Post Syndicated from Keith Joelner original https://aws.amazon.com/blogs/security/how-to-integrate-aws-sts-sourceidentity-with-your-identity-provider/
You can use third-party identity providers (IdPs) such as Okta, Ping, or OneLogin to federate with the AWS Identity and Access Management (IAM) service using SAML 2.0, allowing your workforce to configure services by providing authorization access to the AWS Management Console or Command Line Interface (CLI). When you federate to AWS, you assume a role through the AWS Security Token Service (AWS STS), which through the AssumeRole API returns a set of temporary security credentials you then use to access AWS resources. The use of temporary credentials can make it challenging for administrators to trace which identity was responsible for actions performed.
To address this, with AWS STS you set a unique attribute called SourceIdentity, which allows you to easily see which identity is responsible for a given action.
This post will show you how to set up the AWS STS SourceIdentity attribute when using Okta, Ping, or OneLogin as your IdP. Your IdP administrator can configure a corporate directory attribute, such as an email address, to be passed as the SourceIdentity value within the SAML assertion. This value is stored as the SourceIdentity element in AWS CloudTrail, along with the activity performed by the assumed role. This post will also show you how to set up a sample policy for setting the SourceIdentity when switching roles. Finally, as an administrator reviewing CloudTrail activity, you can use the source identity information to determine who performed which actions. We will walk you through CloudTrail logs from two accounts to demonstrate the continuance of the source identity attribute, showing you how the SourceIdentity will appear in both accounts’ logs.
For more information about the SAML authentication flow in AWS services, see AWS Identity and Access Management Using SAML. For more information about using SourceIdentity, see How to relate IAM role activity to corporate identity.
Configure the SourceIdentity attribute with Okta integration
You will do this portion of the configuration within the Okta administrative console. This procedure assumes that you have a previously configured AWS and Okta integration. If not, you can configure your integration by following the instructions in the Okta AWS Multi-Account Configuration Guide. You will use the Okta to SAML integration and configure an optional attribute to map as the SourceIdentity.
To set up Okta with SourceIdentity
- Log in to the Okta admin console.
- Navigate to Applications–AWS.
- In the top navigation bar, select the Sign On tab, as shown in Figure 1.

Figure 1 – Navigate to attributes in SAML settings on the Okta applications page
- Under Sign on methods, select SAML 2.0, and choose the arrow next to Attributes (Optional) to expand, as shown in Figure 2.
Figure 2 – Add new attribute SourceIdentity and map it to Okta provided attribute of your choice
- Add the optional attribute definition for SourceIdentity using the following parameters:
- For Name, enter:
https://aws.amazon.com/SAML/Attributes/SourceIdentity - For Name format, choose URI Reference.
- For Value, enter user.login.
Note: The Name format options are the following:
Unspecified – can be any format defined by the Okta profile and must be interpreted by your application.
URI Reference – the name is provided as a Uniform Resource Identifier string.
Basic – a simple string; the default if no other format is specified. - For Name, enter:


The examples shown in Figure 1 and Figure 2 show how to map an email address to the SourceIdentity attribute by using an on-premises Active Directory sync. The SourceIdentity can be mapped to other attributes from your Active Directory.
Configure the SourceIdentity attribute with PingOne integration
You do this portion of the configuration in the Ping Identity administrative console. This procedure assumes that you have a previously configured AWS and Ping integration. If not, you can set up the PingFederate AWS Connector by following the Ping Identity instructions Configuring an SSO connection to Amazon Web Services.
You’re using the Ping to SAML integration and configuring an optional attribute to map as the source identity.
Configuring PingOne as an IdP involves setting up an identity repository (in this case, the PingOne Directory), creating a user group, and adding users to the individual groups.
To configure PingOne as an IdP for AWS
- Navigate to https://admin.pingone.com/ and log in using your administrator credentials.
- Choose the My Applications tab, as shown in Figure 3.
Figure 3. PingOne My Applications tab
- On the Amazon Web Services line, choose on the arrow on the right side to show application details to edit and add a new attribute for the source identity.
- Choose Continue to Next Step to open the Attribute Mapping section, as shown in Figure 4.
Figure 4. Attribute mappings
- In the Attribute Mapping section line 1, for SAML_SUBJECT, choose Advanced.
- On the Advanced Attribute Options page, for Name ID Format to send to SP select urn:oasis:names:tc:SAML:2.0:nameid-format:persistent. For IDP Attribute Name or Literal Value, select SAML_SUBJECT, as shown in Figure 4.
Figure 5. Advanced Attribute Options for SAML_SUBJECT
- In the Attribute Mapping section line 2 as shown in Figure 4, for the application attribute https://aws.amazon.com/SAML/Attributes/Role, select Advanced.
- On the Advanced Attribute Options page, for Name Format, select urn:oasis:names:tc:SAML:2.0:attrname-format:uri, as shown in Figure 6.
Figure 6. Advanced Attribute Options for https://aws.amazon.com/SAML/Attributes/Role
- In the Attribute Mapping section line 2 as shown in Figure 4, select As Literal.
- For IDP Attribute Name or Literal Value, format the role and provider ARNs (which are not yet created on the AWS side) in the following format. Be sure to replace the placeholders with your own values. Make a note of the role name and SAML provider name, as you will be using these exact names to create an IAM role and an IAM provider on the AWS side.
arn:aws:iam::<AWS_ACCOUNT_ID>:role/<IAM_ROLE_NAME>,arn:aws:iam:: ::<AWS_ACCOUNT_ID>:saml-provider/<SAML_PROVIDER_NAME>
- In the Attribute Mapping section line 3 as shown in Figure 4, for the application attribute https://aws.amazon.com/SAML/Attributes/RoleSessionName, enter Email (Work).
- In the Attribute Mapping section as shown in Figure 4, to create line 5, choose Add a new attribute in the lower left.
- In the newly added Attribute Mapping section line 5 as shown in Figure 4, add the SourceIdentity.
- For Application Attribute, enter:
https://aws.amazon.com/SAML/Attributes/SourceIdentity - For Identity Bridge Attribute or Literal Value, enter:
SAML_SUBJECT
- For Application Attribute, enter:
- Choose Continue to Next Step in the lower right.
- For Group Access, add your existing PingOne Directory Group to this application.
- Review your setup configuration, as shown in Figure 7, and choose Finish.
Figure 7. Review mappings





Configure the SourceIdentity attribute with OneLogin integration
For the OneLogin SAML integration with AWS, you use the Amazon Web Services Multi Account application and configure an optional attribute to map as the SourceIdentity. You do this portion of the configuration in the OneLogin administrative console.
This procedure assumes that you already have a previously configured AWS and OneLogin integration. For information about how to configure the OneLogin application for AWS authentication and authorization, see the OneLogin KB article Configure SAML for Amazon Web Services (AWS) with Multiple Accounts and Roles.
After the OneLogin Multi Account application and AWS are correctly configured for SAML login, you can further customize the application to pass the SourceIdentity parameter upon login.
To change OneLogin configuration to add SourceIdentity attribute
- In the OneLogin administrative console, in the Amazon Web Services Multi Account application, on the app administration page, navigate to Parameters, as shown in Figure 8.
Figure 8. OneLogin AWS Multi Account Application Configuration Parameters
- To add a parameter, choose the + (plus) icon to the right of Value.
- As shown in Figure 9, for Field Name enter https://aws.amazon.com/SAML/Attributes/SourceIdentity, select Include in SAML assertion, then choose Save.

Figure 9. OneLogin AWS Multi Account Application add new field
- In the Edit Field page, select the default value you want to use for SourceIdentity. For the example in this blog post, for Value, select Email, then choose Save, as shown in Figure 10.

Figure 10. OneLogin AWS Multi Account Application map new field to email



After you’ve completed this procedure, review the final mapping details, as shown in Figure 11, to confirm that you see the additional parameter that will be passed into AWS through the SAML assertion.
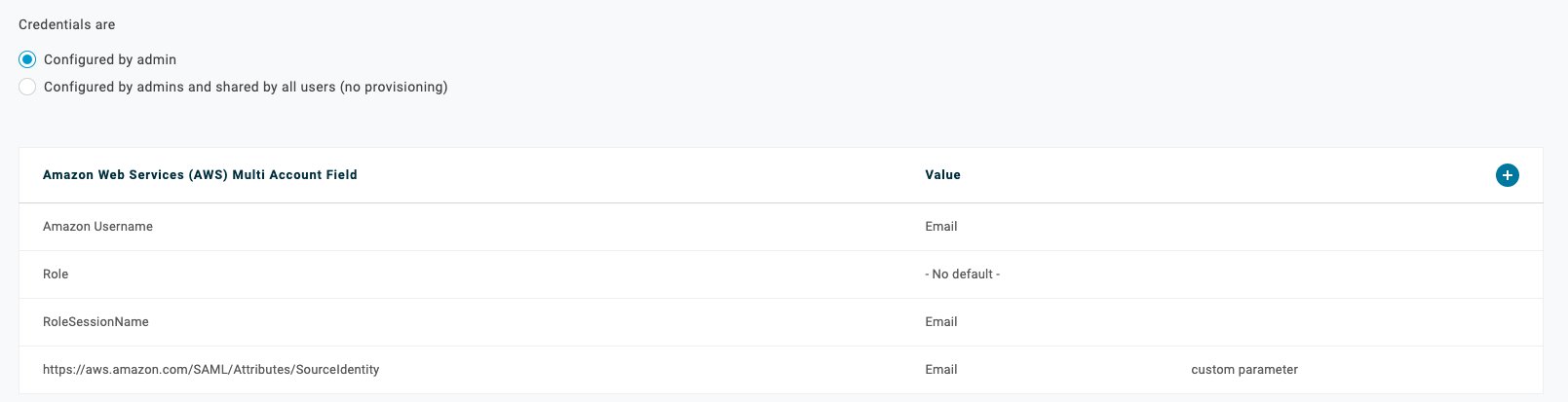
Figure 11. OneLogin AWS Multi Account Application final mapping details
Configuring AWS IAM role trust policy
Now that the IdP configuration is complete, you can enable your AWS accounts to use SourceIdentity by modifying the IAM role trust policy.
For the workforce identity or application to be able to define their source identity when they assume IAM roles, you must first grant them permission for the sts:SetSourceIdentity action, as illustrated in the sample policy document below. This will permit the workforce identity or application to set the SourceIdentity themselves without any need for manual intervention.
To modify an AWS IAM role trust policy
- Log in to the AWS Management Console for your account as a user with privileges to configure an IdP, typically an administrator.
- Navigate to the AWS IAM service.
- For trusted identity, choose SAML 2.0 federation.
- From the SAML Provider drop down menu, select the IAM provider you created previously.
- Modify the role trust policy and add the SetSourceIdentity action.
Sample policy document
This is a sample policy document attached to a role you assume when you log in to Account1 from the Okta dashboard. Edit your Account1/Role1 trust policy document and add sts:AssumeRoleWithSAML and sts:setSourceIdentity to the Action section.
Notes: The SetSourceIdentity action has to be allowed in the trust policy for assumeRole to work when the IdP is set up to pass SourceIdentity in the assertion. Future version of the sign-in URL may contain a Region code. When this occurs, you will need to modify the URL appropriately.
Policy statement
The following are examples of how the line “Federated”: “arn:aws:iam::<AccountId>:saml-provider/<IdP>” should look, based on the different IdPs specified in this post:
- “Federated”: “arn:aws:iam::12345678990:saml-provider/Okta”
- “Federated”: “arn:aws:iam::12345678990:saml-provider/PingOne”
- “Federated”: “arn:aws:iam::12345678990:saml-provider/OneLogin”
Modify Account2/Role2 policy statement
The following is a sample access control policy document in Account2 for Role2 that allows you to switchRole from Account1. Edit the control policy and add sts:AssumeRole and sts:SetSourceIdentity in the Action section.
Trace the SourceIdentity attribute in AWS CloudTrail
Use the following procedure for each IdP to illustrate passing a corporate directory attribute mapped as the SourceIdentity.
To trace the SourceIdentity attribute in AWS CloudTrail
- Use an IdP to log in to an account Account1 (111122223333) using a role named Role1.
- Create a new Amazon Simple Storage Service (Amazon S3) bucket in Account1.
- Validate that the CloudTrail log entries for Account1 contain the Active Directory mapped SourceIdentity.
- Use the Switch Role feature to switch to a second account Account2 (444455556666), using a role named Role2.
- Create a new Amazon S3 bucket in Account2.
To summarize what you’ve done so far, you have:
- Configured your corporate directory to pass a unique attribute to AWS as the source identity.
- Configured a role that will persist the SourceIdentity attribute in AWS STS, which an employee will use to federate into your account.
- Configured an Amazon S3 bucket that user will access.
Now you’ll observe in CloudTrail the SourceIdentity attribute that will be associated with every IAM action.
To see the SourceIdentity attribute in CloudTrail
- From the your preferred IdP dashboard, select the AWS tile to log into the AWS console. The example in Figure 12 shows the Okta dashboard.
Figure 12. Login to AWS from IdP dashboard
- Choose the AWS icon, which will take you to the AWS Management Console. Notice how the user has assumed the role you created earlier.
- To test the SourceIdentity action, you will create a new Amazon S3 bucket.
Amazon S3 bucket names are globally unique, and the namespace is shared by all AWS accounts, so you will need to create a unique bucket name in your account. For this example, we used a bucket named DOC-EXAMPLE-BUCKET1 to validate CloudTrail log entries containing the SourceIdentity attribute.
- Log into an account Account1 (111122223333) using a role named Role1.
- Next, create a new Amazon S3 bucket in Account1, and validate that the Account1 CloudTrail logs entries contain the SourceIdentity attribute.
- Create an Amazon S3 bucket called DOC-EXAMPLE-BUCKET1, as shown in Figure 13.
Figure 13. Create S3 bucket
- In the AWS Management Console go to CloudTrail and check the log entry for bucket creation event, as shown in Figure 14.
Figure 14 – Bucket creating entry in CloudTrail



Sample CloudTrail entry showing SourceIdentity entry
The following example shows the new sourceIdentity entry added to the JSON message for the CreateBucket event above.
- Switch to Account2 (444455556666) using assume role, and switch to Account2/assumeRoleSourceIdentity.
- Create a new Amazon S3 bucket in Account2 and validate that the Account2 CloudTrail log entries contain the SourceIdentity attribute, as shown in Figure 15.
Figure 15 – Switch role to assumeRoleSourceIdentity
- Create a new Amazon S3 bucket in account2 called DOC-EXAMPLE-BUCKET2, as shown in Figure 16.
Figure 16 – Create DOC-EXAMPLE-BUCKET2 bucket while logged into account2 using assumeRoleSourceIdentity
- Check the CloudTrail logs for account2 (444455556666) to see if the original SourceIdentity is logged, as shown in Figure 17.
Figure 17 – CloudTrail log entry for the above action



CloudTrail entry showing original SourceIdentity after assuming a role
You logged into Account1/Role1 and switched to Account2/Role2. All the user activities performed in AWS using the Assume Role were also logged with the original user’s sourceIdentity attribute. This makes it simple to trace user activity in CloudTrail.
Conclusion
Now that you have configured your SourceIdentity, you have made it easier for the security team of your organization to use CloudTrail logs to investigate and identify the originating identity of a user. In this post, you learned how to configure the AWS STS SourceIdentity attribute for three different popular IdPs, as well as how to configure each IdP using SAML and their optional attributes. We also provided sample control policy documents outlining how to configure the SourceIdentity for each provider. Additionally, we provide a sample policy for setting the SourceIdentity when switching roles. Lastly, the post walks through how the source identity will show in CloudTrail logs, and provides logs from two accounts to demonstrate the continuance of the source identity attribute. You can now test this capability yourself in your own environment, validate activity in your CloudTrail logs, and determine which user performed a specific action while using the assumeRole functionality.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.








