Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=V56wxGQr2XQ
Yearly Archives: 2024
More Memory Safety for Let’s Encrypt: Deploying ntpd-rs
Post Syndicated from Let's Encrypt original https://letsencrypt.org/2024/06/24/ntpd-rs-deployment/
When we look at the general security posture of Let’s Encrypt, one of the things that worries us most is how much of the operating system and network infrastructure is written in unsafe languages like C and C++. The CA software itself is written in memory safe Golang, but from our server operating systems to our network equipment, lack of memory safety routinely leads to vulnerabilities that need patching.
Partially for the sake of Let’s Encrypt, and partially for the sake of the wider Internet, we started a new project called Prossimo in 2020. Prossimo’s goal is to make some of the most critical software infrastructure for the Internet memory safe. Since then we’ve invested in a range of software components including the Rustls TLS library, Hickory DNS, River reverse proxy, sudo-rs, Rust support for the Linux kernel, and ntpd-rs.
Let’s Encrypt has now taken a step that was a long time in the making: we’ve deployed ntpd-rs, the first piece of memory safe software from Prossimo that has made it into the Let’s Encrypt infrastructure.
Most operating systems use the Network Time Protocol (NTP) to accurately determine what time it is. Keeping track of time is a critical task for an operating system, and since it involves interacting with the Internet it’s important to make sure NTP implementations are secure.
In April of 2022, Prossimo started work on a memory safe and generally more secure NTP implementation called ntpd-rs. Since then, the implementation has matured and is now maintained by Project Pendulum. In April of 2024 ntpd-rs was deployed to the Let’s Encrypt staging environment, and as of now it’s in production.
Over the next few years we plan to continue replacing C or C++ software with memory safe alternatives in the Let’s Encrypt infrastructure: OpenSSL and its derivatives with Rustls, our DNS software with Hickory, Nginx with River, and sudo with sudo-rs. Memory safety is just part of the overall security equation, but it’s an important part and we’re glad to be able to make these improvements.
We depend on contributions from our community of users and supporters in order to provide our services. If your company or organization would like to sponsor Let’s Encrypt please email us at [email protected]. We ask that you make an individual contribution if it is within your means.
Situation
Post Syndicated from xkcd.com original https://xkcd.com/2950/

More Memory Safety for Let’s Encrypt: Deploying ntpd-rs
Post Syndicated from Let's Encrypt original https://letsencrypt.org/2024/06/24/ntpd-rs-deployment.html
When we look at the general security posture of Let’s Encrypt, one of the things that worries us most is how much of the operating system and network infrastructure is written in unsafe languages like C and C++. The CA software itself is written in memory safe Golang, but from our server operating systems to our network equipment, lack of memory safety routinely leads to vulnerabilities that need patching.
Partially for the sake of Let’s Encrypt, and partially for the sake of the wider Internet, we started a new project called Prossimo in 2020. Prossimo’s goal is to make some of the most critical software infrastructure for the Internet memory safe. Since then we’ve invested in a range of software components including the Rustls TLS library, Hickory DNS, River reverse proxy, sudo-rs, Rust support for the Linux kernel, and ntpd-rs.
Let’s Encrypt has now taken a step that was a long time in the making: we’ve deployed ntpd-rs, the first piece of memory safe software from Prossimo that has made it into the Let’s Encrypt infrastructure.
Most operating systems use the Network Time Protocol (NTP) to accurately determine what time it is. Keeping track of time is a critical task for an operating system, and since it involves interacting with the Internet it’s important to make sure NTP implementations are secure.
In April of 2022, Prossimo started work on a memory safe and generally more secure NTP implementation called ntpd-rs. Since then, the implementation has matured and is now maintained by Project Pendulum. In April of 2024 ntpd-rs was deployed to the Let’s Encrypt staging environment, and as of now it’s in production.
Over the next few years we plan to continue replacing C or C++ software with memory safe alternatives in the Let’s Encrypt infrastructure: OpenSSL and its derivatives with Rustls, our DNS software with Hickory, Nginx with River, and sudo with sudo-rs. Memory safety is just part of the overall security equation, but it’s an important part and we’re glad to be able to make these improvements.
We depend on contributions from our community of users and supporters in order to provide our services. If your company or organization would like to sponsor Let’s Encrypt please email us at [email protected]. We ask that you make an individual contribution if it is within your means.
Kernel prepatch 6.10-rc5
Post Syndicated from corbet original https://lwn.net/Articles/979442/
The 6.10-rc5 kernel prepatch is out for
testing. “So far, the 6.10 release cycle has been fairly calm, and rc5
“
continues that trend. Let’s hope things stay that way.
Larry Finger RIP
Post Syndicated from corbet original https://lwn.net/Articles/979419/
The linux-wireless mailing list carries the terse
notice that longtime networking developer Larry Finger passed away on
June 21. The LWN Kernel
Source Database shows that Finger contributed to 94 releases in
the (Git era) kernel history, starting with 2.6.16 — 1,464 commits in
total. He will be missed.
Comic for 2024.06.23 – Content
Post Syndicated from Explosm.net original https://explosm.net/comics/content
New Cyanide and Happiness Comic
Forgotten murder in New York Harbor – Pirate Albert Hicks
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=bWjywbQJ-jM
Social Climber
Post Syndicated from Oglaf! -- Comics. Often dirty. original https://www.oglaf.com/socialclimber/


Gigabyte MS04-CE0 Intel Xeon 6 Motherboard Shown
Post Syndicated from John Lee original https://www.servethehome.com/gigabyte-ms04-ce0-intel-xeon-6-motherboard-shown/
The Gigabyte MS04-CE0 we saw at Computex 2024 is a single socket Intel Xeon 6 motherboard that packs up to 144 cores onto an ATX motherboard
The post Gigabyte MS04-CE0 Intel Xeon 6 Motherboard Shown appeared first on ServeTheHome.
Comic for 2024.06.22 – Wasn’t Listening
Post Syndicated from Explosm.net original https://explosm.net/comics/wasnt-listening
New Cyanide and Happiness Comic
Big Ben: The Tolling of the Iron Bell
Post Syndicated from Geographics original https://www.youtube.com/watch?v=x_SfkU44jSw
Micah Siva | Nosh | Talks at Google
Post Syndicated from Talks at Google original https://www.youtube.com/watch?v=k5Jd3OZVOR8
Fault-isolated, zonal deployments with AWS CodeDeploy
Post Syndicated from Michael Haken original https://aws.amazon.com/blogs/devops/fault-isolated-zonal-deployments-with-aws-codedeploy/
In this blog post you’ll learn how to use a new feature in AWS CodeDeploy to deploy your application one Availability Zone (AZ) at a time to help increase the operational resilience or your services through improved fault isolation.
Introducing change to a system can be a time of risk. Even the most advanced CI/CD systems with comprehensive testing and phased deployments can still promote a bad change into production. A common approach to reduce this risk is using fractional deployments and closely monitoring critical metrics like availability and latency to gauge a deployment’s success. If the deployment shows signs of failure, the CI/CD system initiates an
This blog post will show you how to leverage CodeDeploy zonal deployments as part of a holistic AZ independent (AZI) architecture strategy, both patterns that many AWS service teams follow. With this feature, you no longer need to distinguish between infrastructure or deployment failures in order to respond to the event. You can use the same observability tools and recovery techniques for both, which allows you to contain the scope of impact to a single AZ and mitigate the impact more quickly and with less complexity. First, let’s define what an AZI architecture is so we can understand how this feature in CodeDeploy supports it.
Availability Zone independence
Fault isolation is an architectural pattern that limits the scope of impact of failures by creating independent fault containers that don’t share fate. It also allows you to quickly recover from failures by shifting traffic or resources away from the impaired fault container. AWS provides a number of different fault isolation boundaries, but the ones most people are familiar with are AZs and Regions. When you build multi-AZ architectures, you can design your application to implement AZI that uses the fault boundary provided by AZs to keep the interaction of resources isolated to their respective AZ (to the greatest extent possible).

An Availability Zone independent (AZI) architecture implemented by disabling cross-zone load balancing and using an independent database read replica per AZ. Only database writes have to cross an AZ boundary.
The result is that the impacts from an impairment in one AZ don’t cascade to resources in other AZs, making the operation of your application in one AZ independent from events in the others. You should also monitor the health of each AZ independently, for example by looking at per-AZ load balancer HTTPCode_Target_5XX_Count metrics, or by sending synthetic requests to the load balancer nodes in each AZ and recording availability and latency metrics for each. When an event occurs that impacts your availability or latency in a single AZ, you can use capabilities like Amazon Route 53 Application Recovery Controller zonal shift to shift traffic away from that AZ to quickly mitigate impact, often in single-digit minutes.

Using zonal shift to move traffic away from the AZ experiencing a service impairment
Traditional deployment strategy challenges
During an event, SRE, engineering, or operations teams can spend a lot of time trying to figure out if the source of impact is an infrastructure problem or related to a failed deployment. Then, based on the identified cause, they may take different mitigation actions. Thus, precious time is spent investigating the source of impact and deciding on the appropriate mitigation plan.
When the cause is due to a failed deployment, traditionally rollbacks are used to mitigate the problem. But rollbacks, even when automated, take time to complete. For example, let’s say your deployment batches take 5 minutes to complete, you deploy in 10% batches, and you’re halfway through a deployment to 100 instances when the rollback is initiated. This means it’s going to take at least 25 minutes to finish the rollback (5 batches, each taking 5 minutes to re-deploy to). And it’s entirely possible during that time that instances where the new software was deployed continue to pass health checks, but result in errors being returned to your customers. In the worst case, if all instances had been deployed to, this event could last for almost an hour with customers being impacted during the entire rollback process. In some cases, deployments can’t be rolled back and have to be rolled forward, meaning a new, updated version needs to be deployed to fix the previous deployment. Writing the code for the new deployment and testing it adds to the recovery time of your system and can be error prone.
Additionally, if your unit of deployment includes multiple AZs, then your potential scope of impact from a failed deployment isn’t predictably bounded. For example, if your CodeDeploy deployment groups target Amazon Elastic Compute Cloud (Amazon EC2) instances based on tags or an Amazon EC2 Auto Scaling group that spans multiple AZs, then you could see impact across the whole Region, even if you’re using fractional deployments. There’s not a smaller fault container that helps consistently limit the scope of impact to a predictable size.
Let’s look at how we can overcome these two challenges by using zonal deployments with CodeDeploy.
Zonal deployments with AWS CodeDeploy
One of the best practices we follow at AWS, described in My CI/CD pipeline is my release captain, is performing fractional deployments aligned to intended fault isolation boundaries, like individual hosts, cells, AZs, and Regions. When we release a change, the deployment is separated into waves, which represent fault containers (like Regions) that are deployed to in parallel, and those are further separated into stages. Within a single Region, the deployment starts with a one-box environment, representing a single host, then moves on to fractional batches (like 10% at a time) inside a single AZ, waits for a period of bake time, moves on to the next AZ, and so on until we’ve completed rolling out the change.

Deployment stages aligned to intended fault isolation boundaries within a single deployment wave for one Region
By aligning each stage to an expected fault isolation boundary, we create well-defined fault containers that provide an understood and bounded scope of impact in the case that something goes wrong with a deployment. You can take advantage of this same deployment strategy in your own applications by using zonal deployments in CodeDeploy. To utilize this capability, you need to define a custom deployment configuration shown below.

Creating a zonal deployment configuration that deploys to 10% of the EC2 instances in each AZ at a time, one AZ at a time
This configuration defines a few important properties. First, it enables the zonal configuration, which ensures deployments will be phased one AZ at a time. In this case, updates will be deployed to batches of 10% of the instances in each AZ (see the minimum number of healthy instances per Availability Zone for more details on configuring this setting). Second, it defines a monitor duration, which is the bake time where the effects of the changes are observed before moving on to the next AZ. This ensures sufficient use of the new software to discover any potential bugs or problems before moving on. The value in this example is defined as 900 seconds, or 15 minutes. You should ensure this value is longer than the time it takes for your alarms to trigger. For example, if you are using an M of N alarm for availability and/or latency, that is using 3 data points out of 5 with 1-minute intervals, you need to make sure your bake time is set to greater than 600 seconds, otherwise, you might move on to the next AZ before your alarm has a chance to mark the deployment as unsuccessful. Finally, I’ve also defined a first zone monitor duration. This overrides the “monitor duration” for the first AZ being deployed to. This is useful since the first AZ is acting as our canary or one-box environment and we may want to wait additional time to be really confident the deployment is successful before moving on to the second AZ.
If your service is deployed behind a load balancer with cross-zone load balancing disabled (which is important to achieve AZI), carefully consider your batch size. The load balancer evenly splits traffic across AZs regardless of how many healthy hosts are in each AZ. Ensure your batch size is small enough that the temporary reduction in capacity during each batch doesn’t overwhelm the remaining instances in the same AZ. You can use the CodeDeploy minimum healthy hosts per AZ option to ensure there are enough healthy hosts in the AZ during a deployment batch or Elastic Load Balancing (ELB) target group minimum healthy target count with DNS failover to shift traffic away from the AZ if too few targets are present.
Recovering from a failed zonal deployment.
When a failure occurs, the highest priority is mitigating the impact, not fixing the root cause. While an automated rollback can help achieve both for a failed deployment, using a zonal shift can improve your recovery time. Let’s take a simple dashboard like the following figure. The top graph shows your availability as perceived by customers through using the regional endpoint of your load balancer like https://load-balancer-name-and-id.elb.us-east-1.amazonaws.com. The graphs below it show the measured availability from Amazon CloudWatch Synthetics canaries that test the load balancer endpoints in each AZ using endpoints like https://us-east-1a.load-balancer-name-and-id.elb.us-east-1.amazonaws.com.

Dashboard showing impact in one AZ that affects the availability of the service
We can see that something starts impacting resources in AZ1 at 10:38 causing an availability drop. As we would expect, this impact is also seen by customers, shown in the top graph, but it’s unclear what the underlying cause of the availability drop is. Using the approach described in this post, it turns out that it doesn’t matter. Within a few minutes, at 10:41 the CloudWatch composite alarm monitoring the health of AZ1 transitions to the ALARM state and invokes a Lambda function that reads the alarm’s definition to get the AZ ID and ALB ARN involved, and initiates the zonal shift. It’s important that the alarm logic only reacts when a single AZ is impacted, if there was impact in more than one AZ, we would need to treat this as a Regional issue.

After a failed deployment to AZ1, an automatically initiated zonal shift quickly mitigates the customer impact
Then, after a few more minutes, at 10:44, we can see availability from the customer perspective has gone back up to 100% by shifting traffic away from AZ1.

The impact of the failed deployment is mitigated by shifting traffic away from AZ1
It turns out the cause of impact in this case was a failed deployment, and we can see that our synthetic canaries still see the failure while the deployment is rolling back, but we’ve achieved our primary goal of quickly removing the impact to the customer experience. From the start of impact to mitigation, 6 minutes elapsed, which was significantly faster than waiting for the deployment to completely rollback. After the rollback is complete, at 10:58, 20 minutes after the start of the event, we can see the alarm transition back to the OK state and availability return to normal in AZ1, meaning we can end the zonal shift and return to normal operation.

After the deployment rollback is complete, the availability in AZ1 recovers and the zonal shift can be ended
Conclusion
Performing zonal deployments helps improve the effectiveness of AZI architectures. Aligning your deployments to your intended fault isolation boundaries, in this case AZs, creates a predictable scope of impact and helps prevents cascading failures. This in turn allows you to use a common set of observability and mitigation tools for both single-AZ infrastructure events and failed deployments, which can mitigate the impact faster than automated rollbacks. Additionally, by removing the ambiguity on selecting a recovery strategy for operators, it further reduces recovery time and complexity. Learn more about zonal deployments in AWS CodeDeploy here.
Five ways Amazon Q simplifies AWS CloudFormation development
Post Syndicated from Ryan Kiel original https://aws.amazon.com/blogs/devops/five-ways-amazon-q-simplifies-aws-cloudformation-development/
Introduction
As a builder, AWS CloudFormation provides a reliable way for you to model, provision, and manage AWS and third-party resources by treating infrastructure as code. First-time and experienced users of CloudFormation can often encounter some challenges when it comes to development of templates and stacks. CloudFormation offers a vast library of over 1,250 resource types covering AWS services, and supports numerous features and functionalities in both the construction of a template, as well as the deployment of a stack using that template. The broad array of options at one’s disposal provides a broad landscape to navigate.
In 2023, AWS introduced a new generative AI-powered assistant, Amazon Q. Amazon Q is the most capable generative AI-powered assistant for accelerating software development and leveraging companies’ internal data. Amazon Q Developer can answer questions about AWS architecture, best practices, documentation, support, and more. When used in an integrated development environment (IDE), Amazon Q Developer additionally provides software development assistance, including code explanation, code generation, and code improvements such as debugging and optimization.
In this blog post, we will show you five ways Amazon Q Developer can help you work with CloudFormation for template code generation, querying CloudFormation resource requirements, explaining existing template code, understanding deployment options and issues, and querying CloudFormation documentation.
Prerequisites
- An AWS account
- Access to Amazon Q console or Q in IDE
- IAM permissions to use Amazon Q
Amazon Q can be interacted with in different ways. The first way is native integration within the AWS Console. When logged into the console, you will see a “Q” logo. Click on it to open a chat window, and then you can begin asking questions to Amazon Q without any setup.
You can also interact with Amazon Q Developer after following these instructions to set it up in your Interactive Development Environment (IDE).
1. Template Code Generation
The foundational element of any CloudFormation stack begins with a template that describes your infrastructure as code, in either a JSON or YML format. The anatomy of what comprises a stack can be found here. Creating a template requires knowledge of the template format, as well as the proper structure of each CloudFormation resource that you include in the ‘Resources’ section.
With Amazon Q, you can generate a template from natural language without having to look up the particular definition of each resource.

Figure 1: Template code Generation using Amazon Q
In Figure 1 above, I asked Amazon Q if it could provide me with a CloudFormation template with Lambda code in python to list all EBS volumes in a region. It generated sample code that provides the minimum template I would need to create it. It also added the IAM role needed to execute the Lambda code. Finally, it included documentation links that can be reference for further usage.
With a single message to Amazon Q, I am off and running in seconds, ready to deploy my first CloudFormation stack.
2. Understanding CloudFormation Resource Properties
Another area where Q can help if you are already familiar with the structure of a resource, is by informing you of resource properties and their significance.
In the next use case, I encountered an issue with my template where certain properties were missing that are required for the resource. With Amazon Q, I can quickly understand the required property, and what it defines for my resource.


Figure 2: Stack Events & Q information on Required Parameters
Since the CloudFormation Events tab indicated that the error was a missing resource property, I asked Amazon Q to help me understand why the property was required, and what it defines. Now, without having to dig through documentation, I can make sure that my template code includes DefaultCacheBehavior and what that will define for my resource.
3. Explaining Existing Template Code
A benefit of Amazon CloudFormation and Infrastructure as Code is that templates allow developers to share and distribute both snippets and entire stacks as pre-defined JSON or YML files. Template reusability can help with the development of new systems, or the augmentation of existing ones – without needing to do any of the template development yourself.
In this example, I have borrowed a template snippet from the AWS documentation for a DynamoDB table. I have copied and pasted this template into my IDE.
In my IDE, I have integrated Amazon Q. As shown in Figure 3, I can highlight a specified section of my template code, and then ask Amazon Q to explain what it is doing for us.

Figure 3: Explaining CloudFormation code by Amazon Q
After asking Amazon Q to ‘Explain selected code’, I am given a detailed description of my highlighted template snippet. Q tells me that this is an Auto Scaling policy for a DynamoDB Table write capacity. It informs me what resource type it is (AWS::ApplicationAutoScaling::ScalingPolicy), and also describes what the function of that resource is, in the context of my DynamoDB Table. Next, it gives me detailed bullet points explaining all of the parameters of the resource definition, and how that impacts my table as well. It then concludes with a summary of the highlighted code that is easily digestible and understandable to the reader, and even offers to provide more information if needed.
In just one simple question to Amazon Q, I have quickly gone from copy and pasting existing code to now understanding its usage and functionality.
4. Understanding Deployment Issues
Sometimes developers may encounter issues when creating, updating or deleting CloudFormation stacks. When you come across errors with your AWS CloudFormation stack, you can ask Amazon Q to help you find the source of the problems.
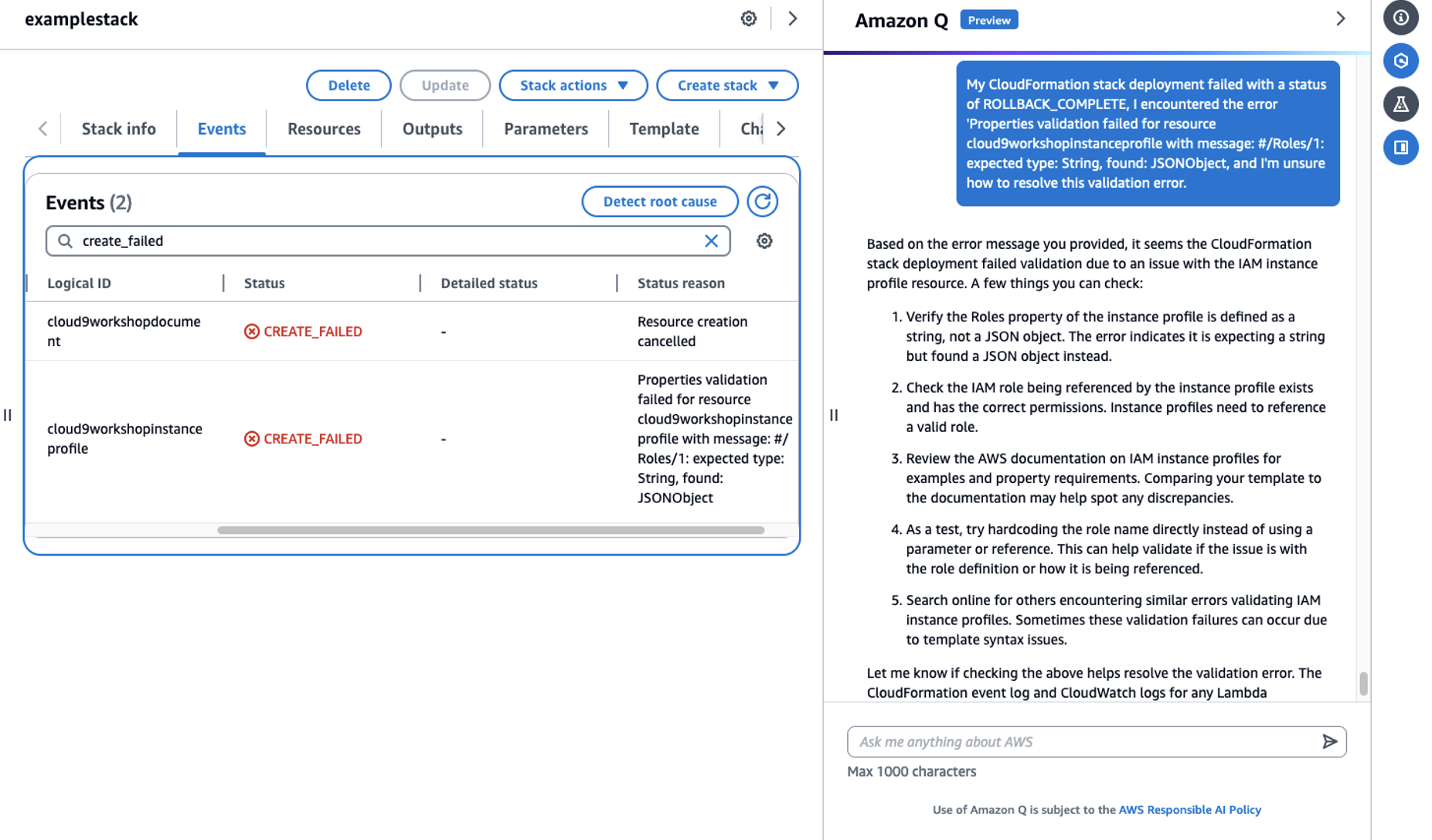
Figure 4: Reasoning stack failures by Amazon Q
Amazon Q answered why my CloudFormation stack failed to deploy and gave me different ways to check and fix the issues before trying again.
5. Querying CloudFormation Documentation & Functionality
Sometimes developers need to query CloudFormation documentation and functionality to build templates for their use case. Amazon Q can help with these requests straight from IDE. One such example is where developers ask Amazon Q to explain how to make sure my database is not deleted when a CloudFormation stack is deleted. In Figure 5, Amazon Q recommends few ways to make sure the RDS database is not deleted.
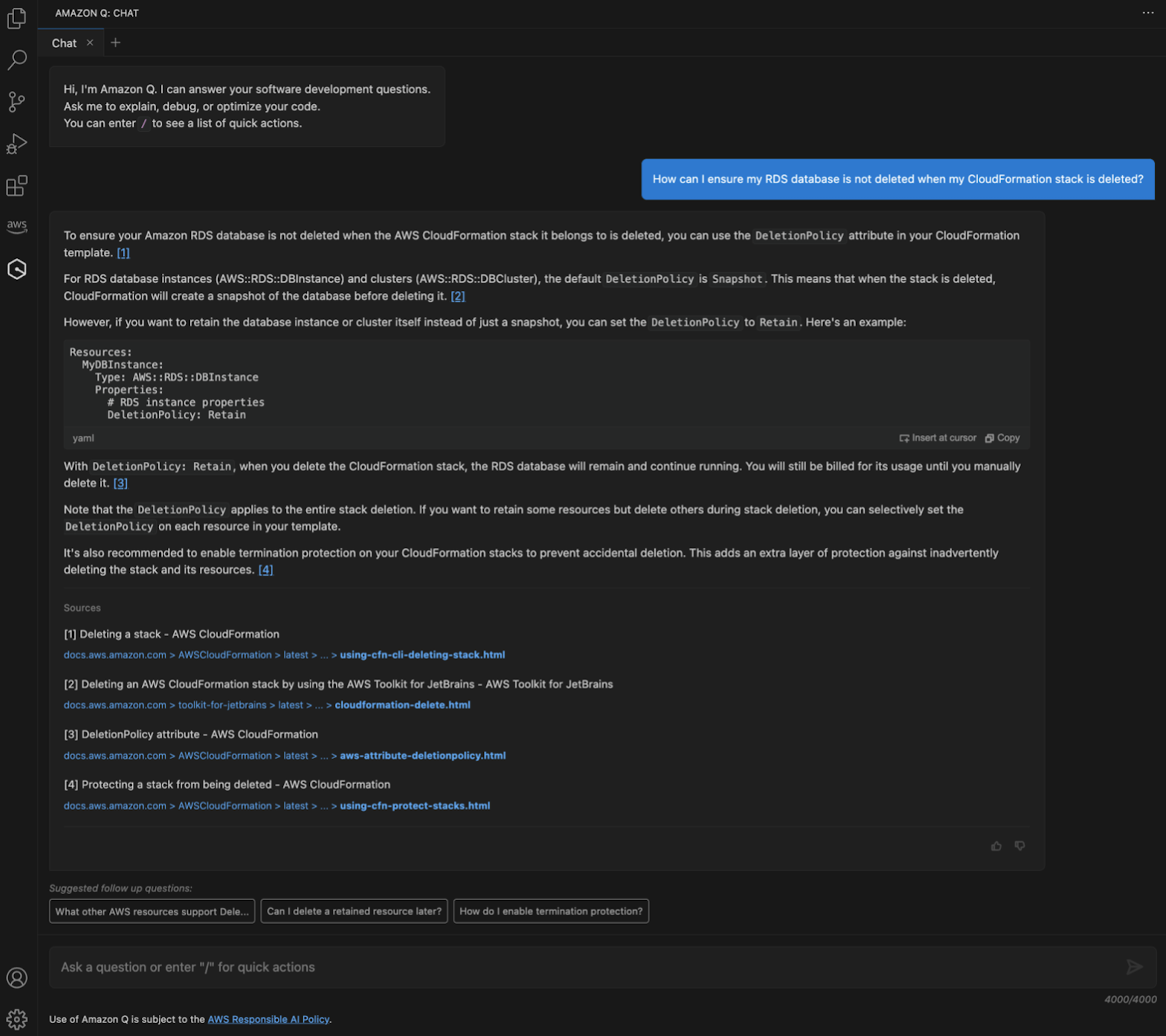
Figure 5: Query Amazon Q for CloudFormation documentation
Sometimes developers need deploy the CloudFormation stack across regions and accounts which can be achieved by using StackSets. In the following example, I asked it for help to understand this feature.

Figure 6: Query Amazon Q for CloudFormation StackSets functionality
It is also possible to ask Amazon Q for help with the prompts themselves. In the example below, I ask it to provide some hints on what kinds of questions I could ask about CloudFormation.

Figure 7: CloudFormation functionality prompts
In the example below, I ask one of those questions to dive into stack dependencies.

Figure 8: CloudFormation stack dependencies
Conclusion
Utilizing Amazon Q allows developers and builders to be more efficient. As a builder you can use Amazon Q in your IDE to create CloudFormation templates and improve existing CloudFormation templates. If you have inherited an existing CloudFormation template, you can use Amazon Q to understand it. Reducing template and stack development time is one exciting way that Amazon Q and Generative AI are enabling customers to move faster.
Japanese Kara-tech washout
Post Syndicated from Techmoan original https://www.youtube.com/watch?v=-UJFO3pRTPM
Седмицата (17–22 юни)
Post Syndicated from Йовко Ламбрев original https://www.toest.bg/sedmitsata-17-22-yuni/

Ако ситуацията беше малко по-различна, вероятно новина на седмицата щеше да бъде началото на 50-тото Народно събрание. Но то, заченато в грях, се роди трудно, а перспективите за бъдещето му съвсем не изглеждат обнадеждаващо, както и да се развият събитията. Това, за съжаление, налива вода в мелницата на тези, които нямат търпение да обявят смъртта на парламентарната република и да я подменят с президентска например.
Според Емилия Милчева обаче, колкото и изкушаващо да изглежда това политическо приключение за сегашния български президент, то е изпълнено с предизвикателства, които без подходящ контекст трудно биха се реализирали. Прочетете повече в нейния анализ, озаглавен „Ще стане ли президентът Радев партийно величие?“.
Свикнали сме Стефан Иванов да ни представя интересни книги или да четем поезията му, но тази седмица той ни показва една от другите си суперсили – тази на публициста. Под заглавието „За природата на поезията и политиката в думите“ ще намерите едно брилянтно и изключително важно интервю с поетите Линда Грегърсън и Ник Леърд, което само привидно гравитира около поезията, а всъщност болезнено откровено посяга към най-актуални теми от ежедневието на човечеството. Не подминавайте това четиво и си отделете достатъчно време за него. Включително за размишления.
В някакъв смисъл, макар че темата е архитектура, със сходна нагласа ще ви остави и текстът на Анета Василева „Make Architecture Great Again. Новият български архитектурен популизъм“, който е продължение на друг неин материал с подобно заглавие, публикуван в „Тоест“ през май. Първата част е посветена на това как духът на времето, политиката и идеологията оставят отпечатък върху сградите. И защо популизмът прониква и в сферата на архитектурата. Втората част е поглед към родните му проявления.
И ако играта на думи в заглавието на предишния материал ви е провокирала да насочите мисълта си отвъд океана, Александър Детев тъкмо се завърна оттам успокоен, че въпреки всичко американската мечта още си е на мястото. Не подминавайте интересния му и доста забавен обзор.
Отвъд океана идва и историческият повод през юни да се отбелязва необходимостта от зачитане на правата на ЛГБТИ хората. У нас тази година „София прайд“ ще се проведе за 17-ти пореден път. И отново смисълът, който събитието носи, е замъглен от шумни дискусии „за“ или „против“. Но за първи път от 17 години най-голямата група общински съветници от София – тази на „Продължаваме Промяната“, „Демократична България“ и „Спаси София“ – се обяви в подкрепа на прайда с нарочна декларация. За този прецедент пише Светла Енчева в материала си „Изгрява ли дъга над София и България?“.
Нека завършим седмицата с два много интересни текста от научната сфера. В първия Анастасия Орманджиева разказва за усъвършенстваните методи за извличане и разчитане на ДНК от вкаменелости, което е голям пробив в областта на еволюционната генетика. И ако искате да научите как ДНК на хора, живeли преди хилядолетия, може да ни помогне да се справим по-добре с бъдещи пандемии, инфекциозни болести или за разработване на нови лекарства и терапии, не пропускайте да прочетете „Палеогеномиката и тайните на античната ДНК“.
А Михаил Ангелов в новата си статия от поредицата „Научни новини“ разказва за ползите от употребата на някои отпадъци. Например в производството на шоколад или за пречистване на вода. Ако пък се интересувате от космически изследвания, може да прочетете за премеждията на капсулата „Старлайнер“ в орбита или за последните новини около поправената (от разстояние над 24 млрд. км) сонда „Вояджър 1“, която продължава мисията си.
Приятно четене!
Inventec Artemis 1U and 2U NVIDIA GB200 Systems Shown
Post Syndicated from Cliff Robinson original https://www.servethehome.com/inventec-artemis-1u-and-2u-nvidia-gb200-arm-systems-shown/
The Inventec Artemis 1U and 2U NVIDIA GB200 systems offer different power density for next-gen Grace Blackwell compute
The post Inventec Artemis 1U and 2U NVIDIA GB200 Systems Shown appeared first on ServeTheHome.
Tornado! The Super Outbreak of 1974
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=i2tgmIWZQW8
Comic for 2024.06.22 – You’re Fat
Post Syndicated from Explosm.net original https://explosm.net/comics/youre-fat
New Cyanide and Happiness Comic