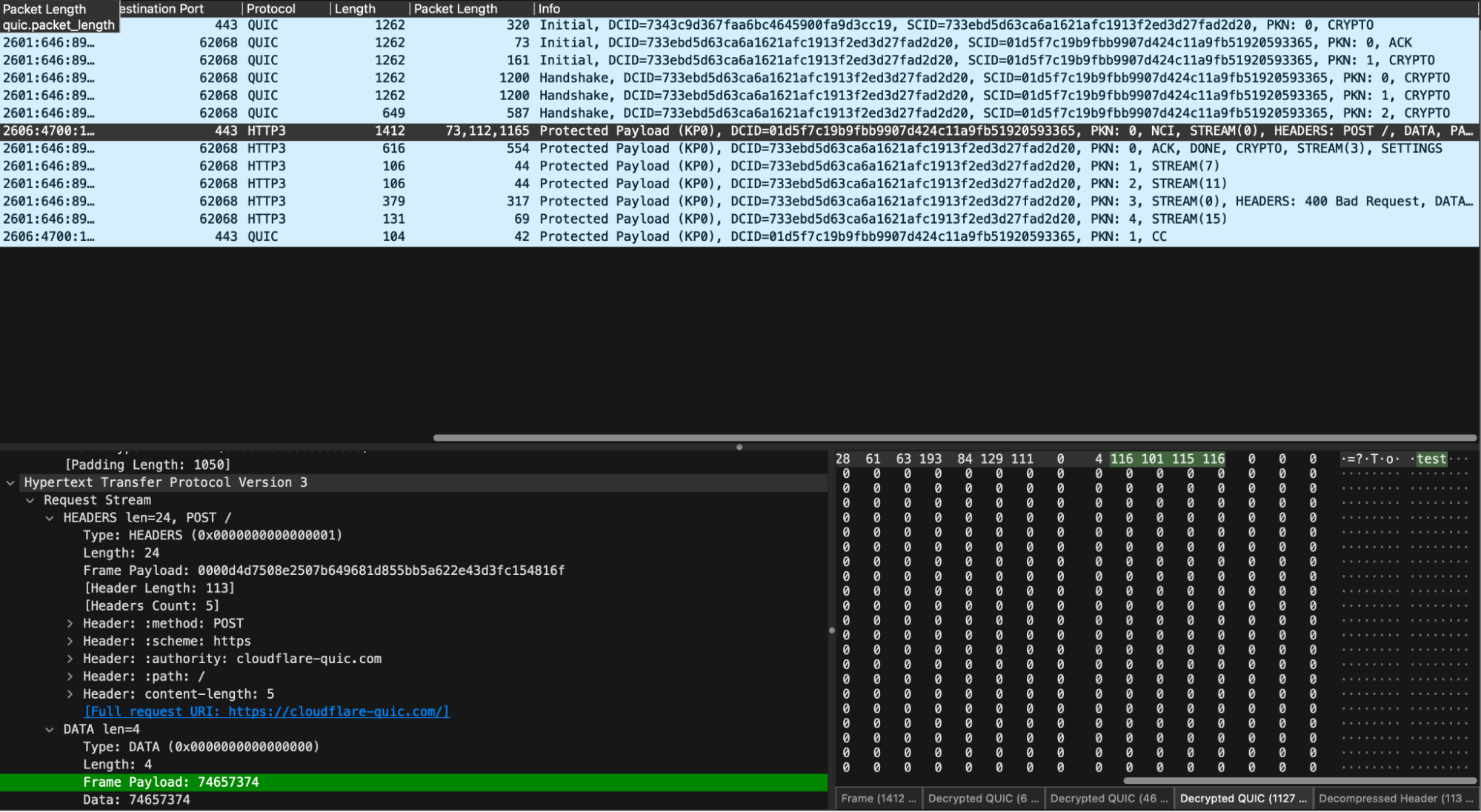
In the simplest case, you can think of h3i a bit like curl but with access to some extra HTTP/3 parameters. In the example below, we issue a request to https://cloudflare-quic.com/ and receive a response.
Walking through a simple GET with h3i step-by-step:
Grab a copy of the h3i binary either by running cargo install h3i or cloning the quiche source repo at https://github.com/cloudflare/quiche/. Both methods assume you have some familiarity with Rust and Cargo. See the cargo documentation for more information.
cargo install will place the binary on your path, so you can then just run it by executing h3i.
If running from source, navigate to the quiche/h3i directory and then use cargo run.
Run the binary and provide the name and port of the target server. If the port is omitted, the default value 443 is assumed. E.g, cargo run cloudflare-quic.com
h3i then enters the action prompting phase. A series of one or more HTTP/3 actions can be queued up, such as sending frames, opening or terminating streams, or waiting on data from the server. The full set of options is documented in the readme.
The prompting interface adapts to keyboard inputs and supports tab completion.
In the example above, the headers action is selected, which walks through populating the fields in a HEADERS frame. It includes mandatory fields from RFC 9114 for convenience. If a test requires omitting these, the headers_no_pseudo can be used instead.
The commit prompt choice finalizes the action list and moves to the connection phase. h3i initiates a QUIC connection to the server identified in step 2. Once connected, actions are executed in order.
By default, h3i reports some limited information about the frames the server sent. To get more detailed information, the RUST_LOG environment can be set with either debug or trace levels.
Instant record and replay, powered by qlog
It can be fun to play around with the h3i command line tool to see how different servers respond to different combinations or sequences of actions. Occasionally, you’ll find a certain set that you want to run over and over again, or share with a friend or colleague. Having to manually enter the prompts repeatedly, or share screenshots of the h3i input can turn tedious. Fortunately, h3i records all the actions in a log file by default — the file path is printed immediately after h3i starts. The format of this file is based on qlog, an in-progress standard in development at the IETF for network protocol logging. It’s a perfect fit for our low-level needs.
h3i logs can be replayed using the --qlog-input option. You can change the target server host and port, and keep all the same actions. However, most servers will validate the :authority pseudo-header or Host header contained in a HEADERS frame. The –replay-host-override option allows changing these fields without needing to modify the file by hand.
And yes, qlog files are human-readable text in the JSON-SEQ format. So you can also just write these by hand in the first place if you like! However, if you’re going to start writing things, maybe Rust is your preferred option…
Using the h3i library to send a malformed request with Rust
In our previous example, we just sent a valid request so there wasn’t anything interesting to observe. Where h3i really shines is in generating traffic that isn’t RFC compliant, such as malformed HTTP messages, invalid frame sequences, or other actions on streams. This helps determine if a server is acting robustly and defensively.
Let’s explore this more with an example of HTTP content-length mismatch. RFC 9114 section 4.1.2 specifies:
A request or response that is defined as having content when it contains a Content-Length header field (Section 8.6 of [HTTP]) is malformed if the value of the Content-Length header field does not equal the sum of the DATA frame lengths received. A response that is defined as never having content, even when a Content-Length is present, can have a non-zero Content-Length header field even though no content is included in DATA frames.
Intermediaries that process HTTP requests or responses (i.e., any intermediary not acting as a tunnel) MUST NOT forward a malformed request or response. Malformed requests or responses that are detected MUST be treated as a stream error of type H3_MESSAGE_ERROR.
For malformed requests, a server MAY send an HTTP response indicating the error prior to closing or resetting the stream.
There are good reasons that the RFC is so strict about handling mismatched content lengths. They can be a vector for desynchronization attacks (similar to request smuggling), especially when a proxy is converting inbound HTTP/3 to outbound HTTP/1.1.
We’ve provided an example of how to use the h3i Rust library to write a tailor-made test client that sends a mismatched content length request. It sends a Content-Length header of 5, but its body payload is “test”, which is only 4 bytes. It then waits for the server to respond, after which it explicitly closes the connection by sending a QUIC CONNECTION_CLOSE frame.
When running low-level tests, it can be interesting to also take a packet capture (pcap) and observe what is happening on the wire. Since QUIC is an encrypted transport, we’ll need to use the SSLKEYLOG environment variable to capture the session keys so that tools like Wireshark can decrypt and dissect.
To follow along at home, clone a copy of the quiche repository, start a packet capture on the appropriate network interface and then run:
cd quiche/h3i
SSLKEYLOGFILE="h3i-example.keys" cargo run --example content_length_mismatch
In our decrypted capture, we see the expected sequence of handshake, request, response, and then closure.
Surveying the example code
The example is a simple binary app with a main() entry point. Let’s survey the key elements.
First, we set up an h3i configuration to a target server:
let config = Config::new()
.with_host_port("cloudflare-quic.com".to_string())
.with_idle_timeout(2000)
.build()
.unwrap();
The idle timeout is a QUIC concept which tells each endpoint when it should close the connection if the connection has been idle. This prevents endpoints from spinning idly if the peer hasn’t closed the connection. h3i’s default is 30 seconds, which can be too long for tests, so we set ours to 2 seconds here.
Next, we define a set of request headers and encode them with QPACK compression, ready to put in a HEADERS frame. Note that h3i does provide a send_headers_frame helper method which does this for you, but the example does it manually for clarity:
let headers = vec![
Header::new(b":method", b"POST"),
Header::new(b":scheme", b"https"),
Header::new(b":authority", b"cloudflare-quic.com"),
Header::new(b":path", b"/"),
// We say that we're going to send a body with 5 bytes...
Header::new(b"content-length", b"5"),
];
let header_block = encode_header_block(&headers).unwrap();
Then, we define the set of h3i actions that we want to execute in order: send HEADERS, send a too-short DATA frame, wait for the server’s HEADERS, then close the connection.
let actions = vec![
Action::SendHeadersFrame {
stream_id: STREAM_ID,
fin_stream: false,
headers,
frame: Frame::Headers { header_block },
},
Action::SendFrame {
stream_id: STREAM_ID,
fin_stream: true,
frame: Frame::Data {
// ...but, in actuality, we only send 4 bytes. This should yield a
// 400 Bad Request response from an RFC-compliant
// server: https://datatracker.ietf.org/doc/html/rfc9114#section-4.1.2-3
payload: b"test".to_vec(),
},
},
Action::Wait {
wait_type: WaitType::StreamEvent(StreamEvent {
stream_id: STREAM_ID,
event_type: StreamEventType::Headers,
}),
},
Action::ConnectionClose {
error: quiche::ConnectionError {
is_app: true,
error_code: quiche::h3::WireErrorCode::NoError as u64,
reason: vec![],
},
},
];
Finally, we’ll set things in motion with connect(), which sets up the QUIC connection, executes the actions list and collects the summary.
let summary =
sync_client::connect(config, &actions).expect("connection failed");
println!(
"=== received connection summary! ===\n\n{}",
serde_json::to_string_pretty(&summary).unwrap_or_else(|e| e.to_string())
);
ConnectionSummary provides data about the connection, including the frames h3i received, details about why the connection closed, and connection statistics. The example prints the summary out. However, you can programmatically check it. We do this to write our own internal automation tests.
If you’re running the example, it should print something like the following:
Let’s walk through the output. Up first is the StreamMap, which is a record of all frames received on each stream. We can see that we received 5 frames on stream 0: 2 UNKNOWNs, one EnrichedHeaders frame, and two DATA frames.
The UNKNOWN frames are extension frames that are unknown to h3i; the server under test is sending what are known as GREASE frames to help exercise the protocol and ensure clients are not erroring when they receive something unexpected per RFC 9114 requirements.
The EnrichedHeaders frame is essentially an HTTP/3 HEADERS frame, but with some small helpers, like one to get the response status code. The server under test sent a 400 as expected.
The DATA frames carry response body bytes. In this case, the body is the HTML required to render the Cloudflare Bad Request page (you can peek at the HTML yourself in Wireshark). We chose to omit the raw bytes from the ConnectionSummary since they may not be representable safely as text. A future improvement could be to encode the bytes in base64 or hex, in order to support tests that need to check response content.
h3i for test automation
We believe h3i is a great library for building automated tests on. You can take the above example and modify it to fit within various types of (continuous) integration tests.
We outlined earlier how the Protocols team HTTP/3 testing has organically grown to use three different frameworks. Even within those, we still didn’t have much flexibility and ease of use. Over the last year we’ve been building h3i itself and reimplementing our suite of ingress proxy test cases using the Rust library. This has helped us improve test coverage with a range of new tests not previously possible. It also surprisingly identified some problems with the old tests, particularly for some edge cases where it wasn’t clear how the old test code implementation was running under the hood.
Bake offs, interop, and wider testing of HTTP
RFC 1025 was published in 1987. Authored by Jon Postel, it discusses bake offs:
In the early days of the development of TCP and IP, when there were very few implementations and the specifications were still evolving, the only way to determine if an implementation was “correct” was to test it against other implementations and argue that the results showed your own implementation to have done the right thing. These tests and discussions could, in those early days, as likely change the specification as change the implementation.
There were a few times when this testing was focused, bringing together all known implementations and running through a set of tests in hopes of demonstrating the N squared connectivity and correct implementation of the various tricky cases. These events were called “Bake Offs”.
While nearly 4 decades old, the concept of exercising Internet protocol implementations and seeing how they compare to the specification still holds true. The QUIC WG made heavy use of interoperability testing through its standardization process. We started off sitting in a room and running tests manually by hand (or with some help from scripts). Then Marten Seemann developed the QUIC Interop Runner, which runs regular automated testing and collects and renders all the results. This has proven to be incredibly useful.
The state of HTTP/3 interoperability testing is not quite as mature. Although there are tools such as Kazu Yamamoto’s excellent h3spec (in Haskell) for testing conformance, there isn’t a similar continuous integration process of collection and rendering of results. While h3i shares similarities with h3spec, we felt it important to focus on the framework capabilities rather than creating a corpus of tests and assertions. Cloudflare is a big fan of Rust and as several teams move to Rust-based proxies, having a consistent ecosystem provides advantages (such as developer velocity).
We certainly feel there is a great opportunity for continued collaboration and cross-pollination between projects in the QUIC and HTTP space. For example, h3i might provide a suitable basis to build another tool (or set of scripts) to run bake offs or interop tests. Perhaps it even makes sense to have a common collection of test cases owned by the community, that can be specialized to the most appropriate or preferred tooling. This topic was recently presented at the HTTP Workshop 2024 by Mohammed Al-Sahaf, and it excites us to see new potential directions of testing improvements.
When using any tools or methods for protocol testing, we encourage responsible handling of security-related matters. If you believe you may have identified a vulnerability in an IETF Internet protocol itself, please follow the IETF’s reporting guidance. If you believe you may have discovered an implementation vulnerability in a product, open source project, or service using QUIC or HTTP, then you should report these directly to the responsible party. Implementers or operators often provide their own publicly-available guidance and contact details to send reports. For example, the Cloudflare quiche security policy is available in the Security tab of the GitHub repository.
Summary and outlook
Cloudflare takes testing very seriously. While h3i has a limited feature set as a test HTTP/3 client, we believe it provides a strong framework that can be extended to a wider range of different cases and different protocols. For example, we’d like to add support for low-level HTTP/2.
We’ve designed h3i to integrate into a wide range of testing methodologies, from manual ad-hoc testing, to native Rust tests, to conformance testbenches built with scripting languages. We’ve had great success migrating our existing zoo of test tools to a single one that is more accessible and easier to maintain.
Now that you’ve read about h3i’s capabilities, it’s left as an exercise to the reader to go back to the example of HTTP/3 control streams and consider how you could write tests to exercise a server.
We encourage the community to experiment with h3i and provide feedback, and propose ideas or contributions to the GitHub repository as issues or Pull Requests.
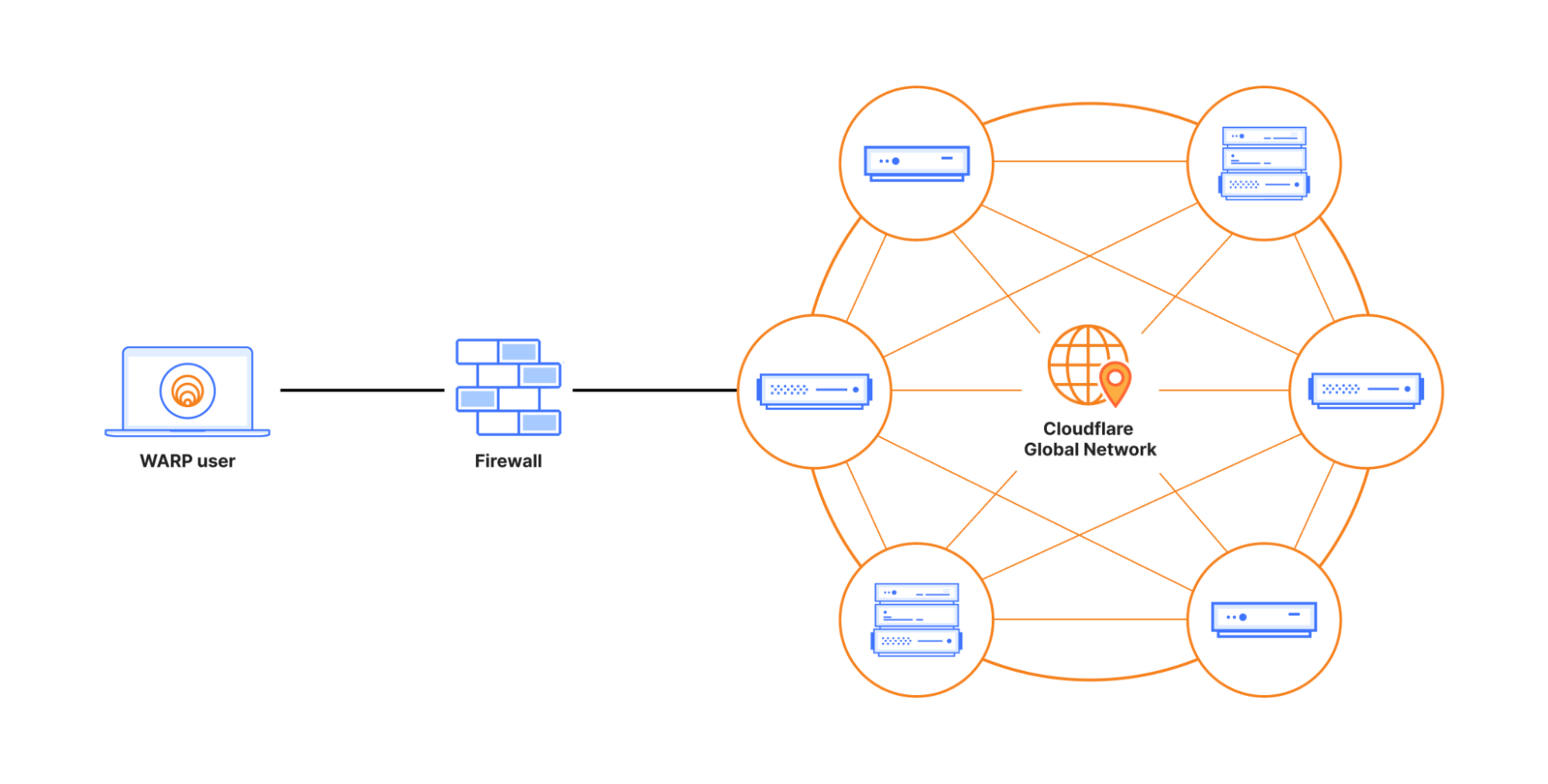
In June 2023, we told you that we were building a new protocol, MASQUE, into WARP. MASQUE is a fascinating protocol that extends the capabilities of HTTP/3 and leverages the unique properties of the QUIC transport protocol to efficiently proxy IP and UDP traffic without sacrificing performance or privacy
At the same time, we’ve seen a rising demand from Zero Trust customers for features and solutions that only MASQUE can deliver. All customers want WARP traffic to look like HTTPS to avoid detection and blocking by firewalls, while a significant number of customers also require FIPS-compliant encryption. We have something good here, and it’s been proven elsewhere (more on that below), so we are building MASQUE into Zero Trust WARP and will be making it available to all of our Zero Trust customers — at WARP speed!
This blog post highlights some of the key benefits our Cloudflare One customers will realize with MASQUE.
Before the MASQUE
Cloudflare is on a mission to help build a better Internet. And it is a journey we’ve been on with our device client and WARP for almost five years. The precursor to WARP was the 2018 launch of 1.1.1.1, the Internet’s fastest, privacy-first consumer DNS service. WARP was introduced in 2019 with the announcement of the 1.1.1.1 service with WARP, a high performance and secure consumer DNS and VPN solution. Then in 2020, we introduced Cloudflare’s Zero Trust platform and the Zero Trust version of WARP to help any IT organization secure their environment, featuring a suite of tools we first built to protect our own IT systems. Zero Trust WARP with MASQUE is the next step in our journey.
The current state of WireGuard
WireGuard was the perfect choice for the 1.1.1.1 with WARP service in 2019. WireGuard is fast, simple, and secure. It was exactly what we needed at the time to guarantee our users’ privacy, and it has met all of our expectations. If we went back in time to do it all over again, we would make the same choice.
But the other side of the simplicity coin is a certain rigidity. We find ourselves wanting to extend WireGuard to deliver more capabilities to our Zero Trust customers, but WireGuard is not easily extended. Capabilities such as better session management, advanced congestion control, or simply the ability to use FIPS-compliant cipher suites are not options within WireGuard; these capabilities would have to be added on as proprietary extensions, if it was even possible to do so.
Plus, while WireGuard is popular in VPN solutions, it is not standards-based, and therefore not treated like a first class citizen in the world of the Internet, where non-standard traffic can be blocked, sometimes intentionally, sometimes not. WireGuard uses a non-standard port, port 51820, by default. Zero Trust WARP changes this to use port 2408 for the WireGuard tunnel, but it’s still a non-standard port. For our customers who control their own firewalls, this is not an issue; they simply allow that traffic. But many of the large number of public Wi-Fi locations, or the approximately 7,000 ISPs in the world, don’t know anything about WireGuard and block these ports. We’ve also faced situations where the ISP does know what WireGuard is and blocks it intentionally.
This can play havoc for roaming Zero Trust WARP users at their local coffee shop, in hotels, on planes, or other places where there are captive portals or public Wi-Fi access, and even sometimes with their local ISP. The user is expecting reliable access with Zero Trust WARP, and is frustrated when their device is blocked from connecting to Cloudflare’s global network.
Now we have another proven technology — MASQUE — which uses and extends HTTP/3 and QUIC. Let’s do a quick review of these to better understand why Cloudflare believes MASQUE is the future.
Unpacking the acronyms
HTTP/3 and QUIC are among the most recent advancements in the evolution of the Internet, enabling faster, more reliable, and more secure connections to endpoints like websites and APIs. Cloudflare worked closely with industry peers through the Internet Engineering Task Force on the development of RFC 9000 for QUIC and RFC 9114 for HTTP/3. The technical background on the basic benefits of HTTP/3 and QUIC are reviewed in our 2019 blog post where we announced QUIC and HTTP/3 availability on Cloudflare’s global network.
Most relevant for Zero Trust WARP, QUIC delivers better performance on low-latency or high packet loss networks thanks to packet coalescing and multiplexing. QUIC packets in separate contexts during the handshake can be coalesced into the same UDP datagram, thus reducing the number of receive and system interrupts. With multiplexing, QUIC can carry multiple HTTP sessions within the same UDP connection. Zero Trust WARP also benefits from QUIC’s high level of privacy, with TLS 1.3 designed into the protocol.
MASQUE unlocks QUIC’s potential for proxying by providing the application layer building blocks to support efficient tunneling of TCP and UDP traffic. In Zero Trust WARP, MASQUE will be used to establish a tunnel over HTTP/3, delivering the same capability as WireGuard tunneling does today. In the future, we’ll be in position to add more value using MASQUE, leveraging Cloudflare’s ongoing participation in the MASQUE Working Group. This blog post is a good read for those interested in digging deeper into MASQUE.
OK, so Cloudflare is going to use MASQUE for WARP. What does that mean to you, the Zero Trust customer?
Proven reliability at scale
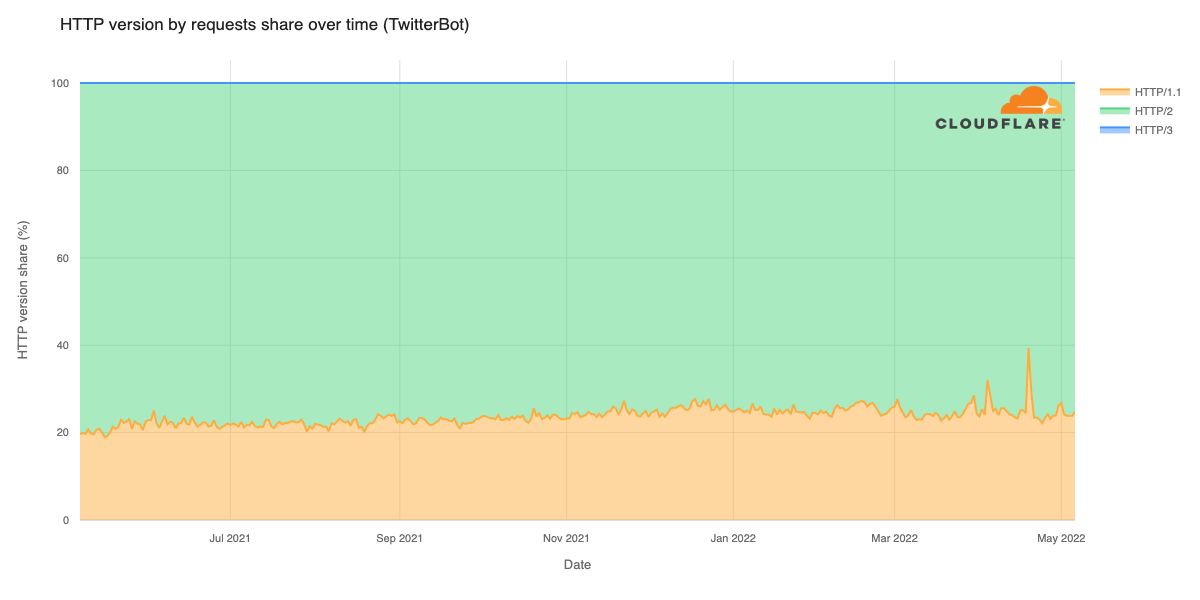
Cloudflare’s network today spans more than 310 cities in over 120 countries, and interconnects with over 13,000 networks globally. HTTP/3 and QUIC were introduced to the Cloudflare network in 2019, the HTTP/3 standard was finalized in 2022, and represented about 30% of all HTTP traffic on our network in 2023.
We are also using MASQUE for iCloud Private Relay and other Privacy Proxy partners. The services that power these partnerships, from our Rust-based proxy framework to our open source QUIC implementation, are already deployed globally in our network and have proven to be fast, resilient, and reliable.
Cloudflare is already operating MASQUE, HTTP/3, and QUIC reliably at scale. So we want you, our Zero Trust WARP users and Cloudflare One customers, to benefit from that same reliability and scale.
Connect from anywhere
Employees need to be able to connect from anywhere that has an Internet connection. But that can be a challenge as many security engineers will configure firewalls and other networking devices to block all ports by default, and only open the most well-known and common ports. As we pointed out earlier, this can be frustrating for the roaming Zero Trust WARP user.
We want to fix that for our users, and remove that frustration. HTTP/3 and QUIC deliver the perfect solution. QUIC is carried on top of UDP (protocol number 17), while HTTP/3 uses port 443 for encrypted traffic. Both of these are well known, widely used, and are very unlikely to be blocked.
We want our Zero Trust WARP users to reliably connect wherever they might be.
Compliant cipher suites
MASQUE leverages TLS 1.3 with QUIC, which provides a number of cipher suite choices. WireGuard also uses standard cipher suites. But some standards are more, let’s say, standard than others.
NIST, the National Institute of Standards and Technology and part of the US Department of Commerce, does a tremendous amount of work across the technology landscape. Of interest to us is the NIST research into network security that results in FIPS 140-2 and similar publications. NIST studies individual cipher suites and publishes lists of those they recommend for use, recommendations that become requirements for US Government entities. Many other customers, both government and commercial, use these same recommendations as requirements.
Our first MASQUE implementation for Zero Trust WARP will use TLS 1.3 and FIPS compliant cipher suites.
How can I get Zero Trust WARP with MASQUE?
Cloudflare engineers are hard at work implementing MASQUE for the mobile apps, the desktop clients, and the Cloudflare network. Progress has been good, and we will open this up for beta testing early in the second quarter of 2024 for Cloudflare One customers. Your account team will be reaching out with participation details.
Continuing the journey with Zero Trust WARP
Cloudflare launched WARP five years ago, and we’ve come a long way since. This introduction of MASQUE to Zero Trust WARP is a big step, one that will immediately deliver the benefits noted above. But there will be more — we believe MASQUE opens up new opportunities to leverage the capabilities of QUIC and HTTP/3 to build innovative Zero Trust solutions. And we’re also continuing to work on other new capabilities for our Zero Trust customers. Cloudflare is committed to continuing our mission to help build a better Internet, one that is more private and secure, scalable, reliable, and fast. And if you would like to join us in this exciting journey, check out our open positions.
Today, Cloudflare is very excited to announce full support for HTTP/3 Extensible Priorities, a new standard that speeds the loading of webpages by up to 37%. Cloudflare worked closely with standards builders to help form the specification for HTTP/3 priorities and is excited to help push the web forward. HTTP/3 Extensible Priorities is available on all plans on Cloudflare. For paid users, there is an enhanced version available that improves performance even more.
Web pages are made up of many objects that must be downloaded before they can be processed and presented to the user. Not all objects have equal importance for web performance. The role of HTTP prioritization is to load the right bytes at the most opportune time, to achieve the best results. Prioritization is most important when there are multiple objects all competing for the same constrained resource. In HTTP/3, this resource is the QUIC connection. In most cases, bandwidth is the bottleneck from server to client. Picking what objects to dedicate bandwidth to, or share bandwidth amongst, is a critical foundation to web performance. When it goes askew, the other optimizations we build on top can suffer.
Today, we're announcing support for prioritization in HTTP/3, using the full capabilities of the HTTP Extensible Priorities (RFC 9218) standard, augmented with Cloudflare's knowledge and experience of enhanced HTTP/2 prioritization. This change is compatible with all mainstream web browsers and can improve key metrics such as Largest Contentful Paint (LCP) by up to 37% in our test. Furthermore, site owners can apply server-side overrides, using Cloudflare Workers or directly from an origin, to customize behavior for their specific needs.
Looking at a real example
The ultimate question when it comes to features like HTTP/3 Priorities is: how well does this work and should I turn it on? The details are interesting and we'll explain all of those shortly but first lets see some demonstrations.
In order to evaluate prioritization for HTTP/3, we have been running many simulations and tests. Each web page is unique. Loading a web page can require many TCP or QUIC connections, each of them idiosyncratic. These all affect how prioritization works and how effective it is.
To evaluate the effectiveness of priorities, we ran a set of tests measuring Largest Contentful Paint (LCP). As an example, we benchmarked blog.cloudflare.com to see how much we could improve performance:
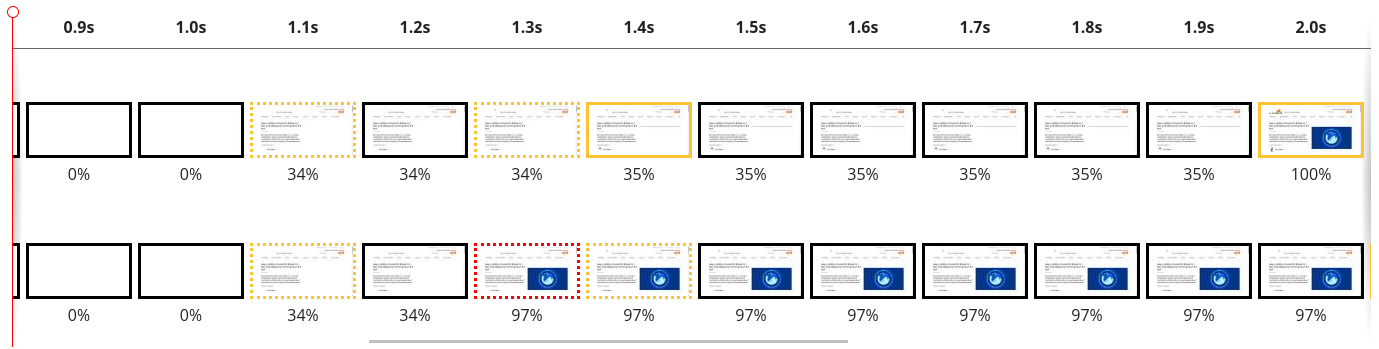
As a film strip, this is what it looks like:
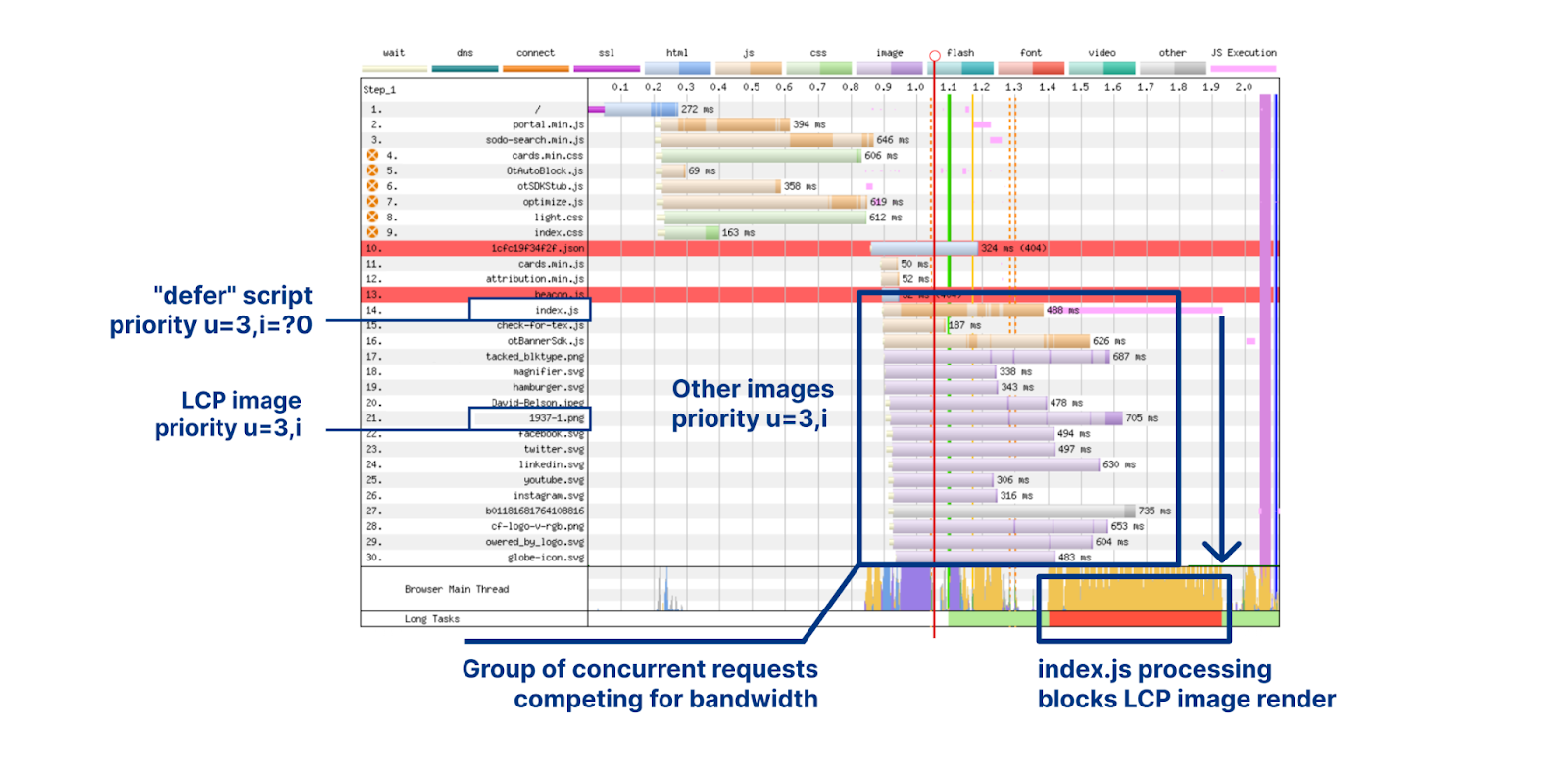
In terms of actual numbers, we see Largest Contentful Paint drop from 2.06 seconds down to 1.29 seconds. Let’s look at why that is. To analyze exactly what’s going on we have to look at a waterfall diagram of how this web page is loading. A waterfall diagram is a way of visualizing how assets are loading. Some may be loaded in parallel whilst some might be loaded sequentially. Without smart prioritization, the waterfall for loading assets for this web page looks as follows:
There are several interesting things going on here so let's break it down. The LCP image at request 21 is for 1937-1.png, weighing 30.4 KB. Although it is the LCP image, the browser requests it as priority u=3,i, which informs the server to put it in the same round-robin bandwidth-sharing bucket with all of the other images. Ahead of the LCP image is index.js, a JavaScript file that is loaded with a "defer" attribute. This JavaScript is non-blocking and shouldn't affect key aspects of page layout.
What appears to be happening is that the browser gives index.js the priority u=3,i=?0, which places it ahead of the images group on the server-side. Therefore, the 217 KB of index.js is sent in preference to the LCP image. Far from ideal. Not only that, once the script is delivered, it needs to be processed and executed. This saturates the CPU and prevents the LCP image from being painted, for about 300 milliseconds, even though it was delivered already.
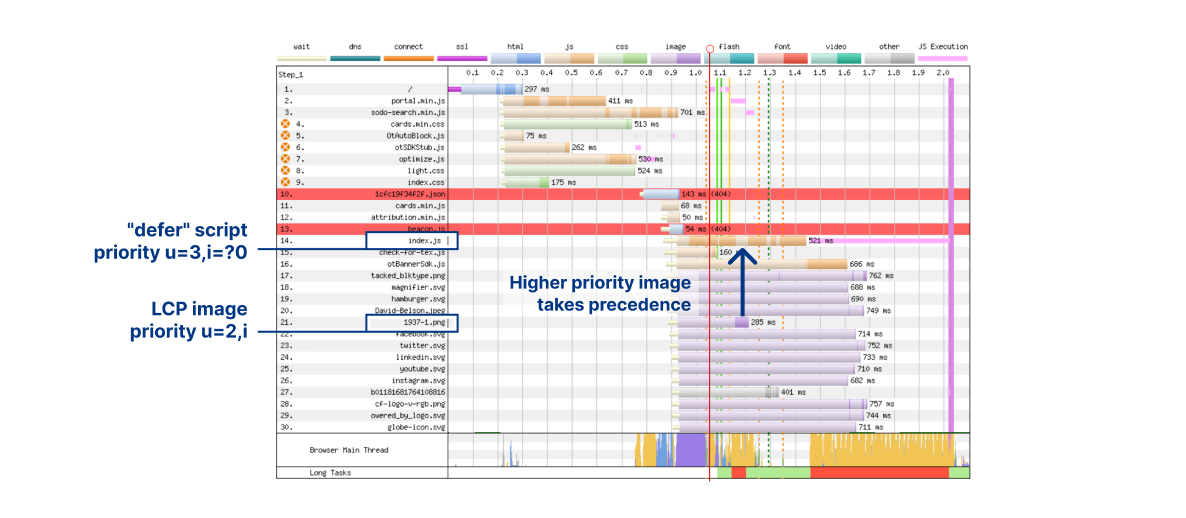
The waterfall with prioritization looks much better:
We used a server-side override to promote the priority of the LCP image 1937-1.png from u=3,i to u=2,i. This has the effect of making it leapfrog the "defer" JavaScript. We can see at around 1.2 seconds, transmission of index.js is halted while the image is delivered in full. And because it takes another couple of hundred milliseconds to receive the remaining JavaScript, there is no CPU competition for the LCP image paint. These factors combine together to drastically improve LCP times.
How Extensible Priorities actually works
First of all, you don't need to do anything yourselves to make it work. Out of the box, browsers will send Extensible Priorities signals alongside HTTP/3 requests, which we'll feed into our priority scheduling decision making algorithms. We'll then decide the best way to send HTTP/3 response data to ensure speedy page loads.
Extensible Priorities has a similar interaction model to HTTP/2 priorities, client send priorities and servers act on them to schedule response data, we'll explain exactly how that works in a bit.
HTTP/2 priorities used a dependency tree model. While this was very powerful it turned out hard to implement and use. When the IETF came to try and port it to HTTP/3 during the standardization process, we hit major issues. If you are interested in all that background, go and read my blog post describing why we adopted a new approach to HTTP/3 prioritization.
Extensible Priorities is a far simpler scheme. HTTP/2's dependency tree with 255 weights and dependencies (that can be mutual or exclusive) is complex, hard to use as a web developer and could not work for HTTP/3. Extensible Priorities has just two parameters: urgency and incremental, and these are capable of achieving exactly the same web performance goals.
Urgency is an integer value in the range 0-7. It indicates the importance of the requested object, with 0 being most important and 7 being the least. The default is 3. Urgency is comparable to HTTP/2 weights. However, it's simpler to reason about 8 possible urgencies rather than 255 weights. This makes developer's lives easier when trying to pick a value and predicting how it will work in practice.
Incremental is a boolean value. The default is false. A true value indicates the requested object can be processed as parts of it are received and read – commonly referred to as streaming processing. A false value indicates the object must be received in whole before it can be processed.
Let's consider some example web objects to put these parameters into perspective:
An HTML document is the most important piece of a webpage. It can be processed as parts of it arrive. Therefore, urgency=0 and incremental=true is a good choice.
A CSS style is important for page rendering and could block visual completeness. It needs to be processed in whole. Therefore, urgency=1 and incremental=false is suitable, this would mean it doesn't interfere with the HTML.
An image file that is outside the browser viewport is not very important and it can be processed and painted as parts arrive. Therefore, urgency=3 and incremental=true is appropriate to stop it interfering with sending other objects.
An image file that is the "hero image" of the page, making it the Largest Contentful Pain element. An urgency of 1 or 2 will help it avoid being mixed in with other images. The choice of incremental value is a little subjective and either might be appropriate.
When making an HTTP request, clients decide the Extensible Priority value composed of the urgency and incremental parameters. These are sent either as an HTTP header field in the request (meaning inside the HTTP/3 HEADERS frame on a request stream), or separately in an HTTP/3 PRIORITY_UPDATE frame on the control stream. HTTP headers are sent once at the start of a request; a client might change its mind so the PRIORITY_UPDATE frame allows it to reprioritize at any point in time.
For both the header field and PRIORITY_UPDATE, the parameters are exchanged using the Structured Fields Dictionary format (RFC 8941) and serialization rules. In order to save bytes on the wire, the parameters are shortened – urgency to 'u', and incremental to 'i'.
Here's how the HTTP header looks alongside a GET request for important HTML, using HTTP/3 style notation:
The PRIORITY_UPDATE frame only carries the serialized Extensible Priority value:
PRIORITY_UPDATE:
u=0,i
Structured Fields has some other neat tricks. If you want to indicate the use of a default value, then that can be done via omission. Recall that the urgency default is 3, and incremental default is false. A client could send "u=1" alongside our important CSS request (urgency=1, incremental=false). For our lower priority image it could send just "i=?1" (urgency=3, incremental=true). There's even another trick, where boolean true dictionary parameters are sent as just "i". You should expect all of these formats to be used in practice, so it pays to be mindful about their meaning.
Extensible Priority servers need to decide how best to use the available connection bandwidth to schedule the response data bytes. When servers receive priority client signals, they get one form of input into a decision making process. RFC 9218 provides a set of scheduling recommendations that are pretty good at meeting a board set of needs. These can be distilled down to some golden rules.
For starters, the order of requests is crucial. Clients are very careful about asking for things at the moment they want it. Serving things in request order is good. In HTTP/3, because there is no strict ordering of stream arrival, servers can use stream IDs to determine this. Assuming the order of the requests is correct, the next most important thing is urgency ordering. Serving according to urgency values is good.
Be wary of non-incremental requests, as they mean the client needs the object in full before it can be used at all. An incremental request means the client can process things as and when they arrive.
With these rules in mind, the scheduling then becomes broadly: for each urgency level, serve non-incremental requests in whole serially, then serve incremental requests in round robin fashion in parallel. What this achieves is dedicated bandwidth for very important things, and shared bandwidth for less important things that can be processed or rendered progressively.
Let's look at some examples to visualize the different ways the scheduler can work. These are generated by using quiche'sqlog support and running it via the qvis analysis tool. These diagrams are similar to a waterfall chart; the y-dimension represents stream IDs (0 at the top, increasing as we move down) and the x-dimension shows reception of stream data.
Example 1: all streams have the same urgency and are non-incremental so get served in serial order of stream ID.
Example 2: the streams have the same urgency and are incremental so get served in round-robin fashion.
Example 3: the streams have all different urgency, with later streams being more important than earlier streams. The data is received serially but in a reverse order compared to example 1.
Beyond the Extensible Priority signals, a server might consider other things when scheduling, such as file size, content encoding, how the application vs content origins are configured etc.. This was true for HTTP/2 priorities but Extensible Priorities introduces a new neat trick, a priority signal can also be sent as a response header to override the client signal.
This works especially well in a proxying scenario where your HTTP/3 terminating proxy is sat in front of some backend such as Workers. The proxy can pass through the request headers to the backend, it can inspect these and if it wants something different, return response headers to the proxy. This allows powerful tuning possibilities and because we operate on a semantic request basis (rather than HTTP/2 priorities dependency basis) we don't have all the complications and dangers. Proxying isn't the only use case. Often, one form of "API" to your local server is via setting response headers e.g., via configuration. Leveraging that approach means we don't have to invent new APIs.
Let's consider an example where server overrides are useful. Imagine we have a webpage with multiple images that are referenced via <img> tags near the top of the HTML. The browser will process these quite early in the page load and want to issue requests. At this point, it might not know enough about the page structure to determine if an image is in the viewport or outside the viewport. It can guess, but that might turn out to be wrong if the page is laid out a certain way. Guessing wrong means that something is misprioritized and might be taking bandwidth away from something that is more important. While it is possible to reprioritize things mid-flight using the PRIORITY_UPDATE frame, this action is "laggy" and by the time the server realizes things, it might be too late to make much difference.
Fear not, the web developer who built the page knows exactly how it is supposed to be laid out and rendered. They can overcome client uncertainty by overriding the Extensible Priority when they serve the response. For instance, if a client guesses wrong and requests the LCP image at a low priority in a shared bandwidth bucket, the image will load slower and web performance metrics will be adversely affected. Here's how it might look and how we can fix it:
Priority response headers are one tool to tweak client behavior and they are complementary to other web performance techniques. Methods like efficiently ordering elements in HTML, using attributes like "async" or "defer", augmenting HTML links with Link headers, or using more descriptive link relationships like “preload” all help to improve a browser's understanding of the resources comprising a page. A website that optimizes these things provides a better chance for the browser to make the best choices for prioritizing requests.
More recently, a new attribute called “fetchpriority” has emerged that allows developers to tune some of the browser behavior, by boosting or dropping the priority of an element relative to other elements of the same type. The attribute can help the browser do two important things for Extensible priorities: first, the browser might send the request earlier or later, helping to satisfy our golden rule #1 – ordering. Second, the browser might pick a different urgency value, helping to satisfy rule #2. However, "fetchpriority" is a nudge mechanism and it doesn't allow for directly setting a desired priority value. The nudge can be a bit opaque. Sometimes the circumstances benefit greatly from just knowing plainly what the values are and what the server will do, and that's where the response header can help.
Conclusions
We’re excited about bringing this new standard into the world. Working with standards bodies has always been an amazing partnership and we’re very pleased with the results. We’ve seen great results with HTTP/3 priorities, reducing Largest Contentful Paint by up to 37% in our test. If you’re interested in turning on HTTP/3 priorities for your domain, just head on over to the Cloudflare dashboard and hit the toggle.
At over thirty years old, HTTP is still the foundation of the web and one of the Internet’s most popular protocols—not just for browsing, watching videos and listening to music, but also for apps, machine-to-machine communication, and even as a basis for building other protocols, forming what some refer to as a “second waist” in the classic Internet hourglass diagram.
What makes HTTP so successful? One answer is that it hits a “sweet spot” for most applications that need an application protocol. “Building Protocols with HTTP” (published in 2022 as a Best Current Practice RFC by the HTTP Working Group) argues that HTTP’s success can be attributed to factors like:
– familiarity by implementers, specifiers, administrators, developers, and users; – availability of a variety of client, server, and proxy implementations; – ease of use; – availability of web browsers; – reuse of existing mechanisms like authentication and encryption; – presence of HTTP servers and clients in target deployments; and – its ability to traverse firewalls.
Another important factor is the community of people using, implementing, and standardising HTTP. We work together to maintain and develop the protocol actively, to assure that it’s interoperable and meets today’s needs. If HTTP stagnates, another protocol will (justifiably) replace it, and we’ll lose all the community’s investment, shared understanding and interoperability.
Cloudflare and many others do this by sending engineers to participate in the IETF, where most Internet protocols are discussed and standardised. We also attend and sponsor community events like the HTTP Workshop to have conversations about what problems people have, what they need, and understand what changes might help them.
So what happened at all of those working group meetings, specification documents, and side events in 2022? What are implementers and deployers of the web’s protocol doing? And what’s coming next?
New Specification: HTTP/3
Specification-wise, the biggest thing to happen in 2022 was the publication of HTTP/3, because it was an enormous step towards keeping up with the requirements of modern applications and sites by using the network more efficiently to unblock web performance.
Way back in the 90s, HTTP/0.9 and HTTP/1.0 used a new TCP connection for each request—an astoundingly inefficient use of the network. HTTP/1.1 introduced persistent connections (which were backported to HTTP/1.0 with the `Connection: Keep-Alive` header). This was an improvement that helped servers and the network cope with the explosive popularity of the web, but even back then, the community knew it had significant limitations—in particular, head-of-line blocking (where one outstanding request on a connection blocks others from completing).
That didn’t matter so much in the 90s and early 2000s, but today’s web pages and applications place demands on the network that make these limitations performance-critical. Pages often have hundreds of assets that all compete for network resources, and HTTP/1.1 wasn’t up to the task. After some false starts, the community finally addressed these issues with HTTP/2 in 2015.
However, removing head-of-line blocking in HTTP exposed the same problem one layer lower, in TCP. Because TCP is an in-order, reliable delivery protocol, loss of a single packet in a flow can block access to those after it—even if they’re sitting in the operating system’s buffers. This turns out to be a real issue for HTTP/2 deployment, especially on less-than-optimal networks.
HTTP/3 is the version of HTTP that uses QUIC. While the working group effectively finished it in 2021 along with QUIC, its publication was held until 2022 to synchronise with the publication of other documents (see below). 2022 was also a milestone year for HTTP/3 deployment; Cloudflare saw increasing adoption and confidence in the new protocol.
While there was only a brief gap of a few years between HTTP/2 and HTTP/3, there isn’t much appetite for working on HTTP/4 in the community soon. QUIC and HTTP/3 are both new, and the world is still learning how best to implement the protocols, operate them, and build sites and applications using them. While we can’t rule out a limitation that will force a new version in the future, the IETF built these protocols based upon broad industry experience with modern networks, and have significant extensibility available to ease any necessary changes.
New specifications: HTTP “core”
The other headline event for HTTP specs in 2022 was the publication of its “core” documents — the heart of HTTP’s specification. The core comprises: HTTP Semantics – things like methods, headers, status codes, and the message format; HTTP Caching – how HTTP caches work; HTTP/1.1 – mapping semantics to the wire, using the format everyone knows and loves.
Additionally, HTTP/2 was republished to properly integrate with the Semantics document, and to fix a few outstanding issues.
This is the latest in a long series of revisions for these documents—in the past, we’ve had the RFC 723x series, the (perhaps most well-known) RFC 2616, RFC 2068, and the grandparent of them all, RFC 1945. Each revision has aimed to improve readability, fix errors, explain concepts better, and clarify protocol operation. Poorly specified (or implemented) features are deprecated; new features that improve protocol operation are added. See the ‘Changes from…’ appendix in each document for the details. And, importantly, always refer to the latest revisions linked above; the older RFCs are now obsolete.
Deploying Early Hints
HTTP/2 included server push, a feature designed to allow servers to “push” a request/response pair to clients when they knew the client was going to need something, so it could avoid the latency penalty of making a request and waiting for the response.
After HTTP/2 was finalised in 2015, Cloudflare and many other HTTP implementations soon rolled out server push in anticipation of big performance wins. Unfortunately, it turned out that’s harder than it looks; server push effectively requires the server to predict the future—not only what requests the client will send but also what the network conditions will be. And, when the server gets it wrong (“over-pushing”), the pushed requests directly compete with the real requests that the browser is making, representing a significant opportunity cost with real potential for harming performance, rather than helping it. The impact is even worse when the browser already has a copy in cache, so it doesn’t need the push at all.
As a result, Chrome removed HTTP/2 server push in 2022. Other browsers and servers might still support it, but the community seems to agree that it’s only suitable for specialised uses currently, like the browser notification-specific Web Push Protocol.
That doesn’t mean that we’re giving up, however. The 103 (Early Hints) status code was published as an Experimental RFC by the HTTP Working Group in 2017. It allows a server to send hints to the browser in a non-final response, before the “real” final response. That’s useful if you know that the content is going to include some links to resources that the browser will fetch, but need more time to get the response to the client (because it will take more time to generate, or because the server needs to fetch it from somewhere else, like a CDN does).
Early Hints can be used in many situations that server push was designed for — for example, when you have CSS and JavaScript that a page is going to need to load. In theory, they’re not as optimal as server push, because they only allow hints to be sent when there’s an outstanding request, and because getting the hints to the client and acted upon adds some latency.
In practice, however, Cloudflare and our partners (like Shopify and Google) spent 2022 experimenting with Early Hints and finding them much safer to use, with promising performance benefits that include significant reductions in key web performance metrics.
We’re excited about the potential that Early Hints show; so excited that we’ve integrated them into Cloudflare Pages. We’re also evaluating new ways to improve performance using this new capability in the protocol.
Privacy-focused intermediation
For many, the most exciting HTTP protocol extensions in 2022 focused on intermediation—the ability to insert proxies, gateways, and similar components into the protocol to achieve specific goals, often focused on improving privacy.
The MASQUE Working Group, for example, is an effort to add new tunneling capabilities to HTTP, so that an intermediary can pass the tunneled traffic along to another server.
While CONNECT has enabled TCP tunnels for a long time, MASQUE enabled UDP tunnels, allowing more protocols to be tunneled more efficiently–including QUIC and HTTP/3.
At Cloudflare, we’re enthusiastic to be working with Apple to use MASQUE to implement iCloud Private Relay and enhance their customers’ privacy without relying solely on one company. We’re also very interested in the Working Group’s future work, including IP tunneling that will enable MASQUE-based VPNs. Another intermediation-focused specification is Oblivious HTTP (or OHTTP). OHTTP uses sets of intermediaries to prevent the server from using connections or IP addresses to track clients, giving greater privacy assurances for things like collecting telemetry or other sensitive data. This specification is just finishing the standards process, and we’re using it to build an important new product, Privacy Gateway, to protect the privacy of our customers’ customers.
We and many others in the Internet community believe that this is just the start, because intermediation can partition communication, a valuable tool for improving privacy.
Protocol security
Finally, 2022 saw a lot of work on security-related aspects of HTTP. The Digest Fields specification is an update to the now-ancient `Digest` header field, allowing integrity digests to be added to messages. The HTTP Message Signatures specification enables cryptographic signatures on requests and responses — something that has widespread ad hoc deployment, but until now has lacked a standard. Both specifications are in the final stages of standardisation.
A revision of the Cookie specification also saw a lot of progress in 2022, and should be final soon. Since it’s not possible to get rid of them completely soon, much work has taken place to limit how they operate to improve privacy and security, including a new `SameSite` attribute.
Another set of security-related specifications that Cloudflare has invested in for many years is Privacy Pass also known as “Private Access Tokens.” These are cryptographic tokens that can assure clients are real people, not bots, without using an intrusive CAPTCHA, and without tracking the user’s activity online. In HTTP, they take the form of a new authentication scheme.
While Privacy Pass is still not quite through the standards process, 2022 saw its broad deployment by Apple, a huge step forward. And since Cloudflare uses it in Turnstile, our CAPTCHA alternative, your users can have a better experience today.
At the 2022 HTTP Workshop, the community also talked about what new work we can take on to improve the protocol. Some ideas discussed included improving our shared protocol testing infrastructure (right now we have a few resources, but it could be much better), improving (or replacing) Alternative Services to allow more intelligent and correct connection management, and more radical changes, like alternative, binary serialisations of headers.
There’s also a continuing discussion in the community about whether HTTP should accommodate pub/sub, or whether it should be standardised to work over WebSockets (and soon, WebTransport). Although it’s hard to say now, adjacent work on Media over QUIC that just started might provide an opportunity to push this forward.
Of course, that’s not everything, and what happens to HTTP in 2023 (and beyond) remains to be seen. HTTP is still evolving, even as it stays compatible with the largest distributed hypertext system ever conceived—the World Wide Web.
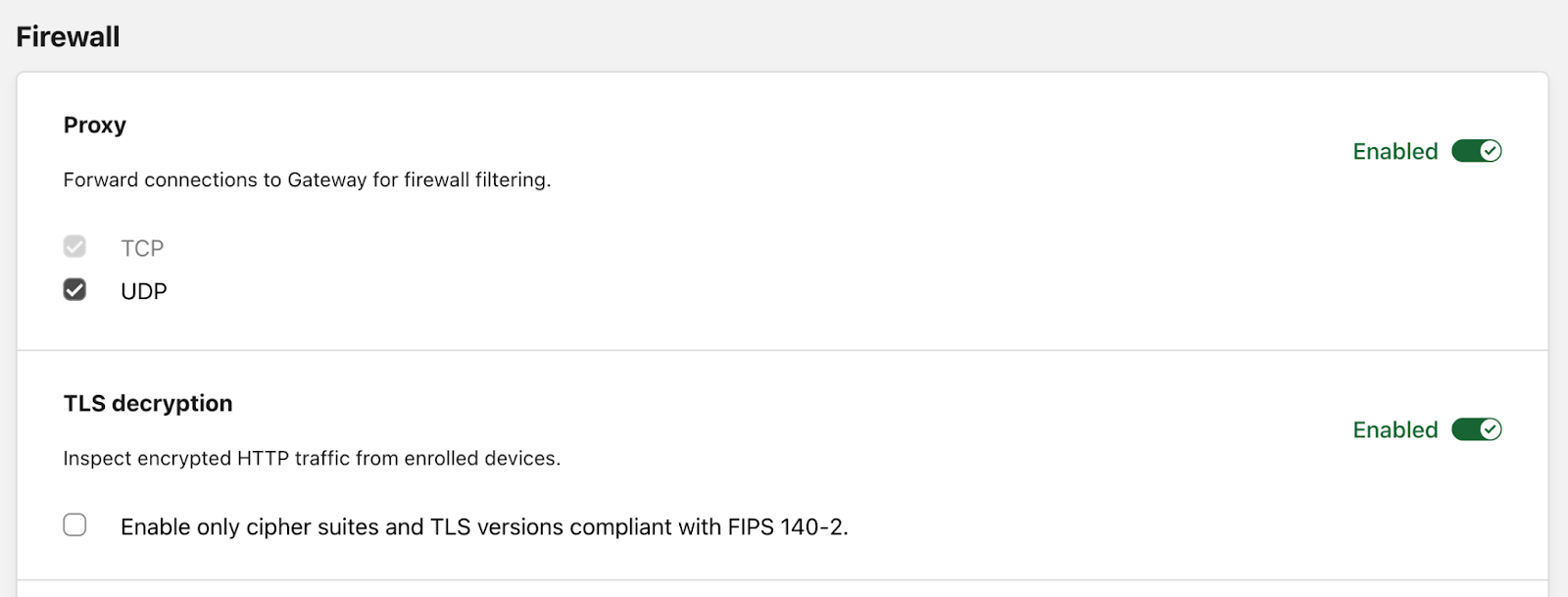
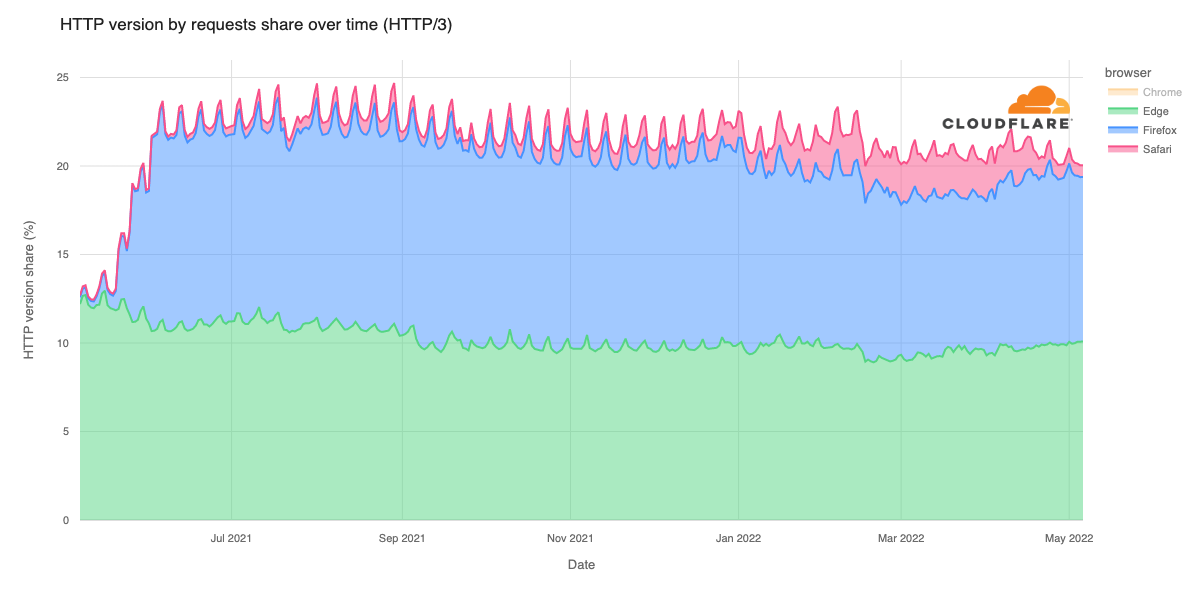
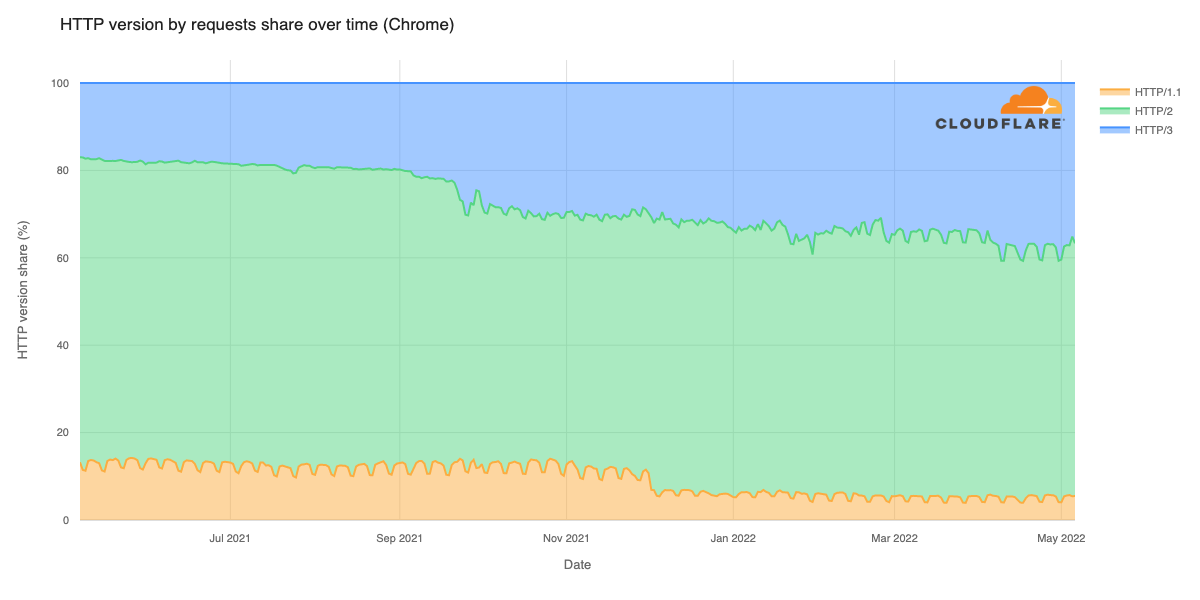
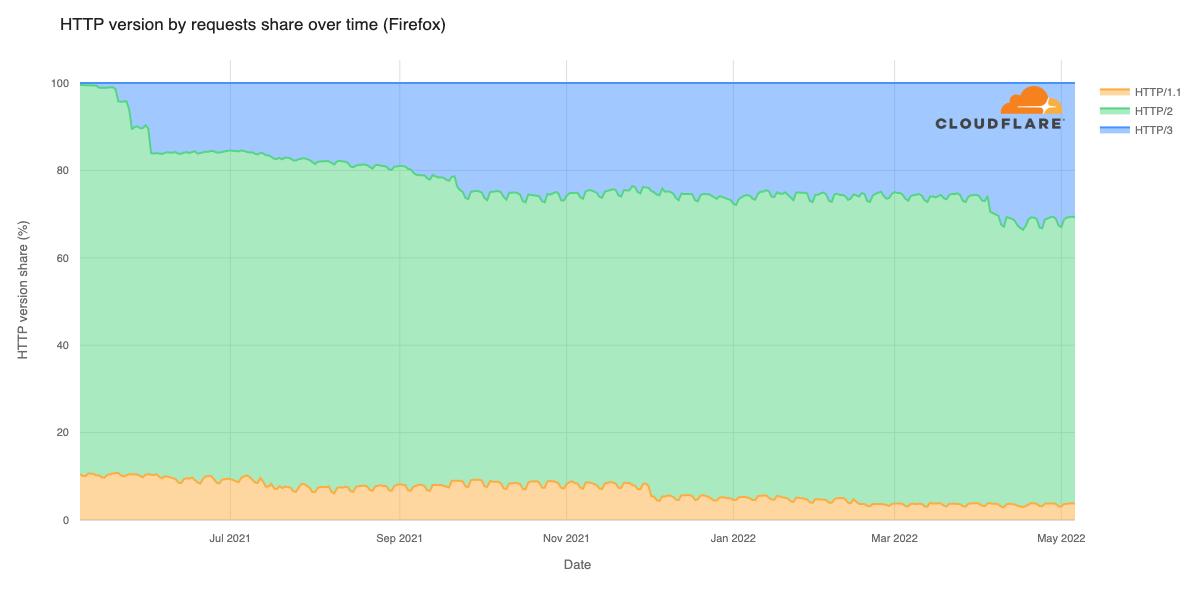
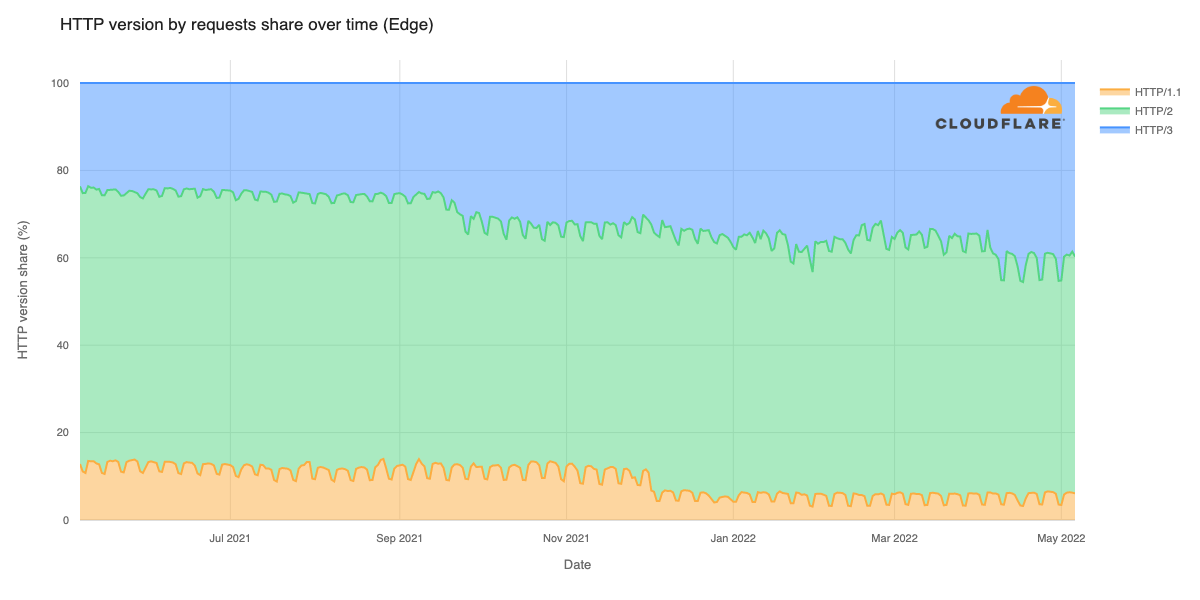
Today, we’re excited to announce upcoming support for HTTP/3 inspection through Cloudflare Gateway, our comprehensive secure web gateway. HTTP/3 currently powers 25% of the Internet and delivers a faster browsing experience, without compromising security. Until now, administrators seeking to filter and inspect HTTP/3-enabled websites or APIs needed to either compromise on performance by falling back to HTTP/2 or lose visibility by bypassing inspection. With HTTP/3 support in Cloudflare Gateway, you can have full visibility on all traffic and provide the fastest browsing experience for your users.
Why is the web moving to HTTP/3?
HTTP is one of the oldest technologies that powers the Internet. All the way back in 1996, security and performance were afterthoughts and encryption was left to the transport layer to manage. This model doesn’t scale to the performance needs of the modern Internet and has led to HTTP being upgraded to HTTP/2 and now HTTP/3.
HTTP/3 accelerates browsing activity by using QUIC, a modern transport protocol that is always encrypted by default. This delivers faster performance by reducing round-trips between the user and the web server and is more performant for users with unreliable connections. For further information about HTTP/3’s performance advantages take a look at our previous blog here.
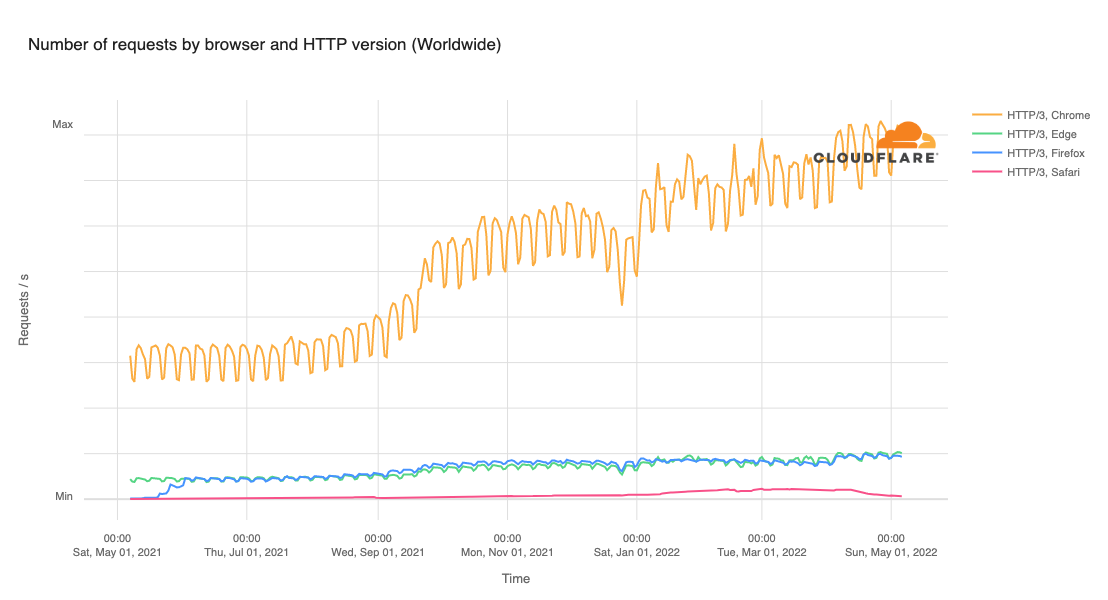
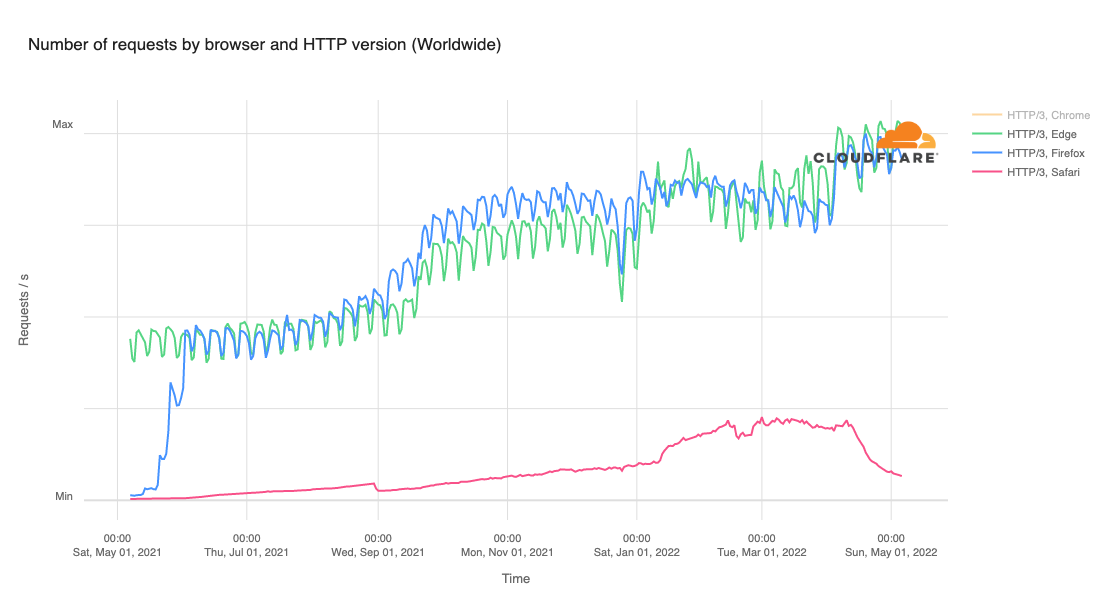
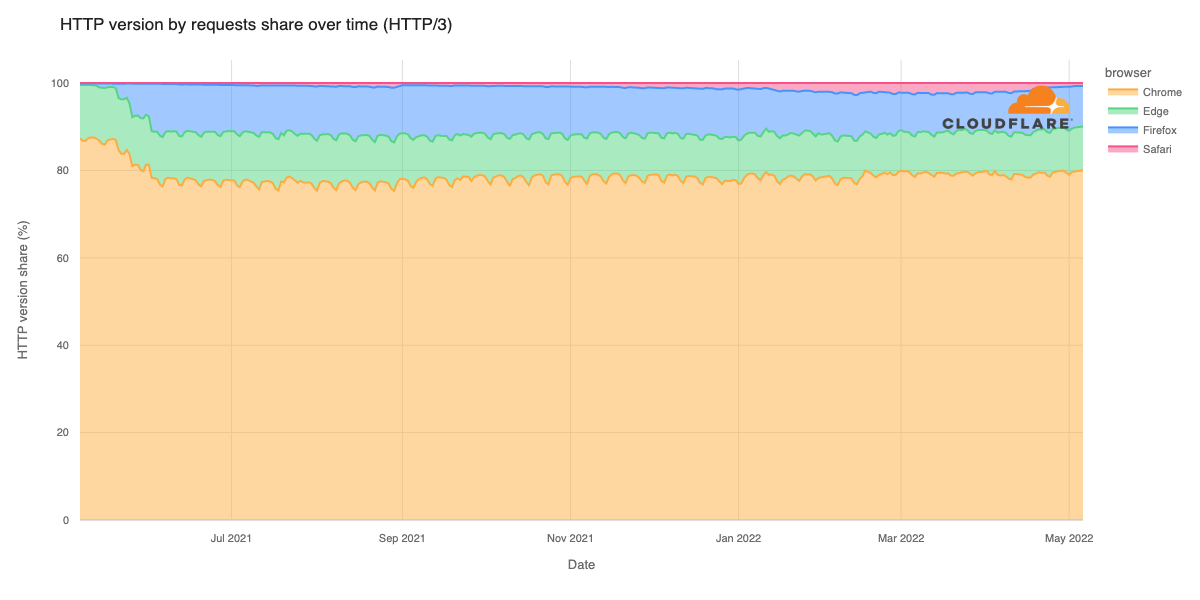
HTTP/3 development and adoption
Cloudflare’s mission is to help build a better Internet. We see HTTP/3 as an important building block to make the Internet faster and more secure. We worked closely with the IETF to iterate on the HTTP/3 and QUIC standards documents. These efforts combined with progress made by popular browsers like Chrome and Firefox to enable QUIC by default have translated into HTTP/3 now being used by over 25% of all websites and for an even more thorough analysis.
We’ve advocated for HTTP/3 extensively over the past few years. We first introduced support for the underlying transport layer QUIC in September 2018 and then from there worked to introduce HTTP/3 support for our reverse proxy services the following year in September of 2019. Since then our efforts haven’t slowed down and today we support the latest revision of HTTP/3, using the final “h3” identifier matching RFC 9114.
HTTP/3 inspection hurdles
But while there are many advantages to HTTP/3, its introduction has created deployment complexity and security tradeoffs for administrators seeking to filter and inspect HTTP traffic on their networks. HTTP/3 offers familiar HTTP request and response semantics, but the use of QUIC changes how it looks and behaves “on the wire”. Since QUIC runs atop UDP, it is architecturally distinct from legacy TCP-based protocols and has poor support from legacy secure web gateways. The combination of these two factors has made it challenging for administrators to keep up with the evolving technological landscape while maintaining the users’ performance expectations and ensuring visibility and control over Internet traffic.
Without proper secure web gateway support for HTTP/3, administrators have needed to choose whether to compromise on security and/or performance for their users. Security tradeoffs include not inspecting UDP traffic, or even worse forgoing critical security capabilities such as inline anti-virus scanning, data-loss prevention, browser isolation and/or traffic logging. Naturally, for any security conscious organization discarding security and visibility is not an acceptable approach and this has led administrators to proactively disable HTTP/3 on their end user devices. This introduces deployment complexity and sacrifices performance as it requires disabling QUIC-support within the users web browsers.
How to enable HTTP/3 Inspection
Once support for HTTP/3 inspection is available for select browsers later this year, you’ll be able to enable HTTP/3 inspection through the dashboard. Once logged into the Zero Trust dashboard you will need to toggle on proxying, click the box for UDP traffic, and enable TLS decryption under Settings > Network > Firewall. Once these settings have been enabled; AV-scanning, remote browser isolation, DLP, and HTTP filtering can be applied via HTTP policies to all of your organization’s proxied HTTP traffic.
What’s next
Administrators will no longer need to make security tradeoffs based on the evolving technological landscape and can focus on protecting their organization and teams. We’ll reach out to all Cloudflare One customers once HTTP/3 inspection is available and are excited to simplify secure web gateway deployments for administrators.
HTTP/3 traffic inspection will be available to all administrators of all plan types; if you have not signed up already click here to get started.
Today, a cluster of Internet standards were published that rationalize and modernize the definition of HTTP – the application protocol that underpins the web. This work includes updates to, and refactoring of, HTTP semantics, HTTP caching, HTTP/1.1, HTTP/2, and the brand-new HTTP/3. Developing these specifications has been no mean feat and today marks the culmination of efforts far and wide, in the Internet Engineering Task Force (IETF) and beyond. We thought it would be interesting to celebrate the occasion by sharing some analysis of Cloudflare’s view of HTTP traffic over the last 12 months.
However, before we get into the traffic data, for quick reference, here are the new RFCs that you should make a note of and start using:
HTTP’s overall architecture, common terminology and shared protocol aspects such as request and response messages, methods, status codes, header and trailer fields, message content, representation data, content codings and much more. Obsoletes RFCs 2818, 7231, 7232, 7233, 7235, 7538, 7615, 7694, and portions of 7230.
A syntax of HTTP that uses a binary framing format, which provides streams to support concurrent requests and responses. Message fields can be compressed using HPACK. Typically used over TCP and TLS. Obsoletes RFCs 7540 and 8740.
A variation of HPACK field compression that is optimized for the QUIC transport protocol.
On May 28, 2021, we enabled QUIC version 1 and HTTP/3 for all Cloudflare customers, using the final “h3” identifier that matches RFC 9114. So although today’s publication is an occasion to celebrate, for us nothing much has changed, and it’s business as usual.
A browser and web server typically automatically negotiate the highest HTTP version available. Thus, HTTP/3 takes precedence over HTTP/2. We looked back over the last year to understand HTTP/3 usage trends across the Cloudflare network, as well as analyzing HTTP versions used by traffic from leading browser families (Google Chrome, Mozilla Firefox, Microsoft Edge, and Apple Safari), major search engine indexing bots, and bots associated with some popular social media platforms. The graphs below are based on aggregate HTTP(S) traffic seen globally by the Cloudflare network, and include requests for website and application content across the Cloudflare customer base between May 7, 2021, and May 7, 2022. We used Cloudflare bot scores to restrict analysis to “likely human” traffic for the browsers, and to “likely automated” and “automated” for the search and social bots.
Traffic by HTTP version
Overall, HTTP/2 still comprises the majority of the request traffic for Cloudflare customer content, as clearly seen in the graph below. After remaining fairly consistent through 2021, HTTP/2 request volume increased by approximately 20% heading into 2022. HTTP/1.1 request traffic remained fairly flat over the year, aside from a slight drop in early December. And while HTTP/3 traffic initially trailed HTTP/1.1, it surpassed it in early July, growing steadily and roughly doubling in twelve months.
HTTP/3 traffic by browser
Digging into just HTTP/3 traffic, the graph below shows the trend in daily aggregate request volume over the last year for HTTP/3 requests made by the surveyed browser families. Google Chrome (orange line) is far and away the leading browser, with request volume far outpacing the others.
Below, we remove Chrome from the graph to allow us to more clearly see the trending across other browsers. Likely because it is also based on the Chromium engine, the trend for Microsoft Edge closely mirrors Chrome. As noted above, Mozilla Firefox first enabled production support in version 88 in April 2021, making it available by default by the end of May. The increased adoption of that updated version during the following month is clear in the graph as well, as HTTP/3 request volume from Firefox grew rapidly. HTTP/3 traffic from Apple Safari increased gradually through April, suggesting growth in the number of users enabling the experimental feature or running a Technology Preview version of the browser. However, Safari’s HTTP/3 traffic has subsequently dropped over the last couple of months. We are not aware of any specific reasons for this decline, but our most recent observations indicate HTTP/3 traffic is recovering.
Looking at the lines in the graph for Chrome, Edge, and Firefox, a weekly cycle is clearly visible in the graph, suggesting greater usage of these browsers during the work week. This same pattern is absent from Safari usage.
Across the surveyed browsers, Chrome ultimately accounts for approximately 80% of the HTTP/3 requests seen by Cloudflare, as illustrated in the graphs below. Edge is responsible for around another 10%, with Firefox just under 10%, and Safari responsible for the balance.
We also wanted to look at how the mix of HTTP versions has changed over the last year across each of the leading browsers. Although the percentages vary between browsers, it is interesting to note that the trends are very similar across Chrome, Firefox and Edge. (After Firefox turned on default HTTP/3 support in May 2021, of course.) These trends are largely customer-driven – that is, they are likely due to changes in Cloudflare customer configurations.
Most notably we see an increase in HTTP/3 during the last week of September, and a decrease in HTTP/1.1 at the beginning of December. For Safari, the HTTP/1.1 drop in December is also visible, but the HTTP/3 increase in September is not. We expect that over time, once Safari supports HTTP/3 by default that its trends will become more similar to those seen for the other browsers.
Traffic by search indexing bot
Back in 2014, Google announced that it would start to consider HTTPS usage as a ranking signal as it indexed websites. However, it does not appear that Google, or any of the other major search engines, currently consider support for the latest versions of HTTP as a ranking signal. (At least not directly – the performance improvements associated with newer versions of HTTP could theoretically influence rankings.) Given that, we wanted to understand which versions of HTTP the indexing bots themselves were using.
Despite leading the charge around the development of QUIC, and integrating HTTP/3 support into the Chrome browser early on, it appears that on the indexing/crawling side, Google still has quite a long way to go. The graph below shows that requests from GoogleBot are still predominantly being made over HTTP/1.1, although use of HTTP/2 has grown over the last six months, gradually approaching HTTP/1.1 request volume. (A blog post from Google provides some potential insights into this shift.) Unfortunately, the volume of requests from GoogleBot over HTTP/3 has remained extremely limited over the last year.
Microsoft’s BingBot also fails to use HTTP/3 when indexing sites, with near-zero request volume. However, in contrast to GoogleBot, BingBot prefers to use HTTP/2, with a wide margin developing in mid-May 2021 and remaining consistent across the rest of the past year.
Traffic by social media bot
Major social media platforms use custom bots to retrieve metadata for shared content, improve language models for speech recognition technology, or otherwise index website content. We also surveyed the HTTP version preferences of the bots deployed by three of the leading social media platforms.
Although Facebook supports HTTP/3 on their main website (and presumably their mobile applications as well), their back-end FacebookBot crawler does not appear to support it. Over the last year, on the order of 60% of the requests from FacebookBot have been over HTTP/1.1, with the balance over HTTP/2. Heading into 2022, it appeared that HTTP/1.1 preference was trending lower, with request volume over the 25-year-old protocol dropping from near 80% to just under 50% during the fourth quarter. However, that trend was abruptly reversed, with HTTP/1.1 growing back to over 70% in early February. The reason for the reversal is unclear.
Similar to FacebookBot, it appears TwitterBot’s use of HTTP/3 is, unfortunately, pretty much non-existent. However, TwitterBot clearly has a strong and consistent preference for HTTP/2, accounting for 75-80% of its requests, with the balance over HTTP/1.1.
In contrast, LinkedInBot has, over the last year, been firmly committed to making requests over HTTP/1.1, aside from the apparently brief anomalous usage of HTTP/2 last June. However, in mid-March, it appeared to tentatively start exploring the use of other HTTP versions, with around 5% of requests now being made over HTTP/2, and around 1% over HTTP/3, as seen in the upper right corner of the graph below.
Conclusion
We’re happy that HTTP/3 has, at long last, been published as RFC 9114. More than that, we’re super pleased to see that regardless of the wait, browsers have steadily been enabling support for the protocol by default. This allows end users to seamlessly gain the advantages of HTTP/3 whenever it is available. On Cloudflare’s global network, we’ve seen continued growth in the share of traffic speaking HTTP/3, demonstrating continued interest from customers in enabling it for their sites and services. In contrast, we are disappointed to see bots from the major search and social platforms continuing to rely on aging versions of HTTP. We’d like to build a better understanding of how these platforms chose particular HTTP versions and welcome collaboration in exploring the advantages that HTTP/3, in particular, could provide.
Current statistics on HTTP/3 and QUIC adoption at a country and autonomous system (ASN) level can be found on Cloudflare Radar.
Running HTTP/3 and QUIC on the edge for everyone has allowed us to monitor a wide range of aspects related to interoperability and performance across the Internet. Stay tuned for future blog posts that explore some of the technical developments we’ve been making.
And this certainly isn’t the end of protocol innovation, as HTTP/3 and QUIC provide many exciting new opportunities. The IETF and wider community are already underway building new capabilities on top, such as MASQUE and WebTransport. Meanwhile, in the last year, the QUIC Working Group has adopted new work such as QUIC version 2, and the Multipath Extension to QUIC.
QUIC is a new Internet transport protocol for secure, reliable and multiplexed communications. HTTP/3 builds on top of QUIC, leveraging the new features to fix performance problems such as Head-of-Line blocking. This enables web pages to load faster, especially over troublesome networks.
QUIC and HTTP/3 are open standards that have been under development in the IETF for almost exactly 4 years. On October 21, 2020, following two rounds of Working Group Last Call, draft 32 of the family of documents that describe QUIC and HTTP/3 were put into IETF Last Call. This is an important milestone for the group. We are now telling the entire IETF community that we think we’re almost done and that we’d welcome their final review.
Speaking personally, I’ve been involved with QUIC in some shape or form for many years now. Earlier this year I was honoured to be asked to help co-chair the Working Group. I’m pleased to help shepherd the documents through this important phase, and grateful for the efforts of everyone involved in getting us there, especially the editors. I’m also excited about future opportunities to evolve on top of QUIC v1 to help build a better Internet.
There are two aspects to protocol development. One aspect involves writing and iterating upon the documents that describe the protocols themselves. Then, there’s implementing, deploying and testing libraries, clients and/or servers. These aspects operate hand in hand, helping the Working Group move towards satisfying the goals listed in its charter. IETF Last Call marks the point that the group and their responsible Area Director (in this case Magnus Westerlund) believe the job is almost done. Now is the time to solicit feedback from the wider IETF community for review. At the end of the Last Call period, the stakeholders will take stock, address feedback as needed and, fingers crossed, go onto the next step of requesting the documents be published as RFCs on the Standards Track.
Although specification and implementation work hand in hand, they often progress at different rates, and that is totally fine. The QUIC specification has been mature and deployable for a long time now. HTTP/3 has been generally available on the Cloudflare edge since September 2019, and we’ve been delighted to see support roll out in user agents such as Chrome, Firefox, Safari, curl and so on. Although draft 32 is the latest specification, the community has for the time being settled on draft 29 as a solid basis for interoperability. This shouldn’t be surprising, as foundational aspects crystallize the scope of changes between iterations decreases. For the average person in the street, there’s not really much difference between 29 and 32.
So today, if you visit a website with HTTP/3 enabled—such as https://cloudflare-quic.com—you’ll probably see response headers that contain Alt-Svc: h3-29=”… . And in a while, once Last Call completes and the RFCs ship, you’ll start to see websites simply offer Alt-Svc: h3=”… (note, no draft version!).
Need a deep dive?
We’ve collected a bunch of resource links at https://cloudflare-quic.com. If you’re more of an interactive visual learner, you might be pleased to hear that I’ve also been hosting a series on Cloudflare TV called “Levelling up Web Performance with HTTP/3”. There are over 12 hours of content including the basics of QUIC, ways to measure and debug the protocol in action using tools like Wireshark, and several deep dives into specific topics. I’ve also been lucky to have some guest experts join me along the way. The table below gives an overview of the episodes that are available on demand.
Understanding the role of congestion control in QUIC. Featuring Junho Choi.
Whither QUIC?
So does Last Call mean QUIC is “done”? Not by a long shot. The new protocol is a giant leap for the Internet, because it enables new opportunities and innovation. QUIC v1 is basically the set of documents that have gone into Last Call. We’ll continue to see people gain experience deploying and testing this, and no doubt cool blog posts about tweaking parameters for efficiency and performance are on the radar. But QUIC and HTTP/3 are extensible, so we’ll see people interested in trying new things like multipath, different congestion control approaches, or new ways to carry data unreliably such as the DATAGRAM frame.
We’re also seeing people interested in using QUIC for other use cases. Mapping other application protocols like DNS to QUIC is a rapid way to get its improvements. We’re seeing people that want to use QUIC as a substrate for carrying other transport protocols, hence the formation of the MASQUE Working Group. There’s folks that want to use QUIC and HTTP/3 as a “supercharged WebSocket”, hence the formation of the WebTransport Working Group.
Whatever the future holds for QUIC, we’re just getting started, and I’m excited.
In late June, Cloudflare’s resolver team noticed a spike in DNS requests for the 65479 Resource Record thanks to data exposed through our new Radar service. We began investigating and found these to be a part of Apple’s iOS14 beta release where they were testing out a new SVCB/HTTPS record type.
Once we saw that Apple was requesting this record type, and while the iOS 14 beta was still on-going, we rolled out support across the Cloudflare customer base.
This blog post explains what this new record type does and its significance, but there’s also a deeper story: Cloudflare customers get automatic support for new protocols like this.
That means that today if you’ve enabled HTTP/3 on an Apple device running iOS 14, when it needs to talk to a Cloudflare customer (say you browse to a Cloudflare-protected website, or use an app whose API is on Cloudflare) it can find the best way of making that connection automatically.
And if you’re a Cloudflare customer you have to do… absolutely nothing… to give Apple users the best connection to your Internet property.
Negotiating HTTP security and performance
Whenever a user types a URL in the browser box without specifying a scheme (like “https://” or “http://”), the browser cannot assume, without prior knowledge such as a Strict-Transport-Security (HSTS) cache or preload list entry, whether the requested website supports HTTPS or not. The browser will first try to fetch the resources using plaintext HTTP, and only if the website redirects to an HTTPS URL, or if it specifies an HSTS policy in the initial HTTP response, the browser will then fetch the resource again over a secure connection.
This means that the latency incurred in fetching the initial resource (say, the index page of a website) is doubled, due to the fact that the browser needs to re-establish the connection over TLS and request the resource all over again. But worse still, the initial request is leaked to the network in plaintext, which could potentially be modified by malicious on-path attackers (think of all those unsecured public WiFi networks) to redirect the user to a completely different website. In practical terms, this weakness is sometimes used by said unsecured public WiFi network operators to sneak advertisements into people’s browsers.
Unfortunately, that’s not the full extent of it. This problem also impacts HTTP/3, the newest revision of the HTTP protocol that provides increased performance and security. HTTP/3 is advertised using the Alt-Svc HTTP header, which is only returned after the browser has already contacted the origin using a different and potentially less performant HTTP version. The browser ends up missing out on using faster HTTP/3 on its first visit to the website (although it does store the knowledge for later visits).
The fundamental problem comes from the fact that negotiation of HTTP-related parameters (such as whether HTTPS or HTTP/3 can be used) is done through HTTP itself (either via a redirect, HSTS and/or Alt-Svc headers). This leads to a chicken and egg problem where the client needs to use the most basic HTTP configuration that has the best chance of succeeding for the initial request. In most cases this means using plaintext HTTP/1.1. Only after it learns of parameters can it change its configuration for the following requests.
But before the browser can even attempt to connect to the website, it first needs to resolve the website’s domain to an IP address via DNS. This presents an opportunity: what if additional information required to establish a connection could be provided, in addition to IP addresses, with DNS?
That’s what we’re excited to be announcing today: Cloudflare has rolled out initial support for HTTPS records to our edge network. Cloudflare’s DNS servers will now automatically generate HTTPS records on the fly to advertise whether a particular zone supports HTTP/3 and/or HTTP/2, based on whether those features are enabled on the zone.
Service Bindings via DNS
The new proposal, currently discussed by the Internet Engineering Task Force (IETF) defines a family of DNS resource record types (“SVCB”) that can be used to negotiate parameters for a variety of application protocols.
The generic DNS record “SVCB” can be instantiated into records specific to different protocols. The draft specification defines one such instance called “HTTPS”, specific to the HTTP protocol, which can be used not only to signal to the client that it can connect in over a secure connection (skipping the initial unsecured request), but also to advertise the different HTTP versions supported by the website. In the future, potentially even more features could be advertised.
example.com 3600 IN HTTPS 1 . alpn=”h3,h2”
The DNS record above advertises support for the HTTP/3 and HTTP/2 protocols for the example.com origin.
This is best used alongside DNS over HTTPS or DNS over TLS, and DNSSEC, to again prevent malicious actors from manipulating the record.
The client will need to fetch not only the typical A and AAAA records to get the origin’s IP addresses, but also the HTTPS record. It can of course do these lookups in parallel to avoid additional latency at the start of the connection, but this could potentially lead to A/AAAA and HTTPS responses diverging from each other. For example, in cases where the origin makes use of DNS load-balancing: if an origin can be served by multiple CDNs it might happen that the responses for A and/or AAAA records come from one CDN, while the HTTPS record comes from another. In some cases this can lead to failures when connecting to the origin (say, if the HTTPS record from one of the CDNs advertises support for HTTP/3, but the CDN the client ends up connecting to doesn’t support it).
This is solved by the SVCB and HTTPS records by providing the IP addresses directly, without the need for the client to look at A and AAAA records. This is done via the “ipv4hint” and “ipv6hint” parameters that can optionally be added to these records, which provide lists of IPv4 and IPv6 addresses that can be used by the client in lieu of the addresses specified in A and AAAA records. Of course clients will still need to query the A and AAAA records, to support cases where no SVCB or HTTPS record is available, but these IP hints provide an additional layer of robustness.
example.com 3600 IN HTTPS 1 . alpn=”h3,h2” ipv4hint=”192.0.2.1” ipv6hint=”2001:db8::1”
In addition to all this, SVCB and HTTPS can also be used to define alternative endpoints that are authoritative for a service, in a similar vein to SRV records:
example.com 3600 IN HTTPS 1 example.net alpn=”h3,h2”
example.com 3600 IN HTTPS 2 example.org alpn=”h2”
In this case the “example.com” HTTPS service can be provided by both “example.net” (which supports both HTTP/3 and HTTP/2, in addition to HTTP/1.x) as well as “example.org” (which only supports HTTP/2 and HTTP/1.x). The client will first need to fetch A and AAAA records for “example.net” or “example.org” before being able to connect, which might increase the connection latency, but the service operator can make use of the IP hint parameters discussed above in this case as well, to reduce the amount of required DNS lookups the client needs to perform.
This means that SVCB and HTTPS records might finally provide a way for SRV-like functionality to be supported by popular browsers and other clients that have historically not supported SRV records.
There is always room at the top apex
When setting up a website on the Internet, it’s common practice to use a “www” subdomain (like in “www.cloudflare.com”) to identify the site, as well as the “apex” (or “root”) of the domain (in this case, “cloudflare.com”). In order to avoid duplicating the DNS configuration for both domains, the “www” subdomain can typically be configured as a CNAME (Canonical Name) record, that is, a record that maps to a different DNS record.
cloudflare.com. 3600 IN A 192.0.2.1
cloudflare.com. 3600 IN AAAA 2001:db8::1
www 3600 IN CNAME cloudflare.com.
This way the list of IP addresses of the websites won’t need to be duplicated all over again, but clients requesting A and/or AAAA records for “www.cloudflare.com” will still get the same results as “cloudflare.com”.
However, there are some cases where using a CNAME might seem like the best option, but ends up subtly breaking the DNS configuration for a website. For example when setting up services such as GitLab Pages, GitHub Pages or Netlify with a custom domain, the user is generally asked to add an A (and sometimes AAAA) record to the DNS configuration for their domain. Those IP addresses are hard-coded in users’ configurations, which means that if the provider of the service ever decides to change the addresses (or add new ones), even if just to provide some form of load-balancing, all of their users will need to manually change their configuration.
Using a CNAME to a more stable domain which can then have variable A and AAAA records might seem like a better option, and some of these providers do support that, but it’s important to note that this generally only works for subdomains (like “www” in the previous example) and not apex records. This is because the DNS specification that defines CNAME records states that when a CNAME is defined on a particular target, there can’t be any other records associated with it. This is fine for subdomains, but apex records will need to have additional records defined, such as SOA and NS, for the DNS configuration to work properly and could also have records such as MX to make sure emails get properly delivered. In practical terms, this means that defining a CNAME record at the apex of a domain might appear to be working fine in some cases, but be subtly broken in ways that are not immediately apparent.
But what does this all have to do with SVCB and HTTPS records? Well, it turns out that those records can also solve this problem, by defining an alternative format called “alias form” that behaves in the same manner as a CNAME in all the useful ways, but without the annoying historical baggage. A domain operator will be able to define a record such as:
example.com. 3600 IN HTTPS example.org.
and expect it to work as if a CNAME was defined, but without the subtle side-effects.
One more thing
Encrypted SNI is an extension to TLS intended to improve privacy of users on the Internet. You might remember how it makes use of a custom DNS record to advertise the server’s public key share used by clients to then derive the secret key necessary to actually encrypt the SNI. In newer revisions of the specification (which is now called “Encrypted ClientHello” or “ECH”) the custom TXT record used previously is simply replaced by a new parameter, called “echconfig”, for the SVCB and HTTPS records.
This means that SVCB/HTTPS are a requirement to support newer revisions of Encrypted SNI/Encrypted ClientHello. More on this later this year.
What now?
This all sounds great, but what does it actually mean for Cloudflare customers? As mentioned earlier, we have enabled initial support for HTTPS records across our edge network. Cloudflare’s DNS servers will automatically generate HTTPS records on the fly to advertise whether a particular zone supports HTTP/3 and/or HTTP/2, based on whether those features are enabled on the zone, and we will later also add Encrypted ClientHello support.
Thanks to Cloudflare’s large network that spans millions of web properties (we happen to be one of the most popular DNS providers), serving these records on our customers’ behalf will help build a more secure and performant Internet for anyone that is using a supporting client.
Adopting new protocols requires cooperation between multiple parties. We have been working with various browsers and clients to increase the support and adoption of HTTPS records. Over the last few weeks, Apple’s iOS 14 release has included client support for HTTPS records, allowing connections to be upgraded to QUIC when the HTTP/3 parameter is returned in the DNS record. Apple has reported that so far, of the population that has manually enabled HTTP/3 on iOS 14, 8% of the QUIC connections had the HTTPS record response.
Other browser vendors, such as Google and Mozilla, are also working on shipping support for HTTPS records to their users, and we hope to be hearing more on this front soon.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.