Post Syndicated from Julian Wood original https://aws.amazon.com/blogs/compute/introducing-the-powershell-custom-runtime-for-aws-lambda/
The new PowerShell custom runtime for AWS Lambda makes it even easier to run Lambda functions written in PowerShell to process events. Using this runtime, you can run native PowerShell code in Lambda without having to compile code, which simplifies deployment and testing. You can also now view PowerShell code in the AWS Management Console, and have more control over function output and logging.
Lambda has supported running PowerShell since 2018. However, the existing solution uses the .NET Core runtime implementation for PowerShell. It uses the additional AWSLambdaPSCore modules for deployment and publishing, which require compiling the PowerShell code into C# binaries to run on .NET. This adds additional steps to the development process.
This blog post explains the benefits of using a custom runtime and information about the runtime options. You can deploy and run an example native PowerShell function in Lambda.
PowerShell custom runtime benefits
The new custom runtime for PowerShell uses native PowerShell, instead of compiling PowerShell and hosting it on the .NET runtime. Using native PowerShell means the function runtime environment matches a standard PowerShell session, which simplifies the development and testing process.
You can now also view and edit PowerShell code within the Lambda console’s built-in code editor. You can embed PowerShell code within an AWS CloudFormation template, or other infrastructure as code tools.

PowerShell code in Lambda console
This custom runtime returns everything placed on the pipeline as the function output, including the output of Write-Output. This gives you more control over the function output, error messages, and logging. With the previous .NET runtime implementation, your function returns only the last output from the PowerShell pipeline.
Building and packaging the custom runtime
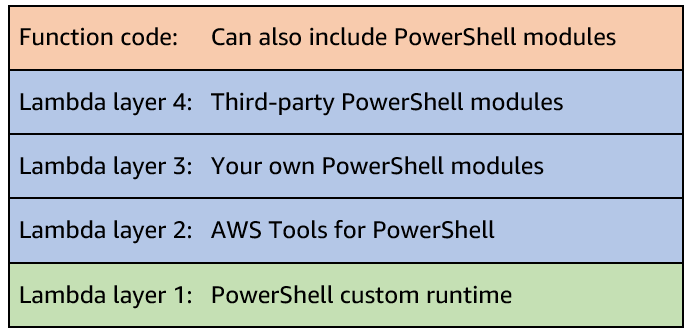
The custom runtime is based on Lambda’s provided.al2 runtime, which runs in an Amazon Linux environment. This includes AWS credentials from an AWS Identity and Access Management (IAM) role that you manage. You can build and package the runtime as a Lambda layer, or include it in a container image. When packaging as a layer, you can add it to multiple functions, which can simplify deployment.
The runtime is based on the cross-platform PowerShell Core. This means that you can develop Lambda functions for PowerShell on Windows, Linux, or macOS.
You can build the custom runtime using a number of tools, including the AWS Command Line Interface (AWS CLI), AWS Tools for PowerShell, or with infrastructure as code tools such as AWS CloudFormation, AWS Serverless Application Model (AWS SAM), Serverless Framework, and AWS Cloud Development Kit (AWS CDK).
Showing the PowerShell custom runtime in action
In the following demo, you learn how to deploy the runtime and explore how it works with a PowerShell function.
The accompanying GitHub repository contains the code for the custom runtime, along with additional installation options and a number of examples.
This demo application uses AWS SAM to deploy the following resources:
- PowerShell custom runtime based on
provided.al2 as a Lambda layer.
- Additional Lambda layer containing the
AWS.Tools.Common module from AWS Tools for PowerShell.
- Both layers store their Amazon Resource Names (ARNs) as parameters in AWS Systems Manager Parameter Store which can be referenced in other templates.
- Lambda function with three different handler options.
To build the custom runtime and the AWS Tools for PowerShell layer for this example, AWS SAM uses a Makefile. This downloads the specified version of PowerShell from GitHub and the AWSTools.
Windows does not natively support Makefiles. When using Windows, you can use either Windows Subsystem for Linux (WSL), Docker Desktop, or native PowerShell.
Pre-requisites:
Clone the repository and change into the example directory
git clone https://github.com/awslabs/aws-lambda-powershell-runtime
cd examples/demo-runtime-layer-function
Use one of the following Build options, A, B, C, depending on your operating system and tools.
A) Build using Linux or WSL
Build the custom runtime, Lambda layer, and function packages using native Linux or WSL.
sam build --parallel

sam build –parallel
B) Build using Docker
You can build the custom runtime, Lambda layer, and function packages using Docker. This uses a Linux-based Lambda-like Docker container to build the packages. Use this option for Windows without WSL or as an isolated Mac/Linux build environment.
sam build --parallel --use-container

sam build –parallel –use-container
C) Build using PowerShell for Windows
You can use native PowerShell for Windows to download and extract the custom runtime and Lambda layer files. This performs the same file copy functionality as the Makefile. It adds the files to the source folders rather than a build location for subsequent deployment with AWS SAM. Use this option for Windows without WSL or Docker.
.\build-layers.ps1

Build layers using PowerShell
Test the function locally
Once the build process is complete, you can use AWS SAM to test the function locally.
sam local invoke
This uses a Lambda-like environment to run the function locally and returns the function response, which is the result of Get-AWSRegion.

sam local invoke
Deploying to the AWS Cloud
Use AWS SAM to deploy the resources to your AWS account. Run a guided deployment to set the default parameters for the first deploy.
sam deploy -g
For subsequent deployments you can use sam deploy.
Enter a Stack Name and accept the remaining initial defaults.

AWS SAM deploy –g
AWS SAM deploys the infrastructure and outputs the details of the resources.

AWS SAM resources
View, edit, and invoke the function in the AWS Management Console
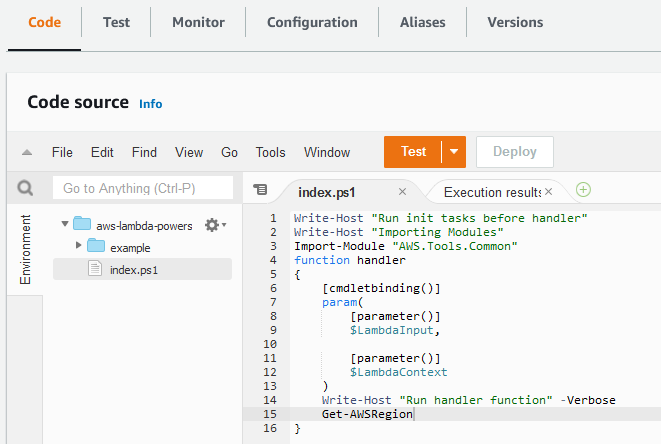
You can view, edit code, and invoke the Lambda function in the Lambda Console.
Navigate to the Functions page and choose the function specified in the sam deploy Outputs.
Using the built-in code editor, you can view the function code.
This function imports the AWS.Tools.Common module during the init process. The function handler runs and returns the output of Get-AWSRegion.
To invoke the function, select the Test button and create a test event. For more information on invoking a function with a test event, see the documentation.
You can see the results in the Execution result pane.

Lambda console test
You can also view a snippet of the generated Function Logs below the Response. View the full logs in Amazon CloudWatch Logs. You can navigate directly via the Monitor tab.
Invoke the function using the AWS CLI
From a command prompt invoke the function. Amend the --function-name and --region values for your function. This should return "StatusCode": 200 for a successful invoke.
aws lambda invoke --function-name "aws-lambda-powershell-runtime-Function-6W3bn1znmW8G" --region us-east-1 invoke-result
View the function results which are outputted to invoke-result.
cat invoke-result

cat invoke result
Invoke the function using the AWS Tools for PowerShell
You can invoke the Lambda function using the AWS Tools for PowerShell and capture the response in a variable. The response is available in the Payload property of the $Response object, which can be read using the .NET StreamReader class.
$Response = Invoke-LMFunction -FunctionName aws-lambda-powershell-runtime-PowerShellFunction-HHdKLkXxnkUn -LogType Tail
[System.IO.StreamReader]::new($Response.Payload).ReadToEnd()
This outputs the result of AWS-GetRegion.
Cleanup
Use AWS SAM to delete the AWS resources created by this template.
sam delete
PowerShell runtime information
Variables
The runtime defines the following variables which are made available to the Lambda function.
$LambdaInput: A PSObject that contains the Lambda function input event data.$LambdaContext: An object that provides methods and properties with information about the invocation, function, and runtime environment. For more information, see the GitHub repository.
PowerShell module support
You can include additional PowerShell modules either via a Lambda Layer, or within your function code package, or container image. Using Lambda layers provides a convenient way to package and share modules that you can use with your Lambda functions. Layers reduce the size of uploaded deployment archives and make it faster to deploy your code.
The PSModulePath environment variable contains a list of folder locations that are searched to find user-supplied modules. This is configured during the runtime initialization. Folders are specified in the following order:
- Modules as part of function package in a
/modules subfolder.
- Modules as part of Lambda layers in a
/modules subfolder.
- Modules as part of the PowerShell custom runtime layer in a
/modules subfolder.
Lambda handler options
There are three different Lambda handler formats supported with this runtime.
<script.ps1>
You provide a PowerShell script that is the handler. Lambda runs the entire script on each invoke.
<script.ps1>::<function_name>
You provide a PowerShell script that includes a PowerShell function name. The PowerShell function name is the handler. The PowerShell runtime dot-sources the specified <script.ps1>. This allows you to run PowerShell code during the function initialization cold start process. Lambda then invokes the PowerShell handler function <function_name>. On subsequent invokes using the same runtime environment, Lambda invokes only the handler function <function_name>.
Module::<module_name>::<function_name>
You provide a PowerShell module. You include a PowerShell function as the handler within the module. Add the PowerShell module using a Lambda Layer or by including the module in the Lambda function code package. The PowerShell runtime imports the specified <module_name>. This allows you to run PowerShell code during the module initialization cold start process. Lambda then invokes the PowerShell handler function <function_name> in a similar way to the <script.ps1>::<function_name> handler method.
Function logging and metrics
Lambda automatically monitors Lambda functions on your behalf and sends function metrics to Amazon CloudWatch. Your Lambda function comes with a CloudWatch Logs log group and a log stream for each instance of your function. The Lambda runtime environment sends details about each invocation to the log stream, and relays logs and other output from your function’s code. For more information, see the documentation.
Output from Write-Host, Write-Verbose, Write-Warning, and Write-Error is written to the function log stream. The output from Write-Output is added to the pipeline, which you can use with your function response.
Error handling
The runtime can terminate your function because it ran out of time, detected a syntax error, or failed to marshal the response object into JSON.
Your function code can throw an exception or return an error object. Lambda writes the error to CloudWatch Logs and, for synchronous invocations, also returns the error in the function response output.
See the documentation on how to view Lambda function invocation errors for the PowerShell runtime using the Lambda console and the AWS CLI.
Conclusion
The PowerShell custom runtime for Lambda makes it even easier to run Lambda functions written in PowerShell.
The custom runtime runs native PowerShell. You can view, and edit your code within the Lambda console. The runtime supports a number of different handler options, and you can include additional PowerShell modules.
See the accompanying GitHub repository which contains the code for the custom runtime, along with installation options and a number of examples. Start running PowerShell on Lambda today.
For more serverless learning resources, visit Serverless Land.
Acknowledgements
This custom runtime builds on the work of Norm Johanson, Kevin Marquette, Andrew Pearce, Jonathan Nunn, and Afroz Mohammed.



















 For testing you can keep both and then later remove the unnecessary one as well as the number suffix.
For testing you can keep both and then later remove the unnecessary one as well as the number suffix.