Post Syndicated from Jeremy Cowan original https://aws.amazon.com/blogs/security/how-to-connect-your-on-premises-active-directory-to-aws-using-ad-connector/
August 17, 2023: We updated the instructions and screenshots in this post to align with changes to the AWS Management Console.
April 25, 2023: We’ve updated this blog post to include more security learning resources.
AD Connector is designed to give you an easy way to establish a trusted relationship between your Active Directory and AWS. When AD Connector is configured, the trust allows you to:
- Sign in to AWS applications such as Amazon WorkSpaces, Amazon WorkDocs, and Amazon WorkMail by using your Active Directory credentials.
- Seamlessly join Windows instances to your Active Directory domain either through the Amazon EC2 launch wizard or programmatically through the EC2 Simple System Manager (SSM) API.
- Provide federated sign-in to the AWS Management Console by mapping Active Directory identities to AWS Identity and Access Management (IAM) roles.
AD Connector cannot be used with your custom applications, as it is only used for secure AWS integration for the three use-cases mentioned above. Custom applications relying on your on-premises Active Directory should communicate with your domain controllers directly or utilize AWS Managed Microsoft AD rather than integrating with AD Connector. To learn more about which AWS Directory Service solution works best for your organization, see the service documentation.
With AD Connector, you can streamline identity management by extending your user identities from Active Directory. It also enables you to reuse your existing Active Directory security policies such as password expiration, password history, and account lockout policies. Also, your users will no longer need to remember yet another user name and password combination. Since AD Connector doesn’t rely on complex directory synchronization technologies or Active Directory Federation Services (AD FS), you can forego the added cost and complexity of hosting a SAML-based federation infrastructure. In sum, AD Connector helps foster a hybrid environment by allowing you to leverage your existing on-premises investments to control different facets of AWS.
This blog post will show you how AD Connector works as well as walk through how to enable federated console access, assign users to roles, and seamlessly join an EC2 instance to an Active Directory domain.
AD Connector – Under the Hood
AD Connector is a dual Availability Zone proxy service that connects AWS apps to your on-premises directory. AD Connector forwards sign-in requests to your Active Directory domain controllers for authentication and provides the ability for applications to query the directory for data. When you configure AD Connector, you provide it with service account credentials that are securely stored by AWS. This account is used by AWS to enable seamless domain join, single sign-on (SSO), and AWS Applications (WorkSpaces, WorkDocs, and WorkMail) functionality. Given AD Connector’s role as a proxy, it does not store or cache user credentials. Rather, authentication, lookup, and management requests are handled by your Active Directory.
In order to create an AD Connector, you must also provide a pair of DNS IP addresses during setup. These are used by AD Connector to retrieve Service (SRV) DNS records to locate the nearest domain controllers to route requests to. The AD connector proxy instances use an algorithm similar to the Active Directory domain controller locator process to decide which domain controllers to connect to for LDAP and Kerberos requests.
For authentication to AWS applications and the AWS Management Console, you can configure an access URL from the AWS Directory Service console. This access URL is in the format of https://<alias>.awsapps.com and provides a publicly accessible sign-in page. You can visit https://<alias>.awsapps.com/workdocs to sign in to WorkDocs, and https://<alias>.awsapps.com/console to sign in to the AWS Management Console. The following image shows the sign-in page for the AWS Management Console.

Figure 1: Login
For added security you can enable multi-factor authentication (MFA) for AD Connector, but you’ll need to have an existing RADIUS infrastructure in your on-premises network set up to leverage this feature. See AD Connector – Multi-factor Authentication Prerequisites for more information about requirements and configuration. With MFA enabled with AD Connector, the sign-in page hosted at your access URL will prompt users for an MFA code in addition to their standard sign-in credentials.
AD Connector comes in two sizes: small and large. A large AD Connector runs on more powerful compute resources and is more expensive than a small AD Connector. Depending on the volume of traffic to be proxied by AD Connector, you’ll want to select the appropriate size for your needs.

Figure 2: Directory size
AD Connector is highly available, meaning underlying hosts are deployed across multiple Availability Zones in the region you deploy. In the event of host-level failure, Directory Service will promptly replace failed hosts. Directory Service also applies performance and security updates automatically to AD Connector.
The following diagram illustrates the authentication flow and network path when you enable AWS Management Console access:
- A user opens the secure custom sign-in page and supplies their Active Directory user name and password.
- The authentication request is sent over SSL to AD Connector.
- AD Connector performs LDAP authentication to Active Directory.
Note: AD Connector locates the nearest domain controllers by querying the SRV DNS records for the domain.
- After the user has been authenticated, AD Connector calls the STS AssumeRole method to get temporary security credentials for that user. Using those temporary security credentials, AD Connector constructs a sign-in URL that users use to access the console.
Note: If a user is mapped to multiple roles, the user will be presented with a choice at sign-in as to which role they want to assume. The user session is valid for 1 hour.

Figure 3: Authentication flow and network path

Before getting started with configuring AD Connector for federated AWS Management Console access, be sure you’ve read and understand the prerequisites for AD Connector. For example, as shown in Figure 3 there must be a VPN or Direct Connect circuit in place between your VPC and your on-premises environment. Your domain also has to be running at Windows 2003 functional level or later. Also, various ports have to be opened between your VPC and your on-premises environment to allow AD Connector to communicate with your on-premises directory.
Configuring AD Connector for federated AWS Management Console access
Enable console access
To allow users to sign in with their Active Directory credentials, you need to explicitly enable console access. You can do this by opening the Directory Service console and clicking the Directory ID name (Figure 4).
This opens the Directory Details page, where you’ll find a dropdown menu on the Apps & Services tab to enable the directory for AWS Management Console access.

Figure 4: Directories
Choose the Application management tab as seen in Figure 5.

Figure 5: Application Management
Scroll down to AWS Management Console as shown in Figure 6, and choose Enable from the Actions dropdown list.

Figure 6: Enable console access
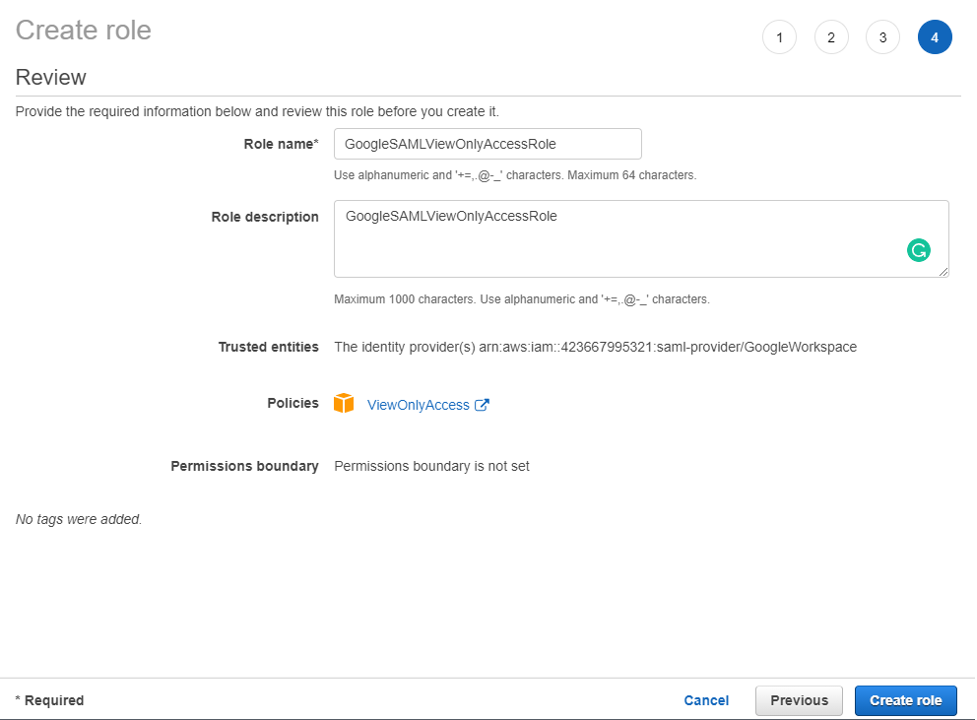
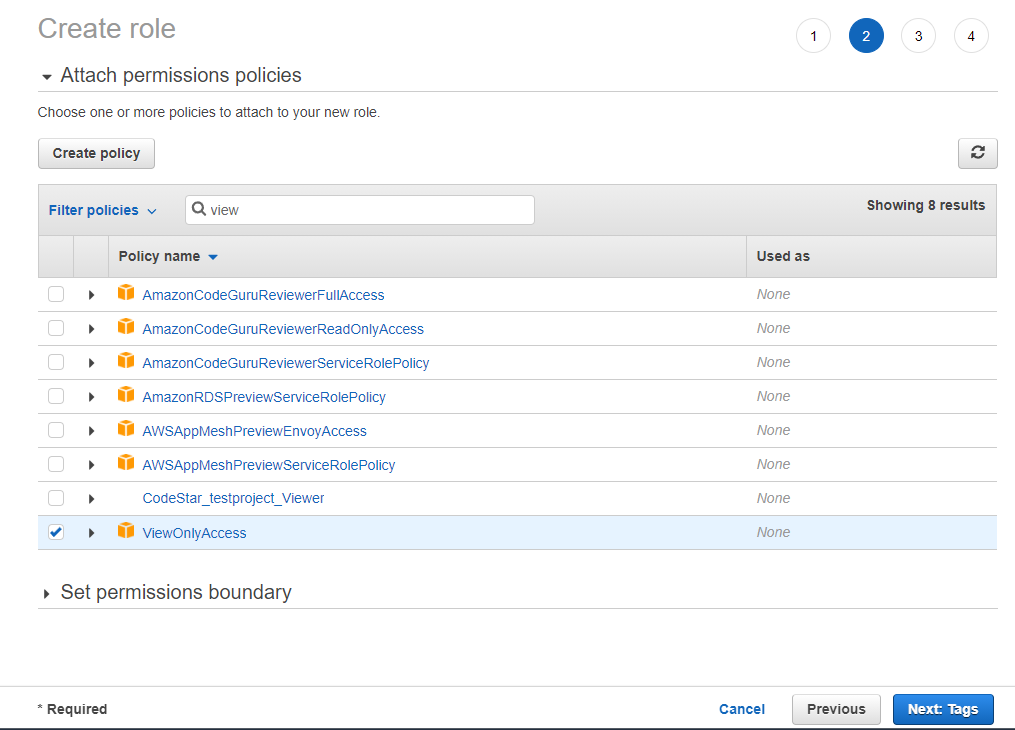
After enabling console access, you’re ready to start configuring roles and associating Active Directory users and groups with those roles.
Follow these steps to create a new role. When you create a new role through the Directory Service console, AD Connector automatically adds a trust relationship to Directory Service. The following code example shows the IAM trust policy for the role, after a role is created.
Assign users to roles
Now that AD Connector is configured and you’ve created a role, your next job is to assign users or groups to those IAM roles. Role mapping is what governs what resources a user has access to within AWS. To do this you’ll need to do the following steps:
- Open the Directory Service console and navigate to the AWS Management Console section.
- In the search bar, type the name of the role you just created.
- Select the role that you just created by choosing the name under the IAM role field.
- Choose Add, and enter the name to be added to find users or groups for this role.
- Choose Add, and the user or group is now assigned to the role.
When you’re finished, you should see the name of the user or group along with the corresponding ID for that object. It is also important to note that this list can be used to remove users or groups from the role. The next time the user signs in to the AWS Management Console from the custom sign-in page, they will be signed in under the EC2ReadOnly security role.
Seamlessly join an instance to an Active Directory domain
Another advantage to using AD Connector is the ability to seamlessly join Windows (EC2) instances to your Active Directory domain. This allows you to join a Windows Server to the domain while the instance is being provisioned instead of using a script or doing it manually. This section of this blog post will explain the steps necessary to enable this feature in your environment and how the service works.
Step 1: Create a role
Until recently you had to manually create an IAM policy to allow an EC2 instance to access the SSM, an AWS service that allows you to configure Windows instances while they’re running and on first launch. Now, there’s a managed policy called AmazonEC2RoleforSSM that you can use instead. The role you are about to create will be assigned to an EC2 instance when it’s provisioned, which will grant it permission to access the SSM service.
To create the role:
- Open the IAM console.
- Click Roles in the navigation pane.
- Click Create Role.
- Type a name for your role in the Role Name field.
- Under AWS Service Roles, select Amazon EC2 and then click Select.
- On the Attach Policy page, select AmazonEC2RoleforSSM and then click Next Step.
- On the Review page, click Create Role.
If you click the role you created, you’ll see a trust policy for EC2, which looks like the following code example.
Step 2: Create a new Windows instance from the EC2 console
With this role in place, you can now join a Windows instance to your domain via the EC2 launch wizard. For a detailed explanation about how to do this, see Joining a Domain Using the Amazon EC2 Launch Wizard.
If you’re instantiating a new instance from the API, however, you will need to create an SSM configuration document and upload it to the SSM service beforehand. We’ll step through that process next.
Note: The instance will require internet access to communicate with the SSM service.
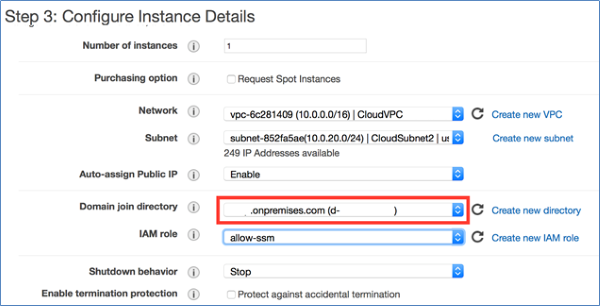
Figure 7: Configure instance details
When you create a new Windows instance from the EC2 launch wizard as shown in Figure 7, the wizard automatically creates the SSM configuration document from the information stored in AD Connector. Presently, the EC2 launch wizard doesn’t allow you to specify which organizational unit (OU) you want to deploy the member server into.
Step 3: Create an SSM document (for seamlessly joining a server to the domain through the AWS API)
If you want to provision new Windows instances from the AWS CLI or API or you want to specify the target OU for your instances, you will need to create an SSM configuration document. The configuration document is a JSON file that contains various parameters used to configure your instances. The following code example is a configuration document for joining a domain.
In this configuration document:
- directoryId is the ID for the AD Connector you created earlier.
- directoryName is the name of the domain (for example, examplecompany.com).
- directoryOU is the OU for the domain.
- dnsIpAddresses are the IP addresses for the DNS servers you specified when you created the AD Connector.
For additional information, see aws:domainJoin. When you’re finished creating the file, save it as a JSON file.
Note: The name of the file has to be at least 1 character and at most 64 characters in length.
Step 4: Upload the configuration document to SSM
This step requires that the user have permission to use SSM to configure an instance. If you don’t have a policy that includes these rights, create a new policy by using the following JSON, and assign it to an IAM user or group.
After you’ve signed in with a user that associates with the SSM IAM policy you created, run the following command from the AWS CLI.
Note: On Linux/Mac systems, you need to add a “/” at the beginning of the path (for example, file:///Users/username/temp).
This command uploads the configuration document you created to the SSM service, allowing you to reference it when creating a new Windows instance from either the AWS CLI or the EC2 launch wizard.
Conclusion
This blog post has shown you how you can simplify account management by federating with your Active Directory for AWS Management Console access. The post also explored how you can enable hybrid IT by using AD Connector to seamlessly join Windows instances to your Active Directory domain. Armed with this information you can create a trust between your Active Directory and AWS. In addition, you now have a quick and simple way to enable single sign-on without needing to replicate identities or deploy additional infrastructure on premises.
We’d love to hear more about how you are using Directory Service, and welcome any feedback about how we can improve the experience. You can post comments below, or visit the Directory Service forum to post comments and questions.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, start a new thread on the AWS Directory Service knowledge Center re:Post or contact AWS Support.
Want more AWS Security news? Follow us on Twitter.