Post Syndicated from Julien Simon original https://aws.amazon.com/blogs/aws/new-amazon-sagemaker-clarify-detects-bias-and-increases-the-transparency-of-machine-learning-models/
Today, I’m extremely happy to announce Amazon SageMaker Clarify, a new capability of Amazon SageMaker that helps customers detect bias in machine learning (ML) models, and increase transparency by helping explain model behavior to stakeholders and customers.
As ML models are built by training algorithms that learn statistical patterns present in datasets, several questions immediately come to mind. First, can we ever hope to explain why our ML model comes up with a particular prediction? Second, what if our dataset doesn’t faithfully describe the real-life problem we were trying to model? Could we even detect such issues? Would they introduce some sort of bias in imperceptible ways? As we will see, these are not speculative questions at all. They are very real, and their implications can be far-reaching.
Let’s start with the bias problem. Imagine that you’re working on a model detecting fraudulent credit card transactions. Fortunately, the huge majority of transactions are legitimate, and they make up 99.9% of your dataset, meaning that you only have 0.1% fraudulent transactions, say 100 out of 100,000. Training a binary classification model (legitimate vs. fraudulent), there’s a strong chance that it would be strongly influenced or biased by the majority group. In fact, a trivial model could simply decide that transactions are always legitimate: as useless as this model would be, it would still be right 99.9% of the time! This simple example shows how careful we have to be about the statistical properties of our data, and about the metrics that we use to measure model accuracy.
There are many variants of this under-representation problem. As the number of classes, features, and unique feature values increase, your dataset may only contain a tiny number of training instances for certain groups. In fact, some of these groups may correspond to various socially sensitive features such as gender, age range, or nationality. Under-representation for such groups could result in a disproportionate impact on their predicted outcomes.
Unfortunately, even with the best of intentions, bias issues may exist in datasets and be introduced into models with business, ethical, and regulatory consequences. It is thus important for model administrators to be aware of potential sources of bias in production systems.
Now, let’s discuss the explainability problem. For simple and well-understood algorithms like linear regression or tree-based algorithms, it’s reasonably easy to crack the model open, inspect the parameters that it learned during training, and figure out which features it predominantly uses. You can then decide whether this process is consistent with your business practices, basically saying: “yes, this is how a human expert would have done it.”
However, as models become more and more complex (I’m staring at you, deep learning), this kind of analysis becomes impossible. Just like the prehistoric tribes in Stanley Kubrick’s “2001: A Space Odyssey,” we’re often left staring at an impenetrable monolith and wondering what it all means. Many companies and organizations may need ML models to be explainable before they can be used in production. In addition, some regulations may require explainability when ML models are used as part of consequential decision making, and closing the loop, explainability can also help detect bias.
Thus, our customers asked us for help on detecting bias in their datasets and their models, and on understanding how their models make predictions. We got to work, and came up with SageMaker Clarify.
Introducing Amazon SageMaker Clarify
SageMaker Clarify is a new set of capabilities for Amazon SageMaker, our fully managed ML service. It’s integrated with SageMaker Studio, our web-based integrated development environment for ML, as well as with other SageMaker capabilities like Amazon SageMaker Data Wrangler, Amazon SageMaker Experiments, and Amazon SageMaker Model Monitor.
Thanks to SageMaker Clarify, data scientists are able to:
- Detect bias in datasets prior to training, and in models after training.
- Measure bias using a variety of statistical metrics.
- Explain how feature values contribute to the predicted outcome, both for the model overall and for individual predictions.
- Detect bias drift and feature importance drift over time, thanks to the integration with Amazon SageMaker Model Monitor.
Let’s look at each of these capabilities.
Detecting dataset bias: This is an important first step. Indeed, a heavily biased dataset may well be unsuitable for training. Knowing this early on certainly saves you time, money, and frustration! Looking at bias metrics computed by SageMaker Clarify on your dataset, you can then add your own bias reduction techniques to your data processing pipeline. Once the dataset has been revised and processed, you can measure bias again, and check if it has actually decreased.
Detecting model bias: After you’ve trained your model, you can run a SageMaker Clarify bias analysis, which includes automatic deployment to a temporary endpoint, and computation of bias metrics using your model and dataset. By computing these metrics, you can figure out if your trained model has similar predictive behavior across groups.
Measuring bias: SageMaker Clarify lets you pick from many different bias metrics. I’ll just give you a few examples here.
- Difference in positive proportions in labels (DPL): Are labels in the dataset correlated or not with specific sensitive feature values? For example, do people living in a certain city have a better chance of getting a positive answer?
- Difference in positive proportions in predicted labels (DPPL): Do we overpredict positive labels for a certain group?
- Accuracy difference (AD): Are the predictions by the model more accurate for one group than the other?
- Counterfactuals – Fliptest (FT): Suppose we look at each member of one group, and compare with similar members from the other group. Do they get different model predictions?
Explaining predictions – to explain how your model predicts, SageMaker Clarify supports a popular technique called SHapley Additive exPlanations (SHAP). Originating in game theory, SHAP analyzes for each data instance the individual contribution of feature values to the predicted output, and represents them as a positive or negative value. For example, predicting with a credit application model, you could see that Alice’s application is approved with a score of 87.5%, that her employment status (+27.2%) and her credit score (+32.4%) are the strongest contributors to this score, and that her income level has a slight negative impact (-5%). Such insights are crucial in building trust that the model is working as expected, and in explaining to customers and regulators why it comes up with a particular prediction. Further analysis of the SHAP values for your complete dataset can also help identify the relative importance of features and feature values, potentially leading to the discovery of prediction issues and biases.
As you can see, SageMaker Clarify has some pretty powerful features for bias detection and explainability. Fortunately, it also makes them very easy to use. First, you should upload a clean and pre-processed copy of your tabular dataset (CSV or JSON) to Amazon Simple Storage Service (S3). Then, using a built-in container, you just launch an Amazon SageMaker Processing job on your dataset, passing a short configuration file defining the name of the target attribute, the name and values of the sensitive columns to analyze for bias, and the bias metrics that you want to compute. As you would expect, this job runs on fully managed infrastructure. For post-training analysis, a temporary endpoint is also automatically created and deleted by the job. Once the job is complete, results are available in S3 and in SageMaker Studio, and include an auto-generated report that summarizes the results.
Now, I’d like to show you how to get started with SageMaker Clarify.
Exploring Datasets and Models with Amazon SageMaker Clarify
The German Credit Data dataset contains 1,000 labeled credit applications, which I’ve used to train a binary classification model with XGBoost. Each data instance has 20 features, such as credit purpose, credit amount, housing status, employment history, and more. Categorical features have been encoded with Axx values. For example, here’s how the credit history feature is encoded: A30 means ‘no credits taken’, A31 means ‘all credits at this bank paid back duly’, and so on.
In particular, the dataset includes a feature telling us if a customer is a foreign worker. In fact, a quick look at the dataset hints at a large imbalance in favor of foreign workers. Could bias be hiding there? What about the model? Did XGBoost increase or decrease the bias? Which features contribute most to the predicted output? Let’s find out.
After training the model, my next step is to run a SageMaker Clarify bias analysis job on the dataset, using a built-in container image that will compute bias metrics. The job inputs are the dataset, and a JSON configuration file that defines:
- The name of the target attribute (
Class1Good2Bad), and the value for the positive answer (1).
- The sensitive features to analyze (called “facets”), and their value. Here, we want to focus on instances where
ForeignWorker is set to 0, as they seem to be under-represented in the dataset.
- The bias metrics that the job should compute. As I already have a model, I pass its name so that post-training metrics can be computed on a temporary endpoint.
Here’s the relevant snippet in the configuration file:
"label": "Class1Good2Bad",
"label_values_or_threshold": [1],
"facet": [
{
"name_or_index" : "ForeignWorker",
"value_or_threshold": [0]
}
],
. . .
"methods": {
"pre_training_bias": {"methods": "all"}
"post_training_bias": {"methods": "all"}
},
"predictor": {
"model_name": "xgboost-german-model",
"instance_type": "ml.m5.xlarge",
"initial_instance_count": 1
}
Then, I configure the job inputs (the dataset and the configuration file) and output (the report), passing all appropriate paths in S3:
config_input = ProcessingInput(
input_name="analysis_config",
source=analysis_config_s3_path,
destination="/opt/ml/processing/input/config")
data_input = ProcessingInput(
input_name="dataset",
source=train_data_s3_path,
destination="/opt/ml/processing/input/data")
result_output = ProcessingOutput(
source="/opt/ml/processing/output",
destination=analysis_result_s3_path,
output_name="analysis_result")
Finally, I run the processing job.
from sagemaker.processing import Processor, ProcessingInput, ProcessingJob, ProcessingOutput
analyzer_image_uri = f'678264136642.dkr.ecr.us-east-2.amazonaws.com/sagemaker-xai-analyzer:latest'
analyzer = Processor(base_job_name='analyzer',
image_uri=analyzer_image_uri,
role=sagemaker.get_execution_role(),
instance_count=1,
instance_type='ml.c5.xlarge')
analyzer.run(inputs=[ data_input, config_input], outputs=[result_output])
Once the processing job is complete, I can retrieve the report. Let’s look at bias metrics.
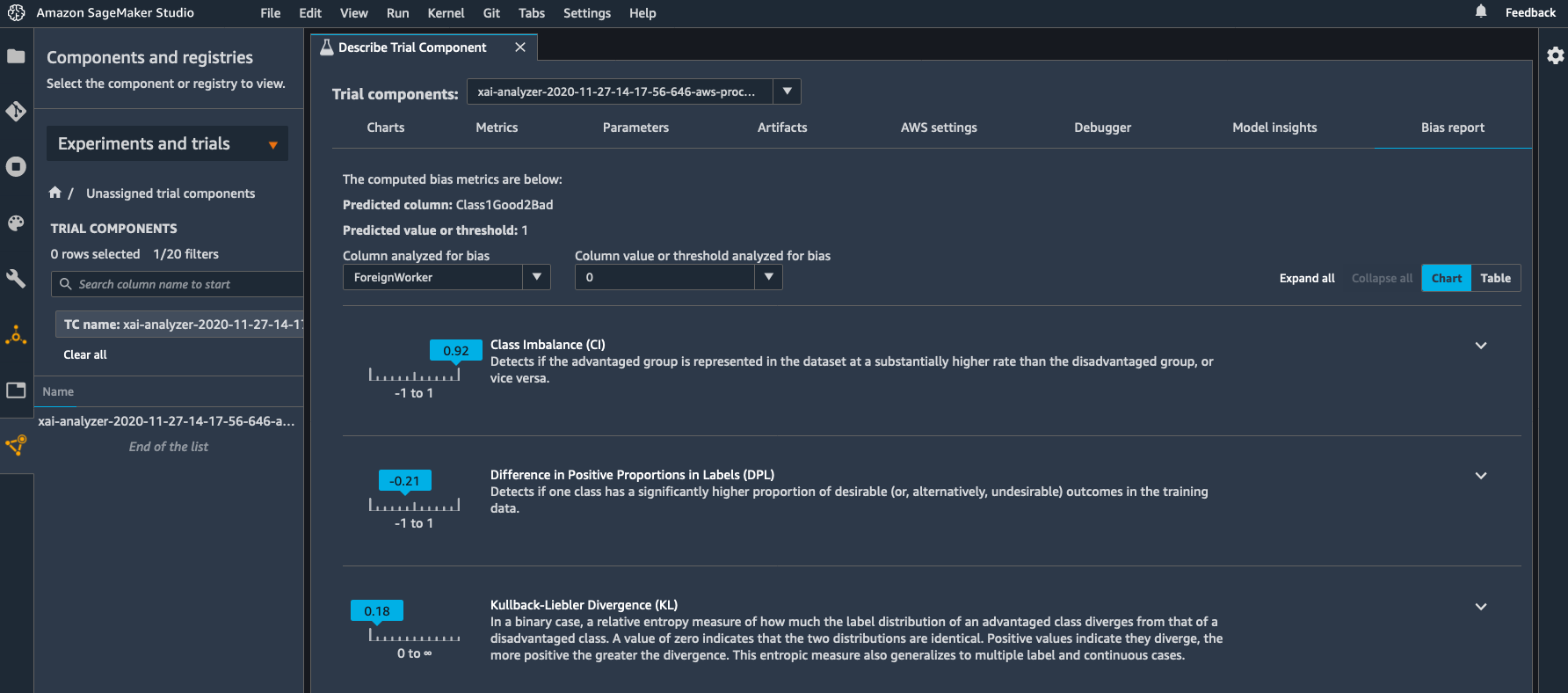
Detecting Bias with Amazon SageMaker Clarify
Here are some of the pre-training bias metrics:
"ForeignWorker": [
{
"value_or_threshold": "0",
"metrics": [
{
"name": "CI",
"description": "Class Imbalance (CI)",
"value": 0.9225
},
{
"name": "DPL",
"description": "Difference in Positive Proportions in Labels (DPL)",
"value": -0.21401904442300435
},
. . .
The class imbalance metric confirms our visual impression. The dataset has about 92% more foreign workers than it has domestic workers to assess. Whether this imbalance is responsible or not, we can also see that the difference in positive proportion for domestic workers is quite negative. In other words, there’s a smaller proportion of domestic workers with positive labels. This statistical pattern could be picked up by an ML algorithm, leading to a larger proportion of domestic workers getting negative answers. Figuring out whether this is actually legitimate or not would require further analysis, and in any case, it’s great that SageMaker Clarify warned us about this potential issue.
As I provided a trained model, post-training metrics are also available. Comparing the DPPL and the DPL, I can see that XGBoost has slightly reduced bias on positive proportions (-18.8% vs -21.4%). We also see that DAR is negative, indicating that the model achieves higher precision for domestic workers compared to foreign workers.
"ForeignWorker": [
{
"value_or_threshold": "0",
"metrics": [
{
"name": "DPPL",
"description": "\"Difference in Positive Proportions in Predicted Labels (DPPL)\")",
"value": -0.18801124208230213
},
{
"name": "DAR",
"description": "Difference in Acceptance Rates (DAR)",
"value": -0.050909090909090904
},
{
"name": "DRR",
"description": "Difference in Rejection Rates (DRR)",
"value": 0.0365296803652968
},
. . .
As SageMaker Clarify is integrated with SageMaker Studio, I can visualize bias metrics there. All I have to do is find the processing job in the list of trials, right-click “Open in trial details”, and select the “Bias report” view.

Finally, deciding whether high value of a certain bias metric is problematic involves domain-specific considerations. This needs to be guided by ethical, social, regulatory, and business considerations. Similarly, interventions for removing bias may often need a careful analysis of the entire ML lifecycle, from problem formulation to feedback loops in deployment.
Now, let’s see how SageMaker Clarify helps us understand what features the models base their predictions on.
Explaining Predictions with Amazon SageMaker Clarify
The report includes global SHAP values, showing the relative importance of all the features in the dataset. On the feature importance graph available in SageMaker Studio, I see that the three most important features are credit duration, not having a checking account (A14), and the loan amount. All things being equal, the bank probably sees you as a safer customer if you’re borrowing a small amount over a short period of time, and without the possibility to write checks!

In S3, I can also find a CSV file with SHAP values for individual data instances, giving me a complete picture of feature and feature value importance.
Getting Started
As you can see, SageMaker Clarify is a powerful tool to detect bias and to understand how your model works. You can start using it today in all regions where Amazon SageMaker is available, at no additional cost.
Sample notebooks are available to get you started quickly. Give them a try, and let us know what you think. We’re always looking forward to your feedback, either through your usual AWS support contacts, or on the AWS Forum for SageMaker.
– Julien
Special thanks to my colleagues Sanjiv Das, Michele Donini, Jason Gelman, Krishnaram Kenthapadi, Pinar Yilmaz, and Bilal Zafar for their precious help.
Dataset credits: Dua, D. and Graff, C. (2019). UCI Machine Learning Repository. Irvine, CA: University of California, School of Information and Computer Science.

 Binghui Ouyang, Senior Data Scientist at Autodesk: “Autodesk is advancing the cognitive technology of our AI-powered virtual assistant, Autodesk Virtual Agent (AVA) by using Inferentia. AVA answers over 100,000 customer questions per month by applying natural language understanding (NLU) and deep learning techniques to extract the context, intent, and meaning behind inquiries. Piloting Inferentia, we are able to obtain a 4.9x higher throughput over G4dn for our NLU models, and look forward to running more workloads on the Inferentia-based Inf1 instances.”
Binghui Ouyang, Senior Data Scientist at Autodesk: “Autodesk is advancing the cognitive technology of our AI-powered virtual assistant, Autodesk Virtual Agent (AVA) by using Inferentia. AVA answers over 100,000 customer questions per month by applying natural language understanding (NLU) and deep learning techniques to extract the context, intent, and meaning behind inquiries. Piloting Inferentia, we are able to obtain a 4.9x higher throughput over G4dn for our NLU models, and look forward to running more workloads on the Inferentia-based Inf1 instances.” Paul Fryzel, Principal Engineer, AI Infrastructure at Condé Nast: “Condé Nast’s global portfolio encompasses over 20 leading media brands, including Wired, Vogue, and Vanity Fair. Within a few weeks, our team was able to integrate our recommendation engine with AWS Inferentia chips. This union enables multiple runtime optimizations for state-of-the-art natural language models on SageMaker’s Inf1 instances. As a result, we observed a 72% reduction in cost than the previously deployed GPU instances.”
Paul Fryzel, Principal Engineer, AI Infrastructure at Condé Nast: “Condé Nast’s global portfolio encompasses over 20 leading media brands, including Wired, Vogue, and Vanity Fair. Within a few weeks, our team was able to integrate our recommendation engine with AWS Inferentia chips. This union enables multiple runtime optimizations for state-of-the-art natural language models on SageMaker’s Inf1 instances. As a result, we observed a 72% reduction in cost than the previously deployed GPU instances.”