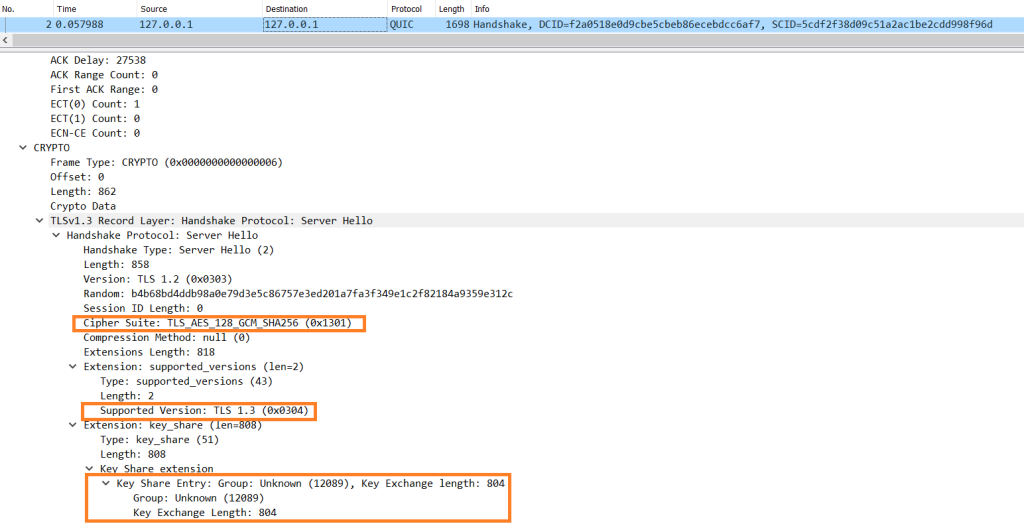
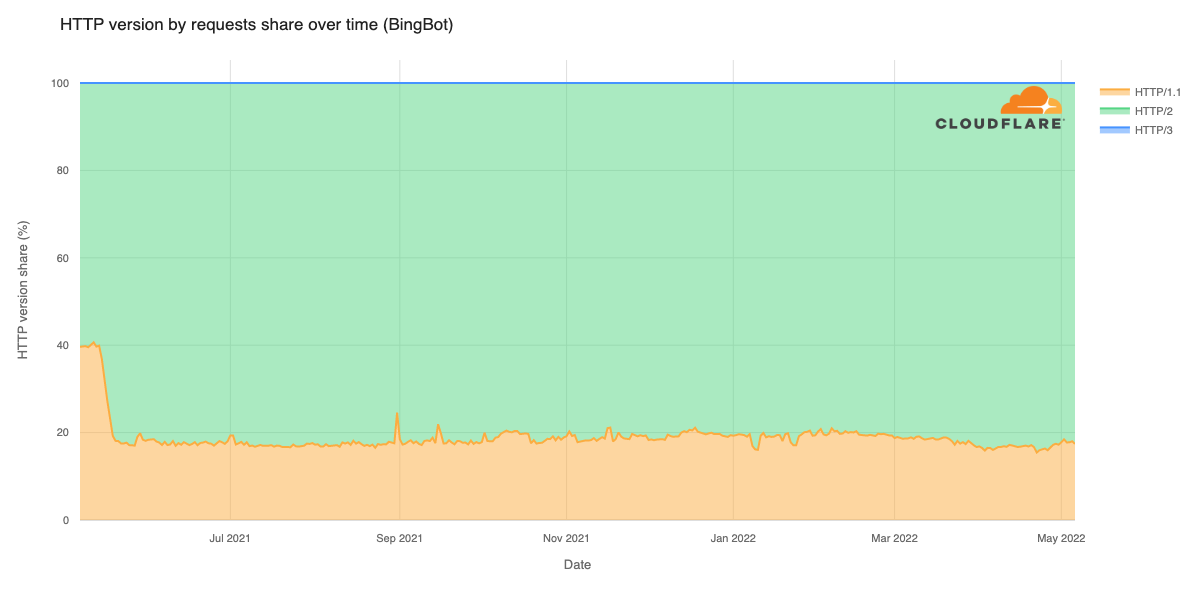
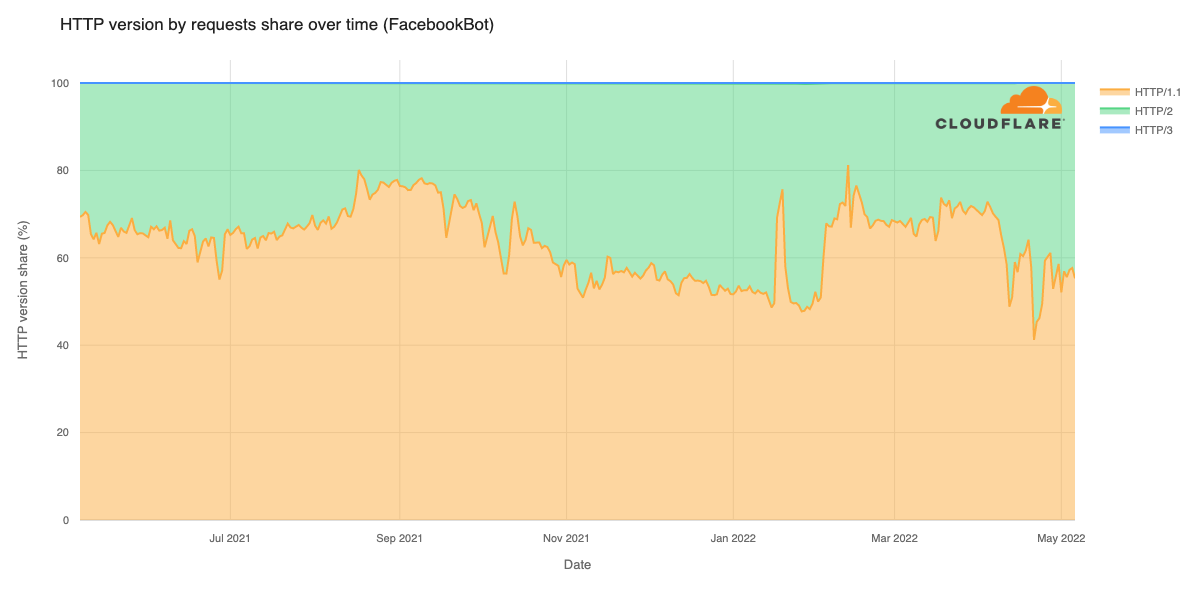
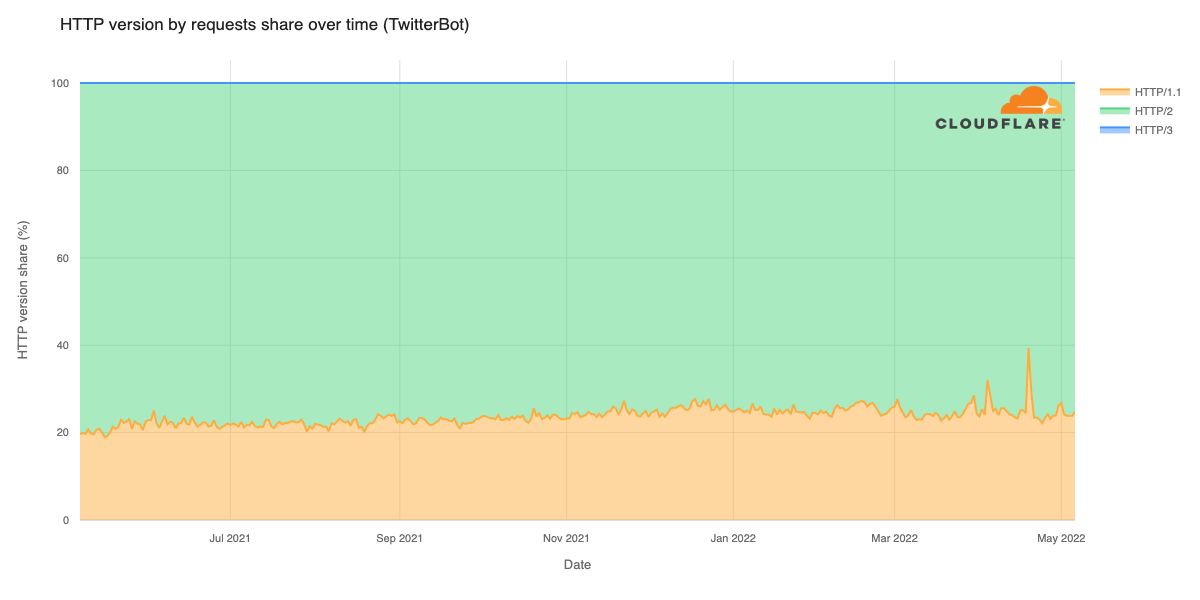
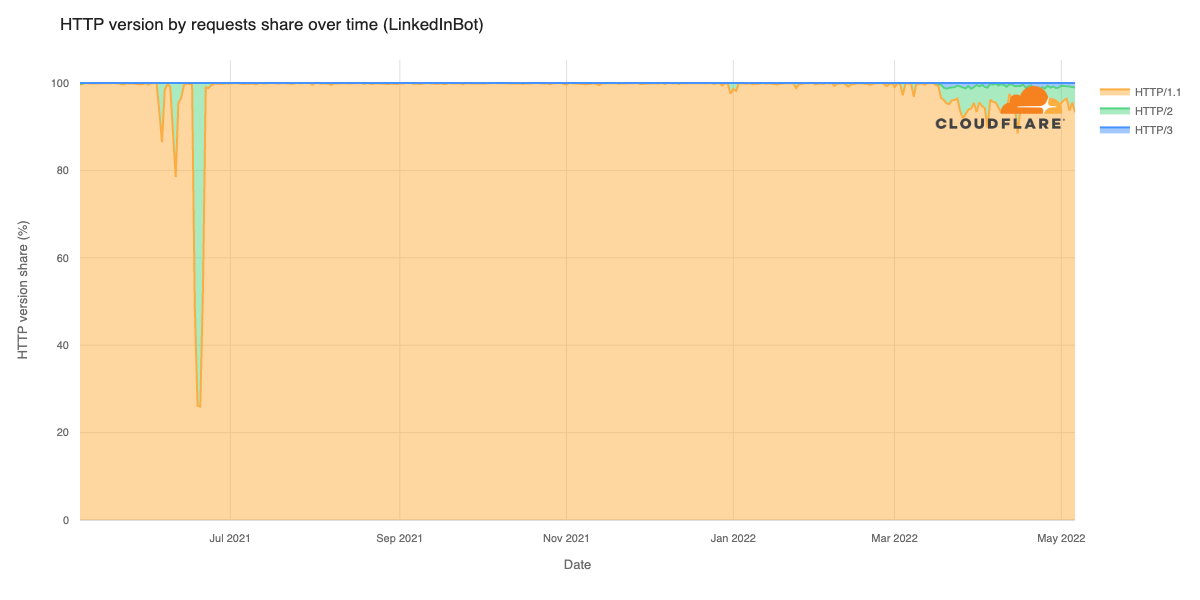
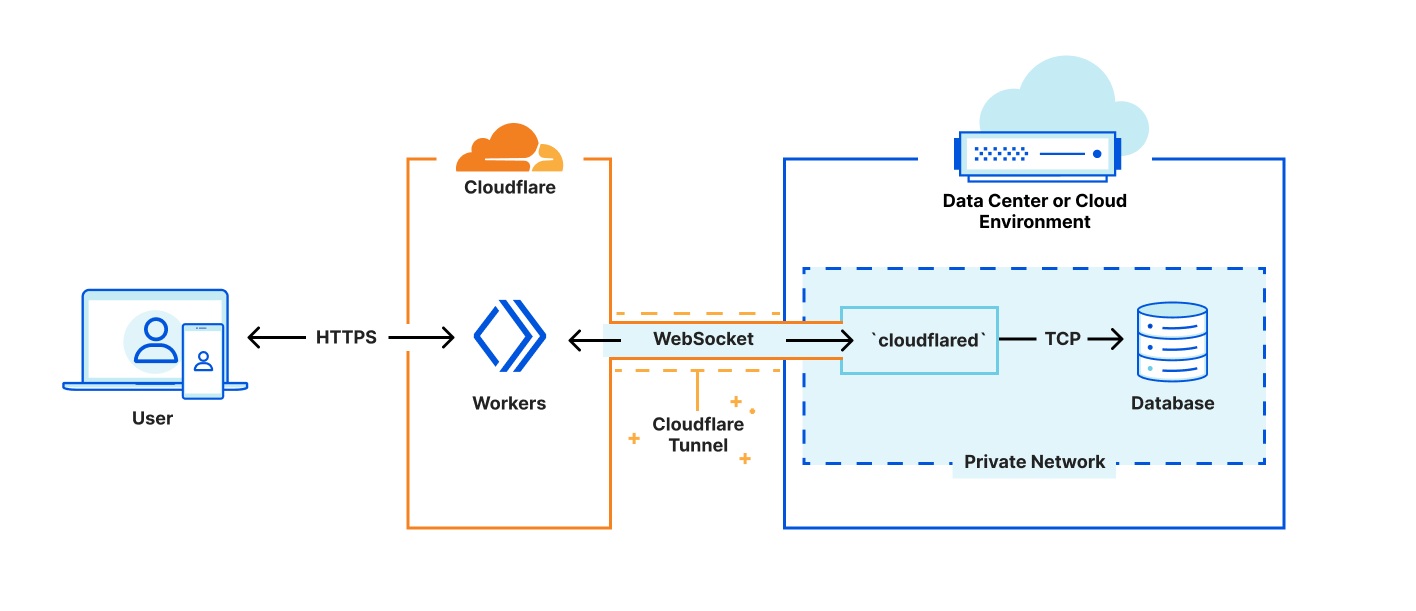
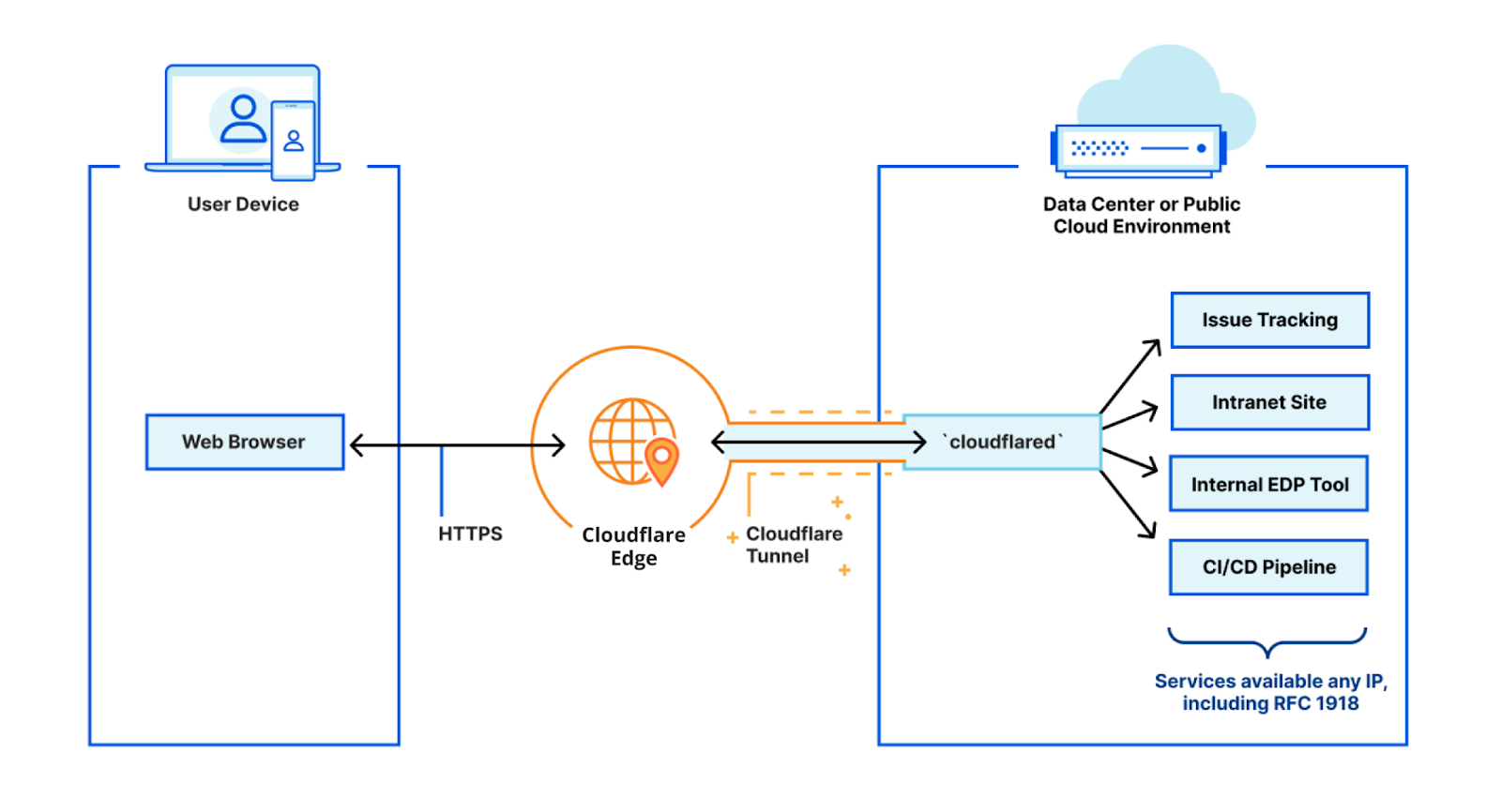
On April 10th, 2025 12:10 UTC, a security researcher notified Cloudflare of two vulnerabilities (CVE-2025-4820 and CVE-2025-4821) related to QUIC packet acknowledgement (ACK) handling, through our Public Bug Bounty program. These were DDoS vulnerabilities in the quiche library, and Cloudflare services that use it. quiche is Cloudflare’s open-source implementation of QUIC protocol, which is the transport protocol behind HTTP/3.
Upon notification, Cloudflare engineers patched the affected infrastructure, and the researcher confirmed that the DDoS vector was mitigated. Cloudflare’s investigation revealed no evidence that the vulnerabilities were being exploited or that any customers were affected. quiche versions prior to 0.24.4 were affected.
Here, we’ll explain why ACKs are important to Internet protocol design and how they help ensure fair network usage. Finally, we will explain the vulnerabilities and discuss our mitigation for the Optimistic ACK attack: a dynamic CWND-aware skip frequency that scales with a connection’s send rate.
Internet Protocols and Attack Vectors
QUIC is an Internet transport protocol that offers equivalent features to TCP (Transmission Control Protocol) and TLS (Transport Layer Security). QUIC runs over UDP (User Datagram Protocol), is encrypted by default and offers a few benefits over the prior set of protocols (including smaller handshake time, connection migration, and preventing head-of-line blocking that can manifest in TCP). Similar to TCP, QUIC relies on packet acknowledgements to make general progress. For example, ACKs are used for liveliness checks, validation, loss recovery signals, and congestion algorithm signals.
ACKs are an important source of signals for Internet protocols, which necessitates validation to ensure a malicious peer is not subverting these signals. Cloudflare’s QUIC implementation, quiche, lacked ACK range validation, which meant a peer could send an ACK range for packets never sent by the endpoint; this was patched in CVE-2025-4821. Additionally, a sophisticated attacker could mount an attack by predicting and preemptively sending ACKs (a technique called Optimistic ACK); this was patched in CVE-2025-4820. By exploiting the lack of ACK validation, an attacker can cause an endpoint to artificially expand its send rate; thereby gaining an unfair advantage over other connections. In the extreme case this can be a DDoS attack vector caused by higher server CPU utilization and an amplification of network traffic.
Fairness and Congestion control
A typical CDN setup includes hundreds of server processes, serving thousands of concurrent connections. Each connection has its own recovery and congestion control algorithm that is responsible for determining its fair share of the network. The Internet is a shared resource that relies on well-behaved transport protocols correctly implementing congestion control to ensure fairness.
To illustrate the point, let’s consider a shared network where the first connection (blue) is operating at capacity. When a new connection (green) joins and probes for capacity, it will trigger packet loss, thereby signaling the blue connection to reduce its send rate. The probing can be highly dynamic and although convergence might take time, the hope is that both connections end up sharing equal capacity on the network.
New connection joining the shared network. Existing flows make room for the new flow.
In order to ensure fairness and performance, each endpoint uses a Congestion Control algorithm. There are various algorithms but for our purposes let’s consider Cubic, a loss-based algorithm. Cubic, when in steady state, periodically explores higher sending rates. As the peer ACKs new packets, Cubic unlocks additional sending capacity (congestion window) to explore even higher send rates. Cubic continues to increase its send rate until it detects congestion signals (e.g., packet loss), indicating that the network is potentially at capacity and the connection should lower its sending rate.
Cubic congestion control responding to loss on the network.
The role of ACKs
ACKs are a feedback mechanism that Internet protocols use to make progress. A server serving a large file download will send that data across multiple packets to the client. Since networks are lossy, the client is responsible for ACKing when it has received a packet from the server, thus confirming delivery and progress. Lack of an ACK indicates that the packet has been lost and that the data might require retransmission. This feedback allows the server to confirm when the client has received all the data that it requested.
The server delivers packets and the client responds with ACKs.
The server delivers packets, but packet [2] is lost. The client responds with ACKs only for packets [1, 3], thereby signalling that packet [2] was lost.
In QUIC, packet numbers don’t have to be sequential; that means skipping packet numbers is natively supported. Additionally, a QUIC ACK Frame can contain gaps and multiple ACK ranges. As we will see, the built-in support for skipping packet numbers is a unique feature of QUIC (over TCP) that will help us enforce ACK validation.
The server delivering packets, but skipping packet [4]. The client responds with ACKs only for packets it received, and not sending an ACK for packet [4].
ACKs also provide signals that control an endpoint’s send rate and help provide fairness and performance. Delay between ACKs, variations in the delay, and lack of ACKs provide valuable signals, which suggest a change in the network and are important inputs to a congestion control algorithm.
Skipping packets to avoid ACK delay
QUIC allows endpoints to encode the ACK delay: the time by which the ACK for packet number ‘X’ was intentionally delayed from when the endpoint received packet number ‘X.’ This delay can result from normal packet processing or be an implementation-specific optimization. For example, since ACKs processing can be expensive (both for CPU and network), delaying ACKs can allow for batching and reducing the associated overhead.
However, since a delay in ACK signal also delays peer feedback, this can be detrimental for loss recovery. QUIC endpoints can therefore signal the peer to avoid delaying an ACK packet by skipping a packet number. This detail will become important as we will see later in the post.
Validating ACK range
It is expected that a well-behaved client should only send ACKs for packets that it has received. A lack of validation meant that it was possible for the client to send a very large ACK range for packets never sent by the server. For example, assuming the server has sent packets 0-5, a client was able to send an ACK Frame with the range 0-100.
By itself this is not actually a huge deal since quiche is smart enough to drop larger ACKs and only process ACKs for packets it has sent. However, as we will see in the next section, this made the Optimistic ACK vulnerability easier to exploit.
The fix was to enforce ACK range validation based on the largest packets sent by the server and close the connection on violation. This matches the RFC recommendation.
An endpoint SHOULD treat receipt of an acknowledgment for a packet it did not send as a connection error of type PROTOCOL_VIOLATION, if it is able to detect the condition. — https://www.rfc-editor.org/rfc/rfc9000#section-13.1
The server validating ACKs: the client sending ACK for packets [4..5] not sent by the server. The server closes the connection since ACK validation fails.
Optimistic ACK attack
In the following scenario, let’s assume the client is trying to mount an Optimistic ACK attack against the server. The goal of a client mounting the attack is to cause the server to send at a high rate. To achieve a high send rate, the client needs to deliver ACKs quickly back to the server, thereby providing an artificially low RTT / high bandwidth signal. Since packet numbers are typically monotonically increasing, a clever client can predict the next packet number and preemptively send ACKs (artificial ACK).
Optimistic ACK attack: the client predicting packets sent by the server and preemptively sending ACKs. ACK validation does not help here.
If the server has proper ACK validation, an invalid ACK for packets not yet sent by the server should trigger a connection close (without ACK range validation, the attack is trivial to execute). Therefore, a malicious client needs to be clever about pacing the artificial ACKs so they arrive just as the server has sent the packet. If the attack is done correctly, the server will see a very low RTT, and result in an inflated send rate.
An endpoint that acknowledges packets it has not received might cause a congestion controller to permit sending at rates beyond what the network supports. An endpoint MAY skip packet numbers when sending packets to detect this behavior. An endpoint can then immediately close the connection with a connection error of type PROTOCOL_VIOLATION — https://www.rfc-editor.org/rfc/rfc9000#section-21.4
Preventing an Optimistic ACK attack: the client predicting packets sent by the server and preemptively sending ACKs. Since the server skipped packet [4], it is able to detect the invalid ACK and close the connection.
The QUIC RFC mentions the Optimistic ACK attack and suggests skipping packets to detect this attack. By skipping packets, the client is unable to easily predict the next packet number and risks connection close if the server implements invalid ACK range validation. Implementation details – like how many packet numbers to skip and how often – are missing, however.
The [malicious] client transmission pattern does not indicate any malicious behavior.
As such, the bit rate towards the server follows normal behavior. Considering that QUIC packets are end-to-end encrypted, a middlebox cannot identify the attack by analyzing the client’s traffic. — MAY is not enough! QUIC servers SHOULD skip packet numbers
Ideally, the client would like to use as few resources as possible, while simultaneously causing the server to use as many as possible. In fact, as the security researchers confirmed in their paper: it is difficult to detect a malicious QUIC client using external traffic analysis, and it’s therefore necessary for QUIC implementations to mitigate the Optimistic ACK attack by skipping packets.
The Optimistic ACK vulnerability is not unique to QUIC. In fact the vulnerability was first discovered against TCP. However, since TCP does not natively support skipping packet numbers, an Optimistic ACK attack in TCP is harder to mitigate and can require additional DDoS analysis. By allowing for packet skipping, QUIC is able to prevent this type of attack at the protocol layer and more effectively ensure correctness and fairness over untrusted networks.
How often to skip packet numbers
According to the QUIC RFC, skipping packet numbers currently has two purposes. The first is to elicit a faster acknowledgement for loss recovery and the second is to mitigate an Optimistic ACK attack. A QUIC implementation skipping packets for Optimistic ACK attack therefore needs to skip frequently enough to mitigate the attack, while considering the effects on eliminating ACK delay.
Since packet skipping needs to be unpredictable, a simple implementation could be to skip packet numbers based on a random number from a static range. However, since the number of packets increases as the send rate increases, this has the downside of not adapting to the send rate. At smaller send rates, a static range will be too frequent, while at higher send rates it won’t be frequent enough and therefore be less effective. It’s also arguably most important to validate the send rate when there are higher send rates. It therefore seems necessary to adapt the skip frequency based on the send rate.
Congestion window (CWND) is a parameter used by congestion control algorithms to determine the amount of bytes that can be sent per round. Since the send rate increases based on the amount of bytes ACKed (capped by bytes sent), we claim that CWND makes a great proxy for dynamically adjusting the skip frequency. This CWND-aware skip frequency allows all connections, regardless of current send rate, to effectively mitigate the Optimistic ACK attack.
// c: the current packet number
// s: range of random packet number to skip from
//
// curr_pn
// |
// v |--- (upper - lower) ---|
// [c x x x x x x x x s s s s s s s s s s s s s x x]
// |--min_skip---| |------skip_range-------|
const DEFAULT_INITIAL_CONGESTION_WINDOW_PACKETS: usize = 10;
const MIN_SKIP_COUNTER_VALUE: u64 = DEFAULT_INITIAL_CONGESTION_WINDOW_PACKETS * 2;
let packets_per_cwnd = (cwnd / max_datagram_size) as u64;
let lower = packets_per_cwnd / 2;
let upper = packets_per_cwnd * 2;
let skip_range = upper - lower;
let rand_skip_value = rand(skip_range);
let skip_pn = MIN_SKIP_COUNTER_VALUE + lower + rand_skip_value;
Skip frequency calculation in quiche.
Timeline
All timestamps are in UTC.
2025–04-10 12:10 – Cloudflare is notified of an ACK validation and Optimistic ACK vulnerability via the Bug Bounty Program.
2025-04-19 00:20 – Cloudflare confirms both vulnerabilities are reproducible and begins working on fix.
2025-05-02 20:12 – Security patch is complete and infrastructure patching starts.
2025–05-16 04:52 – Cloudflare infrastructure patching is complete.
New quiche version released.
Conclusion
We would like to sincerely thank Louis Navarre and Olivier Bonaventure from UCLouvain, who responsibly disclosed this issue via our Cloudflare Bug Bounty Program, allowing us to identify and mitigate the vulnerability. They also published a paper with their findings, notifying 10 other QUIC implementations that also suffered from the Optimistic ACK vulnerability.
We welcome further submissions from our community of researchers to continually improve the security of all of our products and open source projects.
For over two decades, we’ve built real-time communication on the Internet using a patchwork of specialized tools. RTMP gave us ingest. HLS and DASH gave us scale. WebRTC gave us interactivity. Each solved a specific problem for its time, and together they power the global streaming ecosystem we rely on today.
But using them together in 2025 feels like building a modern application with tools from different eras. The seams are starting to show—in complexity, in latency, and in the flexibility needed for the next generation of applications, from sub-second live auctions to massive interactive events. We’re often forced to make painful trade-offs between latency, scale, and operational complexity.
Today Cloudflare is launching the first Media over QUIC (MoQ) relay network, running on every Cloudflare server in datacenters in 330+ cities. MoQ is an open protocol being developed at the IETF by engineers from across the industry—not a proprietary Cloudflare technology. MoQ combines the low-latency interactivity of WebRTC, the scalability of HLS/DASH, and the simplicity of a single architecture, all built on a modern transport layer. We’re joining Meta, Google, Cisco, and others in building implementations that work seamlessly together, creating a shared foundation for the next generation of real-time applications on the Internet.
An evolutionary ladder of compromise
To understand the promise of MoQ, we first have to appreciate the history that led us here—a journey defined by a series of architectural compromises where solving one problem inevitably created another.
The RTMP era: Conquering latency, compromising on scale
In the early 2000s, RTMP (Real-Time Messaging Protocol) was a breakthrough. It solved the frustrating “download and wait” experience of early video playback on the web by creating a persistent, stateful TCP connection between a Flash client and a server. This enabled low-latency streaming (2-5 seconds), powering the first wave of live platforms like Justin.tv (which later became Twitch).
But its strength was its weakness. That stateful connection, which had to be maintained for every viewer, was architecturally hostile to scale. It required expensive, specialized media servers and couldn’t use the commodity HTTP-based Content Delivery Networks (CDNs) that were beginning to power the rest of the web. Its reliance on TCP also meant that a single lost packet could freeze the entire stream—a phenomenon known as head-of-line blocking—creating jarring latency spikes. The industry retained RTMP for the “first mile” from the camera to servers (ingest), but a new solution was needed for the “last mile” from servers to your screen (delivery).
The HLS & DASH era: Solving for scale, compromising on latency
The catalyst for the next era was the iPhone’s rejection of Flash. In response, Apple created HLS (HTTP Live Streaming). HLS, and its open-standard counterpart MPEG-DASH abandoned stateful connections and treated video as a sequence of small, static files delivered over standard HTTP.
This enabled much greater scalability. By moving to the interoperable open standard of HTTP for the underlying transport, video could now be distributed by any web server and cached by global CDNs, allowing platforms to reach millions of viewers reliably and relatively inexpensively. The compromise? A significant trade-off in latency. To ensure smooth playback, players needed to buffer at least three video segments before starting. With segment durations of 6-10 seconds, this baked 15-30 seconds of latency directly into the architecture.
While extensions like Low-Latency HLS (LL-HLS) have more recently emerged to achieve latencies in the 3-second range, they remain complex patches fighting against the protocol’s fundamental design. These extensions introduce a layer of stateful, real-time communication—using clever workarounds like holding playlist requests open—that ultimately strain the stateless request-response model central to HTTP’s scalability and composability.
The WebRTC Era: Conquering conversational latency, compromising on architecture
In parallel, WebRTC (Web Real-Time Communication) emerged to solve a different problem: plugin-free, two-way conversational video with sub-500ms latency within a browser. It worked by creating direct peer-to-peer (P2P) media paths, removing central servers from the equation.
But this P2P model is fundamentally at odds with broadcast scale. In a mesh network, the number of connections grows quadratically with each new participant (the “N-squared problem”). For more than a handful of users, the model collapses under the weight of its own complexity. To work around this, the industry developed server-based topologies like the Selective Forwarding Unit (SFU) and Multipoint Control Unit (MCU). These are effective but require building what is essentially a private, stateful, real-time CDN—a complex and expensive undertaking that is not standardized across infrastructure providers.
This journey has left us with a fragmented landscape of specialized, non-interoperable silos, forcing developers to stitch together multiple protocols and accept a painful three-way tension between latency, scale, and complexity.
Introducing MoQ
This is the context into which Media over QUIC (MoQ) emerges. It’s not just another protocol; it’s a new design philosophy built from the ground up to resolve this historical trilemma. Born out of an open, community-driven effort at the IETF, MoQ aims to be a foundational Internet technology, not a proprietary product.
Its promise is to unify the disparate worlds of streaming by delivering:
Sub-second latency at broadcast scale: Combining the latency of WebRTC with the scale of HLS/DASH and the simplicity of RTMP.
Architectural simplicity: Creating a single, flexible protocol for ingest, distribution, and interactive use cases, eliminating the need to transcode between different technologies.
Transport efficiency: Building on QUIC, a UDP based protocol to eliminate bottlenecks like TCP head-of-line blocking.
The initial focus was “Media” over QUIC, but the core concepts—named tracks of timed, ordered, but independent data—are so flexible that the working group is now simply calling the protocol “MoQ.” The name reflects the power of the abstraction: it’s a generic transport for any real-time data that needs to be delivered efficiently and at scale.
MoQ is now generic enough that it’s a data fanout or pub/sub system, for everything from audio/video (high bandwidth data) to sports score updates (low bandwidth data).
A deep dive into the MoQ protocol stack
MoQ’s elegance comes from solving the right problem at the right layer. Let’s build up from the foundation to see how it achieves sub-second latency at scale.
The choice of QUIC as MoQ’s foundation isn’t arbitrary—it addresses issues that have plagued streaming protocols for decades.
By building on QUIC (the transport protocol that also powers HTTP/3), MoQ solves some key streaming problems:
No head-of-line blocking: Unlike TCP where one lost packet blocks everything behind it, QUIC streams are independent. A lost packet on one stream (e.g., an audio track) doesn’t block another (e.g., the main video track). This alone eliminates the stuttering that plagued RTMP.
Connection migration: When your device switches from Wi-Fi to cellular mid-stream, the connection seamlessly migrates without interruption—no rebuffering, no reconnection.
Fast connection establishment: QUIC’s 0-RTT resumption means returning viewers can start playing instantly.
Baked-in, mandatory encryption: All QUIC connections are encrypted by default with TLS 1.3.
The core innovation: Publish/subscribe for media
With QUIC solving transport issues, MoQ introduces its key innovation: treating media as subscribable tracks in a publish/subscribe system. But unlike traditional pub/sub, this is designed specifically for real-time media at CDN scale.
Instead of complex session management (WebRTC) or file-based chunking (HLS), MoQ lets publishers announce named tracks of media that subscribers can request. A relay network handles the distribution without needing to understand the media itself.
How MoQ organizes media: The data model
Before we see how media flows through the network, let’s understand how MoQ structures it. MoQ organizes data in a hierarchy:
Tracks: Named streams of media, like “video-1080p” or “audio-english”. Subscribers request specific tracks by name.
Groups: Independently decodable chunks of a track. For video, this typically means a GOP (Group of Pictures) starting with a keyframe. New subscribers can join at any Group boundary.
Objects: The actual packets sent on the wire. Each Object belongs to a Track and has a position within a Group.
This simple hierarchy enables two capabilities:
Subscribers can start playback at Group boundaries without waiting for the next keyframe
Relays can forward Objects without parsing or understanding the media format
The network architecture: From publisher to subscriber
MoQ’s network components are also simple:
Publishers: Announce track namespaces and send Objects
Subscribers: Request specific tracks by name
Relays: Connect publishers to subscribers by forwarding immutable Objects without parsing or transcoding the media
A Relay acts as a subscriber to receive tracks from upstream (like the original publisher) and simultaneously acts as a publisher to forward those same tracks downstream. This model is the key to MoQ’s scalability: one upstream subscription can fan out to serve thousands of downstream viewers.
The MoQ Stack
MoQ’s architecture can be understood as three distinct layers, each with a clear job:
The Transport Foundation (QUIC or WebTransport): This is the modern foundation upon which everything is built. MoQT can run directly over raw QUIC, which is ideal for native applications, or over WebTransport, which is required for use in a web browser. Crucially, theWebTransport protocol and its correspondingW3C browser API make QUIC’s multiplexed reliable streams and unreliable datagrams directly accessible to browser applications. This is a game-changer. Protocols like SRT may be efficient, but their lack of native browser support relegates them to ingest-only roles. WebTransport gives MoQ first-class citizenship on the web, making it suitable for both ingest and massive-scale distribution directly to clients.
The MoQT Layer: Sitting on top of QUIC (or WebTransport), the MoQT layer provides the signaling and structure for a publish-subscribe system. This is the primary focus of the IETF working group. It defines the core control messages—like ANNOUNCE, and SUBSCRIBE—and the basic data model we just covered. MoQT itself is intentionally spartan; it doesn’t know or care if the data it’s moving is H.264 video, Opus audio, or game state updates.
The Streaming Format Layer: This is where media-specific logic lives. A streaming format defines things like manifests, codec metadata, and packaging rules. WARP is one such format being developed alongside MoQT at the IETF, but it isn’t the only one. Another standards body, like DASH-IF, could define a CMAF-based streaming format over MoQT. A company that controls both original publisher and end subscriber can develop its own proprietary streaming format to experiment with new codecs or delivery mechanisms without being constrained by the transport protocol.
This separation of layers is why different organizations can build interoperable implementations while still innovating at the streaming format layer.
End-to-End Data Flow
Now that we understand the architecture and the data model, let’s walk through how these pieces come together to deliver a stream. The protocol is flexible, but a typical broadcast flow relies on the ANNOUNCE and SUBSCRIBE messages to establish a data path from a publisher to a subscriber through the relay network.
Here is a step-by-step breakdown of what happens in this flow:
Initiating Connections: The process begins when the endpoints, acting as clients, connect to the relay network. The Original Publisher initiates a connection with its nearest relay (we’ll call it Relay A). Separately, an End Subscriber initiates a connection with its own local relay (Relay B). These endpoints perform a SETUP handshake with their respective relays to establish a MoQ session and declare supported parameters.
Announcing a Namespace: To make its content discoverable, the Publisher sends an ANNOUNCE message to Relay A. This message declares that the publisher is the authoritative source for a given track namespace. Relay A receives this and registers in a shared control plane (a conceptual database) that it is now a source for this namespace within the network.
Subscribing to a Track: When the End Subscriber wants to receive media, it sends a SUBSCRIBE message to its relay, Relay B. This message is a request for a specific track name within a specific track namespace.
Connecting the Relays: Relay B receives the SUBSCRIBE request and queries the control plane. It looks up the requested namespace and discovers that Relay A is the source. Relay B then initiates a session with Relay A (if it doesn’t already have one) and forwards the SUBSCRIBE request upstream.
Completing the Path and Forwarding Objects: Relay A, having received the subscription request from Relay B, forwards it to the Original Publisher. With the full path now established, the Publisher begins sending the Objects for the requested track. The Objects flow from the Publisher to Relay A, which forwards them to Relay B, which in turn forwards them to the End Subscriber. If another subscriber connects to Relay B and requests the same track, Relay B can immediately start sending them the Objects without needing to create a new upstream subscription.
An Alternative Flow: The PUBLISH Model
More recent drafts of the MoQ specification have introduced an alternative, push-based model using a PUBLISH message. In this flow, a publisher can effectively ask for permission to send a track’s objects to a relay without waiting for a SUBSCRIBE request. The publisher sends a PUBLISH message, and the relay’s PUBLISH_OK response indicates whether it will accept the objects. This is particularly useful for ingest scenarios, where a publisher wants to send its stream to an entry point in the network immediately, ensuring the media is available the instant the first subscriber connects.
Advanced capabilities: Prioritization and congestion control
MoQ’s benefits really shine when networks get congested. MoQ includes mechanisms for handling the reality of network traffic. One such mechanism is Subgroups.
Subgroups are subdivisions within a Group that effectively map directly to the underlying QUIC streams. All Objects within the same Subgroup are generally sent on the same QUIC stream, guaranteeing their delivery order. Subgroup numbering also presents an opportunity to encode prioritization: within a Group, lower-numbered Subgroups are considered higher priority.
This enables intelligent quality degradation, especially with layered codecs (e.g. SVC):
Subgroup 0: Base video layer (360p) – must deliver
Subgroup 1: Enhancement to 720p – deliver if bandwidth allows
Subgroup 2: Enhancement to 1080p – first to drop under congestion
When a relay detects congestion, it can drop Objects from higher-numbered Subgroups, preserving the base layer. Viewers see reduced quality instead of buffering.
The MoQ specification defines a scheduling algorithm that determines the order for all objects that are “ready to send.” When a relay has multiple objects ready, it prioritizes them first by group order (ascending or descending) and then, within a group, by subgroup id. Our implementation supports the group order preference, which can be useful for low-latency broadcasts. If a viewer falls behind and its subscription uses descending group order, the relay prioritizes sending Objects from the newest “live” Group, potentially canceling unsent Objects from older Groups. This can help viewers catch up to the live edge quickly, a highly desirable feature for many interactive streaming use cases. The optimal strategies for using these features to improve QoE for specific use cases are still an open research question. We invite developers and researchers to use our network to experiment and help find the answers.
Implementation: building the Cloudflare MoQ relay
Theory is one thing; implementation is another. To validate the protocol and understand its real-world challenges, we’ve been building one of the first global MoQ relay networks. Cloudflare’s network, which places compute and logic at the edge, is very well suited for this.
Our architecture connects the abstract concepts of MoQ to the Cloudflare stack. In our deep dive, we mentioned that when a publisher ANNOUNCEs a namespace, relays need to register this availability in a “shared control plane” so that SUBSCRIBE requests can be routed correctly. For this critical piece of state management, we use Durable Objects.
When a publisher announces a new namespace to a relay in, say, London, that relay uses a Durable Object—our strongly consistent, single-threaded storage solution—to record that this namespace is now available at that specific location. When a subscriber in Paris wants a track from that namespace, the network can query this distributed state to find the nearest source and route the SUBSCRIBE request accordingly. This architecture builds upon the technology we developed for Cloudflare’s real-time services and provides a solution to the challenge of state management at a global scale.
An Evolving Specification
Building on a new protocol in the open means implementing against a moving target. To get MoQ into the hands of the community, we made a deliberate trade-off: our current relay implementation is based on a subset of the features defined in draft-ietf-moq-transport-07. This version became a de facto target for interoperability among several open-source projects and pausing there allowed us to put effort towards other aspects of deploying our relay network.
This draft of the protocol makes a distinction between accessing “past” and “future” content. SUBSCRIBE is used to receive future objects for a track as they arrive—like tuning into a live broadcast to get everything from that moment forward. In contrast, FETCH provides a mechanism for accessing past content that a relay may already have in its cache—like asking for a recording of a song that just played.
Both are part of the same specification, but for the most pressing low-latency use cases, a performant implementation of SUBSCRIBE is what matters most. For that reason, we have focused our initial efforts there and have not yet implemented FETCH.
This is where our roadmap is flexible and where the community can have a direct impact. Do you need FETCH to build on-demand or catch-up functionality? Or is more complete support for the prioritization features within SUBSCRIBE more critical for your use case? The feedback we receive from early developers will help us decide what to build next.
As always, we will announce our updates and changes to our implementation as we continue with development on our developer docs pages.
Kick the tires on the future
We believe in building in the open and interoperability in the community. MoQ is not a Cloudflare technology but a foundational Internet technology. To that end, the first demo client we’re presenting is an open source, community example.
Even though this is a preview release, we are running MoQ relays at Cloudflare’s full scale, like we do every production service. This means every server that is part of the Cloudflare network in more than 330 cities is now a MoQ relay.
We invite you to experience the “wow” moment of near-instant, sub-second streaming latency that MoQ enables. How would you use a protocol that offers the speed of a video call with the scale of a global broadcast?
Interoperability
We’ve been working with others in the IETF WG community and beyond on interoperability of publishers, players and other parts of the MoQ ecosystem. So far, we’ve tested with:
The Internet’s media stack is being refactored. For two decades, we’ve been forced to choose between latency, scale, and complexity. The compromises we made solved some problems, but also led to a fragmented ecosystem.
MoQ represents a promising new foundation—a chance to unify the silos and build the next generation of real-time applications on a scalable protocol. We’re committed to helping build this foundation in the open, and we’re just getting started.
MoQ is a realistic way forward, built on QUIC for future proofing, easier to understand than WebRTC, compatible with browsers unlike RTMP.
The protocol is evolving, the implementations are maturing, and the community is growing. Whether you’re building the next generation of live streaming, exploring real-time collaboration, or pushing the boundaries of interactive media, consider whether MoQ may provide the foundation you need.
Availability and pricing
We want developers to start building with MoQ today. To make that possible MoQ at Cloudflare is in tech preview – this means it’s available free of charge for testing (at any scale). Visit our developer homepage for updates and potential breaking changes.
Indie developers and large enterprises alike ask about pricing early in their adoption of new technologies. We will be transparent and clear about MoQ pricing. In general availability, self-serve customers should expect to pay 5 cents/GB outbound with no cost for traffic sent towards Cloudflare.
Enterprise customers can expect usual pricing in line with regular media delivery pricing, competitive with incumbent protocols. This means if you’re already using Cloudflare for media delivery, you should not be wary of adopting new technologies because of cost. We will support you.
If you’re interested in partnering with Cloudflare in adopting the protocol early or contributing to its development, please reach out to us at [email protected]! Engineers excited about the future of the Internet are standing by.
Have you ever built a piece of IKEA furniture, or put together a LEGO set, by following the instructions closely and only at the end realized at some point you didn’t quite follow them correctly? The final result might be close to what was intended, but there’s a nagging thought that maybe, just maybe, it’s not as rock steady or functional as it could have been.
Internet protocol specifications are instructions designed for engineers to build things. Protocol designers take great care to ensure the documents they produce are clear. The standardization process gathers consensus and review from experts in the field, to further ensure document quality. Any reasonably skilled engineer should be able to take a specification and produce a performant, reliable, and secure implementation. The Internet is central to everyone’s lives, and we depend on these implementations. Any deviations from the specification can put us at risk. For example, mishandling of malformed requests can allow attacks such as request smuggling.
h3i is a binary command line tool and Rust library designed for low-level testing and debugging of HTTP/3, which runs over QUIC. h3i is free and open source as part of Cloudflare’s quiche project. In this post we’ll explain the motivation behind developing h3i, how we use it to help develop robust and safe standards-compliant software and production systems, and how you can similarly use it to test your own software or services. If you just want to jump into how to use h3i, go to the h3i command line tool section.
A recap of QUIC and HTTP/3
QUIC is a secure-by-default transport protocol that provides performance advantages compared to TCP and TLS via a more efficient handshake, along with stream multiplexing that provides head-of-line blocking avoidance. HTTP/3 is an application protocol that maps HTTP semantics to QUIC, such as defining how HTTP requests and responses are assigned to individual QUIC streams.
Cloudflare has supported QUIC on our global network in some shape or form since 2018. We started while the Internet Engineering Task Force (IETF) was earnestly standardizing the protocol, working through early iterations and using interoperability testing and experience to help provide feedback for the standards process. We launched support for QUIC version 1 and HTTP/3 as soon as RFC 9000 (and its accompanying specifications) were published in 2021.
We work on the Protocols team, who own the ingress proxy into the Cloudflare network. This is essentially Cloudflare’s “front door” — HTTP requests that come to Cloudflare from the Internet pass through us first. The majority of requests are passed onwards to things like rulesets, workers, caches, or a customer origin. However, you might be surprised that many requests don’t ever make it that far because they are, in some way, invalid or malformed. Servers listening on the Internet have to be robust to traffic that is not RFC compliant, whether caused by accident or malicious intent.
The Protocols team actively participates in IETF standardization work and has also helped build and maintain other Cloudflare services that leverage quiche for QUIC and HTTP/3, from the proxies that help iCloud Private Relay via MASQUE proxying, to replacing WARP’s use of Wireguard with MASQUE, and beyond.
Throughout all of these different use cases, it is important for us to extensively test all aspects of the protocols. A deep dive into protocol details is a blog post (or three) in its own right. So let’s take a thin slice across HTTP to help illustrate the concepts.
HTTP Semantics are common to all versions of HTTP — the overall architecture, terminology, and protocol aspects such as request and response messages, methods, status codes, header and trailer fields, message content, and much more. Each individual HTTP version defines how semantics are transformed into a “wire format” for exchange over the Internet. You can read more about HTTP/1.1 and HTTP/2 in some of our previous blogposts.
With HTTP/3, HTTP request and response messages are split into a series of binary frames. HEADERS frames carry a representation of HTTP metadata (method, path, status code, field lines). The payload of the frame is the encoded QPACK compression output. DATA frames carry HTTP content (aka “message body”). In order to exchange these frames, HTTP/3 relies on QUIC streams. These provide an ordered and reliable byte stream and each have an identifier (ID) that is unique within the scope of a connection. There are four different stream types, denominated by the two least significant bits of the ID.
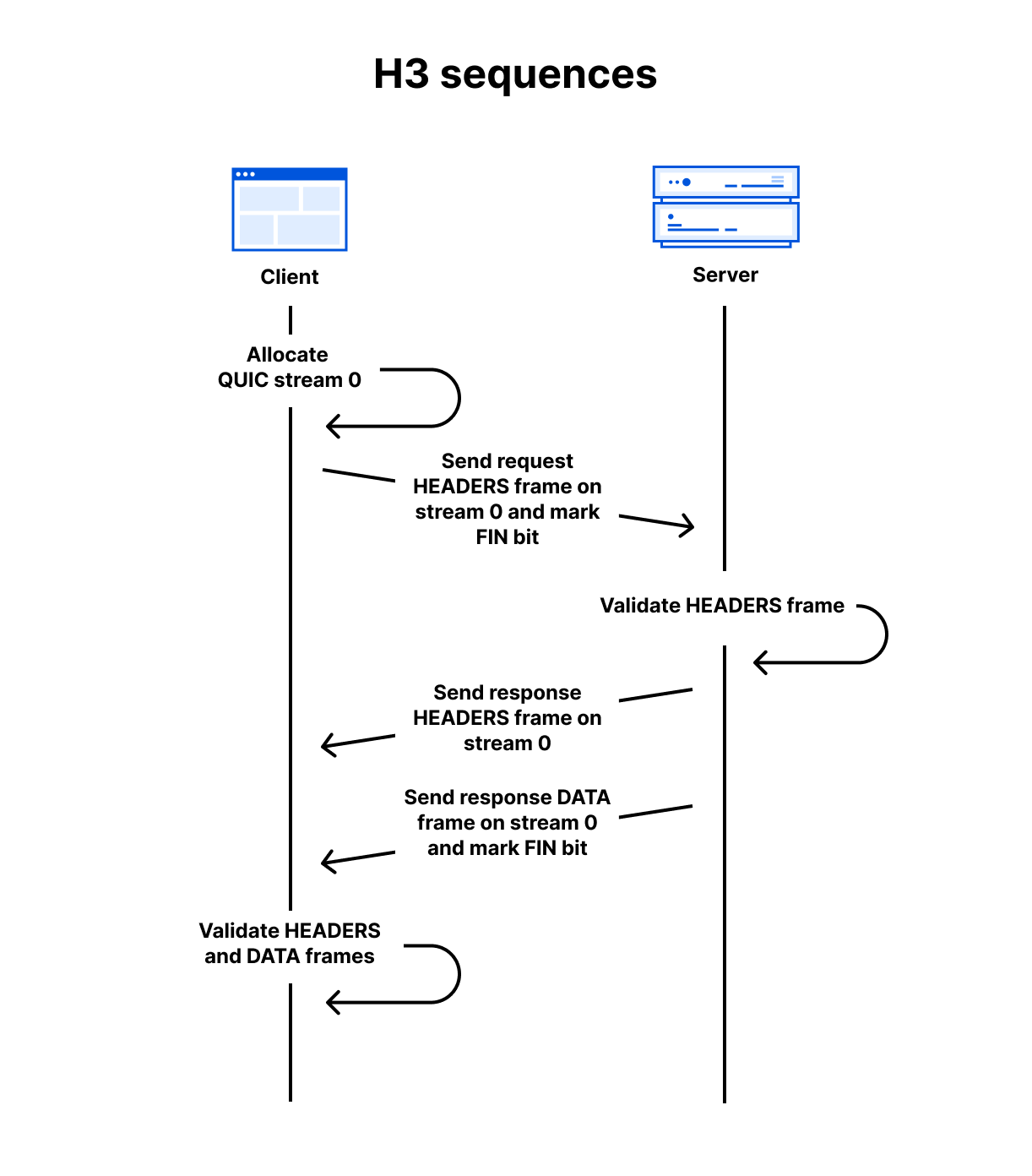
As a simple example, assuming a QUIC connection has already been established, a client can make a GET request and receive a 200 OK response with an HTML body using the follow sequence:
Client allocates the first available client-initiated bidirectional QUIC stream. (The IDs start at 0, then 4, 8, 12 and so on)
Client sends the request HEADERS frame on the stream and sets the stream’s FIN bit to mark the end of stream.
Server receives the request HEADERS frame and validates it against RFC 9114 rules. If accepted, it processes the request and prepares the response.
Server sends the response HEADERS frame on the same stream.
Server sends the response DATA frame on the same stream and sets the FIN bit.
Client receives the response frames and validates them. If accepted, the content is presented to the user.
At the QUIC layer, stream data is split into STREAM frames, which are sent in QUIC packets over UDP. QUIC deals with any loss detection and recovery, helping to ensure stream data is reliable. The layer cake diagram below provides a handy comparison of how HTTP/1.1, HTTP/2 and HTTP/3 use TCP, UDP and IP.
Background on testing QUIC and HTTP/3 at Cloudflare
The Protocols team has a diverse set of automated test tools that exercise our ingress proxy software in order to ensure it can stand up to the deluge that the Internet can throw at it. Just like a bouncer at a nightclub front door, we need to prevent as much bad traffic as possible before it gets inside and potentially causes damage.
HTTP/2 and HTTP/3 share several concepts. When we started developing early HTTP/3 support, we’d already learned a lot from production experience with HTTP/2. While HTTP/2 addressed many issues with HTTP/1.1 (especially problems like request smuggling, caused by its ASCII-based message delineation), HTTP/2 also added complexity and new avenues for attack. Security is an ongoing process, and the Protocols team continually hardens our software and systems to threats. For example, mitigating the range of denial-of-service attacks identified by Netflix in 2019, or the HTTP/2 Rapid Reset attacks of 2023.
For testing HTTP/2, we rely on the Python Requests library for testing conventional HTTP exchanges. However, that mostly only exercises HEADERS and DATA frames. There are eight other frame types and a plethora of ways that they can interact (hence the new attack vectors mentioned above). In order to get full testing coverage, we have to break down into the lower layer h2 library, which allows exact frame-by-frame control. However, even that is not always enough. Libraries tend to want to follow the RFC rules and prevent their users from doing “the wrong thing”. This is entirely logical for most purposes. For our needs though, we need to take off the safety guards just like any potential attackers might do. We have a few cases where the best way to exercise certain traffic patterns is to handcraft HTTP/2 frames in a hex editor, store that as binary, and replay it with a tool such as OpenSSL s_client.
We knew we’d need similar testing approaches for HTTP/3. However, when we started in 2018, there weren’t many other suitable client implementations. The rate of iteration on the specifications also meant it was hard to always keep in sync. So we built tests on quiche, using a mix of our quiche-client and http3_test. Over time, the python library aioquic has matured, and we have used it to add a range of lower-layer tests that break or bend HTTP/3 rules, in order to prove our proxies are robust.
Finally, we would be remiss not to mention that all the tests in our ingress proxy are in addition to the suite of over 500 integration tests that run on the quiche project itself.
Making HTTP/3 testing more accessible and maintainable with h3i
While we are happy with the coverage of our current tests, the smorgasbord of test tools makes it hard to know what to reach for when adding new tests. For example, we’ve had cases where aioquic’s safety guards prevent us from doing something, and it has needed a patch or workaround. This sort of thing requires a time investment just to debug/develop the tests.
We believe it shouldn’t take a protocol or code expert to develop what are often very simple to describe tests. While it is important to provide guide rails for the majority of conventional use cases, it is also important to provide accessible methods for taking them off.
Let’s consider a simple example. In HTTP/3 there is something called the control stream. It’s used to exchange frames such as SETTINGS, which affect the HTTP/3 connection. RFC 9114 Section 6.2.1 states:
Each side MUST initiate a single control stream at the beginning of the connection and send its SETTINGS frame as the first frame on this stream. If the first frame of the control stream is any other frame type, this MUST be treated as a connection error of type H3_MISSING_SETTINGS. Only one control stream per peer is permitted; receipt of a second stream claiming to be a control stream MUST be treated as a connection error of type H3_STREAM_CREATION_ERROR. The sender MUST NOT close the control stream, and the receiver MUST NOT request that the sender close the control stream. If either control stream is closed at any point, this MUST be treated as a connection error of type H3_CLOSED_CRITICAL_STREAM. Connection errors are described in Section 8.
There are many tests we can conjure up just from that paragraph:
Send a non-SETTINGS frame as the first frame on the control stream.
Open two control streams.
Open a control stream and then close it with a FIN bit.
Open a control stream and then reset it with a RESET_STREAM QUIC frame.
Wait for the peer to open a control stream and then ask for it to be reset with a STOP_SENDING QUIC frame.
All of the above actions should cause a remote peer that has implemented the RFC properly to close the connection. Therefore, it is not in the interest of the local client or server applications to ever do these actions.
Many QUIC and HTTP/3 implementations are developed as libraries that are integrated into client or server applications. There may be an extensive set of unit or integration tests of the library checking RFC rules. However, it is also important to run the same tests on the integrated assembly of library and application, since it’s all too common that an unhandled/mishandled library error can cascade to cause issues in upper layers. For instance, the HTTP/2 Rapid Reset attacks affected Cloudflare due to their impact on how one service spoke to another.
We’ve developed h3i, a command line tool and library, to make testing more accessible and maintainable for all. We started with a client that can exercise servers, since that’s what our focus has been. Future developments could support the opposite, a server that behaves in unusual ways in order to exercise clients.
Note: h3i is not intended to be a production client! Its flexibility may cause issues that are not observed in other production-oriented clients. It is also not intended to be used for any type of performance testing and measurement.
The h3i command line tool
The primary purpose of the h3i command line tool is quick low-level debugging and exploratory testing. Rather than worrying about writing code or a test script, users can quickly run an ad-hoc client test against a target, guided by interactive prompts.
In the simplest case, you can think of h3i a bit like curl but with access to some extra HTTP/3 parameters. In the example below, we issue a request to https://cloudflare-quic.com/ and receive a response.
Walking through a simple GET with h3i step-by-step:
Grab a copy of the h3i binary either by running cargo install h3i or cloning the quiche source repo at https://github.com/cloudflare/quiche/. Both methods assume you have some familiarity with Rust and Cargo. See the cargo documentation for more information.
cargo install will place the binary on your path, so you can then just run it by executing h3i.
If running from source, navigate to the quiche/h3i directory and then use cargo run.
Run the binary and provide the name and port of the target server. If the port is omitted, the default value 443 is assumed. E.g, cargo run cloudflare-quic.com
h3i then enters the action prompting phase. A series of one or more HTTP/3 actions can be queued up, such as sending frames, opening or terminating streams, or waiting on data from the server. The full set of options is documented in the readme.
The prompting interface adapts to keyboard inputs and supports tab completion.
In the example above, the headers action is selected, which walks through populating the fields in a HEADERS frame. It includes mandatory fields from RFC 9114 for convenience. If a test requires omitting these, the headers_no_pseudo can be used instead.
The commit prompt choice finalizes the action list and moves to the connection phase. h3i initiates a QUIC connection to the server identified in step 2. Once connected, actions are executed in order.
By default, h3i reports some limited information about the frames the server sent. To get more detailed information, the RUST_LOG environment can be set with either debug or trace levels.
Instant record and replay, powered by qlog
It can be fun to play around with the h3i command line tool to see how different servers respond to different combinations or sequences of actions. Occasionally, you’ll find a certain set that you want to run over and over again, or share with a friend or colleague. Having to manually enter the prompts repeatedly, or share screenshots of the h3i input can turn tedious. Fortunately, h3i records all the actions in a log file by default — the file path is printed immediately after h3i starts. The format of this file is based on qlog, an in-progress standard in development at the IETF for network protocol logging. It’s a perfect fit for our low-level needs.
h3i logs can be replayed using the --qlog-input option. You can change the target server host and port, and keep all the same actions. However, most servers will validate the :authority pseudo-header or Host header contained in a HEADERS frame. The –replay-host-override option allows changing these fields without needing to modify the file by hand.
And yes, qlog files are human-readable text in the JSON-SEQ format. So you can also just write these by hand in the first place if you like! However, if you’re going to start writing things, maybe Rust is your preferred option…
Using the h3i library to send a malformed request with Rust
In our previous example, we just sent a valid request so there wasn’t anything interesting to observe. Where h3i really shines is in generating traffic that isn’t RFC compliant, such as malformed HTTP messages, invalid frame sequences, or other actions on streams. This helps determine if a server is acting robustly and defensively.
Let’s explore this more with an example of HTTP content-length mismatch. RFC 9114 section 4.1.2 specifies:
A request or response that is defined as having content when it contains a Content-Length header field (Section 8.6 of [HTTP]) is malformed if the value of the Content-Length header field does not equal the sum of the DATA frame lengths received. A response that is defined as never having content, even when a Content-Length is present, can have a non-zero Content-Length header field even though no content is included in DATA frames.
Intermediaries that process HTTP requests or responses (i.e., any intermediary not acting as a tunnel) MUST NOT forward a malformed request or response. Malformed requests or responses that are detected MUST be treated as a stream error of type H3_MESSAGE_ERROR.
For malformed requests, a server MAY send an HTTP response indicating the error prior to closing or resetting the stream.
There are good reasons that the RFC is so strict about handling mismatched content lengths. They can be a vector for desynchronization attacks (similar to request smuggling), especially when a proxy is converting inbound HTTP/3 to outbound HTTP/1.1.
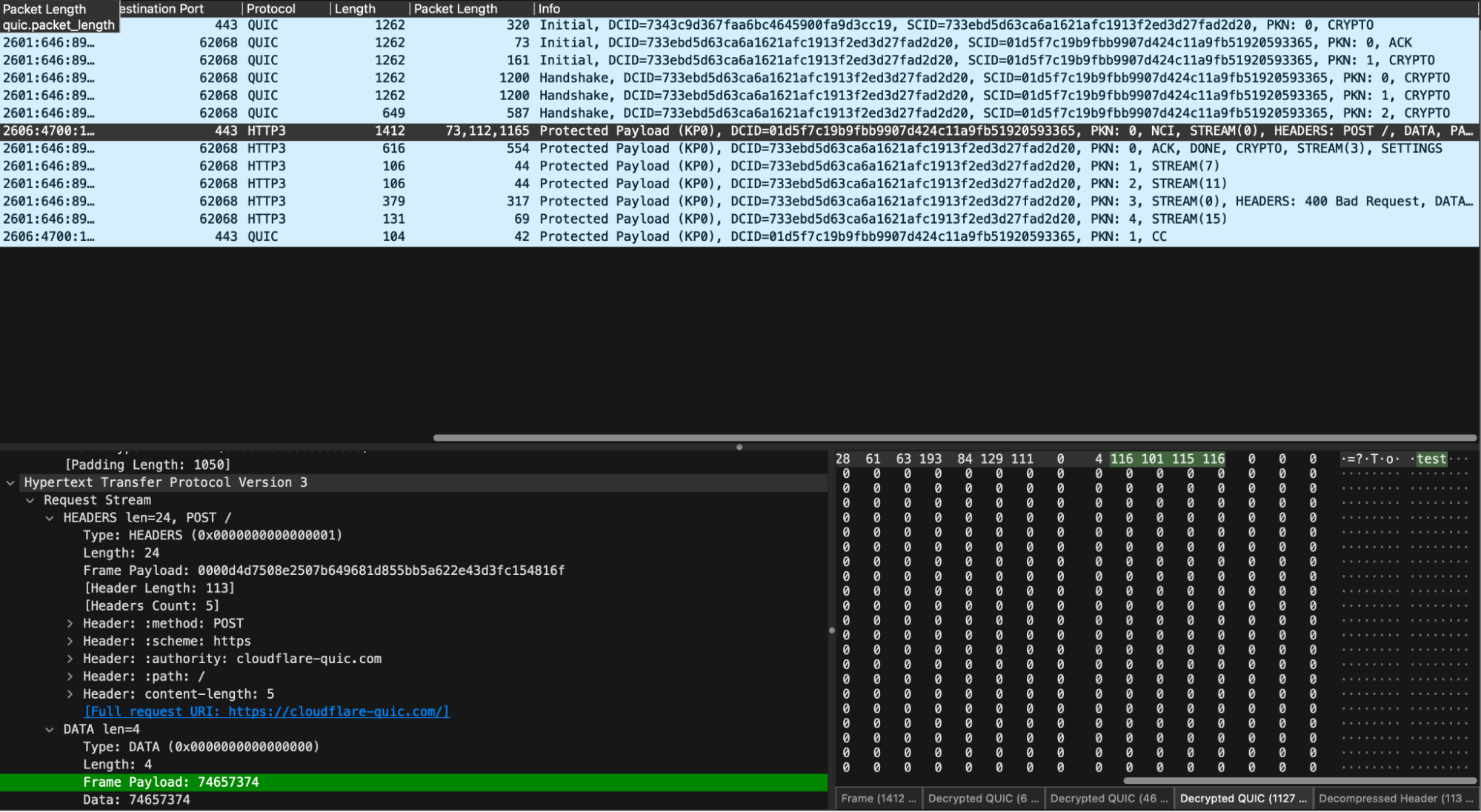
We’ve provided an example of how to use the h3i Rust library to write a tailor-made test client that sends a mismatched content length request. It sends a Content-Length header of 5, but its body payload is “test”, which is only 4 bytes. It then waits for the server to respond, after which it explicitly closes the connection by sending a QUIC CONNECTION_CLOSE frame.
When running low-level tests, it can be interesting to also take a packet capture (pcap) and observe what is happening on the wire. Since QUIC is an encrypted transport, we’ll need to use the SSLKEYLOG environment variable to capture the session keys so that tools like Wireshark can decrypt and dissect.
To follow along at home, clone a copy of the quiche repository, start a packet capture on the appropriate network interface and then run:
cd quiche/h3i
SSLKEYLOGFILE="h3i-example.keys" cargo run --example content_length_mismatch
In our decrypted capture, we see the expected sequence of handshake, request, response, and then closure.
Surveying the example code
The example is a simple binary app with a main() entry point. Let’s survey the key elements.
First, we set up an h3i configuration to a target server:
let config = Config::new()
.with_host_port("cloudflare-quic.com".to_string())
.with_idle_timeout(2000)
.build()
.unwrap();
The idle timeout is a QUIC concept which tells each endpoint when it should close the connection if the connection has been idle. This prevents endpoints from spinning idly if the peer hasn’t closed the connection. h3i’s default is 30 seconds, which can be too long for tests, so we set ours to 2 seconds here.
Next, we define a set of request headers and encode them with QPACK compression, ready to put in a HEADERS frame. Note that h3i does provide a send_headers_frame helper method which does this for you, but the example does it manually for clarity:
let headers = vec![
Header::new(b":method", b"POST"),
Header::new(b":scheme", b"https"),
Header::new(b":authority", b"cloudflare-quic.com"),
Header::new(b":path", b"/"),
// We say that we're going to send a body with 5 bytes...
Header::new(b"content-length", b"5"),
];
let header_block = encode_header_block(&headers).unwrap();
Then, we define the set of h3i actions that we want to execute in order: send HEADERS, send a too-short DATA frame, wait for the server’s HEADERS, then close the connection.
let actions = vec![
Action::SendHeadersFrame {
stream_id: STREAM_ID,
fin_stream: false,
headers,
frame: Frame::Headers { header_block },
},
Action::SendFrame {
stream_id: STREAM_ID,
fin_stream: true,
frame: Frame::Data {
// ...but, in actuality, we only send 4 bytes. This should yield a
// 400 Bad Request response from an RFC-compliant
// server: https://datatracker.ietf.org/doc/html/rfc9114#section-4.1.2-3
payload: b"test".to_vec(),
},
},
Action::Wait {
wait_type: WaitType::StreamEvent(StreamEvent {
stream_id: STREAM_ID,
event_type: StreamEventType::Headers,
}),
},
Action::ConnectionClose {
error: quiche::ConnectionError {
is_app: true,
error_code: quiche::h3::WireErrorCode::NoError as u64,
reason: vec![],
},
},
];
Finally, we’ll set things in motion with connect(), which sets up the QUIC connection, executes the actions list and collects the summary.
let summary =
sync_client::connect(config, &actions).expect("connection failed");
println!(
"=== received connection summary! ===\n\n{}",
serde_json::to_string_pretty(&summary).unwrap_or_else(|e| e.to_string())
);
ConnectionSummary provides data about the connection, including the frames h3i received, details about why the connection closed, and connection statistics. The example prints the summary out. However, you can programmatically check it. We do this to write our own internal automation tests.
If you’re running the example, it should print something like the following:
Let’s walk through the output. Up first is the StreamMap, which is a record of all frames received on each stream. We can see that we received 5 frames on stream 0: 2 UNKNOWNs, one EnrichedHeaders frame, and two DATA frames.
The UNKNOWN frames are extension frames that are unknown to h3i; the server under test is sending what are known as GREASE frames to help exercise the protocol and ensure clients are not erroring when they receive something unexpected per RFC 9114 requirements.
The EnrichedHeaders frame is essentially an HTTP/3 HEADERS frame, but with some small helpers, like one to get the response status code. The server under test sent a 400 as expected.
The DATA frames carry response body bytes. In this case, the body is the HTML required to render the Cloudflare Bad Request page (you can peek at the HTML yourself in Wireshark). We chose to omit the raw bytes from the ConnectionSummary since they may not be representable safely as text. A future improvement could be to encode the bytes in base64 or hex, in order to support tests that need to check response content.
h3i for test automation
We believe h3i is a great library for building automated tests on. You can take the above example and modify it to fit within various types of (continuous) integration tests.
We outlined earlier how the Protocols team HTTP/3 testing has organically grown to use three different frameworks. Even within those, we still didn’t have much flexibility and ease of use. Over the last year we’ve been building h3i itself and reimplementing our suite of ingress proxy test cases using the Rust library. This has helped us improve test coverage with a range of new tests not previously possible. It also surprisingly identified some problems with the old tests, particularly for some edge cases where it wasn’t clear how the old test code implementation was running under the hood.
Bake offs, interop, and wider testing of HTTP
RFC 1025 was published in 1987. Authored by Jon Postel, it discusses bake offs:
In the early days of the development of TCP and IP, when there were very few implementations and the specifications were still evolving, the only way to determine if an implementation was “correct” was to test it against other implementations and argue that the results showed your own implementation to have done the right thing. These tests and discussions could, in those early days, as likely change the specification as change the implementation.
There were a few times when this testing was focused, bringing together all known implementations and running through a set of tests in hopes of demonstrating the N squared connectivity and correct implementation of the various tricky cases. These events were called “Bake Offs”.
While nearly 4 decades old, the concept of exercising Internet protocol implementations and seeing how they compare to the specification still holds true. The QUIC WG made heavy use of interoperability testing through its standardization process. We started off sitting in a room and running tests manually by hand (or with some help from scripts). Then Marten Seemann developed the QUIC Interop Runner, which runs regular automated testing and collects and renders all the results. This has proven to be incredibly useful.
The state of HTTP/3 interoperability testing is not quite as mature. Although there are tools such as Kazu Yamamoto’s excellent h3spec (in Haskell) for testing conformance, there isn’t a similar continuous integration process of collection and rendering of results. While h3i shares similarities with h3spec, we felt it important to focus on the framework capabilities rather than creating a corpus of tests and assertions. Cloudflare is a big fan of Rust and as several teams move to Rust-based proxies, having a consistent ecosystem provides advantages (such as developer velocity).
We certainly feel there is a great opportunity for continued collaboration and cross-pollination between projects in the QUIC and HTTP space. For example, h3i might provide a suitable basis to build another tool (or set of scripts) to run bake offs or interop tests. Perhaps it even makes sense to have a common collection of test cases owned by the community, that can be specialized to the most appropriate or preferred tooling. This topic was recently presented at the HTTP Workshop 2024 by Mohammed Al-Sahaf, and it excites us to see new potential directions of testing improvements.
When using any tools or methods for protocol testing, we encourage responsible handling of security-related matters. If you believe you may have identified a vulnerability in an IETF Internet protocol itself, please follow the IETF’s reporting guidance. If you believe you may have discovered an implementation vulnerability in a product, open source project, or service using QUIC or HTTP, then you should report these directly to the responsible party. Implementers or operators often provide their own publicly-available guidance and contact details to send reports. For example, the Cloudflare quiche security policy is available in the Security tab of the GitHub repository.
Summary and outlook
Cloudflare takes testing very seriously. While h3i has a limited feature set as a test HTTP/3 client, we believe it provides a strong framework that can be extended to a wider range of different cases and different protocols. For example, we’d like to add support for low-level HTTP/2.
We’ve designed h3i to integrate into a wide range of testing methodologies, from manual ad-hoc testing, to native Rust tests, to conformance testbenches built with scripting languages. We’ve had great success migrating our existing zoo of test tools to a single one that is more accessible and easier to maintain.
Now that you’ve read about h3i’s capabilities, it’s left as an exercise to the reader to go back to the example of HTTP/3 control streams and consider how you could write tests to exercise a server.
We encourage the community to experiment with h3i and provide feedback, and propose ideas or contributions to the GitHub repository as issues or Pull Requests.
In June 2023, we told you that we were building a new protocol, MASQUE, into WARP. MASQUE is a fascinating protocol that extends the capabilities of HTTP/3 and leverages the unique properties of the QUIC transport protocol to efficiently proxy IP and UDP traffic without sacrificing performance or privacy
At the same time, we’ve seen a rising demand from Zero Trust customers for features and solutions that only MASQUE can deliver. All customers want WARP traffic to look like HTTPS to avoid detection and blocking by firewalls, while a significant number of customers also require FIPS-compliant encryption. We have something good here, and it’s been proven elsewhere (more on that below), so we are building MASQUE into Zero Trust WARP and will be making it available to all of our Zero Trust customers — at WARP speed!
This blog post highlights some of the key benefits our Cloudflare One customers will realize with MASQUE.
Before the MASQUE
Cloudflare is on a mission to help build a better Internet. And it is a journey we’ve been on with our device client and WARP for almost five years. The precursor to WARP was the 2018 launch of 1.1.1.1, the Internet’s fastest, privacy-first consumer DNS service. WARP was introduced in 2019 with the announcement of the 1.1.1.1 service with WARP, a high performance and secure consumer DNS and VPN solution. Then in 2020, we introduced Cloudflare’s Zero Trust platform and the Zero Trust version of WARP to help any IT organization secure their environment, featuring a suite of tools we first built to protect our own IT systems. Zero Trust WARP with MASQUE is the next step in our journey.
The current state of WireGuard
WireGuard was the perfect choice for the 1.1.1.1 with WARP service in 2019. WireGuard is fast, simple, and secure. It was exactly what we needed at the time to guarantee our users’ privacy, and it has met all of our expectations. If we went back in time to do it all over again, we would make the same choice.
But the other side of the simplicity coin is a certain rigidity. We find ourselves wanting to extend WireGuard to deliver more capabilities to our Zero Trust customers, but WireGuard is not easily extended. Capabilities such as better session management, advanced congestion control, or simply the ability to use FIPS-compliant cipher suites are not options within WireGuard; these capabilities would have to be added on as proprietary extensions, if it was even possible to do so.
Plus, while WireGuard is popular in VPN solutions, it is not standards-based, and therefore not treated like a first class citizen in the world of the Internet, where non-standard traffic can be blocked, sometimes intentionally, sometimes not. WireGuard uses a non-standard port, port 51820, by default. Zero Trust WARP changes this to use port 2408 for the WireGuard tunnel, but it’s still a non-standard port. For our customers who control their own firewalls, this is not an issue; they simply allow that traffic. But many of the large number of public Wi-Fi locations, or the approximately 7,000 ISPs in the world, don’t know anything about WireGuard and block these ports. We’ve also faced situations where the ISP does know what WireGuard is and blocks it intentionally.
This can play havoc for roaming Zero Trust WARP users at their local coffee shop, in hotels, on planes, or other places where there are captive portals or public Wi-Fi access, and even sometimes with their local ISP. The user is expecting reliable access with Zero Trust WARP, and is frustrated when their device is blocked from connecting to Cloudflare’s global network.
Now we have another proven technology — MASQUE — which uses and extends HTTP/3 and QUIC. Let’s do a quick review of these to better understand why Cloudflare believes MASQUE is the future.
Unpacking the acronyms
HTTP/3 and QUIC are among the most recent advancements in the evolution of the Internet, enabling faster, more reliable, and more secure connections to endpoints like websites and APIs. Cloudflare worked closely with industry peers through the Internet Engineering Task Force on the development of RFC 9000 for QUIC and RFC 9114 for HTTP/3. The technical background on the basic benefits of HTTP/3 and QUIC are reviewed in our 2019 blog post where we announced QUIC and HTTP/3 availability on Cloudflare’s global network.
Most relevant for Zero Trust WARP, QUIC delivers better performance on low-latency or high packet loss networks thanks to packet coalescing and multiplexing. QUIC packets in separate contexts during the handshake can be coalesced into the same UDP datagram, thus reducing the number of receive and system interrupts. With multiplexing, QUIC can carry multiple HTTP sessions within the same UDP connection. Zero Trust WARP also benefits from QUIC’s high level of privacy, with TLS 1.3 designed into the protocol.
MASQUE unlocks QUIC’s potential for proxying by providing the application layer building blocks to support efficient tunneling of TCP and UDP traffic. In Zero Trust WARP, MASQUE will be used to establish a tunnel over HTTP/3, delivering the same capability as WireGuard tunneling does today. In the future, we’ll be in position to add more value using MASQUE, leveraging Cloudflare’s ongoing participation in the MASQUE Working Group. This blog post is a good read for those interested in digging deeper into MASQUE.
OK, so Cloudflare is going to use MASQUE for WARP. What does that mean to you, the Zero Trust customer?
Proven reliability at scale
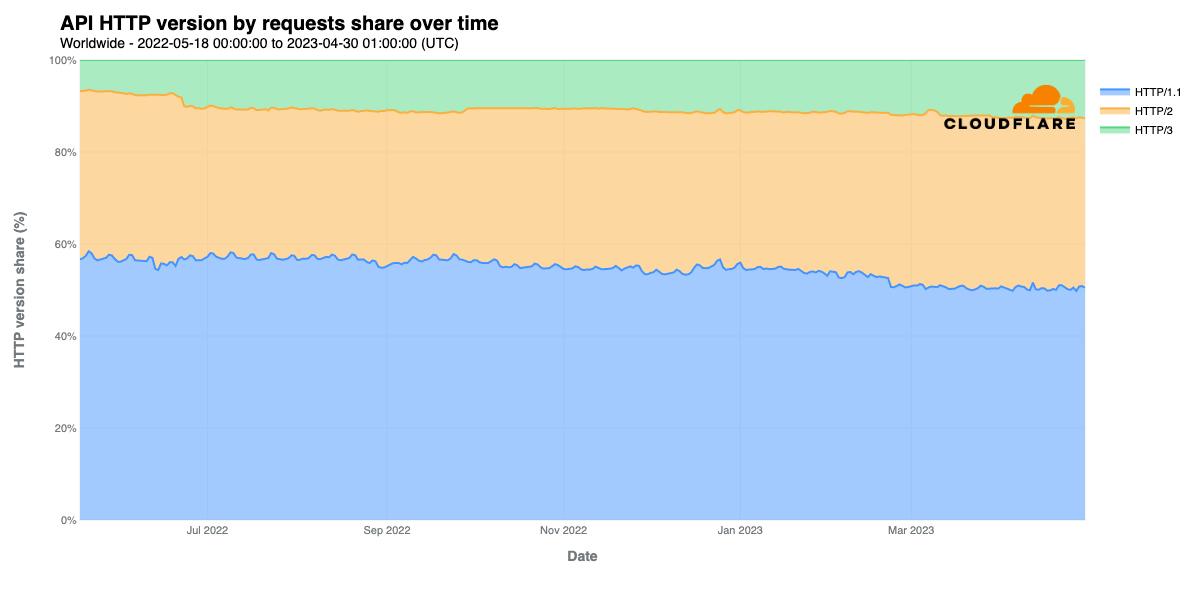
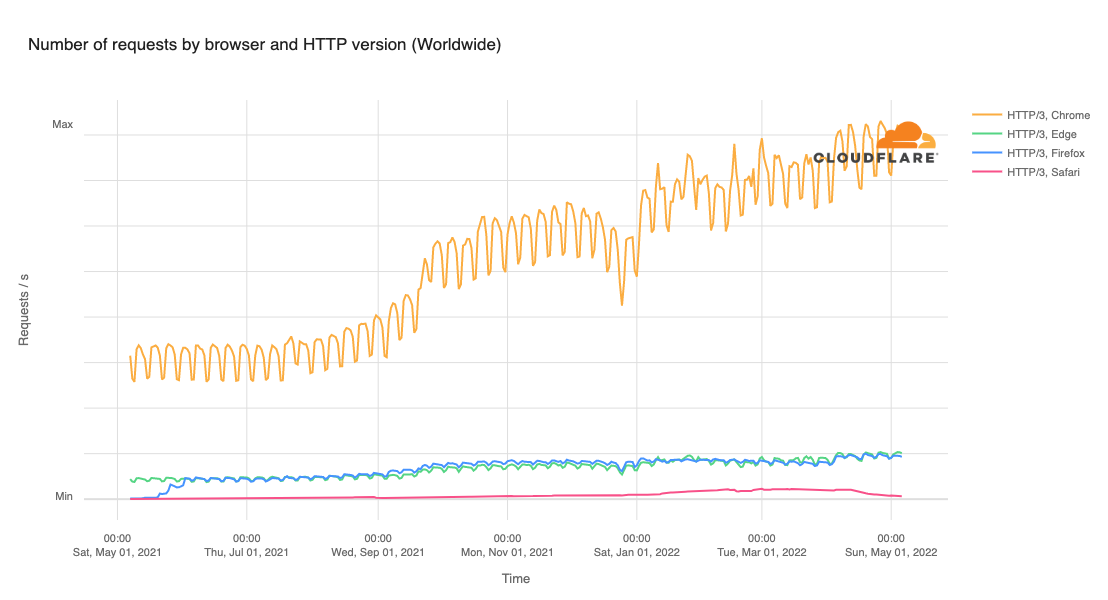
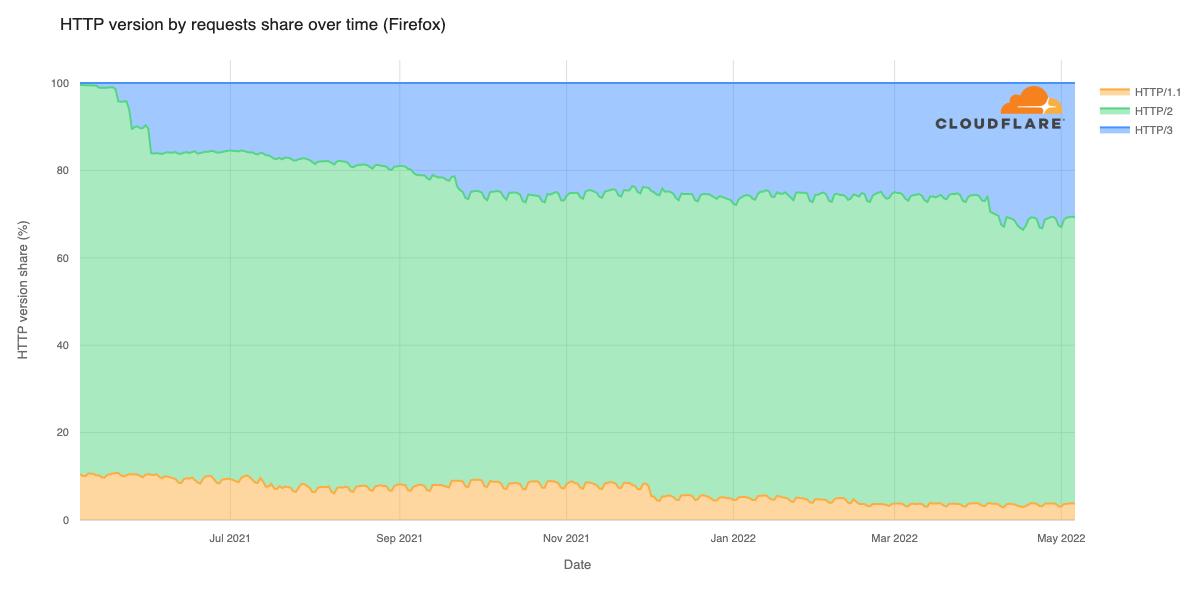
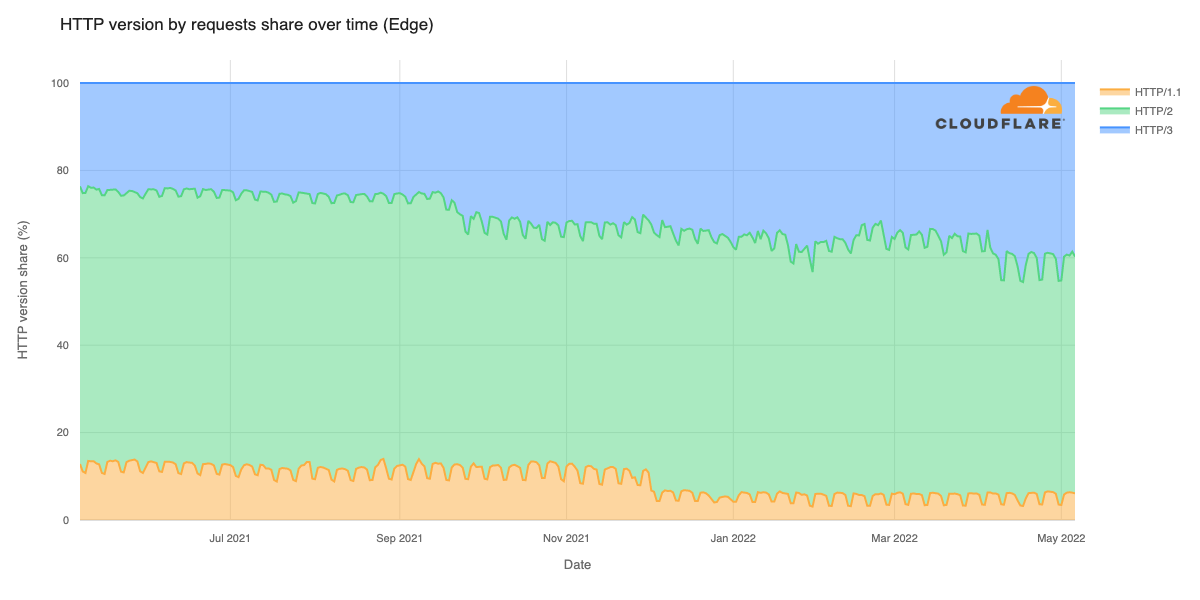
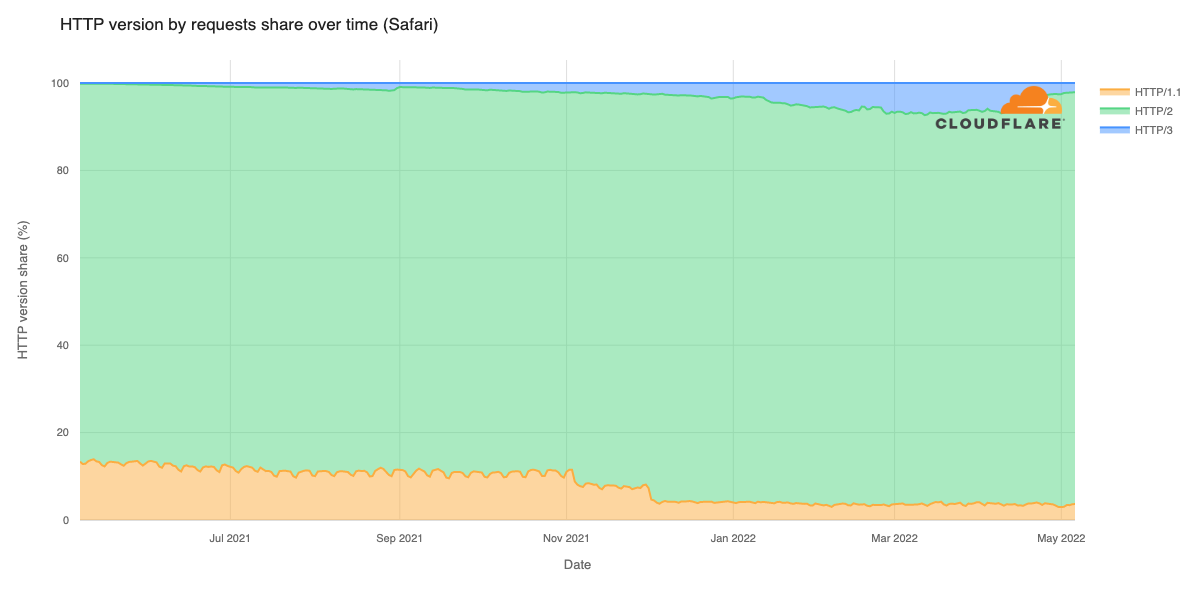
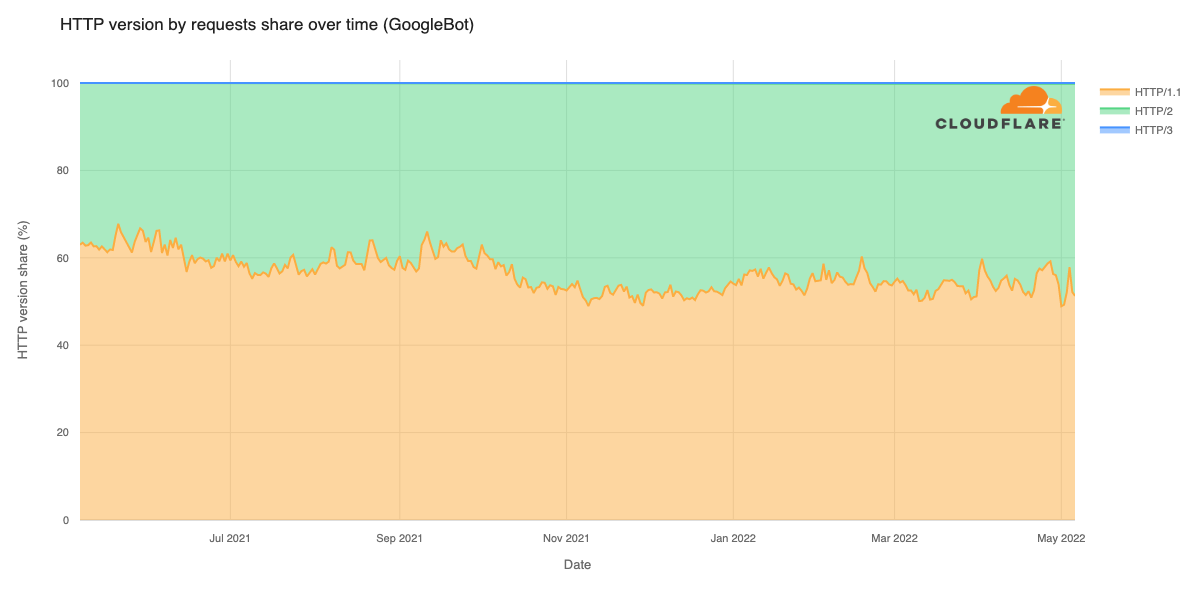
Cloudflare’s network today spans more than 310 cities in over 120 countries, and interconnects with over 13,000 networks globally. HTTP/3 and QUIC were introduced to the Cloudflare network in 2019, the HTTP/3 standard was finalized in 2022, and represented about 30% of all HTTP traffic on our network in 2023.
We are also using MASQUE for iCloud Private Relay and other Privacy Proxy partners. The services that power these partnerships, from our Rust-based proxy framework to our open source QUIC implementation, are already deployed globally in our network and have proven to be fast, resilient, and reliable.
Cloudflare is already operating MASQUE, HTTP/3, and QUIC reliably at scale. So we want you, our Zero Trust WARP users and Cloudflare One customers, to benefit from that same reliability and scale.
Connect from anywhere
Employees need to be able to connect from anywhere that has an Internet connection. But that can be a challenge as many security engineers will configure firewalls and other networking devices to block all ports by default, and only open the most well-known and common ports. As we pointed out earlier, this can be frustrating for the roaming Zero Trust WARP user.
We want to fix that for our users, and remove that frustration. HTTP/3 and QUIC deliver the perfect solution. QUIC is carried on top of UDP (protocol number 17), while HTTP/3 uses port 443 for encrypted traffic. Both of these are well known, widely used, and are very unlikely to be blocked.
We want our Zero Trust WARP users to reliably connect wherever they might be.
Compliant cipher suites
MASQUE leverages TLS 1.3 with QUIC, which provides a number of cipher suite choices. WireGuard also uses standard cipher suites. But some standards are more, let’s say, standard than others.
NIST, the National Institute of Standards and Technology and part of the US Department of Commerce, does a tremendous amount of work across the technology landscape. Of interest to us is the NIST research into network security that results in FIPS 140-2 and similar publications. NIST studies individual cipher suites and publishes lists of those they recommend for use, recommendations that become requirements for US Government entities. Many other customers, both government and commercial, use these same recommendations as requirements.
Our first MASQUE implementation for Zero Trust WARP will use TLS 1.3 and FIPS compliant cipher suites.
How can I get Zero Trust WARP with MASQUE?
Cloudflare engineers are hard at work implementing MASQUE for the mobile apps, the desktop clients, and the Cloudflare network. Progress has been good, and we will open this up for beta testing early in the second quarter of 2024 for Cloudflare One customers. Your account team will be reaching out with participation details.
Continuing the journey with Zero Trust WARP
Cloudflare launched WARP five years ago, and we’ve come a long way since. This introduction of MASQUE to Zero Trust WARP is a big step, one that will immediately deliver the benefits noted above. But there will be more — we believe MASQUE opens up new opportunities to leverage the capabilities of QUIC and HTTP/3 to build innovative Zero Trust solutions. And we’re also continuing to work on other new capabilities for our Zero Trust customers. Cloudflare is committed to continuing our mission to help build a better Internet, one that is more private and secure, scalable, reliable, and fast. And if you would like to join us in this exciting journey, check out our open positions.
Today, Cloudflare is very excited to announce full support for HTTP/3 Extensible Priorities, a new standard that speeds the loading of webpages by up to 37%. Cloudflare worked closely with standards builders to help form the specification for HTTP/3 priorities and is excited to help push the web forward. HTTP/3 Extensible Priorities is available on all plans on Cloudflare. For paid users, there is an enhanced version available that improves performance even more.
Web pages are made up of many objects that must be downloaded before they can be processed and presented to the user. Not all objects have equal importance for web performance. The role of HTTP prioritization is to load the right bytes at the most opportune time, to achieve the best results. Prioritization is most important when there are multiple objects all competing for the same constrained resource. In HTTP/3, this resource is the QUIC connection. In most cases, bandwidth is the bottleneck from server to client. Picking what objects to dedicate bandwidth to, or share bandwidth amongst, is a critical foundation to web performance. When it goes askew, the other optimizations we build on top can suffer.
Today, we're announcing support for prioritization in HTTP/3, using the full capabilities of the HTTP Extensible Priorities (RFC 9218) standard, augmented with Cloudflare's knowledge and experience of enhanced HTTP/2 prioritization. This change is compatible with all mainstream web browsers and can improve key metrics such as Largest Contentful Paint (LCP) by up to 37% in our test. Furthermore, site owners can apply server-side overrides, using Cloudflare Workers or directly from an origin, to customize behavior for their specific needs.
Looking at a real example
The ultimate question when it comes to features like HTTP/3 Priorities is: how well does this work and should I turn it on? The details are interesting and we'll explain all of those shortly but first lets see some demonstrations.
In order to evaluate prioritization for HTTP/3, we have been running many simulations and tests. Each web page is unique. Loading a web page can require many TCP or QUIC connections, each of them idiosyncratic. These all affect how prioritization works and how effective it is.
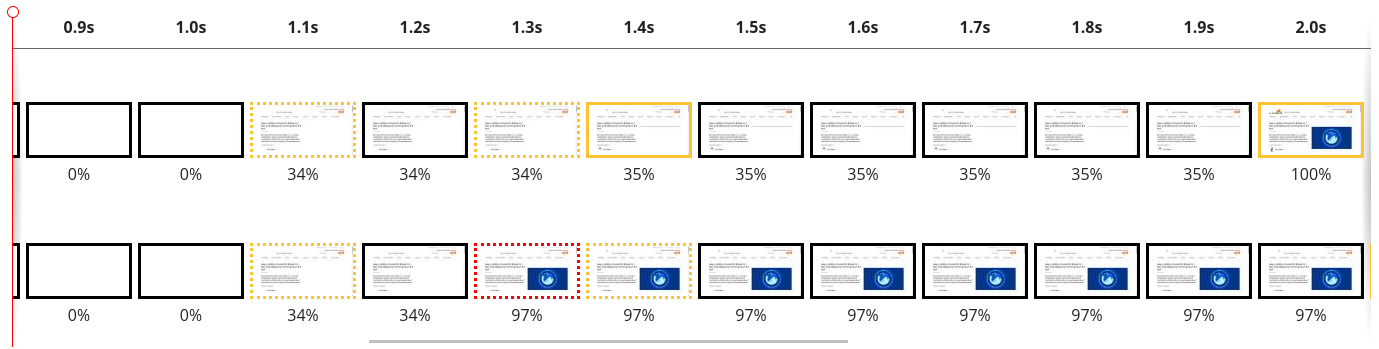
To evaluate the effectiveness of priorities, we ran a set of tests measuring Largest Contentful Paint (LCP). As an example, we benchmarked blog.cloudflare.com to see how much we could improve performance:
As a film strip, this is what it looks like:
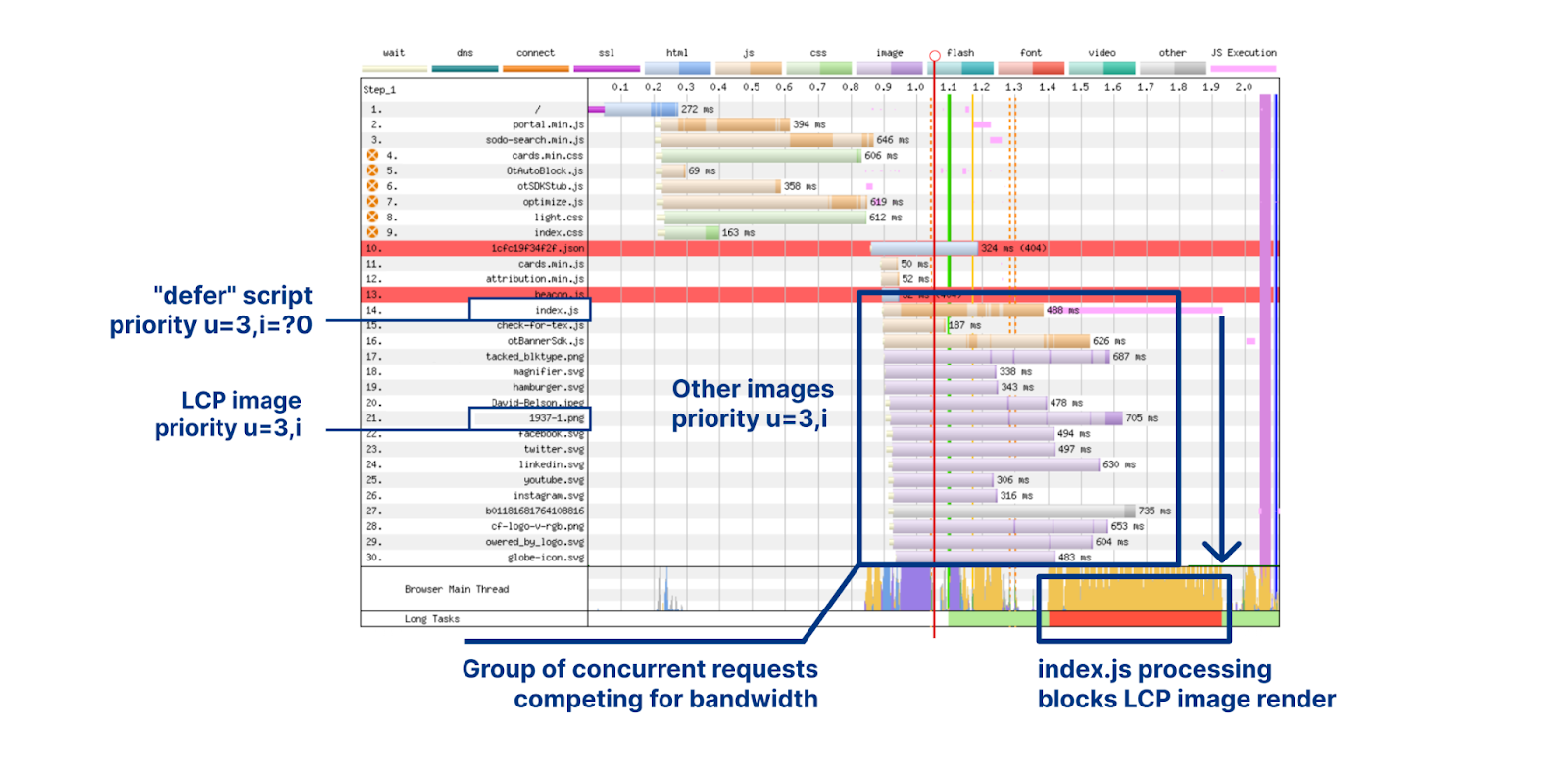
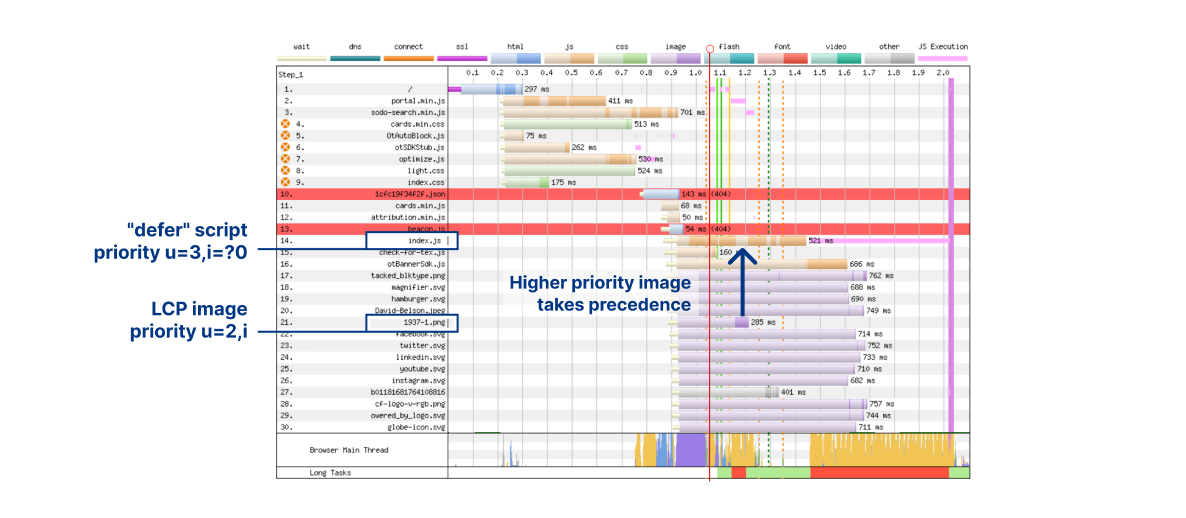
In terms of actual numbers, we see Largest Contentful Paint drop from 2.06 seconds down to 1.29 seconds. Let’s look at why that is. To analyze exactly what’s going on we have to look at a waterfall diagram of how this web page is loading. A waterfall diagram is a way of visualizing how assets are loading. Some may be loaded in parallel whilst some might be loaded sequentially. Without smart prioritization, the waterfall for loading assets for this web page looks as follows:
There are several interesting things going on here so let's break it down. The LCP image at request 21 is for 1937-1.png, weighing 30.4 KB. Although it is the LCP image, the browser requests it as priority u=3,i, which informs the server to put it in the same round-robin bandwidth-sharing bucket with all of the other images. Ahead of the LCP image is index.js, a JavaScript file that is loaded with a "defer" attribute. This JavaScript is non-blocking and shouldn't affect key aspects of page layout.
What appears to be happening is that the browser gives index.js the priority u=3,i=?0, which places it ahead of the images group on the server-side. Therefore, the 217 KB of index.js is sent in preference to the LCP image. Far from ideal. Not only that, once the script is delivered, it needs to be processed and executed. This saturates the CPU and prevents the LCP image from being painted, for about 300 milliseconds, even though it was delivered already.
The waterfall with prioritization looks much better:
We used a server-side override to promote the priority of the LCP image 1937-1.png from u=3,i to u=2,i. This has the effect of making it leapfrog the "defer" JavaScript. We can see at around 1.2 seconds, transmission of index.js is halted while the image is delivered in full. And because it takes another couple of hundred milliseconds to receive the remaining JavaScript, there is no CPU competition for the LCP image paint. These factors combine together to drastically improve LCP times.
How Extensible Priorities actually works
First of all, you don't need to do anything yourselves to make it work. Out of the box, browsers will send Extensible Priorities signals alongside HTTP/3 requests, which we'll feed into our priority scheduling decision making algorithms. We'll then decide the best way to send HTTP/3 response data to ensure speedy page loads.
Extensible Priorities has a similar interaction model to HTTP/2 priorities, client send priorities and servers act on them to schedule response data, we'll explain exactly how that works in a bit.
HTTP/2 priorities used a dependency tree model. While this was very powerful it turned out hard to implement and use. When the IETF came to try and port it to HTTP/3 during the standardization process, we hit major issues. If you are interested in all that background, go and read my blog post describing why we adopted a new approach to HTTP/3 prioritization.
Extensible Priorities is a far simpler scheme. HTTP/2's dependency tree with 255 weights and dependencies (that can be mutual or exclusive) is complex, hard to use as a web developer and could not work for HTTP/3. Extensible Priorities has just two parameters: urgency and incremental, and these are capable of achieving exactly the same web performance goals.
Urgency is an integer value in the range 0-7. It indicates the importance of the requested object, with 0 being most important and 7 being the least. The default is 3. Urgency is comparable to HTTP/2 weights. However, it's simpler to reason about 8 possible urgencies rather than 255 weights. This makes developer's lives easier when trying to pick a value and predicting how it will work in practice.
Incremental is a boolean value. The default is false. A true value indicates the requested object can be processed as parts of it are received and read – commonly referred to as streaming processing. A false value indicates the object must be received in whole before it can be processed.
Let's consider some example web objects to put these parameters into perspective:
An HTML document is the most important piece of a webpage. It can be processed as parts of it arrive. Therefore, urgency=0 and incremental=true is a good choice.
A CSS style is important for page rendering and could block visual completeness. It needs to be processed in whole. Therefore, urgency=1 and incremental=false is suitable, this would mean it doesn't interfere with the HTML.
An image file that is outside the browser viewport is not very important and it can be processed and painted as parts arrive. Therefore, urgency=3 and incremental=true is appropriate to stop it interfering with sending other objects.
An image file that is the "hero image" of the page, making it the Largest Contentful Pain element. An urgency of 1 or 2 will help it avoid being mixed in with other images. The choice of incremental value is a little subjective and either might be appropriate.
When making an HTTP request, clients decide the Extensible Priority value composed of the urgency and incremental parameters. These are sent either as an HTTP header field in the request (meaning inside the HTTP/3 HEADERS frame on a request stream), or separately in an HTTP/3 PRIORITY_UPDATE frame on the control stream. HTTP headers are sent once at the start of a request; a client might change its mind so the PRIORITY_UPDATE frame allows it to reprioritize at any point in time.
For both the header field and PRIORITY_UPDATE, the parameters are exchanged using the Structured Fields Dictionary format (RFC 8941) and serialization rules. In order to save bytes on the wire, the parameters are shortened – urgency to 'u', and incremental to 'i'.
Here's how the HTTP header looks alongside a GET request for important HTML, using HTTP/3 style notation:
The PRIORITY_UPDATE frame only carries the serialized Extensible Priority value:
PRIORITY_UPDATE:
u=0,i
Structured Fields has some other neat tricks. If you want to indicate the use of a default value, then that can be done via omission. Recall that the urgency default is 3, and incremental default is false. A client could send "u=1" alongside our important CSS request (urgency=1, incremental=false). For our lower priority image it could send just "i=?1" (urgency=3, incremental=true). There's even another trick, where boolean true dictionary parameters are sent as just "i". You should expect all of these formats to be used in practice, so it pays to be mindful about their meaning.
Extensible Priority servers need to decide how best to use the available connection bandwidth to schedule the response data bytes. When servers receive priority client signals, they get one form of input into a decision making process. RFC 9218 provides a set of scheduling recommendations that are pretty good at meeting a board set of needs. These can be distilled down to some golden rules.
For starters, the order of requests is crucial. Clients are very careful about asking for things at the moment they want it. Serving things in request order is good. In HTTP/3, because there is no strict ordering of stream arrival, servers can use stream IDs to determine this. Assuming the order of the requests is correct, the next most important thing is urgency ordering. Serving according to urgency values is good.
Be wary of non-incremental requests, as they mean the client needs the object in full before it can be used at all. An incremental request means the client can process things as and when they arrive.
With these rules in mind, the scheduling then becomes broadly: for each urgency level, serve non-incremental requests in whole serially, then serve incremental requests in round robin fashion in parallel. What this achieves is dedicated bandwidth for very important things, and shared bandwidth for less important things that can be processed or rendered progressively.
Let's look at some examples to visualize the different ways the scheduler can work. These are generated by using quiche'sqlog support and running it via the qvis analysis tool. These diagrams are similar to a waterfall chart; the y-dimension represents stream IDs (0 at the top, increasing as we move down) and the x-dimension shows reception of stream data.
Example 1: all streams have the same urgency and are non-incremental so get served in serial order of stream ID.
Example 2: the streams have the same urgency and are incremental so get served in round-robin fashion.
Example 3: the streams have all different urgency, with later streams being more important than earlier streams. The data is received serially but in a reverse order compared to example 1.
Beyond the Extensible Priority signals, a server might consider other things when scheduling, such as file size, content encoding, how the application vs content origins are configured etc.. This was true for HTTP/2 priorities but Extensible Priorities introduces a new neat trick, a priority signal can also be sent as a response header to override the client signal.
This works especially well in a proxying scenario where your HTTP/3 terminating proxy is sat in front of some backend such as Workers. The proxy can pass through the request headers to the backend, it can inspect these and if it wants something different, return response headers to the proxy. This allows powerful tuning possibilities and because we operate on a semantic request basis (rather than HTTP/2 priorities dependency basis) we don't have all the complications and dangers. Proxying isn't the only use case. Often, one form of "API" to your local server is via setting response headers e.g., via configuration. Leveraging that approach means we don't have to invent new APIs.
Let's consider an example where server overrides are useful. Imagine we have a webpage with multiple images that are referenced via <img> tags near the top of the HTML. The browser will process these quite early in the page load and want to issue requests. At this point, it might not know enough about the page structure to determine if an image is in the viewport or outside the viewport. It can guess, but that might turn out to be wrong if the page is laid out a certain way. Guessing wrong means that something is misprioritized and might be taking bandwidth away from something that is more important. While it is possible to reprioritize things mid-flight using the PRIORITY_UPDATE frame, this action is "laggy" and by the time the server realizes things, it might be too late to make much difference.
Fear not, the web developer who built the page knows exactly how it is supposed to be laid out and rendered. They can overcome client uncertainty by overriding the Extensible Priority when they serve the response. For instance, if a client guesses wrong and requests the LCP image at a low priority in a shared bandwidth bucket, the image will load slower and web performance metrics will be adversely affected. Here's how it might look and how we can fix it:
Priority response headers are one tool to tweak client behavior and they are complementary to other web performance techniques. Methods like efficiently ordering elements in HTML, using attributes like "async" or "defer", augmenting HTML links with Link headers, or using more descriptive link relationships like “preload” all help to improve a browser's understanding of the resources comprising a page. A website that optimizes these things provides a better chance for the browser to make the best choices for prioritizing requests.
More recently, a new attribute called “fetchpriority” has emerged that allows developers to tune some of the browser behavior, by boosting or dropping the priority of an element relative to other elements of the same type. The attribute can help the browser do two important things for Extensible priorities: first, the browser might send the request earlier or later, helping to satisfy our golden rule #1 – ordering. Second, the browser might pick a different urgency value, helping to satisfy rule #2. However, "fetchpriority" is a nudge mechanism and it doesn't allow for directly setting a desired priority value. The nudge can be a bit opaque. Sometimes the circumstances benefit greatly from just knowing plainly what the values are and what the server will do, and that's where the response header can help.
Conclusions
We’re excited about bringing this new standard into the world. Working with standards bodies has always been an amazing partnership and we’re very pleased with the results. We’ve seen great results with HTTP/3 priorities, reducing Largest Contentful Paint by up to 37% in our test. If you’re interested in turning on HTTP/3 priorities for your domain, just head on over to the Cloudflare dashboard and hit the toggle.
Our previous post reviewed usage trends for HTTP/1.1, HTTP/2, and HTTP/3 observed across Cloudflare’s network between May 2021 and May 2022, broken out by version and browser family, as well as for search engine indexing and social media bots. At the time, we found that browser-driven traffic was overwhelmingly using HTTP/2, although HTTP/3 usage was showing signs of growth. Search and social bots were mixed in terms of preference for HTTP/1.1 vs. HTTP/2, with little-to-no HTTP/3 usage seen.
Between May 2022 and May 2023, we found that HTTP/3 usage in browser-retrieved content continued to grow, but that search engine indexing and social media bots continued to effectively ignore the latest version of the web’s core protocol. (Having said that, the benefits of HTTP/3 are very user-centric, and arguably offer minimal benefits to bots designed to asynchronously crawl and index content. This may be a key reason that we see such low adoption across these automated user agents.) In addition, HTTP/3 usage across API traffic is still low, but doubled across the year. Support for HTTP/3 is on by default for zones using Cloudflare’s free tier of service, while paid customers have the option to activate support.
HTTP/1.1 and HTTP/2 use TCP as a transport layer and add security via TLS. HTTP/3 uses QUIC to provide both the transport layer and security. Due to the difference in transport layer, user agents usually require learning that an origin is accessible using HTTP/3 before they'll try it. One method of discovery is HTTP Alternative Services, where servers return an Alt-Svc response header containing a list of supported Application-Layer Protocol Negotiation Identifiers (ALPN IDs). Another method is the HTTPS record type, where clients query the DNS to learn the supported ALPN IDs. The ALPN ID for HTTP/3 is "h3" but while the specification was in development and iteration, we added a suffix to identify the particular draft version e.g., "h3-29" identified draft 29. In order to maintain compatibility for a wide range of clients, Cloudflare advertised both "h3" and "h3-29". However, draft 29 was published close to three years ago and clients have caught up with support for the final RFC. As of late May 2023, Cloudflare no longer advertises h3-29 for zones that have HTTP/3 enabled, helping to save several bytes on each HTTP response or DNS record that would have included it. Because a browser and web server typically automatically negotiate the highest HTTP version available, HTTP/3 takes precedence over HTTP/2.
In the sections below, “likely automated” and “automated” traffic based on Cloudflare bot score has been filtered out for desktop and mobile browser analysis to restrict analysis to “likely human” traffic, but it is included for the search engine and social media bot analysis. In addition, references to HTTP requests or HTTP traffic below include requests made over both HTTP and HTTPS.
Overall request distribution by HTTP version
Aggregating global web traffic to Cloudflare on a daily basis, we can observe usage trends for HTTP/1.1, HTTP/2, and HTTP/3 across the surveyed one year period. The share of traffic over HTTP/1.1 declined from 8% to 7% between May and the end of September, but grew rapidly to over 11% through October. It stayed elevated into the new year and through January, dropping back down to 9% by May 2023. Interestingly, the weekday/weekend traffic pattern became more pronounced after the October increase, and remained for the subsequent six months. HTTP/2 request share saw nominal change over the year, beginning around 68% in May 2022, but then starting to decline slightly in June. After that, its share didn’t see a significant amount of change, ending the period just shy of 64%. No clear weekday/weekend pattern was visible for HTTP/2. Starting with just over 23% share in May 2022, the percentage of requests over HTTP/3 grew to just over 30% by August and into September, but dropped to around 26% by November. After some nominal loss and growth, it ended the surveyed time period at 28% share. (Note that this graph begins in late May due to data retention limitations encountered when generating the graph in early June.)
API request distribution by HTTP version
Although API traffic makes up a significant amount of Cloudflare’s request volume, only a small fraction of those requests are made over HTTP/3. Approximately half of such requests are made over HTTP/1.1, with another third over HTTP/2. However, HTTP/3 usage for APIs grew from around 6% in May 2022 to over 12% by May 2023. HTTP/3’s smaller share of traffic is likely due in part to support for HTTP/3 in key tools like curl still being considered as “experimental”. Should this change in the future, with HTTP/3 gaining first-class support in such tools, we expect that this will accelerate growth in HTTP/3 usage, both for APIs and overall as well.
Mitigated request distribution by HTTP version
The analyses presented above consider all HTTP requests made to Cloudflare, but we also thought that it would be interesting to look at HTTP version usage by potentially malicious traffic, so we broke out just those requests that were mitigated by one of Cloudflare’s application security solutions. The graph above shows that the vast majority of mitigated requests are made over HTTP/1.1 and HTTP/2, with generally less than 5% made over HTTP/3. Mitigated requests appear to be most frequently made over HTTP/1.1, although HTTP/2 accounted for a larger share between early August and late November. These observations suggest that attackers don’t appear to be investing the effort to upgrade their tools to take advantage of the newest version of HTTP, finding the older versions of the protocol sufficient for their needs. (Note that this graph begins in late May 2022 due to data retention limitations encountered when generating the graph in early June 2023.)
HTTP/3 use by desktop browser
As we noted last year, support for HTTP/3 in the stable release channels of major browsers came in November 2020 for Google Chrome and Microsoft Edge, and April 2021 for Mozilla Firefox. We also noted that in Apple Safari, HTTP/3 support needed to be enabled in the “Experimental Features” developer menu in production releases. However, in the most recent releases of Safari, it appears that this step is no longer necessary, and that HTTP/3 is now natively supported.
Looking at request shares by browser, Chrome started the period responsible for approximately 80% of HTTP/3 request volume, but the continued growth of Safari dropped it to around 74% by May 2023. A year ago, Safari represented less than 1% of HTTP/3 traffic on Cloudflare, but grew to nearly 7% by May 2023, likely as a result of support graduating from experimental to production.
Removing Chrome from the graph again makes trends across the other browsers more visible. As noted above, Safari experienced significant growth over the last year, while Edge saw a bump from just under 10% to just over 11% in June 2022. It stayed around that level through the new year, and then gradually dropped below 10% over the next several months. Firefox dropped slightly, from around 10% to just under 9%, while reported HTTP/3 traffic from Internet Explorer was near zero.
As we did in last year’s post, we also wanted to look at how the share of HTTP versions has changed over the last year across each of the leading browsers. The relative stability of HTTP/2 and HTTP/3 seen over the last year is in some contrast to the observations made in last year’s post, which saw some noticeable shifts during the May 2021 – May 2022 timeframe.
In looking at request share by protocol version across the major desktop browser families, we see that across all of them, HTTP/1.1 share grows in late October. Further analysis indicates that this growth was due to significantly higher HTTP/1.1 request volume across several large customer zones, but it isn’t clear why this influx of traffic using an older version of HTTP occurred. It is clear that HTTP/2 remains the dominant protocol used for content requests by the major browsers, consistently accounting for 50-55% of request volume for Chrome and Edge, and ~60% for Firefox. However, for Safari, HTTP/2’s share dropped from nearly 95% in May 2022 to around 75% a year later, thanks to the growth in HTTP/3 usage.
HTTP/3 share on Safari grew from under 3% to nearly 18% over the course of the year, while its share on the other browsers was more consistent, with Chrome and Edge hovering around 40% and Firefox around 35%, and both showing pronounced weekday/weekend traffic patterns. (That pattern is arguably the most pronounced for Edge.) Such a pattern becomes more, yet still barely, evident with Safari in late 2022, although it tends to vary by less than a percent.
HTTP/3 usage by mobile browser
Mobile devices are responsible for over half of request volume to Cloudflare, with Chrome Mobile generating more than 25% of all requests, and Mobile Safari more than 10%. Given this, we decided to explore HTTP/3 usage across these two key mobile platforms.
Looking at Chrome Mobile and Chrome Mobile Webview (an embeddable version of Chrome that applications can use to display Web content), we find HTTP/1.1 usage to be minimal, topping out at under 5% of requests. HTTP/2 usage dropped from 60% to just under 55% between May and mid-September, but then bumped back up to near 60%, remaining essentially flat to slightly lower through the rest of the period. In a complementary fashion, HTTP/3 traffic increased from 37% to 45%, before falling just below 40% in mid-September, hovering there through May. The usage patterns ultimately look very similar to those seen with desktop Chrome, albeit without the latter’s clear weekday/weekend traffic pattern.
Perhaps unsurprisingly, the usage patterns for Mobile Safari and Mobile Safari Webview closely mirror those seen with desktop Safari. HTTP/1.1 share increases in October, and HTTP/3 sees strong growth, from under 3% to nearly 18%.
Search indexing bots
Exploring usage of the various versions of HTTP by search engine crawlers/bots, we find that last year’s trend continues, and that there remains little-to-no usage of HTTP/3. (As mentioned above, this is somewhat expected, as HTTP/3 is optimized for browser use cases.) Graphs for Bing & Baidu here are trimmed to a period ending April 1, 2023 due to anomalous data during April that is being investigated.
GoogleBot continues to rely primarily on HTTP/1.1, which generally comprises 55-60% of request volume. The balance is nearly all HTTP/2, although some nominal growth in HTTP/3 usage sees it peaking at just under 2% in March.
Through January 2023, around 85% of requests from Microsoft’s BingBot were made via HTTP/2, but dropped to closer to 80% in late January. The balance of the requests were made via HTTP/1.1, as HTTP/3 usage was negligible.
Looking at indexing bots from search engines based outside of the United States, Russia’s YandexBot appears to use HTTP/1.1 almost exclusively, with HTTP/2 usage generally around 1%, although there was a period of increased usage between late August and mid-November. It isn’t clear what ultimately caused this increase. There was no meaningful request volume seen over HTTP/3. The indexing bot used by Chinese search engine Baidu also appears to strongly prefer HTTP/1.1, generally used for over 85% of requests. However, the percentage of requests over HTTP/2 saw a number of spikes, briefly reaching over 60% on days in July, November, and December 2022, as well as January 2023, with several additional spikes in the 30% range. Again, it isn’t clear what caused this spiky behavior. HTTP/3 usage by BaiduBot is effectively non-existent as well.
Social media bots
Similar to Bing & Baidu above, the graphs below are also trimmed to a period ending April 1.
Facebook’s use of HTTP/3 for site crawling and indexing over the last year remained near zero, similar to what we observed over the previous year. HTTP/1.1 started the period accounting for under 60% of requests, and except for a brief peak above it in late May, usage of HTTP/1.1 steadily declined over the course of the year, dropping to around 30% by April 2023. As such, use of HTTP/2 increased from just over 40% in May 2022 to over 70% in April 2023. Meta engineers confirmed that this shift away from HTTP/1.1 usage is an expected gradual change in their infrastructure's use of HTTP, and that they are slowly working towards removing HTTP/1.1 from their infrastructure entirely.
In last year’s blog post, we noted that “TwitterBot clearly has a strong and consistent preference for HTTP/2, accounting for 75-80% of its requests, with the balance over HTTP/1.1.” This preference generally remained the case through early October, at which point HTTP/2 usage began a gradual decline to just above 60% by April 2023. It isn’t clear what drove the week-long HTTP/2 drop and HTTP/1.1 spike in late May 2022. And as we noted last year, TwitterBot’s use of HTTP/3 remains non-existent.
In contrast to Facebook’s and Twitter’s site crawling bots, HTTP/3 actually accounts for a noticeable, and growing, volume of requests made by LinkedIn’s bot, increasing from just under 1% in May 2022 to just over 10% in April 2023. We noted last year that LinkedIn’s use of HTTP/2 began to take off in March 2022, growing to approximately 5% of requests. Usage of this version gradually increased over this year’s surveyed period to 15%, although the growth was particularly erratic and spiky, as opposed to a smooth, consistent increase. HTTP/1.1 remained the dominant protocol used by LinkedIn’s bots, although its share dropped from around 95% in May 2022 to 75% in April 2023.
Conclusion
On the whole, we are excited to see that usage of HTTP/3 has generally increased for browser-based consumption of traffic, and recognize that there is opportunity for significant further growth if and when it starts to be used more actively for API interactions through production support in key tools like curl. And though disappointed to see that search engine and social media bot usage of HTTP/3 remains minimal to non-existent, we also recognize that the real-time benefits of using the newest version of the web’s foundational protocol may not be completely applicable for asynchronous automated content retrieval.
At Amazon Web Services (AWS) we prioritize security, performance, and strong encryption in our cloud services. In order to be prepared for quantum computer advancements, we’ve been investigating the use of quantum-safe algorithms for key exchange in the TLS protocol. In this blog post, we’ll first bring you up to speed on what we’ve been doing on the TLS front. Then, we’ll focus on the QUIC transport protocol and show how you can enable and experiment with the newly released post-quantum (PQ) key exchange by using our s2n-quic library. The s2n-quic library is an open-source implementation of the QUIC protocol.
Why use PQ-hybrid key establishment in s2n-quic?
A large-scale quantum computer could break the current public key cryptography that is used to establish keys for secure communication connections. Although a large-scale quantum computer isn’t available today, traffic that is recorded now could be decrypted by one in the future. With such concerns in mind, the recent US Congress Quantum Computing Cybersecurity Preparedness Act and the White House National Security Memorandum set a goal of a timely and equitable transition of cryptographic systems to quantum-resistant cryptography.
PQ-hybrid key establishment in TLS is a feature that introduces post-quantum KEMs used in conjunction with classical Elliptic Curve Diffie-Hellman (ECDH) key exchange. The client and server still do an ECDH key exchange. Additionally, the server encapsulates a post-quantum shared secret to the client’s post-quantum KEM public key, which is advertised in the ClientHello message. This strategy combines the high assurance of a classical key exchange with the security of the proposed post-quantum key exchanges, to ensure that the handshakes are protected as long as the ECDH or the post-quantum shared secret cannot be broken.
After decapsulating the secret, the client and server have an ECDH and a post-quantum shared secret, which they concatenate and use to derive the symmetric keys that are used in the Authenticated Encryption with Additional Data (AEAD) cipher in TLS. These symmetric keys used by the AEAD cipher for data encryption will be secure against a quantum computer, which means that the TLS communication is secure against a quantum computer. The AWS implementation of TLS is s2n-tls, a streamlined open source implementation of TLS. The s2n-tls implementation already supports PQ-hybrid key exchange with ECDH and three NIST PQC Project KEMs (Kyber, BIKE, and SIKE) for TLS 1.2 and 1.3. The use of KEMs for TLS 1.2 is described in the draft-campagna-tls-bike-sike-hybrid IETF draft, and the use of KEMs for TLS 1.3 is described in the draft-ietf-tls-hybrid-design IETF draft.
Note: The Kyber, BIKE, and SIKE implementations follow the algorithm specifications described in NIST PQ Project Round 3, which are expected to be updated as standardization proceeds.
How PQ-hybrid key exchange works in s2n-quic
AWS recently announceds2n-quic, an open-source Rust implementation of the QUIC protocol. QUIC is an encrypted transport protocol that is designed for performance and is the foundation of HTTP/3. For tunnel establishment, QUIC uses TLS 1.3 carried over QUIC transport. To alleviate the harvest-now-decrypt-later concerns for customers that use s2n-quic, in the next section we show you how to enable PQ-hybrid key establishment in s2n-quic. AWS services and software that use s2n-quic will automatically inherit the ability to support quantum-safe key exchanges in the future when post-quantum algorithms are standardized and are officially supported in s2n-quic.
The s2n-quic implementation is written in the Rust programming language. It can use either s2n-tls (the TLS library for AWS) or rustls (the TLS library in Rust) to perform the TLS handshake. If you build s2n-quic with s2n-tls, then s2n-quic inherits the post-quantum support that is offered in s2n-tls. In turn, s2n-tls is built over other crypto libraries such as the AWS libcrypto (AWS-LC) or alternatively OpenSSL crypto library (libcrypto). AWS-LC is a general-purpose cryptographic library that is maintained by AWS, which will incorporate standardized post-quantum algorithms. Therefore, building s2n-tls with AWS-LC will provide s2n-tls with the post-quantum cryptographic algorithms for use in s2n-quic.
Such a model allows for AWS services and software that use s2n-quic to automatically inherit the standardized post-quantum options as they are implemented in s2n-tls and its underlying crypto libraries. There will be no need to tweak s2n-quic to support post-quantum TLS 1.3 handshakes. The whole stack of protocol implementations is architected in an agile manner without duplication of work.
The public s2n-quic GitHub repository includes an example that demonstrates how to build the library with PQ-hybrid key exchange support, along with a server and client to test. The PQ-hybrid key exchange feature test requires CMake in Linux or macOS. The experiments below were run in an Amazon Linux 2 instance with rustc, Cargo, Clang, and CMake installed. Connections that you establish with this experimental build of s2n-quic will support PQ-hybrid key exchange.
To test PQ-hybrid key establishment
Clone s2n-quic by using the following commands:
git clone https://github.com/aws/s2n-quic cd s2n-quic
Run the example post-quantum s2n-quic client and server in the post-quantum directory to confirm that they negotiate a PQ-hybrid key by using the following commands:
cd examples/post-quantum cargo run –bin pq_server cargo run –bin pq_client
Note: Although these examples with the PQ-hybrid feature experimental build of s2n-quic are self-contained, if you want to manually change and build s2n-quic and s2n-tls to enable PQ-hybrid key exchange, you have to update the default_tls13 policy in s2n-tls to point to security_policy_pq_tls_1_0_2021_05_26 in tls/s2n_security_policies.c. Then you rebuild s2n-tls and override the location that s2n-quic links to by setting the S2N_TLS_DIR, S2N_TLS_LIB_DIR, and S2N_TLS_INCLUDE_DIR environment variables at build time.
To confirm the PQ-hybrid key establishment, you capture the QUIC negotiation by using the following tcpdump command:
sudo tcpdump -i lo port 4433 -w test.pcap
Open the capture by using a packet capture visualization application. First you look at the ClientHello message, as shown in the capture in Figure 1 taken from Wireshark.
Figure 1: pq_client ClientHello in QUIC
In the QUIC CRYPTO frame, you can see the TLS 1.3 cipher suites, and that the TLS version is 1.3 while the supported key exchange groups are classical ECDH (with identifiers 0x0017, 0x0018, 0x001d) and 0x2f39, 0x2f3a, 0x2f37…. 0x2f1f. The 0x2f… groups are the agreed upon identifiers (not standardized yet) for PQ-hybrid key exchange. You also see the PQ-hybrid X25519+Kyber512 (with identifier 12089 or 0x2f39) key share that is offered by the client. That key share includes 32 bytes for the Curve25519 ephemeral ECDH client public key, 800 bytes for the ephemeral Kyber512 public key, and 4 bytes for the identifier and the key share length.
Note: The post-quantum KEMs implementations at the time of this writing follow the NIST Round 3 Kyber, BIKE, and SIKE specifications. We expect these specifications to change as the NIST PQC Project proceeds with standardization. Post-quantum support in s2n-tls and s2n-quic will be experimental until NIST has selected and published standardized algorithms and identifiers. Pushing the change to the main branch now would mean that s2n-quic clients would be sending a PQ-hybrid key share that won’t be used until the servers on the internet start supporting it. The actual algorithms and their identifiers will still be integrated in future releases of s2n-tls and AWS-LC. Therefore, s2n-quic will still be able to negotiate the NIST and IETF standardized options. Meanwhile, we will continue to experiment with post-quantum QUIC and its potential challenges.
Next, take a look at the server-negotiated keys in the ServerHello message, as shown in Figure 2.
Figure 2: pq_server ServerHello in QUIC
You can again see the TLS 1.3 cipher suite, the TLS version being 1.3, and the picked PQ-hybrid X25519+Kyber512 key share. The key share includes 4 bytes for the identifier and the key share length, 32 bytes for the Curve25519 ephemeral ECDH server public key, and 768 bytes for the Kyber512 ciphertext that encapsulates a post-quantum shared secret to the client’s ephemeral Kyber512 public key (included in its ClientHello message).
The rest of the handshake completes successfully by deriving symmetric keys from the X25519 and Kyber512 post-quantum shared secrets (as defined in the draft-ietf-tls-hybrid-design IETF draft) and encrypting the rest of the messages with Advanced Encryption Standard with Galois/Counter Mode (AES-GCM) by using these symmetric keys over QUIC.
Benchmark
Now you can benchmark the post-quantum QUIC client and server by using netbench, a transport protocol benchmarking tool that is available in the s2n-quic repository.
To benchmark the post-quantum QUIC client and server
Go in the netbench directory and build it with the correct flags for the experimental post-quantum QUIC examples, by using the following commands:
cd s2n-quic/netbench RUSTFLAGS=”–cfg s2n_quic_unstable –cfg s2n_quic_enable_pq_tls” cargo build –release
Generate the netbench scenario by using the following commands:
In this example, you’re trying to create 10,000 sequential QUIC connections. The scenario opens a connection, sends a single byte, receives a single byte, closes it, and repeats 10,000 times.
The drivers read the request_response.json to run the scenario. Then the driver is wrapped in a collector that outputs statistics to another JSON file. At the end of all of the 10,000 runs, the cli feature is used to generate the report.
Figure 3 shows the performance results for X25519, X25519+Kyber512, X25519+BIKE-1, and X25519+SIKEp434 key exchange. All connections used an ECDSA P256 server certificate for authentication.
Figure 3: PQ-hybrid key exchange impact on QUIC connection rates
The x-axis is time in seconds. The y-axis is the number of times send is called—which, for 1 byte per connection, practically means that the diagram shows the connection establishment rate (per second). The absolute performance numbers in these benchmarks are not important, because the results could change based on the netbench scenario parameters. The performance difference between PQ-hybrid key exchange algorithms is what this graph is highlighting.
You can see that the classical X25519 achieves higher connection rates, because it is the most efficient option (that offers no post-quantum protection). The performance of Kyber is competitive and achieves 8% fewer connections per second when used with X25519 in a PQ-hybrid key exchange. BIKE-1 is relatively efficient, but adds some extra latency and introduces two frames for the ClientHello, which leads to 37% fewer connections per second. SIKEp434, although it offers much smaller public keys and ciphertexts, is orders of magnitude slower, which means it offers 95% fewer connections per second. These results match previous results we have shared before and other research works, where the most efficient signature algorithms ended up with higher connection rates and lower connection failure probabilities due to overload.
Conclusion
In this post, we showed how you can use s2n-quic in conjunction with s2n-tls to enable QUIC connections to negotiate encryption keys in a quantum-resistant manner. If you’re interested in learning more about s2n-quic, join us at AWS re:Inforce in July for the breakout session entitled NIS304: Using s2n-quic: Bringing QUIC, the secure transport protocol, to AWS.
As always, if you’re interested in using or contributing to s2n-quic, the source code and documentation are publicly available under the terms of the Apache Software License 2.0 from our s2n-quic GitHub repository. If you package or distribute s2n-quic or s2n-tls, or use it as part of a large multi-user service, you might be eligible for pre-notification of security issues. Contact [email protected] for more information. If you discover a potential security issue in s2n-quic or s2n-tls, we ask that you notify AWS Security by using our vulnerability reporting page.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
Today, a cluster of Internet standards were published that rationalize and modernize the definition of HTTP – the application protocol that underpins the web. This work includes updates to, and refactoring of, HTTP semantics, HTTP caching, HTTP/1.1, HTTP/2, and the brand-new HTTP/3. Developing these specifications has been no mean feat and today marks the culmination of efforts far and wide, in the Internet Engineering Task Force (IETF) and beyond. We thought it would be interesting to celebrate the occasion by sharing some analysis of Cloudflare’s view of HTTP traffic over the last 12 months.
However, before we get into the traffic data, for quick reference, here are the new RFCs that you should make a note of and start using:
HTTP’s overall architecture, common terminology and shared protocol aspects such as request and response messages, methods, status codes, header and trailer fields, message content, representation data, content codings and much more. Obsoletes RFCs 2818, 7231, 7232, 7233, 7235, 7538, 7615, 7694, and portions of 7230.
A syntax of HTTP that uses a binary framing format, which provides streams to support concurrent requests and responses. Message fields can be compressed using HPACK. Typically used over TCP and TLS. Obsoletes RFCs 7540 and 8740.
A variation of HPACK field compression that is optimized for the QUIC transport protocol.
On May 28, 2021, we enabled QUIC version 1 and HTTP/3 for all Cloudflare customers, using the final “h3” identifier that matches RFC 9114. So although today’s publication is an occasion to celebrate, for us nothing much has changed, and it’s business as usual.
A browser and web server typically automatically negotiate the highest HTTP version available. Thus, HTTP/3 takes precedence over HTTP/2. We looked back over the last year to understand HTTP/3 usage trends across the Cloudflare network, as well as analyzing HTTP versions used by traffic from leading browser families (Google Chrome, Mozilla Firefox, Microsoft Edge, and Apple Safari), major search engine indexing bots, and bots associated with some popular social media platforms. The graphs below are based on aggregate HTTP(S) traffic seen globally by the Cloudflare network, and include requests for website and application content across the Cloudflare customer base between May 7, 2021, and May 7, 2022. We used Cloudflare bot scores to restrict analysis to “likely human” traffic for the browsers, and to “likely automated” and “automated” for the search and social bots.
Traffic by HTTP version
Overall, HTTP/2 still comprises the majority of the request traffic for Cloudflare customer content, as clearly seen in the graph below. After remaining fairly consistent through 2021, HTTP/2 request volume increased by approximately 20% heading into 2022. HTTP/1.1 request traffic remained fairly flat over the year, aside from a slight drop in early December. And while HTTP/3 traffic initially trailed HTTP/1.1, it surpassed it in early July, growing steadily and roughly doubling in twelve months.
HTTP/3 traffic by browser
Digging into just HTTP/3 traffic, the graph below shows the trend in daily aggregate request volume over the last year for HTTP/3 requests made by the surveyed browser families. Google Chrome (orange line) is far and away the leading browser, with request volume far outpacing the others.
Below, we remove Chrome from the graph to allow us to more clearly see the trending across other browsers. Likely because it is also based on the Chromium engine, the trend for Microsoft Edge closely mirrors Chrome. As noted above, Mozilla Firefox first enabled production support in version 88 in April 2021, making it available by default by the end of May. The increased adoption of that updated version during the following month is clear in the graph as well, as HTTP/3 request volume from Firefox grew rapidly. HTTP/3 traffic from Apple Safari increased gradually through April, suggesting growth in the number of users enabling the experimental feature or running a Technology Preview version of the browser. However, Safari’s HTTP/3 traffic has subsequently dropped over the last couple of months. We are not aware of any specific reasons for this decline, but our most recent observations indicate HTTP/3 traffic is recovering.
Looking at the lines in the graph for Chrome, Edge, and Firefox, a weekly cycle is clearly visible in the graph, suggesting greater usage of these browsers during the work week. This same pattern is absent from Safari usage.
Across the surveyed browsers, Chrome ultimately accounts for approximately 80% of the HTTP/3 requests seen by Cloudflare, as illustrated in the graphs below. Edge is responsible for around another 10%, with Firefox just under 10%, and Safari responsible for the balance.
We also wanted to look at how the mix of HTTP versions has changed over the last year across each of the leading browsers. Although the percentages vary between browsers, it is interesting to note that the trends are very similar across Chrome, Firefox and Edge. (After Firefox turned on default HTTP/3 support in May 2021, of course.) These trends are largely customer-driven – that is, they are likely due to changes in Cloudflare customer configurations.
Most notably we see an increase in HTTP/3 during the last week of September, and a decrease in HTTP/1.1 at the beginning of December. For Safari, the HTTP/1.1 drop in December is also visible, but the HTTP/3 increase in September is not. We expect that over time, once Safari supports HTTP/3 by default that its trends will become more similar to those seen for the other browsers.
Traffic by search indexing bot
Back in 2014, Google announced that it would start to consider HTTPS usage as a ranking signal as it indexed websites. However, it does not appear that Google, or any of the other major search engines, currently consider support for the latest versions of HTTP as a ranking signal. (At least not directly – the performance improvements associated with newer versions of HTTP could theoretically influence rankings.) Given that, we wanted to understand which versions of HTTP the indexing bots themselves were using.
Despite leading the charge around the development of QUIC, and integrating HTTP/3 support into the Chrome browser early on, it appears that on the indexing/crawling side, Google still has quite a long way to go. The graph below shows that requests from GoogleBot are still predominantly being made over HTTP/1.1, although use of HTTP/2 has grown over the last six months, gradually approaching HTTP/1.1 request volume. (A blog post from Google provides some potential insights into this shift.) Unfortunately, the volume of requests from GoogleBot over HTTP/3 has remained extremely limited over the last year.
Microsoft’s BingBot also fails to use HTTP/3 when indexing sites, with near-zero request volume. However, in contrast to GoogleBot, BingBot prefers to use HTTP/2, with a wide margin developing in mid-May 2021 and remaining consistent across the rest of the past year.
Traffic by social media bot
Major social media platforms use custom bots to retrieve metadata for shared content, improve language models for speech recognition technology, or otherwise index website content. We also surveyed the HTTP version preferences of the bots deployed by three of the leading social media platforms.
Although Facebook supports HTTP/3 on their main website (and presumably their mobile applications as well), their back-end FacebookBot crawler does not appear to support it. Over the last year, on the order of 60% of the requests from FacebookBot have been over HTTP/1.1, with the balance over HTTP/2. Heading into 2022, it appeared that HTTP/1.1 preference was trending lower, with request volume over the 25-year-old protocol dropping from near 80% to just under 50% during the fourth quarter. However, that trend was abruptly reversed, with HTTP/1.1 growing back to over 70% in early February. The reason for the reversal is unclear.
Similar to FacebookBot, it appears TwitterBot’s use of HTTP/3 is, unfortunately, pretty much non-existent. However, TwitterBot clearly has a strong and consistent preference for HTTP/2, accounting for 75-80% of its requests, with the balance over HTTP/1.1.
In contrast, LinkedInBot has, over the last year, been firmly committed to making requests over HTTP/1.1, aside from the apparently brief anomalous usage of HTTP/2 last June. However, in mid-March, it appeared to tentatively start exploring the use of other HTTP versions, with around 5% of requests now being made over HTTP/2, and around 1% over HTTP/3, as seen in the upper right corner of the graph below.
Conclusion
We’re happy that HTTP/3 has, at long last, been published as RFC 9114. More than that, we’re super pleased to see that regardless of the wait, browsers have steadily been enabling support for the protocol by default. This allows end users to seamlessly gain the advantages of HTTP/3 whenever it is available. On Cloudflare’s global network, we’ve seen continued growth in the share of traffic speaking HTTP/3, demonstrating continued interest from customers in enabling it for their sites and services. In contrast, we are disappointed to see bots from the major search and social platforms continuing to rely on aging versions of HTTP. We’d like to build a better understanding of how these platforms chose particular HTTP versions and welcome collaboration in exploring the advantages that HTTP/3, in particular, could provide.
Current statistics on HTTP/3 and QUIC adoption at a country and autonomous system (ASN) level can be found on Cloudflare Radar.
Running HTTP/3 and QUIC on the edge for everyone has allowed us to monitor a wide range of aspects related to interoperability and performance across the Internet. Stay tuned for future blog posts that explore some of the technical developments we’ve been making.
And this certainly isn’t the end of protocol innovation, as HTTP/3 and QUIC provide many exciting new opportunities. The IETF and wider community are already underway building new capabilities on top, such as MASQUE and WebTransport. Meanwhile, in the last year, the QUIC Working Group has adopted new work such as QUIC version 2, and the Multipath Extension to QUIC.
At Amazon Web Services (AWS), security, high performance, and strong encryption for everyone are top priorities for all our services. With these priorities in mind, less than a year after QUIC ratification in the Internet Engineering Task Force (IETF), we are introducing support for the QUIC protocol which can boost performance for web applications that currently use Transport Layer Security (TLS) over Transmission Control Protocol (TCP). We are pleased to announce the availability of s2n-quic, an open-source Rust implementation of the QUIC protocol added to our set of AWS encryption open-source libraries.
What is QUIC?
QUIC is an encrypted transport protocol designed for performance and is the foundation of HTTP/3. It is specified in a set of IETF standards ratified in May 2021. QUIC protects its UDP datagrams by using encryption and authentication keys established in a TLS 1.3 handshake carried over QUIC transport. It is designed to improve upon TCP by providing improved first-byte latency and handling of multiple streams, and solving issues such as head-of-line blocking, mobility, and data loss detection. This enables web applications to perform faster, especially over poor networks. Other potential uses include latency-sensitive connections and UDP connections currently using DTLS, which now can run faster.
Renaming s2n
AWS has long supported open-source encryption libraries; in 2015 we introduced s2n as a TLS library. The name s2n is short for signal to noise, and is a nod to the almost magical act of encryption—disguising meaningful signals, like your critical data, as seemingly random noise.
Now that AWS introduces our new QUIC open-source library, we are renaming s2n to s2n-tls. s2n-tls is an efficient TLS library built over other crypto libraries like OpenSSL libcrypto or AWS libcrypto (AWS-LC). AWS-LC is a general-purpose cryptographic library maintained by AWS which originated from the Google project BoringSSL. The s2n family of AWS encryption open-source libraries now consists of s2n-tls, s2n-quic, and s2n-bignum. s2n-bignum is a collection of bignum arithmetic routines maintained by AWS designed for crypto applications.
s2n-quic details
Similar to s2n-tls, s2n-quic is designed to be small and fast, with simplicity as a priority. It is written in Rust, so it reaps some of its benefits such as performance, thread and memory-safety. s2n-quic depends either on s2n-tls or rustls for the TLS 1.3 handshake.
Highly configurable. s2n-quic is configured with code through providers that allow an application to granularly control functionality. You can see an example of the server’s simple config in the QUIC echo server-example.
Extensive testing. Fuzzing (libFuzzer, American Fuzzy Fop (AFL), and honggfuzz), corpus replay unit testing of derived corpus files, testing of concrete and symbolic execution engines with bolero, and extensive integration and unit testing are used to validate the correctness of our implementation.
Thorough interoperability testing for every code change. There are multiple public QUIC implementations; s2n-quic is continuously tested to interoperate with many of them.
Verified correctness, post-quantum hybrid key exchange, and maturity for the TLS handshake when built with s2n-tls.
Some important features in s2n-quic that can improve performance and connection management include CUBIC congestion controller support, packet pacing, Generic Segmentation Offload (GSO) support, Path MTU Discovery, and unique connection identifiers detached from the address.
AWS is continuing to invest in encryption optimization techniques, UDP performance improvement technologies, and formal code verification with the AWS Automated Reasoning Group to further enhance the library.
Like s2n-tls, which has already been introduced in various AWS services, AWS services that need to make use of the benefits of QUIC will begin integrating s2n-quic. QUIC is a standardized protocol which, when introduced in a service like web content delivery, can improve user experience or application performance. AWS still plans to continue support for existing protocols like TLS, so existing applications will remain interoperable. Amazon CloudFront is scheduled to be the first AWS service to integrate s2n-quic with its support for HTTP/3 in 2022.
Conclusion
If you are interested in using or contributing to s2n-quic source code or documentation, they are publicly available under the terms of the Apache Software License 2.0 from our s2n-quic GitHub repository.
If you package or distribute s2n-quic or s2n-tls, or use it as part of a large multi-user service, you may be eligible for pre-notification of security issues. Please contact [email protected].
If you discover a potential security issue in s2n-quic or s2n-tls, we ask that you notify AWS Security by using our vulnerability reporting page.
Stay tuned for more topics on s2n-quic like quantum-resistance, performance analyses, uses, and other technical details.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
Today we are excited to announce that we are developing APIs and infrastructure to support more TCP, UDP, and QUIC-based protocols in Cloudflare Workers. Once released, these new capabilities will make it possible to use non-HTTP socket connections to and from a Worker or Durable Object as easily as one can use HTTP and WebSockets today.
Out of the box, fetch and WebSocket APIs. With just a few internal changes to make it operational in Workers, we’ve developed an example using an off-the-shelf driver (in this example, a Deno-based Postgres client driver) to communicate with a remote Postgres server via WebSocket over a secure Cloudflare Tunnel.
import { Client } from './driver/postgres/postgres'
export default {
async fetch(request: Request, env, ctx: ExecutionContext) {
try {
const client = new Client({
user: 'postgres',
database: 'postgres',
hostname: 'https://db.example.com',
password: '',
port: 5432,
})
await client.connect()
const result = await client.queryArray('SELECT * FROM users WHERE uuid=1;')
ctx.waitUntil(client.end())
return new Response(JSON.stringify(result.rows[0]))
} catch (e) {
return new Response((e as Error).message)
}
},
}
The example works by replacing the bits of the Postgres client driver that use the Deno-specific TCP socket APIs with standard fetch and WebSockets APIs. We then establish a WebSocket connection with a remote Cloudflare Tunnel daemon running adjacent to the Postgres server, establishing what is effectively TCP-over-WebSockets.
While the fact we were able to build the example and communicate effectively and efficiently with the Postgres server — without making any changes to the Cloudflare Workers runtime — is impressive, there are limitations to the approach. For one, the solution requires additional infrastructure to establish and maintain the WebSocket tunnel — in this case, the instance of the Cloudflare Tunnel daemon running adjacent to the Postgres server. While we are certainly happy to provide that daemon to customers, it would just be better if that component were not required at all. Second, tunneling TCP over WebSockets, which is itself tunneled via HTTP over TCP is a bit suboptimal. It works, but we can do better.
Making connections from Cloudflare Workers
Currently, there is no standard API for socket connections in JavaScript. We want to change that.
If you’ve used Node.js before, then you’re most likely familiar with the net.Socket and net.TLSSocket objects. If you use Deno, then you might know that they’ve recently introduced the Deno.connect() and Deno.connectTLS() APIs. When you look at those APIs, what should immediately be apparent is how different they are from one another despite doing the exact same thing.
When we decided that we would add the ability to open and use socket connections from within Workers, we also agreed that we really have no interest in developing yet another non-standard, platform-specific API that is unlike the APIs provided by other platforms. Therefore, we are extending an invitation to all JavaScript runtime platforms that need socket capabilities to collaborate on a new (and eventually standardized) API that just works no matter which runtime you choose to develop on.
Here’s a rough example of what we have in mind for opening and reading from a simple TCP client connection:
const socket = new Socket({
remote: { address: '123.123.123.123', port: 1234 },
})
for await (const chunk of socket.readable)
console.log(chunk)
Or, this example, sending a simple “hello world” packet using UDP:
The API will be designed generically enough to work both client and server-side; for TCP, UDP, and QUIC; with or without TLS, and will not rely on any mechanism specific to any single JavaScript runtime. It will build on existing broadly supported Web Platform standards such as EventTarget, ReadableStream, WritableStream, AbortSignal, and promises. It will be familiar to developers who are already familiar with the fetch() API, service workers, and promises using async/await.
This is just a proposal at this point and the details will very likely change from the examples above by the time the capability is delivered in Workers. It is our hope that other platforms will join us in the effort of developing and supporting this new API so that developers have a consistent foundation upon which to build regardless of where they run their code.
Introducing Socket Workers
The ability to open socket client connections is only half of the story.
When we first started talking about adding these capabilities an obvious question was asked: What about using non-HTTP protocols to connect to Workers? What if instead of just having the ability to connect a Worker to some other back-end database, we could implement the entire database itself on the edge, inside Workers, and have non-HTTP clients connect to it? For that matter, what if we could implement an SMTP server in Workers? Or an MQTT message queue? Or a full VoIP platform? Or implement packet filters, transformations, inspectors, or protocol transcoders?
Workers are far too powerful to limit to just HTTP and WebSockets, so we will soon introduce Socket Workers — that is, Workers that can be connected to directly using raw TCP, UDP, or QUIC protocols without using HTTP.
What will this new Workers feature look like? Many of the details are still being worked through, but the idea is to deploy a Worker script that understands and responds to “connect” events in much the same way that “fetch” events work today. Importantly, this would build on the same common socket API being developed for client connections:
The new socket API for JavaScript and Socket Workers are under active development, with focus initially on enabling better and more efficient ways for Workers to connect to databases on the backend — you can sign up here to join the waitlist for access to Database Connectors and Socket Workers. We are excited to work with early users, as well as our technology partners to develop, refine, and test these new capabilities.
Once released, we expect Socket Workers to blow the doors wide open on the types of intelligent distributed applications that can be deployed to the Cloudflare network edge, and we are excited to see what you build with them.
I work on Cloudflare Tunnel, which lets customers quickly connect their private services and networks through the Cloudflare network without having to expose their public IPs or ports through their firewall. Tunnel is managed for users by cloudflared, a tool that runs on the same network as the private services. It proxies traffic for these services via Cloudflare, and users can then access these services securely through the Cloudflare network.
Recently, I was trying to get Cloudflare Tunnel to connect to the Cloudflare network using a UDP protocol, QUIC. While doing this, I ran into an interesting connectivity problem unique to UDP. In this post I will talk about how I went about debugging this connectivity issue beyond the land of firewalls, and how some interesting differences between UDP and TCP came into play when sending network packets.
How does Cloudflare Tunnel work?
cloudflared works by opening several connections to different servers on the Cloudflare edge. Currently, these are long-lived TCP-based connections proxied over HTTP/2 frames. When Cloudflare receives a request to a hostname, it is proxied through these connections to the local service behind cloudflared.
While our HTTP/2 protocol mode works great, we’d like to improve a few things. First, TCP traffic sent over HTTP/2 is susceptible to Head of Line (HoL) blocking — this affects both HTTP traffic and traffic from WARP routing. Additionally, it is currently not possible to initiate communication from cloudflared’s HTTP/2 server in an efficient way. With the current Go implementation of HTTP/2, we could use Server-Sent Events, but this is not very useful in the scheme of proxying L4 traffic.
The upgrade to QUIC solves possible HoL blocking issues and opens up avenues that allow us to initiate communication from cloudflared to a different cloudflared in the future.
Naturally, QUIC required a UDP-based listener on our edge servers which cloudflared could connect to. We already connect to a TCP-based listener for the existing protocols, so this should be nice and easy, right?
Failed to dial to the edge
Things weren’t as straightforward as they first looked. I added a QUIC listener on the edge, and the ability for cloudflared to connect to this new UDP-based listener. I tried to run my brand new QUIC tunnel and this happened.
$ cloudflared tunnel run --protocol quic my-tunnel
2021-09-17T18:44:11Z ERR Failed to create new quic connection, err: failed to dial to edge: timeout: no recent network activity
cloudflared wasn’t even establishing a connection to the edge. I started looking at the obvious places first. Did I add a firewall rule allowing traffic to this port? Check. Did I have iptables rules ACCEPTing or DROPping appropriate traffic for this port? Check. They seemed to be in order. So what else could I do?
tcpdump all the packets
I started by logging for UDP traffic on the machine my server was running on to see what could be happening.
$ sudo tcpdump -n -i eth0 port 7844 and udp
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
14:44:27.742629 IP 173.13.13.10.50152 > 198.41.200.200.7844: UDP, length 1252
14:44:27.743298 IP 203.0.113.0.7844 > 173.13.13.10.50152: UDP, length 37
Looking at this tcpdump helped me understand why I had no connectivity! Not only was this port getting UDP traffic but I was also seeing traffic flow out. But there seemed to be something strange afoot. Incoming packets were being sent to 198.41.200.200:7844 while responses were being sent back from 203.0.113.0:7844 (this is an example IP used for illustration purposes) instead.
Why is this a problem? If a host (in this case, the server) chooses an address from a network unable to communicate with a public Internet host, it is likely that the return half of the communication will never arrive. But wait a minute. Why is some other IP getting prioritized over a source address my packets were already being sent to? Let’s take a deeper look at some IP addresses. (Note that I’ve deliberately oversimplified and scrambled results to minimally illustrate the problem)
$ ip addr list
eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1600 qdisc noqueue state UP group default qlen 1000
inet 203.0.113.0/32 scope global eth0
inet 198.41.200.200/32 scope global eth0
$ ip route show
default via 203.0.113.0 dev eth0
So this was clearly why the server was working fine on my machine but not on the Cloudflare edge servers. It looks like I have multiple IPs on the interface my service is bound to. The IP that is the default route is being sent back as the source address of the packet.
Why does this work for TCP but not UDP?
Connection-oriented protocols, like TCP, initiate a connection (connect()) with a three-way handshake. The kernel therefore maintains a state about ongoing connections and uses this to determine the source IP address at the time of a response.
Because UDP (unless SOCK_SEQPACKET is involved) is connectionless, the kernel cannot maintain state like TCP does. The recvfrom system call is invoked from the server side and tells who the data comes from. Unfortunately, recvfrom does not tell us which IP this data is addressed for. Therefore, when the UDP server invokes the sendto system call to respond to the client, we can only tell it which address to send the data to. The responsibility of determining the source-address IP then falls to the kernel. The kernel has certain heuristics that it uses to determine the source address. This may or may not work, and in the ip routes example above, these heuristics did not work. The kernel naturally (and wrongly) picks the address of the default route to respond with.
Telling the kernel what to do
I had to rely on my application to set the source address explicitly and therefore not rely on kernel heuristics.
Linux has some generic I/O system calls, namely recvmsg and sendmsg. Their function signatures allow us to both read or write additional out-of-band data we can pass the source address to. This control information is passed via the msghdr struct’s msg_control field.
ssize_t sendmsg(int socket, const struct msghdr *message, int flags)
ssize_t recvmsg(int socket, struct msghdr *message, int flags);
struct msghdr {
void * msg_name; /* Socket name */
int msg_namelen; /* Length of name */
struct iovec * msg_iov; /* Data blocks */
__kernel_size_t msg_iovlen; /* Number of blocks */
void * msg_control; /* Per protocol magic (eg BSD file descriptor passing) */
__kernel_size_t msg_controllen; /* Length of cmsg list */
unsigned int msg_flags;
};
We can now copy the control information we’ve gotten from recvmsg back when calling sendmsg, providing the kernel with information about the source address.The library I used (https://github.com/lucas-clemente/quic-go) had a recent update that did exactly this! I pulled the changes into my service and gave it a spin.
But alas. It did not work! A quick tcpdump showed that the same source address was being sent back. It seemed clear from reading the source code that the recvmsg and sendmsg were being called with the right values. It did not make sense.
So I had to see for myself if these system calls were being made.
strace all the system calls
strace is an extremely useful tool that tracks all system calls and signals sent/received by a process. Here’s what it had to say. I’ve removed all the information not relevant to this specific issue.
Let’s start with recvmsg . We can clearly see that the ipi_addr for the source is being passed correctly: ipi_addr=inet_addr(“172.16.90.131”). This part works as expected. Looking at sendmsg almost instantly tells us where the problem is. The field we want, ip_spec_dst is not being set as we make this system call. So the kernel continues to make wrong guesses as to what the source address may be.
This turned out to be a bug where the library was using IPROTO_TCP instead of IPPROTO_IPV4 as the control message level while making the sendmsg call. Was that it? Seemed a little anticlimactic. I submitted a slightly more typesafe fix and sure enough, straces now showed me what I was expecting to see.
While the programmatic bug causing this issue was a trivial one, the journey into systematically discovering the issue and understanding how Linux internals worked for UDP along the way turned out to be very rewarding for me. It also reiterated my belief that tcpdump and strace are indeed invaluable tools in anybody’s arsenal when debugging network problems.
What’s next?
You can give this a try with the latest cloudflared release at https://github.com/cloudflare/cloudflared/releases/latest. Just remember to set the protocol flag to quic. We plan to leverage this new mode to roll out some exciting new features for Cloudflare Tunnel. So upgrade away and keep watching this space for more information on how you can take advantage of this.
QUIC is a new Internet transport protocol for secure, reliable and multiplexed communications. HTTP/3 builds on top of QUIC, leveraging the new features to fix performance problems such as Head-of-Line blocking. This enables web pages to load faster, especially over troublesome networks.
QUIC and HTTP/3 are open standards that have been under development in the IETF for almost exactly 4 years. On October 21, 2020, following two rounds of Working Group Last Call, draft 32 of the family of documents that describe QUIC and HTTP/3 were put into IETF Last Call. This is an important milestone for the group. We are now telling the entire IETF community that we think we’re almost done and that we’d welcome their final review.
Speaking personally, I’ve been involved with QUIC in some shape or form for many years now. Earlier this year I was honoured to be asked to help co-chair the Working Group. I’m pleased to help shepherd the documents through this important phase, and grateful for the efforts of everyone involved in getting us there, especially the editors. I’m also excited about future opportunities to evolve on top of QUIC v1 to help build a better Internet.
There are two aspects to protocol development. One aspect involves writing and iterating upon the documents that describe the protocols themselves. Then, there’s implementing, deploying and testing libraries, clients and/or servers. These aspects operate hand in hand, helping the Working Group move towards satisfying the goals listed in its charter. IETF Last Call marks the point that the group and their responsible Area Director (in this case Magnus Westerlund) believe the job is almost done. Now is the time to solicit feedback from the wider IETF community for review. At the end of the Last Call period, the stakeholders will take stock, address feedback as needed and, fingers crossed, go onto the next step of requesting the documents be published as RFCs on the Standards Track.
Although specification and implementation work hand in hand, they often progress at different rates, and that is totally fine. The QUIC specification has been mature and deployable for a long time now. HTTP/3 has been generally available on the Cloudflare edge since September 2019, and we’ve been delighted to see support roll out in user agents such as Chrome, Firefox, Safari, curl and so on. Although draft 32 is the latest specification, the community has for the time being settled on draft 29 as a solid basis for interoperability. This shouldn’t be surprising, as foundational aspects crystallize the scope of changes between iterations decreases. For the average person in the street, there’s not really much difference between 29 and 32.
So today, if you visit a website with HTTP/3 enabled—such as https://cloudflare-quic.com—you’ll probably see response headers that contain Alt-Svc: h3-29=”… . And in a while, once Last Call completes and the RFCs ship, you’ll start to see websites simply offer Alt-Svc: h3=”… (note, no draft version!).
Need a deep dive?
We’ve collected a bunch of resource links at https://cloudflare-quic.com. If you’re more of an interactive visual learner, you might be pleased to hear that I’ve also been hosting a series on Cloudflare TV called “Levelling up Web Performance with HTTP/3”. There are over 12 hours of content including the basics of QUIC, ways to measure and debug the protocol in action using tools like Wireshark, and several deep dives into specific topics. I’ve also been lucky to have some guest experts join me along the way. The table below gives an overview of the episodes that are available on demand.
Understanding the role of congestion control in QUIC. Featuring Junho Choi.
Whither QUIC?
So does Last Call mean QUIC is “done”? Not by a long shot. The new protocol is a giant leap for the Internet, because it enables new opportunities and innovation. QUIC v1 is basically the set of documents that have gone into Last Call. We’ll continue to see people gain experience deploying and testing this, and no doubt cool blog posts about tweaking parameters for efficiency and performance are on the radar. But QUIC and HTTP/3 are extensible, so we’ll see people interested in trying new things like multipath, different congestion control approaches, or new ways to carry data unreliably such as the DATAGRAM frame.
We’re also seeing people interested in using QUIC for other use cases. Mapping other application protocols like DNS to QUIC is a rapid way to get its improvements. We’re seeing people that want to use QUIC as a substrate for carrying other transport protocols, hence the formation of the MASQUE Working Group. There’s folks that want to use QUIC and HTTP/3 as a “supercharged WebSocket”, hence the formation of the WebTransport Working Group.
Whatever the future holds for QUIC, we’re just getting started, and I’m excited.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.