MinIO is
a popular object-storage server that offered compatibility with the Amazon Simple Storage Service (S3)
API. In December 2025, the company behind the project (also named MinIO) announced
that the project was in maintenance mode and would not accept new changes; it
was archived
completely in February 2026. MinIO users have been hunting for alternatives
since then, but the array of choices can be baffling. While many other projects
aim to fill the space, their strengths and areas of focus tend to vary. Two of
the alternatives—Ceph and Garage—are particularly compelling,
and both offer solid S3 compatibility.
Earlier this month, a German court ruled that Google is liable for its AI search summaries. Rejecting defenses like “users can check for themselves,” and that they generally know “that information generated with AI should not be blindly trusted,” the court held that the AI’s summaries are reflections of the company and “above all an expression of Google’s business activities.”
This is the latest skirmish in a decades-old battle over internet publishing. Historically, there were two different types of information distributors: carriers and publishers. A phone company is a carrier. It’ll transmit whatever you say, even discussions about committing a crime. Words are words, and the phone company does not know—nor is it liable for—the words you choose to speak. A newspaper, on the other hand, is a publisher. It decides the words it publishes, and what quotes to include in its articles. If those words or quotes are defamatory or otherwise illegal, it’s liable.
Internet companies have long tried to play both ends of this distinction. They claim to be a carrier when it suits them, and also to be a publisher when that is advantageous. Section 230 of the 1996 Communication Decency Act enshrined this straddling when it shielded internet providers from liability for the speech of others on their platforms: “No provider or user of an interactive computer service shall be treated as the publisher or speaker of any information provided by another information content provider.”
For years, a debate has continued about how to apply this law to social media platforms. When platforms merely displayed people’s posts and comments in reverse-chronological order, they behaved largely like carriers, relaying people’s words without regard to their contents. But the next generation of platforms, like Facebook, curated feeds with algorithms and thereby acted more like publishers, making editorial decisions about who sees what. Some experts think section 230 has gone too far and needs reform; others think that it’s what holds the modern internet together.
Google’s AI overviews are far less nuanced. They work differently from traditional search, which courts have held involves archiving and facilitating access to the editorial content of third parties. AI overviews don’t just quote and republish words from different websites. With overviews, the AI rewrites other people’s words, exercising editorial discretion like a newspaper article or an original essay on a topic.
It’s not only Google’s AI that falls into this category. Imagine a restaurant review site that provides AI summaries, or a site summarizing laws and government procedures. Or a traditional publisher that uses AI to summarize its own publication. Accuracy matters, and liability is one of the most important ways we as a public can demand accuracy and hold companies accountable when they cause harm.
Two years ago, Air Canada learned this lesson. Its AI chatbot promised a discount the company later rescinded, arguing in court that the airline wasn’t responsible for the promises the bot made because it was a “separate legal entity that is responsible for its own actions.” The court sided with the flyer, saying that the airline was just as responsible for what its chatbot says as what’s on its website. The potential precedent here is that corporations have a duty of care for the performance of the AI chatbots they employ.
AI agents are agents of the person or organization that deploys them—and should be treated by the law as such. If a company hired human writers to write its summaries, that company would be liable for inaccuracies in those summaries. If a company’s human agent signed contracts in the company’s name, that company would be bound by those contracts. And if a doctor gave dangerously wrong medical advice, they would be liable for malpractice.
To allow businesses to hide behind the excuse of faulty AI in those same circumstances would be a massive handout to companies, and would introduce disastrous incentives for corporate misbehavior. Why hire human writers, lawyers or doctors when AIs are not only cheaper, but also absolve employers whenever they make a mistake?
We are rapidly moving to a world where AI-powered chatbots will be at the other end of all sorts of corporate communications channels. It makes no sense for a company to be able to honor its statements when it wants to and disavow them when it doesn’t.
Visa and OpenAI recently announced a partnership to build personal AI agents to, among other things, make purchases on our behalf. This is just one of many similar projects in the works, as companies race to provide us all with AI assistants. Will Visa take responsibility when its AI makes a purchase in your name that you don’t want? And if Visa won’t, why would anyone trust the system? Properly allocating liability is key to make this kind of thing work.
If the German ruling holds, it could be devastating for Google’s AI Overview feature. Tests from earlier this year found that it had mistakes about 10% percent of the time. At more than 5tn searches per year, that’s 16,000 erroneous summaries every second. And while most of those errors are benign, some of them will cause harm, be defamatory, or otherwise trigger liability.
Earlier this year, Google’s AI summary falsely identified the Canadian fiddler Ashley MacIsaac of being a sex offender. His lawsuit, filed in Ontario, is ongoing. If Google is forced to invest in improving its AI system until those kinds of errors are exceedingly rare, that seems like a good outcome for users, as well as the subjects of search, like MacIsaac.
More generally, liability concerns could mean that many current use cases for agents won’t be commercially viable. Companies may not be able to profitably operate AI lawyers, doctors and media influencers if they are held responsible for what they say and do.
We’re OK with this outcome. There’s nothing in the law that requires us to accommodate AI systems if they are fundamentally untrustworthy, just as we don’t need to accommodate untrustworthy human systems. Any company that won’t stand by the statements its agents make—whether human or AI—doesn’t deserve users’ time or money.
Version 6.0.0 of the Podman
container-management tool has been released. Notable new features
include the ability to set multiple static IP addresses for
containers, improvements in network isolation that make Podman more
compatible with Docker, changes to the way Quadlet
commands function, many new options for many existing podman
commands, and a
rewrite of Podman’s configuration file handling. There are many
breaking changes; see the release
notes for a full list of all new features, changes, and bug fixes.
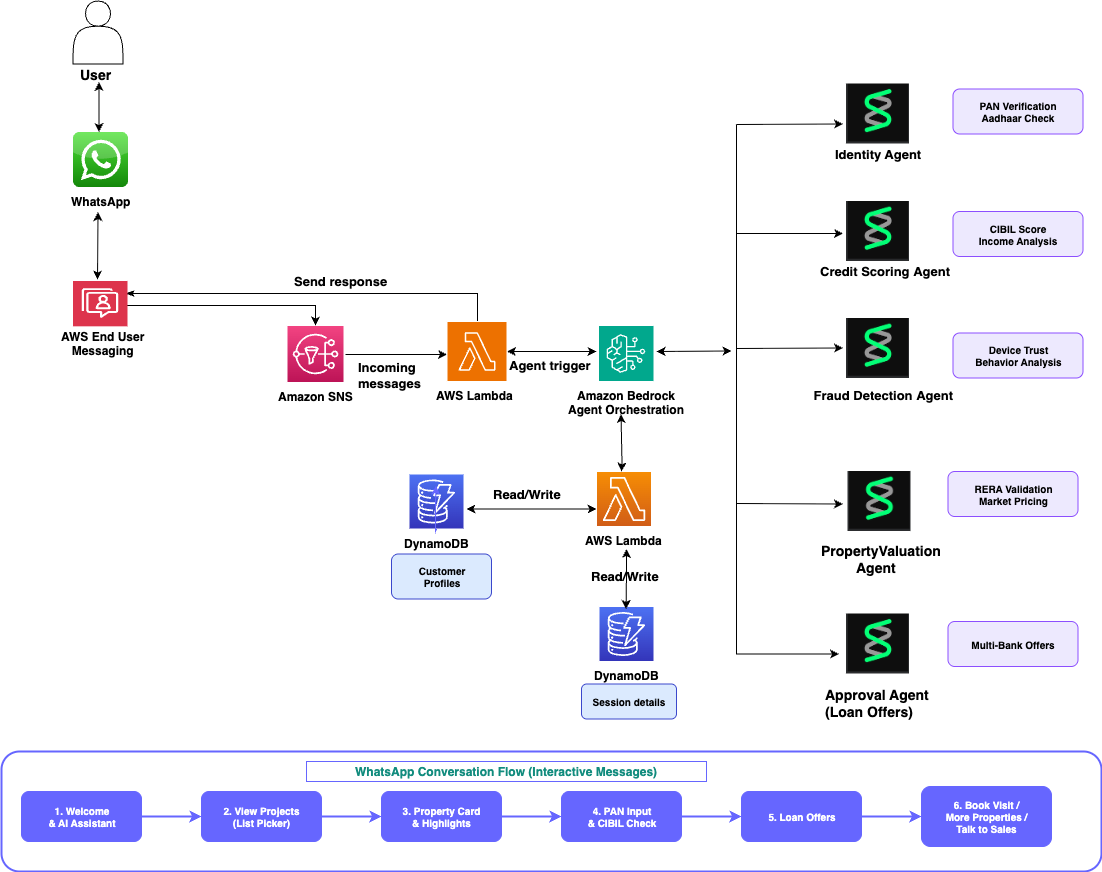
Most real estate websites collect form submissions and route them to sales teams who respond hours or days later. Customers who expect immediate answers often move on. This post shows how to close that gap with a WhatsApp assistant that responds instantly. We show you how to build a real estate assistant powered by AI that delivers property discovery, home loan pre-approval, and site visit booking entirely within WhatsApp. The solution uses the Strands Agents SDK to orchestrate specialized AI agents on Amazon Bedrock, with AWS End User Messaging Social for WhatsApp integration. The serverless backend runs on AWS Lambda and Amazon DynamoDB.
Prerequisites
You need an AWS account with permissions for AWS CloudFormation, Lambda, Amazon Simple Notification Service (Amazon SNS), Amazon Bedrock, and DynamoDB. You also need a WhatsApp Business account integrated with AWS End User Messaging. For instructions to locate your WhatsApp phone number ID, see View a phone number’s ID in AWS End User Messaging Social.
AWS Serverless Application Model (AWS SAM) CLI is required to deploy the demo solution. For installation instructions, see the AWS SAM CLI installation guide.
Overview of solution
The architecture uses four AI agents built with the Strands Agents SDK. Each agent handles a specific task: identity verification, credit scoring, fraud detection, or property valuation. The agents use Strands SDK decorators to access external data sources. The agents run on Amazon Bedrock with the Nova Lite model and are deployed to AWS Lambda using the official Strands Agents Lambda Layer. AWS End User Messaging Social handles WhatsApp Business API integration, publishing incoming messages to Amazon SNS for routing. The webhook handler Lambda function processes these events and invokes the supervisor agent. The supervisor agent orchestrates the conversation flow, maintains session state in Amazon DynamoDB, and sends rich interactive messages back to customers on WhatsApp.
For this post, we use a demo landing page to simulate the “Enquire Now” button on a real estate website. In a production scenario, you can add this integration point to any existing website. The only requirement is a WhatsApp click-to-chat link that pre-fills the initial message with the property details.
The following diagram illustrates the solution architecture:
Strands Agents SDK — multi-agent pipeline
The Strands Agents SDK is an open source framework from AWS for building AI agents. Each agent gets a system prompt and tools. The agent then decides when to use those tools based on what the user asks.
This solution uses four specialized agents, each with its own tools:
Identity Agent – uses the verify_identity tool to validate the customer’s tax identification number.
Credit Scoring Agent – uses check_credit_score and get_loan_offers tools to assess creditworthiness and generate lending offers.
Fraud Detection Agent – uses check_fraud_risk to evaluate application risk.
Property Valuation Agent – uses validate_property to check regulatory registration and market value.
The following example shows how to define agents using the Strands @tool decorator pattern. Each tool is region-agnostic by design. You adapt the implementation for your local tax authority, credit bureau, and property registry.
from strands import Agent, tool
from strands.models.bedrock import BedrockModel
MODEL_ID = "amazon.nova-lite-v1:0"
def get_model():
return BedrockModel(model_id=MODEL_ID, region_name="us-east-1")
@tool
def verify_identity(tax_id: str) -> dict:
"""Verify customer identity using their tax identification number.
Adapt for your region: PAN (India), SSN (US), NIN (UK), TFN (Australia)."""
# Call your regional tax authority API here
return {"tax_id": tax_id, "valid": True,
"holder_name": "Customer", "status": "Active"}
@tool
def check_credit_score(tax_id: str) -> dict:
"""Fetch customer credit score from a credit bureau.
Adapt for your region: CIBIL (India), FICO (US), Experian (Global)."""
# Call your regional credit bureau API here
return {"credit_score": 782, "risk_category": "Low"}
@tool
def get_loan_offers(property_price: int, credit_score: int) -> dict:
"""Get mortgage offers from partner lending institutions.
Adapt for your region's banks and lending regulations."""
# Call your partner bank APIs here
return {"offers": [...]}
@tool
def validate_property(name: str, registration_id: str, price: int) -> dict:
"""Validate property registration with the local regulatory authority.
Adapt for your region: RERA (India), Land Registry (UK), MLS (US)."""
# Call your regional property registry API here
return {"registration_valid": True, "investment_rating": "good"}
You then orchestrate the agents in a pipeline:
def run_full_pipeline(tax_id, phone, project):
# Agent 1: Identity Verification
agent = Agent(
model=get_model(),
system_prompt="You are an Identity Verification Agent. "
"Use verify_identity to check the customer's tax ID.",
tools=[verify_identity],
callback_handler=None
)
identity = agent(f"Verify tax ID: {tax_id}")
# Agent 2: Credit Scoring + Loan Offers
agent = Agent(
model=get_model(),
system_prompt="You are a Credit Scoring Agent. "
"Use check_credit_score then get_loan_offers.",
tools=[check_credit_score, get_loan_offers],
callback_handler=None
)
credit = agent(f"Check credit for {tax_id}, "
f"get offers for price {project['price']}")
# Agent 3: Fraud Detection
# Agent 4: Property Valuation
# ... similar pattern
return consolidated_results
AWS End User Messaging Social
AWS End User Messaging Social handles WhatsApp Business API integration. Incoming messages arrive as events. Outgoing messages, including text, buttons, lists, and location cards, go through the SendWhatsAppMessage API.
Message routing with Amazon SNS
An SNS topic receives events from AWS End User Messaging Social whenever customers send WhatsApp messages.
Webhook handler – AWS Lambda
The webhook handler Lambda function parses the EUM Social event envelope, extracts the WhatsApp message payload, and routes it based on message type.
Supervisor agent – AWS Lambda with Strands Agents
The supervisor agent orchestrates the full conversation flow. It maintains session state in Amazon DynamoDB and sends rich WhatsApp messages back to the customer. When the customer submits their identification, the supervisor invokes the Strands agent pipeline, which runs four agents sequentially on Amazon Bedrock.
The supervisor sends interactive WhatsApp messages using the EUM Social API:
The Strands Agents SDK provides an official Lambda Layer that includes all required dependencies pre-built for the Lambda runtime.
Session state – Amazon DynamoDB
Two DynamoDB tables store conversation state. The sessions table tracks the full conversation state machine (INITIATED, AWAITING_PROJECT_SELECT, AWAITING_ACTION, AWAITING_ID, LOAN_APPROVED, VISIT_CONFIRMED), with a 30-minute TTL.
Conversation flow
The customer journey unfolds across four steps in WhatsApp.
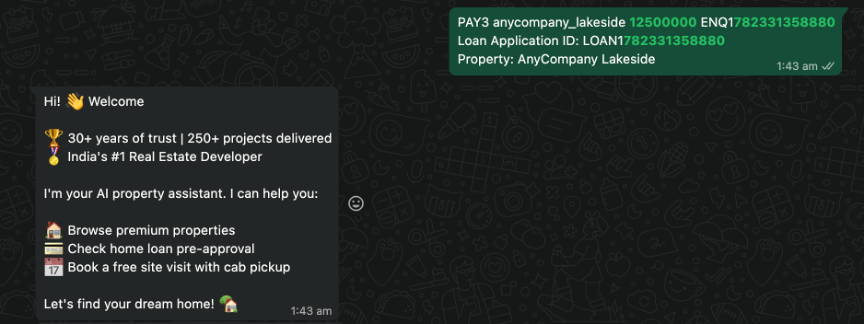
Step 1: Property discovery
When the customer sends the initial message, the supervisor agent sends a welcome message followed by an interactive list picker showing properties grouped by developer. The list picker uses WhatsApp’s native interactive message format.
Step 2: Property detail with action buttons
When the customer selects a property, the supervisor sends a rich detail card with key highlights, regulatory registration, and three action buttons:
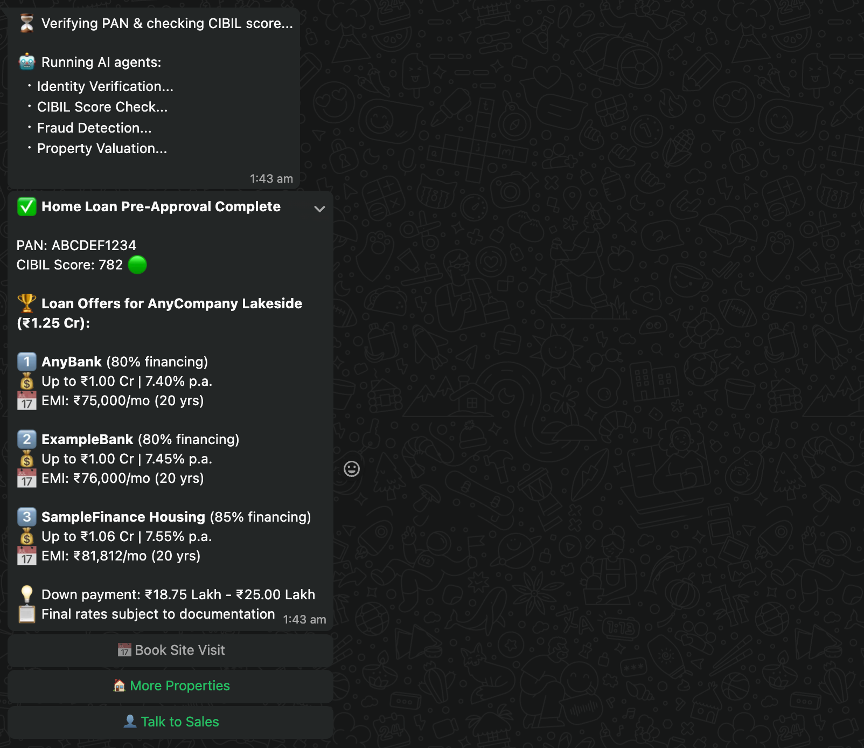
When the customer chooses Check Loan and submits their tax identification number, the supervisor invokes the Strands agent pipeline. Four agents run sequentially on Amazon Bedrock, each using its specialized tools. The following log output shows the pipeline in action:
Running Strands agent pipeline for ID: ABCD****
Identity agent: True
Credit agent: score=782, offers=3
Fraud agent: low
Property agent: good
The customer receives a loan approval card with offers from multiple lending institutions, each with personalized interest rates based on the credit score returned by the credit agent. The full pipeline typically runs in under 10 seconds.
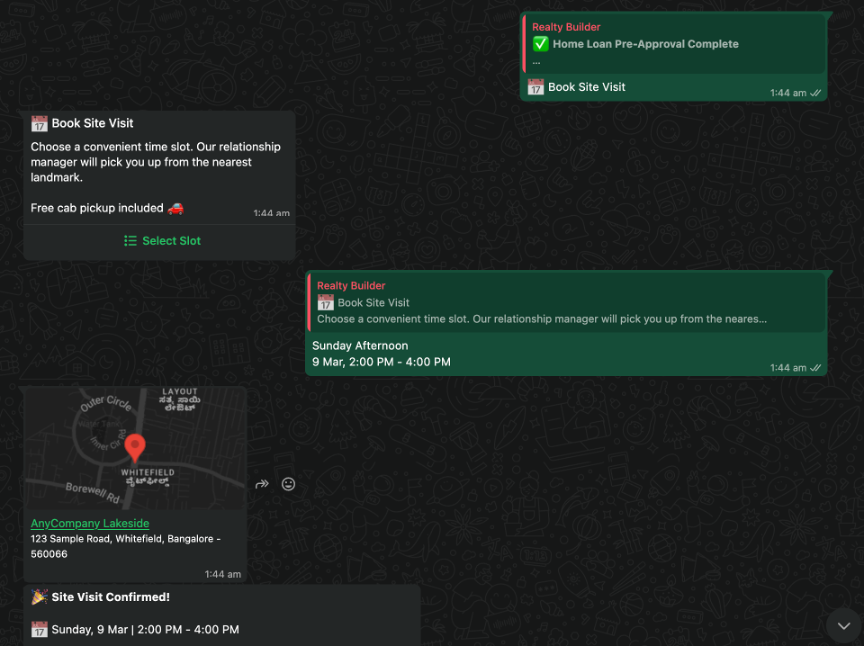
Step 4: Site visit booking
The customer selects a time slot from an interactive list picker and receives a confirmation with relationship manager details and a location card.
Demo implementation: India real estate market
This demo uses India-specific implementations: PAN validation for identity, CIBIL scores for credit (300-900 range), example bank offers with EMI in Rupees, RERA registration validation, and free cab pickup for site visits.
To adapt this solution for another region, you replace the tool implementations with calls to your local tax authority, credit bureau, lending institutions, and property registry. The agent architecture, WhatsApp integration, and conversation flow remain unchanged.
Deployment
To deploy the demo solution, run the following commands:
After deployment, in the AWS End User Messaging Social console, route incoming messages for your phone number ID to the SNS topic demo-whatshome-incoming-messages created by the stack.
Test the solution
open demo/real-estate-landing.html
Select Enquire Now on any property card. WhatsApp opens at the configured business number with a prefilled message. Send the message and finish the loan pre-approval flow on WhatsApp.
Sample conversation
The following images show how a customer interacts with the real estate AI assistant.
The customer lands on WhatsApp with a predefined message from the website, and the AI assistant greets them with a welcome message.
The customer selects the Check Loan option for one of the properties listed.
The agents are invoked to verify the customer details and provide loan quotations.
The customer books a site visit after selecting a suitable time slot.
Clean up
To avoid ongoing charges, delete the resources you created during this walkthrough:
sam delete --stack-name whatshome-demo --region us-east-1
Deleting the CloudFormation stack removes the Lambda functions, DynamoDB tables, Amazon SNS topics, Amazon Simple Queue Service (Amazon SQS) queue, AWS Key Management Service (AWS KMS) key, and AWS Identity and Access Management (IAM) roles. If you deployed the demo landing page to Amazon Simple Storage Service (Amazon S3) and Amazon CloudFront, delete those resources separately.
Conclusion
You can combine the Strands Agents SDK, Amazon Bedrock, AWS End User Messaging Social, and Lambda to build an end-to-end WhatsApp assistant. The multi-agent architecture has specialized agents for identity verification, credit scoring, fraud detection, and property valuation. This decomposition shows how you can break complex business workflows into focused AI agents that collaborate to deliver instant results.
The same pattern works for banking loan applications, insurance claims, healthcare appointments, and ecommerce order tracking.
In our previous post, we introduced Amazon EC2 Capacity Manager and its data export capability. Amazon EC2 Capacity Manager provides centralized visibility into your Amazon Elastic Compute Cloud (Amazon EC2) capacity usage across all accounts and Regions in your organization. It tracks capacity usage for three types of EC2 capacity: On-Demand instances, Spot instances, and On-Demand Capacity Reservations (ODCR). On the AWS Management Console, it provides 90 days of historical capacity data. With data exports to Amazon Simple Storage Service (Amazon S3), you can retain and analyze capacity trends beyond this period using your preferred analytics tools.
In this post, we demonstrate how to configure EC2 Capacity Manager data exports to Amazon S3 and query historical capacity data using Amazon Athena. This approach helps you identify long-term usage patterns, plan capacity needs, and optimize resource allocation across your organization.
Solution overview
The following diagram illustrates the solution architecture. EC2 Capacity Manager exports capacity data to Amazon S3, where Amazon Athena queries it using SQL with automatic partition discovery.
The solution involves the following steps:
Set up an S3 bucket for capacity data export.
Configure EC2 Capacity Manager data export.
Set up Amazon Athena to query the exported data.
Run queries to analyze capacity patterns.
Prerequisites:
An AWS account with permissions to create S3 buckets and configure EC2 Capacity Manager.
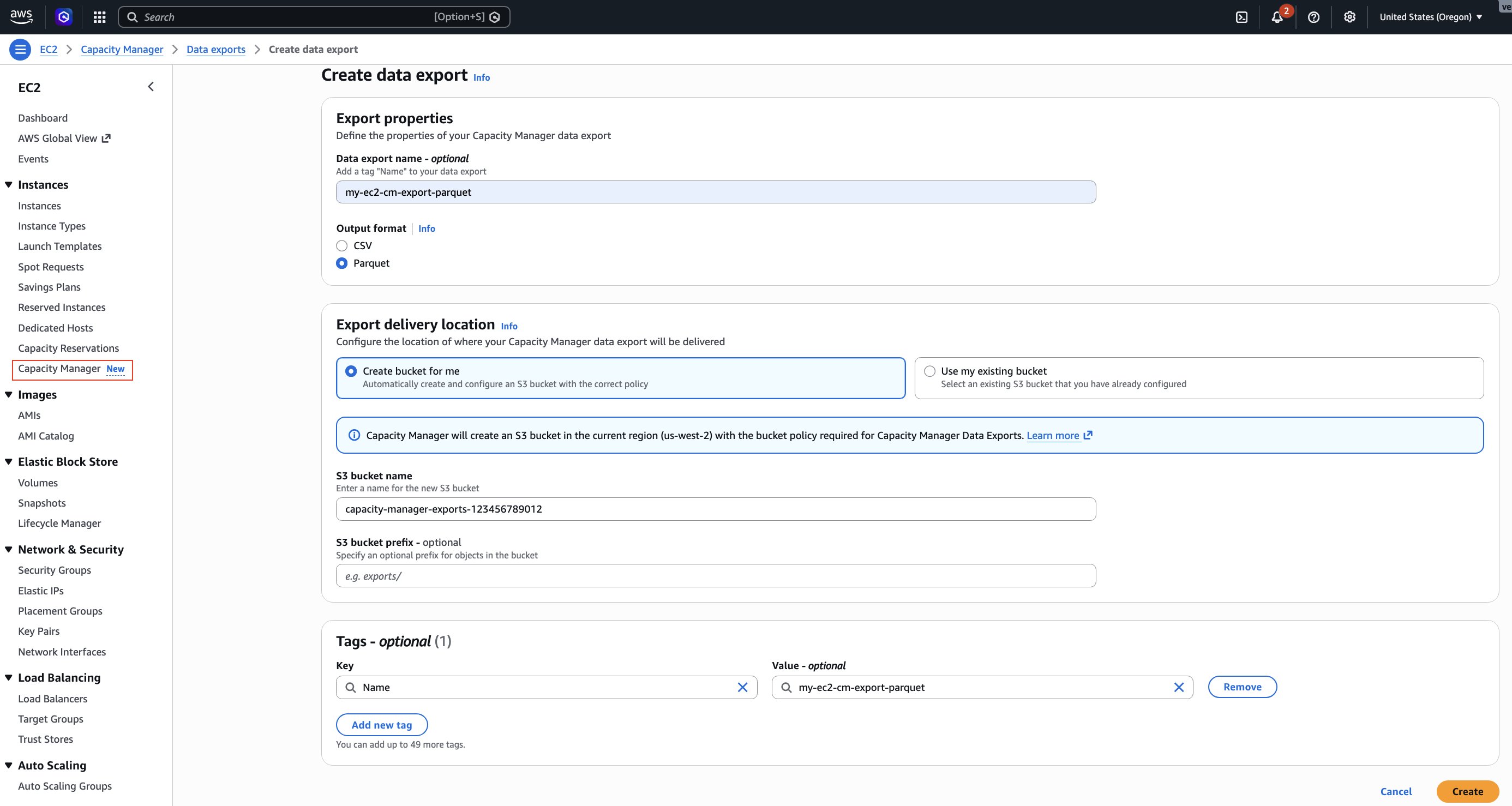
EC2 Capacity Manager can export capacity data in compressed CSV (Gzip) or compressed Parquet (Snappy) format. Use Parquet format for query performance in Athena (Parquet’s columnar format is designed to optimize analytical queries).
Configure the data export
You can configure data export through the EC2 Capacity Manager console or AWS CLI.
Replace <AWS_ACCOUNT_NUMBER> with your AWS account number, <AWS_REGION> with your AWS Region (for example, us-west-2), and <BUCKET_NAME> with your bucket name.
aws ec2 create-capacity-manager-data-export \
--s3-bucket-name <BUCKET_NAME> \
--s3-bucket-prefix <BUCKET_PREFIX>/ \
--schedule hourly \
--output-format <FORMAT> \
--region <AWS_REGION>
# Replace:
# <BUCKET_NAME> with your bucket name,
# <BUCKET_PREFIX> with your bucket prefix (for example, capacity-data/),
# <FORMAT> with parquet or csv, and
# <AWS_REGION> with your AWS Region (for example, us-west-2)
# The output of the above command would give you a Data Export ID
{ "CapacityManagerDataExportId": "cmde-00a7d0e64e43889f1" }
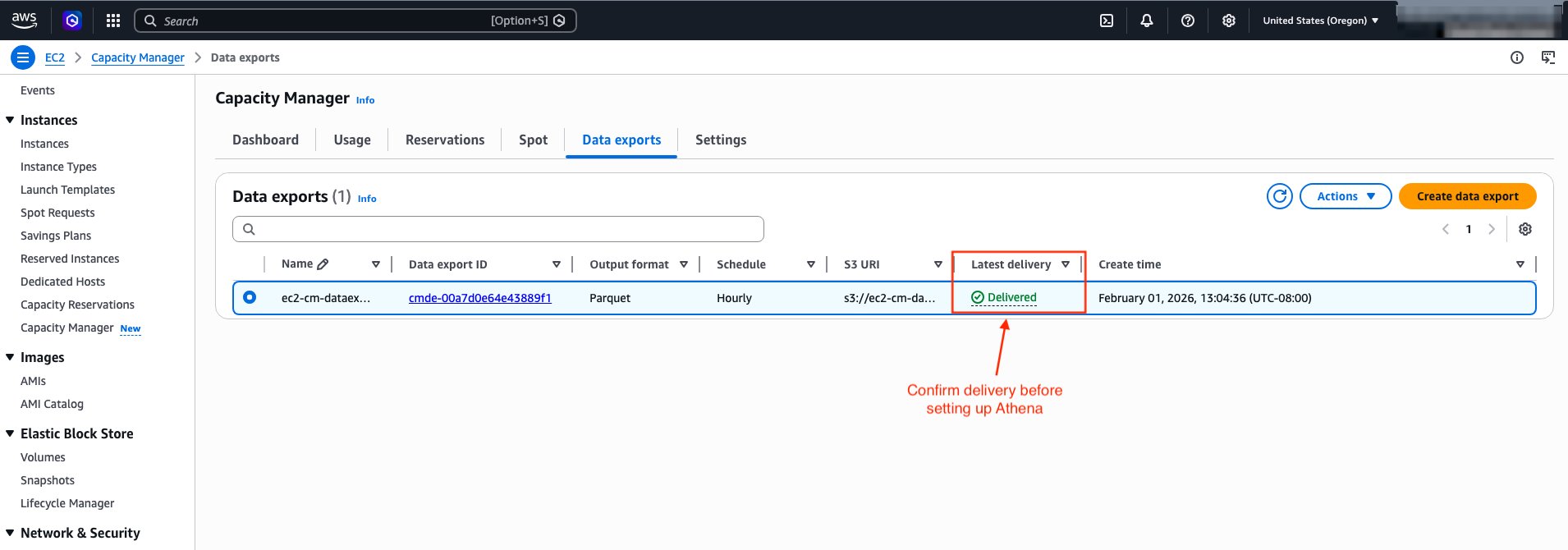
After creating the data export, wait for the first export to complete before proceeding to set up Athena. You can check the export status using the following command:
Wait until LatestDeliveryStatus shows "delivered" before proceeding to the next section. The first export typically appears in your S3 bucket in a couple of hours. Subsequent exports follow your configured schedule.
Setting up Amazon Athena to query capacity data
After EC2 Capacity Manager exports data to your S3 bucket, you can use Amazon Athena to query the data using standard SQL. Athena uses AWS Glue as its metadata store. Specifically, it relies on the AWS Glue Data Catalog, which contains table definitions that tell Athena where you have stored your data in S3 and how you have structured it. When you create tables in Athena, you’re actually creating metadata entries in the Data Catalog that Athena references when running queries.
Create an Athena database and table
You can create the table using AWS Glue crawler or manually with SQL. AWS Glue crawler automatically discovers the complete schema from your exported Parquet files, including optional fields like resource tags if enabled. It helps minimize manual schema definition efforts. If the export format changes in the future, you can re-run the crawler to update the table definition. For detailed instructions on creating a Glue Crawler, see Use a crawler to add a table in the Amazon Athena User Guide.
In this post, we create the table manually using a SQL statement. We also use partition projection for automatic partition discovery. We do this because EC2 Capacity Manager continuously adds new partitions to the S3 bucket according to your configured schedule. As new partitions arrive in S3, Athena doesn’t know about them until you run MSCK REPAIR TABLE or ALTER TABLE ADD PARTITION to update the AWS Glue Data Catalog. This becomes an overhead when data arrives frequently.
With partition projection, you define the partition scheme and specify its range/rules in the table properties. Athena then computes the partitions at query time instead of looking them up in the Glue Data Catalog. So partition projection automatically makes new partitions visible as soon as EC2 Capacity Manager exports the data to S3, eliminating the need for you to update metadata. The CREATE TABLE statement that follows defines the schema for EC2 Capacity Manager exports. If your capacity reservations are already tagged, add the corresponding tag columns (for example, tag_environment string or tag_costcenter string). Alternatively, use an AWS Glue crawler to automatically discover your complete schema, including tag columns.
If prompted, configure a query result location in S3. This is where Athena writes query output. It is separate from the S3 bucket that stores your capacity data.
Run the following query to create a database:
CREATE DATABASE IF NOT EXISTS capacity_manager_db;
Replace <BUCKET_NAME> in the LOCATION clause and storage.location.template property with your bucket name, and capacity-data/ with table name of your choice.
Now that your table is set up, you can explore how to query the exported data.
Example queries for common use cases
The following queries demonstrate how to analyze your EC2 capacity data for cost optimization and capacity planning. The queries use date values (year=‘2026’, month=‘04’) and table name capacity_data. Adjust the partition values to match your actual data’s time period and table name to match your value. When querying EC2 Capacity Manager export data:
Metric group filtering: EC2 Capacity Manager exports contain two types of data that the metricgroupname column identifies: Reservation Usage for analyzing ODCR utilization and optimization opportunities, and Instance Usage for analyzing overall capacity consumption across reserved, unreserved, and Spot instances. Always filter by the appropriate metric group for your analysis needs.
Partition filtering: Always include partition filters (y, m, d, h) to improve query performance.
Numeric operations: Use CAST to convert string columns to numeric types for proper comparison and sorting (for example, CAST(reservationavgutilizationinst AS double)).
NULL handling: Use COALESCE to handle NULL values in calculations (for example, COALESCE(CAST(column AS double), 0)) to prevent NULL results in totals. Without COALESCE, when you add a column value NULL to a non-NULL value, the result is NULL.
Use case 1: Identify underutilized ODCRs
Discover On-Demand Capacity Reservations with low utilization that are generating cost waste. Identify specific reservations to downsize, cancel, or share with other teams to reduce unnecessary spending.
SELECT
reservationid,
instancetype,
region,
"az-id",
reservationstate,
ROUND(CAST(reservationavgutilizationinst AS double) * 100, 2) AS utilization_pct,
CAST(reservationtotalcapacityhrsinst AS double) AS total_capacity_hrs,
CAST(reservationunusedtotalcapacityhrsinst AS double) AS unused_capacity_hrs,
ROUND(CAST(reservationunusedtotalestimatedcost AS double), 4) AS wasted_cost_usd
FROM capacity_data
WHERE metricgroupname = 'Reservation Usage'
AND CAST(reservationavgutilizationinst AS double) < 0.5
AND reservationavgutilizationinst IS NOT NULL
AND y = '2026'
AND m = '04'
ORDER BY wasted_cost_usd DESC
LIMIT 3;
Sample output:
reservationid
instancetype
region
az-id
reservationstate
utilization_pct
total_capacity_hrs
unused_capacity_hrs
wasted_cost_usd
cr-041aedfba865106c1
m5.8xlarge
us-west-2
usw2-az2
active
0
1
1
1.536
cr-089f17dc178e993a8
m5.8xlarge
us-west-2
usw2-az1
active
0
1
1
1.536
cr-089f17dc178e993a8
m5.8xlarge
us-west-2
usw2-az1
active
0
1
1
1.536
Use case 2: ODCR utilization summary by instance type
Get a comprehensive view of ODCR utilization across instance types to identify which instance families have the worst utilization rates. This helps prioritize optimization efforts on the reservations with the highest cost impact.
SELECT
instancetype,
COUNT(DISTINCT accountid) AS account_count,
COUNT(DISTINCT reservationid) AS reservation_count,
ROUND(SUM(COALESCE(CAST(reservationtotalcapacityhrsinst AS double), 0)), 2) AS total_odcr_capacity,
ROUND(SUM(COALESCE(CAST(reservationunusedtotalcapacityhrsinst AS double), 0)), 2) AS total_unused_capacity,
ROUND(AVG(COALESCE(CAST(reservationavgutilizationinst AS double), 0)) * 100, 2) AS avg_utilization_pct,
ROUND(SUM(COALESCE(CAST(reservationunusedtotalestimatedcost AS double), 0)), 2) AS total_unused_cost_usd
FROM capacity_data
WHERE metricgroupname = 'Reservation Usage'
AND y = '2026'
AND m = '04'
GROUP BY instancetype
ORDER BY total_unused_cost_usd DESC
LIMIT 3;
Sample output:
instancetype
account_count
reservation_count
total_odcr_capacity
total_unused_capacity
avg_utilization_pct
total_unused_cost_usd
m5.8xlarge
1
2
311.99
311.99
0.0
479.22
c5.9xlarge
1
1
211.0
211.0
0.0
322.83
t3.micro
1
1
1055.0
1055.0
0.0
10.97
Use case 3: Identify peak usage patterns
Analyze average hourly usage patterns across reserved, unreserved, and Spot capacity to identify when your workloads typically hit peak demand. This breakdown helps you understand your capacity mix, plan for peak periods, and optimize your purchasing strategy.
SELECT
h AS hour,
ROUND(AVG(COALESCE(CAST(reservedtotalusagehrsinst AS double), 0)), 2) AS avg_reserved_usage_hours,
ROUND(AVG(COALESCE(CAST(unreservedtotalusagehrsinst AS double), 0)), 2) AS avg_unreserved_usage_hours,
ROUND(AVG(COALESCE(CAST(spottotalusagehrsinst AS double), 0)), 2) AS avg_spot_usage_hours,
ROUND(AVG(COALESCE(CAST(reservedtotalusagehrsinst AS double), 0) + COALESCE(CAST(unreservedtotalusagehrsinst AS double), 0) + COALESCE(CAST(spottotalusagehrsinst AS double), 0)), 2) AS avg_total_usage_hours
FROM capacity_data
WHERE metricgroupname = 'Instance Usage'
AND y = '2026'
AND m = '04'
GROUP BY h
ORDER BY avg_total_usage_hours DESC
LIMIT 3;
Sample output:
hour
avg_reserved_usage_hours
avg_unreserved_usage_hours
avg_spot_usage_hours
avg_total_usage_hours
09
0.75
0.5
0
1.25
10
0.75
0.5
0
1.25
15
0.75
0.5
0
1.25
Use case 4: Regional capacity distribution
Understand how your ODCR capacity is distributed across AWS Regions and instance types. This geographic view helps you identify Regions with excess capacity that could be redistributed or consolidated to improve utilization and reduce costs.
SELECT
region,
instancetype,
ROUND(SUM(COALESCE(CAST(reservationtotalcapacityhrsinst AS double), 0)), 2) AS total_reserved_capacity,
ROUND(SUM(COALESCE(CAST(reservationunusedtotalcapacityhrsinst AS double), 0)), 2) AS unused_reserved_capacity,
ROUND(AVG(COALESCE(CAST(reservationavgutilizationinst AS double), 0)) * 100, 2) AS avg_utilization_pct
FROM capacity_data
WHERE metricgroupname = 'Reservation Usage'
AND y = '2026'
AND m = '04'
GROUP BY region, instancetype
ORDER BY region, total_reserved_capacity DESC
LIMIT 3;
Sample output:
region
instancetype
total_reserved_capacity
unused_reserved_capacity
avg_utilization_pct
us-west-2
t2.nano
1484.0
1060.0
33.34
us-west-2
t3.micro
1060.0
1060.0
0.0
us-west-2
t2.micro
848.0
636.0
25.0
Use case 5: Unused capacity reservations by Region and Availability Zone
Pinpoint exactly where you have unused ODCR capacity at the Availability Zone level. This granular view enables you to share unused capacity with other teams in the same AZ or modify reservations to better match actual usage patterns.
SELECT
region,
"az-id",
instancetype,
ROUND(SUM(COALESCE(CAST(reservationunusedtotalcapacityhrsinst AS double), 0)), 2) AS unused_capacity_instances,
ROUND(AVG(COALESCE(CAST(reservationavgutilizationinst AS double), 0)) * 100, 2) AS avg_utilization_pct,
ROUND(SUM(COALESCE(CAST(reservationunusedtotalestimatedcost AS double), 0)), 2) AS unused_cost_usd
FROM capacity_data
WHERE metricgroupname = 'Reservation Usage'
AND y = '2026'
AND m = '04'
AND CAST(reservationunusedtotalcapacityhrsinst AS double) > 0
GROUP BY region, "az-id", instancetype
ORDER BY unused_cost_usd DESC
LIMIT 3;
Sample output:
region
az-id
instancetype
unused_capacity_instances
avg_utilization_pct
unused_cost_usd
us-west-2
usw2-az1
c5.9xlarge
212.0
0.0
324.36
us-west-2
usw2-az2
m5.8xlarge
157.0
0.0
241.15
us-west-2
usw2-az1
m5.8xlarge
157.0
0.0
241.15
Clean up
To avoid incurring future charges, delete the resources you created:
Warning: This permanently deletes the table definition. Verify that you no longer need to query this data before proceeding.
Delete the Athena table by running the following query: DROP TABLE IF EXISTS capacity_manager_db.capacity_data;
Delete the database by running the following query: DROP DATABASE IF EXISTS capacity_manager_db;
Navigate to the Athena console settings.
Note the query result location S3 bucket.
If you created this bucket specifically for this tutorial:
Empty the S3 bucket by running: aws s3 rm s3://<QUERY_RESULT_BUCKET_NAME> --recursive
Delete the S3 bucket by running: aws s3 rb s3://<QUERY_RESULT_BUCKET_NAME>
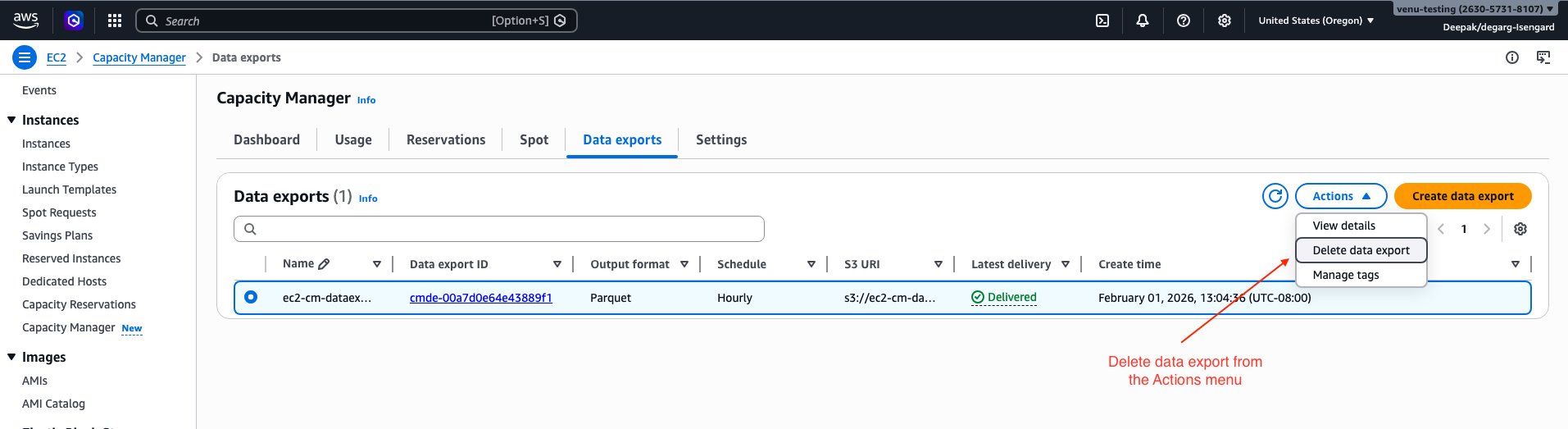
Delete the data export configuration by using AWS Management Console or AWS CLI.
If using AWS Console, select the “Delete data export” option in the Actions menu.
To delete the configuration using AWS CLI:
# List your data export configurations to find the export ID.
aws ec2 describe-capacity-manager-data-exports --region <AWS_REGION>
# The output shows details for export configuration which has the Data Export ID
# Sample output is shown in the configure data export section above.
# Then delete the export configuration using the ID from the output
aws ec2 delete-capacity-manager-data-export \
--data-export-id <EXPORT_ID> \
--region <AWS_REGION>
Replace <EXPORT_ID> with your data export ID and <AWS_REGION> with your AWS Region.
Warning: Deleting the S3 bucket permanently removes all exported capacity data. Verify that you have backed up any data you need before proceeding.
(Optional) Delete the S3 bucket and data: If you no longer need the exported data, complete the following steps:
Empty the S3 bucket by running: aws s3 rm s3://<BUCKET_NAME> --recursive
Delete the S3 bucket by running: aws s3 rb s3://<BUCKET_NAME>
Conclusion
In this post, we demonstrated how to configure EC2 Capacity Manager data exports to Amazon S3 and query historical capacity data using Amazon Athena. This approach enables you to retain capacity data beyond the 90-day console limit.
As you scale your capacity management practices, consider integrating these exports with your existing analytics and monitoring workflows. By combining EC2 Capacity Manager data with your broader infrastructure metrics, you can make data-driven decisions about capacity allocation and optimization across your organization.
To deepen your understanding, explore the EC2 Capacity Manager documentation for additional features, learn more about Amazon Athena for advanced query capabilities, and review EC2 capacity optimization best practices. Share your feedback and tell us how you’re using EC2 Capacity Manager data exports to optimize your capacity planning in the comments.
There is a lot of work going into eliminating exploitable bugs from the
kernel and preventing the addition of new ones. Even if this work is
maximally successful, though, there is no chance that the kernel will be
free of these bugs anytime soon. Thus, there is also ongoing interest in
hardening the kernel to make the existing bugs more difficult to exploit.
The upcoming 7.2 kernel release will include a change to how dynamically
allocated structures are placed in memory to make them harder to overwrite,
while a project to randomize structure layout at boot time has a rather
longer timeline.
Украинските българи са най-голямата историческа българска общност извън границите на държавата. Общият им брой е над 200 000, а по-голямата част от тях живеят в Одеска област. Около 30 000 етнически българи населяват Запорожка, Херсонска и Донецка област и след февруари 2022 г. се намират под временна руска военна окупация. За съдбата на тези 30 000 души през последните четири години се знае твърде малко, а българското общество и политиците у нас очевидно смятат темата за доста неудобна заради нуждата от пряка конфронтация с руската държава.
Крайно време е това да се промени.
Украинските българи са успели да запазят народните си обичаи, езика и културата си още от средата на XIX век, когато на вълни се преместват от Балканите на север към дивата степ, каквато е представлявала тогава Южна Украйна. Техните общности са преминали през изключителни исторически изпитания, включително сталинския терор в СССР, Гладомор и целенасочена съветска политика за изличаване на българската им идентичност. България като свободна страна, членка на ЕС и НАТО е длъжна да защити украинските българи под руска окупация чрез максимален дипломатически натиск върху Русия и чрез допълнителна военна помощ за Киев и да не допусне унищожаване на националната им идентичност. Това е въпрос на национален интерес, но преди всичко на морал.
Руската доктрина за изличаване на идентичност
За да се разбере в дълбочина трагедията на българското малцинство, живеещо в момента под вражеска окупация в Украйна, случващото се трябва да бъде разгледано през призмата на общата стратегия на Кремъл. Руската политика във временно окупираните области на Украйна не се изчерпва с военен контрол на територии и заграбване на ресурси. Целта ѝ е пълно асимилиране на местното население с целенасочена, системна и брутална кампания.
В анализ на Atlantic Council тези действия от страна на Москва се дефинират като опит за „изличаване на идентичността“ на окупираното население. Крайната цел на Владимир Путин е изграждането на нова изкуствена демографска реалност, в която няма място за национално самоопределяне, различно от официалния имперски наратив на Москва.
В тази доктрина на културен геноцид образованието и администрацията са превърнати в оръжие. Веднага след установяването на военен контрол в Запорожка, Херсонска и Донецка област окупационните власти задействат насилствена русификация. Местните училищни програми са заменени с руските държавни стандарти. Руският език е наложен като единствен език на администрацията, образованието и публичните институции, а използването на украински е системно ограничавано и репресирано.
Този жесток подход не е нов. Исторически е познат от германизацията на окупираните полски територии през Втората световна война, русификацията на Полша, Литва и Украйна в Руската империя през XIX век, съветизацията на балтийските държави след 1940 г., дори и отвъд океана, в САЩ и Канада през XIX и XX век, когато деца от коренните народи са извеждани насилствено от семействата им и са настанявани в интернати, където им се забранява да говорят на родния си език и да практикуват традиционната си култура в опит да им се наложи нова национална идентичност. В тези интернати много от тях загиват.
Руската окупационна политика е насочена както срещу украинците като по-голяма част от населението на окупираните територии, така и срещу десетки хиляди хора, които не са етнически украинци, но представляват неразделна част от културната мозайка на региона. Такива са местните българи, гърци, татари и др. Именно в капана на тази безмилостна машина за заличаване на идентичност и език днес са уловени и 30-те хиляди таврийски българи, чиито вековни традиции са на път да бъдат унищожени от Русия.
Българската реакция – твърде скромна и много закъсняла
Преди руската инвазия през 2022 г. таврийските българи в Украйна имат пълни граждански права и свободно се възползват от образование на български език и от широко развити български културни дейности. Местните общности с подкрепата на властите в Киев активно работят за запазване на българското народно самосъзнание в Запорожка област, координирайки откриването на неделни училища и културни центрове с подкрепата на София.
Сред най-важните места на тези общности са училище „Васил Левски“ в Бердянск, неделното българско училище в Мелитопол и украинско-българският лицей в град Приморск. През 2023 г. образователният център в Приморск е ограбен от руски военни, които изнасят от сградата компютърна техника и ценно имущество, както свидетелстват очевидци. Учебното заведение има 27-годишна история, като близо половината от неговите над 1000 завършили ученици са продължили образованието си в университети в България.
След разпадането на СССР и обявяването на украинската независимост таврийските българи успяват да изградят мемориална мрежа, посветена на националните ни герои, а тези паметници стават центрове на ежегодни събори, фестивали и чествания на Деня на бесарабските българи. До началото на войната регионът се развива като свободна и сигурна среда, в която българската култура и език съжителстват в пълен синхрон с украинската гражданска идентичност.
Населените с българи украински територии в Запорожка област са окупирани от руската армия още в първите дни и седмици на пълномащабната инвазия след 24 февруари 2022 г. През юли 2022 г. разследване на „Свободна Европа“ разкрива руската окупационна политика в Южна Украйна, под чиито удари попадат всички български училища и културни центрове в региона. Москва прехвърля пропагандни методи, които десетилетия наред са прилагани в самата Русия.
Според документирани свидетелства на Human Rights Watch и други международни организации окупационните власти са налагали руските учебни програми чрез натиск върху родители и учители. В отделни случаи родители са били заплашвани с глоби, задържане или отнемане на родителски права, ако откажат да запишат децата си в училища под руски контрол или ако продължат обучението им по украинската програма.
Тази принудителна русификация и заличаване на украинския, българския и други езици в областта протича в почти пълен информационен вакуум поради блокирани комуникации с външния свят в условията на война. През септември 2022 г. в интервю по Нова телевизия проф. Владимир Милчев, етнически българин и декан на Историческия факултет в Запорожкия университет, за първи път официално алармира, че в окупираните територии руските власти са наложили пълна забрана на българския език.
Всички неделни училища, културни центрове и дружества в Мелитополски и Бердянски район – сърцето на таврийските българи, са затворени. Учебните програми по български език, история и традиции са ликвидирани, а на местните преподаватели е поставен ултиматум: да преминат изцяло към руските държавни стандарти или да напуснат.
Тази политика на етническо заличаване на българите от страна на руските нашественици в Украйна получава своето институционално потвърждение в България няколко месеца по-късно. През декември 2022 г. Агенцията за българите в чужбина официално обобщава мащаба на образователната катастрофа под руска окупация. Данните сочат, че руската окупационна администрация е прекратила дейността на 13 български неделни училища в Запорожка област, в които дотогава са се обучавали над 1000 деца.
Според руската посланичка у нас Елеонора Митрофанова забрана за изучаване на български език в училищата в Запорожка област, Мариупол и Бердянск няма. Има специфичнаорганизация.
Нямаме никакви забрани за изучаване на езици, но имаме специфична система за организиране на този процес. По-конкретно, това зависи от броя на децата, които искат да изучават български, литовски, грузински или друг език. Ако се достигне необходимият брой деца, училището винаги ще се съобрази с техните желания. Но тъй като българската страна повдигна този въпрос, аз, разбира се, ще изясня ситуацията с ръководството и хората, отговорни за тези региони, за да се разбере реалната ситуация,
казва Митрофанова в интервю за ТАСС, цитирано от OffNews.bg.
Физически терор, репресии и заплахи за сексуално насилие
Зад фасадата на административните забрани и затварянето на училища обаче се крие далеч по-мрачна реалност – физически терор, изтезания и страх за живота, които принуждават местните българи масово да напускат домовете си. Специален доклад на украинския омбудсман за правата на националните малцинства в условията на руска агресия разкрива шокиращи лични свидетелства на етнически българи, преминали през ада на окупацията в Запорожка и Херсонска област.
Един от основните мотиви за бягство на жените от българската общност е постоянният страх от сексуално насилие от страна на руските окупатори. За армията на Путин изнасилванията на жени в Украйна са просто още едно оръжие във войната, средство за унижение и мъчение на нападната страна. Цитирана в доклада представителка на българското малцинство от окупираната част на Запорожието разказва пред разследващите за системния натиск, на който са подложени жените на публични места в Мелитопол от страна на руските военни формирования и в частност от т.нар. кадировци:
Пътувах от селото до пазара в Мелитопол, за да продавам мляко и да изкарам пари. Често вземах дъщеря си с мен, защото училището в селото вече не работеше – окупаторите го превърнаха във военна база, а ме беше страх да я оставя сама. В един момент в града дойдоха много кадировци. Постоянно се заканваха и тормозеха младите жени на пазара, по улиците, по спирките. Пияни, с оръжие в ръце, те се държаха с нас като с робини и демонстрираха пълната си власт.
Българите в окупираните територии са обект на политически репресии, филтрация и затваряне в тайни центрове за изтезания (т.нар. мъчилища). В доклада е документиран тежкият случай на мъж с български корени от Херсон, задържан от руските сили заради участие в проукраински протести, доброволческа дейност и изразяване на позиции в социалните мрежи. Той отказва да напусне града преди окупацията, защото се грижи за 77-годишния си баща, болен от рак. Свидетелството му за момента на ареста показва абсолютната безмилостност на окупационния режим:
Към 5 сутринта се събудих от ярка светлина в прозореца и крясъци в двора, последвани от силно блъскане по вратата. Петима въоръжени окупатори с маски нахлуха в къщата, докато други петима чакаха отвън. Наредиха на мен и баща ми да седнем на дивана, докато обискират. Когато ме натикаха в колата, видях как баща ми изскочи на улицата – викаше и плачеше. Той е на 77 години, с онкологично заболяване, много слаб. Един от войниците го удари с автомат в гърдите. Видях как падна на земята. Това беше последният път, в който го видях.
Тези и други свидетелства, събрани от кабинета на украинския омбудсман, категорично доказват, че руската окупационна политика спрямо таврийските българи е част от кампания на терор, при която отстояването на човешкото достойнство, свободната воля или каквато и да е идентичност, различна от наложената от Кремъл, се наказват с насилие, отвличания и масов страх.
Срещу това унищожаване на българската идентичност държавата ни реагира едва през 2025 г., когато в отговор на депутатски въпрос Георг Георгиев, министър на външните работи, потвърждава, че над 30 000 таврийски българи в окупираните Запорожка, Херсонска и Донецка област са подложени на системно и грубо погазване на основните човешки права от страна на Москва.
България официално отчита, че окупационните власти целенасочено унищожават възможностите за изучаване на майчиния език и затварят българските неделни училища и центрове. От външното ни министерство подчертават, че тези действия на Кремъл представляват грубо нарушение на международното хуманитарно право и са директен опит за насилствено заличаване на етническата и културна идентичност на българската общност в Украйна.
България на Радев като съучастник във войната срещу българите
В контекста на доказаното унищожаване на част от най-старата българска общност, опазила българския дух от XIX век насам, позицията на държавата изглежда, меко казано, неадекватна и клони към национално предателство. Румен Радев практически от началото на политическата си кариера повтаря опорните точки на руската пропаганда и се доказва като един от най-близките до Путин европейски политици.
Руският терор срещу българите под окупация е тема, която властта активно прикрива с мълчанието си, помагайки по този начин за унищожаването на общността на таврийските българи. Това престъпно мълчание превръща българските управляващи в директни съучастници в етническото прочистване на нашите сънародници под руска окупация. Докато таврийските българи биват подложени на терор и насилствена русификация, София позорно си затваря очите заради зависимостта на Румен Радев от Москва. Подобно абдикиране от националния интерес е исторически срам и унижение, което с всеки изминал ден заличава вековната история на българите в Украйна и обрича сънародниците ни на забвение.
Cloudflare Workflows allows you to build durable, multi-step applications with built-in retries and state persistence across long-running processes. When a Workflow executes, each step can call external systems, retry failures, and persist state across restarts. But if one step fails, it may leave earlier work from completed steps in an inconsistent or partial state.
Today we’re shipping saga rollbacks for Workflows, allowing you to declare rollback logic within the step itself, in case of failure.
For example, consider a workflow for transferring funds between accounts at two different banks:
Debit from account at Bank A
Credit to account at Bank B
Send email confirmation to both account owners
What happens if Step 2, the credit to account at Bank B, fails? Once the debit succeeds at Bank A, the transaction is committed and the money has left its system. As the orchestrator of the transaction, you cannot simply “undo” the operation in Bank A’s system. Instead, the money must be credited back to the account at Bank A through a new operation that semantically reverses the first one.
This pairing of an operation and its compensation logic is called the saga pattern.
Before today, developers had to implement their own compensation logic to track what succeeded, what failed, and what actions should be taken upon failure, outside of the steps’ direct definitions. Now, you can define compensation logic for each step.do() as an argument within the steps themselves, maintaining your workflow’s durability for the rollback as well.
// track what completed so we know what to undo
let debitA;
let creditB;
try {
debitA = await step.do("debit-bank-a", () => bankA.debit(from, amount));
creditB = await step.do("credit-bank-b", () => bankB.credit(to, amount));
await step.do("notify", () => notifyBoth(from, to, amount));
} catch (error) {
// unwind in reverse. each undo is its own durable step,
// must be idempotent, and must keep going if one fails.
if (creditB) {
try {
await step.do("reverse-credit-b", () => bankB.debit(to, amount, creditB.id));
} catch (e) {
await alertOnCall("reverse-credit-b failed", e);
}
}
if (debitA) {
try {
await step.do("refund-debit-a", () => bankA.credit(from, amount, debitA.id));
} catch (e) {
await alertOnCall("refund-debit-a failed", e);
}
}
throw error;
}
Without rollbacks
// each step ships with its own undo. add a step,
// add its rollback right here. no growing catch
// block, no manual ordering, no replay logic.
await step.do("debit-bank-a", () => bankA.debit(from, amount), {
rollback: async ({ output }) => bankA.credit(from, amount, output.id),
});
await step.do("credit-bank-b", () => bankB.credit(to, amount), {
rollback: async ({ output }) => bankB.debit(to, amount, output.id),
});
await step.do("notify", () => notifyBoth(from, to, amount));
With rollbacks
Try it out
To use rollbacks, just pass an options object containing a rollback function as the last argument to step.do().
const debit = await step.do(
"debit-account-a",
async () => {
return await bankA.debit({
accountId: fromAccountId,
amount,
idempotencyKey: `${transferId}:debit-account-a`,
});
},
{
rollback: async () => {
await bankA.credit({
accountId: fromAccountId,
amount,
idempotencyKey: `${transferId}:rollback-debit-account-a`,
});
},
}
);
// The idempotency keys make both the forward operations and rollback operations safe to retry without duplicating the transfer
const credit = await step.do(
"credit-account-b",
async () => {
return await bankB.credit({
accountId: toAccountId,
amount,
idempotencyKey: `${transferId}:credit-account-b`,
});
},
{
rollback: async ({ output }) => {
if (output === undefined) {
return;
}
await bankB.debit({
accountId: toAccountId,
amount,
idempotencyKey: `${transferId}:rollback-credit-account-b`,
});
},
}
);
// If we fail here, we may want to revert all previous payments. Users should not have to wrap their code in complex try-catch logic just to revert two small payments (see below)
await step.do("send-confirmation", async () => {
await sendTransferConfirmation({ ... });
});
Rollback functions should be idempotent, just like regular Workflow steps. If you refund a charge, use the payment provider’s idempotency key. If you release inventory, make the release safe to call more than once.
If any step fails, the rollback handlers will execute in reverse step-start order. It sounds simple: run the undo steps when something fails. In practice, there are a few details that make the API and execution model important.
1. The failed step may still need rollback. A failed step.do() can still be rollback-eligible if it registered a rollback handler.
The rollback will not start if user code catches an error and the Workflow continues, but if a step error is caught and the Workflow later fails for another reason, rollback can still run for previously registered handlers, which execute in reverse step-start order.
Why? The step may have partially interacted with an external system before failing. For example, a payment provider may capture a charge, but the step may fail before returning the chargeId to Workflows. That is why rollback handlers receive output, but must handle output === undefined.
2. Rollback only starts when the Workflow fails. Adding a rollback handler does not mean every step error triggers rollback. If user code catches an error and continues, the Workflow continues. Rollback starts when the Workflow itself is about to fail terminally.
When rollback starts, Workflows finds eligible step.do() calls, runs their rollback handlers, then records the final Workflow failure.
3. Ordering has to be predictable. For sequential Workflows, rollback order feels obvious:
Reserve inventory.
Charge card.
Create shipment.
If shipment fails, refund the card and release the inventory.
Parallel steps make this more subtle. Completion order can differ from start order, so Workflows uses reverse step-start order instead of reverse completion order.
The practical rules are:
Any started or completed steps with rollback handlers are eligible.
The failing step.do() is also eligible if it registered a rollback handler.
Handlers run in reverse step-start order, not completion order.
How we designed the API
Once we had the expected behavior in mind, we had to add this new pattern into the Workflows API. Rollbacks went through a few iterations before we landed on rollback options.
Why not a fluent or builder API?
The first approach was a fluent form: step.do(...).rollback(...) It reads well. The forward action and the compensation sit next to each other, and the call site looks like ordinary JavaScript chaining.
The problem is that step.do() already has an important meaning: it starts a durable step and returns a Promise for the step output. In Workers, promise-like values are especially meaningful because Workers RPC supports promise pipelining, a pattern inherited from systems like Cap’n Proto.
Promise pipelining lets code call a method on a future value before that value has fully returned to the caller. For example:
const session = api.authenticate(apiKey);
const name = await session.whoami();
Here, session is not the real session object yet. It is more like a handle to the session that will exist soon. When you call session.whoami(), Workers can send that call to the remote side early and say: “once authentication creates the session, call whoami() on it.”
That saves a round trip. The caller does not need to wait for authenticate() to fully finish before asking for whoami().
To a reader, that can look like “call .rollback() on the result of charge-card.” But rollback is not part of the step’s output. It is part of the step.do() options, registered before the step starts, so Workflows knows how to compensate the step if a later step fails.
A fluent API also makes step timing harder to reason about. Today, step.do() starts the step when it is called, so developers can start a step, do other work, and await the first step later:
With today’s execution model, first starts immediately, before second. A fluent API would complicate that. Workflows would need to wait and see whether .rollback() gets attached before it knows the full step definition. That could delay when the step is sent to the engine.
In the earlier example, first could start at await first instead of at step.do("first", ...), after second has already completed.
That makes concurrent Workflows harder to reason about: step timing would depend on when the returned Promise is consumed, not just where step.do() is called.
A builder API avoids the Promise ambiguity. It also gives us an obvious place for future step-level options, and makes it clear that the forward action and rollback action belong to the same saga step.
But it adds ceremony. Every step needs a final .run(), forgetting .run() would be easy and hard to spot without tooling, and simple one-step cases start to look like configuration chains. It also introduces a new step.saga() builder, breaking from the existing step.<action> pattern. Most importantly, it makes step.do() feel like an older API rather than the primary Workflows primitive. The goal of rollback was to extend step.do(), not replace it.
Rollback as step metadata
step.do(..., { rollback })
Ultimately, we chose the explicit form where rollback is metadata on the step.
This way, each rollback is defined within the forward step itself. Each handler receives the error that caused the rollback to start, the step context, and the output, which is either the persisted value returned by the forward step (which can be undefined) or undefined if the step failed before persisting a value.
Rollbacks emit lifecycle events, so you can tell whether compensation started, which rollback handler failed, and whether rollback completed successfully.
Crucially, the original Workflow failure remains separate: rollback is what Workflows does after the failure, not the reason the Workflow failed.
Just as you can define custom retry and timeout behavior in thestep configuration via WorkflowStepConfig, you add rollback-specific values in rollbackConfig.
This matches the lifecycle-event mental model we wanted. A step.do() already describes a durable unit of work that Workflows records, retries, and later shows in logs. Rollback is another lifecycle behavior for that same unit of work. It should travel with the step definition, not live in a separate wrapper or builder.
The step still starts when step.do() normally starts.
The returned promise still represents the step output.
Concurrent Workflow code keeps the same execution model.
Retry and timeout options for rollback live next to the rollback handler.
Existing step.do() calls keep working exactly as they do today.
This shape is slightly more explicit than the fluent API, but that explicitness is useful. The operation and its compensation are still in one place, and the API does not introduce a new step builder or a new kind of promise. Developers who already understand step.do() only need to learn one additional options object.
This is less magical, but it is simpler to adopt, and clearer to understand.
How it works under the hood
Rollback feels like a small API addition, but it changes what Workflows needs to record about each step.
A regular step.do() already has a durable record. Workflows records that the step started, whether it completed, what it returned, and whether it should be skipped instead of repeated if the Workflow resumes later.
Rollbacks add one more thing to that record: whether the step registered compensation logic.
This means Workflows has two pieces of information to bring together if the Workflow fails.
The first is durable step history. The Workflow engine stores data to know what ran, what completed, what output was saved, and whether rollback was registered.
The second is the rollback handler itself, which is the function written to compensate for that step. Workflows does not save the text of that function as data. Instead, it keeps a callable reference to the handler while the Workflow is running.
In Workers RPC, this kind of callable reference is called a stub. A stub lets one part of the system call code that is running somewhere else. Stubs also have lifetimes such that they can be disposed when a call or execution context ends. If you need to keep a stub past that point, Workers RPC provides a dup() method, which creates another handle to the same target.
For rollback, that model is useful. The durable step history records what needs compensation. The rollback stub gives Workflows a way to invoke the compensation code. And because rollback handlers may need to outlive the immediate step.do() call that registered them, Workflows keeps its own callable reference to the handler for the rollback phase.
In the common case, when a Workflow enters rollback in the same engine lifetime, Workflows already has the rollback stubs it needs. It can use the durable step history to find eligible steps, then invoke the rollback stubs that were registered during forward execution.
This gets more subtle when Workflows has to recover after a restart.
If the engine is evicted, crashes, or restarts while rollback is needed, Workflows still has the durable step history, but it may no longer have the in-memory rollback stubs. To recover, Workflows uses replay: a recovery mode where it can re-run the Workflow code without re-executing completed forward step bodies.
When replay reaches a completed step.do(), Workflows reads the persisted result instead of running the step body again. For rollback recovery, Workflows only needs to rebuild handlers for steps that had rollback attached and are eligible for rollback. As those step.do() calls are encountered, their rollback options can register the callable stubs again
That lets Workflows recover the rollback handlers it needs without duplicating the original external side effects.
With those pieces in place, rollback can work whether the handler is still available in memory or has to be rebuilt during recovery.
When the workflow is about to fail, Workflows does not ask your application to reconstruct what happened. It already has the step history. It can look at the persisted record and answer the important questions:
Which steps started?
Which steps finished?
Which failed step may still need cleanup?
Which steps registered rollback handlers?
What output should each rollback handler receive?
What order should compensation run in?
Then Workflows invokes each rollback stub with a rollback context: the original error, the step context, and the step output, if one was persisted.
The ordering detail matters. In normal JavaScript, especially with Promise.all(), completion order is not always the same as start order. If step A starts first and step B starts second, step B might finish first. For rollback, Workflows uses the persisted start order as the stable source of truth, then unwinds it in reverse.
Rollback handlers also run through Workflows’ normal step machinery. That means compensation gets the same operational properties you expect from Workflows: retries, timeouts, lifecycle events, logs, and a final recorded outcome. If a rollback handler keeps failing after its configured retries, Workflows records the rollback outcome as failed, stops running the remaining rollback handlers, and the Workflow instance ultimately ends in the Errored state.
This is the main difference between saga rollbacks and a catch block. A catch block only knows what is still in memory at its exact point in your JavaScript execution. Workflows rollback uses persisted step history to decide what already happened, invokes the stubs it already has in the common case, and safely rebuilds missing stubs during recovery when it needs to.
That is also why the API puts rollback on step.do() itself. Rollback is not a separate global error handler — it is metadata attached to the durable unit of work Workflows already understands.
When a multi-step application fails halfway through, the hardest part is often not knowing that it failed. It is knowing what already happened, and what needs to happen next.
Saga rollbacks let you put that answer directly beside each step. If you are building multi-step applications with Workflows, try saga rollbacks and tell us what compensation patterns you want next. Get started with the Workflows documentation and share feedback in the Cloudflare Community.
This is a fascinating explotation of how LLMs fall for prompt injection attacks. It turns out that they learn to recognize the style of text in different role/instruction blocks, and not just the tags.
Their conclusion:
Role tags were a formatting trick that became the security architecture and the cognitive scaffolding of modern LLMs. We’ve shown that this architecture doesn’t survive into the model’s actual representations, and that such role confusion is linked to prompt injection.
Unless LLMs achieve genuine role perception, we think injection defense will remain a perpetual whack-a-mole game. And the continuous nature of role boundaries opens the threat of injections designed to subtly shift LLM states through seemingly innocuous text, legally and at scale.
More generally, roles are quietly one of the most important abstractions in the LLM stack, providing the boundaries meant to separate self from other, thought from communication, instruction from data. They’re human-controlled switches in an otherwise continuous system. We think they deserve a lot more study than they’ve gotten.
Today IBM is unveiling their nanostack transistor architecture. Meant to drive chip construction in the sub-1nm era in the 2030s, nanostack aims for building better and smaller chips by building them taller via wafer stacking
From first-time coders to seasoned makers, this year every single Coolest Projects creator brought all their creativity to their tech projects and made something to be proud of. Over 15,000 young people showcased more than 4,500 creations on a global stage. With participants from 40 countries and 47% girls, this year’s online showcase is a true reflection of what the next generation of tech creators looks like.
Yesterday our global livestream brought together the whole Coolest Projects community to celebrate the young people’s creations with some very special guests.
Meet our 2026 VIP judges and their favourite projects
Every year, we invite new special VIP judges to choose their favourite projects from each of the seven Coolest Projects categories. Meet our 2026 judges and find out about the projects they picked.
Ronit Levavi Morad, Chief of Staff at Google Research
Ronit’s role involves reimagining the future of learning and she is a passionate advocate for technology in service of pedagogy, leading Google Research’s global Al literacy initiatives. She champions a human-centered vision for technology, leading programmes like Al Quests, a gamified experience designed to teach teens how Al can be applied to humanity’s greatest challenges.
Ben is a senior developer at British video game company Jagex, working on RuneScape to deliver immersive experiences for both new and existing players. He previously worked at Ubisoft on the Assassin’s Creed series and the Avatar Frontiers of Pandora game. Ben learned to code at 12 through making mods for Minecraft, and he has been passionate about game development ever since.
Akari is a 16-year-old CoderDojo member from Japan who has showcased her own projects at Coolest Projects seven times. She knows exactly what it takes to make something special for the showcase, and we’re so excited to have a young creator’s perspective on the judging panel!
AI: TideGuard AI by Vladimir from the Russian Federation
Sebin Sunny, CEO, EIC IIITM-K
Sebin is CEO of the Entrepreneurship and Innovation Center (EIC) and the Centre of Excellence in loT Sensors at the Indian Institute of Information Technology and Management – Kerala (IIITM-K). A passionate advocate for innovation, he is committed to empowering entrepreneurs, creating sustainable solutions, and shaping the future of technology-driven industries.
The Broadcom Coding With Commitment® award shines a light on creators who use coding to support and strengthen their communities with a project that aligns with 17 sustainable development goals of the United Nations.
The start screen of Viridia – Back to the World
This year’s Broadcom Coding with Commitment® recipient for the online showcase is Egehan from Türkiye, with their Scratch project Viridia – Back to the World, an educational game designed to teach players about the importance of water and how to use it responsibly.
Inspired to make your own project? Or encourage a young person you know? To get you started, we offer over 200 free coding projects, in English and many other languages.
Want to know more about next year’s showcase?
Coolest Projects will be back online in 2027. Sign up to the newsletter to be the first to hear about dates, deadlines, and exciting updates.
And did you know there are in-person Coolest Projects events around the globe? There is still time to take part in Coolest Projects India and other partner events this year. Find out more.
Thank you to the Coolest Projects sponsors
We want to say a big thank you to Broadcom Foundation, Allianz, Amazon Future Engineer, Qube-RT, Avnet, and GoTo for sponsoring Coolest Projects 2026 and helping to celebrate young tech creators around the world.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.