Post Syndicated from Edgars Melveris original https://blog.zabbix.com/a-guide-to-migrating-to-zabbix-6-0-lts-by-edgars-melveris-zabbix-summit-online-2021/18569/
Upgrading to a new software version can be an intimidating process, especially if you are upgrading your Zabbix instance for the first time. In this blog post, we will take a look at the upgrade process itself, the necessary pre-requisites, and also what changes you can expect to the existing functionality when you’ve migrated to Zabbix 6.0 LTS.
The full recording of the speech is available on the official Zabbix Youtube channel.
Pre-upgrade checklist
Database versions
The first step before performing the upgrade to a new Zabbix version is ensuring that your underlying infrastructure is ready for the upgrade process. There are some changes in Zabbix that you should be aware of and address before the upgrade. One of these changes is the list of supported database engines and their versions for Zabbix 6.0 LTS:
- MySQL/Percona 8.0.x
- MariaDB 10.5.0 -10.6.x
- PostgreSQL 13.x
- Oracle 19c – 21c
And if you’re using PostgreSQL + TimescaleDB or Zabbix proxies:
- TimescaleDB 2.0.1-2.3
- SQLite 3.3.5 – 3.34.x
You may have noticed that we have increased the version requirements for the Zabbix backend databases. The reason for this is Zabbix utilizes the features that only these newer database versions provide, thus ensuring optimal Zabbix performance. If you’re using an unsupported database version, Zabbix will not start. There will be a configuration parameter to override this behavior, but that is not recommended since we cannot ensure that your Zabbix version will work without encountering any performance issues or crashes. A database upgrade to a supported version should be performed first before moving to Zabbix 6.0 LTS.
Supported operating systems
Zabbix supports all Linux distributions and many other Unix-like operating systems. Unfortunately, it is not feasible to provide Zabbix packages for each and every distribution out there. One of the major changes that were made back in Zabbix 5.2 – we no longer provide packages for RHEL/CentOS 7. This is because some of the libraries included in these distributions are outdated, and it becomes more and more complicated to build Zabbix on these OS versions. Though it is still possible to build Zabbix from sources if you provide the correct versions of the required libraries.
Some of the officially supported operating systems for Zabbix 6.0 LTS:
- RHEL/CentOS/Oracle Linux 8
- Ubuntu 18.04+
- Debian 10+
- SLES 12+
Other installation options
There are additional Zabbix deployment options:
- Docker – all of the dependencies are already provided in the official docker images
- Cloud image – the image includes all of the required dependencies
- Zabbix appliance – All of the available Zabbix appliance images contain the required dependencies
Environment review
Before upgrading between major Zabbix versions, it is very much recommended to do an environment review and take a look at the pending maintenance tasks for our environment and also do a health check. Some of the things that we should consider before performing the upgrade to Zabbix 6.0 LTS:
- Apply any required OS or DB upgrades before upgrading Zabbix and check for any issues before moving on
- Check for any customizations in your installation – are there any DB schema changes? Any custom modules or patches?
- The best way to test this is to make a copy of your existing Zabbix instance and test the upgrade in a QA environment.
- Are the required packages available for all of the Zabbix components?
- Are all proxies installed on the supported OS versions?
- Check the documentation for any known issues in the version to which you are upgrading
Important changes that affect the upgrade process
There are some changes in Zabbix 6.0 LTS that could potentially affect the upgrade process or your existing Zabbix workflows.
API Changes
Below is a list of documentation pages related to API changes between versions 5.0 and 6.0:
- https://www.zabbix.com/documentation/6.0/manual/api/changes_5.4_-_6.0
- https://www.zabbix.com/documentation/current/manual/api/changes_5.2_-_5.4
- https://www.zabbix.com/documentation/5.2/manual/api/changes_5.0_-_5.2
Some of the more important API changes:
- Trigger and calculated/aggregated item syntax change introduced in Zabbix 5.4 also change the API calls responsible for creating triggers (ZBXNEXT-6451)
- You will need to change the trigger syntax in your API calls to avoid any issues
- For user.create and user.update methods the user_medias parameter was renamed to medias (ZBX-17955)
- user_medias parameter is now deprecated
- The type property is no longer supported for user.create, user.update, and user.get methods (ZBXNEXT-6148)
- The type property is not supported for the user object since we now define it in user roles
- Items no longer support applications. Applications have been replaced with tags (ZBXNEXT-2976)
- Since value maps can no longer be defined globally, the valuemap.create and valuemap.get methods now require a hostid field (ZBXNEXT-5868)
Other important changes
There are a couple of important changes that users should be aware of when migrating to Zabbix 6.0 LTS:
- Previously, trailing spaces in passwords – both when setting a password and entering it, were trimmed. This has been changed, and trailing spaces in passwords are no longer trimmed.
- Global value maps that remain unused will be removed
- Existing audit log records will be removed due to major changes in the audit log design.
Upgrade steps
Next, let’s discuss the steps that you should take to perform the upgrade procedure in a correct and safe manner:
- Backup your database, as well as any customizations (external scripts, alert scripts) and configuration files
- Update the Zabbix server and Zabbix frontend
- Once the new Zabbix server process is started, it will automatically check the database schema version and automatically upgrade it
- Depending on the database size and the version from which you are migrating – this can take a while
- Once the automatic database schema upgrade is done, the Zabbix server will be started automatically
- Update your proxies. Proxies are required to have the same major version as the Zabbix server
- Check if there are no issues and your Zabbix instance is up and running
- Check if the metrics are being collected by your Zabbix server and Zabbix proxies
- Check if the triggers are detecting any problems and if you’re receiving notifications about them
Backup
Let’s take a more in-depth look at the backup process and discuss the required steps with some examples:
- Backup the database – methods depend on the DB type
- In most cases, you can ignore history and trends tables – simply backing up only your configuration data
- History and trends tables tend to be extremely large. That’s why the above approach is a lot faster
- If at some point you are required to perform a restore from this backup, history, and trends tables will have to be manually recreated
- Backup the Zabbix configuration files
- Optionally – backup any custom alert scripts, external scripts, and any other customizations
Example MySQL database backup with history and trends tables ignored:
mysqldump -uroot -p --single-transaction --ignore-table=zabbix.history --ignore-table=zabbix.history_uint --ignoretable=zabbix.history_text --ignore-table=zabbix.history_log --ignore-table=zabbix.history_str --ignore-table=zabbix.trends --ignore-table=zabbix.trends_uint zabbix | gzip > zabbix_backup.sql.gz
Backing up the configuration
At the very least, you should back up the configuration files located in:
- /etc/zabbix/*
- external scripts from /usr/lib/zabbix/externalscripts/
- alert scripts from /usr/lib/zabbix/alertscripts
- /etc/httpd/conf.d/zabbix.conf
- /etc/php-fpm.d/zabbix.conf
Upgrade process with docker
There are multiple approaches to running Zabbix in docker. For this example, we will assume that you’re running Zabbix server and Zabbix frontend in docker and using the official Zabbix docker images with a MySQL backend database and apache web backend.
Stop the Zabbix server, frontend, and proxy containers:
docker stop my-zabbix-server
docker stop my-zabbix-frontend
Start the Zabbix 6.0 LTS container and point it at the same backend database:
docker run --name my-zabbix-server-6.0 -e DB_SERVER_HOST="some-mysql-server" -e MYSQL_USER="some-user" -e MYSQL_PASSWORD="some-password" -d zabbix/zabbixserver-mysql:6.0-latest
Once again, an automatic DB schema upgrade will be started
Lastly, start the Zabbix frontend container:
docker run --name my-zabbix-web-apache-6.0 -e DB_SERVER_HOST="some-mysqlserver" -e MYSQL_USER="some-user" -e MYSQL_PASSWORD="some-password" -e ZBX_SERVER_HOST= "my-zabbix-server-6.0" -d zabbix/zabbix-web-apache-mysql:6.0-latest
Upgrade process with Zabbix packages
Upgrading the main Zabbix components
If you’re using the official Zabbix packages, then the upgrade process will take a few more steps and can seem a bit more complicated. Let’s take a look at the required upgrade steps in detail. For our example, we will use a CentOS 8 OS distribution.
Install the Zabbix 6.0 LTS release package. This will add the necessary Zabbix 6.0 LTS repository information:
rpm -Uvh https://repo.zabbix.com/zabbix/6.0/rhel/8/x86_64/zabbix-release-6.0-1.el8.noarch.rpm
Clear the DNF package manager cache:
dnf clean all
Install all of the required packages:
dnf install zabbix-server-mysql zabbix-web zabbix-web-mysql zabbix-web-deps zabbix-apache-conf zabbix-selinux-policy
Start Zabbix components and observe the log file. You should see that the database schema upgrade is in progress. Once it has finished, all of the internal Zabbix processes should be started without any issues:
17602:20210921:131335.333 completed 96% of database upgrade 17602:20210921:131335.355 completed 97% of database upgrade 17602:20210921:131335.379 completed 98% of database upgrade 17602:20210921:131335.606 completed 99% of database upgrade 17602:20210921:131335.711 completed 100% of database upgrade 17602:20210921:131335.711 database upgrade fully completed 17602:20210921:131335.804 server #0 started [main process] 17602:20210921:131335.808 server #2 started [configuration syncer #1] 17602:20210921:131335.810 server #1 started [service manager #1]
Upgrading the Zabbix proxies
In addition, we are also required to update our Zabbix proxies. The procedure is very similar to what we did in our previous steps:
Install the Zabbix 6.0 LTS release package:
rpm -Uvh https://repo.zabbix.com/zabbix/6.0/rhel/8/x86_64/zabbix-release-6.0-1.el8.noarch.rpm
Clear the DNF package manager cache:
dnf clean all
Update the Zabbix proxy packages:
dnf update zabbix-proxy-mysql(pgsql, sqlite3)
For MySQL, PostgreSQL, and Oracle proxy backend databases, the DB schema is performed automatically.
For Zabbix proxies using SQLite3 backend databases, automatic database schema upgrade is not supported. We will simply have to remove the old SQLite3 database file – it will then be automatically recreated once we start the Zabbix proxy.
rm –rf /tmp/proxy.sqlite
Post-upgrade tasks
After the upgrade to Zabbix 6.0 LTS, there are a few additional tasks that we should take care of. Let’s take a look at what needs to be done.
History table primary key
Zabbix 6.0 LTS backend database history table schema has been changed. These tables now contain primary keys. The upgrade or these history tables is not done automatically since it can cause additional downtime. Depending on the size of the database, executing the required changes can be extremely slow since every record in the history tables needs to be altered. In addition, duplicate entries in history tables could potentially cause this manual database schema upgrade to fail. There are multiple benefits to the history table schema changes:
- All history tables will now have primary keys
- Decreased history table storage size
- Increased history table query performance
- Not recommended when upgrading an existing instance
For new Zabbix 6.0 LTS installations, this change will be included by default, while for the existing installations, it is recommended to thoroughly test the history table schema change procedure and evaluate the potential downtimes. The exact history table upgrade steps will be documented with the release of Zabbix 6.0 LTS.
Check new processes
There are some new Zabbix processes that have been added to Zabbix 6.0 LTS that yous should be aware of:
- StartHistoryPollers
- The process responsible for handling calculated, aggregated, and internal checks requiring a database connection
- The default value is 5. Consider increasing this number if you have many such items
- If migrating from 4.0: StartLLDProcessors
- Worker process for low-level discovery tasks
- The default value is 2. Consider increasing if you have many low-level discovery rules.
Update the existing templates
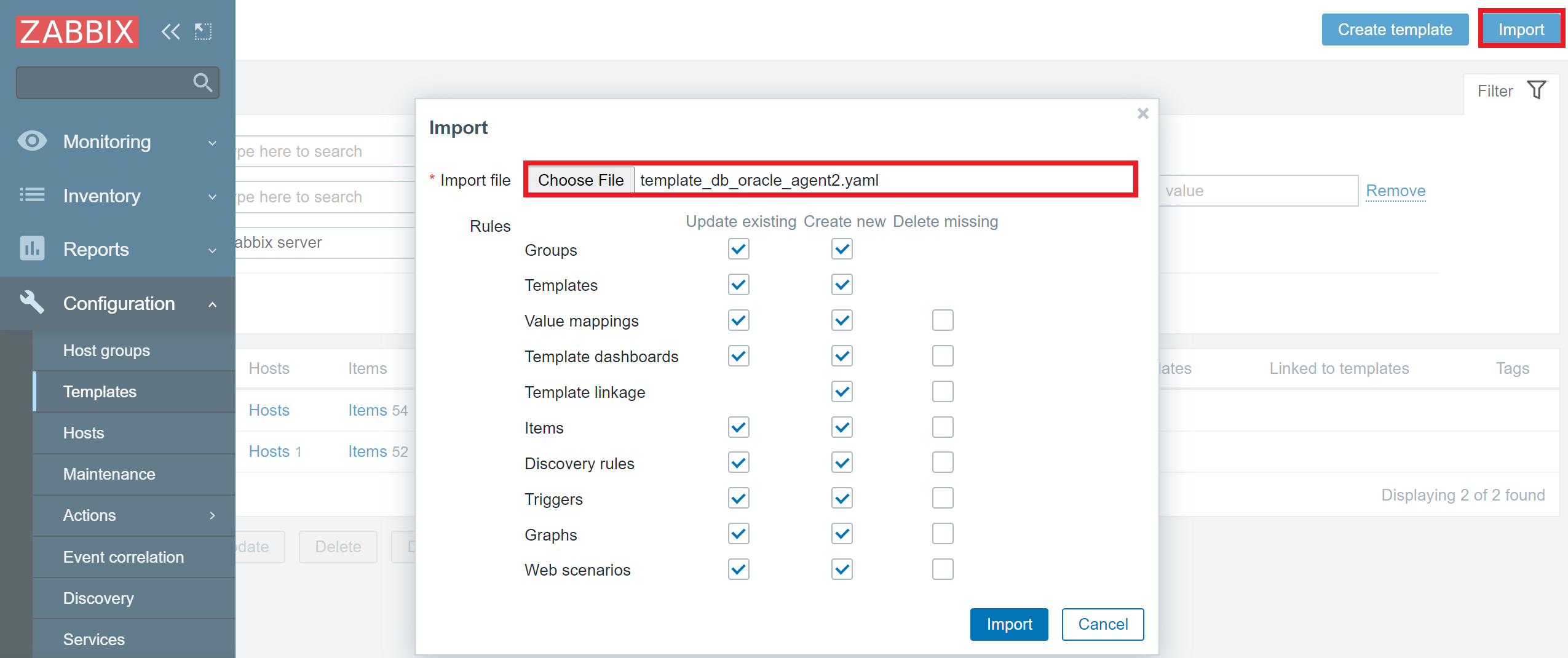
If you’ve performed a Zabbix upgrade before, you will be aware of the fact that Zabbix does not update your existing templates automatically since we assume there could be some custom changes performed by the end-users on said templates. Therefore, to see the aforementioned new processes in the Zabbix server internal monitoring graphs, you should download and import the latest Zabbix server template.
You can download the templates from the official Zabbix git page. You can read the release notes to see the full list of the updated templates and changes that have been performed on said templates.
Update the Zabbix agents
You may also consider upgrading your Zabbix agents. This is not mandatory since Zabbix agents are backward compatible, so you can use an older version of Zabbix agents with Zabbix 6.0 LTS. All of the previous functionality will continue to function, but you may still consider updating the agents since the updates could contain some bug fixes or support for a brand new set of items.
Upgrading the Zabbix agent:
dnf install zabbix-agent
Upgrading the Zabbix agent 2:
dnf install zabbix-agent2
New Zabbix packages
You may have noticed that in Zabbix 6.0 LTS, there are multiple new packages. Most of these packages are repackagings of some of the old components for better package management, but there are exceptions:
- zabbix-selinux-policy – basic SELinux policy for Zabbix
- zabbix-sql-scripts – All of the .sql backend database scripts
- These used to be a part of the zabbix-server package
- This package is required to, for example, deploy the initial Zabbix database schema or data during the Zabbix install process.
- zabbix-web-service – The service responsible for the scheduled report generation
Questions
Q: Are my custom templates going to be affected in any way by the upgrade process?
A: Yes, all of your templates will continue to work. Any changes that we have made to trigger syntax, for example, will be automatically applied to your existing entities.
Q: How long will the migration process take? How can I estimate the downtime?
A: Unfortunately, it’s impossible to estimate a precise downtime duration without creating a QA copy of your existing Zabbix instance with the same exact hardware and checking the downtime duration there with a test upgrade. At the end of the day, this will depend not only on the size of the database but also on the size of individual tables, the version from which you are upgrading, and how optimized your software and hardware are.
Q: What about migrating from a very old version – say Zabbix 3.0 or older?
A: It should work, but there can be some caveats and additional pre-requisites required for the older version upgrades. I would recommend going through our previous Summit recordings since we have covered the upgrade process for older versions in previous years. Those should provide you a pre-requisite checklist that you can perform before upgrading to Zabbix 6.0 LTS.
The post A guide to migrating to Zabbix 6.0 LTS by Edgars Melveris / Zabbix Summit Online 2021 appeared first on Zabbix Blog.