Post Syndicated from Arturs Lontons original https://blog.zabbix.com/whats-new-in-zabbix-7-4/30597/
With the release of Zabbix 7.4, Zabbix users will be able to further extend their existing resource discovery workflows and enjoy a wastly improved user experience when it comes to configuring Zabbix entities. In addition, the latest release introduces multiple dashboard and network map improvements which will further enhance the visualization of infrastructure and resources.
Table of Contents
Host Wizard
Host creation can be somewhat confusing for Zabbix beginners. Creating a host and applying a template involves numerous steps – from creating a host and assigning it to a host group, to configuring appropriate host interfaces, applying a template, and editing template-level macros to adjust the default problem thresholds and filters.
The Host Wizard aims to simplify the host onboarding process by providing a step-by-step guide for creating and configuring a host.
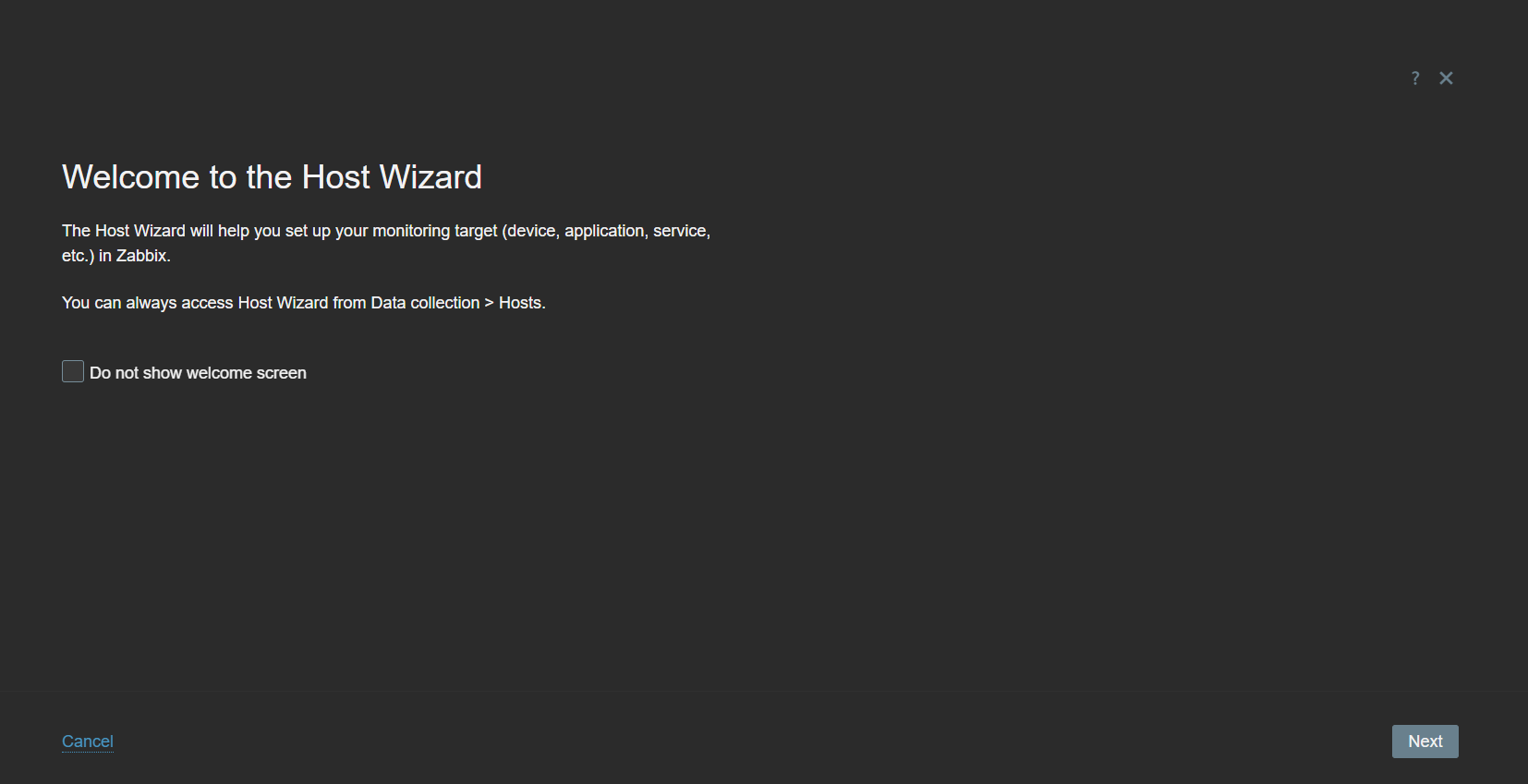
A new Host Wizard button has been added to the Data Collection – Hosts section. Once you click on it, you will first have to select the template you wish to apply on the new host. Only one template can be applied at a time, so if you wish to apply multiple templates on a single host via Host Wizard, you will have to do so via one template and one Host Wizard session at a time.
Under the hood, if we look at the template files, the templates have also received 2 new parameters: wizard_ready and readme. Only templates marked with wizard_ready: ‘YES’ can be selected in the Host Wizard.
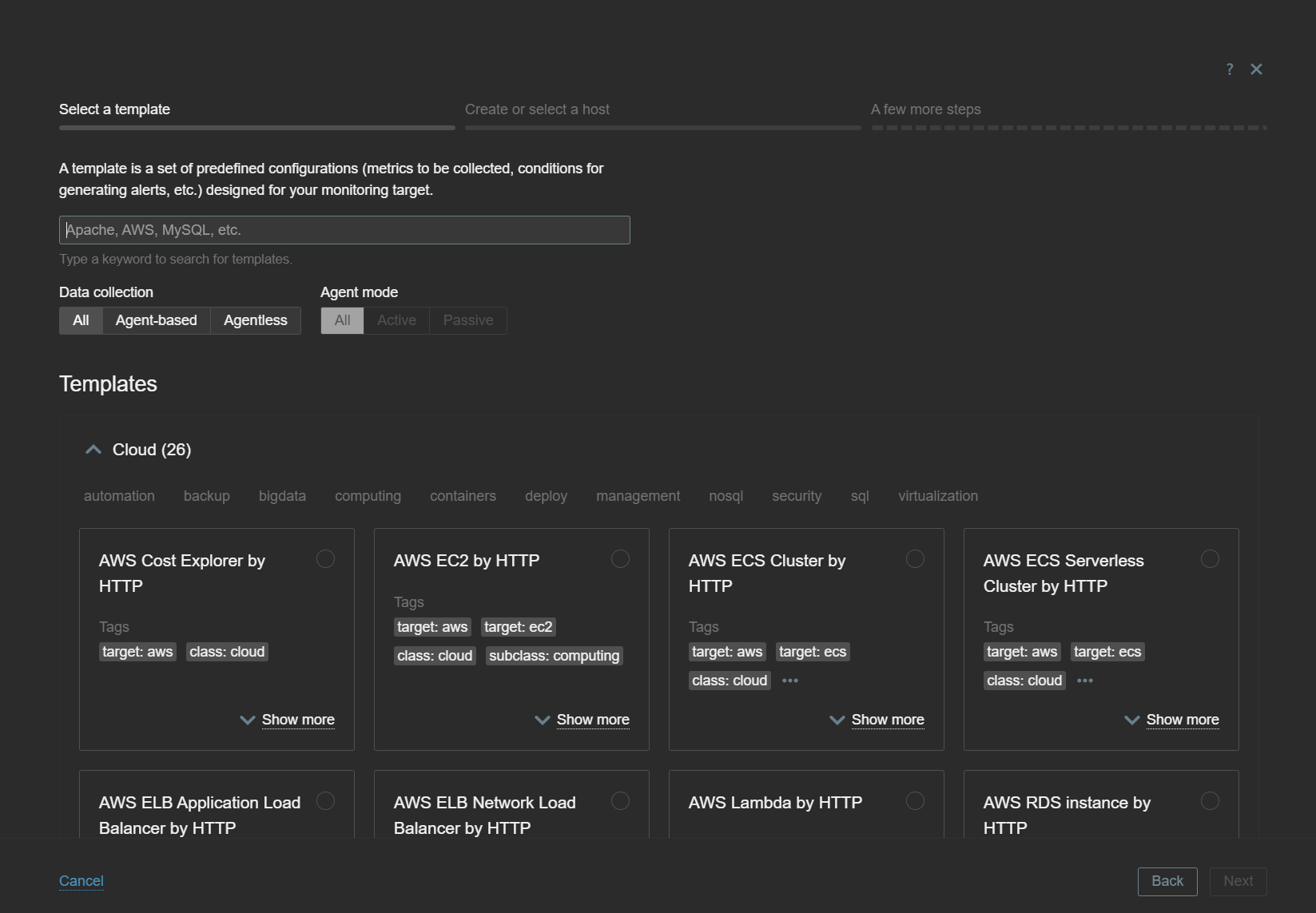
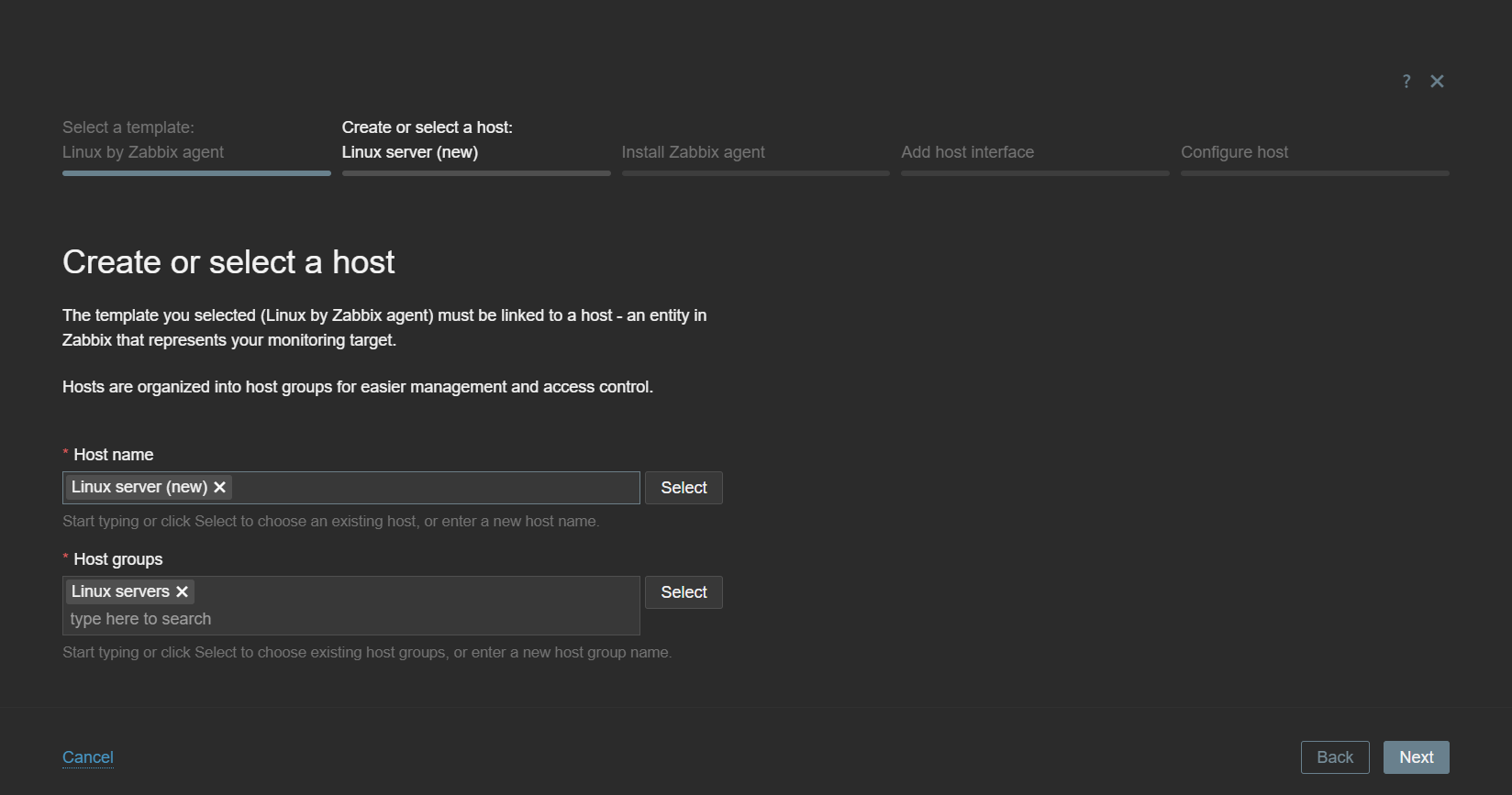
After you have selected the template, you will be prompted to enter a host name and select host groups. You can create a new host or apply the template on an existing host.
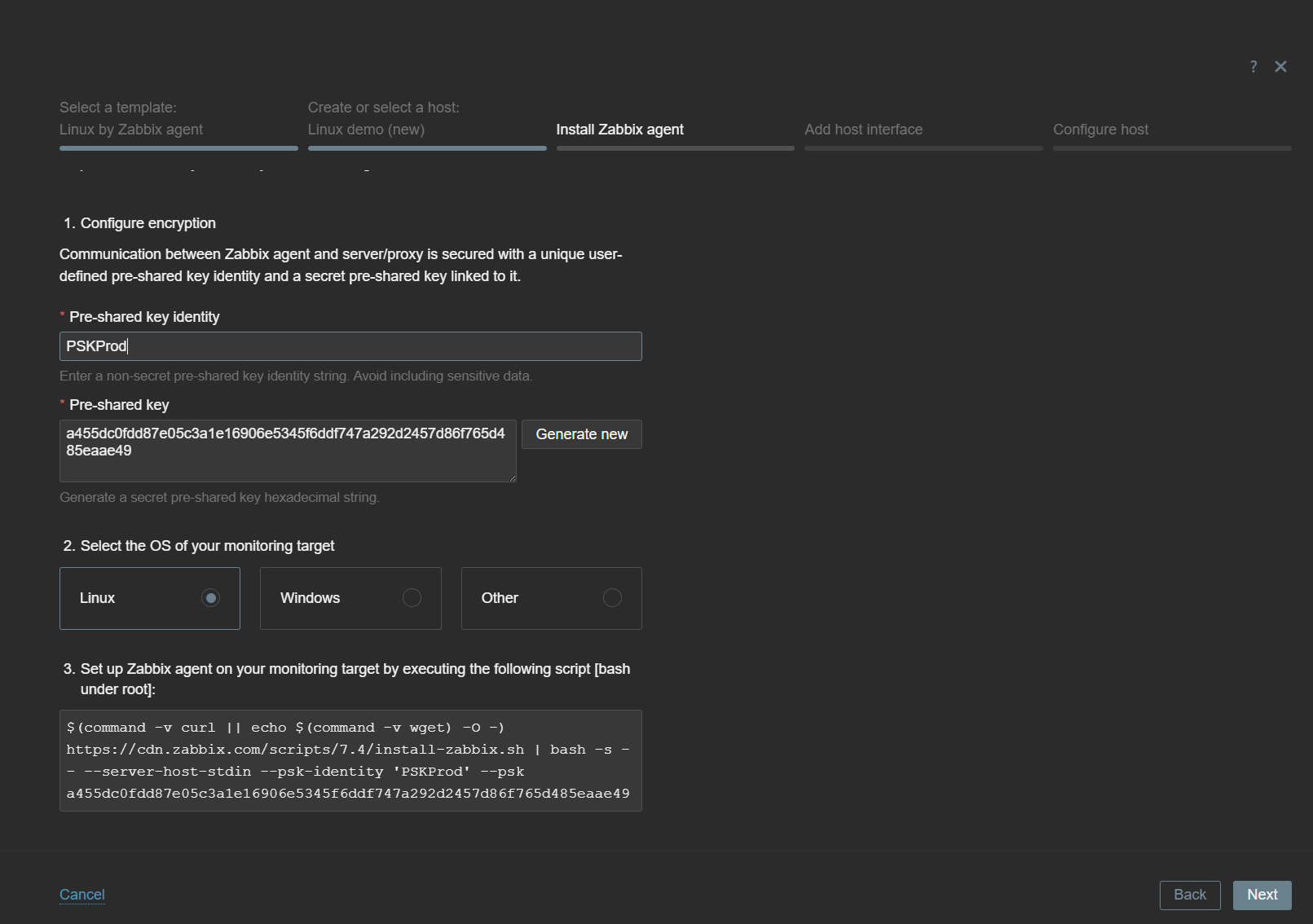
The next steps include the deployment instructions. Depending on the selected template type, the Host Wizard will provide all of the required instructions to start monitoring the host with the chosen template.
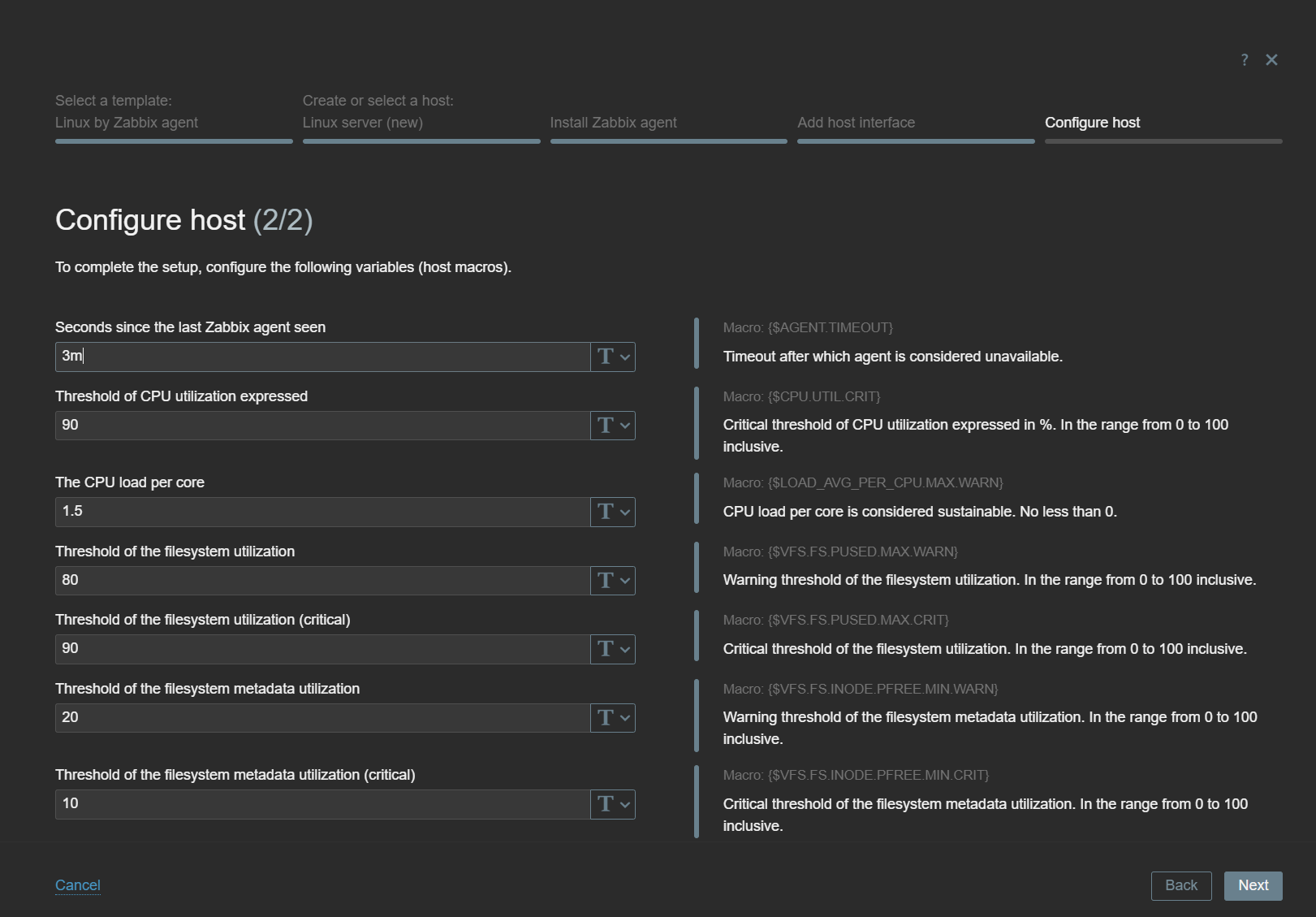
In the final Host Wizard steps, you will be prompted to add the required host interface, read the template notes, and customize the template-level macros.
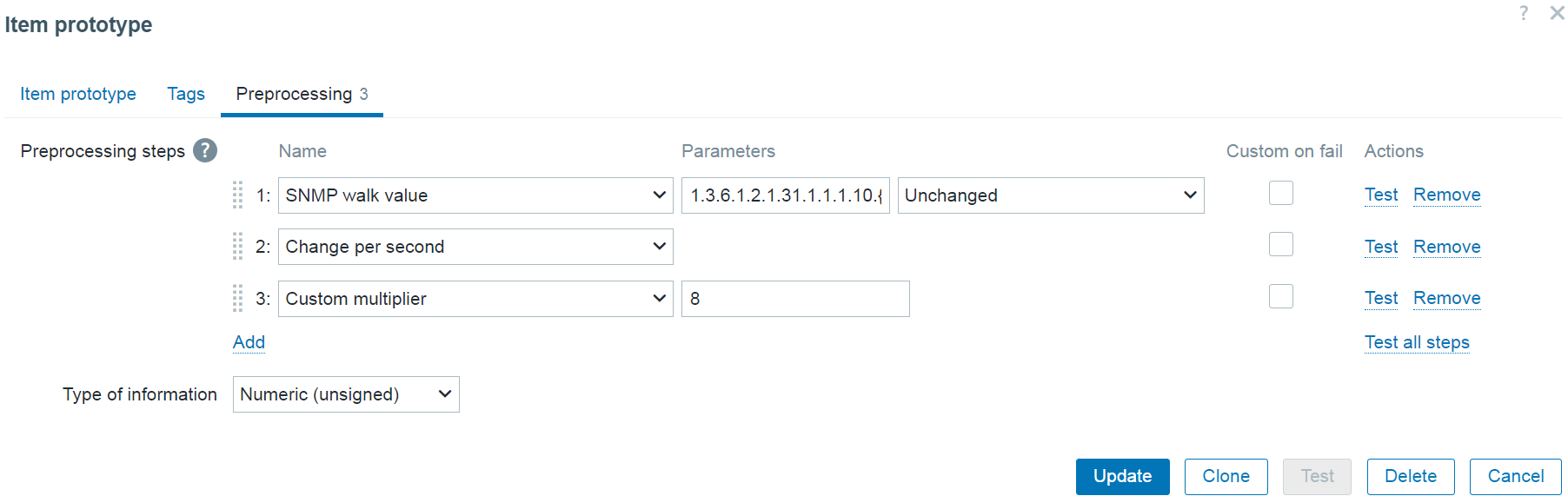
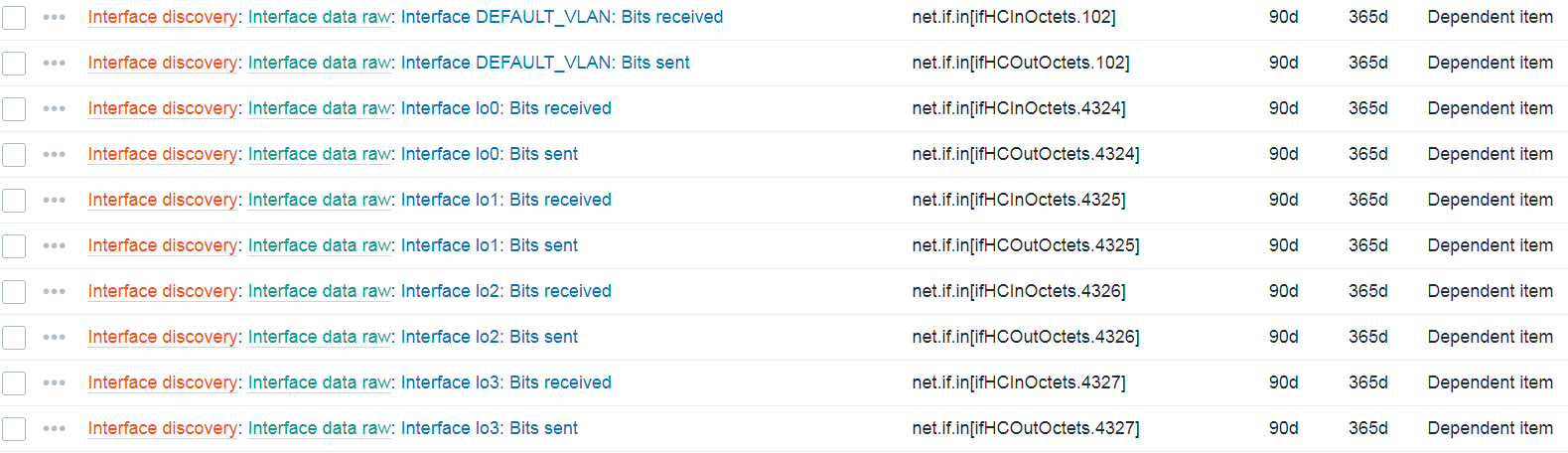
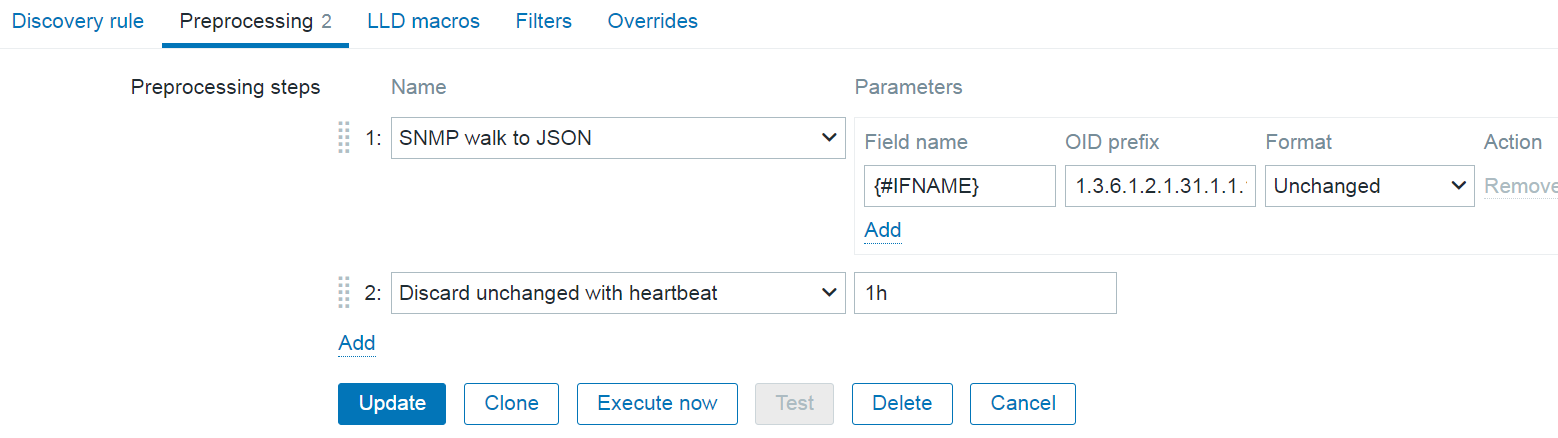
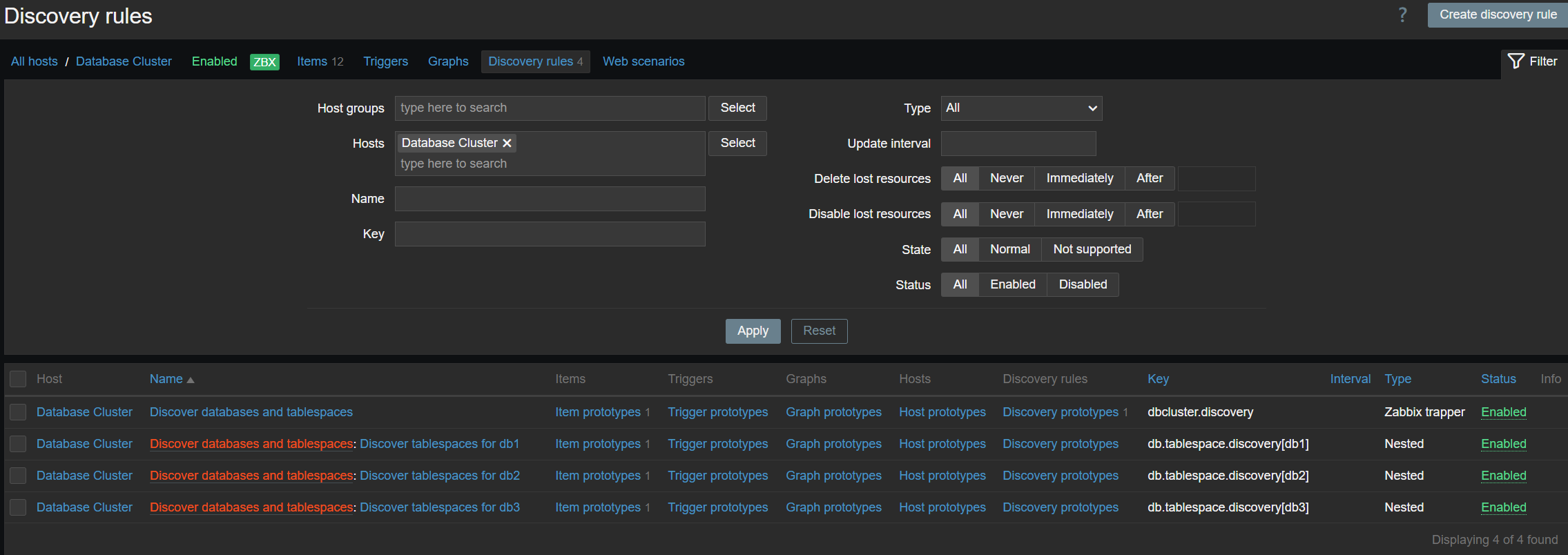
Nested low-level discovery rules and host prototypes
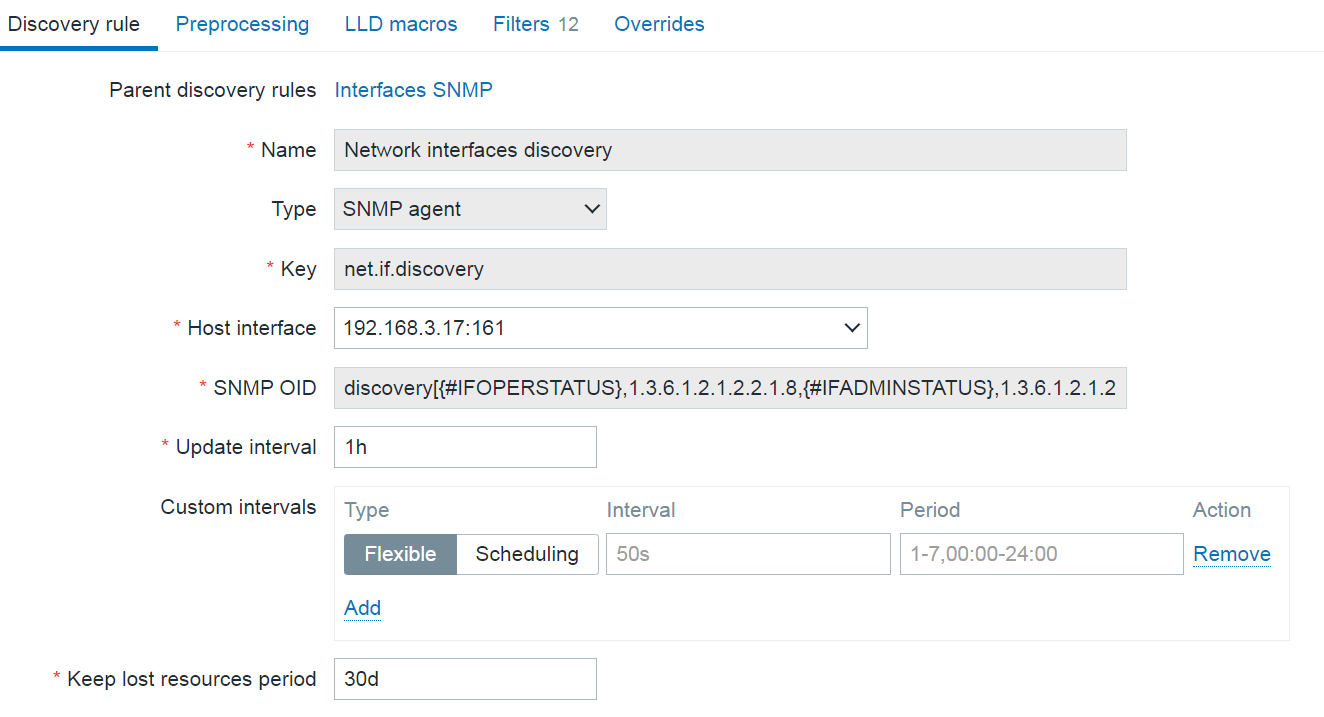
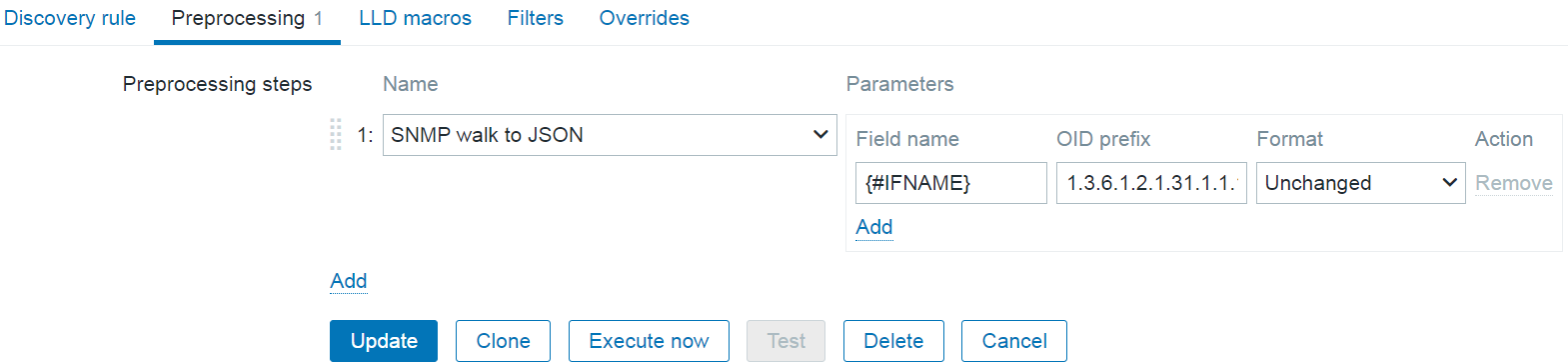
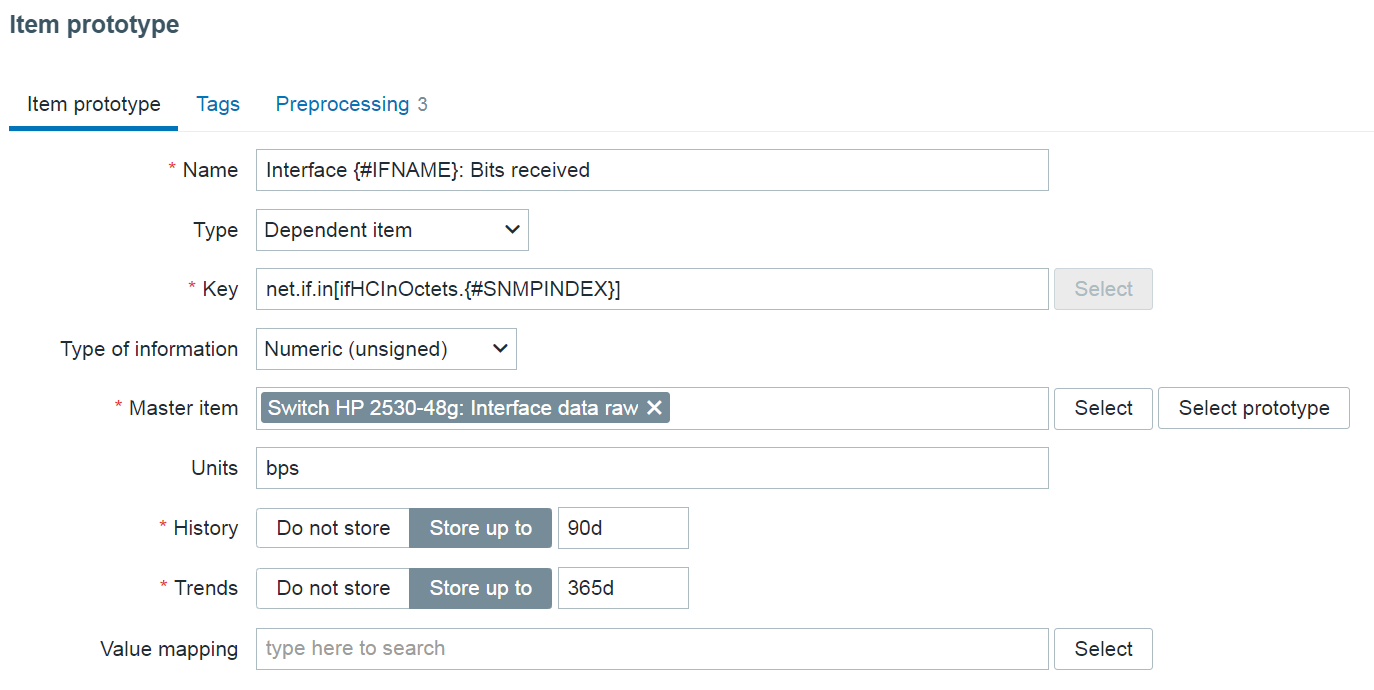
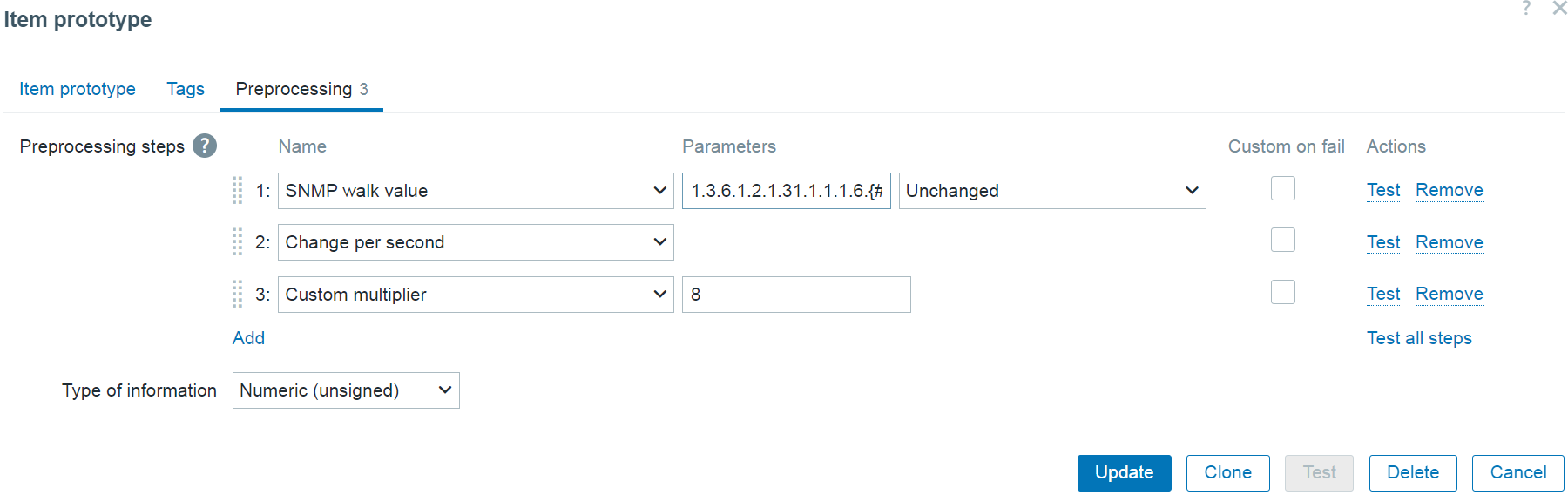
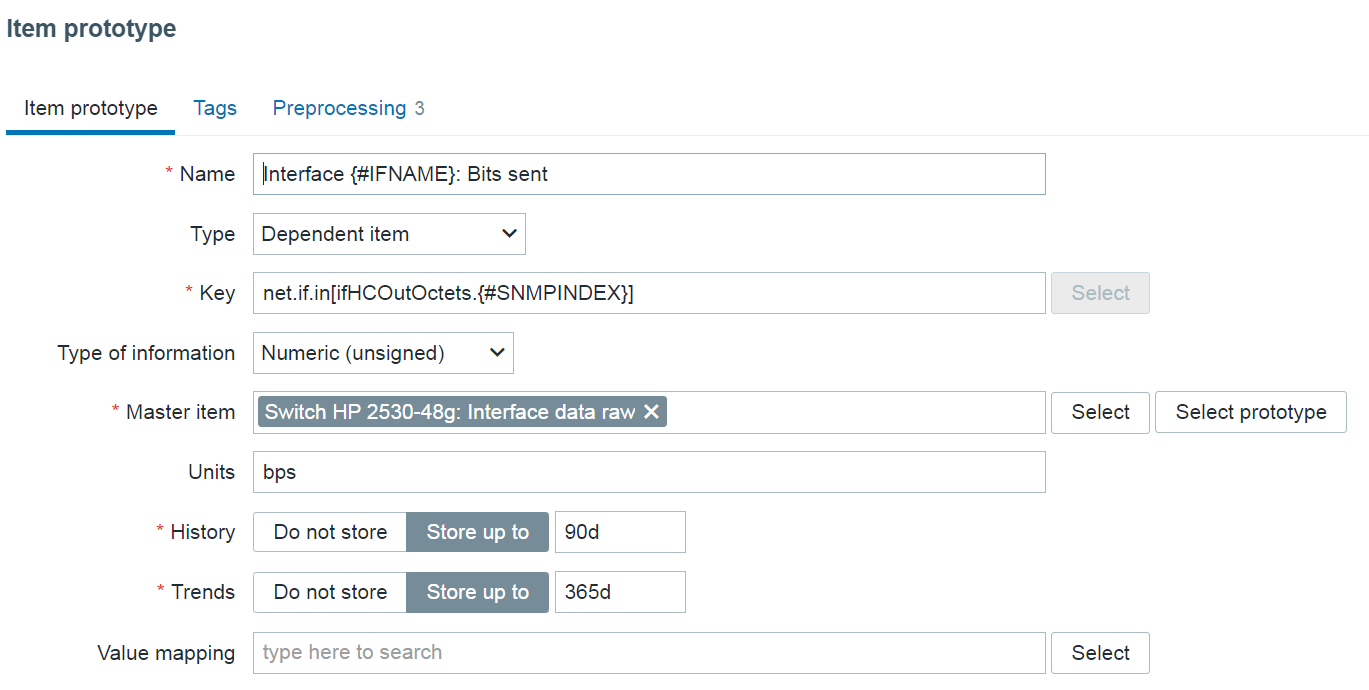
Low-level discovery rules have received major improvements in Zabbix 7.4. It is now possible to create nested low-level discovery rules, while host prototypes are now capable of discovering hosts of their own with low-level discovery.
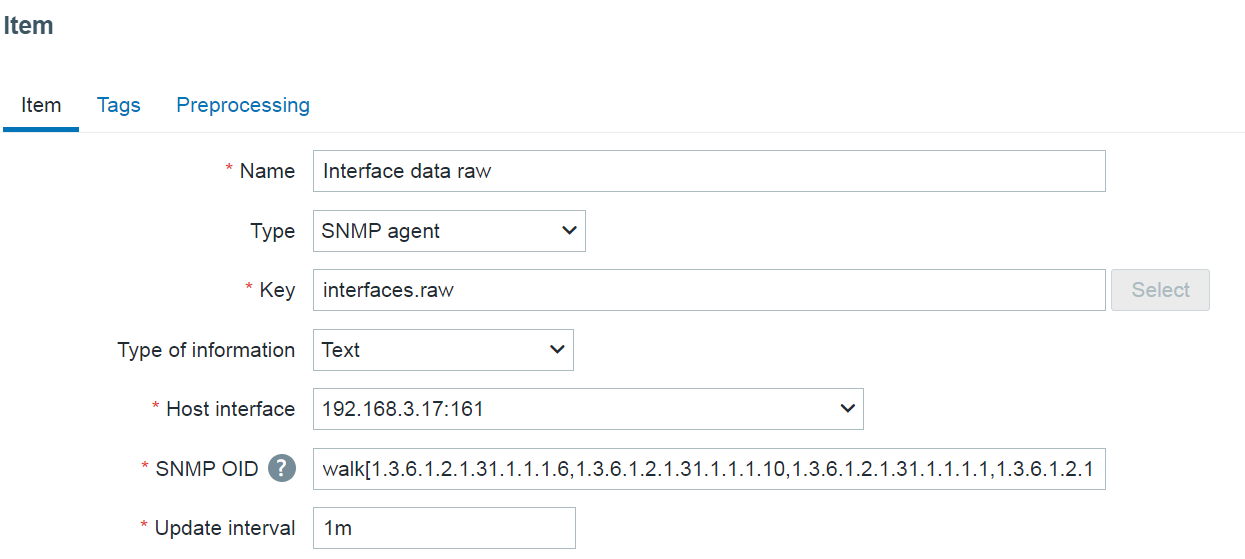
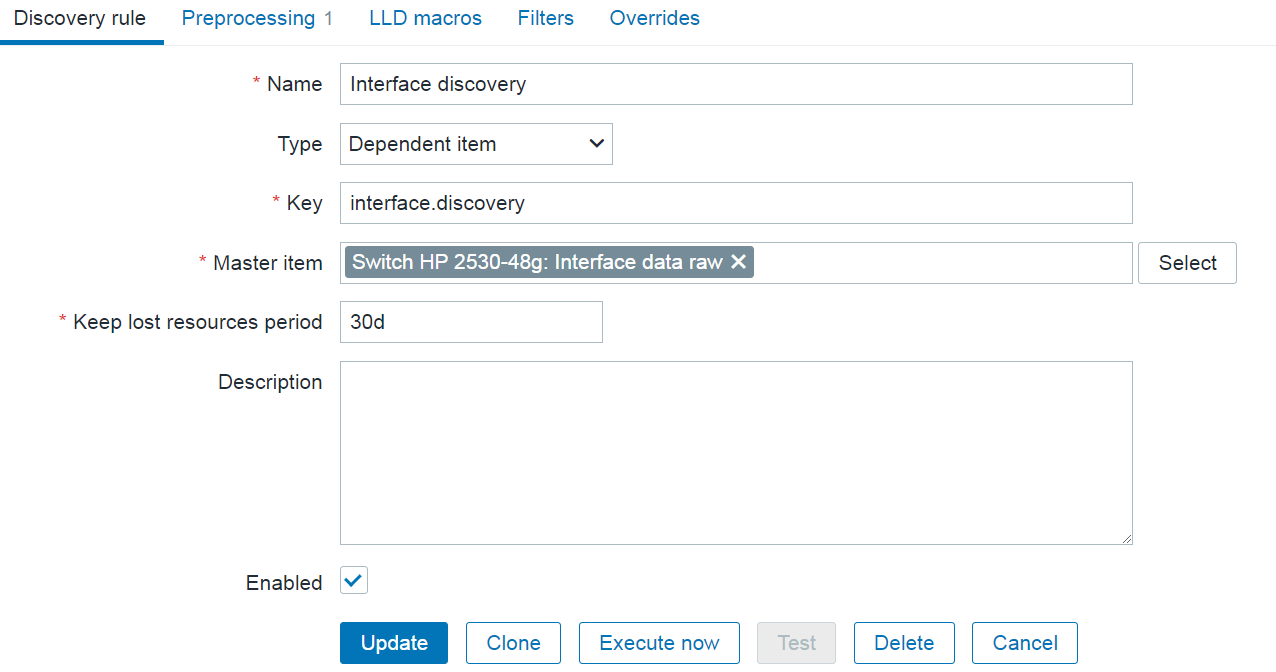
A new type of prototype has been added to low-level discovery rules – discovery prototype. These prototypes are used together with low-level discovery macros to automatically create low-level discovery rules for resource discovery.
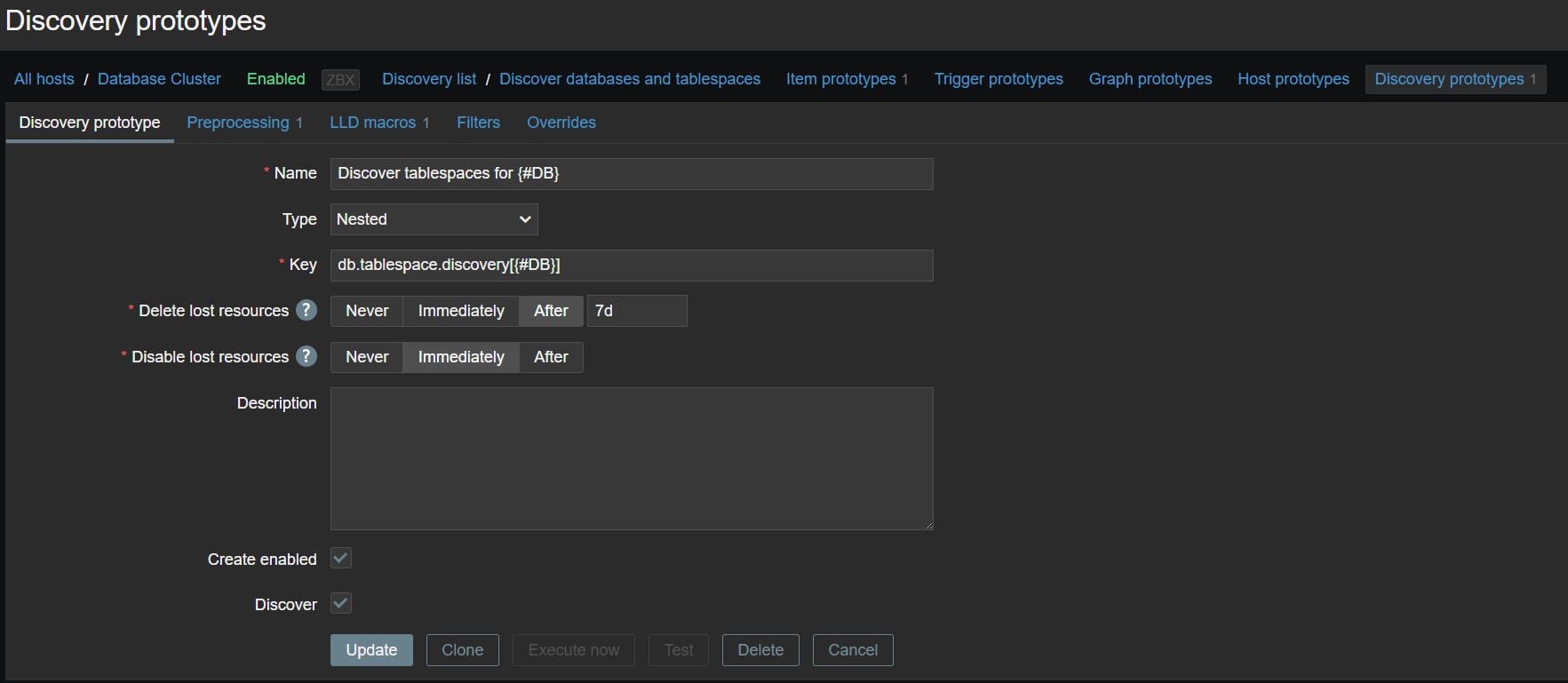
A new item type has been added for discovery rule prototypes – Nested. This type of discovery rule iterates through the JSON file received by the parent low-level discovery rule to discover child entities. For example:
[{"database":"db1","created_at":"2024-02-01T12:30:00Z","encoding":"UTF8","tablespaces": [{"name":"ts1","max_size":"10GB"},{"name":"ts2","max_size":"20GB"},{"name":"ts3","max_size":"15GB"}]},{"database":"db2","created_at":"2023-11-15T08:45:00Z","encoding":"UTF16","tablespaces": [{"name":"ts1","max_size":"5GB"},{"name":"ts2","max_size":"25GB"},{"name":"ts3","max_size":"30GB"}]},{"database":"db3","created_at":"2024-01-05T15:10:00Z","encoding":"UTF8","tablespaces": [{"name":"ts1","max_size":"12GB"},{"name":"ts2","max_size":"18GB"},{"name":"ts3","max_size":"22GB"}]}]
If we set the jsonpath preprocessing in the discovery rule prototype to JSONPath=$.tablespaces and set the low-level discovery macro to {#TSNAME}=$.name, the nested low-level discovery rule will create discovery rules to discover tablespaces for each database.
Inline form validation
Inline validation has been introduced with the goal of improving the overall user experience when configuring a variety of Zabbix entities. As of Zabbix 7.4, inline form validation is supported in:
- Host configuration
- Template configuration
- Item configuration
- Trigger configuration
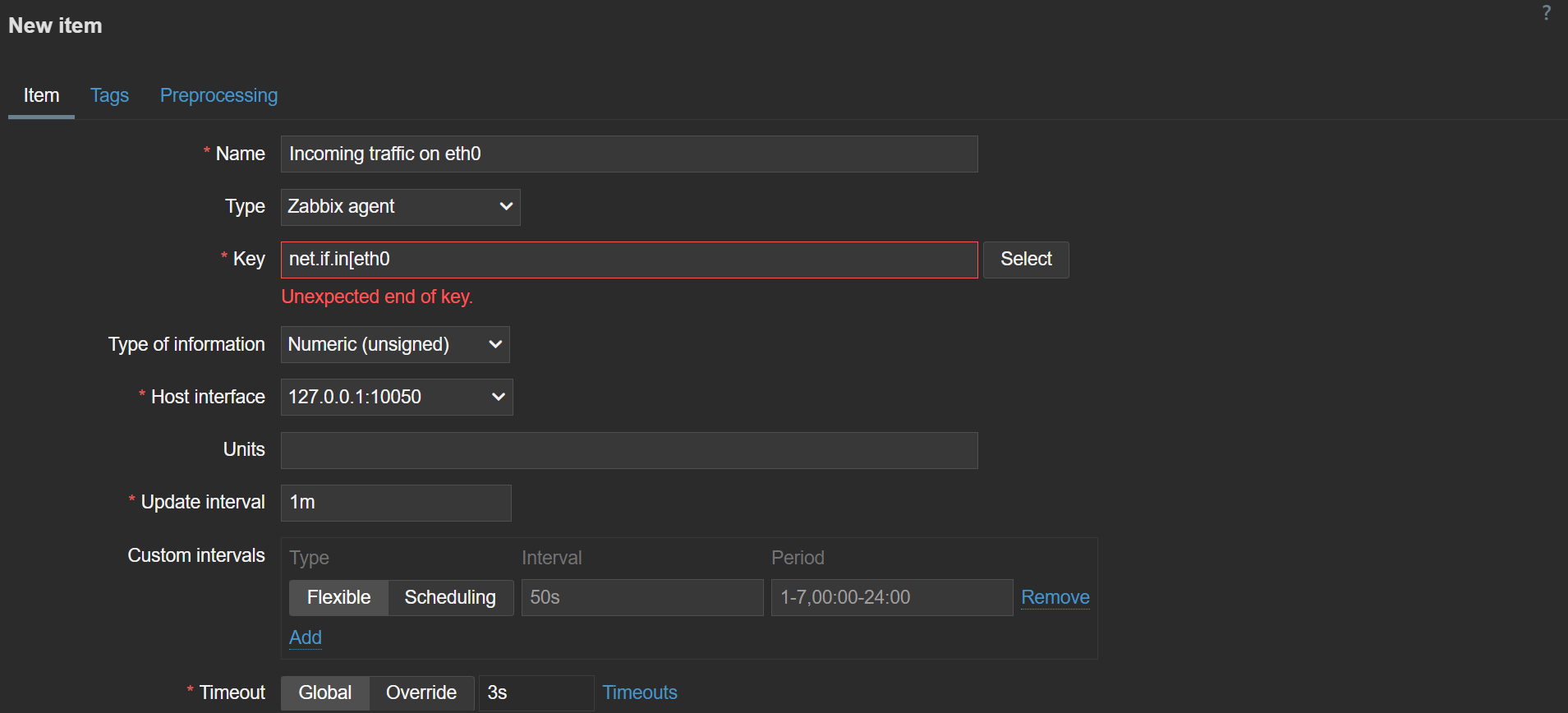
With inline validation in place, users will now receive immediate feedback regarding any configuration mistakes they have made in the sections above. Configuring new entities, especially items and triggers with complex keys and expressions, is now faster than ever.
Frontend-to-server communication encryption
To further strengthen Zabbix communication flow security, Zabbix 7.4 introduces the ability to secure frontend to server communication with certificate encryption. The encryption must be configured from two sides, and the frontend setup now includes the options to enable and configure encrypted connections to the server.
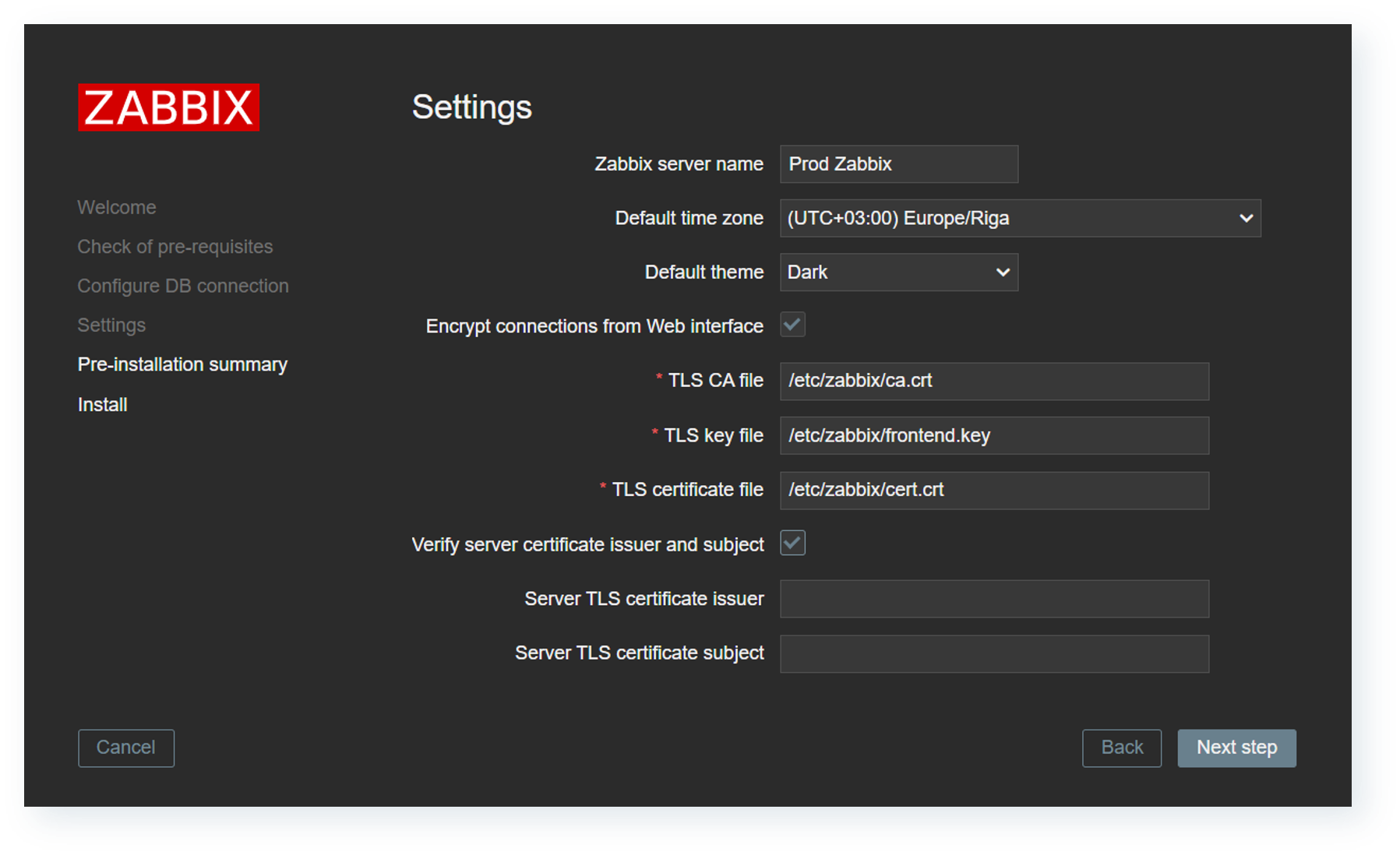
On the Zabbix server side, multiple new configuration parameters have been added:
- TLSFrontendAccept – which incoming connections to accept from frontend
- TLSFrontendCertIssuer – allowed frontend certificate issuer
- TLSFrontendCertSubject – allowed frontend certificate subject
- FrontendAllowedIP – frontend connections will be accepted only from addresses listed here if the parameter is set
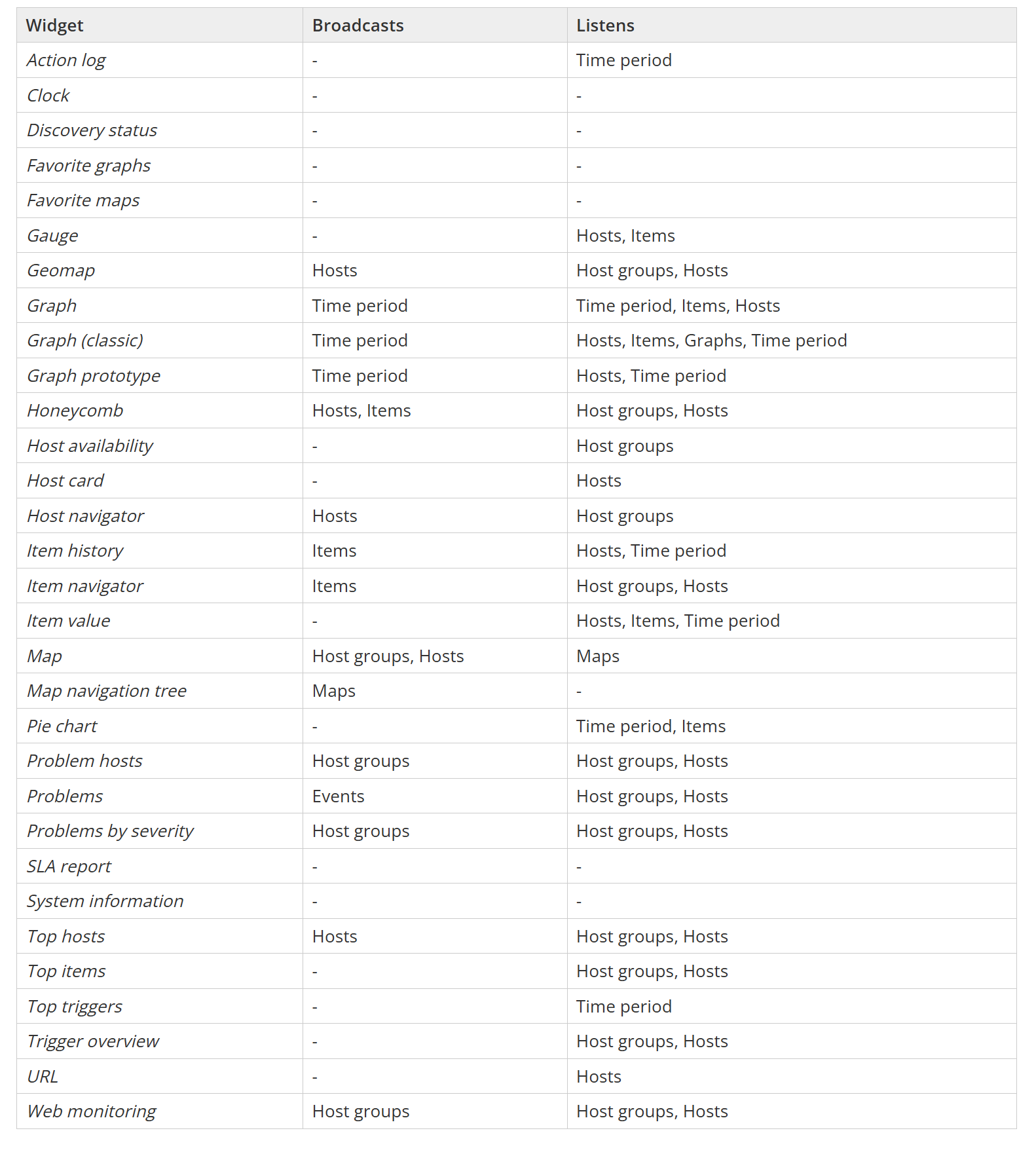
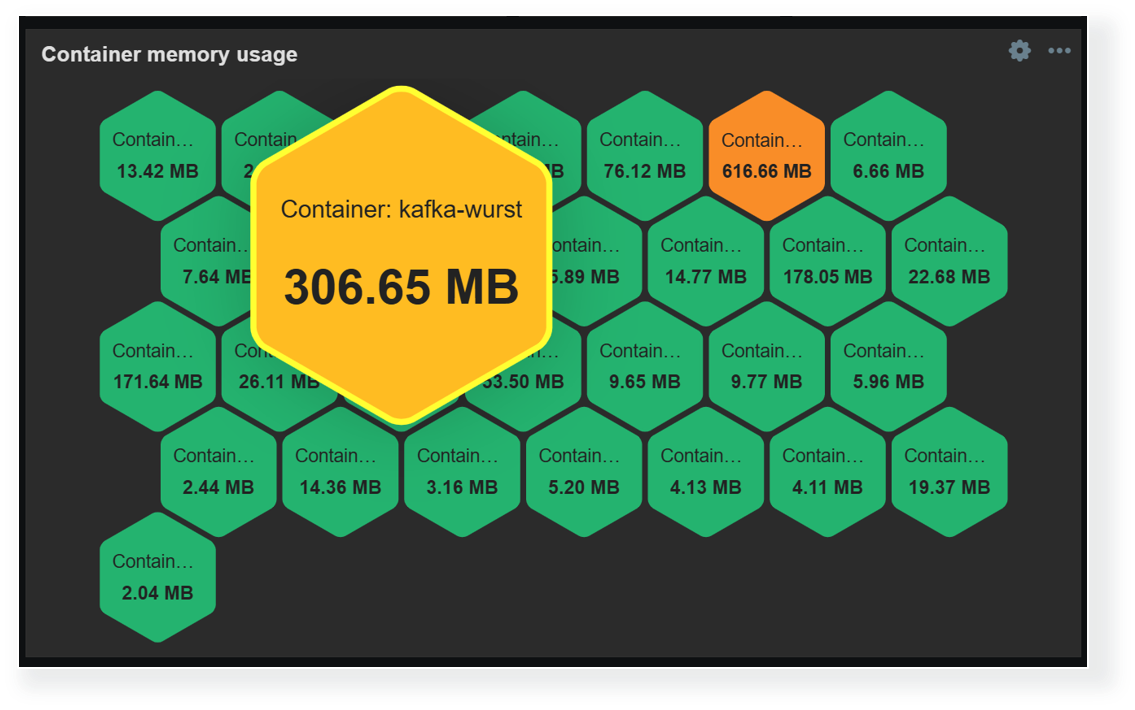
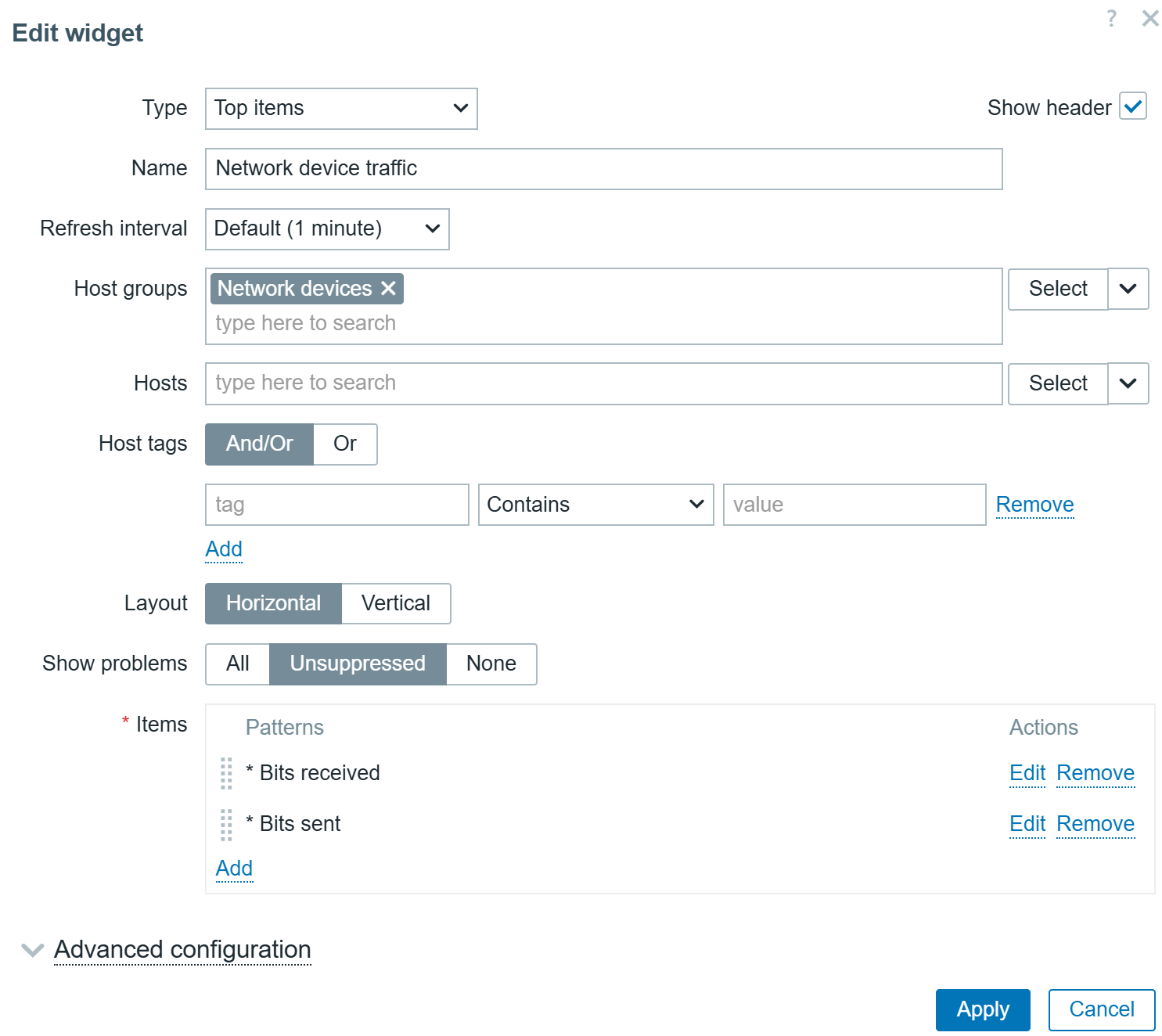
New widgets and visualization improvements
Zabbix 7.4 introduces a new widget (Item card) and multiple visualization improvements for dashboards and network maps.
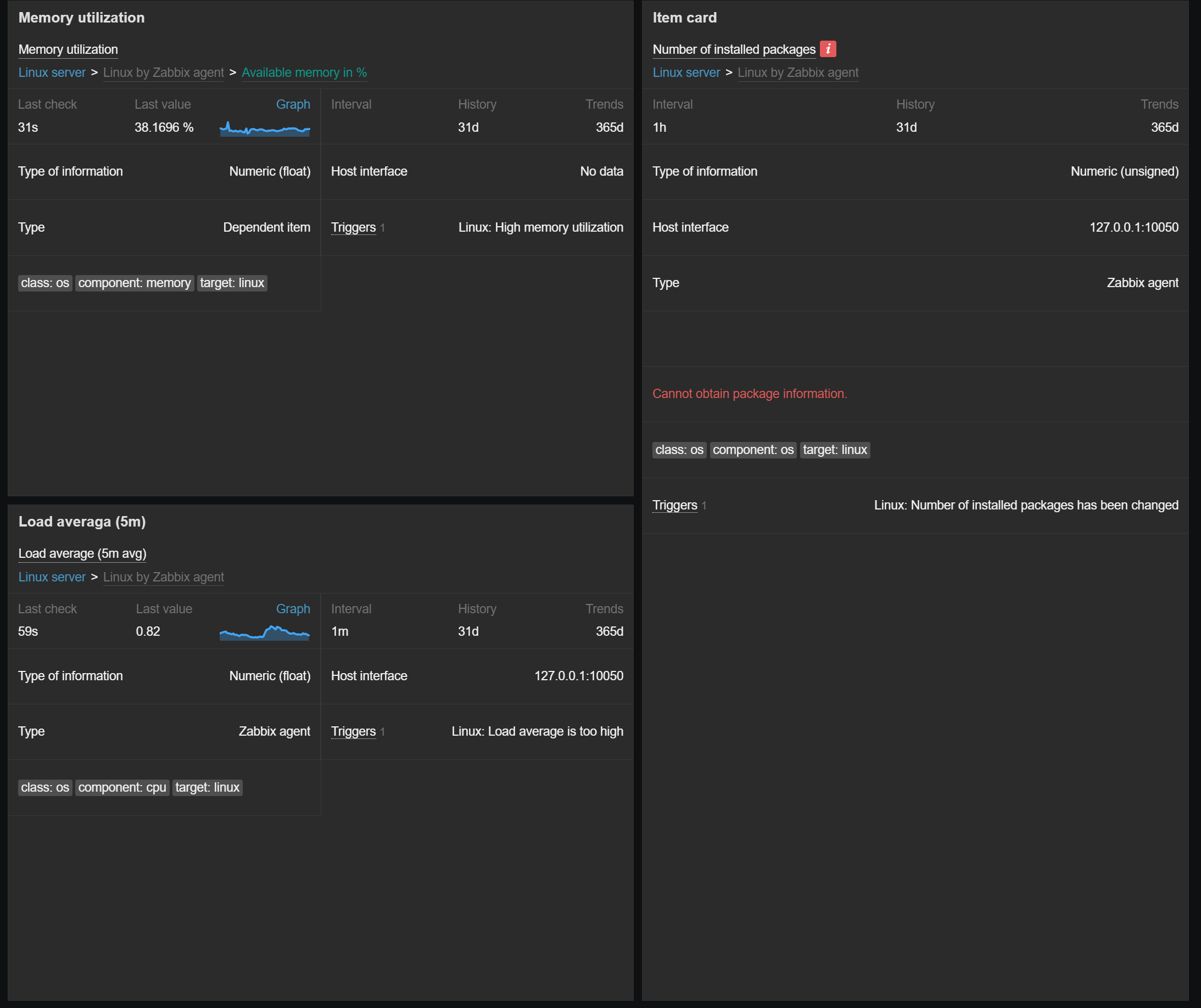
Item card widget
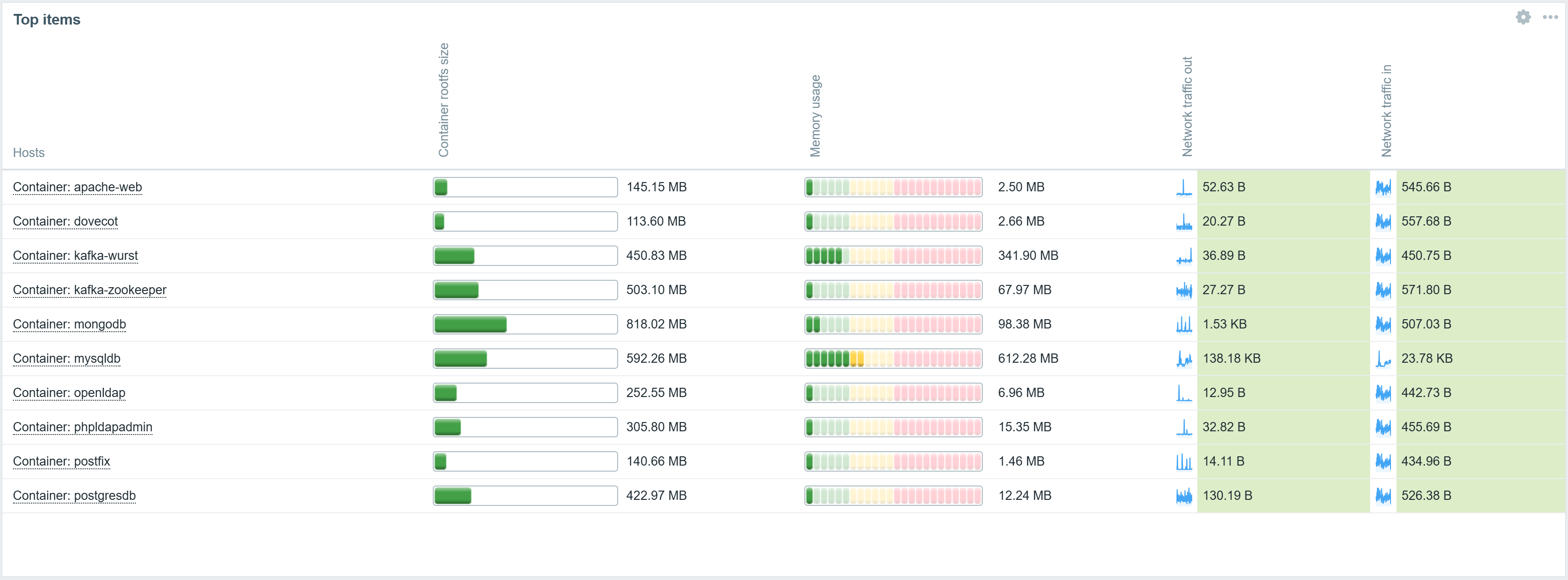
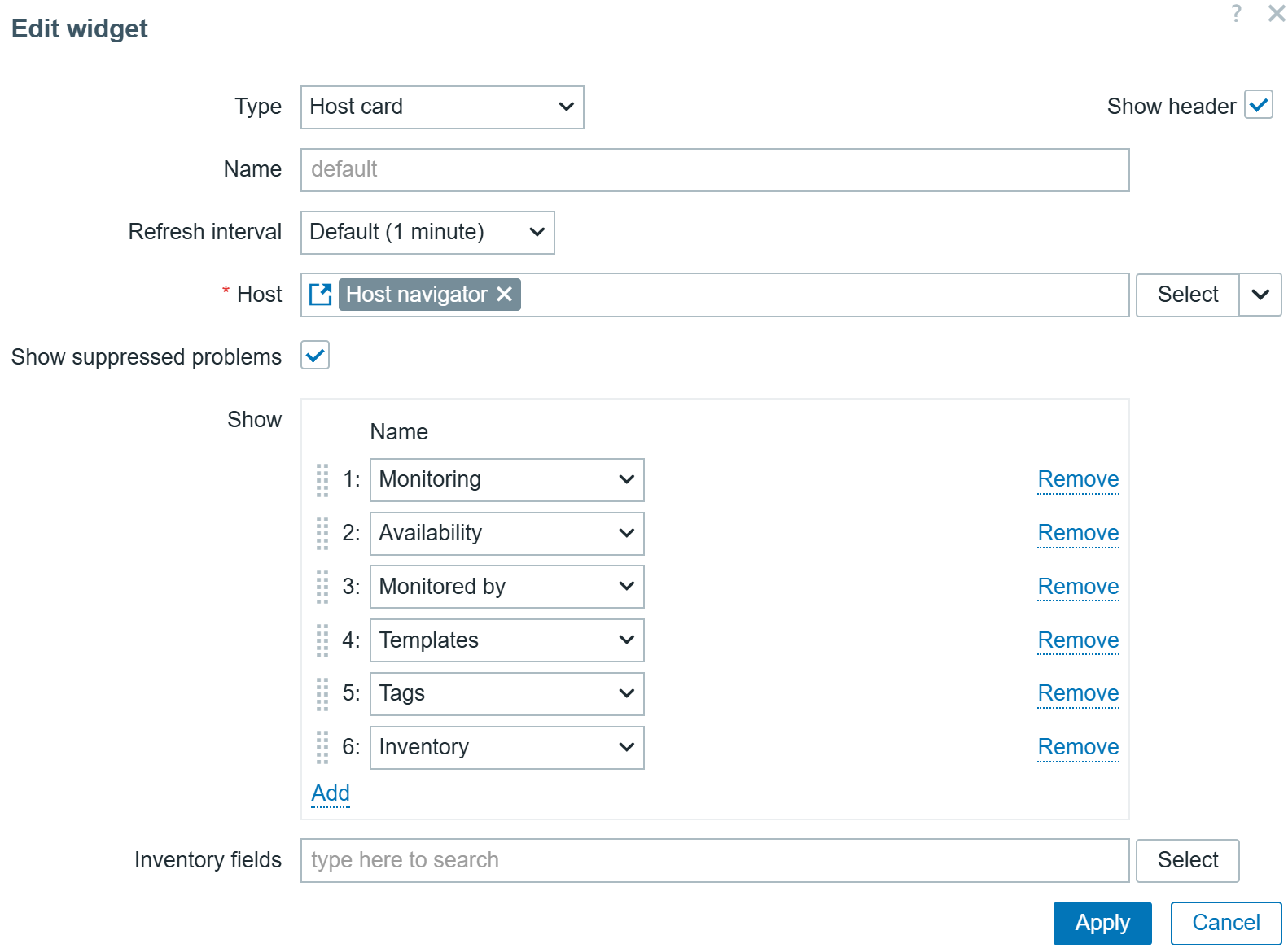
The new Item card widget behaves similarly to the existing Host card widget introduced in Zabbix 7.2. The Item card widget provides a customizable view of an item and its attributes, such as latest data together with a sparkling chart, error messages, interfaces, tags, triggers, and more. The attributes for display can be selected and ordered in the widget configuration.
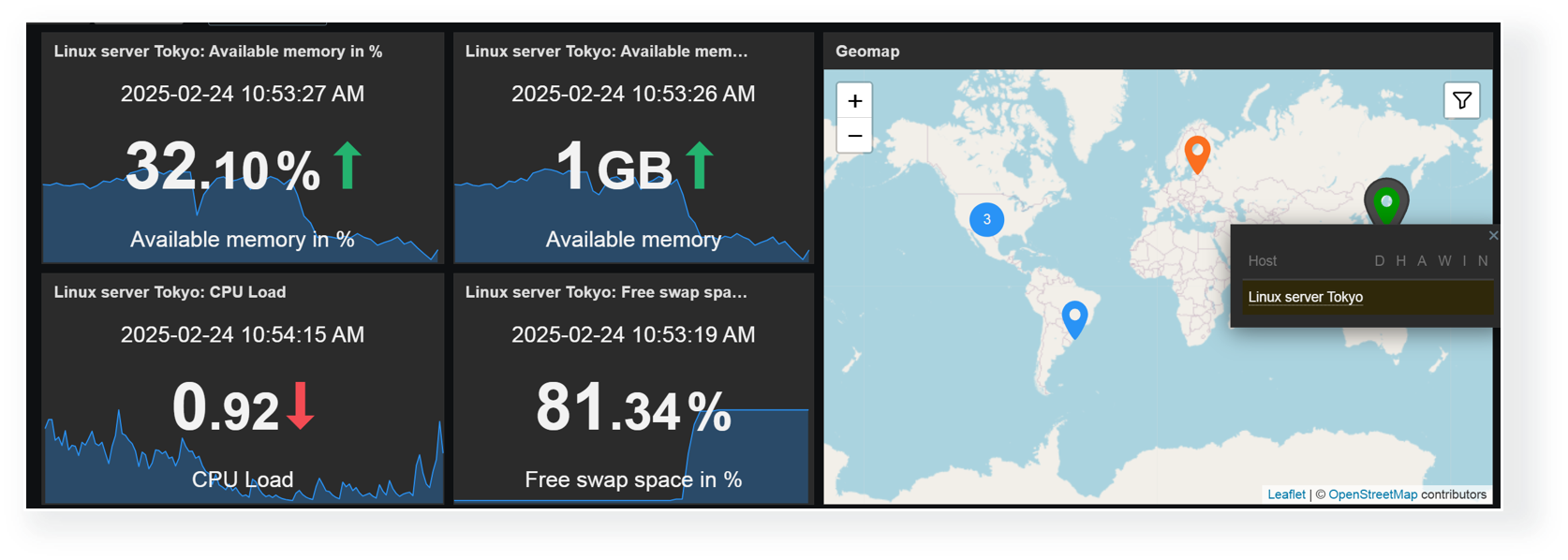
Network map improvements
Network maps have also received multiple improvements, enabling new use cases and simplifying existing network map scenarios.
- Map background images can now be scaled proportionally to the map dimensions
- Map links now support link indicators based on item value thresholds
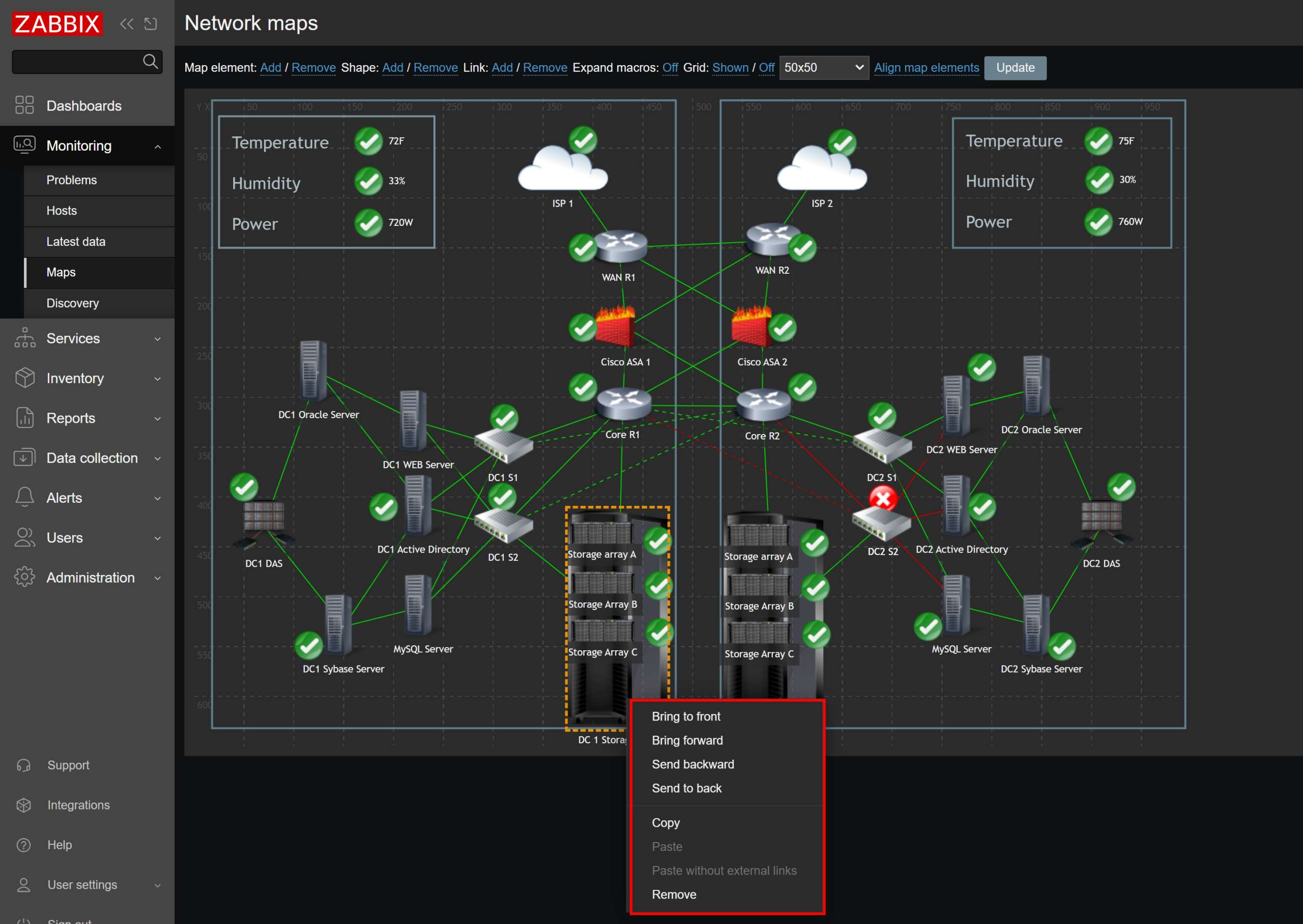
- Map element icons can now be ordered when placed on top of one another
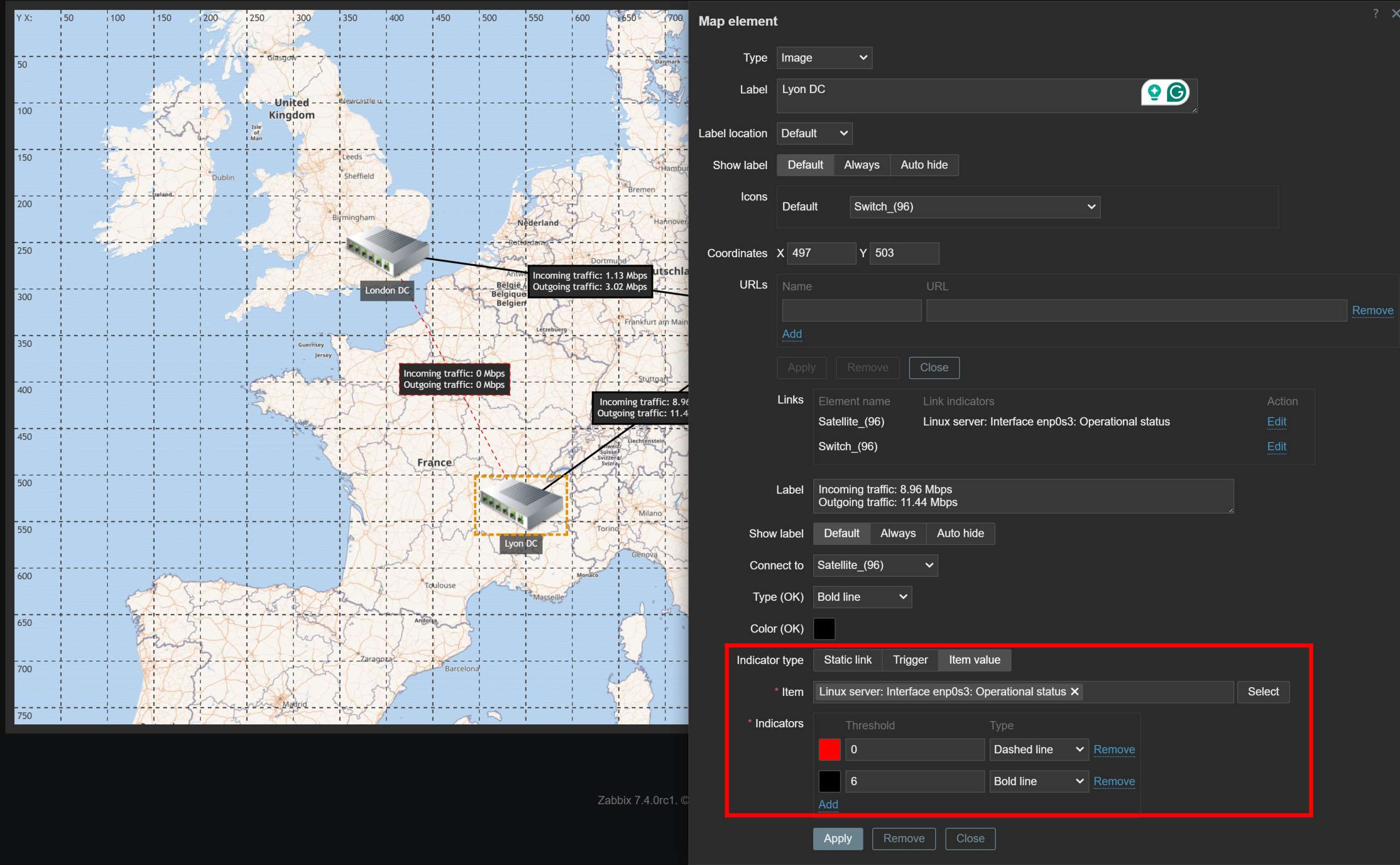
- Map element icons can now be ordered when placed on top of one another
- Host group map elements will now take into account nested host groups when displaying host group-related information
- Map link and element labels can now be hidden and only displayed on mouse hover
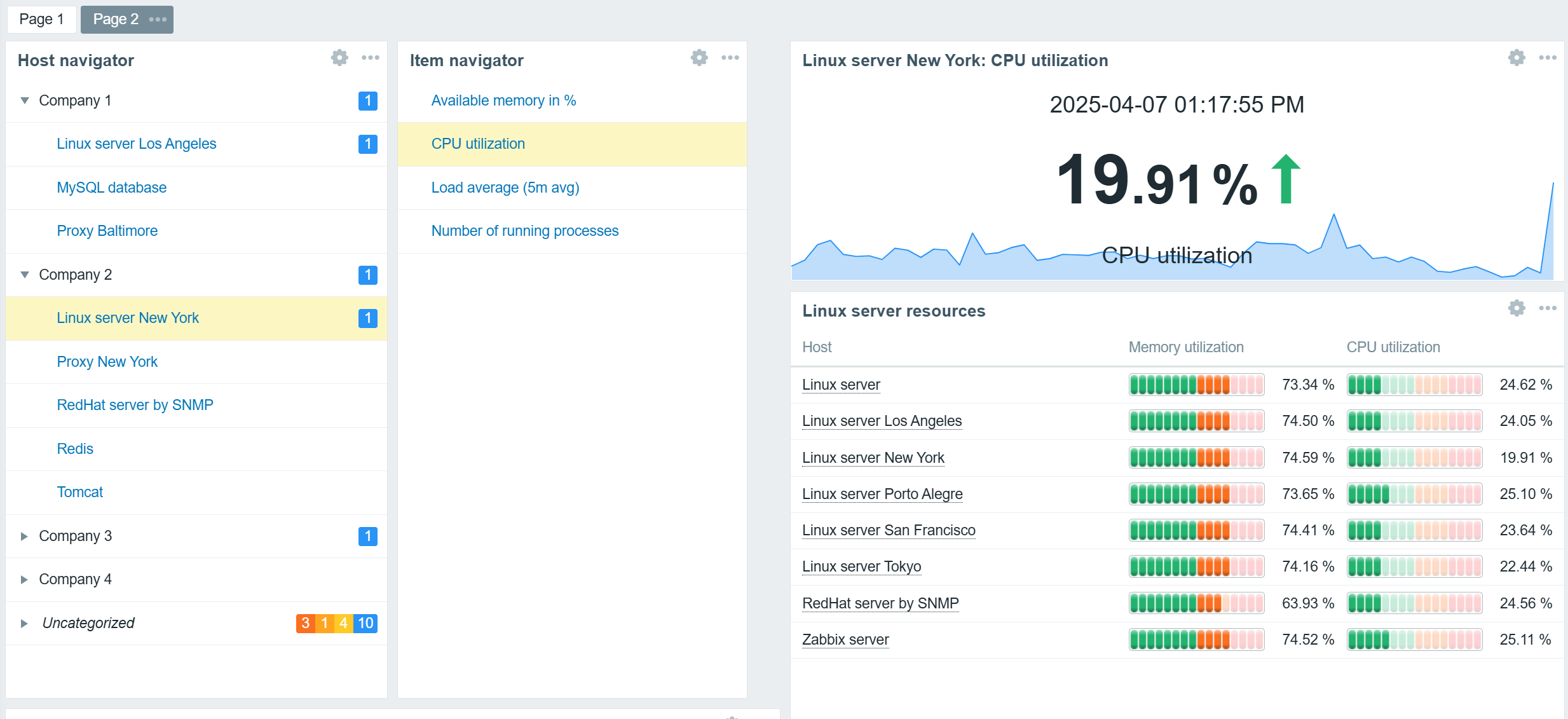
Dashboard improvements
Zabbix 7.4 introduces multiple dashboard improvements to facilitate faster and smoother dashboard configuration.
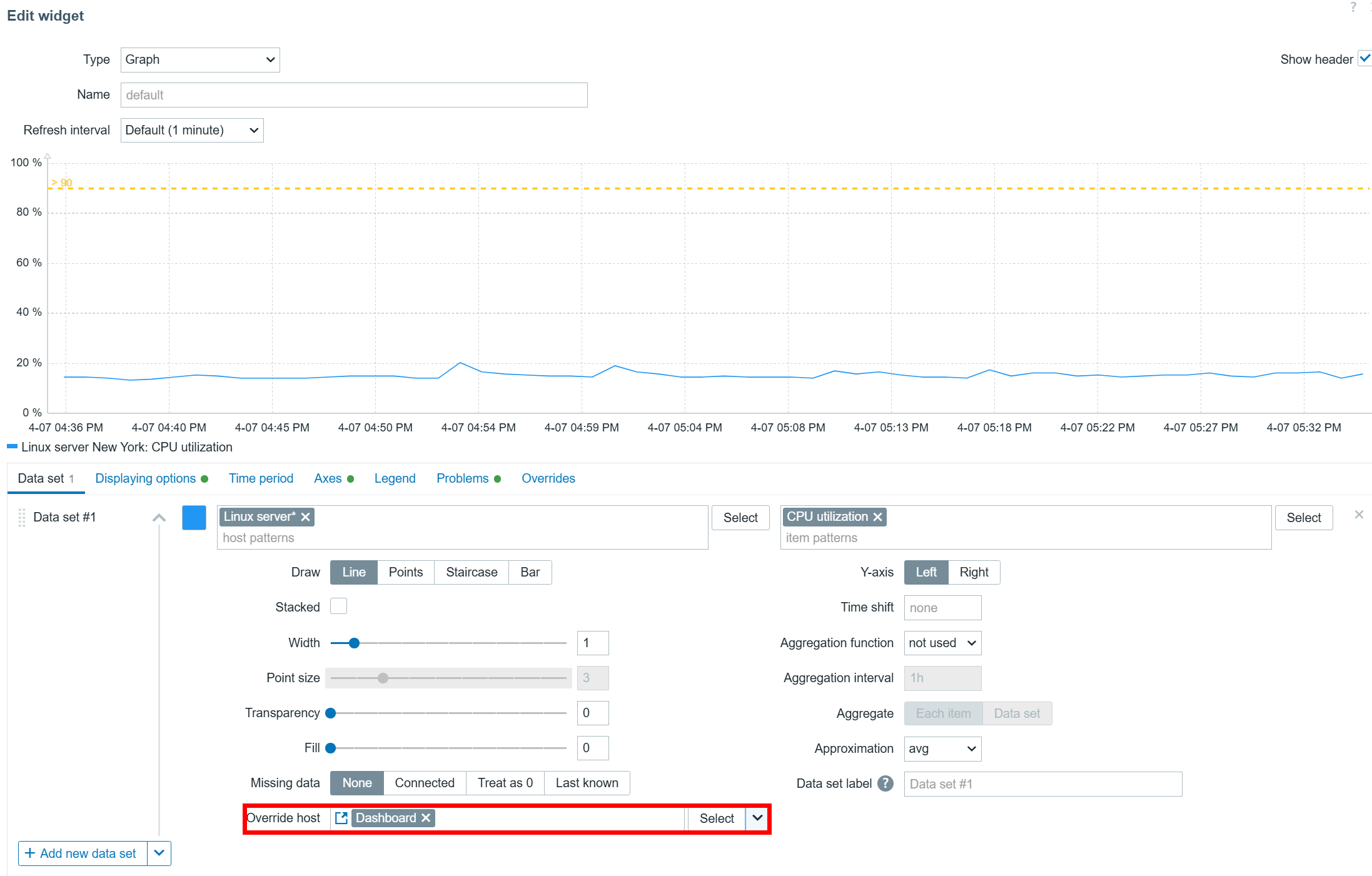
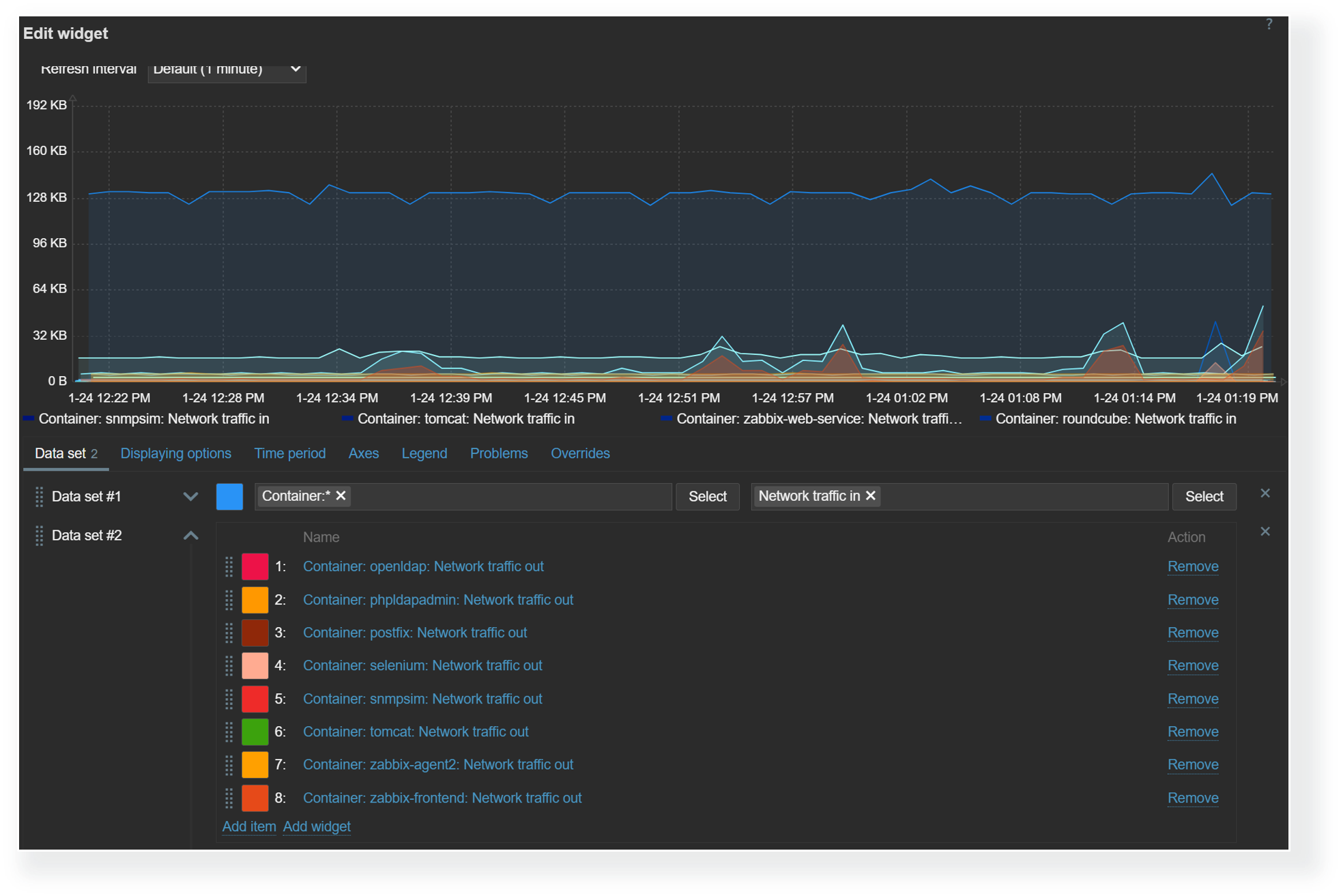
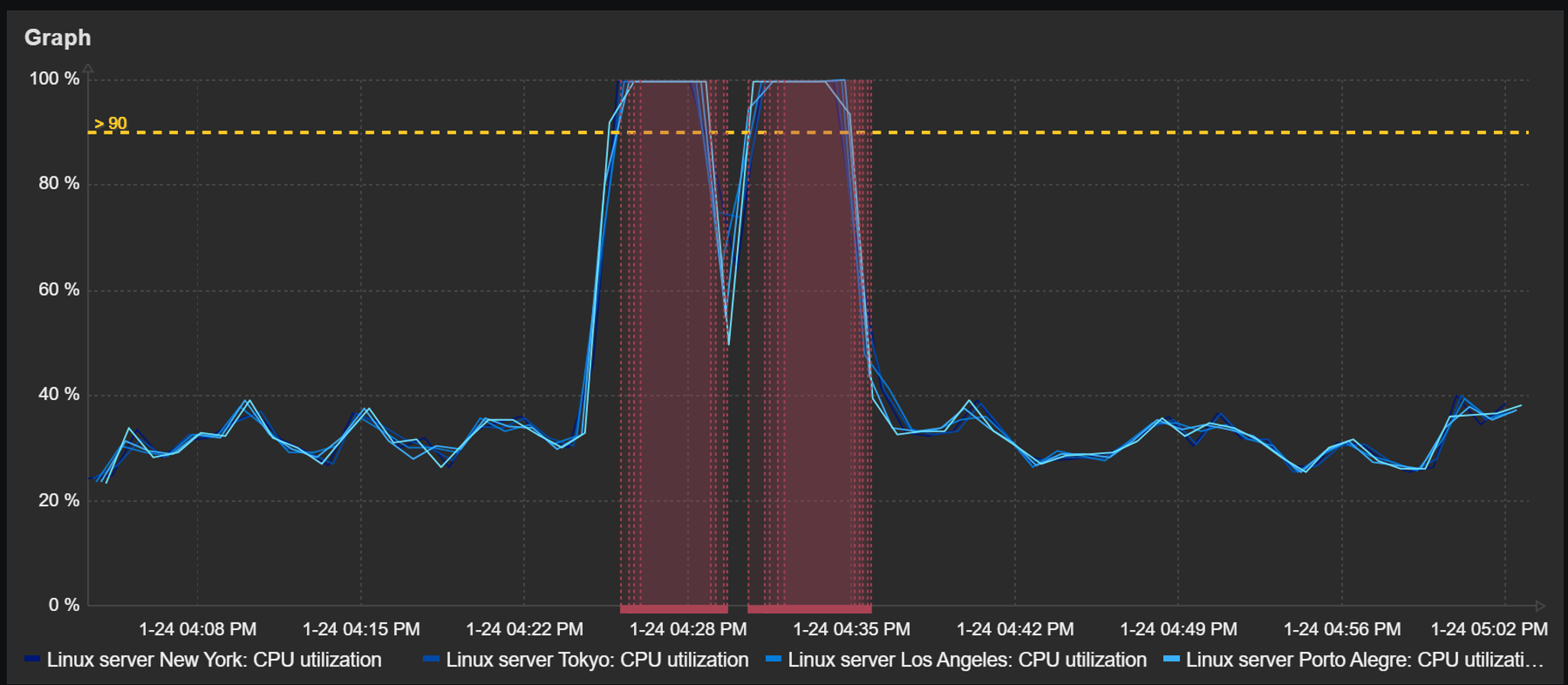
The color picker in graph and pie chart widgets has been extended with the new palette color scheme in addition to the existing solid color scheme. Users can choose from the available palette color schemes. The new palette color schemes display the values within a data set in a more distinguishable way, while the existing solid color scheme displays the data set values in shades of the selected color.
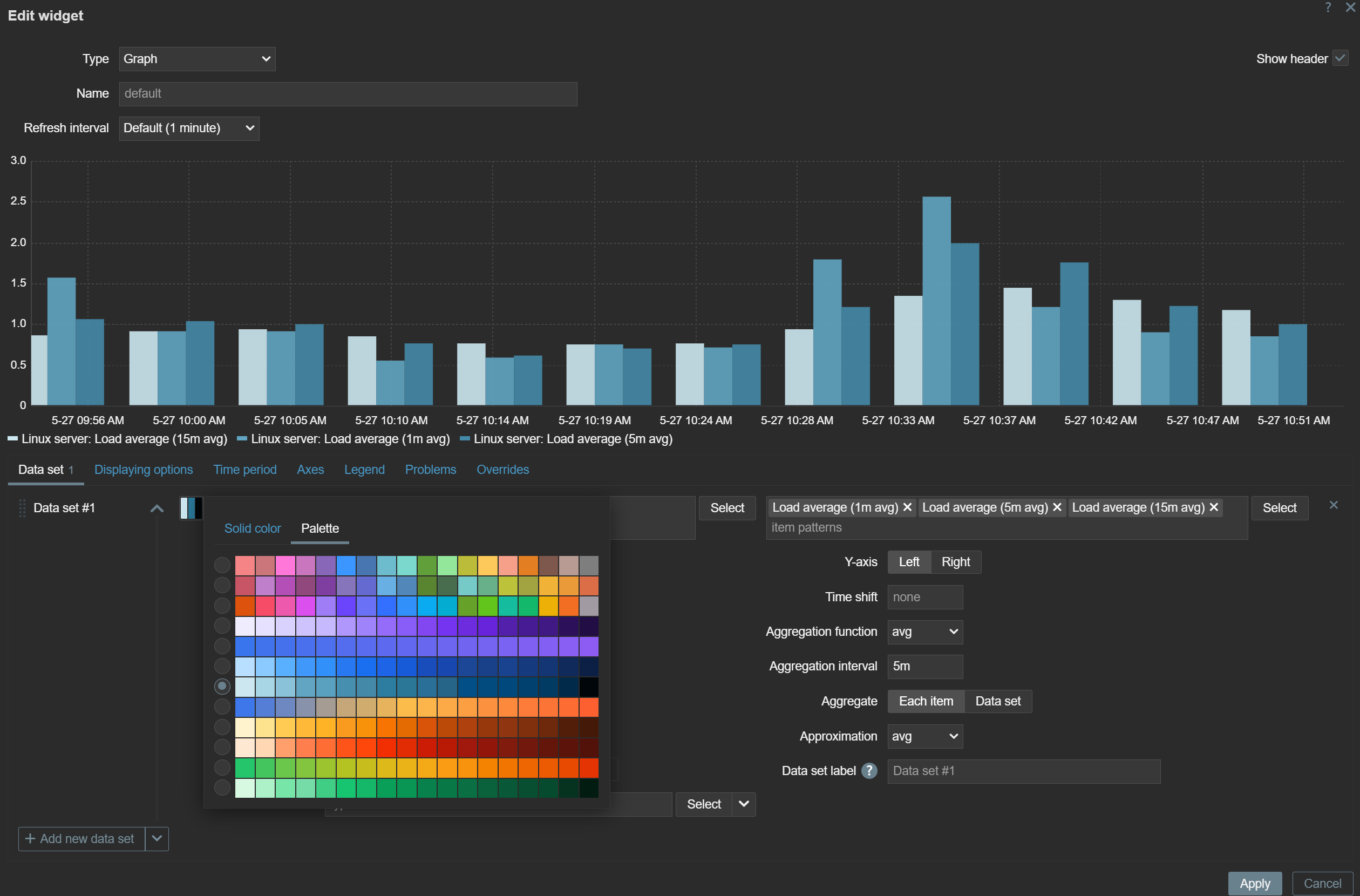
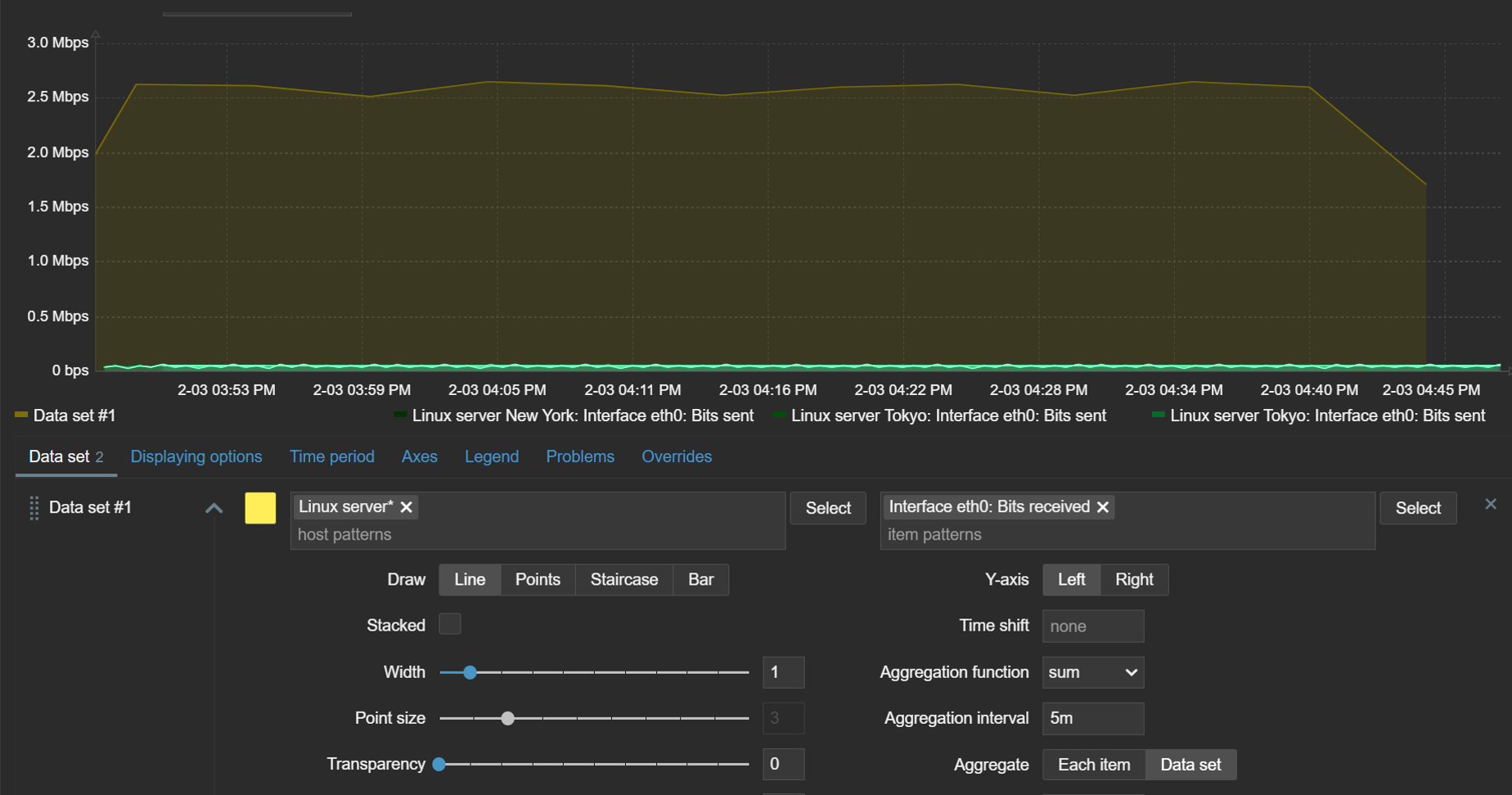
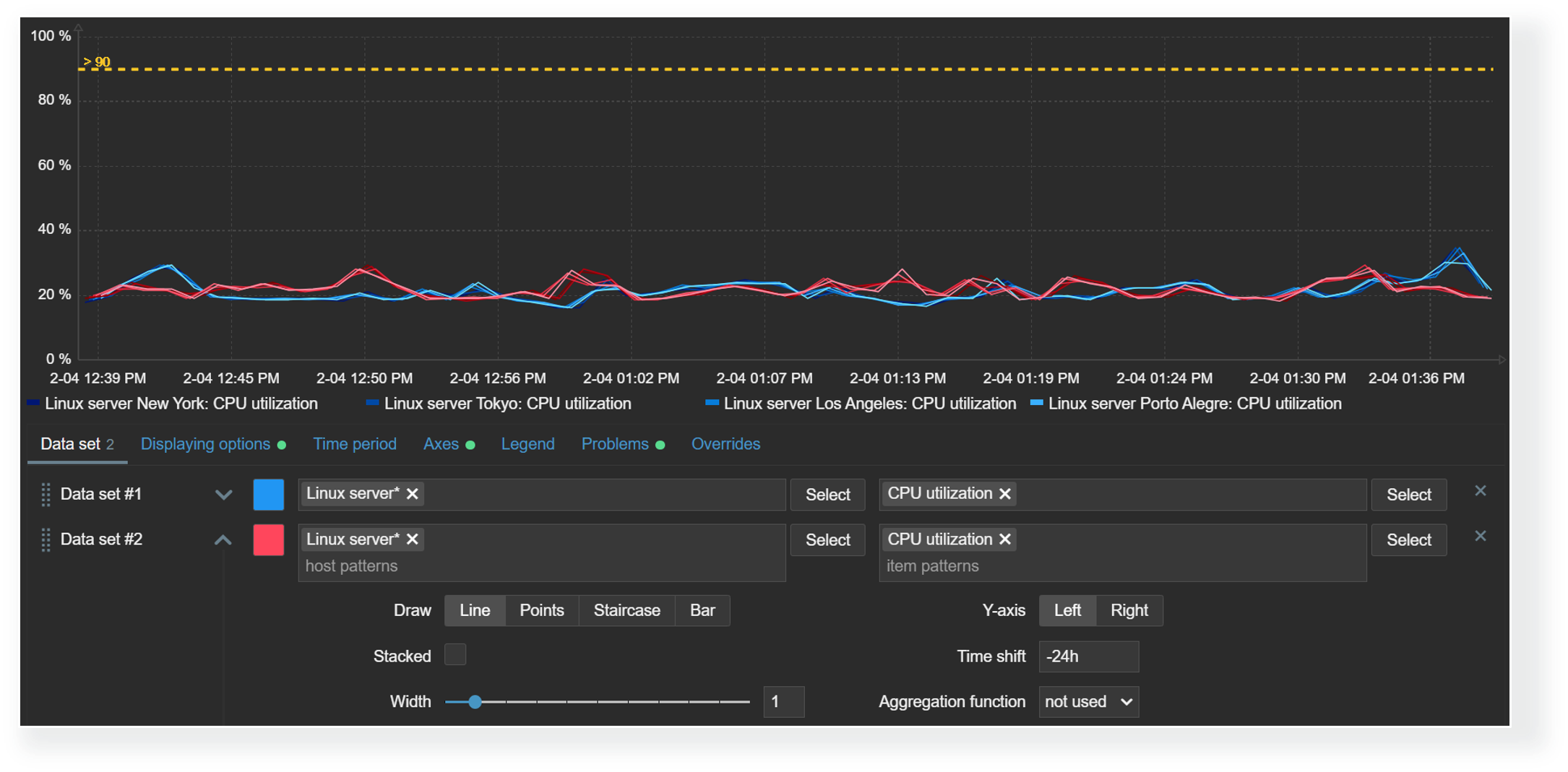
Widget configuration changes are also displayed instantly in Zabbix 7.4 – there’s no need anymore to apply the changes to see them reflected in the widget.
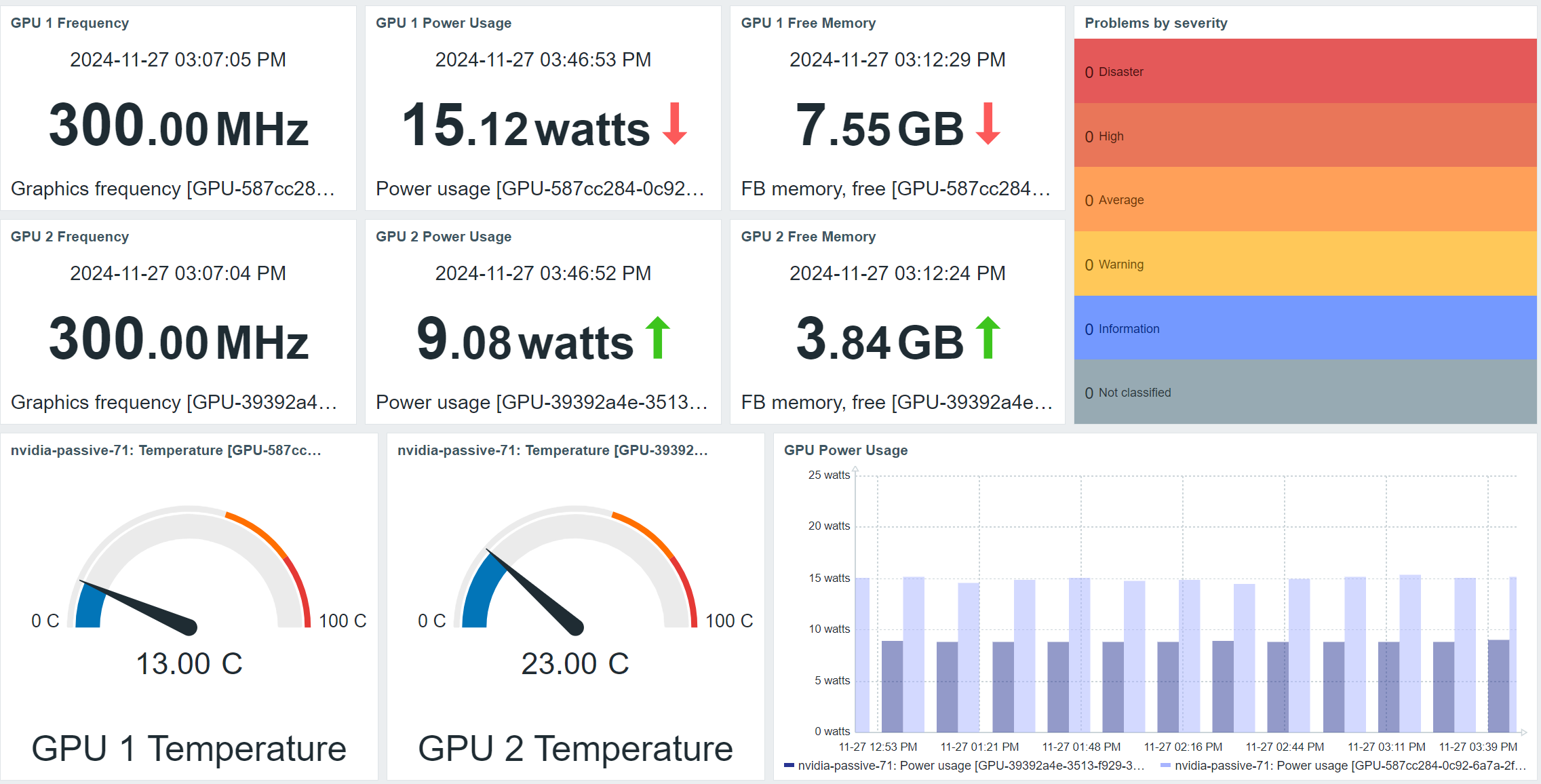
In addition, the default Global view dashboard has received an overhaul and now utilizes the latest Zabbix widgets to provide additional insights about the Zabbix instance.

Other changes in Zabbix 7.4
Multiple smaller fixes have been introduced in Zabbix 7.4, such as new history functions, new macros, security fixes, and more:
- Preprocessing results can now be copied directly to clipboard by using the “Copy to clipboard” button
- All users are now allowed to manage their own media by default. These permissions can now be revoked in user role settings
- A new Notifications section for customizing notification settings has been added under “User Settings”
- Vault secret macros can now be resolved by either the Zabbix server or Zabbix proxy
- A new icmppingretry simple check has been added to monitor host responses to ICMP ping with the ability to modify retries
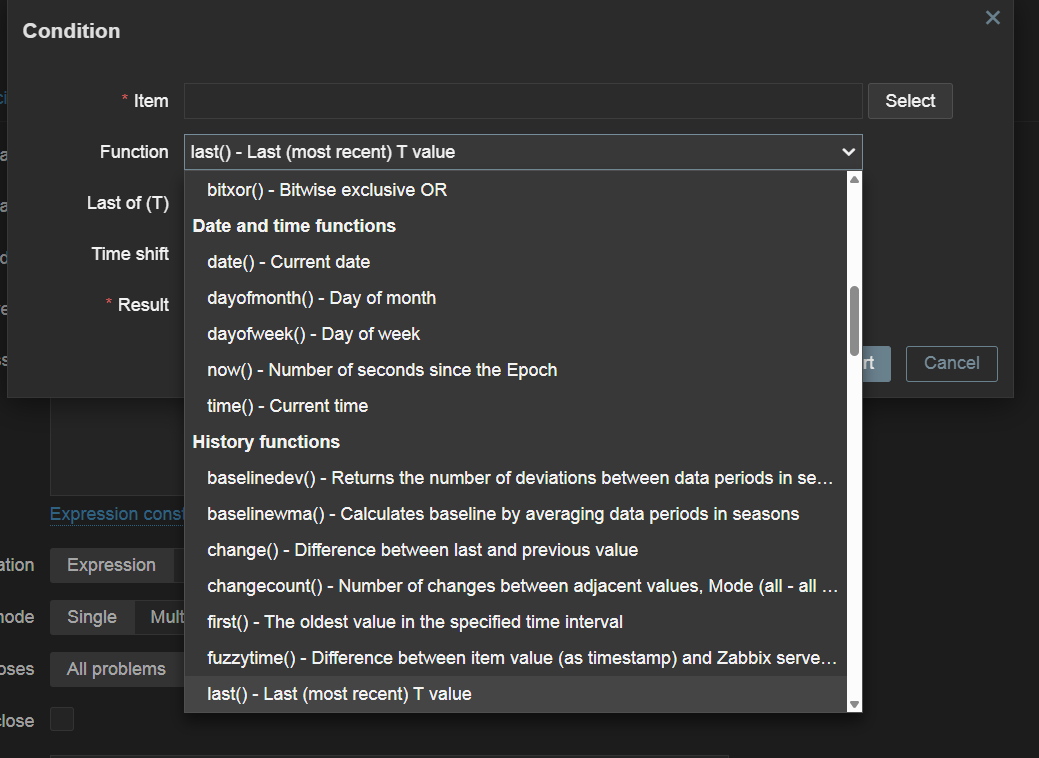
- New timestamp tracking history functions have been added
- Multiple new macros added for item-value time tracking
- Zabbix server/proxy automatically logs history cache diagnostic information when the history cache is full
- Disabled items are now immediately removed from the history cache
- It is now possible to manually clear the history cache for a specific item by its id with the history_cache_clear=target runtime command
- Added support of Gmail OAuth authentication
New templates and integrations in Zabbix 7.4
Many of the existing webhook integrations have been refactored in Zabbix 7.4. The webhooks have been optimized for the best possible performance and include a variety of fixes:
- Discord
- GitHub
- GLPi
- Jira
- Jira Service management
- MS Teams
- MS Teams Workflows
- OTRS CE
- PagerDuty
- Slack
- Telegram
- Zammad

Multiple new templates have also been introduced:
- Pure Storage FlashArray
- Azure SQL Managed Instance
- Azure MSSQL DTU database by HTTP
- Azure Backup Jobs by HTTP
- Palo Alto PA-440
- Juniper MX
- Improvements for Dell by HTTP and SNMP templates

The post What’s new in Zabbix 7.4 appeared first on Zabbix Blog.