Post Syndicated from Vinodh Subramanian original https://backblazeprod.wpenginepowered.com/blog/whats-the-diff-bandwidth-vs-throughput/

You probably wouldn’t buy a car without knowing its horsepower. The metric might not matter as much to you as things like fuel efficiency, safety, or spiffy good looks. It might not even matter at all, but it’s still something you want to know before driving off the lot.
Similarly, you probably wouldn’t buy cloud storage without knowing a little bit about how it performs. Whether you need the metaphorical Ferrari of cloud providers, the safety features of a Volvo, or the towing capacity of a semitruck, understanding how each performs can significantly impact your cloud storage decisions. And to understand cloud performance, you have to understand the difference between bandwidth and throughput.
In this blog, I’ll explain what bandwidth and throughput are and how they differ, as well as other key concepts like threading, multi-threading, and throttling—all of which can add more complexity and potential confusion to a cloud storage decision and the efficiency of data transfers.
Bandwidth, Throughput, and Latency: A Primer
Three critical components form the cornerstone of cloud performance: bandwidth, throughput, and latency. To easily understand their impact, imagine the flow of data to water moving through a pipe—an analogy that paints a visual picture of how data travels across a network.

- Bandwidth: The diameter of the pipe represents bandwidth. It’s the maximum width that dictates how much water (data) can flow through it at any given time. In technical terms, bandwidth is the data transfer rate that a network connection can support. It’s usually measured in bits per second (bps). A wider pipe (higher bandwidth) means more data can flow, similar to having a multi-lane road where more vehicles can travel side by side.
- Throughput: If bandwidth is the pipe’s width, then throughput is the rate at which water moves through the pipe successfully. In the context of data, throughput is the actual data transfer rate that is sent over a network. It is also measured in bits per second (bps). Various factors can affect throughput—such as network traffic, processing power, packet loss, etc. While bandwidth is the potential capacity, throughput is the reality of performance, which is often less than the theoretical maximum due to real-world constraints.
- Latency: Now, consider the time it takes for water to start flowing from the pipe’s opening after the tap is turned on. That time delay can be considered as latency. It’s the time it takes for a packet of data to travel from the source to the destination. Latency is crucial in use cases where time is of the essence, and even a slight delay can be detrimental to the user experience.
Understanding how bandwidth, throughput, and latency are interrelated is vital for anyone relying on cloud storage services. Bandwidth sets the stage for potential performance, but it’s the throughput that delivers actual results. Meanwhile, latency is a measure of how long it takes data to be delivered to the end user in real time.
Threading and Multi-Threading in Cloud Storage
When we talk about moving data in the cloud, two concepts often come up: threading and multi-threading. These might sound very technical, but they’re actually pretty straightforward once broken down into simpler terms.
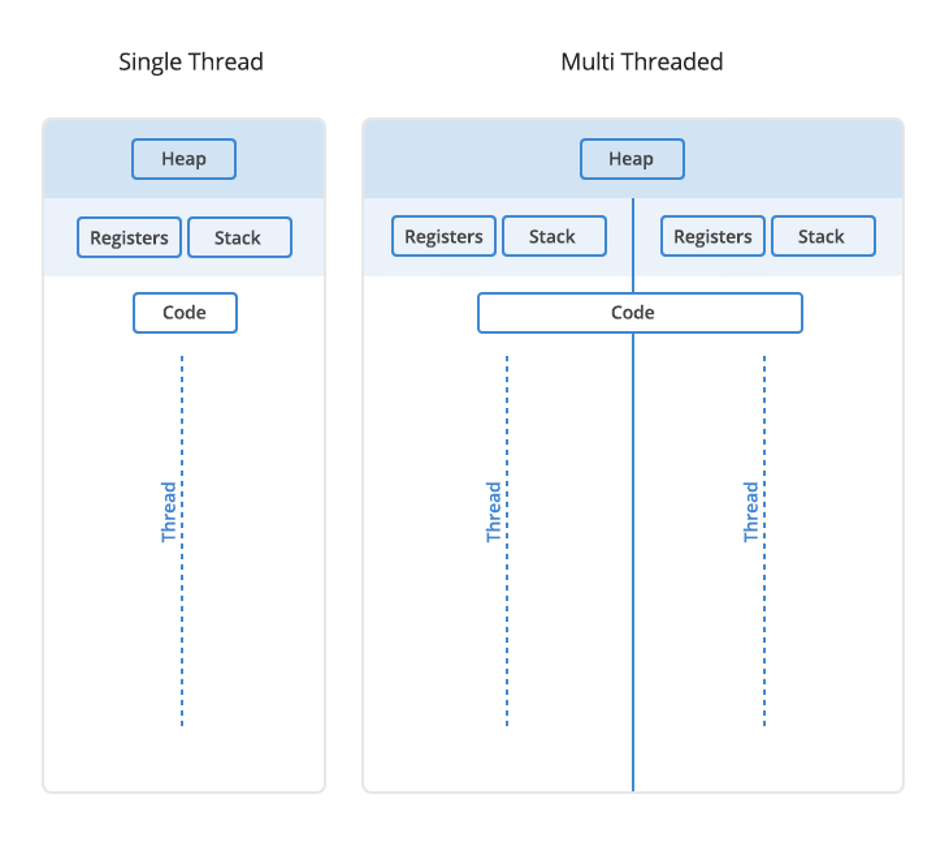
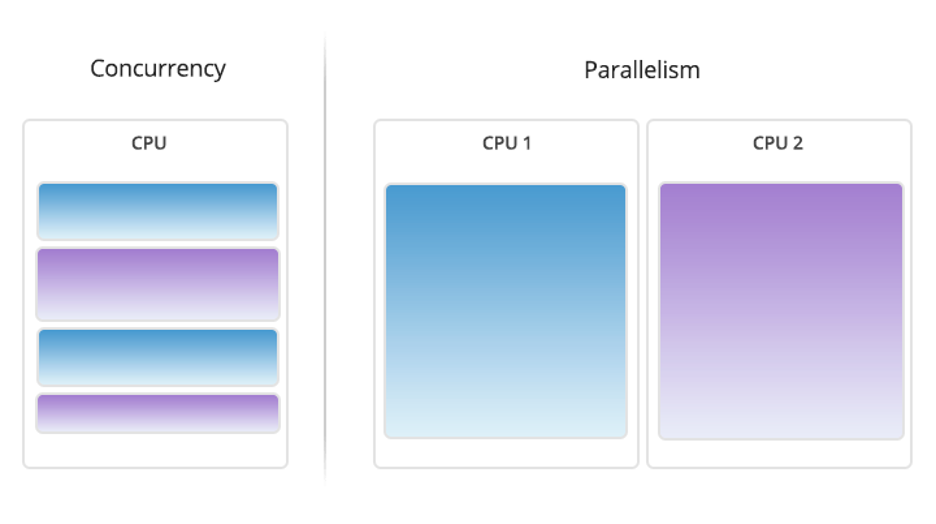
First of all, threads go by many different names. Different applications may refer to them as streams, concurrent threads, parallel threads, concurrent uploads, parallelism, etc. But what all these terms refer to when we’re discussing cloud storage is the process of uploading files. To understand threads, think of a big pipe with a bunch of garden hoses running through it. The garden hose is a single thread in our pipe analogy. The hose carries water (your data) from one point to another—say from your computer to the cloud or vice versa. In simple terms, it’s the pathway your data takes. Each hose represents an individual pathway through which data can move between a storage device and the network.
Cloud storage systems use sophisticated algorithms to manage and prioritize threads. This ensures that resources are allocated efficiently to optimize data flow. Threads can be prioritized based on various criteria such as the type of data being transferred, network conditions, and overall load on the system.
Multi-Threading
Now, imagine: instead of just one garden hose within a pipe, you have several in parallel to each other. This setup is multi-threading. It lets multiple streams of water (data) flow at the same time, significantly speeding up the entire process. In the context of cloud storage, multi-threading enables the simultaneous transfer of multiple data streams, significantly speeding up data upload and download.
Cloud storage takes advantage of multithreading. It can take pretty much as many threads as you can throw at it and its performance should scale accordingly. But it doesn’t do so automatically—because the effectiveness of multi-threading depends on the underlying network infrastructure and the ability of the software to efficiently manage multiple threads.
Chances are most devices can’t handle or take advantage of the maximum number of threads cloud storage can handle as it puts additional load on your network and device. Therefore, it often takes a trial-and-error approach to find the sweet spot to get optimal performance without severely affecting the usability of your device.
Managing Thread Count
Certain applications automatically manage threading and adjust the number of threads for optimal performance. When you’re using cloud storage with an integration like backup software or a network attached storage (NAS) device, the multi-threading setting is typically found in the integration’s settings.
Many backup tools, like Veeam, are already set to multi-thread by default. However, some applications might default to using a single thread unless manually configured otherwise.
That said, there are limitations associated with managing multiple threads. The gains from increasing the number of threads are limited by the bandwidth, processing power, and memory. Additionally, not all tasks are suitable for multi-threading; some processes need to be executed sequentially to maintain data integrity and dependencies between tasks.

In essence, threading is about creating a pathway for your data and multi-threading is about creating multiple pathways to move more data at the same time. This makes storing and accessing files in the cloud much faster and more efficient.
The Role of Throttling
Throttling is the deliberate slowing down of internet speed by service providers. In the pipe analogy, it’s similar to turning down the water flow from a faucet. Service providers use throttling to manage network traffic and prevent the system from becoming overloaded. By controlling the flow, they ensure that no single user or application monopolizes the bandwidth.
Why Do Cloud Service Providers Throttle?
The primary reason cloud service providers would throttle is to maintain an equitable distribution of network resources. During peak usage times, networks can become congested, much like roads during rush hour. Throttling helps manage these peak loads, ensuring all users have access to the network without significant drops in quality or service. It’s a balancing act, aiming to provide a steady, reliable service to as many users as possible.
Scenarios Where Throttling Can Be a Hindrance
While throttling aims to manage network traffic for fairness purposes, it can be frustrating in certain situations. For heavy data users, such as businesses that rely on real-time data access and media teams uploading and downloading large files, throttling can slow operations and impact productivity. Additionally, for services not directly causing any congestion, throttling can seem unnecessary and restrictive.
Do CSPs Have to Throttle?
As a quick plug, Backblaze does not throttle, so customers can take advantage of all their bandwidth while uploading to B2 Cloud Storage. Many other public cloud storage providers do throttle, although they certainly may not make it widely known. If you’re considering a cloud storage provider and your use case demands high throughput or fast transfer times, it’s smart to ask the question upfront.
Optimizing Cloud Storage Performance
Achieving optimal performance in cloud storage involves more than just selecting a service; it requires a clear understanding of how bandwidth, throughput, latency, threading, and throttling interact and affect data transfer. Tailoring these elements to your specific needs can significantly enhance your cloud storage experience.
- Balancing bandwidth, throughput, and latency: The key to optimizing cloud performance lies in your use case. For real-time applications like video conferencing or gaming, low latency is crucial, whereas, for backup use cases, high throughput might be more important. Assessing the types of files you’re transferring and their size along with content delivery networks (CDN) can help in optimizing and achieving peak performance.
- Effective use of threading and multi-threading: Utilizing multi-threading effectively means understanding when it can be beneficial and when it might lead to diminishing returns. For large file transfers, multi-threading can significantly reduce transfer times. However, for smaller files, the overhead of managing multiple threads might outweigh the benefits. Using tools that automatically adjust the number of threads based on file size and network conditions can offer the best of both worlds.
- Navigating throttling for optimal performance: When selecting a cloud storage provider (CSP), it’s crucial to consider their throttling policies. Providers vary in how and when they throttle data transfer speeds, affecting performance. Understanding these policies upfront can help you choose a provider that aligns with your performance needs.
In essence, optimizing cloud storage performance is an ongoing process of adjustment and adaptation. By carefully considering your specific needs, experimenting with settings, and staying informed about your provider’s policies, you can maximize the efficiency and effectiveness of your cloud storage solutions.
The post What’s the Diff: Bandwidth vs. Throughput appeared first on Backblaze Blog | Cloud Storage & Cloud Backup.