Post Syndicated from Sakti Mishra original https://aws.amazon.com/blogs/big-data/unstructured-data-management-and-governance-using-aws-ai-ml-and-analytics-services/
Unstructured data is information that doesn’t conform to a predefined schema or isn’t organized according to a preset data model. Unstructured information may have a little or a lot of structure but in ways that are unexpected or inconsistent. Text, images, audio, and videos are common examples of unstructured data. Most companies produce and consume unstructured data such as documents, emails, web pages, engagement center phone calls, and social media. By some estimates, unstructured data can make up to 80–90% of all new enterprise data and is growing many times faster than structured data. After decades of digitizing everything in your enterprise, you may have an enormous amount of data, but with dormant value. However, with the help of AI and machine learning (ML), new software tools are now available to unearth the value of unstructured data.
In this post, we discuss how AWS can help you successfully address the challenges of extracting insights from unstructured data. We discuss various design patterns and architectures for extracting and cataloging valuable insights from unstructured data using AWS. Additionally, we show how to use AWS AI/ML services for analyzing unstructured data.
Why it’s challenging to process and manage unstructured data
Unstructured data makes up a large proportion of the data in the enterprise that can’t be stored in a traditional relational database management systems (RDBMS). Understanding the data, categorizing it, storing it, and extracting insights from it can be challenging. In addition, identifying incremental changes requires specialized patterns and detecting sensitive data and meeting compliance requirements calls for sophisticated functions. It can be difficult to integrate unstructured data with structured data from existing information systems. Some view structured and unstructured data as apples and oranges, instead of being complementary. But most important of all, the assumed dormant value in the unstructured data is a question mark, which can only be answered after these sophisticated techniques have been applied. Therefore, there is a need to being able to analyze and extract value from the data economically and flexibly.
Solution overview
Data and metadata discovery is one of the primary requirements in data analytics, where data consumers explore what data is available and in what format, and then consume or query it for analysis. If you can apply a schema on top of the dataset, then it’s straightforward to query because you can load the data into a database or impose a virtual table schema for querying. But in the case of unstructured data, metadata discovery is challenging because the raw data isn’t easily readable.
You can integrate different technologies or tools to build a solution. In this post, we explain how to integrate different AWS services to provide an end-to-end solution that includes data extraction, management, and governance.
The solution integrates data in three tiers. The first is the raw input data that gets ingested by source systems, the second is the output data that gets extracted from input data using AI, and the third is the metadata layer that maintains a relationship between them for data discovery.
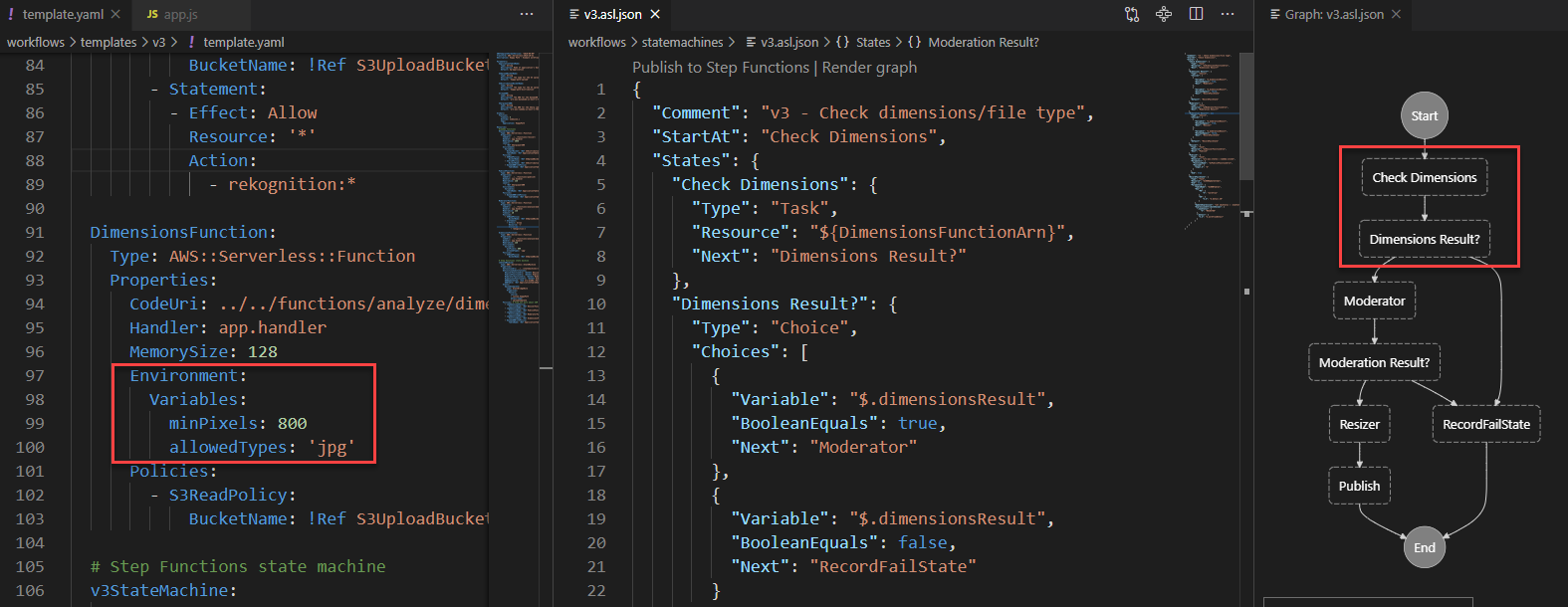
The following is a high-level architecture of the solution we can build to process the unstructured data, assuming the input data is being ingested to the raw input object store.
The steps of the workflow are as follows:
- Integrated AI services extract data from the unstructured data.
- These services write the output to a data lake.
- A metadata layer helps build the relationship between the raw data and AI extracted output. When the data and metadata are available for end-users, we can break the user access pattern into additional steps.
- In the metadata catalog discovery step, we can use query engines to access the metadata for discovery and apply filters as per our analytics needs. Then we move to the next stage of accessing the actual data extracted from the raw unstructured data.
- The end-user accesses the output of the AI services and uses the query engines to query the structured data available in the data lake. We can optionally integrate additional tools that help control access and provide governance.
- There might be scenarios where, after accessing the AI extracted output, the end-user wants to access the original raw object (such as media files) for further analysis. Additionally, we need to make sure we have access control policies so the end-user has access only to the respective raw data they want to access.
Now that we understand the high-level architecture, let’s discuss what AWS services we can integrate in each step of the architecture to provide an end-to-end solution.
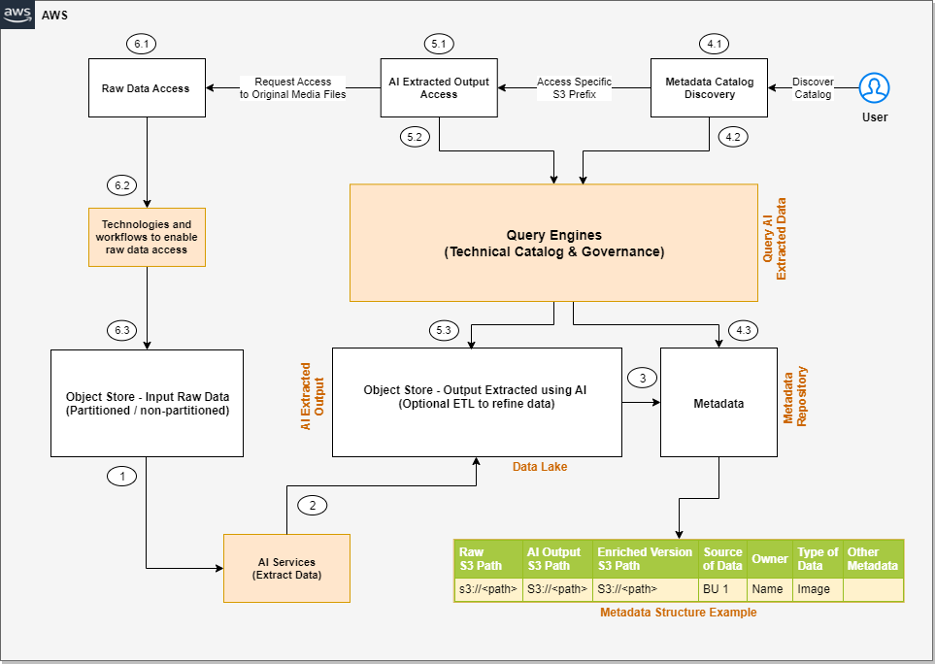
The following diagram is the enhanced version of our solution architecture, where we have integrated AWS services.

Let’s understand how these AWS services are integrated in detail. We have divided the steps into two broad user flows: data processing and metadata enrichment (Steps 1–3) and end-users accessing the data and metadata with fine-grained access control (Steps 4–6).
- Various AI services (which we discuss in the next section) extract data from the unstructured datasets.
- The output is written to an Amazon Simple Storage Service (Amazon S3) bucket (labeled Extracted JSON in the preceding diagram). Optionally, we can restructure the input raw objects for better partitioning, which can help while implementing fine-grained access control on the raw input data (labeled as the Partitioned bucket in the diagram).
- After the initial data extraction phase, we can apply additional transformations to enrich the datasets using AWS Glue. We also build an additional metadata layer, which maintains a relationship between the raw S3 object path, the AI extracted output path, the optional enriched version S3 path, and any other metadata that will help the end-user discover the data.
- In the metadata catalog discovery step, we use the AWS Glue Data Catalog as the technical catalog, Amazon Athena and Amazon Redshift Spectrum as query engines, AWS Lake Formation for fine-grained access control, and Amazon DataZone for additional governance.
- The AI extracted output is expected to be available as a delimited file or in JSON format. We can create an AWS Glue Data Catalog table for querying using Athena or Redshift Spectrum. Like the previous step, we can use Lake Formation policies for fine-grained access control.
- Lastly, the end-user accesses the raw unstructured data available in Amazon S3 for further analysis. We have proposed integrating Amazon S3 Access Points for access control at this layer. We explain this in detail later in this post.
Now let’s expand the following parts of the architecture to understand the implementation better:
- Using AWS AI services to process unstructured data
- Using S3 Access Points to integrate access control on raw S3 unstructured data
Process unstructured data with AWS AI services
As we discussed earlier, unstructured data can come in a variety of formats, such as text, audio, video, and images, and each type of data requires a different approach for extracting metadata. AWS AI services are designed to extract metadata from different types of unstructured data. The following are the most commonly used services for unstructured data processing:
- Amazon Comprehend – This natural language processing (NLP) service uses ML to extract metadata from text data. It can analyze text in multiple languages, detect entities, extract key phrases, determine sentiment, and more. With Amazon Comprehend, you can easily gain insights from large volumes of text data such as extracting product entity, customer name, and sentiment from social media posts.
- Amazon Transcribe – This speech-to-text service uses ML to convert speech to text and extract metadata from audio data. It can recognize multiple speakers, transcribe conversations, identify keywords, and more. With Amazon Transcribe, you can convert unstructured data such as customer support recordings into text and further derive insights from it.
- Amazon Rekognition – This image and video analysis service uses ML to extract metadata from visual data. It can recognize objects, people, faces, and text, detect inappropriate content, and more. With Amazon Rekognition, you can easily analyze images and videos to gain insights such as identifying entity type (human or other) and identifying if the person is a known celebrity in an image.
- Amazon Textract – You can use this ML service to extract metadata from scanned documents and images. It can extract text, tables, and forms from images, PDFs, and scanned documents. With Amazon Textract, you can digitize documents and extract data such as customer name, product name, product price, and date from an invoice.
- Amazon SageMaker – This service enables you to build and deploy custom ML models for a wide range of use cases, including extracting metadata from unstructured data. With SageMaker, you can build custom models that are tailored to your specific needs, which can be particularly useful for extracting metadata from unstructured data that requires a high degree of accuracy or domain-specific knowledge.
- Amazon Bedrock – This fully managed service offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon with a single API. It also offers a broad set of capabilities to build generative AI applications, simplifying development while maintaining privacy and security.
With these specialized AI services, you can efficiently extract metadata from unstructured data and use it for further analysis and insights. It’s important to note that each service has its own strengths and limitations, and choosing the right service for your specific use case is critical for achieving accurate and reliable results.
AWS AI services are available via various APIs, which enables you to integrate AI capabilities into your applications and workflows. AWS Step Functions is a serverless workflow service that allows you to coordinate and orchestrate multiple AWS services, including AI services, into a single workflow. This can be particularly useful when you need to process large amounts of unstructured data and perform multiple AI-related tasks, such as text analysis, image recognition, and NLP.
With Step Functions and AWS Lambda functions, you can create sophisticated workflows that include AI services and other AWS services. For instance, you can use Amazon S3 to store input data, invoke a Lambda function to trigger an Amazon Transcribe job to transcribe an audio file, and use the output to trigger an Amazon Comprehend analysis job to generate sentiment metadata for the transcribed text. This enables you to create complex, multi-step workflows that are straightforward to manage, scalable, and cost-effective.
The following is an example architecture that shows how Step Functions can help invoke AWS AI services using Lambda functions.
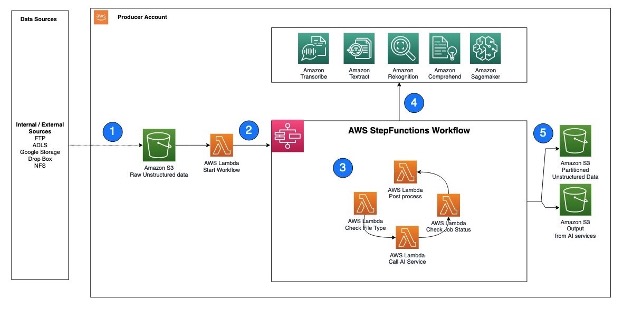
The workflow steps are as follows:
- Unstructured data, such as text files, audio files, and video files, are ingested into the S3 raw bucket.
- A Lambda function is triggered to read the data from the S3 bucket and call Step Functions to orchestrate the workflow required to extract the metadata.
- The Step Functions workflow checks the type of file, calls the corresponding AWS AI service APIs, checks the job status, and performs any postprocessing required on the output.
- AWS AI services can be accessed via APIs and invoked as batch jobs. To extract metadata from different types of unstructured data, you can use multiple AI services in sequence, with each service processing the corresponding file type.
- After the Step Functions workflow completes the metadata extraction process and performs any required postprocessing, the resulting output is stored in an S3 bucket for cataloging.
Next, let’s understand how can we implement security or access control on both the extracted output as well as the raw input objects.
Implement access control on raw and processed data in Amazon S3
We just consider access controls for three types of data when managing unstructured data: the AI-extracted semi-structured output, the metadata, and the raw unstructured original files. When it comes to AI extracted output, it’s in JSON format and can be restricted via Lake Formation and Amazon DataZone. We recommend keeping the metadata (information that captures which unstructured datasets are already processed by the pipeline and available for analysis) open to your organization, which will enable metadata discovery across the organization.
To control access of raw unstructured data, you can integrate S3 Access Points and explore additional support in the future as AWS services evolve. S3 Access Points simplify data access for any AWS service or customer application that stores data in Amazon S3. Access points are named network endpoints that are attached to buckets that you can use to perform S3 object operations. Each access point has distinct permissions and network controls that Amazon S3 applies for any request that is made through that access point. Each access point enforces a customized access point policy that works in conjunction with the bucket policy that is attached to the underlying bucket. With S3 Access Points, you can create unique access control policies for each access point to easily control access to specific datasets within an S3 bucket. This works well in multi-tenant or shared bucket scenarios where users or teams are assigned to unique prefixes within one S3 bucket.
An access point can support a single user or application, or groups of users or applications within and across accounts, allowing separate management of each access point. Every access point is associated with a single bucket and contains a network origin control and a Block Public Access control. For example, you can create an access point with a network origin control that only permits storage access from your virtual private cloud (VPC), a logically isolated section of the AWS Cloud. You can also create an access point with the access point policy configured to only allow access to objects with a defined prefix or to objects with specific tags. You can also configure custom Block Public Access settings for each access point.
The following architecture provides an overview of how an end-user can get access to specific S3 objects by assuming a specific AWS Identity and Access Management (IAM) role. If you have a large number of S3 objects to control access, consider grouping the S3 objects, assigning them tags, and then defining access control by tags.
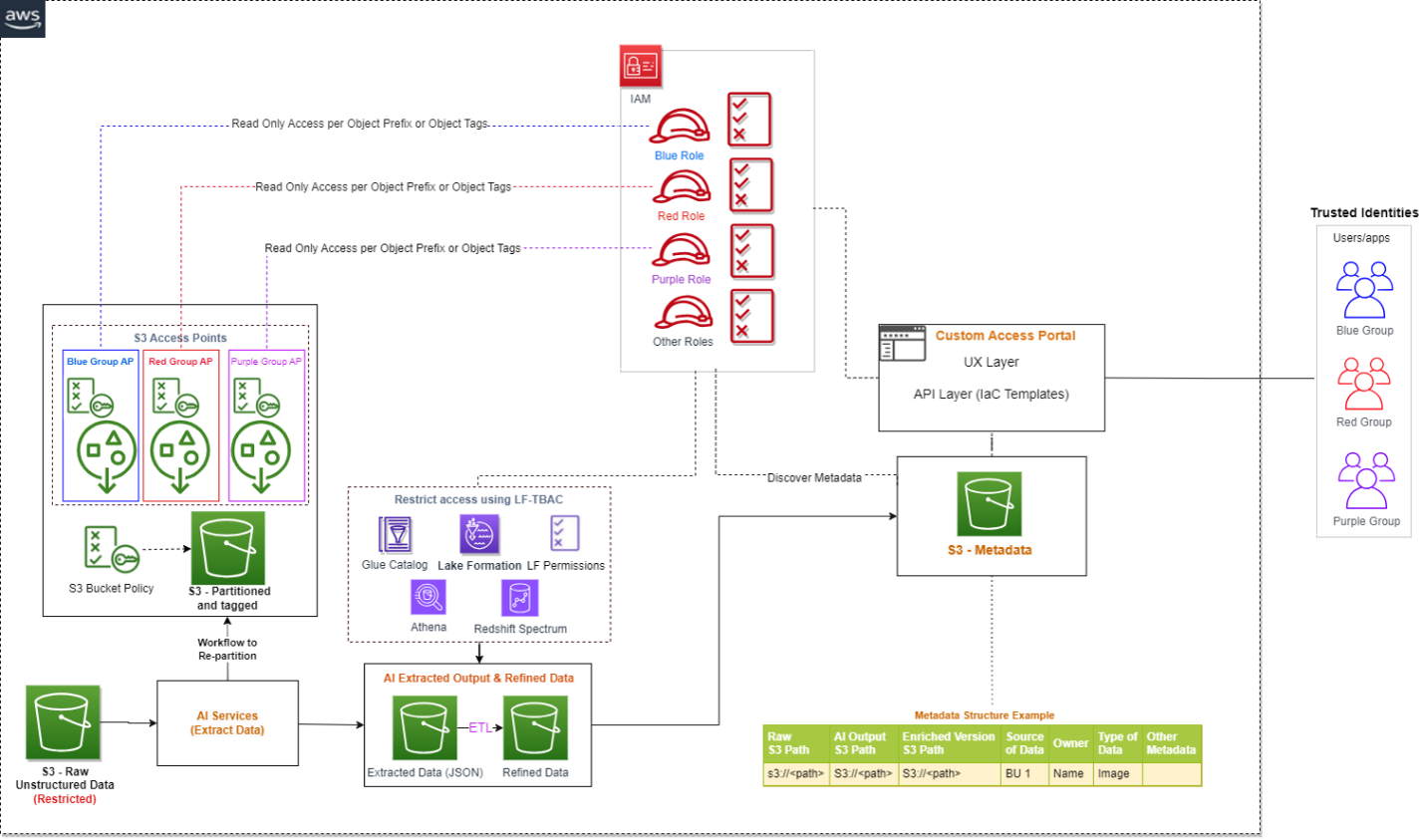
If you are implementing a solution that integrates S3 data available in multiple AWS accounts, you can take advantage of cross-account support for S3 Access Points.
Conclusion
This post explained how you can use AWS AI services to extract readable data from unstructured datasets, build a metadata layer on top of them to allow data discovery, and build an access control mechanism on top of the raw S3 objects and extracted data using Lake Formation, Amazon DataZone, and S3 Access Points.
In addition to AWS AI services, you can also integrate large language models with vector databases to enable semantic or similarity search on top of unstructured datasets. To learn more about how to enable semantic search on unstructured data by integrating Amazon OpenSearch Service as a vector database, refer to Try semantic search with the Amazon OpenSearch Service vector engine.
As of writing this post, S3 Access Points is one of the best solutions to implement access control on raw S3 objects using tagging, but as AWS service features evolve in the future, you can explore alternative options as well.
About the Authors
 Sakti Mishra is a Principal Solutions Architect at AWS, where he helps customers modernize their data architecture and define their end-to-end data strategy, including data security, accessibility, governance, and more. He is also the author of the book Simplify Big Data Analytics with Amazon EMR. Outside of work, Sakti enjoys learning new technologies, watching movies, and visiting places with family.
Sakti Mishra is a Principal Solutions Architect at AWS, where he helps customers modernize their data architecture and define their end-to-end data strategy, including data security, accessibility, governance, and more. He is also the author of the book Simplify Big Data Analytics with Amazon EMR. Outside of work, Sakti enjoys learning new technologies, watching movies, and visiting places with family.
 Bhavana Chirumamilla is a Senior Resident Architect at AWS with a strong passion for data and machine learning operations. She brings a wealth of experience and enthusiasm to help enterprises build effective data and ML strategies. In her spare time, Bhavana enjoys spending time with her family and engaging in various activities such as traveling, hiking, gardening, and watching documentaries.
Bhavana Chirumamilla is a Senior Resident Architect at AWS with a strong passion for data and machine learning operations. She brings a wealth of experience and enthusiasm to help enterprises build effective data and ML strategies. In her spare time, Bhavana enjoys spending time with her family and engaging in various activities such as traveling, hiking, gardening, and watching documentaries.
 Sheela Sonone is a Senior Resident Architect at AWS. She helps AWS customers make informed choices and trade-offs about accelerating their data, analytics, and AI/ML workloads and implementations. In her spare time, she enjoys spending time with her family—usually on tennis courts.
Sheela Sonone is a Senior Resident Architect at AWS. She helps AWS customers make informed choices and trade-offs about accelerating their data, analytics, and AI/ML workloads and implementations. In her spare time, she enjoys spending time with her family—usually on tennis courts.
 Daniel Bruno is a Principal Resident Architect at AWS. He had been building analytics and machine learning solutions for over 20 years and splits his time helping customers build data science programs and designing impactful ML products.
Daniel Bruno is a Principal Resident Architect at AWS. He had been building analytics and machine learning solutions for over 20 years and splits his time helping customers build data science programs and designing impactful ML products.

 .NET Developer Day –
.NET Developer Day – 
 AWS Global Summits – Check your calendars and sign up for the AWS Summit close to where you live or work:
AWS Global Summits – Check your calendars and sign up for the AWS Summit close to where you live or work: