Post Syndicated from Tibor Volanszki original https://blog.zabbix.com/json-is-your-friend-certificate-monitoring-on-microsoft-ca-server/20697/
Introduction
By transforming our data into JSON we can achieve great results with Zabbix without the need to have a complex external script logic. The article will provide an example of obtaining a set of master data with a single PowerShell script and then using the Zabbix native functionality to configure low-level discovery and collect the required metrics from the master JSON data set.
In this example, we will implement certificate monitoring by using a Microsoft Windows Certificate Authority server. The goal is to see how many days we have before our internally signed certificates will expire. As an extra, we will be able to filter the monitored items by requestors and template names.
- Target system version: MS Windows Server 2019 (also tested on 2012)
- Zabbix server & agent version: 6.0.3 (Other Zabbix versions should be supported too with no or minimal changes)
Core logic
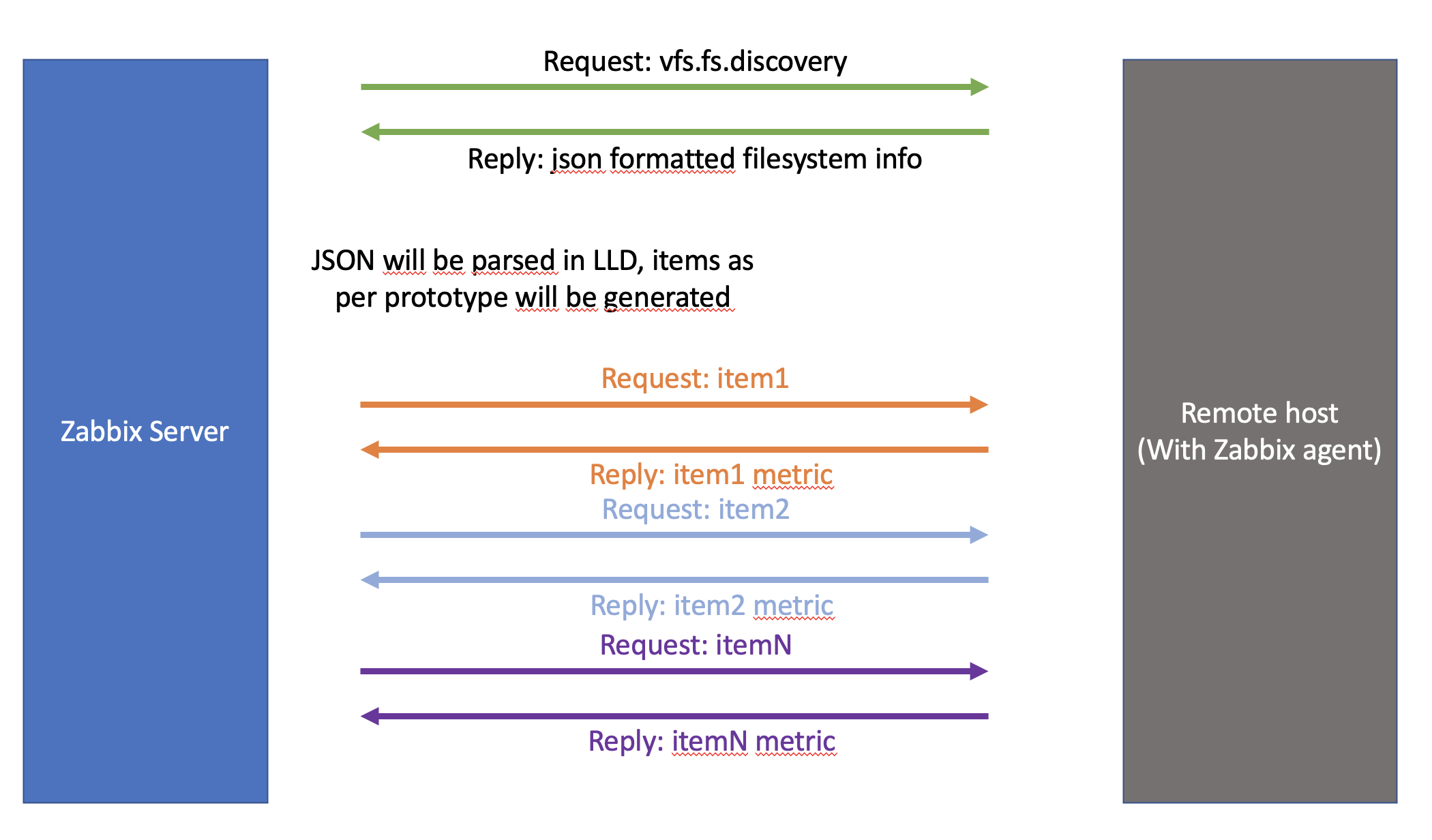
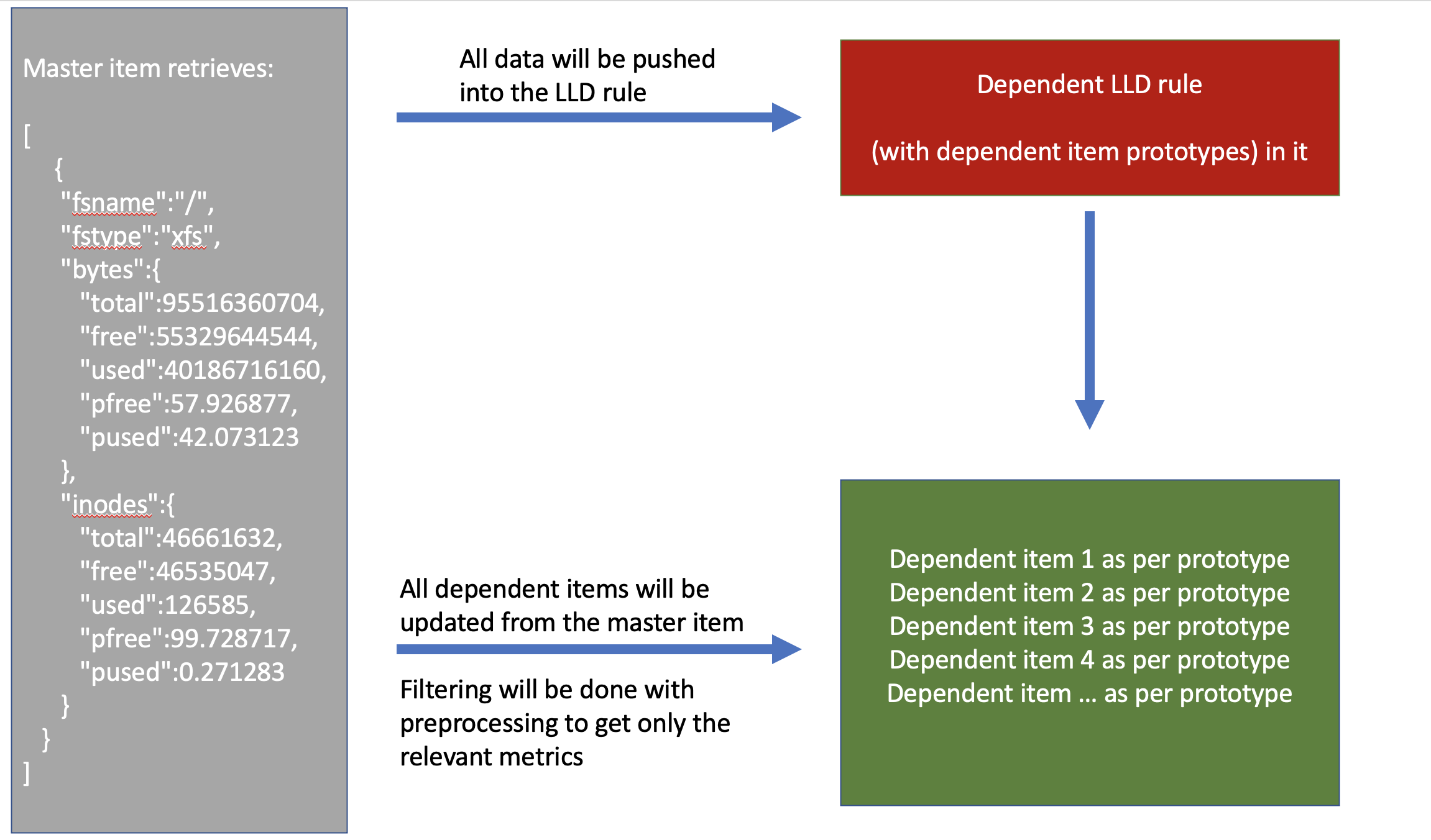
The below diagram shows the concept itself and you will find a detailed guide to implement this step by step in the next sections.


Prerequisites
To start, you will need to deploy Zabbix agent 2 on your target system – confirm that the Zabbix agent can communicate with your Zabbix server. For the calculated item, we will require local time monitoring. The easiest way is to use the key “system.localtime”, which is already provided by the default Windows OS monitoring template. This item is intentionally not included within the certificate monitoring template to avoid key conflicts.
Below you can find the Powershell script which you have to implement: (name: “certmon_get_certs.ps1″) :
To import module PSPKI you may have to install the module first: https://pkisolutions.com/tools/pspki/
Import-Module PSPKI $ca_hostname=$args[0] $start = (Get-Date).AddDays(-7) Get-IssuedRequest -CertificationAuthority $ca_hostname -Filter "NotAfter -ge $start" | Select-Object -Property RequestID,Request.RequesterName,CommonName,NotAfter,CertificateTemplateOid | ConvertTo-Json -Compress
*for Windows 2012 systems use CertificateTemplate instead of CertificateTemplateOid within this script.
This script expects one parameter, which is your CA server’s FQDN. That name will be loaded into variable “$ca_hostname”, so for testing purposes, you can just replace it with a static entry. Based on your needs you can adjust the “AddDays” parameter. Essentially this means to track back certificates, which are already expired for up to 7 days. Consider a situation, when you miss one just before a long weekend.
Script output
Let’s check the first part of the main command without further piping:

As you can see, we are getting some basic information about the certificate. We do not need all the returned lines for the next steps, so it is better to filter the output down. Before we do that, we will use the option called “-Property”, and if you use it with a wildcard character, then it will list all the available parameters for a certificate. If you need more than the basic output, then you can list the extra parameters by using this option. Please be aware, that this will add extra lines compared to the basic output, but it will not do any filtering (the common lines will always remain visible).

Compare this with the output after using “Select-Object -Property RequestID,Request.RequesterName,CommonName,NotAfter,CertificateTemplateOid”

This looks good for us, but it is still not machine-readable. Let’s add the JSON output conversion, but without the “-Compress” option first:

What is especially great in this conversion, is that the “CertificateTemplateOid” part got 2 child entries, so later we can target the “FriendlyName” entry for discovery. Lastly, adding the “-Compress” option will help us to use less space by removing the white spaces and newlines from the output.
Depending on the amount of issued and valid certificates the output can be huge, especially without any filtering and compression (even megabytes in size). The current Zabbix server version (6.0.3) supports only 512KB as item output, this is why the output reduction is crucial. In my example the text data of one certificate takes approx 300 bytes, so 512KB will result in a limit of 1747 certificates. In case you are expecting more than this amount of ACTIVE certs within your CA, then I recommend cloning the PS script and adding some extra filtering to each variant (filter for template name / requestor / OU) and adjusting the template accordingly. Another approach would be to monitor the certificates, which will expire in the coming N days in case you have too many entries.
Agent configuration
To run the defined script, you have to allow it within the Zabbix Agent configuration file. You can either modify the main config or just define the extra lines within an additional file under zabbix_agent2.d folder. Below you can find the additional Zabbix agent configuration lines:
AllowKey=system.run[powershell -NoProfile -ExecutionPolicy bypass -File "C:\Program Files\Zabbix Agent 2\scripts\certmon_get_certs.ps1" *] Timeout=20
The wildcard character at the end is needed to specify any hostname, which is expected by the script. The default timeout is 3 seconds, which is unfortunately insufficient. Importing Module PSPKI alone takes a few seconds, so the overall execution time is somewhere between 5 and 10 seconds. My assumption is that more certificates will not increase this significantly, but some extra seconds can be expected. 20 seconds sounds like a safe bet.
We are done with the pre-requisites, now we can start the real work!
Template
Let’s create our template from scratch.
- Name: “Microsoft Certificate Authority – Certificate monitoring”
- Host group: any group will do
Master item
We need only the following item:
- Name: “Get certificate data”
- Type: “Zabbix agent / Zabbix agent (active)” – for testing I recommend the passive mode
- Key: “system.run[powershell -NoProfile -ExecutionPolicy bypass -File “C:\Program Files\Zabbix Agent 2\scripts\certmon_get_certs.ps1″ {HOST.DNS}]”
- Type of information: “Text”
- Update interval: “6h”
- History: “1d”

Assign the template to a CA server and you can test the item already. The result should be a big block of data in JSON format. To review the output I recommend the following external websites:
The latter one is especially helpful to find the correct JSON path, which we will require in the upcoming steps.

Measuring the script execution time
To measure the execution time, you can test it by using Zabbix get, which can connect to your Zabbix agent and request the item value over a CLI:
time zabbix_get -s [CA_SERVER_FQDN] --tls-connect psk --tls-psk-identity [PSK_IDEN] --tls-psk-file [PSK_FILE] -k 'system.run[powershell -NoProfile -ExecutionPolicy bypass -File "C:\Program Files\Zabbix Agent 2\scripts\certmon_get_certs.ps1" [CA_SERVER_FQDN]]'
This will give you the normal output and the execution time info:
real 0m5.771s user 0m0.003s sys 0m0.005s
To test the size of the output, redirect your command output to any file and measure it by “du -sk” to get it in kilobytes.
zabbix_get -s [CA_SERVER_FQDN] --tls-connect psk --tls-psk-identity [PSK_IDEN] --tls-psk-file [PSK_FILE] -k 'system.run[powershell -NoProfile -ExecutionPolicy bypass -File "C:\Program Files\Zabbix Agent 2\scripts\certmon_get_certs.ps1" [CA_SERVER_FQDN]]' > output.test du -sk output.test
Low-level discovery rule definition
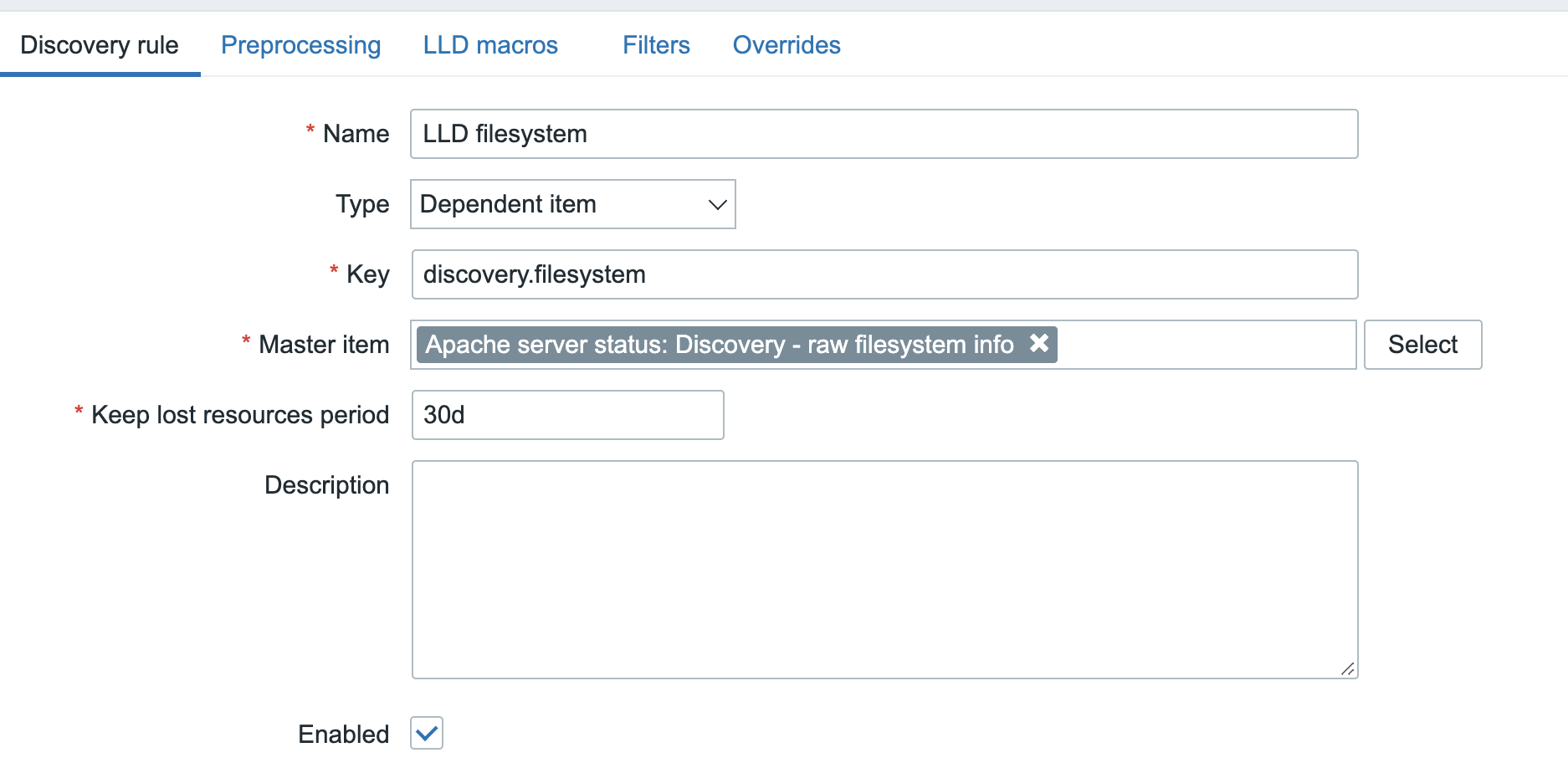
If the above part works just fine, then proceed with defining the low-level discovery rule as per the below example:
- Name: “Certificate discovery”
- Type: “Dependent item”
- Key: “certificate.discovery”
- Master item: select our previously created item
- Keep lost resources period: “6h”

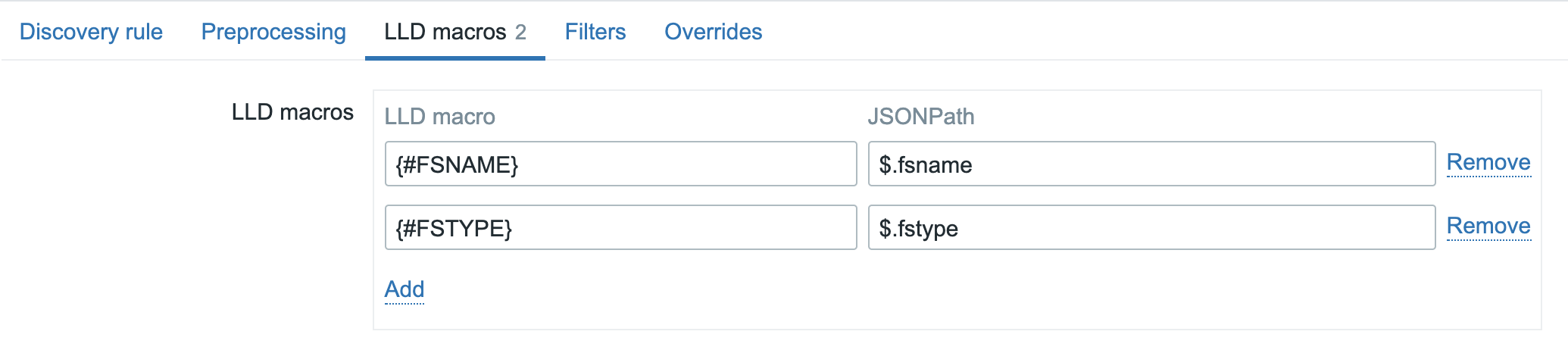
Then switch to LLD macros and define the below lines:
- “{#COMMON_NAME}”: “$.CommonName”
- “{#REQUESTOR_NAME}”: “$.[“Request.RequesterName”]”
- “{#REQUEST_ID}”: “$.RequestID”
- “{#TEMPLATE_NAME1}”: “$.CertificateTemplate”
- “{#TEMPLATE_NAME2}”: “$.CertificateTemplateOid.FriendlyName”

Some explanation:
The first LLD macro is self-explanatory – it obtains the certificate’s common name. The second one is also trivial, except the special marking, which is required due to the dot character in the middle. The third one is also simple, but the last 2 lines are somewhat special. If you have a fresh OS version, then most probably you will need only the 5th line without the 4th. In case you have a Windows server 2012 system, then you will need only the 4th line without the 5th. Why? Because of Windows  For testing you can keep both and then later remove the unnecessary one as well as the number suffix.
For testing you can keep both and then later remove the unnecessary one as well as the number suffix.
Now you are ready to create your item prototypes and this is where the real magic starts.
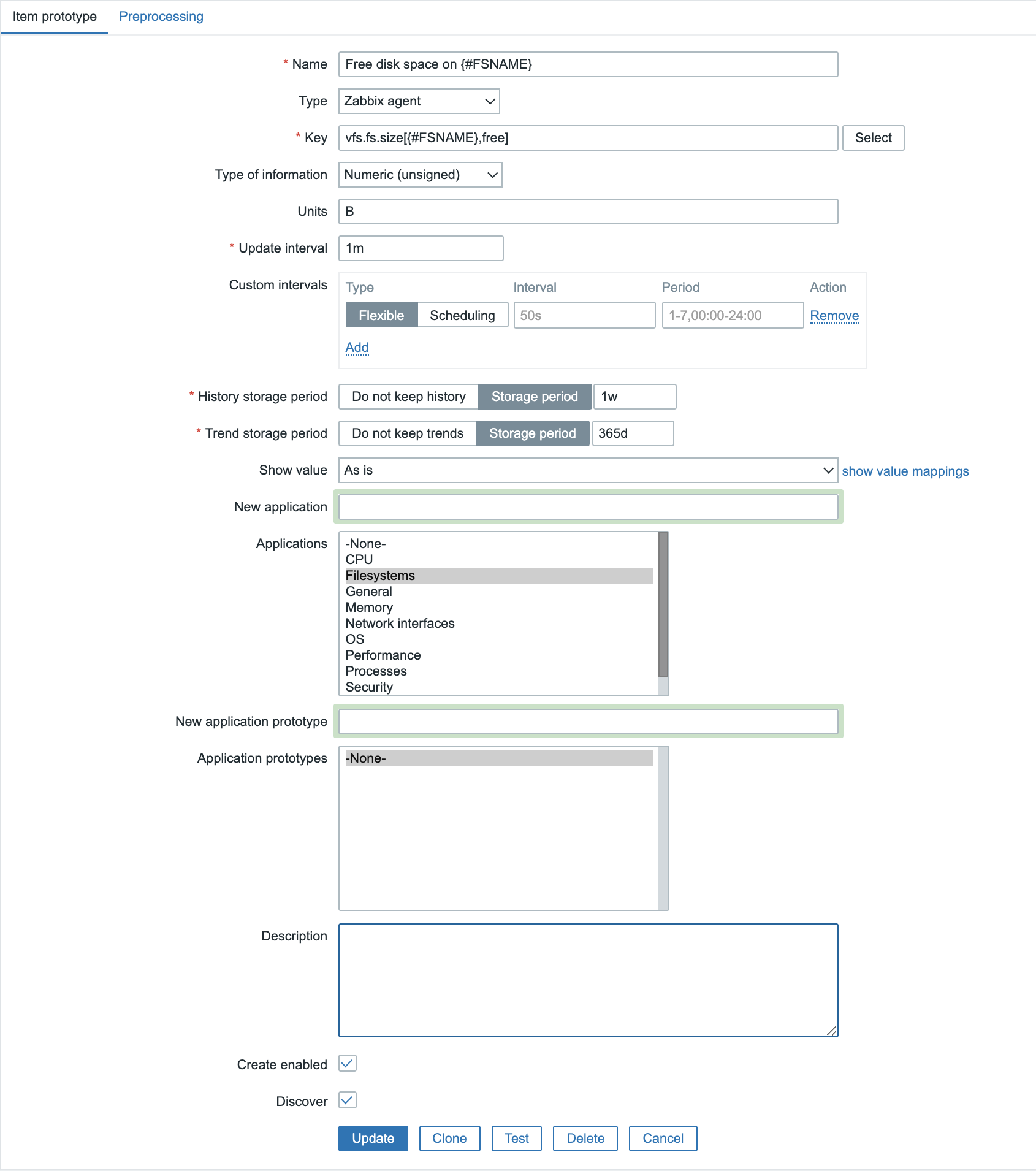
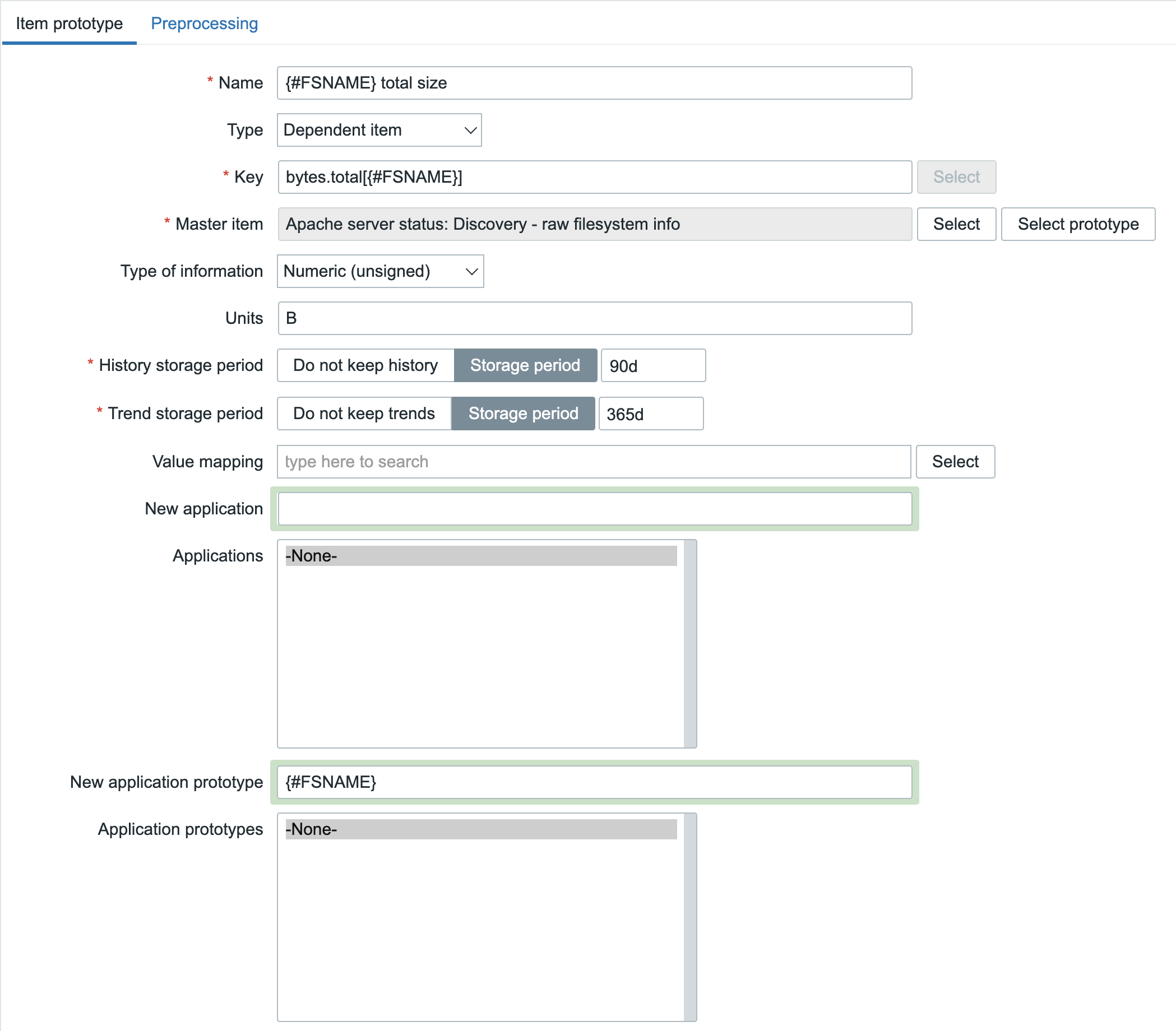
Certificate expiration date item prototype – Dependent item
Define the new item prototype as follows:
- Name: “Certificate [ ID #{#REQUEST_ID} ] {#COMMON_NAME} – Expiration date”
- Type: “Dependent item”
- Key: “certificate.expiration_date[{#REQUEST_ID}]”
- Type of information: “Numeric (unsigned)”
- Master item: pick the previously created master item
- Units: “unixtime”
- History: “1d”

Tags
- “cert_requestor“: “{{#REQUESTOR_NAME}.regsub(“\\(\w+)”, “\1″)}”
- “cert_template1“: “{#TEMPLATE_NAME1}”
- “cert_template2“: “{#TEMPLATE_NAME2}”
- “scope”: “certifcate / expiration date”

As mentioned previously, it makes sense to keep only one template tag later, but for now, such an approach is fine.
The first line requires some explanation:
The requestor name starts with a domain prefix followed by 2 backslashes. If you are submitting CSRs from different domains to this CA server, then you can remove the extra formatting, but in a simple setup, we do not need the domain prefix, since it will be the same for all requestors.
Example: “DOMAIN\\someuser → someuser”
Preprocessing
- JSONPath: “$[?(@.RequestID == {#REQUEST_ID})].NotAfter”
- Regular expression: “(\d+) \1″
- Custom multiplier: “0.001″
- Discard unchanged with heartbeat: “1d”

Explanation:
Since this item is a dependent item, it will point back to our master item, which returns a data block in JSON. Due to the nature of the discovery definitions, we are running a while loop, which is already loaded with our variables (the LLD macros). Therefore the “{#REQUEST_ID}” already has a numerical value within each cycle. With this number, we can go back to the original item and target that exact certificate, which has the same ID. Then we are interested in the NotAfter value considering the selected certificate.
You can find many other examples within Zabbix documentation: jsonpath functionality
At this point, we have the extracted value of the expiration date, but it is quite raw at the moment:
\/Date(1673594922000)\/
In the next step, we are taking the numerical part and then we have to apply a multiplier of 0.001 since by default the time is given in milliseconds. After this, we have an integer, which can be converted to a human-readable form by using the unit “unixtime”. The last line is just a standard discard unchanged entry.
Since our discovery object is also a dependent item, you have to execute our master item to run the low-level discovery rule. The first execution will result in the creation of your certificate items and only the second execution of the master item will execute them all at once. After this point, you should have N certificate objects created and each should have a valid expiration date. This is already something, for which you could define a trigger, but personally, I prefer to see the remaining days and not the exact date itself.
Days to expire item prototype – Calculated item
Let’s define yet another item prototype as follows:
- Name: “Certificate [ ID #{#REQUEST_ID} ] {#COMMON_NAME} – Days to expire”
- Type: “Calculated”
- Key: “certificate.remaining_days[{#REQUEST_ID}]”
- Type of information: “Numeric (float)”
- Formula: “(last(//certificate.expiration_date[{#REQUEST_ID}])-last(//system.localtime))/86400″
- Update interval: “6h”
- History: “1d”

Please do not forget, that you require an existing local time item, which is not provided by this template (but available within “Windows by Zabbix agent*” template).
Tags:
Copy the same tags from the first prototype and only change the last tag to scope: certificate / remaining days

Preprocessing:
- Regular expression: “^(-?\d+)”: “\1”
- Discard unchanged with heartbeat: “1d”

As a result, this will give you a simple number with the remaining days to the expiration date. Then you can decide which item to use in the trigger to implement proper alerting based on your needs.
Certificate expiration trigger prototype
In my case I am just using a simple trigger expression for the remaining days:
- Name: “Certificate will expire within 30 days – {#COMMON_NAME}”
- Operational data: “Expires in {ITEM.LASTVALUE1} days”
- Severity: up to you
- Expression: “last(/Microsoft Certificate Authority – Certificate monitoring/certificate.remaining_days[{#REQUEST_ID}])<=30″

Tags:
- “cert_cn“: “{#COMMON_NAME}”
- “cert_id“: “{#REQUEST_ID}”

When you check the relevant certificates in the Latest data section, then you can do the filtering by the item-based tags. Since we are adding the cert CN and ID only to the trigger, these will appear only in case of alerts. Based on your needs you can implement additional tags, you just have to adjust the PS script to show more properties. When you extend the input data, please always consider the 512KB limit or the configured timeout.
The logic defined in this example can be applied to any JSON formatted data.
Enjoy!
The post JSON is your friend – Certificate monitoring on Microsoft CA server appeared first on Zabbix Blog.